
Avec un peu de pratique des services Azure Machine Learning, vous vous apercevrez qu’un mode de développement idéal peut se dérouler comme suit :
- travailler dans un IDE (par exemple, Visual Studio Code) depuis votre poste
- exécuter et tester le code localement
- ajouter des interactions au service Azure ML : charger un dataset, enregistrer un modèle, logguer des métriques d’évaluation…
- exécuter le code à distance et à l’échelle des données complètes sur une ressource de calcul (compute cluster)
- éventuellement, intégrer ce code au sein d’un objet pipeline qui sera planifiable (scheduling)
Nous pouvons alors écrire un canevas global, basé sur le SDK azureml, qui prendra en entrée le script Python réalisant des traitements ou l’entrainement d’un modèle.
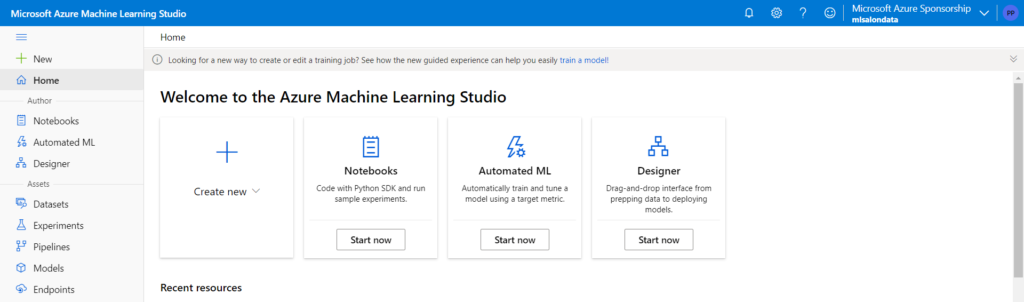
Dans une optique de simplification de ce processus, nous découvrons (septembre 2021) une fonctionnalité dans la home du portail Azure Machine Learning : “train a model“.
Vous pouvez d’ailleurs vous tenir informé.e.s des nouveautés d’Azure Machine Learning sur ce lien officiel.
Nous allons retrouver cette nouveauté dans le menu déroulant “Create new“.

Cliquons sur “Job (preview)” pour ouvrir la fenêtre ci-dessous.
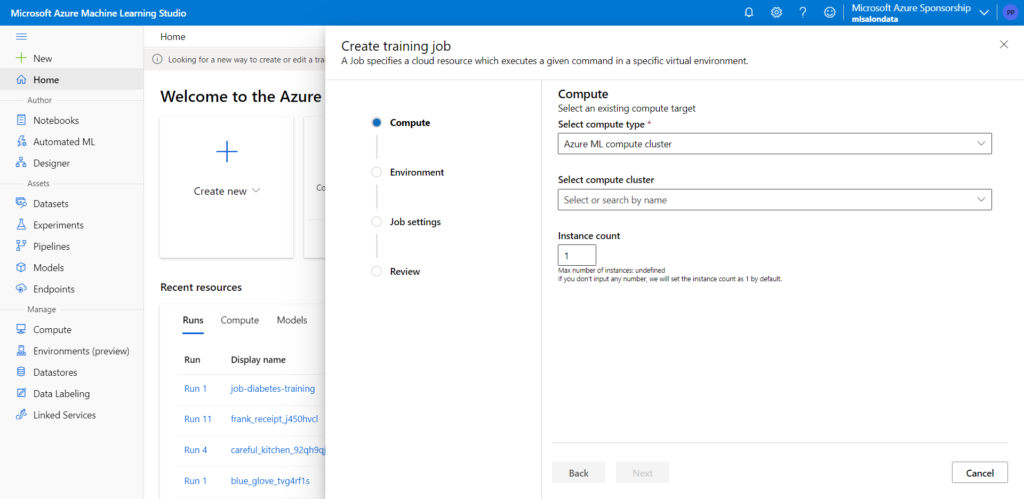
Comme pour toute autre tâche, nous devons choisir une ressource de calcul : compute cluster, compute instance ou Kubernetes.
A la deuxième étape, nous choisissons un environnement d’exécution parmi les environnements prédéfinis, un environnement custom créé préalablement ou bien une image Docker stockée dans un Container Registry.
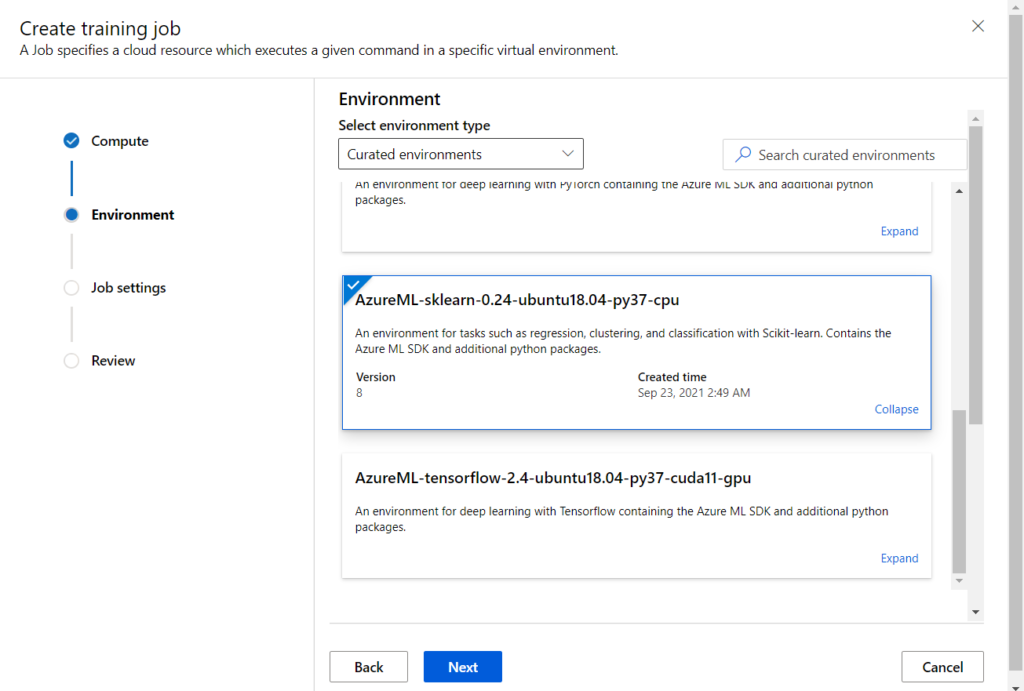
Nous choisissons ici un environnement disposant du SDK azureml, de la librairie Scikit-Learn et quelques packages supplémentaires.
Troisième étape, nous allons soumettre un script Python contenant l’entrainement d’un modèle. Nous choisissons comme exemple un script présent dans les “samples” de code, au niveau du menu notebooks.
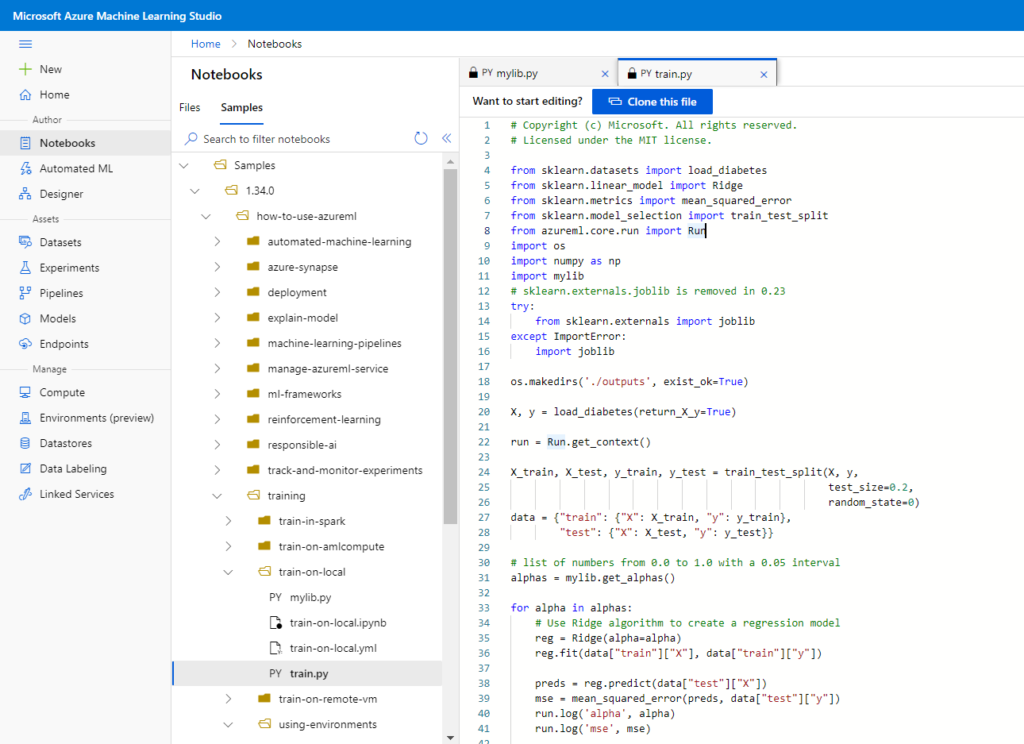
Pour soumettre le fichier .py, nous pouvons réaliser un upload depuis le poste local ou pointer vers un compte de stockage Azure.
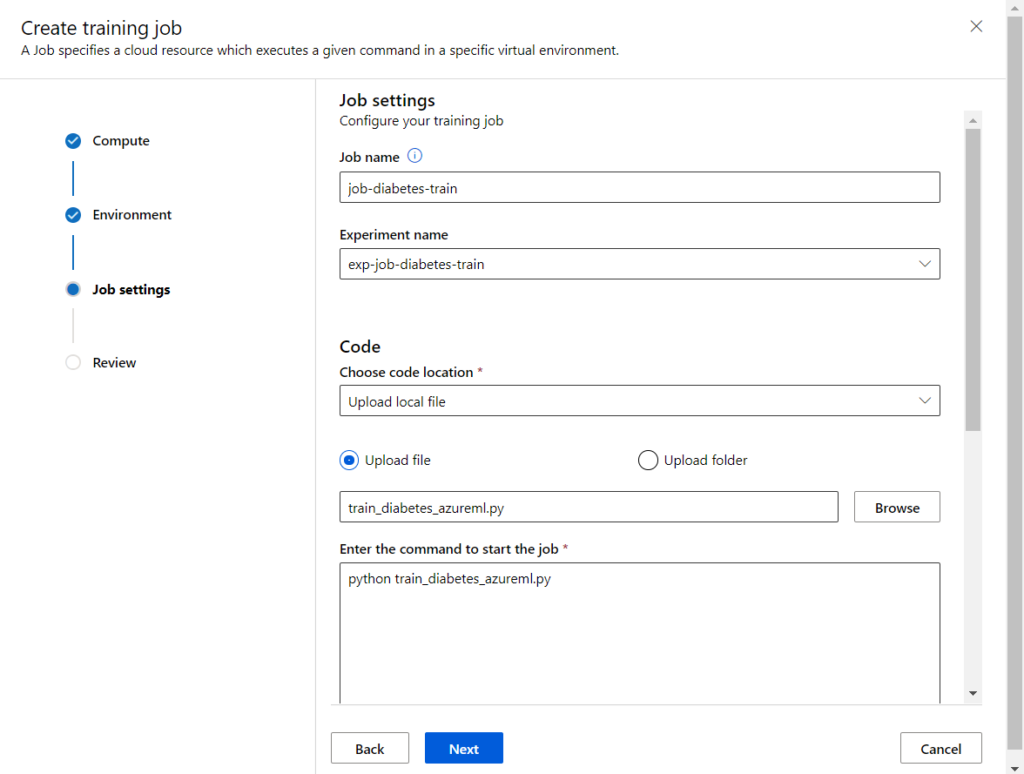
Pensez à donner un nouveau nom d’expérience à la place de “Default”.
Une ligne de commande va lancer le script sur l’environnement défini. Nous écrivons tout simplement l’instruction python suivie du nom du fichier .py.
Nous pourrions nous arrêter ici pour faire marcher cette démonstration mais jetons tout de même un œil sur les options disponibles au bas de cet écran.
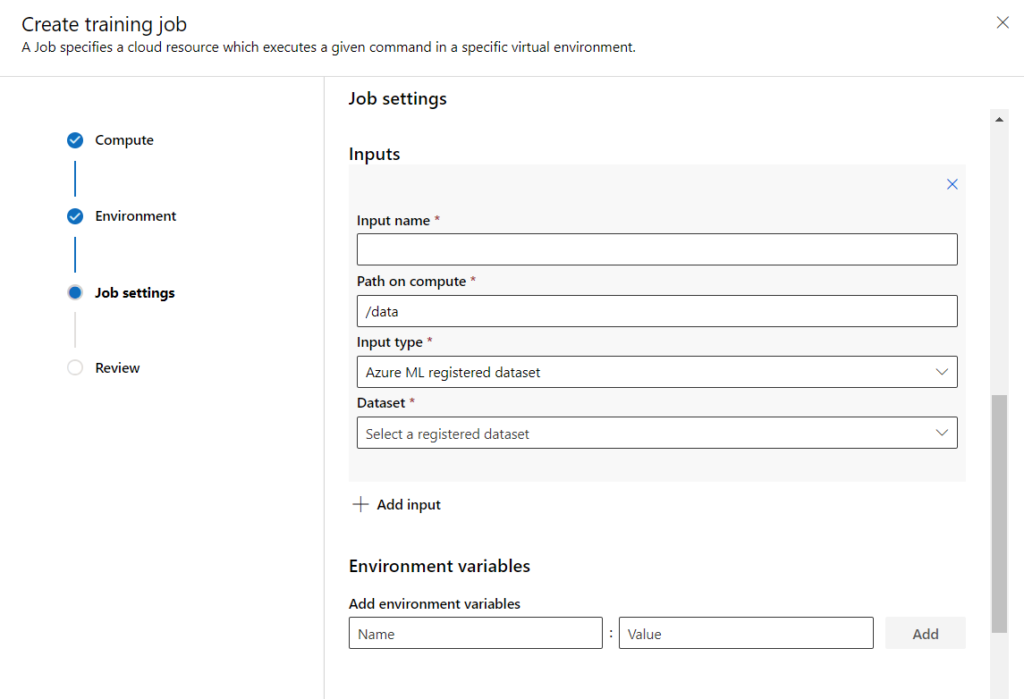
Il est possible d’ajouter un ou plusieurs inputs au script :
- un dataset enregistré sur Azure ML
- un autre fichier local (par exemple, un autre script Python contenant des dépendances)
- un chemin vers le blob storage ou le file share par défaut
Nous retrouvons donc des actions qui demanderaient l’usage du SDK azureml à l’intérieur du script initial.
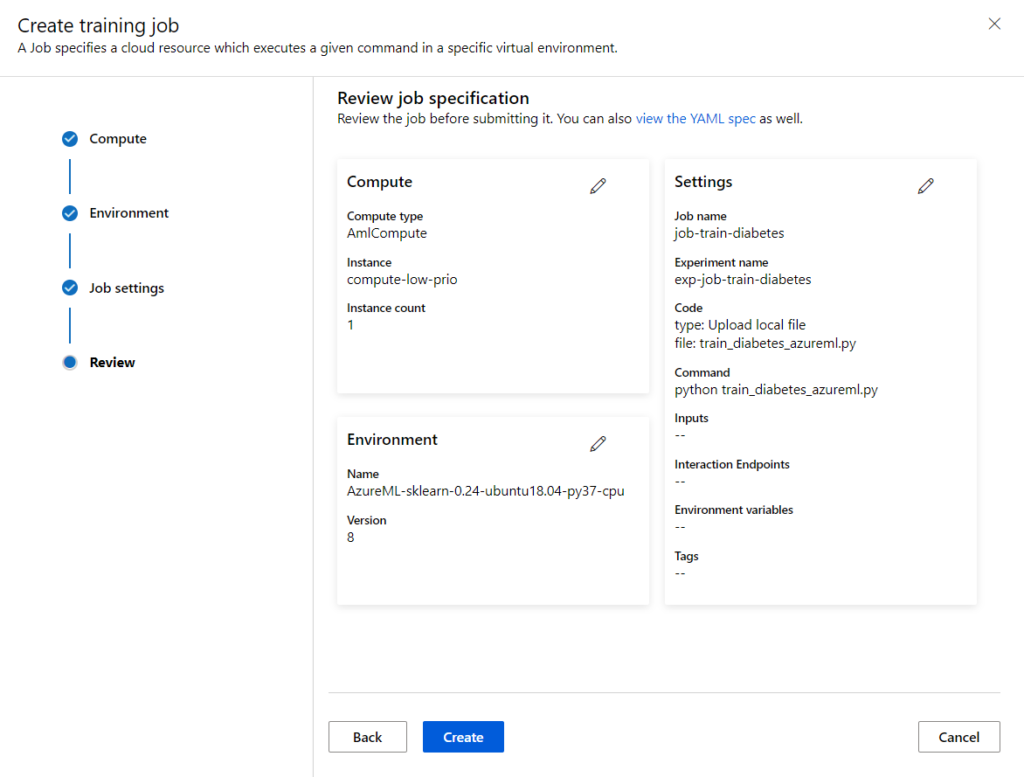
L’écran Review résume enfin les paramètres choisis. Attention, le nom du job ne pourra plus être utilisé !
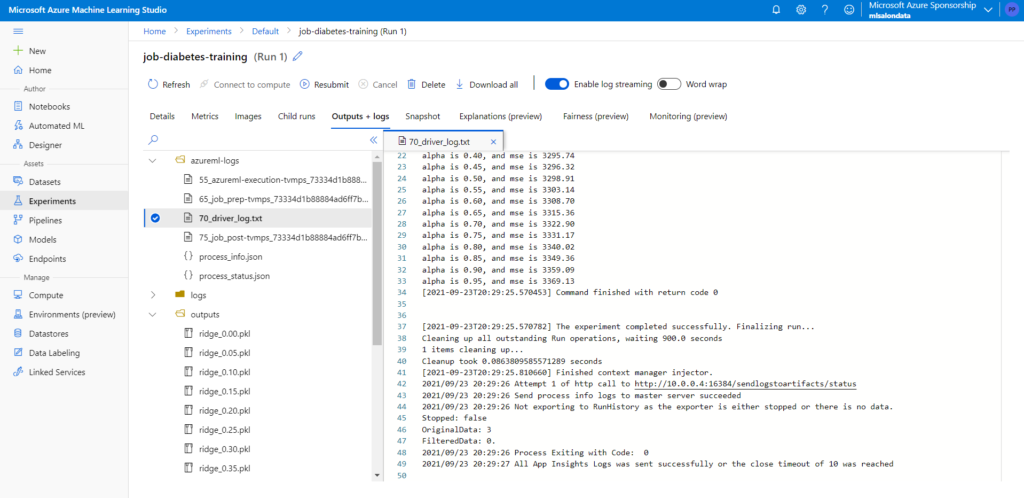
Une fois le job lancé, nous pourrons suivre son exécution dans le menu Experiment. Les logs indiquent ci-dessous les sorties prévues dans le code et des modèles au format pickle sont disponibles dans le répertoire outputs.
En synthèse, Microsoft semble nous mettre sur la voie d’une utilisation plus poussée de l’UI (interface utilisateur) au détriment du SDK azureml qui représente une marche supplémentaire dans l’industrialisation du Machine Learning.
Tout l’intérêt de cette fonctionnalité résidera dans le fait de pointer sur un dataset important (déclaré dans Azure ML) et de réaliser les calculs avec une ressource puissance (plus puissante que notre laptop !).
Il manque peut-être à ce jour une capacité à planifier voire ordonnancer les jobs mais des nouveautés seront sans doute bientôt annoncées.
Dans une optique d’industrialisation, il sera toujours plus intéressant de disposer du code “de bout en bout” afin d’en gérer le versioning, la répétabilité ou encore le déploiement entre workspaces mais nous gagnerons ici un temps précieux dans la phase cruciale de preuve de valeur des algorithmes.