Jusqu’à présent, nous avons l’habitude d’utiliser un espace de travail Azure Databricks en nous connectant au portail, l’authentification étant réalisée par un couple login / password déclaré dans l’annuaire Azure Active Directory.
Dans un but d’automatisation des tâches, il est intéressant de se pencher sur les commandes en lignes ou CLI. Celles-ci sont documentées sur le site de Databricks. Les commandes peuvent être vues comme une surcouche de l’API REST de Databricks.
Installation du CLI Databricks
Un environnement Python est nécessaire. Nous pouvons ensuite lancer le téléchargement du package dédié avec la commande ci-dessous, depuis un terminal.
pip install databricks-cli
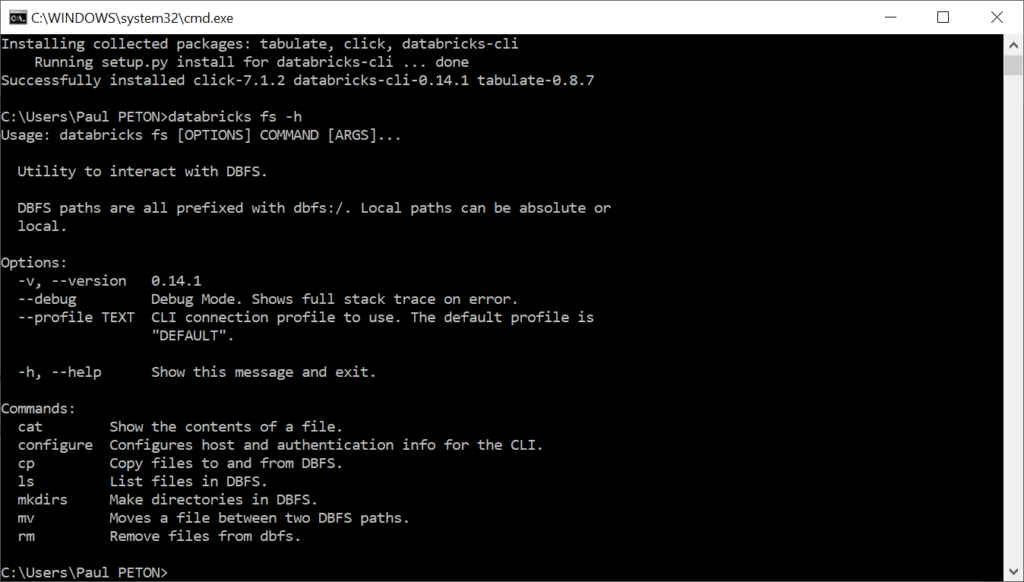
Nous vérifions dans la foulée que l’affichage de l’aide d’une commande, sur laquelle nous reviendrons plus tard, est fonctionnel.
databricks fs -h
La version installée peut être retrouvée par la commande :
databricks --version
C’est un produit qui évolue rapidement et il conviendra de le mettre à jour fréquemment, afin de bénéficier d’un maximum de fonctionnalités.
Authentification
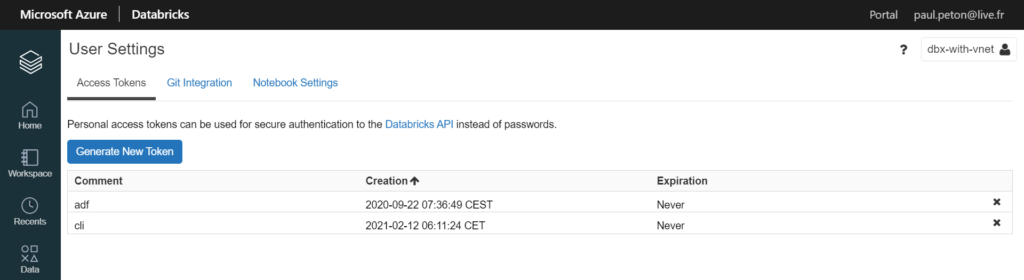
Nous allons utiliser un Personal Access Token pour nous authentifier auprès du service. Ce jeton de sécurité est obtenu sur le portail Databricks, dans le menu User Settings.
Attention à bien noter (dans un coffre-fort électronique !) le jeton obtenu, il ne sera plus possible d’afficher sa valeur par la suite.
Nous démarrons la configuration par la commande :
databricks configure --token
Deux valeurs seront attendues : l’URL de l’espace de travail, puis le token précédemment généré. L’URL pour une ressource Azure est dorénavant de la forme https://adb-XXXXXXXXXXXXXXXX.XX.azuredatabricks.net/.
Un fichier local s’écrit alors et contient les informations renseignées.

Vérifions maintenant que l’authentification est effective en lançant une commande interagissant avec l’espace de travail :
databricks workspace ls
Si nous obtenons un message d’erreur Error: b’Bad Request’, la cause peut être un mauvais enregistrement du token dans le fichier de configuration. En ouvrant celui-ci dans un éditeur de texte, nous visualisons le résultat suivant :

Remplacer les caractères SYN par la valeur du token permettra de résoudre ce problème mais demande de stocker ce secret de manière non sécurisée.
Nous pouvons maintenant lister le contenu de l’espace de travail.
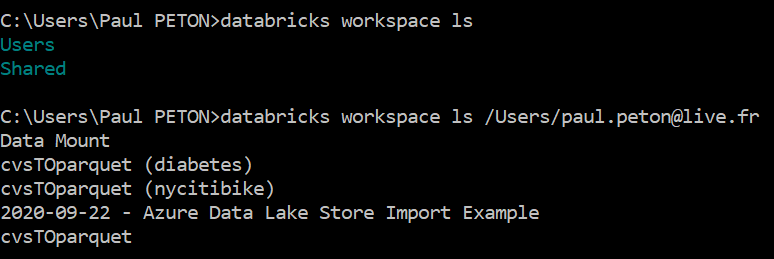
Copier un fichier depuis le FileStore
Le FileStore est une zone de stockage spécifique (un dossier) du DataBricks File System (DBFS). Celui-ci nous permet de réaliser des échanges avec l’extérieur : copie de fichiers vers ou depuis le DBFS. Une documentation complète est disponible ici.
A l’aide des commandes du CLI, nous identifions un fichier que nous pouvons recopier localement.

Comme le CLI est une surcouche de l’API REST de Databricks, il est intéressant de retrouver la commande initiale émise vers l’espace de travail. Nous pouvons l’obtenir en ajoutant –debug après la commande de copie.
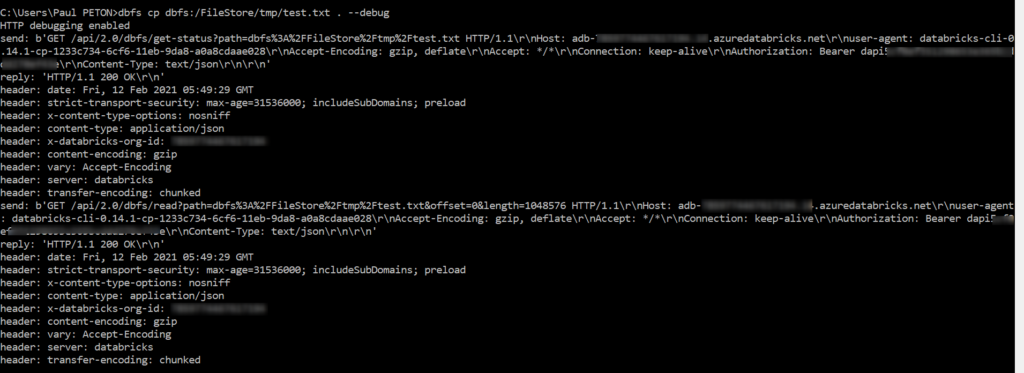
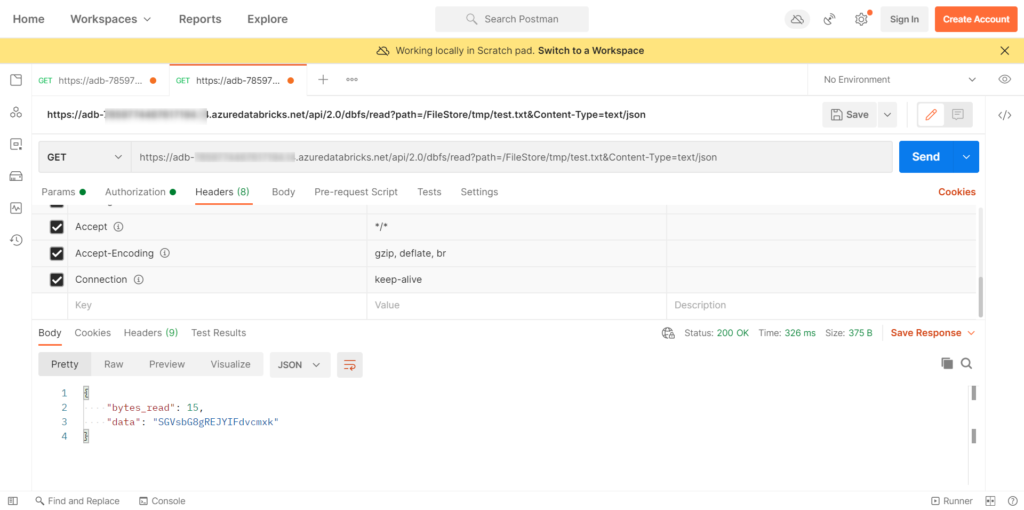
Le premier appel vérifie le statut du fichier. Il est possible d’exécuter la requête dans Postman (coller un token dans la partie Authorization).
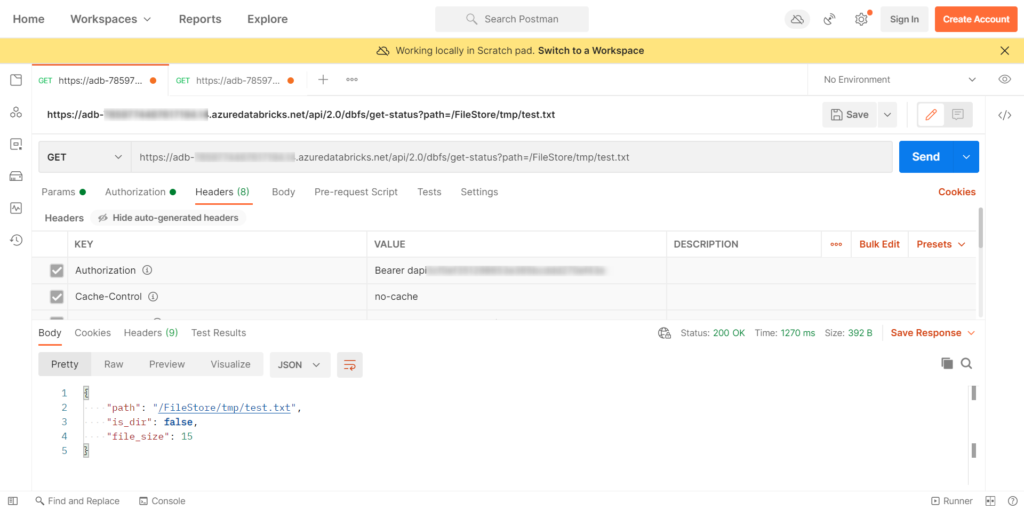
Nous trouvons ici la taille du fichier. Il faut savoir que le contenu du fichier est converti en base 64 et nous allons ensuite mieux comprendre pourquoi.
Un second appel à l’API se fait avec la méthode read et deux options &offset=0&length=1048576. Si le fichier dépasse 1 méga-octet, celui-ci est découpé en morceaux (chunks) et plusieurs appels seront nécessaires. La commande reconstitue toutefois le fichier et le décode automatiquement. Tout cela est donc transparent pour l’utilisateur !