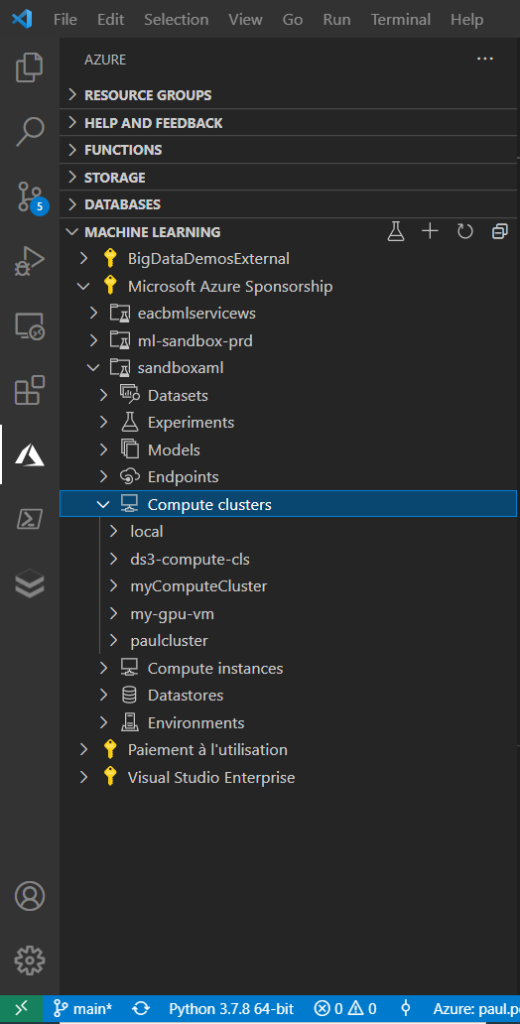
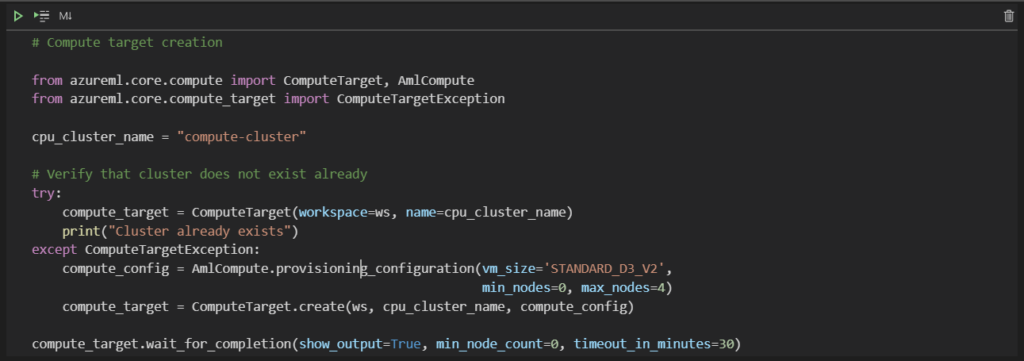
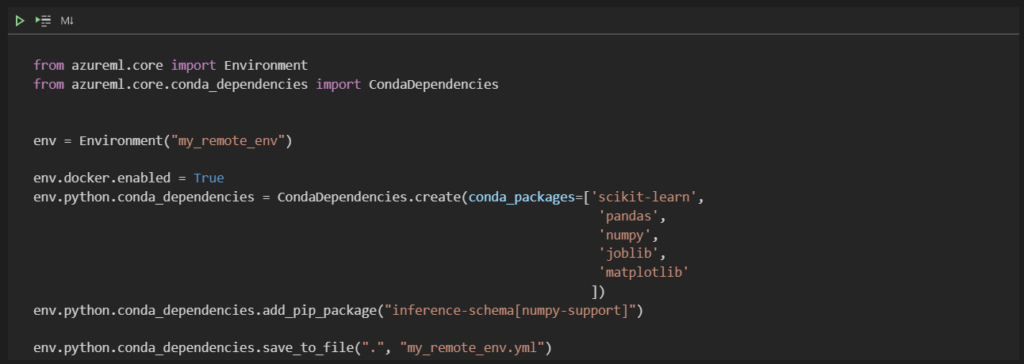
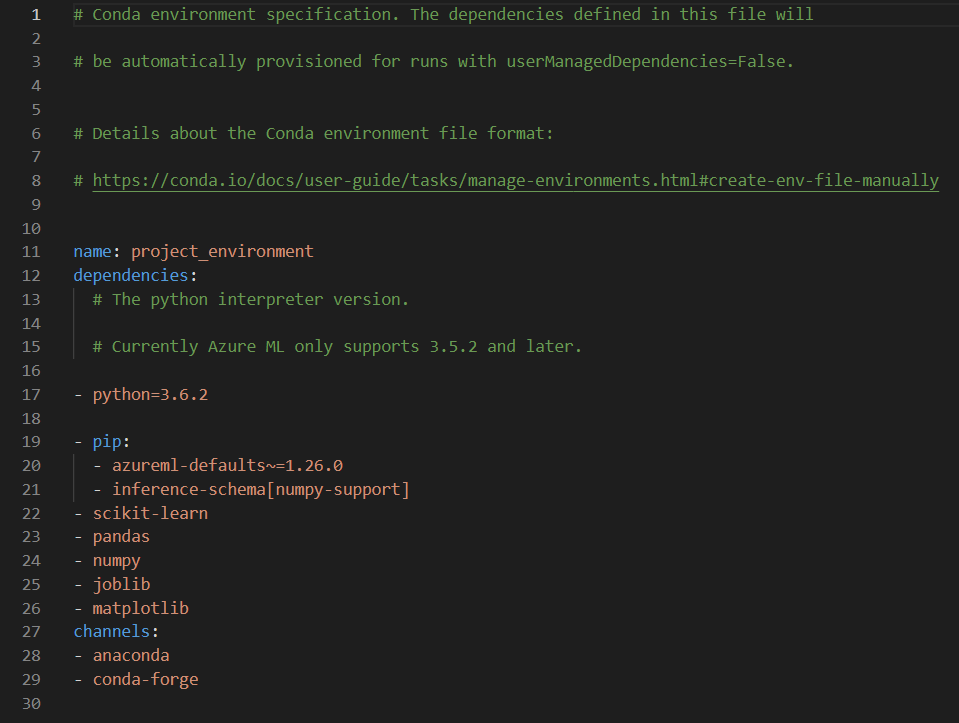
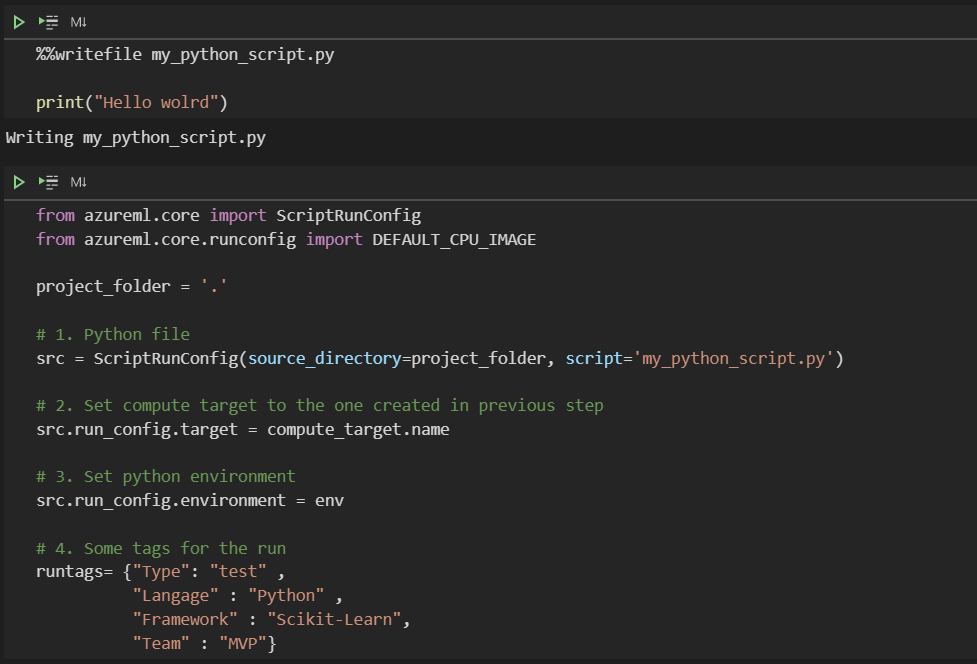
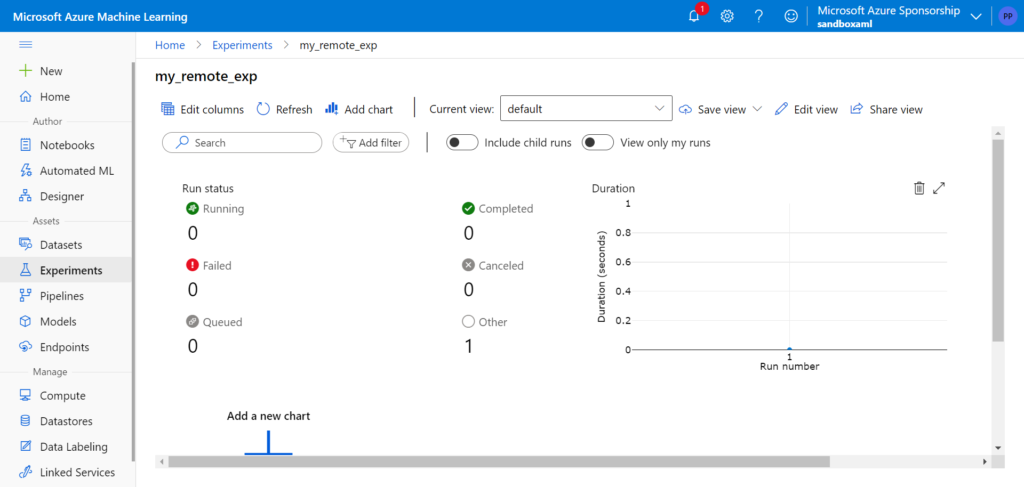
Dans un précédent article, nous explorions la procédure pour lancer simplement du code sur des machines distantes Azure ML (compute target) depuis l’environnement de développement (IDE) Visual Studio Code.
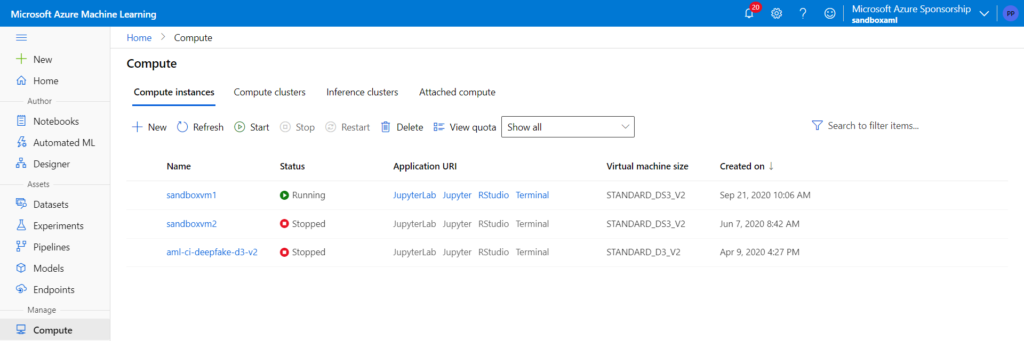
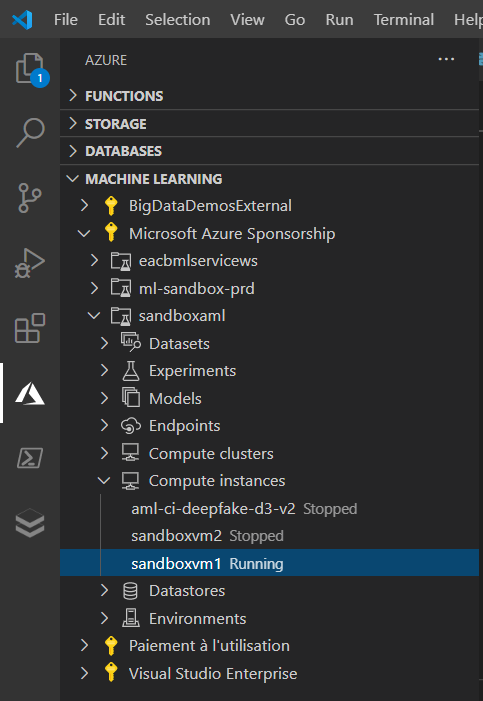
Dans les raccourcis disponibles au niveau du menu des instances de calcul, nous disposons dorénavant d’un lien permettant de lancer l’ouverture de Visual Studio Code.
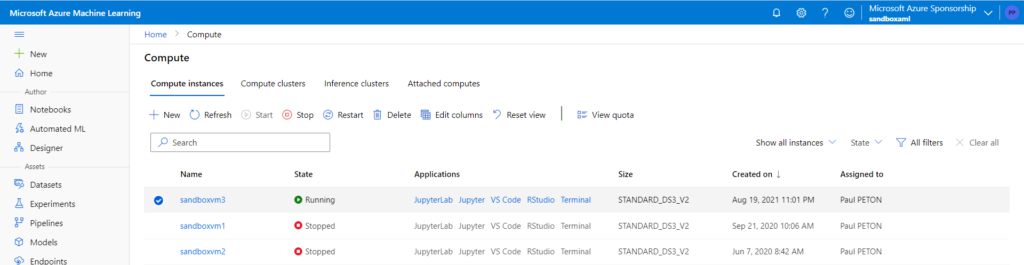
Quel est l’avantage de travailler de la sorte ? Réponse : vous disposez de toute la puissance de l’IDE de Microsoft (en particulier pour les commandes Git), sans toutefois être dépendant de votre poste local.
Vous ne pouvez bien sûr utiliser qu’une instance qui vous est personnellement assignée.
Cliquez sur le lien VS Code et votre navigateur lèvera tout d’abord une alerte. Cochez la case “Toujours autoriser…” pour ne plus voir cette pop-up.

C’est maintenant au tour de VSC de faire une demande d’autorisation avant de lancer la connexion à distance.
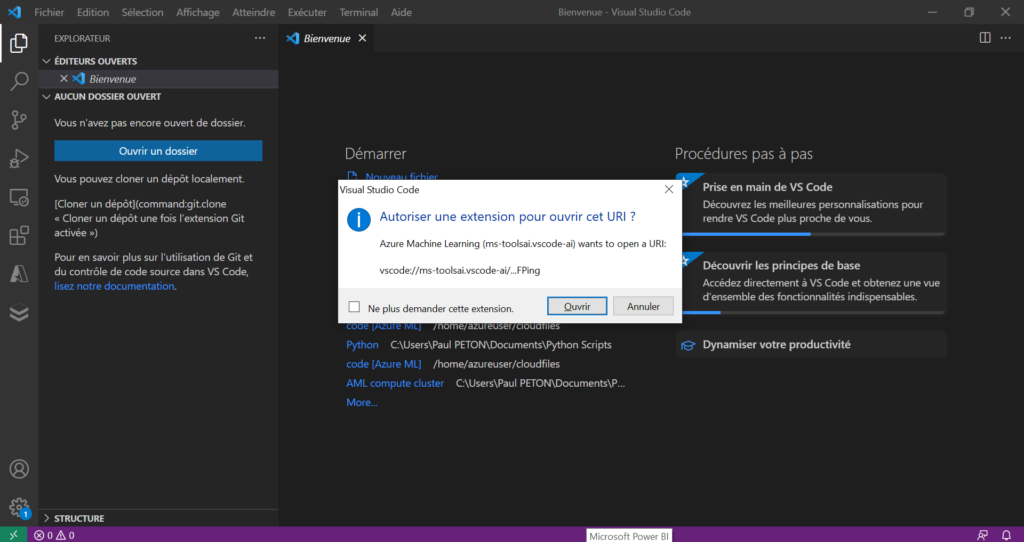
En tâche de fond, nous assistons à l’installation d’un VS Code server sur l’instance de calcul.

Il ne reste plus qu’à “faire confiance” aux fichiers qui seront maintenant accessible depuis l’éditeur local.
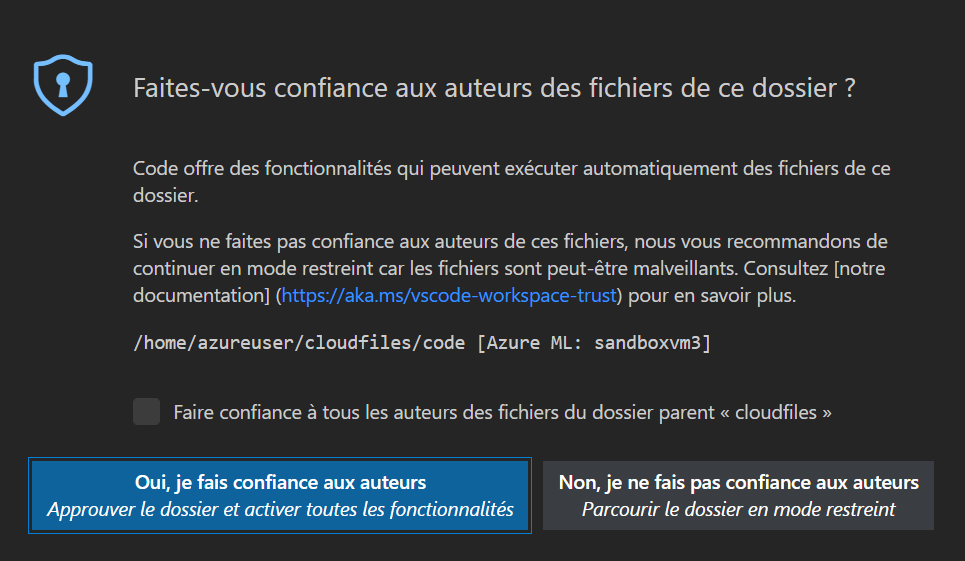
Plusieurs alertes peuvent être levées par VS Code selon votre paramétrage. Ainsi, il faudra choisir un interpréteur Python (mais attention, ce n’est pas une distribution installée sur votre poste local !) ainsi que s’authentifier vis à vis de l’extension Azure pour VS Code (à installer également au préalable).
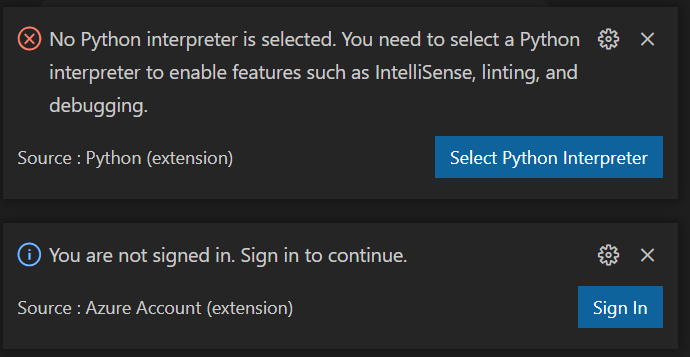
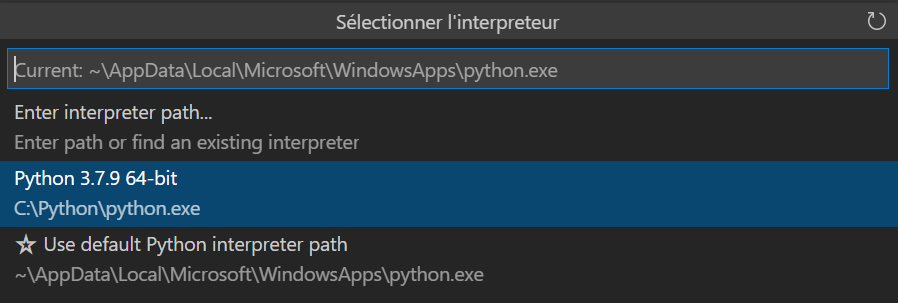
Si le choix entre Python2 et Python3 ne fait plus débat, le choix de la version mineure de Python est important pour votre projet, car celle-ci conditionne les versions de packages nécessaires par la suite.
Le réflexe pourrait alors être de choisir l’interpréteur Python du poste local mais nous voulons justement exécuter le code à distance. Une sélection dans la fenêtre ci-dessous n’est donc pas nécessaire.
Allons plutôt voir dans le coin en bas à droite de notre éditeur.

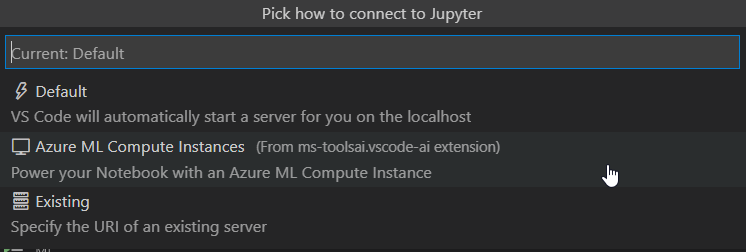
Un clic sur “Jupyter Server” va lancer un autre menu : “Pick how to connect to Jupyter“.
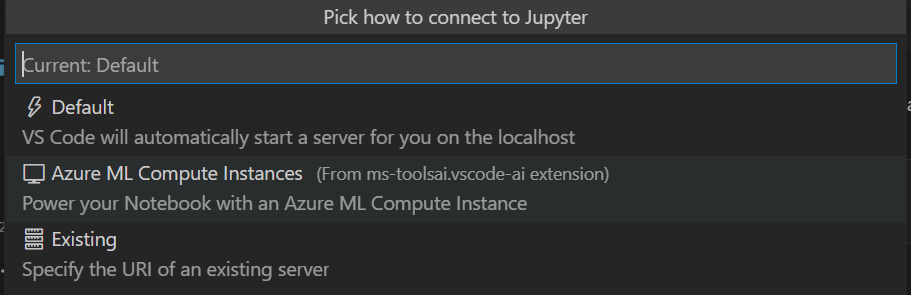
Nous choisissons ici “Azure ML Compute Instances” puis naviguons jusqu’à l’instance voulue. Un message d’alerte concernant la facturation de cette VM va alors apparaître.
Un rechargement de VS Code pourra être nécessaire pour bien valider la connexion.
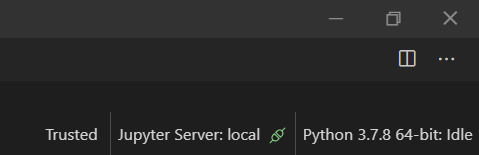
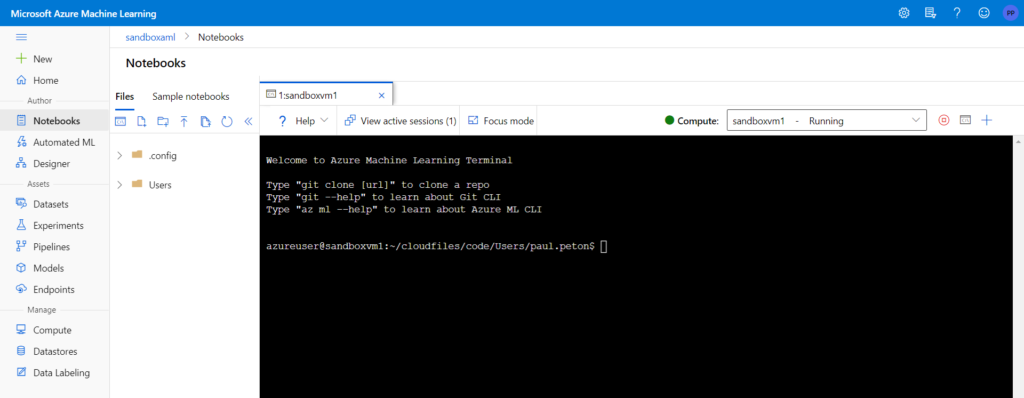
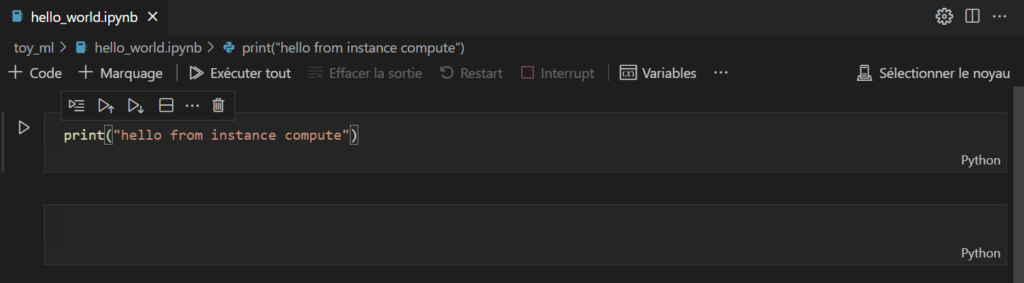
Le statut en bas à droite de l’IDE nous indique que le serveur Jupyter se trouve bien à distance (remote) et c’est donc lui qui exécutera le code.

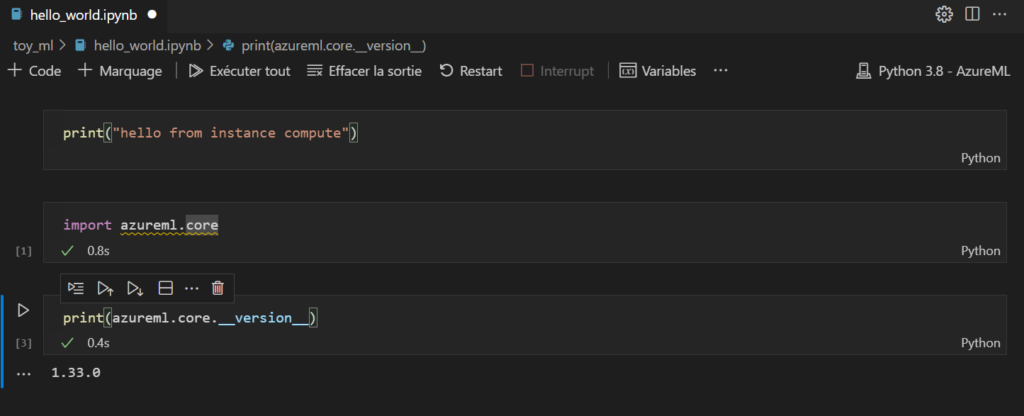
Commençons par un commande simple dans un nouveau notebook.
Il est maintenant temps de choisir l’interpréteur Python de la machine distante (cliquer si besoin sur le bouton “sélectionner le noyau”).
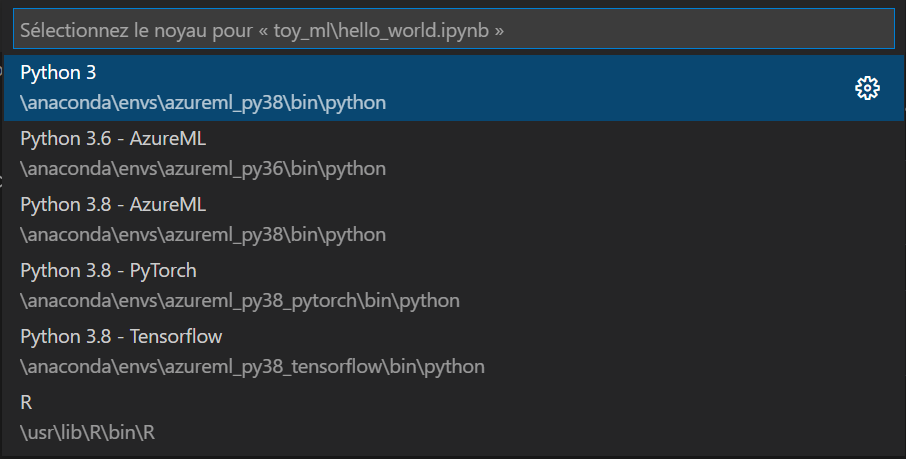
Nous choisissons ici l’environnement Python 3.8, muni des packages azureml, qui nous permettront d’interagir avec le service Azure Machine Learning.
Utiliser les commandes Git de VSC
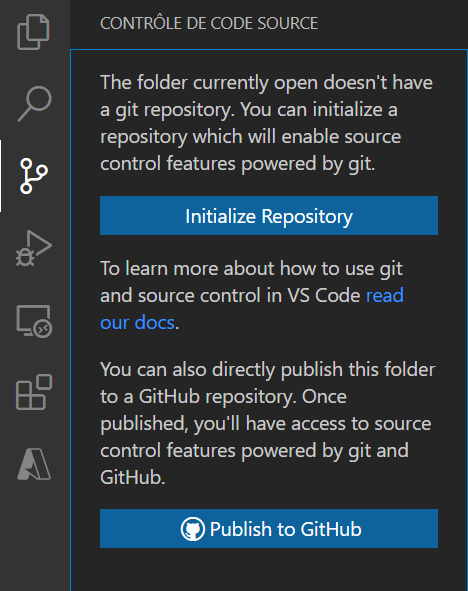
C’est sans doute le plus grand des avantages à passer par l’IDE : pouvoir réaliser du contrôle de code source, avec les fonctionnalités Git intégrées dans VSC.
En cliquant sur le symbole Git du menu du gauche, nous déroulons une première fenêtre demandant de réaliser l’initialisation du repository.
Il est ensuite nécessaire de configurer le nom de l’utilisation ainsi que son adresse de courrier électronique.

Les changements (ici, tous les fichiers lors de l’initialisation) sont détectés par Git et il sera possible de les pousser (git push) sur le repository.
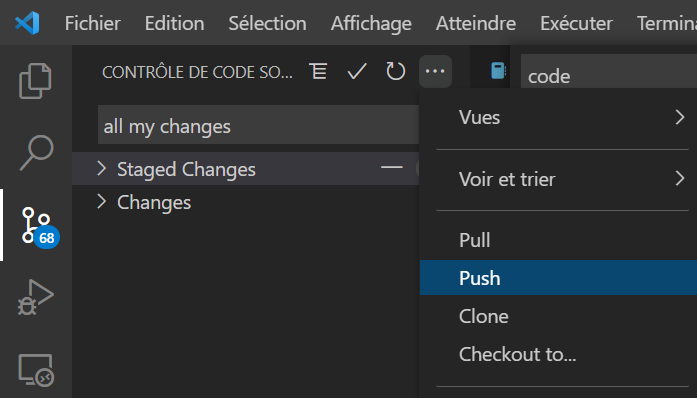
En cliquant ici sur Push, une alerte sera levée car une dernière configuration est nécessaire.
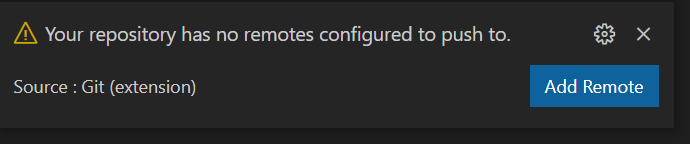
Il faut configurer l’URL du repository, par exemple une adresse GitHub.

Ceci se réalise au moyen de la commande ci-dessous, sur la branche principale (main).
git push --set-upstream <origin_branch> main
Ca y est ! Nous disposons maintenant d’une configuration très efficace pour travailler nos développements de Machine Learning, en lien avec le service Azure ML. Ce système permet également une véritable isolation des fichiers pour chaque développeur. Aucun risque qu’un.e collègue vienne modifier vos scripts, autrement qu’au travers d’un merge de branches.