Si vous parcourez régulièrement ce blog, vous avez déjà lu des articles par ici ou par là évoquant l’approche “automated ML” (force brute élargissant le spectre plus traditionnel de l’hyperparameter tuning), en particulier pour les séries temporelles. J’ai également évoqué le package Prophet, mis à disposition par la recherche de Facebook dans un précédent billet. Ce sont tous ces éléments que nous allons retrouver dans une nouvelle fonctionnalité de Databricks, liée au Runtime 10 !
En upgradant le Runtime (version ML) de notre cluster, nous pouvons enfin accéder à la troisième entrée dans la menu déroulant “ML problem type“.
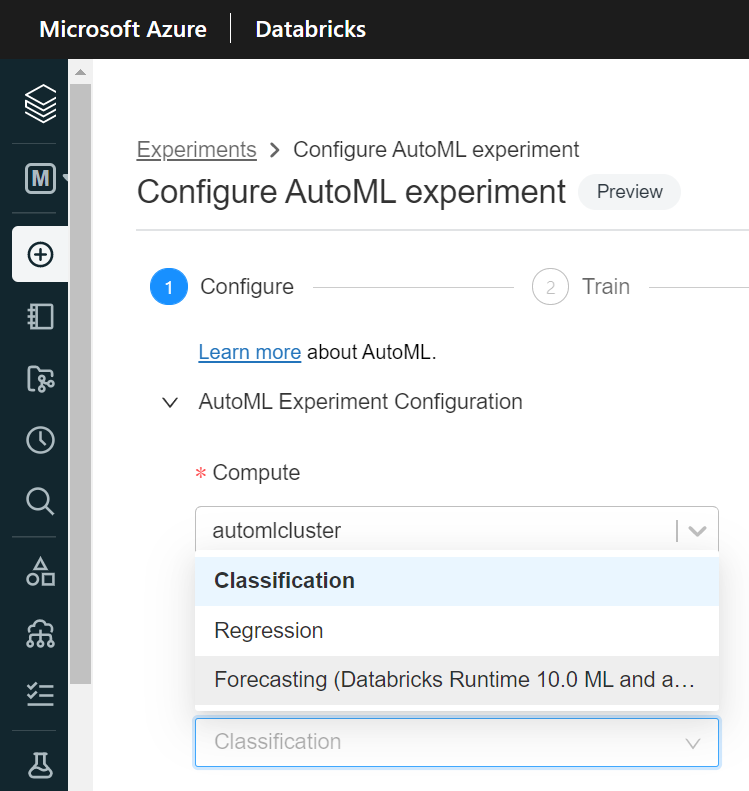
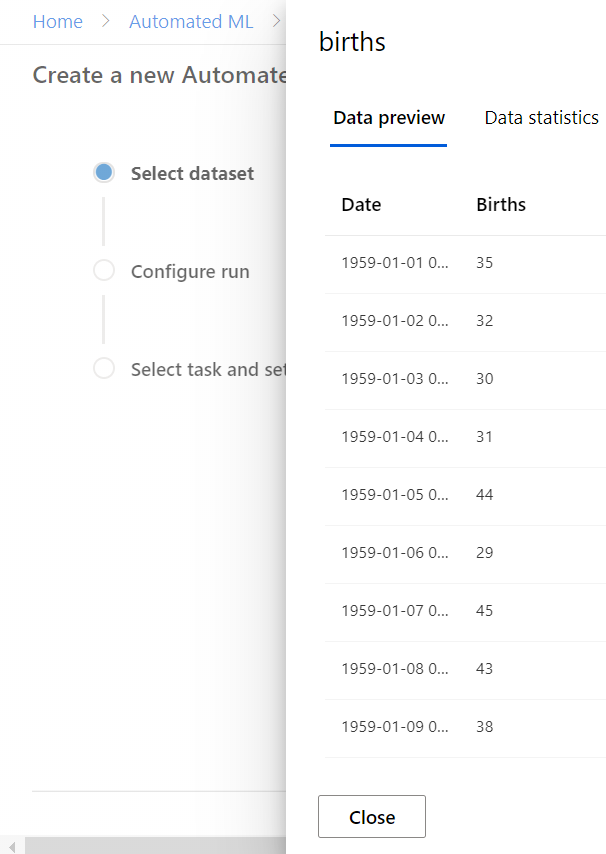
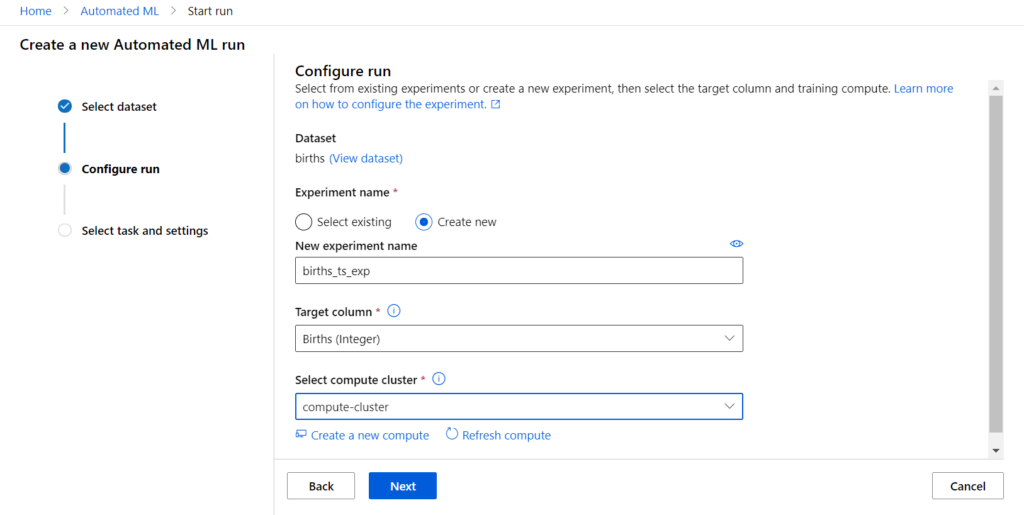
Aucune différence avec les deux autres approches, nous choisissons un jeu de données enregistré comme une table dans le metastore puis nous désignons les colonnes importantes de ce dataset :
- une colonne cible (target)
- une colonne de type date ou timestamp
- d’éventuels “time series identifiers” si nous disposons d’index complémentaires à la date
Pour cette démonstration, nous partirons d’un jeu de données sur la qualité de l’air en 2004 et 2005, disponible sur ce lien.
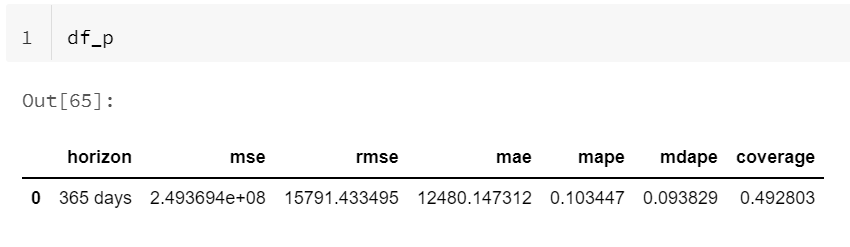
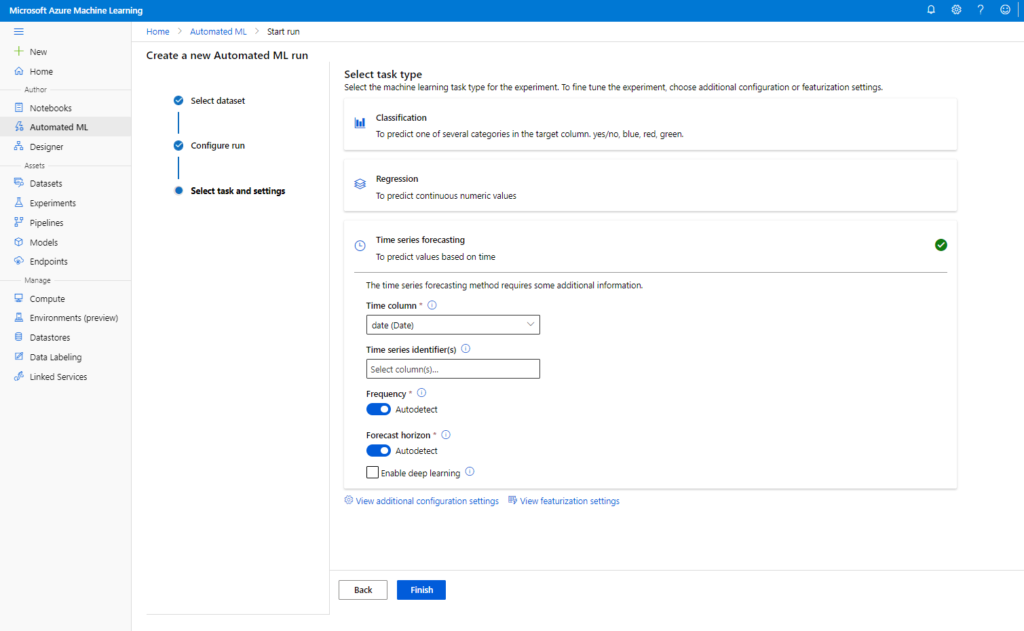
Nous précisions l’horizon de prévision (pour rappel méthodologique, ne vous aventurez pas au-delà du tiers de votre historique, il faut savoir raison garder !). Celui-ci s’entend à partir de la dernière date du jeu de données.
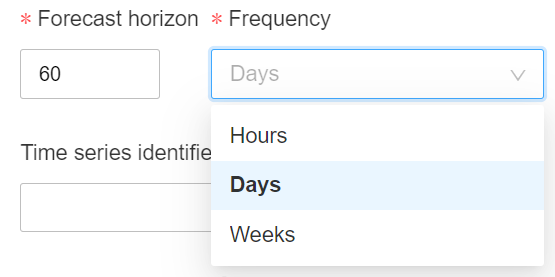
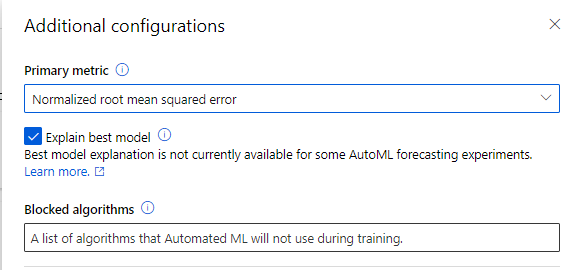
La configuration avancée permet de choisir la métrique d’arrêt parmi des métriques adaptées à la problématique de forecasting.

C’est parti, laissons maintenant notre cluster travailler !
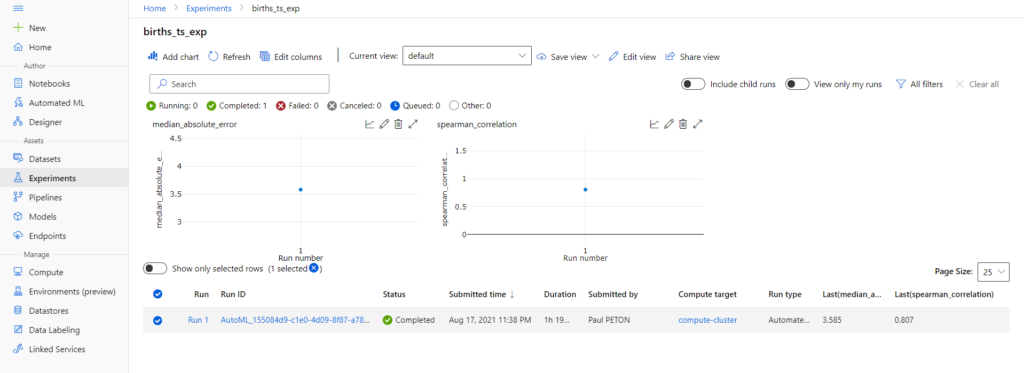
Voici le résultat de l’expérience enregistrée dans notre espace de travail Databricks.
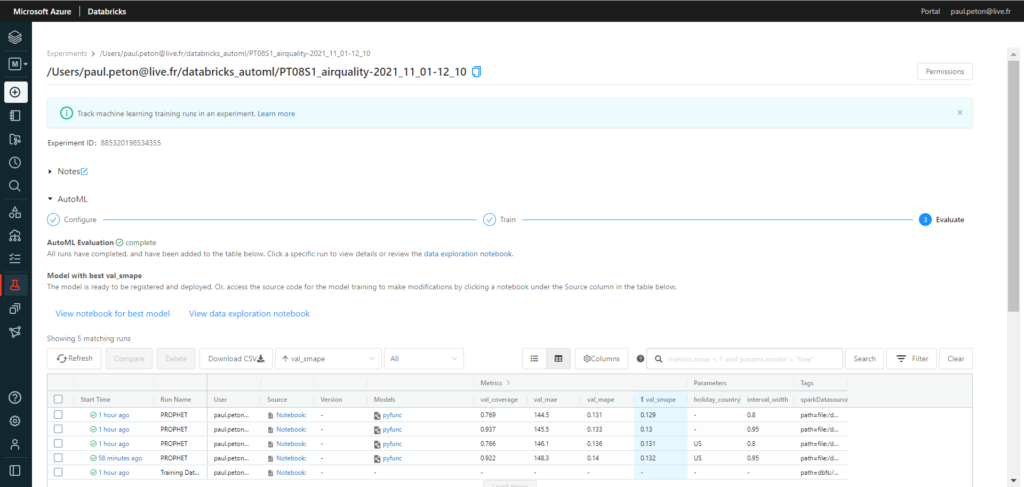
Le premier run n’est pas encore un forecast puisqu’il s’agit d’une exploration des données (mais vous l’aviez réalisée au préalable, rassurez-moi !).
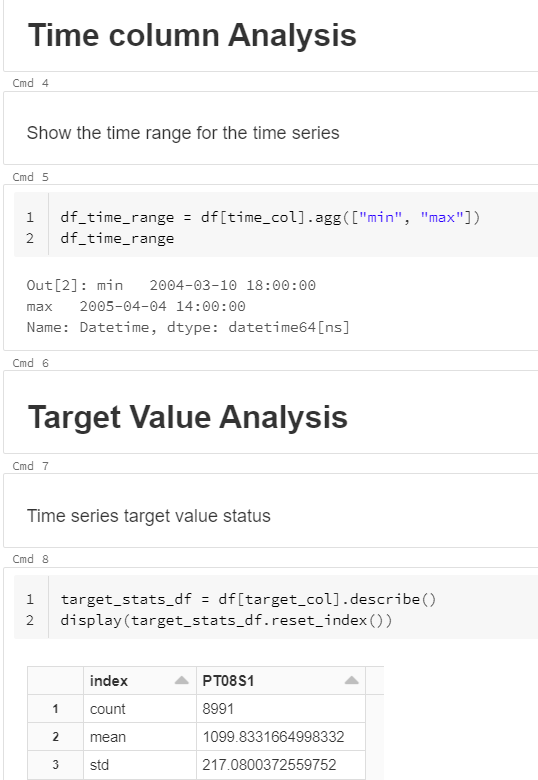
Nous y trouvons des informations importantes :
- plage de dates
- indicateurs de centrage et dispersion sur la variable cible
- nombre de valeurs manquantes
Un diagramme en ligne termine cette rapide analyse.
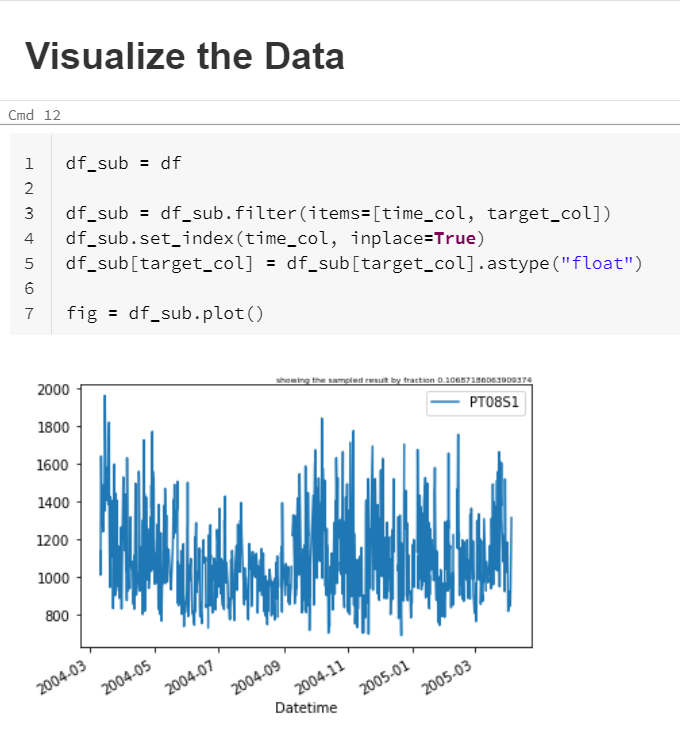
Passons maintenant aux notebooks de forecasting.

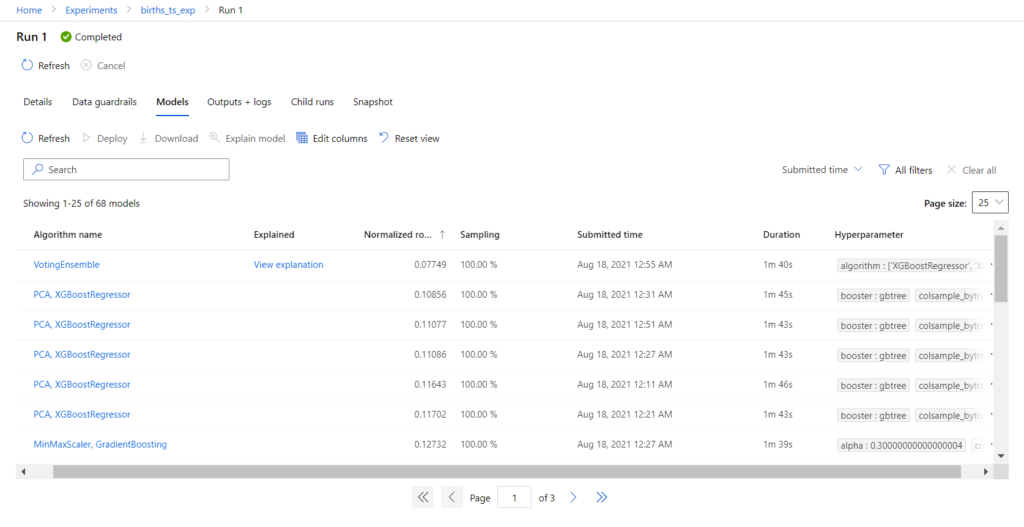
Nous pouvons trier les runs selon leur performance sur les différentes métriques et observer les valeurs des paramètres utilisés. A ce jour (novembre 2021), seuls deux paramètres sont proposés pour un algorithme basé sur le modèle de décomposition de Prophet :
- interval_width : seuil de confiance (1 – risque d’erreur) utilisé pour l’intervalle de prévision
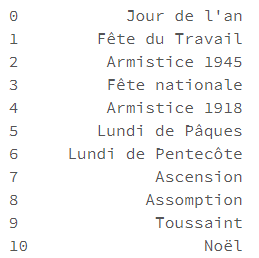
- holiday_country : intégration des jours fériés du pays comme composantes dans la décomposition de la série temporelle
Nous allons maintenant explorer en détail le notebook, généré automatiquement, qui a réalisé la meilleure performance.
Nous retrouvons les paramètres saisies dans l’interface graphique. Si nous souhaitons les modifier, autant le faire maintenant dans le notebook !
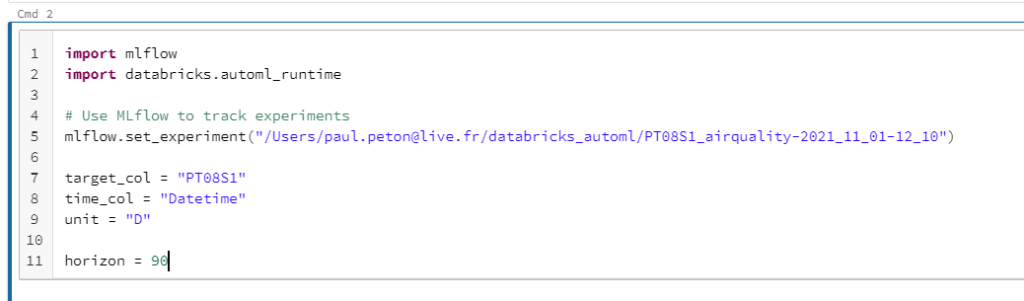
Les données sont tout d’abord chargées puis transformées pour correspondre au standard attendu par Prophet, à savoir une colonne date nommée “ds” et une cible nommée “y”.
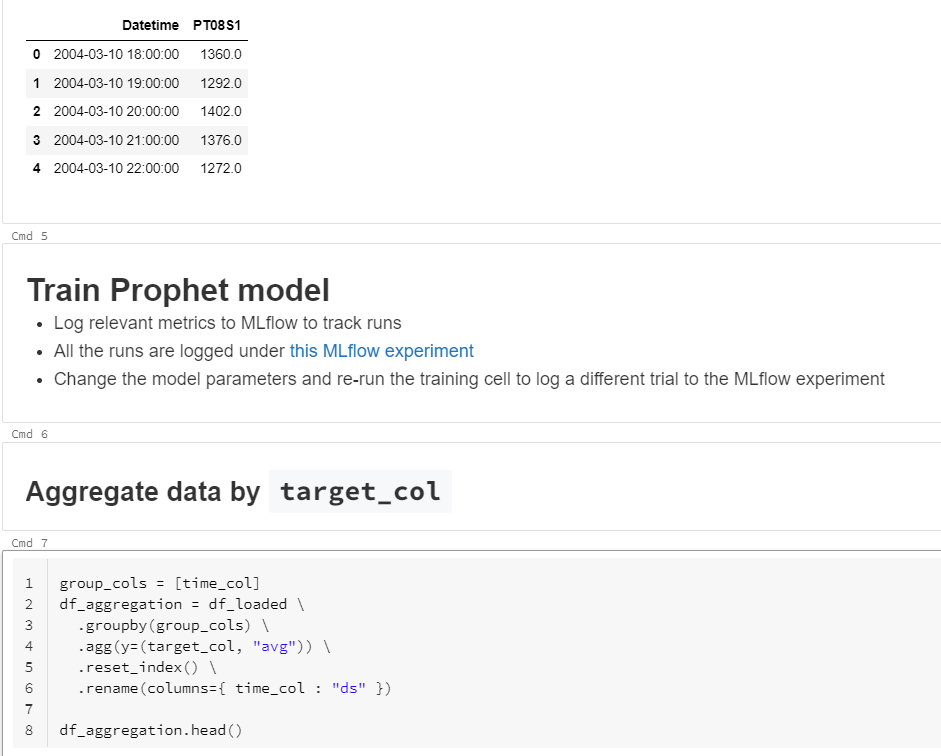
Afin de n’avoir qu’une seule ligne par unité de temps, un agrégat est réalisé, en s’appuyant sur une fonction average. Si votre logique est différente, vous pouvez modifier cette fonction, puis relancer le notebook, ou bien préparer différemment les données en amont. Le Spark dataframe obtenu ainsi sera ensuite converti en pandas dataframe pour être soumis à Prophet.
Une première étape consiste à entrainer le modèle puis à l’évaluer par cross validation.

Il sera possible ici de modifier le code ISO du pays utilisé pour la définition des jours fériés.
La validation croisée utilise un découpage définis dans la variable cutoffs, se basant sur des multiples de l’horizon de prévision. C’est cette opération qui sera la plus longue.

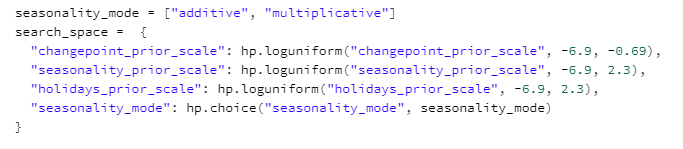
Les hyperparamètres disponibles sont définis comme suit. Il s’agit principalement de tester différentes pondérations pour les différents éléments composant le modèle (changepoint, seasonality, holidays).
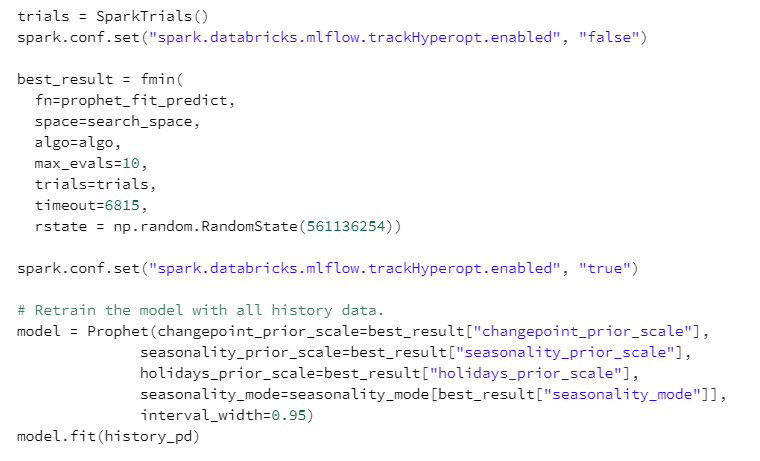
La recherche des meilleures valeurs des hyperparamètres sera assurée par hyperopt et sa classe SparkTrials. Le modèle final sera entrainé sur l’historique complet (ce qui permet de tenir compte des inflexions de tendance des derniers jours), avec les valeurs donnant la meilleure métrique d’évaluation.
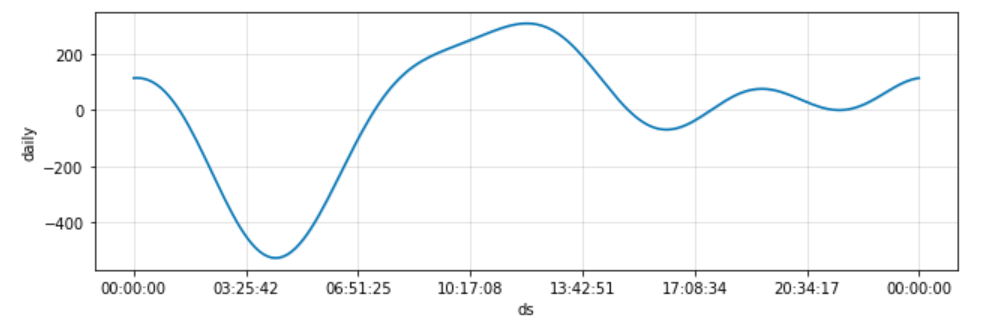
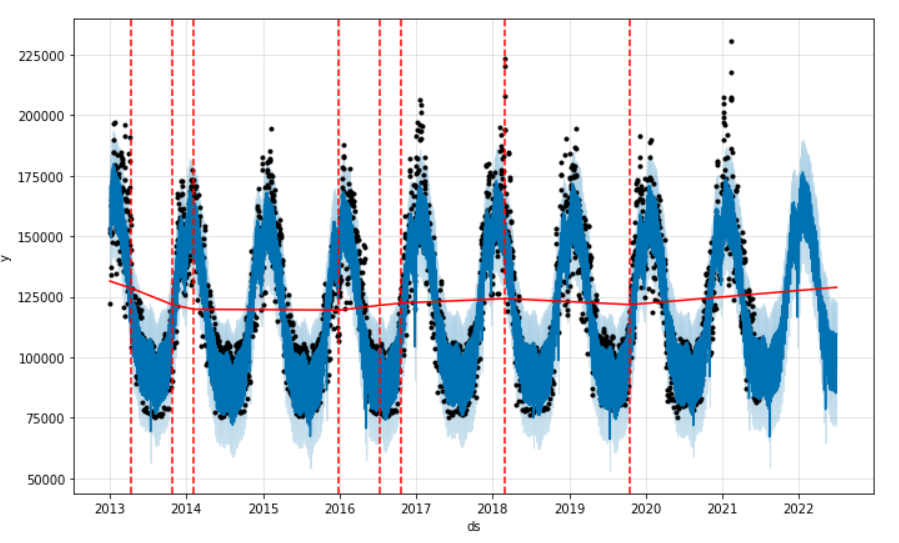
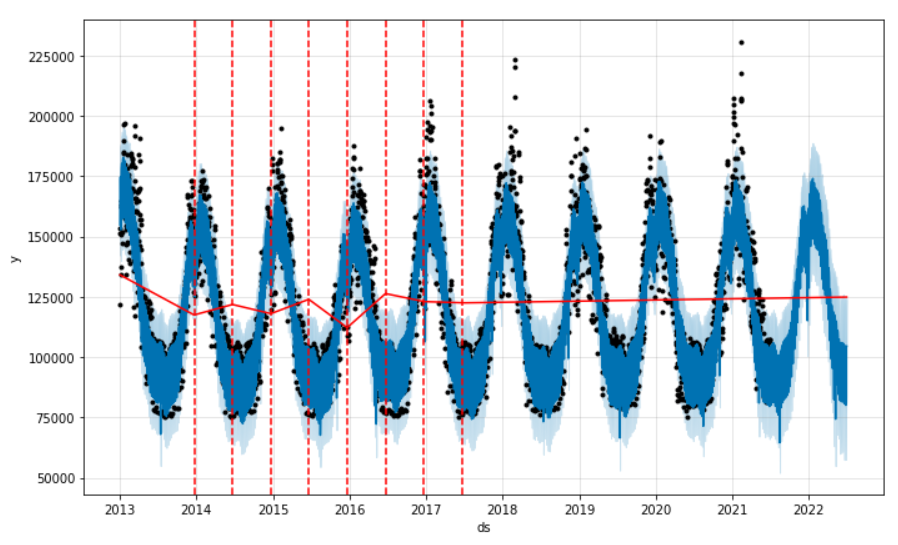
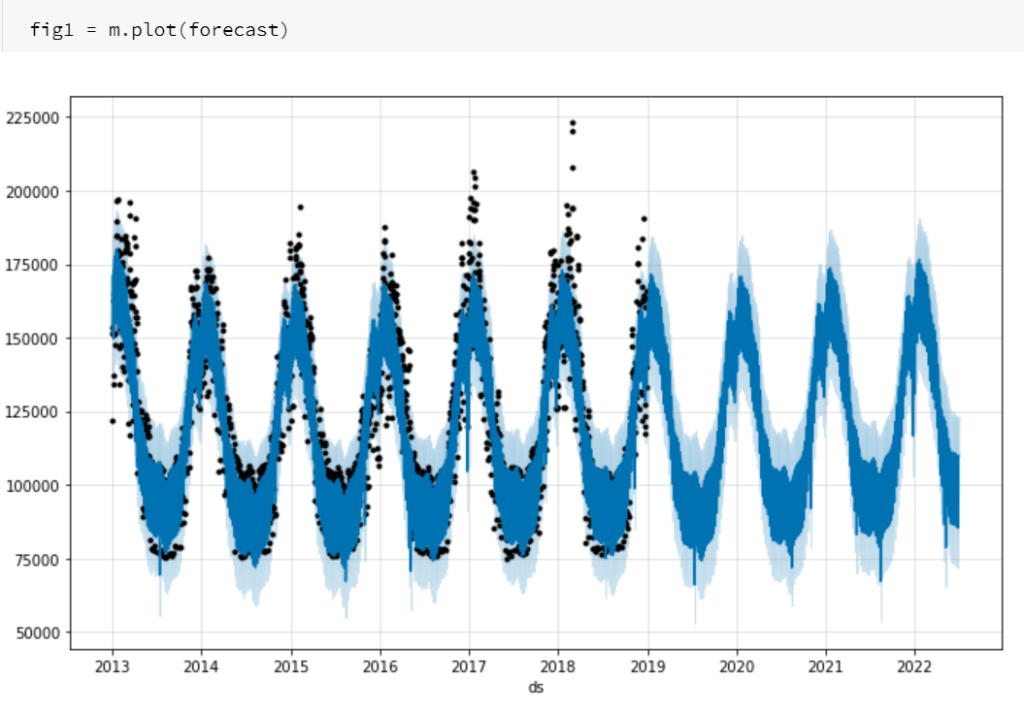
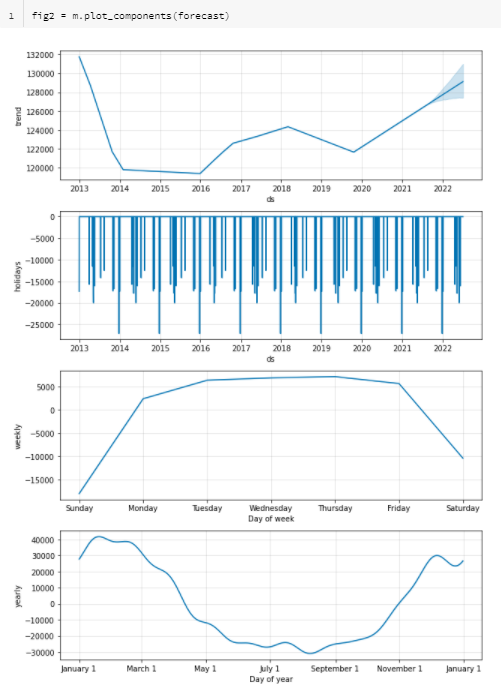
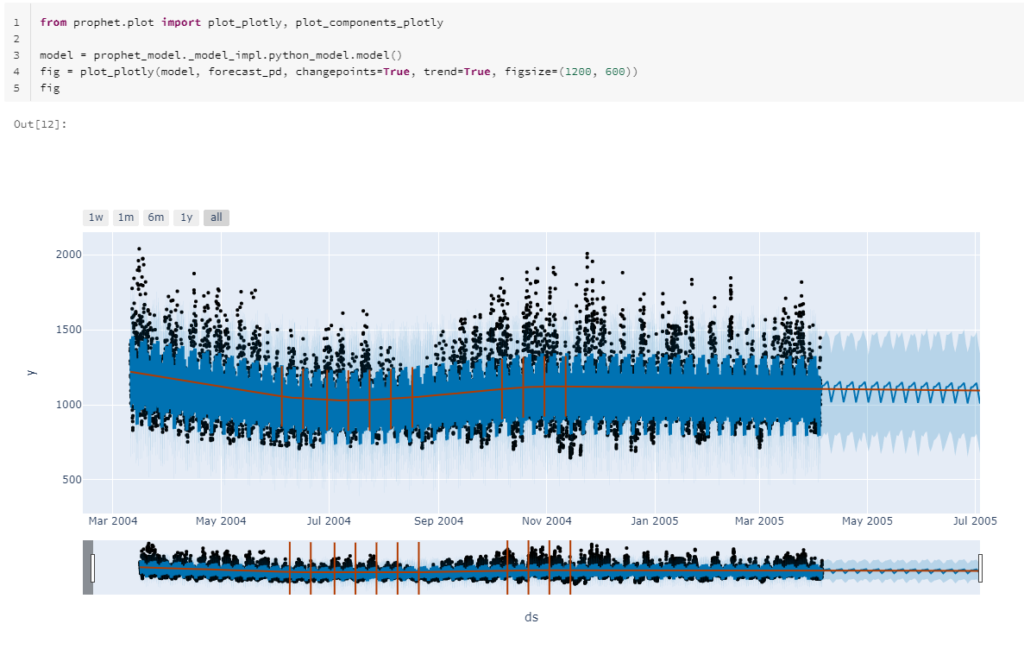
La fin du notebook réalise les opérations de sauvegarde du modèle puis quelques représentations graphiques de l’horizon de prévision, réalisés avec Plotly, ce qui donne des options d’interaction avec le visuel.
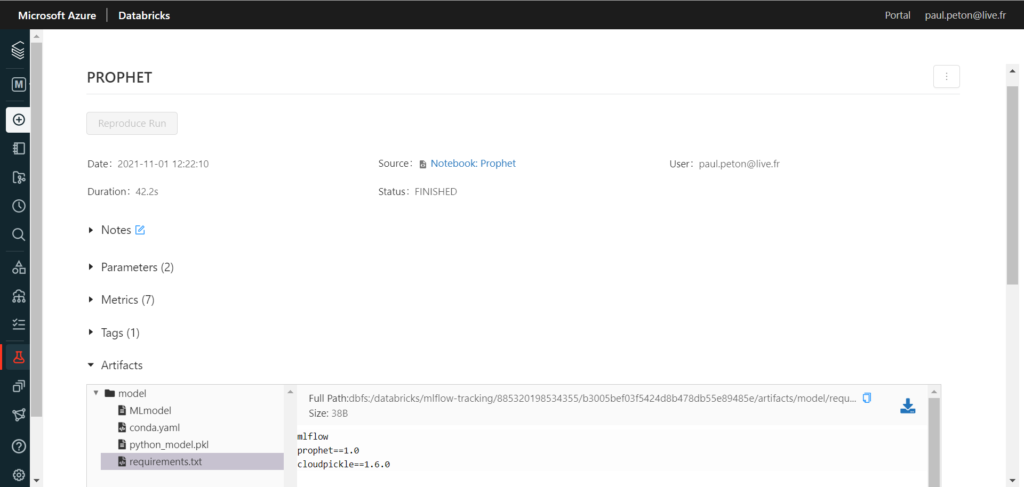
L’exécution du notebook étant redirigée vers MLFlow, nous disposons d’une page dédiée au modèle où nous retrouverons paramètres, tags, métriques et surtout l’artefact au format binaire sérialisé pickle, accompagné des dépendances nécessaires (requirements).
En conclusion, rien de révolutionnaire puisque nous disposions déjà de toutes ces fonctionnalités (dès 2020 avec l’arrivée de Prophet) mais ce qui modifie considérablement les choses est d’aboutir à un premier résultat au bout de quelques dizaines de minutes de calcul, après “quelques clics” dans une interface graphique (sous réserve que vos données soient déjà préparées !). C’est l’approche dédiée à ce que l’on nomme communément “citizen data scientist” où une compétence de programmation n’est pas nécessaire. Pour autant, nous disposons bien de code à la fin de l’expérience et c’est là la principale force de ce que propose Databricks. Nous pouvons reprendre la main sur ce code et surtout l’intégrer dans une démarche d’industrialisation (versioning, tests, intégration et déploiement continus, etc.).
Nous gagnons donc quelques heures à quelques jours de développement de la part d’un.e data scientist, selon son niveau d’expérience. Nous allons rapidement prouver la valeur et le potentiel prédictif de nos données, ce qui permettra de définir plus sereinement les investissements et le ROI attendu.
Enfin, n’oublions pas qu’il n’y a pas que Prophet dans le monde des time series et du forecasting. Mais gageons que les équipes de Databricks feront évoluer la liste des méthodes comparées au sein de cette fonctionnalité d’automated ML. En attendant, allez jeter un coup d’œil sur kats, toujours issu des équipes de Facebook Research.
L’Automated ML est un accélérateur, ne le voyez surtout pas comme une baguette magique qui vous dispenserait de data scientists. Une fois un premier jet (très rapidement) obtenu, il sera nécessaire d’améliorer, simplifier, interpréter, monitorer, etc.