Obtenir le titre “Azure AI Engineer Associate” ne demande que de passer une seule certification Microsoft, celle nommé AI-102 et dont le descriptif est disponible ici. Elle a remplacé la certification AI-100 en 2021 et s’oriente vers le choix et l’utilisation des services cognitifs Azure, alors que la précédente version pouvait également aborder des thèmes comme l’implémentation et le monitoring.
Je vous conseille toutefois d’associer à cette certification la AI-900 “Microsoft Azure AI Fundamentals” qui, comme toutes les “900”, se veut plus générique et moins technique (certains diront plus faciles à obtenir). Elle aborde en particulier les grands principes pour une utilisation responsable de l’Intelligence Artificielle :
fairness (équité)
reliability (fiabilité)
privacy (vie privée)
inclusiveness (inclusivité)
transparency (transparence)
accountability (responsabilité)
Pour préparer l’AI-900, utilisez les parcours d’apprentissage de Microsoft Learn, comme celui-ci.
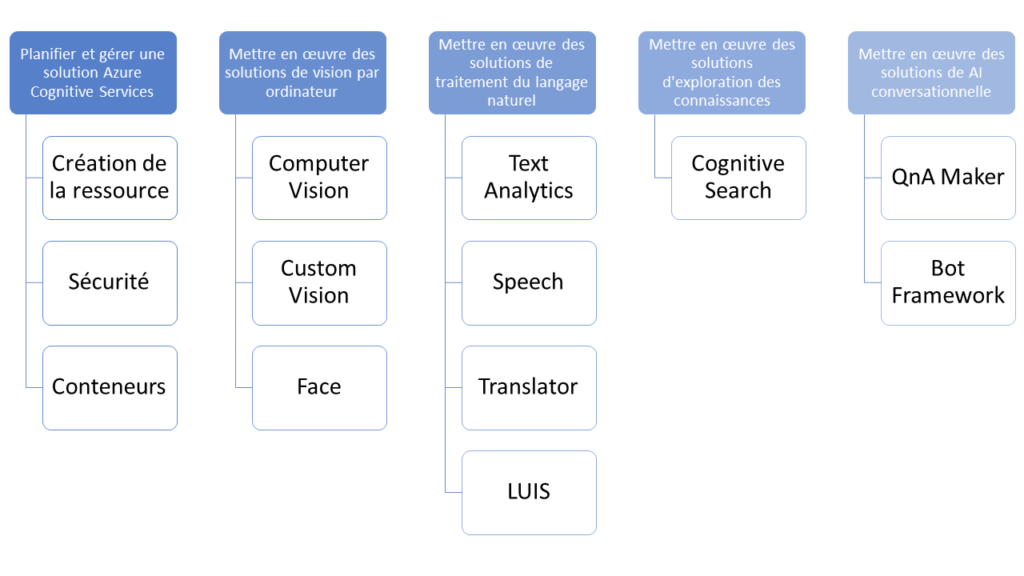
Observons maintenant en détail les cinq compétences mesurées qui seront autant de chapitres dans la liste des éléments à réviser :
Planifier et gérer une solution Azure Cognitive Services
Mettre en œuvre des solutions de vision par ordinateur
Mettre en œuvre des solutions de traitement du langage naturel
Mettre en œuvre des solutions d’exploration des connaissances
Mettre en œuvre des solutions de AI conversationnelle
Le détail est fourni dans ce document PDF, en anglais, et il faut en surveiller les mises à jour.
La documentation Microsoft sera bien sûr l’un de vos principaux alliés. Préférez une lecture en anglais pour vous familiariser avec la terminologie utilisée dans les questions de l’examen.
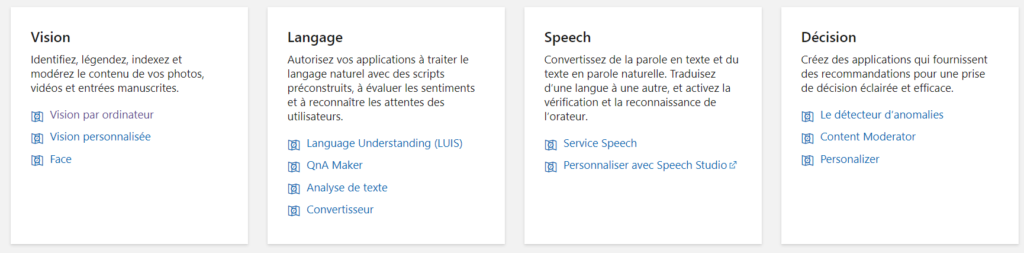
Nous travaillerons autour des quatre familles principales de services cognitifs :
vision
langage
speech
décision
Plusieurs questions porteront vraisemblablement sur le choix du bon service pour répondre à des scénarios précis. Ces questions ne devraient pas vous poser de difficulté une fois que vous aurez en tête les grandes fonctionnalités de chacun des services listés sur l’image ci-dessus.
Les services de la catégorie Décision ne seront pas présentés dans les quatre autres chapitres.
Mais attention, le contenu détaillé agrandit un peu le périmètre des services de base et se réorganise de la sorte :
Computer Vision
Natural Language Processing
Knowledge Mining
Conversational AI
Nous allons donc avoir à faire à quelques services que Microsoft désigne maintenant par le terme “Azure Applied AI Services” (voir ce lien) et en particulier aux services Azure Bot et Cognitive Search.
Plan and Manage an Azure Cognitive Services Solution
Nous allons nous concentrer ici sur trois points du programme :
la création d’une ressource
les aspects de sécurité
l’utilisation de conteneurs
Implement Computer Vision Solutions
Les services cognitifs concernés par ce chapitre sont :
Computer Vision
Custom Vision
Face
Implement Natural Language Processing Solutions
Les services cognitifs concernés par ce chapitre sont :
Text Analytics
Speech to Text & Text to Speech
Translate
Language Understanding Service (LUIS)Computer Vision
Implement Knowledge Mining Solutions
L’unique service cognitif concerné par ce chapitre est Azure Cognitive Search.
A priori, et selon le programme détaillé, vous ne devriez pas rencontrer de questions sur l’API Bing Search (présentée ici).
Implement Conversational AI Solutions
Les services cognitifs concernés par ce chapitre sont :
QnA Maker
Bot Framework
Ne pas oublier le service Dispatch pour la gestion du multi-langue.
En conclusion
Nous espérons vous avoir fourni ici les premières bases pour guider vos révisions. N’oubliez pas que la pratique est indispensable (profitez des free tiers souvent disponibles qui n’affecteront pas votre crédit Azure) et méfiez-vous des bases de questions (et encore plus des réponses !) que l’on peut trouver sur Internet.
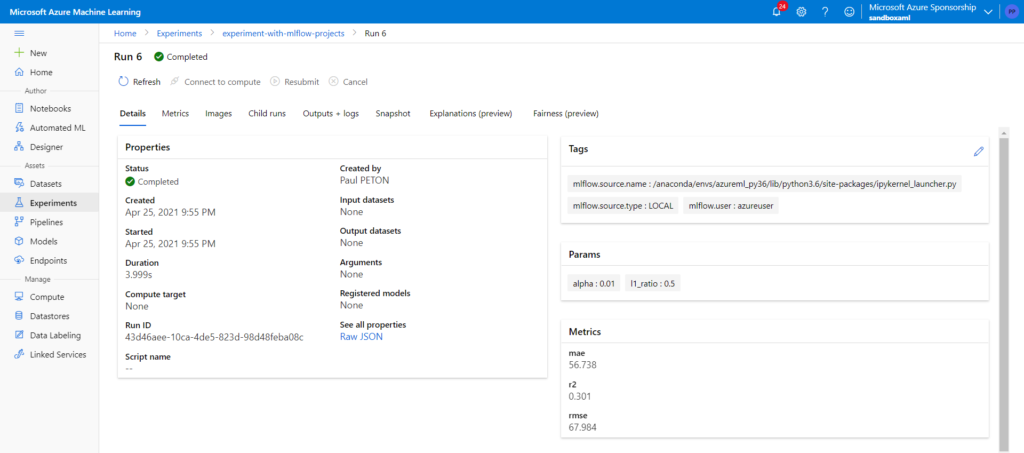
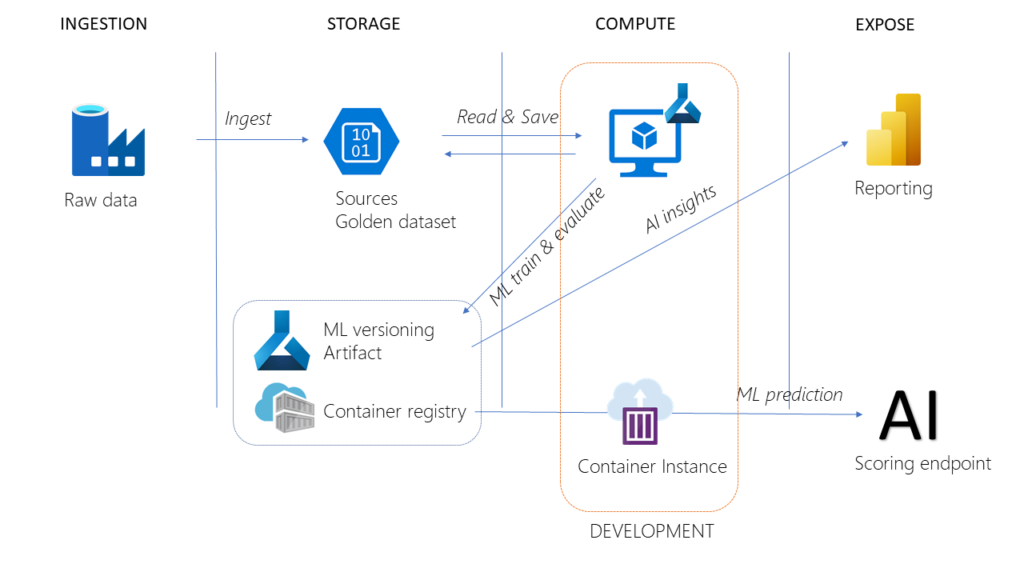
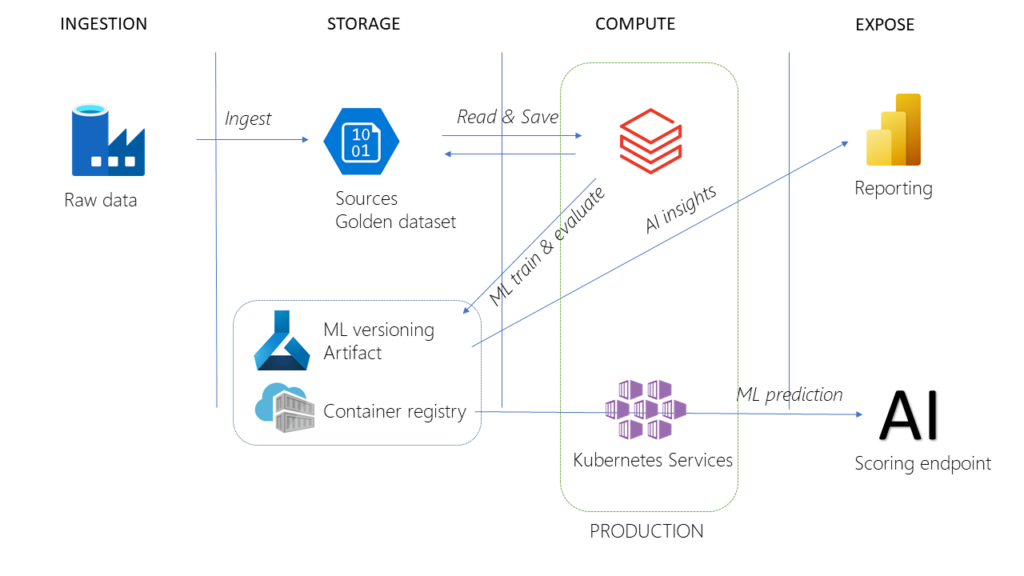
Derrière ces trois notions, se cache une succession d’étapes nécessaires pour obtenir un service prédictif de qualité et apte à gérer des données qui ne sont pas uniquement numériques. Prenons l’exemple du classique jeu de données German Credit disponible sur ce lien, sur lequel nous nous baserons pour entrainer un modèle d’apprentissage supervisé, dans une tâche de classification binaire (risque ou absence de risque sur le non remboursement d’un emprunt bancaire). Pour le déploiement d’un service web prédictif, nous allons utiliser le service Azure Machine Learning avec lequel nous interagirons au travers du SDK Python azureml-core, souvent évoqué sur ce blog (ici et là).
Même si leur champ de compétences grandit de jour en jour, les Data Scientists et Data Engineers ne sont pas attendus sur le développement de l’application finale qui offrira par exemple une interface de saisie et intègrera la restitution des prévisions. Pour autant, il est nécessaire de “passer la main” à une équipe de développeurs en fournissant une documentation claire et précise pour des personnes qui n’ont pas à se pencher sur des notions de feature selection ou encore feature engineering. Cette documentation s’établit communément sous le format dit Swagger qui correspond à un fichier JSON listant les colonnes en entrée du modèle ainsi que le type de données associé (texte, nombres entiers ou décimaux, dates voire fichier binaire dans un cas non structuré).
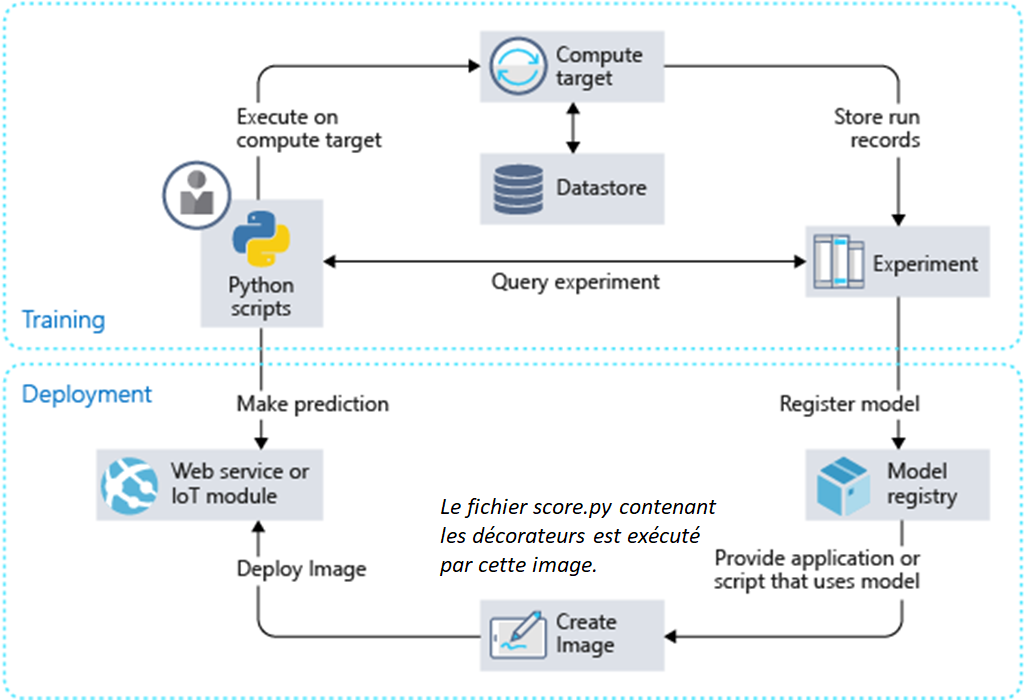
Afin d’obtenir ce résultat, nous devons préciser deux éléments dans la fonction de scoring qui supporte l’inférence du modèle. Rappelons que cette fonction Python score.py est ensuite hébergée sur une image Docker, stockée dans une ressource Azure Container Registry et exposée à l’aide d’Azure Container Instance ou Azure Kubernetes Services.
Nous disposerons alors de deux URLs, dont la propriété dns_name_label aura été précisée dans la définition de l’appel à la fonction deploy_configuration() sur l’objet AciWebservice :
Le fichier score.py se compose de deux fonctions au nom réservé :
init() qui récupère le binaire du modèle (par exemple au format Pickle) et le désérialise en mémoire
run(input) : qui récupère les données en entrée et applique la fonction .predict sur le modèle
def init():
global model
global encoder
# The AZUREML_MODEL_DIR environment variable indicates# a directory containing the model file you registered.model_filename = 'german_credit_log_model.pkl'model_path = os.path.join(os.environ['AZUREML_MODEL_DIR'], model_filename)with open(model_path, 'rb') as f: encoder, model = joblib.load(f)
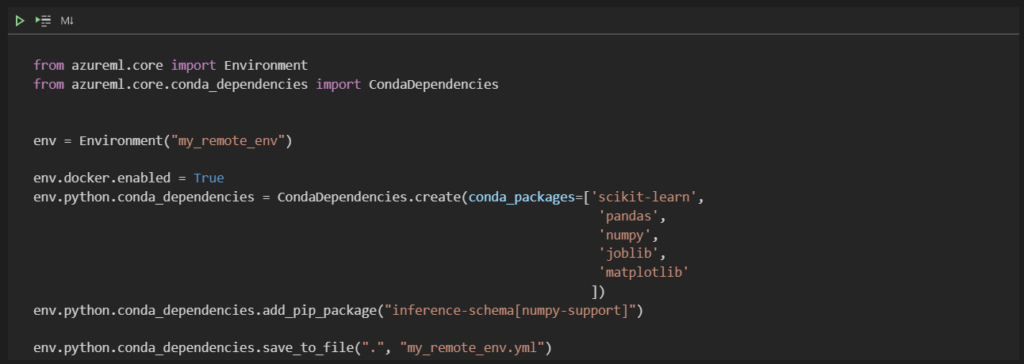
Pour garantir la cohérence des données en entrée (nombre de colonnes et type des données) ainsi qu’en sortie, nous allons définir deux objets appelés décorateurs. Ces objets Python servent à modifier le comportement d’une fonction existante. Cette page GitHub documente ce que Microsoft appelle l’InferenceSchema.
A partir du SDK Python, nous allons commencer par importer les éléments nécessaires à la création des décorateurs.
from inference_schema.schema_decorators import input_schema, output_schema from inference_schema.parameter_types.standard_py_parameter_type import StandardPythonParameterType from inference_schema.parameter_types.numpy_parameter_type import NumpyParameterType from inference_schema.parameter_types.pandas_parameter_type import PandasParameterType
Nous disposons de trois types pour ces décorateurs :
le type standard que nous utiliserons pour une valeur simple comme par exemple un paramètre en entrée ou une valeur en sortie
le type Numpy Array soit un tableau de nombres en entrée (les features sont alors uniquement numériques) ou un tableau de valeurs en sortie (une prévision numérique pour une régression mais pourquoi pas un tableau de probabilités associées à chaque classe pour une classification)
le type Pandas Dataframe qui permet de faire entrer un jeu de données de multiples types, ce qui est bien plus souvent le cas dans la vraie vie que dans les tutoriels visibles sur le Web !
Voici la définition des décorateurs en entrée et sortie pour une tâche de classification sur le jeu de données German Credit. Il faut veiller à donner un exemple respectant le type de données de chaque colonne. Pour obtenir facilement ces informations, je vous recommande de lancer la commande df.iloc[:,1] sur le dataframe.
input_sample = pd.DataFrame(data=[{
"Status of existing checking account": "A12",
"Duration in month": 48,
"Credit history": "A32",
"Purpose": "A43",
"Credit amount": 5951,
"Savings account/bonds": "A61",
"Present employment since": "A73",
"Installment rate in percentage of disposable income": 2,
"Personal status and sex": "A92",
"Other debtors / guarantors": "A101",
"Present residence since": 2,
"Property": "A121",
"Age in years": 22,
"Other installment plans": "A143",
"Housing": "A152",
"Number of existing credits at this bank": 1,
"Job": "A173",
"Number of people being liable to provide maintenance for": 1,
"Telephone": "A191",
"foreign worker": "A201",
}])
output_sample = np.array([0])
@input_schema('data', PandasParameterType(input_sample))
@output_schema(NumpyParameterType(output_sample))
La méthode .predict() de Scikit-Learn accepte en entrée soit un tableau Numpy soit un Pandas dataframe. Nous n’aurons donc pas à intervenir sur le script score.py, le décorateur fera le travail d’interprétation des données en entrée et en particulier associera le nom des colonnes pour un Pandas dataframe.
Jetons un oeil du côté de la syntaxe classique d’appel au service web prédictif, ici en Python mais cet appel peut se faire dans de multiples langages. La seule contrainte est de passer les données dans un format JSON.
def run(data):
print(data.shape)
df_text = data.select_dtypes(include='object')
df_num = data.select_dtypes(include='int64')
df_text_encoded = pd.DataFrame(encoder.transform(df_text).toarray())
df_encoded = pd.concat([df_num, df_text_encoded], axis=1)
# Use the model object loaded by init().
result = model.predict(df_encoded)
# You can return any JSON-serializable object.
return result.tolist()
Explorons maintenant le détail du code de la fonction run(). Celle-ci attend un paramètre en entrée et il est important de respecter le nom associé au Dataframe dans sa définition faite au sein du décorateur d’entrée (la casse également, attention aux majuscules et minuscules !). La première étape consiste à lire le JSON en entrée grâce à la fonction json.loads(). N’oubliez pas de faire un import json dans le début du script ainsi que de charger la librairie pandas dans l’environnement d’inférence.
Nous passons ensuite un traitement spécifique aux colonnes de type texte, qui était lui-même stocké dans le fichier pickle.
Il n’y a plus qu’à demander la prédiction à partir du modèle avec l’instruction model.predict(data) puis à restituer le résultat en convertissant le Numpy array en liste, objet dit “JSON-serializable”.
Modification de la méthode de prévision
Puisque nous travaillons sur une classification binaire, nous pourrions préférer appliquer au modèle la méthode predict_proba() et
Voici le nouveau code à positionner dans la fonction score.py.
pandas_sample_input = pd.DataFrame(data=[{
"Status of existing checking account": "A12",
"Duration in month": 48,
"Credit history": "A32",
"Purpose": "A43",
"Credit amount": 5951,
"Savings account/bonds": "A61",
"Present employment since": "A73",
"Installment rate in percentage of disposable income": 2,
"Personal status and sex": "A92",
"Other debtors / guarantors": "A101",
"Present residence since": 2,
"Property": "A121",
"Age in years": 22,
"Other installment plans": "A143",
"Housing": "A152",
"Number of existing credits at this bank": 1,
"Job": "A173",
"Number of people being liable to provide maintenance for": 1,
"Telephone": "A191",
"foreign worker": "A201",
}])
method_sample_input = "predict"
output_sample = np.array([0])
@input_schema('data', PandasParameterType(pandas_sample_input))
@input_schema('method', StandardPythonParameterType(method_sample_input))
@output_schema(NumpyParameterType(output_sample))
def run(data, method):
df_text = data.select_dtypes(include='object')
df_num = data.select_dtypes(include='int64')
df_text_encoded = pd.DataFrame(encoder.transform(df_text).toarray())
df_encoded = pd.concat([df_num, df_text_encoded], axis=1)
print(method)
# Use the model object loaded by init().
result = model.predict(df_encoded) if method=="predict" else model.predict_proba(df_encoded)
# You can return any JSON-serializable object.
return result.tolist()
Nous exploitons ici deux paramètres en entrée de la fonction run(). Le second est du type StandardPythonParameterType, c’est-à-dire tout simplement une chaîne de texte ! Ensuite, nous jouons avec une condition pour appliquer soit predict(), soit predict_proba() qui renverra alors les probabilités appliquées à chacune des deux classes :
[[0.27303021717776266, 0.7269697828222373]]
En conclusion
Voilà un fonctionnement qui est satisfaisant autant pour les développeurs du modèle et du service que pour les personnes qui l’exploiteront ensuite. Attention toutefois à ne pas oublier de venir modifier ces décorateurs si jamais votre modèle n’utilise plus les mêmes données en entrée. Il est recommandé de rester à l’identique de la donnée de départ et si une étape de préparation (feature engineering, scaling…) est nécessaire, il faudra l’inclure dans un pipeline, ce que nous verrons dans un prochain article.
Le notebook complet sera disponible dans ce repository.
En 2021, toute société proposant une plateforme autour de la data semble vouloir se doter d’un outil d’automated Machine Learning, sorte de “force brute” de la recherche du meilleur algorithme. Databricks ne déroge pas à la règle et propose depuis peu (mai 2021) un menu de création d’une expérience “AutoML”.
Le concept d’expérience au sein de Databricks se rattache historiquement à l’utilisation de MLFlow pour le stockage, versionning et déploiement de modèles d’apprentissage. L’approche proposée ici s’adresse directement aux “citizen data scientists” au travers d’une interface graphique.
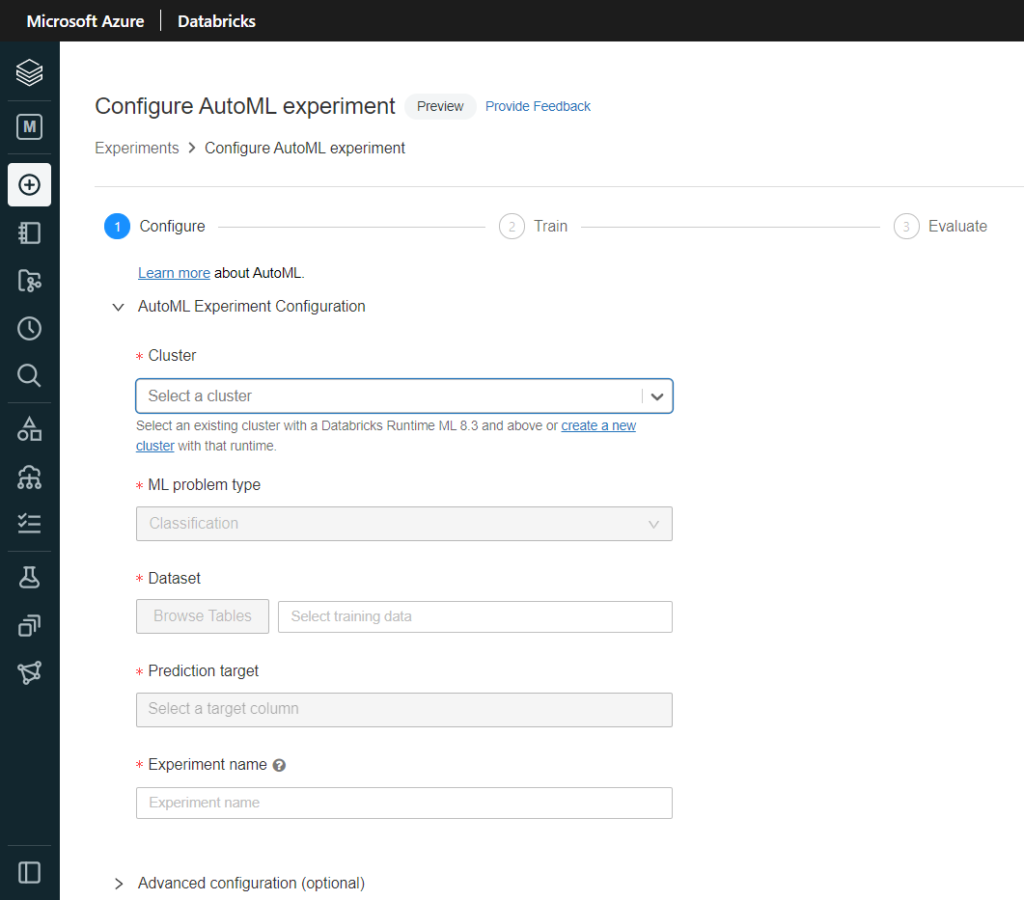
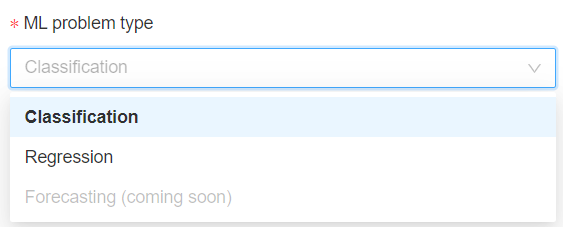
Nous aurons bien sûr besoin d’un cluster pour exécuter le code puis nous pourrons choisir entre les deux problématiques supervisées que sont la classification et la régression. La prévision sur série temporelle (forecasting) sera disponible prochainement.
Ce cluster doit disposer d’un runtime 8.3 ML ou supérieur (à venir), incluant donc Spark 3 et des packages spécifiques pour l’apprentissage automatique.
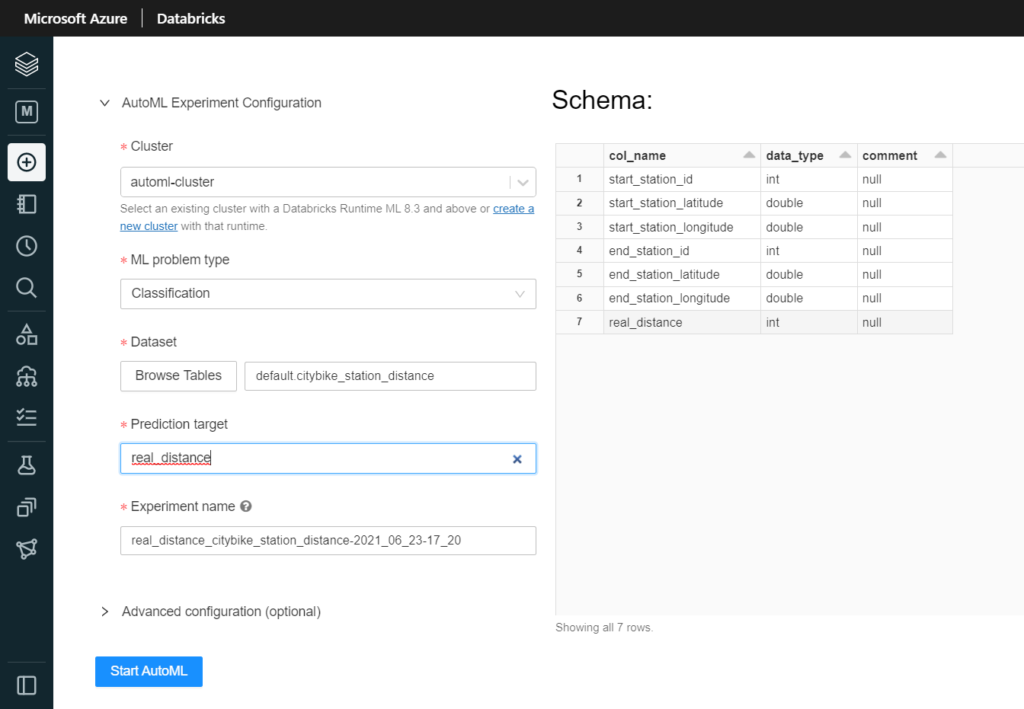
On devra ensuite désigner le dataset à utiliser. Celui-ci doit exister sous forme de table sur un cluster de l’espace de travail (pas obligatoirement celui qui exécutera l’entrainement), cluster devant être démarré pour que les tables soient visibles… et accessibles !
La table choisie doit présenter des données entièrement préparées pour le processus d’apprentissage (nettoyage des valeurs aberrantes, feature selection, feature engineering, etc.) car de telles opérations ne seront pas possibles par la suite.
Nous désignons ensuite la “prediction target“, puisque nous travaillons dans une approche d’apprentissage supervisé.
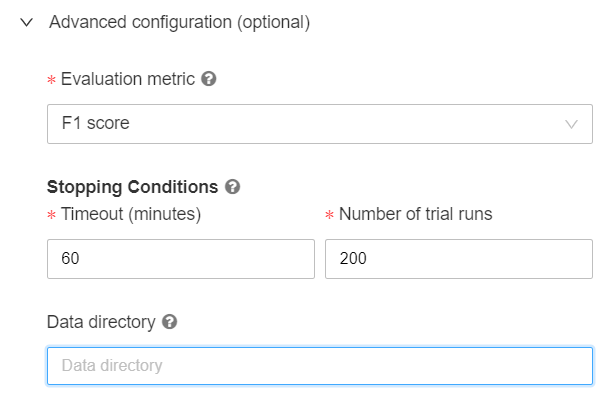
Dans les options d’évaluation, nous pourrons modifier la métrique d’évaluation qui servira à comparer les différents modèles, ainsi que donner des conditions d’arrêt, soit sur le temps d’entrainement, soit sur le nombre maximum d’essais réalisés.
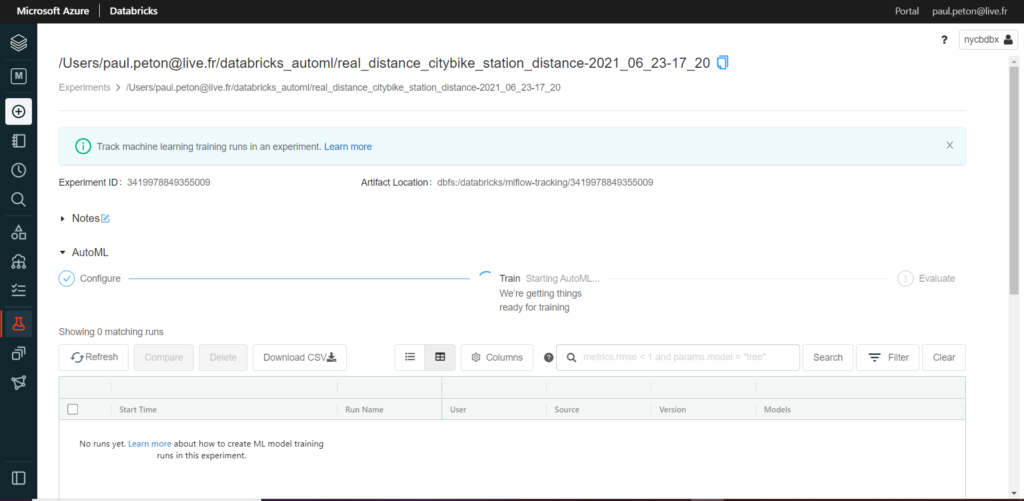
C’est parti, l’expérience se lance !
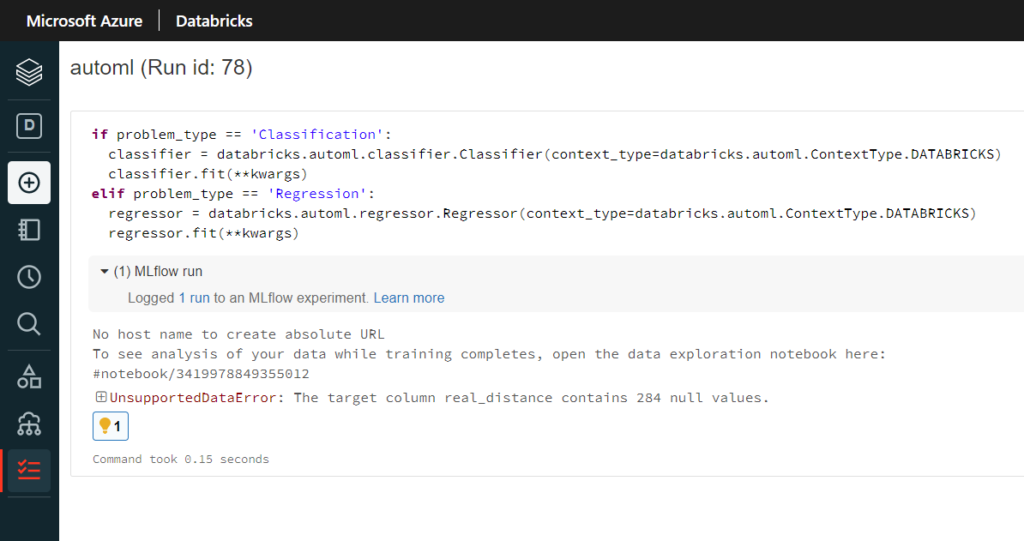
Pas de chance, échec dès le démarrage, mais nous allons chercher la cause.
Nous disposons pour cela d’un notebook contenant l’exécution du job.
Des valeurs vides viennent polluer notre variable cible (“target“). Une meilleure préparation de données aurait dû être réalisée. Heureusement, Databricks vient à nouveau à notre secours avec un second lien vers un notebook de “Data exploration”.
Il s’agit du package pandas_profiling qui est mis en oeuvre dans un notebook.
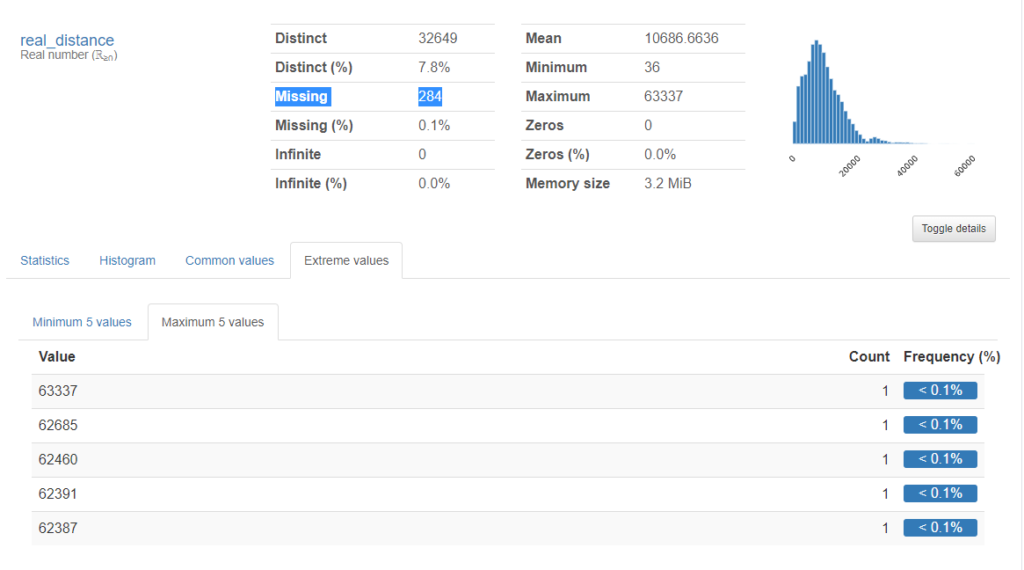
En affichant le détail, nous retrouvons bien les 284 valeurs manquantes mais nous pouvons aussi observer des valeurs extrêmes, potentiellement aberrantes.
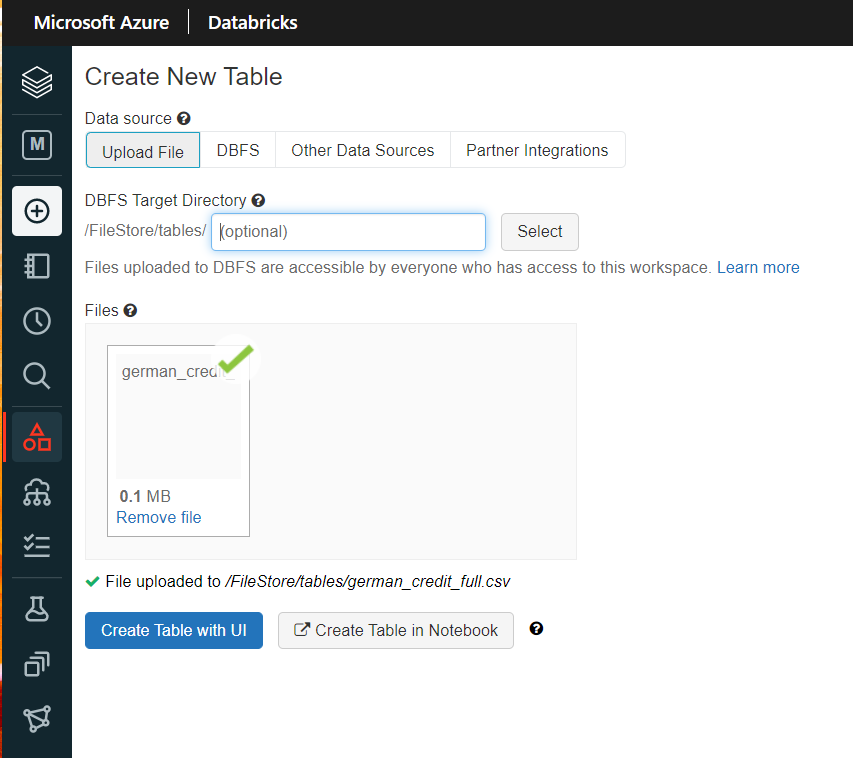
Nous allons repartir d’un dataset plus simple et déjà nettoyé : “German Credit” (disponible par exemple ici), que nous pouvons uploader directement sur le FileStore depuis le menu Data.
Relançons maintenant une expérience d’autoML, cette fois-ci sur une tâche de classification (la variable binaire class est ici la cible).
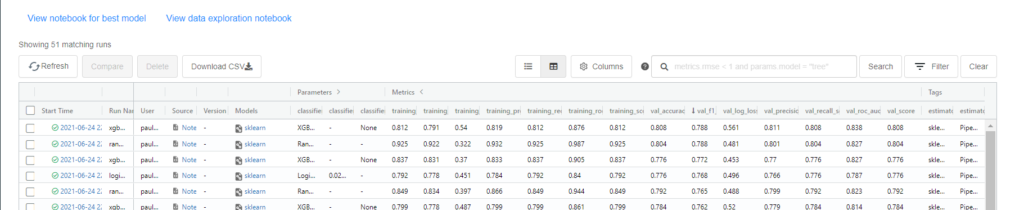
Au bout du temps imparti ou du nombre d’itérations, nous obtenons une liste des algorithmes que nous pouvons trier selon les différentes métriques.
Une très bonne surprise est de trouver, associé à chaque exécution, le notebook correspondant !
C’est encore XGBoost qui a gagné (comme souvent sans feature engineering préalable).
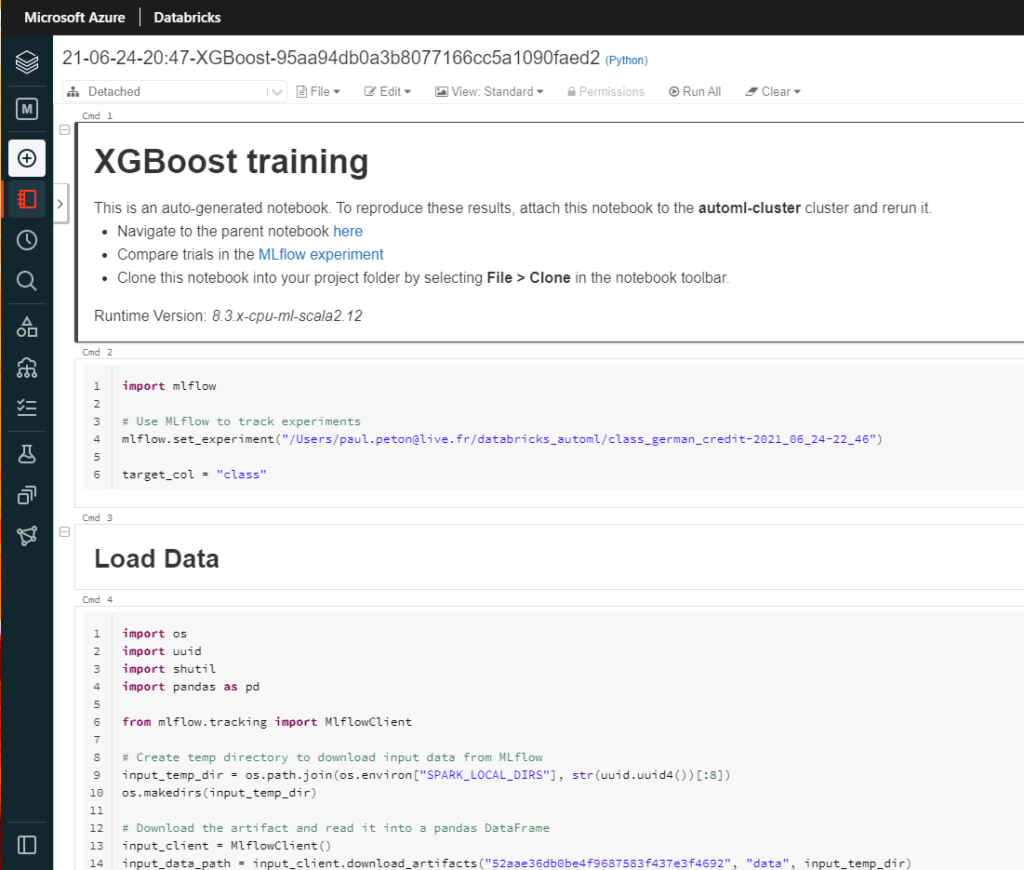
Celui-ci suit une cheminement tout à fait classique, donné par le plan en Markdown.
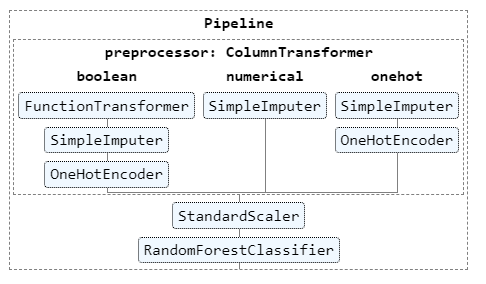
Une preprocessing des données est appliqué, sous forme depipeline Scikit Learn, pour les différents types de variables :
variables binaires : imputation des valeurs manquantes et recodage en 0/1
variables numériques : imputation par la moyenne
variables catégorielles : dichotomisation (one hot encoding)
Cette première étape du pipeline est suivi d’un standardisation, par exemple avec la méthode StandardScaler(), toujours issue du package Scikit Learn.
Nous pouvons visualiser ce pipeline graphiquement.
Le modèle est lui aussi explicitement codé et nous pouvons donc découvrir les valeurs spécifiques des hyperparamètres du modèle utilisés lors de l’exécution.
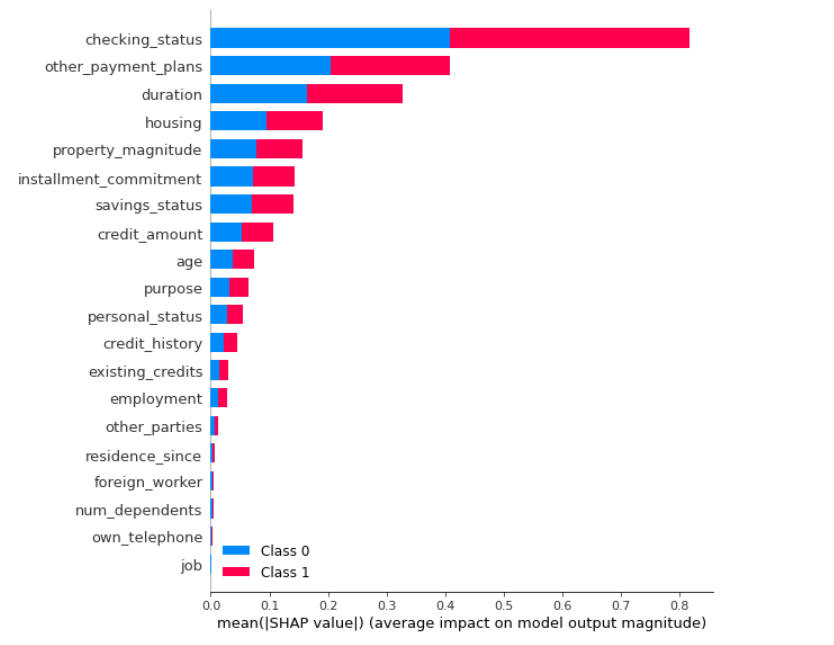
Enfin, une explication du modèle par la méthode SHAP, classant les features par importance,a été codée ainsi que les commandes MLFlow permettant d’enregistrer puis de charger un modèle (inférence).
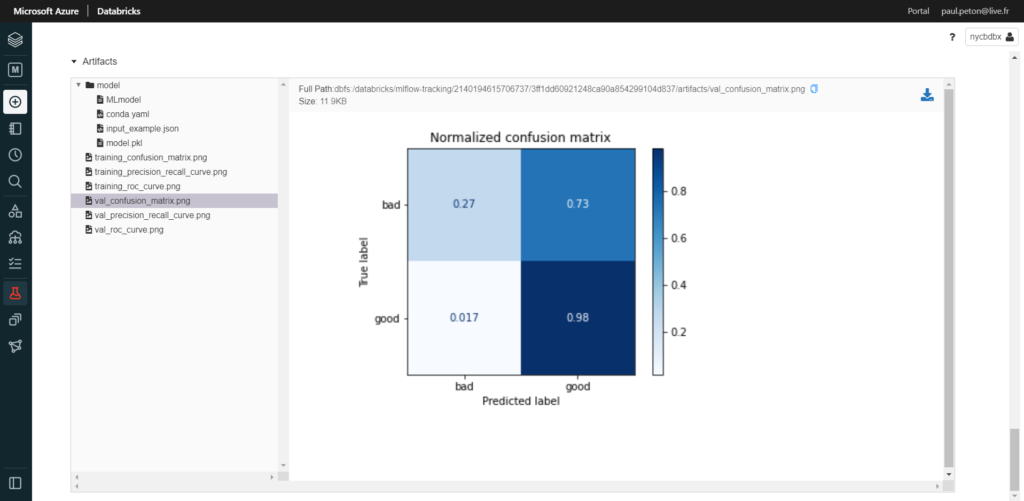
En cliquant sur le lien de la colonne “Models”, nous retrouvons les artefacts liés au modèle : un binaire sérialisé au format Pickle, mais aussi quelques graphiques comme la courbe ROC ou la matrice de confusion.
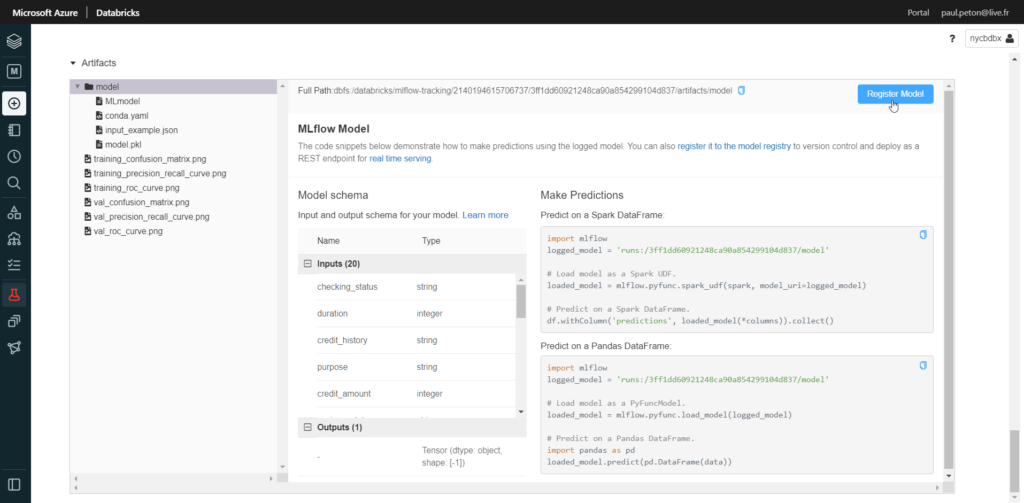
Il ne restera plus qu’à enregistrer le modèle dans MLFlow register pour pouvoir ensuite l’exposer.
En conclusion, nous avons ici un outil d’apprentissage automatisé qui vient ajouter une fonctionnalité à “la plateforme unifiée de données” qu’est Databricks. Cet outil se destine, à mon sens, à des Data Scientists voulant gagner du temps sur le codage de modèles simples (issus de la bibliothèque de Scikit Learn), sur des données déjà contrôlées et nettoyées (a minima, le retrait des valeurs aberrantes).
Nous pourrons regretter l’absence d’alertes automatiques sur les colinéarité entre variables soumises au modèle mais le notebook d’exploration basé sur pandas_profiling nous permet d’obtenir ces informations. Ce type d’outils pousse facilement au sur-apprentissage et c’est une limite qu’il faudra bien garder en tête.
Le fait de proposer le code sous forme de notebooks est un très grand avantage sur d’autres plateformes d’automated ML (rien n’empêche d’améliorer ce code par soi-même !). En étant exigeants, nous pourrions attendre de Databricks que celui-ci soit écrit pour profiter de la puissance du calcul distribué sur les nœuds du cluster (pourquoi pas avec le package koalas ?) mais des évolutions viendront sûrement prochainement.
Voici un article simple pour vous accompagner dans les premières étapes de création d’un espace de travail (workspace) Azure Machine Learning, et en particulier sur le choix des paramètres de ce service et de ceux qui l’accompagnent.
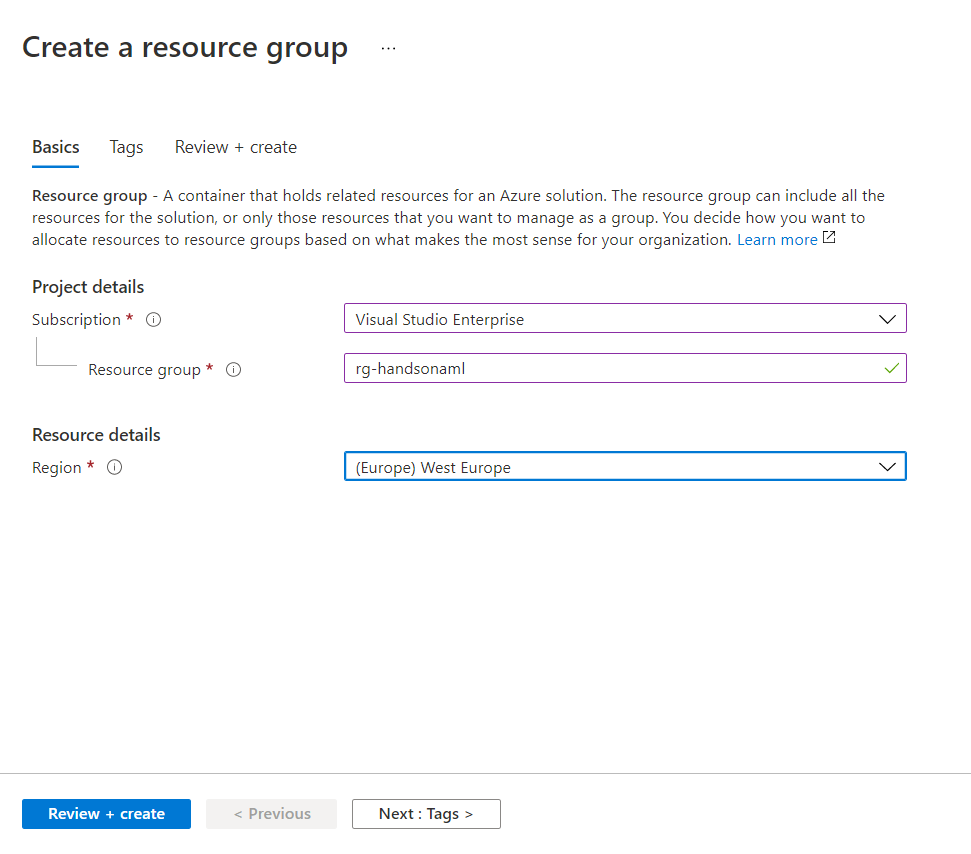
Depuis le portail Azure, nous commençons par créer un groupe de ressources dédié.
Une bonne (excellente !) pratique consiste à ajouter des tags lors de la création de chaque ressource Azure. Nous appliquerons également cette pratique lors de la création des éléments propres à l’univers Azure ML.
Le groupe de ressources est maintenant prêt. En cliquant sur le bouton “Create” puis en recherchant “Machine Learning”, nous trouvons le service recherché.
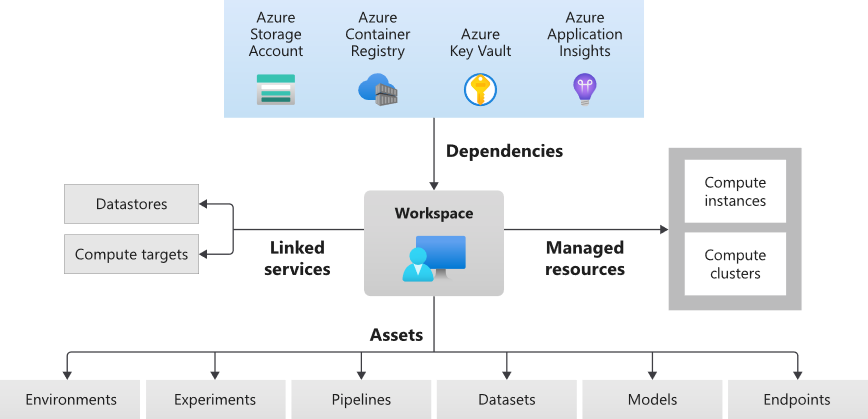
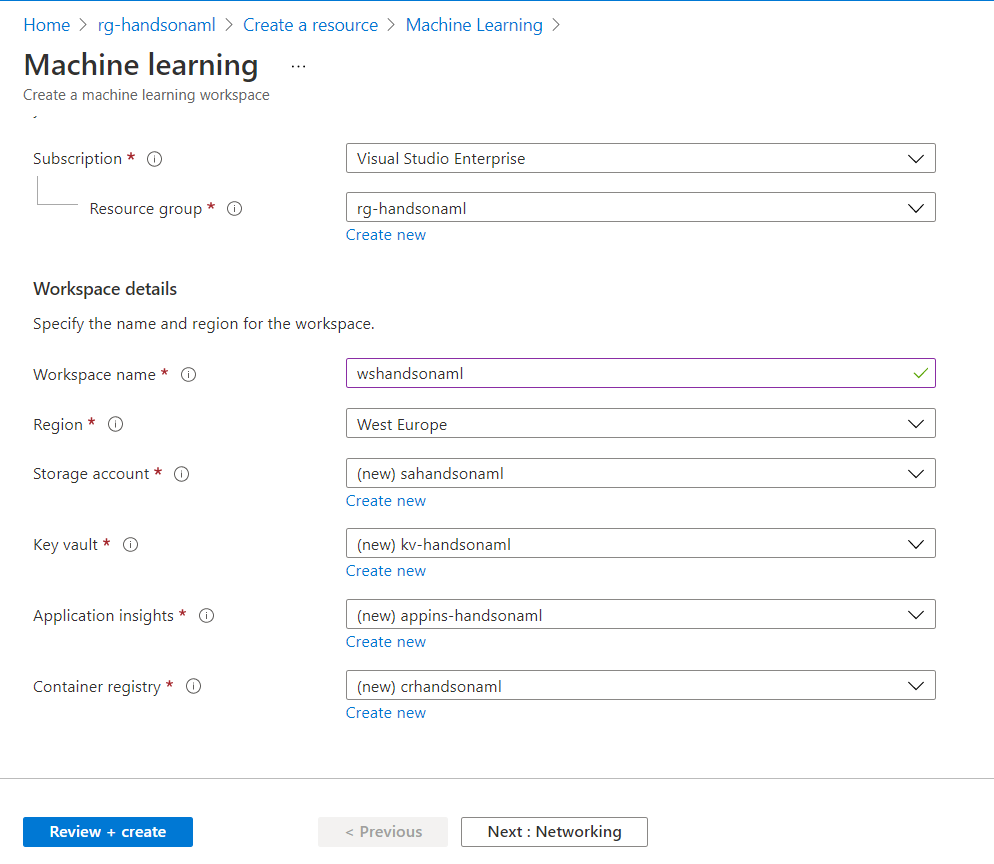
Même si nous ne choisissons ici qu’un seul service, il faut comprendre que celui-ci s’accompagnera de trois à quatre autres services Azure, comme détaillé sur ce schéma, issu de la documentation officielle de Microsoft.
Storage Account : le compte de stockage, où seront écrits tous les fichiers nécessaires à l’utilisation d’Azure ML comme par exemple des jeux de données importés, des journaux d’exécution, des artefacts de modèles, etc.
Key Vault : le magasin de secrets qui permettra le stockage sécurisé des clés, jetons d’authentification, mots de passe, etc.
Application Insights : fonctionnalité d’Azure Monitor, ce service permettra le suivi des ressources en temps réel, comme par exemple la disponibilité et les temps de réponse d’un point de terminaison (endpoint)
Container Registry : cette ressource est facultative, elle ne deviendra nécessaire que lors du déploiement de modèles prédictifs sur un service web. Mais comme ce scénario correspond à la finalité de nombreux cas d’usage du Machine Learning, nous ne pourrons nous en passer, dans les faits. Ce sont des images Docker qui seront enregistrées dans cette ressource.
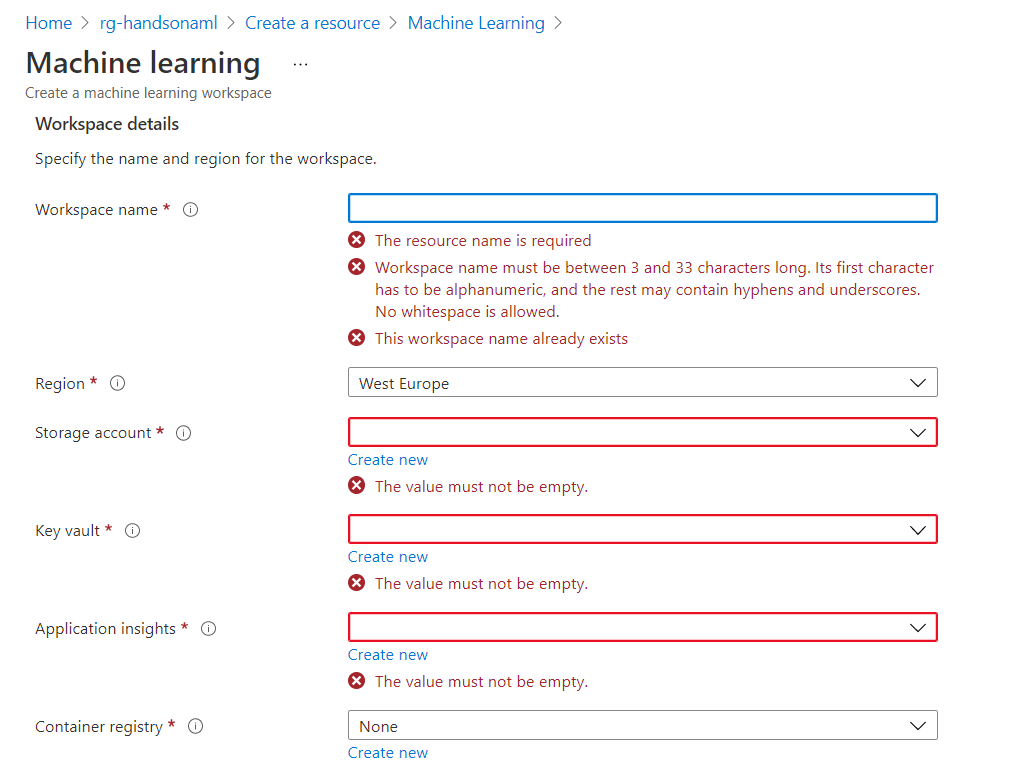
Des règles de nommage (malheureusement variables d’un service à l’autre) devront être respectées : nombre de caractères, autorisation ou non de l’usage des tirets haut ou bas, chiffres… et parfois unicité du nom dans l’ensemble du cloud Azure !
Pour un usage en entreprise, le plan de nommage ne doit pas être pris à la légère. Il ne serait pas incohérent d’y passer plusieurs jours de réflexion tant celui-ci sera ensuite immuable et jouera sur la capacité des utilisateurs à bien appréhender les ressources (distinguer les environnements de développement et de production, simplifier l’analyse de la facturation, etc.).
Idéalement, ou dans une approche d’Infrastructure as Code avec l’outil Terraform, nous aurions préalablement créé ces quatre services, dans le même groupe de ressources, afin de les associer dans cet écran de paramétrage.
Nous pouvons néanmoins les créer individuellement en cliquant sur le bouton “Create new“. Nous n’aurons toutefois pas la main sur l’ensemble des paramètres disponibles lors de la création individuelle de ces ressources.
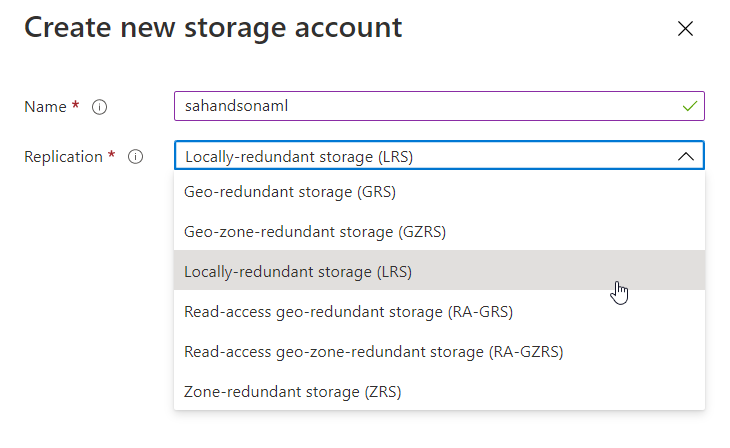
Pour le compte de stockage, nous choisissons le niveau de redondance le plus faible, et donc le moins coûteux: LRS.
Ce choix s’entend dans une approche de test, mais pour un usage “en production”, il se poserait la question de comment restaurer le service Azure ML en cas de perte du compte de stockage associé. La documentation actuelle ne fait pas part de ce type de procédure.
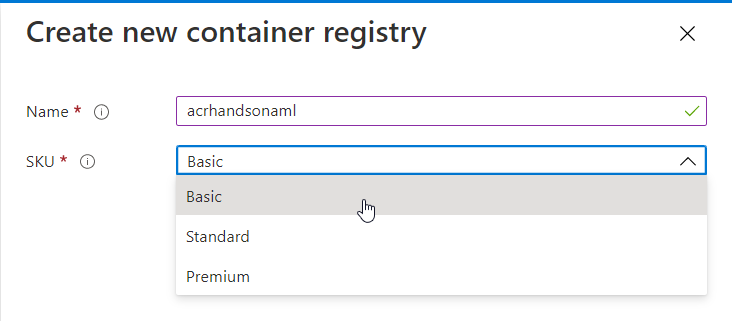
Pour la création de la ressource Container Registry, nous choisissons le mode de licence Basic qui autorisera la stockage, sans surcoût, de 10Go d’images.
Voici donc nos ressources créées et correctement nommées.
Nous ne modifierons pas ici les paramètres réseaux par défaut. Ceux-ci autorisent la connexion issue de tous réseaux à notre service.
Deux options sont disponibles dans les paramètres avancés, nous les laisserons positionnées par défaut.
Terminons enfin par cette bonne pratique consistant à taguer notre nouveau service.
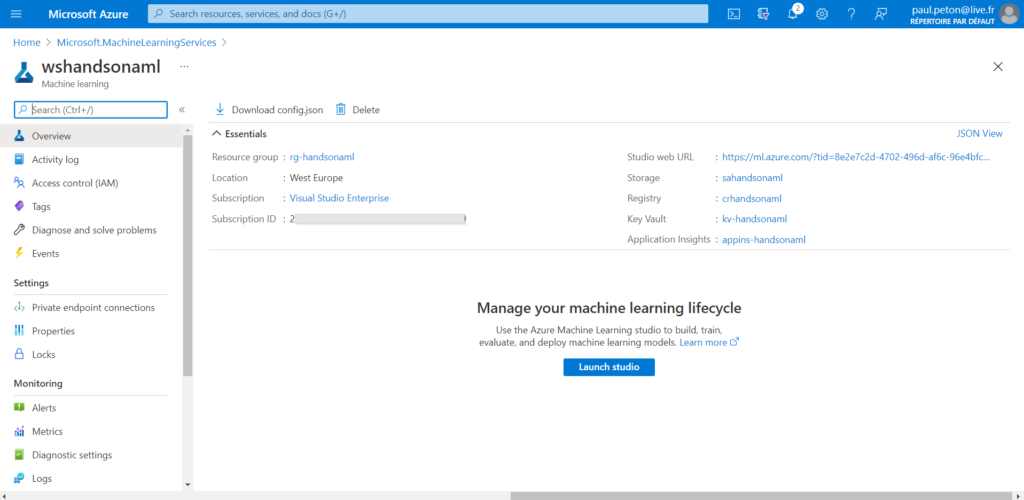
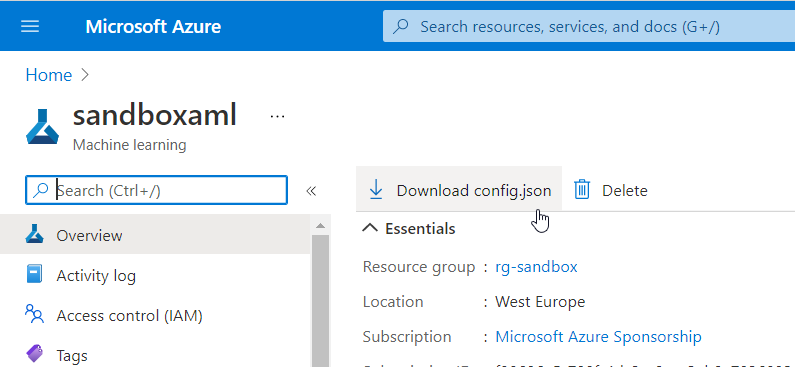
La ressource est maintenant créée et prête à l’usage !
Notez le bouton “download config.json“, ce fichier contiendra des informations de connexion à la ressource depuis un autre environnement que le portail Azure Machine Learning.
Nous retrouvons bien nos quatre ressources liées, listées sur la droite de la page.
Le bouton “Launch studio” permet d’ouvrir dans une nouvelle fenêtre le portail dédié à cet espace de travail Azure ML.
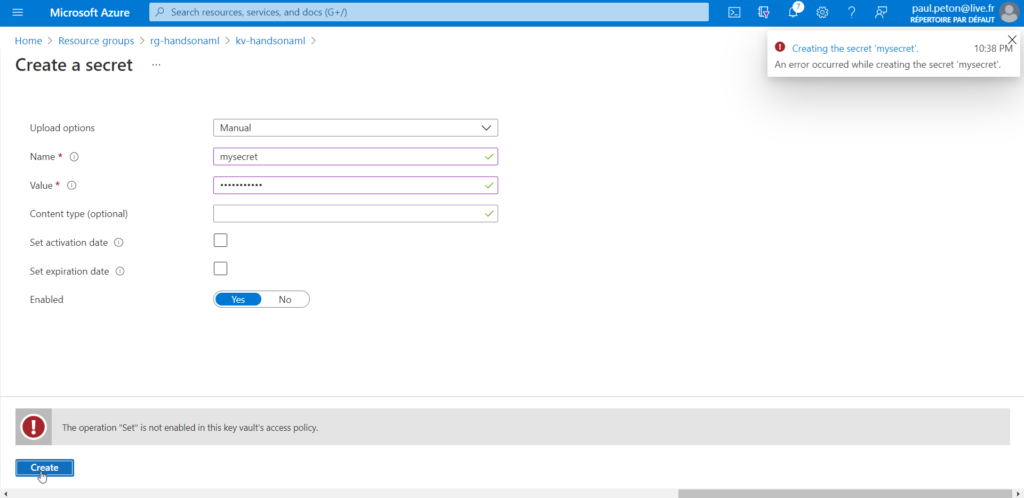
EDIT 20210616: la configuration du Key Vault n’est pas tout à fait complète ou tout du moins utilisable. En effet, même si vous êtes “owner” de la ressource, vous ne pourrez pas par défaut ajouter de secrets.
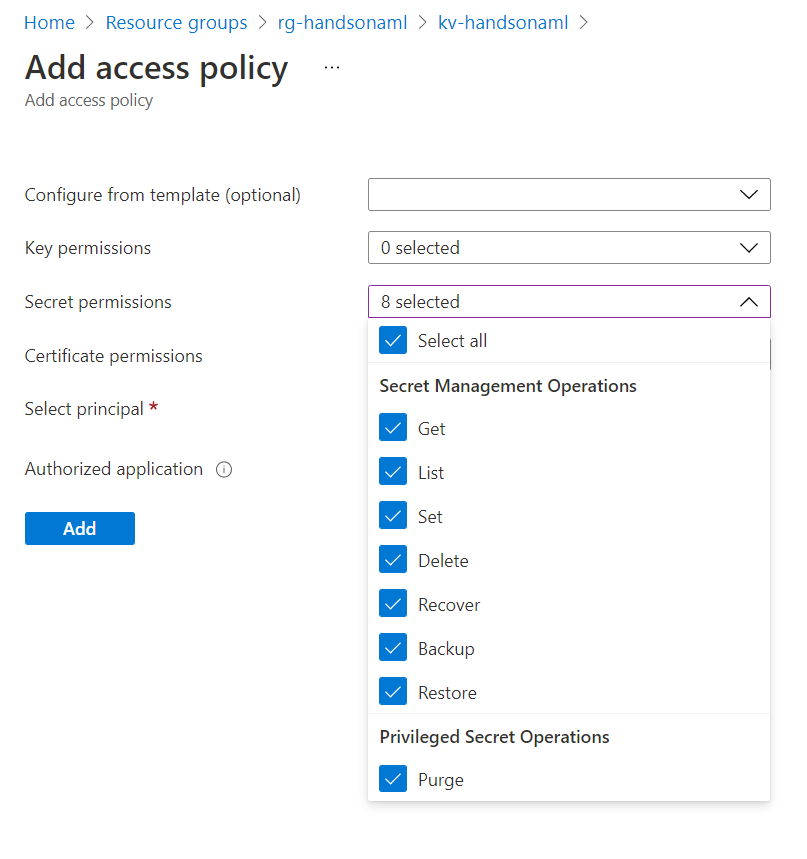
Il sera nécessaire d’ajouter une “access policy” pour l’utilisateur (à désigner dans la case “select principal”, à partir des utilisateurs déclarés dans Azure Active Directory).
Ne pas oublier d’enregistrer cette nouvelle policy avec le bouton “save” !
Il sera alors possible d’y renseigner des informations propres à la connexion, comme par exemple l’account key d’un compte de stockage ou le client secret d’un principal de service.
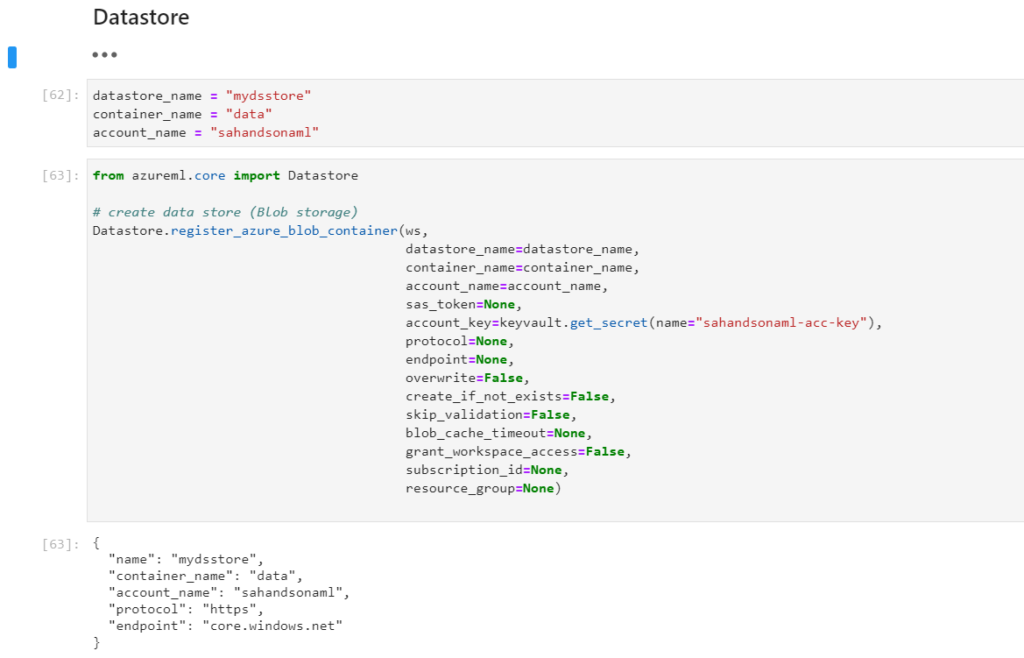
Ensuite, une approche par le code permettra de créer de nouveaux datastores.
Le code illustré ci-dessus est disponible dans ce notebook.
En résumé, toute cette installation mériterait d’être abordée en infra as code, par exemple avec l’outil Terraform !
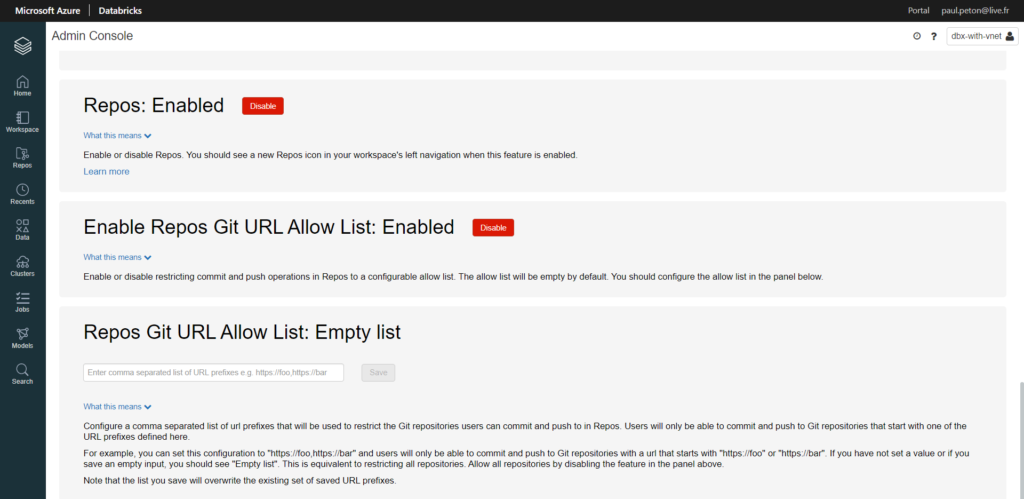
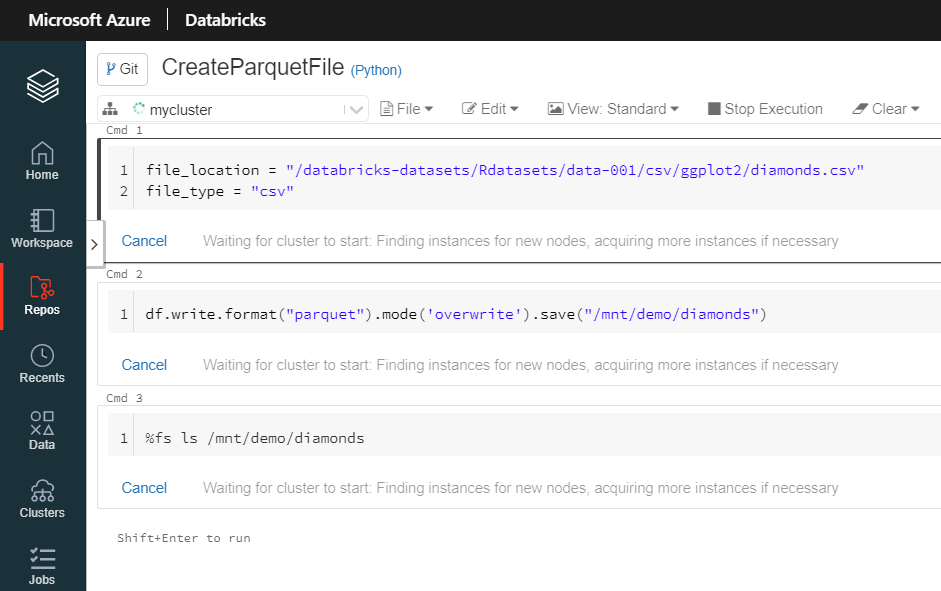
Au mois de mars 2021, une nouvelle fonctionnalité vient accompagner les espaces de travail Azure Databricks : les repos Git.
Pour l’activer, nous devons passer par la console d’administration, cliquer sur “Enable” puis rafraîchir la page.
Une nouvelle icône apparaît alors dans le menu latéral.
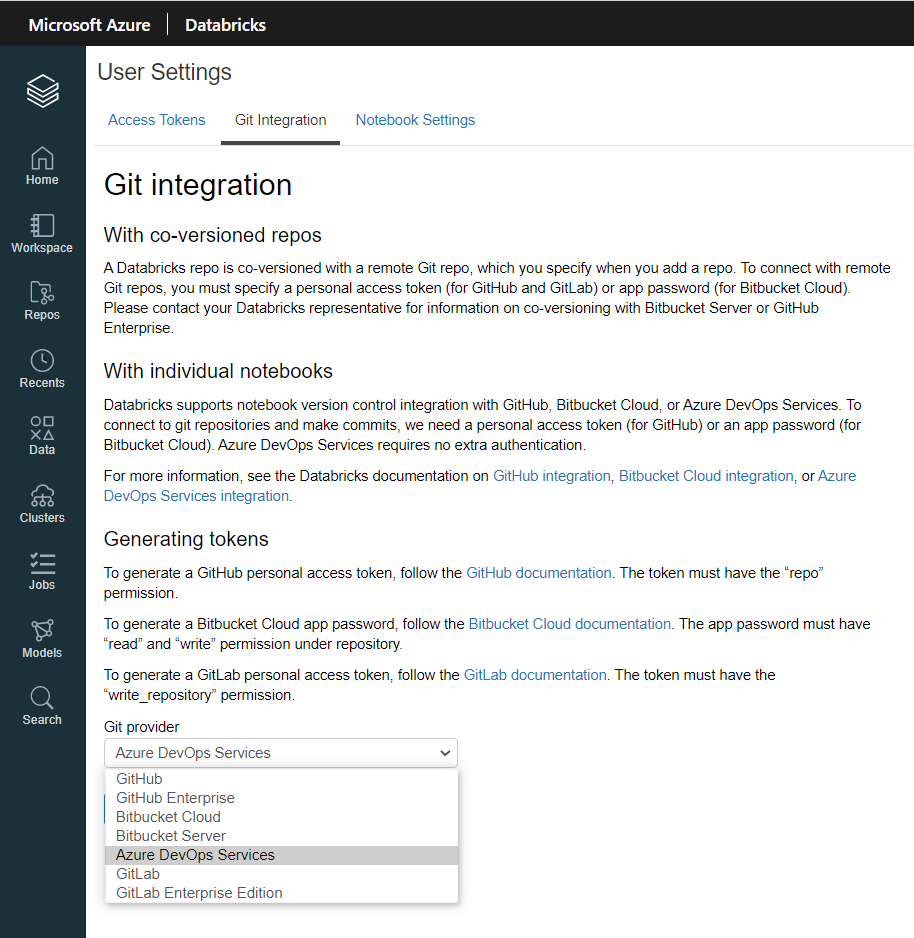
Jusqu’ici, le lien avec un gestionnaire de versions se faisait individuellement, par le biais de de la fenêtre “user settings“, comme expliqué dans cet article.
Chaque notebook devait alors être relié manuellement à un repository. Pour des actions de masse, il fallait employer les commandes en ligne (Databricks CLI).
Pour démarrer, nous cliquons sur l’icône Repos et le menu propose un bouton “Add Repo“.
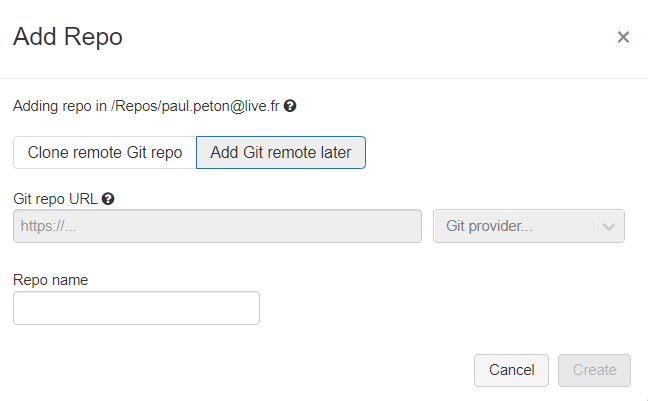
Une boîte de dialogue s’ouvre alors.
Il faut comprendre ici qu’il s’agit de créer un repository local au sens de l’espace de travail (“Add Git remote later”) ou bien de cloner un repo “remote“, c’est-à-dire relié à un des fournisseurs présents dans la liste. Ce dernier peut être vide si le projet débute.
Nous créons ici un premier notebook dans ce nouveau repository local.
Il faut alors s’habituer à une nouvelle façon de travailler. Les notebooks ne sont plus visibles depuis l’icône “Workspace”. Le lien “Git: Synced” que l’on trouvait en cliquant sur “Revision history” n’existe plus. Mais une icône Git apparaît maintenant en haut à gauche du notebook.
L’historique des modifications s’enregistre toujours bien automatiquement et des retours arrières (“Restore this version”) sont possibles.
Sans réaliser l’association avec un gestionnaire de versions tiers, nous ne disposons pas d’autres fonctionnalités.
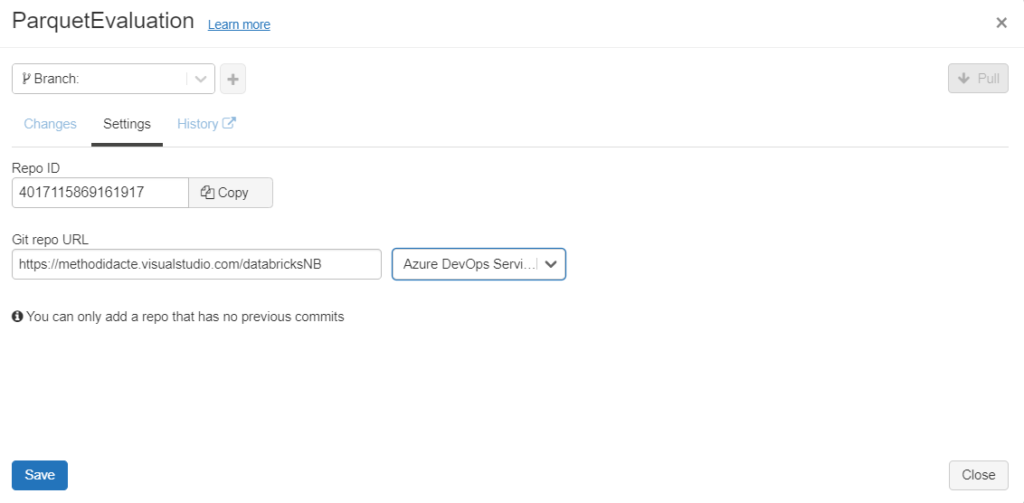
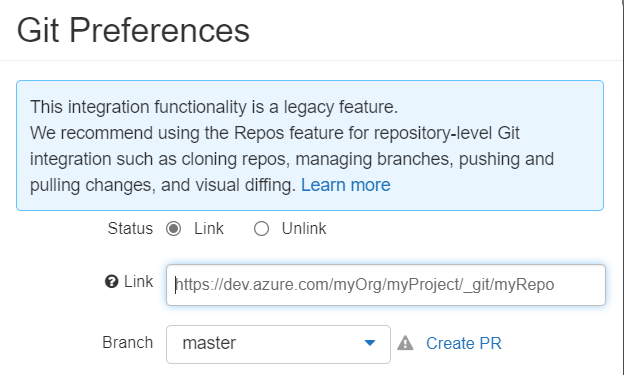
Un clic sur l’icône Git nous propose de réaliser cette association, ici avec le service Azure DevOps.
Attention, on ne peut attacher qu’un dépôt qui ne contient pas de commit.
Pour un repository de type privé, il va être nécessaire de réaliser des manipulations de sécurité.
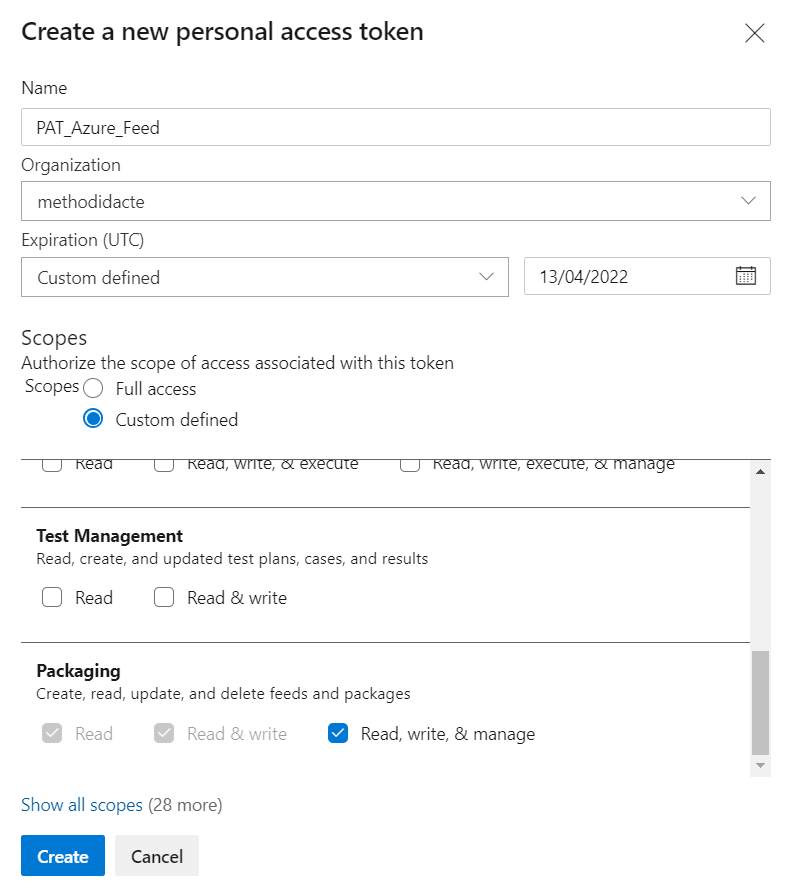
Il s’agit de fournir un Personal Access Token (PAT) généré depuis le gestionnaire de versions.
Une fois la configuration réalisée, la boîte de dialogues ci-dessous apparaît alors.
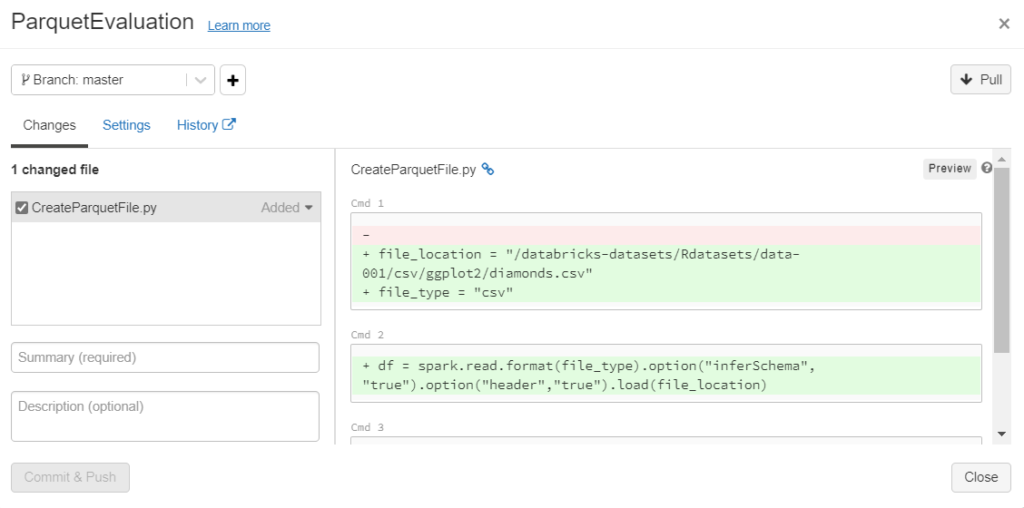
Nous retrouvons des notions familières aux utilisateurs de Git : branche (master ou main), pull, commit & push.
Il sera nécessaire (c’est même obligatoire) de saisir un résumé (summary) des modifications pour pouvoir cliquer sur le bouton “Commit & Push“.
En effet, une liste de repositories autorisés doit être donné dans la console d’administration (seulement si cette option a été activée). Ce scénario s’inscrit dans le cadre de la licence Premium de Databricks où tous les utilisateurs ne sont pas obligatoirement administrateurs.
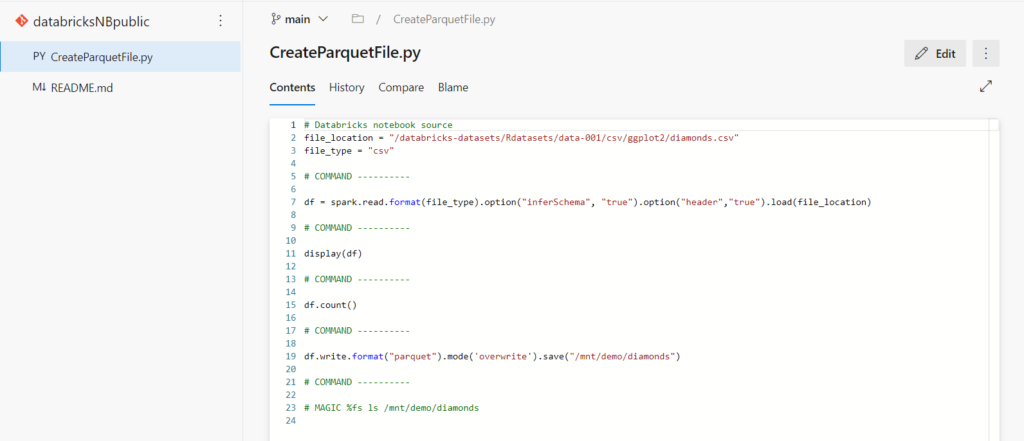
Notons que l’extension du fichier est .py mais il s’agit bien d’un notebook Databricks. Le contenu de celui-ci, en particulier les cellules Markdown, est arrangée pour “ressembler” à un script Python.
Attention, une commande comme display est propre à l’environnement des notebooks Databricks.
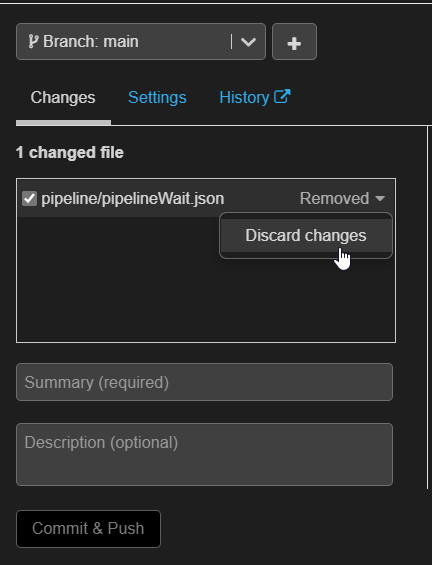
Si le repository est aussi utilisé pour conserver d’autres éléments que ceux propres à Databricks, nous verrons apparaître les dossiers du repo dans le menu de navigation de Databricks. Il pourrait être tentant de les supprimer depuis Databricks (ils sembleront vides puisque seules quelques extensions .py et .ipynb sont affichées) mais ne le faîtes surtout pas !
Une action “removed” serait alors être proposée au prochain commit. Il sera bien sûr possible de l’éviter en basculant sur “Discard changes“.
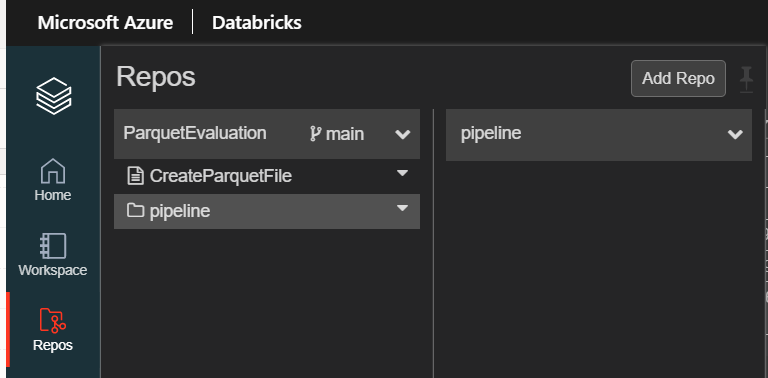
Ici, le repo est partagé avec des pipelines Azure Data Factory.
Le répertoire “vide” va alors réapparaître dans l’arborescence.
En conclusion, il serait préférable de dédier un repository à Databricks pour éviter les confusions.
EDIT 2021-08-23 :
La fonctionnalité originelle de liaison avec un repository Git est dorénavant une “legacy feature” et il est recommandé de ne plus l’utiliser.
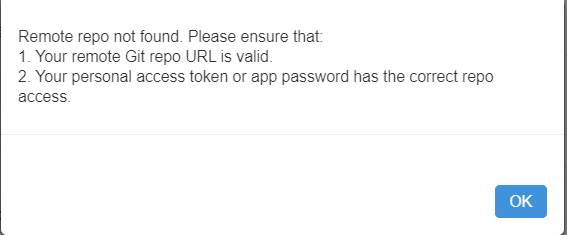
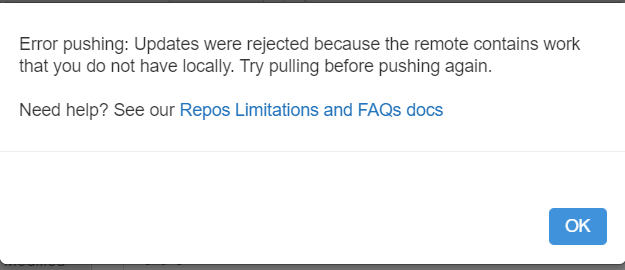
En poussant les tests, on obtient un blocage pour commiter depuis Databricks lors du scénario suivant :
publication réalisée depuis un outil tiers dans le repository partagé (par exemple, création d’un nouveau pipeline dans Azure Data Factory)
modifications d’un notebook dans Azure Databricks
sauvegarde de ces modifications
tentative de commit & push depuis Databricks
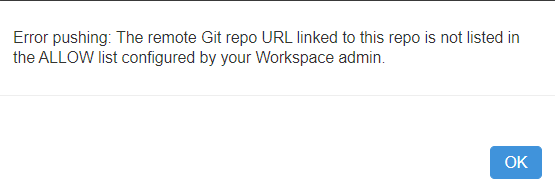
Nous obtenons alors le message d’erreur ci-dessous.
Il est indispensable de réaliser une action Pull avant de modifier les notebooks et nous recommandons de le faire avant même de débuter vos travaux sous Databricks.
Si les deux outils ont en partie des fonctionnalités qui se recouvrent, avec quelques différences (voir cet article), il est tout à fait possible de tirer profit du meilleur de chacun d’eux et de les associer dans une architecture data sur Azure.
Le scénario générique d’utilisation sera alors l’industrialisation de modèles d’apprentissage (machine learning) entrainés sur des données nécessitant la puissance de Spark (grande volumétrie voire streaming).
Nous allons détailler ici comment Databricks va interagir avec les services d’Azure Machine Learning au moyen du SDK azureml-core.
A l’inverse, il sera possible de lancer, depuis Azure ML, des traitements qui s’appuieront sur la ressource de calcul Databricks déclarée en tant que attached compute.
Le SDK azureml sous Databricks
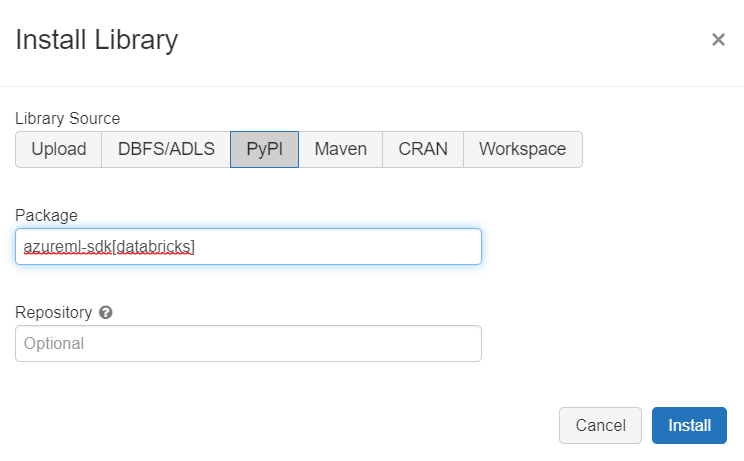
Nous commencerons par installer le package azureml-sdk[databricks] au niveau du cluster interactif (d’autres approches d’installation sont possibles, en particulier pour les automated clusters). Le cluster doit être démarré pour pouvoir effectuer l’installation.
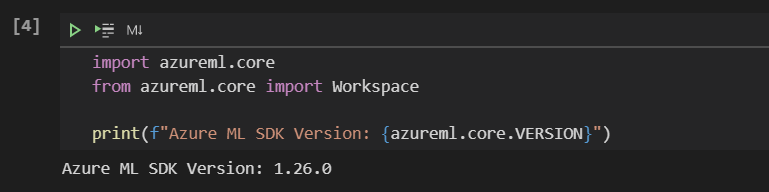
Nous pouvons vérifier la version installée en lançant le code suivant dans un notebook :
import azureml.core
print("Azure ML SDK Version: ", azureml.core.VERSION)
Un décalage peut exister avec la version du SDK non spécifique à Databricks. Des dépendances peuvent également être demandées pour certaines parties du SDK comme l’annonce l’avertissement reçu à l’exécution de la commande précendente.
Failure while loading azureml_run_type_providers. Failed to load entrypoint automl = azureml.train.automl.run:AutoMLRun._from_run_dto with exception (cryptography 3.1.1 (/databricks/python3/lib/python3.8/site-packages), Requirement.parse('cryptography<4.0.0,>=3.3.1; extra == "crypto"'), {'PyJWT'}).
L’étape suivante consistera à se connecter à l’espace de travail d’Azure Machine Learning depuis le script, ce qui se fait par le code ci-dessous :
from azureml.core import Workspace
ws = Workspace.from_config()
Plusieurs possibilités s’ouvrent à nous pour réaliser ce lien. La première consiste à établir explicitement ce lien dans le portail Azure, depuis la ressource Databricks.
Mais cette approche ne permet d’avoir qu’un seul espace lié, celui-ci n’étant plus modifiable au travers de l’interface Azure (mais peut-être en ligne de commandes ?). La configuration étant donnée par un fichier config.json, téléchargeable depuis la page du service Azure ML, nous pouvons placer ce fichier sur le DataBricks File System (DBFS), et donner son chemin (au format “File API format”) dans le code .
from azureml.core import Workspace
ws = Workspace.from_config(path='/dbfs/FileStore/azureml/config.json')
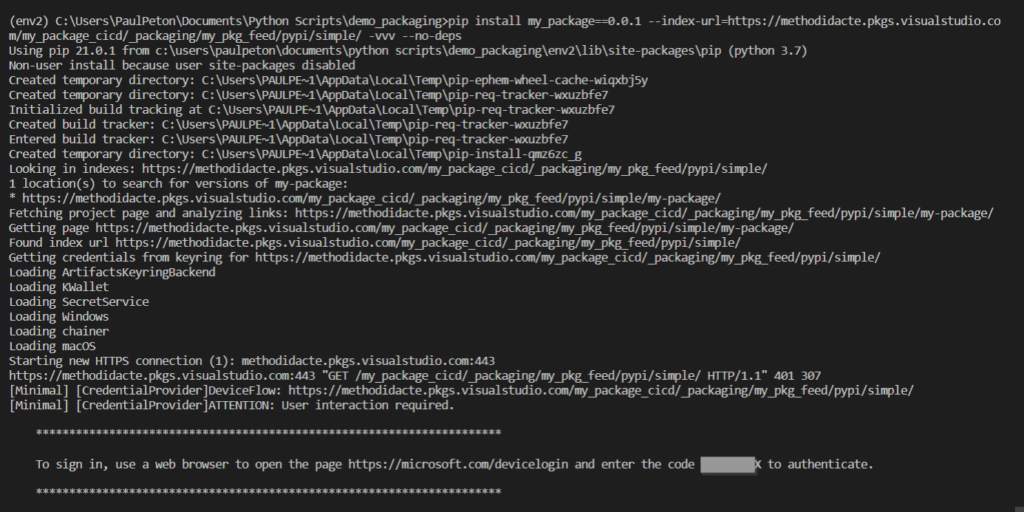
Une authentification “interactive” sera alors demandée : il faut saisir le code donné dans l’URL https://microsoft.com/devicelogin puis entrer ses login et mot de passe Azure.
Pour une authentification non interactive, nous utiliserons un principal de service.
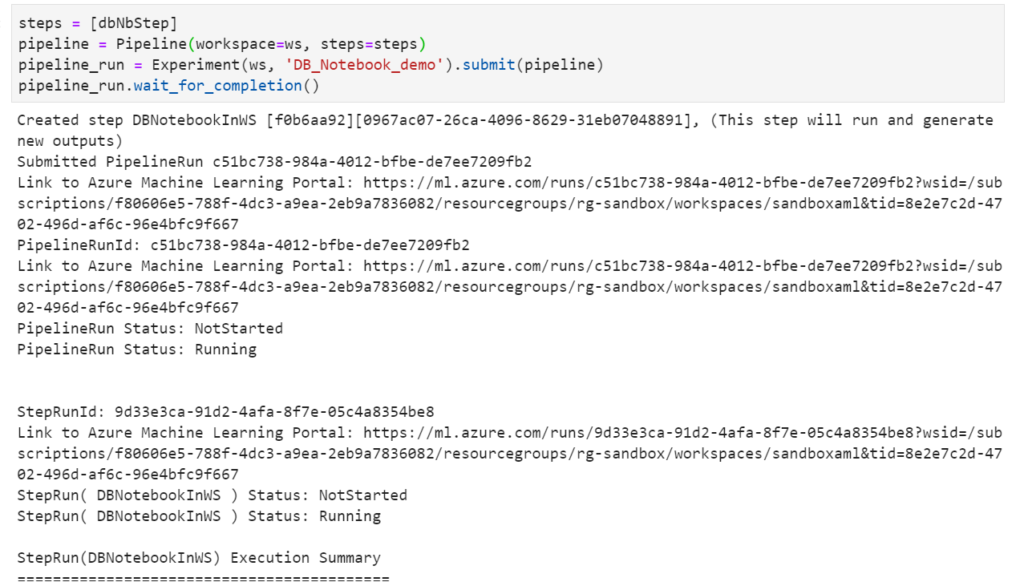
Nous pouvons maintenant interagir avec les ressources du portail Azure Machine Learning et en particulier, exécuter notre code au sein d’une expérience.
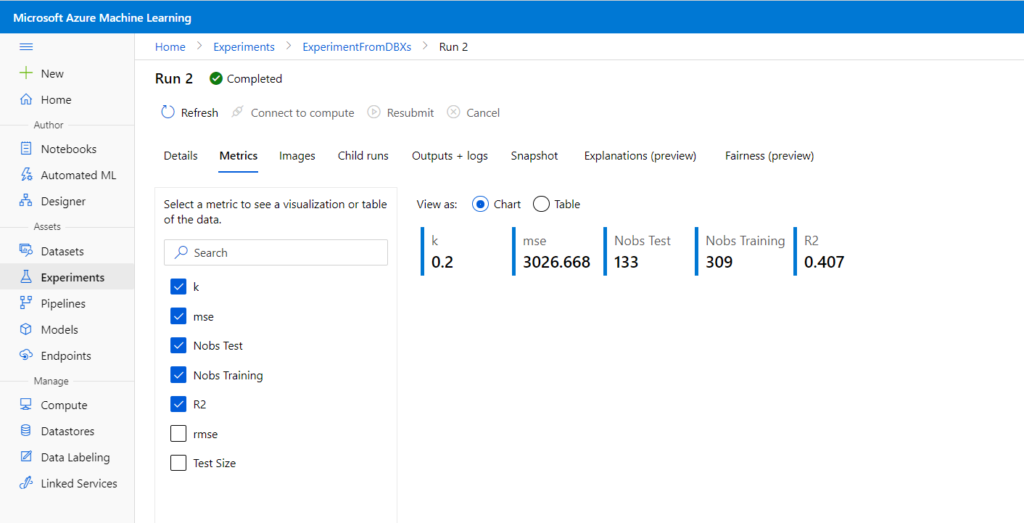
from azureml.core import experiment experiment = Experiment(workspace=ws, name="ExperimentFromDBXs")
Après l’entrainement d’un modèle, idéalement réalisé grâce à Spark, nous pouvons enregistrer celui-ci sur le portail.
L’instruction run.log() permet de conserver les métriques d’évaluation.
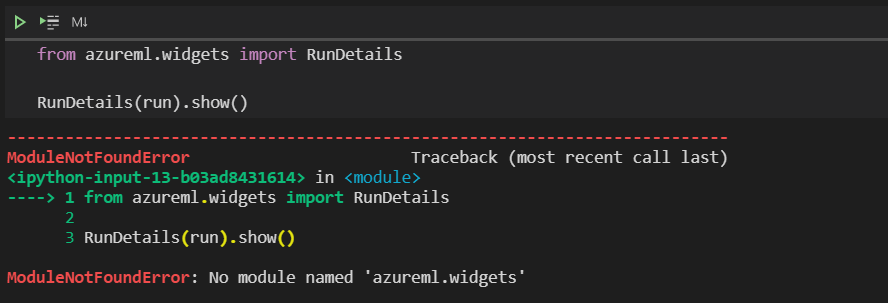
A noter que les widgets ne peuvent pas s’afficher dans les notebooks Databricks.
Databricks comme attached compute
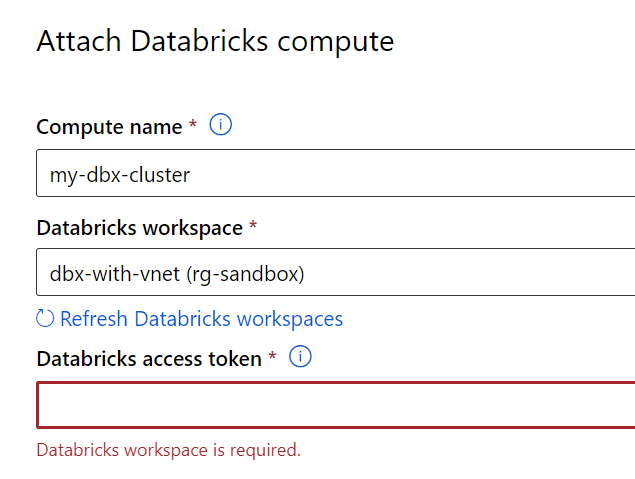
Comme pour toute ressource de calcul, nous commençons par déclarer le cluster Databricks dans le portail Azure Machine Learning.
Un jeton d’accès (access token) est attendu pour réaliser l’authentification. Nous prendrons soin de le générer grâce à un principal de service pour éviter qu’il ne soit attaché à une personne (“Personal Access Token”).
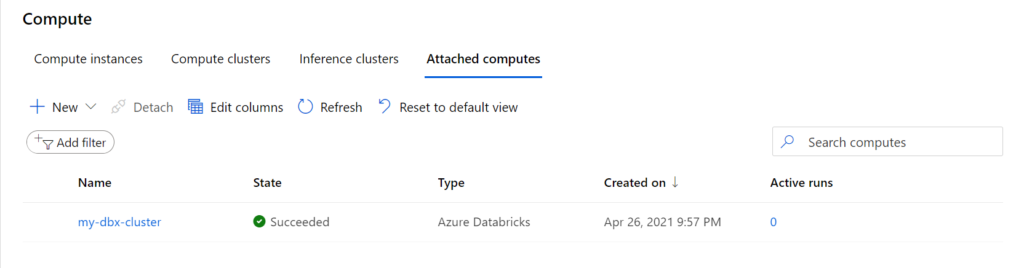
La ressource est maintenant correctement déclarée.
Nous allons l’exploiter au travers du SDK Python azureml dans lequel nous disposons de deux objets liés à Databricks.
La documentation présente la classe qui permettrait de créer cette ressource au travers du code :
DatabricksCompute(workspace, name)
Nous trouvons aussi dans la documentation l’objet qui crée une étape de pipeline exécutée ensuite au sein d’une expérience :
Il est possible de lancer un script Python qui sera exécuté sur le cluster Databricks mais l’usage le plus intéressant est sans doute l’exécution d’un notebook.
Nous pourrons alors suivre les logs du cluster dans l’expérience.
Je vous recommande ce notebook pour découvrir tous les usages de DatabricksStep, comme par exemple l’exécution d’un JAR.
En conclusion
La souplesse des services managés et la séparation stockage / calcul autorisent aujourd’hui à penser les architectures data avec les services qui sont les plus utiles au moment souhaité, quitte à avoir des redondances de fonctionnalités. Nous veillerons à préserver au maximum l’indépendance de certaines parties du code (a minima la préparation de données et l’entrainement) vis à vis des plateformes propriétaires. Il sera alors possible d’envisager des alternatives chez d’autres fournisseurs cloud ou bien encore dans le monde de l’Open Source.
Des machines virtuelles, du code R ou Python, des accès au Data Lake, du versionning et de l’exposition de modèles de Machine Learning, les points communs entre Azure Databricks et le service Azure Machine Learning sont nombreux ! Mais nous allons détailler dans cet article les différences entre ces deux produits, qui vous permettront de choisir le meilleur outil selon vos cas d’usage. N’oublions pas que ce sont aussi des outils complémentaires mais cet aspect sera traité dans un autre article.
S’il fallait résumer en quelques mots chacun des deux produits, voici comment l’on pourrait les présenter :
Databricks est un cluster Spark managé dans le cloud Azure (mais aussi AWS et GCP), dédié à exécuter du code de manière distribuée. Autour de cette fonctionnalité principale, s’intègrent des produits comme MLFlow pour le versionning et serving des modèles de ML ou encore SQL Analytics et Redash pour la visualisation de données.
Azure Machine Learning est un portail (dit “studio”) regroupant toutes les briques d’un projet de ML, allant de l’import des données depuis des sources Azure à l’exposition (web service) et monitoring de modèles, en passant par l’entrainement de ces modèles sur différentes solutions de calcul.
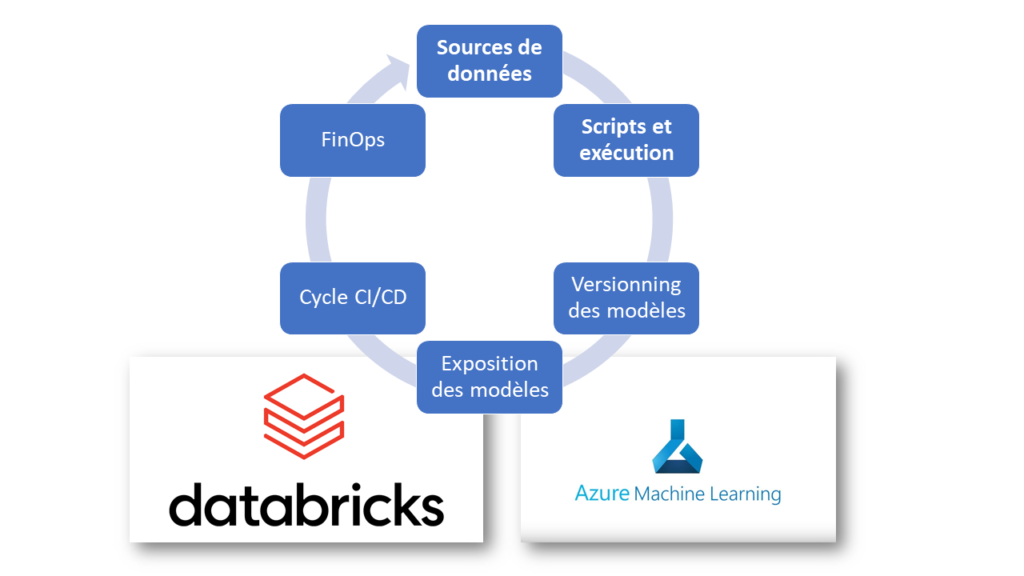
Nous allons pointer les différences entre ces deux services sur les thèmes indiqués dans le schéma ci-dessous, qui sont au cœur d’un workflow de Data Science.
Les sources de données
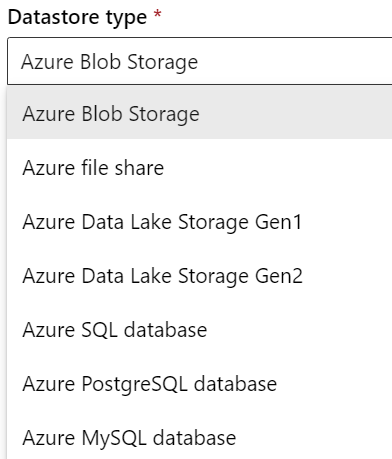
Les sources possibles pour Azure ML sont toutes des services managés du cloud de Microsoft, de type systèmes de fichiers ou bases de données.
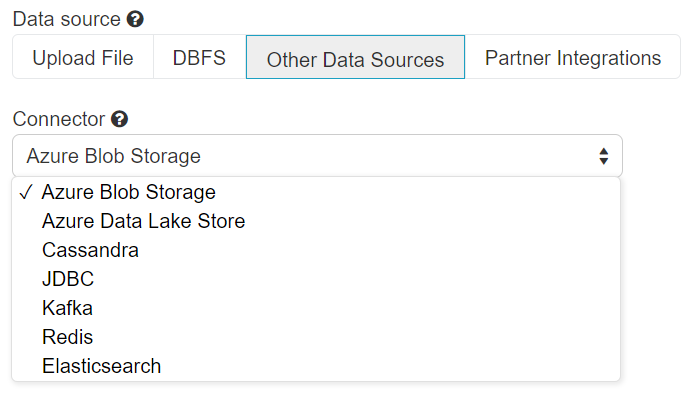
Les sources pour Azure Databricks sont représentées ci-dessous :
Le périmètre est ici plus large et intègre des produits classiques des architectures Big Data dans les domaines NoSQL, temps réel ou search.
La connexion à des ressources de type Azure SQL DB ou DWH se fait par un pilote générique JDBC, comme cela a été présenté ici préalablement. C’est une approche plus générique mais qui ne pas bénéficier d’optimisations propres à la communication de services Microsoft entre eux. C’est un point qui mériterait d’être testé, dans des conditions de sécurisation des échanges réseaux (VNET).
L’un des projets Open Source très présent dans Databricks est Delta Lake : un format de fichier “amélioré” par rapport au format Parquet classique, puisqu’il s’accompagne d’une capacité à traiter des transactions ACID et d’un historique au format JSON des logs transactionnels. Ce sont des opérations comme des delete, insert, update et upsert qui seront possibles ! La fonctionnalité de time travel permet de retrouver l’état des données à une date ou sur une version donnée. Nous sommes donc dans une logique “schema-on-write” d’habitude propres aux systèmes de gestion de bases de données. Est-ce déjà la fin annoncée de ces derniers ? Certainement pas !
Voici la syntaxe permettant d’écrire un dataframe Spark au format delta.
Delta Lake est un produit à part entière, alors peut-on l’utiliser depuis Azure ML ? Rappelons qu’il faut un contexte Spark et c’est ici toute la difficulté pour Azure ML qui doit, pour cela, se baser sur une ressource tierce comme Azure Synapse Analytics ou… Azure Databricks !
Les scripts et leur exécution (calcul)
Azure ML disposent de deux SDK, Python et R, mais il ne sera pas possible d’utiliser de langage Java ou Scala. Au delà de la création d’un dataset sur une source Azure SQL DB, le SQL ne pourra être utilisé qu’au travers de packages R ou Python.
Le périmètre est plus large pour Databricks dont les notebooks exécuteront Python, R, Scala ou du SQL. Ce choix se fait à la création du notebook mais n’est pas rédhibitoire car les commandes magiques permettent de changer de langage dans une cellule : %python, %r, %scala, %sql.
Même si la plupart des Data Scientists sont plus enclins à développer en R ou Python, et dans les déclinaisons SparkR et PySpark, Scala reste le langage natif de Spark et certainement pour l’instant le plus efficace car compilé avant de s’exécuter.
Pour utiliser Scala avec Azure ML, nous attendrons la fonctionnalité de “linked service” vers Azure Synapse Analytics.
L’exécution d’un script dans Azure ML peut se faire une instance de calcul (la VM qui exécute également le serveur de notebooks ou RStudio Server) ou sur un cluster de machines virtuelles.
Databricks est prévu “by design” pour les exécutions distribuées sur un cluster mais il est possible d’utiliser un “cluster single node“, c’est-à-dire une machine unique.
Le versionning des modèles
Commençons par le produit Open Source présent dans les deux services : MLFlow.
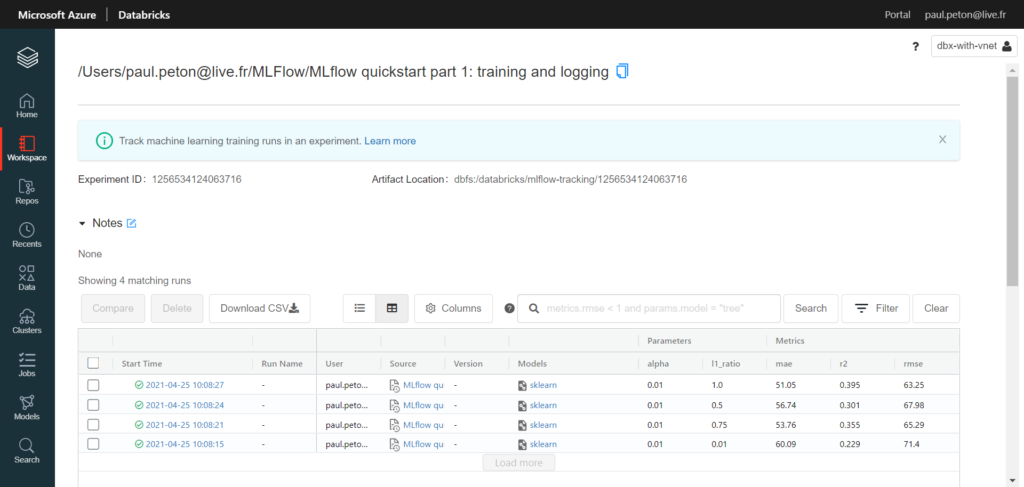
La même équipe se trouvant à l’origine de Spark et de MLFlow, nous disposons naturellement dans Databricks d’une intégration très simple et fluide. Le package est même installé par défaut sur les runtimes de type ML.
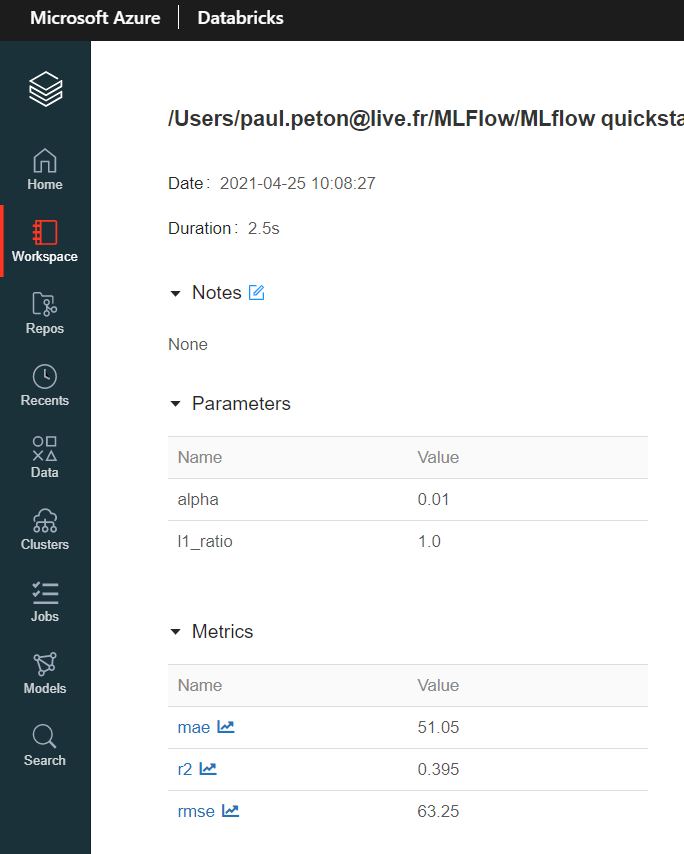
Les éléments nécessaires à l’évaluation et à la reproductibilité du modèle sont simples à enregistrer à l’aide de commandes comme mlflow.log_param, mlflow.log_metric, etc.
Azure ML permet donc également d’activer une URI MLFlow mais qui ne sera valable qu’une heure.
Vous risquez aussi le message d’erreur suivant :
WARNING mlflow.models: Logging model metadata to the tracking server has failed, possibly due older server version.
Il faut à mon sens voir le portail Azure ML comme principalement un outil d’affichage des logs d’exécution (runs) des scripts lancés au sein d’expériences. A nouveau, quelques commandes simples permettent d’enregistrer le binaire d’un modèle (artifact) et les informations associées : model.register, run.log, etc.
Pour remplacer la commande mlflow.sklearn.save_model, nous utiliserons dans Azure ML une déclinaison de l’exemple suivant :
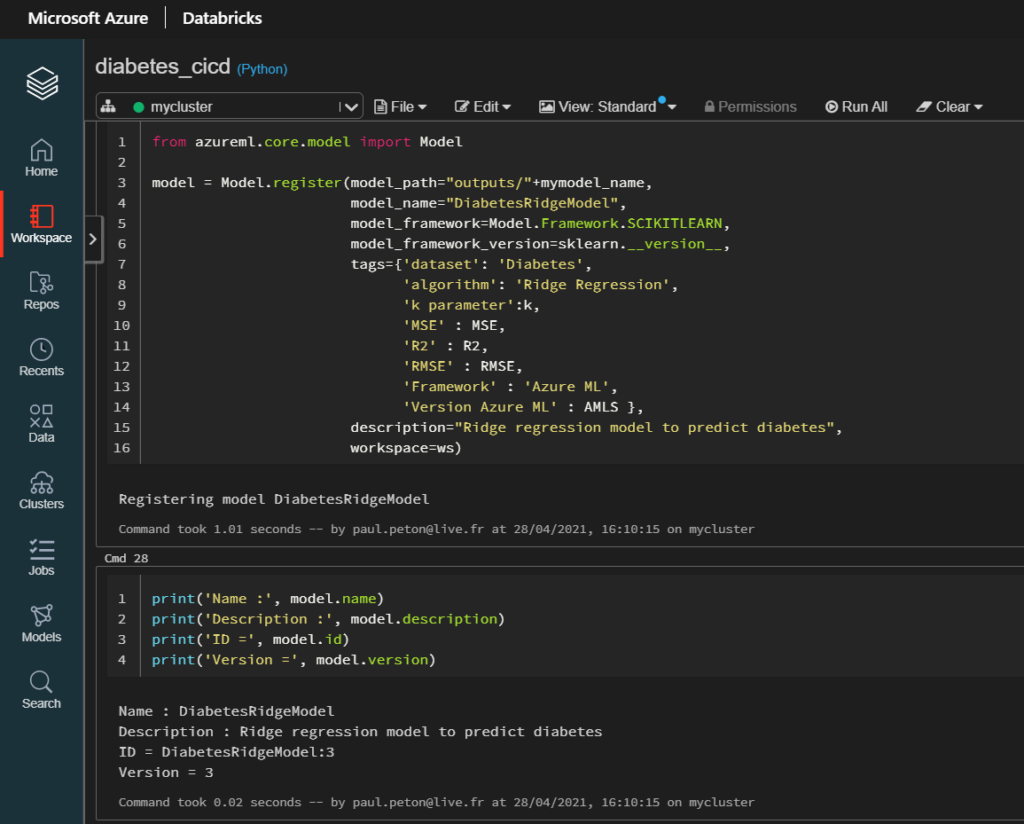
from azureml.core.model import Model
Model.register(workspace=ws,
model_name="diabetes_regression_model",
model_path="test_diabetes/model.pkl",
model_framework=Model.Framework.SCIKITLEARN, # Framework used to create the model.
model_framework_version='0.20.3', # Version of scikit-learn used to create the model.
tags={'alpha': alpha, 'l1_ratio': l1_ratio},
description="Linear regression model to predict diabetes"
)
Il est indispensable d’effectuer cette opération pour retrouver l’artefact en dehors du menu “Output & logs” de l’exécution.
L’exposition des modèles
Nous sommes ici dans le domaine de prédilection d’Azure ML qui permet une approche par l’interface ou au travers du SDK pour piloter deux ressources Azure : Container Instance et Kubernetes Services.
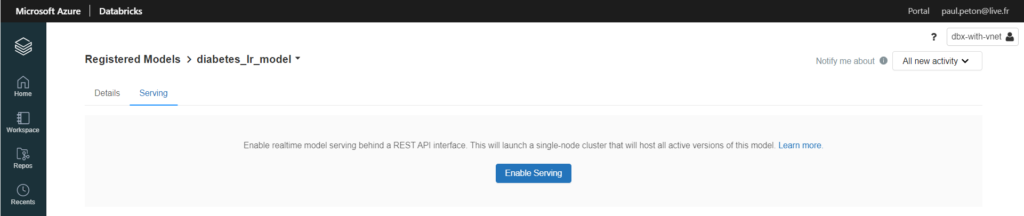
Mais Databricks n’est pas en reste pour l’exposition et celle-ci s’appuiera naturellement sur MLFlow. Nous commençons par enregistrer le modèle retenu.
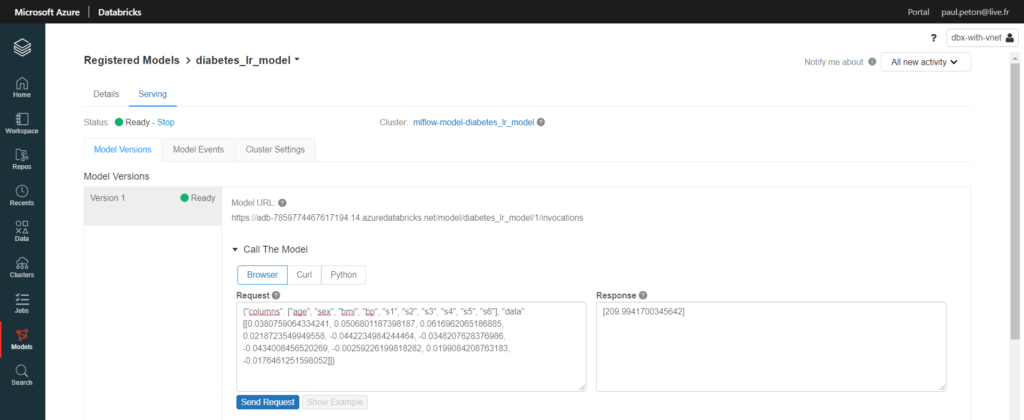
Ensuite, depuis le menu Model, nous pouvons activer le serving, qui se fera sur une ressource de type single-node.
Dès que la ressource (une machine virtuelle) est active, il est possible d’interroger l’API.
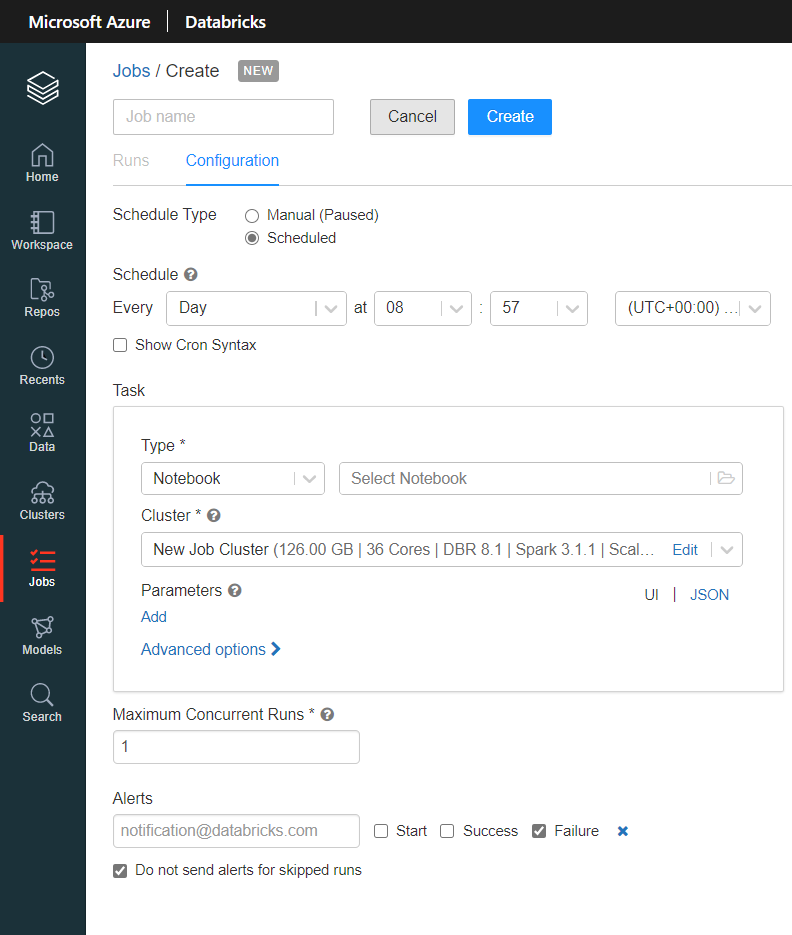
Ordonnancement
Dans une architecture Azure PaaS, c’est Azure Data Factory (ADF) qui est la solution toute désignée pour ordonnancer les traitements. Nous y disposons d’un module pour chacun des deux services. La différence se situe sur les éléments pouvant être appelés par ADF. Seuls les objets “Pipeline” issus d’Azure ML sont utilisables et ces objets ne sont pas simples à développer.
Les deux premiers modules ML concernent l’ancienne version du studio.
Côté Databricks, ce sont des scripts Python, des notebooks ou bien des Jar qui sont exécutables au travers de l’interface.
Les deux services ont également leur propre outil de scheduling, pilotable au travers de l’interface pour Databricks ou bien grâce à leur API.
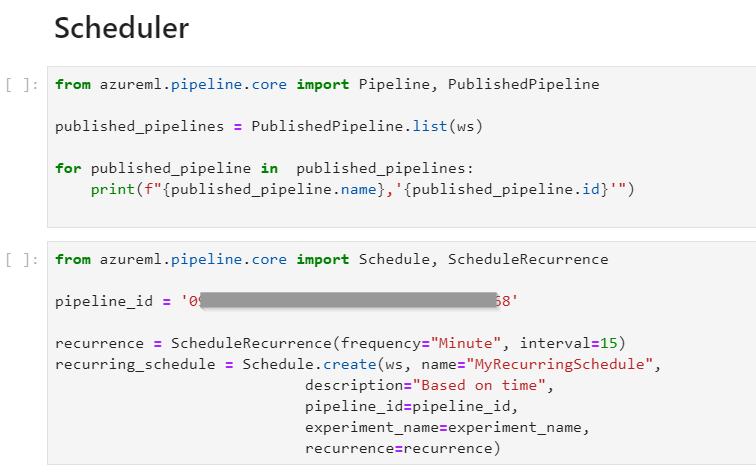
A l’aide du SDK Azure ML, nous pourrons mettre en place un trigger à l’aide du code ci-dessous :
Versionning du code et cycle CI/CD
Databricks permet de définir un fournisseur Git parmi les suivants :
Chaque notebook doit ensuite être lié au repository et il est possible de faire un commit sur une branche déjà créée (une pull request devant ensuite être faite depuis le fournisseur Git).
Récemment (mars 2021), une nouvelle approche est disponible et fournit plus de fonctionnalités.
Dans les notebooks d’Azure ML, aucun lien n’est fait avec un gestionnaire de version. Il faut donc ruser et passer par un IDE local comme Visual Studio Code qui pilotera les ressources de calcul à distance. J’ai détaillé ce fonctionnement dans cet article.
Passons maintenant à la problématique du déploiement entre deux environnements (par exemple, développement et production).
Lorsque le code se trouve versionné sur un dépôt Azure Repos, il est très simple de lancer de manière automatique un pipeline d’intégration qui réalisera des tests automatisés. Databricks s’appuiera sur une machine virtuelle munie du module databricks-connect qui permet d’exécuter du code à distance sur l’environnement Spark.
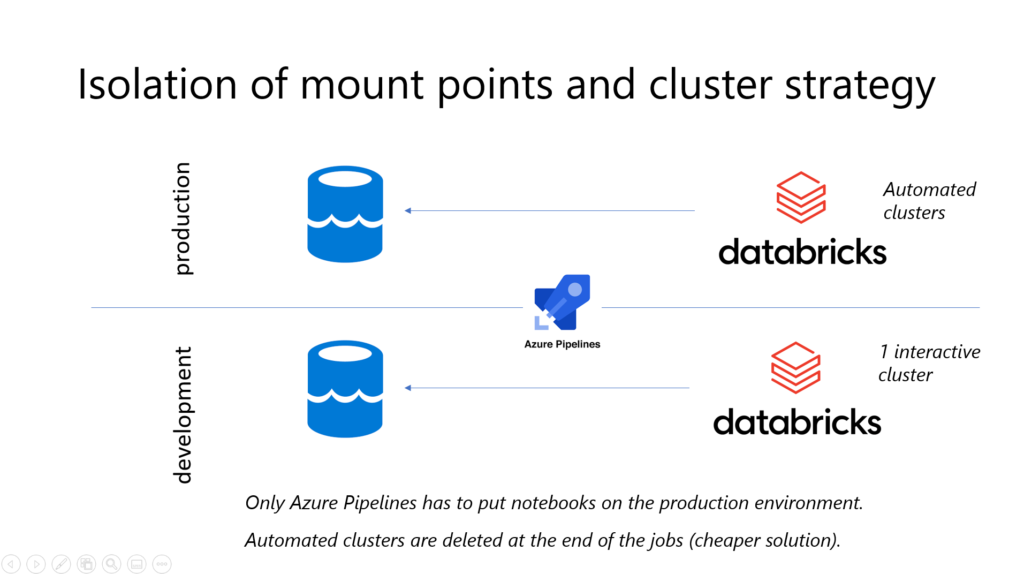
Le schéma ci-dessous résume l’isolation des environnements avec une architecture simple reposant sur un stockage Azure Data Lake et un espace de travail Databricks.
Des outils de release de la Market Place vont permettre de déplacer automatiquement des notebooks de l’environnement de développement vers celui de production.
En revanche, utiliser des ressources Azure ML par environnement est une question qui n’est pas simple à trancher. En effet, le portail est finalement une sorte d’outil “DevOps” (disons plutôt MLOps) en lui-même. Nous y trouverons ainsi les versions des datasets et des modèles, ainsi que les logs d’exécution permettant un suivi de production. Mais en pratique, et par manque d’outils de nettoyage (des expériences, des exécutions…), l’usage pour le développement va “polluer” le portail. Il sera donc indispensable de se donner des pratiques de gouvernance et de limiter les droits aux différents utilisateurs, par le biais des custom roles, comme décrit dans ce billet.
Databricks peut être utilisé comme “attached compute”, environnement d’exécution des scripts Spark.
Le Machine Learning ne se marie pas forcément bien avec l’isolation des environnements : en effet, pour démarrer le projet, il faut des données qui soient de qualité et suffisamment représentatives de la réalité. Ce n’est pas le cas des environnements de développement qui sont incomplets voire erronés. Un accès (en lecture) à la production depuis l’environnement de développement pourrait être à envisager.
Coût et FinOps
Suite au retrait de la licence Entreprise d’Azure ML, le coût d’utilisation ne correspond qu’au temps où sont utilisées les ressources de calcul. A cela s’ajoutent les services qui accompagnent Azure ML : compte de stockage, Key Vault, app insights et surtout container registry. Il faut penser à purger régulièrement ce dernier car un container registry ne donne que 10Go de stockage gratuit.
Il est tout à fait possible d’utiliser les mêmes types de VMs sur les deux outils. Pour autant, le coût d’une VM est “surchargé” par la licence Databricks, exprimée en DBU. Cette licence se décline elle-même selon le type d’espace de travail (standard ou premium) et le type de cluster (interactif ou automated).
Une piste supplémentaire est d’utiliser des “spot instances” moins chères, donnant une nouvelle opportunité d’optimisation des coûts (au détriment de la rapidité d’exécution), comme présenté dans cette vidéo.
Quelques points inclassables
En plus des outils “no code” (Concepteur et AutomatedML), Azure ML dispose d’un module de labellisation d’images, assisté par une approche d’active learning (au bout d’un nombre suffisant d’images taggés, les tags peuvent être automatiquement proposés).
Databricks s’est pourvu d’un nouvel outil “SQL Analytics” qui permet, à l’aide de requêtes SQL, de préparer des vues à destination d’un outil de reporting comme Microsoft Power BI.
En licence Premium, le service Power BI donne accès aux modèles enregistrés sur Azure ML pour que ceux-ci soient appliqués lors de la phase de préparation de données (Power Query).
Alors, lequel choisir ?
En conclusion, il faudra bien évaluer les prérequis des projets (par exemple, l’utilisation de Delta Lake) qui s’exécuteront sur l’architecture Azure pour choisir le bon outil, mais il faut aussi bien comprendre qu’il n’y a pas un surcoût trop important à les utiliser tous les deux et nous verrons surtout dans un prochain article qu’ils peuvent se montrer très complémentaires !
Assurer la qualité d’un développement Python passe par le fait de packager du code (des classes, des fonctions…) dans des modules que l’on pourra ensuite simplement installer dans un nouvel environnement (avec un classique pip install...) et importer dans des scripts à l’aide des syntaxes habituelles que sont import package ou from package import function.
Créer le package Wheel
C’est bien sûr la toute première étape une fois que notre code a été écrit. Et bien écrit, c’est-à-dire en respectant par exemple la norme PEP8 (nous en reparlerons) et en intégrant des docstrings dans les fonctions.
Nous aurons besoin de quelques librairies, dont bien évidemment wheel et nous profiterons d’un environnement virtuel pour les installer (commandes Windows ci-dessous pour créer, activer et configurer cet environnement).
Notre exemple se basera sur du code simple générant un pandas dataframe avec des nombres aléatoires. Notons au passage (pour les puristes :)) que ce code poserait problème dès que nb_col dépasserait la valeur 26.
import pandas as pd
import numpy as np
import string
def generate_df(nb_col, nb_row):
"""
Generate a pandas DataFrame
with nb_col columns and nb_row rows
"""
alphabet_string = string.ascii_uppercase
columns_string = alphabet_string[:nb_col]
columns_list = list(columns_string)
df = pd.DataFrame(np.random.randint(0, 100, size=(nb_row, nb_col)), columns=columns_list)
return df
Le script, nommé ici my_function.py, doit se trouver dans une arborescence de fichiers définie comme suit :
Le fichier __init__.py est tout simplement un fichier vide, seul le nom est obligatoire. Ce fichier doit être dans le répertoire dédié aux fichiers développés (sous-répertoire du répertoire principal). Il peut toutefois contenir également des fonctions qui seront chargées à l’appel du module. Pour réaliser des tests simples, voici ce qu’il contient.
def function_init():
print('Successfully imported Init.py')
def print_hello_iam(name):
print(f'Hello, I am {name}')
Nous complétons avec un fichier d’informations README au format Markdown, un fichier texte contenant la licence (ci-dessous) et un répertoire, éventuellement vide dans un premier temps, qui contiendra des tests.
Copyright (c) 2018 The Python Packaging Authority
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Le dernier élément nécessaire est le fichier setup.py dont un modèle de contenu peut être retrouver sur cette page. Il faudra en particulier y préciser le nom souhaité pour le package.
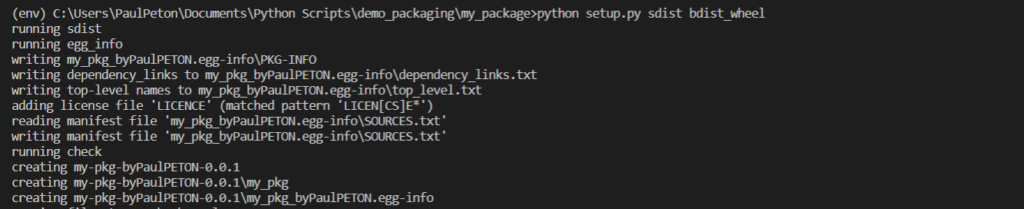
Pour générer l’archive de distribution, nous lançons la commande suivante, au niveau du répertoire contenant le fichier setup.py :
python setup.py sdist bdist_wheel
Un répertoire dist est alors créé et contient deux fichiers : le fichier .whl et une archive .tar.gz.
Le nom du package wheel est normalisé de la sorte :
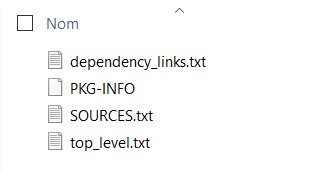
EDIT : vérifiez également que le dossier finissant par “egg-info” contient bien les fichiers suivants.
Le fichier top_level.txt contient en particulier le nom qui servira à appeler le package dans les syntaxes du type from package import …
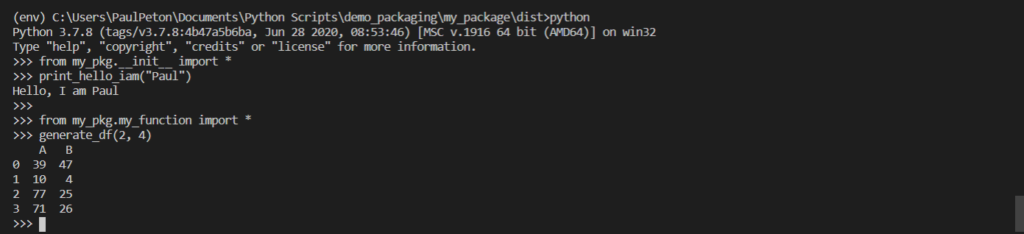
Réalisons tout de suite un premier test pour valider que notre package est bien construit. Au niveau du dossier contenant le fichier .whl, nous lançons dans un terminal la commande suivante, depuis le répertoire dist :
Puis dans un prompt Python, nous vérifions que l’import des nos méthodes est bien reconnu :
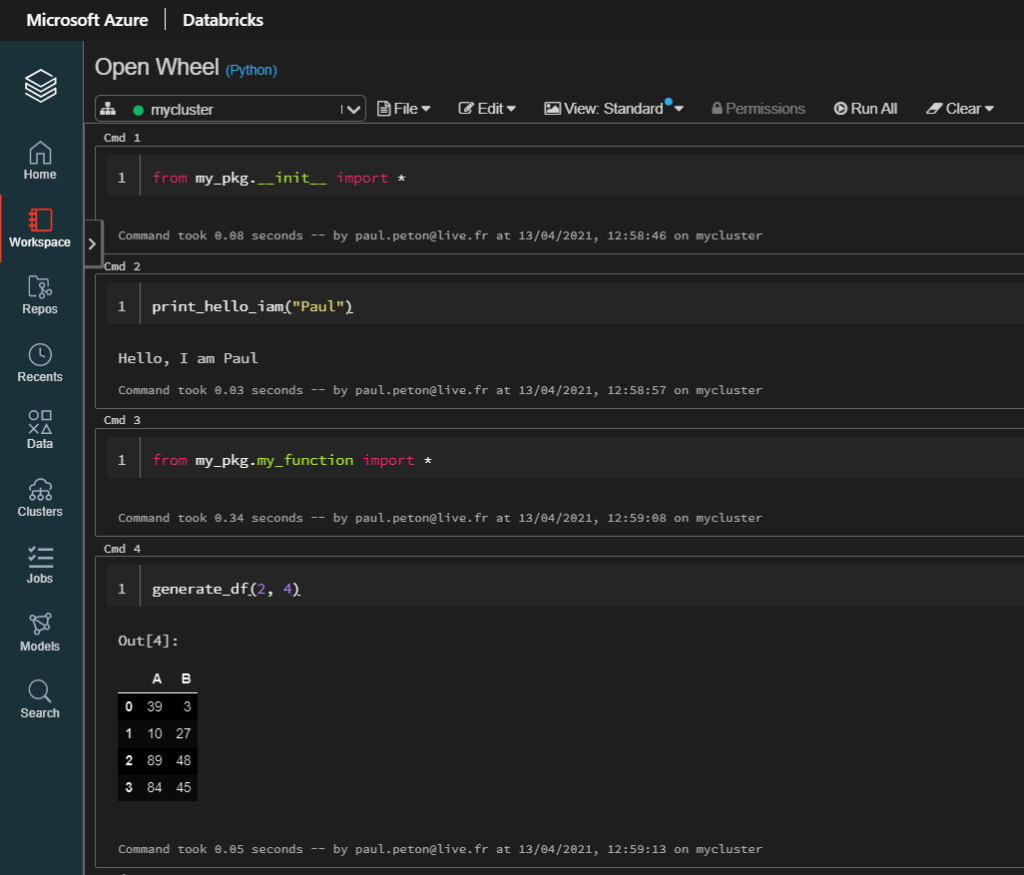
from my_pkg.__init__ import *
from my_pkg.my_function import *
Tester le package depuis un cluster Azure Databricks
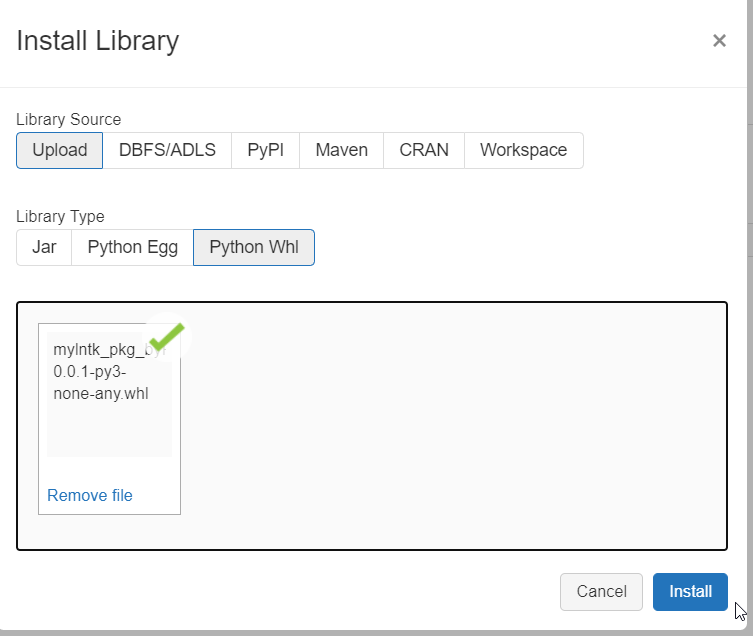
Nous allons maintenant installer manuellement le fichier .whl disponible dans le répertoire dist sur un cluster Databricks. Nous commençons par le télécharger sur un cluster interactif démarré.
Dès lors, les fonctions deviennent disponibles dans un notebook.
Notez au passage le “dark mode” des notebooks Databricks 🙂
Charger le package sur un feed Azure DevOps
Nous n’allons bien sûr pas utiliser le fichier .whl localement, celui-ci doit être hébergé sur une plateforme accessible de tous les développeurs de l’équipe.
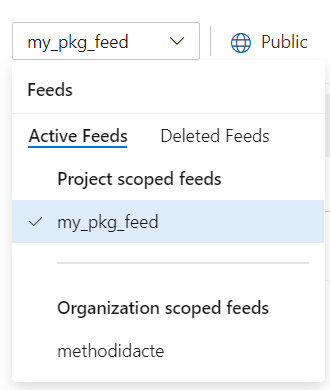
Tout comme le code est placé dans un dépôt (repository) d’un gestionnaire de versions comme Azure DevOps, nous allons placer le package, ici nommé artefact, dans un feed, accessible aux personnes autorisées.
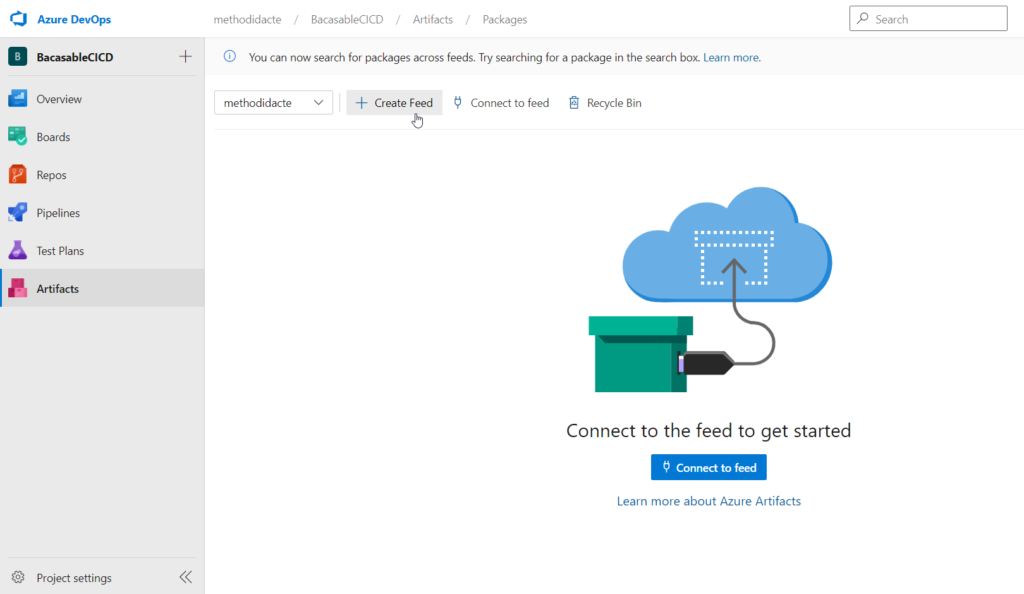
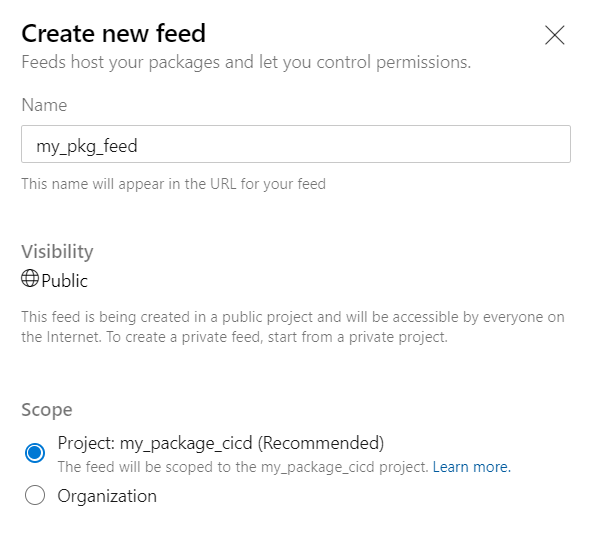
Nous réalisons tout d’abord la création du feed. Il sera ici public, donc accessible au travers d’Internet. Pour une pratique en entreprise, un projet privé est bien évidemment recommandé.
Le feed est maintenant bien actif.
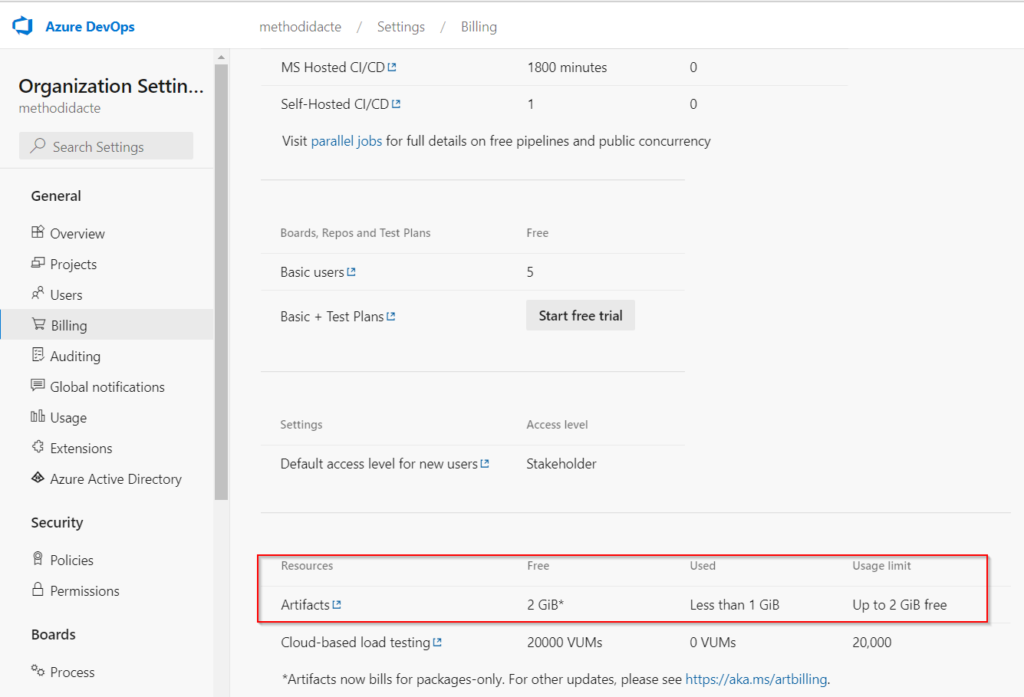
Attention, il est préférable de vérifier vos options de facturation (dans le menu “Organization Settings”). Un compte gratuit présentera des limites de taille pour l’usage des artefacts stockés dans le feed.
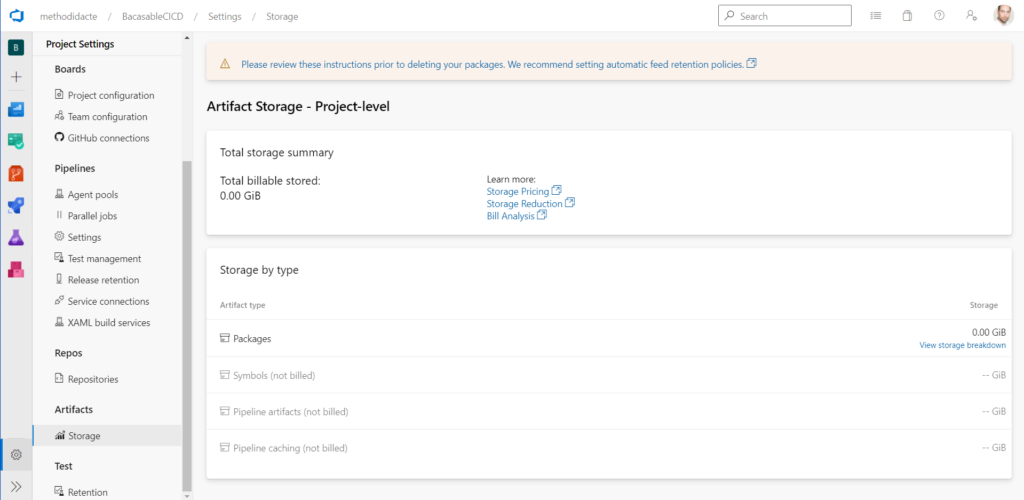
Vérifions également le stockage associé aux artefacts (ici au niveau projet, puisque c’est le périmètre qui a été défini).
Il s’agit ensuite d’automatiser la création du package wheel par un pipeline d’intégration continue. Nous démarrons à partir d’un “starter pipeline”.
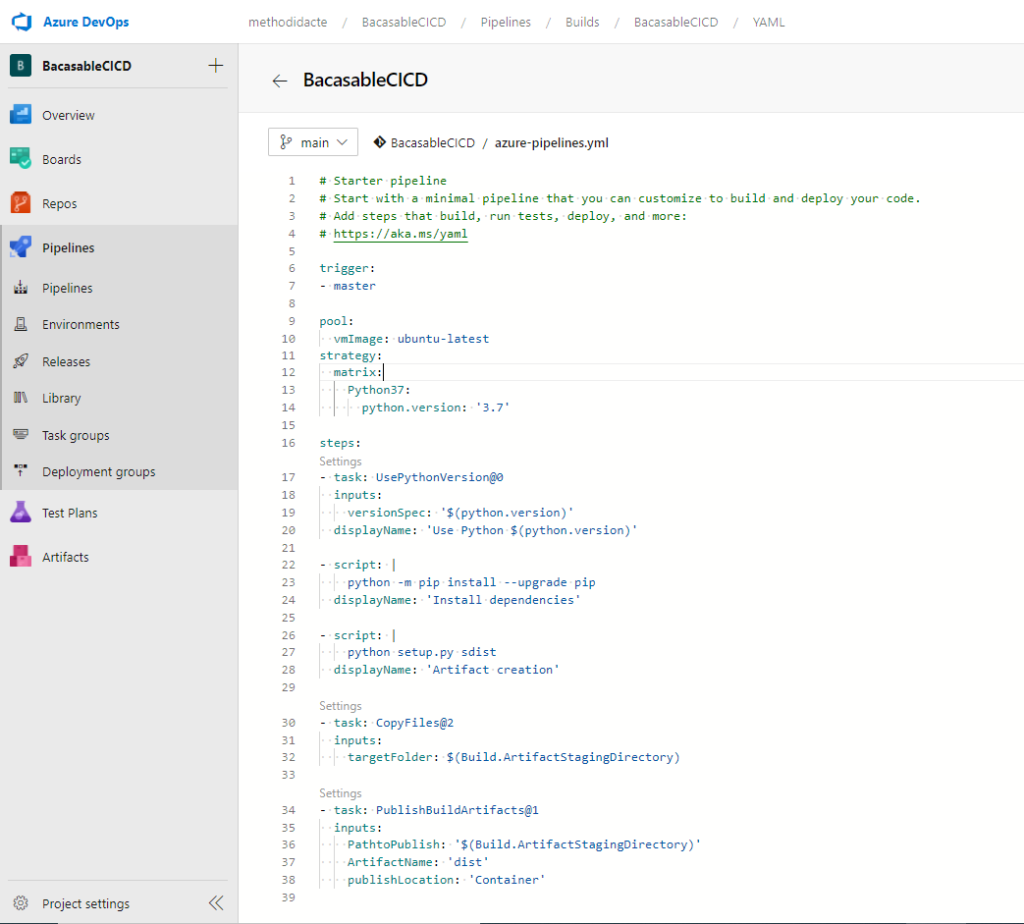
Le code complet de ce pipeline, enregistré automatiquement dans un fichier azure-pipelines.yml, ajouté au repository, est disponible par exemple sur ce GitHub (veillez à adapter si besoin la version de Python attendue ainsi que le nom de la branche – main pour master – si vous souhaitez un lancement automatique de la pipeline à chaque commit).
Ce script YAML reprend l’exécution du fichier setup.py pour créer l’artefact dans un conteneur dédié.
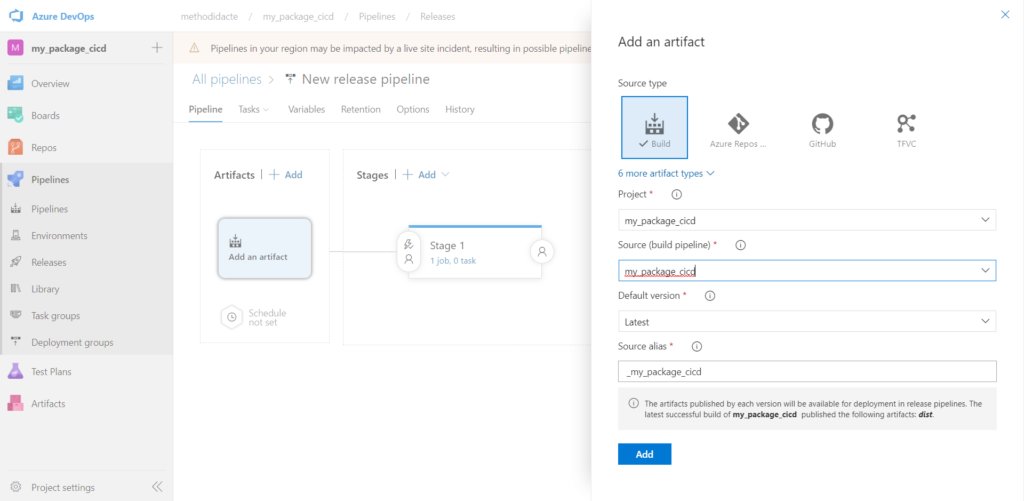
Nous avons ensuite besoin d’un pipeline de releasequi déposera l’artefact dans le feed qui servira de point de distribution.
A partir d’un modèle vide de pipeline de release (“empty job“), nous attachons le résultat du pipeline de build réalisé précédemment.
Nous ajoutons trois activités qui sont :
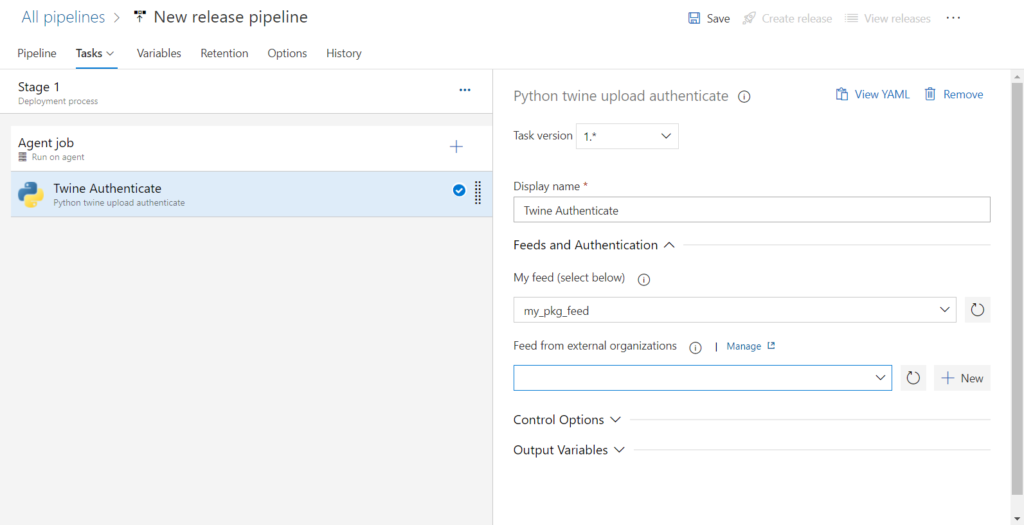
Python twine upload authenticate
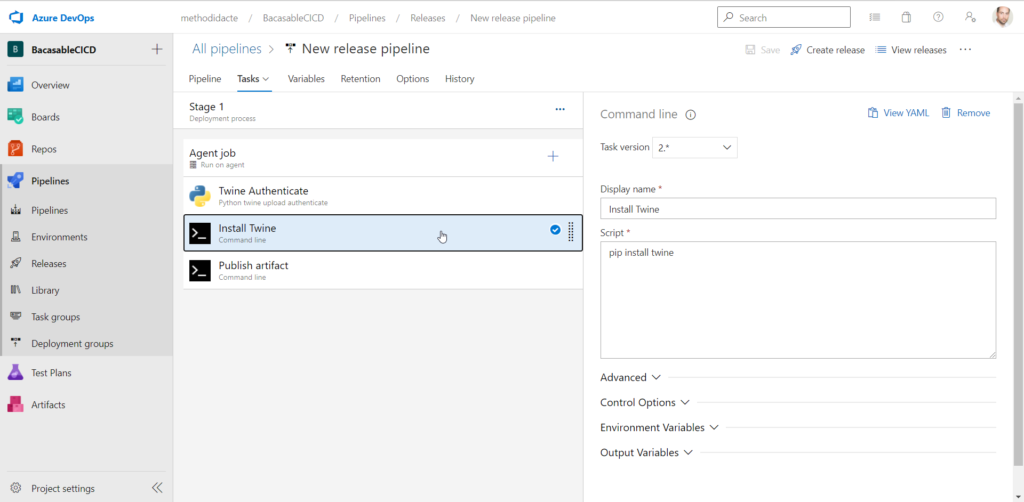
Command line pour l’installation de Twine
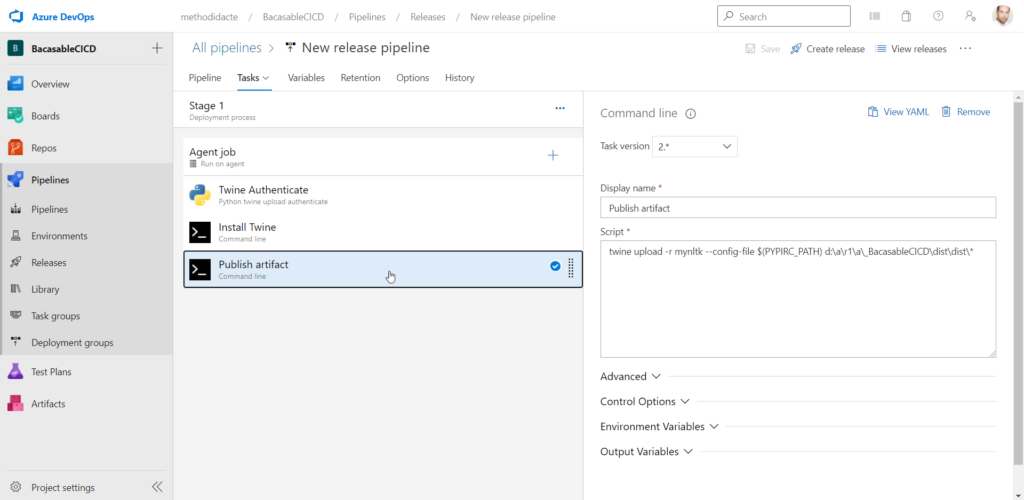
Command line pour la publication de l’artefact
L’étape 1 s’authentifie auprès du feed, dont il faut saisir le nom.
L’étape 2 réalise l’installation du package Twine par la commande pip install.
L’étape 3 utilise Twine pour télécharger le package.
Cette étape est sans doute la plus délicate. En cas d’erreur pour localiser ce répertoire, je vous conseille de regarder les logs de la première étape du pipeline de build afin de visualiser l’artefact dans son arborescence.
Utiliser le package depuis un nouveau script
Nous allons avoir besoin d’une nouvelle librairie : artifacts-keyring..
pip install artifacts-keyring
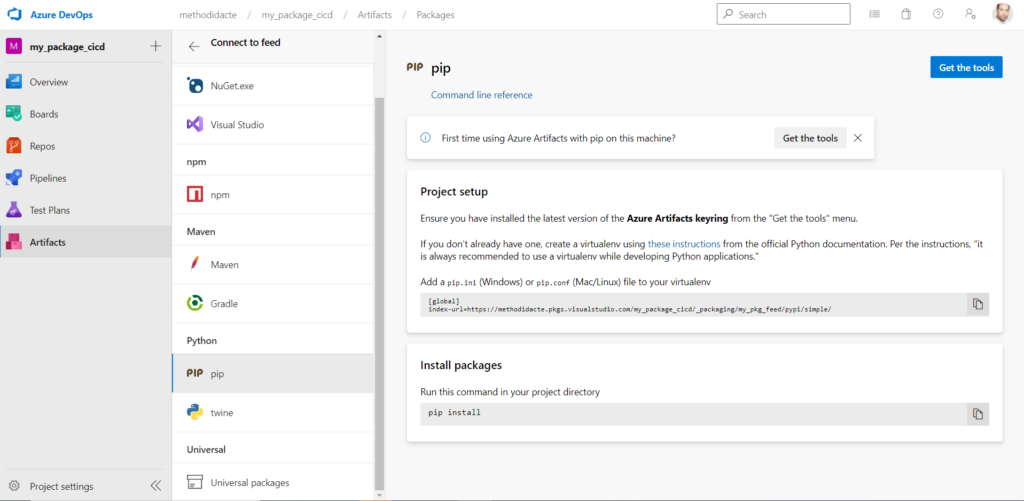
Ensuite, nous pouvons faire appel à la commande classique “pip install” pointant vers notre feed.
Le “project_name” est facultatif si le feed est déclaré au niveau de l’organisation. Il sera possible de remplacer par l’option –index-url par –extra-index-url comme indiqué dans cet article mais ceci est à réaliser seulement si l’on utilise la méthode proposée dans le portail Azure DevOps : la création d’un fichier pip.ini.
En cas de project privé, une authentification sera alors demandée, de manière interactive, au travers d’un navigateur.
Ce mode n’est bien sûr pas envisageable pour une installation devant s’exécuter de manière autonome. Nous allons donc générer un Personal Access Token (PAT) qui permettra de nous authentifier. Ce jeton s’obtient dans Azure DevOps.
Nous donnons les droits au niveau “packaging“.
Dans l’environnement d’exécution, une variable d’environnement sera nécessaire pour désactiver l’authentification interactive et tenir compte du PAT. Cela se fait par exemple dans Windows par le menu “Modifier les variables d’environnement système” ou dans un dockerfile avec la ligne ci-dessous.
VAR ARTIFACTS_KEYRING_NONINTERACTIVE_MODE=true
Il sera alors possible d’appeler le package avec la syntaxe suivante :
Ca y est ! Le package est maintenant installé et nous pouvons nous appuyer sur les fonctions qu’il contient.
from my_pkg.my_function import *
En conclusion
Nous avons mis en place ici une approche dédiée à l’industrialisation d’un développement, accompagné d’un processus CI/CD. Cela demande un investissement en temps et en prise en main de cette procédure mais c’est une garantie de stabilité et de non régression sur le livrable en production.
Travailler avec une ressource Azure Machine Learning peut se faire de plusieurs façons : approche “no code” depuis le Concepteur, Automated ML ou encore par scripts R ou Python exploitant le SDK azureml qui permet d’interagir avec tous les composants du studio.
C’est bien sûr cette dernière approche “full code” que nous allons privilégier. Il est possible de lancer les notebooks natifs du studio mais ceux-ci ne donnent pas à ce jour (avril 2021) la même expérience que les notebooks Jupyter. Nous pouvons alors créer une instance de calcul qui se déploiera avec un serveur JupyterLab (ainsi que RStudio qu’il n’est pas impossible dans l’absolu d’utiliser… avec Python !).
Plusieurs limites apparaissent alors pour un usage professionnel, c’est-à-dire vérifiant un niveau de sécurité au travers de l’isolement des développements, de leur versionning et de leur déploiement en production. Si les instances de calcul sont personnelles (attribuées à un et un seul utilisateur, nominativement), les scripts enregistrés sont visibles par toutes les personnes disposant d’une ressource. De plus, il n’y a pas (à ce jour) de possibilité de lier les notebooks et autres fichiers à un dépôt (repository) de type Git. Enfin, si l’on pousse la réflexion sur le passage à l’échelle, il faudra envisager d’exécuter les scripts sur un cluster de calcul plutôt que sur l’instance de calcul elle-même.
Nous allons répondre à toutes ces problématiques par l’utilisation de l’IDE de Microsoft : Visual Studio Code. Au préalable, il faudra installer les extensions suivantes :
Python
Jupyter
Azure Account
Azure Machine Learning
En appuyant sur F1, nous pouvons nous authentifier sur Azure.
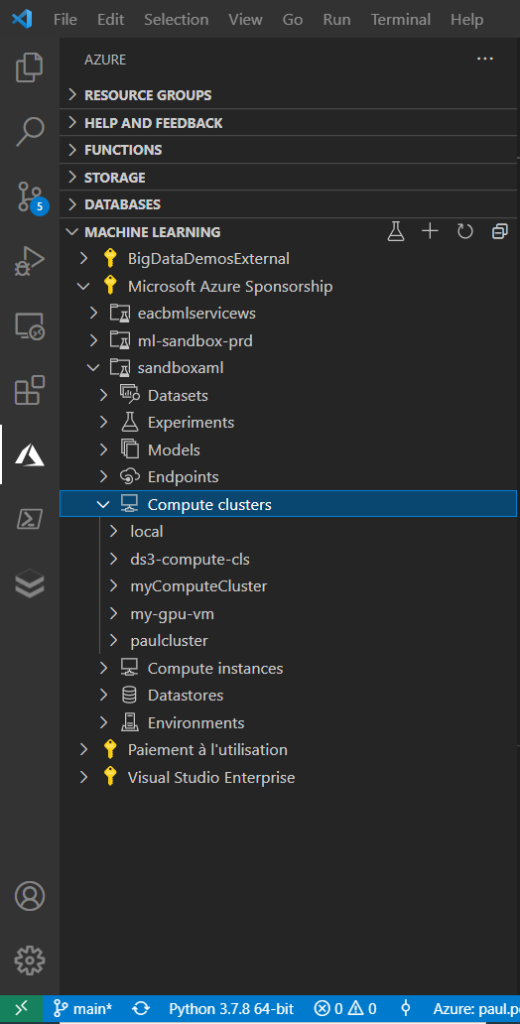
L’icône Azure donne alors la visibilité des ressources Azure Machine Learning et de tous les éléments qui les composent.
Nous souhaiterons en particulier utiliser un “compute cluster” pour exécuter un script Python. Nous allons pour cela créer un notebook d’interaction avec Azure Machine Learning qui pilotera l’exécution du script.
Pour assurer la gestion “Git” de nos fichiers, nous avons maintenant tous les outils à disposition. Il suffira d’utiliser les fonctions intégrées, par le menu ou en lignes de code, ce que nous développerons dans un autre article.
Les notebooks sont “suspects” pour VSC et il faudra déclarer qu’ils sont fiables (“trust“) à chaque ouverture. Pour simplifier ce processus, il est possible de modifier les paramètres pour accepter par défaut tous les notebooks.
Nous allons utiliser un serveur local Jupyter pour exécuter le code Python (et c’est une source d’économies !).
Les librairies spécifiques à Azure Machine Learning doivent bien sûr être installées dans cet environnement local.
Le package azureml-core évolue souvent, pensez à le mettre régulièrement à jour car les composants du studio Azure ML évolueront automatiquement.
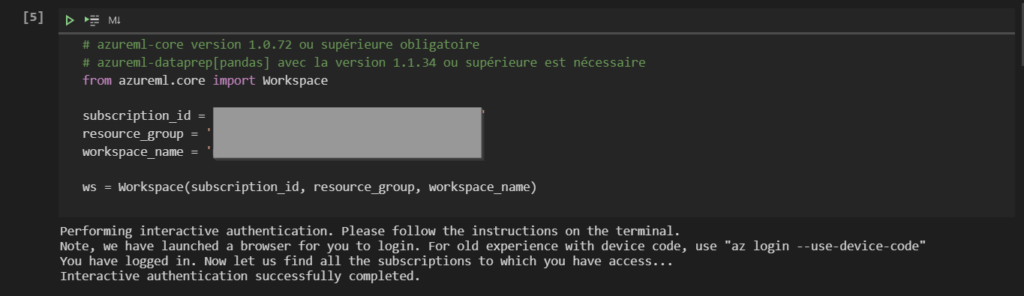
Il faut maintenant nous authentifier vis à vis de ce service. Les informations nécessaires sont accessibles dans le fichier “config.json” téléchargeable depuis le portail Azure.
Nous donnons ces informations dans le code ci-dessous.
A l’exécution du code, une fenêtre va s’ouvrir dans un navigateur demandant de s’authentifier avec le compte Azure autorisé sur la ressource Azure ML. Une fois cette opération réalisée, la cellule du notebook est validée.
Ceci ne sera bien sûr pas envisageable dans une scénario tout automatisé et nous privilégierons alors l’authentification au travers d’un principal de service.
Nous pouvons vérifier la bonne connexion à la ressource avec l’instruction suivante :
Nous allons maintenant mettre en place les éléments qui permettront d’exécuter un script Python.
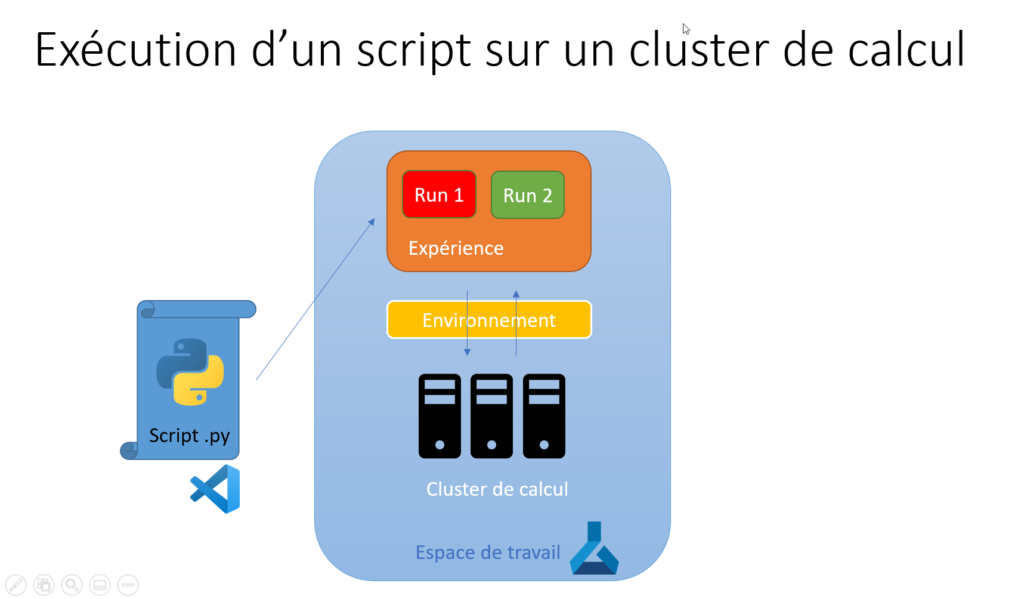
Ce schéma décrit le fonctionnement global :
VSC lance l’exécution (run) d’un script Python
exécuté sur un cluster de calcul
accompagné d’un environnement (les dépendances de packages)
loggé dans une expérience
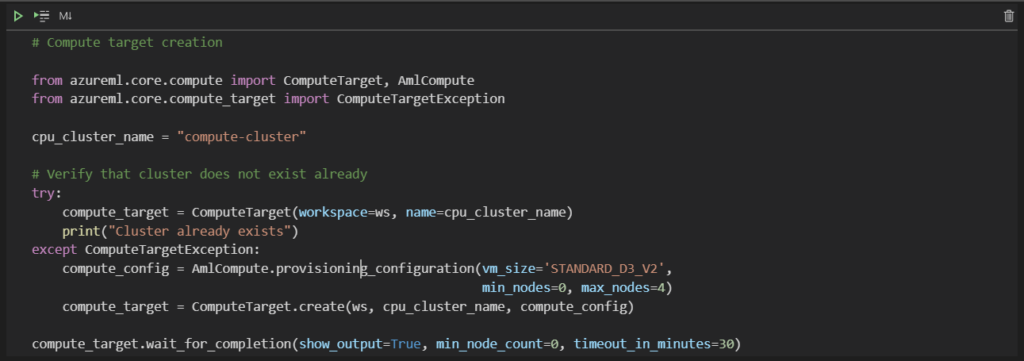
Les éléments de script ci-dessous ont été piochés dans différents tutoriels disponibles sur le Web. Nous commençons par la cellule qui déclarer le cluster de calcul ou bien le crée à la volée s’il n’existe pas de cluster nommé de la sorte.
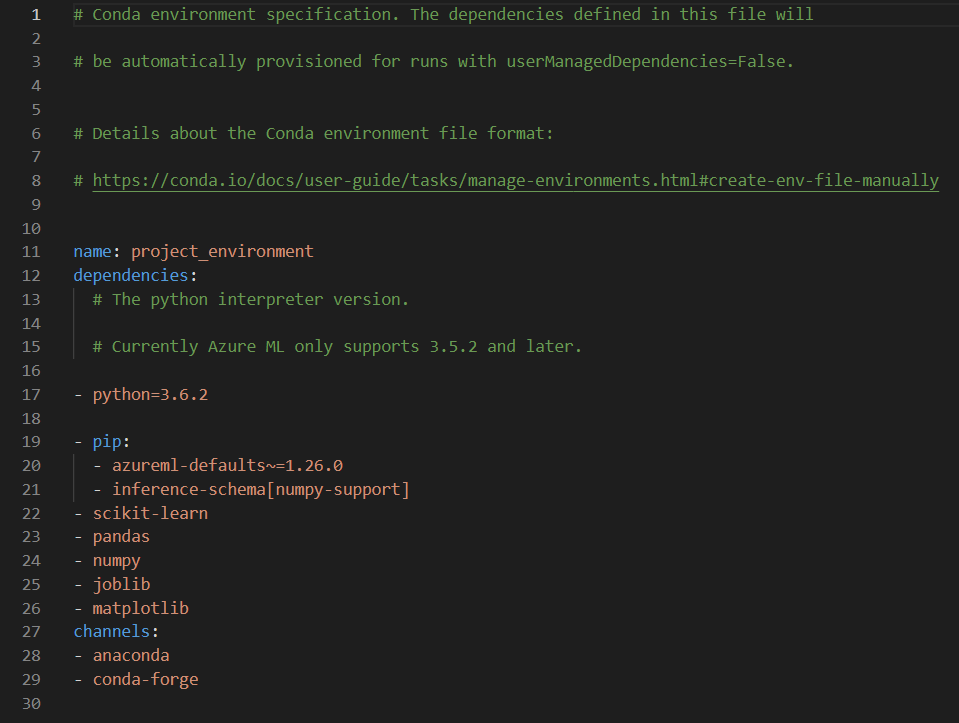
Les packages nécessaires au script Python sont déclarés dans un environnement.
Notez la dernière commande qui permet de sauvegarder cet environnement dans un fichier YAML.
Il sera alors possible de réutiliser directement ce fichier pour définir de nouveaux environnements. Voici son contenu.
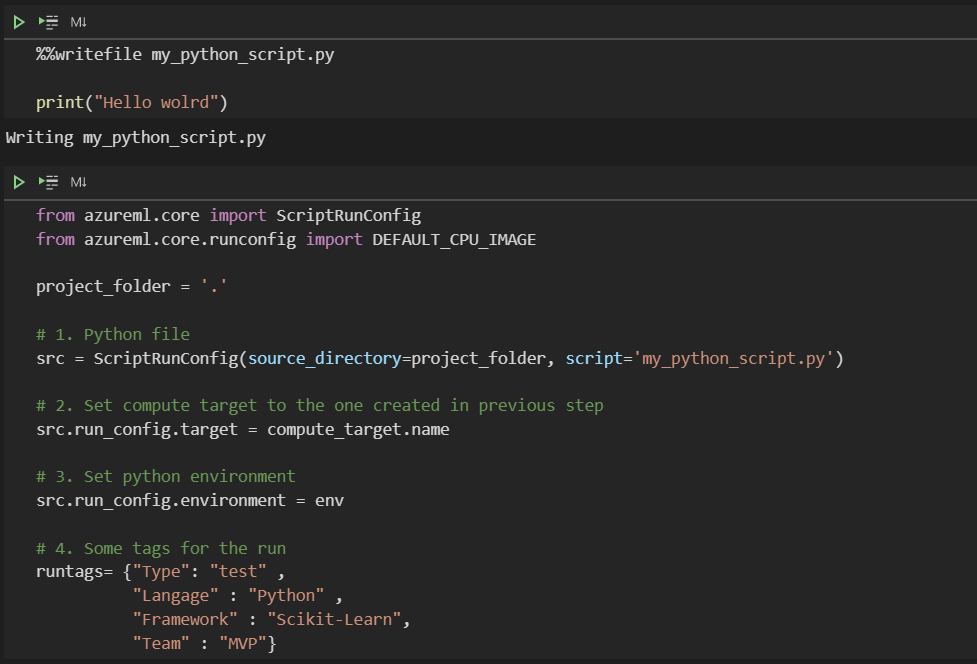
Enfin, l’expérience s’instancie tout simplement, en relation avec l’espace de travail Azure ML.
Le script Python peut être écrit dans une cellule du notebook. Il pourra alors être donné en paramètre de l’objet ScriptRunConfig.
A l’intérieur du script Python, il sera certainement utile de retrouver la référence à l’exécution réalisée au sein de l’espace de travail. Ceci se fait en enchainant ces trois lignes de code, précédées de l’import de la librairie azureml-core.
from azureml.core.run import Run
run = Run.get_context()
exp = run.experiment
ws = run.experiment.workspace
La soumission du script au sein de l’expérience se fait alors par la commande ci-dessous.
run = exp.submit(config=src, tags=runtags)
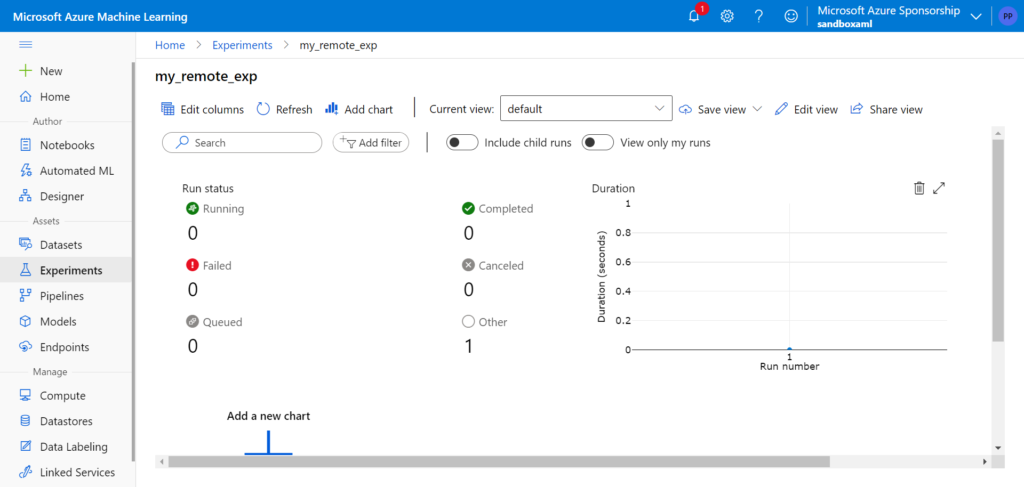
Nous pouvons dès lors suivre l’évolution dans le studio Azure ML.
A noter que les widgets qui permettent de suivre l’exécution dans un notebook semblent ne pas être compatibles avec VSC.
Mais ce n’est là qu’un détail au regard de ce que nous gagnons à utiliser VSC : versionning du code, approche DevOps, diminution des coûts de développement.
Le notebook utilisé dans cet article est disponible sur ce repository.
Développer un rapport Power BI peut-il s’apparenter à un développement « classique » au sens du code ? Pas entièrement sans doute mais des bonnes pratiques sont à mettre en œuvre et la documentation en fait sans nul doute partie.
Pourtant, car comme nous savons tous que ce n’est pas l’aspect le plus intéressant d’un développement, nous souhaiterons le faire :
Sans y passer trop de temps et de la manière la plus automatisée possible
En produisant un contenu utile pour un autre développeur qui n’aurait pas connaissance du projet initial
En sécurisant et versionnant les contenus les plus précieux (M, DAX)
En effet, nous ne sommes jamais à l’abri d’une corruption de fichier et conserver toute « l’intelligence » du développement permettrait de ne pas tout refaire de zéro.
A faire au cours développement
Les pratiques qui seront présentées ici visent bien sûr à améliorer la qualité du rapport Power BI mais aussi à faciliter la documentation qui pourra être produite par la suite.
Réduire les étapes de transformation
Par exemple, il est possible de “typer“une nouvelle colonne à la création.
= Table.AddColumn(#"Previous step", "Test approved = 0", each [#"Approved amount (local currency)"] * [Approved quantity] = 0, type logical)
Une bonne approche pour réduire les étapes consiste à privilégier les transformations réalisées au niveau de la source de données, par exemple en langage SQL.
Nommer certaines étapes de transformation
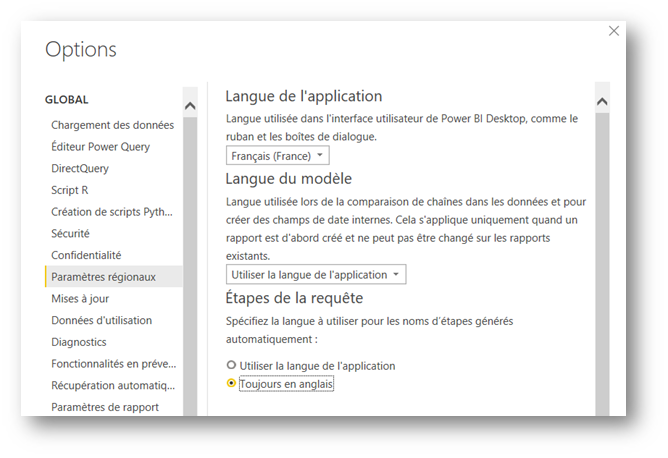
Les étapes d’une requête Power Query peuvent être renommées. Il est recommandé de privilégier le nommage automatique en anglais et de préciser certaines étapes.
Du point de vue de la relecture du script, il n’est pas optimal de disposer de plusieurs étapes similaires (par exemple : Change Type ou Renamed Columns) mais cela est parfois inévitable comme pour l’action Replaced Value. On précisera ainsi la valeur remplacée par cette étape. De même pour des opérations comme Added Custom, Merge Queries, Filtered Rows, etc.
Ajouter si besoin une description plus détaillée au moyen d’un commentaire dans le script M entre /*…*/ ou sur une seule ligne à l’aide de //.
Comme dans tout développement, un commentaire vient expliquer la logique adoptée par le développeur lorsque celle-ci est plus complexe que l’usage nominal de la formule.
Déterminer la bonne stratégie de filtres
Il y a tellement d’endroits où l’on peut filtrer les données lors d’un développement Power BI ! Dans une ordre « chronologique » au sens des phases de développement, nous pouvons identifier :
La requête vers la source (par exemple avec une clause WHERE dans un script SQL)
Une étape de transformation Power Query
Un contexte dans une mesure DAX avec des fonctions comme CALCULATE() ou FILTER()
Un rôle de sécurité
Le volet de filtre latéral :
Au niveau du rapport
Au niveau de la page
Au niveau du visuel
D’emblée, précisons tout de suite que si vous êtes tentés par les filtres de rapport, c’est très vraisemblablement une mauvaise idée et il était sûrement possible de le faire dans une étape précédente ! Une règle (non absolue) est de réaliser l’opération le plus tôt possible, dans la liste précédente.
Ainsi, on privilégiera la requête SQL, ou le query folding, qui délégueront toute la préparation de données au serveur, qui sera vraisemblablement plus puissant que le service Power BI.
Appliquer une nomenclature aux noms de tables, champs et mesures
Il n’est pas pertinent de préfixer les noms de tables par DIM_ ou FACT_, ceci étant des notions propres aux développeurs décisionnels mais ne parlant pas aux utilisateurs métiers.
Les noms de tables peuvent comporter des espaces, accents ou caractères spéciaux mais l’usage de ces caractères complexifiera l’utilisation de l’auto-complétion des formules. L’utilisation d’émoticônes peut entrainer une corruption du fichier.
Il vaut mieux utiliser des noms de tables courts pour limiter la taille du volet latéral Fields.
Les noms des champs et des mesures doivent être parlants pour un être humain, on bannira donc les _ ou l’écriture CamelCase.
Il est possible d’utiliser des symboles tels que % ou ∑ pour donner une information sur le calcul réalisé.
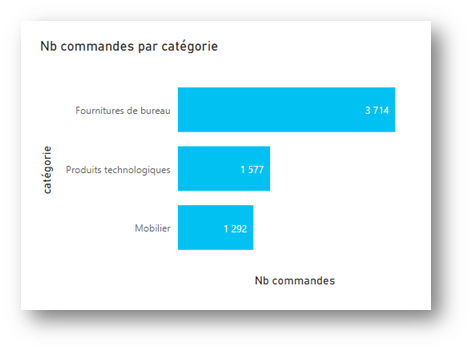
Afin de profiter de l’écriture dynamique des titres, les mesures peuvent être écrites avec une majuscule et les autres noms de champs en minuscules uniquement. Cela donnera par exemple : « Nb commandes par catégorie » à partir d’une mesure « Nb commandes » et d’un champ nommé « catégorie ».
Mettre en place une stratégie d’imbrication de mesures
Il est recommandé de produire des mesures avancées en se basant sur des mesures simples (et toujours explicites !), quitte à masquer celles-ci.
Par exemple :
# ventes = COUNTROWS(VENTES)
# ventes en ligne = CALCULATE([# ventes], VENTES[Canal] = "en ligne")
Les mesures appelées dans une autre mesure ne seront pas préfixées par un nome de table à l’inverse des noms de colonnes.
Décrire les mesures
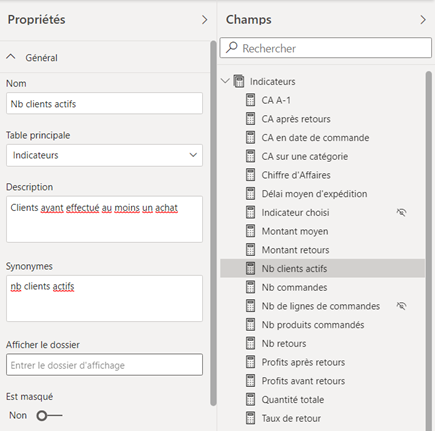
La description fonctionnelle des mesures se fait (et ce n’est pas très intuitif…) dans l’affichage de modèle.
Cet affichage permet également de regrouper les mesures (d’une même table uniquement) dans un dossier ou plusieurs dossiers (« display folder »).
Nous utiliserons ici la propriété « is hidden » pour masquer les colonnes qui ne sont pas utiles à un utilisateur : identifiants, clés techniques, valeurs numériques reprises dans des mesures explicites.
Commenter les formules DAX
Comme dans tout langage de programmation, le commentaire ne doit intervenir que lorsque la stratégie mise en place par le code n’est pas intuitive.
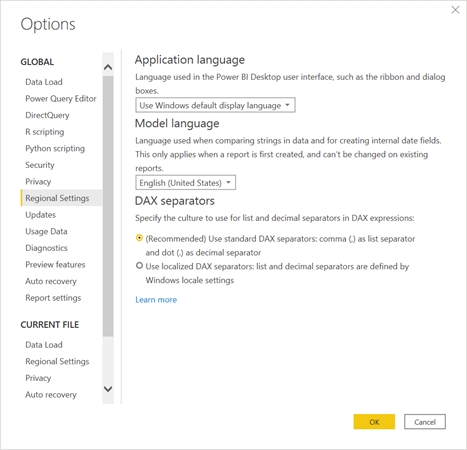
Il est recommandé d’utiliser les séparateurs virgule (paramètres) et point (décimales) dans les formules DAX. Ceci est paramétrable dans les options globales.
Penser également à mettre en forme systématiquement les champs DAX à l’aide de l’outil en ligne DAX formatter.
Nommer les composants visuels
Pour nommer un composant, on utilise le champ « Title », que celui-ci soit activé ou désactivé. C’est pourquoi il faut activer le titre pour le renseigner, quitte ensuite à le désactiver. Les objets peuvent donc avoir un nom qui est un titre utilisé de manière visuelle.
Le nom de l’objet est ensuite visible dans le volet de sélection.
Les objets ont un identifiant et un nom qui sont utilisés dans les fichiers JSON constituant le contenu du fichier .pbix.
Documenter à l’aide d’outils externes
Nous allons mettre en place une approche pragmatique, à partir d’outils tiers, qui ne sont ni développés ni maintenus par Microsoft mais intégrés maintenant au sein du menu « External Tools ».
Suite à l’installation de ces outils, des raccourcis seront disponibles dans le nouveau menu.
Les différents exécutables sont simples à trouver au travers d’un moteur de recherche.
Power BI Helper
Nous utilisons ici la version de décembre 2020.
Ouvrir le rapport dans Power BI Desktop.
Lancer Power BI Helper. Depuis l’onglet Model Analysis, cliquer sur Connect to Model.
Le nom du fichier doit apparaître dans la liste déroulante « Choose the Power BI file ».
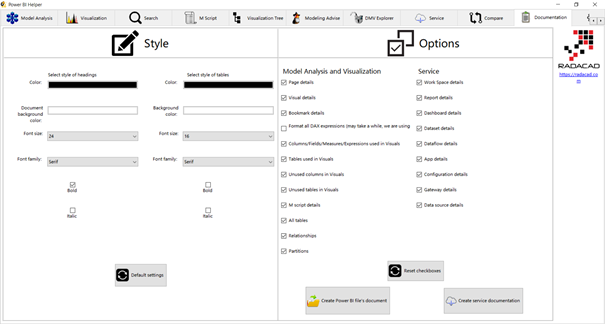
Créer le fichier HTML en cliquant sur « export to document » ou aller sur l’onglet « Document » du menu horizontal.
Choisir les éléments voulus dans la liste « Model Analysis and Visualisation » puis cliquer sur « Create Power BI file’s document ». Nous obtenons un fichier au format .htm contenant des tableaux.
Voici pourquoi il est important de renseigner la description dans le rapport Power BI.
Tiens, pourquoi pas brancher un Power BI sur ce fichier HTML et ainsi charger les tableaux dans un « méta-rapport » ?
Le code M est visible dans l’onglet du menu « M script ».
Le bouton d’export semble avoir disparu mais il est possible de faire un simple copier-coller de la zone de texte grisée.
Sans même utiliser un outil externe, il était déjà possible de copier une requête dans l’éditeur (clic droit, copier), puis de coller dans un bloc-notes pour obtenir le script, qu’on enregistre par convention dans un fichier d’extension .M.
Ouvrir le modèle .pbit et renseigner comme valeur de paramètre le chemin du fichier .pbix que l’on souhaite documenter.
Les données vont se mettre à jour et il sera possible d’enregistrer le rapport au format .pbix, puis de le mettre à jour en cas de modification dans le fichier d’origine.
Je tiens à signaler que je suis vraiment bluffé par la qualité de cet outil qui rend d’immenses services au quotidien. Bravo, Stéphanie BRUNO ! L’outil est présenté plus en détail sur ce site.
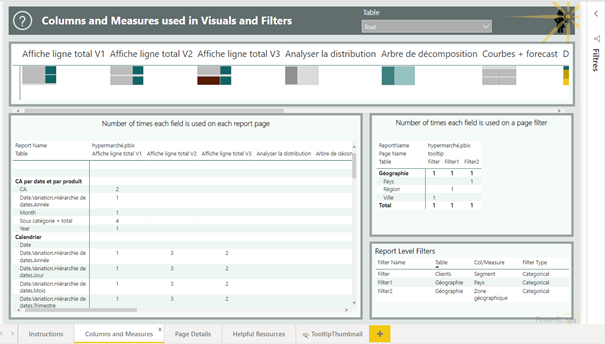
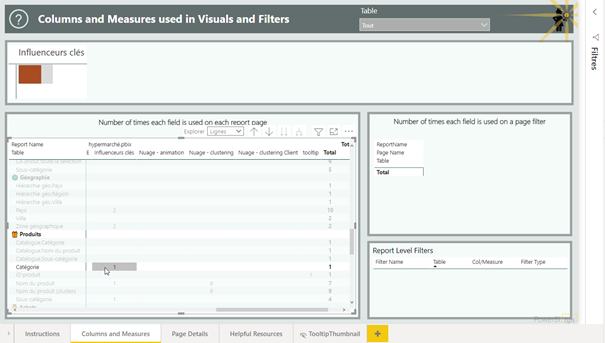
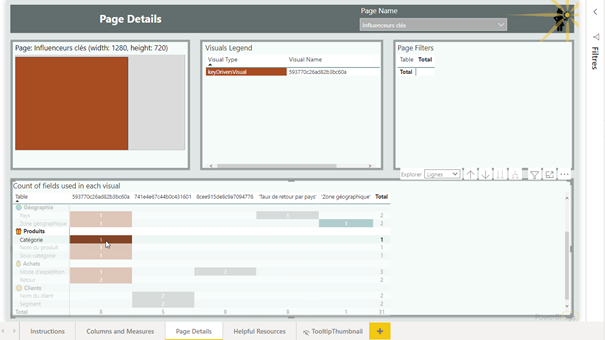
Cliquer sur un nom de champ pour identifier la ou les pages où il est utilisé.
La page détaillée indique ensuite le(s) visuel(s) utilisant ce champ.
DAX Studio
Quelques requêtes permettent de synthétiser le code DAX écrit dans le fichier .pbix. Conservez-les précieusement, par exemple dans un fichier texte d’extension .dax. Le résultat pourra ensuite être enregistré dans un format CSV ou Excel en paramétrant l’output.
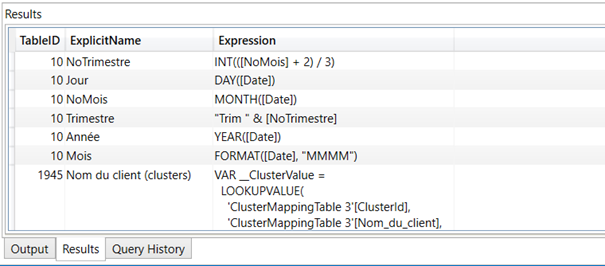
Liste de toutes les colonnes calculées
select
TableID,
ExplicitName,
Expression
from $SYSTEM.TMSCHEMA_COLUMNS
where [Type] = 2
order by TableID
Liste de toutes les mesures
select
MEASUREGROUP_NAME,
MEASURE_NAME,
EXPRESSION
from $SYSTEM.MDSCHEMA_MEASURES
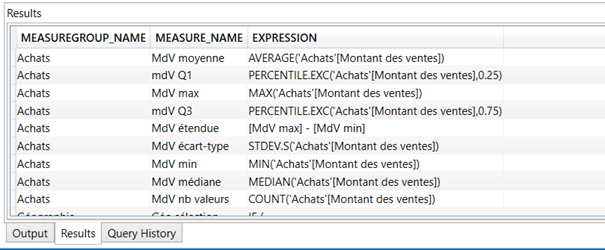
where MEASURE_AGGREGATOR = 0
order by MEASUREGROUP_NAME
Dépendances entre les formules DAX
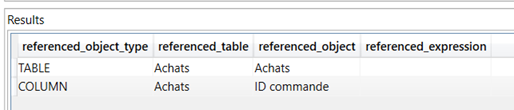
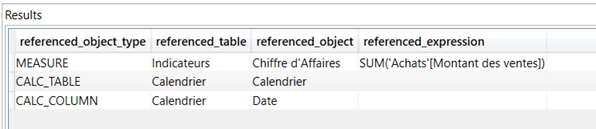
Puisque je vous ai encouragés à utiliser les mesures imbriquant d’autres mesures, vous chercherez certainement les dépendances créés. Celles-ci peuvent être obtenues par la requête suivante, où l’on précisera le nom de la mesure entre simples cotes.
select referenced_object_type, referenced_table, referenced_object, referenced_expression
from $system.discover_calc_dependency
where [object]='Nom de la mesure'
Ainsi, pour la mesure simple (mais explicite !) ‘Nb commandes’, nous obtenons :
Puis, pour une mesure ‘CA A-1’ basé sur une autre mesure :
Vous avez quelques belles cartes en main pour créer et maintenir une documentation robuste autour de vos rapports Power BI. Maintenant, à vous de jouer ! Les personnes qui prendront votre relais sur ces développements vous remercient déjà par avance !