
Jusqu’ici réservée aux domaines supervisés (régression & classification) ainsi qu’aux séries temporelles, l’automated ML de Microsoft s’ouvre maintenant aux données de type texte ou image pour entrainer des modèles de NLP ou de Computer Vision destinés à des tâches de classification, et ceci au travers de l’interface utilisateur d’Azure Machine Learning.
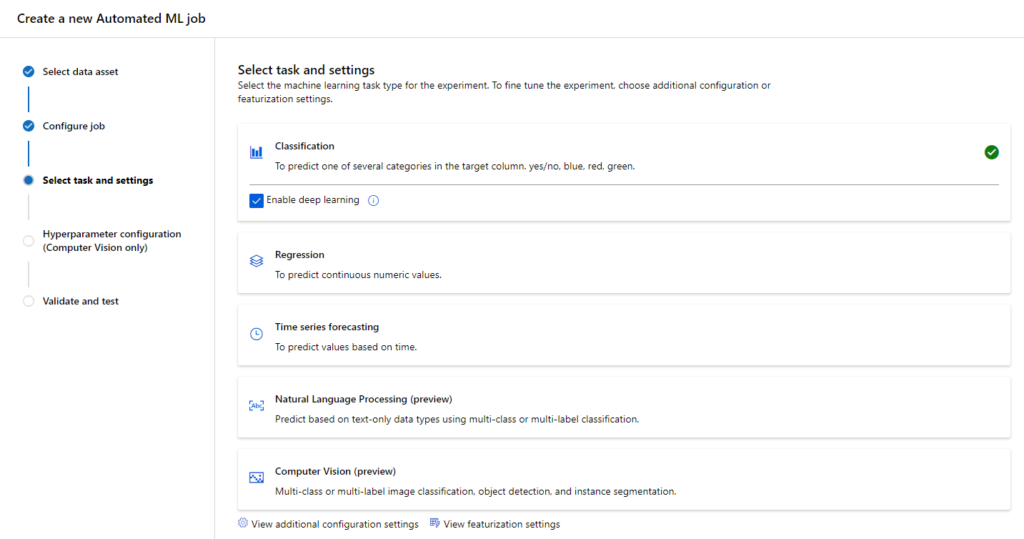
Nous allons ici réaliser un premier entrainement pour une problématique simple de classification de spams / non spams (ou hams), à partir d’un dataset connu pour débuter sur cette problématique.
Ce jeu de données aura été préalablement déclaré en tant que dataset, au sens d’Azure ML et nous prendrons soin de le découper en amont de l’expérience d’automated ML. Il nous faut donc deux datasets enregistrés : le jeu d’entrainement et le jeu de test. En effet, l’interface graphique ne nous proposera pas (encore ?) de séparer aléatoirement les données soumises. Notons enfin que ces données doivent être enregistrées au format tabulaire. Nous devons donc a minima disposer de deux colonnes : un label (spam / ham) et le texte en lui-même.

L’entrainement va nécessiter une machine virtuel (compute instance ou compute cluster) disposant d’un GPU. Attention, le coût de ces VMs est naturellement plus élevé que celui de VMs équipées de CPU.
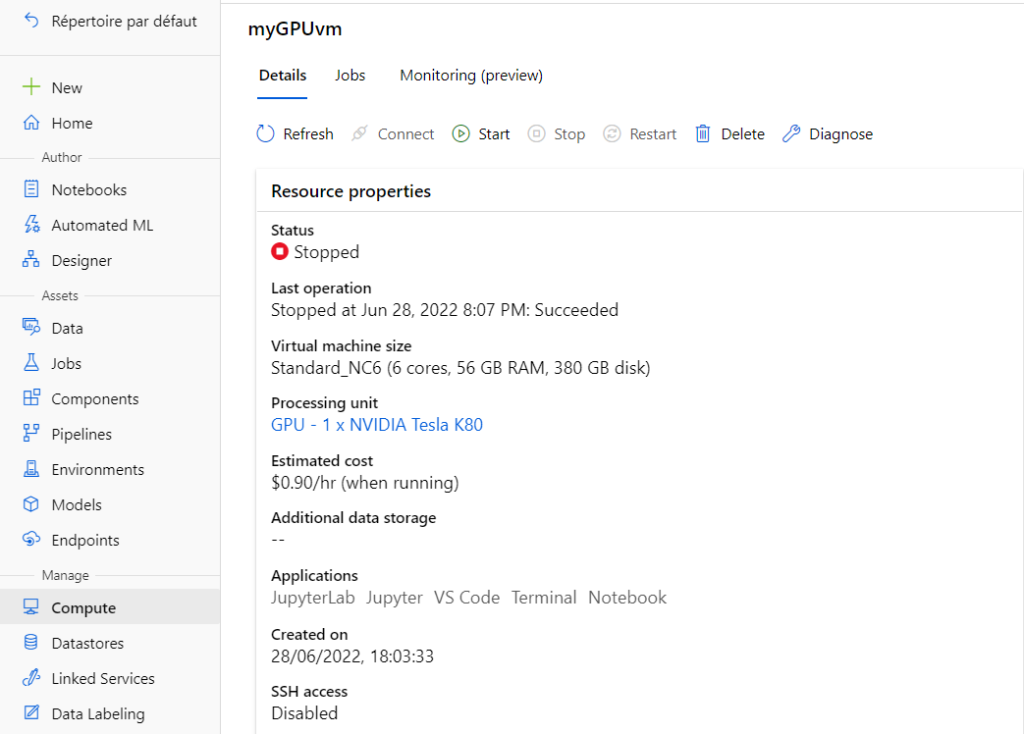
Le premier écran de l’interface se configure de la sorte.
Nous choisissons ensuite une tâche de type “Multi-class classification”.
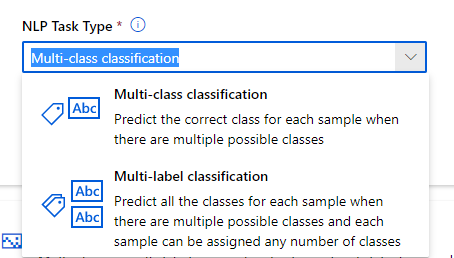
Si celle-ci est unique, il est recommandé de préciser la langue du texte contenu dans le dataset.
Attention au temps maximum de recherche du meilleur modèle, celui-ci est par défaut de 24h ! Et nous savons que le GPU coûte cher…

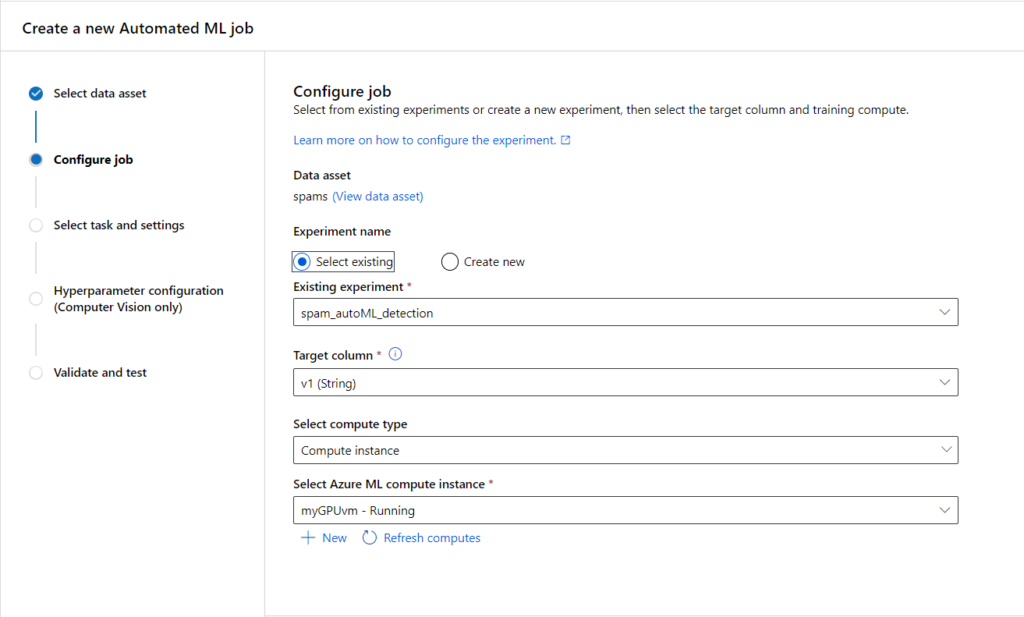
Nous finissions le paramétrage en indiquant le dataset de test.
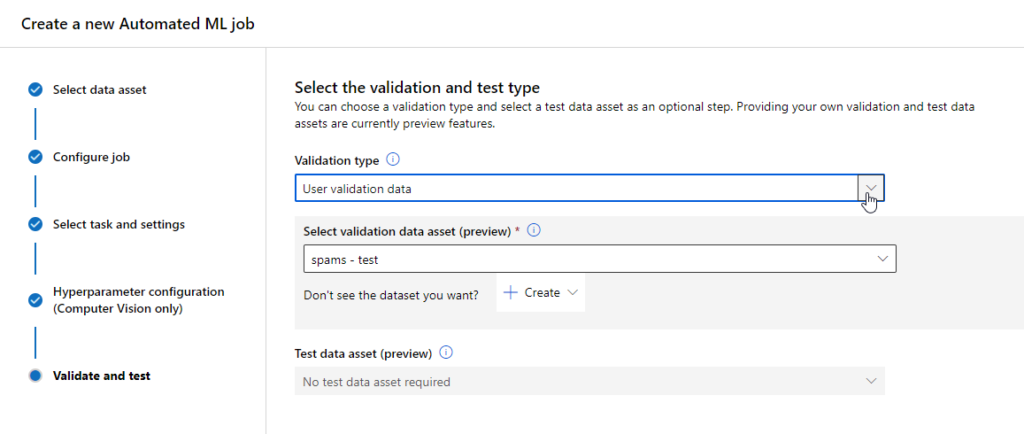
Un seul modèle a été ici évalué : un modèle de type BERT.

En observant les outputs de ce modèle, nous retrouvons le binaire sérialisé (.pkl) ainsi que des fichiers définissant l’environnement d’entrainement et les dépendances de librairies nécessaires. C’est ici un standard MLFlow qui est respecté.
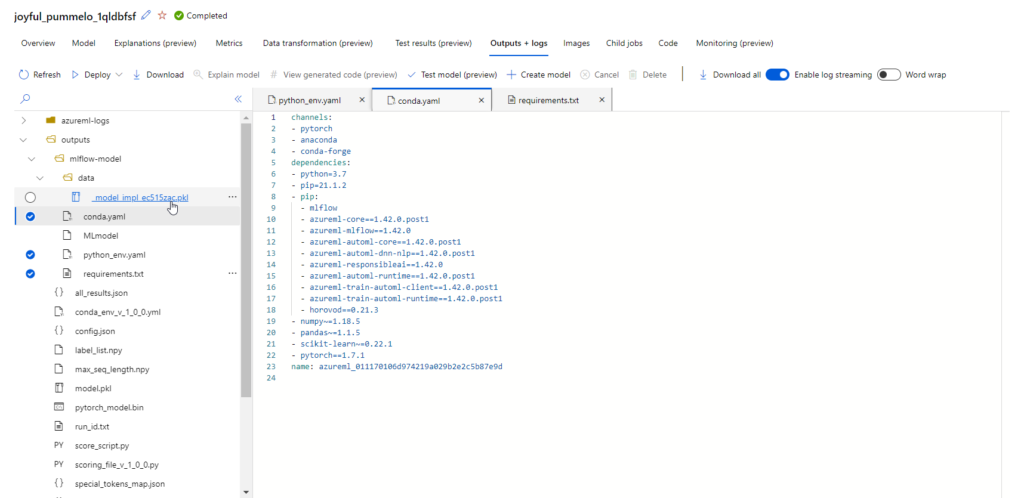
Toujours au moyen de l’interface graphique, nous pouvons maintenant déployer ce modèle sous forme de point de terminaison prédictif.
Nous allons opter ici pour un Managed Online Endpoint (MOE), qui offre un niveau de management des ressources plus fort que le service Kubernetes d’Azure.
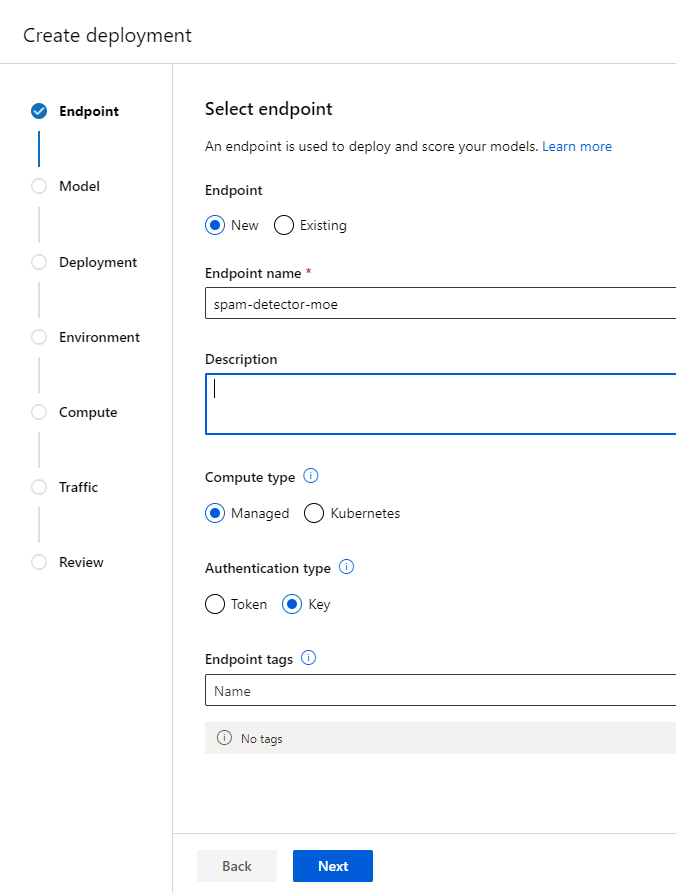
Ce Management Online Endpoint s’appuie sur des ressources de calcul qui sont simplement des VMs Azure. A noter qu’une ressource spécifique Azure sera bien visible au travers du portail, dans le groupe de ressources contenant le service Azure ML.
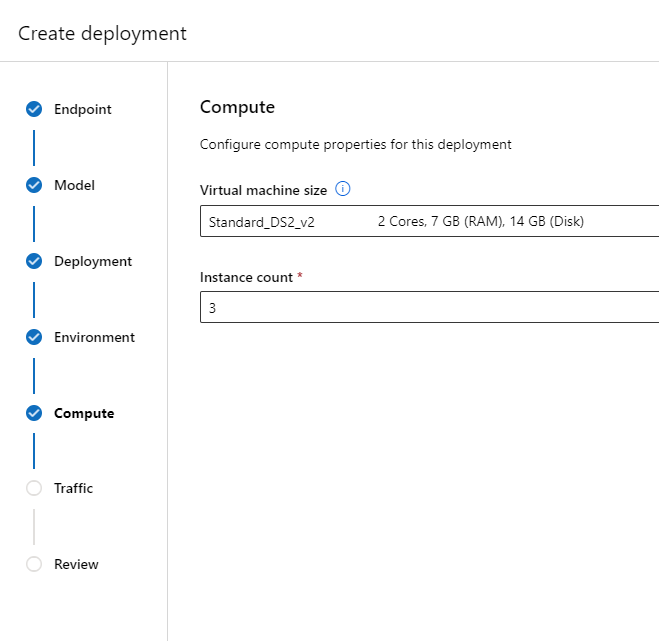
Il est maintenant possible d’interroger ce point de terminaison !
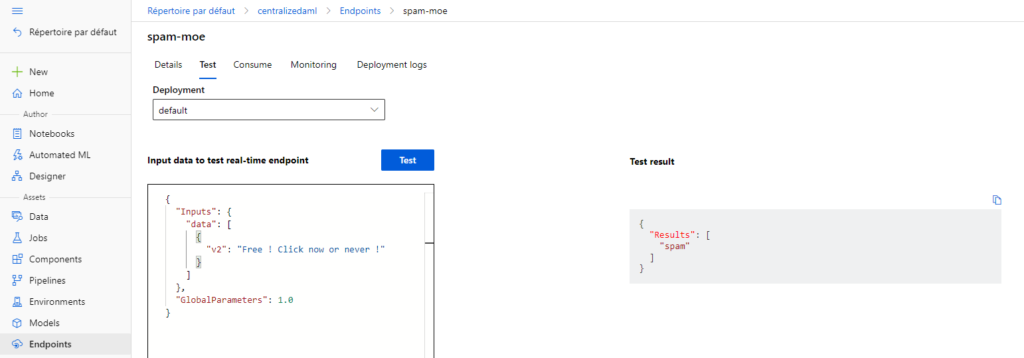
Voici en quelques clics dans l’interface d’Azure Machine Learning comment nous avons pu parvenir à un service Web prédictif. Bien sûr, la préparation de données sera indispensable dans un cas réel d’utilisation de l’automated ML pour une tâche de NLP.
Enfin, sachez que le SDK Python d’Azure ML dispose de la classe permettant d’effectuer cette tâche par du code (v1 et v2).