
Cette certification Microsoft a vu son contenu complètement remis à jour au 22 janvier 2020. Le contenu tourne maintenant exclusivement autour de Azure Machine Learning Service. Mais ce service Azure et son portail d’accès (dit le « studio ») regorgent d’outils aussi bien graphiques (Designer, Automated ML) que destinés au code (SDK et la librairie azureml.core). Dans cet article, je vous propose mes notes préparatoires à cette certification, en conservant la terminologie d’origine et non la traduction française car la certification se passe en anglais.
A la question qui m’est fréquemment posée sur les conseils pour réussir les certifications Microsoft, je réponds toujours : de la pratique, de la pratique et encore de la pratique. Prenez également soin de noter les noms des différents services ainsi qu’une courte définition de leurs rôles respectifs.

Si vous n’avez jamais passé de certifications Microsoft, sachez qu’il s’agit essentiellement de QCM et que vous pourrez revenir en arrière sur la plupart des questions, à l’exception des « Yes/No questions ».
La formulation « May include but is not limited to» qui revient tout au long du programme de la certification met en garde sur le fait que certaines questions pourront sortir de cette liste.
Set up an Azure Machine Learning workspace (30-35%)
Create an Azure Machine Learning workspace
May include but is not limited to:
create an Azure Machine Learning workspace
Le workspace (ou espace de travail) désigne la ressource Azure qu’il est nécessaire de créer afin d’accéder aux fonctionnalités d’Azure ML Service et en particulier au portail encore appelé « studio ». Ce dernier est aussi accessible depuis l’URL https://ml.azure.com/ et attend votre identifiant et mot de passe reconnu par Azure Active Directory.
Le terme « studio » peut porter à confusion car la première ébauche du Designer s’est appelée Azure Machine Learning à sa création, puis Azure Machine Learning Studio. Il est encore possible de s’inscrire sur cette ressource renommée « classic » et accessible sur l’URL https://studio.azureml.net/ sans inscription préalable sur le portail Azure. Cette interface correspond aujourd’hui au Designer (Concepteur en français) qui s’est lui-même rapidement appelé « Visual interface ».
Depuis la Marketplace Azure, dans la catégorie AI + Machine Learning, rechercher le service « Machine Learning ».
Aucun paramétrage particulier si ce n’est le choix de la licence entre Basic et Enterprise. Nous indiquerons plus tard les fonctionnalités uniquement disponibles en version Enterprise.
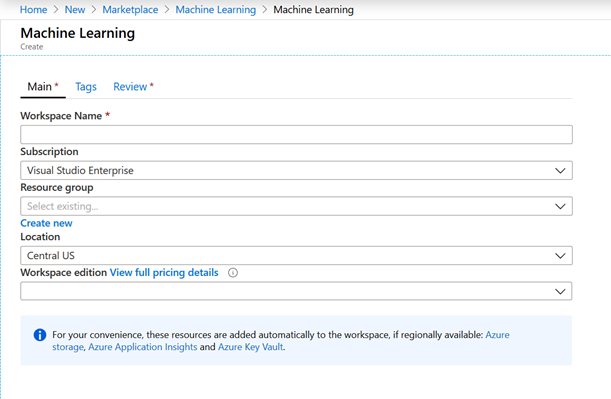
A noter que la création de cette ressource engendrera la création simultanée :
- d’un compte de stockage (Azure Storage)
- d’un coffre fort (Azure Key Vault)
- d’un outil de monitoring (Azure Application Insights)
Par la suite, de nouveaux services pourront être ajoutés, pour l’exposition des services prédictifs :
- Azure Container Instance
- Azure Kubernetes Service
configure workspace settings
Le menu latéral de l’interface Azure donne les entrées classiques d’une ressource. Le groupe de fonctionnalités Assets correspond à l’ensemble des manipulations qui pourront être faites depuis le portail dédié.
On définira en particulier l’accès des autres personnes à la ressource en configurant l’Access Control (IAM).
Il est également possible de télécharger un fichier de configuration JSON dont nous comprendrons l’intérêt lorsque nous réaliserons des interactions avec les fonctionnalités depuis un script.
Celui-ci contient les informations suivantes :
{
"subscription_id": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXX",
"resource_group": "YYYYYYYYY",
"workspace_name": "ZZZZZZZZZ"
}
Enfin, La page de la ressource Azure donne le lien vers le studio et lancera le portail dédié dans un nouvel onglet du navigateur.
manage a workspace by using Azure Machine Learning Studio
A partir de cet item du programme, nous passons sur le portail (dit « studio »), à ce jour (février 2020) toujours en préversion. La barre latérale permet de naviguer dans les différentes parties du studio dont deux uniquement sont exclusives à la licence Enterprise : Automated ML et Designer.
Les seuls paramètres disponibles concernent la langue d’affichage et les formats régionaux. Pour préparer la certification, nous recommandons d’utiliser l’anglais pour l’interface.
Si l’on dispose de plusieurs ressources Azure ML Service, sur une ou plusieurs souscriptions, il sera possible de passer de l’une à l’autre sans quitter le portail.
Manage data objects in an Azure Machine Learning workspace
May include but is not limited to:
register and maintain data stores
Les data stores sont des sources de données répertoriées dans le but de mettre ensuite à disposition des datasets.
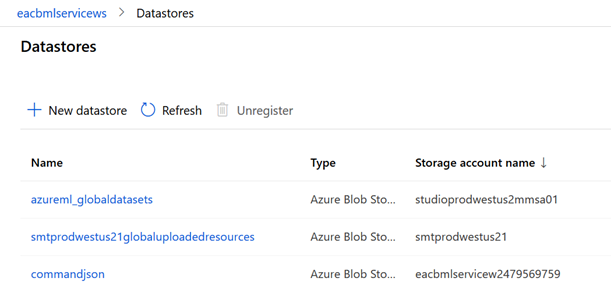
La création d’un nouveau datastore se fait à partir de l’écran ci-dessous, pour l’instant uniquement à partir de ressources Azure de type compte de stockage (Blob, file share ou Data Lake) ou service managé de bases de données (SQL DB, PostgreSQL ou MySQL).
Les informations habituelles d’authentification seront attendues. Il n’est pas possible à ce jour de pointer vers un coffre-fort de type Azure Key Vault déjà paramétré.
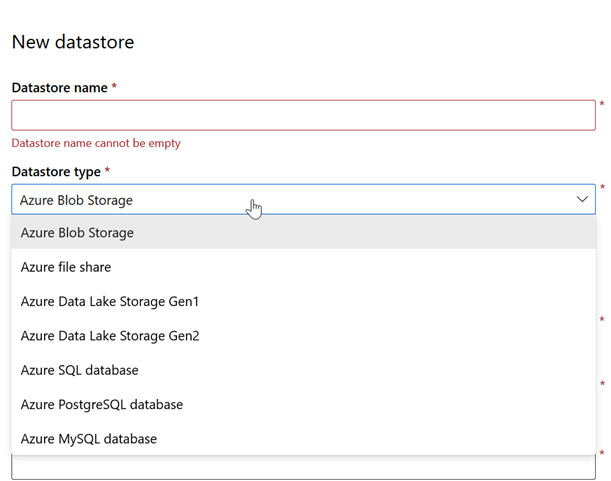
Pour le paramétrage d’un compte de stockage, il faudra descendre du niveau du container, c’est-à-dire le premier niveau d’organisation des données.
L’étape suivante de création d’un jeu de données sera indispensable pour donner réellement accès aux données depuis les interfaces de traitement.
create and manage datasets
Les datasets (jeux de données) sont également créés depuis le menu latéral.
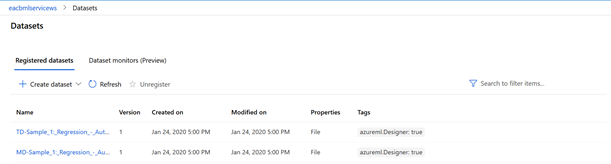
Cliquer ici sur le bouton « Create dataset ».
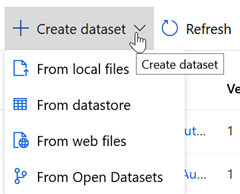
Les datasets sont issus des data sources définis préalablement (« from datastore ») mais peuvent aussi venir d’autres sources :
- Fichiers locaux
- Fichiers disponibles au travers d’une URL Web
- Jeux de données issus d’Azure Open Datasets
Cette initiative de Microsoft met à disposition des jeux de données Open Data, très utiles pour tester rapidement un algorithme et prendre en main l’interface. J’utilise dans les exemples ci-dessous le jeu de données « diabetes ».
Une fois le jeu de données chargé, de nombreuses fonctionnalités sont disponibles.
Les datasets sont tout d’abord versionnés, il est donc possible de revenir à une version précédemment chargée.
Le bouton Refresh réalise l’actualisation du jeu de données.
La génération du profil (« Generate profile ») demande une ressource de calcul de type « training cluster » (voir ci-après).
La génération du profil est considérée comme « le run d’une experiment », notion qui sera revue plus tard.
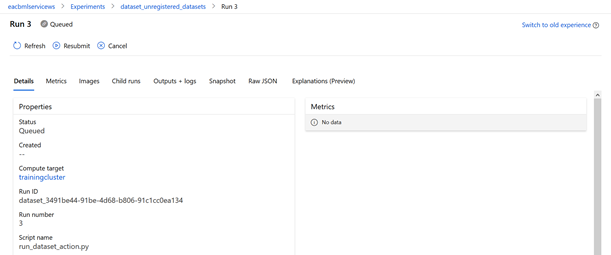
Une fois la préparation terminée, le menu Explore donne les informations suivantes par variables :
- Distribution
- Type (string, integer, etc.)
- Min, Max
- Count, Missing count, Empty count, Error count
La fonctionnalité Unregister supprime simplement le jeu de données de l’interface, mais le datastore correspond est conservé.
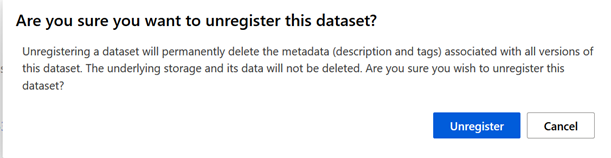
Le menu Consume est particulièrement pratique puisqu’il donne les lignes de script Python permettant de charger le jeu de données sous forme de pandas dataframe.
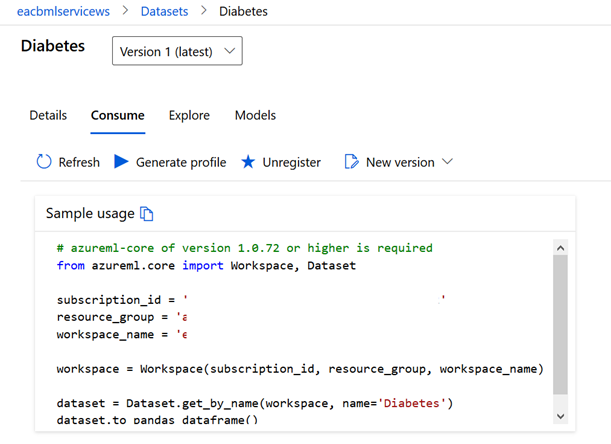
Le menu Explore donne également un aperçu des lignes du jeu de données.
Le menu Models ne sera renseigné que lorsqu’un premier modèle aura été entrainé à partir du jeu de données.
Enfin, il reste une fonctionnalité très prometteuse : Datasets monitor. Si j’interprète bien la documentation, il s’agira de détecter l’éventuelle dérive prédictive d’un modèle de Machine Learning (ce que l’on nomme parfois silent failure).
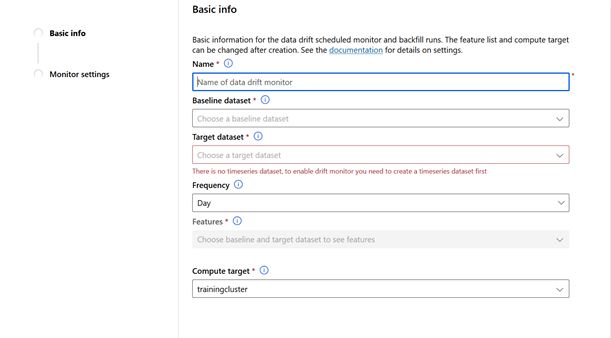
Le monitoring peut être défini à des fréquentes quotidienne, hebdomadaire ou mensuelle.
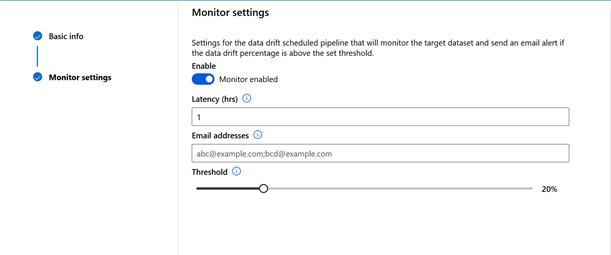
Les alertes sont envoyées à une adresse email en cas de dépassement d’un seuil défini arbitrairement.
Manage experiment compute contexts
May include but is not limited to:
create a compute instance
Les cibles de calcul sont indispensables pour le lancement de tout traitement, quelque-soit l’outil mis en œuvre (notebook, pipeline, endpoint…). C’est aussi ce qui induit sur la facturation du service Azure. Tant que le service Azure Machine Learning est en préversion, il n’existe pas de coefficient multiplicateur sur le montant associé à la ressource de calcul.
Les compute instances (instance de calcul) remplacent dorénavant les « notebooks VM » comme annoncé ici.
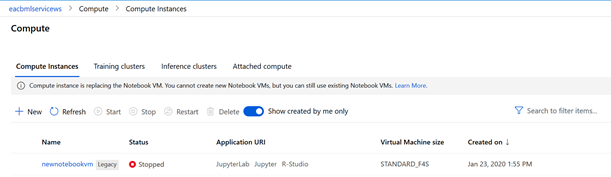
Une instance de calcul se paramètre de la manière suivante :
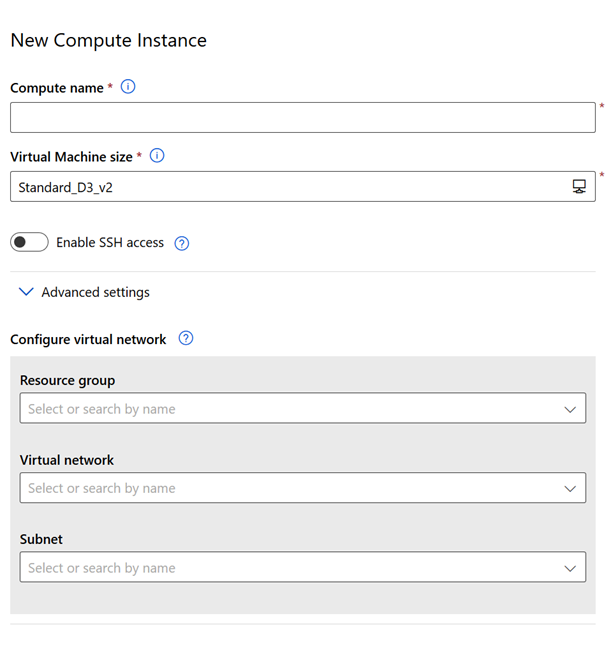
Les instances de calcul disposent d’environnements et d’outils déjà installés pour R et Python, et en particulier le SDK Python d’Azure Machine Learning. Nous évoquerons ce SDK au cours des prochains points de cette préparation. Nous trouvons ainsi un raccourci pour lancer RStudio et deux autres pour Jupyter et JupyterLab sur lesquelles le kernel Python 3 sera disponible.
Pensez à arrêter vos instances de calcul une fois que vous ne les utilisez plus, afin d’arrêter la facturation (hormis celle associée au disque).
determine appropriate compute specifications for a training workload
Le tableau suivant, issu de la documentation officielle Microsoft, donne les correspondances entre les cibles de calcul et les différentes approches permettant de réaliser du Machine Learning.

Nous reviendrons plus tard sur la notion de pipeline. Celle-ci peut être comprise comme la succession d’étapes nécessaires dans un projet de Machine Learning : préparation des données (sélection des variables, normalisation…), entrainement du modèle, calcul des métriques d’évaluation, etc.
Les cibles de calcul doivent être différenciées des cibles de déploiement dont le rôle sera de porter le modèle prédictif une fois que celui-ci aura été entrainé et validé.
create compute targets for experiments and training
Un training cluster est un environnement managé constitué d’un ou plusieurs nœuds, qui ne sont autres que des machines virtuelles, dont les caractéristiques seront choisies lors de la création du training cluster. La documentation complète est disponible ici.
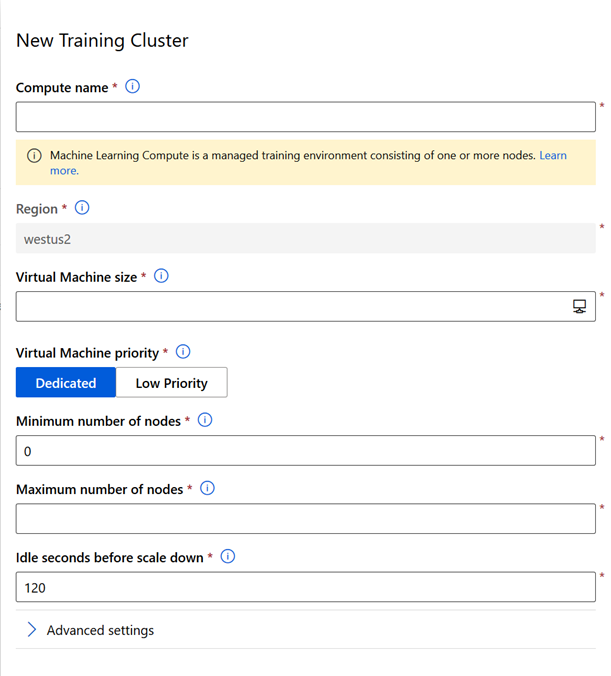
Le nouveau cluster apparaît alors dans la liste des ressources de calcul disponibles.
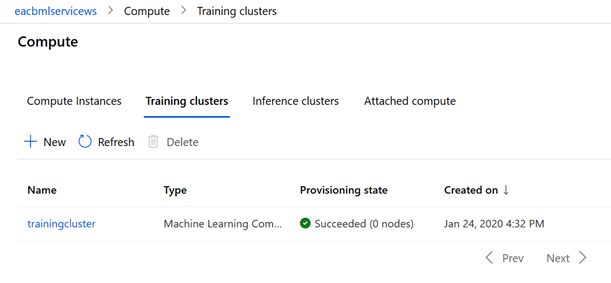
A l’inverse d’une instance de calcul, le training cluster ne peut être éteint mais il passera par différents états. En cliquant sur le nom du cluster, nous accédons aux compute details qui donnent en particulier l’état du cluster :
- Idle
- Leaving
- Preparing
- Running
- Preempted
- Unsuable
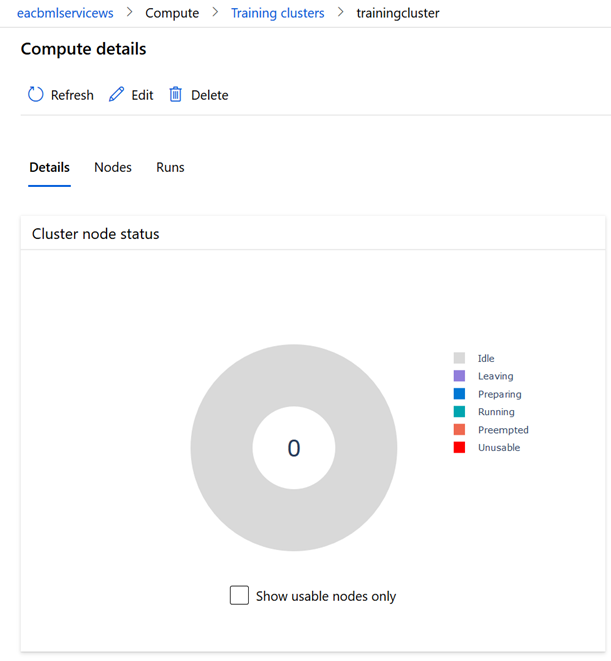
L’état Idle (inactif) correspond à l’état lorsque le cluster est arrêté.
Enfin, le menu attached compute permet d’associer une ressource Azure déjà créée et de l’utiliser ainsi pour des tâches réalisées dans Azure Machine Learning. Seules les machines virtuelles Linux Ubuntu sont supportées. Il est ainsi possible d’exploiter l’image Data Science Virtual Machine, préconfigurée avec les principaux packages utilisés en Data Science, et récemment mise à jour (fin 2019).
Afin de terminer le tour de ce menu, nous évoquons les cibles de déploiement que sont les inference clusters. Ceux-ci servirontpour supporter les Web services Web prédictifs, une fois qu’un modèle aura été entrainé et déployé. Ces clusters sont basés sur le service managé Kubernetes d’Azure et créeront une ressource correspondante dans le groupe de ressources contenant l’espace de travail Azure Machine Learning. Nous aborderons ce point dans le 4e chapitre de la préparation à cette certification.
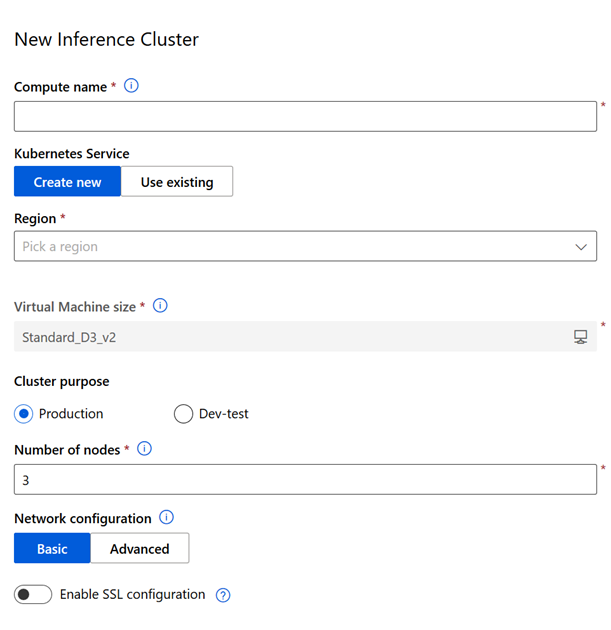
En version Dev-test, un seul nœud est proposé contre 3 minimum pour un cluster de production.
Nous terminons ici le premier chapitre du programme de la certification DP-100, nouvelle version. Celui-ci a permis de découvrir l’environnement de travail, les principales configurations et la mise à disposition des données, accompagnées par des ressources de calcul. Maintenant, il va être temps de coder !