En 2021, toute société proposant une plateforme autour de la data semble vouloir se doter d’un outil d’automated Machine Learning, sorte de “force brute” de la recherche du meilleur algorithme. Databricks ne déroge pas à la règle et propose depuis peu (mai 2021) un menu de création d’une expérience “AutoML”.
Il s’agit à ce jour d’une fonctionnalité en préversion et celle-ci est documentée sur ce lien : Databricks AutoML | Databricks on AWS
Le concept d’expérience au sein de Databricks se rattache historiquement à l’utilisation de MLFlow pour le stockage, versionning et déploiement de modèles d’apprentissage. L’approche proposée ici s’adresse directement aux “citizen data scientists” au travers d’une interface graphique.
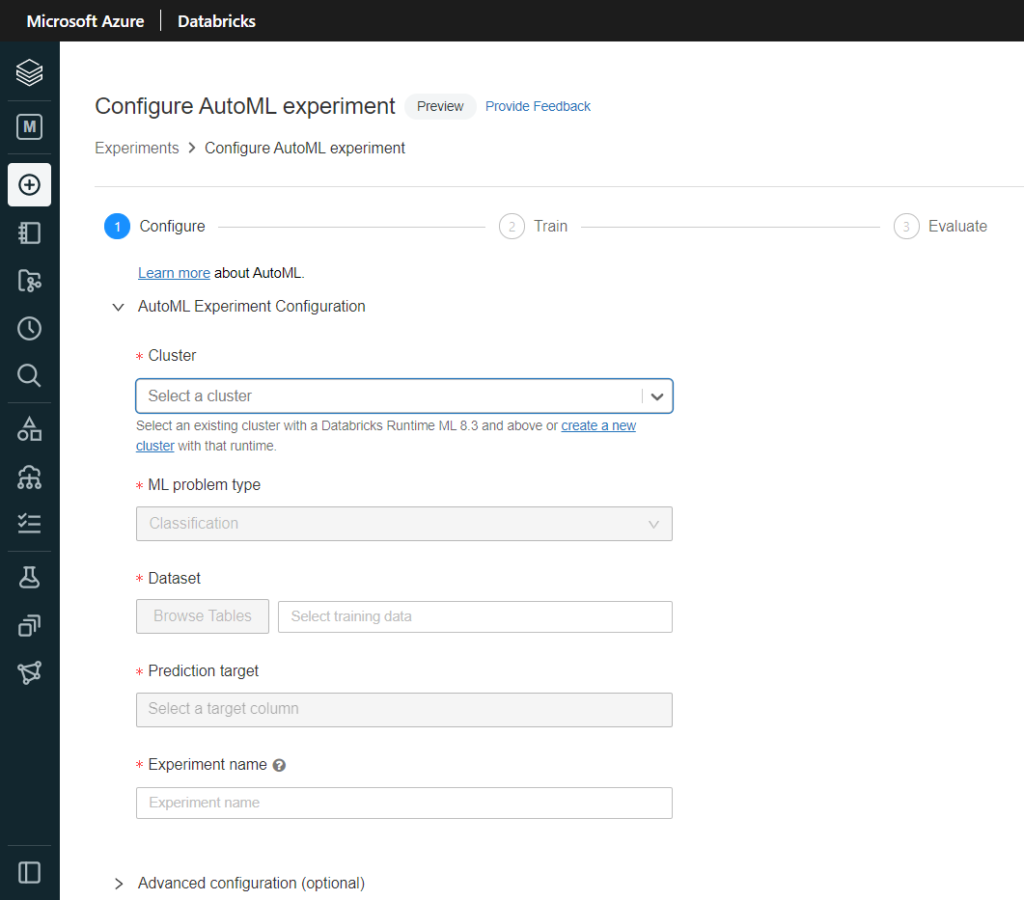
Nous aurons bien sûr besoin d’un cluster pour exécuter le code puis nous pourrons choisir entre les deux problématiques supervisées que sont la classification et la régression. La prévision sur série temporelle (forecasting) sera disponible prochainement.
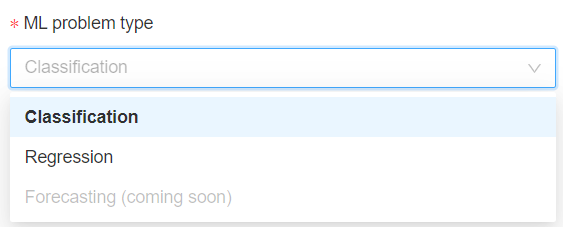
Ce cluster doit disposer d’un runtime 8.3 ML ou supérieur (à venir), incluant donc Spark 3 et des packages spécifiques pour l’apprentissage automatique.

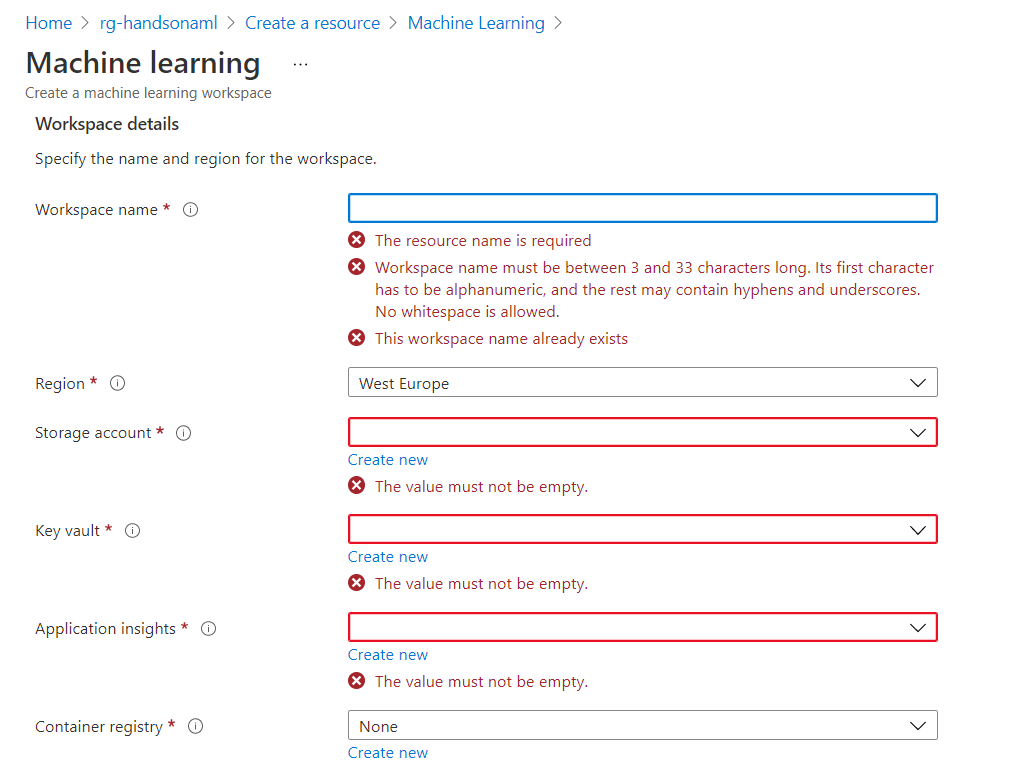
On devra ensuite désigner le dataset à utiliser. Celui-ci doit exister sous forme de table sur un cluster de l’espace de travail (pas obligatoirement celui qui exécutera l’entrainement), cluster devant être démarré pour que les tables soient visibles… et accessibles !
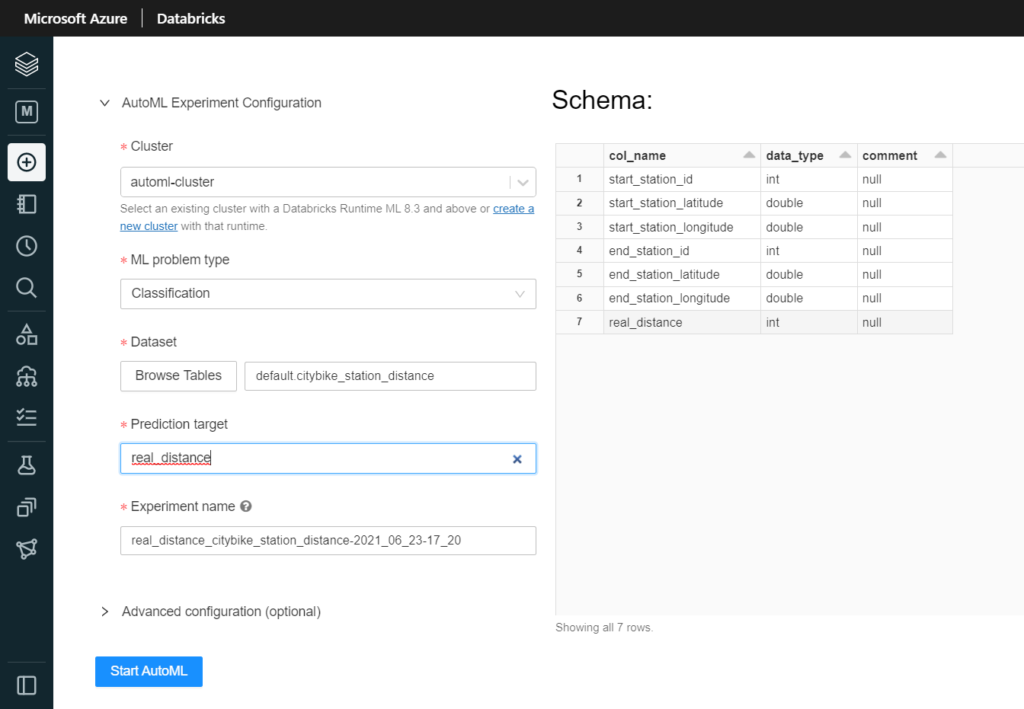
La table choisie doit présenter des données entièrement préparées pour le processus d’apprentissage (nettoyage des valeurs aberrantes, feature selection, feature engineering, etc.) car de telles opérations ne seront pas possibles par la suite.
Nous désignons ensuite la “prediction target“, puisque nous travaillons dans une approche d’apprentissage supervisé.
Dans les options d’évaluation, nous pourrons modifier la métrique d’évaluation qui servira à comparer les différents modèles, ainsi que donner des conditions d’arrêt, soit sur le temps d’entrainement, soit sur le nombre maximum d’essais réalisés.
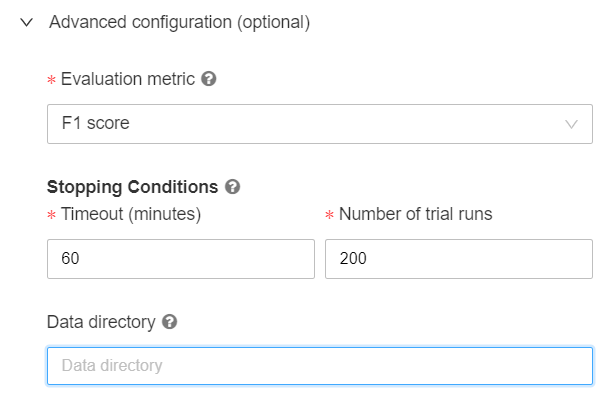
C’est parti, l’expérience se lance !
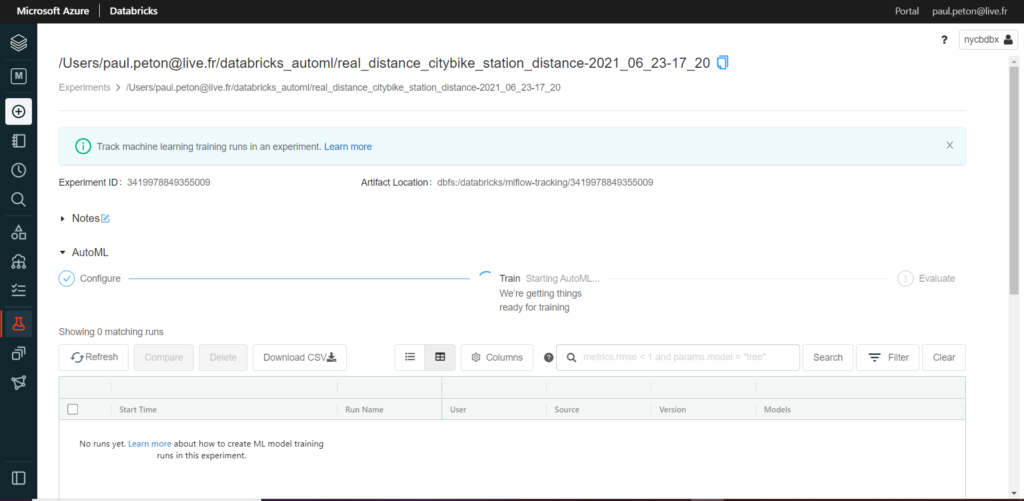
Pas de chance, échec dès le démarrage, mais nous allons chercher la cause.

Nous disposons pour cela d’un notebook contenant l’exécution du job.
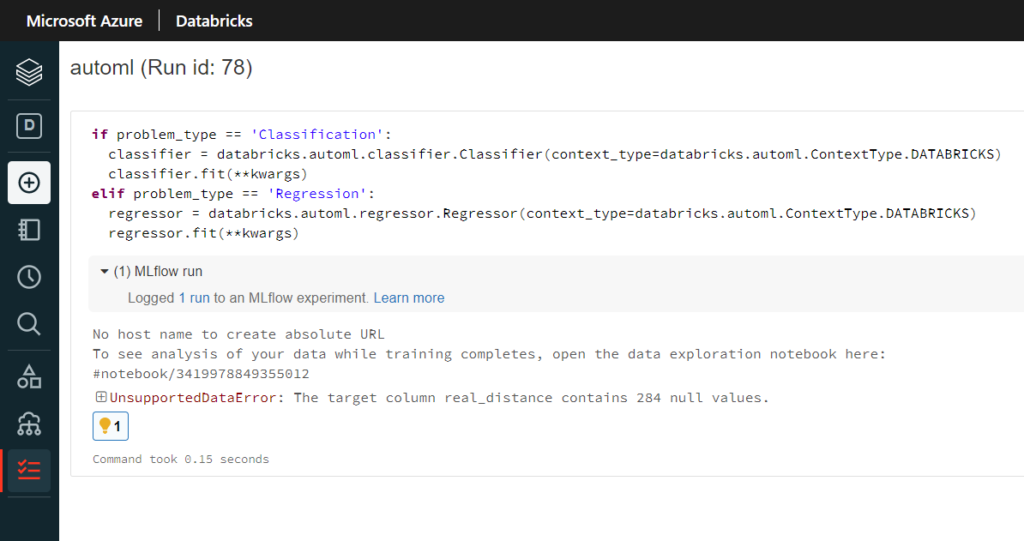
Des valeurs vides viennent polluer notre variable cible (“target“). Une meilleure préparation de données aurait dû être réalisée. Heureusement, Databricks vient à nouveau à notre secours avec un second lien vers un notebook de “Data exploration”.
Il s’agit du package pandas_profiling qui est mis en oeuvre dans un notebook.
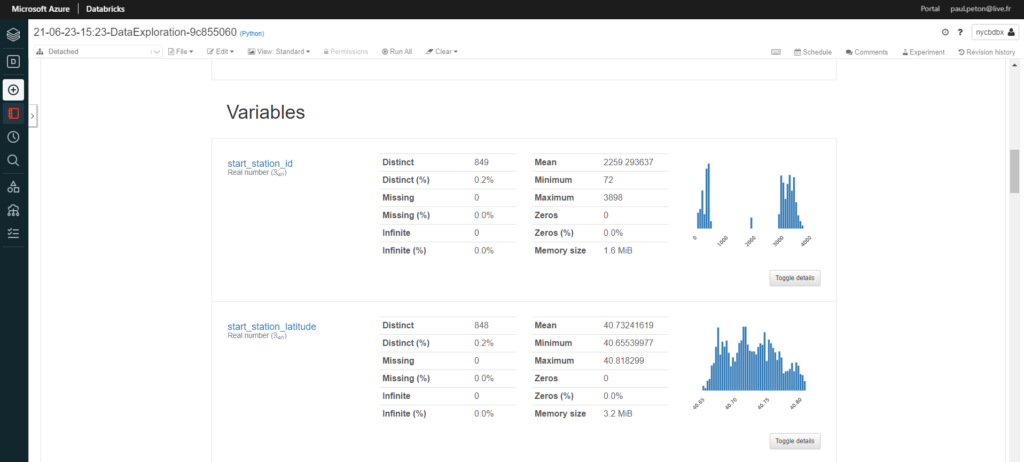
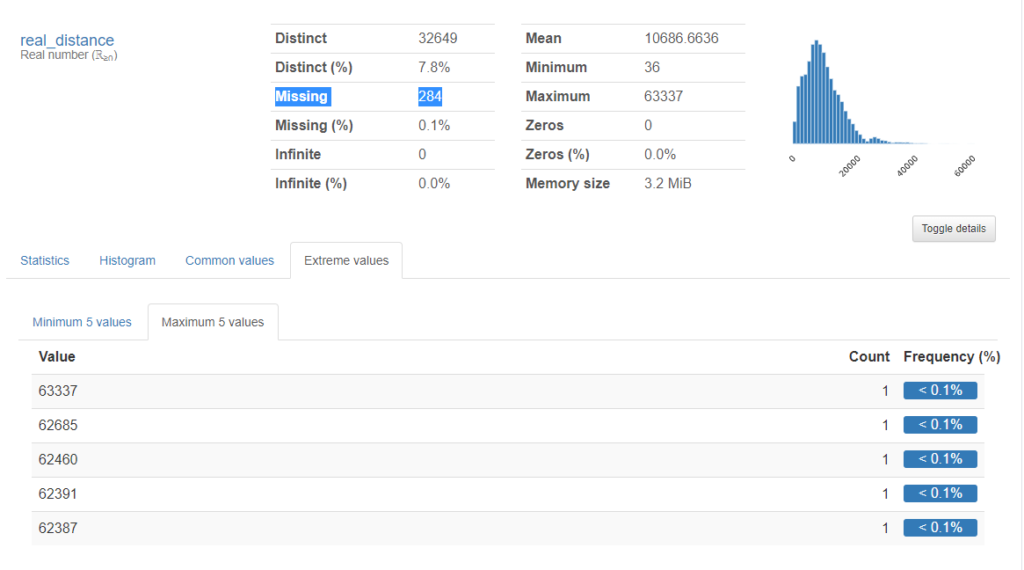
En affichant le détail, nous retrouvons bien les 284 valeurs manquantes mais nous pouvons aussi observer des valeurs extrêmes, potentiellement aberrantes.
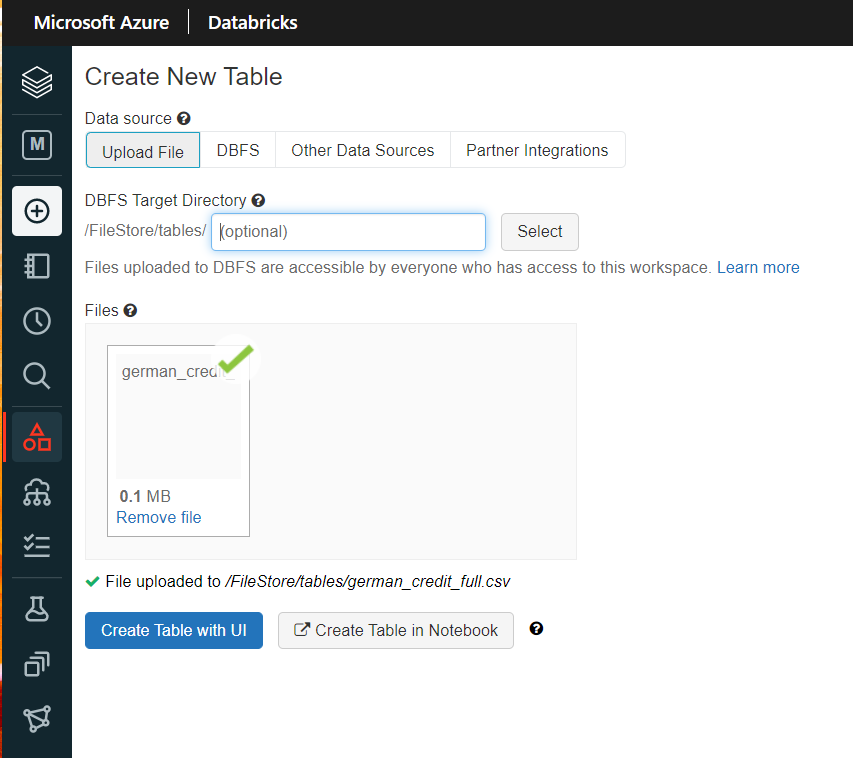
Nous allons repartir d’un dataset plus simple et déjà nettoyé : “German Credit” (disponible par exemple ici), que nous pouvons uploader directement sur le FileStore depuis le menu Data.
Relançons maintenant une expérience d’autoML, cette fois-ci sur une tâche de classification (la variable binaire class est ici la cible).
Au bout du temps imparti ou du nombre d’itérations, nous obtenons une liste des algorithmes que nous pouvons trier selon les différentes métriques.
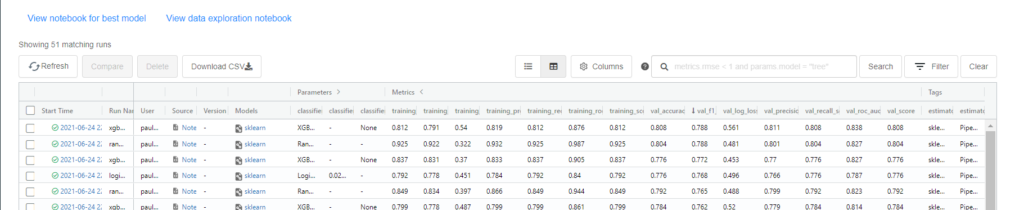
Une très bonne surprise est de trouver, associé à chaque exécution, le notebook correspondant !
Celui-ci suit une cheminement tout à fait classique, donné par le plan en Markdown.

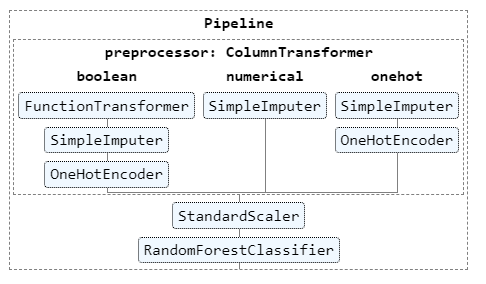
Une preprocessing des données est appliqué, sous forme de pipeline Scikit Learn, pour les différents types de variables :
- variables binaires : imputation des valeurs manquantes et recodage en 0/1
- variables numériques : imputation par la moyenne
- variables catégorielles : dichotomisation (one hot encoding)
Cette première étape du pipeline est suivi d’un standardisation, par exemple avec la méthode StandardScaler(), toujours issue du package Scikit Learn.
Nous pouvons visualiser ce pipeline graphiquement.
Le modèle est lui aussi explicitement codé et nous pouvons donc découvrir les valeurs spécifiques des hyperparamètres du modèle utilisés lors de l’exécution.
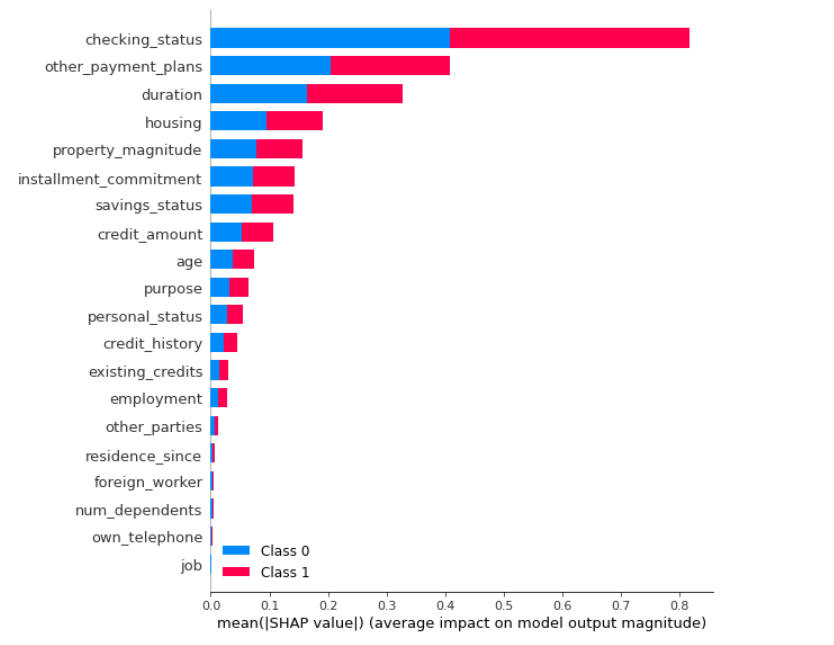
Enfin, une explication du modèle par la méthode SHAP, classant les features par importance, a été codée ainsi que les commandes MLFlow permettant d’enregistrer puis de charger un modèle (inférence).
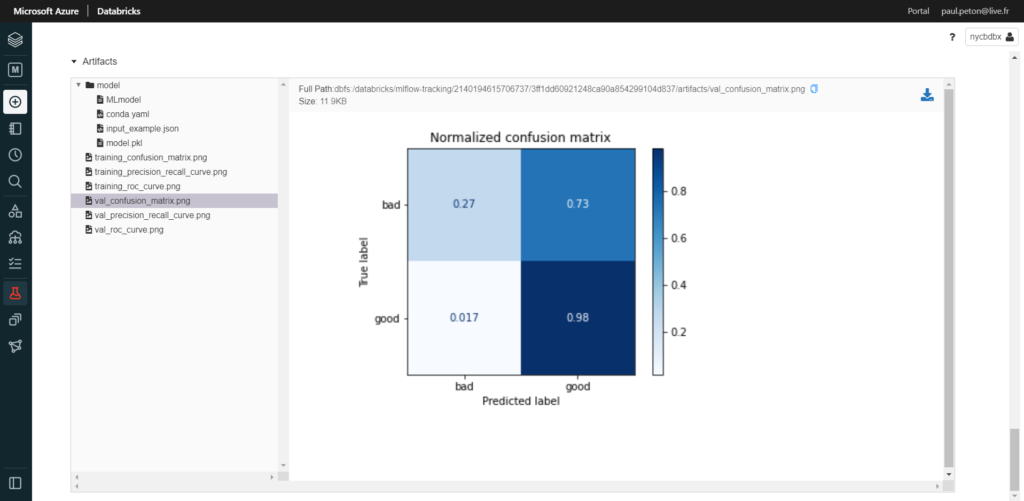
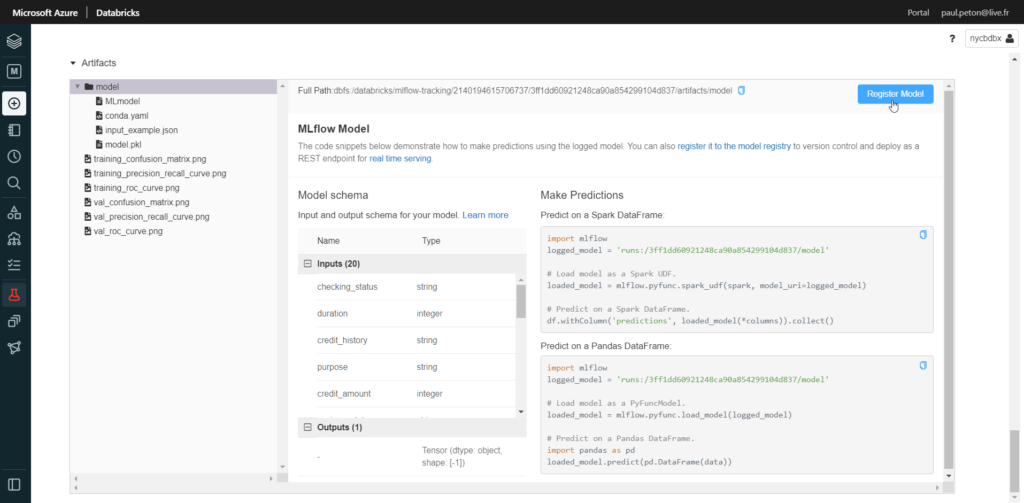
En cliquant sur le lien de la colonne “Models”, nous retrouvons les artefacts liés au modèle : un binaire sérialisé au format Pickle, mais aussi quelques graphiques comme la courbe ROC ou la matrice de confusion.
Il ne restera plus qu’à enregistrer le modèle dans MLFlow register pour pouvoir ensuite l’exposer.
En conclusion, nous avons ici un outil d’apprentissage automatisé qui vient ajouter une fonctionnalité à “la plateforme unifiée de données” qu’est Databricks. Cet outil se destine, à mon sens, à des Data Scientists voulant gagner du temps sur le codage de modèles simples (issus de la bibliothèque de Scikit Learn), sur des données déjà contrôlées et nettoyées (a minima, le retrait des valeurs aberrantes).
Nous pourrons regretter l’absence d’alertes automatiques sur les colinéarité entre variables soumises au modèle mais le notebook d’exploration basé sur pandas_profiling nous permet d’obtenir ces informations. Ce type d’outils pousse facilement au sur-apprentissage et c’est une limite qu’il faudra bien garder en tête.
Le fait de proposer le code sous forme de notebooks est un très grand avantage sur d’autres plateformes d’automated ML (rien n’empêche d’améliorer ce code par soi-même !). En étant exigeants, nous pourrions attendre de Databricks que celui-ci soit écrit pour profiter de la puissance du calcul distribué sur les nœuds du cluster (pourquoi pas avec le package koalas ?) mais des évolutions viendront sûrement prochainement.