
Si vous êtes habitués à manipuler le package Python scikit learn, la notion de pipeline vous est sans doute familière. Cet objet permet d’enchainer des étapes (“steps“) comme la préparation de données (normalisation, réduction de dimensions, etc.), l’entrainement puis l’évaluation d’un modèle. La documentation officielle du package donne ainsi cet exemple.
>>> from sklearn.svm import SVC
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import Pipeline
>>> X, y = make_classification(random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... random_state=0)
>>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
>>> # The pipeline can be used as any other estimator
>>> # and avoids leaking the test set into the train set
>>> pipe.fit(X_train, y_train)
Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
>>> pipe.score(X_test, y_test)
0.88
Le SDK Python azureml que nous avons déjà évoqué sur ce blog dispose également d’un concept de pipeline. Celui-ci ne doit pas être confondu avec les pipelines pouvant être définis dans l’interface visuelle du concepteur (“designer“). Les pipelines en tant que tels sont visibles dans un menu dédié.
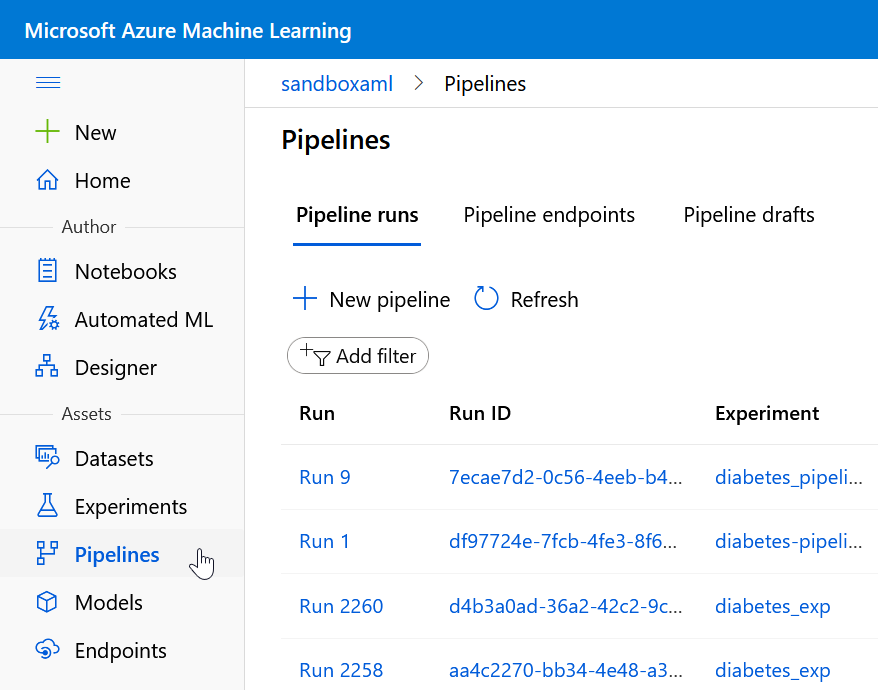
(NDA : on serait en droit d’espérer à termes une fusion de ces éléments, c’est-à-dire d’observer le pipeline dans l’interface du concepteur, voire de retrouver le pipeline créé par le code dans les objets manipulables visuellement).
Les avantages des pipelines
La manipulation des pipelines, en particulier des entrées-sorties, ne sera pas triviale, alors nous allons insister sur tous les bénéfices d’un tel objet. Au delà de la représentation visuelle toujours plus parlante, le principal avantage sera la planification du pipeline. Celle-ci peut se faire de trois manières. Le code présenté ici est disponible dans ce dépôt GitHub.
Objet Scheduler
L’interface du studio Azure Machine Learning ne présente pas d’ordonnanceur visuel des notebooks. Pour autant, cette notion d’ordonnancement existe bien et se manipule au travers du SDK. Une fois publié, un pipeline dispose d’un identifiant. A partir de cet id, un objet Schedule peut être défini, et se déclenchera selon une récurrence déclarée au moyen de l’objet ScheduleRecurrence.

A sa création, l’ordonnancement est activé. Il sera possible de le désactiver à partir de son identifiant (à ne pas confondre avec l’identifiant du pipeline).
Les points négatifs de cet approche sont le manque de visibilité sur les ordonnancements définis (il est nécessaire de lancer la commande Schedule.list) et le fait que d’autres activités non définies dans des scripts présents sur dans l’espace de travail Azure Machine Learning.
Pipeline Azure DevOps
Encore un pipeline à ne pas confondre avec le pipeline du SDK azureml ! Nous parlons ici des pipelines de release d’Azure DevOps. En recherchant le terme “azureml” dans l’assistant (volet de droite), nous trouvons trois tâches, dont une permettant de lancer un pipeline Azure ML désigné à nouveau par son identifiant.
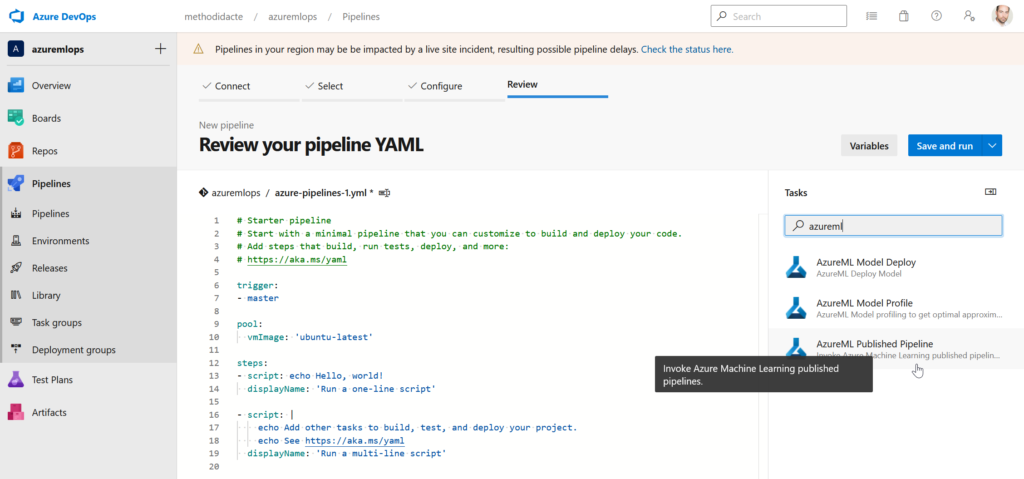
Un pipeline de release peut ensuite être ordonnancé au moyen des standards d’écriture du fichier YAML.
Activité Azure Data Factory
Nous disposons de trois activités distinctes dans le groupe “Machine Learning”. Les deux premières concernent l’ancien Azure Machine Learning studio, aujourd’hui déprécié. Concentrons-nous sur la troisième activité qui permet d’exécuter un pipeline Azure ML.
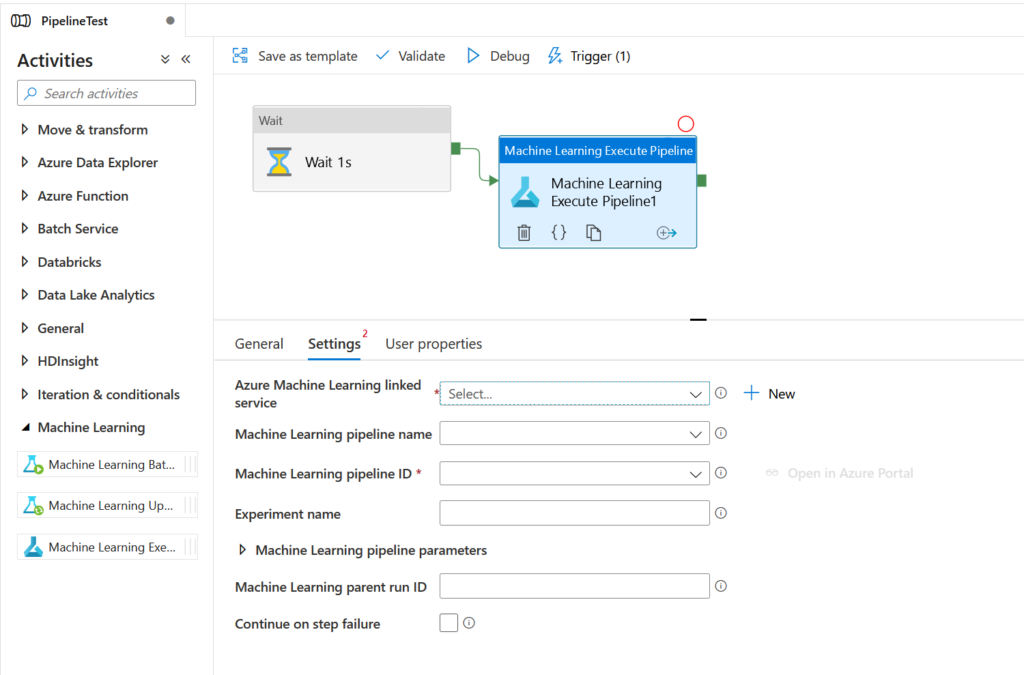
Pour remplir les différents paramètres, nous devons tout d’abord fournir un service lié (linked service) de type Azure Machine Learning (catégorie “compute“).
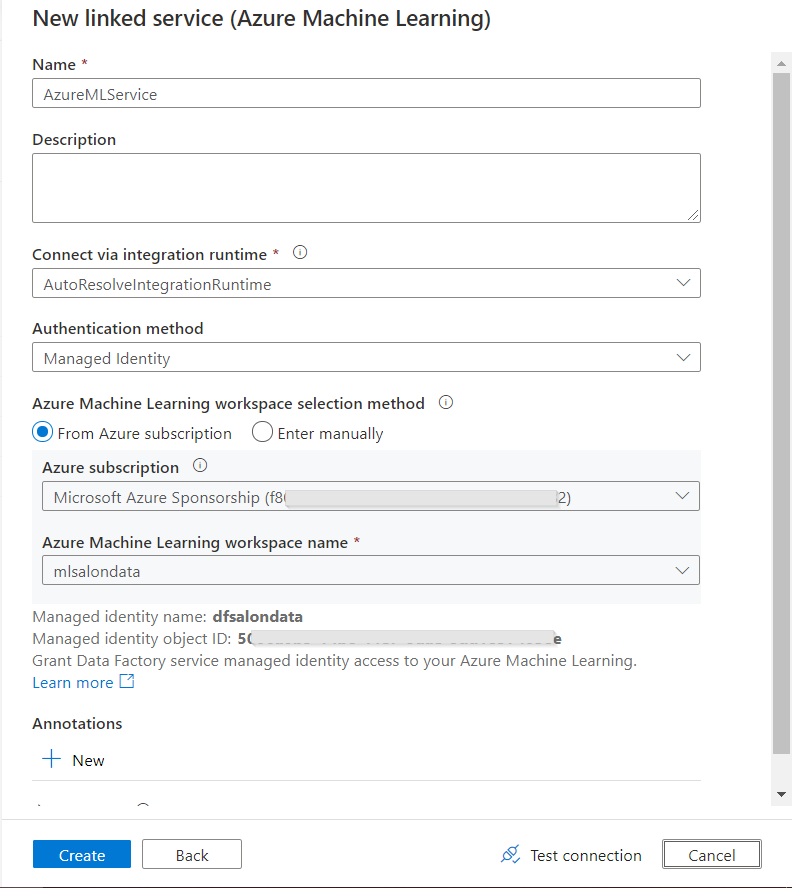
Nous privilégions l’authentification par identité managée, celle-ci se voyant attribuer un rôle de contributeur sur la ressource Azure Machine Learning.
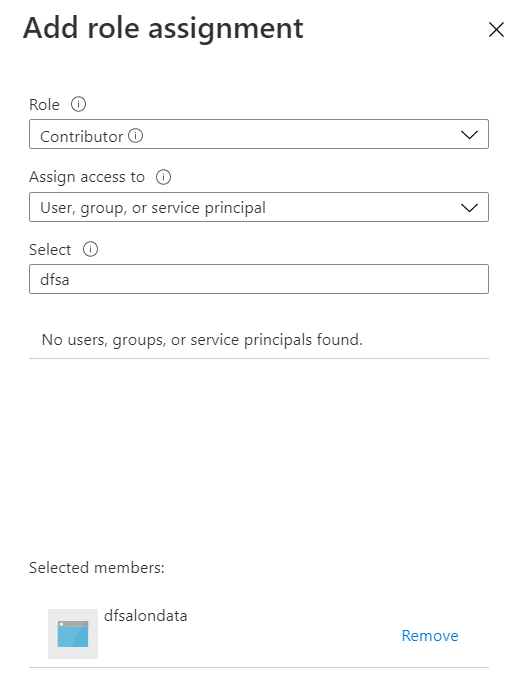
Seconde information obligatoire : l’ID du pipeline publié. Un menu déroulant nous permettra de le choisir. Nous constatons ici que cette information sera particulièrement sensible lorsque nous devrons re-publier le pipeline. Il faudra donc limiter au maximum cette action, car elle engendrera une modification dans les paramètres de l’activité Data Factory. Une problématique similaire se posera dans le cas d’un déploiement automatique entre environnements (par exemple, de dev à prod) avec des ID de pipelines différents.
Et maintenant, comment réaliser un pipeline
Nous allons maintenant plonger dans le SDK Python azureml pour décortiquer les étapes de création d’un pipeline.
Il nous faut pour base un script Python qui contiendra le code à exécuter par une étape (step) du pipeline. Nous ne travaillerons ici qu’avec des étapes de PythonStepScript mais il en existe d’autres types, référencés dans la documentation officielle. Nous prendrons la bonne habitude de faire figurer dans ces scripts les lignes de code suivantes :
from azureml.core.run import Run run = Run.get_context() exp = run.experiment ws = run.experiment.workspace
Celles-ci permettront de retrouver les éléments du “niveau supérieur”, c’est-à-dire l’expérience, son exécution ainsi que l’espace de travail.
Ensuite, nous pourrons travailler sur les entrées et sorties de chaque étape. Cette gestion des entrées-sorties nécessitera un article à part entière sur ce blog.
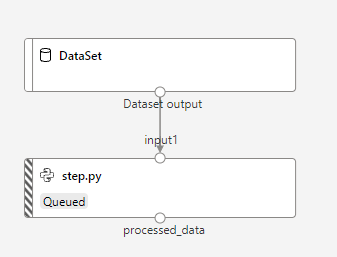
Nous recréons ainsi, par le code (et au prix de nombreux efforts !), un objet similaire au pipeline obtenu dans le Designer.
from azureml.pipeline.core import Pipeline
from azureml.pipeline.steps import PythonScriptStep
step1 = PythonScriptStep(
script_name="step1.py",
compute_target=compute_target,
source_directory="scripts",
allow_reuse=True
)
step2 = PythonScriptStep(
script_name="step1.py",
compute_target=compute_target,
source_directory="scripts",
allow_reuse=True
)
steps = [ step1, step2 ]
pipeline = Pipeline(workspace=ws, steps=steps)
pipeline.validate()
Nous pouvons maintenant soumettre le pipeline, dont la logique des étapes aura préalablement été validée par l’instruction .validate().
pipeline_run = experiment.submit(pipeline)
pipeline_run.wait_for_completion()
Mais cela ne nous permettrait pas de réutiliser ce pipeline dans les scénarios évoqués ci-dessus, nous allons donc le publier avec l’instruction .publish().
published_pipeline = pipeline.publish( name=published_pipeline_name, description="ceci est un pipeline à deux étapes" ) published_pipeline
Ceci nous permet de connaître l’identifiant du pipeline (masqué dans la copie d’écran ci-dessous).

Il ne reste plus qu’à soumettre le pipeline pour l’exécuter même si nous utiliserons vraisemblablement d’autres méthodes comme l’appel par Azure Data Factory ou l’emploi de l’API REST.
published_pipeline.submit(ws, published_pipeline_name)
Les logs de l’exécution seront accessibles dans le menu Pipelines du portail, qui nous redirigera vers le menu Experiments. N’oubliez pas d’activer l’affichage des “child runs” pour visualiser les traces de l’exécution de chacune des étapes.

Voici enfin un exemple de code qui permettra de lancer ce pipeline par requête HTTP.
from azureml.core.authentication import InteractiveLoginAuthentication
import requests
auth = InteractiveLoginAuthentication()
aad_token = auth.get_authentication_header()
rest_endpoint1 = published_pipeline.endpoint
print("You can perform HTTP POST on URL {} to trigger this pipeline".format(rest_endpoint1))
response = requests.post(rest_endpoint1,
headers=aad_token,
json={"ExperimentName": "My_Pipeline_batch",
"RunSource": "SDK"}
)
try:
response.raise_for_status()
except Exception:
raise Exception('Received bad response from the endpoint: {}\n'
'Response Code: {}\n'
'Headers: {}\n'
'Content: {}'.format(rest_endpoint, response.status_code, response.headers, response.content))
run_id = response.json().get('Id')
print('Submitted pipeline run: ', run_id)
Attention, une réponse “correcte” à cet appel HTTP sera de confirmer le bon lancement du pipeline. Mais rien ne vous garantit que son exécution se fera avec succès jusqu’au bout ! Il faudra pour cela se pencher sur la remontée de logs (et d’alertes !) à l’aide d’un outil comme Azure Monitor.