Nous avons présenté dans un précédent article la plateforme de Data Science de Dataïku et son installation sur une VM dans Azure. Nous avons également déjà abordé la connexion à un compte de stockage Azure, afin de lire des fichiers de données ou d’écrire les différents résultats obtenus.
Dans un Système d’Information non centré autour du Data Lake, certaines données particulièrement intéressantes pour le Machine Learning peuvent être stockées dans les tables d’une base de données, souvent orientée “analytique”. Le Data Warehouse d’Azure, Synapse Analytics, est disponible dans les connexions prévues par Dataïku DSS. Nous allons détailler ici les actions à réaliser pour définir la connexion à la base de données. Un grand merci à mon collègue Benjamin BENITO qui a réalisé les opérations techniques décrites ci-dessous.
Dans les paramètres de Dataïku DSS, nous pouvons trouver la liste des différentes bases de données SQL compatibles avec le Studio de Data Science.
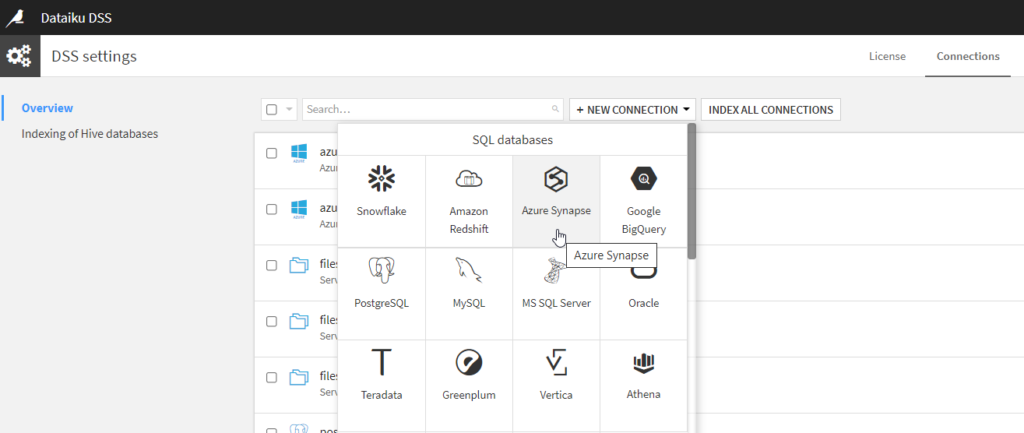
Nous choisissons Azure Synapse. Il faut noter, que dans une exploitation plus large des capacités de Synapse Analytics, il sera aussi possible d’utiliser cette ressource comme moteur de calcul Spark. Nous verrons ceci dans un prochain article.
Dedicated SQL Pool
Une base de données de type “dedicated SQL pool” aura été préalablement créée du côté de Synapse Analytics.
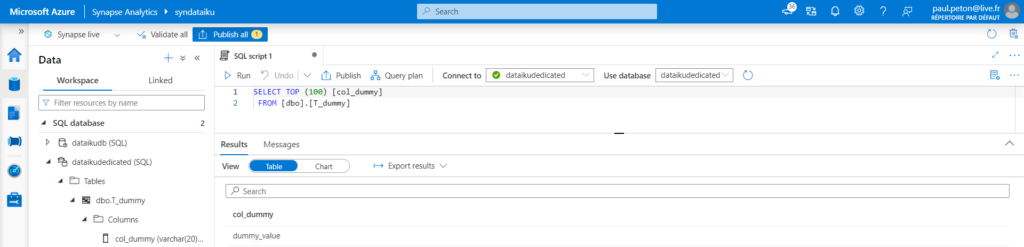
Nous pouvons maintenant renseigner les différents éléments attendus pour la définition de la connexion. Commençons par cocher la case “Use custom JDBC URL”.
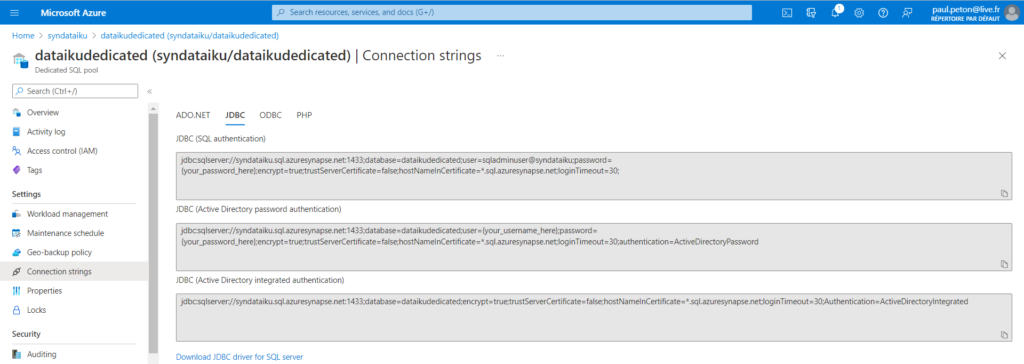
L’URL JDBC se trouve sur le portail Azure, à la page de la ressource Dedicated SQL Pool, onglet “connection strings“. Nous utiliserons ici la première version, utilisant la connexion SQL.
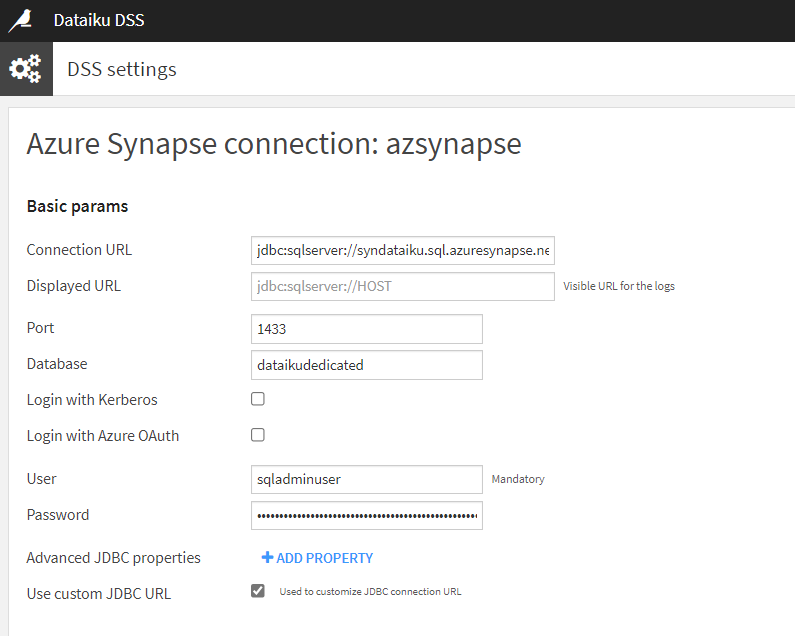
L’URL JDBC se détaille comme ci-dessous.
jdbc:sqlserver://<synapse-name>.sql.azuresynapse.net:1433;database=<db-name>;user=<admin-login>@<synapse-name>;password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;
Il faudra remplacer ici le texte {your_password_here} par le mot de passe du compte administrateur.
Ces informations, ainsi que le port ouvert (1433) pourront également être précisées dans les cases disponibles. Il ne reste plus alors qu’à tester la connexion à l’aide du bouton situé en bas à gauche de l’écran. Je vous recommande de créer la connexion (bouton “create”) au préalable afin de sauvegarder les informations saisies.
Il est alors fort probable que vous soyez confronté.e.s à l’erreur ci-dessous.
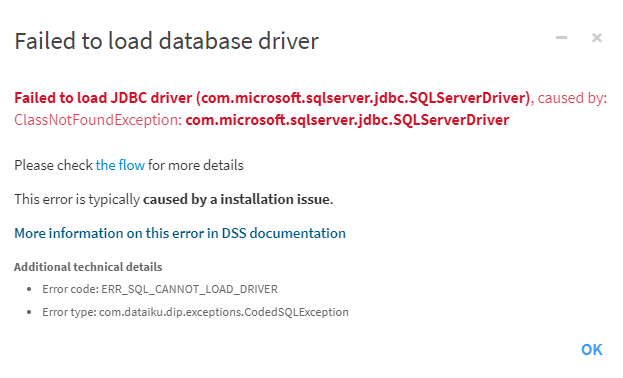
Cette erreur est due à l’absence de driver SQL Server sur la VM où est installé Dataïku DSS. L’URL suivante détaille cette erreur.
ERR_SQL_CANNOT_LOAD_DRIVER: Failed to load database driver — Dataiku DSS 9.0 documentation
Nous allons donc nous connecter à cette machine virtuelle Linux pour effectuer manuellement l’installation du driver attendu. Nous devons disposer pour cela d’un login / password ou d’une clé SSH.
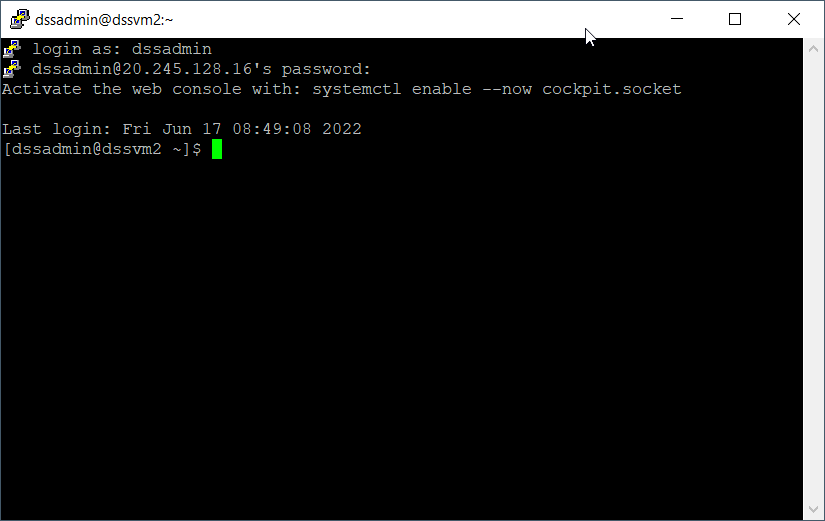
Voici les différentes commandes à jouer successivement.
wget -O /tmp/sqljdbc_10.2.1.0_enu.zip https://download.microsoft.com/download/4/d/5/4d5a79be-35f8-48d4-a984-473747362f99/sqljdbc_10.2.1.0_enu.zip unzip /tmp/sqljdbc_10.2.1.0_enu.zip -d /tmp/ sudo cp /tmp/sqljdbc_10.2\enu/mssql-jdbc-10.2.1.jre8.jar /home/dataiku/dss/lib/jdbc/ sudo su dataiku dataiku/dss/bin/dss stop dataiku/dss/bin/dss start
Les premières commandes réalisent le téléchargement du binaire nécessaire, le dézippe puis le copie à l’endroit attendu. Un restart de DSS est ensuite nécessaire.
La connexion est maintenant établie !
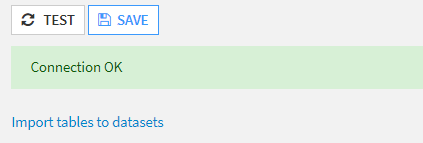
Nous pouvons utiliser le lien “Import tables to datasets” pour obtenir des données stockées dans le Data Warehouse.

Serverless SQL Pool
Pour utiliser le mode serverless de Synapse Analytics, nous devrions nous orienter vers un autre type d’authentification. En effet, ce mode correspond à la création de méta-données sur des fichiers présents dans un Data Lake mais sans matérialisation dans le Data Warehouse. Des droits sous-jacents (sur les fichiers du Data Lake) sont donc nécessaires et il n’est pas possible d’attribuer de tels droits au user connu uniquement de la base de données.
Le message d’erreur rencontré sera alors :
Failed to read data from table, caused by: SQLServerException: External table 'dbo.<external_table>' is not accessible because location does not exist or it is used by another process.
La documentation officielle de Dataïku donne toutes les étapes permettant d’utiliser l’authentification au travers d’Azure Active Directory.
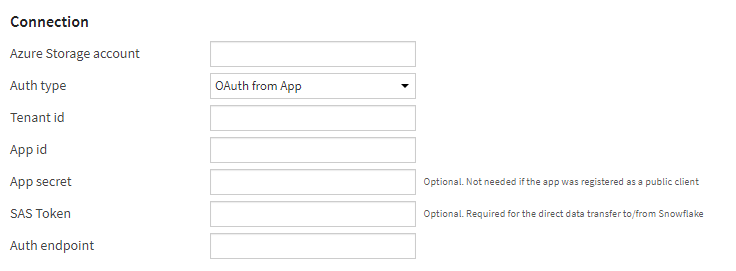
Nous avons besoin d’un Principal de Service, c’est-à-dire d’une identité dans Azure. Nous relevons tout d’abord l’application ID (ou client ID) qu’il sera nécessaire de renseigner dans Dataïku DSS.
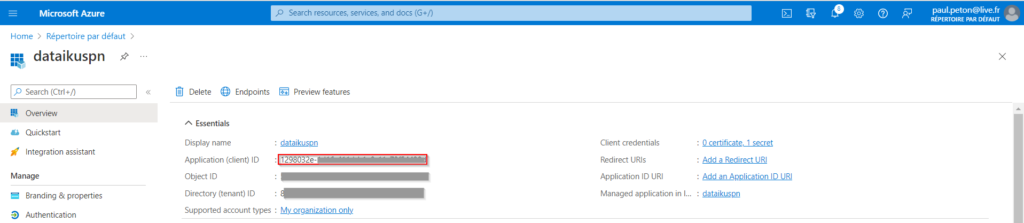
Dans le menu “Endpoints”, nous notons l’information de l’OAuth 2.0 token endpoint (v1).
Dans le menu “API permisssions”, nous devons ajouter la permission Azure SQL Database.
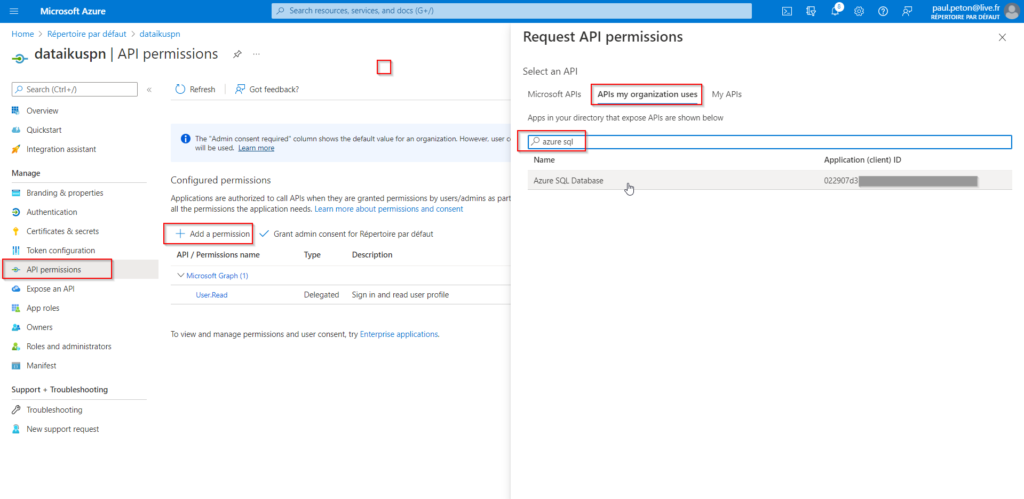
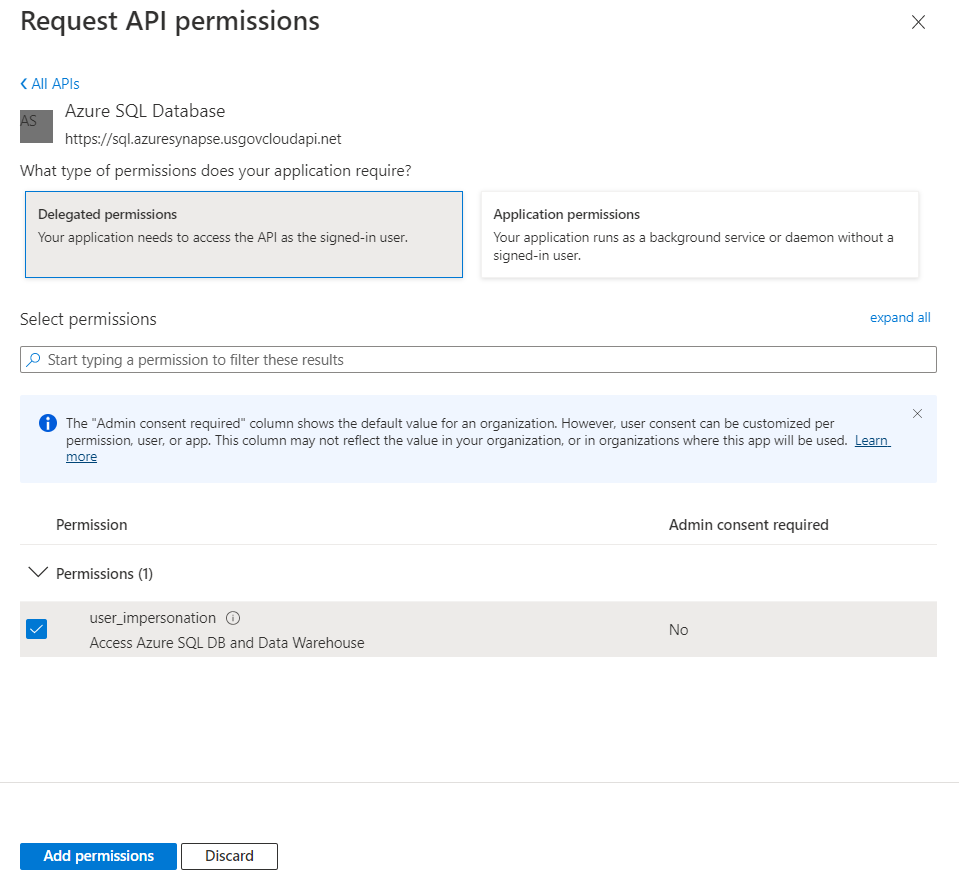
Choisir ensuite “Delegated permissions” puis cocher la case user_impersonation.
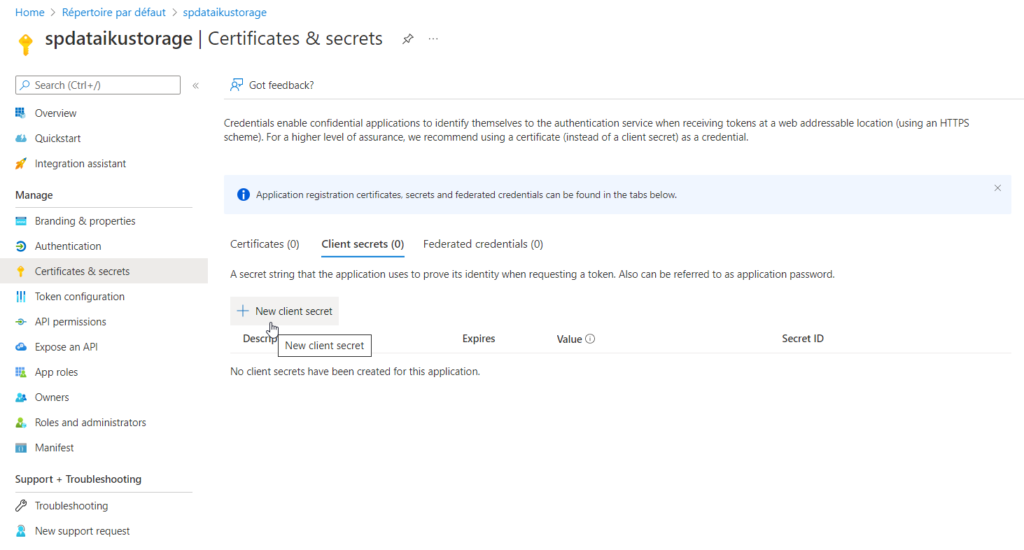
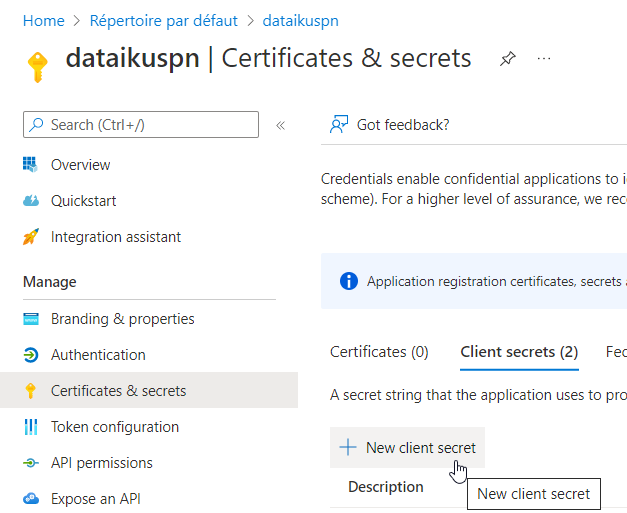
Nous terminons le paramétrage de cette identité en lui associant un secret. Notez ici bien la valeur du secret, que vous ne pourrez plus retrouver par la suite.
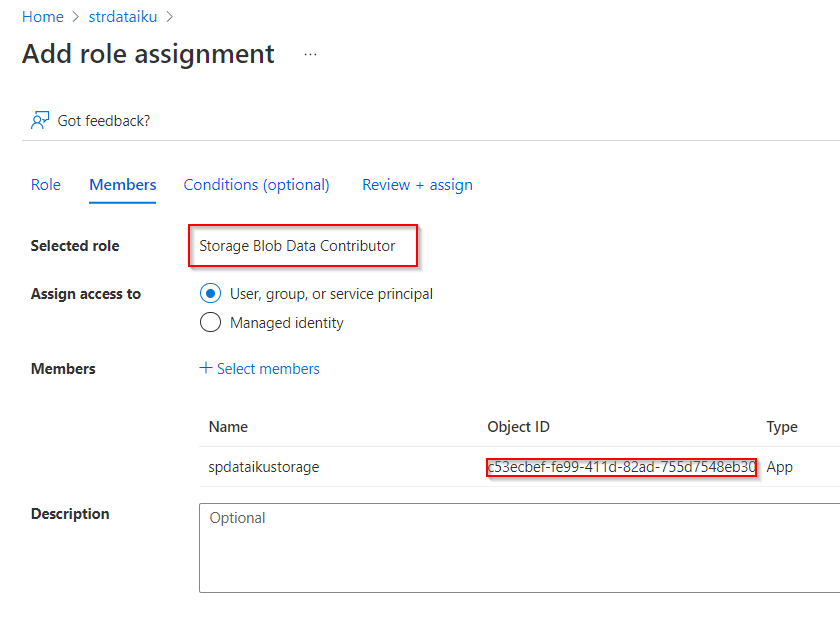
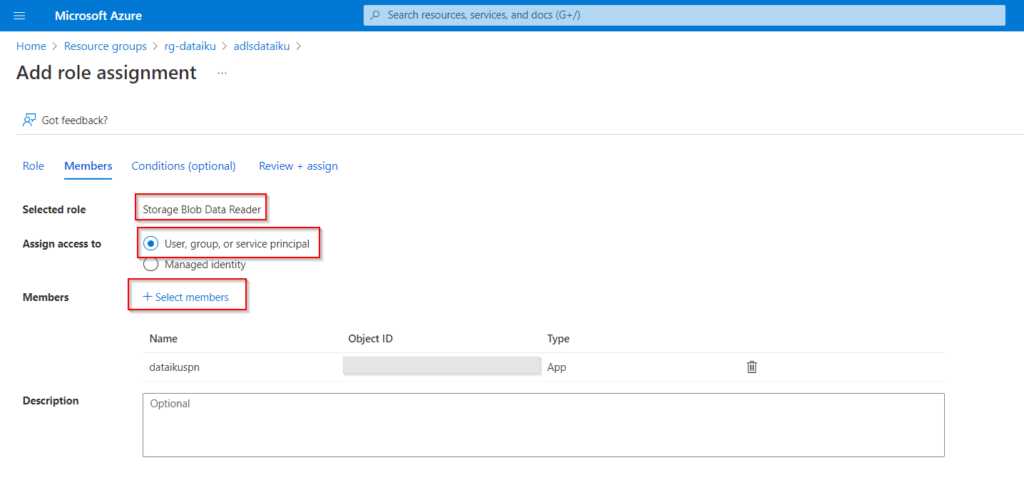
Toujours dans le portail Azure, il faut donner les droits de lecture sur le Data Lake au principal de service. Cela se fait au moyen de l’ajout d’un RBAC de type “Blob storage data reader”.
Sinon, une erreur comme ci-dessous se produira lors de l’aperçu de la table ou de la vue :
Failed to read data from table, caused by: SQLServerException: File 'https://adlsdataiku.dfs.core.windows.net/dataiku/input/diamonds.csv' cannot be opened because it does not exist or it is used by another process.
Nous reprenons maintenant la définition d’une nouvelle connexion Synapse Analytics depuis le Data Science Studio.
En cochant la case “Use custom JDBC URL”, il faut donner une Connection URL de la forme suivante :
jdbc:sqlserver://<synapse-name>-ondemand.sql.azuresynapse.net:1433;database=master;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30
Nous précisons le port (1433 par défaut) et le nom de la Database.
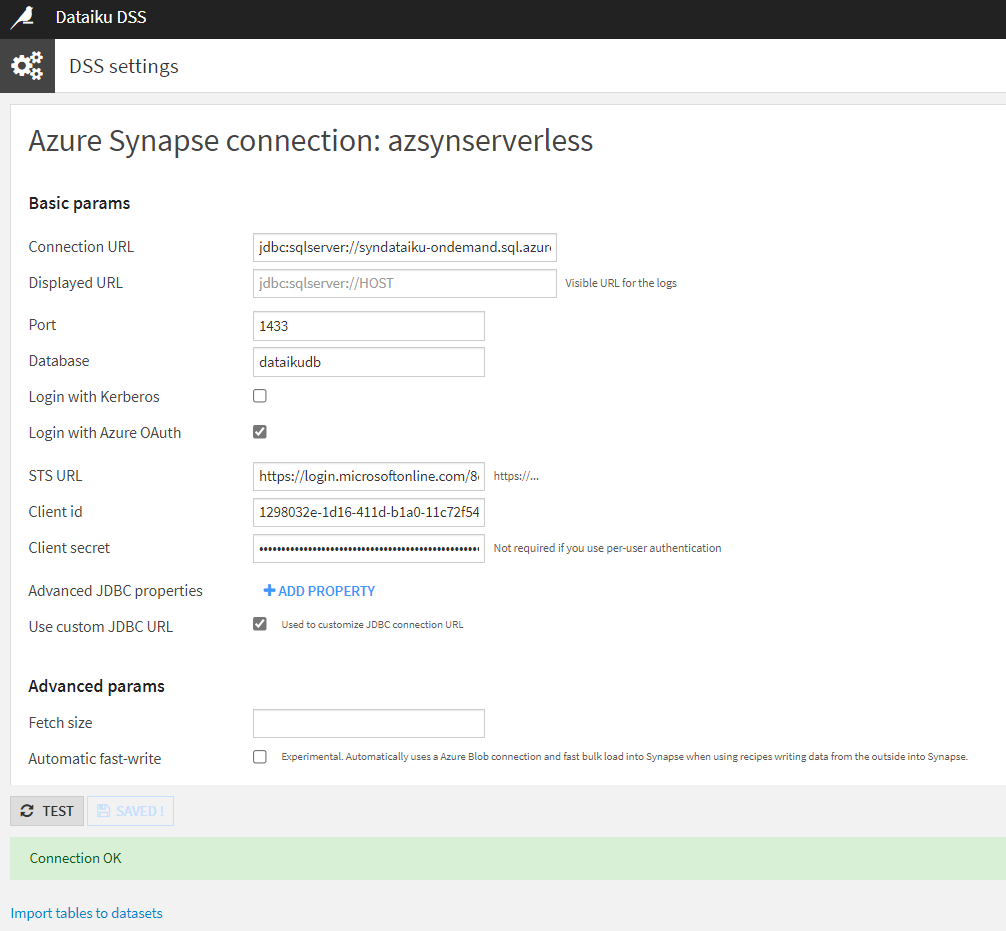
Pour la partie liée à l’Azure AD, il faut cocher la case “Login with Azure OAuth” puis coller les informations préalablement collectées :
- STS URL (OAuth 2.0 token endpoint (v1))
- Client id (application id)
- Client secret (la valeur du secret et non le secret id)
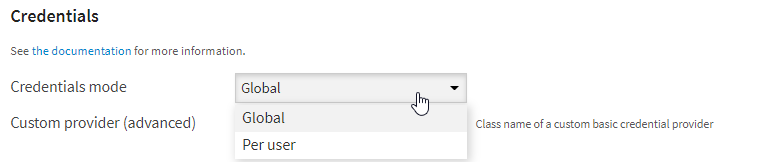
Deux modes de “credentials” sont possibles : Global ou Per user. Ce second mode signifie que c’est le login utilisé dans DSS qui est repris pour s’authentifier auprès de la base Synapse. Il ne sera alors pas nécessaire de renseigner le client secret.
Depuis Synapse Analytics, dans une nouvelle requête SQL, nous allons déclarer le principal de service (SPN) comme un utilisateur de la base de données. Veillez à bien être connecté à “Built-in”, c’est-à-dire la base serverless.

Voici le code à exécuter, où le nom du SPN doit être mis à jour. Il est nécessaire d’attribuer des droits de type “BULK” puis “SELECT” sur les objets qui seront autorisés à Dataïku DSS.
CREATE USER [dataikuspn] FROM EXTERNAL PROVIDER WITH DEFAULT_SCHEMA=[dbo]; GO GRANT ADMINISTER DATABASE BULK OPERATIONS TO dataikuspn; GO GRANT SELECT ON OBJECT::dbo.V_diamonds TO [dataikuspn]; GO
Il est maintenant possible d’ouvrir la liste des tables à importer depuis l’interface de DSS.

Ce second scénario s’avère intéressant pour limiter les coûts d’utilisation de Synapse Analytics (coût à la quantité de données lues) et facilite l’exploitation des données du Data Lake qui auront pu être réorganisées sous forme de vues SQL plus lisibles des utilisateurs de Dataïku.