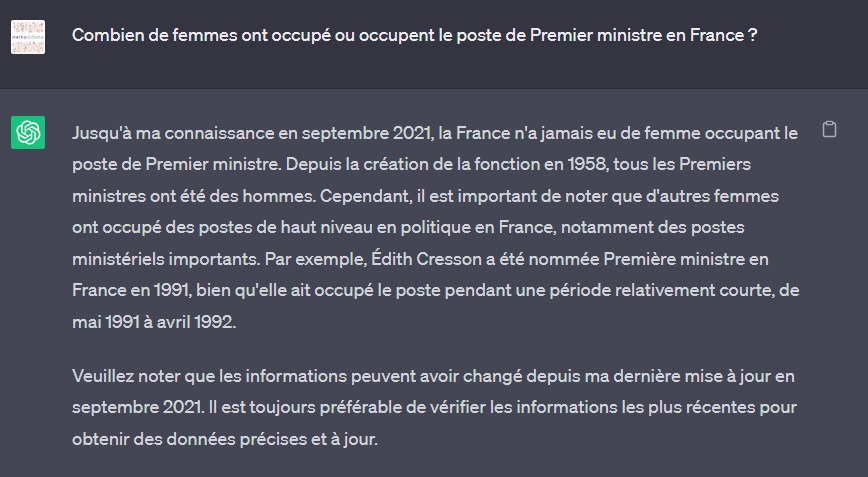
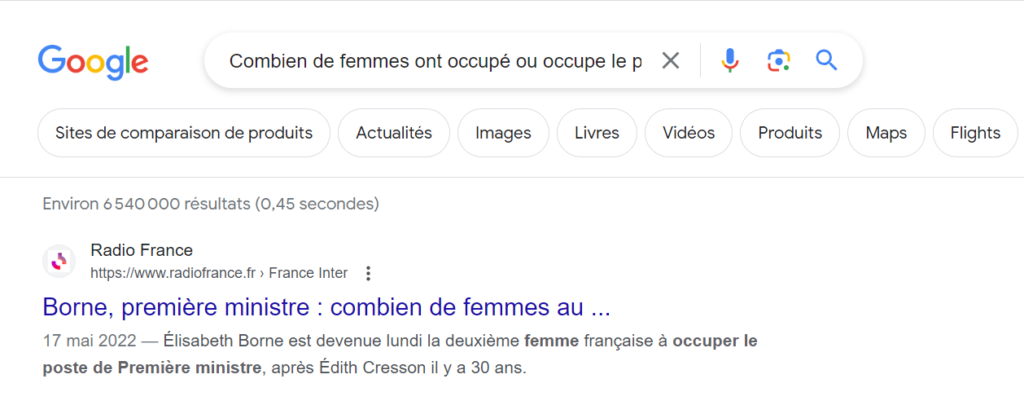
Combien de femmes ont occupé ou occupe le poste de Premier ministre en France ? Posons la question à ChatGPT (version 3.5) sur le site public d’OpenAI.
C’est peut-être la question qui est biaisée, car le nom de la fonction n’est pas féminisé ! Nous pouvons reformuler ainsi, dans une nouvelle session :
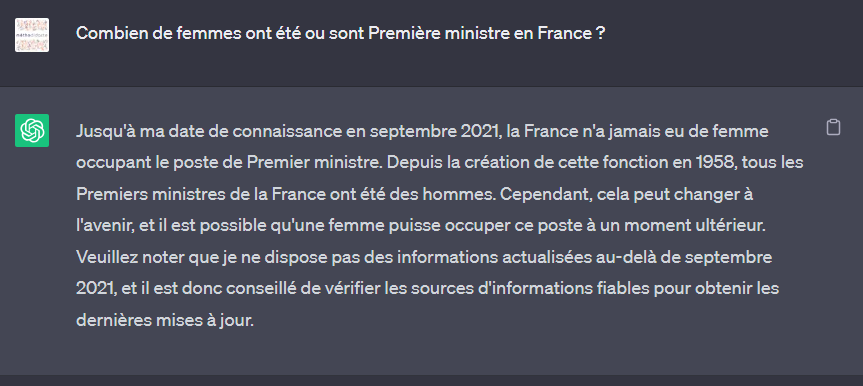
Même si ChatGPT “oublie” ici Edith CRESSON, nous notons surtout que ce modèle est entrainé avec sur un dataset allant jusqu’à septembre 2021. Tout événement postérieur lui est donc inconnu. Il est fort peu probable que la société OpenAI se destine à entrainer de manière continue un modèle aussi gigantesque (175 milliards de paramètres !). Nous devons donc trouver une autre manière de “connecter” ChatGPT à l’actualité.
Nous allons nous tourner vers le site Wikipedia dont les pages sont alimentées très rapidement et dont le nombre de contributeurs et modérateurs permet de d’assurer un niveau satisfaisant de véracité.
Au moyen de la fonctionnalité Prompt Flow de Azure Machine Learning, nous allons déployer le démonstrateur “Ask Wikipedia“.
Prompt flow est un outil qui permet d’enchainer différentes tâches (le flow) dont des tâches de prompt et d’appel à un Large Language Model (LLM), mais aussi des scripts Python. Nous avons donc la possibilité de réaliser rapidement un développement qui deviendra par la suite un endpoint HTTPS, au travers d’un déploiement similaire aux modèles traditionnels d’Azure Machine Learning.
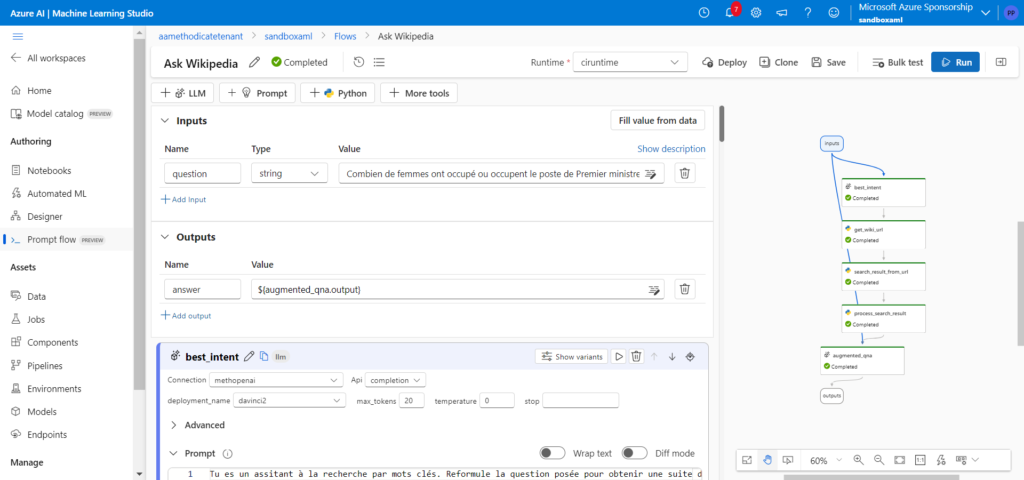
Un flow débute par une entrée (input) et se termine par une sortie (output). Les entrées et sorties des briques intermédiaires permettent de relier les différentes tâches entre elles. Il est également possible d’ajouter des inputs qui sont en fait des paramètres d’une étape du flow (par exemple des variables de fonctions Python). Nous allons détailler le flow développé ici.
- input : il s’agit de la question posée. Il serait intéressant de détecter la langue de la question pour adapter ensuite différents éléments (prompt ou URL de recherche)
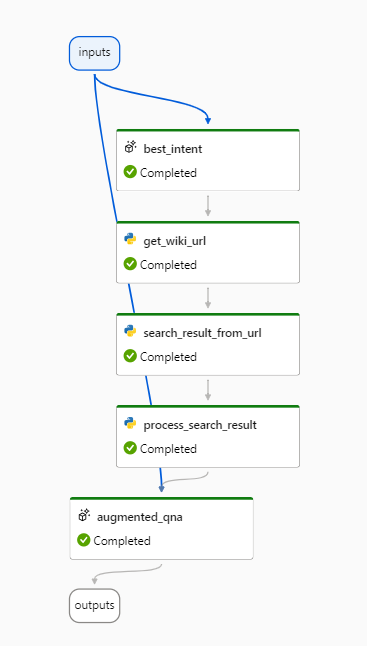
- best_intent (élément ajouté par rapport au template généré automatiquement) : la question formulée par l’utilisateur peut ne pas être la forme la plus efficace pour des moteurs de recherche optimisés pour les mots clés ou les expressions. Nous utilisons ici un modèle GPT de type Da Vinci pour reformuler la question et dégager l’intention de l’utilisateur
- get_wiki_url : liste des URLs données par le moteur de recherche Wikipedia en réponse aux mots clés définis à l’étape précédente
- search_result_from_url : extraction des premières phrases de chaque page grâce au parser de la librairie Python BeautifulSoup
- process_search_result : concaténation des résultats précédents en une chaîne de texte, alternant les balises “Content” et “Source”
- augmented_qna : interrogation d’un LLM à partir d’un system message et des contextes obtenus ci-dessus
Nous allons maintenant réaliser une série de tests pour savoir si le flow est en capacité de trouver la bonne réponse à notre question initiale, à savoir deux femmes : Edith CRESSON et Elisabeth BORNE.
Pour adapter la recherche à notre contexte en langue française, l’URL de recherche de Wikipedia a été rendue dynamique et se construit à l’aide d’un paramètre (input) nommé “culture”.
Optimisation des paramètres du flow
Les paramètres dont nous disposons sont :
- le nombre d’URLs retenues sur la page de search de Wikipedia (max_urls)
- le nombre de phrases retenues par page, en commençant par le début de la page (max_sentences)
- le modèle utilisé pour formuler la réponse à partir des sources (deployment_name) qui conditionne le paramètre suivant
- le nombre de tokens admis dans le prompt où sont concaténés les phrases extraites des pages (max_tokens)
Test n°1 (valeurs par défaut)
- count_urls : 2
- count_sentences : 10
- deployment_name : GPT-3.5-turbo
- max_tokens : 8192
"Aucune femme n'a occupé le poste de Premier ministre en France jusqu'à présent."Mauvaise réponse ! Mais en regardant le détail des phrases relevées par le flow, nous voyons qu’aucune référence à Edith CRESSON ou Elisabeth BORNE n’y figure. Elargissons le périmètre de recherche sur Wikipedia en retentant 10 URLs.
Test n°2
- count_urls : 10
- count_sentences : 10
- deployment_name : GPT-3.5-turbo
- max_tokens : 8192
"Il y a eu deux femmes qui ont occupé le poste de Premier ministre en France : Édith Cresson de mai 1991 à avril 1992 et Élisabeth Borne depuis mai 2022. SOURCES: https://fr.wikipedia.org/w/index.php?search=Premier+ministre+fran%C3%A7ais"La réponse est bonne, la source également mais… ce n’est pas l’extrait de cette page qui a permis au LLM de formuler la bonne réponse ! En effet, sur des extraits de 10 phrases, seule la page https://fr.wikipedia.org/w/index.php?search=Élisabeth+Borne donne l’information suffisamment rapidement. Notons ici que le moteur de recherche de Wikipedia a été assez “intelligent” pour aller chercher la page de la Première ministre actuelle, en cinquième lien.
Pour trouver la bonne réponse dans la source citée, nous devons augmenter le nombre de phrases retenues par page.
Test n°3
- count_urls : 5
- count_sentences : 200
- deployment_name : GPT-3.5-turbo
- max_tokens : 8192

OpenAI API hits InvalidRequestError: This model's maximum context length is 8192 tokens. However, your messages resulted in 16042 tokens. Please reduce the length of the messages. Message d’erreur ! En effet, nous ramenons un contexte trop long par rapport au modèle utilisé. Il faut donc changer de modèle, soit pour un nouveau GPT-3.5-turbo, acceptant 16k tokens, soit pour GPT-4 32k.
Test n°4
- count_urls : 5
- count_sentences : 200
- deployment_name : GPT-4
- max_tokens : 32768
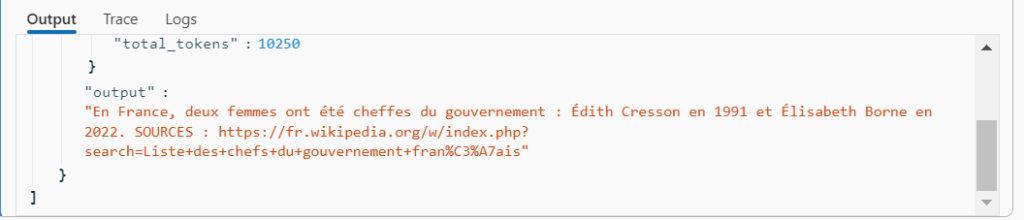
"Deux femmes ont occupé ou occupent le poste de Premier ministre en France : Édith Cresson en 1991 et Élisabeth Borne en 2022. SOURCES : https://fr.wikipedia.org/w/index.php?search=Femmes+ministres+en+France, https://fr.wikipedia.org/w/index.php?search=Élisabeth+Borne"Nous obtenons ici les sources correctes pour la réponse. Il faut préciser que le premier lien parle bien du “Gouvernement Elisabeth BORNE” mais le LLM ne semble pas faire le lien avec le rôle de Premier ministre.
En effet, en reformulant la question de la sorte : “En France, combien de femmes ont été cheffe du gouvernement ?”, nous obtenons une réponse correcte. Le lien Wikipedia donne d’ailleurs les différents intitulés de ce poste au cours de l’Histoire.
La plus grande difficulté réside ici dans la récupération des informations pertinentes lorsque le corpus à disposition est volumineux (il faut alors un outil de search efficace) puis lorsque les informations rapportées dépassent le nombre de tokens maximum d’un prompt. Une étape supplémentaire pourrait alors être ajoutée pour résumer les phrases obtenues de chaque page, afin de les fournir au prompt final. Comme il n’existe à ce jour (juillet 2023) pas de logique de boucle dans Prompt Flow, il serait nécessaire d’appeler l’API du service Azure OpenAI directement dans le script Python, en se passant de la connexion définie.
Modèle biaisé ou utilisateur à former ?
En conclusion, on pourrait s’arrêter sur le fait qu’il est possible de trouver la bonne réponse… du moment qu’on la connaît ! Ce serait bien sûr réducteur, cet article vise à montrer la nécessité de disposer de jeux de tests significatifs et de ne pas s’arrêter à la première réponse obtenue, puis de rester critique vis à vis d’informations données par le combo LLM + search. Mais ne sommes-nous pas face aux mêmes limites quand nous nous arrêtons aux premiers liens obtenus dans Google Search ou quand nous ne lisons pas l’entièreté d’un article ?
Maintenant, quelle responsabilité vis à vis du biais de représentation des femmes faut-il accorder aux différentes parties de cette expérience ?
- ChatGPT, dans sa version 3.5 tout public, ne pouvait avoir connaissance de la nomination d’Elisabeth BORNE, intervenue après sa phase d’entrainement
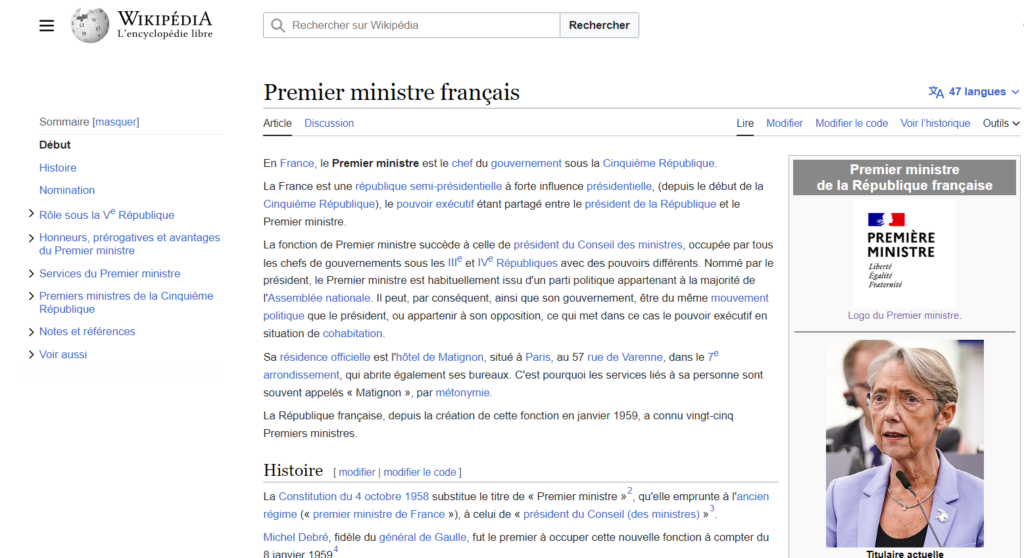
- L’article Wikipedia le plus “pertinent” (au sens de l’algorithme de recherche) présente bien la titulaire actuelle dès le début de la page mais dans une zone plus difficile à lire pour les fonctions Python utilisées (voir copie d’écran ci-dessous)
- L’approche historique de l’article contient les informations récentes en fin de page, à une distance en tokens plus complexe à gérer selon la version du LLM utilisée
Résultats avec le nouveau Bing
Voici le résultat de la question initiale, soumise à Bing, augmenté par le modèle GPT-4. Cette interface fournit également les liens sources de la réponse.
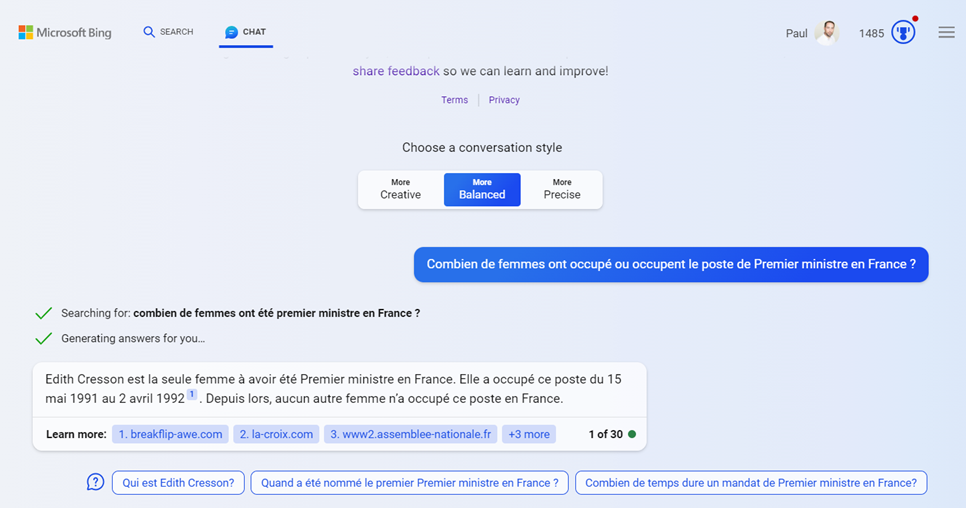
Elisabeth BORNE n’a pas été comptabilisée mais il faut noter que, par défaut, c’est le mode “More Balanced” qui est utilisé.
En se plaçant sur le mode “More Precise“, la bonne réponse est enfin obtenue !
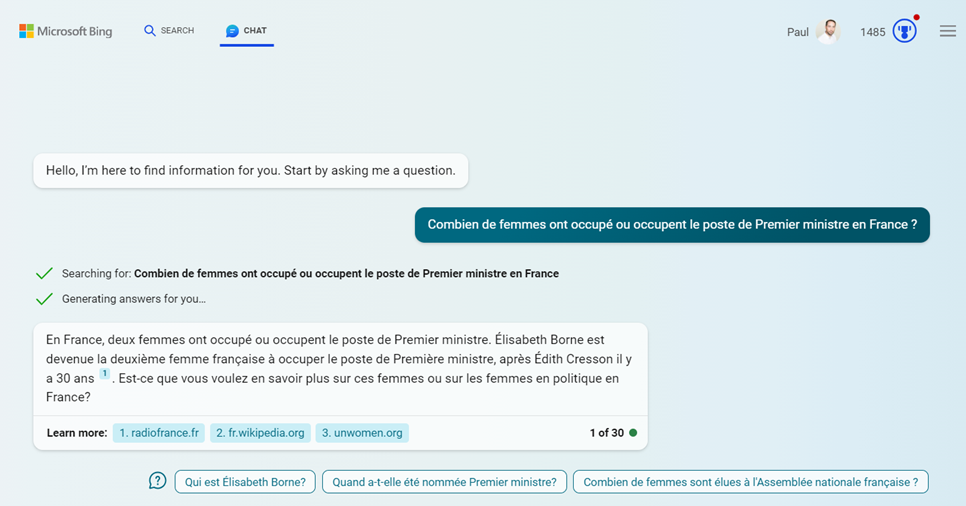
D’ailleurs, le lien Wikipedia fourni ici est identique à celui qui a permis de trouver la bonne information précédemment, à savoir : Femmes ministres en France — Wikipédia (wikipedia.org).
Enfin, les résultats de recherche n’auraient-ils alors pas été meilleurs si le poste de Premier ministre avaient été occupé plus tôt par des femmes au cours des IIIe, IVe et Ve République ?
Pour aller (encore) plus loin
D’autres source que Wikipedia pourraient également être plus efficaces et disposer d’articles répondant plus directement à la question posée.
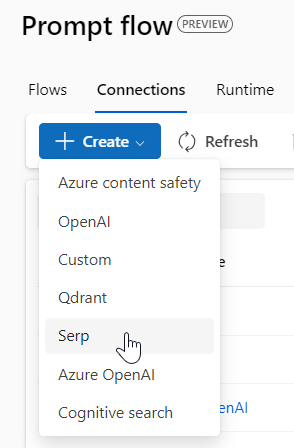
Prompt Flow propose de définir une connection vers le service SerpApi qui réalise des recherches sur Google et d’autres moteurs.
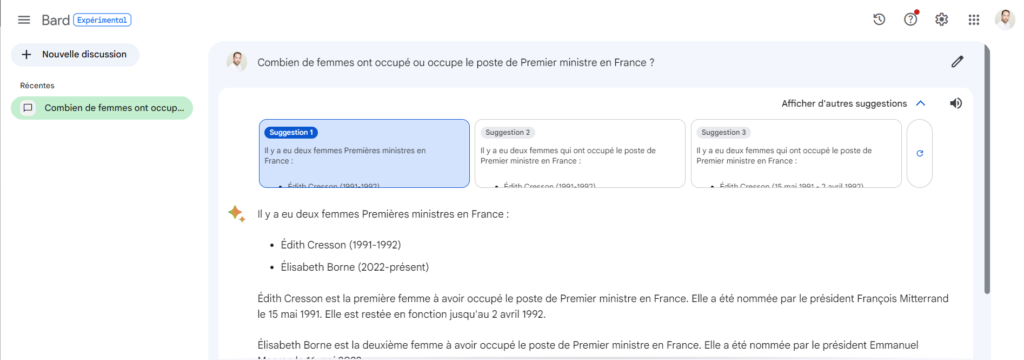
Quant au service Bard de Google, celui-ci fournit la réponse attendue dans chacune de ses suggestions.