
Au mois de mars 2021, une nouvelle fonctionnalité vient accompagner les espaces de travail Azure Databricks : les repos Git.
Pour l’activer, nous devons passer par la console d’administration, cliquer sur “Enable” puis rafraîchir la page.
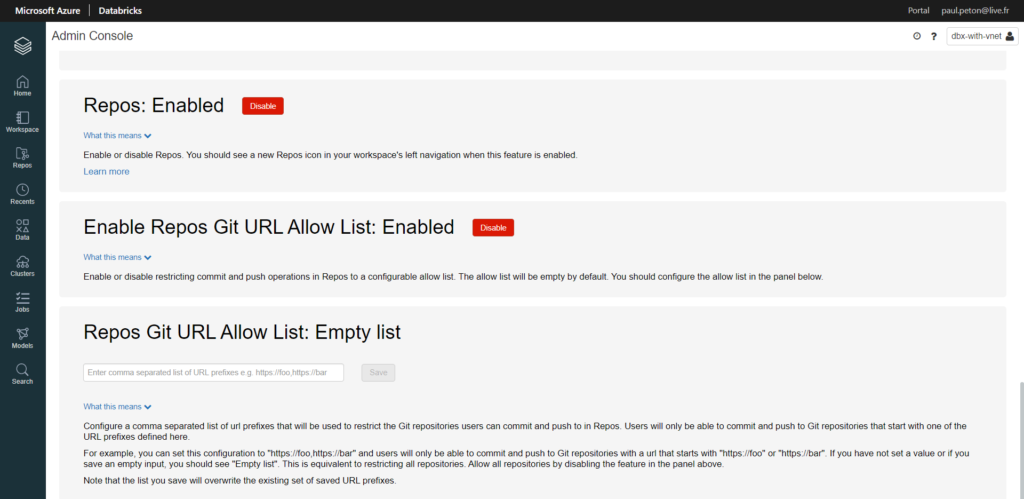
Une nouvelle icône apparaît alors dans le menu latéral.
Jusqu’ici, le lien avec un gestionnaire de versions se faisait individuellement, par le biais de de la fenêtre “user settings“, comme expliqué dans cet article.
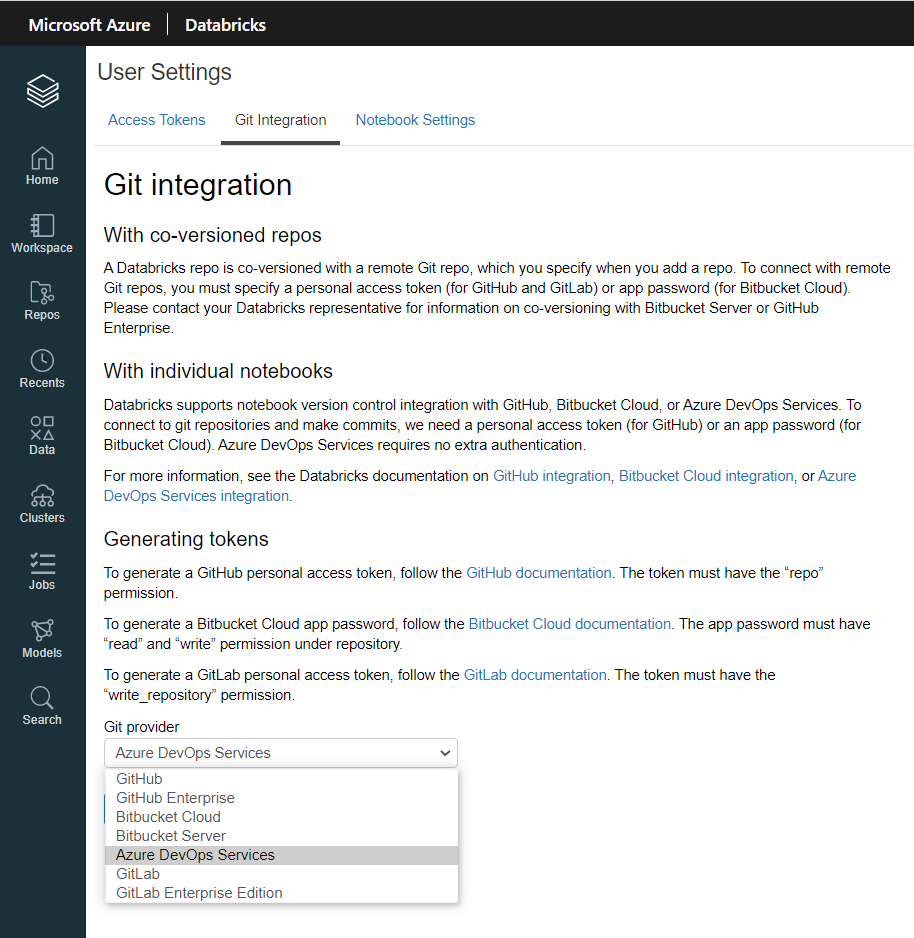
Chaque notebook devait alors être relié manuellement à un repository. Pour des actions de masse, il fallait employer les commandes en ligne (Databricks CLI).
Pour démarrer, nous cliquons sur l’icône Repos et le menu propose un bouton “Add Repo“.
Une boîte de dialogue s’ouvre alors.
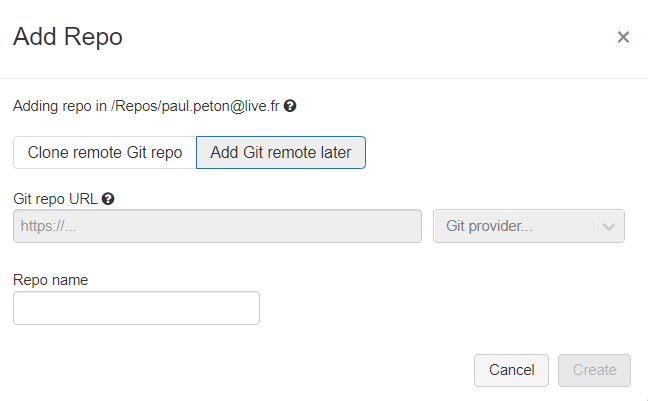
Il faut comprendre ici qu’il s’agit de créer un repository local au sens de l’espace de travail (“Add Git remote later”) ou bien de cloner un repo “remote“, c’est-à-dire relié à un des fournisseurs présents dans la liste. Ce dernier peut être vide si le projet débute.
Nous créons ici un premier notebook dans ce nouveau repository local.
Il faut alors s’habituer à une nouvelle façon de travailler. Les notebooks ne sont plus visibles depuis l’icône “Workspace”. Le lien “Git: Synced” que l’on trouvait en cliquant sur “Revision history” n’existe plus. Mais une icône Git apparaît maintenant en haut à gauche du notebook.
L’historique des modifications s’enregistre toujours bien automatiquement et des retours arrières (“Restore this version”) sont possibles.
Sans réaliser l’association avec un gestionnaire de versions tiers, nous ne disposons pas d’autres fonctionnalités.
Un clic sur l’icône Git nous propose de réaliser cette association, ici avec le service Azure DevOps.
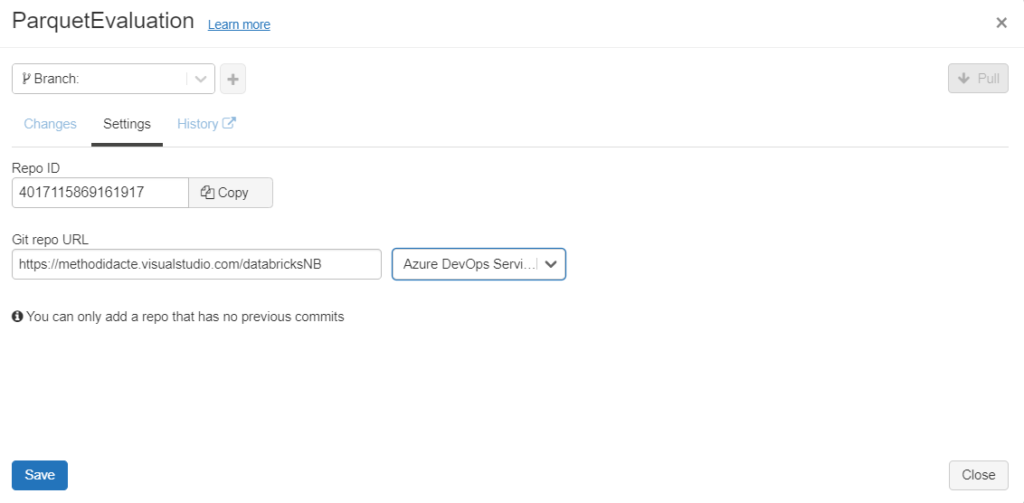
Pour un repository de type privé, il va être nécessaire de réaliser des manipulations de sécurité.
Il s’agit de fournir un Personal Access Token (PAT) généré depuis le gestionnaire de versions.
Une fois la configuration réalisée, la boîte de dialogues ci-dessous apparaît alors.
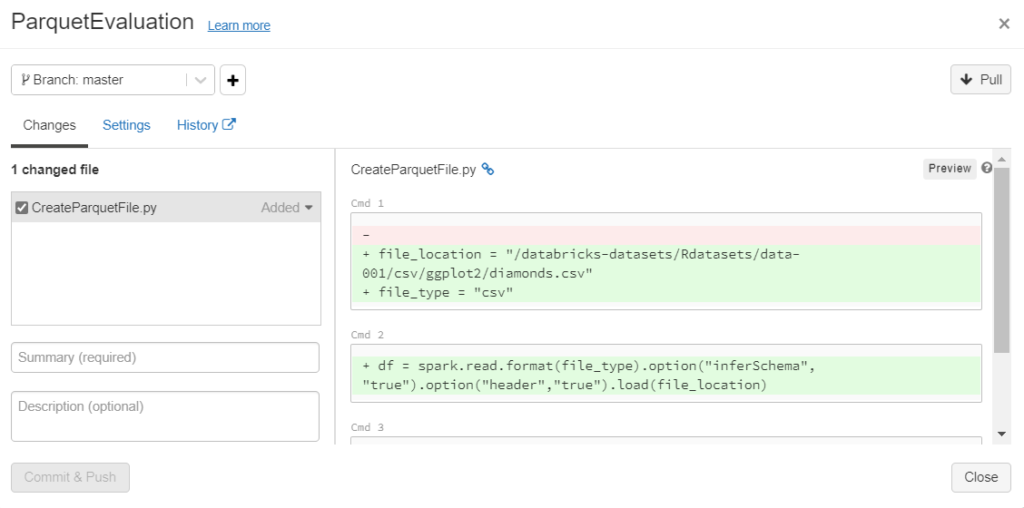
Nous retrouvons des notions familières aux utilisateurs de Git : branche (master ou main), pull, commit & push.
Il sera nécessaire (c’est même obligatoire) de saisir un résumé (summary) des modifications pour pouvoir cliquer sur le bouton “Commit & Push“.
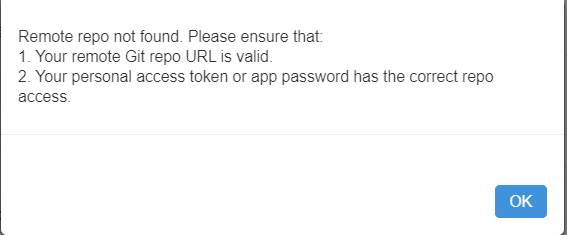
Attention, vous pourriez rencontrer l’erreur suivante.
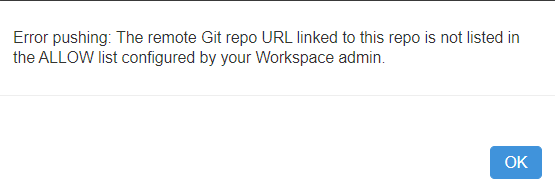
En effet, une liste de repositories autorisés doit être donné dans la console d’administration (seulement si cette option a été activée). Ce scénario s’inscrit dans le cadre de la licence Premium de Databricks où tous les utilisateurs ne sont pas obligatoirement administrateurs.
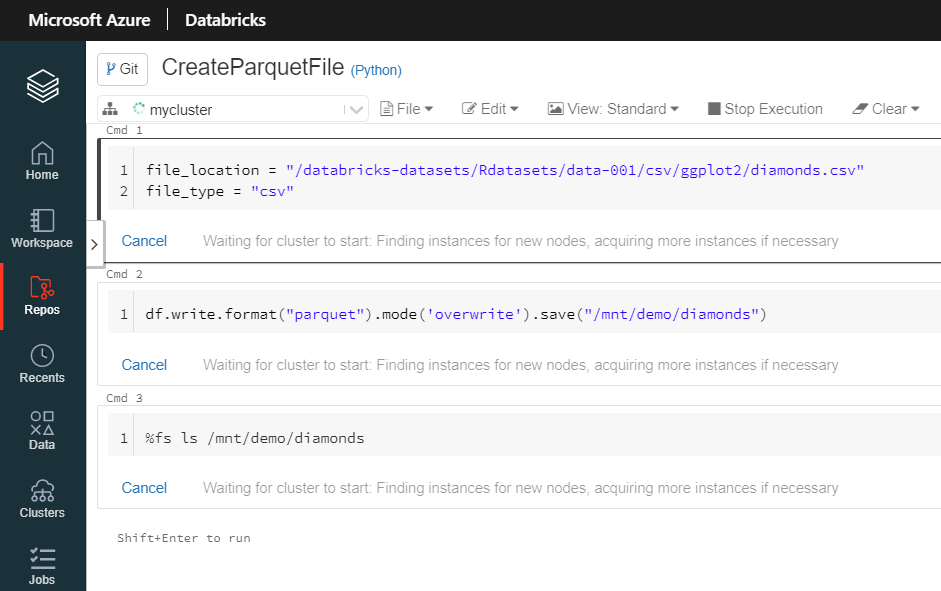
Notons que l’extension du fichier est .py mais il s’agit bien d’un notebook Databricks. Le contenu de celui-ci, en particulier les cellules Markdown, est arrangée pour “ressembler” à un script Python.
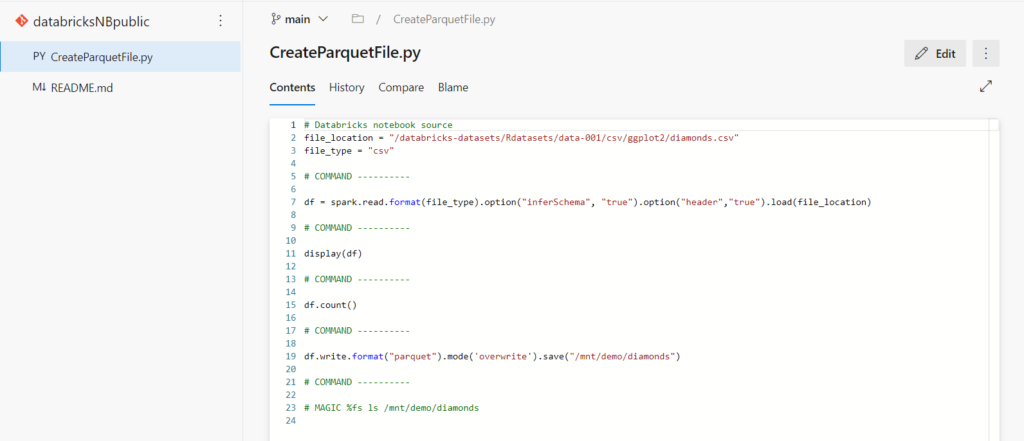
Si le repository est aussi utilisé pour conserver d’autres éléments que ceux propres à Databricks, nous verrons apparaître les dossiers du repo dans le menu de navigation de Databricks. Il pourrait être tentant de les supprimer depuis Databricks (ils sembleront vides puisque seules quelques extensions .py et .ipynb sont affichées) mais ne le faîtes surtout pas !
Une action “removed” serait alors être proposée au prochain commit. Il sera bien sûr possible de l’éviter en basculant sur “Discard changes“.
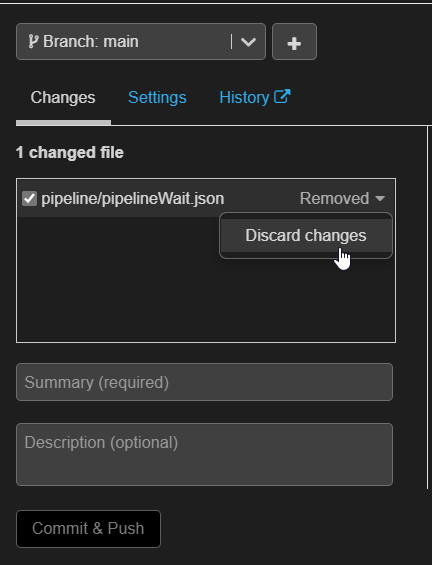
Le répertoire “vide” va alors réapparaître dans l’arborescence.
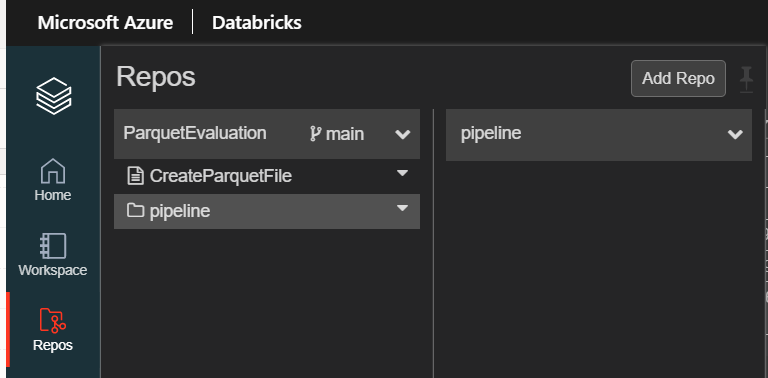
En conclusion, il serait préférable de dédier un repository à Databricks pour éviter les confusions.
EDIT 2021-08-23 :
La fonctionnalité originelle de liaison avec un repository Git est dorénavant une “legacy feature” et il est recommandé de ne plus l’utiliser.
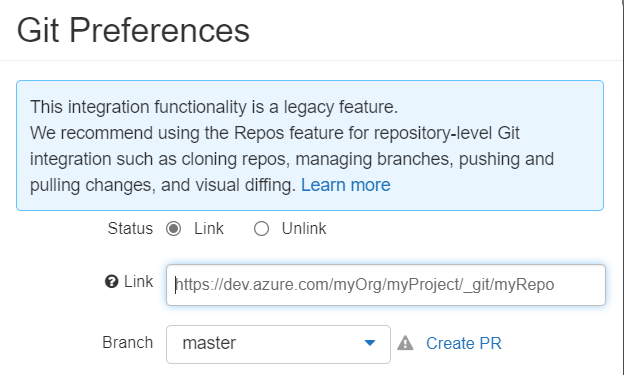
En poussant les tests, on obtient un blocage pour commiter depuis Databricks lors du scénario suivant :
- publication réalisée depuis un outil tiers dans le repository partagé (par exemple, création d’un nouveau pipeline dans Azure Data Factory)
- modifications d’un notebook dans Azure Databricks
- sauvegarde de ces modifications
- tentative de commit & push depuis Databricks
Nous obtenons alors le message d’erreur ci-dessous.
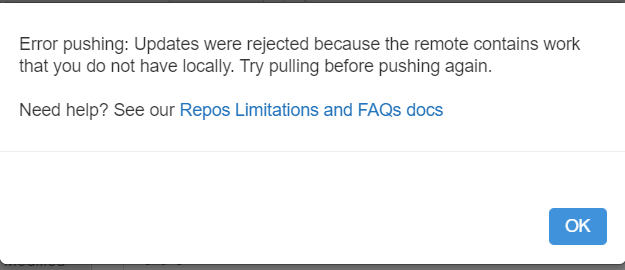
Il est indispensable de réaliser une action Pull avant de modifier les notebooks et nous recommandons de le faire avant même de débuter vos travaux sous Databricks.
Un message d’alerte s’affiche alors.
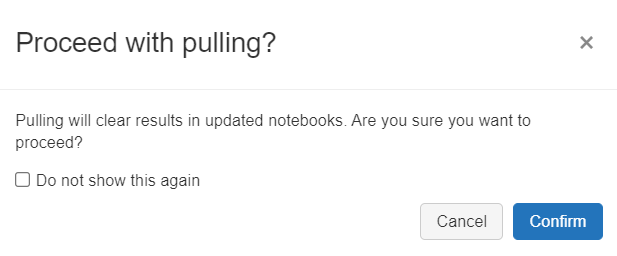
Toutes les limitations liées à la fonctionnalité “Repos” dans Azure Databricks sont données sur ce lien officiel de la documentation Microsoft.