
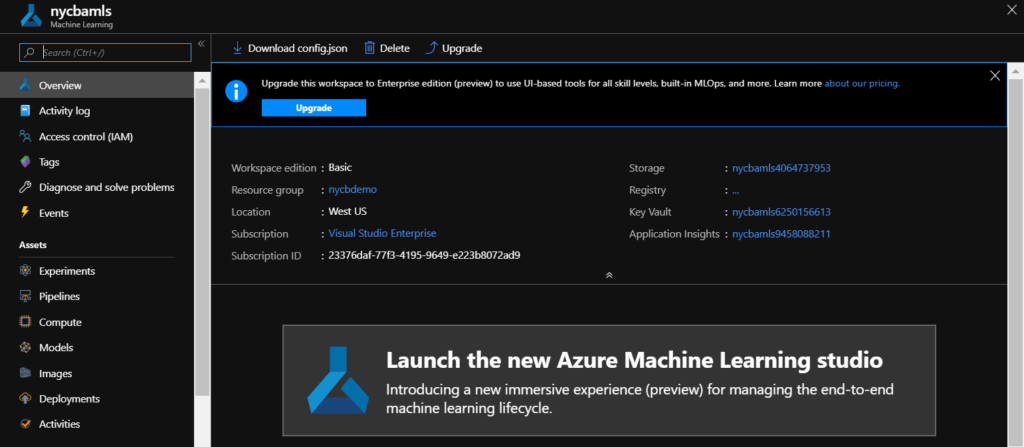

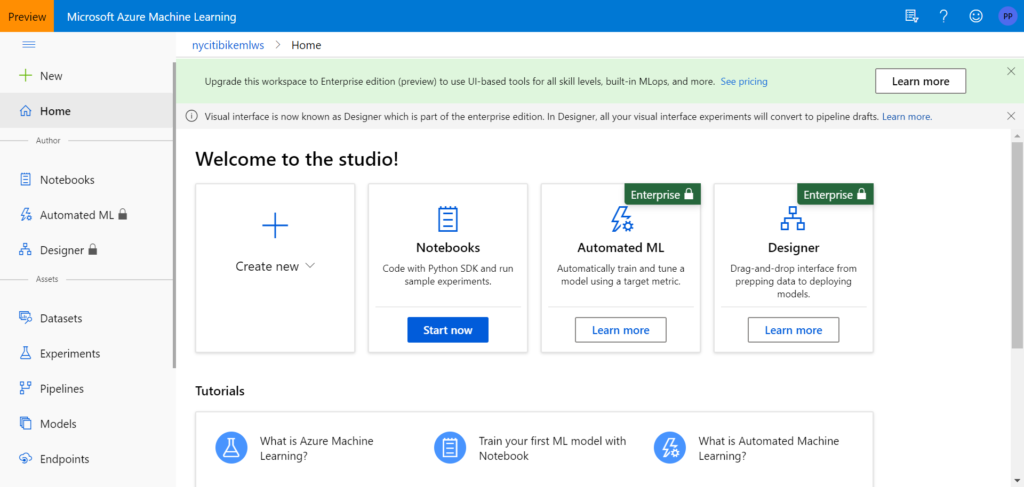
Au 15 janvier 2021, le service Azure Notebooks disparaît complètement. Nous cherchons donc une alternative en version SaaS, toujours sur Azure et celle-ci se trouve dans le portail Azure Machine Learning.
Un article d’introduction à ce service est disponible dans les archives de ce blog.
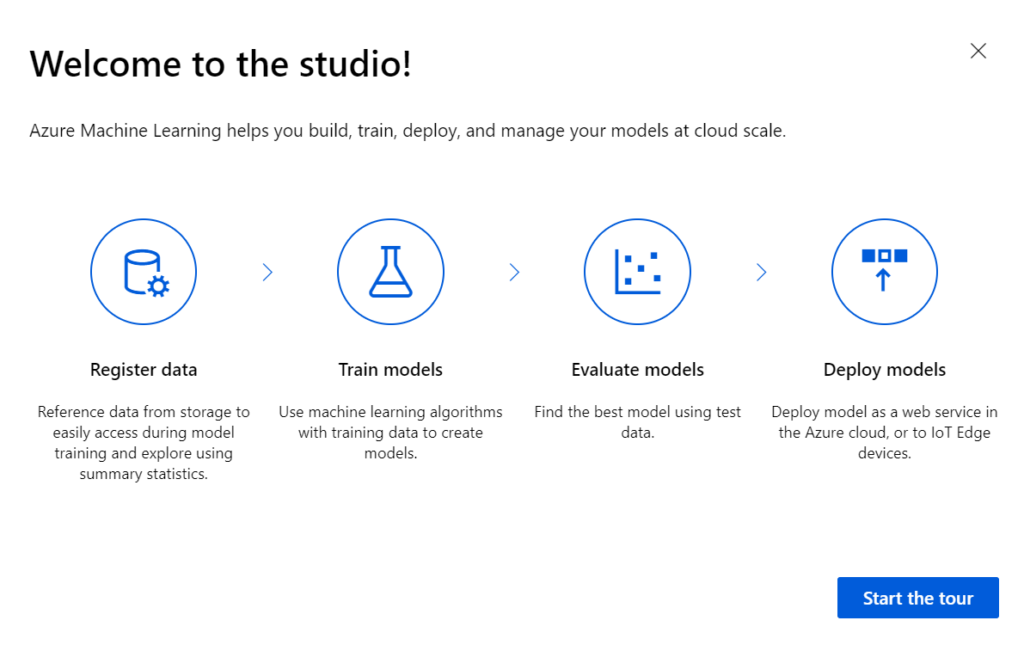
Quelques nouveautés sont disponibles et annoncées à l’ouverture d’un premier notebook. Nous reviendrons sur ces nouveautés dans la suite de cet article.
Nous pouvons alors nommer un nouveau fichier, à l’extension classique .ipynb.
Nous retrouvons ce qui caractérise les notebooks : des cellules de code, suivies par les sorties des différentes instructions, ou bien des cellules de type formaté en Markdown.
Il n’est pourtant pas possible d’exécuter du code immédiatement, il faut au préalable relier ce notebook à une instance de calcul, déjà définie dans le portail (menu “Compute”).
Dans le menu dédié aux ressources de calcul, nous retrouvons des raccourcis vers l’utilisation d’une interface Jupyter, JupyterLab ou encore RStudio.
La nécessité d’une instance de calcul rend ce service payant, et facturé au temps d’utilisation de la machine virtuelle définie. Il sera très important de ne pas oublier d’éteindre la machine après utilisation, il n’existe à ce jour aucun système natif d’extinction planifiée !
Les utilisateurs férus de Visual Studio Code (VSC) peuvent travailler à distance avec l’environnement de calcul d’Azure Machine Learning. En installant conjointement les extensions Python et Jupyter, il était déjà possible de travailler avec un notebook (fichier reconnu par son extension .ipynb) dans l’IDE de Microsoft. En ajoutant l’extension Azure Machine Learning, nous pouvons nous connecter à la ressource Azure.
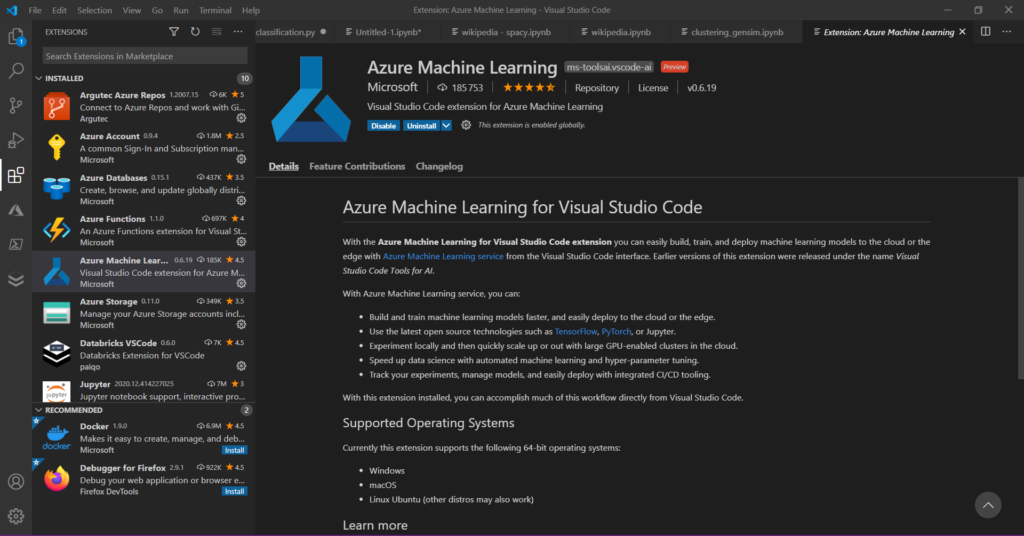
Les “objets” de l’espace Azure ML sont alors visibles depuis le menu Azure de VSC.
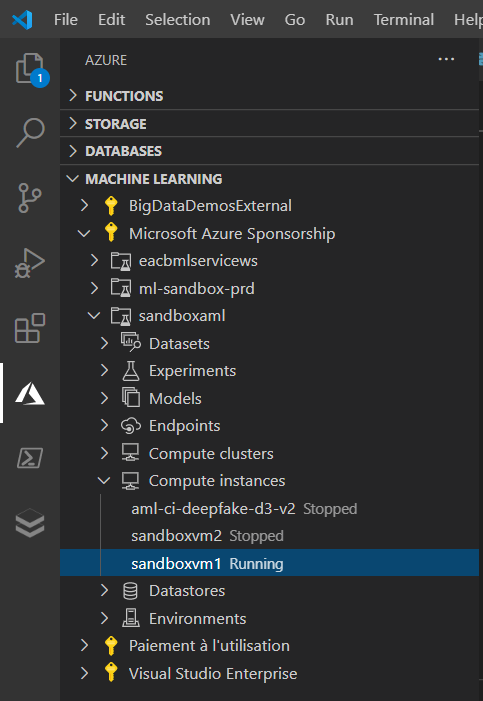
Il est possible de réaliser des actions à distance sur les instances de calcul.
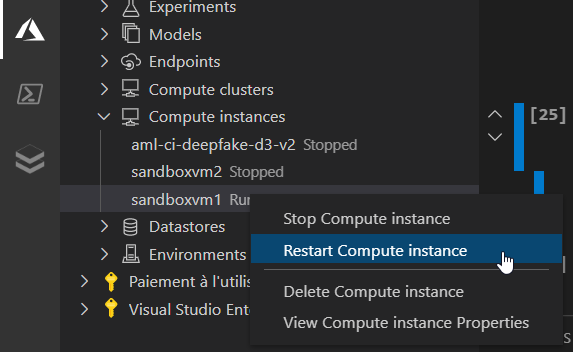
Par défaut, un notebook dans VSC utilise le serveur Jupyter local. Mais il est possible de désigner un serveur à distance (“remote“) en cliquant sur le bouton en haut à droite indiquant “Jupyter Server : local”.
Nous obtenons la boîte de dialogues ci-dessous.
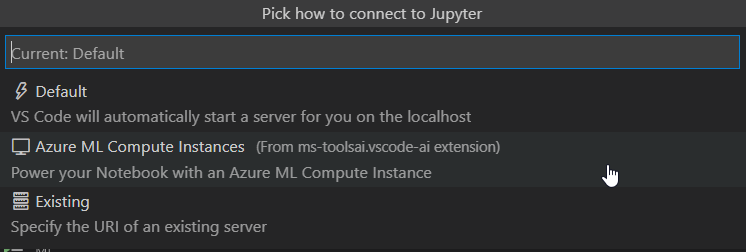
La succession de choix proposés permettra d’associer le notebook à une instance de calcul Azure ML.
Une composante indispensable de l’approche par le code est le gestion du versionnig, par un service compatible avec Git (GitHub, GitLab, Bitbucket, Azure DevOps, etc.), comme décrit sur ce lien.
Nous allons bénéficier ici de l’affichage en terminal présentés parmi les nouvelles (janvier 2021) fonctionnalités disponibles.
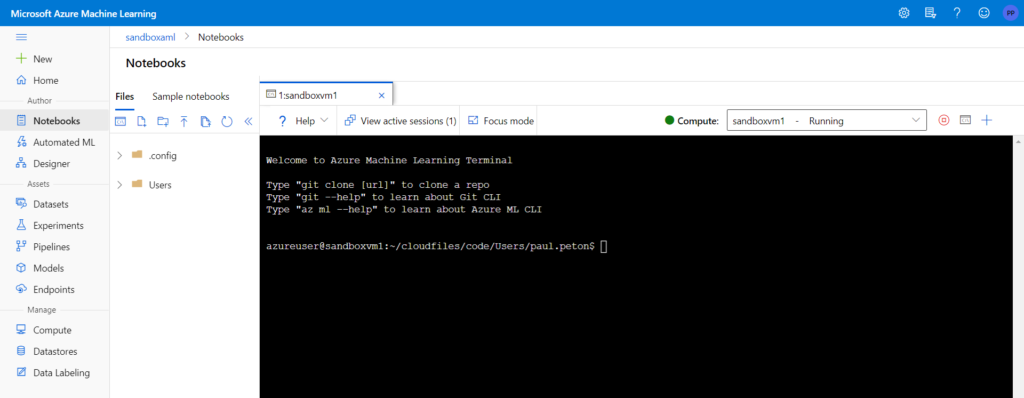
Nous devons tout d’abord créer une clé SSH au moyen de la commande ci-dessous :
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
La clé SSH doit être enregistrée dans le chemin /home/azureuser/.ssh qui est spécifique à l’instance de calcul (valider par Entrée le prompt proposé après la commande précédente). Il est alors possible de saisir une passphrase, facultative mais fortement conseillée. Un fichier id_rsa.pub est ainsi créé et son contenu peut être copié (ctrl + inser).
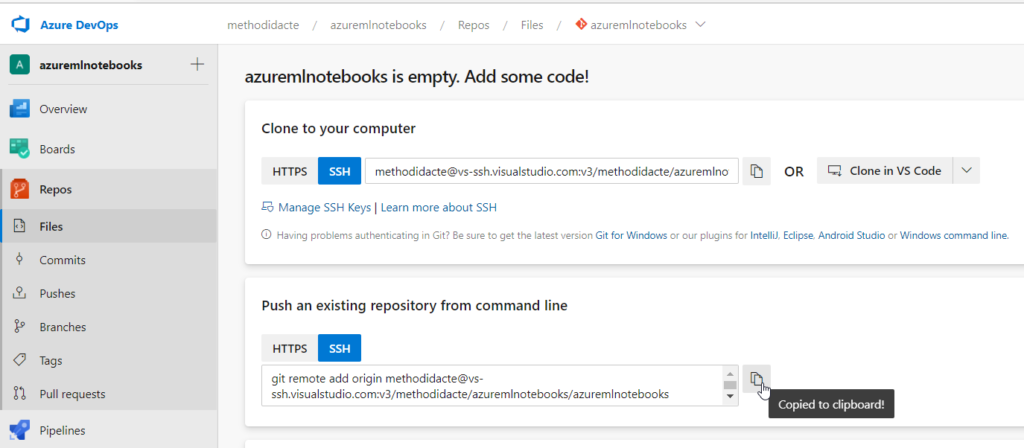
Nous utiliserons dans cet article Azure DevOps, où nous allons pouvoir saisir cette clé publique.
De retour dans le terminal, nous pouvons lancer la commande de test :
ssh -T git@ssh.dev.azure.com
Le résultat attendu est le suivant :

Depuis le repository Azure DevOps, nous obtenons la syntaxe SSH qui viendra compléter une instruction git remote, lancée depuis le terminal.
Si cela n’a pas fait, dans le terminal et depuis le chemin voulu, saisir la commande git init pour initialiser le répertoire. Définir également l’utilisateur qui réalisera les instructions de commit :
git config --global user.email "you@example.com" git config --global user.name "Your Name"
La commande git remote add origin peut alors être exécutée avec succès.
Il pourra être nécessaire de passer la commande git add . pour ajouter l’intégralité du contenu dans ce qui doit être géré par git, puis un git commit.
De même, le repository Azure doit avoir été initialisé, par exemple avec un fichier readme.md et disposer ainsi d’une branche (main ou master).
git push -u origin --all
Enfin, un rappel des commandes Git indispensables est donné ici : Git · GitHub
Une autre nouvelle intéressante consiste à “nettoyer” le notebook avant de le publier. C’est en effet un reproche souvent fait aux notebooks : ceux-ci mélangent code, sorties et commentaires et ne sont pas optimaux pour les tests unitaires et le déploiement dans un environnement de production.
La fonctionnalité “Gather” (documentation officielle) sur une cellule permet de créer un autre notebook qui conservera uniquement les cellules de code dépendant de la cellule sélectionnée.
Si vous avez provisionné un service Azure Machine Learning, vous vous êtes certainement aperçu que celui-ci ne venait pas seul au sein du resource group.
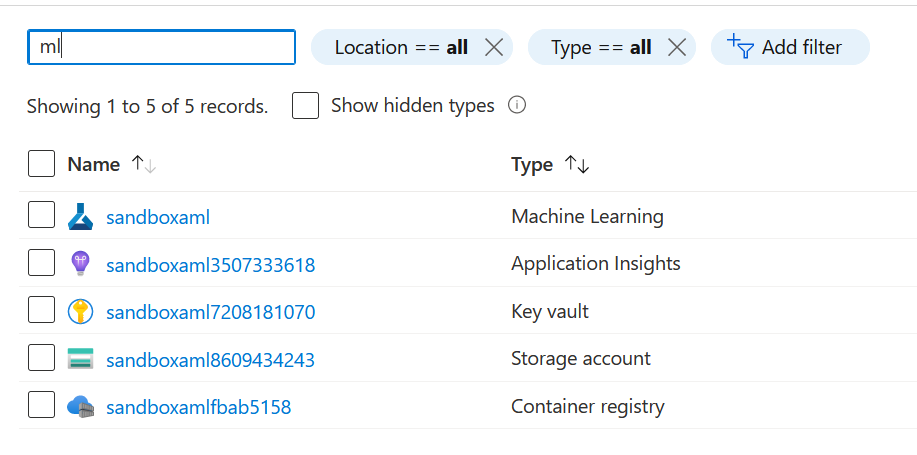
Il est en effet accompagné par un compte de stockage qui servira à enregistrer des éléments comme des datasets ou bien les artefacts liés aux modèles. Le container registry servira quant à lui à conserver les images Docker générées pour les services web prédictifs. Le Key Vault jouera son rôle de stockage des clés, secrets ou passphrases. Reste le service Application Insights.
Application Insights est une branche du service Azure Monitor qui permet de réaliser le monitoring d’applications comme des applications Web, côté front mais aussi back. De nombreux services Azure (Azure Function, Azure Databricks dans sa version enterprise, etc.) peuvent être surveiller grâce à Application Insights.
Le détail des éléments supervisés est disponible dans la documentation officielle.
La manière la plus concrète d’obtenir un résultat avec ce service est sans doute d’utiliser l’interface Log Analytics. Celle-ci se lance en cliquant sur le bouton logs.
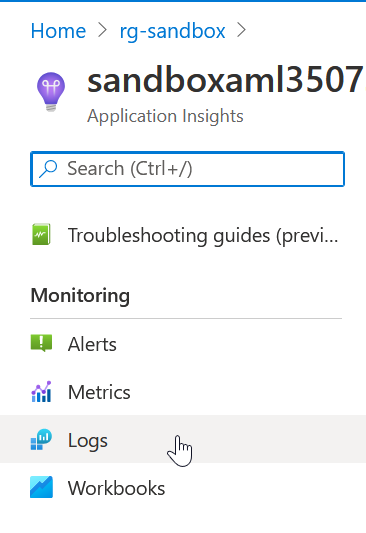
L’interface de Log Analytics nous invite à écrire une nouvelle requête dans le langage KustoQL, dont la syntaxe est disponible ici. Ce langage est aussi utilisé dans l’outil Azure Data Explorer.
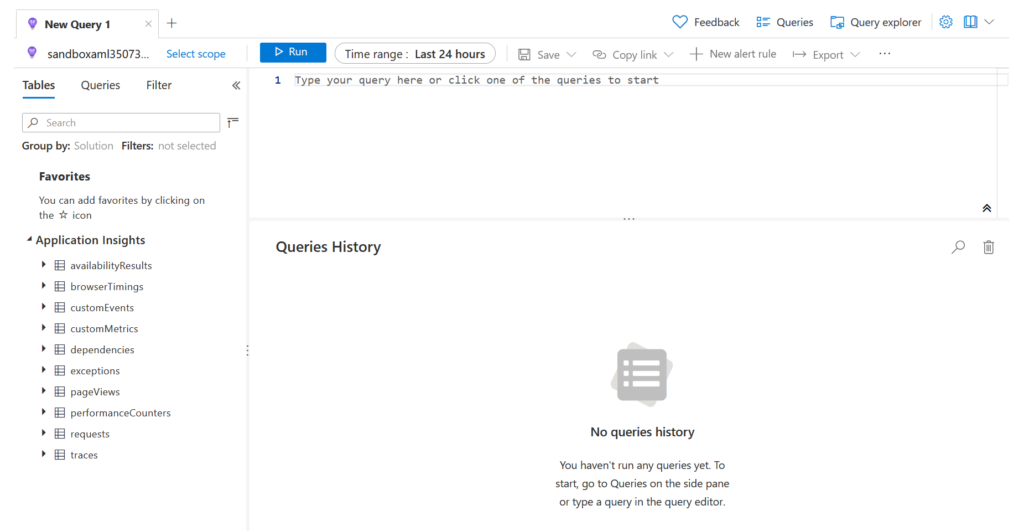
Mais avant de pouvoir obtenir des résultats, nous devons déployer un service web prédictif sur lequel App Insights a été activé. Nous le faisons en ajoutant la propriété enable_app_insights=True dans la définition de la configuration d’inférence.
Il faut également que du texte soit “imprimé” au moment de l’exécution de la fonction run(), tout simplement à l’aide de la fonction print().

Quelques exemples de notebooks sont disponibles dans ce dépôt GitHub.
Après publication ou mise à jour du service web, une URL apparaît dans l’interface et donne accès au service App Insights correspondant.
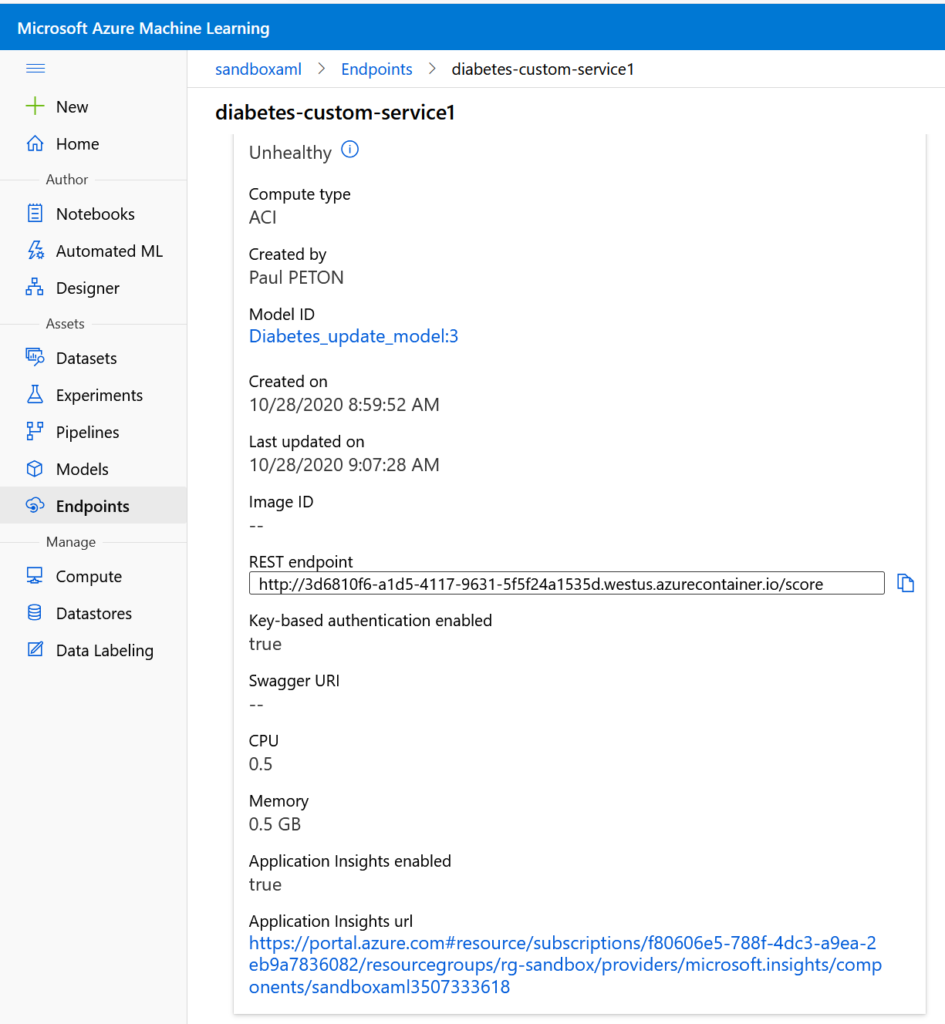
Il est maintenant possible de lancer une première requête dans l’interface Log Analytics, avec la syntaxe suivante :
traces |where message == "STDOUT" and customDimensions.["Service Name"] == "diabetes-custom-service1" |project timestamp, customDimensions.Content
Nous obtenons le résultat ci-dessous.
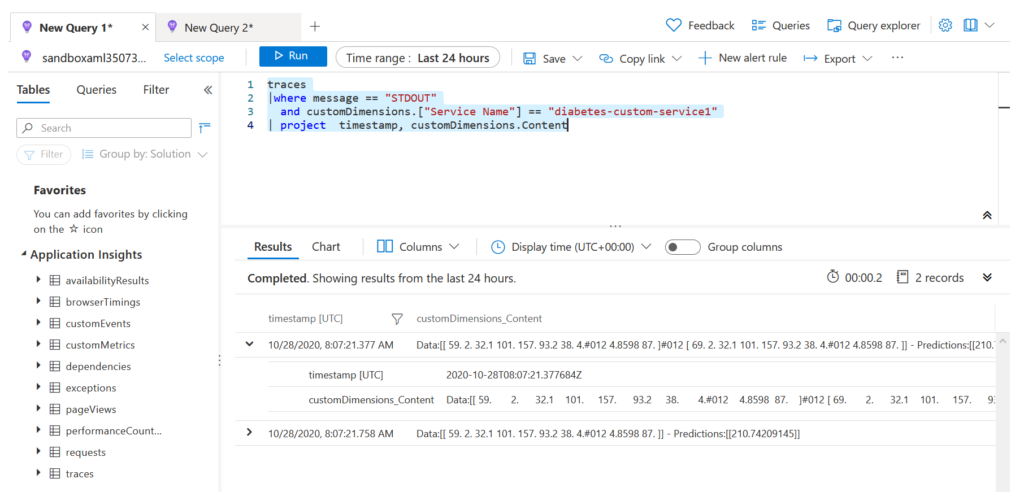
Le service Azure Machine Learning a créé une “custom dimension“, nouvel objet au format JSON, interrogeable par le langage KustoQL. Celui-ci contient des informations comme l’identifiant du container associé, le nom de l’espace de travail ainsi que du service déployé.
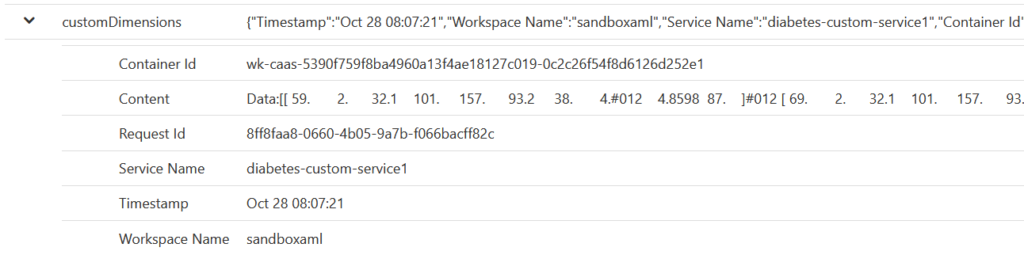
Afin de conserver les logs sur la durée, un mécanisme d’export continu pourra être mis en œuvre et stockera les informations sur un compte de stockage.
Suite à mon premier article sur le nouveau programme 2020 de cette certification Microsoft, je continue à décrire les différents outils présents dans le nouveau studio Azure Machine Learning, en suivant le plan donnée par le programme de la certification. Attention, le contenu peut ne pas être exhaustif comme le rappelle la mention “may include but is not limited to“.
Le Concepteur (ou Designer en anglais) n’est accessible qu’avec la licence Enterprise et correspond à l’ancien portail Azure Machine Learning Studio. La documentation complète est disponible ici.
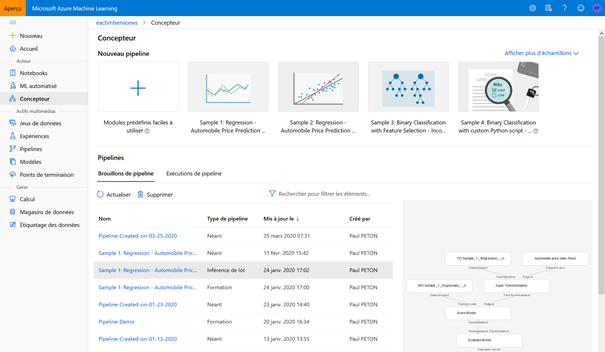
Nous cliquons ensuite sur le bouton « + » pour démarrer une nouvelle expérimentation. Mais il sera très intéressant regarder les différents exemples disponibles, en cliquant sur « afficher plus d’échantillons ».
May include but is not limited to:
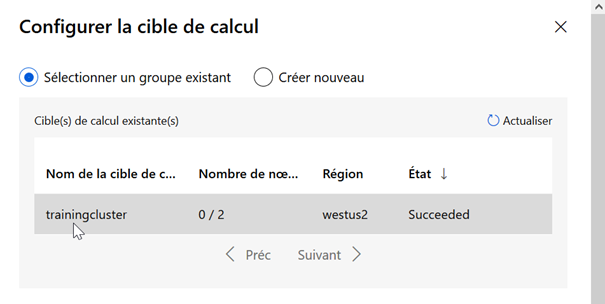
La première chose à paramétrer est l’association de l’expérience avec une cible de calcul de type « cluster d’entrainement ».
Nous utiliserons ensuite les modules disponibles dans le menu latéral de gauche.

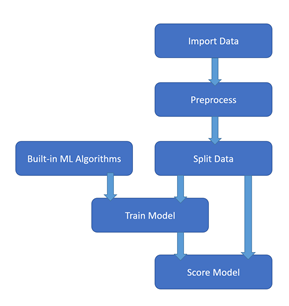
Ces modules nous permettront de construire un « pipeline » dont la structure classique est décrite par le schéma ci-dessous.
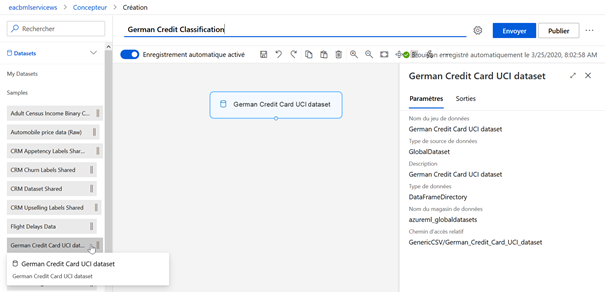
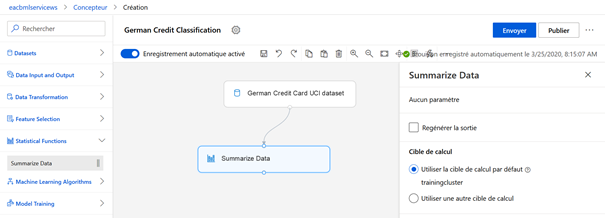
La première étape consiste à désigner les données qui serviront à l’expérience. Nous choisissons pour cet exemple le jeu de données « German Credit Card UCI dataset » en réalisant un glisser-déposer du module de la catégorie Datasets > Samples.
Les jeux de données préalablement chargés à partir des magasins de données sont quant à eux disponibles dans Datasets > My Datasets.
Le module « Import Data » permet de se connecter directement à une URL via HTTP ou bien à un magasin de données.
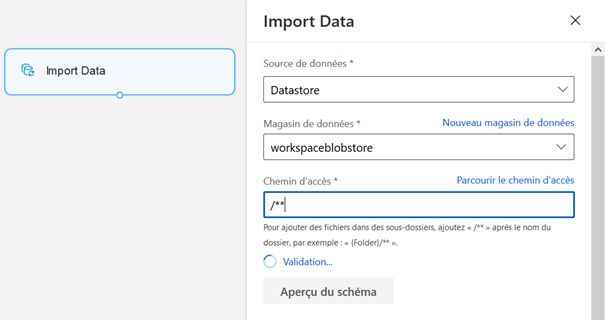
Il est enfin possible de charger des données manuellement à l’aide du module « Enter Data Manually ».
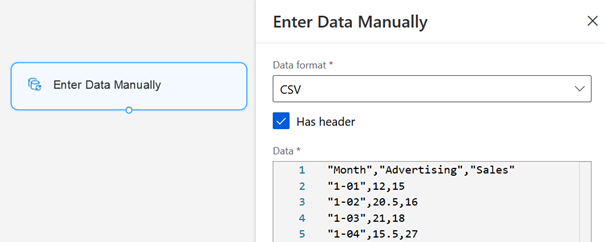
Ces deux dernières méthodes ne sont pas recommandées, il est préférable de passer par la création propre d’un jeu de données dans le menu dédié.
Afin de bien appréhender le jeu de données, nous ajoutons temporairement un composant « Summarize Data », de la catégorie Statistical Functions. Les deux modules doivent être reliés l’un à l’autre, en glissant la sortie du précédent vers l’entrée du suivant.
Nous cliquons sur le bouton « Envoyer » pour exécuter ce premier pipeline.
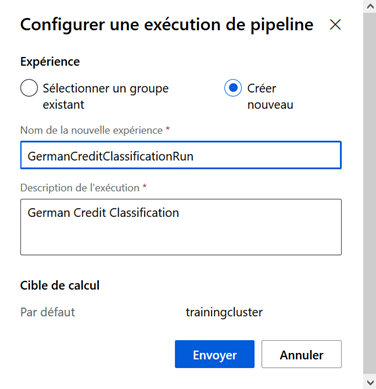
Un nom doit être donné à l’expérience (entre 2 et 36 caractères, sans espace ni caractères spéciaux hormis les tirets haut et bas).
Au cours de l’exécution, une vue d’ensemble est disponible.
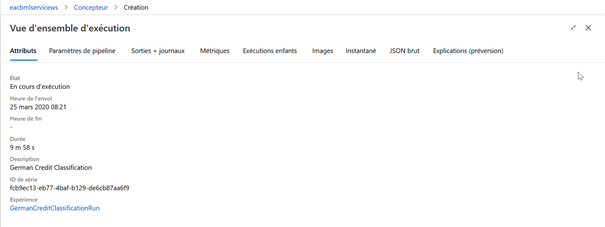
Depuis le menu Calcul, un graphique résume l’état des nœuds du cluster d’entrainement.
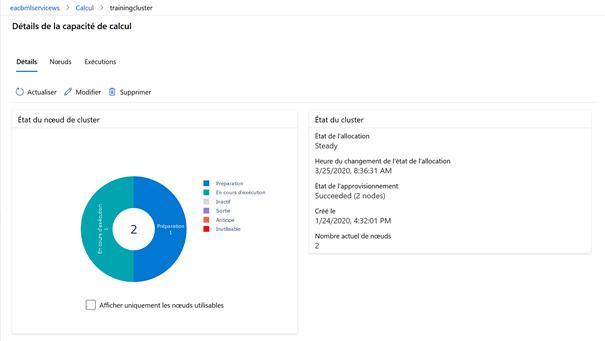
Une fois les étapes validées (coche verte sur chaque module), les sorties et journaux d’exécution sont accessibles. Le symbole du diagramme en barres donne accès aux indicateurs de centrage et de dispersion sur les différentes variables.
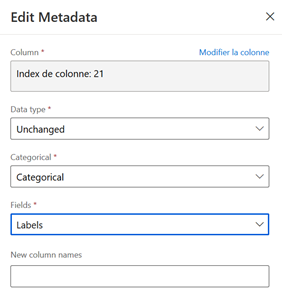
Nous recommandons d’utiliser l’édition des métadonnées pour identifier la variable jouant le rôle de label. Cette astuce permettra par la suite de conserver un paramétrage des modules utilisant la colonne de type « label ». Il sera également possible de désigner toutes les autres colonnes du jeu de données par « all features » dans les boîtes de dialogue de sélection.
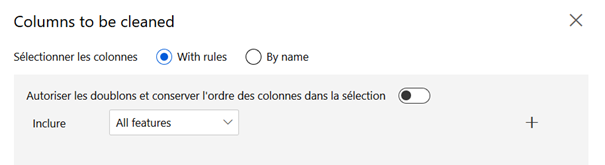
Pour une variable binaire dans la cadre d’une classification, la variable est également déclarée comme catégorielle.
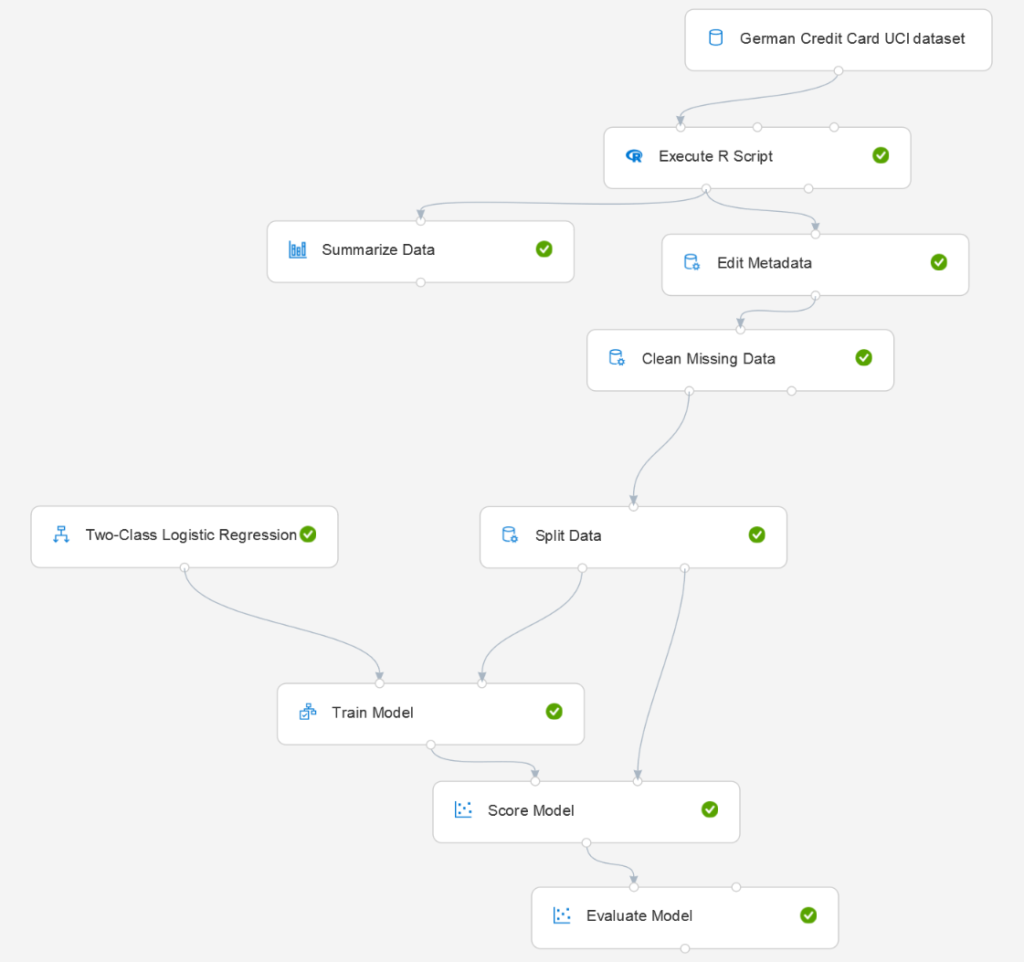
Nous construisons ensuite un pipeline classique de la sorte :
Une fois un modèle entrainé avec succès, un nouveau bouton apparaît en haut à droite de l’écran.
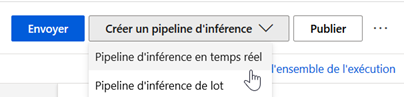
Nous créons un pipeline d’inférence en temps réel pour obtenir un service Web prédictif à partir de notre modèle. Des modules d’input ou d’output sont automatiquement ajoutés.
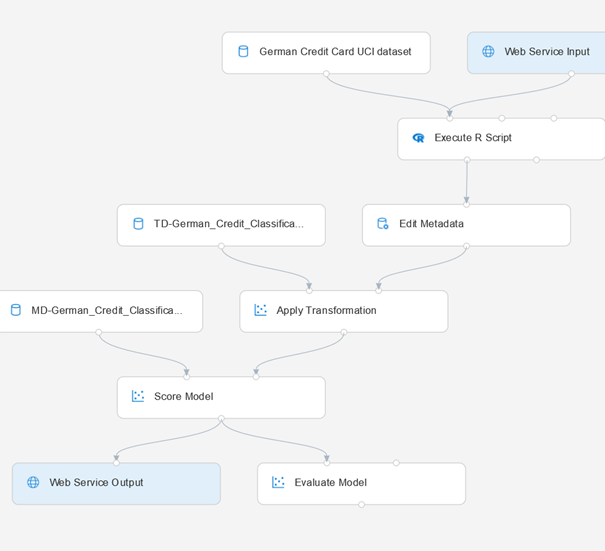
Il est alors nécessaire d’exécuter une nouvelle fois le pipeline pour ensuite publier le service d’inférence. Le bouton « déployer » est ensuite accessible.
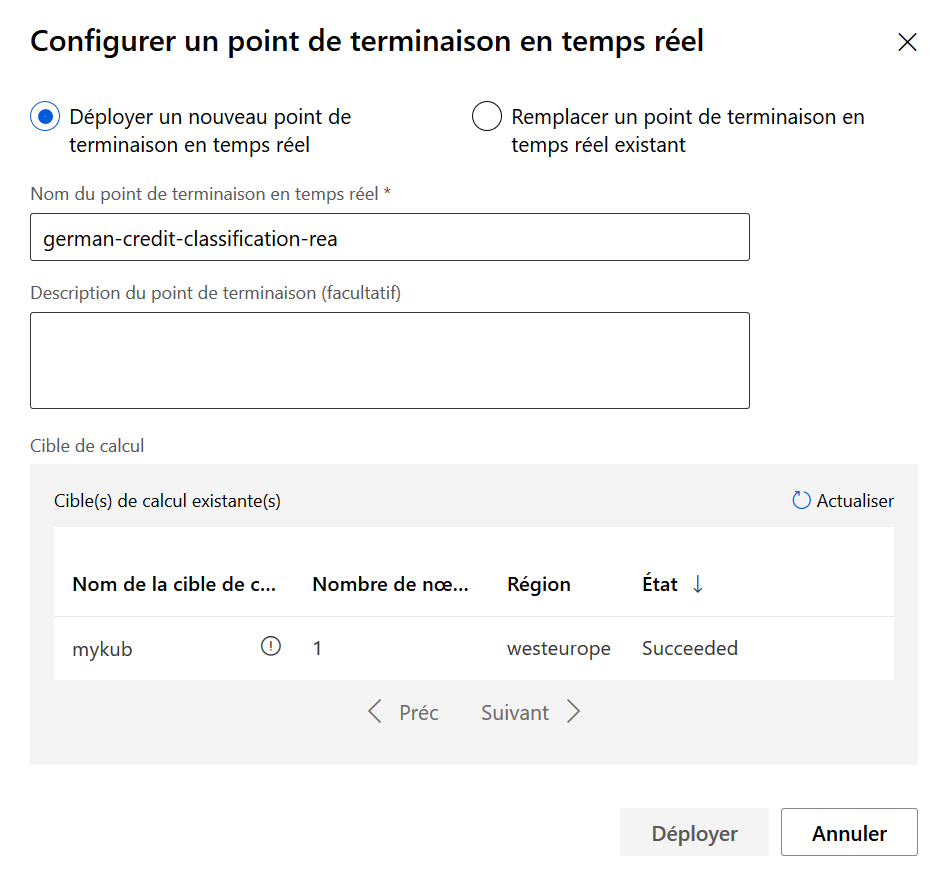
Une fois le déploiement réussi avec succès, le point de terminaison (“endpoint“) est visible dans le menu dédié.
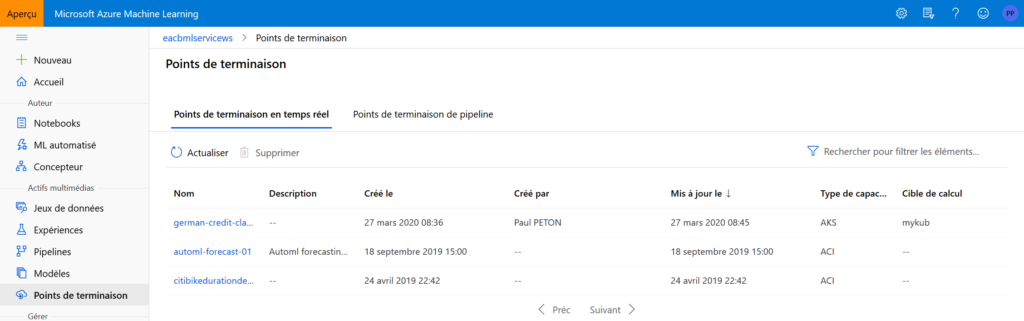
Nous retrouvons dans les écrans dédiés l’URL du point qui donnera accès aux prévisions. Il s’agit d’une API REST, sous la forme suivante :
http://XXX.XXX.XXX.XXX:80/api/v1/service/german-credit-classification-rea/score
Une fenêtre de test facilite la soumission de nouvelles données.
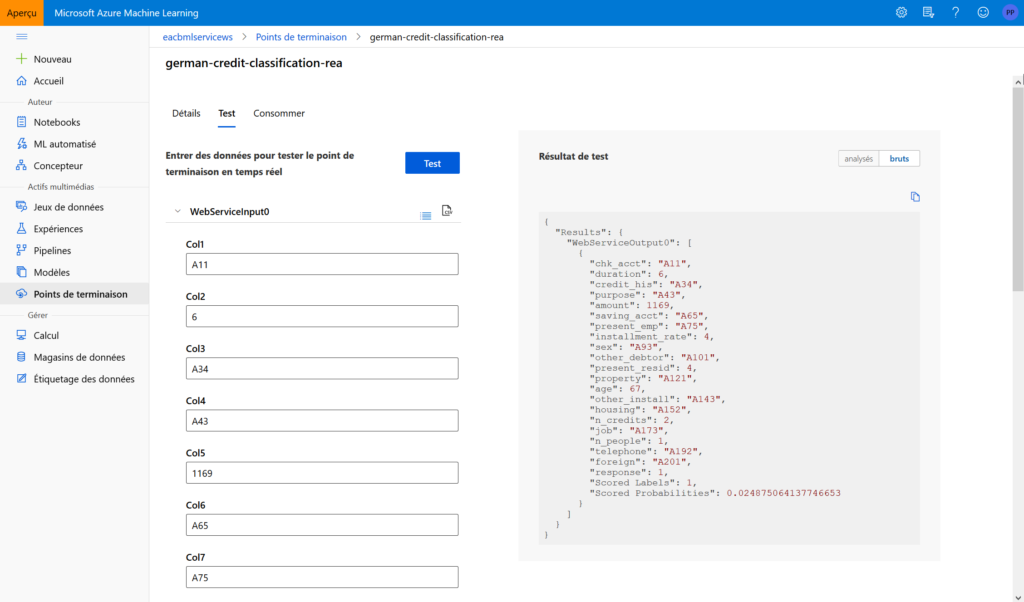
L’onglet “consommer” donne enfin des exemples de codes prêts à l’emploi en C#, Python ou R, ainsi qu’un mécanisme de sécurité basé sur des clés ou jetons d’authentification.
Des modules personnalisés peuvent être intégrés dans le pipeline, en langage R ou Python.
Les modules de script disposent d’entrées et de sorties, accessibles au travers de noms de variables réservés.
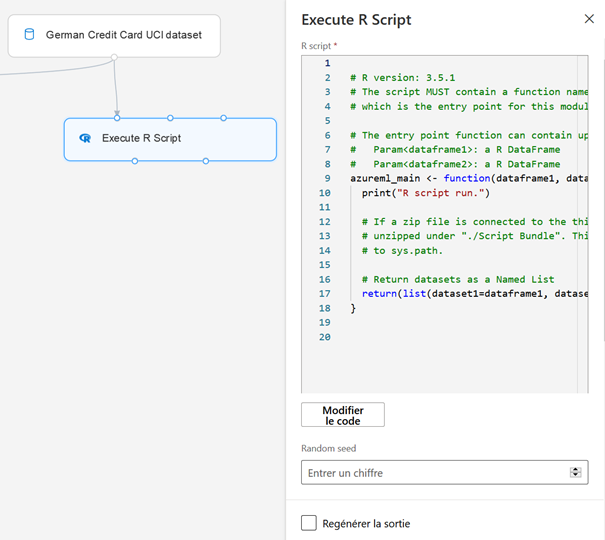
Ainsi, pour un script R personnalisé, le modèle de code généré est une structure de fonction :
# R version: 3.5.1
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a zip file is connected to the third input port, it is
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Les entrées 1 & 2 sont identifiées respectivement sous les noms dataframe1 et dataframe2.
Les deux sorties sont par défaut nommées dataset1 et dataset2 et retournées sous forme d’une liste de deux éléments. Il est possible de modifier ces noms même si cela n’est pas conseillé.
Pour nommer les colonnes du jeu de données German Credit Card, nous utilisons le code R suivant :
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
colnames(dataframe1) = c("chk_acct", "duration", "credit_his", "purpose", "amount", "saving_acct", "present_emp", "installment_rate", "sex", "other_debtor", "present_resid", "property", "age", "other_install", "housing", "n_credits", "job", "n_people", "telephone", "foreign", "response")
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
La troisième entrée du module est dédiée à un fichier zip contenant des librairies supplémentaires. Ces packages doivent être au préalable installer sur un poste local, généralement dans le répertoire :
C:\Users\[user]\Documents\R\win-library\3.2
Créer un dossier contenant les sous-dossiers des packages transformés en archives (.zip) puis réaliser une nouvelle archive .zip à partir de ce dossier. Importer ensuite l’archive obtenu comme un jeu de données. Le module obtenu sera raccordé à la troisième entrée du module Execute R/Python Script : Script Bundle (Zip).
Pour les scripts Python, nous disposons également d’un module permettant de créer un modèle d’apprentissage qui sera ensuite connecté à un module « Train Model ».

Le code Python à rédiger se base sur les packages pandas et scikit-learn et doit s’intégrer dans le modèle suivant :
import pandas as pd
from sklearn.linear_model import LogisticRegression
class AzureMLModel:
# The init method is only invoked in module "Create Python Model",
# and will not be invoked again in the following modules "Train Model" and "Score Model".
# The attributes defined in the init method are preserved and usable in the train and predict method.
def init(self):
# self.model must be assigned
self.model = LogisticRegression()
self.feature_column_names = list()
# Train model
# Param: a pandas.DataFrame
# Param: a pandas.Series
def train(self, df_train, df_label):
# self.feature_column_names record the names of columns used for training
# It is recommended to set this attribute before training so that later the predict method
# can use the columns with the same names as the train method
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
# Predict results
# Param: a pandas.DataFrame
# Must return a pandas.DataFrame
def predict(self, df):
# Predict using the same column names as the training
return pd.DataFrame({'Scored Labels': self.model.predict(df[self.feature_column_names])})
Le modèle utilisé peut être remplacé dans la fonction __init__. Les variables en entrée du modèle peuvent être également listées dans cette fonction.
Décrire, approfondir, prédire sont les trois étapes d’une analyse avancée de données, auxquelles il est possible d’ajouter « prévenir » ou « prescrire » qui sont l’aboutissement d’une stratégie pilotée par la data.
Nous avons vu dans un précédent billet comment l’approche statistique permettait d’identifier des facteurs explicatifs dans les données, en particulier quand une variable est centrale dans l’analyse et qu’elle joue le rôle de variable à expliquer. Il s’agit tout simplement de la donnée qui répond à la problématique principale : le chiffre d’affaires ou la marge pour une entreprise, le taux de conversion pour un site de e-commerce, la présence d’une pathologie ou dans l’exemple que nous reprenons ci-dessous, la gravité d’un accident pour la sécurité routière.
Nous entrons ici dans la discipline dite du Machine Learning ou apprentissage automatique. Le Machine Learning se base sur des événements passés pour construire un modèle statistique qui sera ensuite appliqué à de nouvelles données (ici, les caractéristiques d’un accident de la route). En fonction de ces données et du modèle, une prévision du résultat (la variable à expliquer, ici la gravité de l’accident) sera rendue, accompagnée d’une probabilité exprimant la chance ou le risque qu’un tel résultat se produise.
Lorsque la variable prédite est catégorielle, voire au plus simple, binaire, on parle de techniques de classification. Certaines méthodes de classification ont fait leurs preuves depuis de nombreuses années : régression logistique, arbre de décisions, Naïve Bayes. Elles ont été, avec l’essor du Big Data, complétées par des algorithmes puissants mais gourmands en ressources de calcul comme les forêts aléatoires (random forest) ou le Gradient Boosting (XGBoost),
Les Data Scientists disposent aujourd’hui d’un grand panel d’outils pour travailler la donnée et entraîner des modèles de Machine Learning. Il existe ainsi des plateformes graphiques permettant de construire le pipeline de données (la Visual Interface d’Azure Machine Learning Service, Alteryx, Dataïku DSS, etc.). Une autre approche, souvent complémentaire, consiste à utiliser un langage de développement comme R, Python ou encore Scala, ce dernier pour une approche distribuée dans un environnement Spark.
Lorsque la volumétrie de données permet de travailler en plaçant le jeu de données (dataset) complet en mémoire, les langages R et Python sont tout à fait appropriés. Nous choisirons ici Python pour la simplicité d’usage et l’efficacité de sa librairie dédiée au Machine Learning : scikit-learn.
Les développeurs apprécieront d’utiliser un environnement de développement intégré (IDE) comme Visual Studio Code ou PyCharm. Pour donner plus de lisibilité à notre code, nous choisissons pour cet article de travailler dans un notebook Jupyter qui permet d’alterner dans une même page, code, sorties visuelles et commentaires.
Le service Azure Notebooks est accessible gratuitement sur cette URL : https://notebooks.azure.com/

Afin de maîtriser les ressources de calcul qui seront associées à l’exécution des traitements, il est également possible de souscrire à un espace de travail Azure Machine Learning Service. Celui-ci permet de lancer une machine virtuelle de son choix sur laquelle sont déjà configurés les notebooks Jupyter ainsi que l’environnement Jupyter Lab.
Dans la fenêtre Jupyter Lab ci-dessous, nous retrouvons le code à exécuter ainsi qu’un menu latéral permettant de naviguer dans les fichiers précédemment téléchargés dans l’environnement.
Avant de soumettre les données chargées à l’approche algorithmique, il est nécessaire d’effectuer quelques calculs préparatoires pour mettre en forme les données et les rendre utilisables par les différents algorithmes.
Ainsi, la date et l’heure de l’accident sont exploitées pour créer deux nouvelles variables : le jour de la semaine et la tranche horaire.
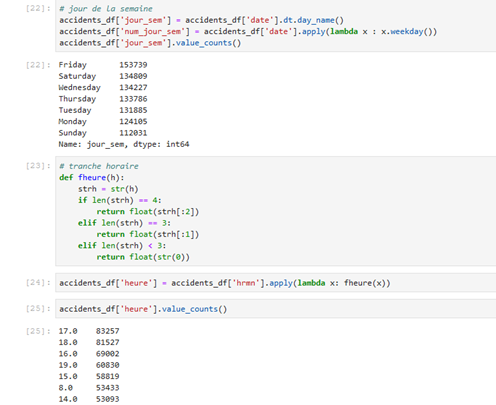
Ces deux calculs illustrent le principe du feature engineering, c’est-à-dire du travail sur les variables en entrée du modèle pour proposer les plus pertinentes et les plus efficaces. Attention, il n’est parfois pas possible de le déterminer a priori. Au-delà de toute formule mathématique et en l’absence d’une quelconque baguette magique, des échanges avec les personnes ayant une connaissance métier forte seront très profitables aux Data Scientists et les orienteront vers une bonne préparation des données.
Nous comparons ici deux modèles, l’un étant un modèle « simple » : celui des K plus proches voisins, le second étant un modèle « ensembliste », c’est-à-dire combinant plusieurs modèles : une forêt aléatoire d’arbres de décisions.
Une fois l’entraînement réalisé, nous pouvons calculer différentes métriques évaluant la qualité des modèles.
Nous observons tout d’abord la matrice de confusion qui nous permet de comparer la valeur prédite (décès ou non) avec la valeur réelle qui a été « oubliée » le temps du calcul de la prévision.
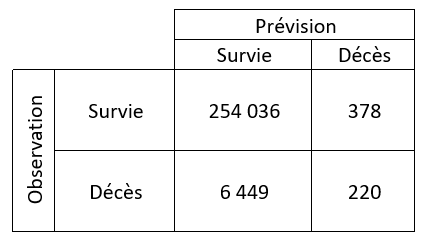
Nous observons ici 6 449 « faux positifs », personnes réellement décédées suite à l’accident, pour lesquelles l’algorithme n’a pas été en mesure de prévoir ce niveau de gravité. Il sera possible de jouer sur le seuil de la probabilité de décès (par défaut à 50%) pour réduire ce nombre.
Une vision graphique de ces informations est possible au travers de la courbe ROC et du calcul de l’aire situé sous cette courbe : l’AUC. Cet indicateur prend une valeur en 0 et 1 et plus celle-ci s’approche de 1, meilleur est le modèle.
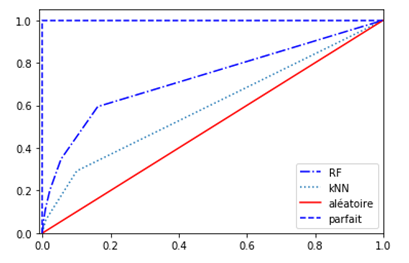
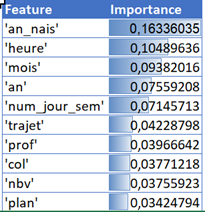
Nous retenons ici le modèle de la forêt aléatoire (AUC = 0.730 contre 0.597), tout en étant bien conscients que son coût de calcul est plus élevé que celui des K plus proches voisins. Une propriété de l’objet nous permet d’obtenir un coefficient d’importance des variables dans le modèle. Cette information est particulièrement appréciable pour prioriser par exemple une campagne d’actions contre la mortalité sur les routes. Nous remarquons dans le top 10 ci-dessous que l’année de naissance de la personne, et donc son âge au moment de l’accident, constitue le facteur le plus aggravant. Viennent ensuite des informations sur la temporalité de l’accident (tranche horaire, mois, etc.) puis enfin le motif de déplacement (trajet), la déclivité de la route (prof), le type de collision (col), le nombre de voies (nbv) et le tracé de la route (plan). Ces derniers facteurs sont toutefois 4 à 5 fois moins importants que l’âge de la personne impliquée.
Le meilleur modèle est enfin enregistré dans un format binaire sérialisé (package pickle) afin d’être exploité par la suite en production, comme le permet par exemple la ressource Azure Machine Learning Service.

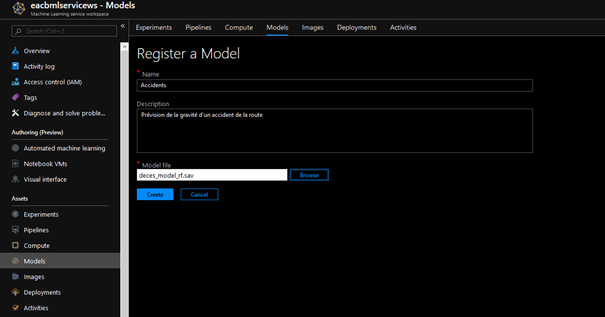
Le travail de sélection du meilleur modèle (ainsi que de ces meilleurs hyper paramètres, c’est-à-dire le réglage fin de l’algorithme) peut s’avérer une tâche répétitive et fastidieuse car il n’existe pas réellement à l’heure actuelle de méthode ne nécessitant pas de réaliser toutes les évaluations. « No free lunch » !
Heureusement, l’investigation peut se faire de manière automatique, sorte de « force brute » du Machine Learning. Au travers d’Azure Machine Learning Service, nous soumettons le jeu de données à une batterie d’algorithmes qui seront comparés selon leur performance sur les différentes métriques d’évaluation.
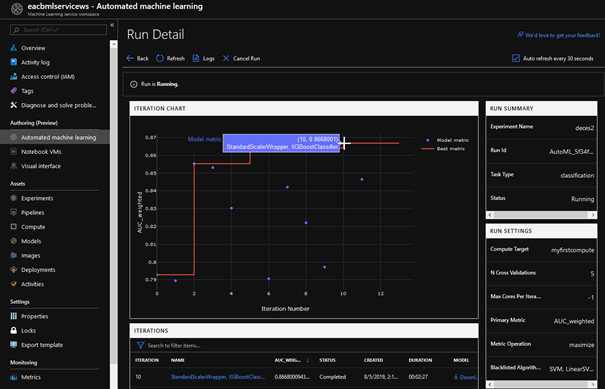
Nous retenons ici l’approche XGBoostClassifier dont l’AUC atteint la valeur 0.867, soit 0.137 point supplémentaire, par rapport au modèle trouvé manuellement.
L’approche prédictive, au travers du Machine Learning, se révèle être incontournable pour quiconque souhaite aujourd’hui anticiper les valeurs de ses données et découvrir des leviers d’action qui permettront de mettre en place des actions concrètes pour par exemple, éviter l’attrition (churn) d’une clientèle, prévenir d’un défaut de paiement ou d’une tentative de fraude, élaborer un premier diagnostic ou encore anticiper des pannes.
En conclusion, nous avons vu ici que le cloud Azure se marie au meilleur de l’Open Source pour devenir une plateforme parfaite pour les Data Scientists et les Data Engineers.
L’essor actuel du Machine Learning (apprentissage automatique, branche de l’intelligence artificielle) est en partie dû à la puissance de calcul obtenue au travers du Cloud Computing, représenté en particulier par Microsoft Azure.
De plus, l’approche des « Platforms as a Service » permet d’aller à l’essentiel, sans perdre de temps dans la configuration fine de machines virtuelles.
Au travers du service Azure Machine Learning, Microsoft propose un panel d’outils permettant d’accompagner les data scientists et les data engineers du développement de modèles prédictifs jusqu’à leur mise en production.
Afin de construire un premier modèle prédictif, trois solutions sont accessibles depuis le portail et correspondent à différents scénarios d’utilisation ainsi qu’à différents profils d’utilisateurs. Nous détaillerons ces trois services ci-dessous.
Anciennement connu sous le nom de Azure Machine Learning Studio, ce produit est une interface graphique permettant de construire un « pipeline » de Machine Learning, depuis le chargement des données jusqu’à l’entrainement et l’évaluation du modèle, en passant par des étapes classiques de préparation des données.
Il existe des dizaines de modèles de Machine Learning et tous méritent d’être essayés sur les données, car, sauf grande expérience (et bonne intuition !), il est difficile de choisir a priori le modèle le plus adapté. L’approche de l’Automated Machine Learning consiste à tester une batterie de modèles et à trouver leur meilleur paramétrage, sur la base de métriques de performance, le tout de manière automatique.
Les notebooks Jupyter se sont imposés comme un environnement de développement chez les Data Scientists qui affectionnent particulièrement son aspect interactif et sa capacité à devenir rapidement un support de présentation.
JupyterHub et JupyterLab sont deux moyens de lancer des notebooks pour lesquels on choisira un « kernel » parmi ceux disponibles (Python, R, Scala…). La puissance de calcul est ici définie par une taille de machine virtuelle associée au serveur de notebooks.
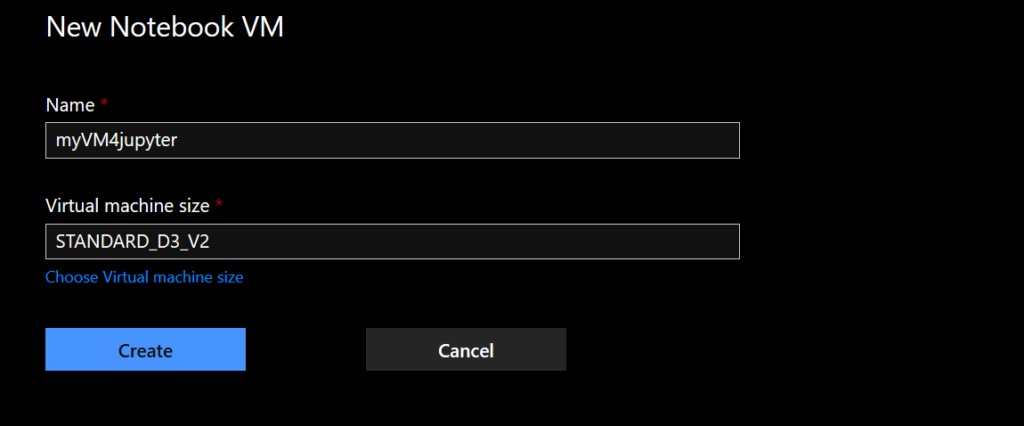
Les machines peuvent être démarrées ou arrêtées selon les besoins, lorsqu’elles sont arrêtées, le service n’est bien sûr pas facturé.

Dès que la machine est démarrée, il est possible d’accéder à JupyterHub ou JupyterLab.
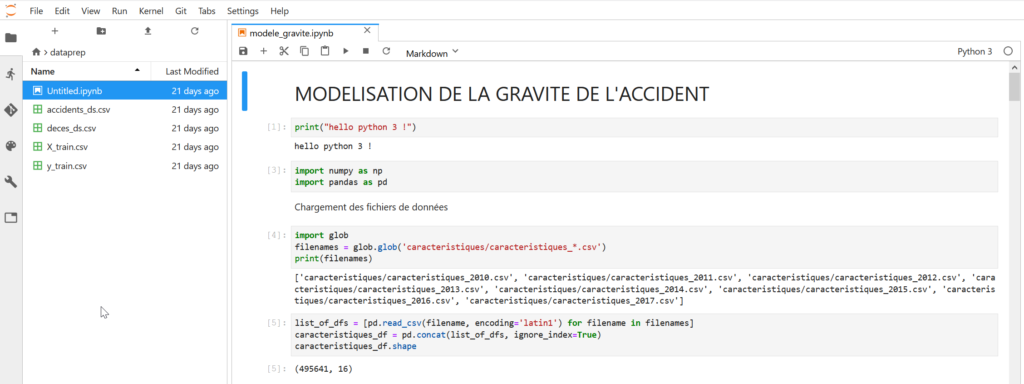
D’autres moyens existent pour utiliser les notebooks Jupyter comme par exemple le site https://notebooks.azure.com/ qui met à disposition une capacité de calcul gratuite (free compute) mais sur lequel il est également possible de relier une ou plusieurs machines virtuelles créées dans Azure (direct compute).
En mars 2019, je publiais sur un blog ami cet état des lieux de l’offre Microsoft pour la Data Science : https://www.stat4decision.com/fr/microsoft-pour-la-data-science/
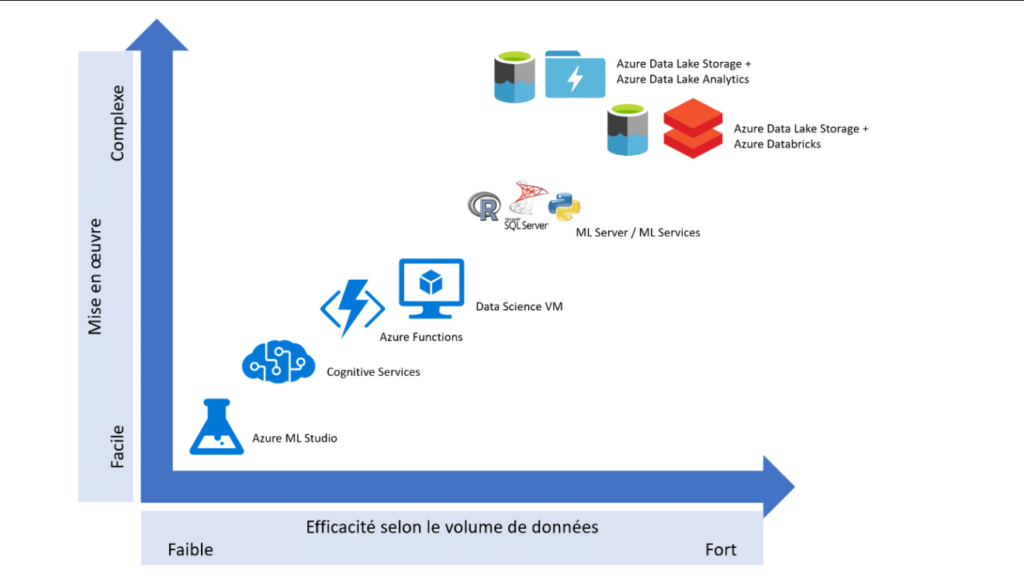
Depuis, la version Gen2 d’Azure Data Lake Storage est sortie (le logo a évolué). Azure Machine Learning Service est devenu un portail à part entière : ml.azure.com et depuis
Voici un aperçu des fonctionnalités en vidéo de ce qui s’appelle pour l’instant Azure Machine Learning Web Experience.