
Travailler avec une ressource Azure Machine Learning peut se faire de plusieurs façons : approche “no code” depuis le Concepteur, Automated ML ou encore par scripts R ou Python exploitant le SDK azureml qui permet d’interagir avec tous les composants du studio.
C’est bien sûr cette dernière approche “full code” que nous allons privilégier. Il est possible de lancer les notebooks natifs du studio mais ceux-ci ne donnent pas à ce jour (avril 2021) la même expérience que les notebooks Jupyter. Nous pouvons alors créer une instance de calcul qui se déploiera avec un serveur JupyterLab (ainsi que RStudio qu’il n’est pas impossible dans l’absolu d’utiliser… avec Python !).
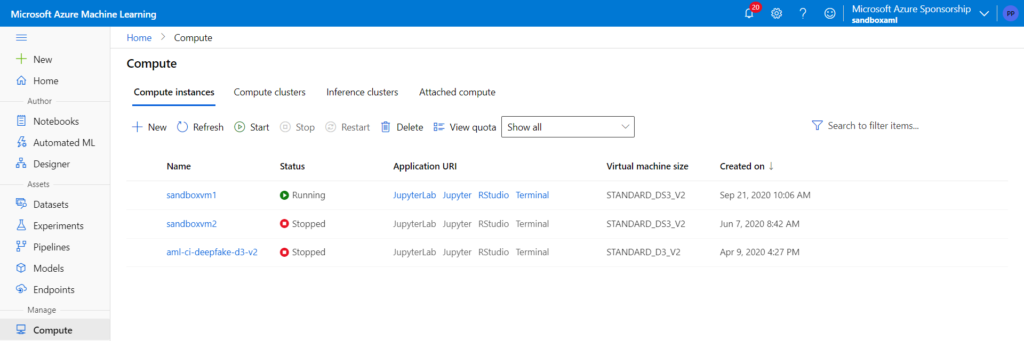
Plusieurs limites apparaissent alors pour un usage professionnel, c’est-à-dire vérifiant un niveau de sécurité au travers de l’isolement des développements, de leur versionning et de leur déploiement en production. Si les instances de calcul sont personnelles (attribuées à un et un seul utilisateur, nominativement), les scripts enregistrés sont visibles par toutes les personnes disposant d’une ressource. De plus, il n’y a pas (à ce jour) de possibilité de lier les notebooks et autres fichiers à un dépôt (repository) de type Git. Enfin, si l’on pousse la réflexion sur le passage à l’échelle, il faudra envisager d’exécuter les scripts sur un cluster de calcul plutôt que sur l’instance de calcul elle-même.
Nous allons répondre à toutes ces problématiques par l’utilisation de l’IDE de Microsoft : Visual Studio Code. Au préalable, il faudra installer les extensions suivantes :
- Python
- Jupyter
- Azure Account
- Azure Machine Learning
En appuyant sur F1, nous pouvons nous authentifier sur Azure.

L’icône Azure donne alors la visibilité des ressources Azure Machine Learning et de tous les éléments qui les composent.
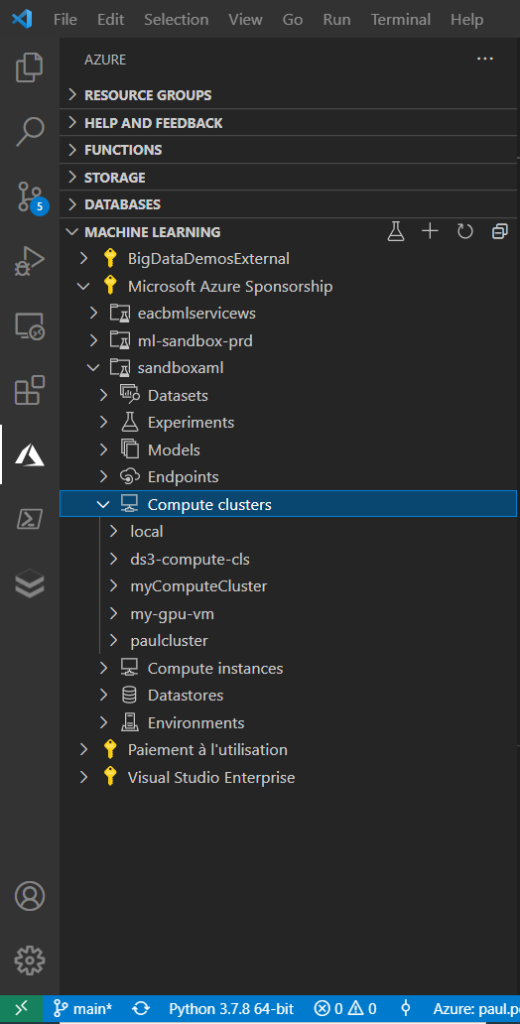
Nous souhaiterons en particulier utiliser un “compute cluster” pour exécuter un script Python. Nous allons pour cela créer un notebook d’interaction avec Azure Machine Learning qui pilotera l’exécution du script.
Pour assurer la gestion “Git” de nos fichiers, nous avons maintenant tous les outils à disposition. Il suffira d’utiliser les fonctions intégrées, par le menu ou en lignes de code, ce que nous développerons dans un autre article.
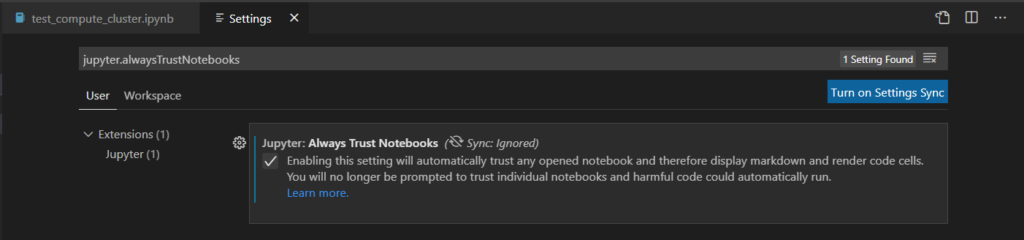
Les notebooks sont “suspects” pour VSC et il faudra déclarer qu’ils sont fiables (“trust“) à chaque ouverture. Pour simplifier ce processus, il est possible de modifier les paramètres pour accepter par défaut tous les notebooks.
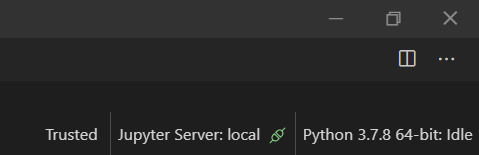
Nous allons utiliser un serveur local Jupyter pour exécuter le code Python (et c’est une source d’économies !).
Les librairies spécifiques à Azure Machine Learning doivent bien sûr être installées dans cet environnement local.
!python -m pip install azureml-sdk --upgrade --user
!python -m pip install azureml-core --upgrade --user
Le package azureml-core évolue souvent, pensez à le mettre régulièrement à jour car les composants du studio Azure ML évolueront automatiquement.
Il faut maintenant nous authentifier vis à vis de ce service. Les informations nécessaires sont accessibles dans le fichier “config.json” téléchargeable depuis le portail Azure.
Nous donnons ces informations dans le code ci-dessous.
A l’exécution du code, une fenêtre va s’ouvrir dans un navigateur demandant de s’authentifier avec le compte Azure autorisé sur la ressource Azure ML. Une fois cette opération réalisée, la cellule du notebook est validée.
Ceci ne sera bien sûr pas envisageable dans une scénario tout automatisé et nous privilégierons alors l’authentification au travers d’un principal de service.
Nous pouvons vérifier la bonne connexion à la ressource avec l’instruction suivante :
print(ws.name, ws.location, ws.resource_group, ws.location, sep='\t')
Nous allons maintenant mettre en place les éléments qui permettront d’exécuter un script Python.
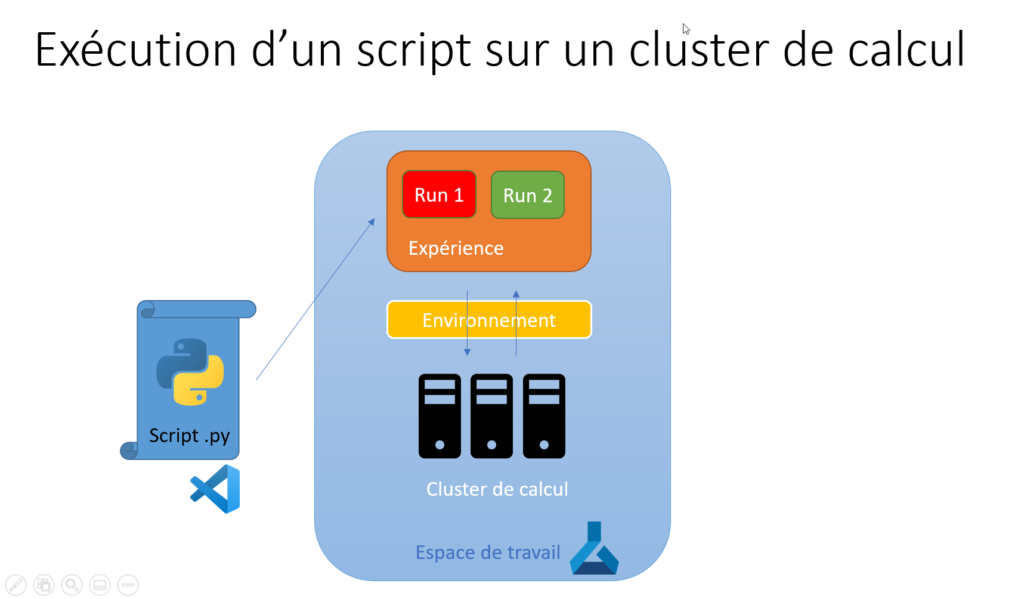
Ce schéma décrit le fonctionnement global :
- VSC lance l’exécution (run) d’un script Python
- exécuté sur un cluster de calcul
- accompagné d’un environnement (les dépendances de packages)
- loggé dans une expérience
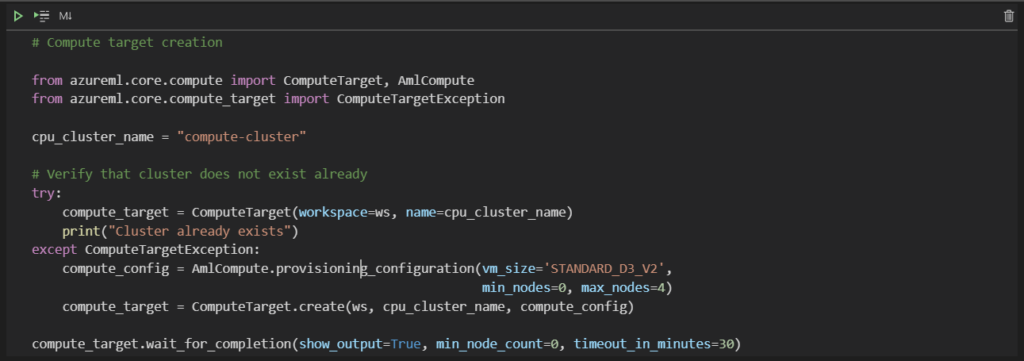
Les éléments de script ci-dessous ont été piochés dans différents tutoriels disponibles sur le Web. Nous commençons par la cellule qui déclarer le cluster de calcul ou bien le crée à la volée s’il n’existe pas de cluster nommé de la sorte.
Les packages nécessaires au script Python sont déclarés dans un environnement.
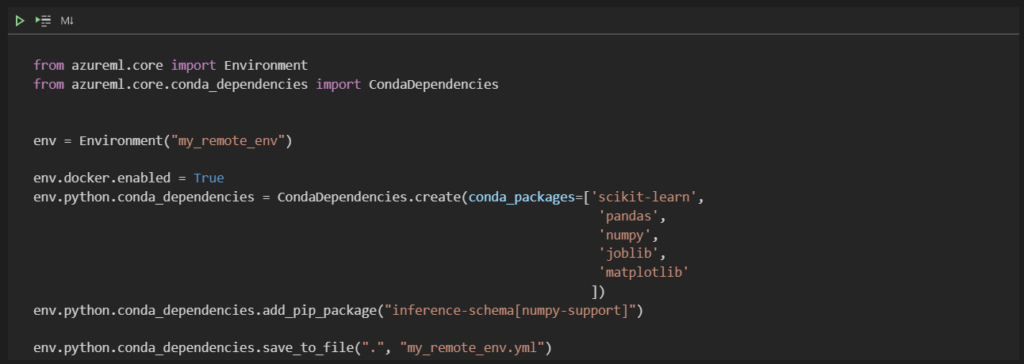
Notez la dernière commande qui permet de sauvegarder cet environnement dans un fichier YAML.
env.python.conda_dependencies.save_to_file(".", "my_remote_env.yml")
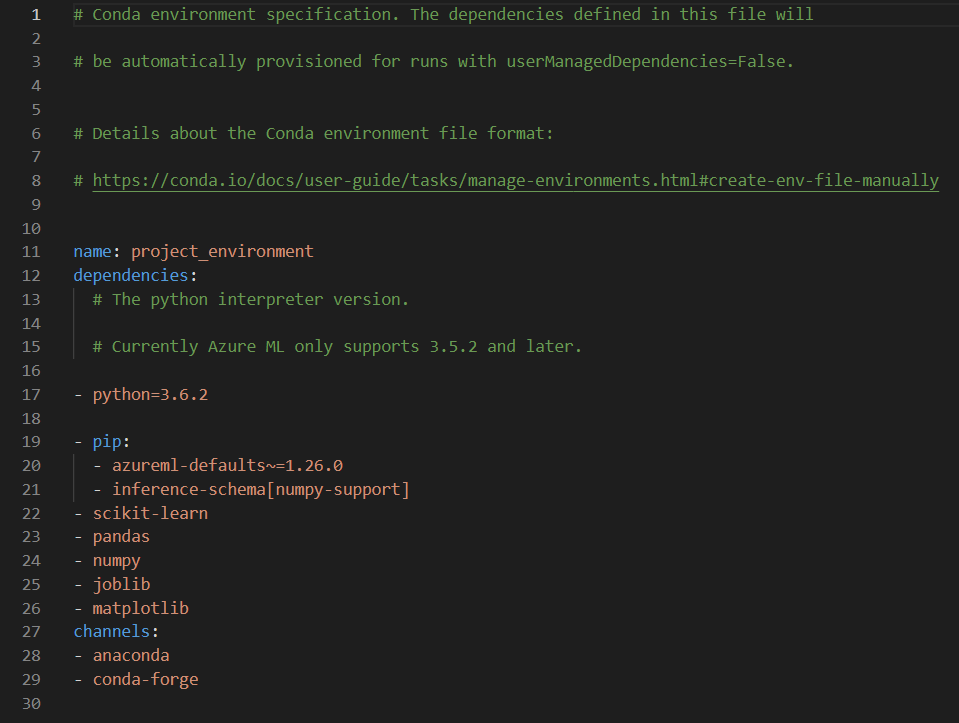
Il sera alors possible de réutiliser directement ce fichier pour définir de nouveaux environnements. Voici son contenu.
Enfin, l’expérience s’instancie tout simplement, en relation avec l’espace de travail Azure ML.

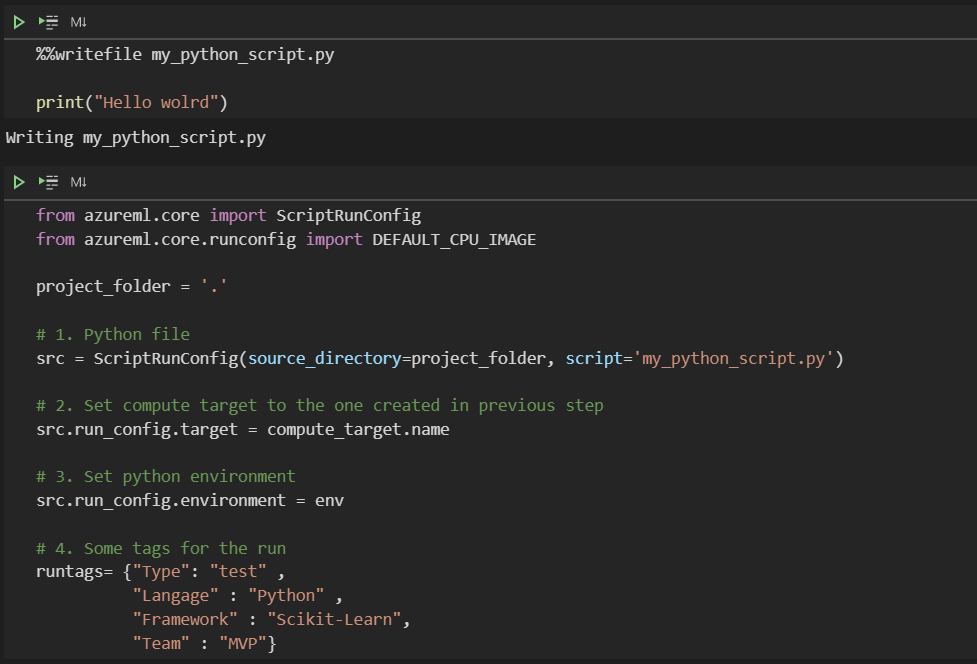
Le script Python peut être écrit dans une cellule du notebook. Il pourra alors être donné en paramètre de l’objet ScriptRunConfig.
A l’intérieur du script Python, il sera certainement utile de retrouver la référence à l’exécution réalisée au sein de l’espace de travail. Ceci se fait en enchainant ces trois lignes de code, précédées de l’import de la librairie azureml-core.
from azureml.core.run import Run run = Run.get_context() exp = run.experiment ws = run.experiment.workspace
La soumission du script au sein de l’expérience se fait alors par la commande ci-dessous.
run = exp.submit(config=src, tags=runtags)
Nous pouvons dès lors suivre l’évolution dans le studio Azure ML.
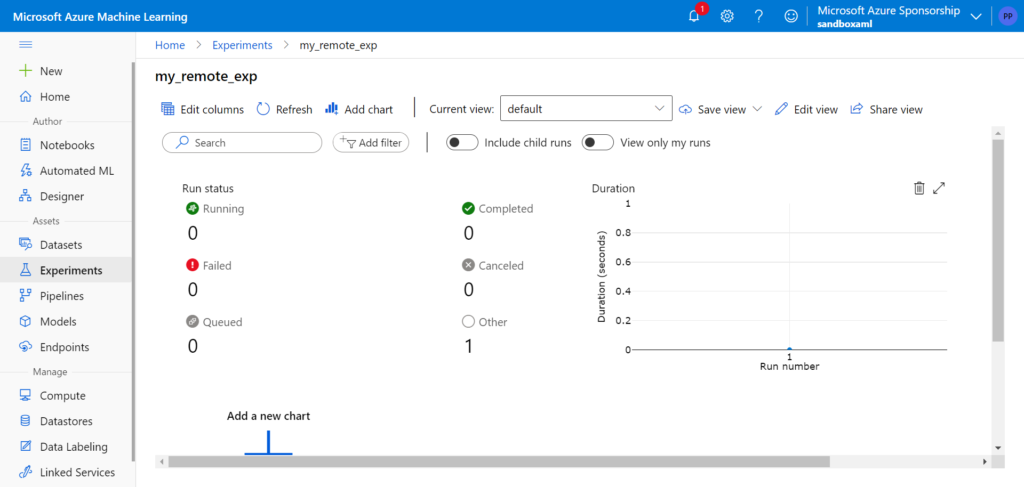
A noter que les widgets qui permettent de suivre l’exécution dans un notebook semblent ne pas être compatibles avec VSC.
Mais ce n’est là qu’un détail au regard de ce que nous gagnons à utiliser VSC : versionning du code, approche DevOps, diminution des coûts de développement.
Le notebook utilisé dans cet article est disponible sur ce repository.