Nous avons vu dans un précédent post les possibilités des modèles basés sur GTP au travers du studio et du playground. Ce bac à sable n’est bien sûr destiné qu’à de premiers tests et une utilisation de l’inférence au sein d’une application se fera de manière programmatique, à l’aide de l’API de service disponible. (Il existe également une API dite de gestion pour la création, mise à jour ou suppression de la ressource Azure.)
Mais avant de nous lancer dans le code, nous allons réaliser un premier appel dans l’outil Postman.
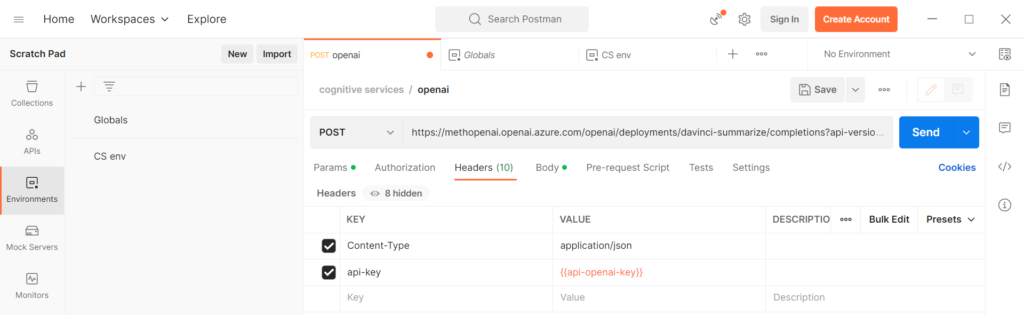
Nous allons utiliser l’URL suivante, à compléter par les valeurs de paramètres :
YOUR_RESSOURCE_NAME : le nom de la ressource Azure OpenAI provisionnée
YOUR_DEPLOYMENT_NAME : le nom du déploiement de modèle (réalisé en amont dans le studio)
la version de l’API, exprimée sous forme de date (en février 2023, nous utilisons la version 2022-12-01)
POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/deployments/YOUR_DEPLOYMENT_NAME/completions?api-version=YYYY-MM-DD
Nous remarquons que l’URL se termine par le terme “completions“, nous sommes donc bien ici dans le scénario d’une prévision de texte par l’API
Il existe deux manières de s’authentifier :
clé d’API
jeton Azure Active Directory
Utilisons la clé d’API dans un premier temps, même s’il sera plus précis de passer par un jeton AAD, celui-ci étant lié au profil de l’utilisateur et donc à des droits mieux définis. Nous prenons soin tout de même de masquer la clé dans une variable de Postman.
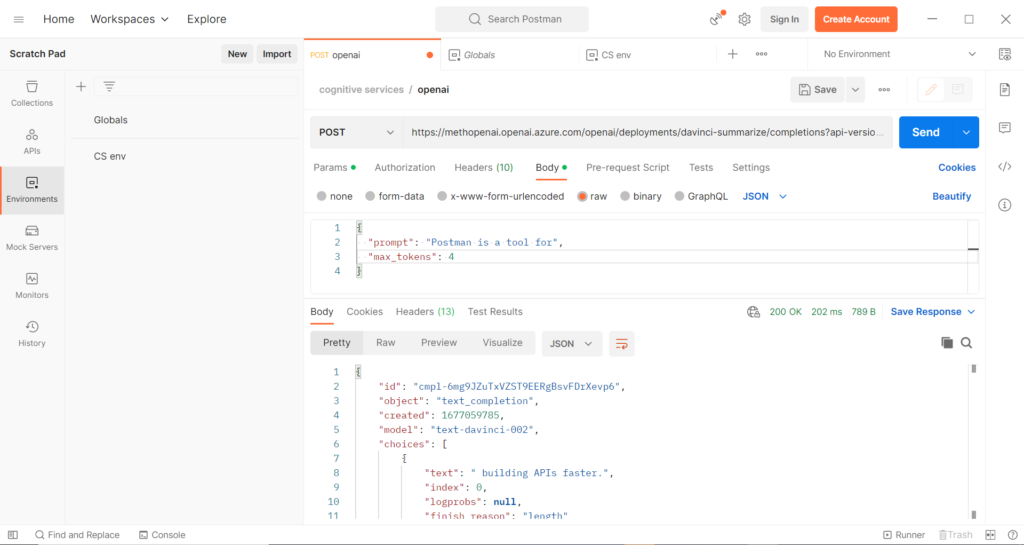
Le corps (body) de la requête sera de type JSON (application/json) et devra contenir le fameux prompt soumis au modèle.
Au texte soumis “Postman is a tool for…“, nous obtenons une complétion “building APIs faster“, en quatre tokens (valeur précisée dans le body par le paramètre max_tokens). Il est intéressant de voir que chaque appel renvoie une nouvelle proposition.
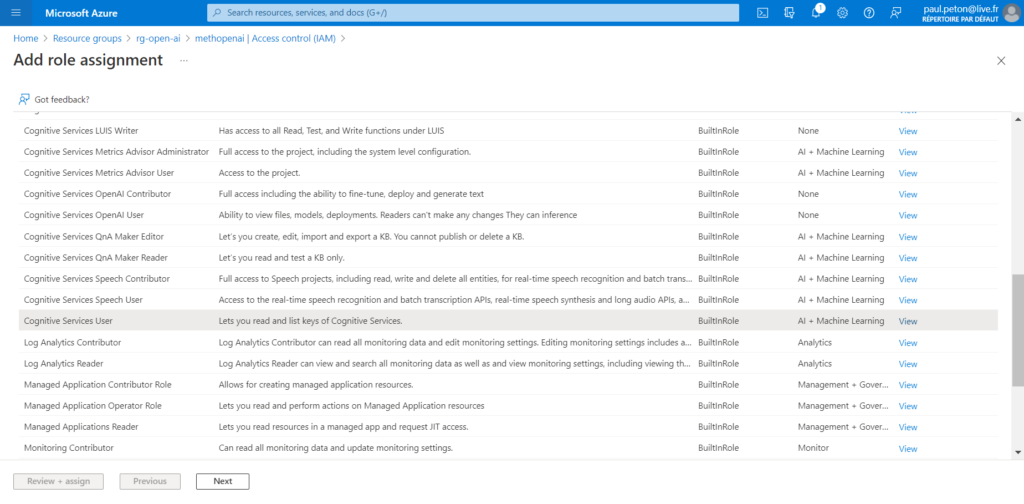
Pour utiliser l’authentification par jeton Azure Active Directory, nous devons réaliser deux étapes. Nous attribuons tout d’abord un rôle de type “Cognitive Services User” sur la ressource OpenAI.
Le token peut être obtenu par cette commande az cli :
az account get-access-token --resource https://cognitiveservices.azure.com | jq -r .accessToken
Le header de la requête devient alors, en remplacement de l’entrée api-key :
'Authorization': 'Bearer ***'
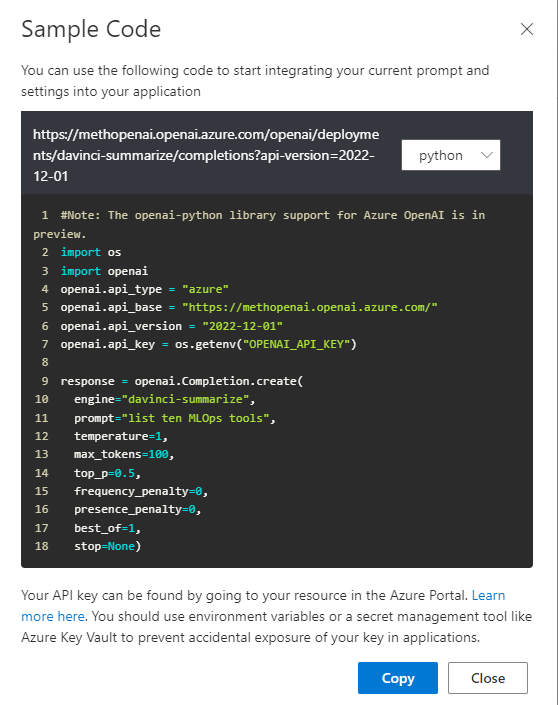
Il faut noter également qu’une librairie Python openai existe également. Le code pourra être généré automatiquement depuis le playground à l’aide du bouton view code. Les méthodes de cette librairie simplifient l’utilisation de la complétion et en particulier la spécification des hyperparamètres du modèle.
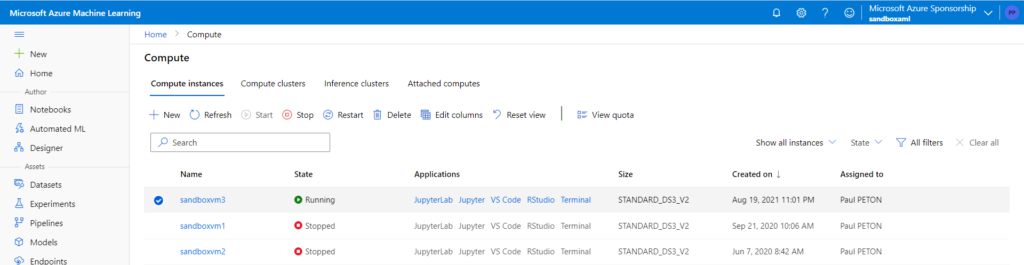
Dans un précédent article, nous explorions la procédure pour lancer simplement du code sur des machines distantes Azure ML (compute target) depuis l’environnement de développement (IDE) Visual Studio Code.
Dans les raccourcis disponibles au niveau du menu des instances de calcul, nous disposons dorénavant d’un lien permettant de lancer l’ouverture de Visual Studio Code.
Quel est l’avantage de travailler de la sorte ? Réponse : vous disposez de toute la puissance de l’IDE de Microsoft (en particulier pour les commandes Git), sans toutefois être dépendant de votre poste local.
Vous ne pouvez bien sûr utiliser qu’une instance qui vous est personnellement assignée.
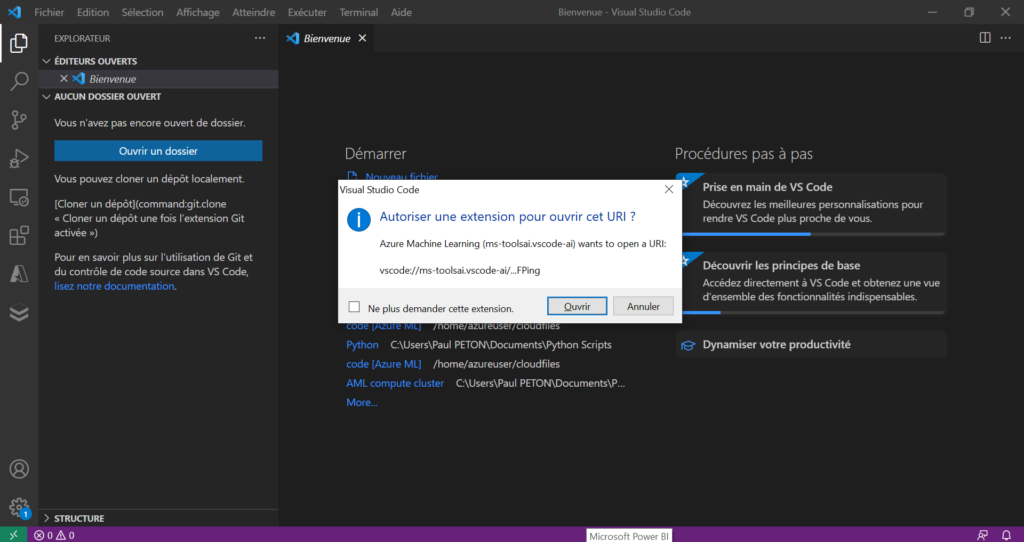
Cliquez sur le lien VS Code et votre navigateur lèvera tout d’abord une alerte. Cochez la case “Toujours autoriser…” pour ne plus voir cette pop-up.
C’est maintenant au tour de VSC de faire une demande d’autorisation avant de lancer la connexion à distance.
En tâche de fond, nous assistons à l’installation d’un VS Code server sur l’instance de calcul.
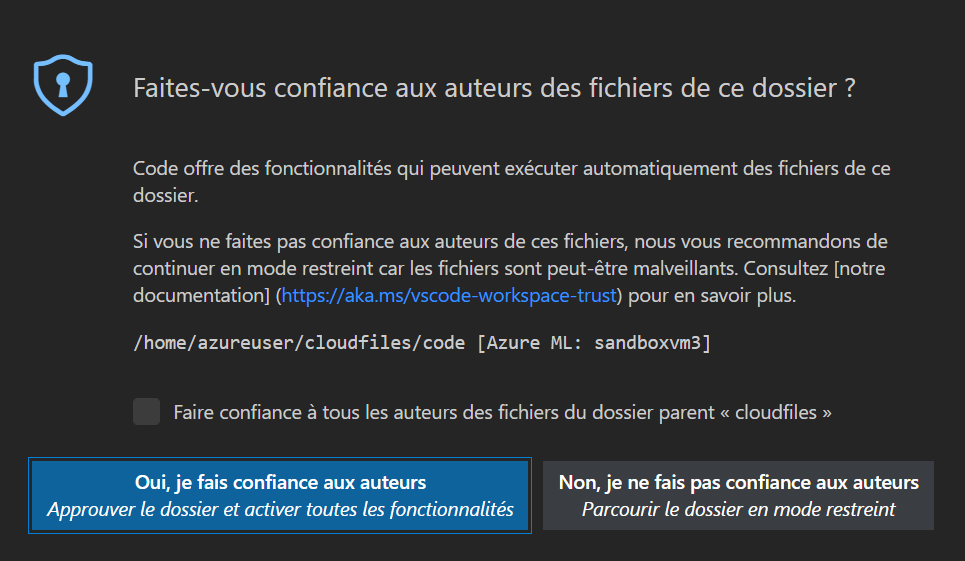
Il ne reste plus qu’à “faire confiance” aux fichiers qui seront maintenant accessible depuis l’éditeur local.
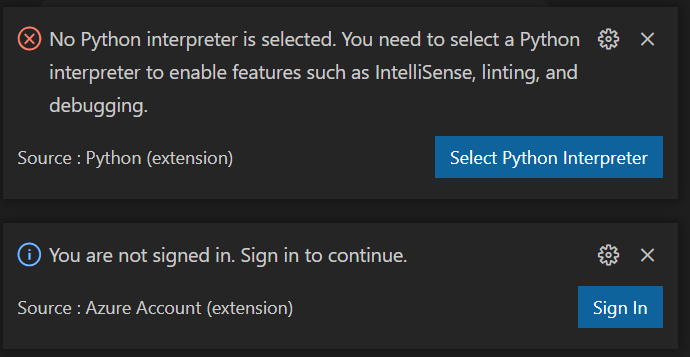
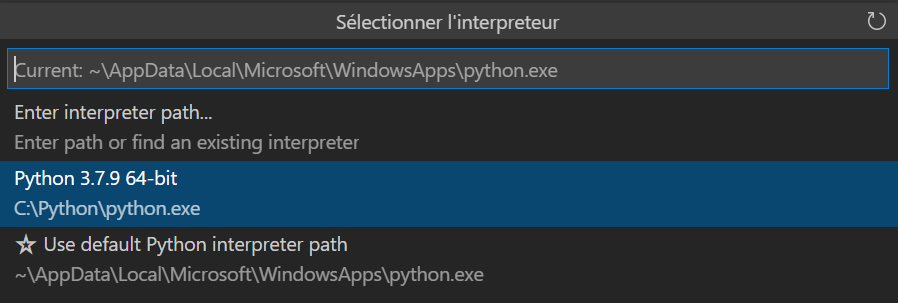
Plusieurs alertes peuvent être levées par VS Code selon votre paramétrage. Ainsi, il faudra choisir un interpréteur Python (mais attention, ce n’est pas une distribution installée sur votre poste local !) ainsi que s’authentifier vis à vis de l’extension Azure pour VS Code (à installer également au préalable).
Si le choix entre Python2 et Python3 ne fait plus débat, le choix de la version mineure de Python est important pour votre projet, car celle-ci conditionne les versions de packages nécessaires par la suite.
Le réflexe pourrait alors être de choisir l’interpréteur Python du poste local mais nous voulons justement exécuter le code à distance. Une sélection dans la fenêtre ci-dessous n’est donc pas nécessaire.
Etape à ne PAS réaliser
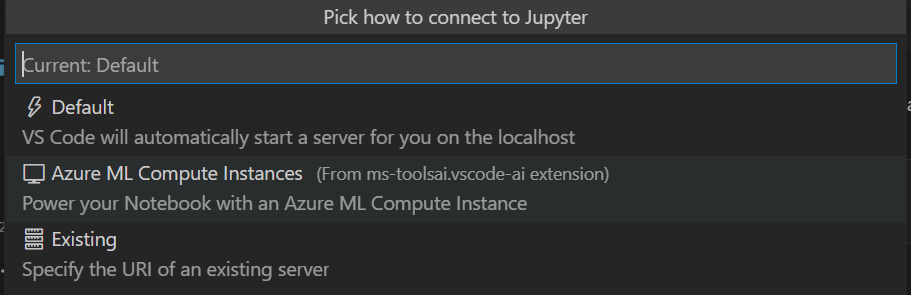
Allons plutôt voir dans le coin en bas à droite de notre éditeur.
Un clic sur “Jupyter Server” va lancer un autre menu : “Pick how to connect to Jupyter“.
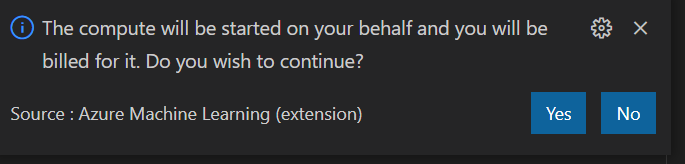
Nous choisissons ici “Azure ML Compute Instances” puis naviguons jusqu’à l’instance voulue. Un message d’alerte concernant la facturation de cette VM va alors apparaître.
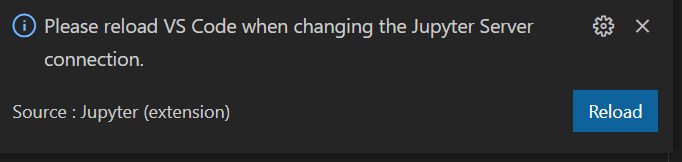
Un rechargement de VS Code pourra être nécessaire pour bien valider la connexion.
Le statut en bas à droite de l’IDE nous indique que le serveur Jupyter se trouve bien à distance (remote) et c’est donc lui qui exécutera le code.
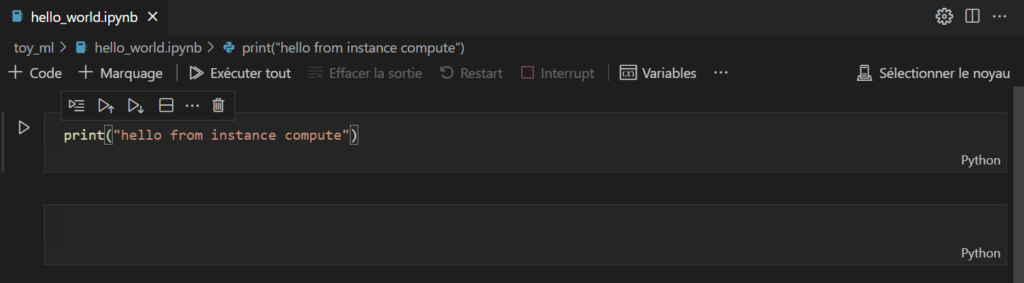
Commençons par un commande simple dans un nouveau notebook.
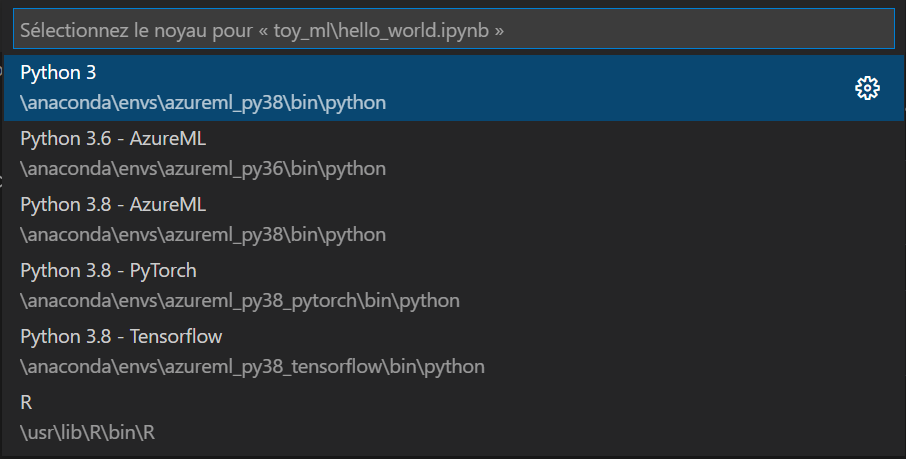
Il est maintenant temps de choisir l’interpréteur Python de la machine distante (cliquer si besoin sur le bouton “sélectionner le noyau”).
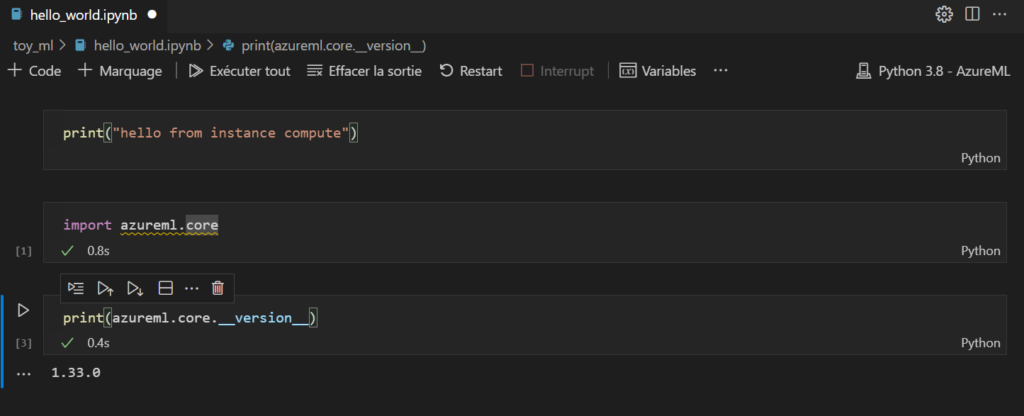
Nous choisissons ici l’environnement Python 3.8, muni des packages azureml, qui nous permettront d’interagir avec le service Azure Machine Learning.
Vérification de la version du package azureml-core
Utiliser les commandes Git de VSC
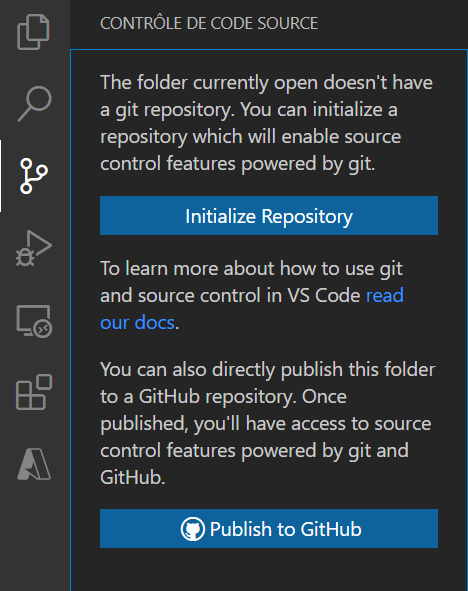
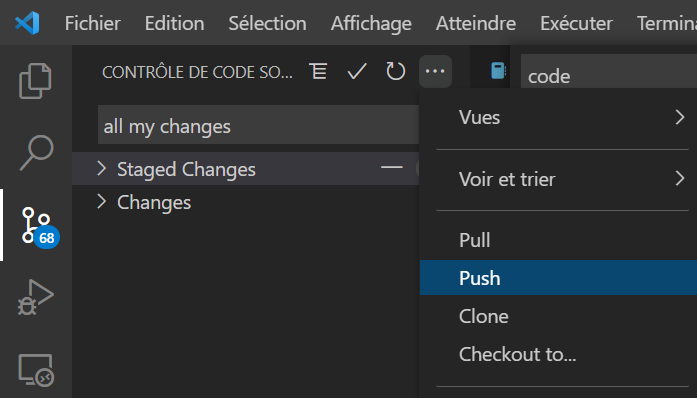
C’est sans doute le plus grand des avantages à passer par l’IDE : pouvoir réaliser du contrôle de code source, avec les fonctionnalités Git intégrées dans VSC.
En cliquant sur le symbole Git du menu du gauche, nous déroulons une première fenêtre demandant de réaliser l’initialisation du repository.
Il est ensuite nécessaire de configurer le nom de l’utilisation ainsi que son adresse de courrier électronique.
Les changements (ici, tous les fichiers lors de l’initialisation) sont détectés par Git et il sera possible de les pousser (git push) sur le repository.
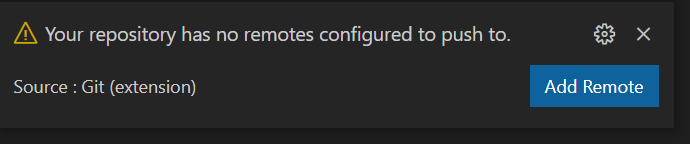
En cliquant ici sur Push, une alerte sera levée car une dernière configuration est nécessaire.
Il faut configurer l’URL du repository, par exemple une adresse GitHub.
Ceci se réalise au moyen de la commande ci-dessous, sur la branche principale (main).
git push --set-upstream <origin_branch> main
Ca y est ! Nous disposons maintenant d’une configuration très efficace pour travailler nos développements de Machine Learning, en lien avec le service Azure ML. Ce système permet également une véritable isolation des fichiers pour chaque développeur. Aucun risque qu’un.e collègue vienne modifier vos scripts, autrement qu’au travers d’un merge de branches.
Si vous êtes habitués à manipuler le package Python scikit learn, la notion de pipeline vous est sans doute familière. Cet objet permet d’enchainer des étapes (“steps“) comme la préparation de données (normalisation, réduction de dimensions, etc.), l’entrainement puis l’évaluation d’un modèle. La documentation officielle du package donne ainsi cet exemple.
>>> fromsklearn.svmimport SVC
>>> fromsklearn.preprocessingimport StandardScaler
>>> fromsklearn.datasetsimport make_classification
>>> fromsklearn.model_selectionimport train_test_split
>>> fromsklearn.pipelineimport Pipeline
>>> X, y = make_classification(random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... random_state=0)
>>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
>>> # The pipeline can be used as any other estimator>>> # and avoids leaking the test set into the train set>>> pipe.fit(X_train, y_train)
Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
>>> pipe.score(X_test, y_test)
0.88
Le SDK Python azureml que nous avons déjà évoqué sur ce blog dispose également d’un concept de pipeline. Celui-ci ne doit pas être confondu avec les pipelines pouvant être définis dans l’interface visuelle du concepteur (“designer“). Les pipelines en tant que tels sont visibles dans un menu dédié.
(NDA : on serait en droit d’espérer à termes une fusion de ces éléments, c’est-à-dire d’observer le pipeline dans l’interface du concepteur, voire de retrouver le pipeline créé par le code dans les objets manipulables visuellement).
Les avantages des pipelines
La manipulation des pipelines, en particulier des entrées-sorties, ne sera pas triviale, alors nous allons insister sur tous les bénéfices d’un tel objet. Au delà de la représentation visuelle toujours plus parlante, le principal avantage sera la planification du pipeline. Celle-ci peut se faire de trois manières. Le code présenté ici est disponible dans ce dépôt GitHub.
Objet Scheduler
L’interface du studio Azure Machine Learning ne présente pas d’ordonnanceur visuel des notebooks. Pour autant, cette notion d’ordonnancement existe bien et se manipule au travers du SDK. Une fois publié, un pipeline dispose d’un identifiant. A partir de cet id, un objet Schedule peut être défini, et se déclenchera selon une récurrence déclarée au moyen de l’objet ScheduleRecurrence.
A sa création, l’ordonnancement est activé. Il sera possible de le désactiver à partir de son identifiant (à ne pas confondre avec l’identifiant du pipeline).
Les points négatifs de cet approche sont le manque de visibilité sur les ordonnancements définis (il est nécessaire de lancer la commande Schedule.list) et le fait que d’autres activités non définies dans des scripts présents sur dans l’espace de travail Azure Machine Learning.
Pipeline Azure DevOps
Encore un pipeline à ne pas confondre avec le pipeline du SDK azureml ! Nous parlons ici des pipelines de release d’Azure DevOps. En recherchant le terme “azureml” dans l’assistant (volet de droite), nous trouvons trois tâches, dont une permettant de lancer un pipeline Azure ML désigné à nouveau par son identifiant.
Un pipeline de release peut ensuite être ordonnancé au moyen des standards d’écriture du fichier YAML.
Activité Azure Data Factory
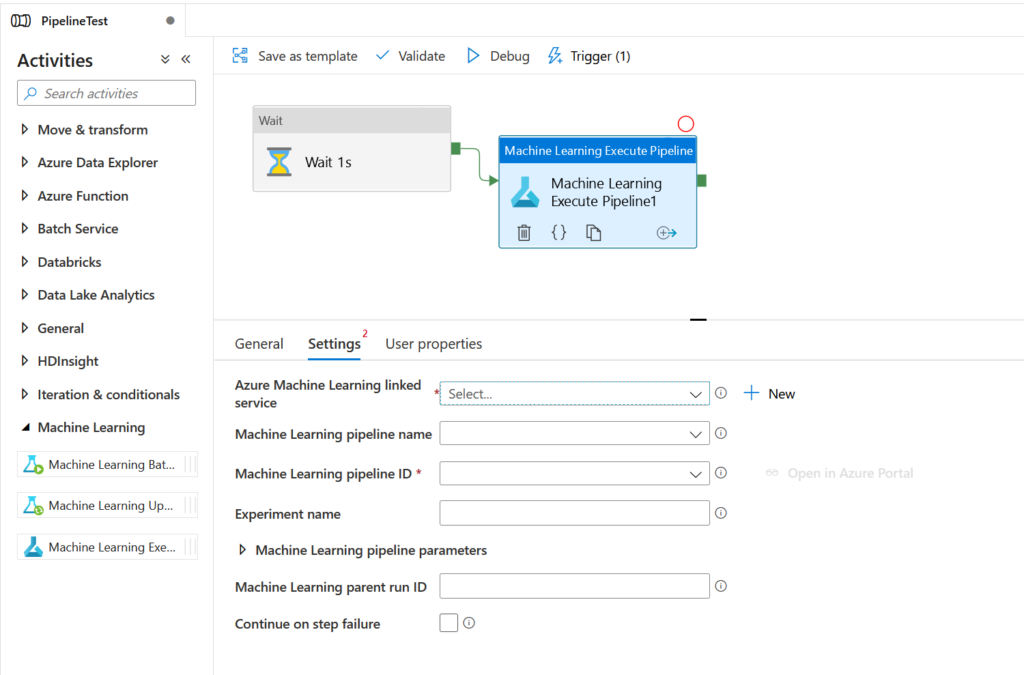
Nous disposons de trois activités distinctes dans le groupe “Machine Learning”. Les deux premières concernent l’ancien Azure Machine Learning studio, aujourd’hui déprécié. Concentrons-nous sur la troisième activité qui permet d’exécuter un pipeline Azure ML.
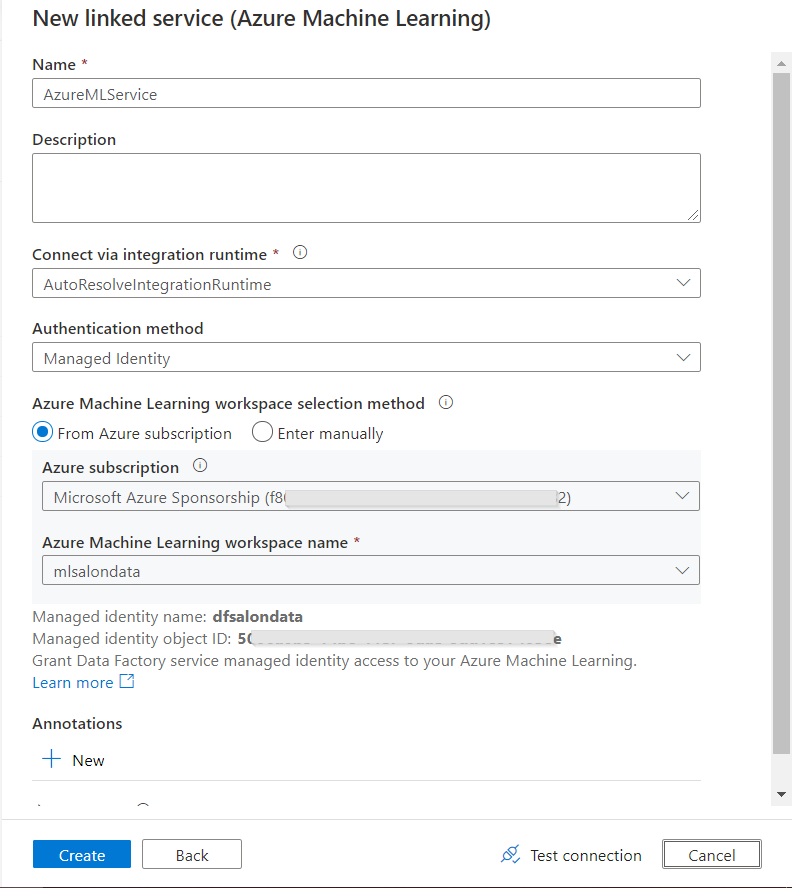
Pour remplir les différents paramètres, nous devons tout d’abord fournir un service lié (linked service) de type Azure Machine Learning (catégorie “compute“).
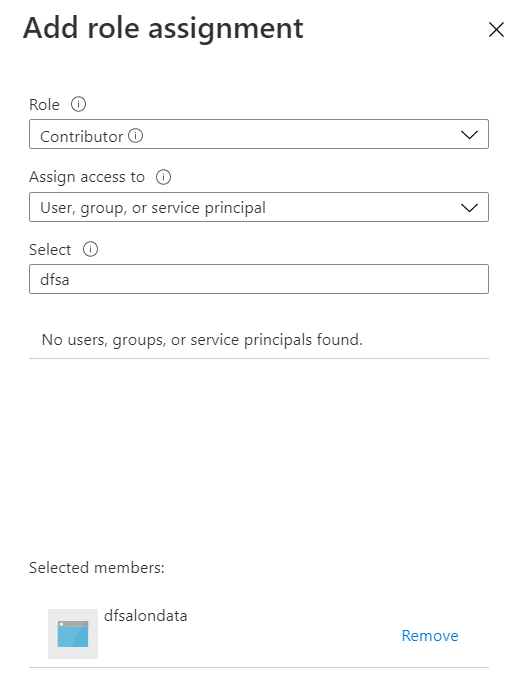
Nous privilégions l’authentification par identité managée, celle-ci se voyant attribuer un rôle de contributeur sur la ressource Azure Machine Learning.
Seconde information obligatoire : l’ID du pipeline publié. Un menu déroulant nous permettra de le choisir. Nous constatons ici que cette information sera particulièrement sensible lorsque nous devrons re-publier le pipeline. Il faudra donc limiter au maximum cette action, car elle engendrera une modification dans les paramètres de l’activité Data Factory. Une problématique similaire se posera dans le cas d’un déploiement automatique entre environnements (par exemple, de dev à prod) avec des ID de pipelines différents.
Et maintenant, comment réaliser un pipeline
Nous allons maintenant plonger dans le SDK Python azureml pour décortiquer les étapes de création d’un pipeline.
Il nous faut pour base un script Python qui contiendra le code à exécuter par une étape (step) du pipeline. Nous ne travaillerons ici qu’avec des étapes de PythonStepScript mais il en existe d’autres types, référencés dans la documentation officielle. Nous prendrons la bonne habitude de faire figurer dans ces scripts les lignes de code suivantes :
from azureml.core.run import Run
run = Run.get_context()
exp = run.experiment
ws = run.experiment.workspace
Celles-ci permettront de retrouver les éléments du “niveau supérieur”, c’est-à-dire l’expérience, son exécution ainsi que l’espace de travail.
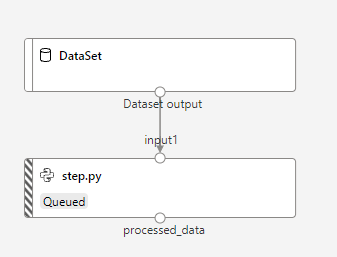
Ensuite, nous pourrons travailler sur les entrées et sorties de chaque étape. Cette gestion des entrées-sorties nécessitera un article à part entière sur ce blog.
Exemple de “graph” de sortie du pipeline (experiment)
Nous recréons ainsi, par le code (et au prix de nombreux efforts !), un objet similaire au pipeline obtenu dans le Designer.
Mais cela ne nous permettrait pas de réutiliser ce pipeline dans les scénarios évoqués ci-dessus, nous allons donc le publier avec l’instruction .publish().
published_pipeline = pipeline.publish(
name=published_pipeline_name,
description="ceci est un pipeline à deux étapes"
)
published_pipeline
Ceci nous permet de connaître l’identifiant du pipeline (masqué dans la copie d’écran ci-dessous).
Il ne reste plus qu’à soumettre le pipeline pour l’exécuter même si nous utiliserons vraisemblablement d’autres méthodes comme l’appel par Azure Data Factory ou l’emploi de l’API REST.
Les logs de l’exécution seront accessibles dans le menu Pipelines du portail, qui nous redirigera vers le menu Experiments. N’oubliez pas d’activer l’affichage des “child runs” pour visualiser les traces de l’exécution de chacune des étapes.
Voici enfin un exemple de code qui permettra de lancer ce pipeline par requête HTTP.
from azureml.core.authentication import InteractiveLoginAuthentication
import requests
auth = InteractiveLoginAuthentication()
aad_token = auth.get_authentication_header()
rest_endpoint1 = published_pipeline.endpoint
print("You can perform HTTP POST on URL {} to trigger this pipeline".format(rest_endpoint1))
response = requests.post(rest_endpoint1,
headers=aad_token,
json={"ExperimentName": "My_Pipeline_batch",
"RunSource": "SDK"}
)
try:
response.raise_for_status()
except Exception:
raise Exception('Received bad response from the endpoint: {}\n'
'Response Code: {}\n'
'Headers: {}\n'
'Content: {}'.format(rest_endpoint, response.status_code, response.headers, response.content))
run_id = response.json().get('Id')
print('Submitted pipeline run: ', run_id)
Attention, une réponse “correcte” à cet appel HTTP sera de confirmer le bon lancement du pipeline. Mais rien ne vous garantit que son exécution se fera avec succès jusqu’au bout ! Il faudra pour cela se pencher sur la remontée de logs (et d’alertes !) à l’aide d’un outil comme Azure Monitor.
En 2017, les équipes de recherche de Facebook publiaient ce papier qui introduira la librairie fbprophet, disponible en R et en Python (pas de jaloux !). Cet outil peut être rangé dans la catégorie des modèles additifs généraux car il décompose une série temporelle de la sorte :
y(t) = g(t) + s(t) + h(t) + e(t)
avec respectivement :
g(t) : la tendance (linéaire ou logistique)
s(s) : une ou plusieurs composantes saisonnières (annuelle, hebdomadaire ou quotidienne)
h(t) : l’effet des vacances ou de jours spécifiques qui pourront être paramétrés
e(t) : l’erreur, bruit aléatoire qui mesure l’écart entre le modèle et les données réelles
Si l’on retient le terme “additif”, il est bien sûr possible de modifier le modèle pour le rendre “multiplicatif” (observez les crêtes de votre série temporelles, si celles-ci forment un cône, le modèle est sans doute multiplicatif).
La grande force de ce type de modèle tient dans sa capacité à être interprété ainsi que dans la clarté des représentations graphiques de la décomposition. Il sera particulièrement adapté à des phénomènes comme… la fréquentation d’un réseau social mais aussi des mesures économiques fortement soumises à des saisonnalités et aux périodes de vacances d’un pays. Il est si simple à mettre en œuvre qu’il gagnera à être comparé à des modèles plus classiques comme SARIMA (nous en reparlerons en toute fin d’article).
Installation de la librairie
Pour ne pas “polluer” notre installation locale avec de nouveaux packages et leurs dépendances, nous créons au préalable un environnement virtuel, à l’aide du package pyenv pour Windows (voir ce GitHub). Ne pas oublier d’ajouter les variables d’environnement et de redémarrer votre terminal ou IDE pour terminer l’installation.
pyenv install 3.8.10
pyenv shell 3.8.10
Nous pouvons alors installer les librairies suivantes :
Pystan est une librairie pour l’inférence bayésienne. Si cette installation ne fonctionne pas (les dépendances sont parfois capricieuses…), vous pouvez utiliser un prompt Anaconda et tenter la commande suivante :
conda install -c conda-forge fbprophet
Vérifiez enfin la bonne installation en choisissant l’interpréteur voulu (ici, conda) dans Visual Studio Code.
Lancez ensuite Python dans le terminal et testez un import de la librairie.
Mise en pratique
Déroulons maintenant un exemple simple, de bout en bout, en réalisant quelques tentatives d’optimisation du modèle. RTE France met à disposition les données énergétiques “eco2mix” dont la profondeur d’historique et le niveau de détail sera intéressant pour évaluer notre outil. J’ai pris connaissance de ce jeu de données dans cet excellent article du blog de Publicis Sapient.
Une seule contrainte dans la façon dont les données doivent être soumises à Prophet : les colonnes de temps et de mesure quantitative doivent être respectivement nommées “ds” et “y”.
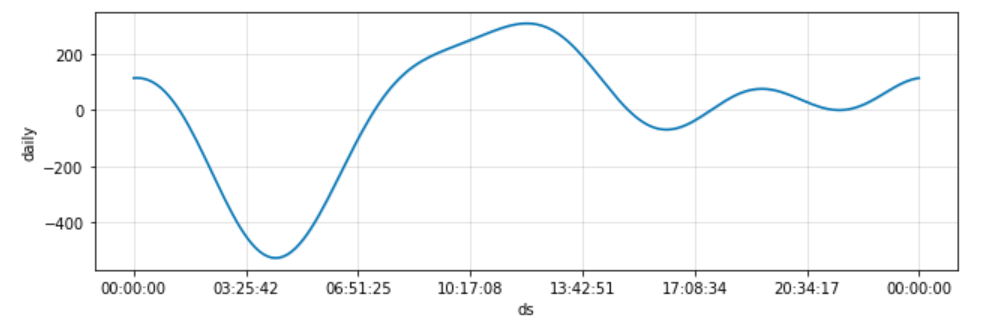
Une granularité plus fine que le jour peut être utilisée dans le champ datetime. C’est alors qu’il sera pertinent d’activer le daily effect qui sera visualisable graphiquement.
La régularité est un élément fondamental pour la modélisation d’une série temporelle, que viennent perturber les années bissextiles. Nous pouvons décider de supprimer les 29 février, par exemple avec le code ci-dessous :
Attention, nous dégradons alors inévitablement la régularité des semaines…
Création du modèle et évaluation
Lançons tout d’abord un modèle simple, sur l’intégralité de l’historique. Dans l’extrait de code ci-dessous, df représente un pandas dataframe regroupant les deux colonnes nommées ds et y.
De nombreux paramètres sont définis par défaut : additivité, pas de saisonnalité journalière, détection automatique des change points (changement de tendance), etc.
m = Prophet(daily_seasonality=False) m.add_country_holidays(country_name='FR') m.fit(df)
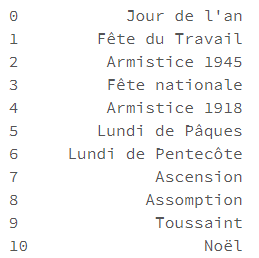
Ici, nous ajoutons au modèle les jours fériés français qui deviendront autant d’indicateurs dans notre modèle additif.
m.train_holiday_names
Comme l’indique cette discussion, il ne semble pas possible d’ajouter plusieurs pays à l’aide de cette méthode.
Nous pouvons également ajouter nos propres dates si nous considérons que des événements (répétitifs sur la saisonnalité attendue) ont un impact sur le phénomène observé. Nous pourrions par exemple identifier les journées les plus froides de l’année qui engendrent certainement une hausse de consommation électrique. Mais serons-nous en capacité de les prédire par la suite ? Mieux vaut se limiter à des événements connus à l’avance tels que des compétitions sportives (lors de la finale de la Coupe du Monde, tout le monde allume la télé !).
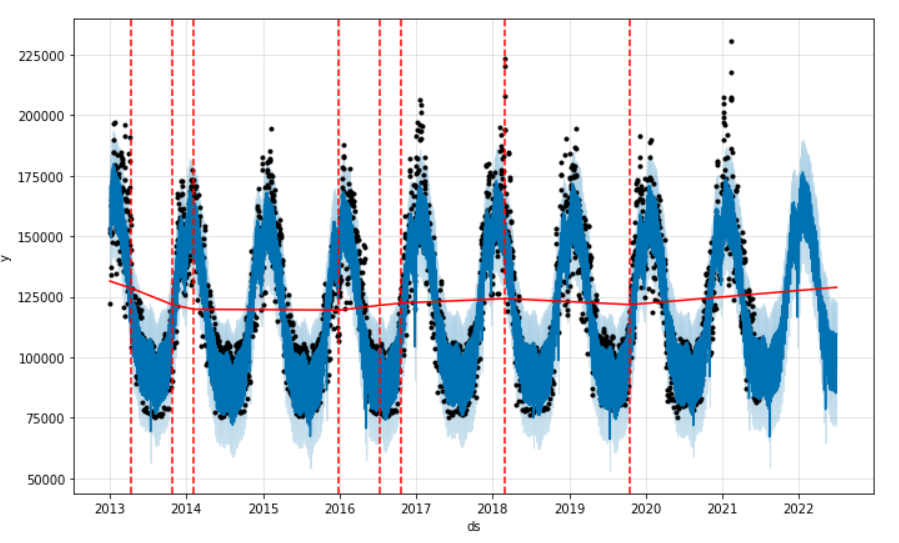
Les séries temporelles seraient si simples si toutes les tendances étaient linéaires ! Mais dans la vraie vie (et encore plus en période de pandémie…), les tendances fluctuent et il est indispensable que notre modèle les comprenne. Prophet identifie automatiquement les “change points” et on les visualise ainsi, en rouge, à l’aide du code ci-dessous.
from prophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
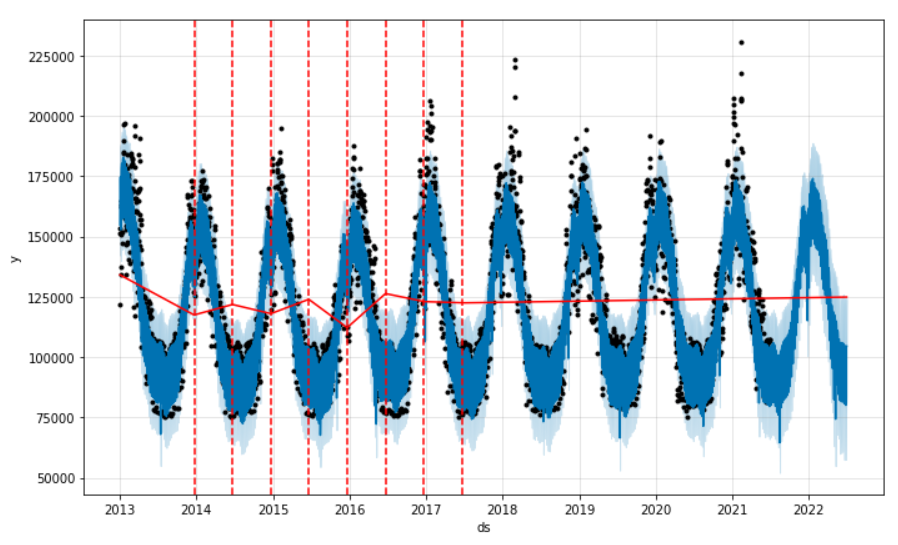
Nous pouvons aussi les définir arbitrairement. Pourquoi pas en donnant les dates des changements de saison (été et hiver) ?
Le paramètre changepoint_prior_scale indique à quel point le modèle doit respecter notre liste (ou sa détection automatique). C’est une valeur entre 0 et 1. Avec 1, nos change points sont bien retenus, comme l’atteste ce graphique.
Forecast
Pour calculer une prévision, nous allons avoir besoin d’un nouveau dataframe contenant une colonne de type datetime, toujours nommée “ds”, que nous soumettrons à la méthode .predict(), appliquée au modèle.
Tout comme pour la méthode .fit(), la syntaxe est ainsi tout à fait similaire à celle du package scikit-learn.
forecast = m.predict(future)
Une autre méthode pour créer la plage de forecast consiste à utiliser la fonction ci-dessous.
future = m.make_future_dataframe(periods=365)
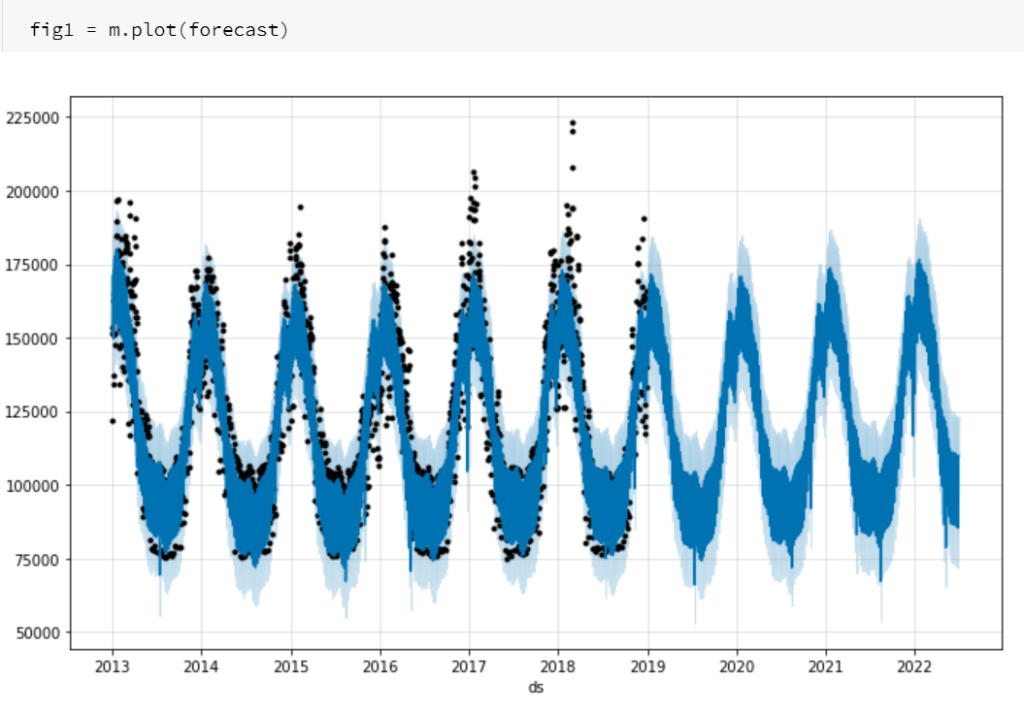
Cette fonction génère automatiquement une plage de dates couvrant l’historique complet auquel s’ajoute la période définie en paramètre. Ceci a pour avantage de nous permettre de comparer les prévisions avec les données réelles qui ont été utilisées pour le modèle, ce que nous allons observer dans les sorties graphiques.
Sorties graphiques
Pour afficher la superposition des historiques et des prévisions, un simple plot suffit !
m.plot(forecast)
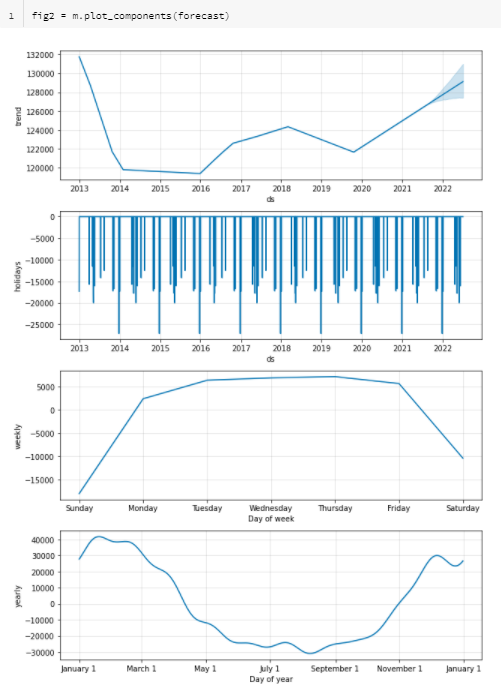
Nous pouvons ensuite obtenir les différents graphiques de décomposition.
m.plot_components(forecast)
D’autres graphiques interactifs sont disponibles conjointement avec la librairie plotly.
Cross validation
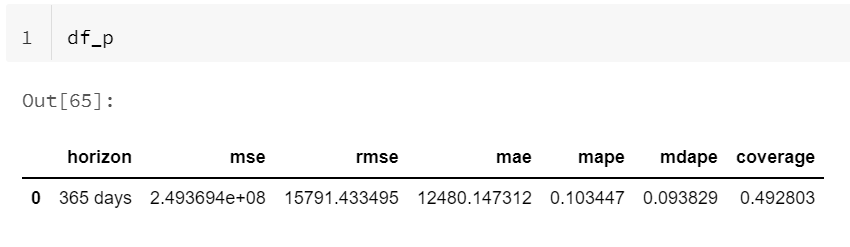
Nous allons maintenant évaluer la qualité de la prévision à l’aide des métriques d’évaluation traditionnelles que sont MSE, RMSE, MAE, MAPE, etc. et d’une méthode de validation croisée. Ici encore, tout est intégré dans une fonction ! Analysons le code ci-dessous.
Nous retrouvons le modèle préalablement entraîné (m). Un seul paramètre est obligatoire, celui de l’horizon de prévision. Mais nous pouvons également préciser la période initiale d’entrainement (par défaut, 3 horizons, et en effet avec ces méthodes dites “à court termes”, ne vous aventurez pas à prédire au delà d’un tiers de votre historique !). Enfin, le paramètre period indique la taille des “découpes” faites dans le jeu de données pour établir de nouvelles prévisions (par défaut, un demi horizon). Voici un exemple de sortie de la commande lancée sur un cluster Databricks.
A partir d’un entrainement sur les années 2013 et 2014, la validation croisée a effectué 4 prévisions sur les années 2015 à 2018.
Nous obtenons alors les métriques d’évaluation, en moyenne sur le nombre de “folds“.
L’argument rolling_window indique le pourcentage de données considérées dans la prévision (1 équivaut à 100%).
Nous pouvons enfin rechercher les meilleurs hyperparamètres pour notre modèle.
Utiliser une approche par hyperparameter tuning implique de lancer un nombre important d’entrainements et d’évaluations. C’est ici que nous tirerons profit d’un cluster de machines, en précisant le paramètre parallel=’processes’ dans la fonction cross_validation(). L’exemple de code donné sur le site officiel sera simple à adapter.
Et maintenant, Kats !
La R&D de Facebook ne s’est pas arrêtée là ! En 2021, une nouvelle librairie est mise à disposition : Kats. Celle-ci a pour vocation de simplifier les tâches des Data Scientists autour de l’analyse et de la modélisation des séries temporelles.
Ici, pas de nommage particulier des colonnes, mais nous transformerons le dataframe en objet spécifique à Kats : TimeSeriesData().
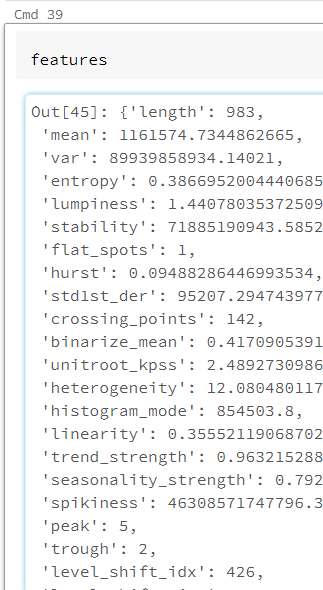
Une première fonctionnalité consiste à déterminer automatiquement 65 features de la série temporelle, c’est-à-dire des caractéristiques de cette série (moyenne, variance, entropie, etc.) qui pourront être par la suite intégrées à des modèles de Machine Learning ou à une approche par régression de la modélisation de la série temporelle.
De nombreuses fonctionnalités s’orientent autour de la détection : seasonalities, outlier, change point, and slow trend changes…
Enfin, Kats intègre un grand nombre de modèles (ARIMA, HW, stlf… et l’inévitable Prophet !). Bref, c’est le couteau suisse rêvé de tout.e Data Scientist qui s’attaque à un sujet de séries temporelles.
Derrière ces trois notions, se cache une succession d’étapes nécessaires pour obtenir un service prédictif de qualité et apte à gérer des données qui ne sont pas uniquement numériques. Prenons l’exemple du classique jeu de données German Credit disponible sur ce lien, sur lequel nous nous baserons pour entrainer un modèle d’apprentissage supervisé, dans une tâche de classification binaire (risque ou absence de risque sur le non remboursement d’un emprunt bancaire). Pour le déploiement d’un service web prédictif, nous allons utiliser le service Azure Machine Learning avec lequel nous interagirons au travers du SDK Python azureml-core, souvent évoqué sur ce blog (ici et là).
Même si leur champ de compétences grandit de jour en jour, les Data Scientists et Data Engineers ne sont pas attendus sur le développement de l’application finale qui offrira par exemple une interface de saisie et intègrera la restitution des prévisions. Pour autant, il est nécessaire de “passer la main” à une équipe de développeurs en fournissant une documentation claire et précise pour des personnes qui n’ont pas à se pencher sur des notions de feature selection ou encore feature engineering. Cette documentation s’établit communément sous le format dit Swagger qui correspond à un fichier JSON listant les colonnes en entrée du modèle ainsi que le type de données associé (texte, nombres entiers ou décimaux, dates voire fichier binaire dans un cas non structuré).
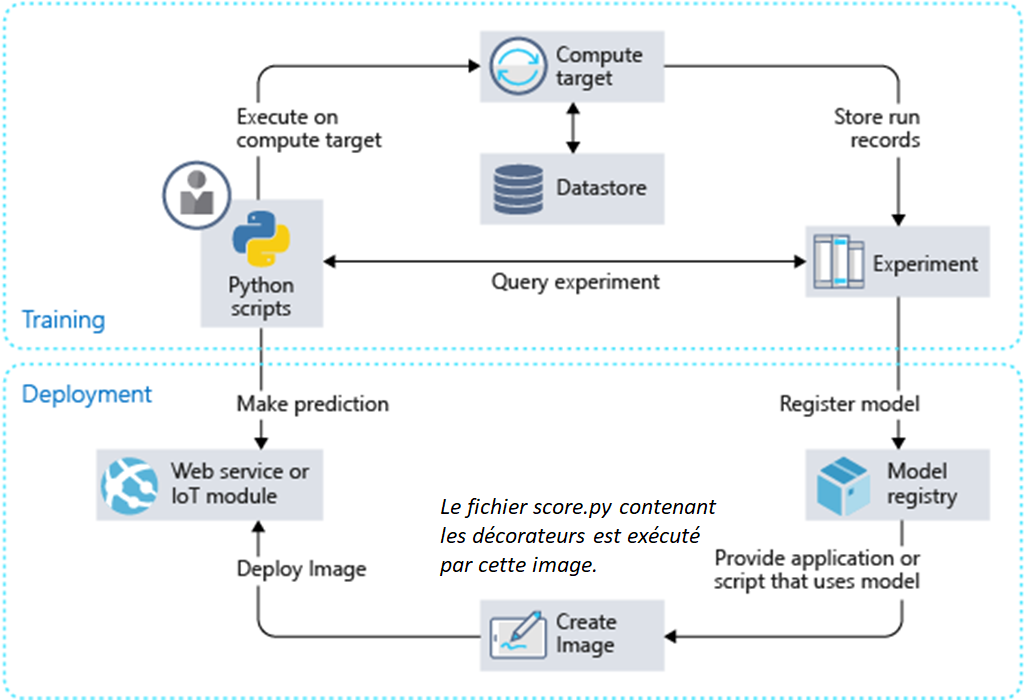
Afin d’obtenir ce résultat, nous devons préciser deux éléments dans la fonction de scoring qui supporte l’inférence du modèle. Rappelons que cette fonction Python score.py est ensuite hébergée sur une image Docker, stockée dans une ressource Azure Container Registry et exposée à l’aide d’Azure Container Instance ou Azure Kubernetes Services.
Nous disposerons alors de deux URLs, dont la propriété dns_name_label aura été précisée dans la définition de l’appel à la fonction deploy_configuration() sur l’objet AciWebservice :
Le fichier score.py se compose de deux fonctions au nom réservé :
init() qui récupère le binaire du modèle (par exemple au format Pickle) et le désérialise en mémoire
run(input) : qui récupère les données en entrée et applique la fonction .predict sur le modèle
def init():
global model
global encoder
# The AZUREML_MODEL_DIR environment variable indicates# a directory containing the model file you registered.model_filename = 'german_credit_log_model.pkl'model_path = os.path.join(os.environ['AZUREML_MODEL_DIR'], model_filename)with open(model_path, 'rb') as f: encoder, model = joblib.load(f)
Pour garantir la cohérence des données en entrée (nombre de colonnes et type des données) ainsi qu’en sortie, nous allons définir deux objets appelés décorateurs. Ces objets Python servent à modifier le comportement d’une fonction existante. Cette page GitHub documente ce que Microsoft appelle l’InferenceSchema.
A partir du SDK Python, nous allons commencer par importer les éléments nécessaires à la création des décorateurs.
from inference_schema.schema_decorators import input_schema, output_schema from inference_schema.parameter_types.standard_py_parameter_type import StandardPythonParameterType from inference_schema.parameter_types.numpy_parameter_type import NumpyParameterType from inference_schema.parameter_types.pandas_parameter_type import PandasParameterType
Nous disposons de trois types pour ces décorateurs :
le type standard que nous utiliserons pour une valeur simple comme par exemple un paramètre en entrée ou une valeur en sortie
le type Numpy Array soit un tableau de nombres en entrée (les features sont alors uniquement numériques) ou un tableau de valeurs en sortie (une prévision numérique pour une régression mais pourquoi pas un tableau de probabilités associées à chaque classe pour une classification)
le type Pandas Dataframe qui permet de faire entrer un jeu de données de multiples types, ce qui est bien plus souvent le cas dans la vraie vie que dans les tutoriels visibles sur le Web !
Voici la définition des décorateurs en entrée et sortie pour une tâche de classification sur le jeu de données German Credit. Il faut veiller à donner un exemple respectant le type de données de chaque colonne. Pour obtenir facilement ces informations, je vous recommande de lancer la commande df.iloc[:,1] sur le dataframe.
input_sample = pd.DataFrame(data=[{
"Status of existing checking account": "A12",
"Duration in month": 48,
"Credit history": "A32",
"Purpose": "A43",
"Credit amount": 5951,
"Savings account/bonds": "A61",
"Present employment since": "A73",
"Installment rate in percentage of disposable income": 2,
"Personal status and sex": "A92",
"Other debtors / guarantors": "A101",
"Present residence since": 2,
"Property": "A121",
"Age in years": 22,
"Other installment plans": "A143",
"Housing": "A152",
"Number of existing credits at this bank": 1,
"Job": "A173",
"Number of people being liable to provide maintenance for": 1,
"Telephone": "A191",
"foreign worker": "A201",
}])
output_sample = np.array([0])
@input_schema('data', PandasParameterType(input_sample))
@output_schema(NumpyParameterType(output_sample))
La méthode .predict() de Scikit-Learn accepte en entrée soit un tableau Numpy soit un Pandas dataframe. Nous n’aurons donc pas à intervenir sur le script score.py, le décorateur fera le travail d’interprétation des données en entrée et en particulier associera le nom des colonnes pour un Pandas dataframe.
Jetons un oeil du côté de la syntaxe classique d’appel au service web prédictif, ici en Python mais cet appel peut se faire dans de multiples langages. La seule contrainte est de passer les données dans un format JSON.
def run(data):
print(data.shape)
df_text = data.select_dtypes(include='object')
df_num = data.select_dtypes(include='int64')
df_text_encoded = pd.DataFrame(encoder.transform(df_text).toarray())
df_encoded = pd.concat([df_num, df_text_encoded], axis=1)
# Use the model object loaded by init().
result = model.predict(df_encoded)
# You can return any JSON-serializable object.
return result.tolist()
Explorons maintenant le détail du code de la fonction run(). Celle-ci attend un paramètre en entrée et il est important de respecter le nom associé au Dataframe dans sa définition faite au sein du décorateur d’entrée (la casse également, attention aux majuscules et minuscules !). La première étape consiste à lire le JSON en entrée grâce à la fonction json.loads(). N’oubliez pas de faire un import json dans le début du script ainsi que de charger la librairie pandas dans l’environnement d’inférence.
Nous passons ensuite un traitement spécifique aux colonnes de type texte, qui était lui-même stocké dans le fichier pickle.
Il n’y a plus qu’à demander la prédiction à partir du modèle avec l’instruction model.predict(data) puis à restituer le résultat en convertissant le Numpy array en liste, objet dit “JSON-serializable”.
Modification de la méthode de prévision
Puisque nous travaillons sur une classification binaire, nous pourrions préférer appliquer au modèle la méthode predict_proba() et
Voici le nouveau code à positionner dans la fonction score.py.
pandas_sample_input = pd.DataFrame(data=[{
"Status of existing checking account": "A12",
"Duration in month": 48,
"Credit history": "A32",
"Purpose": "A43",
"Credit amount": 5951,
"Savings account/bonds": "A61",
"Present employment since": "A73",
"Installment rate in percentage of disposable income": 2,
"Personal status and sex": "A92",
"Other debtors / guarantors": "A101",
"Present residence since": 2,
"Property": "A121",
"Age in years": 22,
"Other installment plans": "A143",
"Housing": "A152",
"Number of existing credits at this bank": 1,
"Job": "A173",
"Number of people being liable to provide maintenance for": 1,
"Telephone": "A191",
"foreign worker": "A201",
}])
method_sample_input = "predict"
output_sample = np.array([0])
@input_schema('data', PandasParameterType(pandas_sample_input))
@input_schema('method', StandardPythonParameterType(method_sample_input))
@output_schema(NumpyParameterType(output_sample))
def run(data, method):
df_text = data.select_dtypes(include='object')
df_num = data.select_dtypes(include='int64')
df_text_encoded = pd.DataFrame(encoder.transform(df_text).toarray())
df_encoded = pd.concat([df_num, df_text_encoded], axis=1)
print(method)
# Use the model object loaded by init().
result = model.predict(df_encoded) if method=="predict" else model.predict_proba(df_encoded)
# You can return any JSON-serializable object.
return result.tolist()
Nous exploitons ici deux paramètres en entrée de la fonction run(). Le second est du type StandardPythonParameterType, c’est-à-dire tout simplement une chaîne de texte ! Ensuite, nous jouons avec une condition pour appliquer soit predict(), soit predict_proba() qui renverra alors les probabilités appliquées à chacune des deux classes :
[[0.27303021717776266, 0.7269697828222373]]
En conclusion
Voilà un fonctionnement qui est satisfaisant autant pour les développeurs du modèle et du service que pour les personnes qui l’exploiteront ensuite. Attention toutefois à ne pas oublier de venir modifier ces décorateurs si jamais votre modèle n’utilise plus les mêmes données en entrée. Il est recommandé de rester à l’identique de la donnée de départ et si une étape de préparation (feature engineering, scaling…) est nécessaire, il faudra l’inclure dans un pipeline, ce que nous verrons dans un prochain article.
Le notebook complet sera disponible dans ce repository.
Assurer la qualité d’un développement Python passe par le fait de packager du code (des classes, des fonctions…) dans des modules que l’on pourra ensuite simplement installer dans un nouvel environnement (avec un classique pip install...) et importer dans des scripts à l’aide des syntaxes habituelles que sont import package ou from package import function.
Créer le package Wheel
C’est bien sûr la toute première étape une fois que notre code a été écrit. Et bien écrit, c’est-à-dire en respectant par exemple la norme PEP8 (nous en reparlerons) et en intégrant des docstrings dans les fonctions.
Nous aurons besoin de quelques librairies, dont bien évidemment wheel et nous profiterons d’un environnement virtuel pour les installer (commandes Windows ci-dessous pour créer, activer et configurer cet environnement).
Notre exemple se basera sur du code simple générant un pandas dataframe avec des nombres aléatoires. Notons au passage (pour les puristes :)) que ce code poserait problème dès que nb_col dépasserait la valeur 26.
import pandas as pd
import numpy as np
import string
def generate_df(nb_col, nb_row):
"""
Generate a pandas DataFrame
with nb_col columns and nb_row rows
"""
alphabet_string = string.ascii_uppercase
columns_string = alphabet_string[:nb_col]
columns_list = list(columns_string)
df = pd.DataFrame(np.random.randint(0, 100, size=(nb_row, nb_col)), columns=columns_list)
return df
Le script, nommé ici my_function.py, doit se trouver dans une arborescence de fichiers définie comme suit :
Le fichier __init__.py est tout simplement un fichier vide, seul le nom est obligatoire. Ce fichier doit être dans le répertoire dédié aux fichiers développés (sous-répertoire du répertoire principal). Il peut toutefois contenir également des fonctions qui seront chargées à l’appel du module. Pour réaliser des tests simples, voici ce qu’il contient.
def function_init():
print('Successfully imported Init.py')
def print_hello_iam(name):
print(f'Hello, I am {name}')
Nous complétons avec un fichier d’informations README au format Markdown, un fichier texte contenant la licence (ci-dessous) et un répertoire, éventuellement vide dans un premier temps, qui contiendra des tests.
Copyright (c) 2018 The Python Packaging Authority
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Le dernier élément nécessaire est le fichier setup.py dont un modèle de contenu peut être retrouver sur cette page. Il faudra en particulier y préciser le nom souhaité pour le package.
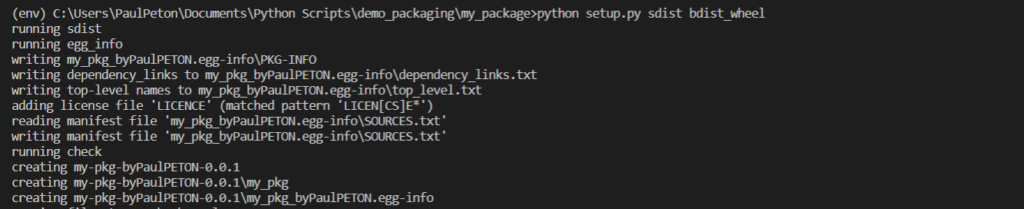
Pour générer l’archive de distribution, nous lançons la commande suivante, au niveau du répertoire contenant le fichier setup.py :
python setup.py sdist bdist_wheel
Un répertoire dist est alors créé et contient deux fichiers : le fichier .whl et une archive .tar.gz.
Le nom du package wheel est normalisé de la sorte :
EDIT : vérifiez également que le dossier finissant par “egg-info” contient bien les fichiers suivants.
Le fichier top_level.txt contient en particulier le nom qui servira à appeler le package dans les syntaxes du type from package import …
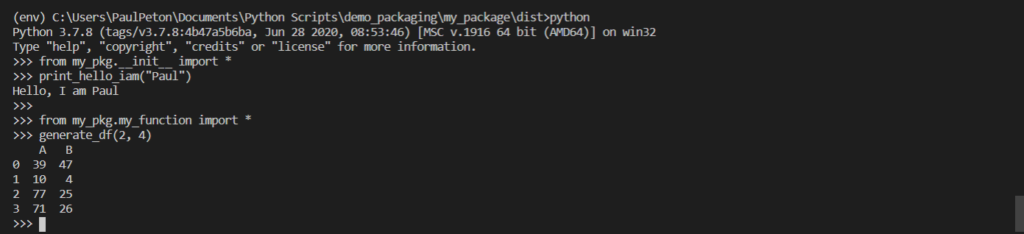
Réalisons tout de suite un premier test pour valider que notre package est bien construit. Au niveau du dossier contenant le fichier .whl, nous lançons dans un terminal la commande suivante, depuis le répertoire dist :
Puis dans un prompt Python, nous vérifions que l’import des nos méthodes est bien reconnu :
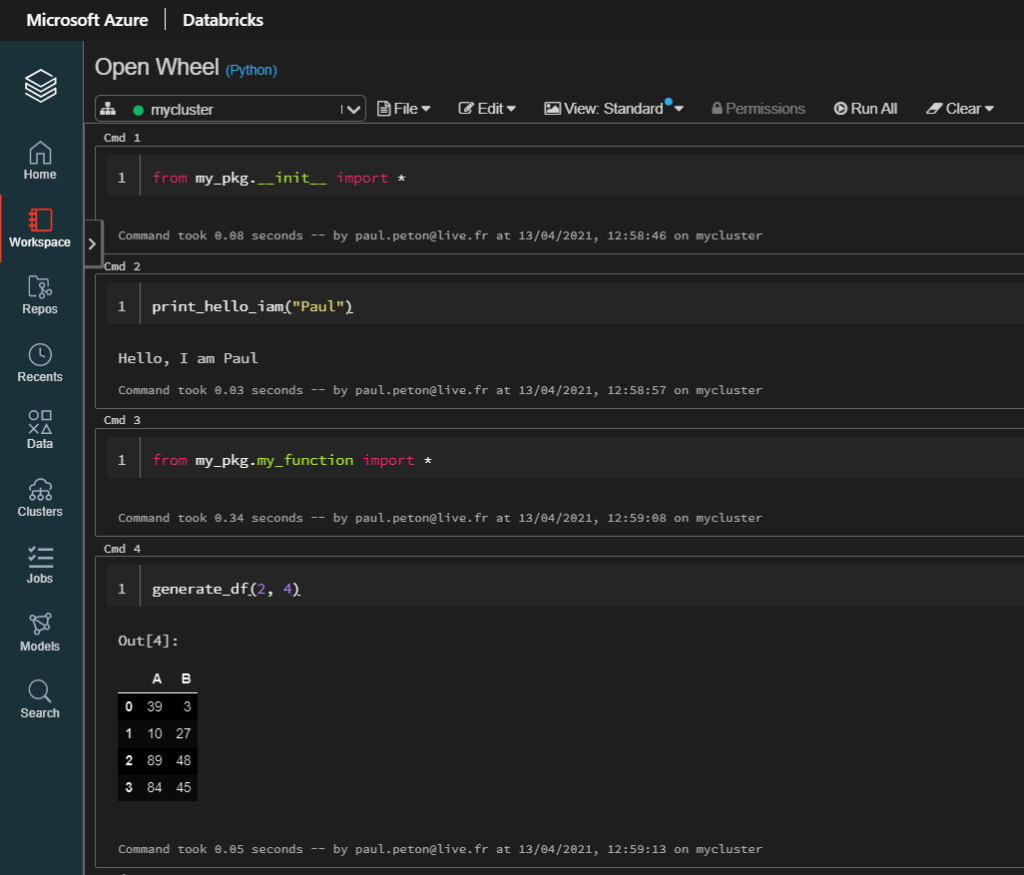
from my_pkg.__init__ import *
from my_pkg.my_function import *
Tester le package depuis un cluster Azure Databricks
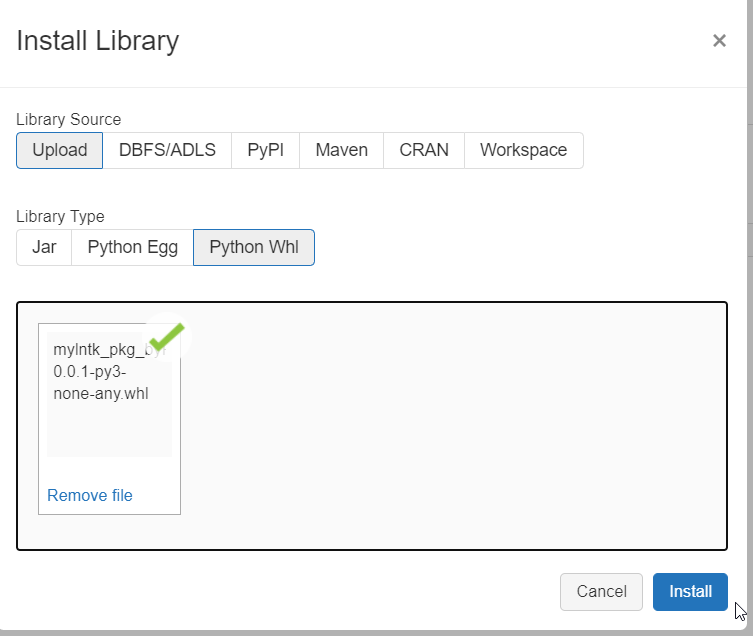
Nous allons maintenant installer manuellement le fichier .whl disponible dans le répertoire dist sur un cluster Databricks. Nous commençons par le télécharger sur un cluster interactif démarré.
Dès lors, les fonctions deviennent disponibles dans un notebook.
Notez au passage le “dark mode” des notebooks Databricks 🙂
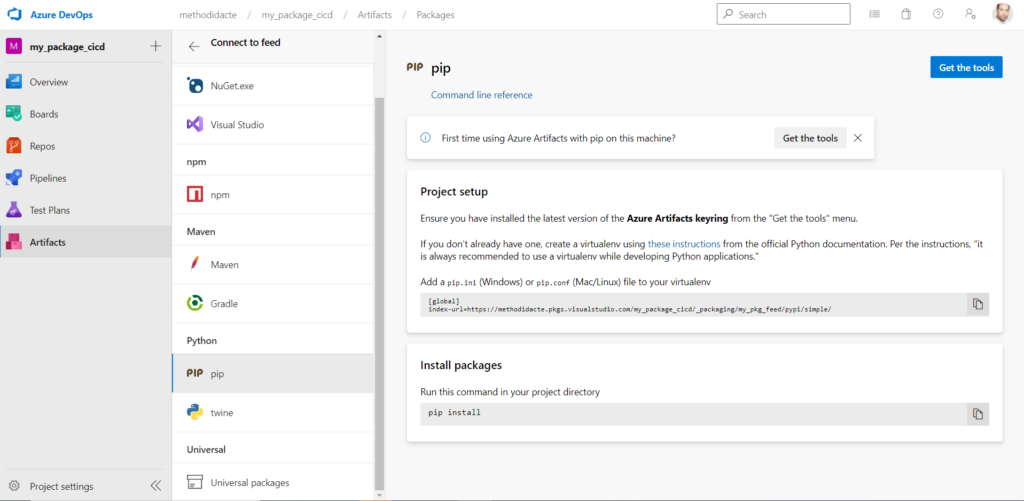
Charger le package sur un feed Azure DevOps
Nous n’allons bien sûr pas utiliser le fichier .whl localement, celui-ci doit être hébergé sur une plateforme accessible de tous les développeurs de l’équipe.
Tout comme le code est placé dans un dépôt (repository) d’un gestionnaire de versions comme Azure DevOps, nous allons placer le package, ici nommé artefact, dans un feed, accessible aux personnes autorisées.
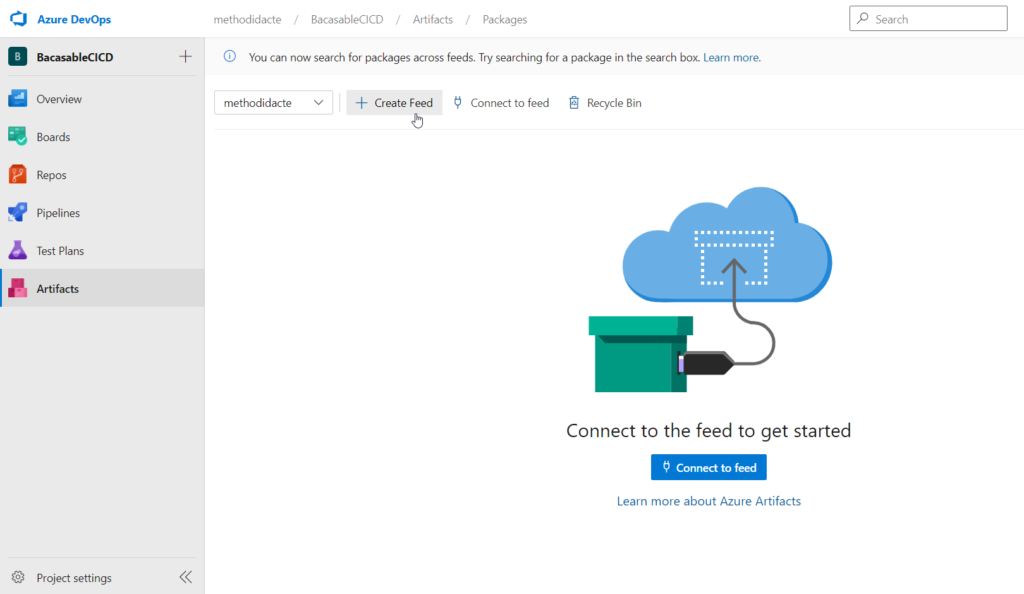
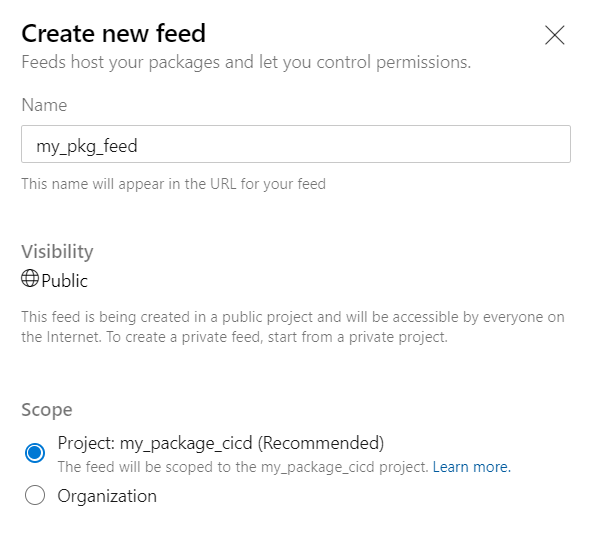
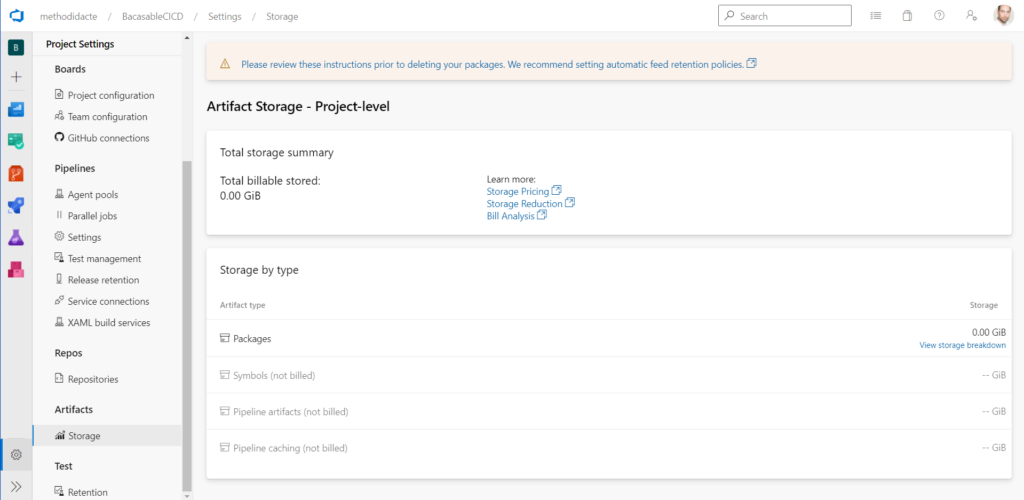
Nous réalisons tout d’abord la création du feed. Il sera ici public, donc accessible au travers d’Internet. Pour une pratique en entreprise, un projet privé est bien évidemment recommandé.
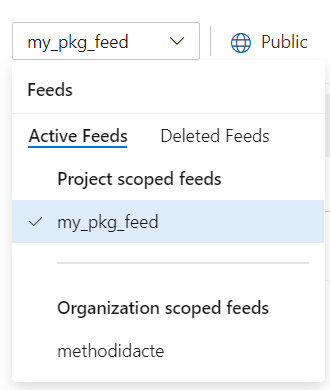
Le feed est maintenant bien actif.
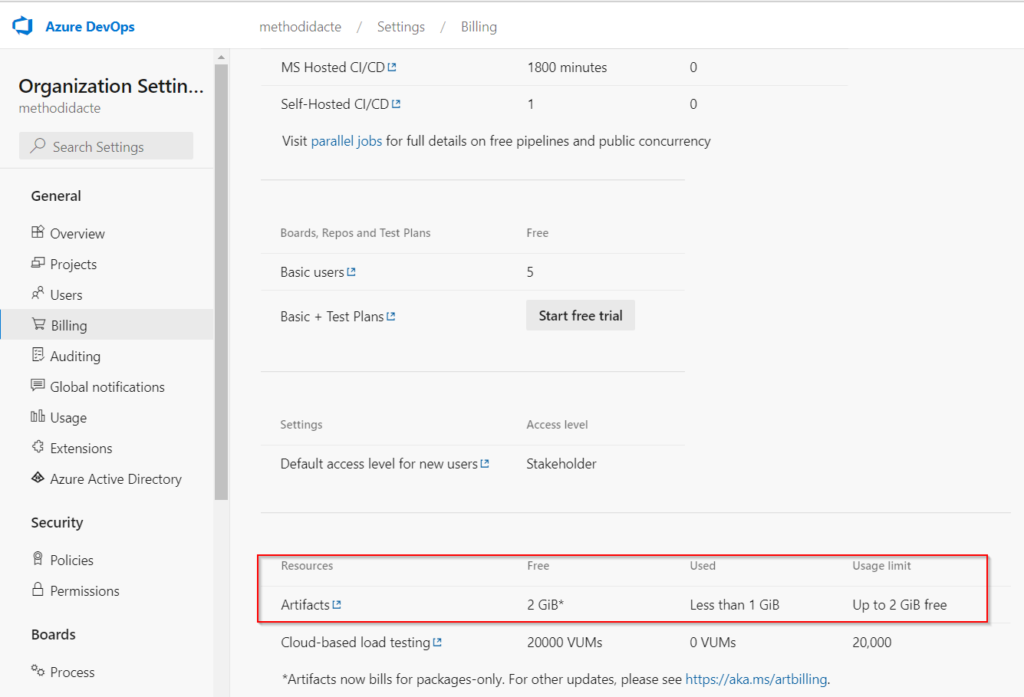
Attention, il est préférable de vérifier vos options de facturation (dans le menu “Organization Settings”). Un compte gratuit présentera des limites de taille pour l’usage des artefacts stockés dans le feed.
Vérifions également le stockage associé aux artefacts (ici au niveau projet, puisque c’est le périmètre qui a été défini).
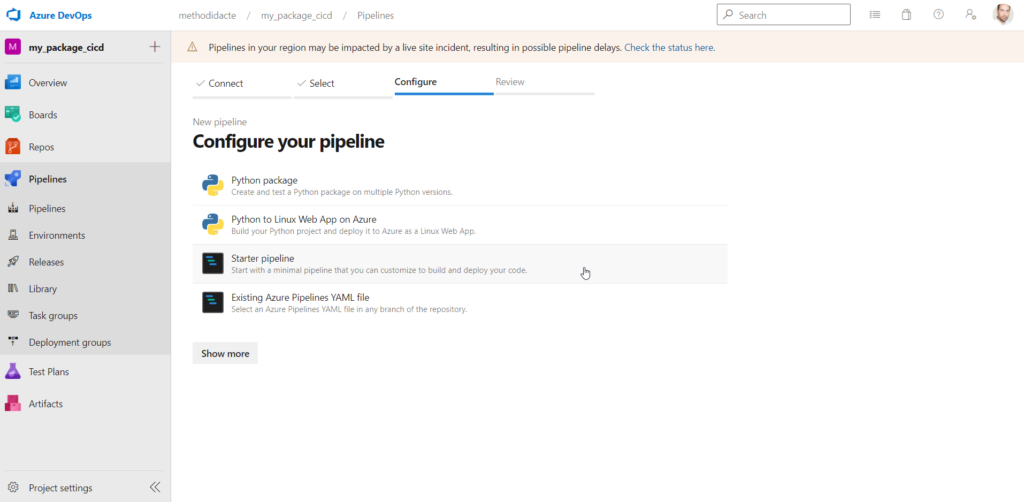
Il s’agit ensuite d’automatiser la création du package wheel par un pipeline d’intégration continue. Nous démarrons à partir d’un “starter pipeline”.
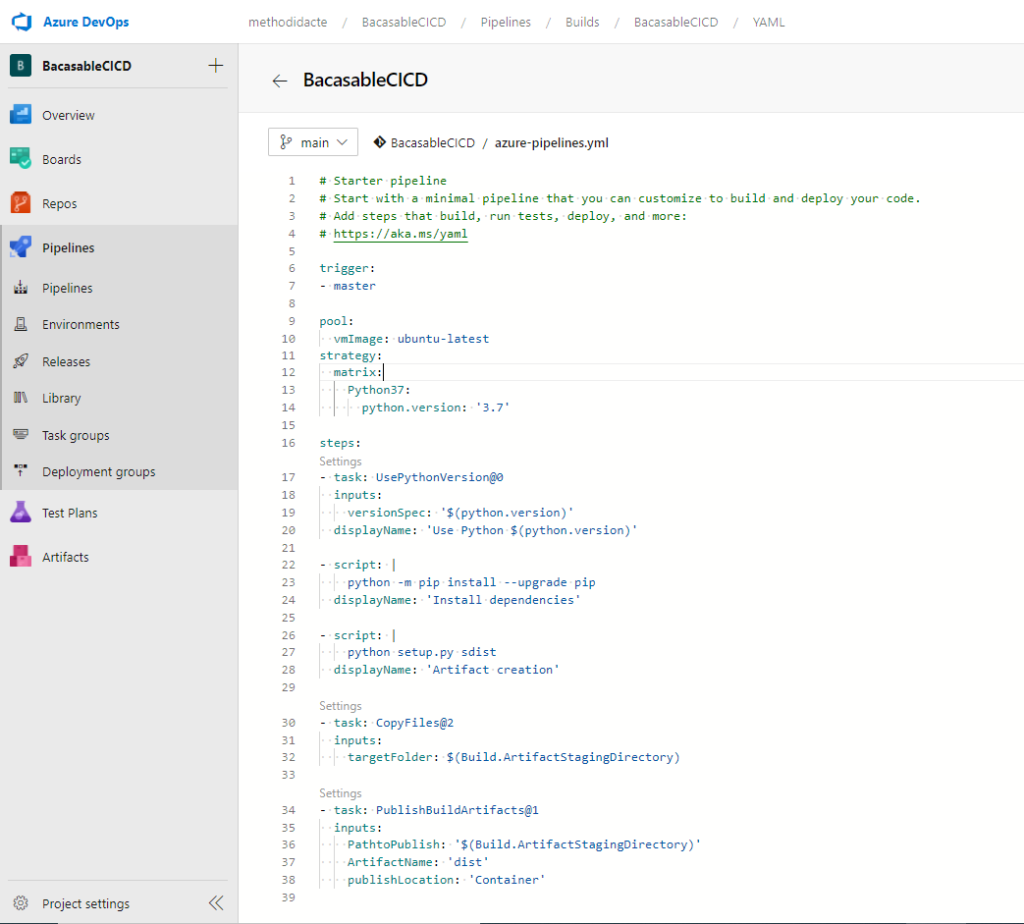
Le code complet de ce pipeline, enregistré automatiquement dans un fichier azure-pipelines.yml, ajouté au repository, est disponible par exemple sur ce GitHub (veillez à adapter si besoin la version de Python attendue ainsi que le nom de la branche – main pour master – si vous souhaitez un lancement automatique de la pipeline à chaque commit).
Ce script YAML reprend l’exécution du fichier setup.py pour créer l’artefact dans un conteneur dédié.
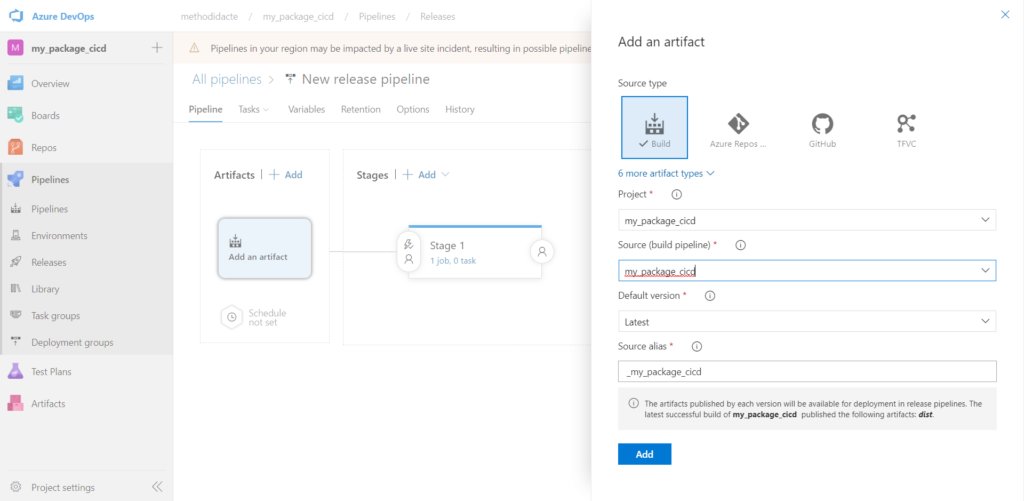
Nous avons ensuite besoin d’un pipeline de releasequi déposera l’artefact dans le feed qui servira de point de distribution.
A partir d’un modèle vide de pipeline de release (“empty job“), nous attachons le résultat du pipeline de build réalisé précédemment.
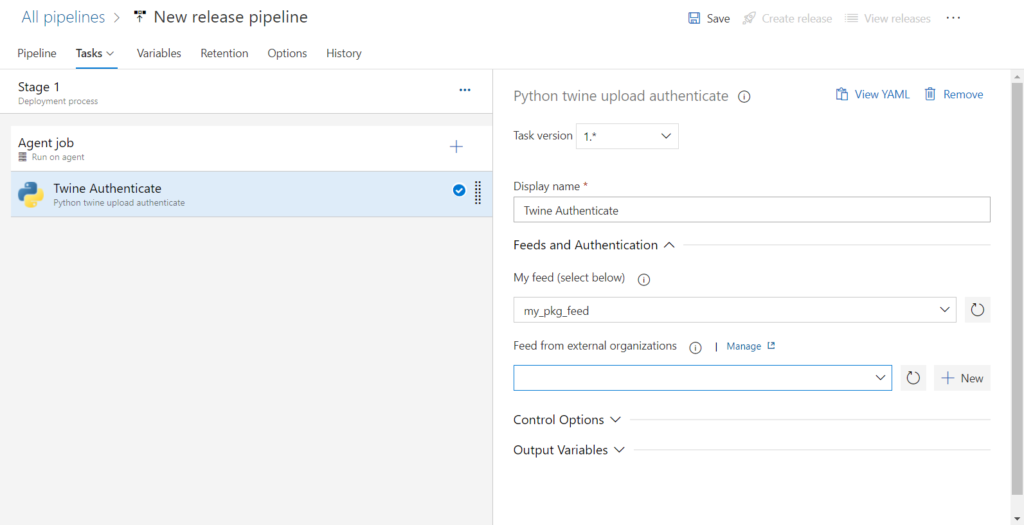
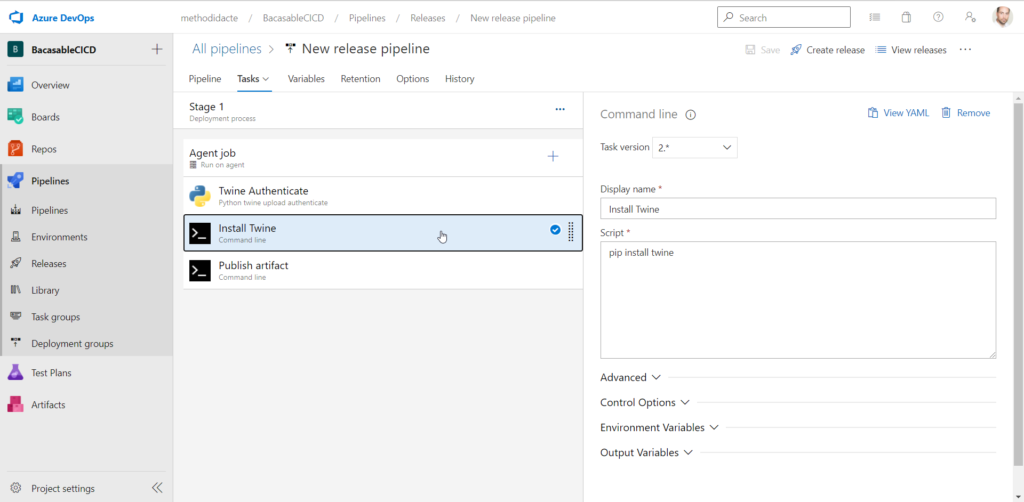
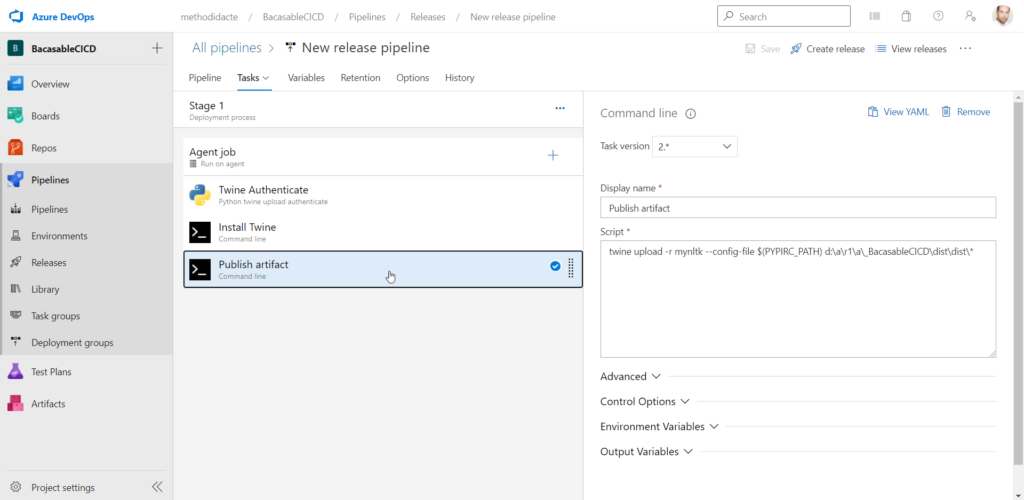
Nous ajoutons trois activités qui sont :
Python twine upload authenticate
Command line pour l’installation de Twine
Command line pour la publication de l’artefact
L’étape 1 s’authentifie auprès du feed, dont il faut saisir le nom.
L’étape 2 réalise l’installation du package Twine par la commande pip install.
L’étape 3 utilise Twine pour télécharger le package.
Cette étape est sans doute la plus délicate. En cas d’erreur pour localiser ce répertoire, je vous conseille de regarder les logs de la première étape du pipeline de build afin de visualiser l’artefact dans son arborescence.
Utiliser le package depuis un nouveau script
Nous allons avoir besoin d’une nouvelle librairie : artifacts-keyring..
pip install artifacts-keyring
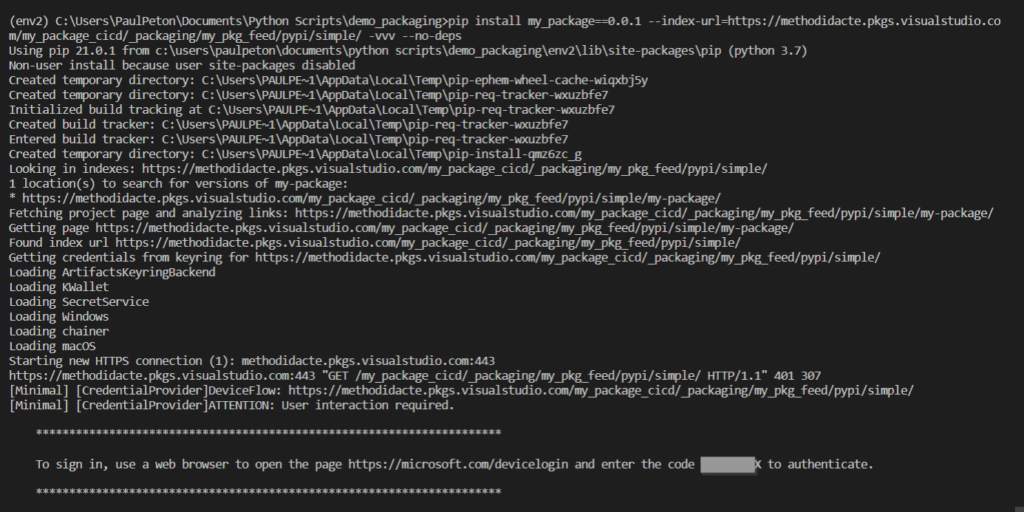
Ensuite, nous pouvons faire appel à la commande classique “pip install” pointant vers notre feed.
Le “project_name” est facultatif si le feed est déclaré au niveau de l’organisation. Il sera possible de remplacer par l’option –index-url par –extra-index-url comme indiqué dans cet article mais ceci est à réaliser seulement si l’on utilise la méthode proposée dans le portail Azure DevOps : la création d’un fichier pip.ini.
En cas de project privé, une authentification sera alors demandée, de manière interactive, au travers d’un navigateur.
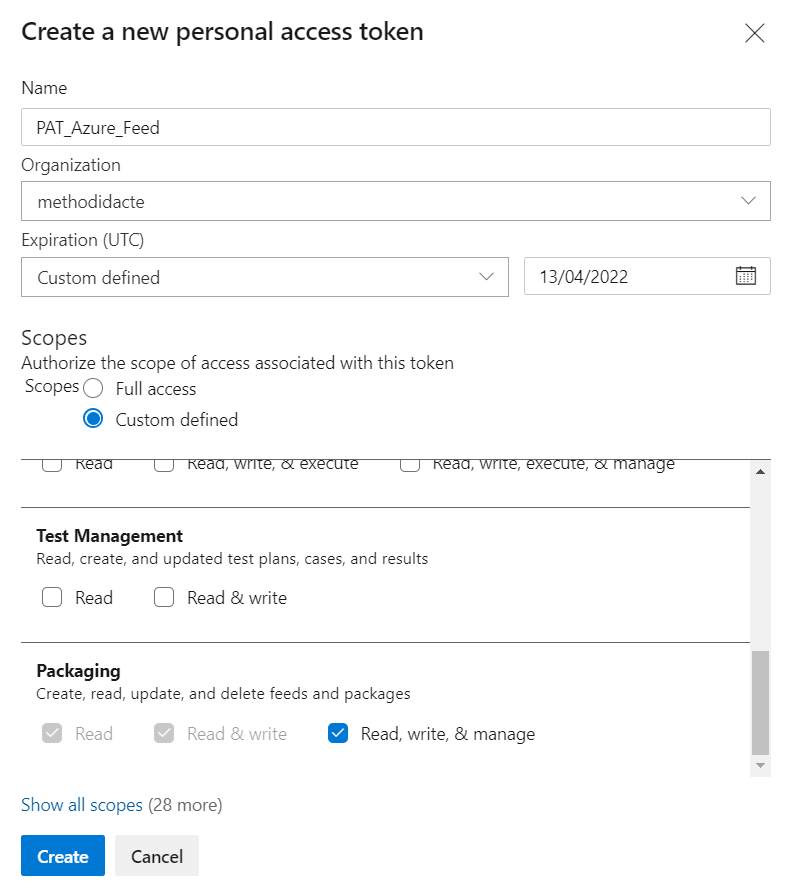
Ce mode n’est bien sûr pas envisageable pour une installation devant s’exécuter de manière autonome. Nous allons donc générer un Personal Access Token (PAT) qui permettra de nous authentifier. Ce jeton s’obtient dans Azure DevOps.
Nous donnons les droits au niveau “packaging“.
Dans l’environnement d’exécution, une variable d’environnement sera nécessaire pour désactiver l’authentification interactive et tenir compte du PAT. Cela se fait par exemple dans Windows par le menu “Modifier les variables d’environnement système” ou dans un dockerfile avec la ligne ci-dessous.
VAR ARTIFACTS_KEYRING_NONINTERACTIVE_MODE=true
Il sera alors possible d’appeler le package avec la syntaxe suivante :
Ca y est ! Le package est maintenant installé et nous pouvons nous appuyer sur les fonctions qu’il contient.
from my_pkg.my_function import *
En conclusion
Nous avons mis en place ici une approche dédiée à l’industrialisation d’un développement, accompagné d’un processus CI/CD. Cela demande un investissement en temps et en prise en main de cette procédure mais c’est une garantie de stabilité et de non régression sur le livrable en production.
Outil décisionnel self-service, de dataviz ou d’analytics, le débat autour de Power BI n’est toujours pas tranché. Les fonctionnalités étiquetées “IA” sont de plus en plus nombreuses mais souvent frustrantes car limitées dans leur paramétrage, comparée à une approche basée sur le code, en langage R ou Python par exemple.
Il serait bien sûr possible de tout réaliser dans ces langages (préparation de données, visualisation, voire partage) mais dans la pratique, nous naviguons souvent entre plusieurs outils. Et si votre seul outil est un marteau…
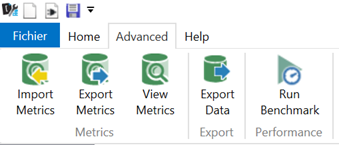
Depuis le menu External Tools, lancer l’outil DAX Studio. Dans le menu Advanced, cliquer sur « Export Data ».
Choisir ensuite un export en fichier CSV et spécifier le séparateur attendu. Nous choisirons le séparateur virgule (comma) pour respecter la valeur par défaut de la méthode read_csv() de la librairie pandas.
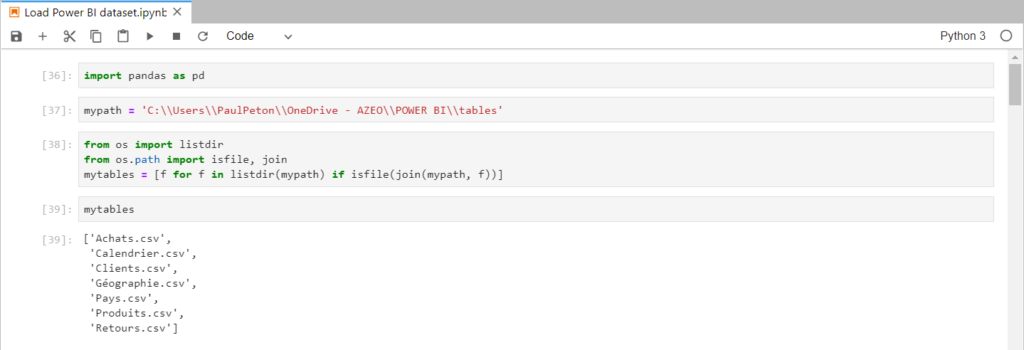
Depuis un notebook, par exemple à partir de Jupyter Lab, nous exécutons le code détaillé ci-dessous. La première étape consiste à lister le contenu du répertoire où ont été exportées les différentes tables.
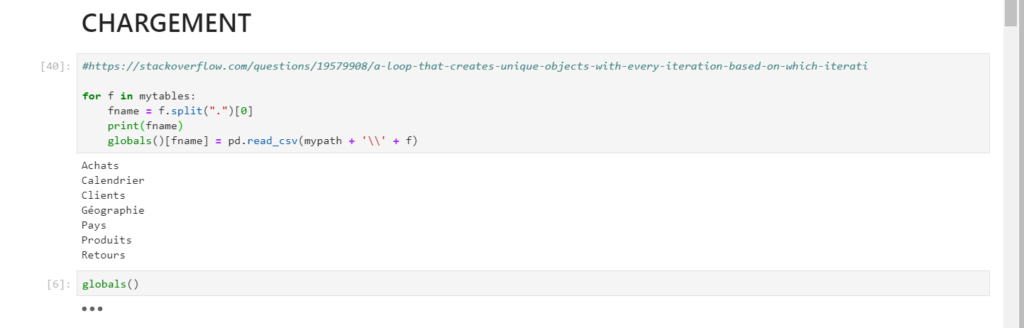
La création d’un pandas dataframe par fichier se fait ensuite de manière itérative. Le nom du fichier est utilisé pour nommer l’objet en mémoire. La fonction globals() permet de vérifier la liste des variables globales définies dans la session.
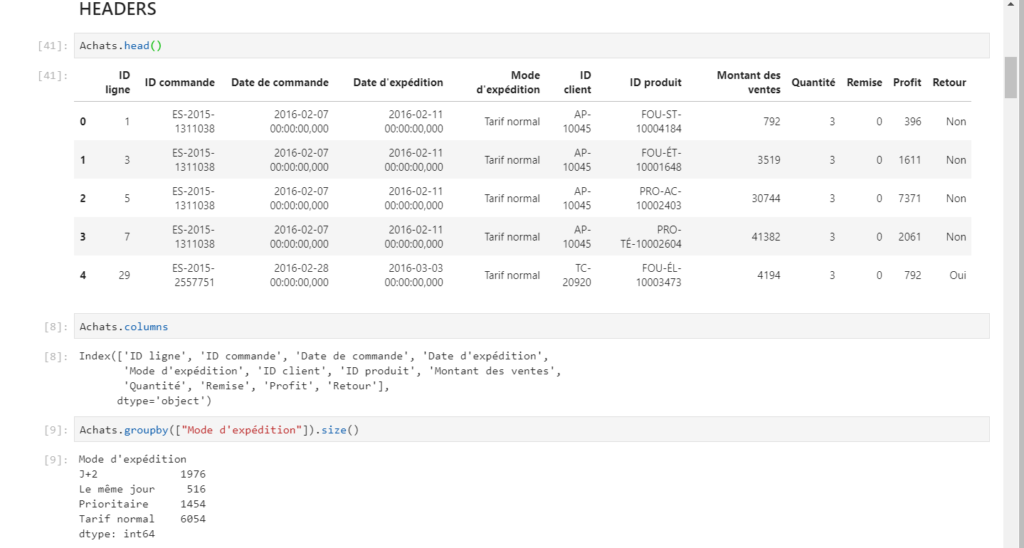
Nous retrouvons alors le “modèle sémantique” à l’identique : noms de tables, de colonnes, à l’exception d’éventuelles mesures. Les colonnes calculées apparaissent quant à elles, comme une “copie en valeur”.
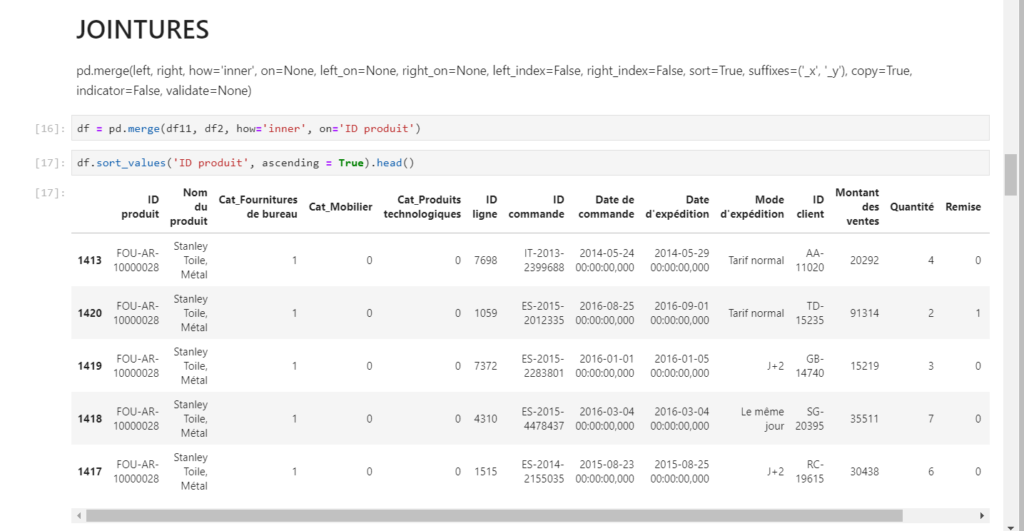
Les relations entre tables pourront être remplacées par des jointures entre dataframes à l’aide de la fonction merge().
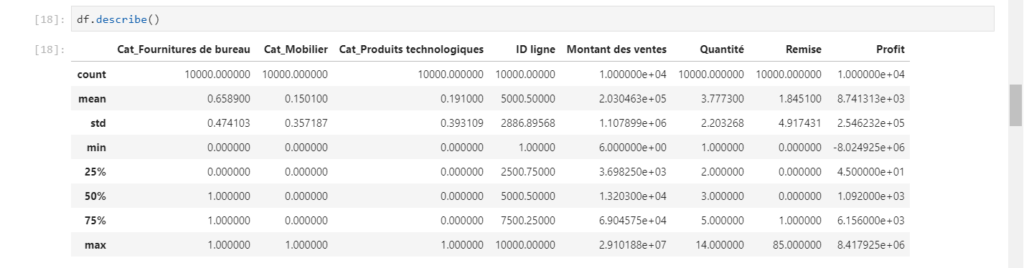
La fonction describe() donne un résumé statistique de toutes les variables numériques.
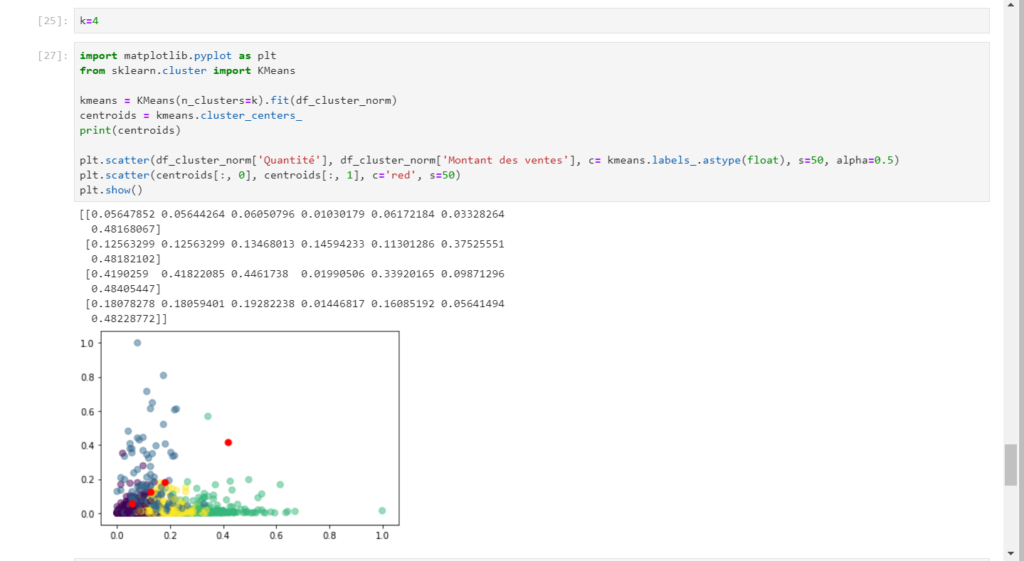
Il est ensuite possible de pousser des analyses exploratoires multidimensionnelles comme un modèle de Machine Learning non supervisé de type KMeans.
Le code complet vous est proposé dans ce notebook.