Avec l’arrivée du CLI et du SDK V2, Azure Machine Learning s’est orientée vers une utilisation centrée sur le MLOps, cette démarche visant à automatiser les étapes du cycle de vie d’un modèle de Machine Learning.
Plutôt que d’alourdir le code Python, ce sont maintenant des opérations décrites dans des fichiers YAML qui se chargent de l’exécution des scripts de préparation de données ou d’entrainement.
L’utilisation du CLI est en particulier efficace pour des tâches comme la création d’un compute cluster ou le déploiement d’un point de terminaison dédié à l’inférence (les prévisions, en temps réel ou en mode batch).
GitHub s’impose quant à lui comme la ressource permettant le versioning des scripts (repositories) mais aussi leur déploiement continu, grâce aux GitHub Actions.
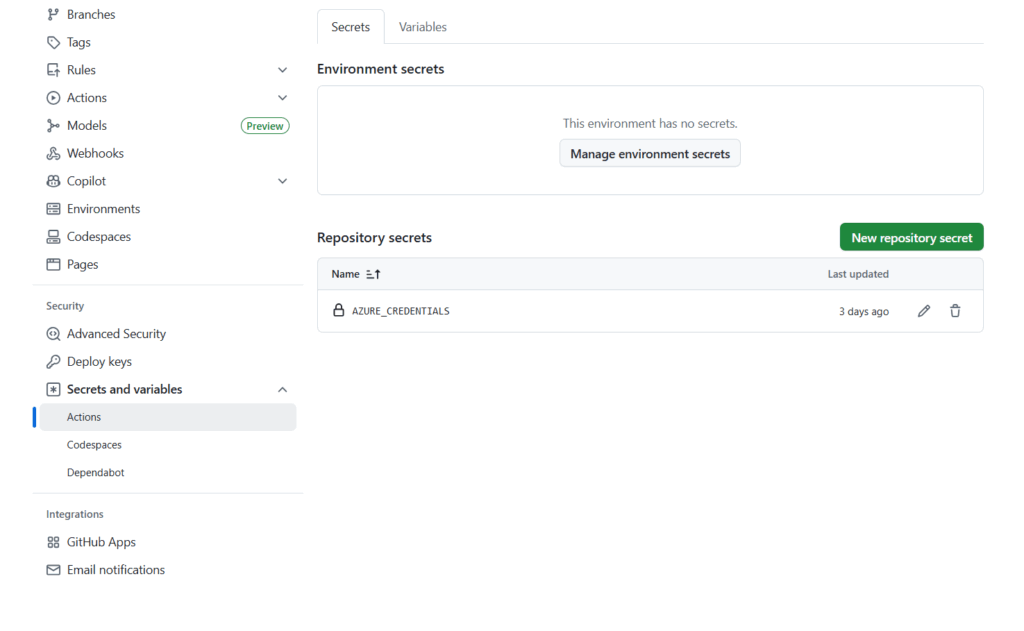
Authentifier GitHub vis à vis du workspace Azure ML
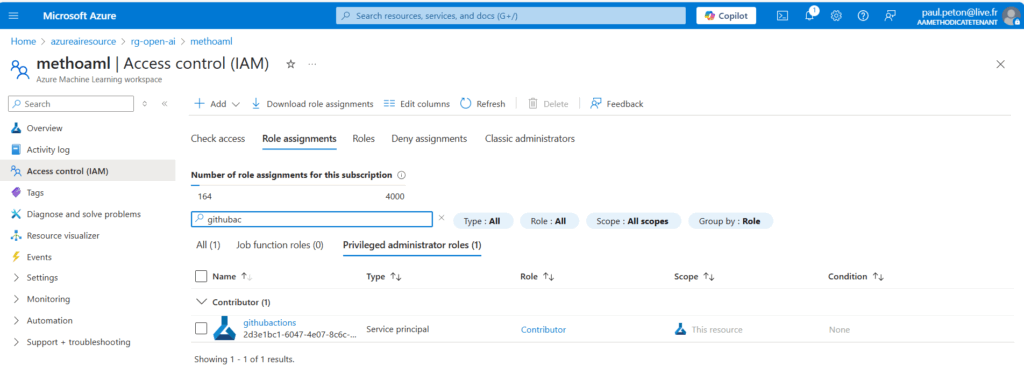
C’est une identité de type Service Principal (SPN) qui va réaliser l’authentification de l’action GitHub vis à vis du workspace Azure ML.
Pour cela, notez le client ID lors de la création du SPN ainsi que le tenant ID et la subscription ID correspondant au déploiement du service Azure ML.
Créez ensuite un secret associé à SPN et notez sa valeur (attention, ce n’est pas le secret ID).
Structurez ces informations de la manière suivante :
Dans une arborescence .github/workflows, un second fichier YAML définit l’action à réaliser.
name: Deploy Azure ML Hello World
on:
push:
branches: [ main ]
permissions:
id-token: write
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout repo
uses: actions/checkout@v3
- name: Login to Azure
uses: azure/login@v1
with:
creds: '${{secrets.AZURE_CREDENTIALS}}'
- name: Set up Azure CLI ML extension
run: |
az extension add -n ml -y
az configure --defaults workspace=<WORKSPACE_NAME> group=<RESOURCE_GROUP_NAME>
- name: Submit job to Azure ML
run: |
az ml job create -f job.yml
Pensez à bien modifier les deux noms nécessaires pour définir le workspace Azure ML et le groupe de ressources qui le contient.
Par défaut, l’action se lance automatiquement lors d’un commit ou d’un merge sur la branche main.
Contrôler la bonne exécution du job
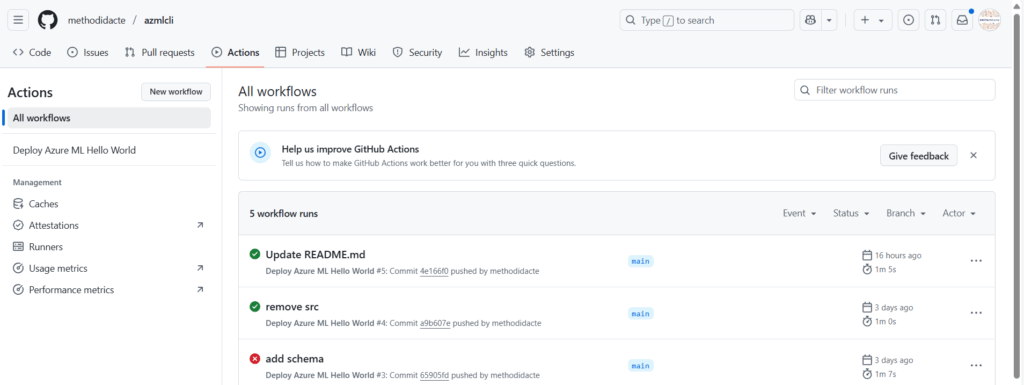
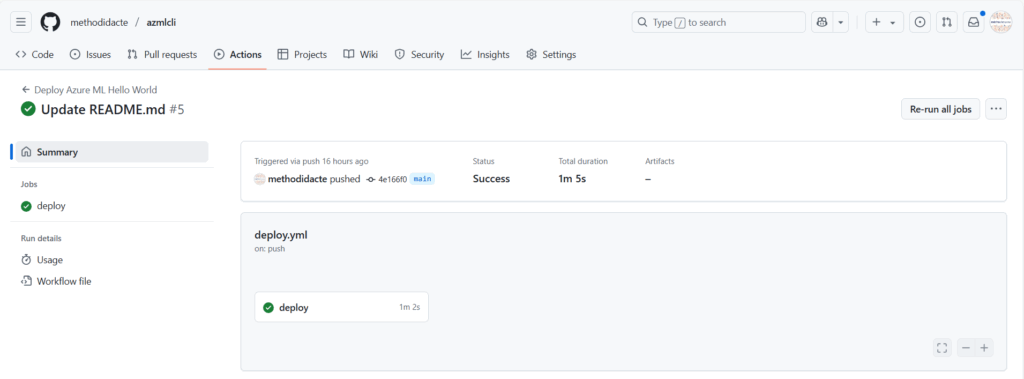
L’action est visible dans le menu Actions.
Le statut de l’action doit indiquer “Success”.
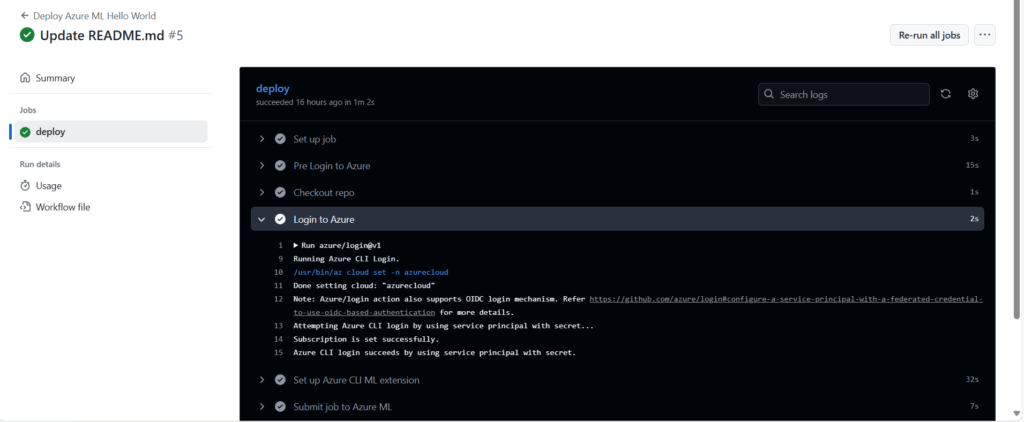
Vérifiez en particulier la bonne authentification de GitHub vis à vis de la ressource Azure.
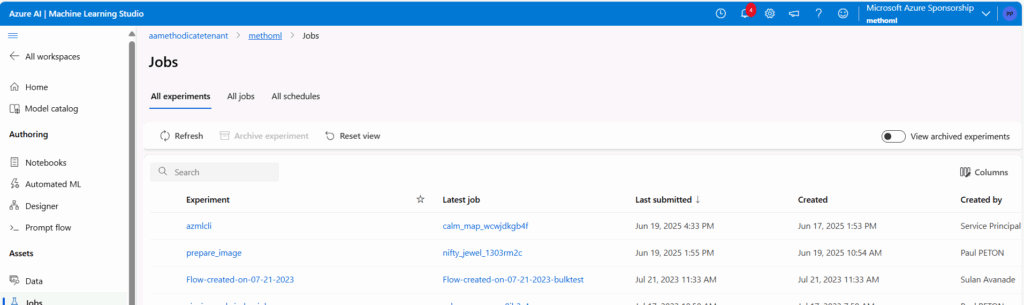
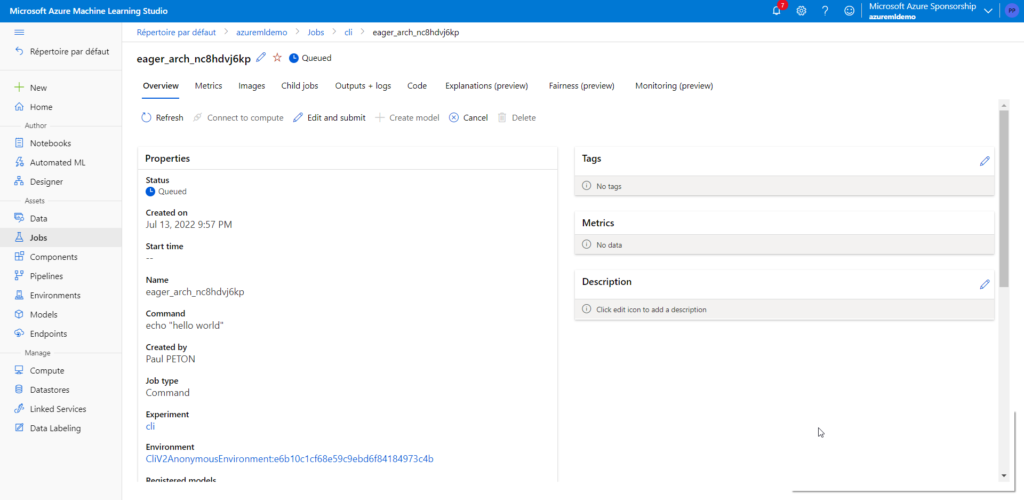
Dans le studio Azure ML, le job est également visible et rattaché à une experiment.
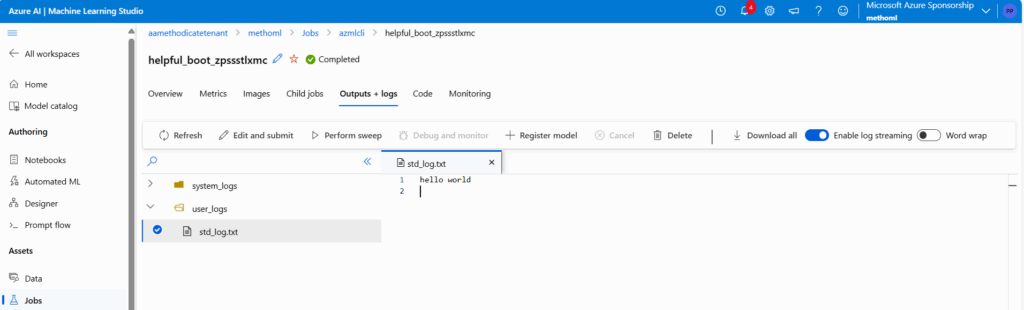
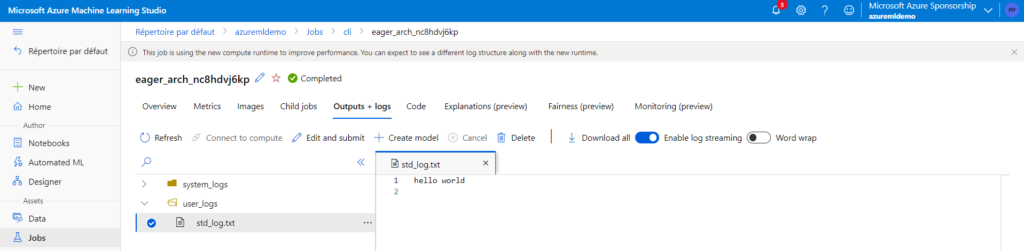
Nous retrouvons le “hello world” dans les logs du job.
Cette stratégie de déploiement continu s’appliquera sur les étapes de préparation de données, d’entrainement ou encore de déploiement du point de terminaison.
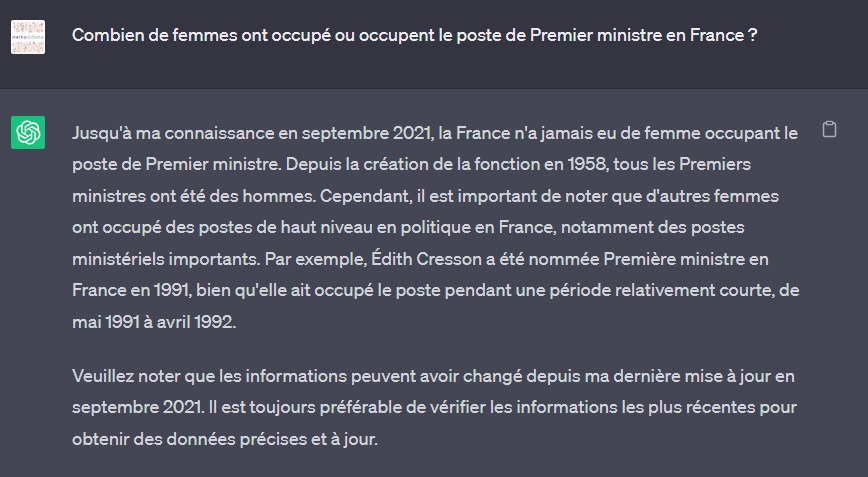
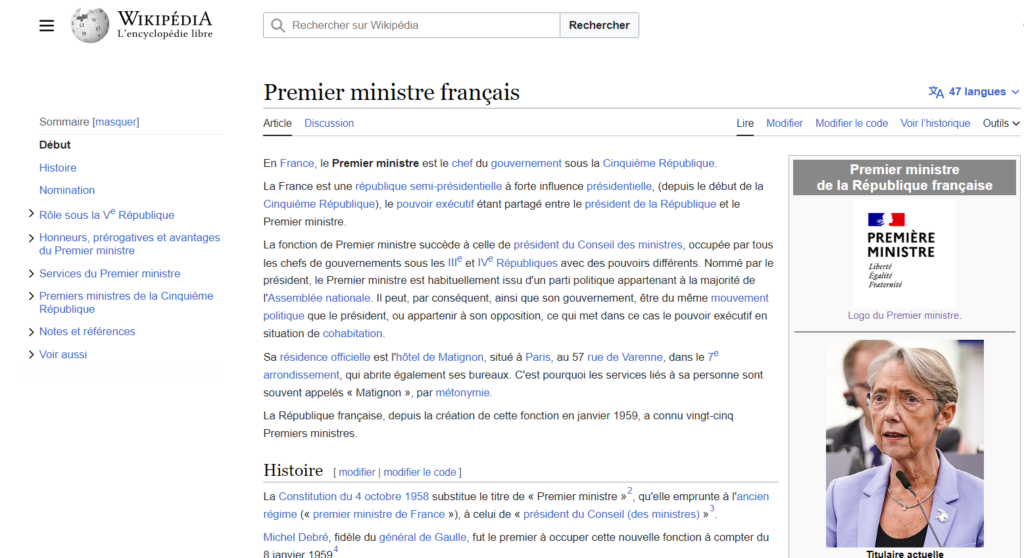
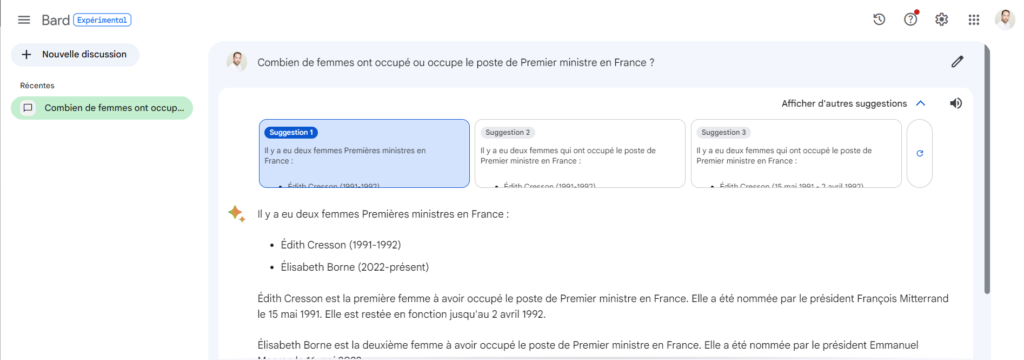
Combien de femmes ont occupé ou occupe le poste de Premier ministre en France ? Posons la question à ChatGPT (version 3.5) sur le site public d’OpenAI.
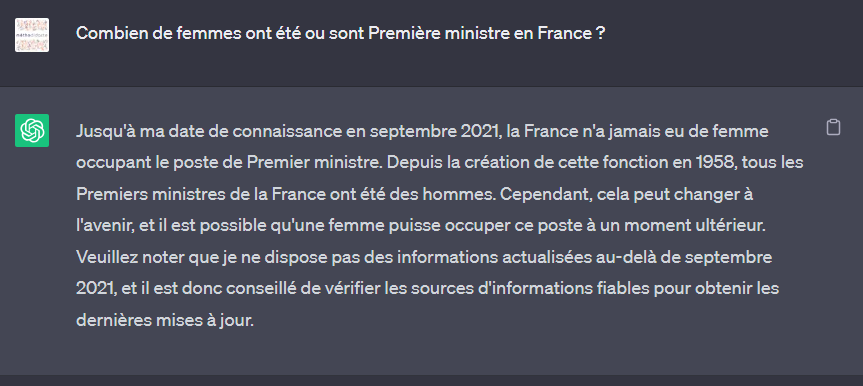
C’est peut-être la question qui est biaisée, car le nom de la fonction n’est pas féminisé ! Nous pouvons reformuler ainsi, dans une nouvelle session :
Même si ChatGPT “oublie” ici Edith CRESSON, nous notons surtout que ce modèle est entrainé avec sur un dataset allant jusqu’à septembre 2021. Tout événement postérieur lui est donc inconnu. Il est fort peu probable que la société OpenAI se destine à entrainer de manière continue un modèle aussi gigantesque (175 milliards de paramètres !). Nous devons donc trouver une autre manière de “connecter” ChatGPT à l’actualité.
Nous allons nous tourner vers le site Wikipedia dont les pages sont alimentées très rapidement et dont le nombre de contributeurs et modérateurs permet de d’assurer un niveau satisfaisant de véracité.
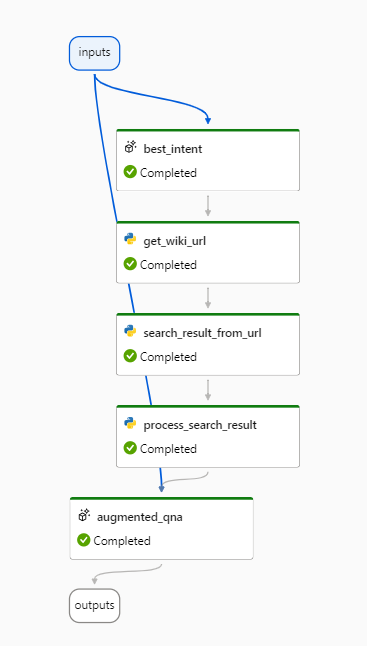
Au moyen de la fonctionnalité Prompt Flow de Azure Machine Learning, nous allons déployer le démonstrateur “Ask Wikipedia“.
Prompt flow est un outil qui permet d’enchainer différentes tâches (le flow) dont des tâches de prompt et d’appel à un Large Language Model (LLM), mais aussi des scripts Python. Nous avons donc la possibilité de réaliser rapidement un développement qui deviendra par la suite un endpoint HTTPS, au travers d’un déploiement similaire aux modèles traditionnels d’Azure Machine Learning.
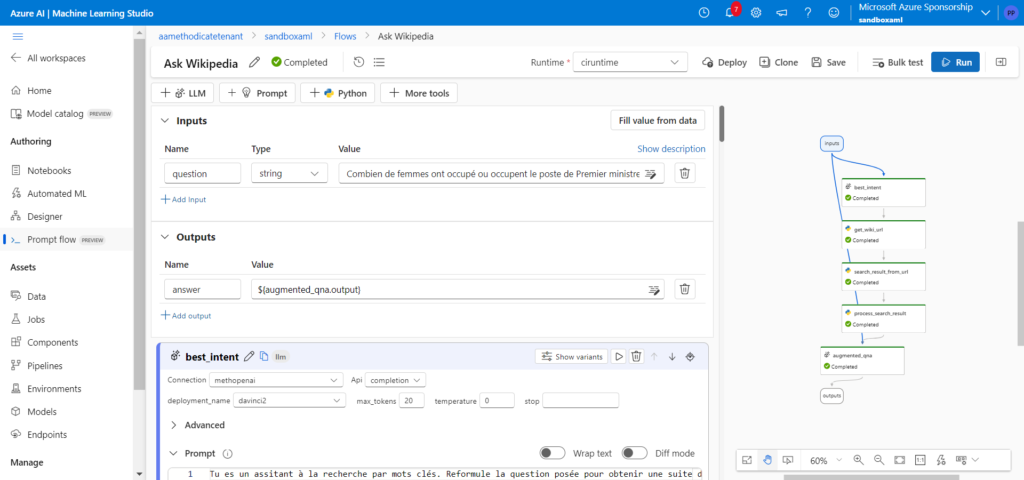
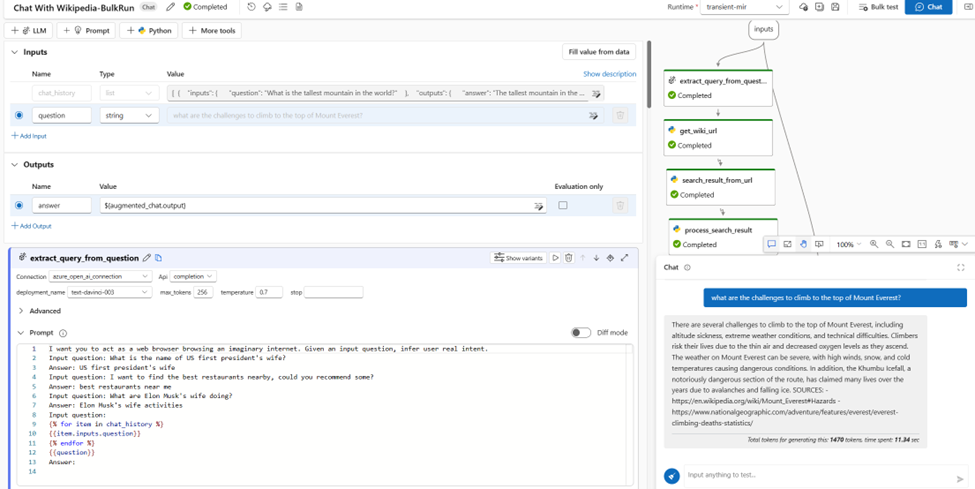
Interface de Prompt Flow dans le studio Azure Machine Learning
Un flow débute par une entrée (input) et se termine par une sortie (output). Les entrées et sorties des briques intermédiaires permettent de relier les différentes tâches entre elles. Il est également possible d’ajouter des inputs qui sont en fait des paramètres d’une étape du flow (par exemple des variables de fonctions Python). Nous allons détailler le flow développé ici.
input : il s’agit de la question posée. Il serait intéressant de détecter la langue de la question pour adapter ensuite différents éléments (prompt ou URL de recherche)
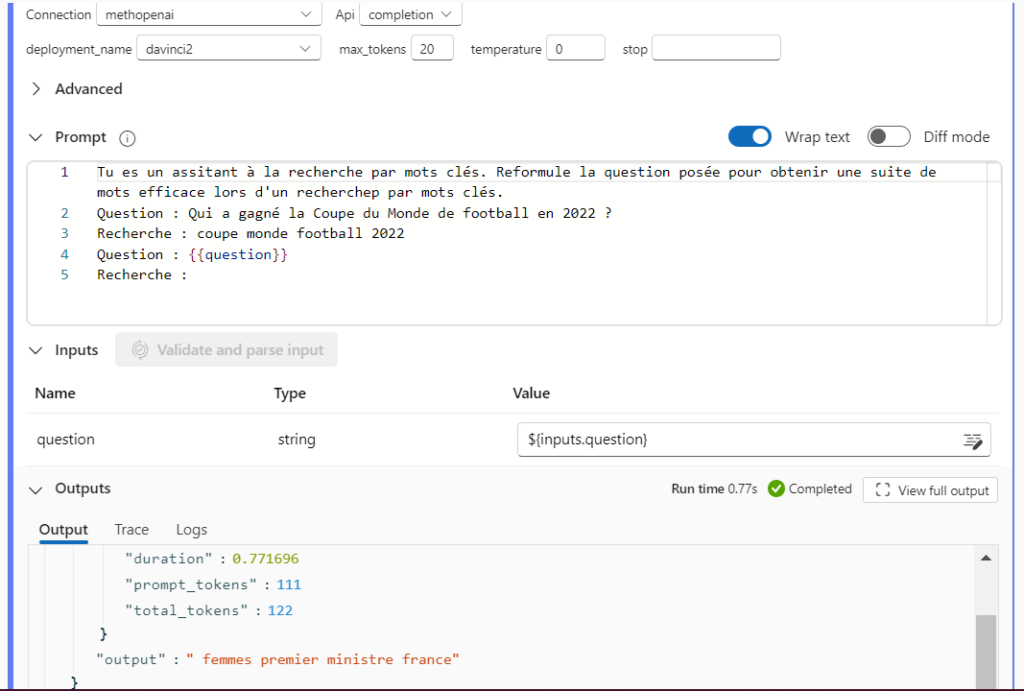
best_intent (élément ajouté par rapport au template généré automatiquement) : la question formulée par l’utilisateur peut ne pas être la forme la plus efficace pour des moteurs de recherche optimisés pour les mots clés ou les expressions. Nous utilisons ici un modèle GPT de type Da Vinci pour reformuler la question et dégager l’intention de l’utilisateur
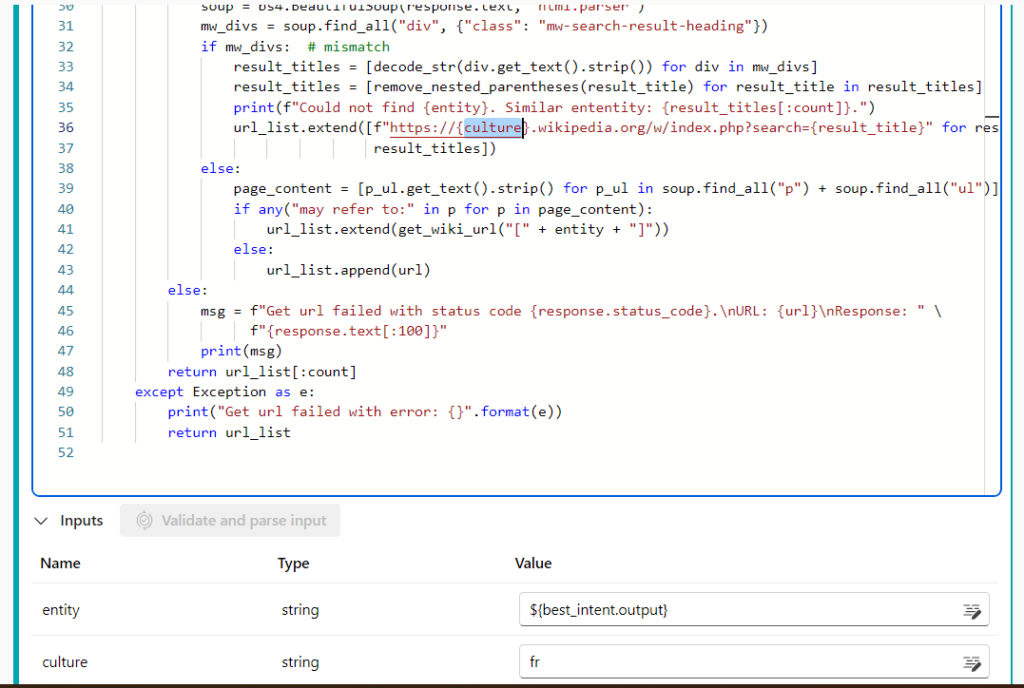
get_wiki_url : liste des URLs données par le moteur de recherche Wikipedia en réponse aux mots clés définis à l’étape précédente
search_result_from_url : extraction des premières phrases de chaque page grâce au parser de la librairie Python BeautifulSoup
process_search_result : concaténation des résultats précédents en une chaîne de texte, alternant les balises “Content” et “Source”
augmented_qna : interrogation d’un LLM à partir d’un system message et des contextes obtenus ci-dessus
Détail de l’étape “best_intent”
Nous allons maintenant réaliser une série de tests pour savoir si le flow est en capacité de trouver la bonne réponse à notre question initiale, à savoir deux femmes : Edith CRESSON et Elisabeth BORNE.
Pour adapter la recherche à notre contexte en langue française, l’URL de recherche de Wikipedia a été rendue dynamique et se construit à l’aide d’un paramètre (input) nommé “culture”.
Optimisation des paramètres du flow
Les paramètres dont nous disposons sont :
le nombre d’URLs retenues sur la page de search de Wikipedia (max_urls)
le nombre de phrases retenues par page, en commençant par le début de la page (max_sentences)
le modèle utilisé pour formuler la réponse à partir des sources (deployment_name) qui conditionne le paramètre suivant
le nombre de tokensadmis dans le prompt où sont concaténés les phrases extraites des pages (max_tokens)
Test n°1 (valeurs par défaut)
count_urls : 2
count_sentences : 10
deployment_name : GPT-3.5-turbo
max_tokens : 8192
"Aucune femme n'a occupé le poste de Premier ministre en France jusqu'à présent."
Mauvaise réponse ! Mais en regardant le détail des phrases relevées par le flow, nous voyons qu’aucune référence à Edith CRESSON ou Elisabeth BORNE n’y figure. Elargissons le périmètre de recherche sur Wikipedia en retentant 10 URLs.
Test n°2
count_urls : 10
count_sentences : 10
deployment_name : GPT-3.5-turbo
max_tokens : 8192
"Il y a eu deux femmes qui ont occupé le poste de Premier ministre en France : Édith Cresson de mai 1991 à avril 1992 et Élisabeth Borne depuis mai 2022. SOURCES: https://fr.wikipedia.org/w/index.php?search=Premier+ministre+fran%C3%A7ais"
La réponse est bonne, la source également mais… ce n’est pas l’extrait de cette page qui a permis au LLM de formuler la bonne réponse ! En effet, sur des extraits de 10 phrases, seule la page https://fr.wikipedia.org/w/index.php?search=Élisabeth+Borne donne l’information suffisamment rapidement. Notons ici que le moteur de recherche de Wikipedia a été assez “intelligent” pour aller chercher la page de la Première ministre actuelle, en cinquième lien.
Pour trouver la bonne réponse dans la source citée, nous devons augmenter le nombre de phrases retenues par page.
Test n°3
count_urls : 5
count_sentences : 200
deployment_name : GPT-3.5-turbo
max_tokens : 8192
OpenAI API hits InvalidRequestError: This model's maximum context length is 8192 tokens. However, your messages resulted in 16042 tokens. Please reduce the length of the messages.
Message d’erreur ! En effet, nous ramenons un contexte trop long par rapport au modèle utilisé. Il faut donc changer de modèle, soit pour un nouveau GPT-3.5-turbo, acceptant 16k tokens, soit pour GPT-4 32k.
Test n°4
count_urls : 5
count_sentences : 200
deployment_name : GPT-4
max_tokens : 32768
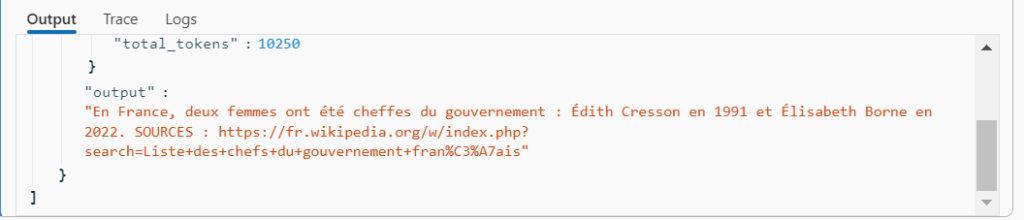
"Deux femmes ont occupé ou occupent le poste de Premier ministre en France : Édith Cresson en 1991 et Élisabeth Borne en 2022. SOURCES : https://fr.wikipedia.org/w/index.php?search=Femmes+ministres+en+France, https://fr.wikipedia.org/w/index.php?search=Élisabeth+Borne"
Nous obtenons ici les sources correctes pour la réponse. Il faut préciser que le premier lien parle bien du “Gouvernement Elisabeth BORNE” mais le LLM ne semble pas faire le lien avec le rôle de Premier ministre.
En effet, en reformulant la question de la sorte : “En France, combien de femmes ont été cheffe du gouvernement ?”, nous obtenons une réponse correcte. Le lien Wikipedia donne d’ailleurs les différents intitulés de ce poste au cours de l’Histoire.
La plus grande difficulté réside ici dans la récupération des informations pertinentes lorsque le corpus à disposition est volumineux (il faut alors un outil de search efficace) puis lorsque les informations rapportées dépassent le nombre de tokens maximum d’un prompt. Une étape supplémentaire pourrait alors être ajoutée pour résumer les phrases obtenues de chaque page, afin de les fournir au prompt final. Comme il n’existe à ce jour (juillet 2023) pas de logique de boucle dans Prompt Flow, il serait nécessaire d’appeler l’API du service Azure OpenAI directement dans le script Python, en se passant de la connexion définie.
Modèle biaisé ou utilisateur à former ?
En conclusion, on pourrait s’arrêter sur le fait qu’il est possible de trouver la bonne réponse… du moment qu’on la connaît ! Ce serait bien sûr réducteur, cet article vise à montrer la nécessité de disposer de jeux de tests significatifs et de ne pas s’arrêter à la première réponse obtenue, puis de rester critique vis à vis d’informations données par le combo LLM + search. Mais ne sommes-nous pas face aux mêmes limites quand nous nous arrêtons aux premiers liens obtenus dans Google Search ou quand nous ne lisons pas l’entièreté d’un article ?
Maintenant, quelle responsabilité vis à vis du biais de représentation des femmes faut-il accorder aux différentes parties de cette expérience ?
ChatGPT, dans sa version 3.5 tout public, ne pouvait avoir connaissance de la nomination d’Elisabeth BORNE, intervenue après sa phase d’entrainement
L’article Wikipedia le plus “pertinent” (au sens de l’algorithme de recherche) présente bien la titulaire actuelle dès le début de la page mais dans une zone plus difficile à lire pour les fonctions Python utilisées (voir copie d’écran ci-dessous)
L’approche historique de l’article contient les informations récentes en fin de page, à une distance en tokens plus complexe à gérer selon la version du LLM utilisée
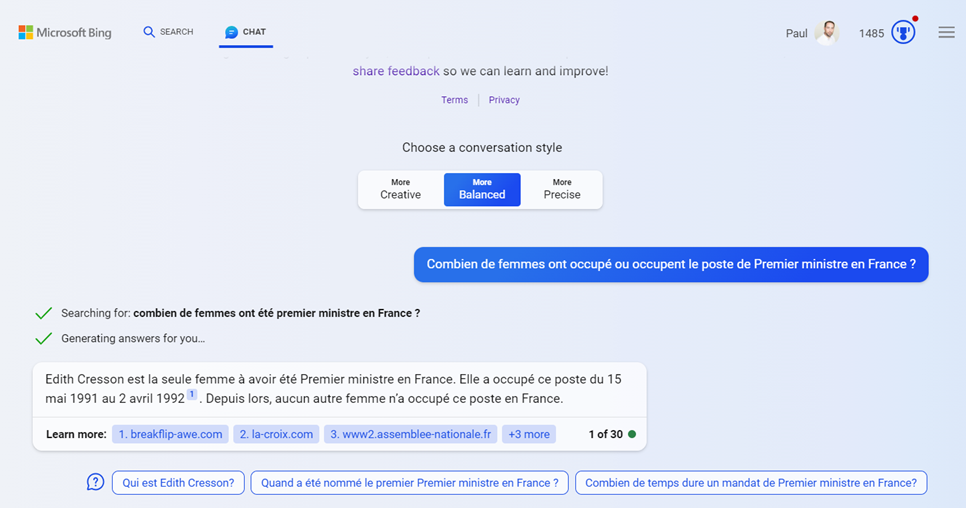
Voici le résultat de la question initiale, soumise à Bing, augmenté par le modèle GPT-4. Cette interface fournit également les liens sources de la réponse.
Elisabeth BORNE n’a pas été comptabilisée mais il faut noter que, par défaut, c’est le mode “More Balanced” qui est utilisé.
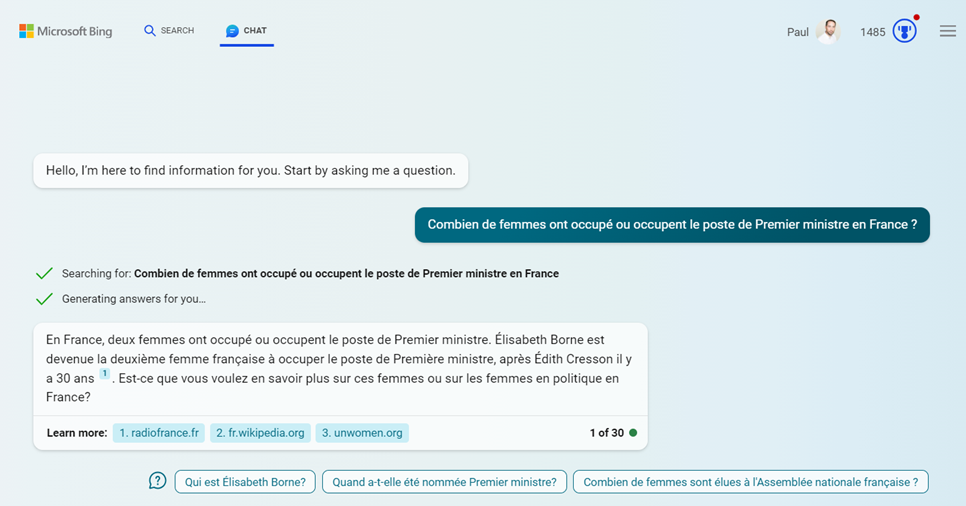
En se plaçant sur le mode “More Precise“, la bonne réponse est enfin obtenue !
Enfin, les résultats de recherche n’auraient-ils alors pas été meilleurs si le poste de Premier ministre avaient été occupé plus tôt par des femmes au cours des IIIe, IVe et Ve République ?
Pour aller (encore) plus loin
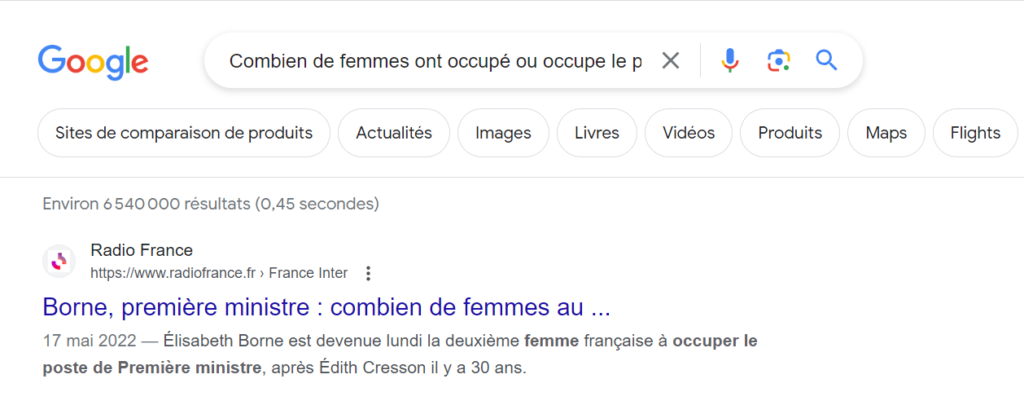
D’autres source que Wikipedia pourraient également être plus efficaces et disposer d’articles répondant plus directement à la question posée.
Premier lien fourni par Google Search
Prompt Flow propose de définir une connection vers le service SerpApi qui réalise des recherches sur Google et d’autres moteurs.
Quant au service Bard de Google, celui-ci fournit la réponse attendue dans chacune de ses suggestions.
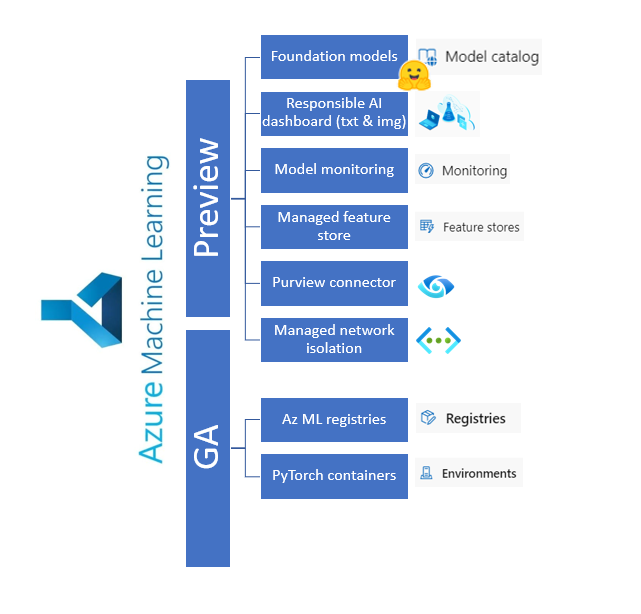
Entre la déferlante OpenAI et le renouveau de la data platform avec Microsoft Fabric, on pouvait craindre qu’il ne reste que la portion congrue pour Azure Machine Learning. Mais c’est loin d’être le cas ! Faisons un tour sur les différentes annonces qui contribuent à faire d’Azure ML une véritable plateforme pour le Machine Learning en production.
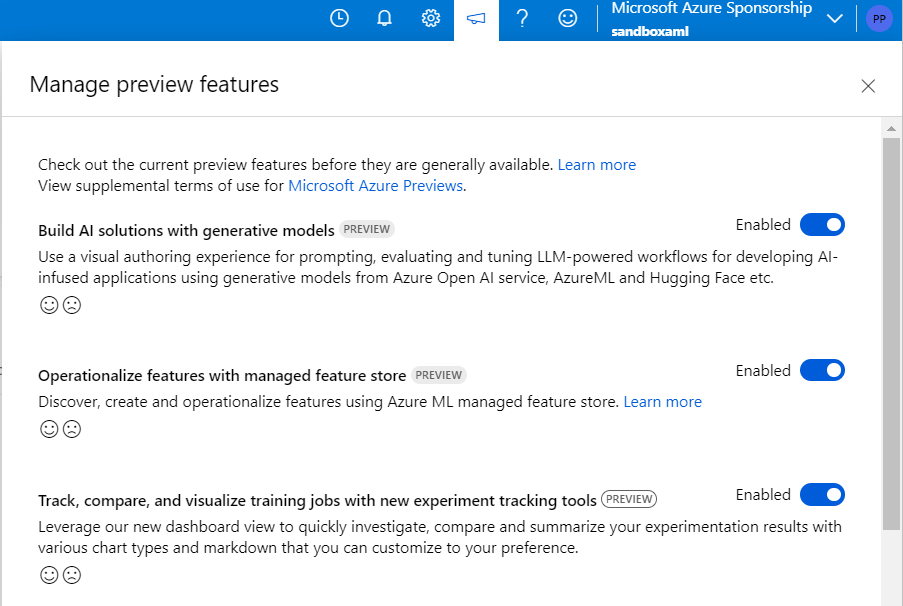
En préversion publique
Rappelons que lors de la phase dite de preview et avant la disponibilité générale (general availability), les services ne sont pas intégrés dans le support proposé par Microsoft. L’utilisateur doit également être conscient que les fonctionnalités, l’interface et bien sûr la tarification peuvent encore évoluer.
Veillez bien à activer les préversions à l’aide du menu dédié “Manage preview features“.
Support for foundation models
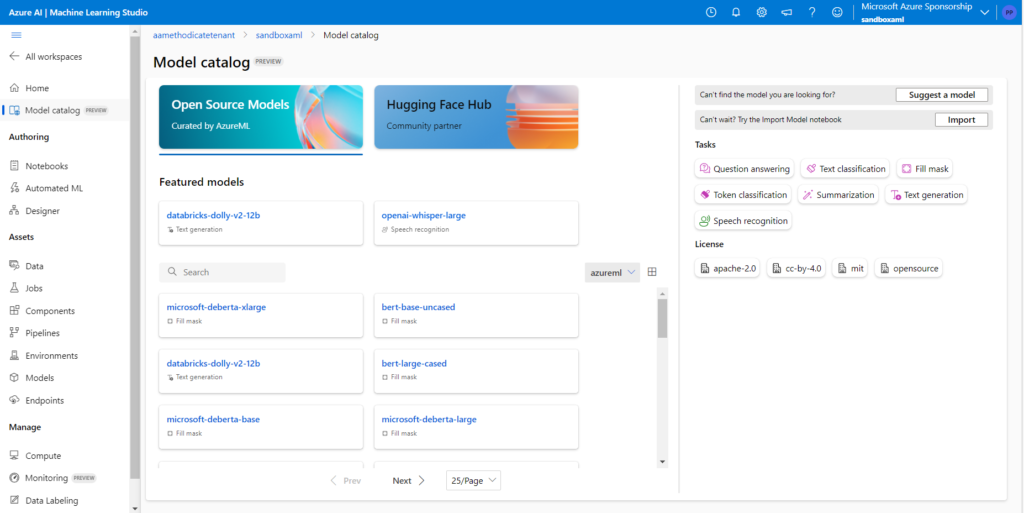
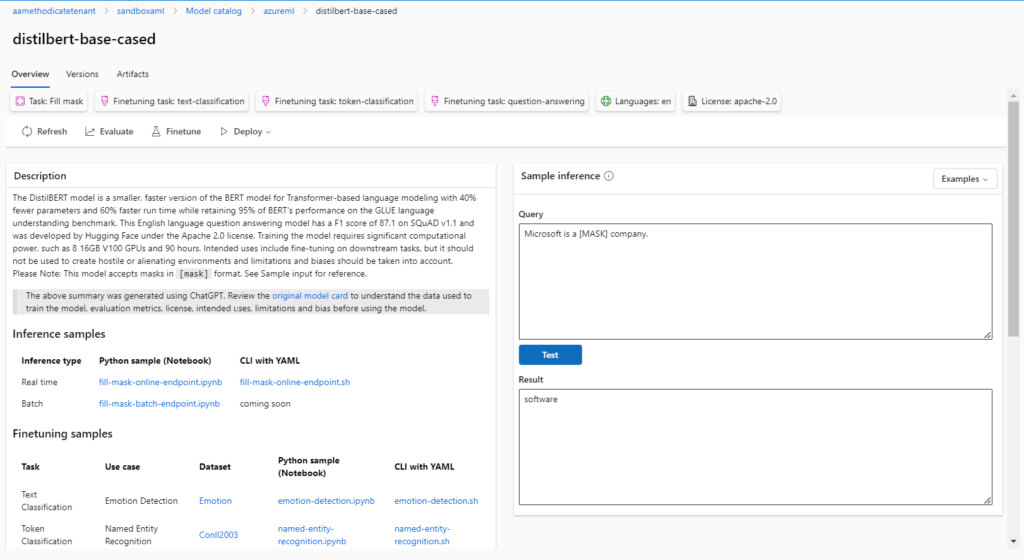
L’époque où les Data Scientists développaient leur propre modèle sur leur laptop semblerait presque révolue ! En effet, des modèles Open Source très puissants sont maintenant disponibles au travers de hubs comme Hugging Face qui se place ici en partenariat avec Microsoft. Il devient possible de déployer ces modèles au sein du workspace Azure Machine Learning pour les utiliser sur des tâches d’inférence.
Après déploiement sous forme de managed online endpoint, nous passons donc directement dans le menu des points de terminaison (endpoints) pour retrouver les modèles disponibles.
Certains modèles proposent aussi une interface de test sans déploiement.
Responsible AI dashboard support for text and image data
Nous connaissions déjà le tableau de bord pour une AI responsable, construit autour de briques Open Source sur l’explicabilité et l’interprétabilité des modèles. Je vous recommande d’ailleurs cet excellent article sur son utilisation.
Le tableau de bord s’étend maintenant aux modèles de Computer Vision (images) et de NLP (textes).
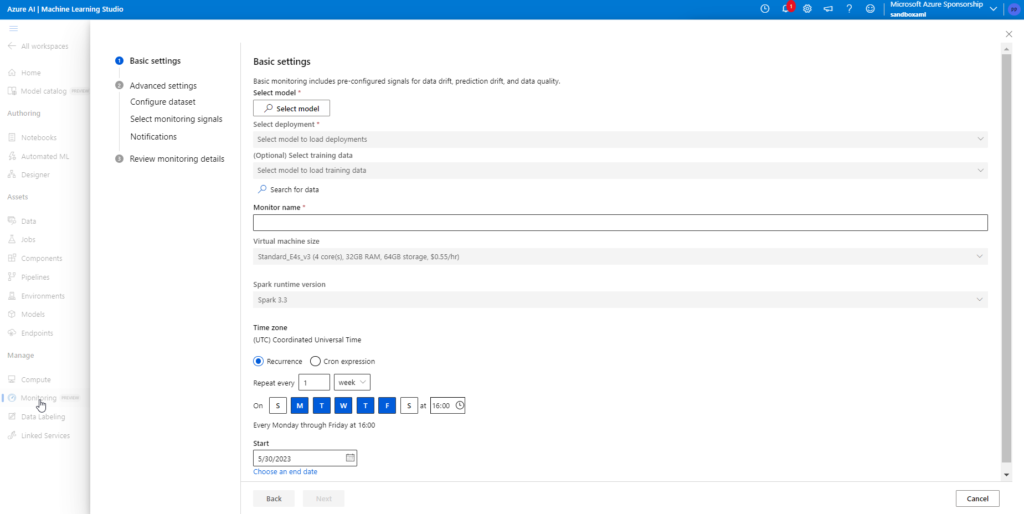
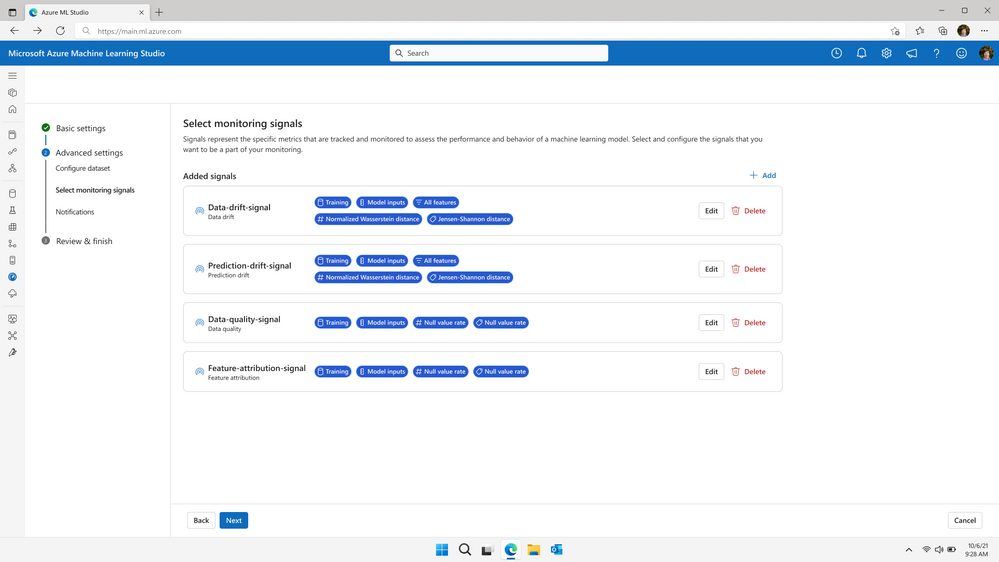
La fonction “Dataset monitors”, toujours en préversion, réalise déjà une détection de dérive sur les nouvelles données qui pourraient être proposées à l’inférence sur un modèle entrainé. Il est important de lever des alertes lorsque la distribution des données d’entrée change et diffère de celle des données d’entrainement. Pour autant, un autre type de dérive est possible : celle du lien entre la variable cible et les variables d’entrée (model drift). C’est ici qu’entre en jeu un nouvel outil, dans un menu dédié “Monitoring“.
Il est possible ici de choisir les différents éléments mis sous contrôle et qui seront visibles dans des tableaux de bord dédiés.
Data drift (dérive des données) : détection de changements dans la distribution des données
Prediction drift (dérive des prédictions) : changements significatifs dans la distribution des prédictions d’un modèle
Data quality (qualité des données) : détection des problèmes de données tels que les valeurs nulles, les violations de plage ou incohérences de type
Feature attribution drift (dérive de l’attribution des caractéristiques) : détection des changements d’importance des features dans le modèle
Cette fonctionnalité native, sans intégration d’un composant tiers, est une avancée majeure pour la plateforme et son usage pour supporter les modèles en production.
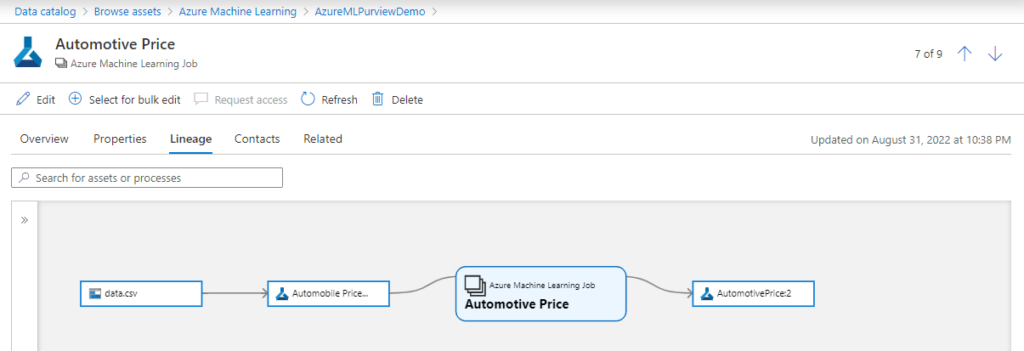
Microsoft Purview connector
L’outil de data discovery, cataloging et lineage Microsoft Purview s’enrichit d’un connecteur pour Azure Machine Learning. Il sera maintenant possible d’établir le lien entre dataset d’entrainement, modèle, job et prévisions.
Le rêve des Data Scientists reste sans doute d’arriver à un niveau de détail du linéage montrant l’impact des features brutes sur les résultats, au travers de l’étape de feature engineering (travail sur les données brutes pour fournir des prédicteurs plus efficaces). Nous nous tournons pour cela vers un autre outil, attendu depuis longtemps dans une version managée : le feature store.
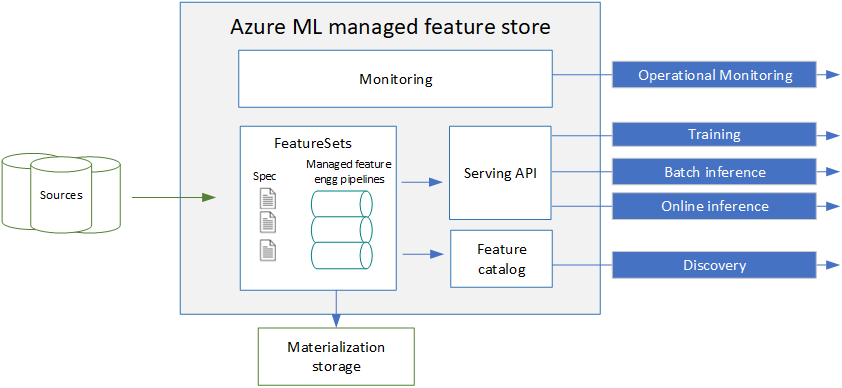
Azure ML managed feature store
Le feature store est une composante indispensable dans une architecture MLOps qui partage plusieurs projets de Machine Learning et surtout des préparations de données communes. Le schéma ci-dessous, issu de la documentation officielle, résume les utilisations potentielles du feature store.
Premier point important : nous sommes à un niveau “supérieur” à celui des workspaces Azure ML (voir la logique des registries présentée ci-dessous) et nous pouvons donc imaginer partager des featureset leur préparation entre workspaces ou entre modèles.
Nous remarquons ici l’utilisation du framework de calcul Apache Spark, qui sera sûrement utilisé pour transformer les données brutes en features enrichies.
La matérialisation va permettre de stocker les features dans une ressource de type Blob Storage ou Data Lake Gen2.
Ensuite, nous pourrons définir des feature sets au niveau des modèles. Ceux-ci se définissent par une source, une fonction de transformation et des paramètres de matérialisation optionnels.
Les différentes manipulations seront réalisées au moyen d’un nouveau SDK Python : azureml-featurestore (voir ce premier tutoriel).
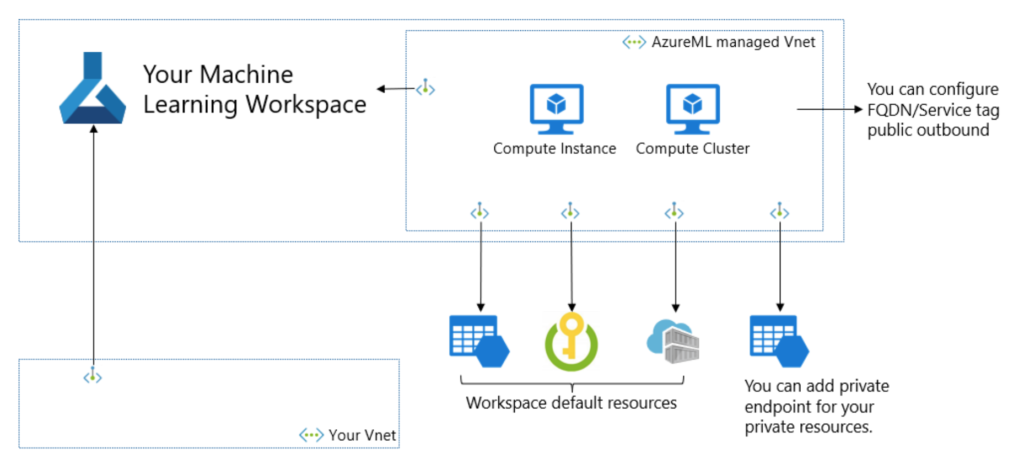
Managed network isolation
Si vous vous êtes déjà confrontés à la complexité de déployer Azure ML, ses ressources liés et les services qui doivent communiquer avec, dans un réseau privé, cette nouvelle devrait vous réjouir.
Le réseau virtuel managé va ainsi contenir les compute instances, compute clusters et Spark serverless. Les règles de trafic sortant (outbound) et les points de terminaison privés (private endpoints) seront déjà configurés.
Le déploiement d’un tel workspace ne semble pas disponible au travers du portail Azure, il faudra donc passer par exemple par une commande Azure CLI comme ci-dessous :
az ml workspace create --name ws --resource-group rg --managed-network allow_only_approved_outbound
En disponibilité générale (“GA”)
Azure Machine Learning registries
L’approche MLOps nécessite de travailler avec plusieurs environnements : développement, qualification (ou UAT) et production a minima. Jusqu’ici, nous pouvions hésiter entre créer différents pipelines au sein d’un même workspace Azure ML (environnements non isolés d’un point de vue sécurité) ou bien créer des ressources séparées (difficulté de transfert des livrables entre environnements). Il manquait un niveau de gestion “supérieur” à celui des workspaces Azure Machine Learning.
Les registres permettent de partager entre workspaces des environnements (distribution de l’OS et librairies), des modèles, des jeux de données et des components.
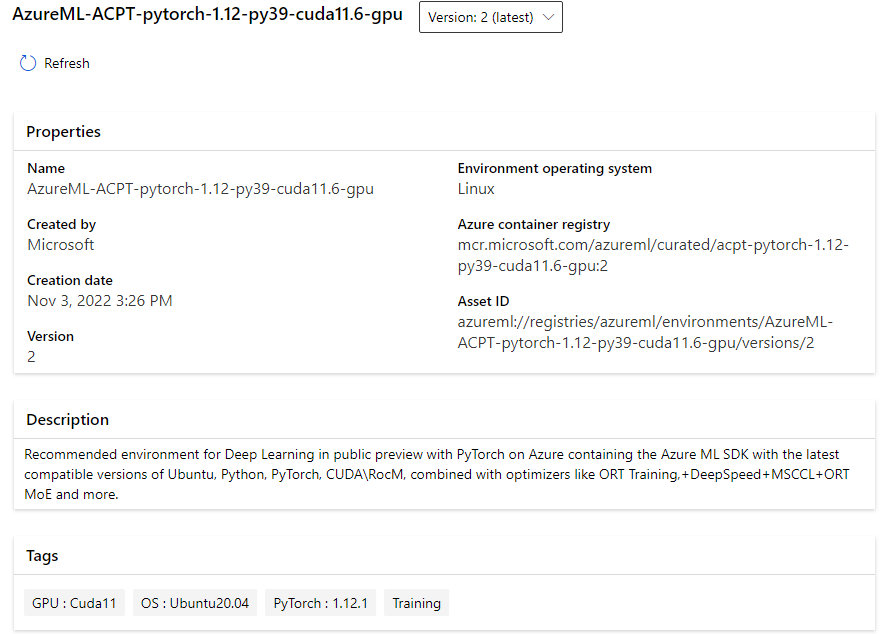
Azure Container for PyTorch
PyTorch est le framework choisi par Microsoft pour le Deep Learning (face à TensorFlow chez Google par exemple). Il est maintenant possible d’utiliser des containers déjà paramétrés pour exécuter ce type de code.
Il ne vous a pas échappé que le prochain métier en vogue (au moins sur les profils LinkedIn) allait être celui de promptologue ou prompt engineer. A mi-chemin entre le développeur no code et le linguiste, cette personne devra maîtriser les hyperparamètres des modèles génératifs (l’aspect déterministe, dit “température”, par exemple), la méthodologie naissante autour des cycles itératifs et surtout l’art du “langage naturel” pour exprimer clairement une intention.
La lecture de la documentation et les quelques démos visibles nous font penser qu’il s’agira d’un véritable outil de CICD (Continuous Integration Continuous Deployment) pour le prompting ! En effet, nous allons pouvoir :
tester, comparer, reproduire des prompts entre eux
évaluer les prompts grâce à une galerie d’outils déjà développés
déployer les modèles et les messages systèmes dans différents environnements (dev, UAT, prod par exemple)
Il faut noter ici que le prompting semble déjà une discipline très mature chez Microsoft qui a anticipé tous les besoins des futurs prompt engineers.
Les chat bots étant un cas d’usage fréquent des LLM, il est intéressant de retrouver la logique de pipeline visuel, connue depuis les débuts d’Azure Machine Learning.
Et en dehors d’Azure ML
Ajoutons à cela les autres annonces liées à l’intelligence artificielle au sens large :
l’essor du service Azure OpenAI, toujours en preview (mai 2023), avec l’ajout des pluginsvers des applications tierces et la possibilité d’avoir une capacité dédiée (Provisioned Throughput Model) vous mettant à l’abri des “voisins bruyants”
le support de DataRobot 9.0, plateforme concurrente qui pourrait ainsi bénéficier d’Azure pour des scénarios de production en entreprise
une base de type “vector DB” ajoutée à Azure Cognitive Search en préversion privée (mai 2023), accessible sur formulaire
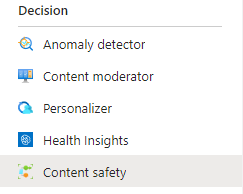
le nouveau service de modération Azure Content Safety
La partie Content Safety est un nouveau service cognitif, dans la catégorie Decision.
Il s’agit d’un service de modération de contenu pour lequel un studio dédié sera disponible à l’URL suivante : https://contentsafety.cognitive.azure.com et qui sera associé à un SDK documenté ici. Il s’agit d’identifier les contenus, créés par les utilisateurs ou bien par une IA générative, tombant dans les catégories suivantes : hate, sexual, violence, self-harm. Quatre niveaux de sécurité sont alors associés à ces contenus, en fonction du contexte : safe, low, medium, high.
Nous voyons enfin apparaître une nouvelle dénomination : Azure AI Studio.
Nous savons que les noms de produits changent souvent chez Microsoft et souvent, les noms expriment une démarche sous-jacente. Le service Azure OpenAI a été présenté comme un service parmi les autres services cognitifs. Maintenant, les différents studios sont préfixés par “Azure AI |” qui unifiera les différentes offres autour de l’intelligence artificielle.
Maintenant, place à la pratique, et à de prochains billets de blog, pour se faire une véritable idée de l’impact de chacune de ces annonces.
Retrouvez l’ensemble des blogs officiels de Microsoft concernant ces annonces du 23 mai 2023 sur ce lien.
Partons à la découverte des commandes en ligne (CLI) en version 2 pour Azure Machine Learning ! En effet, cette manière de travailler devient incontournable dans toute démarche MLOps, c’est-à-dire avec un objectif d’industrialisation des projets de Machine Learning.
Nous allons ainsi suivre les premières étapes permettant de lancer un job Azure ML dans un workspace. Nous pourrons tout d’abord le faire depuis un laptop, puis ensuite, au sein d’un pipeline Azure DevOps.
Le repository GitHub officiel de Microsoft donne des très bons exemples pour débuter dans l’utilisation du CLI. Nous clonons donc ce répertoire localement afin de commencer la mise en pratique.
Installer le CLI Azure ML v2
Depuis une fenêtre de commande (par exemple, un terminal Bash dans Visual Studio Code), nous lançons la commande de mise à jour du CLI Azure.
az upgrade
Nous pouvons ensuite réaliser l’installation de la nouvelle extension ml, en prenant soin de désinstaller au préalable le CLI dans sa première version.
az extension remove -n azure-cli-ml
az extension remove -n ml
az extension add -n ml -y
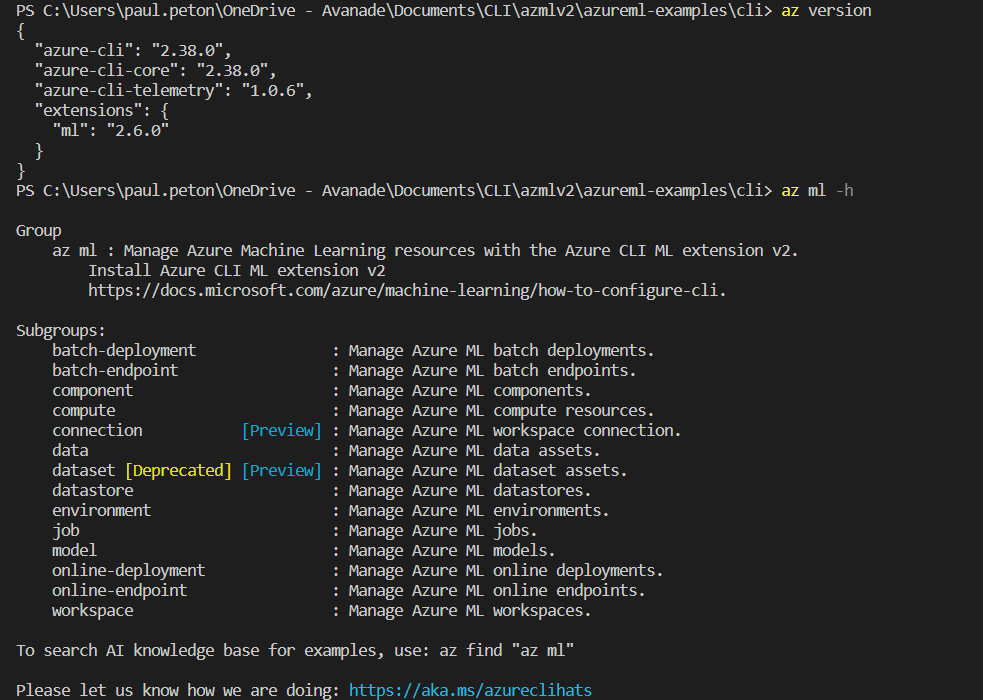
Afin de vérifier que l’extension est bien fonctionnelle, nous pouvons demander l’affichage de l’aide.
az ml -h
Si l’installation a échouée, le message d’erreur suivant apparaîtra.
az ml : 'ml' is misspelled or not recognized by the system
Voici un résumé des versions utilisées pour cet article.
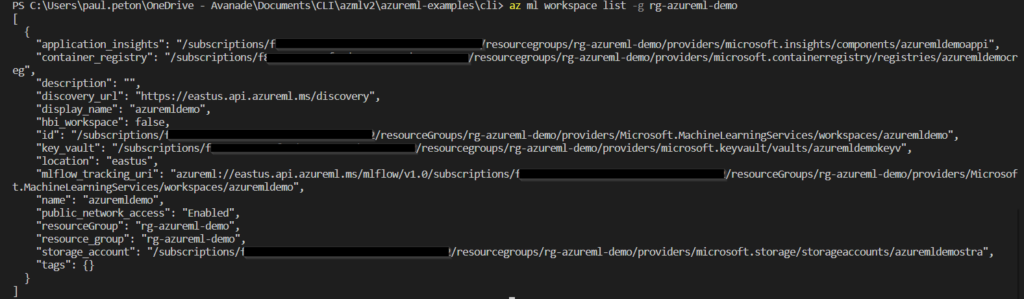
Nous pouvons maintenant voir le workspace déjà existant dans un resource group.
az ml workspace list -g rg-azureml-demo
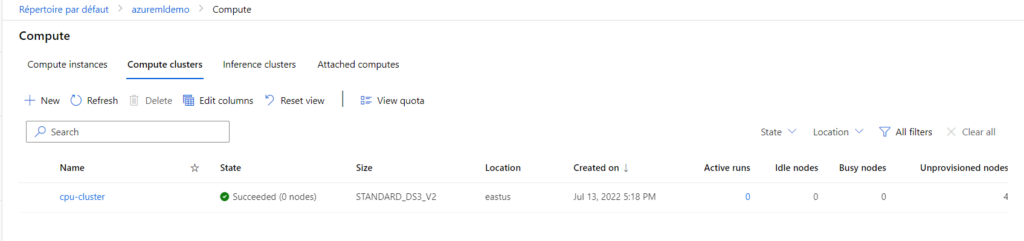
Dans ce workspace, nous pouvons provisionner, toujours par le CLI, une ressource de calcul de type cluster.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 4 --size Standard_DS3_V2 -g rg-azureml-demo --workspace-name azuremldemo
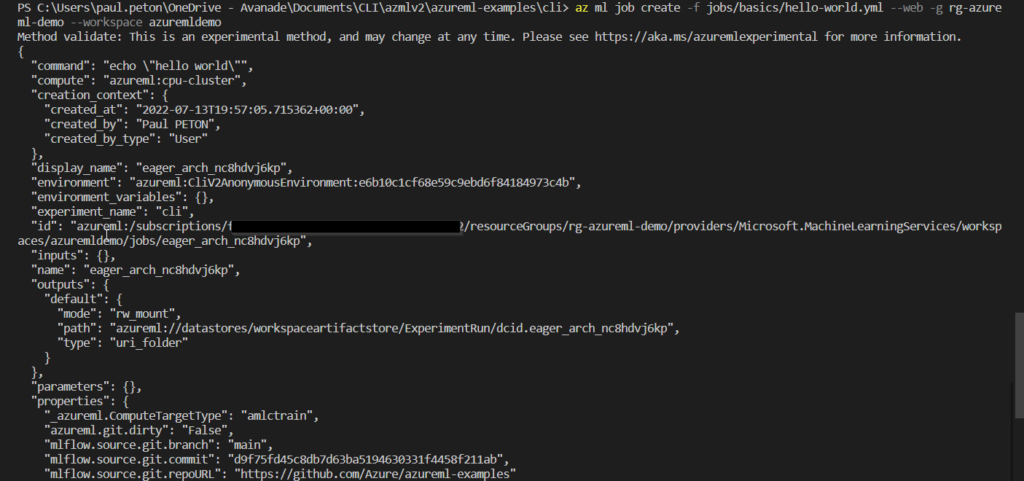
Enfin, nous lançons un job (ce terme regroupe les experiments et leurs runs) défini par un fichier YAML.
az ml job create -f jobs/basics/hello-world.yml --web -g rg-azureml-demo --workspace azuremldemo
Nous allons regarder de plus près la structure de ce fichier YAML.
Il s’agit donc de lancer une commande dans un environnement, spécifié par une image Docker, sur une ressource de calcul (compute). Pour des actions nécessitant des entrées et sorties, les deux termes inputs et outputs s’ajouteront dans le fichier.
Le lancement du job s’effectue correctement.
Nous pouvons maintenant suivre son exécution dans le portail Azure ML.
Les user_logs indiquent le résultat du job : hello, world !
Il faut repérer ici le nom du job : eager_arch_nc8hdvj6kp
Pour ne pas avoir à préciser le groupe de ressources ainsi que le nom du workspace, nous pouvons configurer des valeurs par défaut. Le paramètre location correspond à la région Azure d’installation du workspace. Vérifiez l’orthographe exacte dans le menu Overview de la ressource, sur le portail Azure.
az configure --defaults group=$GROUP workspace=$WORKSPACE location=$LOCATION
Vérifiez alors les valeurs par défaut à l’aide de la commande suivante.
az configure -l -o table
La commande d’archivage du job, appelé par son nom, fait disparaître celui-ci de l’interface graphique.
az ml job archive -n eager_arch_nc8hdvj6kp
Pour un job plus proche des travaux de Machine Learning, je vous recommande d’exécuter la commande suivante, toujours liée aux fichiers du repo cloné initialement.
az ml job create -f jobs/pipelines/nyc-taxi/pipeline.yml --web --resource-group rg-azureml-demo --workspace-name azuremldemo
Exécuter le CLI v2 depuis un pipeline Azure DevOps
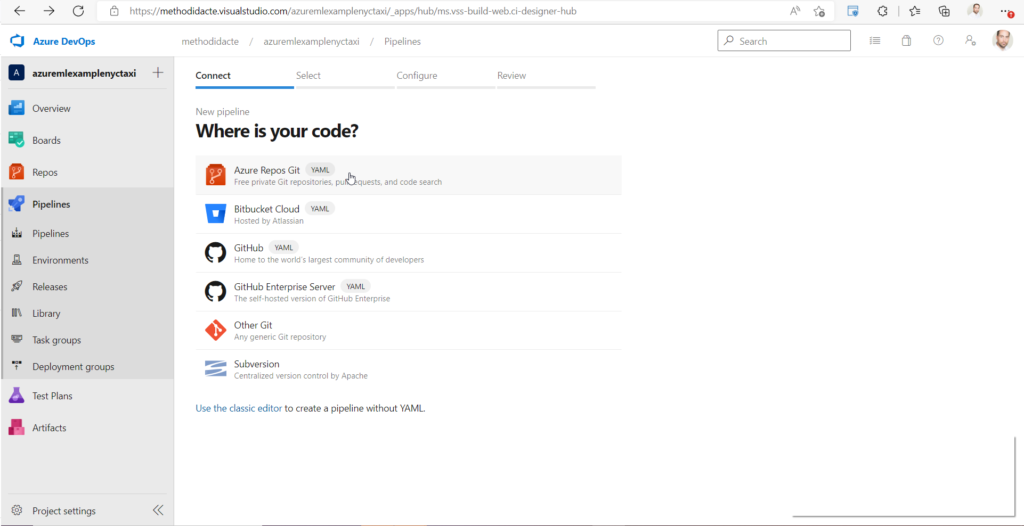
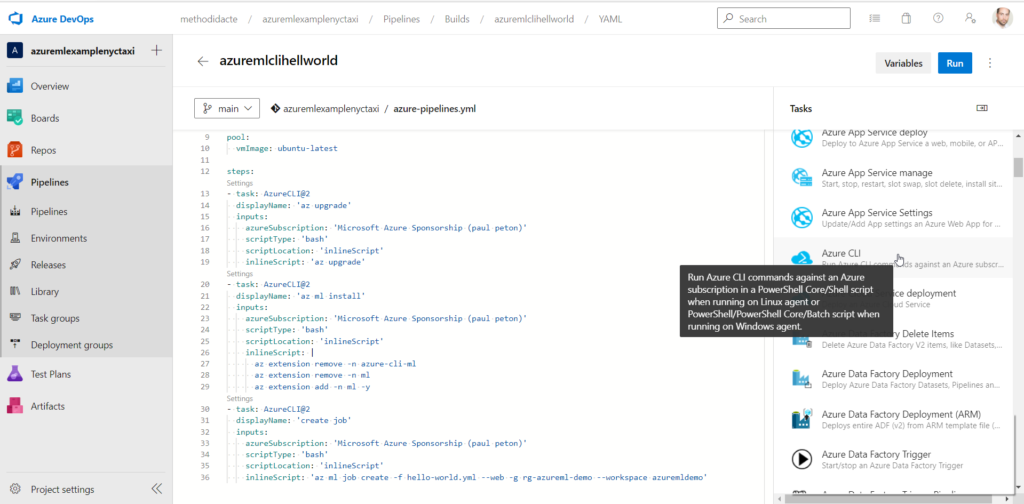
A partir d’un nouveau pipeline, nous allons nous appuyer sur le code présenté dans la première partie de cet article.
Il est important de comprendre que l’environnement d’exécution sera un agent, c’est-à-dire une machine virtuelle dans Azure, avec, par défaut, une distribution Linux Ubuntu. Cet agent ne connaît donc pas le CLI Azure, ni son extension pour le Machine Learning.
Dans une logique d’automatisation, nous souhaitons maintenant lancer ces commandes au travers d’un pipeline Azure DevOps. Nous avons au préalable poussé (“push“) tout le code vers le repository d’un nouveau projet Azure DevOps.
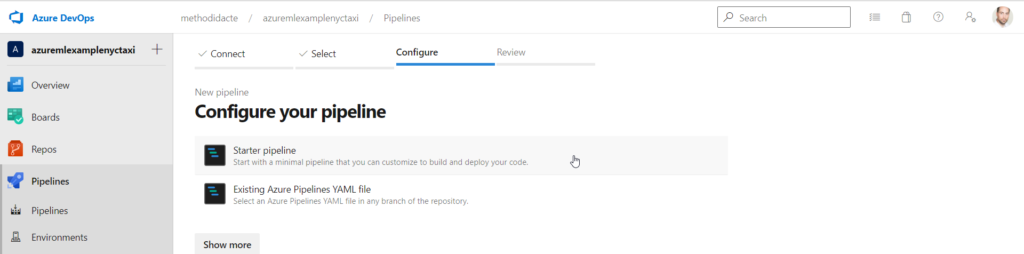
Nous choisissons ensuite un starter pipeline qui nous permettra de coller les commandes CLI v2 testées dans la première partie de cet article.
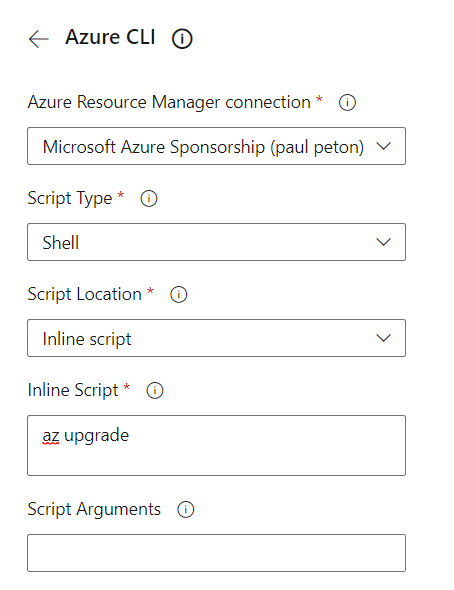
La tâche (task) Azure CLI va permettre d’obtenir la syntaxe YAML adaptée dans le fichier.
Nous choisissons les paramètres suivants pour chaque tâche.
Un service connection est nécessaire.
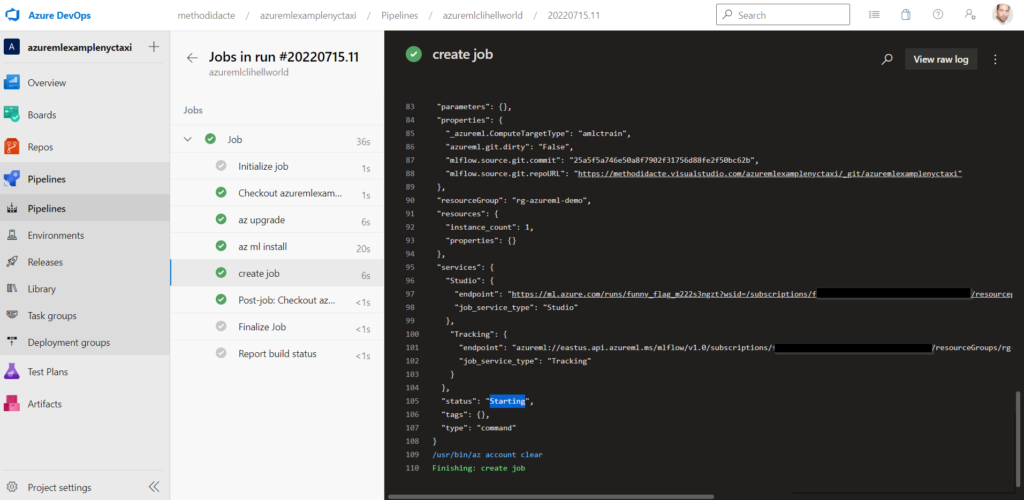
Au commit sur la branche main, le pipeline s’exécute.
Succès ! Le code s’est correctement exécuté et nous pourrons le vérifier dans le workspace Azure Machine Learning.
Ce cours proposé par Microsoft Learn vous permettra d’approfondir l’utilisation des pipelines avec le CLI v2 d’Azure ML.
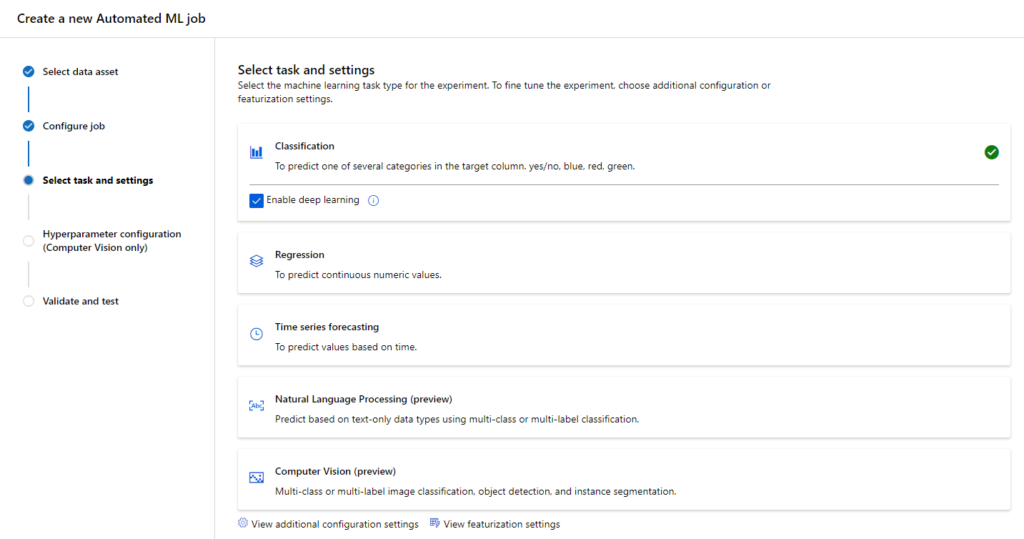
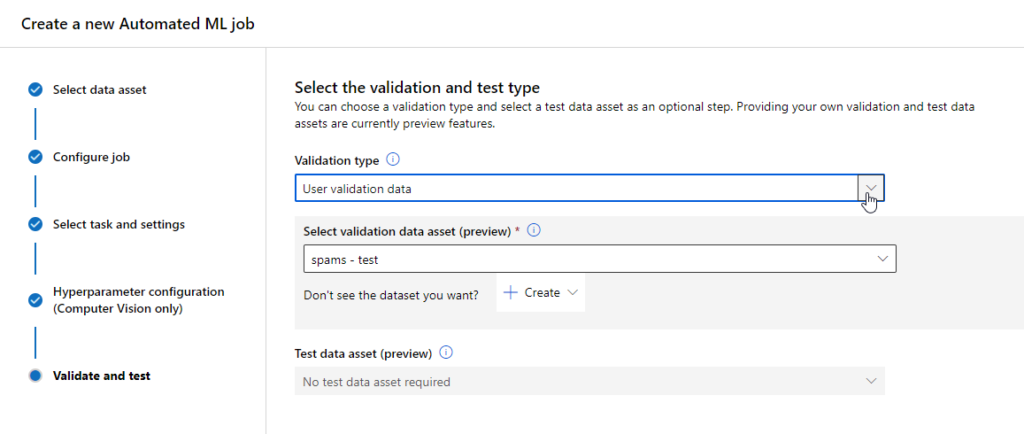
Jusqu’ici réservée aux domaines supervisés (régression & classification) ainsi qu’aux séries temporelles, l’automated ML de Microsoft s’ouvre maintenant aux données de type texte ou image pour entrainer des modèles de NLP ou de Computer Vision destinés à des tâches de classification, et ceci au travers de l’interface utilisateur d’Azure Machine Learning.
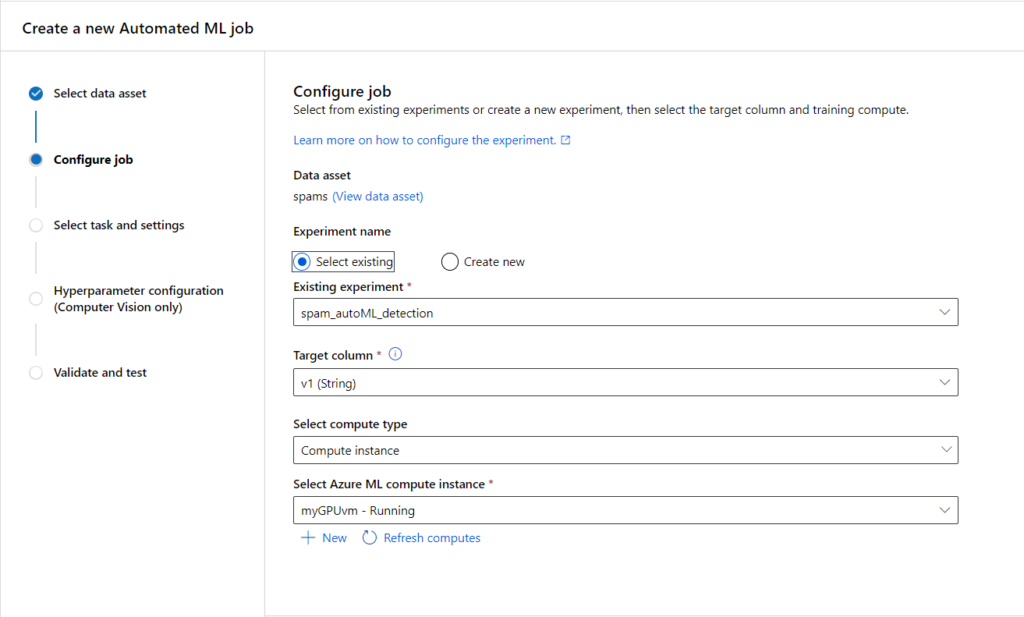
Nous allons ici réaliser un premier entrainement pour une problématique simple de classification de spams / non spams (ou hams), à partir d’un dataset connu pour débuter sur cette problématique.
Ce jeu de données aura été préalablement déclaré en tant que dataset, au sens d’Azure ML et nous prendrons soin de le découper en amont de l’expérience d’automated ML. Il nous faut donc deux datasets enregistrés : le jeu d’entrainement et le jeu de test. En effet, l’interface graphique ne nous proposera pas (encore ?) de séparer aléatoirement les données soumises. Notons enfin que ces données doivent être enregistrées au format tabulaire. Nous devons donc a minima disposer de deux colonnes : un label (spam / ham) et le texte en lui-même.
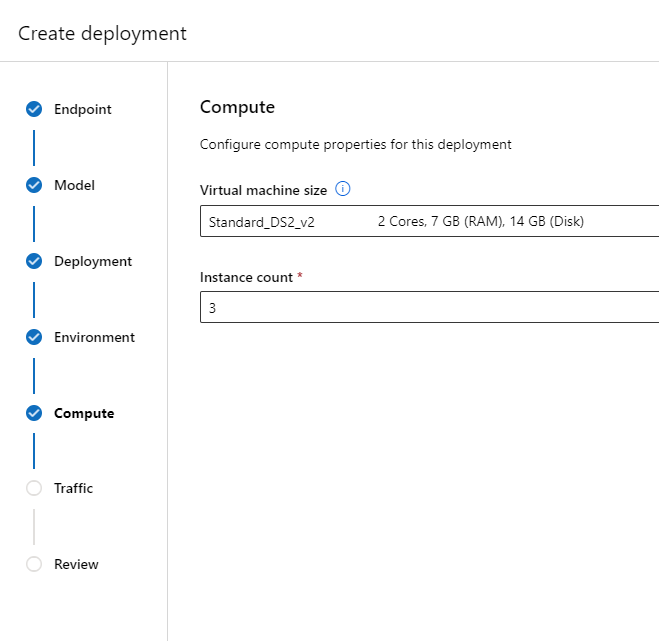
L’entrainement va nécessiter une machine virtuel (compute instance ou compute cluster) disposant d’un GPU. Attention, le coût de ces VMs est naturellement plus élevé que celui de VMs équipées de CPU.
Le premier écran de l’interface se configure de la sorte.
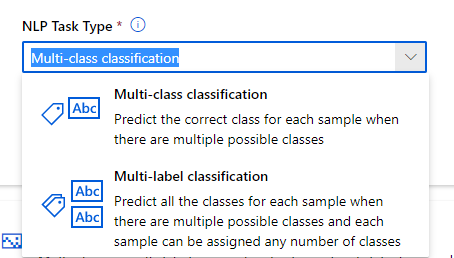
Nous choisissons ensuite une tâche de type “Multi-class classification”.
Si celle-ci est unique, il est recommandé de préciser la langue du texte contenu dans le dataset.
Attention au temps maximum de recherche du meilleur modèle, celui-ci est par défaut de 24h ! Et nous savons que le GPU coûte cher…
Nous finissions le paramétrage en indiquant le dataset de test.
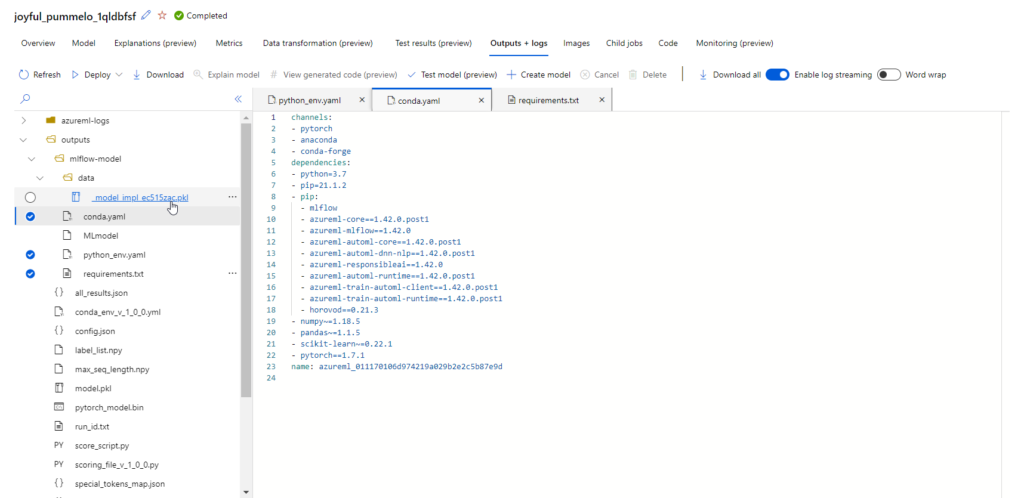
Un seul modèle a été ici évalué : un modèle de type BERT.
En observant les outputs de ce modèle, nous retrouvons le binaire sérialisé (.pkl) ainsi que des fichiers définissant l’environnement d’entrainement et les dépendances de librairies nécessaires. C’est ici un standard MLFlow qui est respecté.
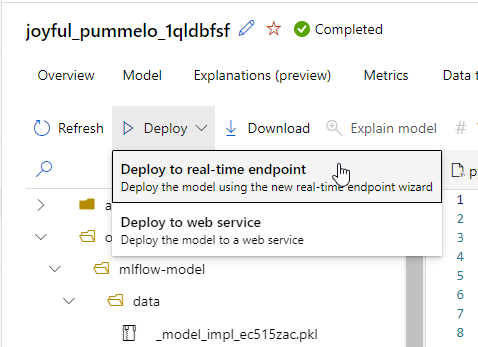
Toujours au moyen de l’interface graphique, nous pouvons maintenant déployer ce modèle sous forme de point de terminaison prédictif.
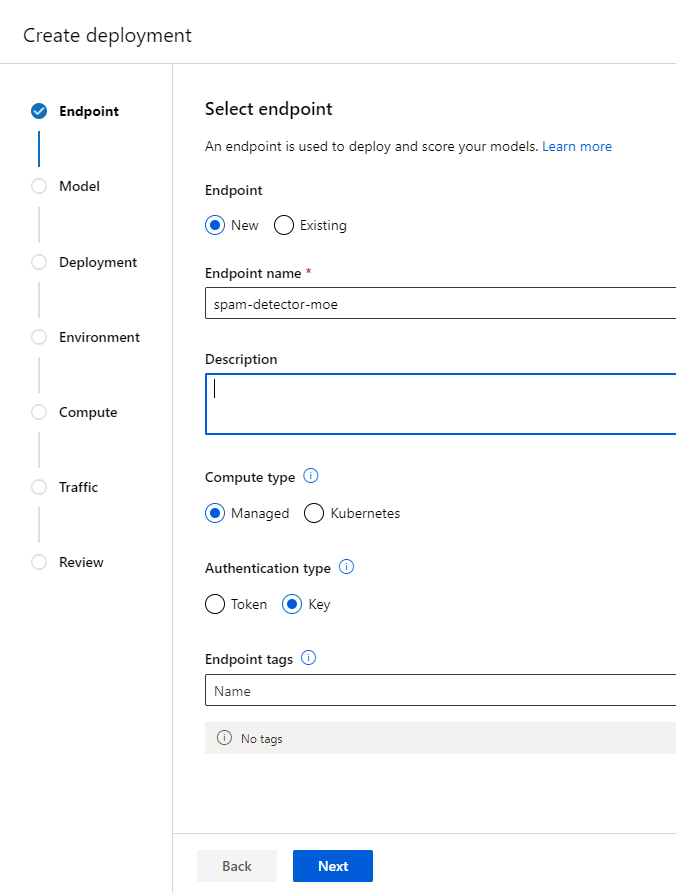
Nous allons opter ici pour un Managed Online Endpoint (MOE), qui offre un niveau de management des ressources plus fort que le service Kubernetes d’Azure.
Ce Management Online Endpoint s’appuie sur des ressources de calcul qui sont simplement des VMs Azure. A noter qu’une ressource spécifique Azure sera bien visible au travers du portail, dans le groupe de ressources contenant le service Azure ML.
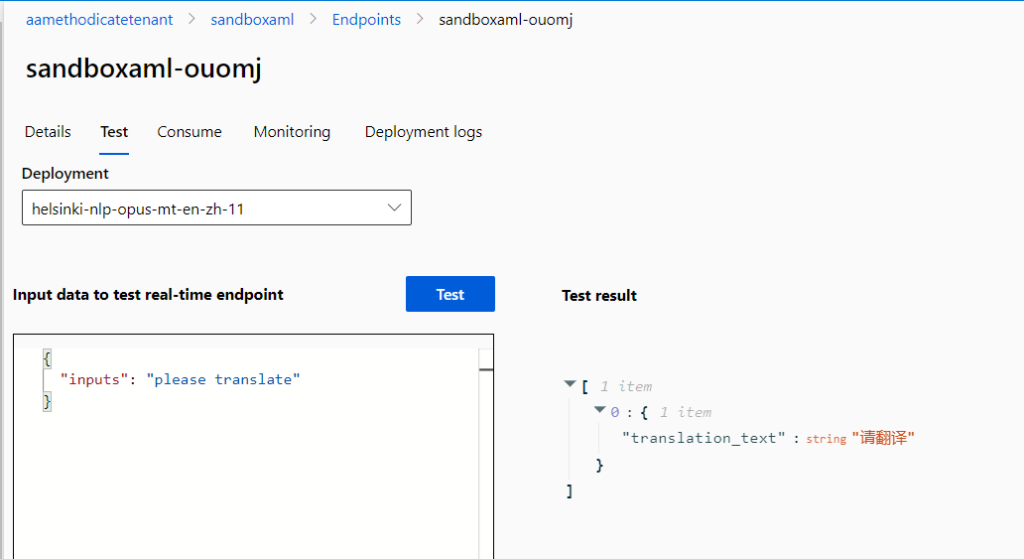
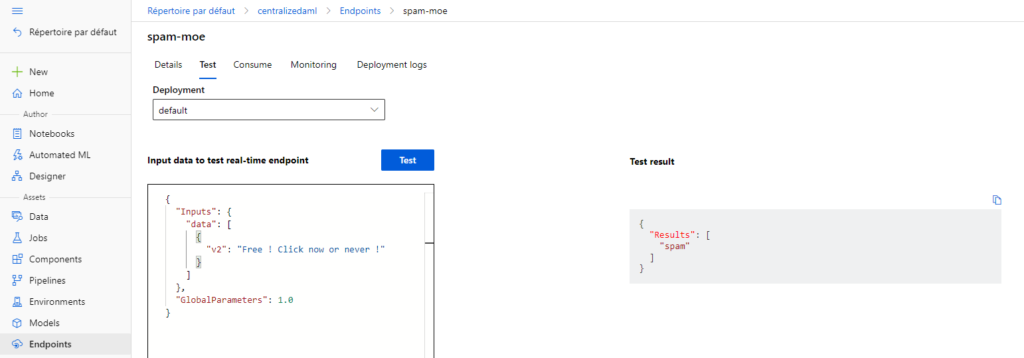
Il est maintenant possible d’interroger ce point de terminaison !
Voici en quelques clics dans l’interface d’Azure Machine Learning comment nous avons pu parvenir à un service Web prédictif. Bien sûr, la préparation de données sera indispensable dans un cas réel d’utilisation de l’automated ML pour une tâche de NLP.
Enfin, sachez que le SDK Python d’Azure ML dispose de la classe permettant d’effectuer cette tâche par du code (v1 et v2).
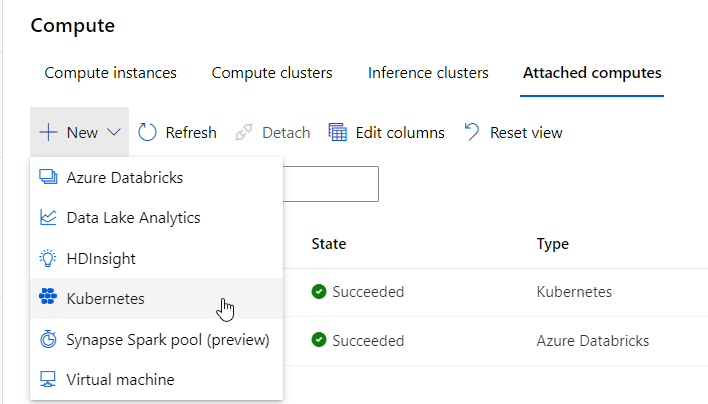
Azure Machine Learning donne la possibilité de supporter les calculs de Machine Learning par des ressources extérieures et différentes des machines virtuelles classiques de l’on retrouve dans les compute instances ou compute clusters.
Nous allons voir dans cet article comment mettre à disposition un attached compute de type Kubernetes. Pour une ressource Azure Kubernetes Service déjà existante dans la souscription Azure, nous allons avoir besoin d’ajouter une extension Azure Machine Learning sur le cluster k8s. Cette installation ne se fait que par l’intermédiaire des commandes en ligne (az cli).
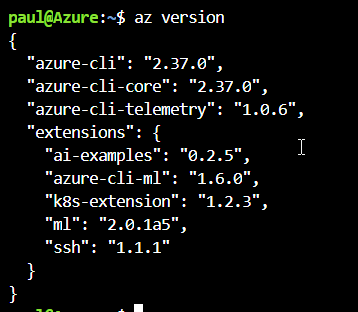
Depuis le portail Azure, il est possible de lancer une fenêtre Cloud Shell déjà connectée, sous le login de l’utilisateur. Vérifions les versions installées.
Si k8s-extension n’est pas présent ou n’est pas à jour (version minimale : 1.2.3, il faut l’installer par la commande ci-dessous.
az extension update --name k8s-extension
Nous allons avoir besoin d’ajouter une identité managée sur la ressource Azure Kubernetes Service, ce qui se fait par la commande suivante.
az aks update --enable-managed-identity --name <aks-name> --resource-group <rg-name>
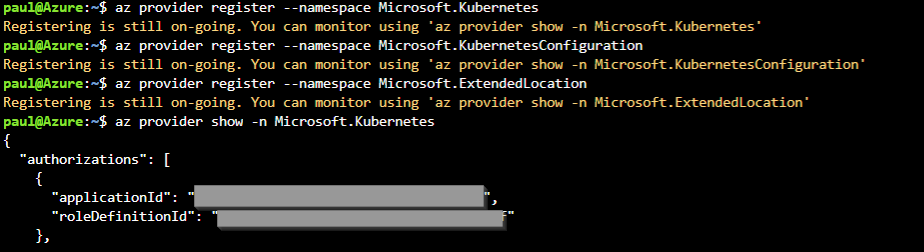
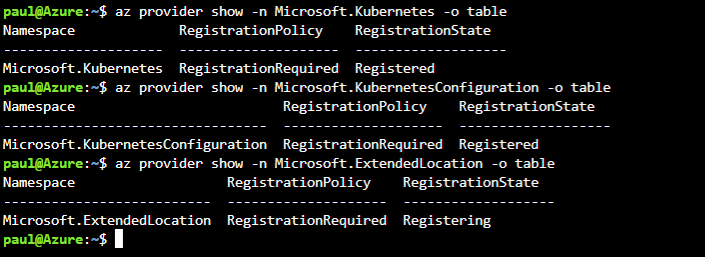
Comme indiqué dans la documentation, il faut tout d’abord inscrire les différents fournisseurs.
Nous pouvons surveiller le bon déroulement des inscriptions, tous les statuts doivent passer sur “Registered”.
Nous pouvons maintenant passer à l’ajout de l’extension.
Nous choisissons dans la documentation disponible sur ce lien la syntaxe adaptée à AKS (manageClusters) pour un test rapide (à ne pas utiliser pour un environnement de production).
Une nouvelle fonctionnalité est disponible dans Databricks, en public preview, depuis février 2022 : les webhooks liés aux événements MLFlow. Il s’agit de lancer une action sur un autre service, déclenchable par API REST, lors d’un changement intervenant sur un modèle stocké dans MLFlow Registry (changement d’état, commentaire, etc.).
Cette fonctionnalité n’a rien d’anecdotique car elle vient mettre le liant nécessaire entre différents outils qui permettront de parfaire une approche MLOps. Mais avant d’évoquer un scénario concret d’utilisation, revenons sur un point de l’interface MLFlow Registry qui peut poser question. Nous disposons dans cette interface d’un moyen de faire évoluer le “stage” d’un modèle entre différentes valeurs :
None
Staging
Production
Archived
Ces valeurs résument le cycle de vie d’un modèle de Machine Learning. Mais “dans la vraie vie”, les étapes de staging et de production se réalisent sur des environnements distincts. Les pratiques DevOps de CI/CD viennent assurer le passage d’un environnement à un autre.
MLFlow étant intégré à un workspace Azure Databricks, ce service se retrouve lié à un environnement. Bien sûr, il existe quelques pistes pour travailler sur plusieurs environnements :
utiliser un workspace Azure Databricks uniquement dédié aux interactions avec MLFlow (en définissant les propriétés tracking_uri et registry_uri)
exporter des experiments MLFlow Tracking puis enregistrer les modèles sur un autre environnement comme décrit dans cet article
Aucune de ces deux approches n’est réellement satisfaisante car manquant d’automatisation. C’est justement sur cet aspect que les webhooks vont être d’une grande utilité.
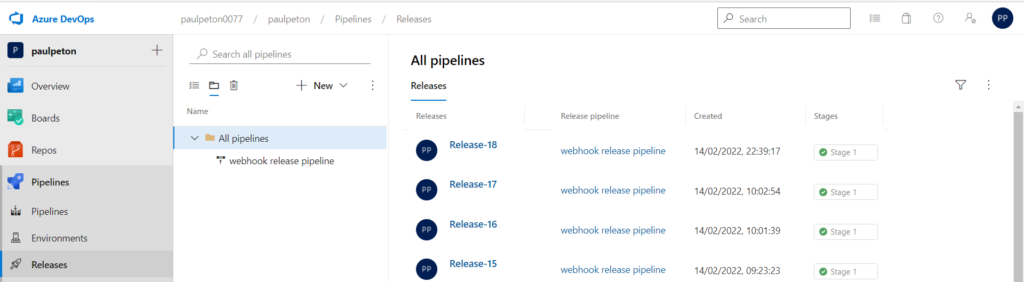
Déclencher un pipeline de release
Dans Azure DevOps, l’opération correspondant au déploiement sur un autre environnement se nomme “release pipeline“.
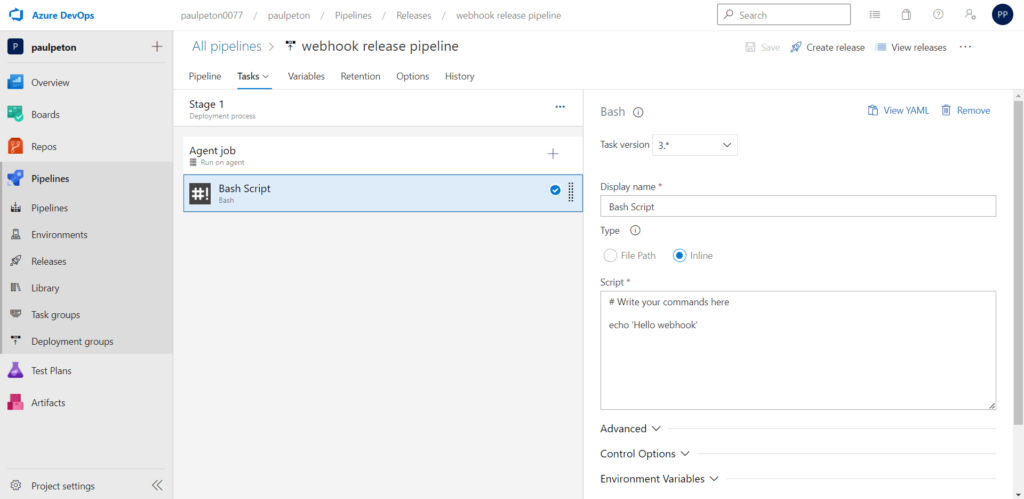
Pour simplifier la démonstration, nous définissions ici une pipeline contenant uniquement un tâche de type bash, réalisant un “hello world”.
Dans un cas d’utilisation plus réalise, nous pourrons par exemple déployer un service web prédictif contenant un modèle passé en production, grâce à une ressource comme Azure Machine Learning.
Nous vérifierons par la suite qu’une modification dans MLFlow Registry déclenche bien une nouvelle release de cette pipeline.
Précisons ici un point important : les webhooks Databricks attendent une URL dont l’appel sera fait par la méthode POST. Il existe une API REST d’Azure DevOps qui permettrait de piloter la release mais le paramétrage de celle-ci s’avère complexe et verbeux.
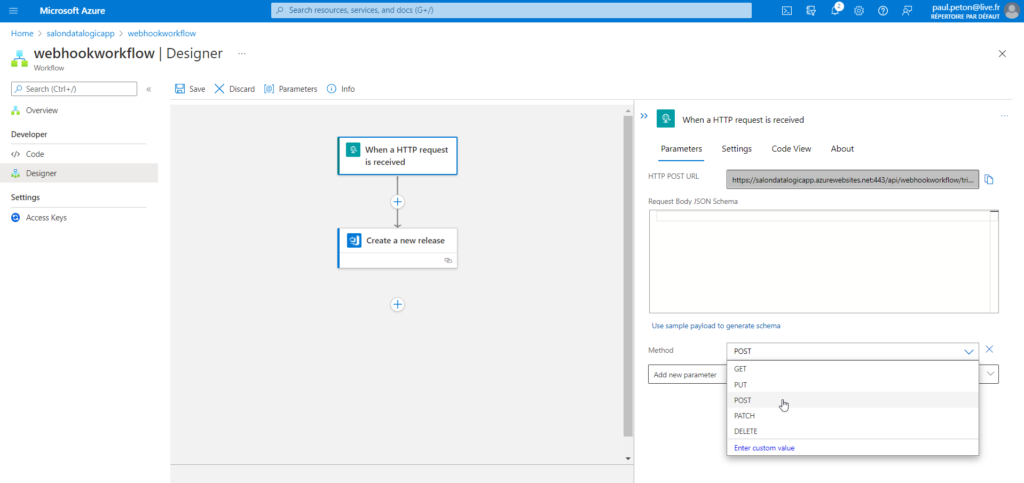
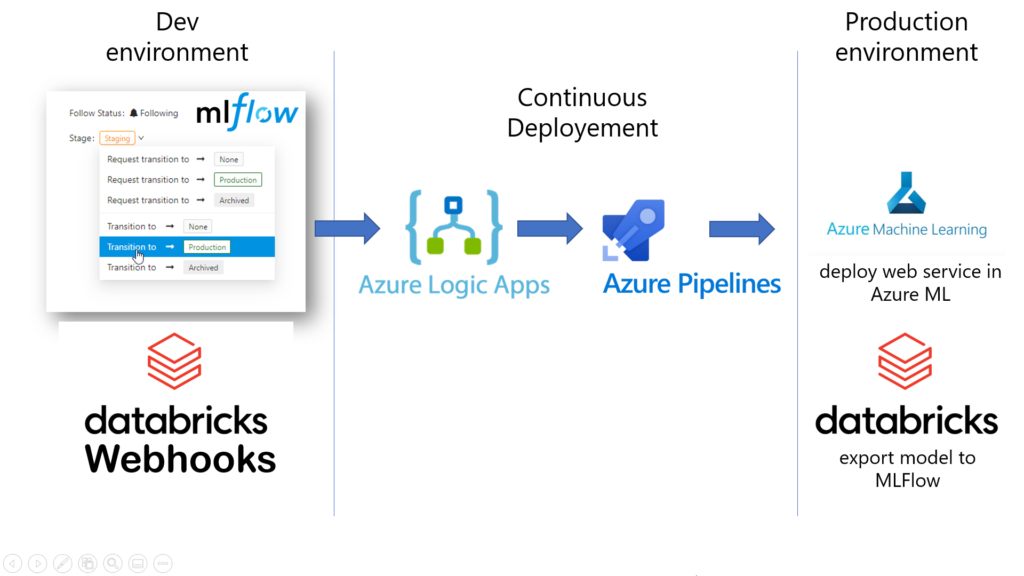
Nous passons donc un ordonnanceur intermédiaire : Azure Logic App. En effet, cette ressource Azure nous permettra d’imaginer des scénarios plus poussés et bénéficie également d’une très bonne intégration avec Azure DevOps. Nous définissons le workflow ci-dessous comprenant deux étapes :
When a HTTP request is received
Create a new release
Veillez à bien sélectionner la méthode POST.
Le workflow nous fournit alors une URL que nous utiliserons à l’intérieur du webhook. Il ne nous reste plus qu’à définir celui-ci dans Databricks. La documentation officielle des webhooks se trouve sur ce lien.
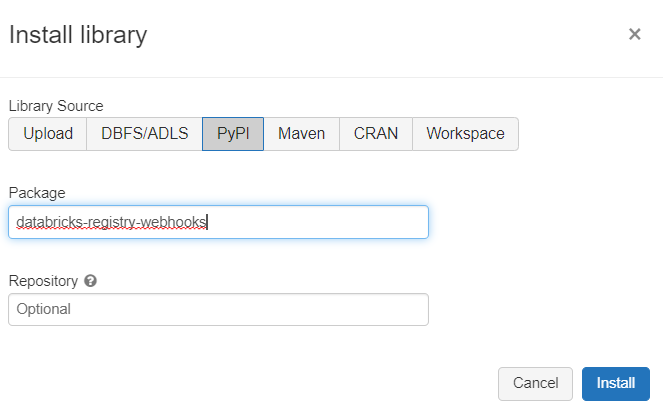
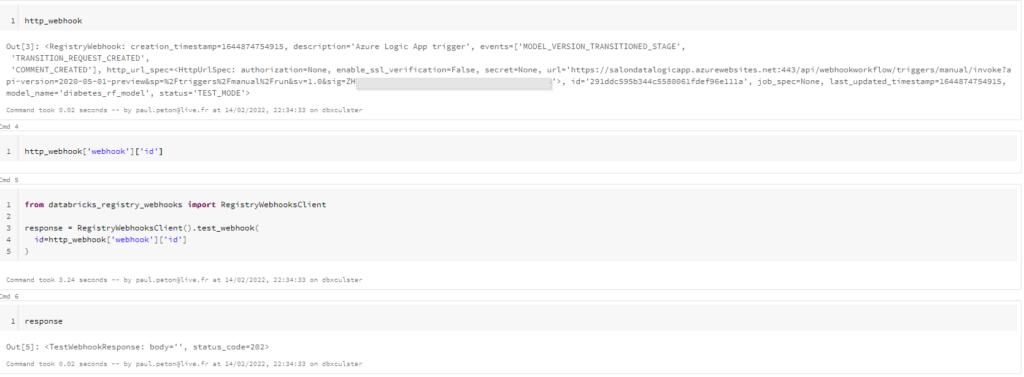
Il existe deux manières d’utiliser les webhooks : par l’API REST de Databricks ou bien par unpackage Python. Nous installons cette librairie databricks-registry-webhooks sur le cluster.
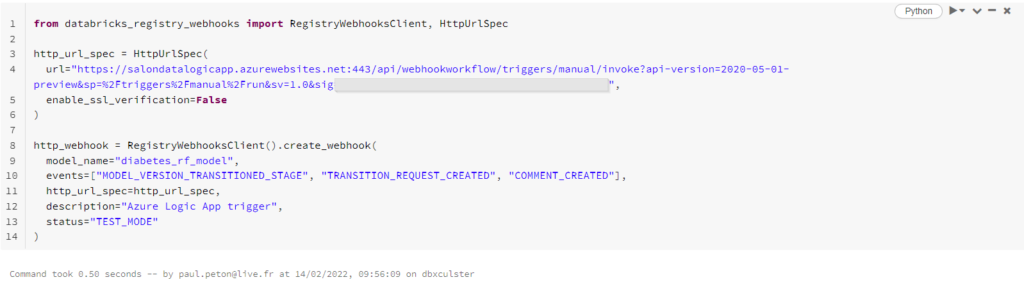
Depuis un nouveau notebook, nous pouvons créer le webhook, tout d’abord dans un statut “TEST_MODE”, en l’associant à un modèle déjà présent dans MLFlow Registry.
Ceci nous permet de tester un appel par la commande .test_webhook() qui attend en paramètre l’identifiant du webhook préalablement créé. Une réponse 202 nous indique que cette URL est acceptée (bannissez les réponses 305, 403, 404, etc.).
Le webhook peut se déclencher sur les événements suivants :
MODEL_VERSION_CREATED
MODEL_VERSION_TRANSITIONED_STAGE
TRANSITION_REQUEST_CREATED
COMMENT_CREATED
MODEL_VERSION_TAG_SET
REGISTERED_MODEL_CREATED
Le webhook peut ensuite être mis à jour au statut ACTIVE par la commande ci-dessous.
Il ne reste plus qu’à réaliser une des actions sélectionnées sur le modèle stocké dans MLFlow Registry et automatiquement, une nouvelle release Azure DevOps se déclenchera.
Maintenant, il n’y a plus qu’à laisser libre cours à vos scénarios les plus automatisés !
Ci-dessous, le schéma résumant les différentes interactions mises en œuvre.
Le Designer est la partie graphique, dédiée aux Citizen Data Scientists, dans le studio Azure Machine Learning. Il s’agit d’un outil “no code” (à l’exception de quelques briques) qui permet de construire un pipeline d’apprentissage supervisé ou non supervisé (clustering). C’est donc un excellent outil d’apprentissage et d’expérimentation qui permet d’aller très vite pour se faire une première idée du potentiel des données. Il permettra également, et c’est son point fort, de déployer un point de terminaison prédictif en mode batch ou temps réel, correspondant à une ressource Azure Container Instance ou Kubernetes Service.
Mais il faut bien avouer que le Designer reste un outil limité à son environnement et qui ne s’inscrit pas dans les pratiques DevOps d’intégration et déploiement multi-environnements (de dev’ en qualif’, de qualif’ en prod’).
Pourtant, en observant bien les logs d’exécution, nous pouvons découvrir beaucoup d’éléments qui montrent que derrière l’interface graphique, tout repose bien sur du code, des fichiers et des conteneurs !
Ressources liées à Azure Machine Learning
Lors de la création de l’espace de travail AzML, nous définissons plusieurs ressources liées (voir cet article) :
Nous définissons en particulier un compte de stockage de type blob qui sera ensuite utilisé pour supporter plusieurs datastores, créés automatiquement.
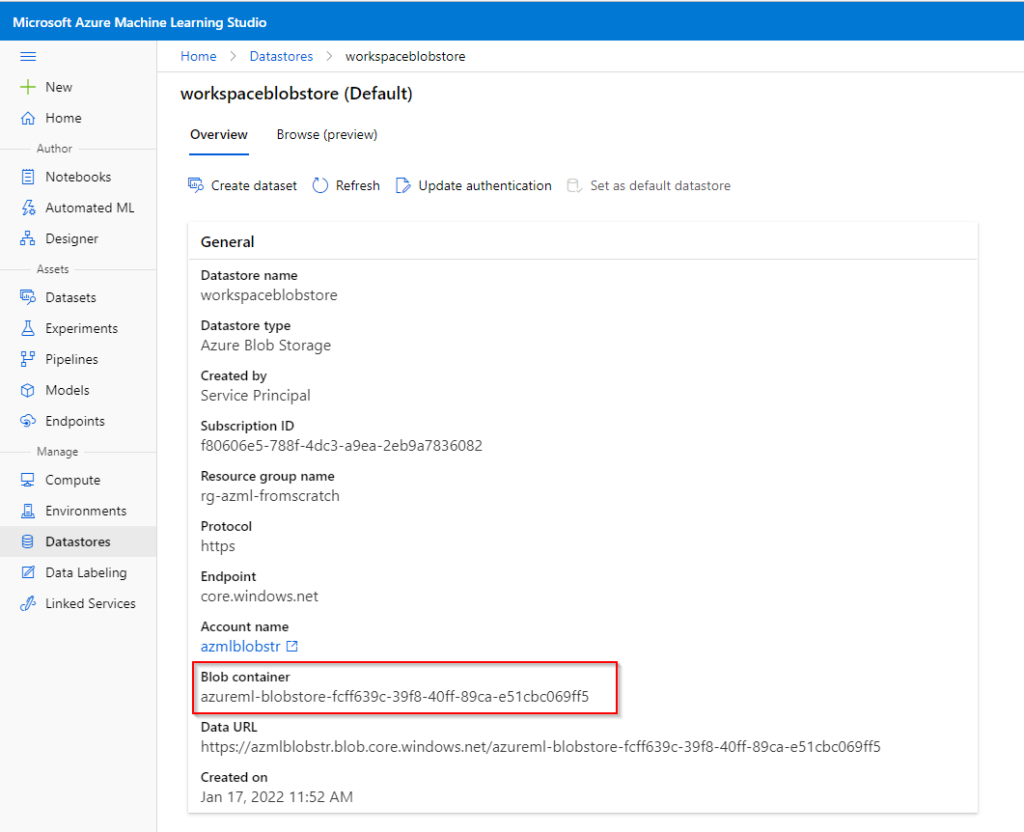
Le datastore par défaut correspond à un blob container, nommé automatiquement. C’est ici que nous retrouverons beaucoup d’informations.
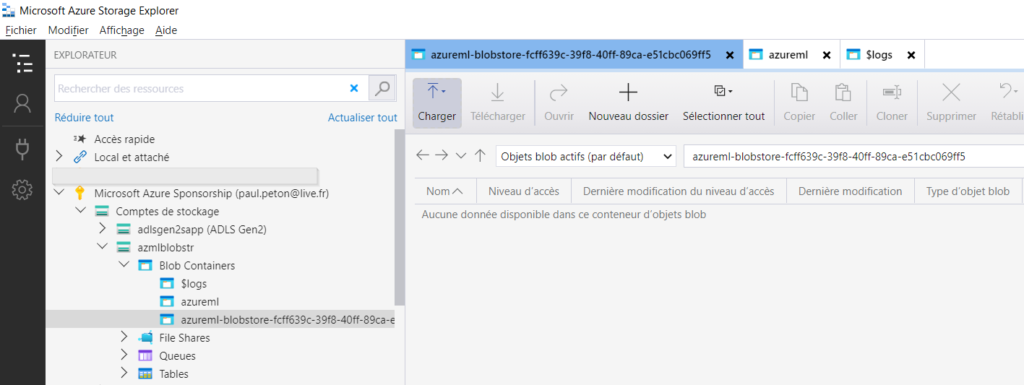
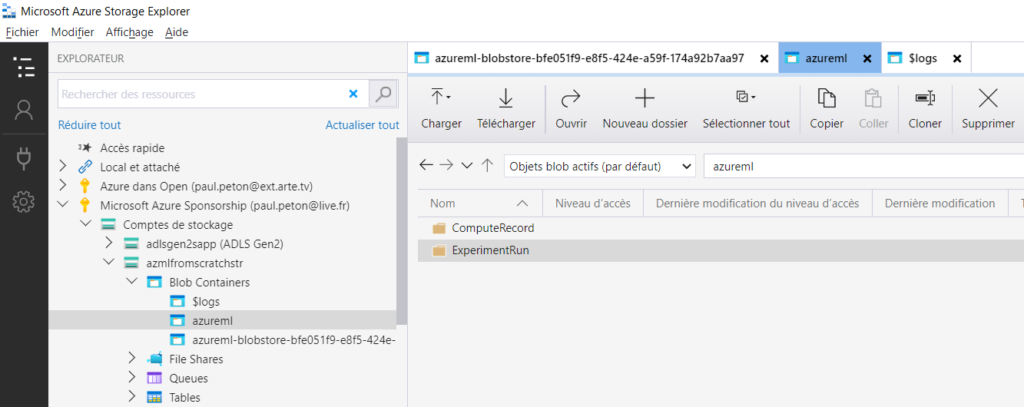
Nous ouvrons donc le client lourd Azure Storage Explorer pour surveiller la création des différents fichiers.
Pour l’instant, les trois répertoires sont vides.
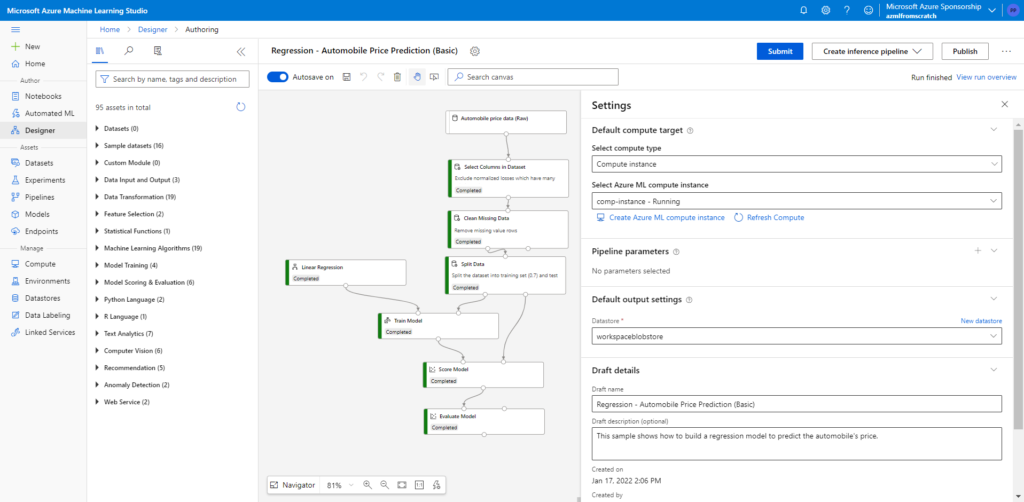
Entrainement par le Designer
Nous allons lancer le sample “Regression – Automobile Price Prediction (Basic)” qui a pour avantage d’être déjà paramétré et de se baser sur un jeu de données accessible depuis cette URL publique : https://mmstorageeastus.blob.core.windows.net/globaldatasets
L’entrainement est lancé sur une ressource de calcul de type “Compute instance”.
Regardons maintenant ce qui est apparu dans le compte de stockage.
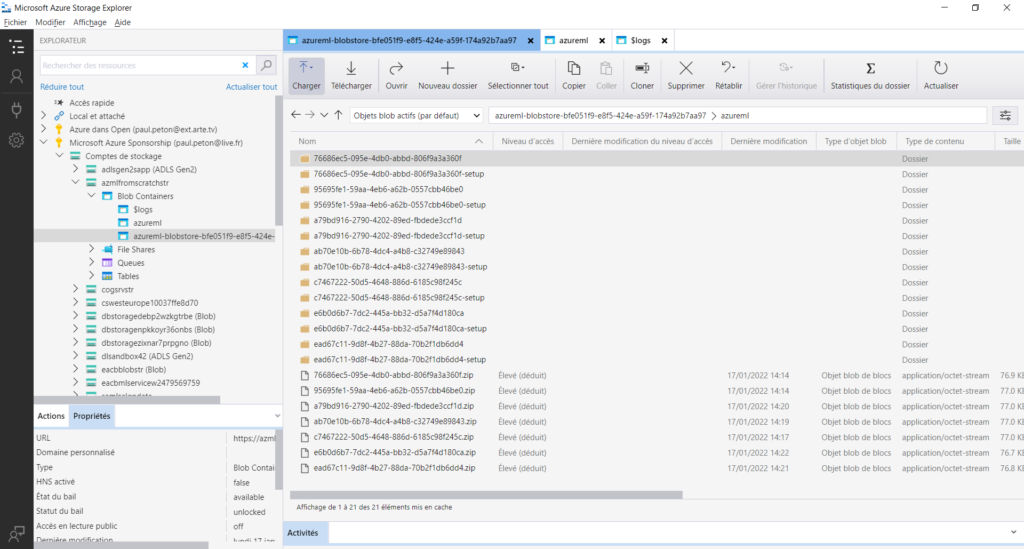
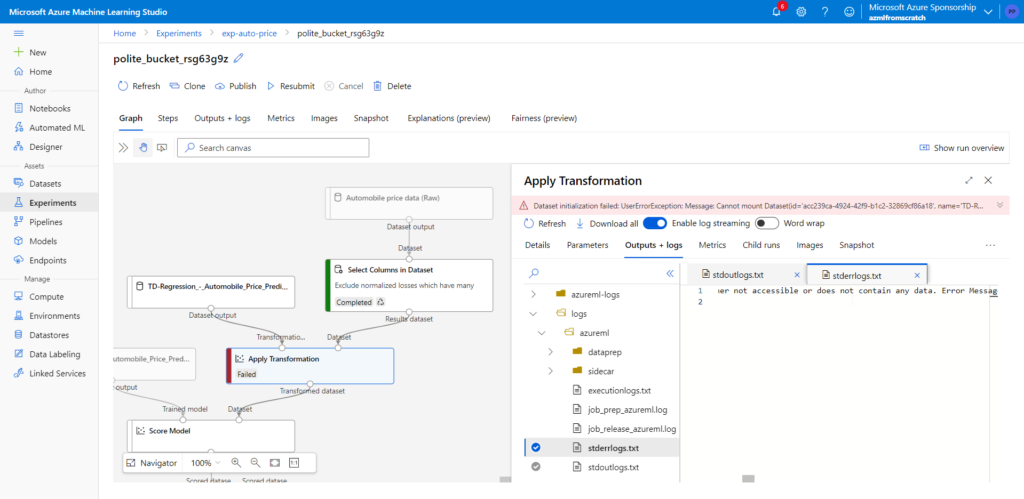
Le répertoire azureml contient deux sous-dossiers, dont ExperimentRun qui recueille tous les fichiers de logs : executionlogs.txt, stderrlogs.txt, stdoutlogs.txt.
Dans le datastore, nous trouvons maintenant une grande quantité de fichiers !
Pour mieux comprendre cette apparition pléthorique, revenons à la notion de “run” à l’intérieur de l’expérience qui a été créée lors de l’entrainement.
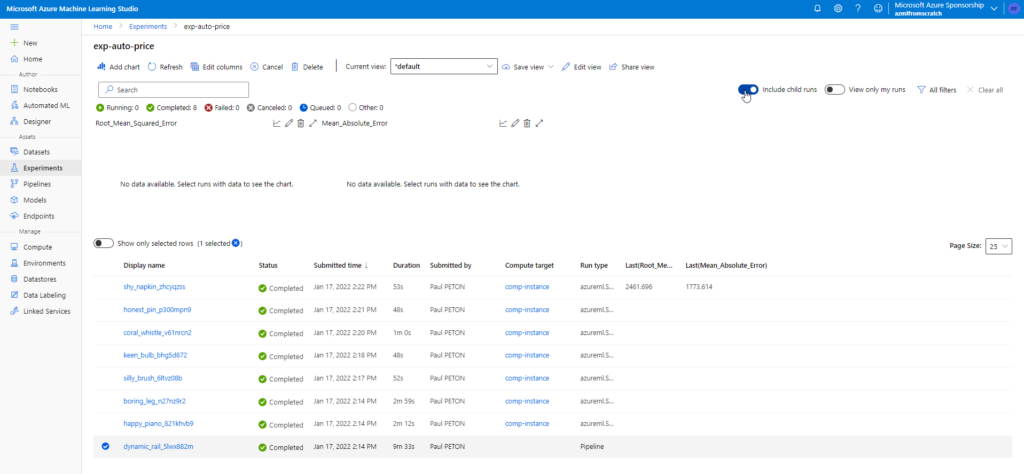
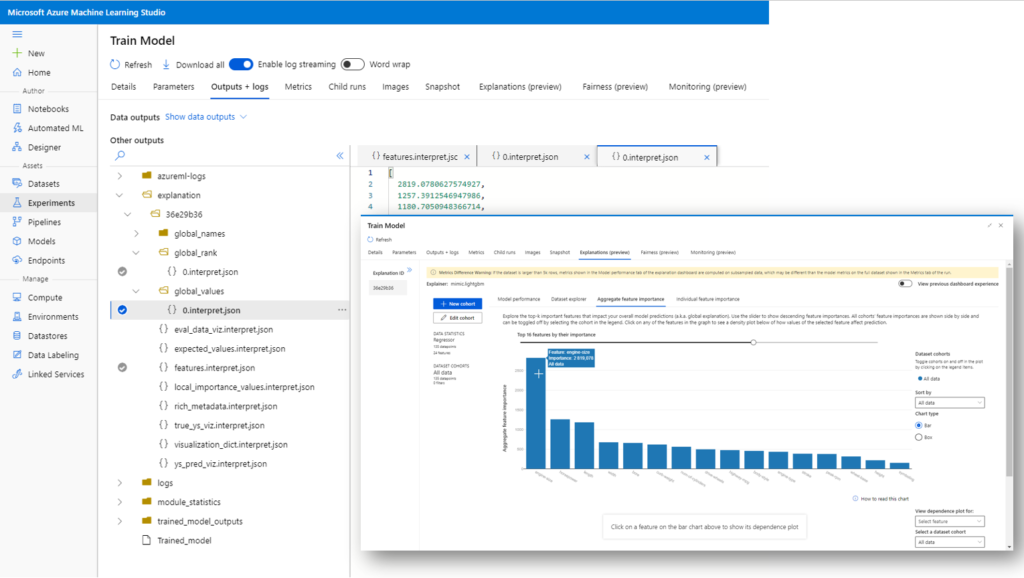
En cochant la case “Include child runs“, nous voyons le run principal (le plus bas) et sept autres correspondant à chacun des briques du pipeline (le dataset n’est pas lié à une exécution).
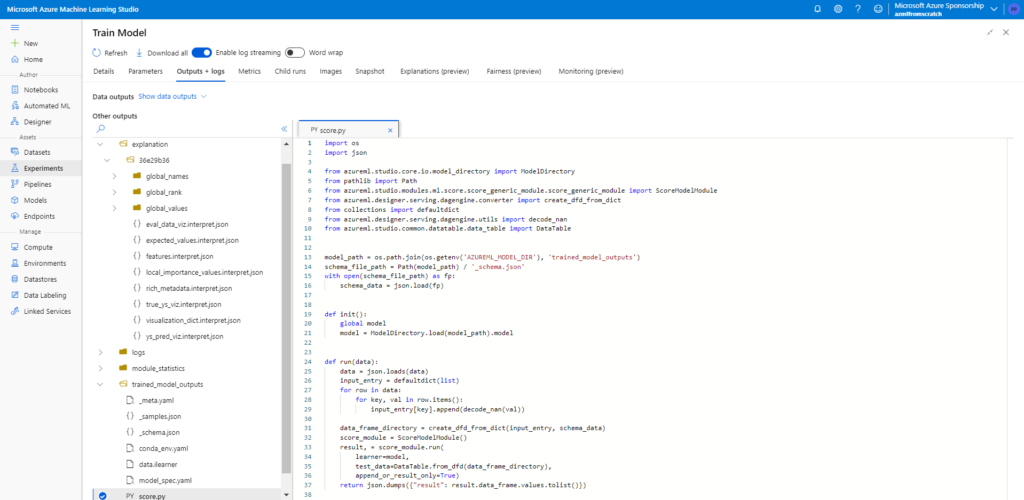
Dans le menu “Outputs + logs”, nous voyons une arborescence de fichiers qui nous permet de retrouver les fichiers liés au modèle entrainés, en particulier un fichier de scoring (score.py) et un fichier d’environnement (conda_env.yml) qui seront utiles pour le déploiement d’un service web d’inférence.
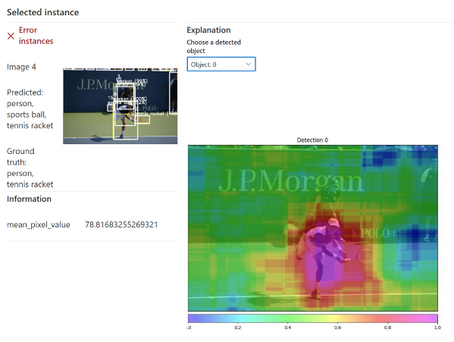
Nous retrouvons également les fichiers portant les visualisations du menu Explanations, en particulier l’importance de chaque feature dans le modèle.
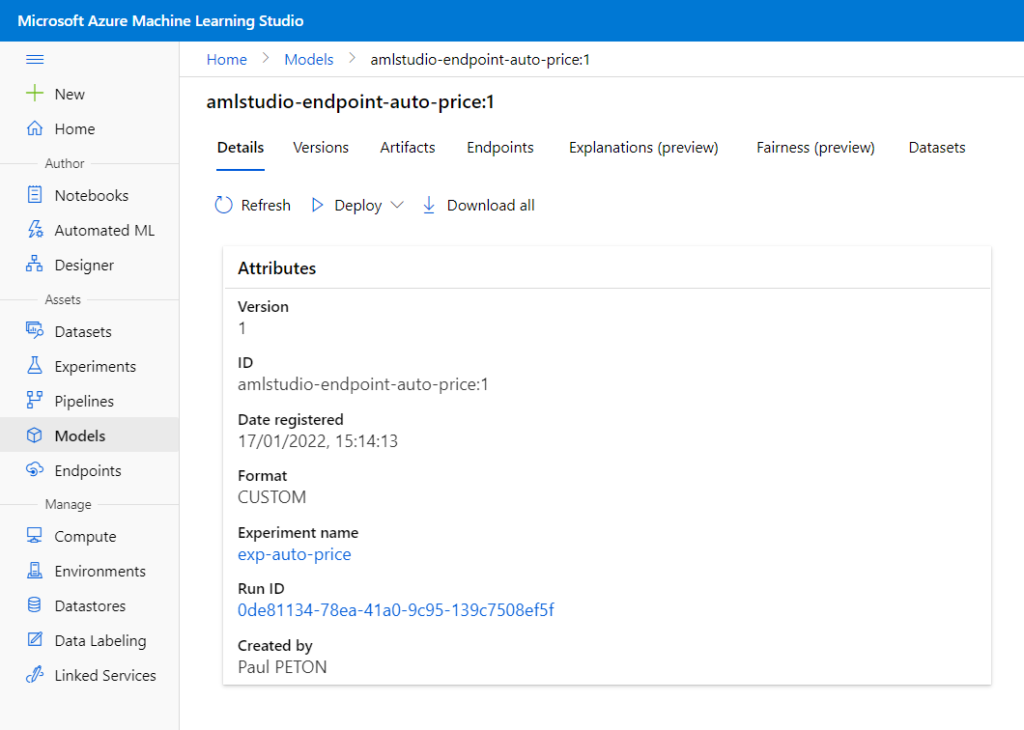
Un dernier fichier attire notre attention : Trained_model. Il s’agit d’un fichier texte dont le contenu est copié ci-dessous et qui correspond à l’URI d’un fichier.
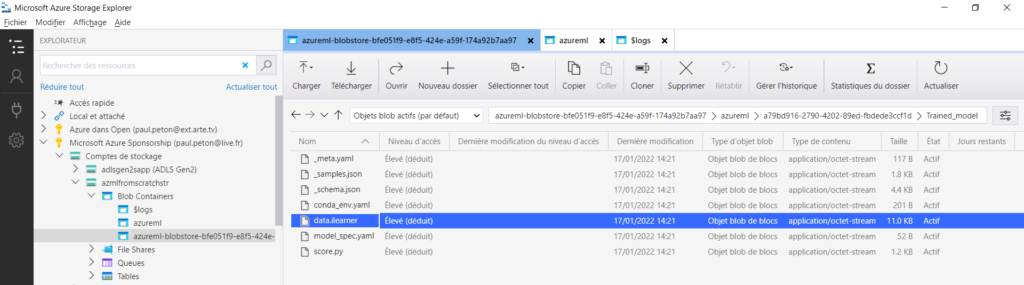
Nous allons voir à partir de l’explorateur ce que contient ce chemin.
Ici se trouve un fichier plus lourd que les autres : data.ilearner
Il s’agit du format (propriétaire ?) utilisé par Microsoft depuis Azure Machine Learning Studio, premier du nom, comme en témoigne cette documentation officielle.
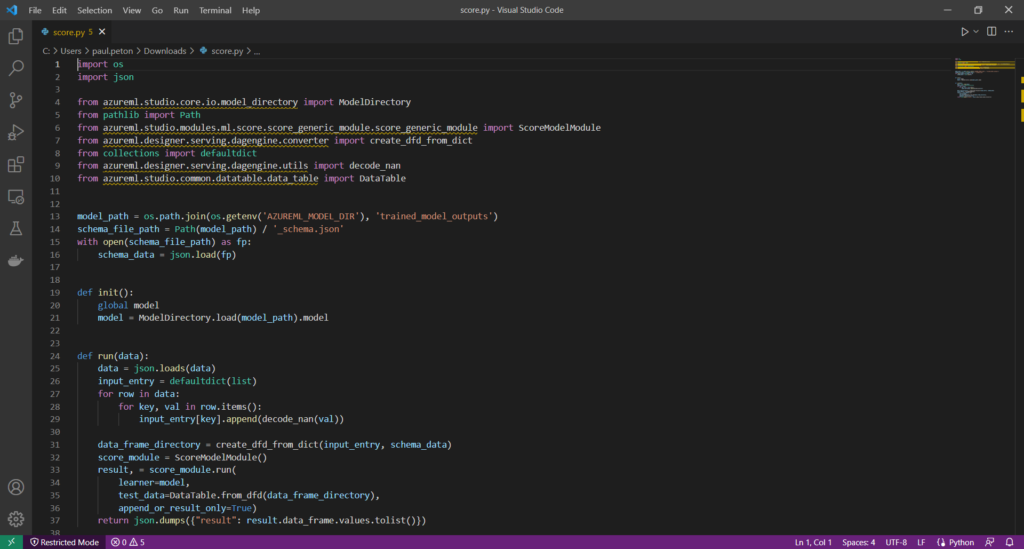
Pour comprendre comment est utilisé ce fichier, nous ouvrons le fichier de scoring dans Visual Studio Code.
De nombreuses librairies apparaissent soulignées, elles ne sont pas disponibles et il s’agit d’éléments propres à l’espace de travail Azure Machine Learning. Le fichier iLearner sera chargé dans une classe ScoreModelModule dont la méthode .run() permettra d’obtenir une prévision.
Le modèle généré n’apparaît pas pour l’instant dans le menu Models de l’espace de travail.
Inférence par le Designer
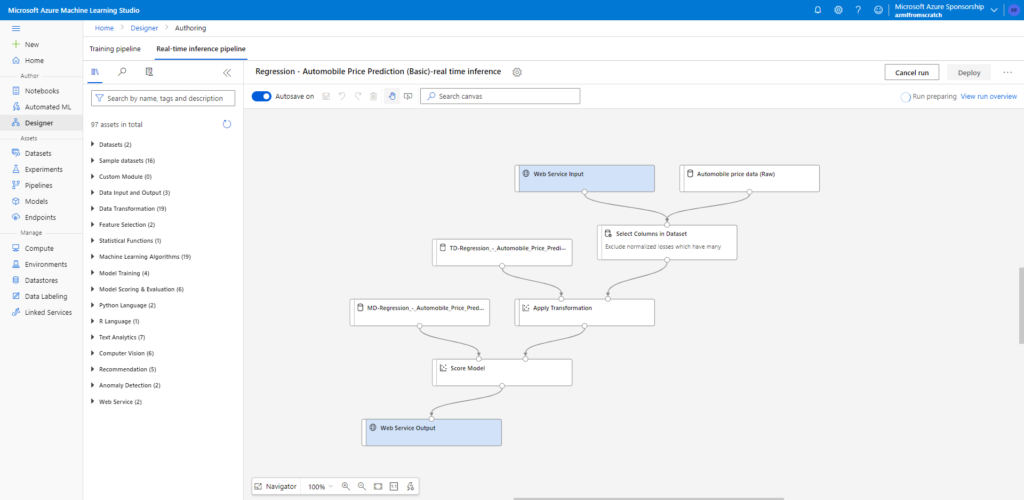
Nous lançons maintenant un pipeline d’inférence, de type temps réel.
Le déploiement permet avoir de choisir entre une ressource Azure Container Instance (ACI) ou Kubernetes Service (AKS) pour porter un service web d’inférence.
C’est alors que le modèle est enregistré en tant qu’objet dans l’espace de travail Azure Machine Learning.
Nous remarquons le format (framework) CUSTOM qui n’est donc pas un des formats “classiques” commet SkLearn, ONNX ou encore PyTorch (liste complète ici).
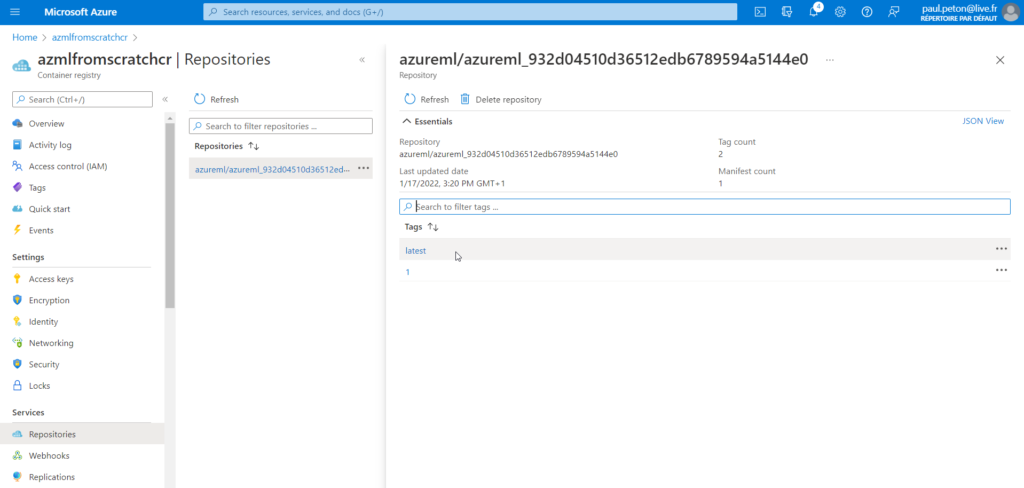
Notons que le déploiement d’un point de terminaison génère une image dans le Container Registry lié au service Azure Machine Learning.
Peut-on restaurer les fichiers d’un pipeline du Designer ?
Nous en venons maintenant à la question cruciale du backup / restore des pipelines créés au travers du Designer.
Certain.e.s se souviendront du mode export dont nous disposions lorsque le Designer s’appelait Azure Machine Learning Studio, qui permettait de sauvegarder le pipeline dans un format JSON, pouvant ensuite être réimporté. Cette fonctionnalité ne semble aujourd’hui plus disponible mais nous avons vu que de nombreux fichiers sur le compte de stockage lié traduisent les manipulations réalisées dans l’interface visuelle.
Un test simple consistant à copier les répertoires vus ci-dessus dans un nouvel espace de travail Azure Machine Learning n’est pas concluant : rien n’apparait dans le nouvel espace. Ce n’est guère étonnant car les chemins semblent très liés au blob container d’origine (voir l’extrait de fichier Trained_model ).
Ma conclusion personnelle est donc qu’il n’est pas possible de restaurer les travaux réalisés avec le Designer dans une autre ressource Azure Machine Learning.
Faisons maintenant un dernier test : la suppression des fichiers du blob container correspondant au datastore. En relançant la création du point de terminaison, nous obtenons une erreur car le fichier binaire du modèle n’est pas accessible.
De ces tests, nous retenons quelques bonnes pratiques visant à sécuriser les développements réalisés dans l’interface graphique d’Azure Machine Learning :
créer un lock sur le groupe de ressources contenant Azure Machine Learning et le compte de stockage lié
utiliser un niveau de réplication a minima ZRS (ne pas choisir LRS qui est le choix par défaut)
mettre en place un système de réplication des fichiers du compte de stockage (object replication)
créer une documentation des pipelines réalisés (quelques copies d’écran et l’indication des paramètres qui ont été modifiés…)
Les instances de calcul (“compute instance“) d’Azure Machine Learning sont très pratiques pour les Data Scientists souhaitant travailler dans un environnement Jupyter, déjà configuré, et disposant du SDK azureml.
Cette simplicité ne doit pas faire oublier la bonne pratique de la gestion de versions du code, au moyen par exemple d’un outil comme Git.
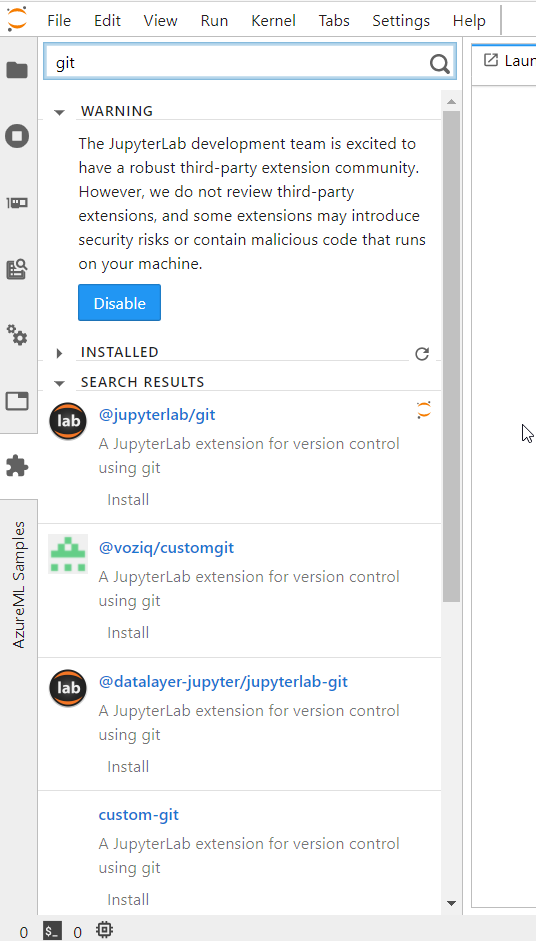
Il existe des extensions pour JupyterLab qui permettent de faciliter les interactions avec un repository git. La recherche du mot-clé “git” nous en montre quelques-unes dans l’image ci-dessous.
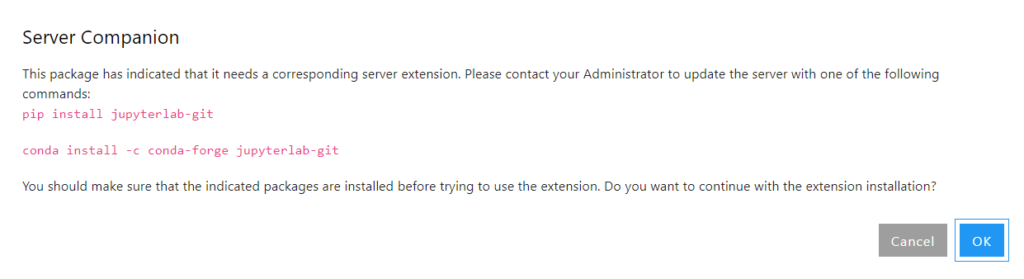
Malheureusement, à ce jour (janvier 2022), des incompatibilités de versions semblent rendre impossible l’installation de jupyterlab-git, qui nécessite en particulier une version de JupyterLab >= 3.0.
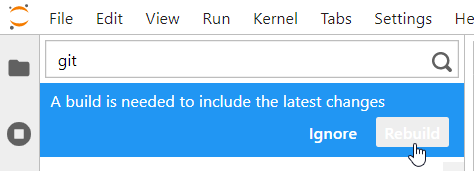
Après lancement d’un “Rebuild”, nous obtenons une erreur 500.
*
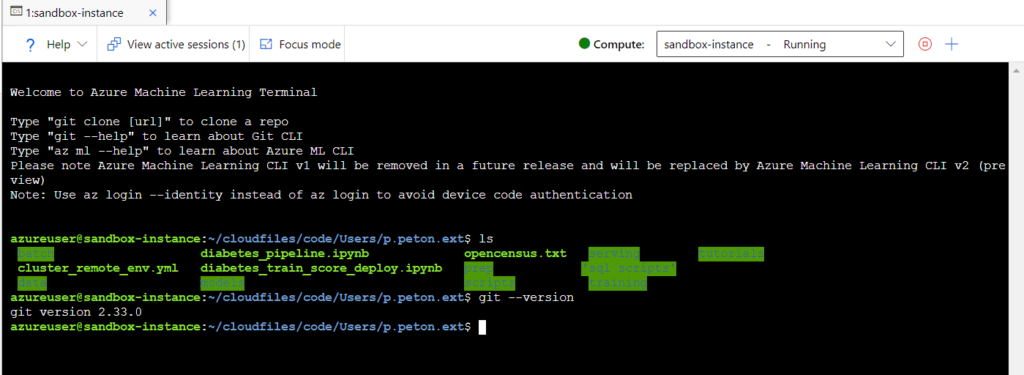
Nous allons donc nous en remettre aux lignes de commandes Git. Pour cela, il sera nécessaire d’ouvrir un terminal sur l’instance de calcul. Nous vérifions tout d’abord la bonne installation de git ainsi que sa version.
git --version
Git en version 2.33.0 est disponible
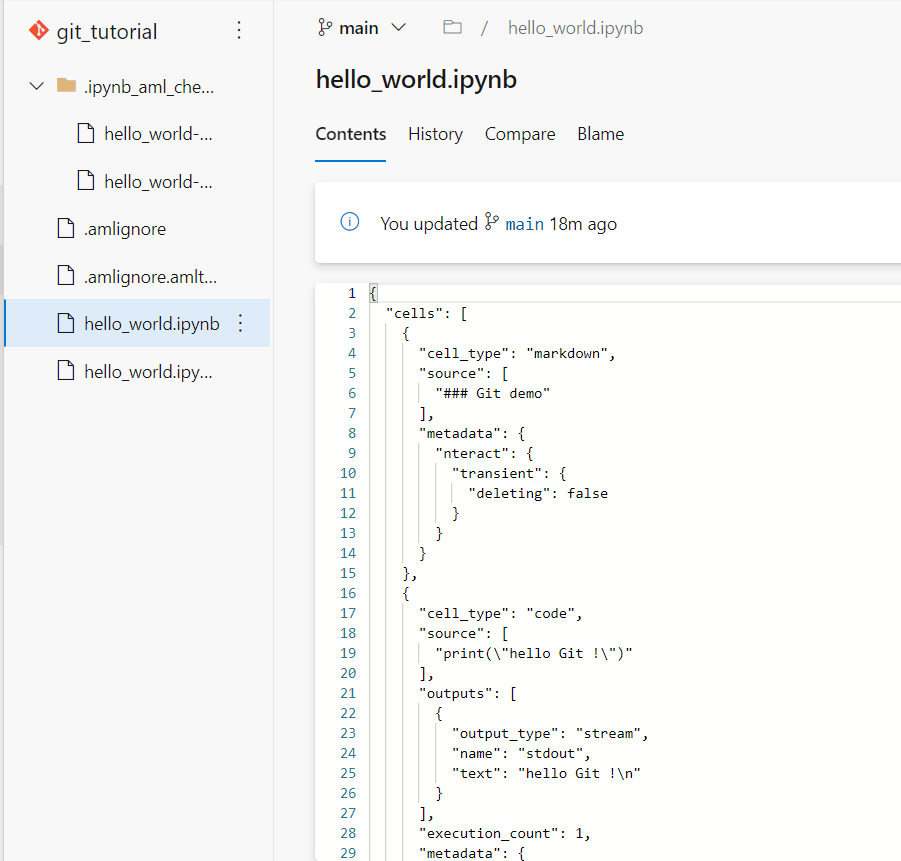
Nous allons créer ici un répertoire local à l’instance de calcul, que nous connecterons ensuite à un repository à distance, hébergé par Azure Repos. Ce répertoire contient un premier notebook, fichier de format .ipynb.
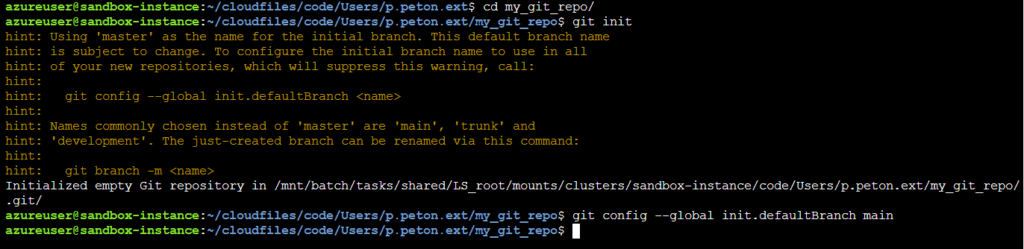
mkdir my_git_repo
git init
Il sera possible de renommer la branche master en main, selon les standards actuels, par la commande :
git branch -M main
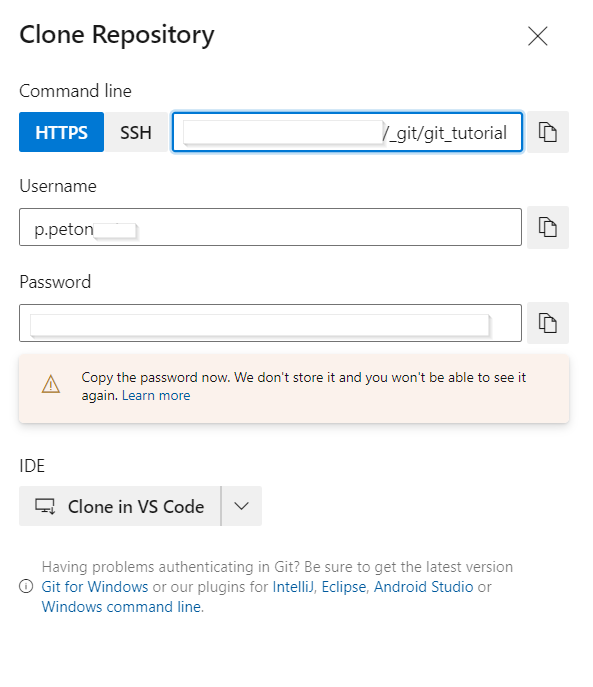
Nous allons maintenant définir le repository à distance dont nous pourrons obtenir l’URL dans l’interface Azure DevOps, en cliquant sur le bouton “Clone”.
git remote add origin <Azure Repos URL>
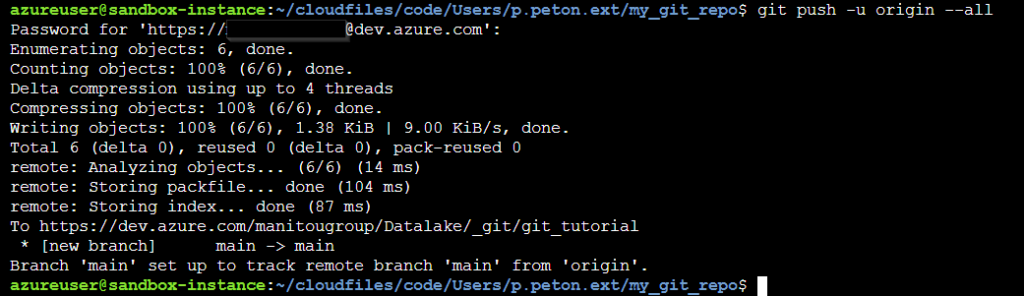
Il ne reste plus qu’à lancer le trio de commandes qui permettront successivement d’ajouter les fichiers du dossier à la liste de ce qui doit être versionné, de “commiter” cette version avec un commentaire puis de pousser les fichiers vers le répertoire à distance.
Lors de la commande git push, il sera demandé à l’utilisateur de s’authentifier. Pour cela, nous pouvons obtenir un password dans la fenêtre vue précédemment : “Clone Repository”.
Les logs de la commande nous montrent que les fichiers sont bien uploadés sur le repository à distance.
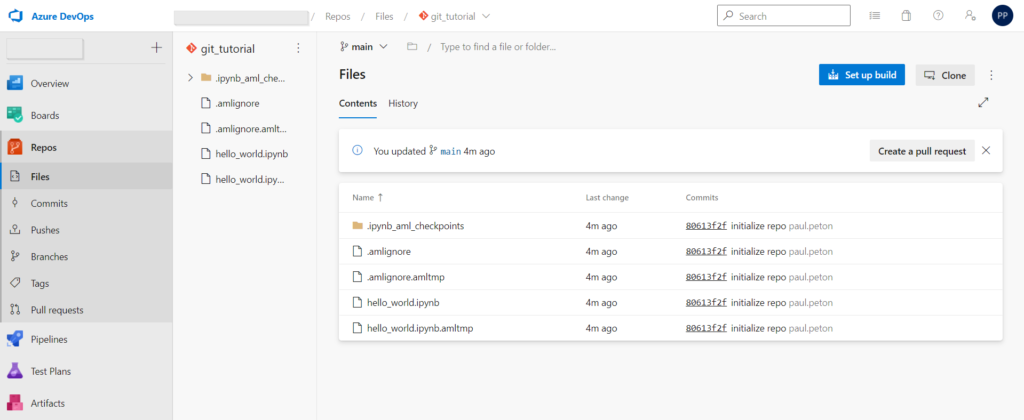
Nous vérifions également la présence des fichiers dans l’interface graphique d’Azure Repos.
Rappelons enfin que les notebooks sont très verbeux lorsqu’on les regarde sous l’angle de fichiers texte que le gestionnaire de versions cherchera à comparer. Mieux vaut limiter le nombre de cellules et privilégier l’appel à des librairies externes, par exemple packagées dans un fichier wheel qui sera mis à disposition par Azure Feed (voir cet article).
Verbosité des notebooks pour un gestionnaire de versions
Dans un précédent article, nous explorions la procédure pour lancer simplement du code sur des machines distantes Azure ML (compute target) depuis l’environnement de développement (IDE) Visual Studio Code.
Dans les raccourcis disponibles au niveau du menu des instances de calcul, nous disposons dorénavant d’un lien permettant de lancer l’ouverture de Visual Studio Code.
Quel est l’avantage de travailler de la sorte ? Réponse : vous disposez de toute la puissance de l’IDE de Microsoft (en particulier pour les commandes Git), sans toutefois être dépendant de votre poste local.
Vous ne pouvez bien sûr utiliser qu’une instance qui vous est personnellement assignée.
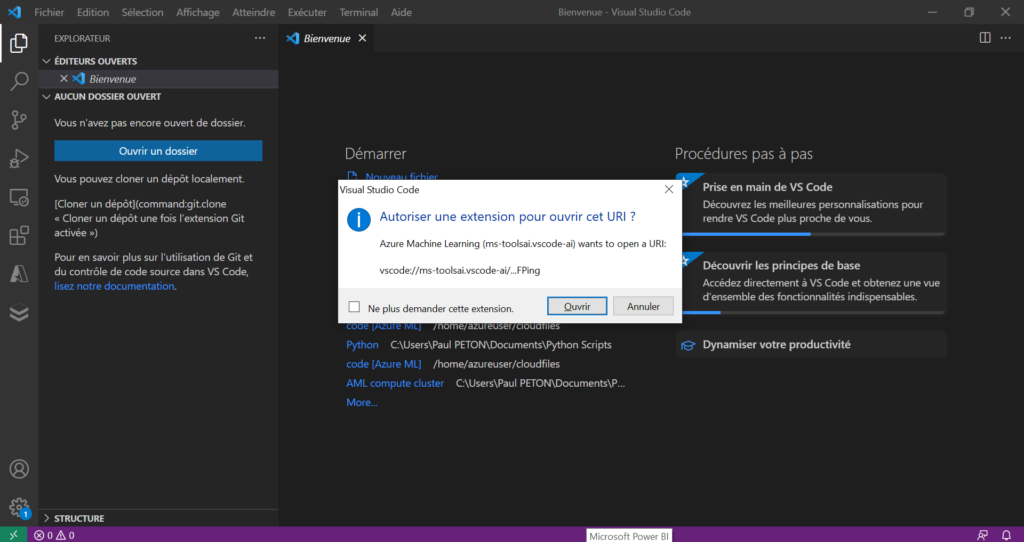
Cliquez sur le lien VS Code et votre navigateur lèvera tout d’abord une alerte. Cochez la case “Toujours autoriser…” pour ne plus voir cette pop-up.
C’est maintenant au tour de VSC de faire une demande d’autorisation avant de lancer la connexion à distance.
En tâche de fond, nous assistons à l’installation d’un VS Code server sur l’instance de calcul.
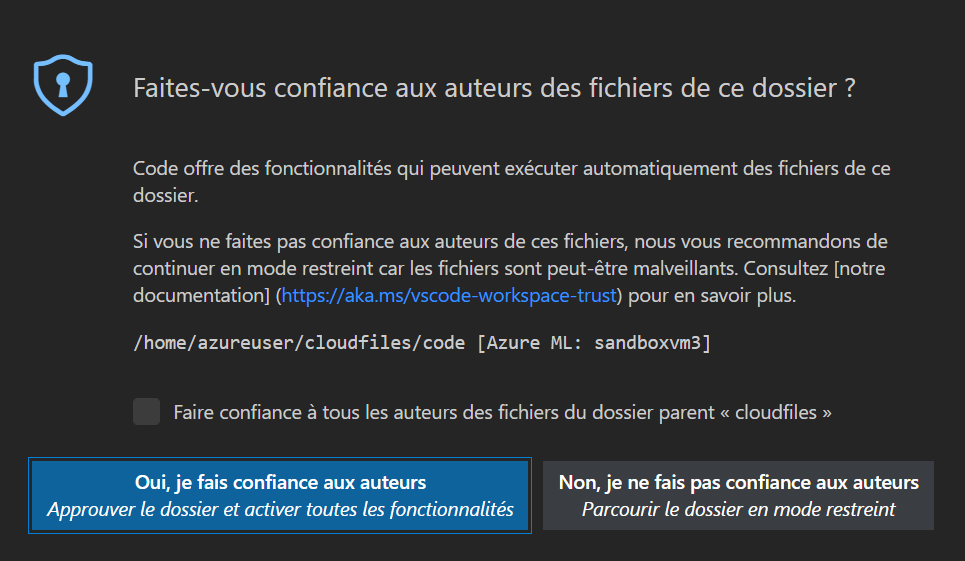
Il ne reste plus qu’à “faire confiance” aux fichiers qui seront maintenant accessible depuis l’éditeur local.
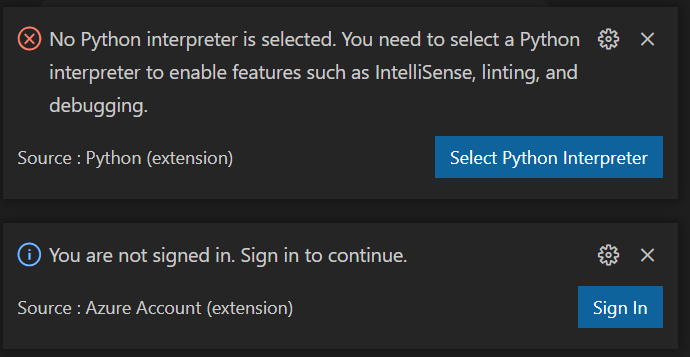
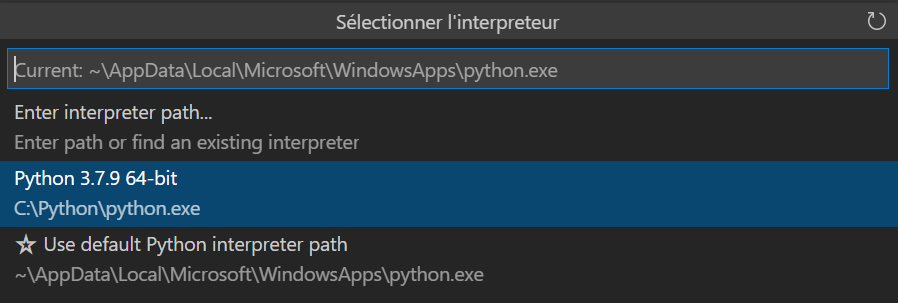
Plusieurs alertes peuvent être levées par VS Code selon votre paramétrage. Ainsi, il faudra choisir un interpréteur Python (mais attention, ce n’est pas une distribution installée sur votre poste local !) ainsi que s’authentifier vis à vis de l’extension Azure pour VS Code (à installer également au préalable).
Si le choix entre Python2 et Python3 ne fait plus débat, le choix de la version mineure de Python est important pour votre projet, car celle-ci conditionne les versions de packages nécessaires par la suite.
Le réflexe pourrait alors être de choisir l’interpréteur Python du poste local mais nous voulons justement exécuter le code à distance. Une sélection dans la fenêtre ci-dessous n’est donc pas nécessaire.
Etape à ne PAS réaliser
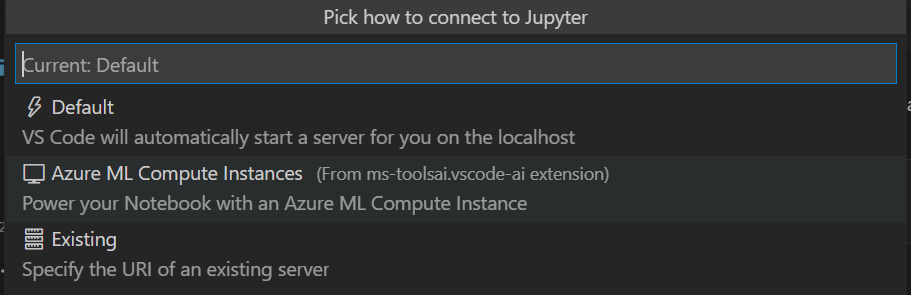
Allons plutôt voir dans le coin en bas à droite de notre éditeur.
Un clic sur “Jupyter Server” va lancer un autre menu : “Pick how to connect to Jupyter“.
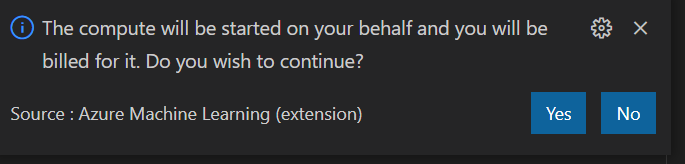
Nous choisissons ici “Azure ML Compute Instances” puis naviguons jusqu’à l’instance voulue. Un message d’alerte concernant la facturation de cette VM va alors apparaître.
Un rechargement de VS Code pourra être nécessaire pour bien valider la connexion.
Le statut en bas à droite de l’IDE nous indique que le serveur Jupyter se trouve bien à distance (remote) et c’est donc lui qui exécutera le code.
Commençons par un commande simple dans un nouveau notebook.
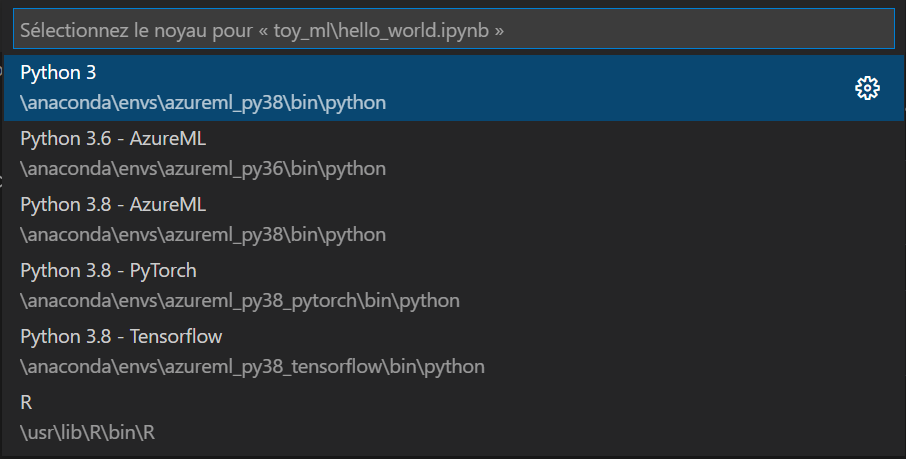
Il est maintenant temps de choisir l’interpréteur Python de la machine distante (cliquer si besoin sur le bouton “sélectionner le noyau”).
Nous choisissons ici l’environnement Python 3.8, muni des packages azureml, qui nous permettront d’interagir avec le service Azure Machine Learning.
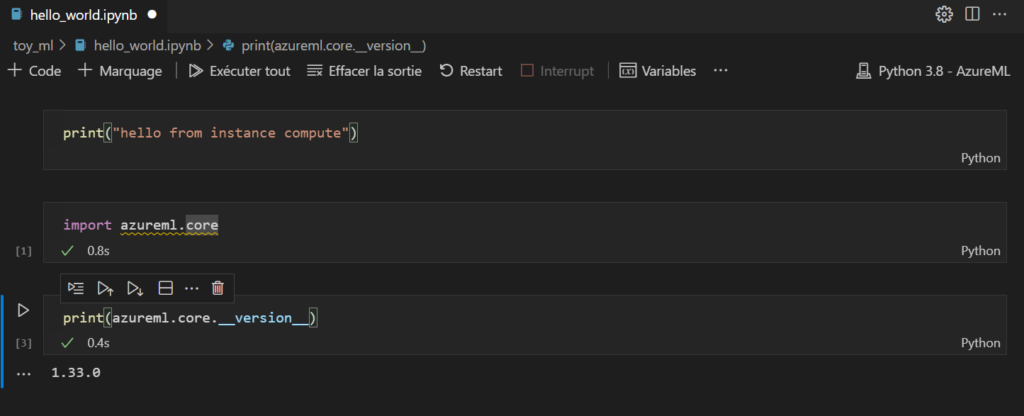
Vérification de la version du package azureml-core
Utiliser les commandes Git de VSC
C’est sans doute le plus grand des avantages à passer par l’IDE : pouvoir réaliser du contrôle de code source, avec les fonctionnalités Git intégrées dans VSC.
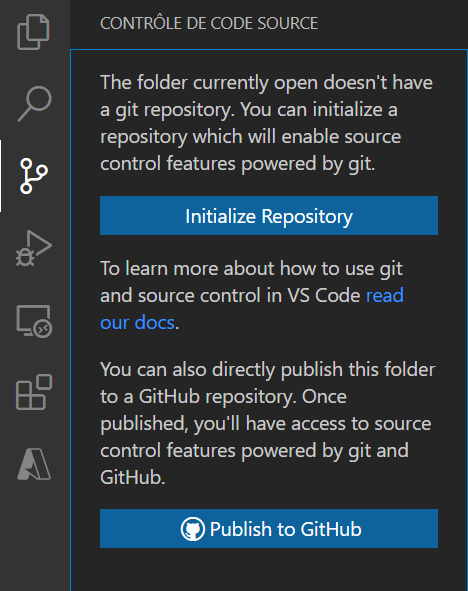
En cliquant sur le symbole Git du menu du gauche, nous déroulons une première fenêtre demandant de réaliser l’initialisation du repository.
Il est ensuite nécessaire de configurer le nom de l’utilisation ainsi que son adresse de courrier électronique.
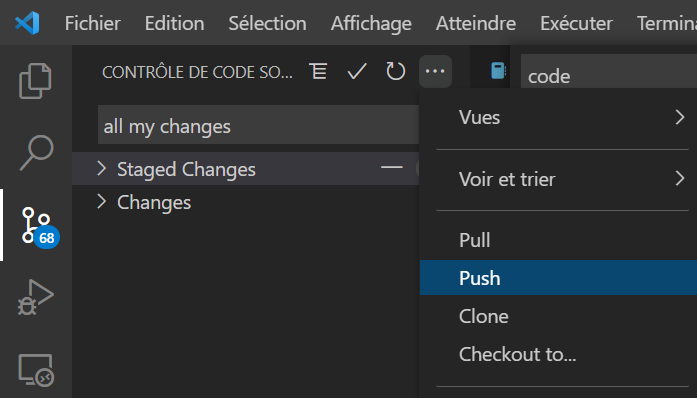
Les changements (ici, tous les fichiers lors de l’initialisation) sont détectés par Git et il sera possible de les pousser (git push) sur le repository.
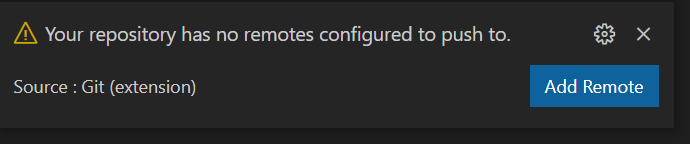
En cliquant ici sur Push, une alerte sera levée car une dernière configuration est nécessaire.
Il faut configurer l’URL du repository, par exemple une adresse GitHub.
Ceci se réalise au moyen de la commande ci-dessous, sur la branche principale (main).
git push --set-upstream <origin_branch> main
Ca y est ! Nous disposons maintenant d’une configuration très efficace pour travailler nos développements de Machine Learning, en lien avec le service Azure ML. Ce système permet également une véritable isolation des fichiers pour chaque développeur. Aucun risque qu’un.e collègue vienne modifier vos scripts, autrement qu’au travers d’un merge de branches.