
Si les deux outils ont en partie des fonctionnalités qui se recouvrent, avec quelques différences (voir cet article), il est tout à fait possible de tirer profit du meilleur de chacun d’eux et de les associer dans une architecture data sur Azure.

Le scénario générique d’utilisation sera alors l’industrialisation de modèles d’apprentissage (machine learning) entrainés sur des données nécessitant la puissance de Spark (grande volumétrie voire streaming).
Nous allons détailler ici comment Databricks va interagir avec les services d’Azure Machine Learning au moyen du SDK azureml-core.
A l’inverse, il sera possible de lancer, depuis Azure ML, des traitements qui s’appuieront sur la ressource de calcul Databricks déclarée en tant que attached compute.
Le SDK azureml sous Databricks
Nous commencerons par installer le package azureml-sdk[databricks] au niveau du cluster interactif (d’autres approches d’installation sont possibles, en particulier pour les automated clusters). Le cluster doit être démarré pour pouvoir effectuer l’installation.
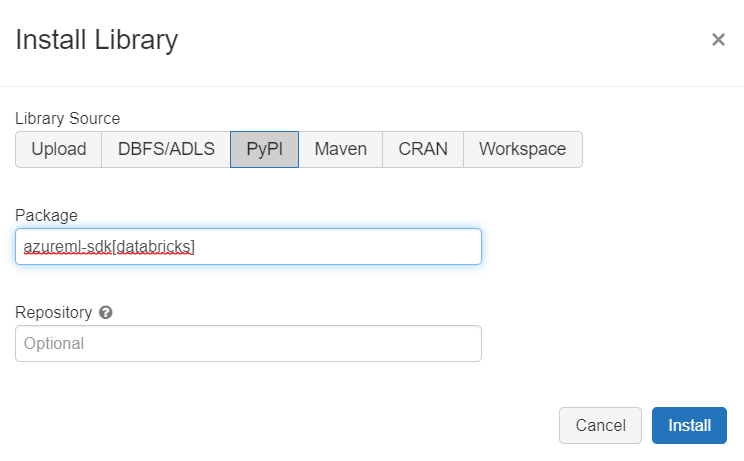
Nous pouvons vérifier la version installée en lançant le code suivant dans un notebook :
import azureml.core
print("Azure ML SDK Version: ", azureml.core.VERSION)

Un décalage peut exister avec la version du SDK non spécifique à Databricks. Des dépendances peuvent également être demandées pour certaines parties du SDK comme l’annonce l’avertissement reçu à l’exécution de la commande précendente.
Failure while loading azureml_run_type_providers. Failed to load entrypoint automl = azureml.train.automl.run:AutoMLRun._from_run_dto with exception (cryptography 3.1.1 (/databricks/python3/lib/python3.8/site-packages), Requirement.parse('cryptography<4.0.0,>=3.3.1; extra == "crypto"'), {'PyJWT'}).
L’étape suivante consistera à se connecter à l’espace de travail d’Azure Machine Learning depuis le script, ce qui se fait par le code ci-dessous :
from azureml.core import Workspace ws = Workspace.from_config()
Plusieurs possibilités s’ouvrent à nous pour réaliser ce lien. La première consiste à établir explicitement ce lien dans le portail Azure, depuis la ressource Databricks.
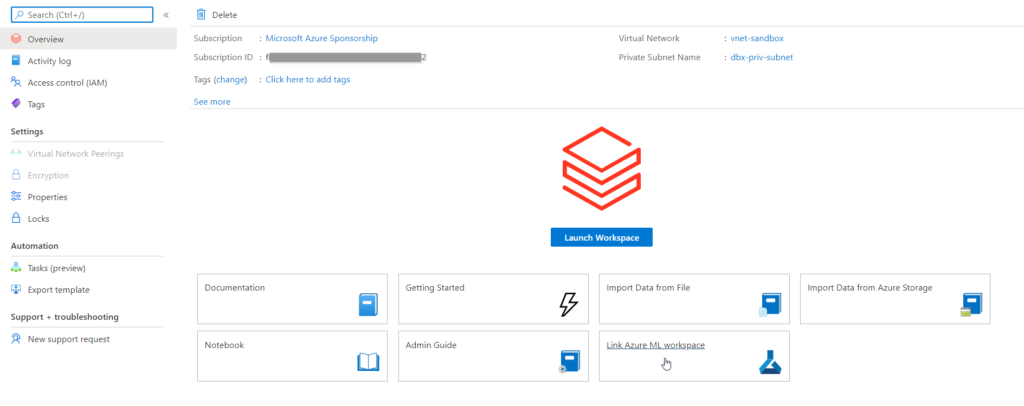
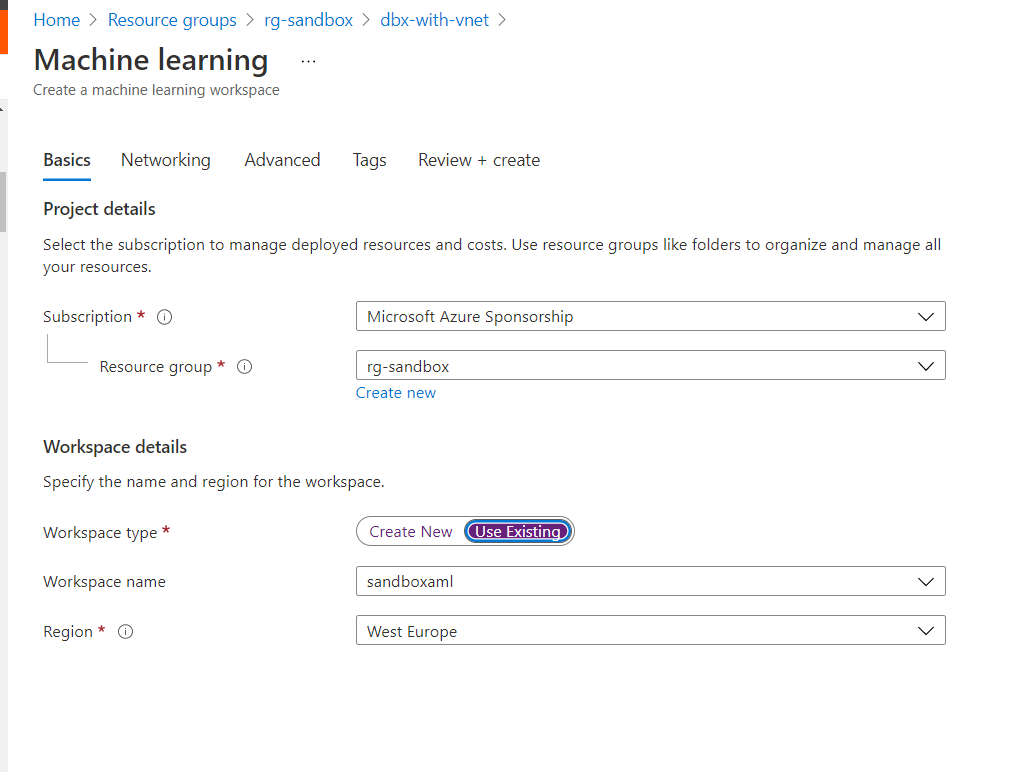
Mais cette approche ne permet d’avoir qu’un seul espace lié, celui-ci n’étant plus modifiable au travers de l’interface Azure (mais peut-être en ligne de commandes ?). La configuration étant donnée par un fichier config.json, téléchargeable depuis la page du service Azure ML, nous pouvons placer ce fichier sur le DataBricks File System (DBFS), et donner son chemin (au format “File API format”) dans le code .
from azureml.core import Workspace ws = Workspace.from_config(path='/dbfs/FileStore/azureml/config.json')
Une authentification “interactive” sera alors demandée : il faut saisir le code donné dans l’URL https://microsoft.com/devicelogin puis entrer ses login et mot de passe Azure.
Pour une authentification non interactive, nous utiliserons un principal de service.
Nous pouvons maintenant interagir avec les ressources du portail Azure Machine Learning et en particulier, exécuter notre code au sein d’une expérience.
from azureml.core import experiment
experiment = Experiment(workspace=ws, name="ExperimentFromDBXs")
Après l’entrainement d’un modèle, idéalement réalisé grâce à Spark, nous pouvons enregistrer celui-ci sur le portail.
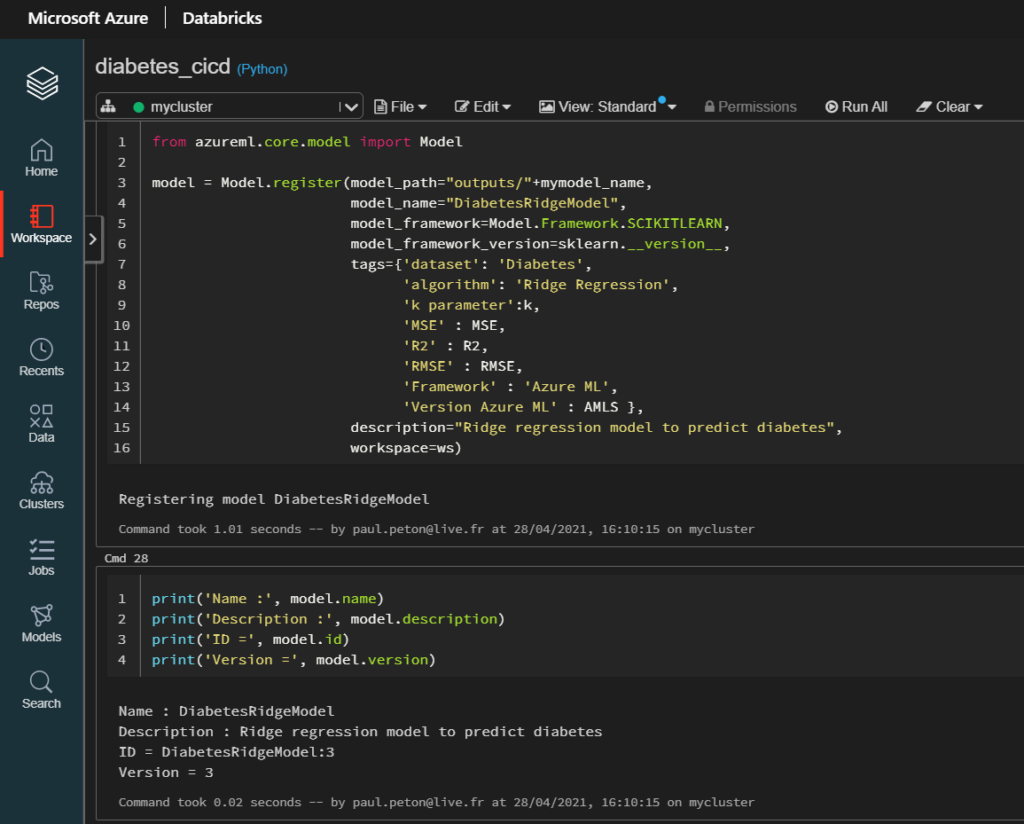
L’instruction run.log() permet de conserver les métriques d’évaluation.
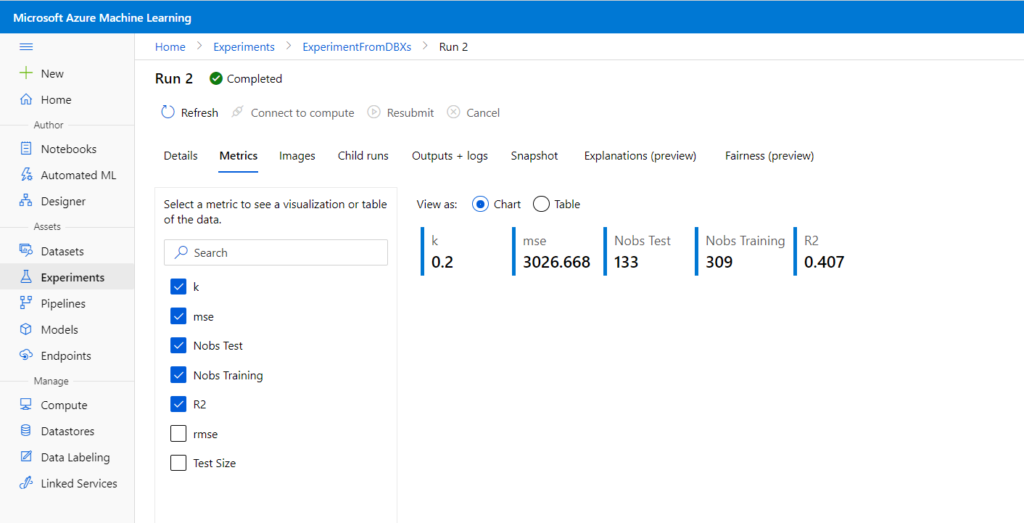
A noter que les widgets ne peuvent pas s’afficher dans les notebooks Databricks.
Databricks comme attached compute
Comme pour toute ressource de calcul, nous commençons par déclarer le cluster Databricks dans le portail Azure Machine Learning.
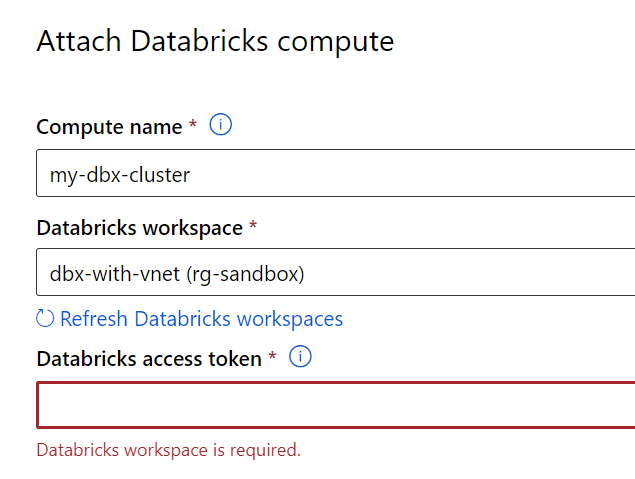
Un jeton d’accès (access token) est attendu pour réaliser l’authentification. Nous prendrons soin de le générer grâce à un principal de service pour éviter qu’il ne soit attaché à une personne (“Personal Access Token”).
La ressource est maintenant correctement déclarée.
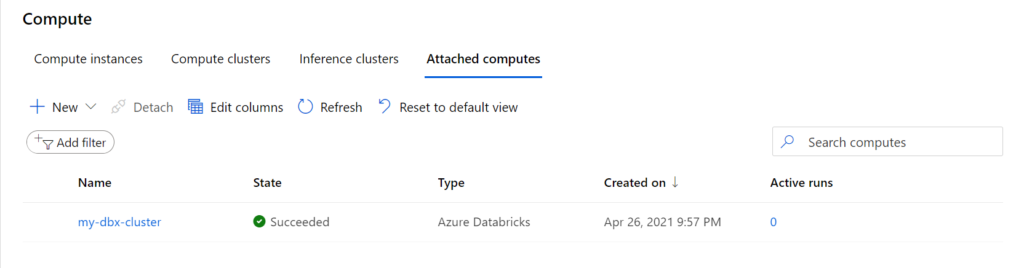
Nous allons l’exploiter au travers du SDK Python azureml dans lequel nous disposons de deux objets liés à Databricks.
La documentation présente la classe qui permettrait de créer cette ressource au travers du code :
DatabricksCompute(workspace, name)
Nous trouvons aussi dans la documentation l’objet qui crée une étape de pipeline exécutée ensuite au sein d’une expérience :
DatabricksStep(name, inputs=None, outputs=None, existing_cluster_id=None, spark_version=None, node_type=None, instance_pool_id=None, num_workers=None, min_workers=None, max_workers=None, spark_env_variables=None, spark_conf=None, init_scripts=None, cluster_log_dbfs_path=None, notebook_path=None, notebook_params=None, python_script_path=None, python_script_params=None, main_class_name=None, jar_params=None, python_script_name=None, source_directory=None, hash_paths=None, run_name=None, timeout_seconds=None, runconfig=None, maven_libraries=None, pypi_libraries=None, egg_libraries=None, jar_libraries=None, rcran_libraries=None, compute_target=None, allow_reuse=True, version=None)
Il est possible de lancer un script Python qui sera exécuté sur le cluster Databricks mais l’usage le plus intéressant est sans doute l’exécution d’un notebook.
from azureml.core.compute import DatabricksCompute from azureml.pipeline.steps import DatabricksStep databricks_compute = DatabricksCompute(workspace=ws, name="my-dbx-cluster") dbNbStep = DatabricksStep( name="DBNotebookInWS", num_workers=1, notebook_path=notebook_path, run_name='DB_Notebook_demo', compute_target=databricks_compute, allow_reuse=True )
Nous pourrons alors suivre les logs du cluster dans l’expérience.
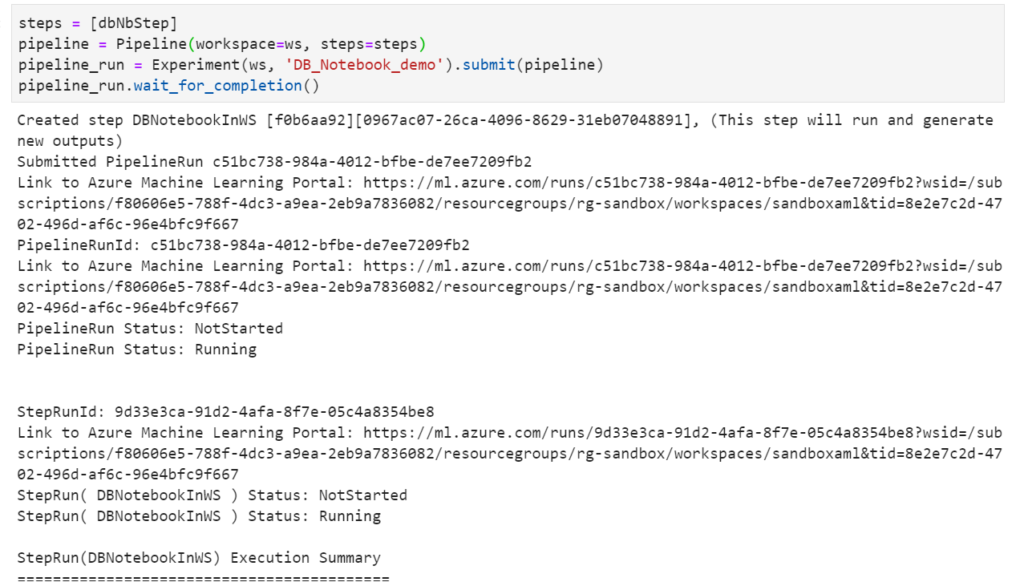
Je vous recommande ce notebook pour découvrir tous les usages de DatabricksStep, comme par exemple l’exécution d’un JAR.
En conclusion
La souplesse des services managés et la séparation stockage / calcul autorisent aujourd’hui à penser les architectures data avec les services qui sont les plus utiles au moment souhaité, quitte à avoir des redondances de fonctionnalités. Nous veillerons à préserver au maximum l’indépendance de certaines parties du code (a minima la préparation de données et l’entrainement) vis à vis des plateformes propriétaires. Il sera alors possible d’envisager des alternatives chez d’autres fournisseurs cloud ou bien encore dans le monde de l’Open Source.