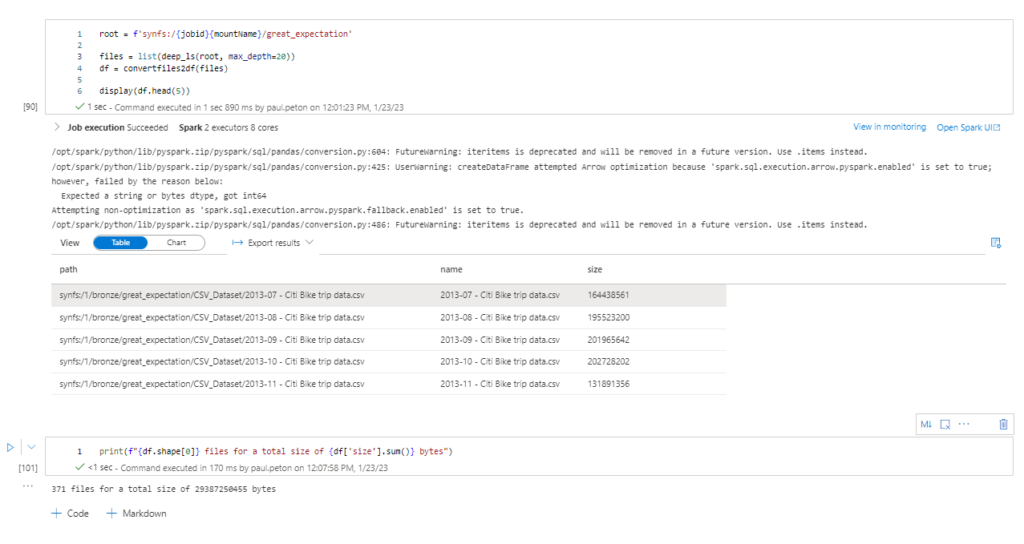
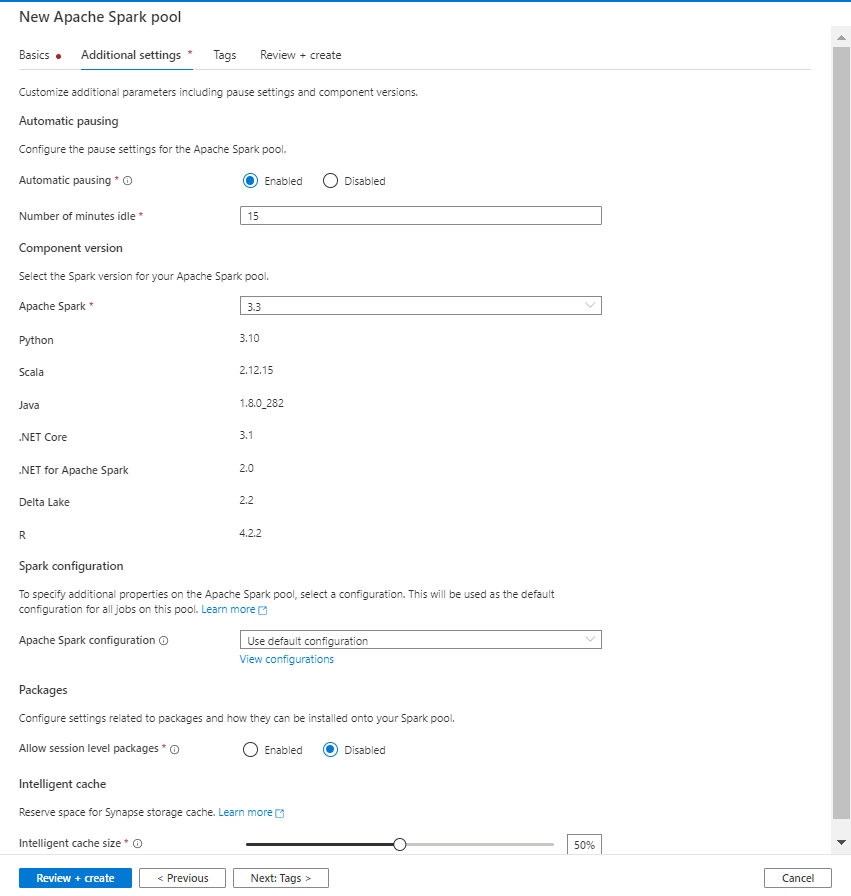
Est-il besoin de présenter la société Open AI dont le modèle GPT3 connaît une renommée planétaire, suite à la mise en service de ChatGPT ?
Au delà du buzz, des exemples humoristiques ou de la recherche des erreurs (souvent dans des cas d’utilisation pour lesquels il n’a pas été entrainé), nous disposons dorénavant d’un accès professionnel aux modèles d’Open AI sous Azure, et ce sous le statut de general availability (GA), c’est-à-dire avec tout le support et garantis de service (SLA) attendus.
Une recherche de “openAI” dans la barre du portail Azure nous donne accès à la création de notre première ressource Azure OpenAI. Il faut remarquer ici que ce service est catégorisé comme un service cognitif, services qui représentent l’intelligence artificielle “appliquée” au sein des services Azure.
Un descriptif du service est donné, citant ses principales fonctionnalités (résumé, génération de contenu ou de code) :
Enable new business solutions with OpenAI’s language generation capabilities powered by GPT-3 models. These models have been pretrained with trillions of words and can easily adapt to your scenario with a few short examples provided at inference. Apply them to numerous scenarios, from summarization to content and code generation.
Azure portal
A ce jour, le modèle GPT est disponible ainsi que CODEX qui s’exprime au travers de GitHub Copilot. La génération d’images grâce au modèle DALL-E est encore en préversion (preview) sous Azure.
Avant de pouvoir réellement accéder à la création du service, un avertissement est donné :
Azure OpenAI Service is currently available to customers via an application process. Request access to Azure OpenAI Service.
Un formulaire sera nécessaire pour obtenir le droit de créer une ressource Azure OpenAI. Au bout d’un délai de quelques jours, vous serez informés de l’approbation ou du rejet de votre demande. Nous allons ici détailler quelques-unes des 35 questions posées afin de bien comprendre les cas d’usage autorisés et les garde-fous posés par Microsoft.

Description des cas d’usage
Please explain how you will use Azure OpenAI Service in your application.
- Please explain the data you will use,
- how you plan to use the models,
- how people will consume or interact with the outputs,
- and more details about the domain or industry in which you will use the application.
PLEASE PROVIDE AT LEAST 5+ SENTENCES. IF YOUR USE CASE IS TOO SHORT OR TOO VAGUE, YOU WILL BE DENIED.
Il s’agit tout d’abord de décrire l’usage qui sera fait du service Azure OpenAI, sur un principe de “bout en bout” : données en entrée, modèle(s) utilisé(s) et interactions avec l’utilisateur. Le cas d’usage doit être suffisamment détaillé et il convient de préciser le domaine ou le secteur d’activités concerné, même si ce dernier point fera l’objet de la question suivante.
Ce paragraphe est particulièrement important et vous devez démontrer qu’une réflexion a déjà été élaborée autour de l’application que vous souhaitez développer. Lorsque vous achetez des outils dans un magasin de bricolage, vous avez sans doute déjà une idée de ce pour quoi vous allez les utiliser !
Domaine(s) d’utilisation
Applications in these domains may require additional mitigations and will be approved only if the customer demonstrates that the risks associated with the application are well-managed and outweighed by the beneficial uses.
Le terme à retenir ici est celui de mitigation (atténuation) que l’on emploie dans l’expression “bias mitigation” pour éviter la correction des biais possibles d’un modèle d’apprentissage. Outre la détection des biais, des actions devront être entreprises pour éviter l’effet néfaste qu’ils pourraient avoir sur les utilisateurs. Des librairies spécifiques existent pour cela comme le produit Open Source FairLearn, développé par Microsoft.
Les différents domaines “à risque” ou dits encore “à enjeux élevés” sont :
- Law enforcement, legal, and criminal justice
- Healthcare and medicine Government and civil services, such as essential private and public services Politics
- Financial services and banking Social media
- Management and operation of critical infrastructure
- Pollution and emission management and control
- Migration, asylum, and border control management
- Education, vocational training, hiring, and employment, such as applications in consequential decision making that impacts one’s opportunities
- Therapy, wellness, relationship coaching or forecasting, such as relationship advice or bots for companionship, emotional support, or romance
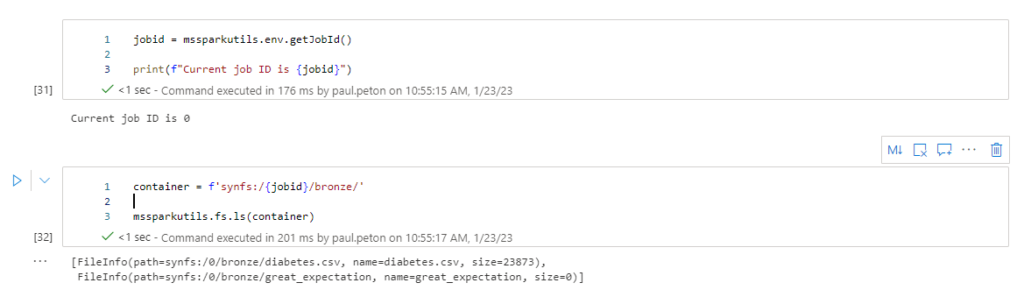
- Military or intelligence
- Other scenario that could have a consequential impact on legal position, life opportunities, or result in physical or psychological injury to an individual if misused
- None of the above. The domain, industry, or scenario do not have the potential to have a consequential impact on legal position, life opportunities, or result in physical or psychological injury to an individual if misused
Il conviendra de cocher “None of the above” si aucun de ces domaines n’est concerné.
Fonctionnalités attendues
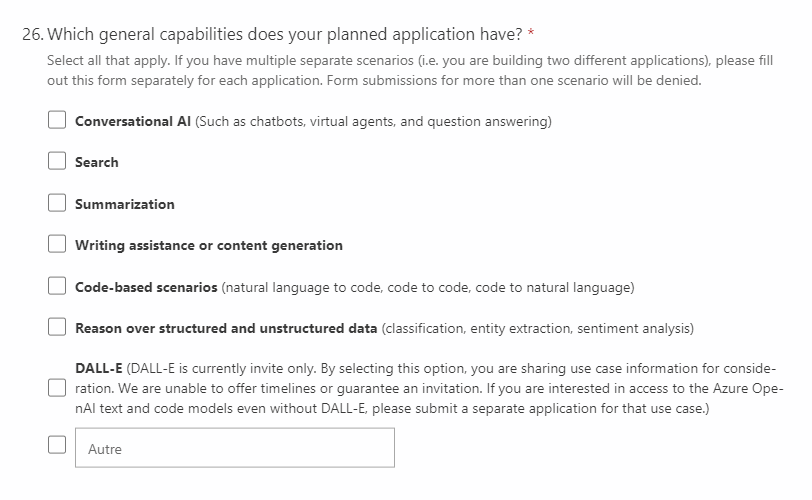
Il serait tentant de tout cocher dans cette question 26 ! En effet, vous avez sûrement beaucoup d’idées d’utilisation des services d’OpenAI mais il faut ici se limiter à ceux qui seront réellement utiles à votre cas d’usage décrit ci-dessus. Il est peu probable qu’un agent conversationnel (chatbot), dans un scénario d’entreprise, propose des images générées par DALL-E ! Soyez donc raisonnables sur les fonctionnalités demandées et si besoin, remplissez plusieurs formulaires, en isolant les applications.
Fonctionnalités spécifiques de l’agent conversationnel
Si vous avez coché la case “Conversational AI” à la question 26, vous devez préciser les fonctionnalités attendues pour l’agent conversationnel.

Attention à nouveau si vous prévoyez de déployer ce bot dans un domaine “à enjeux élevés”.
Acceptation des conditions d’utilisation
Enfin, il sera nécessaire d’approuver explicitement les conditions d’utilisation (“Yes, I agree“) énoncées dans les questions 29 à 35. C’est tout particulièrement sur l’usage en production que vous allez devoir vous engager.
Question 29
29. I understand that mitigations should be considered early in development and must be implemented prior to production.
N’attendez pas d’être en production pour atténuer les biais !
Question 30
30.My application will ensure human oversight prior to production.
This includes never automatically posting generated outputs and never automatically executing generated code. This may also include clearly disclosing AI’s role, communicating relevant limitations to stakeholders (including developers and end users), making sure people (e.g., end users) have a role in decision-making, highlighting inaccuracies in generated outputs, and letting people edit generated outputs.
Ce point nous alerte sur des chaines de CI/CD trop automatisées : un contrôle humain est nécessaire. (Si vous me connaissez bien, vous m’avez déjà entendu pester contre le Continuous Training :))
Question 31
31.My application will implement strong technical limits on inputs from end users and outputs from the system prior to production.
This increases the likelihood your application will perform as expected and decreases the likelihood it can be misused beyond its intended purpose. This may include limiting the length of inputs and outputs, exposing the service to end users through a front end, requiring that inputs and outputs follow a specific structure, returning outputs only from validated source materials, implementing blocklists or content filtering, and implementing rate limits.
En production, un contrôle fort sur les entrées et les sorties sera essentiel. Il s’agit par exemple d’éviter tout détournement de l’usage intial prévu. Ainsi, au démarrage de ChatGPT, il était possible de contourner certaines de ses limites en lui demandant de jouer un rôle.
Question 32
32.I will test my application thoroughly prior to production to ensure it responds in a way that is fit for the application’s purpose.
This includes conducting adversarial testing where trusted testers attempt to find system failures, undesirable behaviors such as producing offensive content, and ways that application can be misused by malicious actors beyond its intended purpose.
Non, tester n’est pas douter ! Ici, il s’agira même d’essayer de “hacker” votre propre application.
Question 33
33.My application will establish feedback channels for users and impacted groups prior to production.
This includes providing ways to report problematic content and misuse such as building feedback features into the user experience and providing an easy to remember email address for feedback submission.
A minima, votre application devra donner un contact simple, par exemple par email, aux utilisateurs qui souhaiteraient faire part de leur réaction. Au mieux, vous pourrez penser une vraie boucle de feedback (human feedback loop), qui vous servira à termes à améliorer le modèle et l’expérience utilisateur.
Question 34
34.My application will follow the Microsoft guidelines for responsible development of conversational AI systems prior to production.
Prenez connaissance des principes pour une IA responsable, donnés par Microsoft.
Question 35
35.I will resubmit this form for a production review before going into production.
Avant le passage en production, et surtout si des changements sont apparus par rapport à l’expression du cas d’usage intial, il sera nécessaire de soumettre à nouveau le formulaire.
Maintenant que vous connaissez les conditions à remplir, vous voilà prêts à décider si l’expérience Azure OpenAI est une opportunité pour vous et votre organisation !