Le cluster Spark managé que propose Azure Databricks permet l’exécution de code, présent dans des notebooks, dans des scripts Python ou bien packagés dans des artefacts JAR (Java) ou Wheel (Python). Si l’on imagine une architecture de production, il est nécessaire de disposer d’un ordonnanceur (scheduler) afin de démarrer et d’enchaîner les différentes tâches automatiquement.
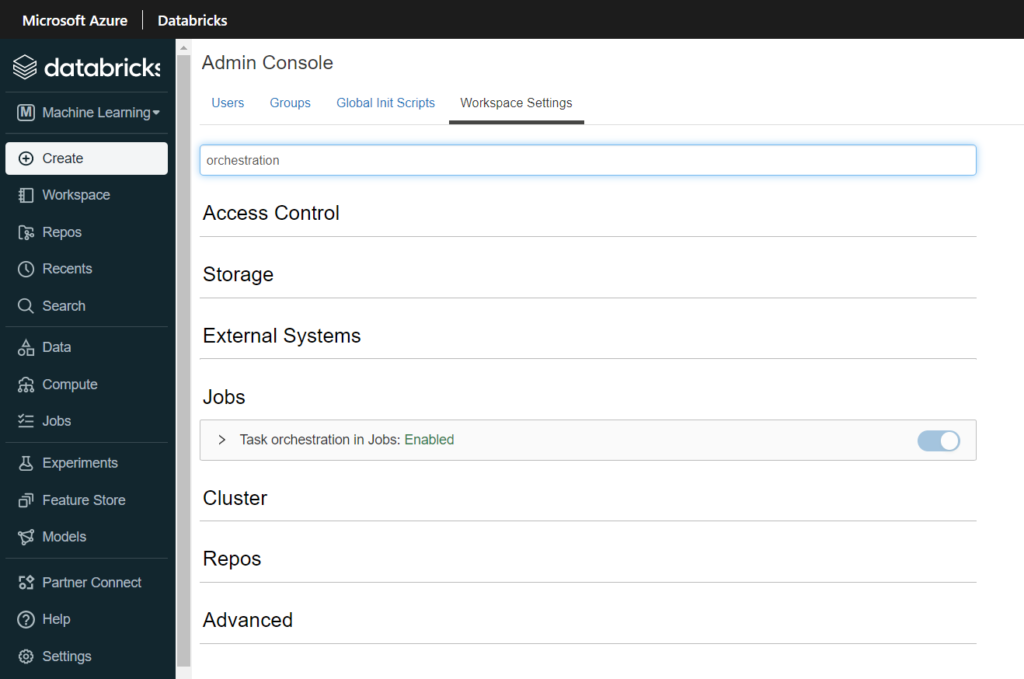
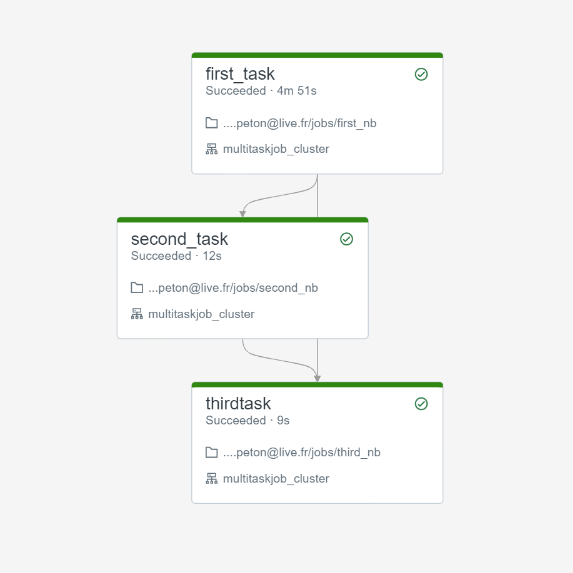
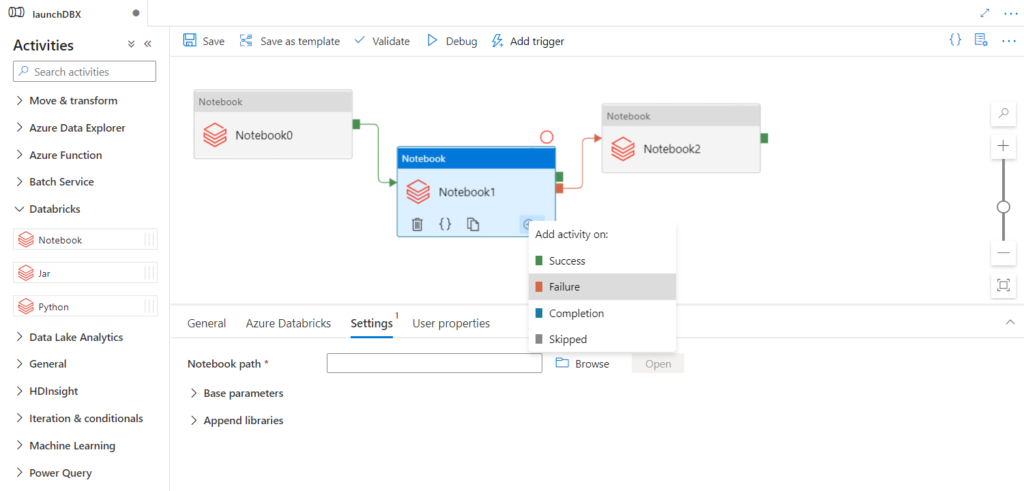
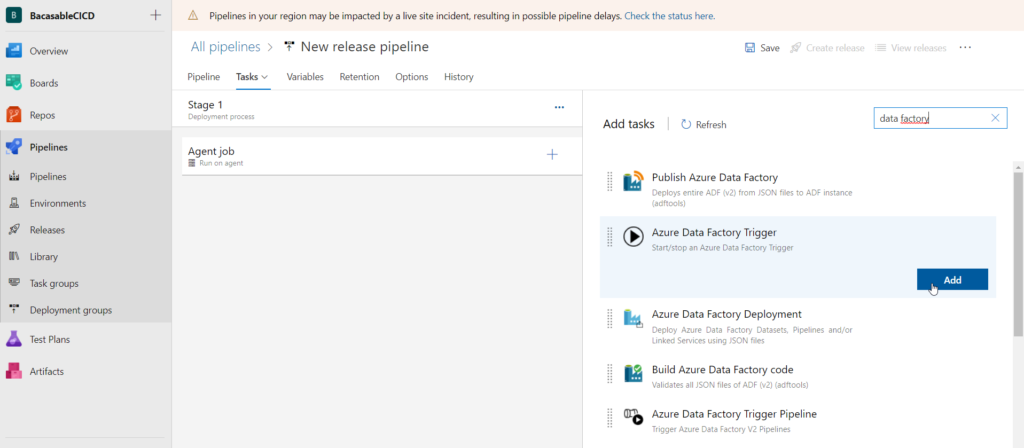
Nous connaissions déjà les jobs Databricks, nous pouvons dorénavant enchaîner plusieurs tasks au sein d’un même job. Chaque task correspond à l’exécution d’un des éléments cités ci-dessus (notebook, script Python, artefact…). Comme il s’agit à ce jour (mars 2022) d’une fonctionnalité en préversion, il est nécessaire de l’activer dans les Workspace Settings de l’espace de travail.
Le principal intérêt d’enchainer des tasks à l’intérieur d’un même job est de conserver le même job cluster, qui se différencie des interactive clusters par… sa tarification ! En effet, celui-ci est environ deux fois moins cher qu’un cluster utilisé par exemple pour des explorations menés par les Data Scientists.
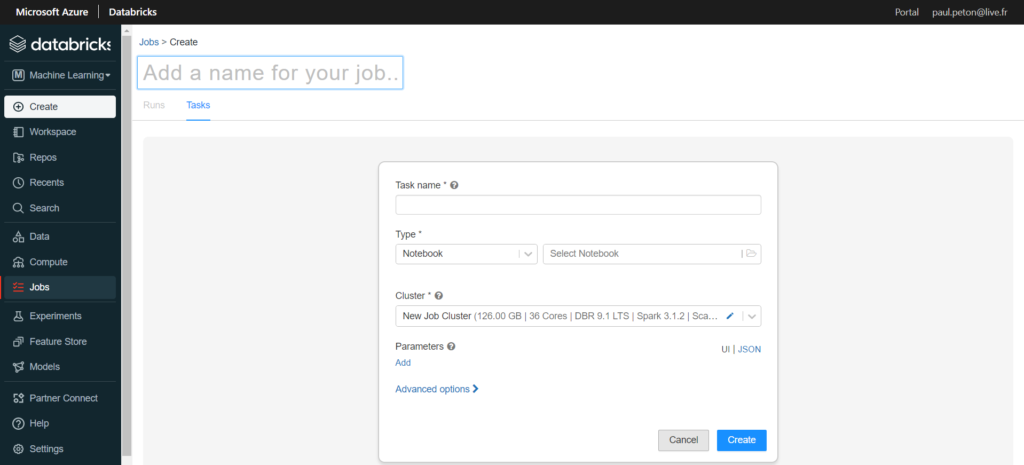
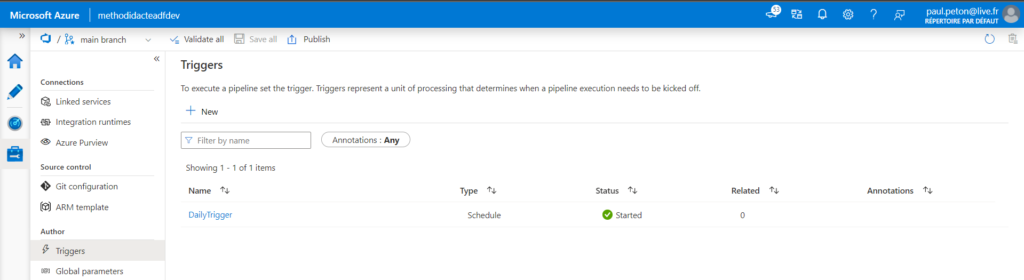
Le menu latéral nous permet de lancer la création d’un nouveau job (pensez à bien le nommer dans la case située en haut à gauche).
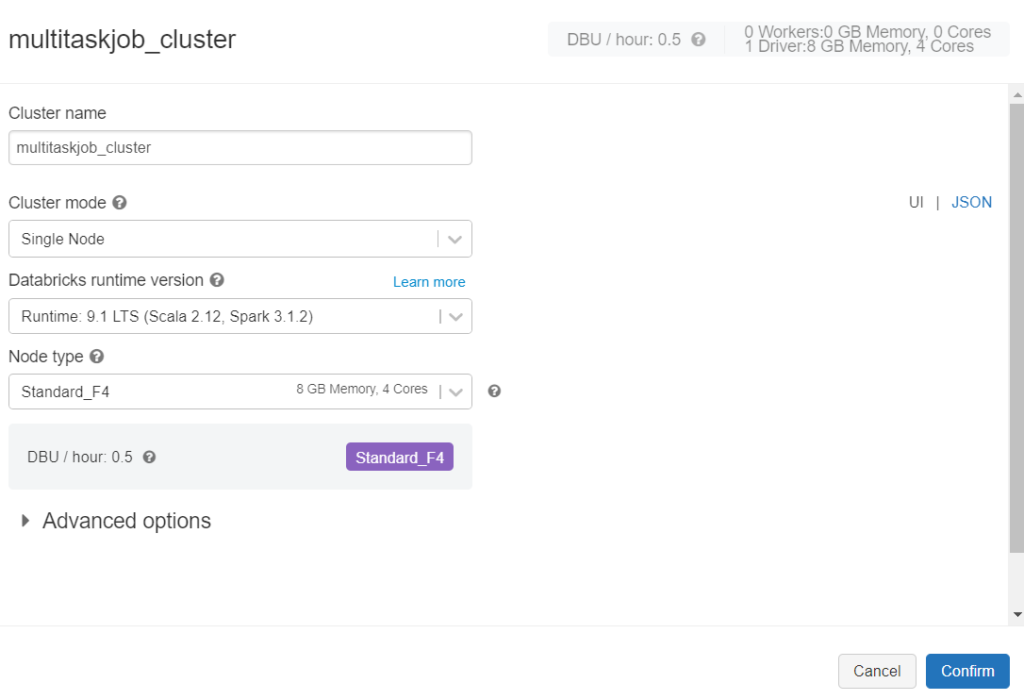
Pour réaliser nos premiers tests, nous utiliserons un job cluster de type “single node”, associée à une machine virtuelle relativement petite.
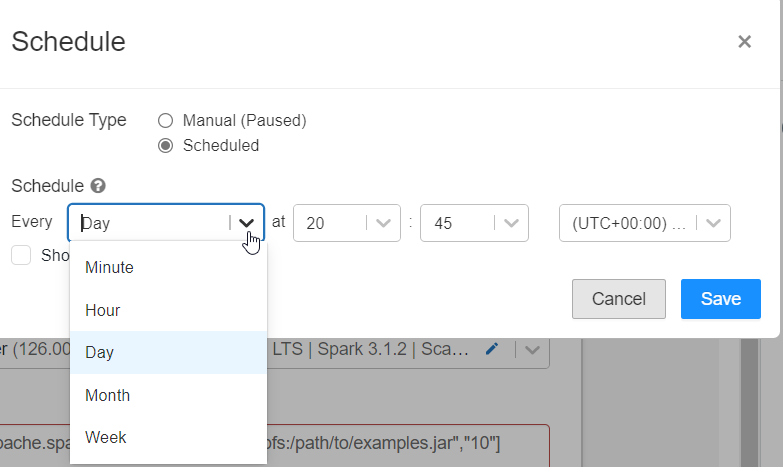
Le job se planifie à un moment donné, défini par une interface graphique ou une syntaxe classique de type CRON telle que : 31 45 20 * * ?
Syntaxe CRON : 31 45 20 * * ?
Nous pourrons retrouver tous les logs d’exécution dans l’interface “jobs” de l’espace de travail.
Passer des informations d’une tâche à une autre
L’enchainement de tâches nous pousse rapidement à imaginer des scénarios où une information pourrait être l’output d’une tâche et l’input de la suivante. Malheureusement, il n’existe pas à ce jour de fonctionnalité native pour répondre à ce besoin. Nous allons toutefois explorer ci-dessous deux possibilités. Il existe également quelques variables réservées pouvant être passées en paramètres de la tâche : job_id, run_id, start_date…
Passer un DataFrame à une autre tâche
Nous nous orienterons tout naturellement vers le stockage d’une table dans le metastore de l’espace de travail Databricks.
écriture d’un DataFrame en table : df = spark.read.parquet(‘dbfs:/databricks-datasets/credit-card-fraud/data/’)
lecture de la table : df = spark.table(“T_credit_fraud”)
Ceci ne peut être réalisé avec une vue temporaire, créée au moyen de la fonction createOrReplaceTempView(), celle-ci disparaissant en dehors de l’environnement créé pour son notebook d’origine.
Passer une valeur à une autre tâche
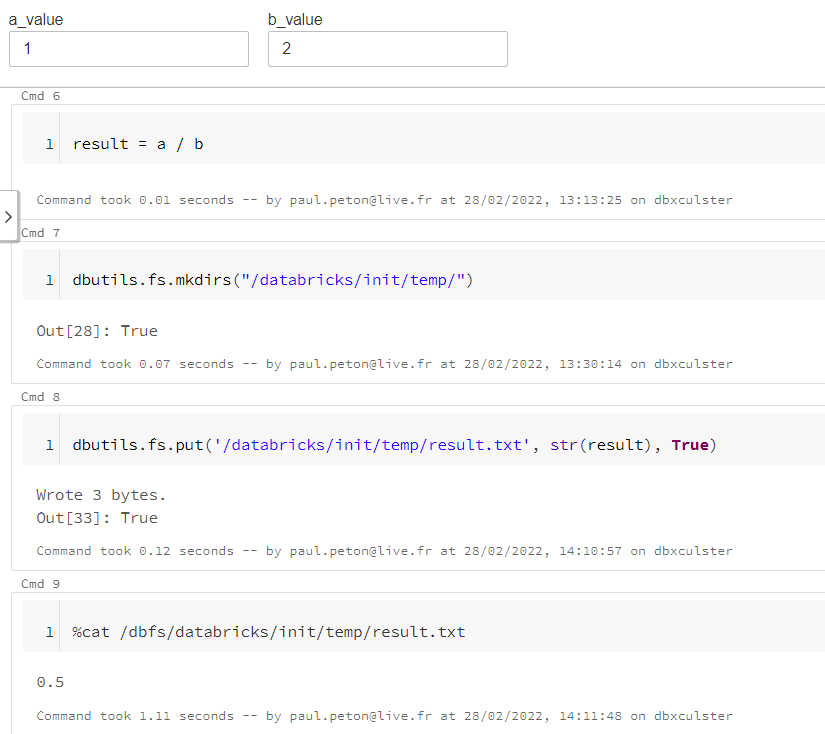
Nous profitons du fait que le job cluster soit commun aux différentes tâches pour utiliser le point de montage /databricks et y écrire un fichier. Nous pouvons ainsi exploiter les commandes dbutils et shell (magic command %sh) :
dbutils.fs.mkdirs() permet de créer un répertoire temporaire
dbutils.fs.put() écrit une chaîne de texte dans un fichier
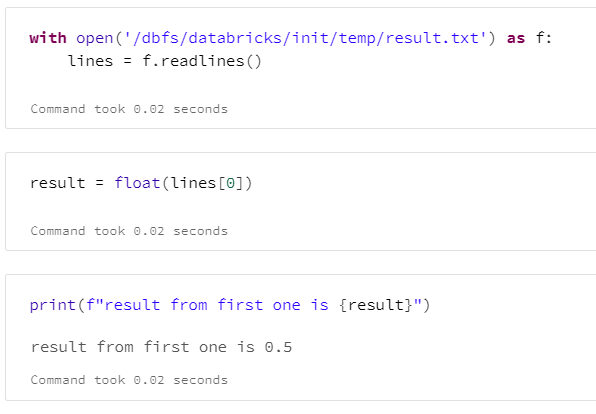
Nous vérifions ici la bonne écriture de la valeur attendue mais la commande shell cat ne permet pas de stocker le résultat dans une variable. Nous utiliserons une commande Python open() en prenant soin de préfixer par /dbfs le chemin du fichier créé lorsla tâche précédente. Attention également à bien récupérer le premier élément de la liste lines avec [0] puis à convertir la valeur dans le type attendu.
Quand continuer à utiliser Azure Data Factory ?
Dans une architecture data classique sous Azure, et orientée autour des outils PaaS, c’est le service Azure Data Factory qui est généralement utilisé comme ordonnanceur.
Si l’enchainement des tâches peut se conditionner en utilisant le nom des tâches précédentes, celui-ci n’aura lieu qu’en cas de succès des autres tâches.
Il n’est donc pas possible de prévoir un scénario similaire à celui présenté ci-dessous, où l’enchainement se ferait sur échec d’une étape précédente.
Les déclenchements de jobs Databricks ne se font que sur une date / heure alors qu’il serait possible dans Azure Data Factory de détecter l’arrivée d’un fichier, par exemple dans un compte de stockage Azure, puis de déclencher un traitement par notebook Databricks.
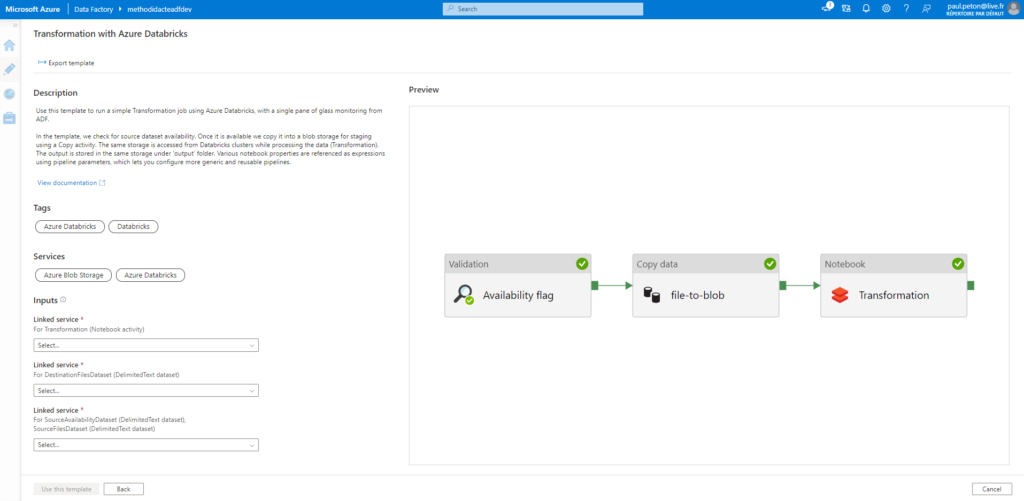
Template “Transformation with Azure Databricks”
Côté fonctionnalité de Data Factory, nous attendons que les activités Databricks puissent exécuter également des packages Wheel, comme il est aujourd’hui possible de le faire pour les JAR. Une solution de contournement consistera à utiliser la nouvelle version de l’API job de Databricks (2.1) dans une activité de type Web.
En conclusion, il s’agit là d’une première avancée vers l’intégration dans Databricks d’un nouvel outil indispensable à une approche DataOps ou MLOps, même si celui-ci est pour l’instant incomplet. Les fonctionnalités de Delta Live Tables, encore en préversion également, viendront aussi compléter les tâches traditionnellement dévolues à un ETL.
Azure Data Factory est un service managé du cloud Azure, de type “low code”, aussi bien utile pour ses fonctionnalités d’ETL/ELT que d’ordonnanceur. On appréciera particulièrement d’y intégrer toute une chaîne de traitements et d’avoir ainsi un espace centralisé de lecture des logs d’exécution.
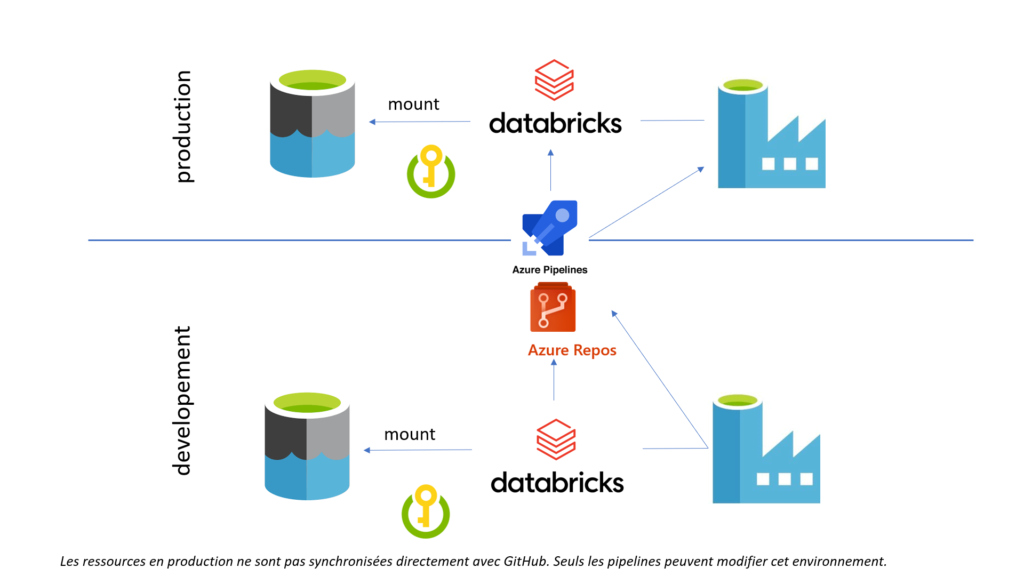
Si ce service commence à prendre de l’importance dans vos projets data, vous souhaiterez certainement développer dans une ressource qui n’est celle de production. Se posera donc alors la question du déploiement continu entre ressources.
Lier Data Factory à un repository
Avant de déployer, il est bien sûr nécessaire de versionner les développements ! Cela sera possible dans l’un des deux outils du monde Microsoft : GitHub ou Azure DevOps. Il est possible de définir le repository à la création de la ressource mais nous pouvons le faire, plus facilement, après l’instanciation.
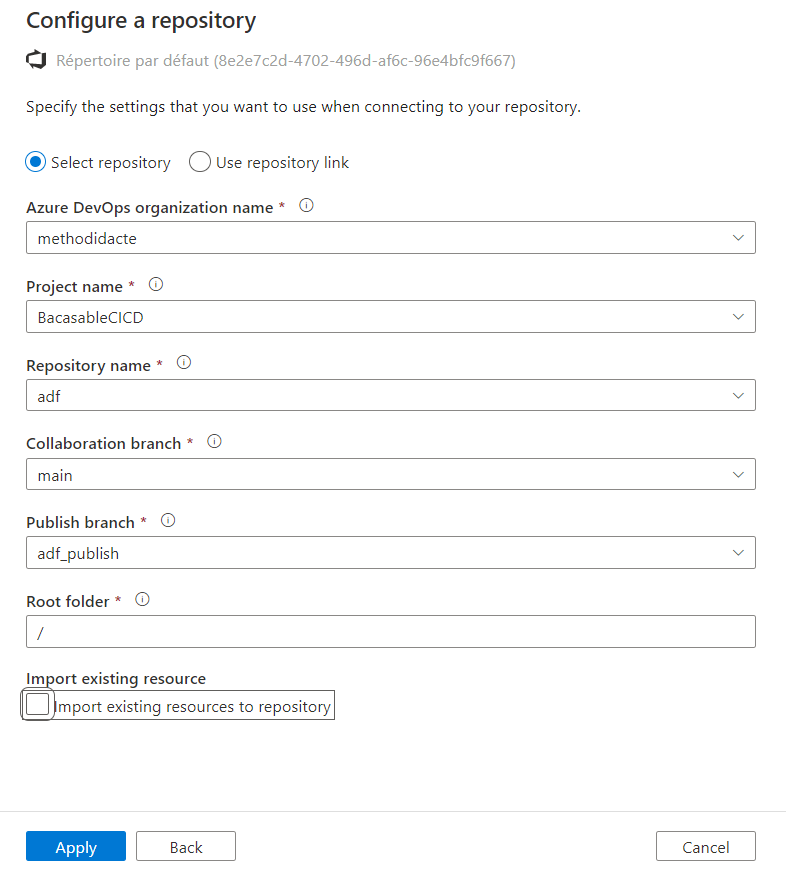
A la première connexion au Studio Data Factory, nous configurons le repository, en choisissant ici une organisation et un projet Azure DevOps. Il n’est pas nécessaire d’importer le contenu de ce repository qui doit être vide pour l’instant.
Décocher la case “Import existing resource”
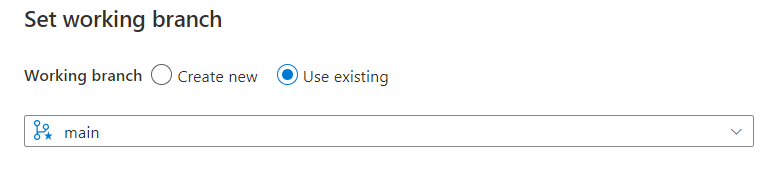
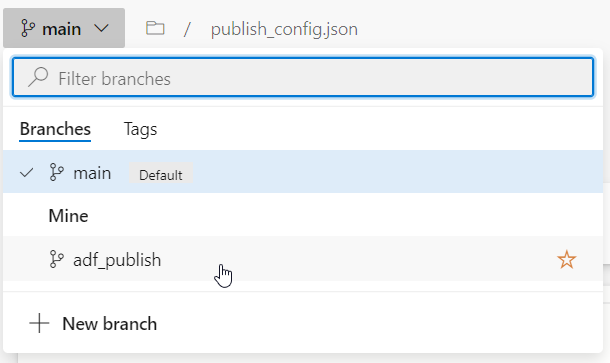
Notons tout de suite un fonctionnement propre à Data Factory que sera le travail sur deux branches :
une branche principale (nommée ici main), de collaboration
une branche de “publication” au nom réservé : adf_publish
Nous verrons lors du déploiement le rôle joué par cette seconde branche. Nous terminons la configuration en définissant la branche main comme la branche de travail.
Il sera possible par la suite de créer des branches apportant de nouvelles fonctionnalités ou réalisant des corrections puis d’effectuer des opérations de merge (fusion) avec la branche principale.
Terminons cette première partie sur une notion fondamentale : les environnements de destination lors du déploiement (pré-production, production…) ne doivent pas être liés au repository. C’est en effet une opération spécifique (un pipeline de release) qui viendra déposer le code, mais ce dernier ne doit pas pouvoir être modifié en dehors de l’environnement de développement.
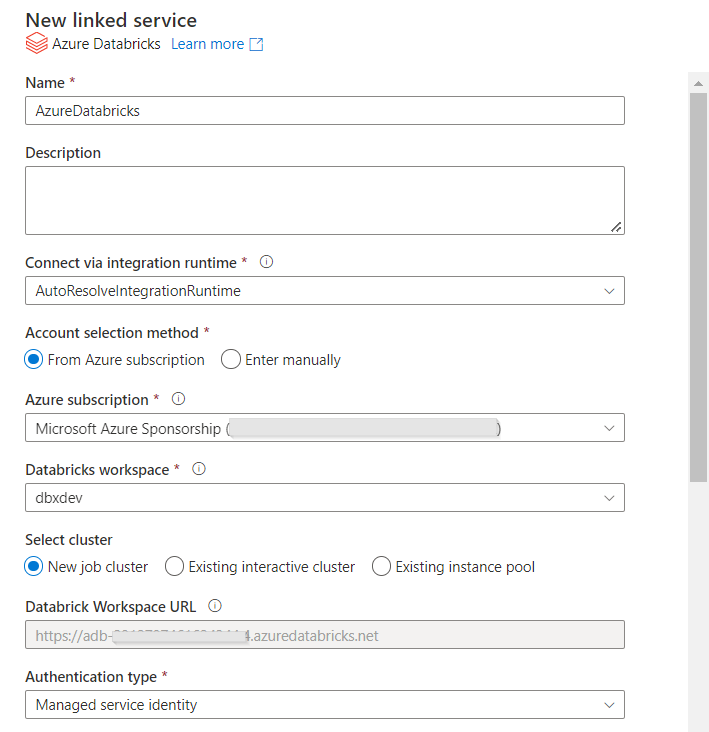
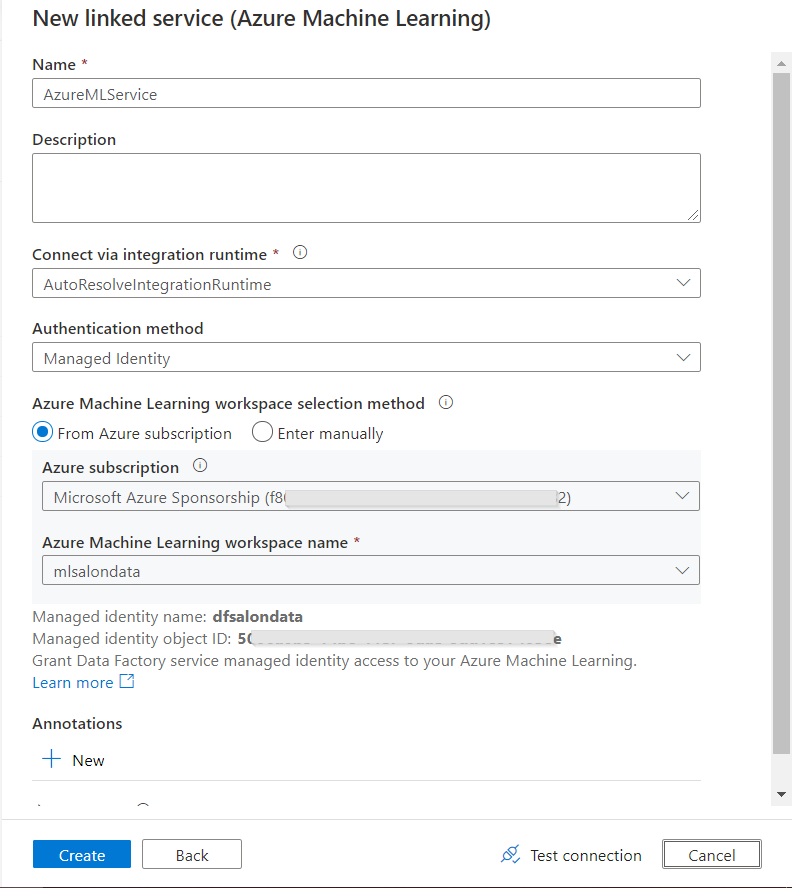
Créer un premier service lié
Les services liés sont les premiers éléments à créer dans Data Factory car ils “hébergent” les datasets ou représentent une ressource de calcul comme c’est le cas pour le service de clusters Spark managé Azure Databricks. Ce sont aussi les services liés qui sont les plus dépendants des environnements (dev, uat, prod…) car ils pointent vers d’autres ressources auprès desquelles une authentification est bien souvent nécessaire.
Voici une bonne pratique : ne pas utiliser un nom spécifique à l’environnement (par exemple ls_DatabricksDev) car ce nom doit refléter la ressource dans chaque environnement et nous ne pourrons pas le modifier.
En revanche, plusieurs propriétés ainsi que l’authentification devront être modifiées lors du déploiement entre environnements.
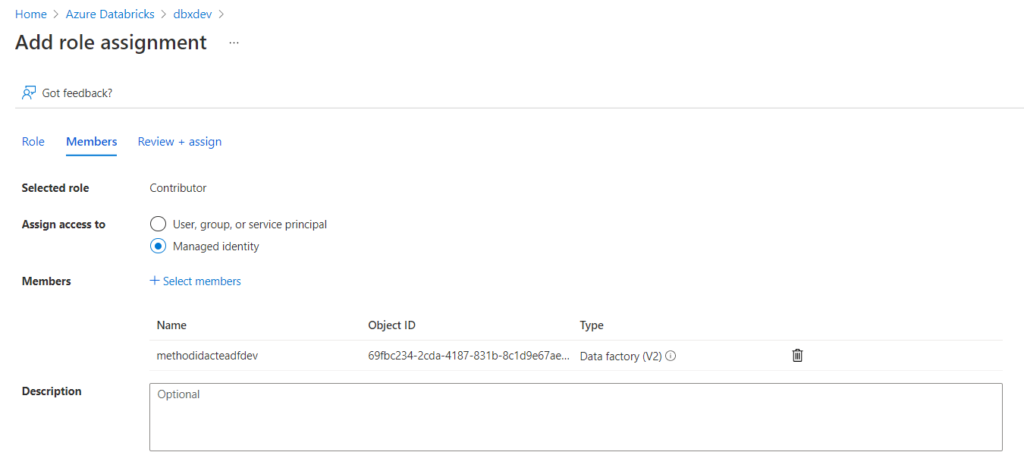
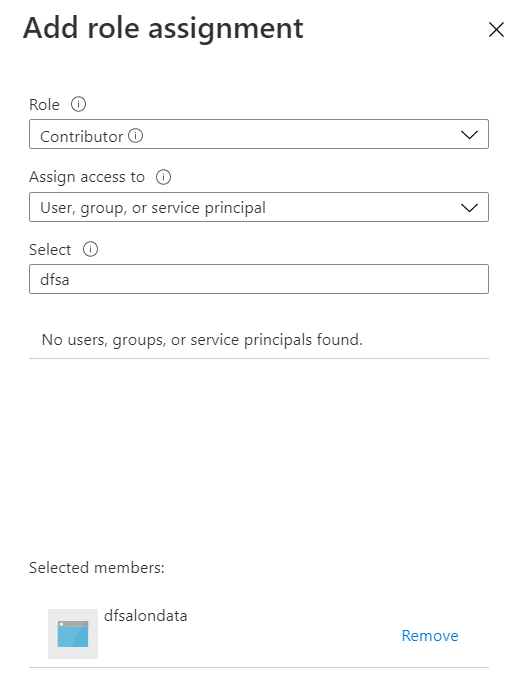
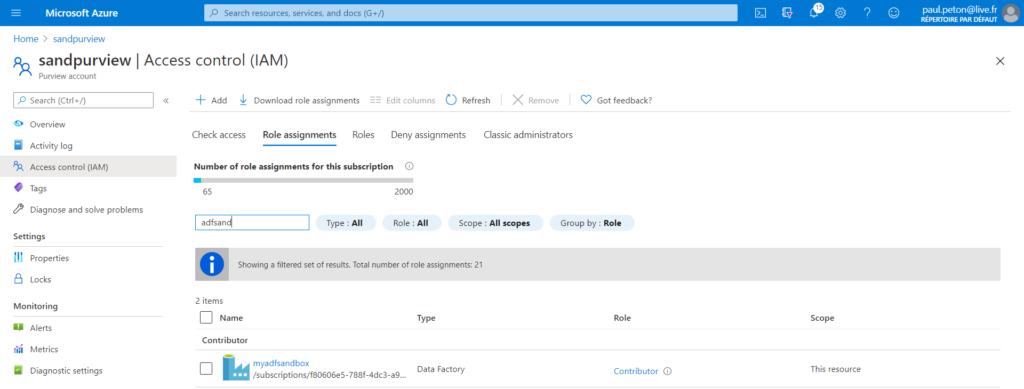
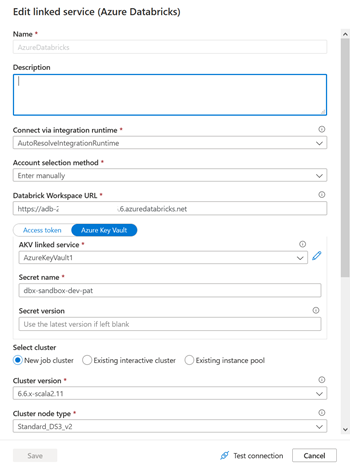
Pour un service lié Databricks, nous choisissons de nous authentifier à l’aide d’une identité managée, qu’il faudra déclarer en tant que “Contributor” au niveau de l’access control (IAM) de la ressource Databricks.
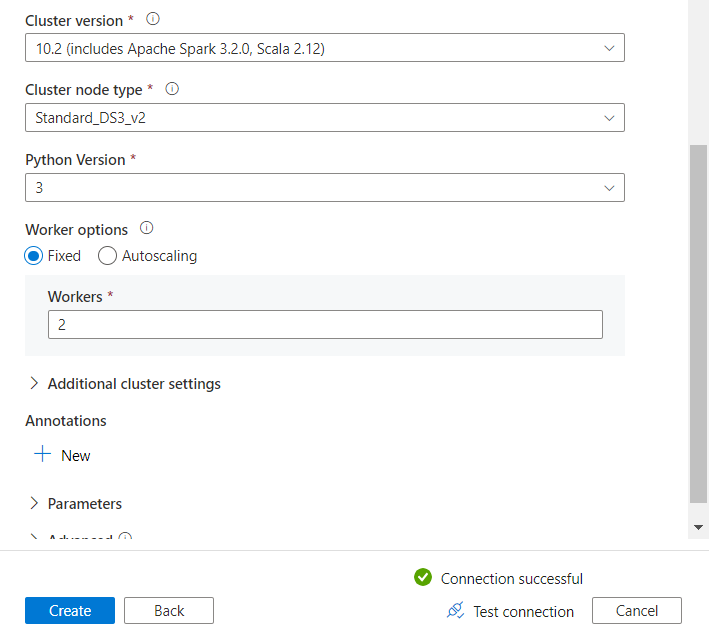
Pour vérifier que l’authentification est bien réalisée, nous déroulons les listes “cluster version” et “cluster node type”, remplacées par un message “failed” si la connexion n’est pas valide.
Il s’agit là d’une autre bonne pratique : privilégier les identités managées car celles-ci ont un périmètre très bien défini, appartiennent à l’annuaire Azure Active Directory et ne demanderont pas de manipulation lors du déploiement continu, à l’inversion d’un token ou d’un password.
Lors de la création ou de la modification d’éléments dans le Studio Data Factory, nous pouvons sauvegarder ces changements à tout moment puis réaliser une publication à l’aide du bouton “Publish”.
L’action Publish correspond à un “commit – push” sur le repository lié.
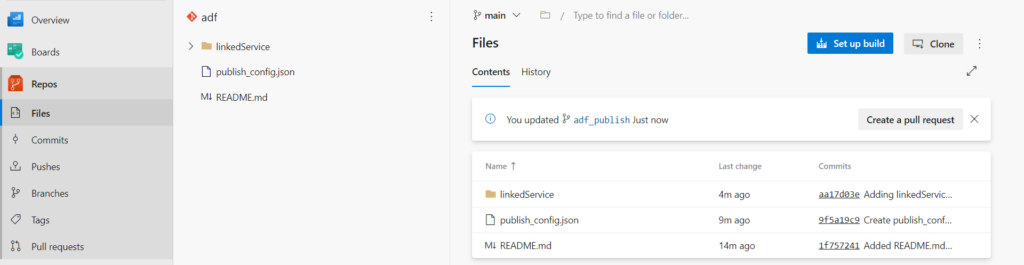
Nous retrouvons dans le repository les deux branches évoquées lors de l’association à Azure DevOps.
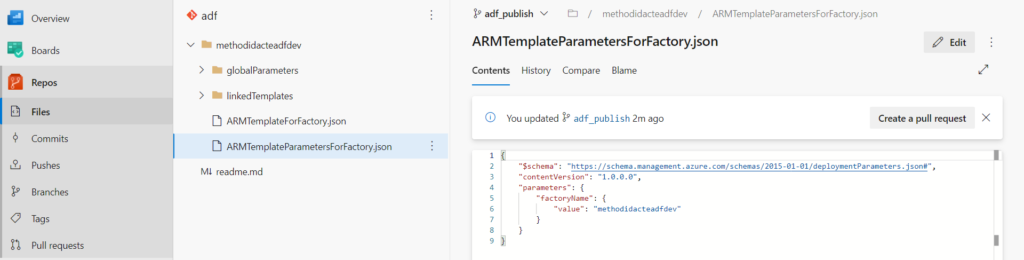
La branche adf_publish contient en particulier deux fichiers nommés respectivement ARMTemplateForFactory.json et ARMTemplateParametersForFactory.json. Ceux-ci contiennent les noms propres à l’environnement et qui devront donc être remplacés lors du déploiement.
Le nom de la ressource ADF est le premier paramètre propre à l’environnement.
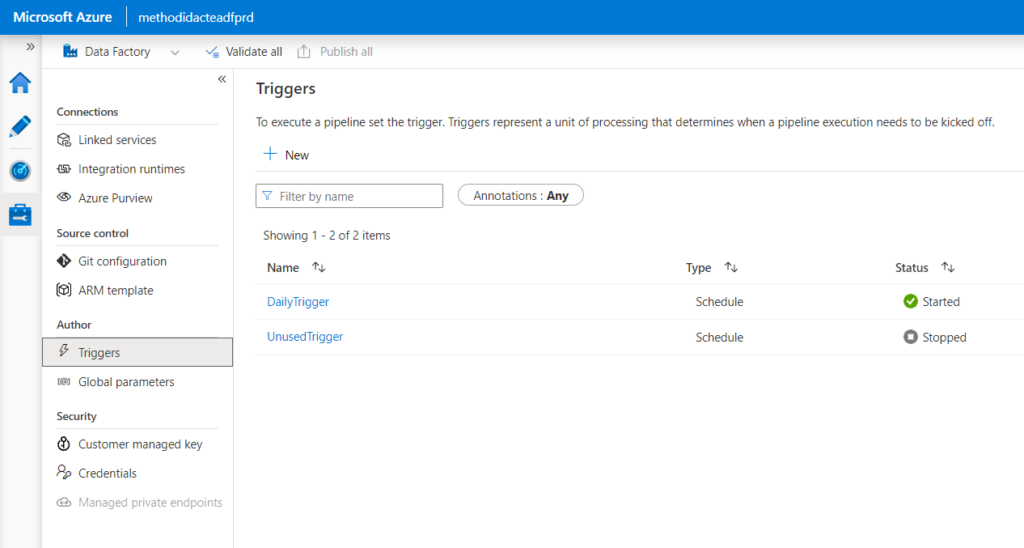
Afin de pousser la démonstration, nous ajoutons et démarrons un trigger dans le Studio Data Factory (nous verrons son importance un peu plus tard dans cet article).
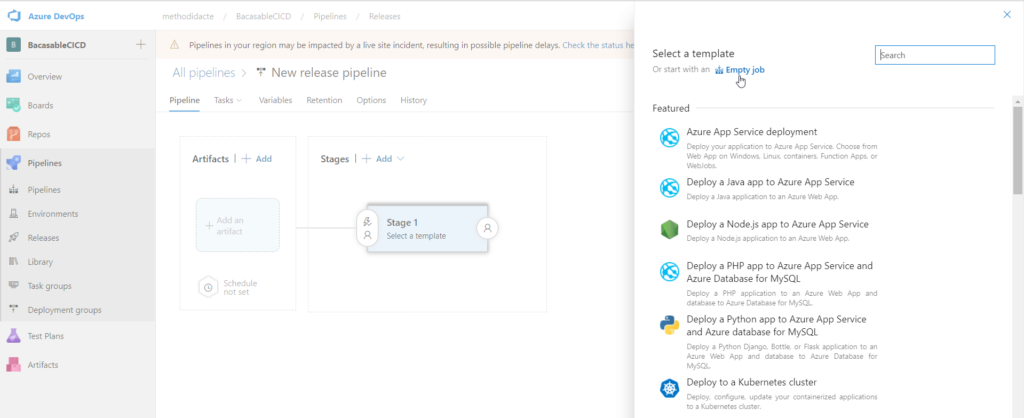
Déployer par pipeline de release
Le pipeline de release convient à ce que nous cherchons à faire : déployer un environnement vers un autre, à partir d’un code versionné.
Nous démarrons le pipeline avec un “empty job”.
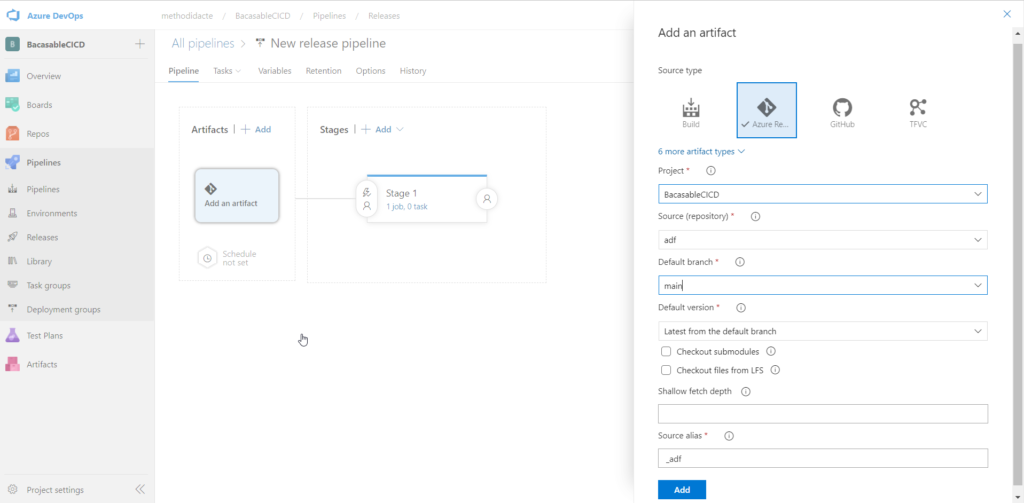
La première chose à faire est de lier l’artefact (le code versionné) au pipeline. Attention, c’est bien la branche main et non adf_publish qui est attendue ici.
La branche par défaut est la branche main.
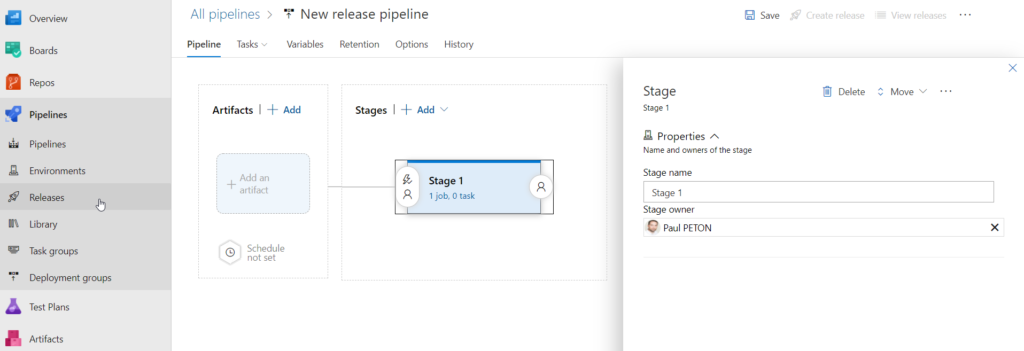
Passons ensuite au paramétrage du stage, qui pourra être renommé par le nom de l’environnement cible (uat, prod…).
Nous recherchons dans la Market Place les tâches correspondant à Data Factory. Une installation sera nécessaire à la première utilisation.
Je vous recommande le produit développé par SQLPlayer. En effet, nous allons voir de multiples avantages (et un inconvénient…).
Autoriser le composant à accéder à une ressource Azure va demander de créer une service connection. Des droits suffisants sur Azure sont nécessaires pour réaliser cette opération.
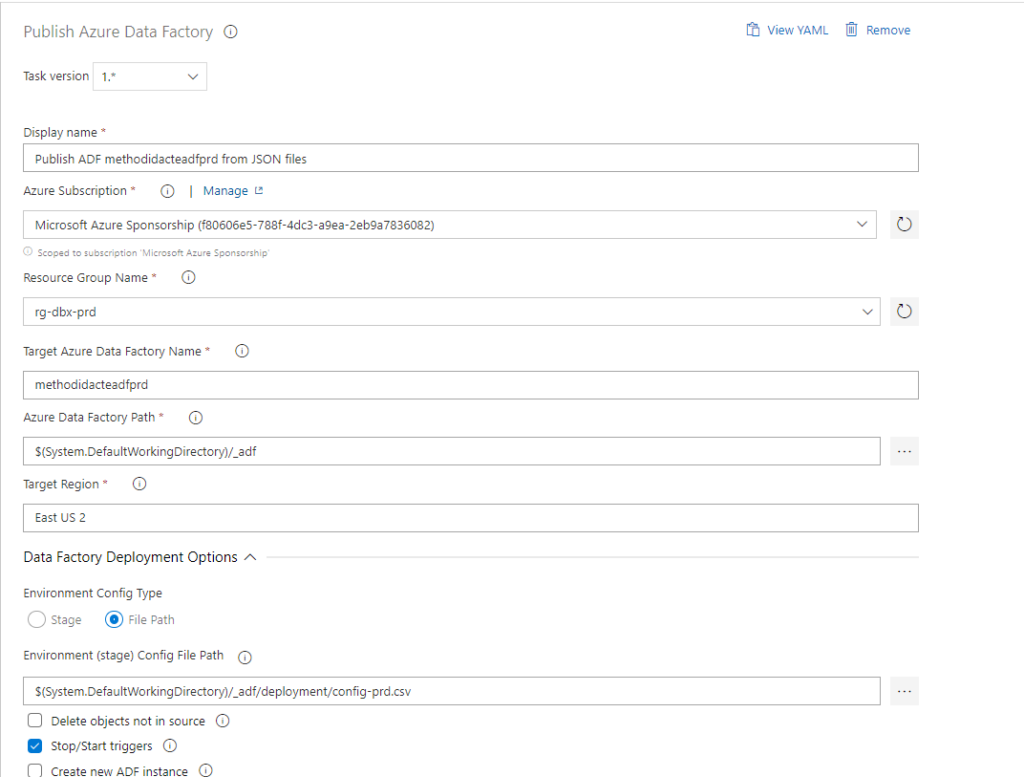
Dans la boîte de dialogue ci-dessous, les champs attendus concernent l’environnement cible :
nom du groupe de ressource
nom de la ressource Azure Data Factory
chemin vers le répertoire des fichiers JSON (branche adf_publish)
nom de la région où est située la ressource
Le fichier de configuration sera précisé plus tard.
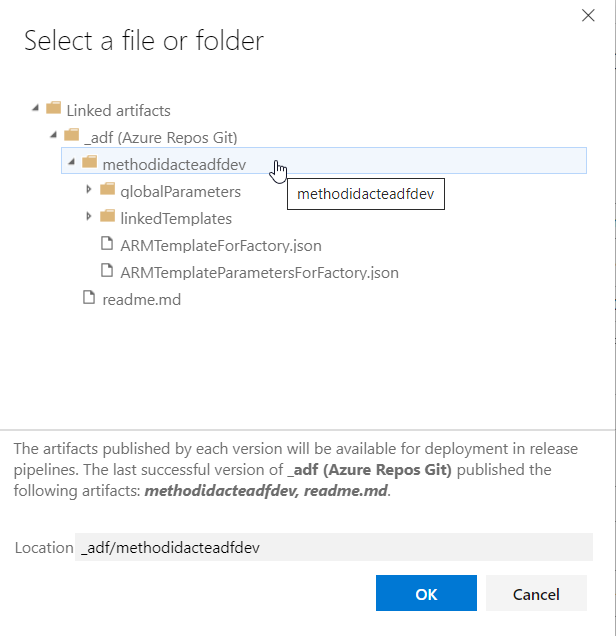
Pour indiquer le path du dossier contenant les fichiers du template ARM, nous utilisons une nouvelle boîte de dialogue, en prenant soin de descendre un cran au-dessous du repository.
Veillez également à cocher la case “Stop/Start triggers”. En effet, le déploiement ARM ne pourra avoir lieu si des triggers sont actifs. C’est ici un avantage de cette extension : il n’est pas nécessaire d’ajouter par exemple un script PowerShell réalisant le stop puis le start. Une limite de l’approche par PowerShell consiste dans le fait que l’intégralité des triggers sont redémarrés. Il serait donc nécessaire de supprimer les triggers qui ne sont pas utilisés, plutôt que de les mettre en pause.
A ce stade, une première release pourrait être lancée et elle déploiera à l’identique l’environnement de développement.
Modifier les paramètres propres à l’environnement
Nous avons évoqué ci-dessus les fichiers JSON de la branche adf_publish. Ceux-ci permettent de réaliser un déploiement de template ARM (Azure Resource Manager), qui correspond à une approche dite Infra as Code, propre à l’univers Azure de Microsoft.
Pour déployer les développements vers un autre environnement, nous devons remplacer certaines valeurs :
nom de la ressource Data Factory
chaines de connexion
identifiant et mot de passe
URL
certains paramétrages spécifiques (ex.: type et dimension d’un cluster Databricks)
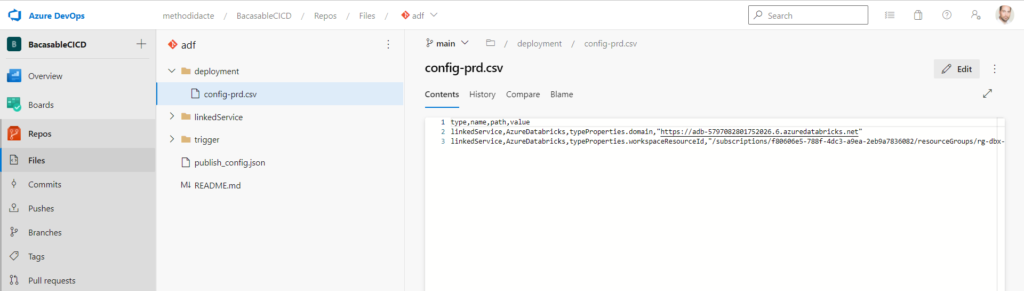
Nous allons ici préciser toutes les modifications à apporter au moyen d’un fichier CSV qui sera stocké sur la branche main du repository, dans un répertoire deployment et nommé config-{stage}.csv où la valeur de stage indique l’environnement cible.
Voici un exemple de fichier CSV qui transforme les informations nécessaires pour changer de workspace Azure Databricks. Les noms de colonnes en première ligne doivent être respectés.
Une documentation complète, sur la page de l’extension, explique comment renseigner ce fichier. Nous serons particulièrement vigilants quant à la gestion des secrets (tokens, mots de passe, etc.). Une astuce pourra être d’utiliser des variables d’environnement dans ce fichier, elles-mêmes sécurisées par Azure DevOps. Une meilleure pratique consistera à utiliser un coffre-fort de secrets Azure Key Vault, lui-même déclaré comme un service lié.
EDIT : en cas d’utilisation d’un firewall sur la ressource Azure Key Vault, il sera nécessaire d’ajouter l’IP de l’agent DevOps à ce firewall. Or, cette adresse IP n’est pas fixe.
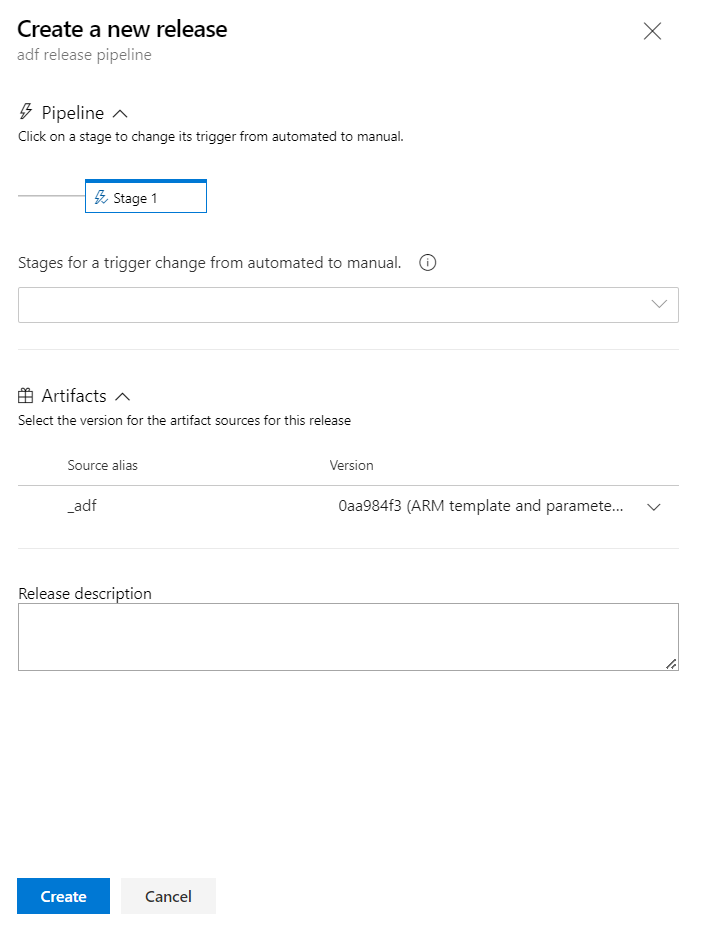
Nous pouvons maintenant lancer la release.
Nous vérifions enfin dans le Studio Data Factory que les éléments développés sont bien présents, en particulier les triggers. Ceux-ci sont alors dans l’état “démarré” ou “arrêté” de l’environnement de développement.
Cette approche pourrait être perturbante si tous les triggers de développement sont arrêtés (les faire tourner ne se justifie sans doute pas). Mais nous avons bénéficier d’une autre fonctionnalité pour améliorer notre déploiement.
Réaliser un déploiement sélectif
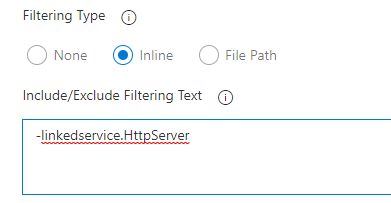
Une autre option de l’extension sera particulièrement intéressante : le déploiement sélectif. Une case de la boîte de dialogue permet de déclarer la liste des objets que l’on souhaite ou non déployer. La syntaxe est explicité sur la page GitHub de l’extension.
Par exemple, nous retirons le déploiement d’un autre service lié, qui ne sera pas utile en production.
Dans une architecture plus complète, intégrant un Data Lake, nous pouvons obtenir le schéma suivant. Chaque cluster Databricks disposera d’un secret scope, lié à un coffre-fort Azure Key Vault. Celui-ci contiendra la définition d’un principal de service (client ID et client secret) permettant de définir un point de montage vers la ressource Azure Data Lake gen2 de l’environnement.
Pour remplacer certains paramètres avancés des services liés, cet article pourra servir de ressource.
Si vous êtes habitués à manipuler le package Python scikit learn, la notion de pipeline vous est sans doute familière. Cet objet permet d’enchainer des étapes (“steps“) comme la préparation de données (normalisation, réduction de dimensions, etc.), l’entrainement puis l’évaluation d’un modèle. La documentation officielle du package donne ainsi cet exemple.
>>> fromsklearn.svmimport SVC
>>> fromsklearn.preprocessingimport StandardScaler
>>> fromsklearn.datasetsimport make_classification
>>> fromsklearn.model_selectionimport train_test_split
>>> fromsklearn.pipelineimport Pipeline
>>> X, y = make_classification(random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... random_state=0)
>>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
>>> # The pipeline can be used as any other estimator>>> # and avoids leaking the test set into the train set>>> pipe.fit(X_train, y_train)
Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
>>> pipe.score(X_test, y_test)
0.88
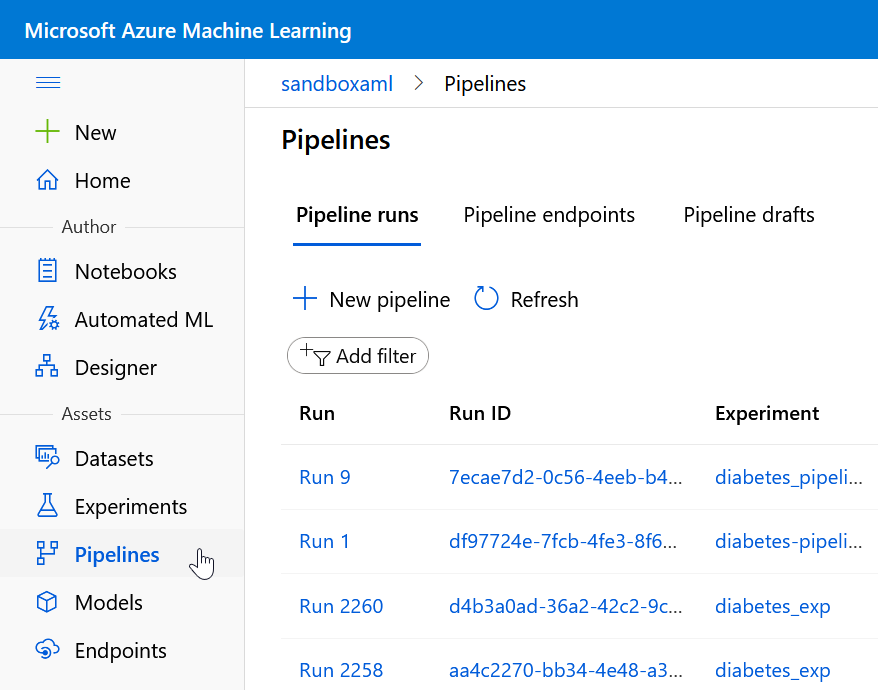
Le SDK Python azureml que nous avons déjà évoqué sur ce blog dispose également d’un concept de pipeline. Celui-ci ne doit pas être confondu avec les pipelines pouvant être définis dans l’interface visuelle du concepteur (“designer“). Les pipelines en tant que tels sont visibles dans un menu dédié.
(NDA : on serait en droit d’espérer à termes une fusion de ces éléments, c’est-à-dire d’observer le pipeline dans l’interface du concepteur, voire de retrouver le pipeline créé par le code dans les objets manipulables visuellement).
Les avantages des pipelines
La manipulation des pipelines, en particulier des entrées-sorties, ne sera pas triviale, alors nous allons insister sur tous les bénéfices d’un tel objet. Au delà de la représentation visuelle toujours plus parlante, le principal avantage sera la planification du pipeline. Celle-ci peut se faire de trois manières. Le code présenté ici est disponible dans ce dépôt GitHub.
Objet Scheduler
L’interface du studio Azure Machine Learning ne présente pas d’ordonnanceur visuel des notebooks. Pour autant, cette notion d’ordonnancement existe bien et se manipule au travers du SDK. Une fois publié, un pipeline dispose d’un identifiant. A partir de cet id, un objet Schedule peut être défini, et se déclenchera selon une récurrence déclarée au moyen de l’objet ScheduleRecurrence.
A sa création, l’ordonnancement est activé. Il sera possible de le désactiver à partir de son identifiant (à ne pas confondre avec l’identifiant du pipeline).
Les points négatifs de cet approche sont le manque de visibilité sur les ordonnancements définis (il est nécessaire de lancer la commande Schedule.list) et le fait que d’autres activités non définies dans des scripts présents sur dans l’espace de travail Azure Machine Learning.
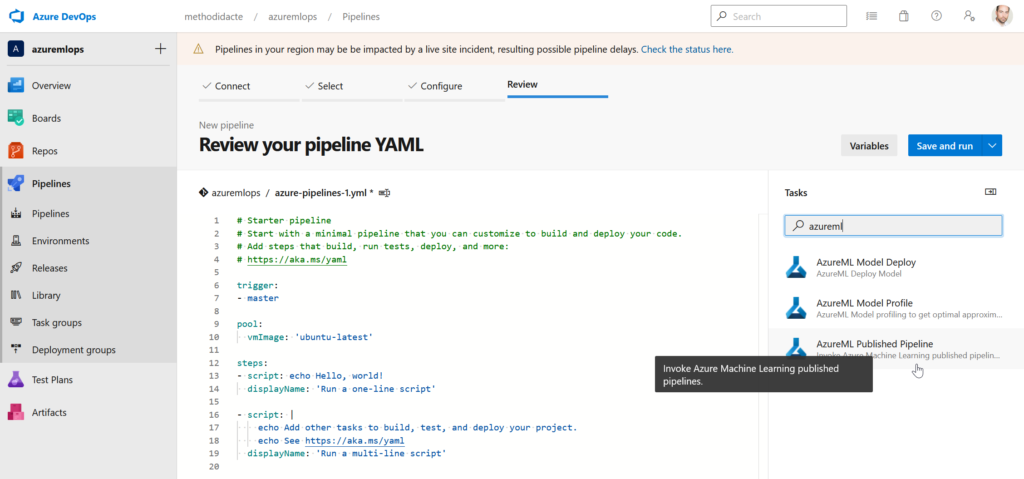
Pipeline Azure DevOps
Encore un pipeline à ne pas confondre avec le pipeline du SDK azureml ! Nous parlons ici des pipelines de release d’Azure DevOps. En recherchant le terme “azureml” dans l’assistant (volet de droite), nous trouvons trois tâches, dont une permettant de lancer un pipeline Azure ML désigné à nouveau par son identifiant.
Un pipeline de release peut ensuite être ordonnancé au moyen des standards d’écriture du fichier YAML.
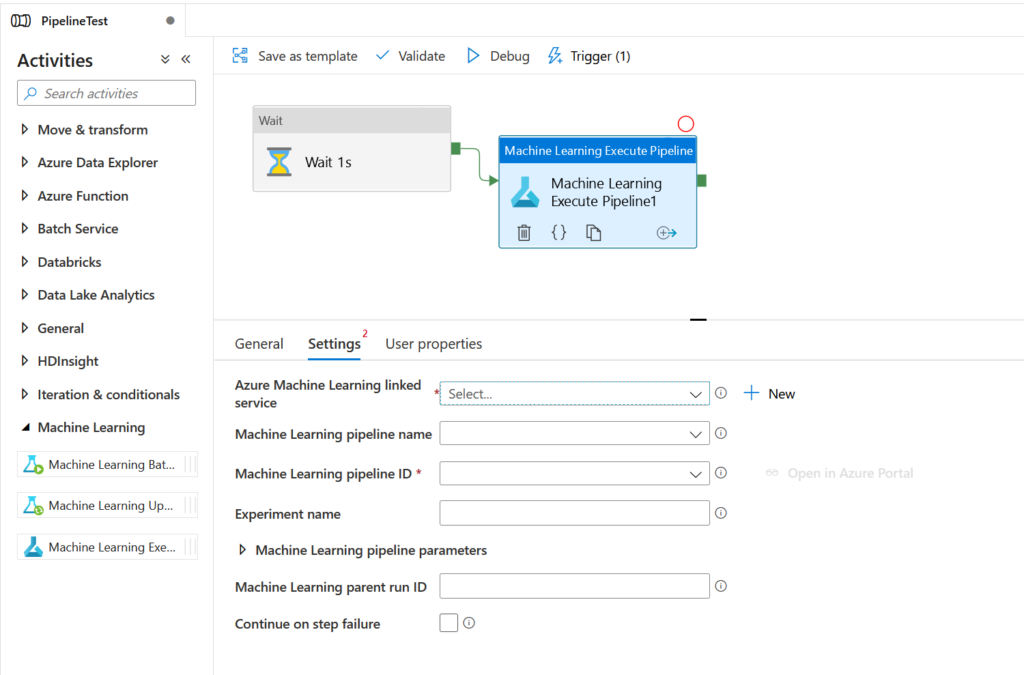
Activité Azure Data Factory
Nous disposons de trois activités distinctes dans le groupe “Machine Learning”. Les deux premières concernent l’ancien Azure Machine Learning studio, aujourd’hui déprécié. Concentrons-nous sur la troisième activité qui permet d’exécuter un pipeline Azure ML.
Pour remplir les différents paramètres, nous devons tout d’abord fournir un service lié (linked service) de type Azure Machine Learning (catégorie “compute“).
Nous privilégions l’authentification par identité managée, celle-ci se voyant attribuer un rôle de contributeur sur la ressource Azure Machine Learning.
Seconde information obligatoire : l’ID du pipeline publié. Un menu déroulant nous permettra de le choisir. Nous constatons ici que cette information sera particulièrement sensible lorsque nous devrons re-publier le pipeline. Il faudra donc limiter au maximum cette action, car elle engendrera une modification dans les paramètres de l’activité Data Factory. Une problématique similaire se posera dans le cas d’un déploiement automatique entre environnements (par exemple, de dev à prod) avec des ID de pipelines différents.
Et maintenant, comment réaliser un pipeline
Nous allons maintenant plonger dans le SDK Python azureml pour décortiquer les étapes de création d’un pipeline.
Il nous faut pour base un script Python qui contiendra le code à exécuter par une étape (step) du pipeline. Nous ne travaillerons ici qu’avec des étapes de PythonStepScript mais il en existe d’autres types, référencés dans la documentation officielle. Nous prendrons la bonne habitude de faire figurer dans ces scripts les lignes de code suivantes :
from azureml.core.run import Run
run = Run.get_context()
exp = run.experiment
ws = run.experiment.workspace
Celles-ci permettront de retrouver les éléments du “niveau supérieur”, c’est-à-dire l’expérience, son exécution ainsi que l’espace de travail.
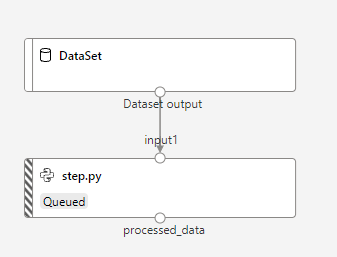
Ensuite, nous pourrons travailler sur les entrées et sorties de chaque étape. Cette gestion des entrées-sorties nécessitera un article à part entière sur ce blog.
Exemple de “graph” de sortie du pipeline (experiment)
Nous recréons ainsi, par le code (et au prix de nombreux efforts !), un objet similaire au pipeline obtenu dans le Designer.
Mais cela ne nous permettrait pas de réutiliser ce pipeline dans les scénarios évoqués ci-dessus, nous allons donc le publier avec l’instruction .publish().
published_pipeline = pipeline.publish(
name=published_pipeline_name,
description="ceci est un pipeline à deux étapes"
)
published_pipeline
Ceci nous permet de connaître l’identifiant du pipeline (masqué dans la copie d’écran ci-dessous).
Il ne reste plus qu’à soumettre le pipeline pour l’exécuter même si nous utiliserons vraisemblablement d’autres méthodes comme l’appel par Azure Data Factory ou l’emploi de l’API REST.
Les logs de l’exécution seront accessibles dans le menu Pipelines du portail, qui nous redirigera vers le menu Experiments. N’oubliez pas d’activer l’affichage des “child runs” pour visualiser les traces de l’exécution de chacune des étapes.
Voici enfin un exemple de code qui permettra de lancer ce pipeline par requête HTTP.
from azureml.core.authentication import InteractiveLoginAuthentication
import requests
auth = InteractiveLoginAuthentication()
aad_token = auth.get_authentication_header()
rest_endpoint1 = published_pipeline.endpoint
print("You can perform HTTP POST on URL {} to trigger this pipeline".format(rest_endpoint1))
response = requests.post(rest_endpoint1,
headers=aad_token,
json={"ExperimentName": "My_Pipeline_batch",
"RunSource": "SDK"}
)
try:
response.raise_for_status()
except Exception:
raise Exception('Received bad response from the endpoint: {}\n'
'Response Code: {}\n'
'Headers: {}\n'
'Content: {}'.format(rest_endpoint, response.status_code, response.headers, response.content))
run_id = response.json().get('Id')
print('Submitted pipeline run: ', run_id)
Attention, une réponse “correcte” à cet appel HTTP sera de confirmer le bon lancement du pipeline. Mais rien ne vous garantit que son exécution se fera avec succès jusqu’au bout ! Il faudra pour cela se pencher sur la remontée de logs (et d’alertes !) à l’aide d’un outil comme Azure Monitor.
Ou en bon français, comment faire coopérer la nouvelle (mars 2021) fonctionnalité Repos de Databricks avec une logique d’intégration continue développée dans GitHub ?
Revenons tout d’abord sur le point à l’origine de la nécessité d’un tel mécanisme (une présentation plus détaillée des Repos Databricks a été faite et mise à jour sur ce blog). Dans une architecture dite “moderne” sur Azure, nous utilisons Azure Data Factory pour piloter les traitements de données et lancer conjointement des notebooks Databricks. Cela nécessite de donner le chemin du notebook sur l’espace de travail déclaré en tant que service lié.
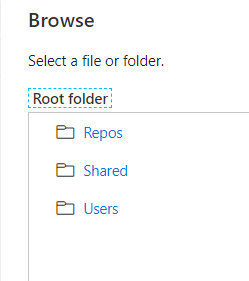
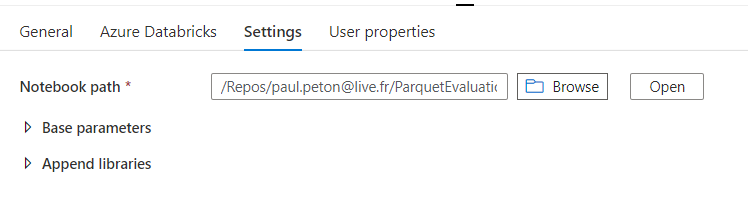
Nous disposons de trois entrées pour définir le “notebook path“.
Si nous choisissons “Repos”, nous allons donner un chemin contenant le nom du développeur !
Les développements livrés en production doivent bien sûr être totalement indépendants d’une telle information. Un contournement consisterait à utiliser un sous-répertoire Shared dans la partie Repos mais cela reviendrait à perdre le rattachement du développement à son auteur.
Nous allons donc mettre en place un mécanisme permettant aux développeurs d’utiliser leur propre répertoire puis de versionner les développements dans un espace tiers, par exemple un repository GitHub (une démarche exploitant les repositories Azure DevOps serait tout à fait similaire).
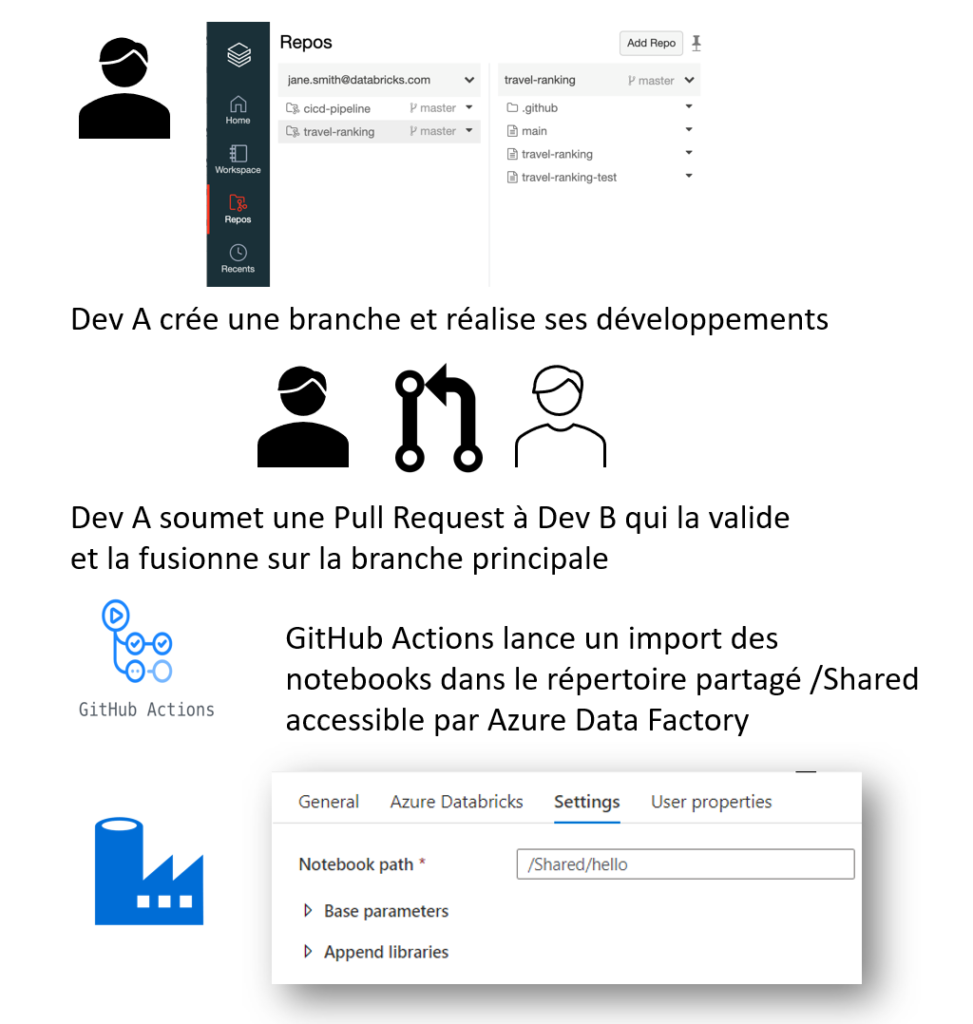
Voici le processus suivi lors d’un développement :
le développeur A crée une nouvelle branche sur laquelle il réalise ses développements
il “commit & push” ensuite son travail
une Pull Request (PR) peut alors être soumise dans le but de fusionner le travail avec la branche principale (master ou main)
le développeur B vient alors valider la PR et le merge se lance sur la branche principale
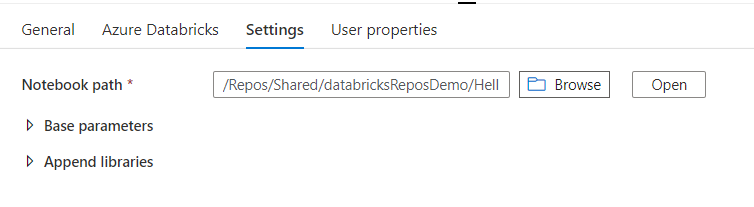
C’est alors que se déclenche notre processus d’intégration continue (CI) qui réalise une copie des notebooks de la branche principale dans le répertoire /Shared de l’espace de travail Databricks.
Nous nous assurons ainsi d’avoir toujours la dernière “bonne” version des notebooks, sur un chemin qui sera identique entre les environnements. En effet, dans un second temps, un processus de déploiement continu (CD) viendra copier ces notebooks sur les autre environnements (qualification, production).
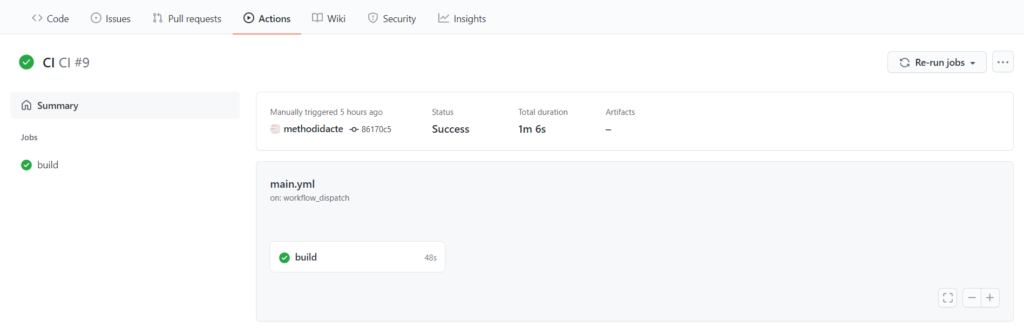
Comment réaliser une GitHub Action d’intégration continue
Nous nous plaçons dans le repository servant à versionner les notebooks. Le menu Actions est accessible dans la barre supérieure.
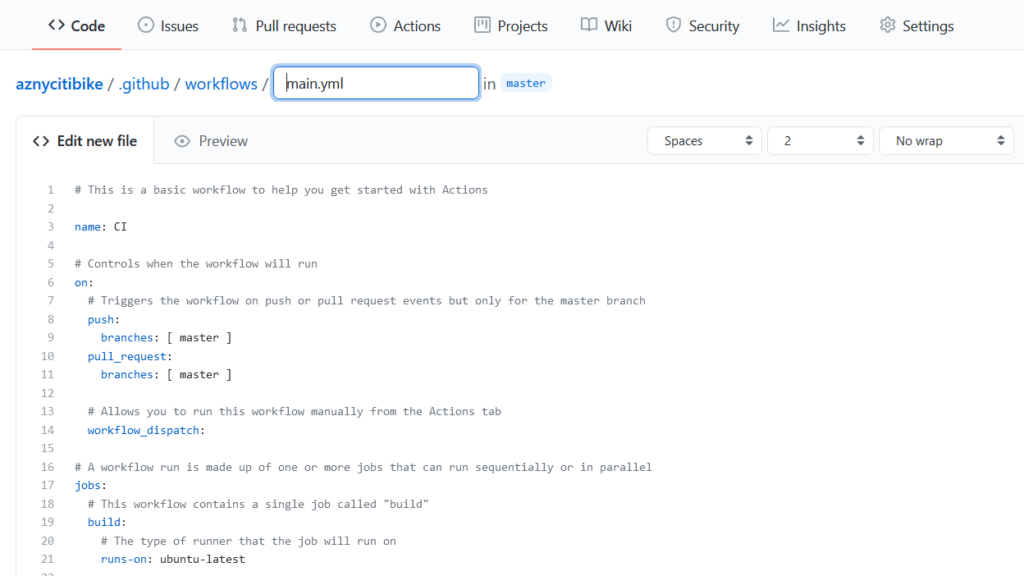
Un modèle de pipeline YAML est alors disponible et nous allons l’adapter.
Détaillons maintenant le code final, étape par étape.
# This is a basic workflow to help you get started with Actions
name: CI
# Controls when the workflow will run
on:
# Triggers the workflow on push or pull request events but only for the master branch
pull_request:
branches: [ master ]
paths: ['**.py']
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
env:
DATABRICKS_HOST: ${{ secrets.DATABRICKS_HOST }}
DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }}
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- name: Checkout
uses: actions/checkout@v2
- name: Setup Python
uses: actions/setup-python@v2.2.2
with:
python-version: '3.8.10'
architecture: 'x64'
# Install pip
- name: Install pip
run: |
python -m pip install --upgrade pip
# Install databricks CLI with pip
- name: Install databricks CLI
run: python -m pip install --upgrade databricks-cli
# Runs
- name: Run a multi-line script
run: |
echo Test python version
python --version
echo Databricks CLI version
databricks --version
# Import notebook to Shared
- name: Import local github directory to Shared
run: databricks workspace import_dir --overwrite . /Shared
# List Shared content
- name: List workspace with databricks CLI
run: databricks workspace list --absolute --long --id /Shared
Le principe est d’utiliser une machine virtuelle munie d’un système d’exploitation Ubuntu (‘latest’ pour obtenir la dernière version disponible), d’y installer un environnement Python dans la version souhaitée (ici, 3.8.10) puis le CLI de Databricks.
Pour connecter ce dernier à notre espace de travail, nous définissons au préalable deux variables d’environnement :
DATABRICKS_HOST qui contient l’URL de notre espace de travail
DATABRICKS_TOKEN qui contient un jeton d’authentification
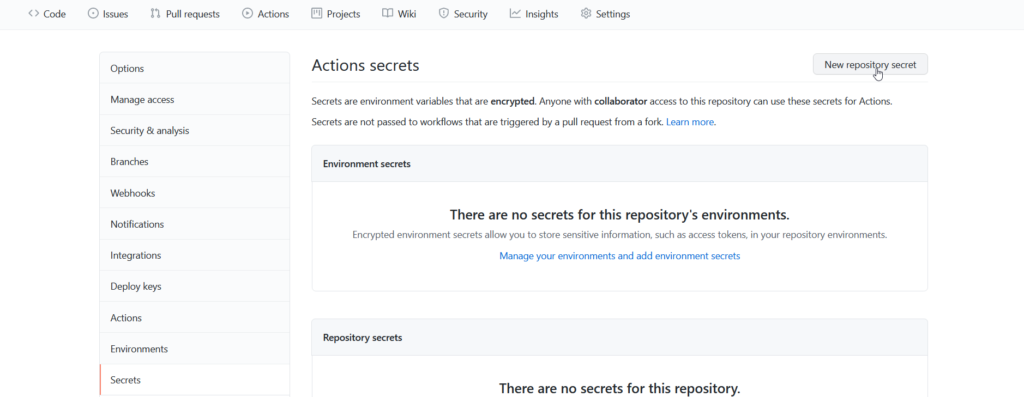
Pour ne pas faire figurer ces valeurs dans le fichier YAML (qui est lui-même versionné dans le repository), nous définirons au préalable deux secrets à l’aide du menu Settings.
Nous choisissons ici une portée des secrets au niveau repository.
L’instruction uses: actions/checkout@v2 garantit la disponibilité des fichiers archivés dans le repository (ceux-ci sont copiés sur la machine virtuelle) et le point (.) indique simplement ce chemin dans l’instruction du CLI import_dir.
Ainsi, dès la fusion d’une Pull Request avec la branche principale, le code se lance automatiquement et nous pouvons vérifier sa bonne exécution dans le menu “View runs”.
Une telle approche sera bien sûr complétée idéalement par une stratégie de tests portant sur le contenu des notebooks ou mieux encore, sur du code packagé qui y sera utilisé (voir cet article).
En quelques années de l’ère “big data”, le format de fichier orienté colonne Parquet s’est imposé comme l’un des standards du stockage sur les lacs de données (data lake) grâce à ses performances de compression, sa gestion des partitions et son intégration avec des frameworks distribués comme Spark. Il s’agit d’un projet porté par la fondation Apache qui héberge la documentation officielle.
Avant d’obtenir un fichier Parquet, le format initial est bien souvent un format texte classique structuré comme du CSV ou semi-structuré comme le JSON. Nous sommes également dans le scénario de réalisation d’un couche “clean” au sein d’un data lake, à partir de nombreux fichiers de la couche “raw“, nécessitant d’être agrégés et optimisés pour des outils d’analyse.
Dans cet article, nous allons dérouler un cas pratique allant de la constitution de ces fichiers Parquet jusqu’à leur utilisation dans un rapport Power BI.
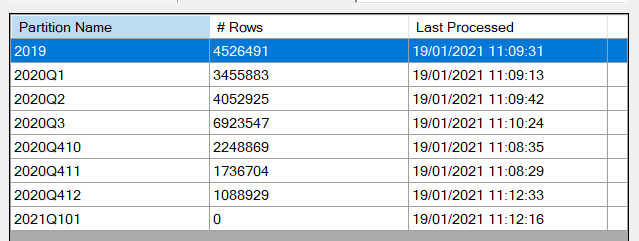
Nous disposons ainsi en tout de 19 506 857 lignes pour l’année 2020.
Avec un peu de script Python, nous pouvons décompresser automatiquement ces fichiers.
import os
import zipfile
def unzip_files(path_to_zip_file) -> None:
directory_to_extract_to = "datasets"
with zipfile.ZipFile(path_to_zip_file, 'r') as zip_ref:
zip_ref.extractall(directory_to_extract_to)
for file in os.listdir("zip"):
print(f"Unzipping : {file}")
unzip_files("zip/"+file)
Ensuite, depuis un environnement Spark comme Azure Databricks, nous pouvons lire tous les CSV, qui auront été déposés au préalable sur un compte de stockage Azure.
Notez qu’il faudra renommer les colonnes comportant un ou plusieurs espaces, interdits en entêtes dans le format Parquet, ce que nous faisons avec le script ci-dessous.
df = df \ .withColumnRenamed("start station id","start_station_id") \ .withColumnRenamed("start station name","start_station_name") \ .withColumnRenamed("start station latitude","start_station_latitude") \ .withColumnRenamed("start station longitude","start_station_longitude") \ .withColumnRenamed("end station id","end_station_id") \ .withColumnRenamed("end station name","end_station_name") \ .withColumnRenamed("end station latitude","end_station_latitude") \ .withColumnRenamed("end station longitude","end_station_longitude") \ .withColumnRenamed("birth year","birth_year")
L’enregistrement au format Parquet est alors possible, toujours à l’aide de l’API PySpark.
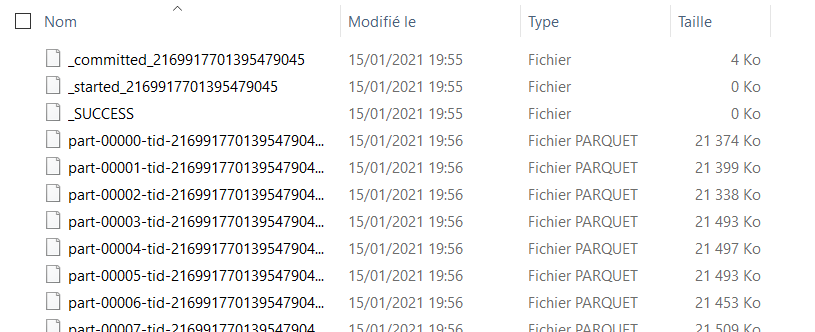
Les données sont automatiquement partitionnées (il est possible d’avoir la main sur ce mécanisme, comme nous le verrons plus tard) et quelques fichiers spécifiques à Databricks sont ajoutés :
– ficher “commited” qui liste les différentes parties
– fichier vide “started”
– fichier vide _SUCCESS
Ces fichiers qui tracent la transaction réalisées vont nous gêner pour une usage dans Power BI. Nous pourrions éviter leur génération en définissant les options suivantes dans notre script Spark comme l’indiquent ces échanges sur le forum Databricks.
Il est possible de prendre la main sur le nombre de fichiers obtenus, ainsi que sur la clé qui aidera au partitionnement. Nous ajoutons deux fonctions que sont repartition() et partitionBy() dans la syntaxe d’écriture du Parquet.
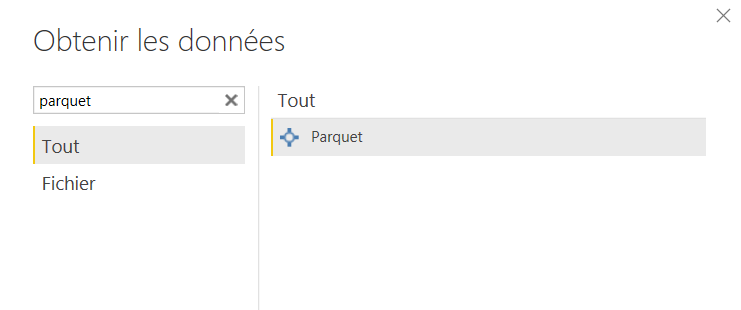
Dans Power BI Desktop, nous disposons d’un type de source Parquet, à partir du menu “Obtenir les données”.
Ce connecteur attend le chemin d’un fichier Parquet et non d’un répertoire contenant les partitions sous forme de fichiers distincts. Nous découvrons ainsi la fonction du langage M qui réalise la lecture du fichier : Parquet.Document().
Cette fonction est documentée depuis juin 2020 mais elle n’a pas fait l’objet d’une grande communication jusqu’à présent (janvier 2021) et la roadmap Power BI indique un (nouveau ?) connecteur Parquet pour mars 2021.
Pour lire le contenu d’un dossier, nous pouvons sans problème appliquer la technique de connexion à un dossier sur un compte de stockage Azure, puis lire chaque fichier à l’aide du bouton “expand” de la colonne “Content” contenant tous les binaries. Cette manipulation crée automatique une fonction d’import contenant le code suivant.
= (Paramètre1) => let Source = Parquet.Document(Paramètre1) in Source
Attention, pour réaliser cette opération, il faut au préalable filtrer les fichiers ne correspondant pas à des partitions (commit, started, SUCCESS pour un dossier Parquet généré par Databricks), qui débutent tous par un caractère underscore.
= Table.SelectRows(Source, each not Text.StartsWith([Name], "_"))
Les données se chargent alors en mettant bout à bout toutes les partitions !
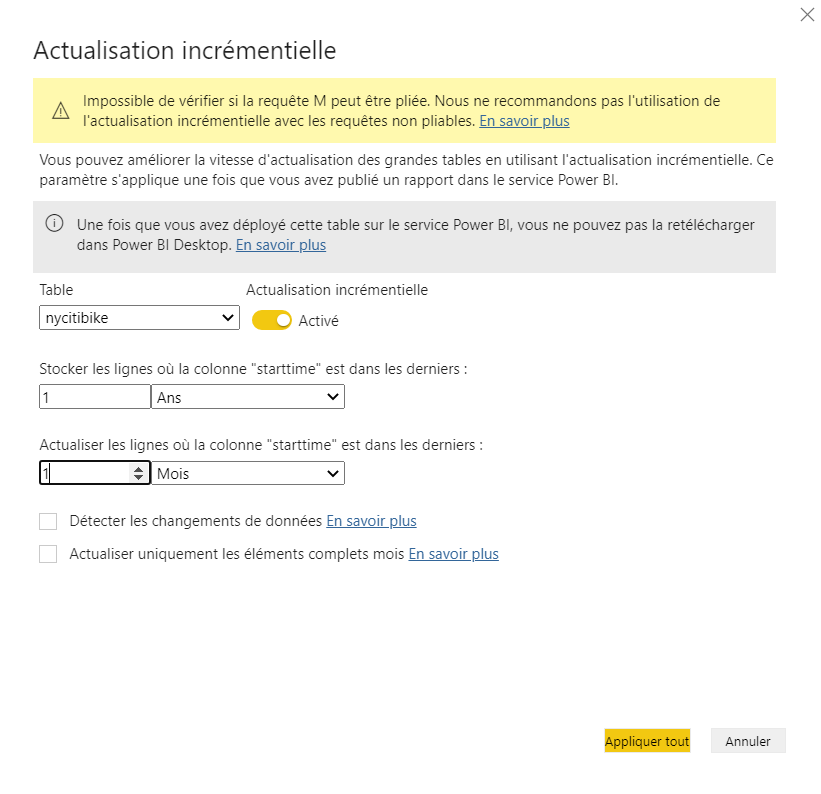
Il est maintenant tentant d’essayer une actualisation incrémentielle de notre dataset, sur une période d’un mois. Pour autant, celle-ci n’est pas garantie comme nous l’indique le message d’alerte dans la pop-up de paramétrage du rafraichissement.
Une traduction approximative annonce que la requête “ne peut être pliée”, il s’agit ici du concept de query folding : la requête ne pourrait appliquer un filtre (de dates) en amont du chargement complet des données. Ceci signifie tout simplement de le mécanisme incrémentiel ne se réaliserait pas.
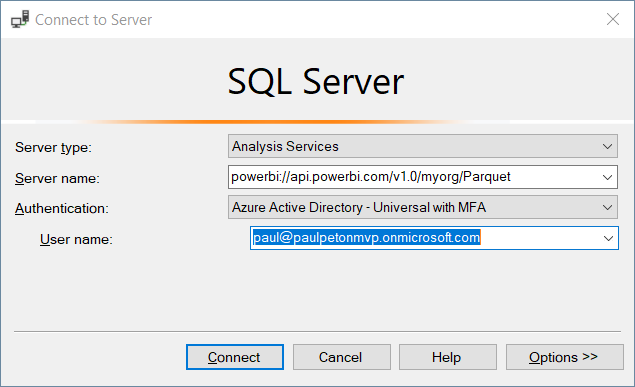
Afin de tester ce fonctionnement, nous publions le rapport sur un espace de travail Premium du service Power BI. Il sera alors possible d’ouvrir une connexion à l’espace à partir du client lourd SQL Server Management Studio.
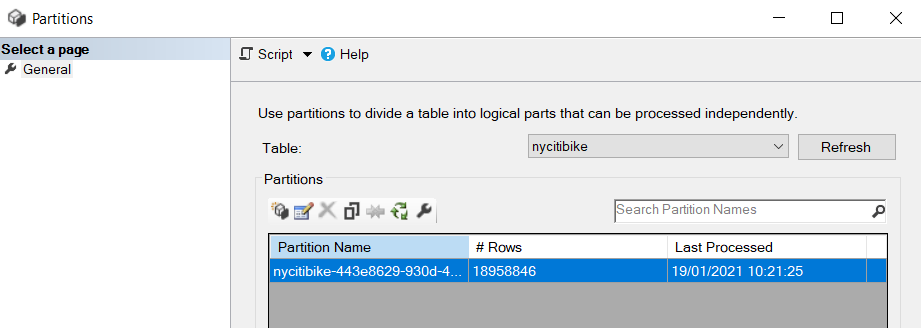
Au premier chargement, nous n’aurons qu’une seule partition.
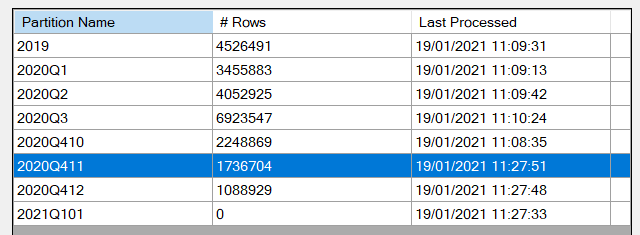
Mais en actualisant le dataset depuis le service, les partitions apparaissent.
Nous observons bien qu’une nouvelle actualisation du jeu de données n’affecte pas toutes les partitions. C’est gagné !
En ajoutant des fichiers supplémentaires, nous observons aussi que le paramètre de stockage de lignes (ici, sur un an) fonctionne et cela permet donc de créer un dataset actualisé sur une période glissante.
Pour terminer, précisons que la requête réalisée ici peut tout à fait être exécutée au sein d’un dataflow Power BI et servir ainsi à la création de différents rapports.
[EDIT du 23/01/2021 : cette approche fonctionne aussi avec le format Delta Lake créé depuis Azure Databricks, et c’est tant mieux car ce format apporte beaucoup d’avantages, qui seront sûrement abordés dans un prochain article.]
Nous avons déjà évoqué sur ce blog le driver JDBC permettant d’écrire depuis un notebook Azure Databricks dans une base de données managée ou encore comment utiliser Polybase pour pérenniser une table du métastore Databricks dans Azure SQL DWH (aujourd’hui Synapse Analytics).
Cette action d’écriture demande souvent un niveau de ressource suffisamment élevé, tout comme l’import de données réalisé dans un dataset Power BI. Le reste du temps, une puissance plus faible peut être tout à fait acceptable. Et comme le niveau de facturation est lié au niveau de la ressource, pouvoir maîtriser par code, et non manuellement depuis l’interface, le scape up ou scale down de sa ressource peut s’avérer très intéressant dans une démarche d’optimisation des coûts (FinOps).
Nous nous plaçons ici dans un scénario de pipeline de transformation de données réalisé par Azure Databricks puis d’import dans un dataset Power BI. L’actualisation par API REST de ce dernier est détaillé dans cet article.
Au démarrage de notre pipeline, nous souhaitons augmenter la puissance (scale up) et ceci peut se faire avec des instructions PowerShell documentées ici.
Il est possible d’exécuter un script PowerShell depuis Azure Data Factory à l’aide de ce qu’on appelle une “custom activity“. Celle-ci s’appuie sur un service lié de type Azure Batch. Et ce service n’est pas gratuit, voire même relativement cher pour ce que l’on souhaite réaliser.
Nous optons donc pour la programmation d’une Azure Function, qui supporte le langage PowerShell ! Nous choisissons le type de fonction Trigger HTTP.
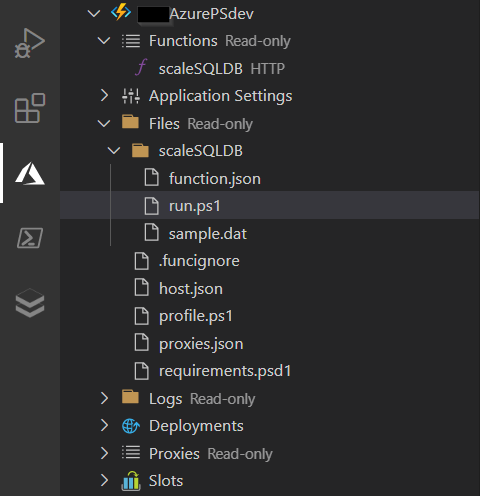
Dans Visual Studio Code, nous obtenons l’arborescence ci-dessous.
Le code principal de la fonction doit se trouver dans le fichier run.ps1.
Un premier point important consistera à renseigner les dépendances de librairies PowerShell dans le fichier requirements.psd1. Une combinaison fonctionnelle est la suivante :
# This file enables modules to be automatically managed by the Functions service
# See https://aka.ms/functionsmanageddependency for additional information.
#
@{
'Az.Accounts' = '2.1.2'
'Az.Sql' = '2.11.1'
}
Second élément indispensable pour l’intégration dans une activité Web de Data Factory : le retour de la fonction doit obligatoirement être un objet JSON. Nous terminons donc la fonction par le code ci-dessous :
$body = @{name = 'Scale done !'} | ConvertTo-Json
#Associate values to output bindings by calling 'Push-OutputBinding'.
Push-OutputBinding -Name Response -Value ([HttpResponseContext]@{
StatusCode = [HttpStatusCode]::OK
Body = $body
})
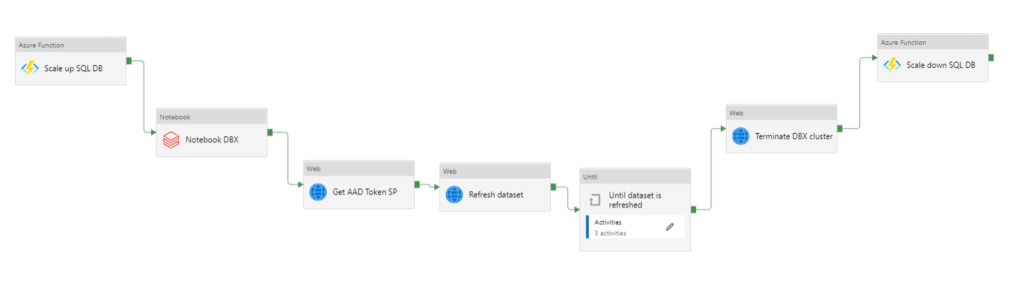
Une fois la fonction publiée sur Azure, nous pouvons définir le pipeline complet.
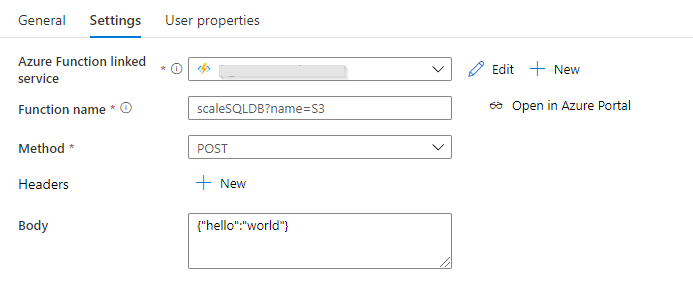
La fonction Azure étant pensée de manière paramétrable, nous pouvons donner le niveau de ressource comme un élément de l’URL appelée par la méthode POST. Nous utilisons dans l’exemple ci-dessous le niveau “S” suivi d’un chiffre.
Ce niveau modifiera automatiquement le configuration de la ressource Azure SQL DB, en mode de tarification basé sur les DTUs (et non les vCores).
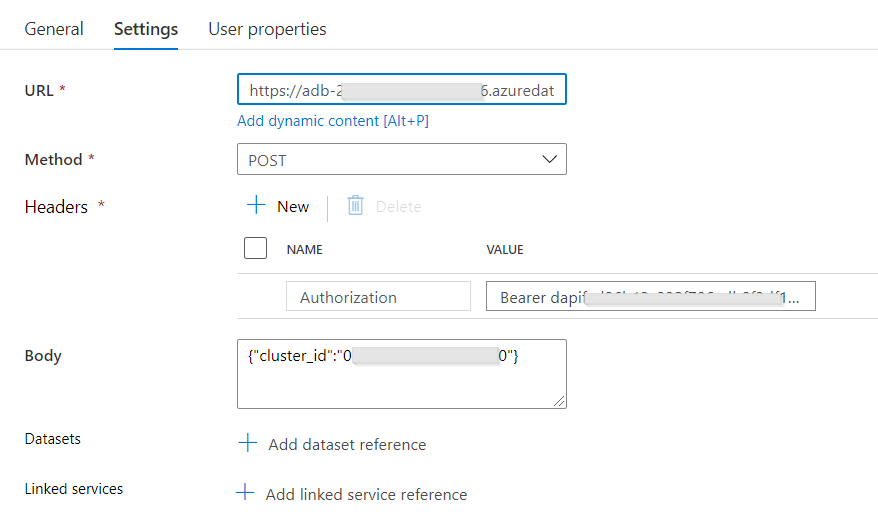
L’activité de traitement de la donnée, ici portée par Azure Databricks, réalise le démarrage d’un cluster de type interactif. Lorsque le traitement est terminé, le cluster peut s’éteindre automatiquement si la fonctionnalité “terminate after…” a été mise en place. Mais il faut ici attendre que l’import du dataset Power BI soit terminé ! Nous gérons donc la fin du cluster Databricks au moyen de l’API dédiée, dans une activité Web.
La syntaxe utilisée est la suivante :
POST https://adb-XXXXXXXXXXXXXXXX.X.azuredatabricks.net/api/2.0/clusters/delete
Les informations nécessaires seront : l’URL du workspace, un personal token d’authentification et l’identifiant du cluster.
Dans un optique d’optimisation des coûts, nous positionnons comme dernière activité du pipeline le scale down de la base de données.
Nous obtenons ainsi une chaîne complète optimisée sur l’enchainement des tâches et sur les coûts engendrés par les services PaaS.
L’actualisation planifiée dans le service Power BI se fait à heure (ou demi-heure) fixe et ne peut pas être conditionnée par un événement antérieur. Le reporting est pourtant bien souvent la dernière étape de toute une chaîne de transformation de la donnée. Nous cherchons donc une solution de trigger (déclencheur) pouvant rejoindre le flux complet sous Azure.
La Power Platform propose des pistes à l’aide de Power Automate (Flow) mais nous souhaitons ici rester dans le monde Azure. Un outil comme Logic Apps dispose de telles fonctionnalités. Mais dans une approche ETL ou ELT, c’est Azure Data Factory (ADF) qui est bien souvent au centre du pilotage des traitements. Nous allons donc exploiter l’API REST de Power BI au travers d’activités Web au sein d’un pipeline ADF.
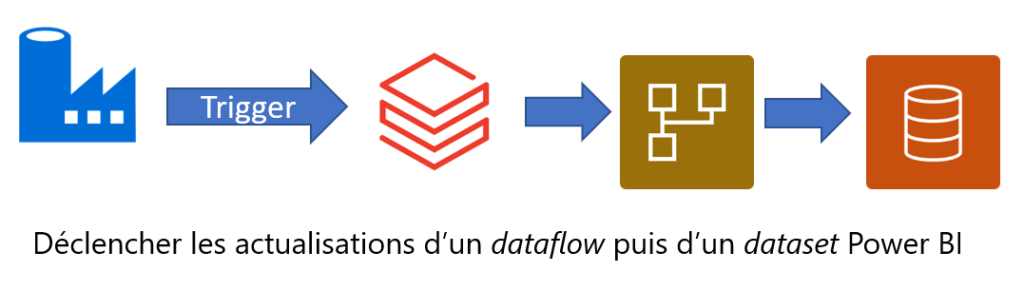
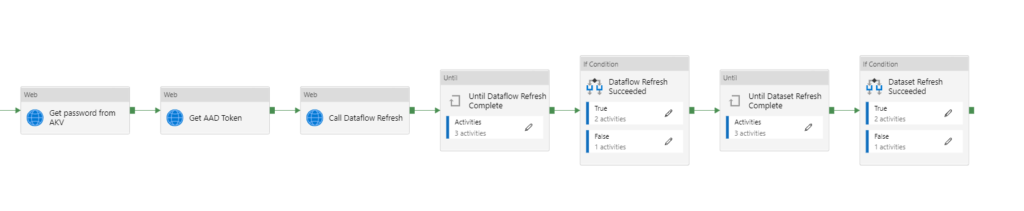
Nous visons un fonctionnement de la sorte (exemple intégrant un notebook Azure Databricks réalisant le pré-traitement de la donnée) :
Sur le schéma ci-dessous, des activités peuvent précéder la série d’activités qui réaliseront les instructions d’API afin d’actualiser un dataflow Power BI.
De nombreux articles de blog ont déjà décrit ce fonctionnement et je vous conseille en particulier cet article de Dave Ruijter et le repository associé qui vous permettra de charger un template complet réalisant l’actualisation d’un dataset.
Les différentes étapes de ce pipeline sont :
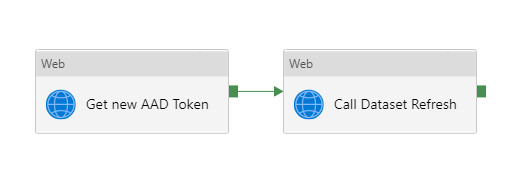
– l’obtention d’un token d’authentification grâce à une application définie dans l’annuaire Azure Active Directory (AAD). Le client secret de cette application est au préalable récupéré dans un coffre-fort Azure Key Vault (AKV).
– la commande d’actualisation du dataflow
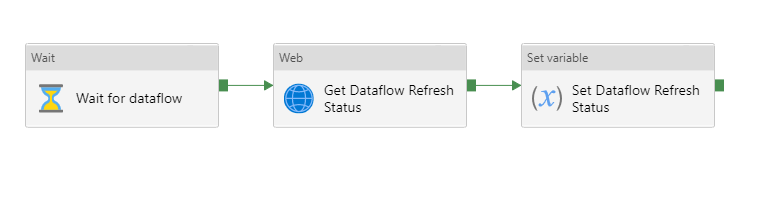
– une boucle d’attente “Until” demandant à intervalles réguliers (activité Wait) le statut de la dernière actualisation. Ce statut est stocké dans une variable.
– dans l’activité “If condition”, la branche True lancera l’actualisation d’un dataset Power BI basé sur le dataflow
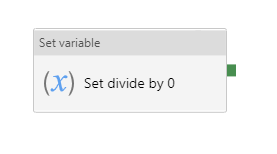
Afin de lever une erreur dans la branche False, nous utilisons l’astuce de définir une variable réalisant une division par 0. Cette division interdite fera échouer l’activité et donc le pipeline complet.
En reprenant une logique similaire, nous ajoutons une boucle d’attente de l’actualisation du dataset et une nouvelle activité “If Condition” permettant de lever une erreur en cas d’échec de l’actualisation.
Il n’est pas possible de placer ces deux dernières briques dans la branche True du “If Condition”, c’est ici une limite d’ADF mais elle ne se révèle pas bloquante.
L’API non documenté des dataflows Power BI
Nous allons préciser ici des éléments ne figurant pas dans la documentation officielle de l’API REST de Power BI.
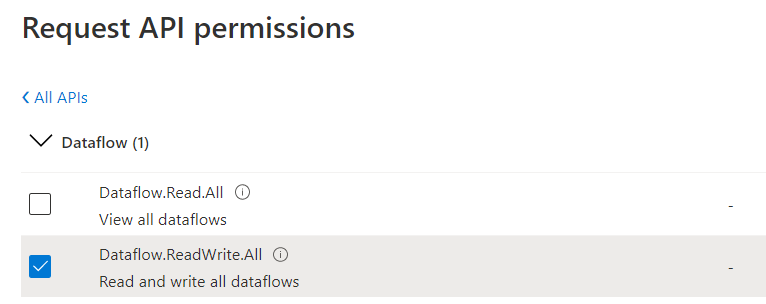
En préambule, nous devons avoir déclarer une application (app registration) disposant des droits Dataflow.ReadWrite.All. Ce point peut être contrôler dans l’annuaire AAD et l’API lèvera une erreur 401 si les droits sont uniquement au niveau Dataflow.Read.All.
L’actualisation d’un dataflow se fait par la commande POST suivante :
POST https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/refreshes
Les identifiants demandés (la notion de group correspondant historiquement à celle d’espace de travail ou workspace) se retrouvent facilement dans les URLs du service Power BI.
Lors de l’actualisation, le statut de l’opération passera à “InProgress” (contre “Unknown” pour un dataset) puis “Success” (contre “Completed”).
L’instruction permettant d’obtenir le dernier statut d’actualisation est une commande GET :
GET https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/transactions?$top=1
Notez le mot-clé “transactions” à l’inverse de “top” pour un dataset en paramètre de cette instruction.
Un grand merci à mon confrère Joël CREST pour son aide sur ce sujet. Je vous encourage à consulter son blog et sa chaîne YouTube.
Avec la sortie fin 2020 d’Azure Purview, beaucoup de démonstrations ont mis en avant la capacité à scanner un tenant Power BI et à présenter le linéage entre les rapports et les données sources.
Ce principe, fort utile, est aussi applicable aux activités Azure Data Factory. Considérons une souscription Azure au sein de laquelle a été créé un service Azure Purview (je vous conseille cette vidéo de Joël CREST pour démarrer votre projet Purview).
Nous nous rendons dans le Management Center sur le portail Purview, au niveau des external connections.
Une permission doit être au préalable accordée, l’utilisateur doit disposer d’un des rôles suivants sur le service Purview : contributor, owner, reader ou User Access Administrator (UAA). Ceci se fait au niveau de l’Access Control (IAM). Le droit doit être “direct” et non hérité d’un niveau supérieur.
Un bouton +New apparaît alors en haut de la fenêtre et permet d’ajouter de désigner la souscription et la ressource Data Factory visée.
Bien vérifier alors que le statut “connected” apparaît au bout de la ligne.
Revenons ensuite dans la partie Sources d’Azure Purview.
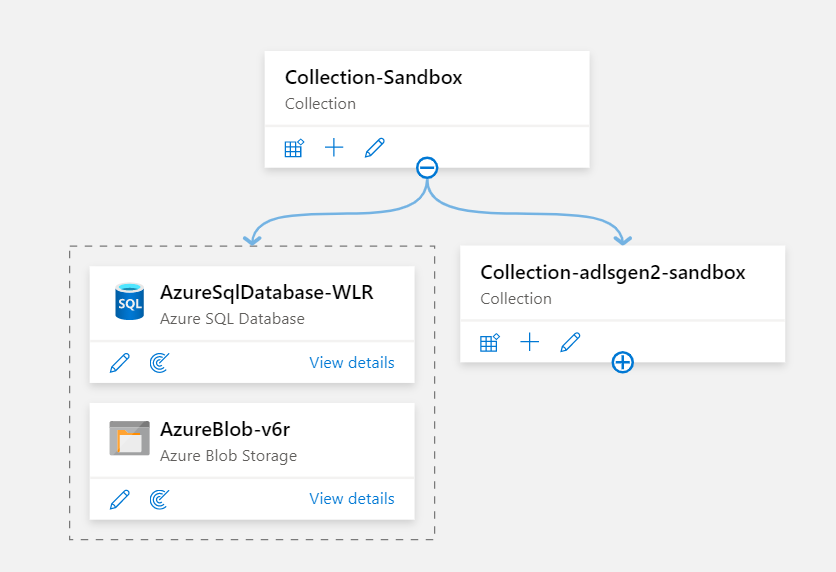
Ici, il faut déclarer une première collection dans laquelle nous définirons les sources des données, qui sont les linked services d’Azure Data Factory.
Pour l’exemple mis ici en œuvre, nous déclarons un compte de stockage Azure Blob et une base de données managée Azure SQL DB. Pour cette dernière, il faut au préalable déclarer l’identité managée (MSI) de Purview en tant que user de la base de données. Cette opération doit être réalisée par un administrateur de la base, présent dans Azure Active Directory. La syntaxe SQL est la suivante :
CREATE USER [nomDuServicePurview] FROM EXTERNAL PROVIDER
GO
EXEC sp_addrolemember 'db_owner', [nomDuServicePurview]
GO
Nous lançons ensuite un scan de ces deux sources.
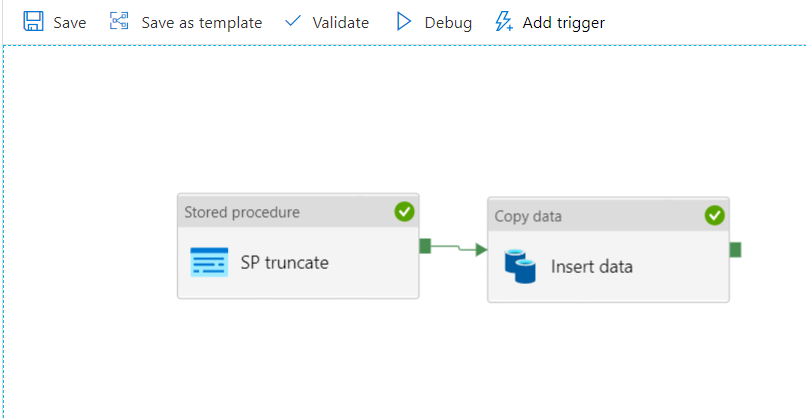
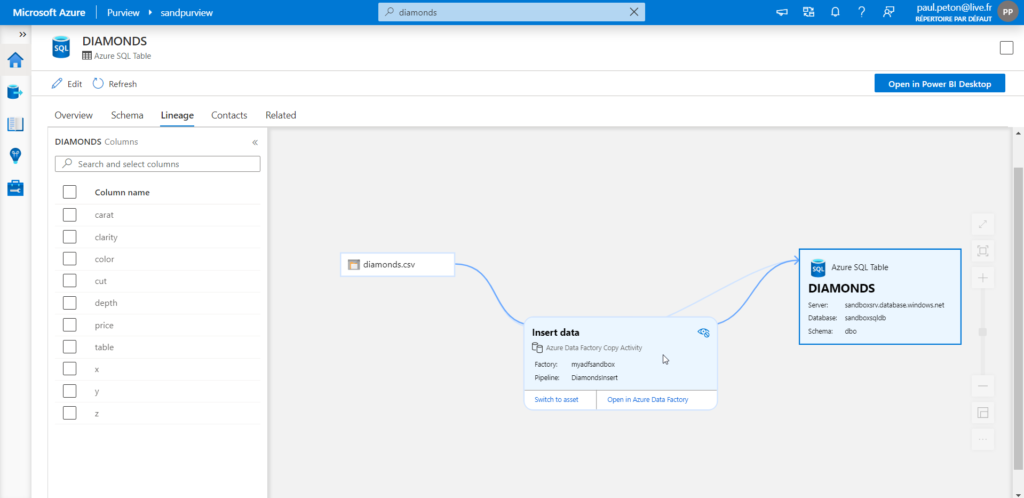
Voici l’activité Data Factory que nous souhaitons retrouver :
Elle réalise la copie d’un fichier CSV dans une table de la base de données, préalablement vidée par une procédure stockée.
Attention, les activités et dont le linéage associés ne seront visibles dans Purview qu’après une exécution, même en debug, de l’activité !
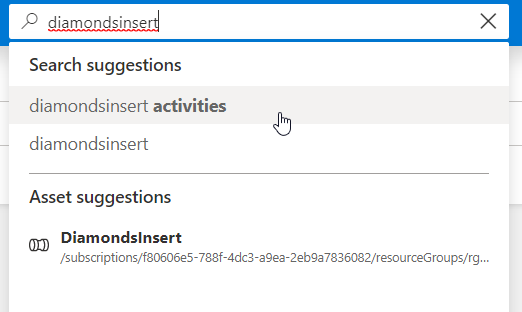
Il suffit de rechercher le nom de l’activité dans la barre de recherche pour vérifier que celle-ci est maintenant bien disponible.
Le linéage est porté par la destination, ici la table de la base de données.
Un lien est disponible pour ouvrir directement cette activité dans le service Azure Data Factory.
Au fil des exécutions des activités, le champ de la recherche dans Purview va ainsi s’étendre pour couvrir l’ensemble des traitements.
Une bonne pratique semble d’ores et déjà s’imposer : seuls les Data Factory de production sont à déclarer dans Azure Purview. La limite est à ce jour de 10 services ADF.
Ne le cachons pas, Spark déploie toute sa puissance lorsque les volumes de données sont significatifs. Pour autant, devant la simplicité d’utilisation d’Azure Databricks, il est tentant de centraliser tous les traitements de données dans des notebooks lancés sur un cluster.
Et un cluster, par définition, est constitué de plusieurs machines, a minima un driver et un worker qui échangeront des informations. C’est toute la puissance de cette architecture qui distribue les traitements sur un nombre de workers éventuellement automatiquement “scalable”.
Mais dans le cas de traitements simples, une seule machine virtuelle (bien dimensionnée) serait suffisante et éviterait en plus des échanges réseaux qui pourraient même perturber le traitement. En étant pragmatique, ce sont aussi des coûts divisés au moins par deux !
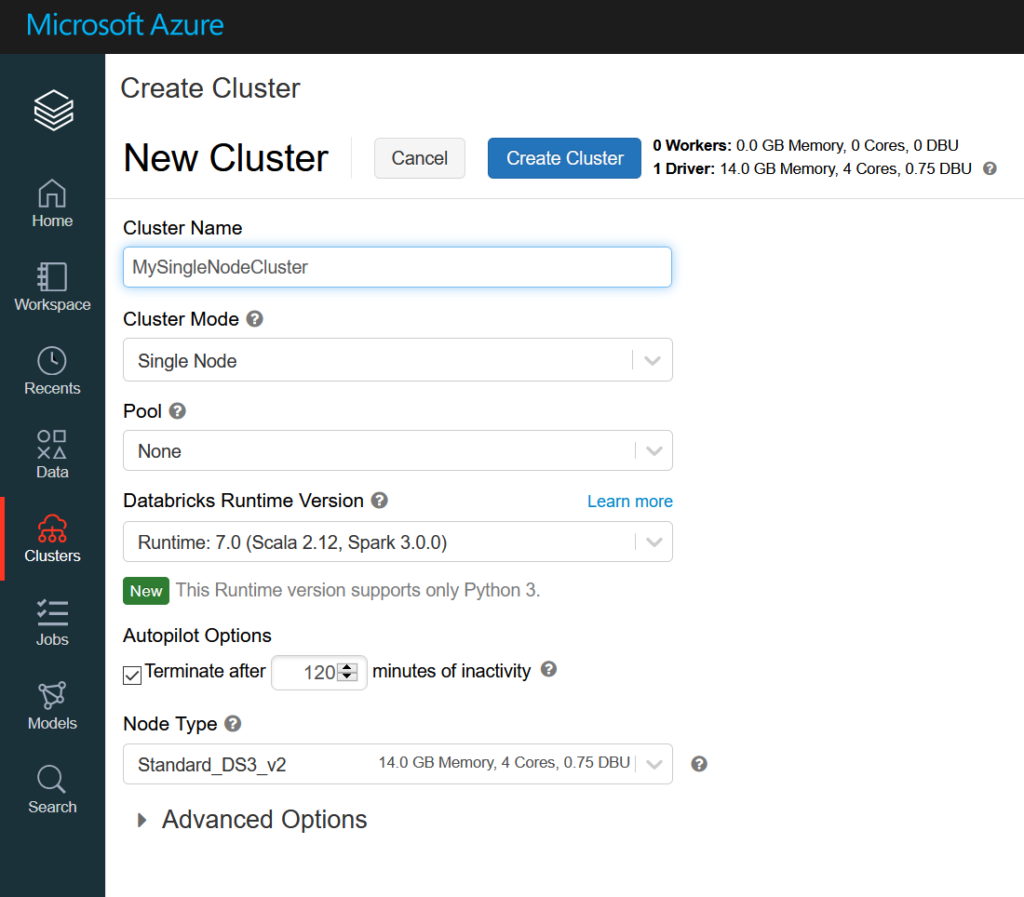
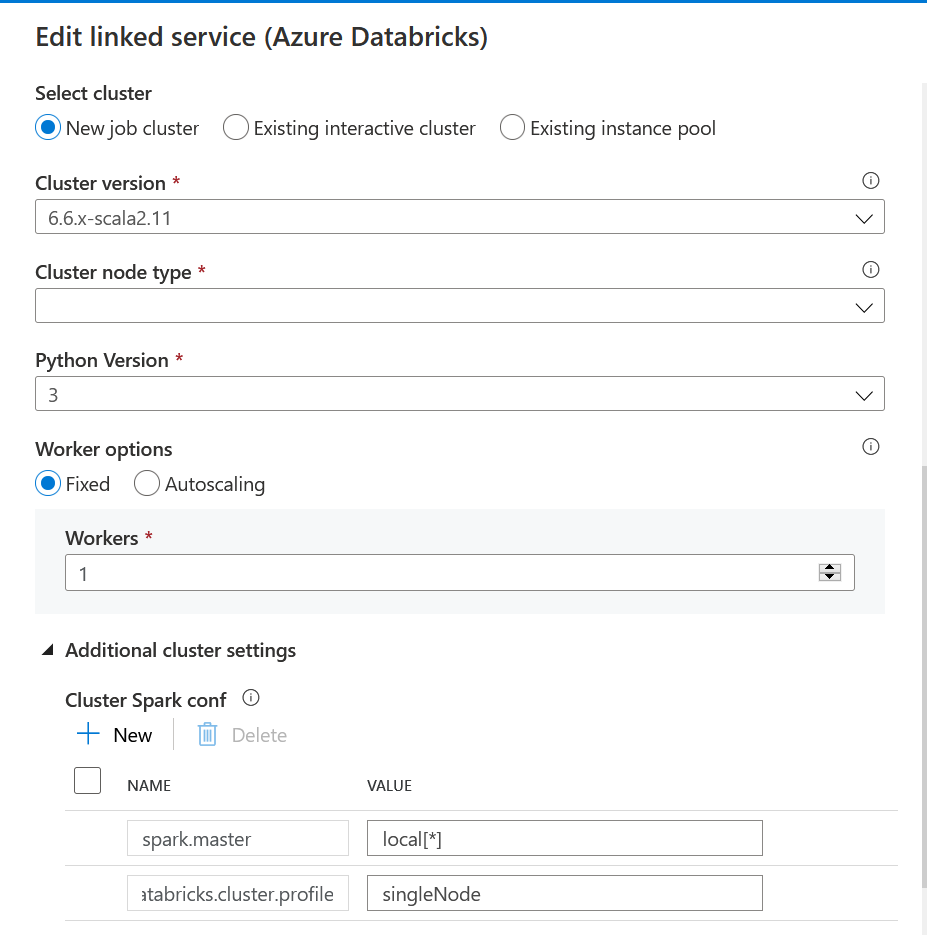
Une solution existe maintenant : le mode de cluster “Single Node“.
Cette fonctionnalité est aujourd’hui (octobre 2020) en préversion publique et décrite sur le site de Databricks.
On observe ce paramétrage dans la version JSON de la définition du cluster, au niveau de la configuration du cluster.
Imaginons maintenant que vous souhaitiez lancer vos traitements avec la logique “automated cluster“, s’appuyant éventuellement sur un pool de machines virtuelles. Cela est tout à fait possible depuis l’interface de jobs de Databricks mais dans une architecture data Azure plus large, on s’appuyera souvent sur le rôle d’ordonnanceur de Azure Data Factory.
Dans Azure Data Factory, nous définissons un service lié Databricks. Dans l’interface graphique, nous ne trouvons pas le mode SingleNode mais la configuration Spark peut être précisée.
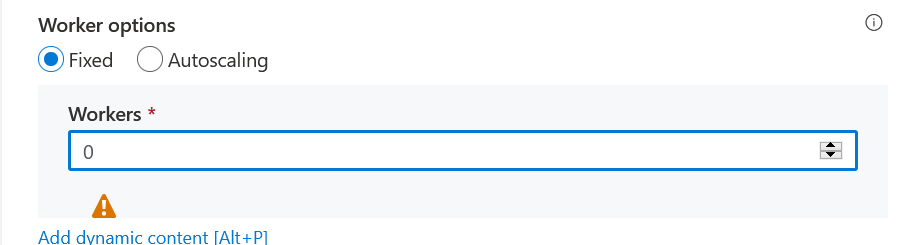
Cela semble suffisant mais nous pouvons aussi préciser le nombre de workers à 0, même si un message d’alerte apparaît alors. Celui-ci n’est pas bloquant.
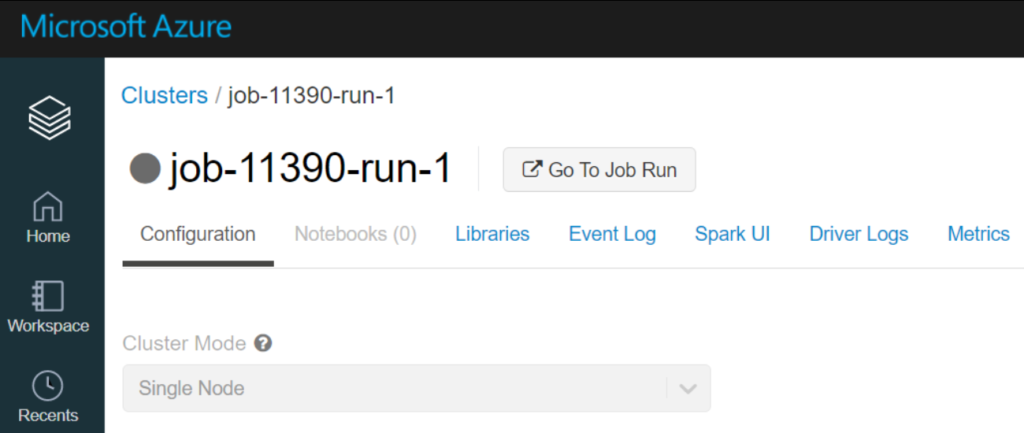
Afin de contrôler que ce sont bien des “automated single node clusters” qui se sont exécutés, vous pouvez consulter les logs de l’activité Data Factory où se trouve un lien pointant vers l’exécution du notebook et la configuration de clsuter associée.
La longueur du titre de cet article laisse présager du niveau de précision dans lequel nous allons nous lancer ! Je vais donc rapidement situer le contexte faisant appel à un tel besoin.
Nous cherchons à déployer de manière automatisée un environnement de développement Azure Data Factory sur l’environnement de production. Nous utilisons pour cela un pipeline de release Azure DevOps. Le processus DevOps pour ADF est expliqué dans ce livre blanc Microsoft ou dans cet excellent article de Florian Eiden.
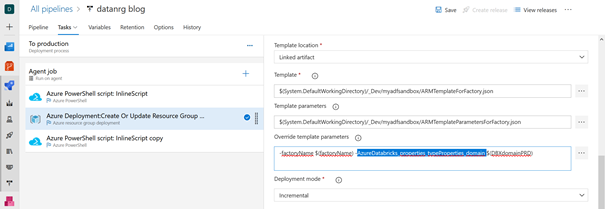
Pour résumer les grandes lignes du fonctionnement, nous remplaçons dans un fichier de paramètres au format JSON les valeurs des chaînes de connexion de l’environnement de développement par celles de production. Ceci se fait au moyen de la case « override template parameters ».
Valeurs manquantes pour le service lié Databricks
La chose se complique lorsque nous utilisons un service lié de calcul de type Azure Databricks puisque les paramètres de ce service n’apparaissent pas par défaut dans le fichier de paramétrage ! Nous avons en particulier besoin de remplacer :
La Databricks Workspace URL
Le Secret name (où se trouve enregistré un Personal Access Token correspondant à l’espace de travail souhaité)
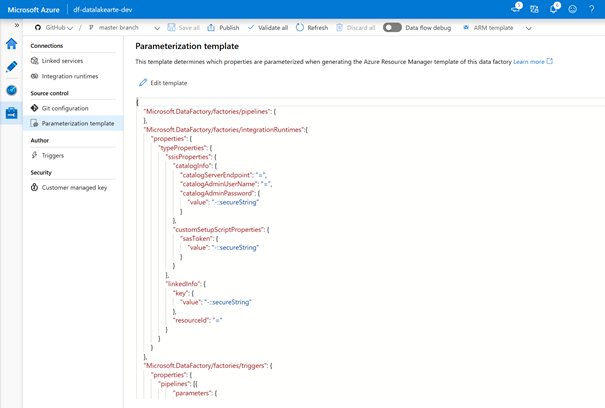
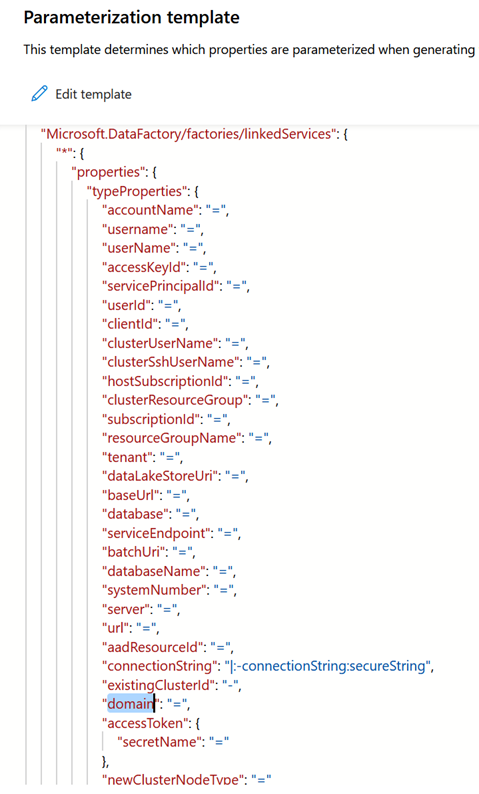
En effet, un choix arbitraire a été fait par Microsoft pour présenter uniquement certains paramètres mais un grand nombre de valeurs existent et elles sont visibles en éditant le fichier disponible dans le menu : Parametrization template.
Ce fichier au format JSON recense l’intégralité des paramètres disponibles par défaut, ainsi que leur visibilité au moyen d’une propriété qui n’est pas simple à interpréter :
= (signe égal) permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre
– (signe moins) permet de ne pas conserver la valeur par défaut pour le paramètre
Le symbole | (pipe) permet de réaliser le lien avec une valeur stockée dans le coffre-fort Azure Key Vault.
Nous allons maintenant rechercher le nom des paramètres manquants. Pour cela, nous passons par la définition du service lié Databricks au format JSON.
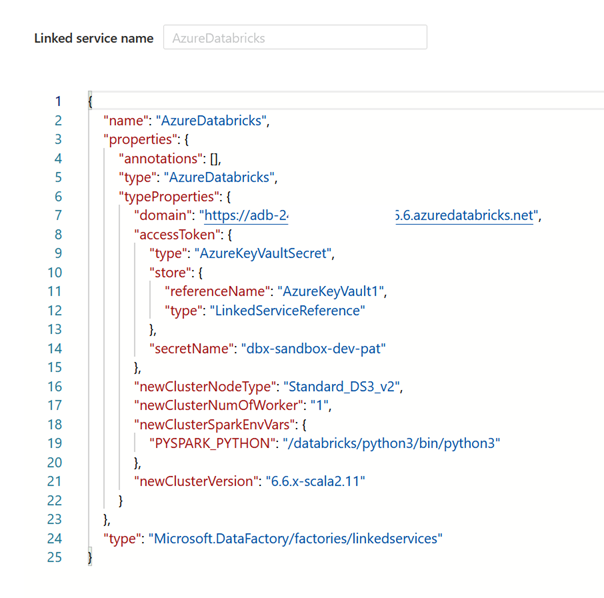
Nous obtenons ainsi le nom exact des paramètres (ne pas se fier à l’interface graphique).
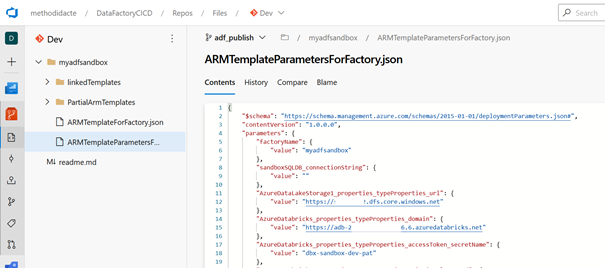
L’URL de l’espace de travail se nomme ainsi domain, le secret du Key Vault se désigne par secretName et ses deux propriétés dépendent du niveau TypeProperties et du sous-niveau accessToken pour le secret.
Nous pouvons donc maintenant citer ces propriétés dans le JSON des paramètres, en respectant l’arborescence des propriétés.
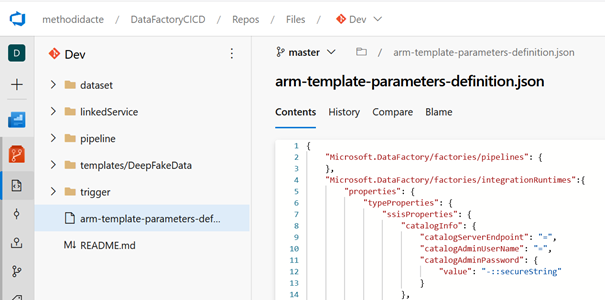
La définition des paramètres dans la branche Master
Arrive ici la partie peut-être la moins documentée (jusqu’à présent !). Il faut comprendre que ce fichier JSON doit figurer à la racine de la branche Master du dépôt contenant la synchronisation du Data Factory avec un gestionnaire de version comme GitHub ou un repo Azure DevOps, sous le nom arm-template-parameters-definition.json.
Il ne faut donc pas utiliser la branche spécifique à Data Factory qui se nomme adf_publish mais nous irons ensuite vérifier que les deux fichiers JSON qu’elle contient ont bien été modifiés en conséquence.
Pour lancer cette modification, nous devons tout d’abord faire les deux actions suivantes :
Refresh
Publish
Le volet latéral du Publish (pending changes) doit s’afficher même si aucune modification n’est visible.
Nous pouvons enfin vérifier que les paramètres sont disponibles dans le fichier ARMTemplateParametersForFactory.json de la branche adf_publish.
Modifier la valeur des paramètres pendant la release
Il ne reste qu’à utiliser ces noms de paramètres dans le pipeline de release Azure DevOps. Les nouvelles valeurs peuvent être définies comme des variables du pipeline pour plus de commodité.
Cet article a pu être écrit grâce à la documentation officielle de Microsoft ainsi que d’autres articles de blog, en anglais, que leurs auteurs en soient ici remerciés :