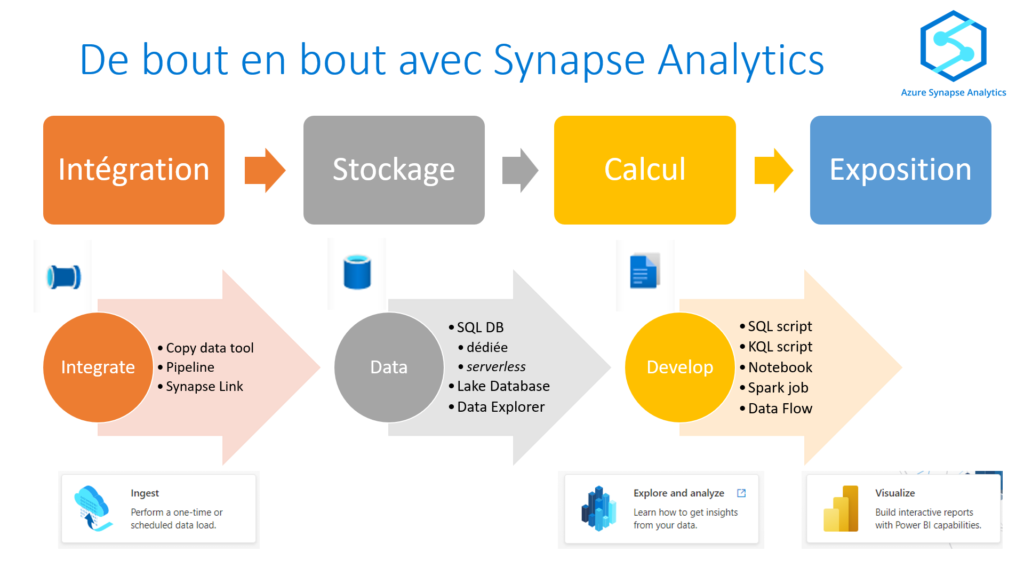
Azure Synapse Analytics (ASA) a remplacé depuis quelques temps Azure SQL Data Warehouse. Mais au delà d’une base SQL de type MPP (“massive parallel processing“), nous avons maintenant accès à des fonctionnalités offrant une vision “bout en bout” des projets data.
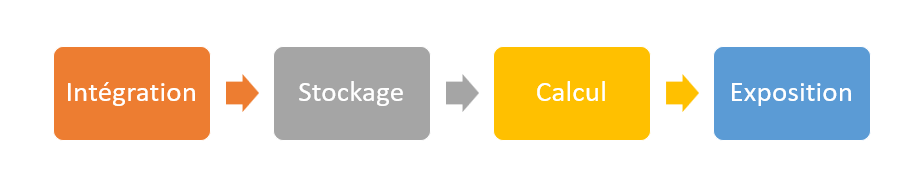
Une fois la ressource Azure provisionnée, nous pouvons lancer le Synapse Studio, dans une fenêtre de navigateur Web.
Le studio présente un menu latéral qui permettra de naviguer entre les différents outils composant Azure Synapse Analytics.
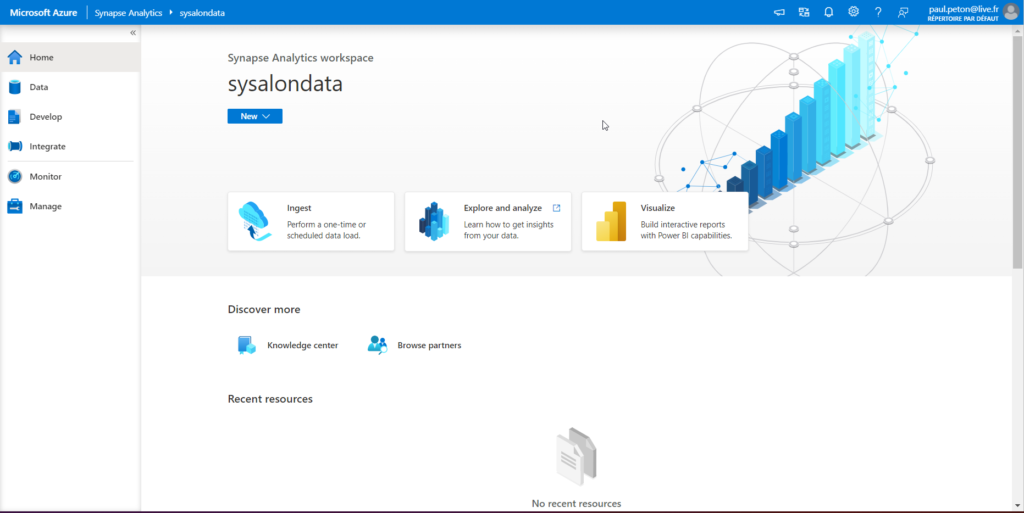
Dans ce premier article introductif, nous allons nous focaliser sur les trois menus Data, Integrate et Develop. Nous traiterons par la suite les aspects de Management et de Monitoring. Nous terminerons cette série sur les bonnes pratiques collaboratives : versioning et intégration / déploiement continus.
Data: le stockage
Si les bases de données (BDD) sont présentes dans notre quotidien depuis plusieurs décennies, le Data Lake (qui reste fondamentalement un système de fichiers…) reste plus récent mais est porté par la dynamique autour des formats de fichiers optimisés pour l’analytique (Parquet, Delta, Iceberg…) et autorisant les transactions (insert, update, delete), opérations qui restaient jusque-là la prérogative des BDD.
Ces deux approches vont se retrouver au sein des services internes à ASA ou en lien (“linked“).
Workspace
De manière “intégrée” dans l’espace de travail (workspace) Synapse, nous retrouvons les bases de données SQL MPP (ex SQL DWH).
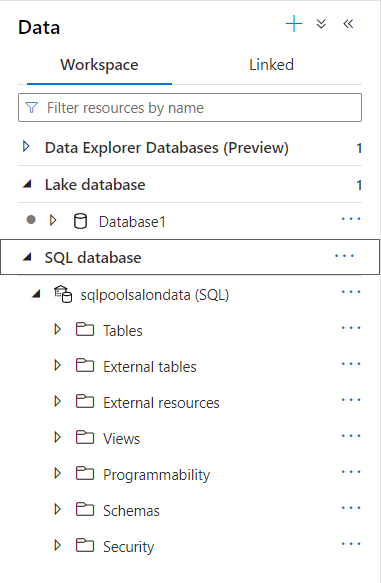
Tous les objets classiques d’une BDD sont disponibles (tables, vues, procédures stockées…) et nous ferons un focus sur la notion de tables externes.
La ressource SQL dite “dédiée” apparaît également dans le groupe de ressources Azure. C’est une ressource dont la performance et l’espace de stockage disponible dépendront du niveau choisi (entre DW100c et DW30000c) et qui pourra être arrêtée ou démarrée. Sa facturation sera fonction de ces éléments.
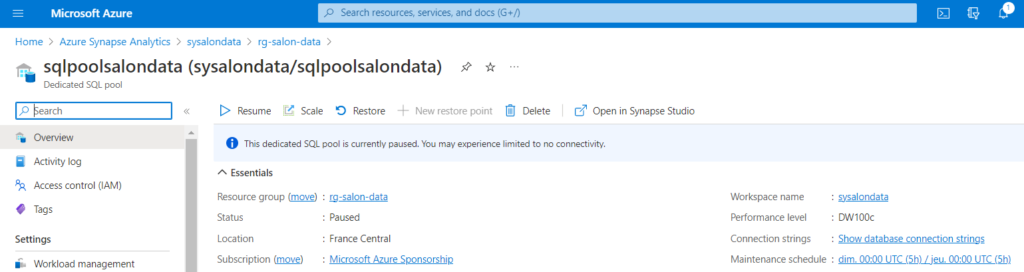
Les tables externes : un fichier “vu” en SQL
Grâce aux tables externes, nous allons pouvoir interroger un système de fichier (Blob Storage, Data Lake) à l’aide d’instructions SQL. Le langage SQL étant si répandu dans le monde professionnel de la data, il s’agit là d’une fonctionnalité particulièrement intéressante.
Un article dédié sera nécessaire pour décrire les cas d’usage des tables externes, différencier tables externes et vues, ainsi que noter les différences entre les deux pools SQL (dédié et serverless).
La nouveauté (2022) : le lake database
Nous avons vu qu’il est désormais facile d’interroger un fichier comme si l’on utilisait une table (plutôt une vue non matérialisée) d’une base de données. Une difficulté va tout de même se présenter lorsqu’il s’agira de bien appréhender le dictionnaire des données (tous les champs disponibles, associés à leur type respectif) ainsi que les relations entre les différents fichiers (au sens des cardinalités : un à plusieurs, plusieurs à plusieurs, etc.).
Le Lake Database vient proposer une solution à cette problématique, en proposant de mieux visualiser toutes les métadonnées, tout en conservant un stockage de type fichier. De manière sous-jacente, ce sont les ressources SQL Pool serverless ou Spark Pool qui seront utilisées.
Nous créons pour cela une base de type lake, en définissant le container de stockage des données (input folder) ainsi que le format à utiliser (.csv ou .parquet, Delta à venir).
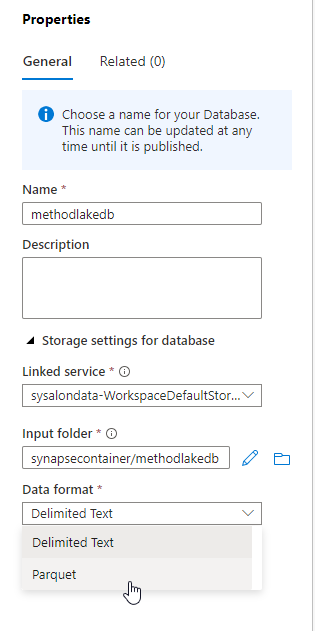
Nous pouvons maintenant utiliser l’interface visuelle pour définir des tables:
- personnalisées (custom), c’est-à-dire en renseignant chaque champ manuellement
- depuis des modèles (template) proposés
- depuis des fichiers du Data Lake
Visitons la galerie de modèles, ceux-ci couvrent de nombreux domaines fonctionnels.
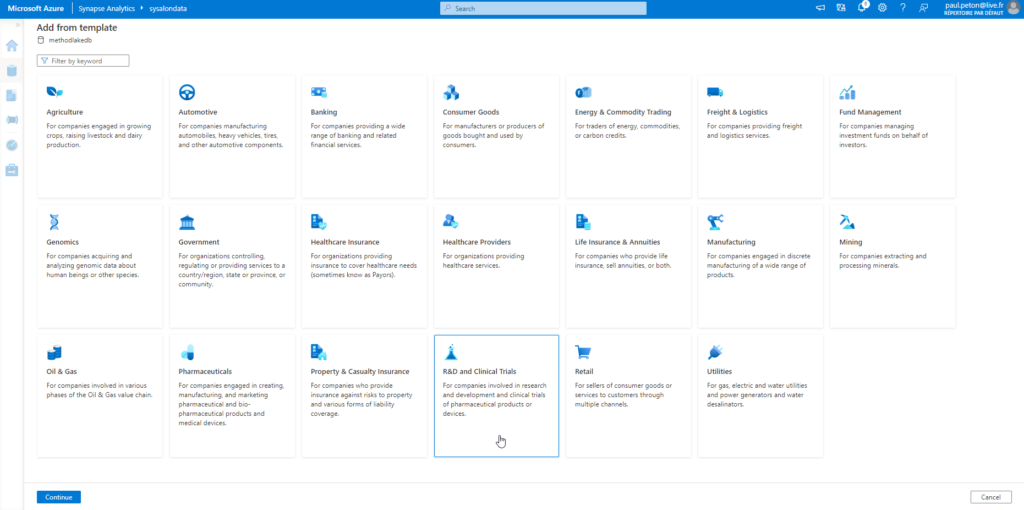
Par domaine, nous disposons d’un grand nombre de schémas de tables, pour lesquelles les clés primaires et étrangères sont déjà déterminées. Nous obtenons donc déjà des relations dans le modèle en cours de création.
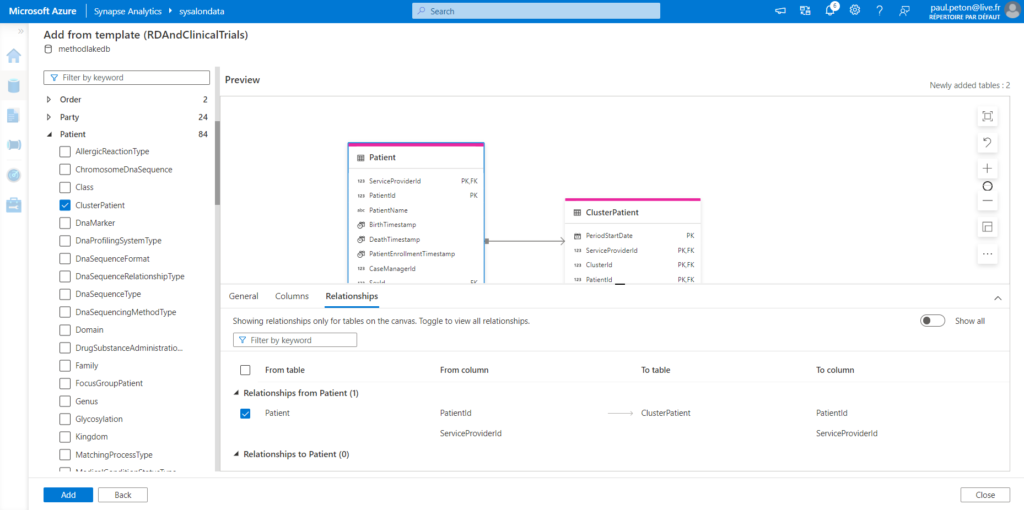
Les tables (vides pour l’instant) sont maintenant visibles dans le menu latéral de navigation.
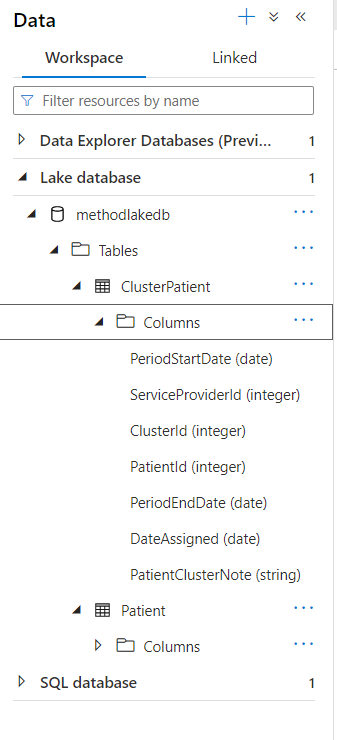
Il sera alors nécessaire de remplir les tables, soit par des instructions SQL INSERT, soit au moyen de l’outil de mapping présenté dans la documentation officielle.
Un bon cas d’usage consiste à mapper les champs du Dataverse utilisé par les produits de la Power Platform. En effet, nous découvrirons ci-dessous la fonctionnalité Synapse Link qui permettra une synchronisation des données en quasi temps réel.
Linked
Les ressources liées sont par définition extérieures à la ressource Synapse Analytics. On utilisera ici principalement un ou plusieurs Data Lake Azure (de génération 2 uniquement) dont les différents file systems seront visibles.
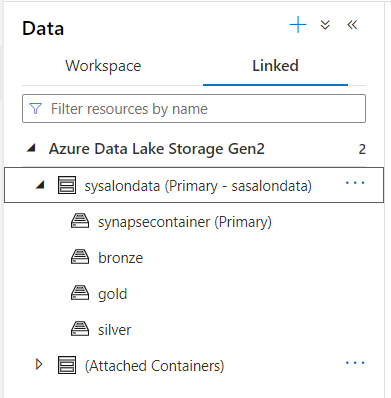
La liste des services externes est présentée ci-dessous.

Il n’est étonnant de retrouver le stockage Blob car le Data Lake de génération 2 n’est autre qu’un Blob Storage augmenté par un “hierarchical namespace“. Nous retrouvons également deux APIs de la base Cosmos DB : l’API native pour le NoSQL et l’API pour MongoDB. Nous écartons donc les APIs PostgreSQL, Cassandra ou Gremlin.
Les integration datasets listeront toutes les sources ou destinations (sink) des pipelines de données qui seront abordés dans le prochain paragraphe. Ainsi, pour une source de type file system, nous disposerons des formats de fichiers suivants:

Integrate : les pipelines “no code”
L’intégration de données consiste à faire entrer dans un environnement de destination des données issues d’une ou plusieurs sources, et ce, à des intervalles de temps réguliers ou sur la détection d’événements (par l’exemple, l’arrivée de fichiers dans un data lake déclenche leur intégration en base de données).
Pipeline
Nous voici dans un univers bien connu des utilisateur.ices d’Azure Data Factory, même si la parité des fonctions n’est pas encore totalement établie (janvier 2023).
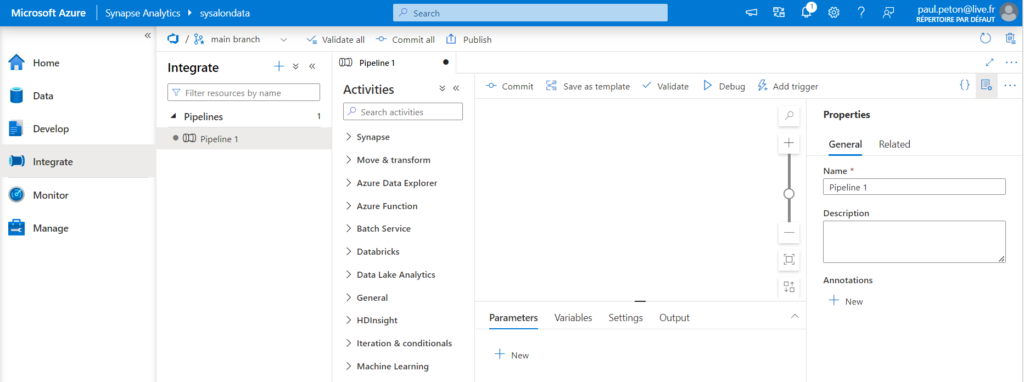
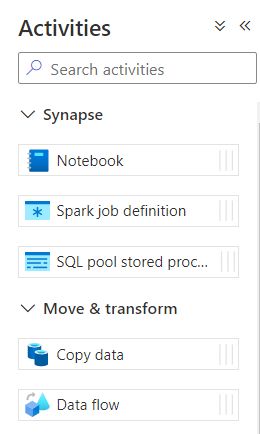
Un pipeline est composé d’une ou plusieurs activités, s’exécutant en parallèle ou bien s’enchaînant selon des règles définies.
L’activité de base est la copie de données (copy data) et nous retrouvons également trois activités permettant d’ordonnancer d’autres éléments propres à ASA : les jobs Spark et les procédures stockées SQL.
Synapse Link Connection
Azure Synapse Link est un outil permettant un transfert rapide de données vers une base SQL dédiée (SQL dedicated pool) depuis des sources comme :
- Azure SQL DB
- SQL Server 2022 (on premises)
- Azure Cosmos DB (APIs NoSQL, Cosmos DB & Gremlin)
- Dataverse
L’objectif est ici de réaliser, “near real time“, des travaux analytiques depuis les données enregistrées dans des bases dont l’usage est plutôt transactionnel. Il n’est plus nécessaire ici de déployer des pipelines ou jobs d’intégration.
Copy Data Tool
Il s’agit sans doute de la manière la plus simple pour copier des données d’une source à une destination (sink).
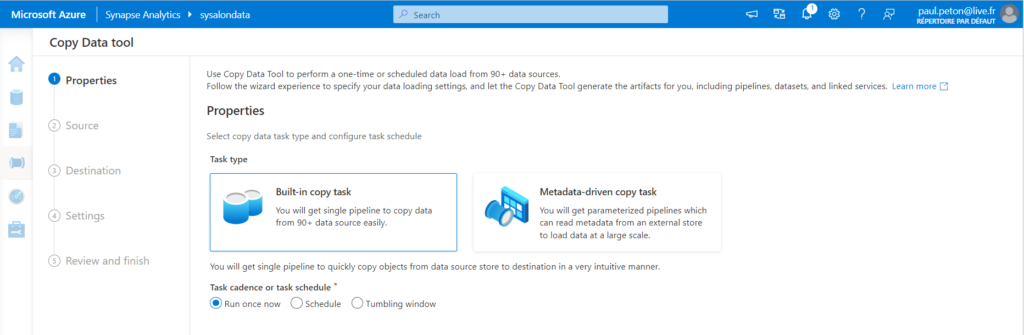
Ici, il n’est pas envisageable d’ajouter des transformations plus poussées lors de la copie. Nous retrouvons toutefois les propriétés de déclenchement :
- unique
- planifié
- sur des fenêtres glissantes (tumbling windows)
Develop : l’approche “full code”
Les différents scripts compatibles avec les éléments de ASA sont présentés ci-dessous.
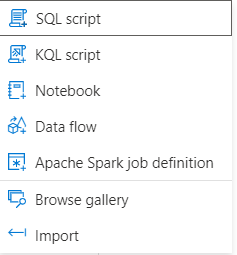
Les data flows pourraient sembler être un intrus dans cette liste car c’est bien une interface de type “no code” qui va permettre de les développer. La justification tient sans doute dans le fait que les data flows sont convertis en langage Spark lors de leur exécution.
De même, les jobs Apache Spark fonctionnent à partir de fichiers .JAR qui ne seront pas développés directement dans le studio ASA.
Les scripts SQL travaillent sur les bases de données de type SQL Pools (serverless ou dedicated).
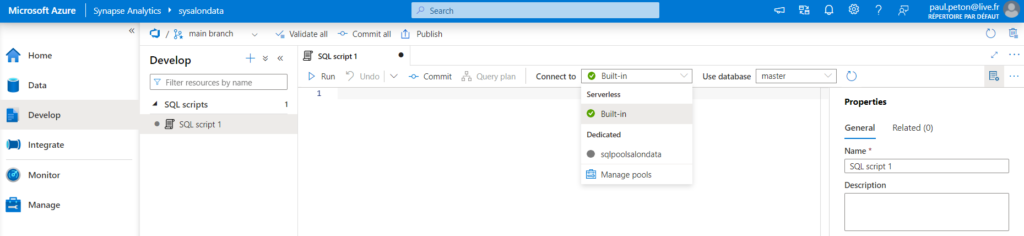
Les scripts KQL (KustoQL) travaillent uniquement sur les bases de données Azure Data Explorer.
Les notebooks s’exécutent grâce à un Pool Spark et peuvent interagir avec les données, qu’elles soient sous forme de fichiers ou intégrées dans les bases de données de type SQL (et non KQL), à l’aide d’un connecteur JDBC.
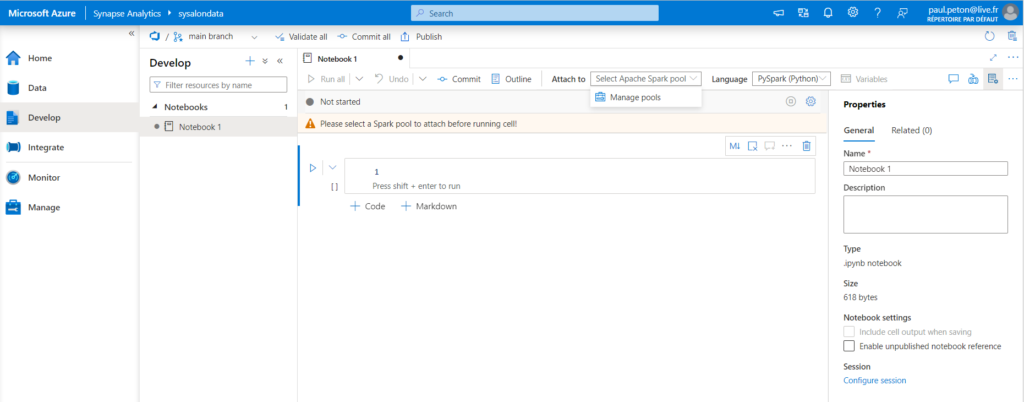
Nous devons tout d’abord instancier un pool Apache Spark, tout comme nous avons dû créer un pool SQL dédié. Seul le pool SQL serverless est présent par défaut dans le workspace ASA.
Le pool est une grappe (cluster) de plusieurs machines virtuelles (nodes), puisque Spark est un framework distribué.
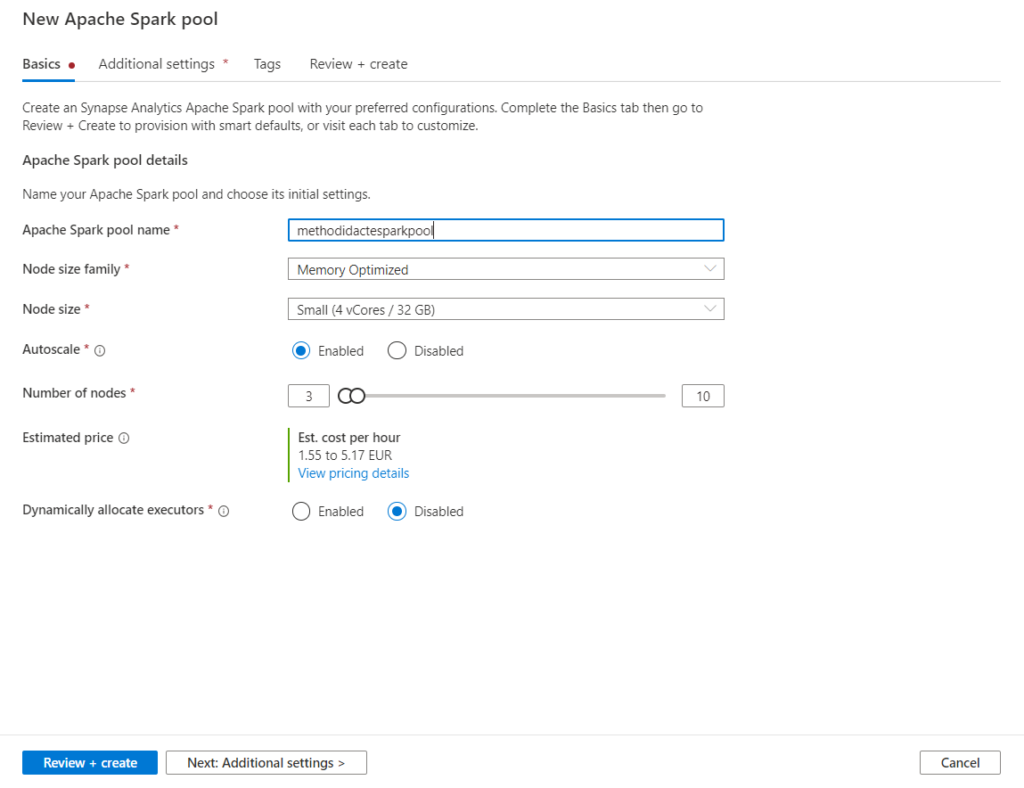
La version de Spark est modifiable, elle conditionne les versions des langages sous-jacents (Python, Scala, Java, .NET, R…)
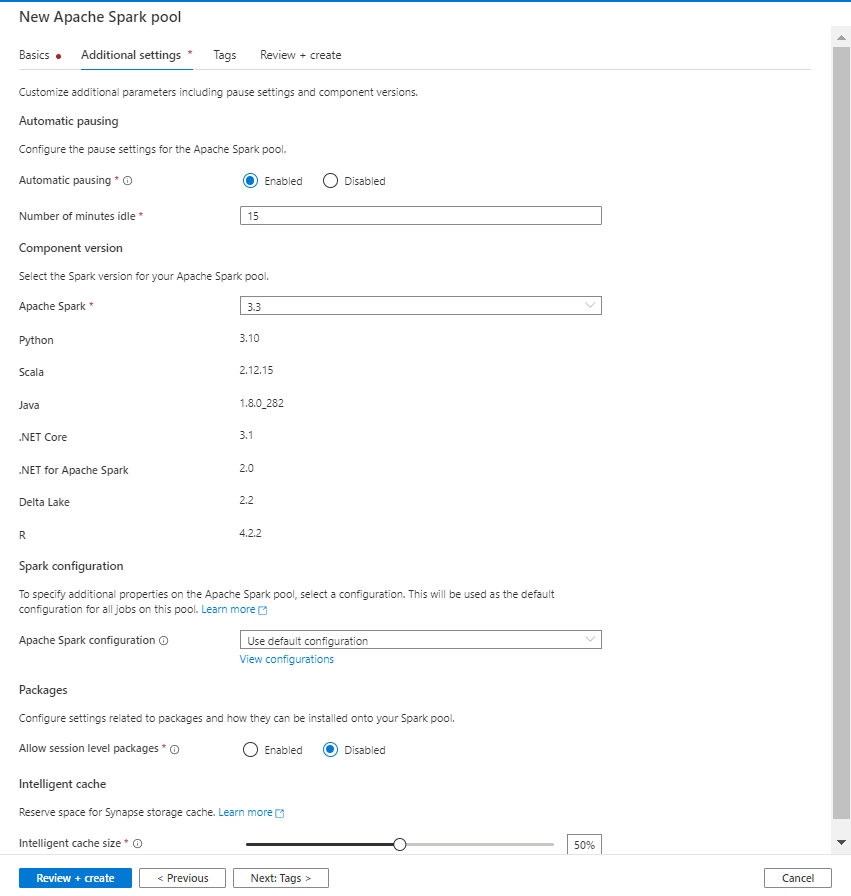
La propriété “automatic pausing” est intéressante afin de réduire les coûts d’utilisation mais nous verrons, dans un prochain article, qu’elle implique une gestion fine des sessions Spark.
Premier exemple “de bout en bout”
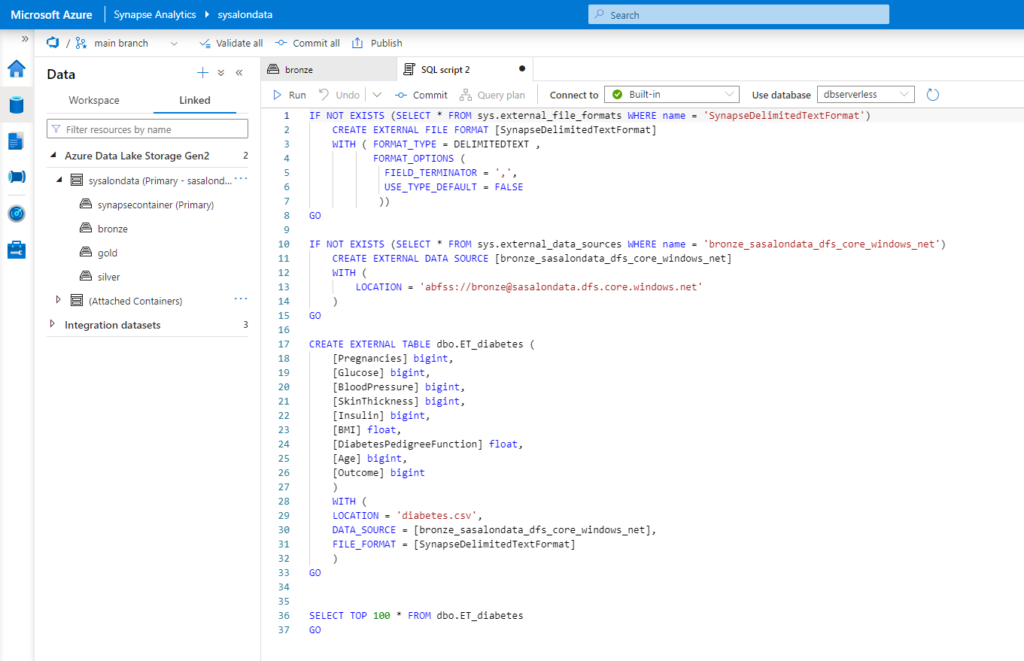
Prenons l’exemple d’un fichier .csv “brut” qui a été uploadé dans le container Bronze du Data Lake.
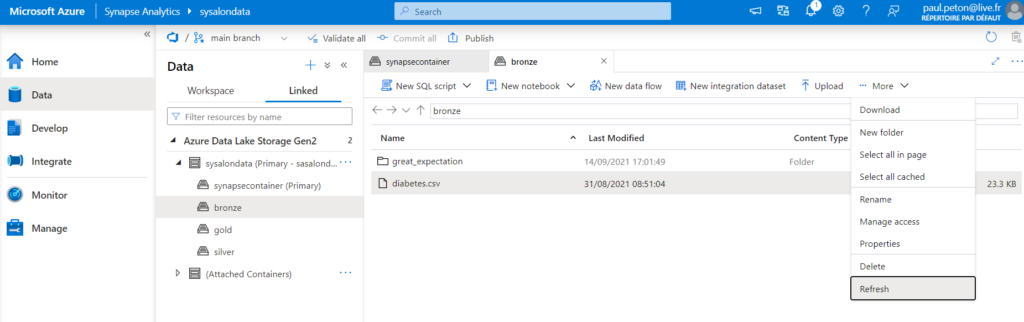
Notre premier objectif sera de stoker le fichier dans un format optimisé comme Parquet dans le container Silver. Nous avons pour cela plusieurs possibilités.
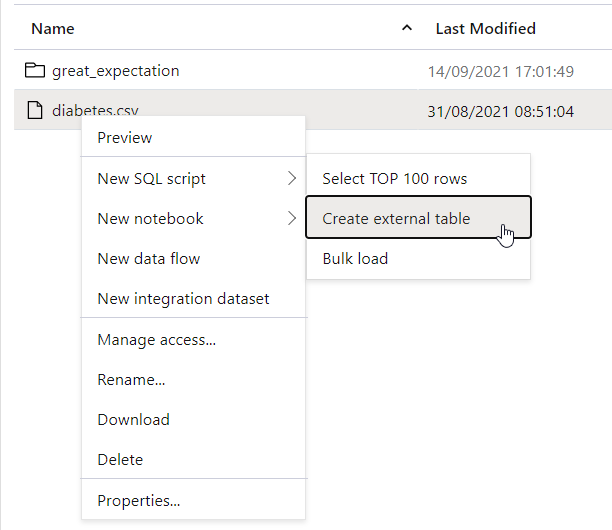
Lire avec OPENROWSET
Un clic droit sur un fichier ou un répertoire propose les options suivantes.
Voici le code automatiquement généré par un “Select TOP 100 rows”.
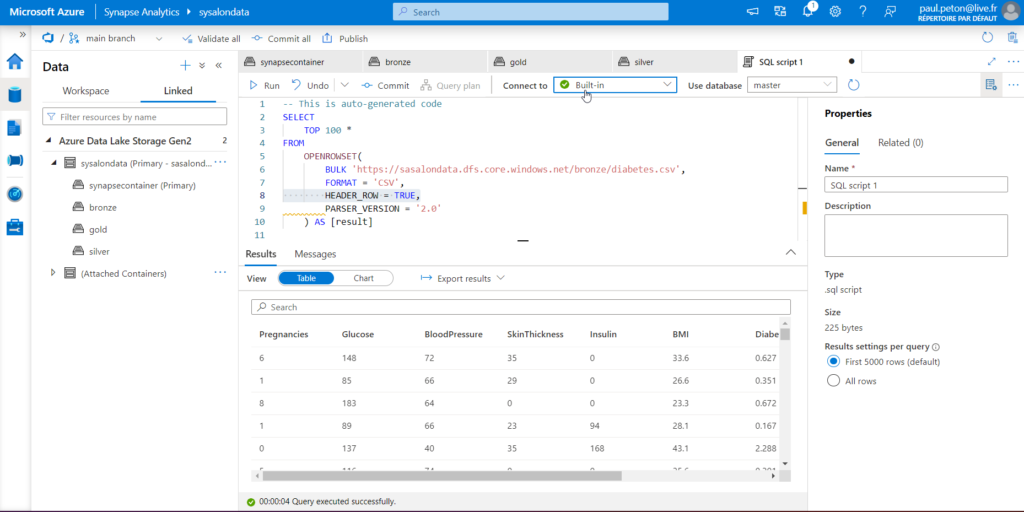
Il est nécessaire d’ajouter l’option HEADER_ROW = TRUE afin de considérer la première ligne du fichier comme l’en-tête. Les autres bulk options sont données dans cette documentation officielle.
Pipeline de copie de CSV vers Parquet
Il s’agit ici de réaliser une copie conforme de la source mais nous allons utiliser pour cela l’outil “copy data tool” car l’objectif est de changer de format de fichier. Nous définissons donc une activité de copie dans un pipeline de type Azure Data Factory.
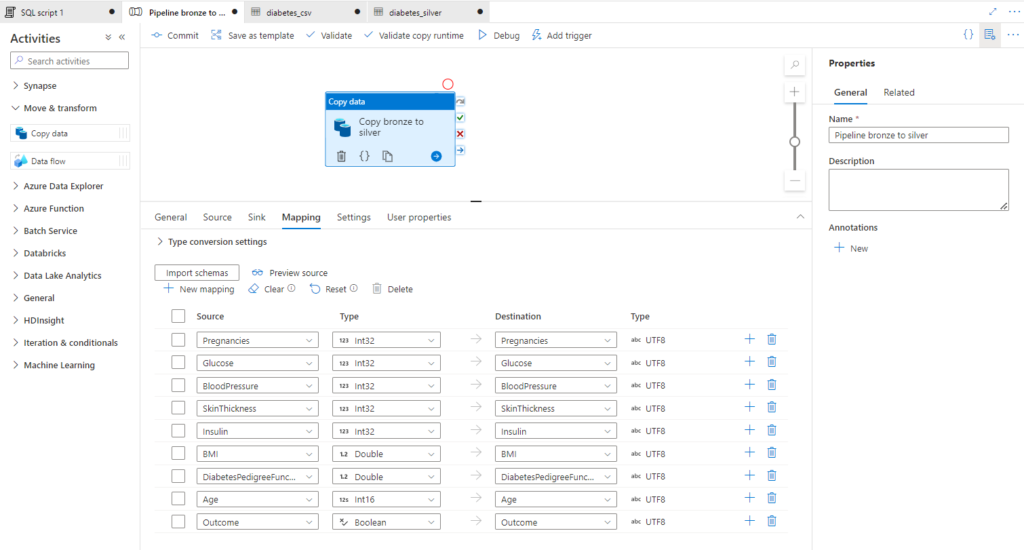
Le mapping permet de définir le type de données contenues dans chaque champ. C’est en effet une propriété des fichiers .parquet que de pouvoir stocker cette information.
Pipeline de copie du fichier Parquet dans une table
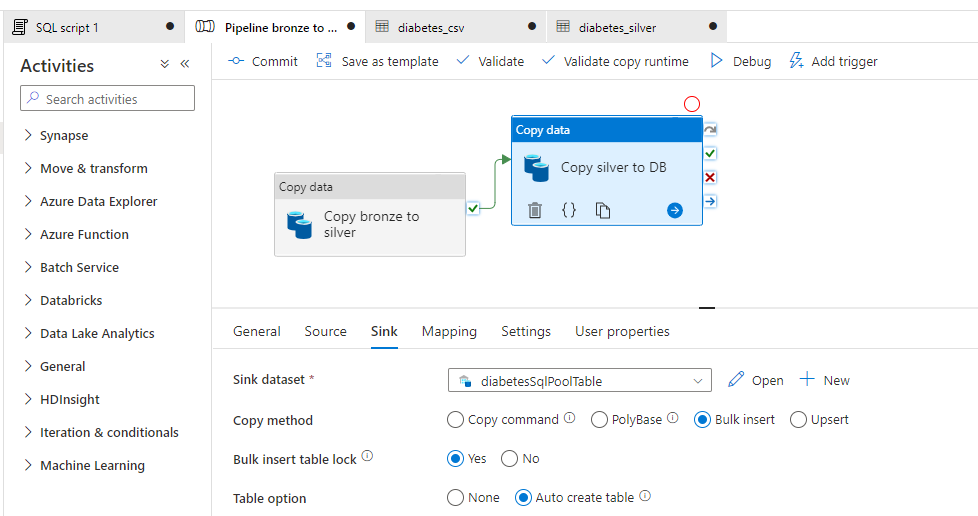
Posons l’objectif de matérialiser les données au sein de la BDD. Nous allons donc utiliser le pool SQL dédié. En effet, dans sa version serverless, nous ne faisons que créer des métadonnées facilitant l’interprétation des fichiers comme des vues.
Nous faisons de nouveau appel à une activité de copie dans un pipeline de type Azure Data Factory. Nous allons laisser le soin à l’activité de copie de créer directement le schéma de table attendu. Pour cela, nous choisissons le mode “Bulk insert” et l’option “Auto create table”.
Nous pouvons maintenant visualiser la table de destination dans le pool dédié et l’interroger au moyen du langage SQL.
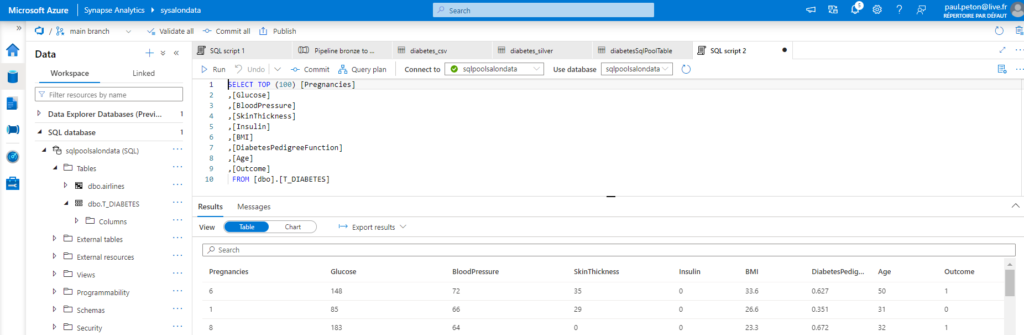
En guise de conclusion, et avant de rentrer plus en détails dans certains aspects de cette ressource Azure, nous avons montré ici la polyvalence de l’outil pour les scénarios analytiques :
- à partir de fichiers de données ou de tables contenues dans une base de données
- avec la simplicité de la syntaxe SQL directement sur le contenu des fichiers
- dans une démarche no code ou full code, selon les compétences des utilisateurs.