
En 2017, les équipes de recherche de Facebook publiaient ce papier qui introduira la librairie fbprophet, disponible en R et en Python (pas de jaloux !). Cet outil peut être rangé dans la catégorie des modèles additifs généraux car il décompose une série temporelle de la sorte :
y(t) = g(t) + s(t) + h(t) + e(t)
avec respectivement :
- g(t) : la tendance (linéaire ou logistique)
- s(s) : une ou plusieurs composantes saisonnières (annuelle, hebdomadaire ou quotidienne)
- h(t) : l’effet des vacances ou de jours spécifiques qui pourront être paramétrés
- e(t) : l’erreur, bruit aléatoire qui mesure l’écart entre le modèle et les données réelles
Si l’on retient le terme “additif”, il est bien sûr possible de modifier le modèle pour le rendre “multiplicatif” (observez les crêtes de votre série temporelles, si celles-ci forment un cône, le modèle est sans doute multiplicatif).
La grande force de ce type de modèle tient dans sa capacité à être interprété ainsi que dans la clarté des représentations graphiques de la décomposition. Il sera particulièrement adapté à des phénomènes comme… la fréquentation d’un réseau social mais aussi des mesures économiques fortement soumises à des saisonnalités et aux périodes de vacances d’un pays. Il est si simple à mettre en œuvre qu’il gagnera à être comparé à des modèles plus classiques comme SARIMA (nous en reparlerons en toute fin d’article).
Installation de la librairie
Pour ne pas “polluer” notre installation locale avec de nouveaux packages et leurs dépendances, nous créons au préalable un environnement virtuel, à l’aide du package pyenv pour Windows (voir ce GitHub). Ne pas oublier d’ajouter les variables d’environnement et de redémarrer votre terminal ou IDE pour terminer l’installation.
pyenv install 3.8.10 pyenv shell 3.8.10
Nous pouvons alors installer les librairies suivantes :
pip install pystan==2.19.1.1 pip install fbprophet
Pystan est une librairie pour l’inférence bayésienne. Si cette installation ne fonctionne pas (les dépendances sont parfois capricieuses…), vous pouvez utiliser un prompt Anaconda et tenter la commande suivante :
conda install -c conda-forge fbprophet
Vérifiez enfin la bonne installation en choisissant l’interpréteur voulu (ici, conda) dans Visual Studio Code.
Lancez ensuite Python dans le terminal et testez un import de la librairie.
Mise en pratique
Déroulons maintenant un exemple simple, de bout en bout, en réalisant quelques tentatives d’optimisation du modèle. RTE France met à disposition les données énergétiques “eco2mix” dont la profondeur d’historique et le niveau de détail sera intéressant pour évaluer notre outil. J’ai pris connaissance de ce jeu de données dans cet excellent article du blog de Publicis Sapient.
Une seule contrainte dans la façon dont les données doivent être soumises à Prophet : les colonnes de temps et de mesure quantitative doivent être respectivement nommées “ds” et “y”.
Une granularité plus fine que le jour peut être utilisée dans le champ datetime. C’est alors qu’il sera pertinent d’activer le daily effect qui sera visualisable graphiquement.
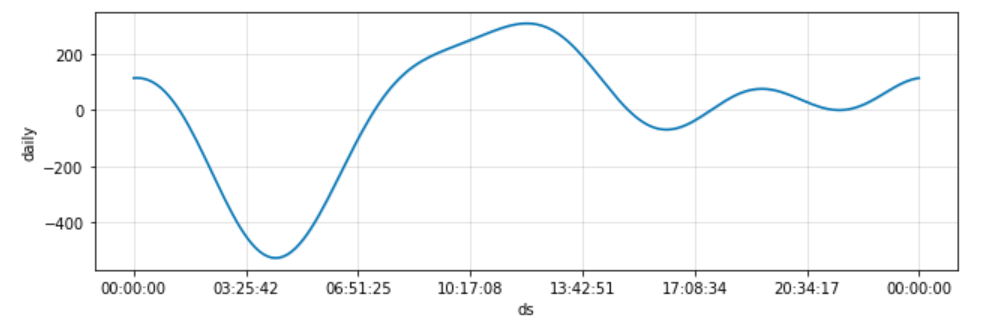
La régularité est un élément fondamental pour la modélisation d’une série temporelle, que viennent perturber les années bissextiles. Nous pouvons décider de supprimer les 29 février, par exemple avec le code ci-dessous :
df= df.loc[~(df['ds'].dt.month.eq(2) & df['ds'].dt.day.eq(29))]
Attention, nous dégradons alors inévitablement la régularité des semaines…
Création du modèle et évaluation
Lançons tout d’abord un modèle simple, sur l’intégralité de l’historique. Dans l’extrait de code ci-dessous, df représente un pandas dataframe regroupant les deux colonnes nommées ds et y.
De nombreux paramètres sont définis par défaut : additivité, pas de saisonnalité journalière, détection automatique des change points (changement de tendance), etc.
m = Prophet(daily_seasonality=False)
m.add_country_holidays(country_name='FR')
m.fit(df)
Ici, nous ajoutons au modèle les jours fériés français qui deviendront autant d’indicateurs dans notre modèle additif.
m.train_holiday_names
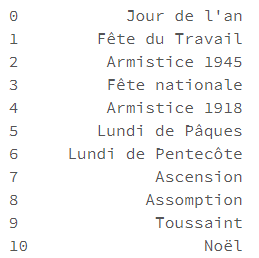
Comme l’indique cette discussion, il ne semble pas possible d’ajouter plusieurs pays à l’aide de cette méthode.
Nous pouvons également ajouter nos propres dates si nous considérons que des événements (répétitifs sur la saisonnalité attendue) ont un impact sur le phénomène observé. Nous pourrions par exemple identifier les journées les plus froides de l’année qui engendrent certainement une hausse de consommation électrique. Mais serons-nous en capacité de les prédire par la suite ? Mieux vaut se limiter à des événements connus à l’avance tels que des compétitions sportives (lors de la finale de la Coupe du Monde, tout le monde allume la télé !).
Les séries temporelles seraient si simples si toutes les tendances étaient linéaires ! Mais dans la vraie vie (et encore plus en période de pandémie…), les tendances fluctuent et il est indispensable que notre modèle les comprenne. Prophet identifie automatiquement les “change points” et on les visualise ainsi, en rouge, à l’aide du code ci-dessous.
from prophet.plot import add_changepoints_to_plot fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)
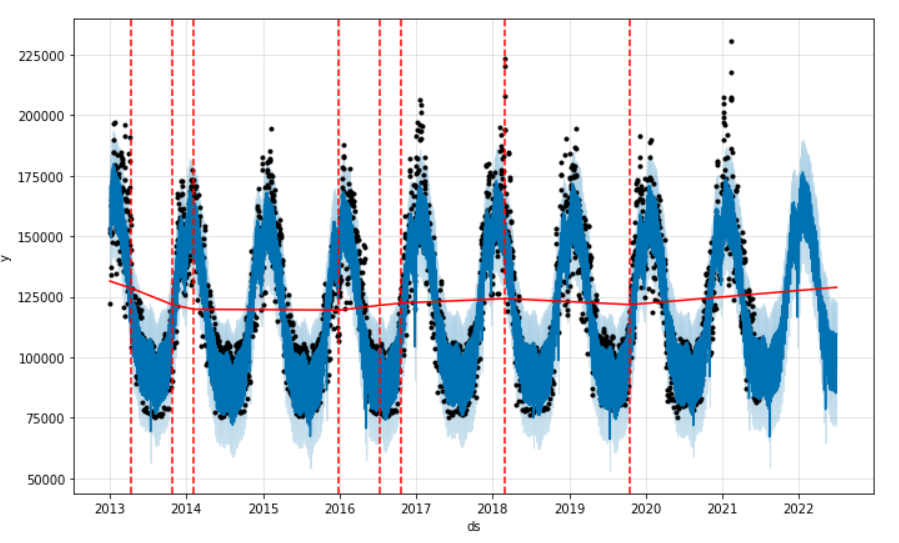
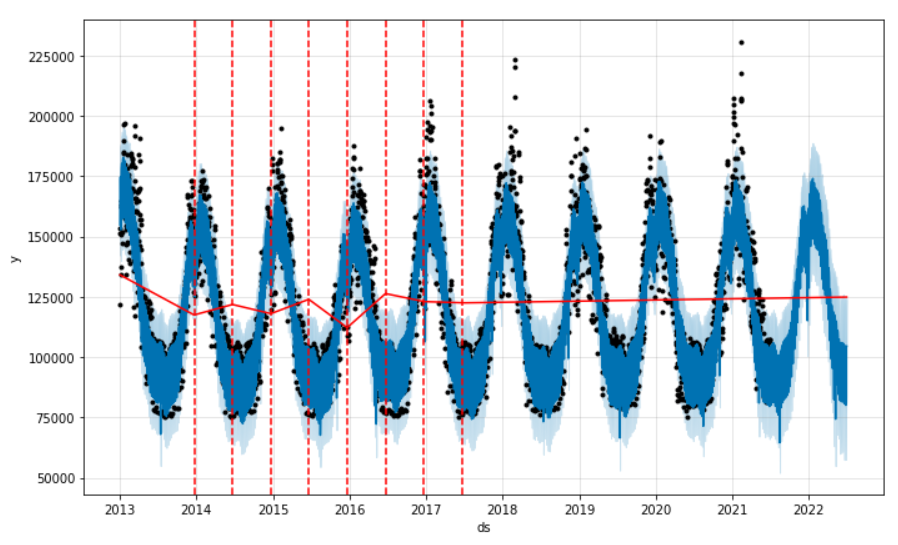
Nous pouvons aussi les définir arbitrairement. Pourquoi pas en donnant les dates des changements de saison (été et hiver) ?
m = Prophet(daily_seasonality=False,
changepoints=['2013-12-21', '2014-06-21', '2014-12-21', '2015-06-21', '2015-12-21', '2016-06-21', '2016-12-21', '2017-06-21'],
changepoint_prior_scale=1)
Le paramètre changepoint_prior_scale indique à quel point le modèle doit respecter notre liste (ou sa détection automatique). C’est une valeur entre 0 et 1. Avec 1, nos change points sont bien retenus, comme l’atteste ce graphique.
Forecast
Pour calculer une prévision, nous allons avoir besoin d’un nouveau dataframe contenant une colonne de type datetime, toujours nommée “ds”, que nous soumettrons à la méthode .predict(), appliquée au modèle.
future = pd.date_range(start="2020-01-01",end="2021-12-31") future = pd.DataFrame(future, columns=['ds'])
Tout comme pour la méthode .fit(), la syntaxe est ainsi tout à fait similaire à celle du package scikit-learn.
forecast = m.predict(future)
Une autre méthode pour créer la plage de forecast consiste à utiliser la fonction ci-dessous.
future = m.make_future_dataframe(periods=365)
Cette fonction génère automatiquement une plage de dates couvrant l’historique complet auquel s’ajoute la période définie en paramètre. Ceci a pour avantage de nous permettre de comparer les prévisions avec les données réelles qui ont été utilisées pour le modèle, ce que nous allons observer dans les sorties graphiques.
Sorties graphiques
Pour afficher la superposition des historiques et des prévisions, un simple plot suffit !
m.plot(forecast)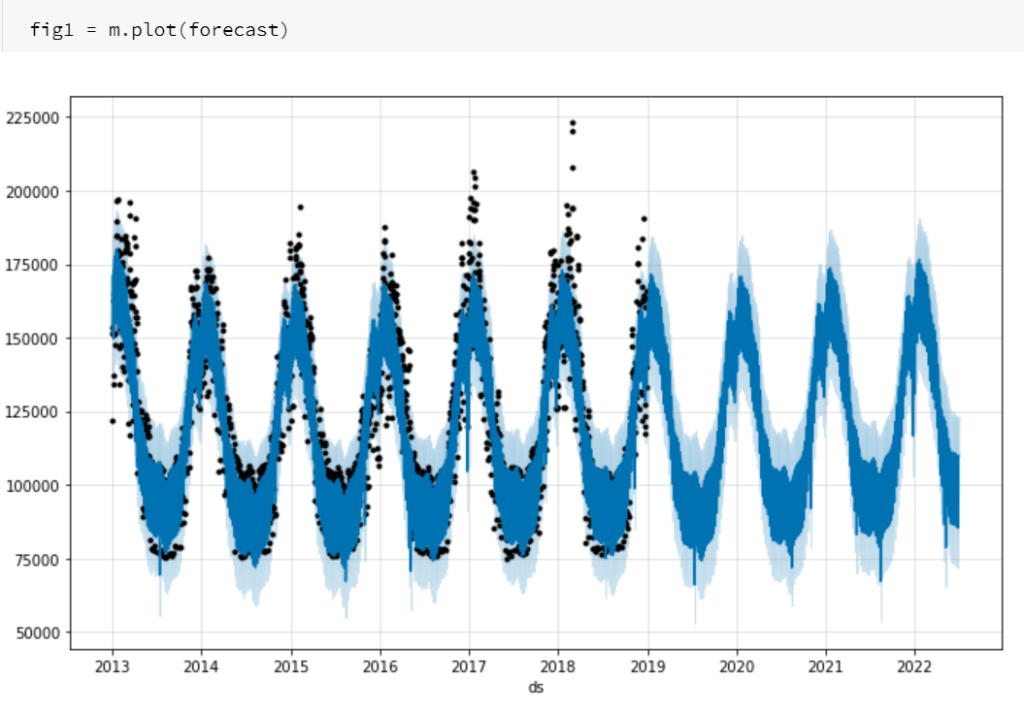
Nous pouvons ensuite obtenir les différents graphiques de décomposition.
m.plot_components(forecast)
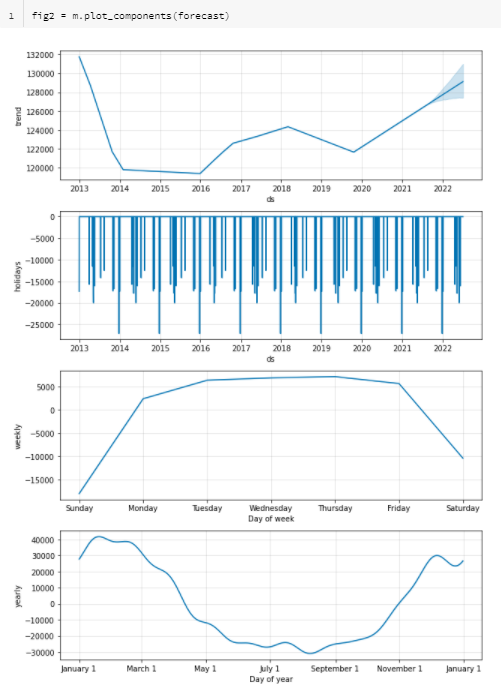
D’autres graphiques interactifs sont disponibles conjointement avec la librairie plotly.
Cross validation
Nous allons maintenant évaluer la qualité de la prévision à l’aide des métriques d’évaluation traditionnelles que sont MSE, RMSE, MAE, MAPE, etc. et d’une méthode de validation croisée. Ici encore, tout est intégré dans une fonction ! Analysons le code ci-dessous.
df_cv = cross_validation(m, initial='730 days', period='365 days', horizon='365 days')
df_p = performance_metrics(df_cv, rolling_window=1)
Nous retrouvons le modèle préalablement entraîné (m). Un seul paramètre est obligatoire, celui de l’horizon de prévision. Mais nous pouvons également préciser la période initiale d’entrainement (par défaut, 3 horizons, et en effet avec ces méthodes dites “à court termes”, ne vous aventurez pas à prédire au delà d’un tiers de votre historique !). Enfin, le paramètre period indique la taille des “découpes” faites dans le jeu de données pour établir de nouvelles prévisions (par défaut, un demi horizon). Voici un exemple de sortie de la commande lancée sur un cluster Databricks.

Nous obtenons alors les métriques d’évaluation, en moyenne sur le nombre de “folds“.
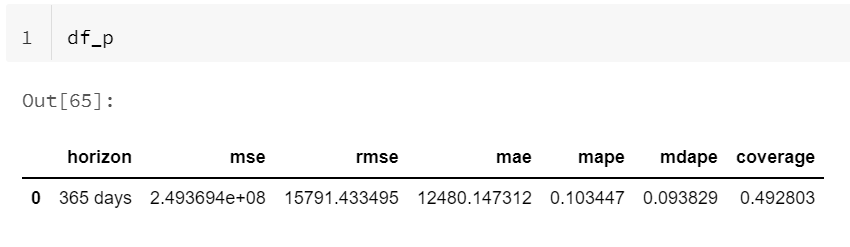
L’argument rolling_window indique le pourcentage de données considérées dans la prévision (1 équivaut à 100%).
Nous pouvons enfin rechercher les meilleurs hyperparamètres pour notre modèle.
Utiliser une approche par hyperparameter tuning implique de lancer un nombre important d’entrainements et d’évaluations. C’est ici que nous tirerons profit d’un cluster de machines, en précisant le paramètre parallel=’processes’ dans la fonction cross_validation(). L’exemple de code donné sur le site officiel sera simple à adapter.
Et maintenant, Kats !
La R&D de Facebook ne s’est pas arrêtée là ! En 2021, une nouvelle librairie est mise à disposition : Kats. Celle-ci a pour vocation de simplifier les tâches des Data Scientists autour de l’analyse et de la modélisation des séries temporelles.
Ici, pas de nommage particulier des colonnes, mais nous transformerons le dataframe en objet spécifique à Kats : TimeSeriesData().
Une première fonctionnalité consiste à déterminer automatiquement 65 features de la série temporelle, c’est-à-dire des caractéristiques de cette série (moyenne, variance, entropie, etc.) qui pourront être par la suite intégrées à des modèles de Machine Learning ou à une approche par régression de la modélisation de la série temporelle.
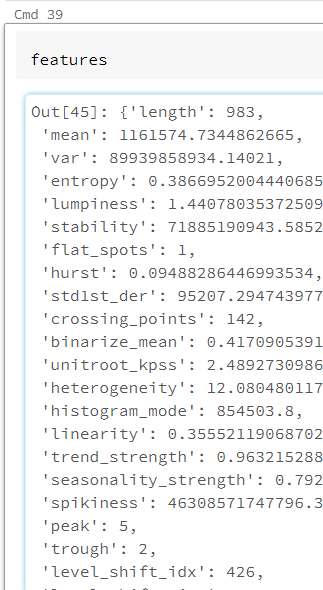
De nombreuses fonctionnalités s’orientent autour de la détection : seasonalities, outlier, change point, and slow trend changes…
Enfin, Kats intègre un grand nombre de modèles (ARIMA, HW, stlf… et l’inévitable Prophet !). Bref, c’est le couteau suisse rêvé de tout.e Data Scientist qui s’attaque à un sujet de séries temporelles.