Le service Azure Machine Learning offre de nombreuses fonctionnalités au travers de son portail accessible par l’URL https://ml.azure.com:
- Notebooks Jupyter
- Interface d’automated Machine Learning
- Interface de conception visuelle de pipelines de Machine Learning
- Gestion de ressources de calcul
- Gestion des sources et des jeux de données
- etc.
Dans une optique d’utilisation en entreprise, et donc en équipe, tout le monde ne bénéficiera pas de toutes ces fonctionnalités. En effet, il faut poser a minima des garde-fous concernant la gestion des ressources de calcul, car la facturation du service en dépend directement !
On pourra également souhaiter que seuls certains administrateurs soient en capacité de créer ou supprimer des sources de données. Bref, il faudra établir des profils types (“personae“) des utilisateurs et leur accorder le bon périmètre d’actions autorisées.
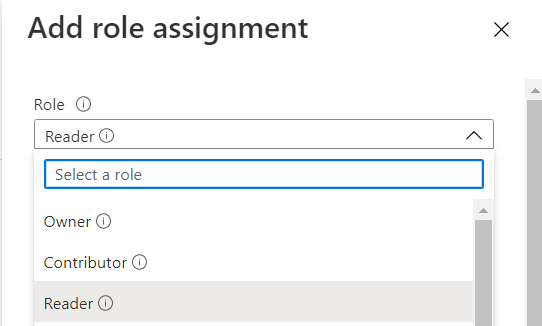
La gestion dite “Role Based Access Control” (RBAC) des ressources Azure permet de répondre à ce besoin. Dans le cas d’Azure Machine Learning, nous disposons de trois rôles prédéfinis, décrits dans la documentation officielle.

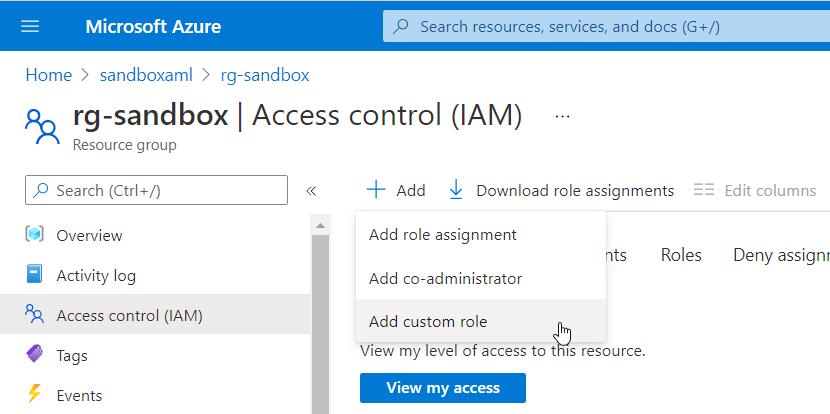
L’affectation d’un rôle se fait dans le menu “Access control (IAM)” de la ressource, depuis le portail Azure.
Mais prenons par exemple le scénario suivant. Une organisation fait travailler des Data Scientists dans un espace de travail Azure Machine Learning et souhaite qu’ils puissent :
- Créer des jeux de données à partir de sources de données définies (et ne pas supprimer ces dernières)
- Créer des expériences de Machine Learning par le biais du Concepteur, de l’Automated ML ou de notebooks
- Solliciter des ressources de calculs de type “compute instance” ou “compute cluster” mais ne pas en créer de nouvelles
- Publier des pipelines d’inférence sous la forme de points de terminaison (endpoint) temps réel ou par lot (batch)
Cette description ne correspond à aucun rôle prédéfini, nous allons donc passer par la création d’un rôle personnalisé ou “custom role“.
Ce rôle ne peut être créé que par le propriétaire de la ressource Azure Machine Learning et se fait au niveau de l’espace de travail contenant cette ressource.
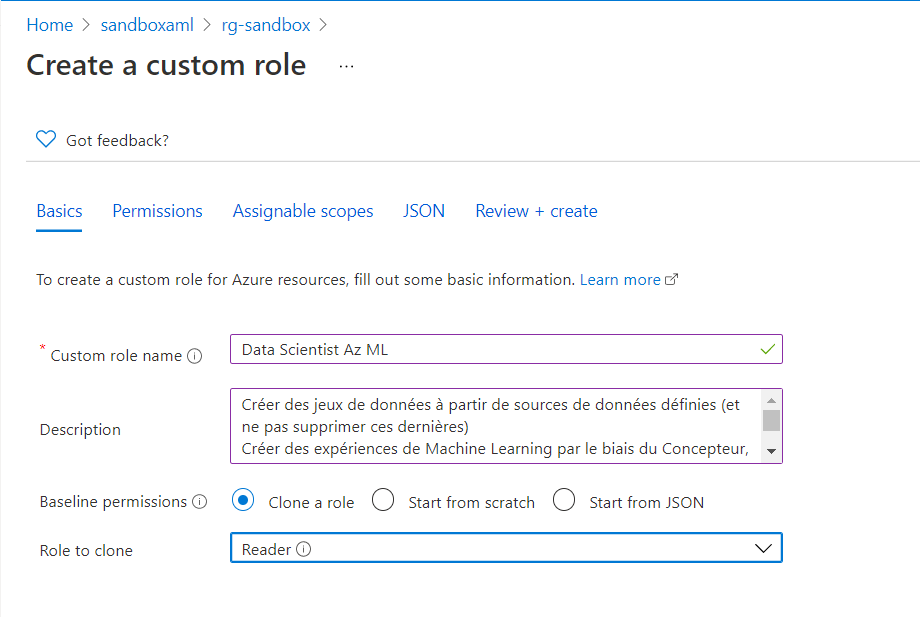
Pour débuter plus simplement, nous commençons par cloner un des trois rôles existants :
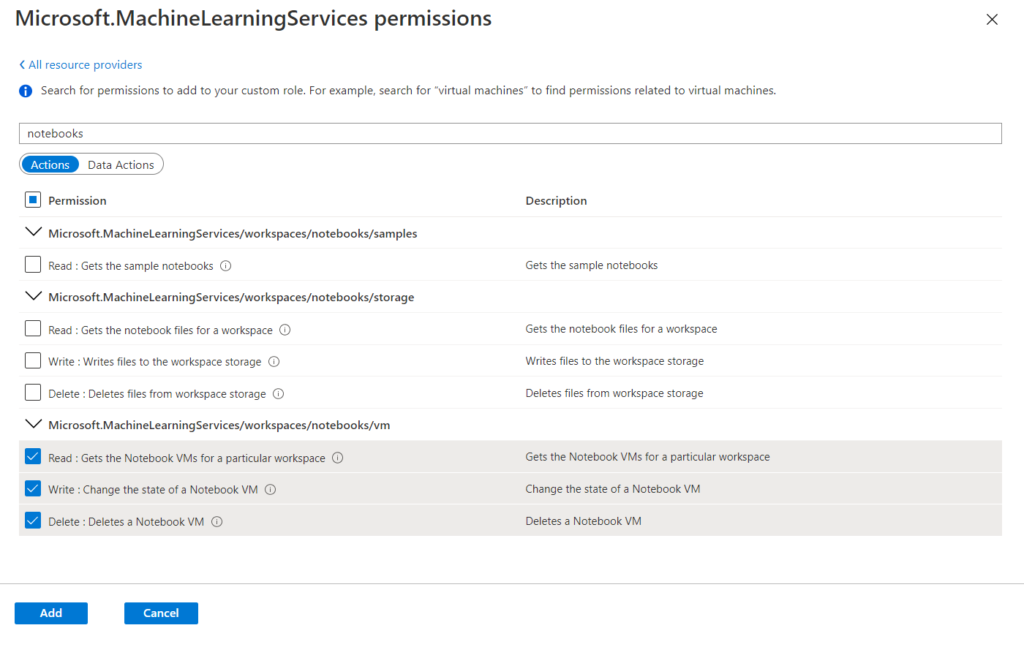
Le menu suivant permet d’ajouter ou de retirer des permissions. La liste de celles-ci s’obtient en recherchant le terme “machine learning”.
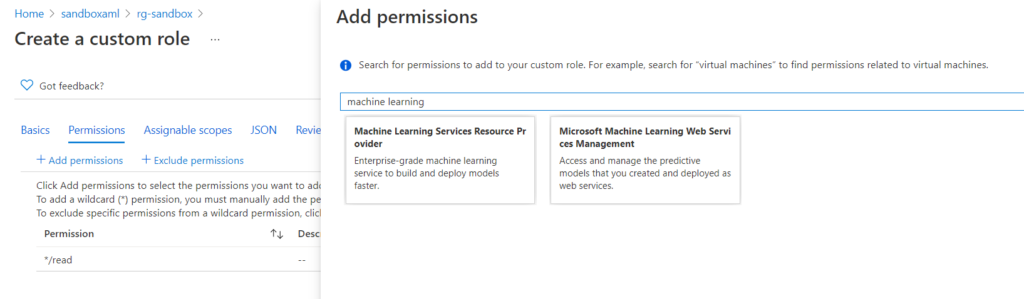
Les (très nombreuses !) actions sont alors détaillées et souvent déclinées sous le forme : read / write / delete / other.
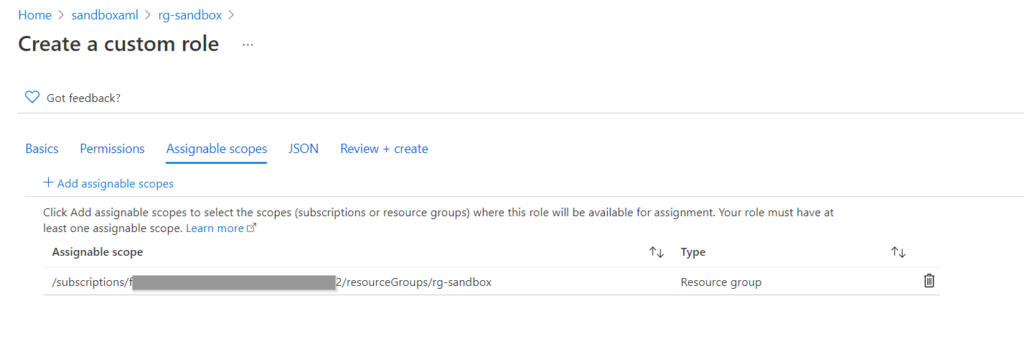
Veillez à bien préciser le périmètre d’application du rôle en notant l’identifiant de souscription suivi du nom du groupe de ressources où se trouve le service Azure Machine Learning.
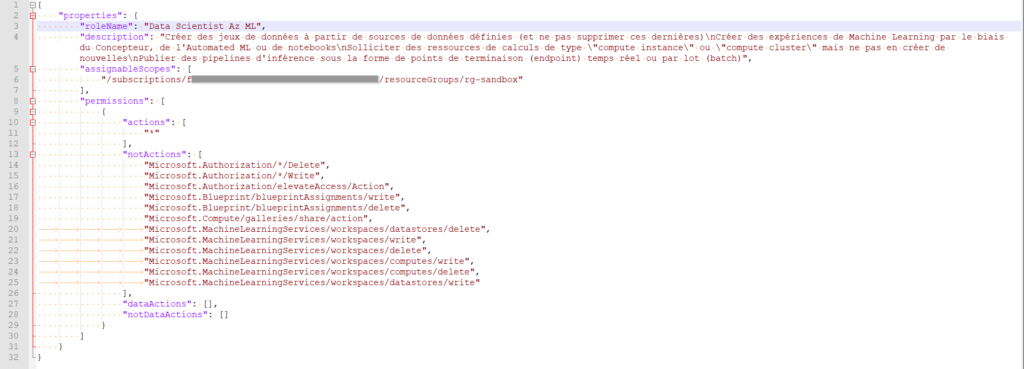
Nous allons ensuite utiliser le langage JSON pour définir précisément chaque action.
{
"properties": {
"roleName": "Data Scientist",
"description": "Create and run experiments, publish endpoints, can't create or delete compute ressources and data sources",
"assignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXX/resourceGroups/rg-sandbox"
],
"permissions": [
{
"Actions": [
"Microsoft.MachineLearningServices/workspaces/*/read",
],
"NotActions": [
"Microsoft.MachineLearningServices/workspaces/*/write",
"Microsoft.MachineLearningServices/workspaces/*/delete",
],
"dataActions": [],
"notDataActions": []
}
]
}
}
Il faut comprendre que certaines actions sont “imbriquées” et il sera possible d’autoriser un niveau supérieur pour sous-entendre l’autorisation sur les niveaux inférieurs. C’est ainsi le rôle du caractère “*” dans la ligne ci-dessous.
"Microsoft.MachineLearningServices/workspaces/*/read"
Voici le JSON complet répondant à notre scénario.
Ainsi, dans la partie Clusters de calcul, le bouton “Nouveau” a disparu mais l’utilisateur pourra toujours affecter un cluster à une expérience lancée par le Concepteur ou par le biais de l’Automated ML.
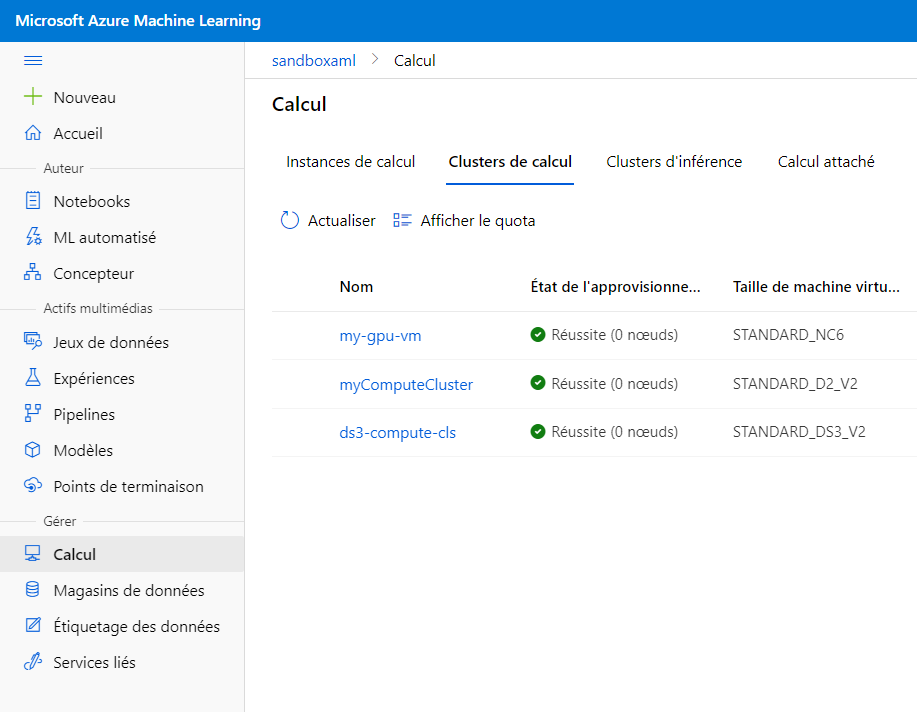
Mais nous verrons que ce rôle interdit l’utilisation d’instance de calcul, c’est-à-dire des machines virtuelles qui sont le support de l’usage de notebooks. Autant dire que les Data Scientists n’iront pas très loin sans cela ! (Sauf peut-être à travailler depuis Visual Studio Code et nous en reparlerons dans un prochain article…).
Nous cherchons donc à ajouter ces ressources de calcul, à l’aide des permissions cochées dans l’image ci-dessous.
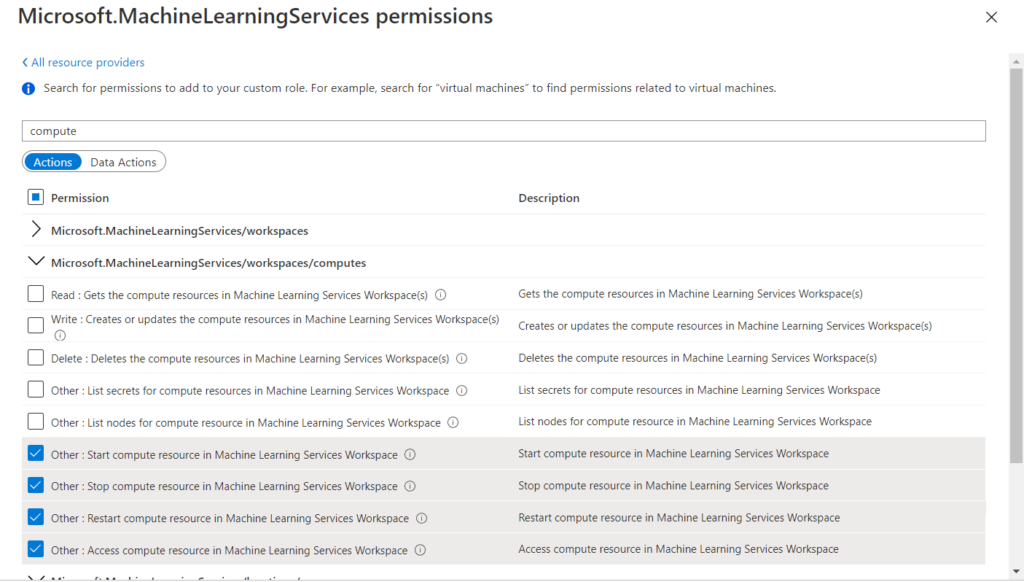
Malheureusement il n’existe pas de droits différenciant les instances de calcul des clusters. Nous ne pouvons donc pas aboutir à un scénario où l’utilisateur pourrait créer son instance personnelle sans pour autant créer un grappe d’une dizaine de machines en GPU ! Une instance de calcul est dédiée à un et un seul utilisateur mais il est possible pour un administrateur de la ressource (profil Owner) de créer des VMs et de les affecter à des utilisateurs. Ce processus se fait au travers du déploiement d’un template ARM et est documenté sur ce lien.

Attention, même si l’utilisateur ne peut pas accéder à la VM, il pourrait tout de même avec ces autorisations la démarrer… et oublier de l’éteindre (pas d’arrêt planifié)… et donc faire augmenter la facturation !
EDIT : Les “notebook VM” ont été remplacées par les instances de calcul mais les droits associés figurent toujours dans la liste des permissions.