La longueur du titre de cet article laisse présager du niveau de précision dans lequel nous allons nous lancer ! Je vais donc rapidement situer le contexte faisant appel à un tel besoin.
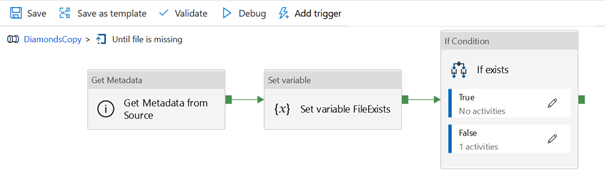
Nous cherchons à déployer de manière automatisée un environnement de développement Azure Data Factory sur l’environnement de production. Nous utilisons pour cela un pipeline de release Azure DevOps. Le processus DevOps pour ADF est expliqué dans ce livre blanc Microsoft ou dans cet excellent article de Florian Eiden.
Pour résumer les grandes lignes du fonctionnement, nous remplaçons dans un fichier de paramètres au format JSON les valeurs des chaînes de connexion de l’environnement de développement par celles de production. Ceci se fait au moyen de la case « override template parameters ».
Valeurs manquantes pour le service lié Databricks
La chose se complique lorsque nous utilisons un service lié de calcul de type Azure Databricks puisque les paramètres de ce service n’apparaissent pas par défaut dans le fichier de paramétrage ! Nous avons en particulier besoin de remplacer :
- La Databricks Workspace URL
- Le Secret name (où se trouve enregistré un Personal Access Token correspondant à l’espace de travail souhaité)
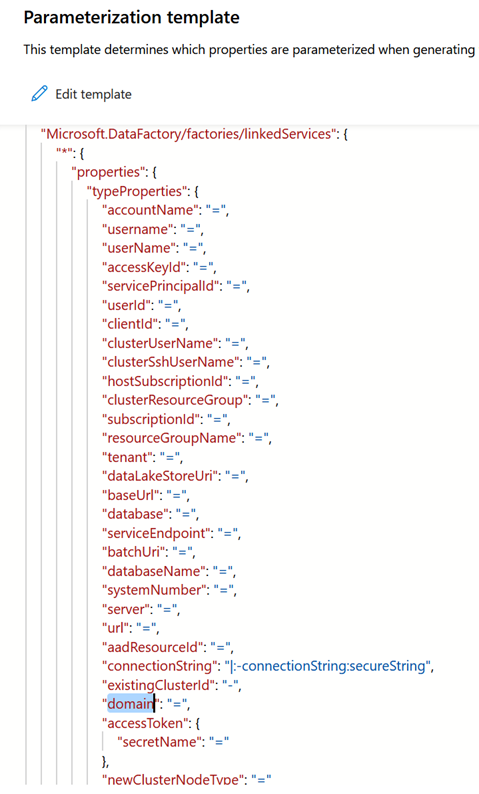
En effet, un choix arbitraire a été fait par Microsoft pour présenter uniquement certains paramètres mais un grand nombre de valeurs existent et elles sont visibles en éditant le fichier disponible dans le menu : Parametrization template.
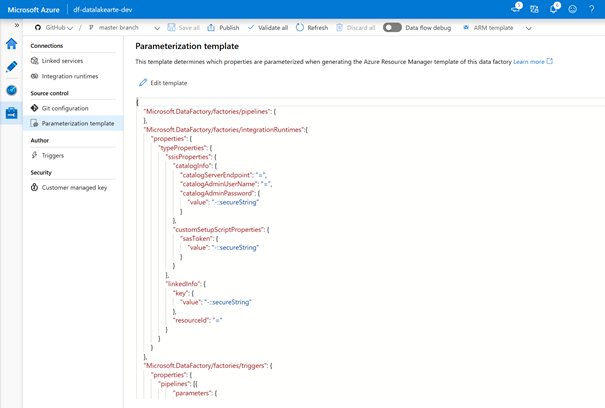
Ce fichier au format JSON recense l’intégralité des paramètres disponibles par défaut, ainsi que leur visibilité au moyen d’une propriété qui n’est pas simple à interpréter :
= (signe égal) permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre
– (signe moins) permet de ne pas conserver la valeur par défaut pour le paramètre
Le symbole | (pipe) permet de réaliser le lien avec une valeur stockée dans le coffre-fort Azure Key Vault.
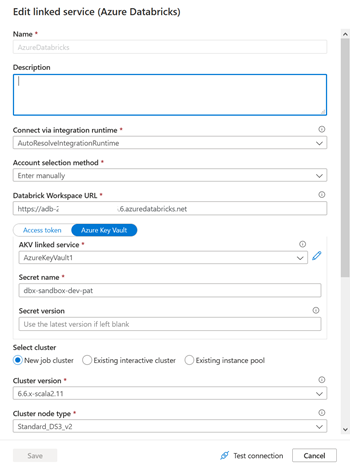
Nous allons maintenant rechercher le nom des paramètres manquants. Pour cela, nous passons par la définition du service lié Databricks au format JSON.
Nous obtenons ainsi le nom exact des paramètres (ne pas se fier à l’interface graphique).
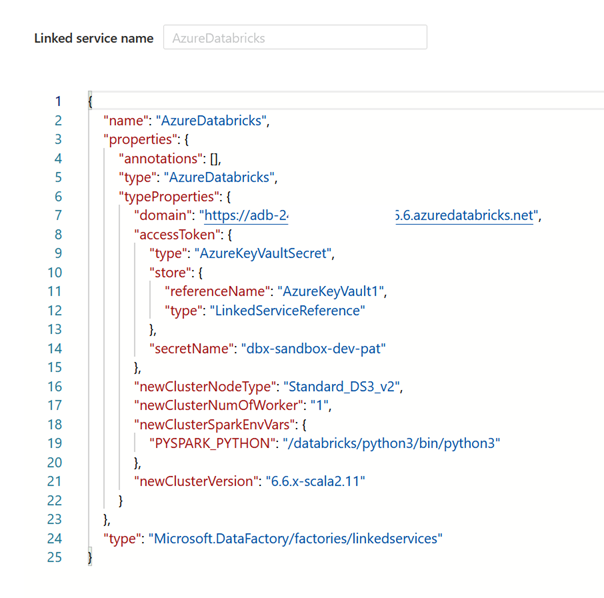
L’URL de l’espace de travail se nomme ainsi domain, le secret du Key Vault se désigne par secretName et ses deux propriétés dépendent du niveau TypeProperties et du sous-niveau accessToken pour le secret.
Nous pouvons donc maintenant citer ces propriétés dans le JSON des paramètres, en respectant l’arborescence des propriétés.
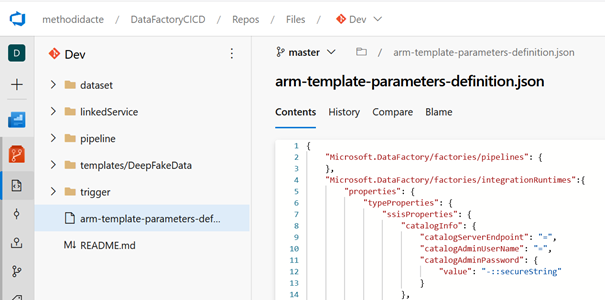
La définition des paramètres dans la branche Master
Arrive ici la partie peut-être la moins documentée (jusqu’à présent !). Il faut comprendre que ce fichier JSON doit figurer à la racine de la branche Master du dépôt contenant la synchronisation du Data Factory avec un gestionnaire de version comme GitHub ou un repo Azure DevOps, sous le nom arm-template-parameters-definition.json.
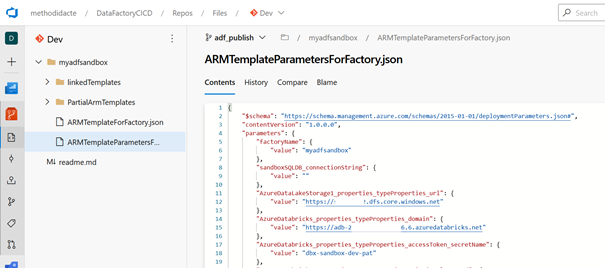
Il ne faut donc pas utiliser la branche spécifique à Data Factory qui se nomme adf_publish mais nous irons ensuite vérifier que les deux fichiers JSON qu’elle contient ont bien été modifiés en conséquence.
Pour lancer cette modification, nous devons tout d’abord faire les deux actions suivantes :
- Refresh
- Publish
Le volet latéral du Publish (pending changes) doit s’afficher même si aucune modification n’est visible.
Nous pouvons enfin vérifier que les paramètres sont disponibles dans le fichier ARMTemplateParametersForFactory.json de la branche adf_publish.
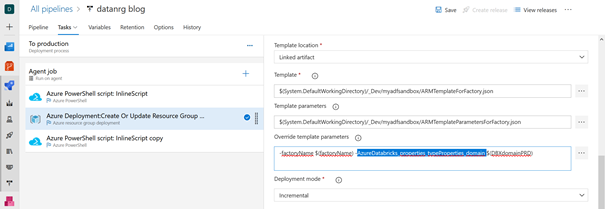
Modifier la valeur des paramètres pendant la release
Il ne reste qu’à utiliser ces noms de paramètres dans le pipeline de release Azure DevOps. Les nouvelles valeurs peuvent être définies comme des variables du pipeline pour plus de commodité.
Cet article a pu être écrit grâce à la documentation officielle de Microsoft ainsi que d’autres articles de blog, en anglais, que leurs auteurs en soient ici remerciés :
https://www.modern-dataengineering.com/post/how-to-add-custom-parameters-to-data-factory-templates