
Assurer la qualité d’un développement Python passe par le fait de packager du code (des classes, des fonctions…) dans des modules que l’on pourra ensuite simplement installer dans un nouvel environnement (avec un classique pip install...) et importer dans des scripts à l’aide des syntaxes habituelles que sont import package ou from package import function.
Créer le package Wheel
C’est bien sûr la toute première étape une fois que notre code a été écrit. Et bien écrit, c’est-à-dire en respectant par exemple la norme PEP8 (nous en reparlerons) et en intégrant des docstrings dans les fonctions.
Nous aurons besoin de quelques librairies, dont bien évidemment wheel et nous profiterons d’un environnement virtuel pour les installer (commandes Windows ci-dessous pour créer, activer et configurer cet environnement).
python -m venv env env\Scripts\activate.bat python -m pip install -U setuptools wheel twine
Notre exemple se basera sur du code simple générant un pandas dataframe avec des nombres aléatoires. Notons au passage (pour les puristes :)) que ce code poserait problème dès que nb_col dépasserait la valeur 26.
import pandas as pd
import numpy as np
import string
def generate_df(nb_col, nb_row):
"""
Generate a pandas DataFrame
with nb_col columns and nb_row rows
"""
alphabet_string = string.ascii_uppercase
columns_string = alphabet_string[:nb_col]
columns_list = list(columns_string)
df = pd.DataFrame(np.random.randint(0, 100, size=(nb_row, nb_col)), columns=columns_list)
return df
Le script, nommé ici my_function.py, doit se trouver dans une arborescence de fichiers définie comme suit :
my_package ├── LICENSE ├── README.md ├── my_pkg │ └── __init__.py │ └── my_function.py ├── setup.py └── tests
Le fichier __init__.py est tout simplement un fichier vide, seul le nom est obligatoire. Ce fichier doit être dans le répertoire dédié aux fichiers développés (sous-répertoire du répertoire principal). Il peut toutefois contenir également des fonctions qui seront chargées à l’appel du module. Pour réaliser des tests simples, voici ce qu’il contient.
def function_init():
print('Successfully imported Init.py')
def print_hello_iam(name):
print(f'Hello, I am {name}')
Nous complétons avec un fichier d’informations README au format Markdown, un fichier texte contenant la licence (ci-dessous) et un répertoire, éventuellement vide dans un premier temps, qui contiendra des tests.
Copyright (c) 2018 The Python Packaging Authority Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Le dernier élément nécessaire est le fichier setup.py dont un modèle de contenu peut être retrouver sur cette page. Il faudra en particulier y préciser le nom souhaité pour le package.
Pour générer l’archive de distribution, nous lançons la commande suivante, au niveau du répertoire contenant le fichier setup.py :
python setup.py sdist bdist_wheel
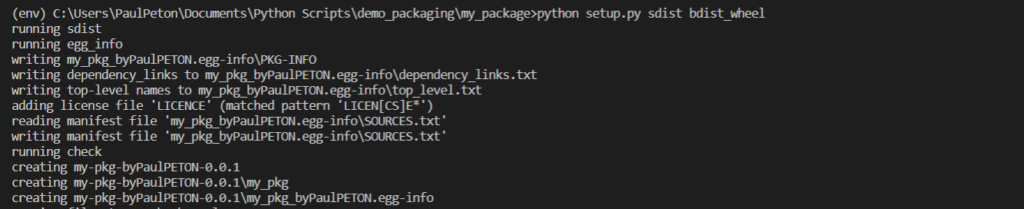
Un répertoire dist est alors créé et contient deux fichiers : le fichier .whl et une archive .tar.gz.

Le nom du package wheel est normalisé de la sorte :
{dist}-{version}(-{build})?-{python}-{abi}-{platform}.whl
EDIT : vérifiez également que le dossier finissant par “egg-info” contient bien les fichiers suivants.
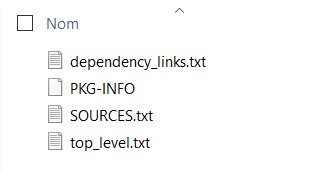
Le fichier top_level.txt contient en particulier le nom qui servira à appeler le package dans les syntaxes du type from package import …
Réalisons tout de suite un premier test pour valider que notre package est bien construit. Au niveau du dossier contenant le fichier .whl, nous lançons dans un terminal la commande suivante, depuis le répertoire dist :
python -m pip install my_pkg_byPaulPETON-0.0.1-py3-none-any.whl

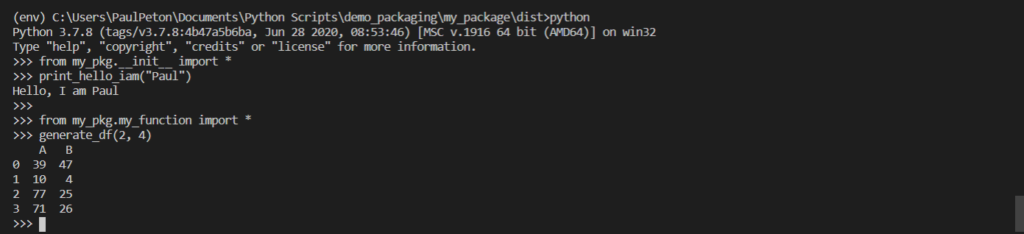
Puis dans un prompt Python, nous vérifions que l’import des nos méthodes est bien reconnu :
from my_pkg.__init__ import * from my_pkg.my_function import *
Tester le package depuis un cluster Azure Databricks
Nous allons maintenant installer manuellement le fichier .whl disponible dans le répertoire dist sur un cluster Databricks. Nous commençons par le télécharger sur un cluster interactif démarré.
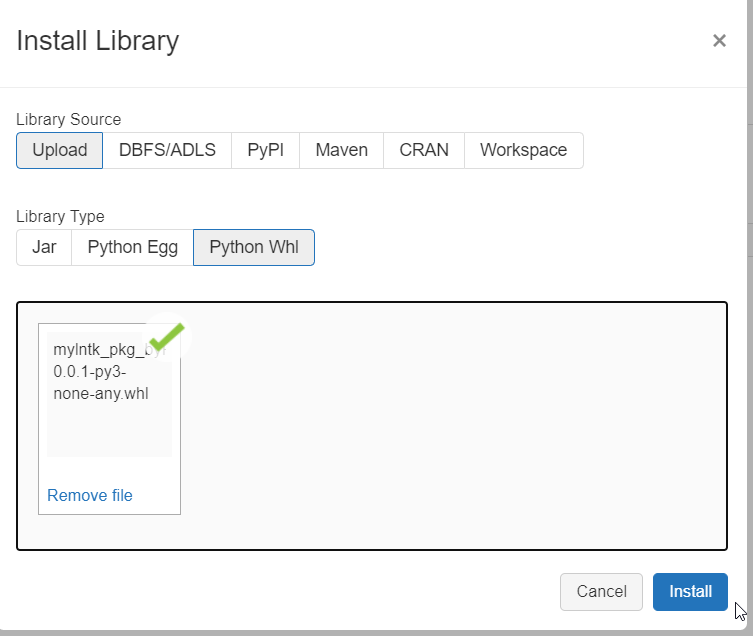
Dès lors, les fonctions deviennent disponibles dans un notebook.
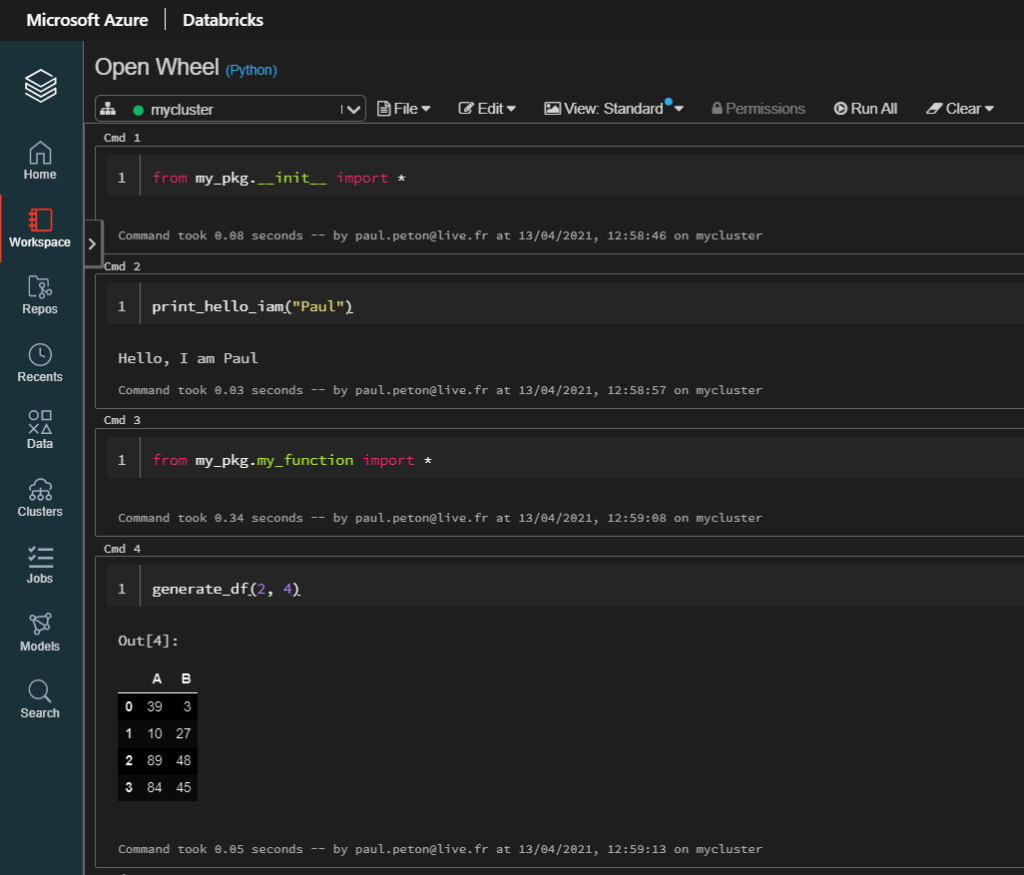
Charger le package sur un feed Azure DevOps
Nous n’allons bien sûr pas utiliser le fichier .whl localement, celui-ci doit être hébergé sur une plateforme accessible de tous les développeurs de l’équipe.
Tout comme le code est placé dans un dépôt (repository) d’un gestionnaire de versions comme Azure DevOps, nous allons placer le package, ici nommé artefact, dans un feed, accessible aux personnes autorisées.
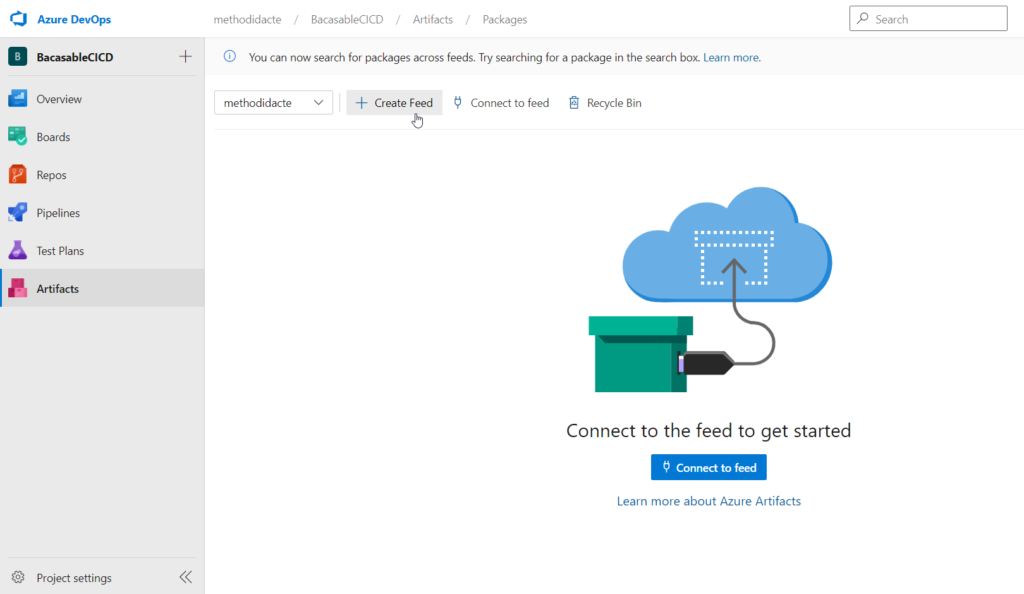
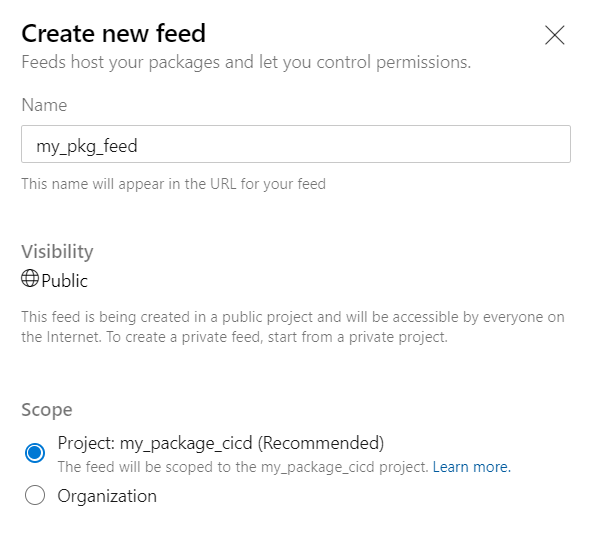
Nous réalisons tout d’abord la création du feed. Il sera ici public, donc accessible au travers d’Internet. Pour une pratique en entreprise, un projet privé est bien évidemment recommandé.
Le feed est maintenant bien actif.
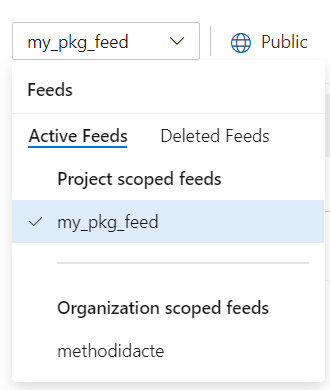
Attention, il est préférable de vérifier vos options de facturation (dans le menu “Organization Settings”). Un compte gratuit présentera des limites de taille pour l’usage des artefacts stockés dans le feed.
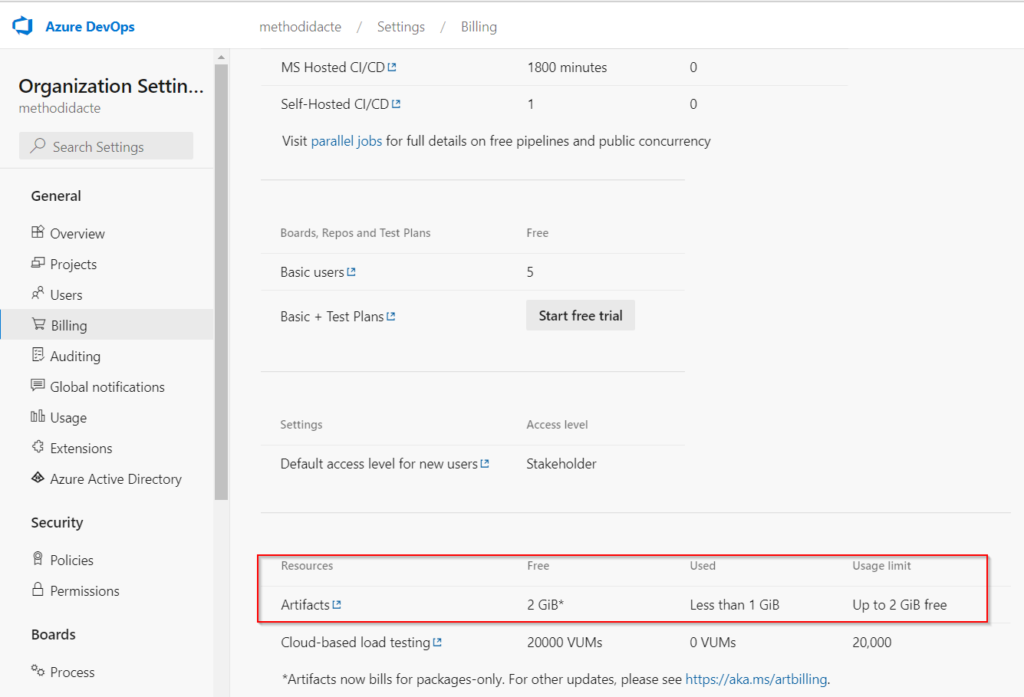
Vérifions également le stockage associé aux artefacts (ici au niveau projet, puisque c’est le périmètre qui a été défini).
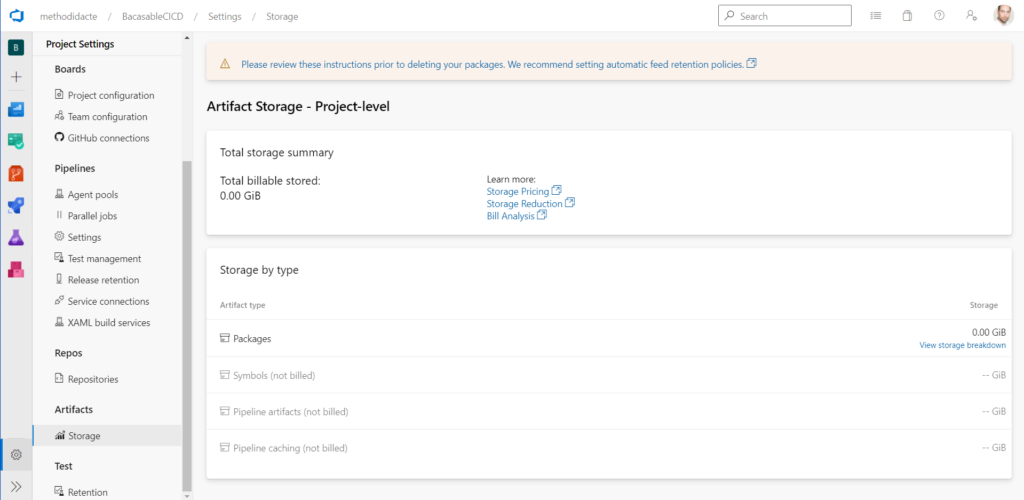
Il s’agit ensuite d’automatiser la création du package wheel par un pipeline d’intégration continue. Nous démarrons à partir d’un “starter pipeline”.
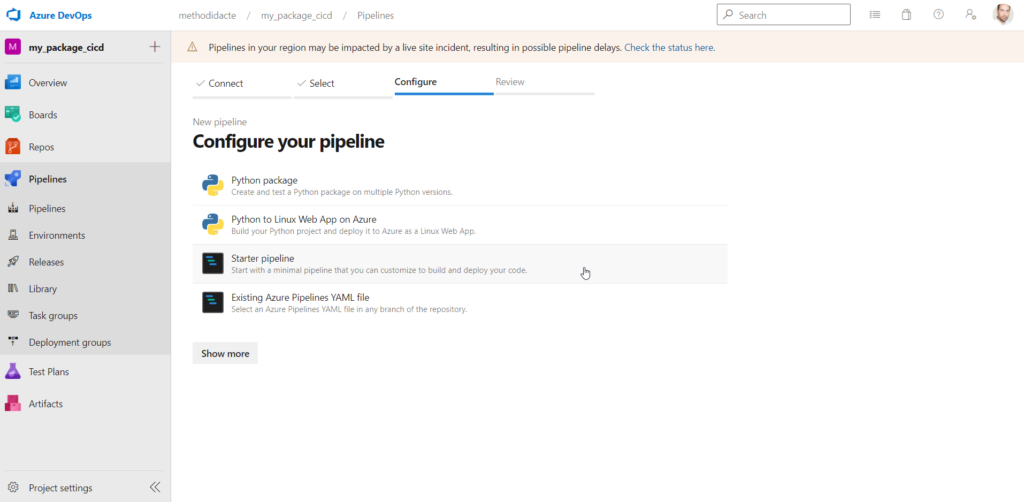
Le code complet de ce pipeline, enregistré automatiquement dans un fichier azure-pipelines.yml, ajouté au repository, est disponible par exemple sur ce GitHub (veillez à adapter si besoin la version de Python attendue ainsi que le nom de la branche – main pour master – si vous souhaitez un lancement automatique de la pipeline à chaque commit).
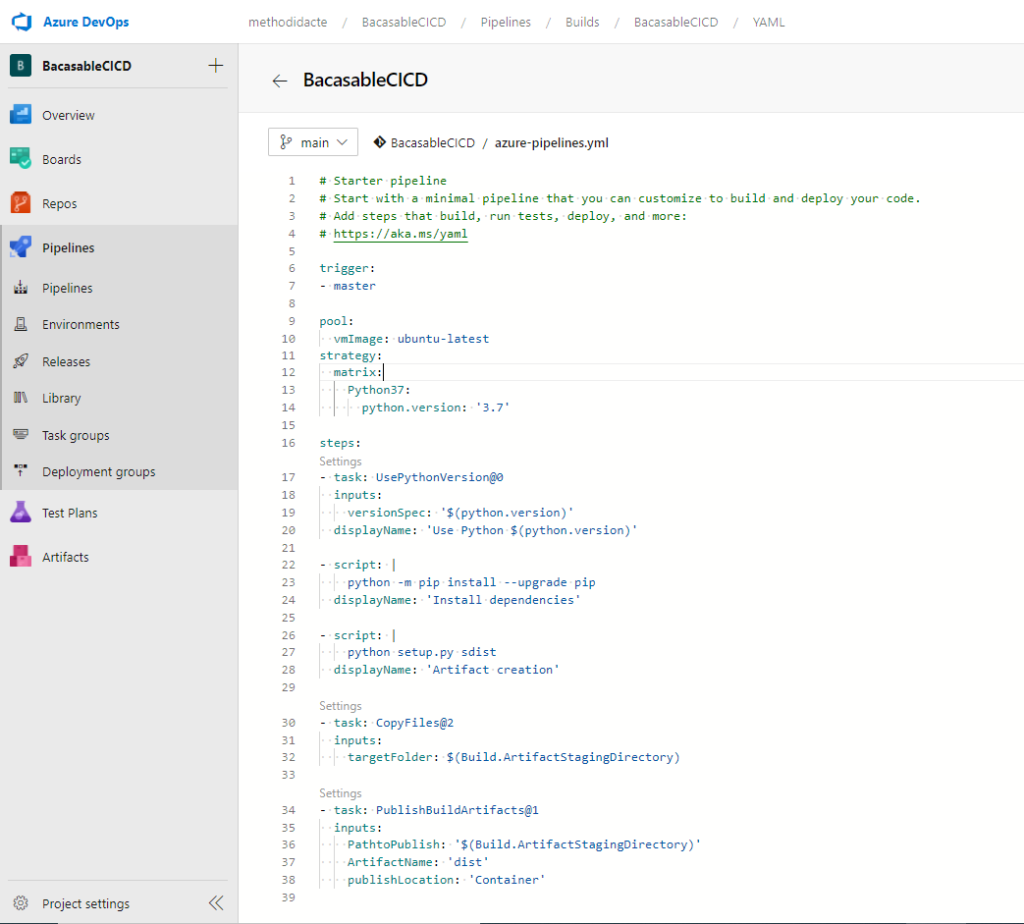
Ce script YAML reprend l’exécution du fichier setup.py pour créer l’artefact dans un conteneur dédié.
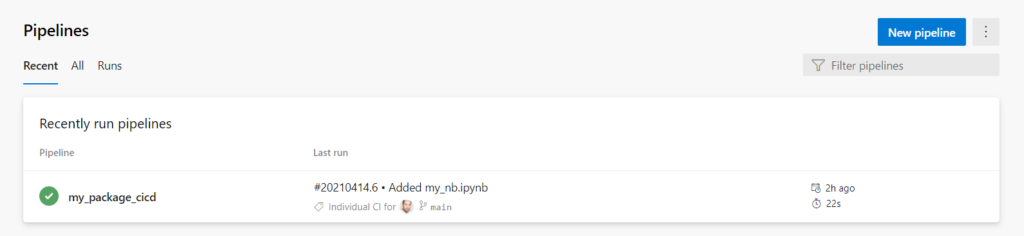
Nous avons ensuite besoin d’un pipeline de release qui déposera l’artefact dans le feed qui servira de point de distribution.
A partir d’un modèle vide de pipeline de release (“empty job“), nous attachons le résultat du pipeline de build réalisé précédemment.
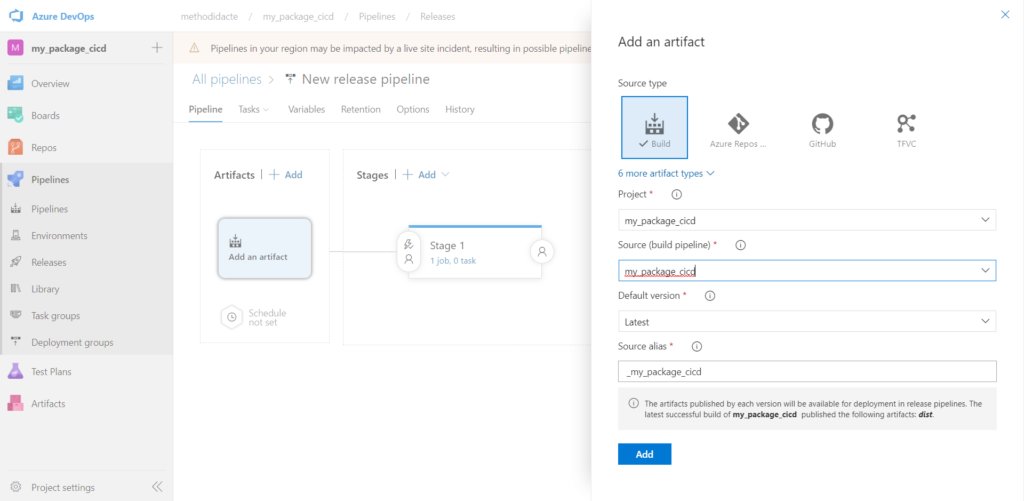
Nous ajoutons trois activités qui sont :
- Python twine upload authenticate
- Command line pour l’installation de Twine
- Command line pour la publication de l’artefact
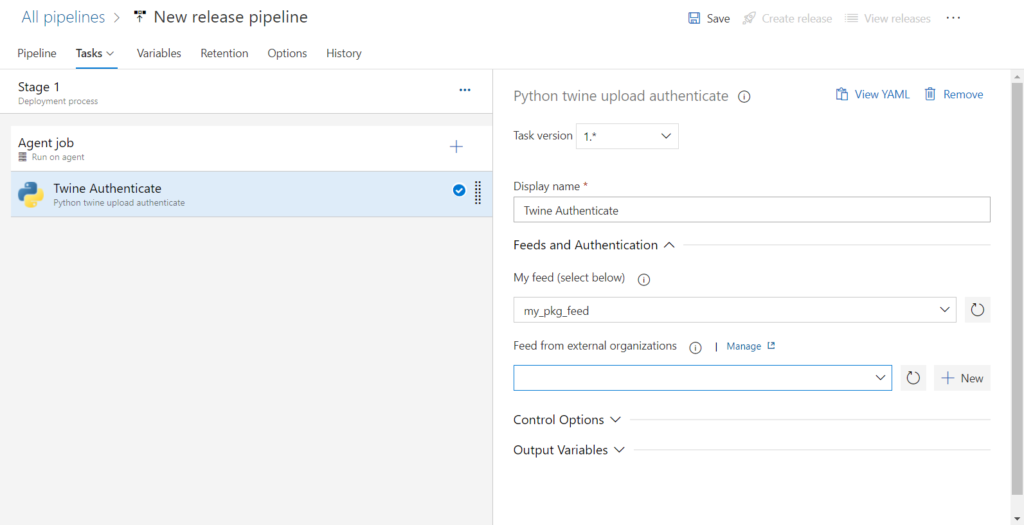
L’étape 1 s’authentifie auprès du feed, dont il faut saisir le nom.
L’étape 2 réalise l’installation du package Twine par la commande pip install.
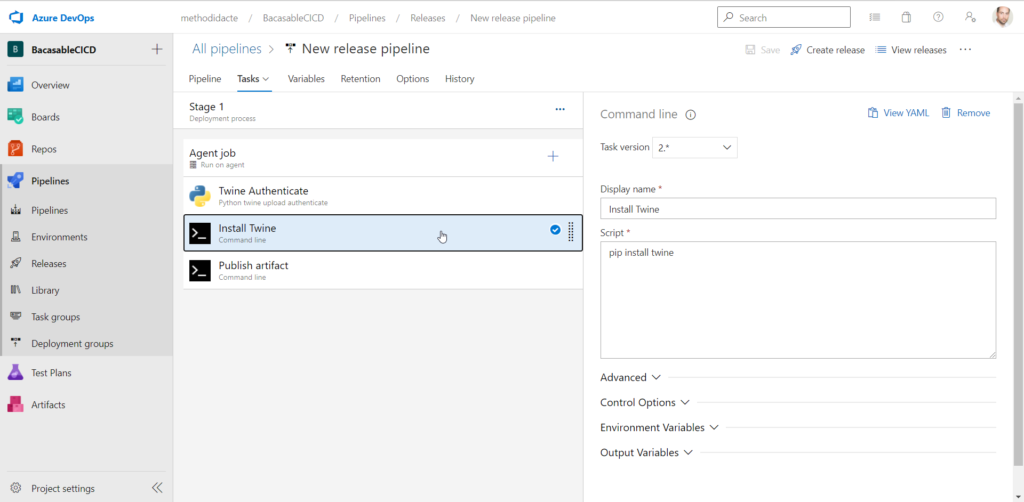
L’étape 3 utilise Twine pour télécharger le package.
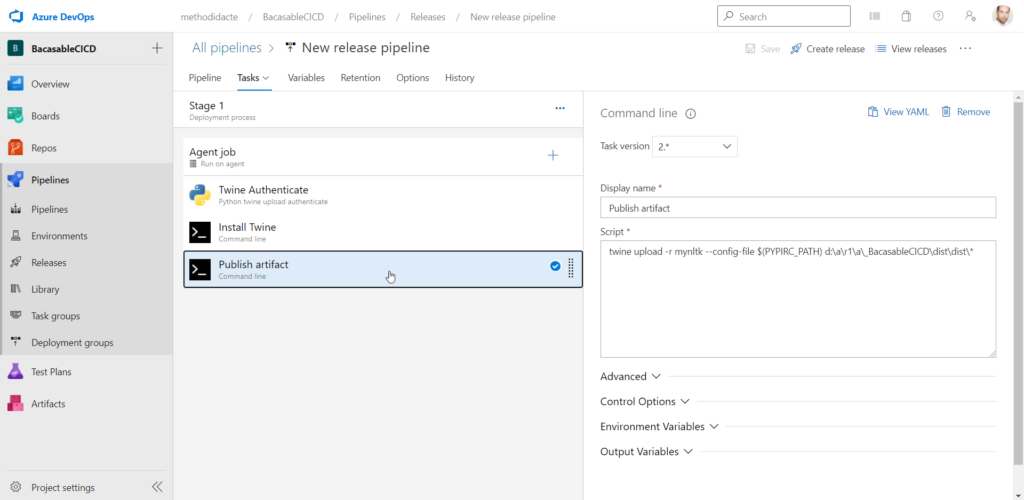
Voici la ligne de code nécessaire :
twine upload -r <feed_name> --config-file $(PYPIRC_PATH) d:\a\r1\a\_<project_name>\dist\dist*
Cette étape est sans doute la plus délicate. En cas d’erreur pour localiser ce répertoire, je vous conseille de regarder les logs de la première étape du pipeline de build afin de visualiser l’artefact dans son arborescence.

Utiliser le package depuis un nouveau script
Nous allons avoir besoin d’une nouvelle librairie : artifacts-keyring..
pip install artifacts-keyring
Ensuite, nous pouvons faire appel à la commande classique “pip install” pointant vers notre feed.
pip install packageName --index-url https://pkgs.dev.azure.com/<organization_name>/<project_name>/_packaging/<feed_name>/pypi/simple/
Le “project_name” est facultatif si le feed est déclaré au niveau de l’organisation. Il sera possible de remplacer par l’option –index-url par –extra-index-url comme indiqué dans cet article mais ceci est à réaliser seulement si l’on utilise la méthode proposée dans le portail Azure DevOps : la création d’un fichier pip.ini.
En cas de project privé, une authentification sera alors demandée, de manière interactive, au travers d’un navigateur.
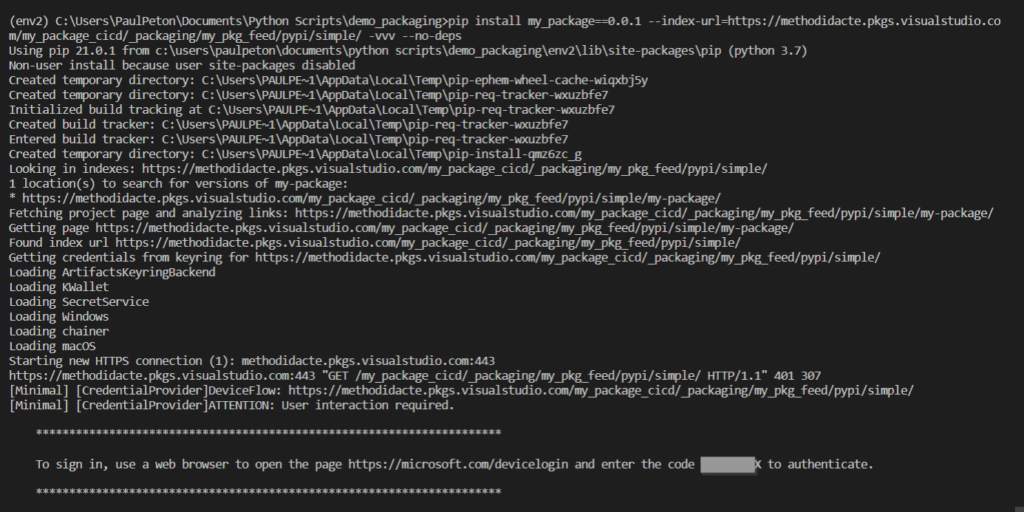
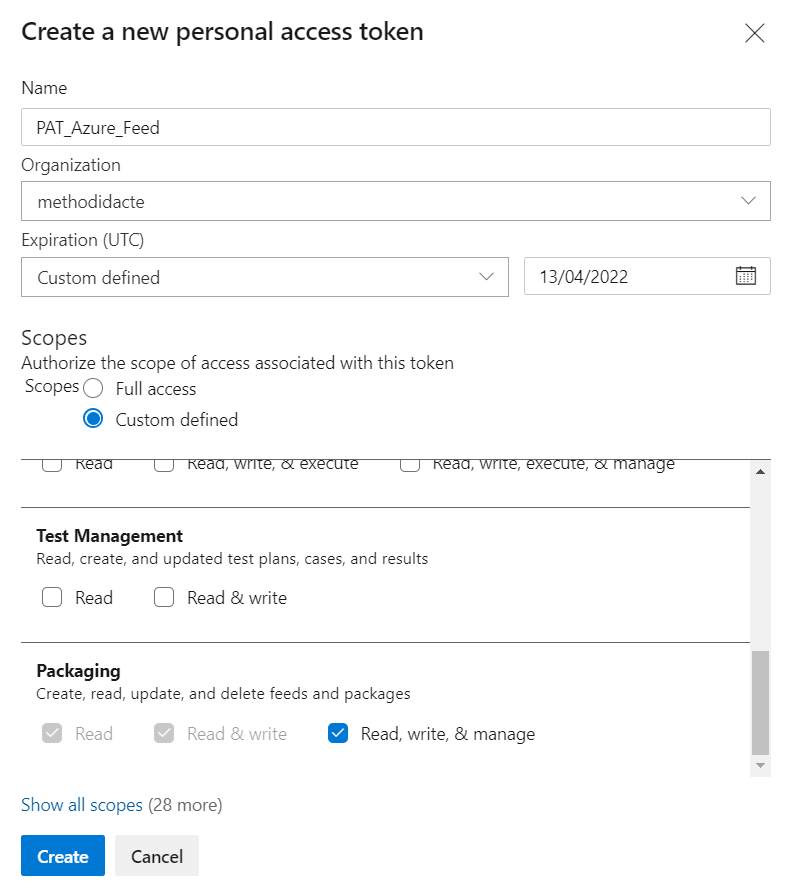
Ce mode n’est bien sûr pas envisageable pour une installation devant s’exécuter de manière autonome. Nous allons donc générer un Personal Access Token (PAT) qui permettra de nous authentifier. Ce jeton s’obtient dans Azure DevOps.
Nous donnons les droits au niveau “packaging“.
Dans l’environnement d’exécution, une variable d’environnement sera nécessaire pour désactiver l’authentification interactive et tenir compte du PAT. Cela se fait par exemple dans Windows par le menu “Modifier les variables d’environnement système” ou dans un dockerfile avec la ligne ci-dessous.
VAR ARTIFACTS_KEYRING_NONINTERACTIVE_MODE=trueIl sera alors possible d’appeler le package avec la syntaxe suivante :
pip install packageName --extra-index-url=https://<PAT>@pkgs.dev.azure.com/<organization_name>/<project_name>/_packaging/<feed_name>/pypi/simple/
Ca y est ! Le package est maintenant installé et nous pouvons nous appuyer sur les fonctions qu’il contient.
from my_pkg.my_function import *
En conclusion
Nous avons mis en place ici une approche dédiée à l’industrialisation d’un développement, accompagné d’un processus CI/CD. Cela demande un investissement en temps et en prise en main de cette procédure mais c’est une garantie de stabilité et de non régression sur le livrable en production.