
Le Designer est la partie graphique, dédiée aux Citizen Data Scientists, dans le studio Azure Machine Learning. Il s’agit d’un outil “no code” (à l’exception de quelques briques) qui permet de construire un pipeline d’apprentissage supervisé ou non supervisé (clustering). C’est donc un excellent outil d’apprentissage et d’expérimentation qui permet d’aller très vite pour se faire une première idée du potentiel des données. Il permettra également, et c’est son point fort, de déployer un point de terminaison prédictif en mode batch ou temps réel, correspondant à une ressource Azure Container Instance ou Kubernetes Service.
Mais il faut bien avouer que le Designer reste un outil limité à son environnement et qui ne s’inscrit pas dans les pratiques DevOps d’intégration et déploiement multi-environnements (de dev’ en qualif’, de qualif’ en prod’).
Pourtant, en observant bien les logs d’exécution, nous pouvons découvrir beaucoup d’éléments qui montrent que derrière l’interface graphique, tout repose bien sur du code, des fichiers et des conteneurs !
Ressources liées à Azure Machine Learning
Lors de la création de l’espace de travail AzML, nous définissons plusieurs ressources liées (voir cet article) :
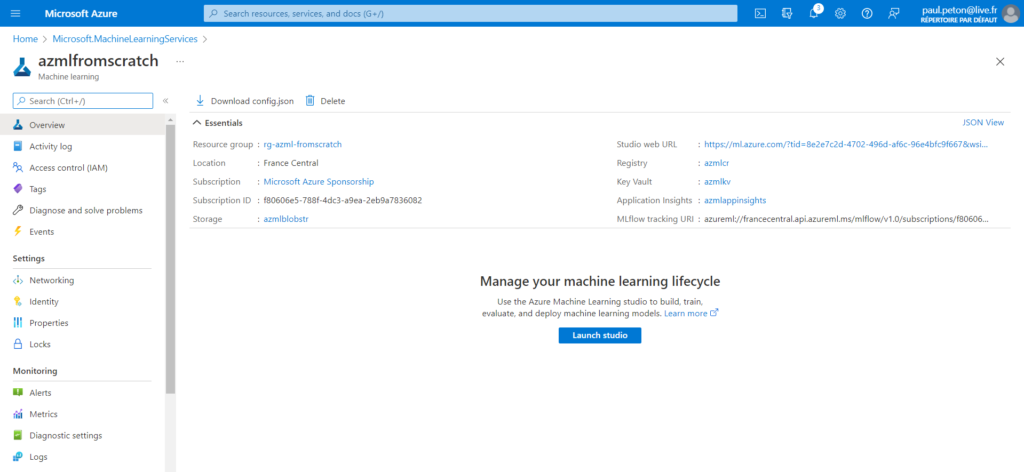
Nous définissons en particulier un compte de stockage de type blob qui sera ensuite utilisé pour supporter plusieurs datastores, créés automatiquement.
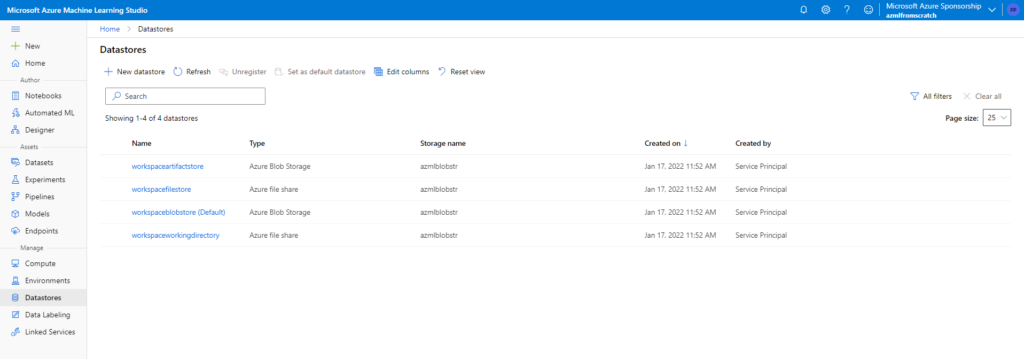
Le datastore par défaut correspond à un blob container, nommé automatiquement. C’est ici que nous retrouverons beaucoup d’informations.
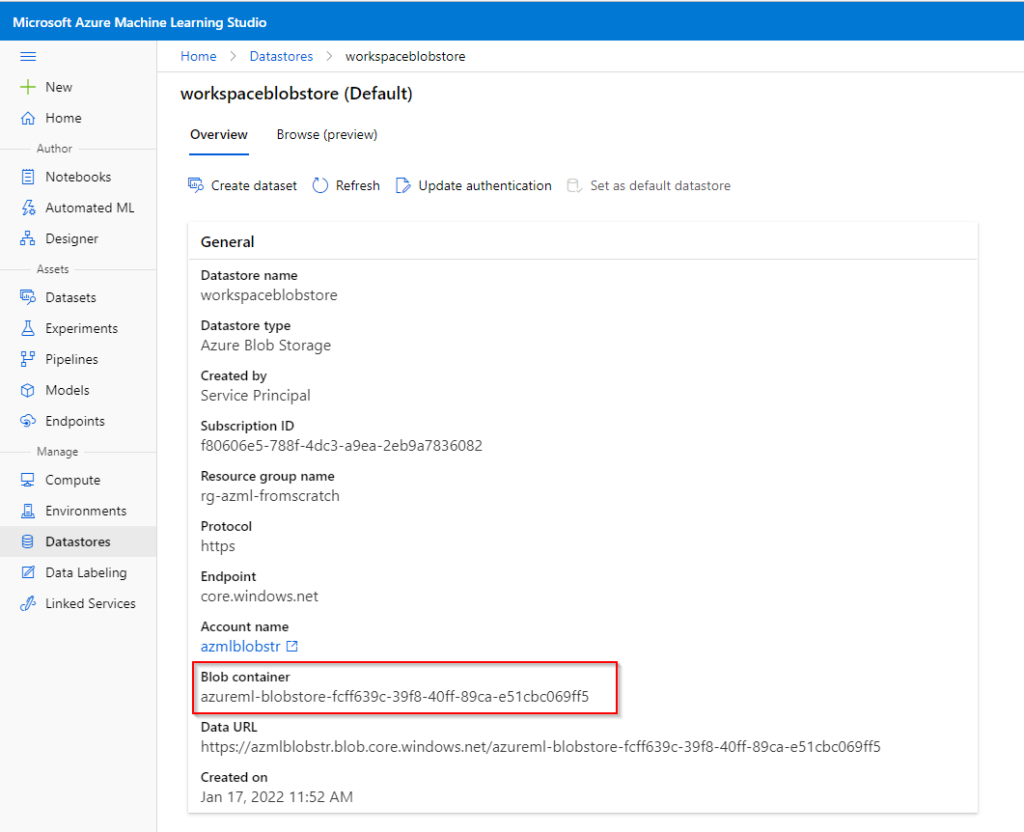
Nous ouvrons donc le client lourd Azure Storage Explorer pour surveiller la création des différents fichiers.
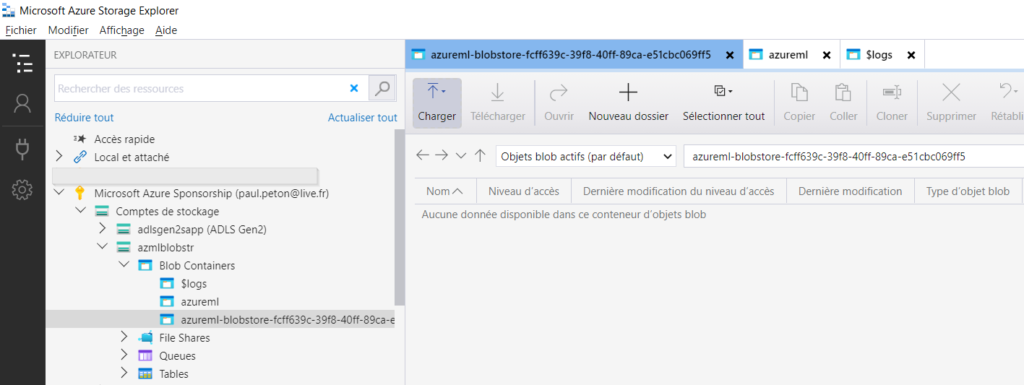
Pour l’instant, les trois répertoires sont vides.
Entrainement par le Designer
Nous allons lancer le sample “Regression – Automobile Price Prediction (Basic)” qui a pour avantage d’être déjà paramétré et de se baser sur un jeu de données accessible depuis cette URL publique : https://mmstorageeastus.blob.core.windows.net/globaldatasets
L’entrainement est lancé sur une ressource de calcul de type “Compute instance”.
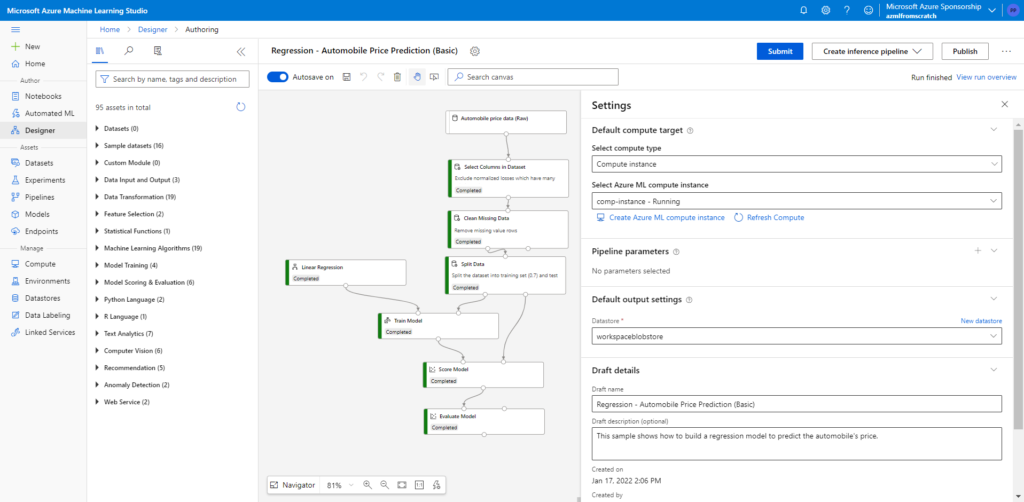
Regardons maintenant ce qui est apparu dans le compte de stockage.
Le répertoire azureml contient deux sous-dossiers, dont ExperimentRun qui recueille tous les fichiers de logs : executionlogs.txt, stderrlogs.txt, stdoutlogs.txt.
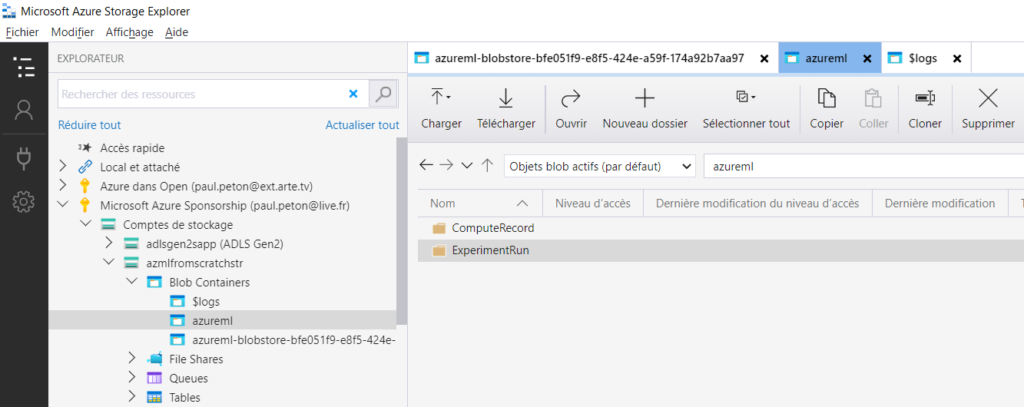
Dans le datastore, nous trouvons maintenant une grande quantité de fichiers !
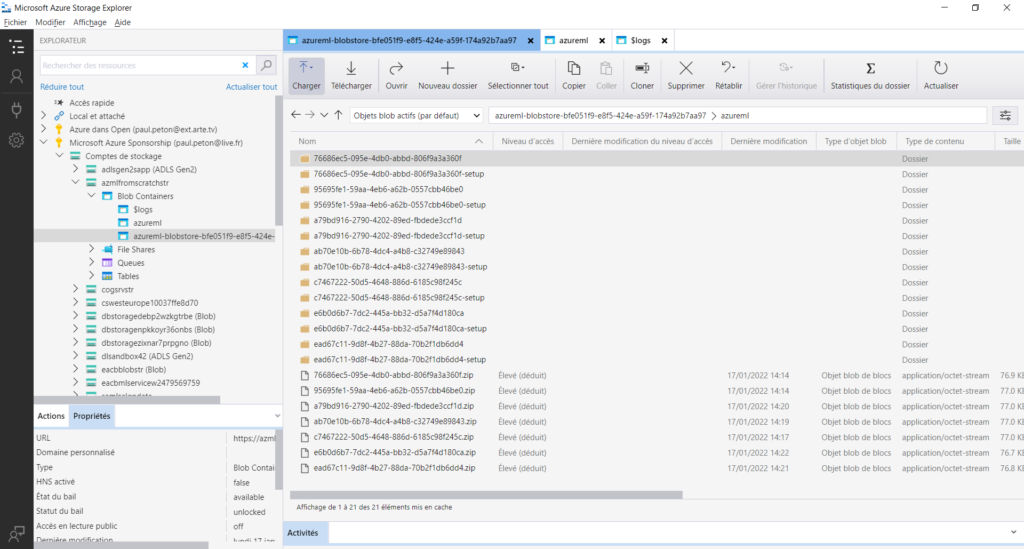
Pour mieux comprendre cette apparition pléthorique, revenons à la notion de “run” à l’intérieur de l’expérience qui a été créée lors de l’entrainement.
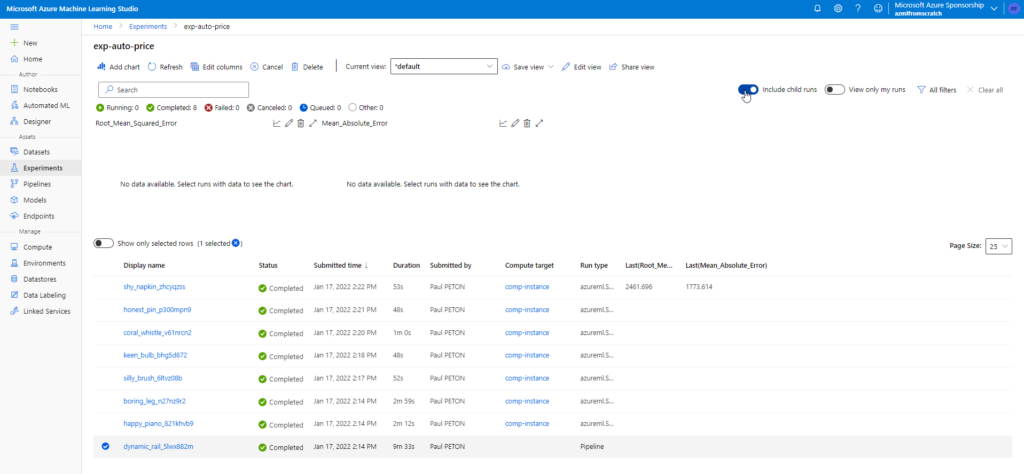
En cochant la case “Include child runs“, nous voyons le run principal (le plus bas) et sept autres correspondant à chacun des briques du pipeline (le dataset n’est pas lié à une exécution).
Dans le menu “Outputs + logs”, nous voyons une arborescence de fichiers qui nous permet de retrouver les fichiers liés au modèle entrainés, en particulier un fichier de scoring (score.py) et un fichier d’environnement (conda_env.yml) qui seront utiles pour le déploiement d’un service web d’inférence.
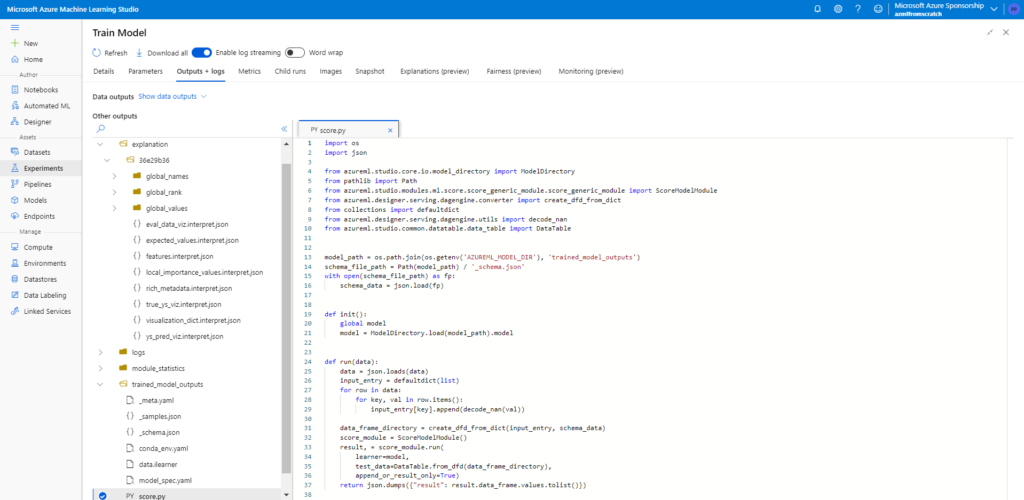
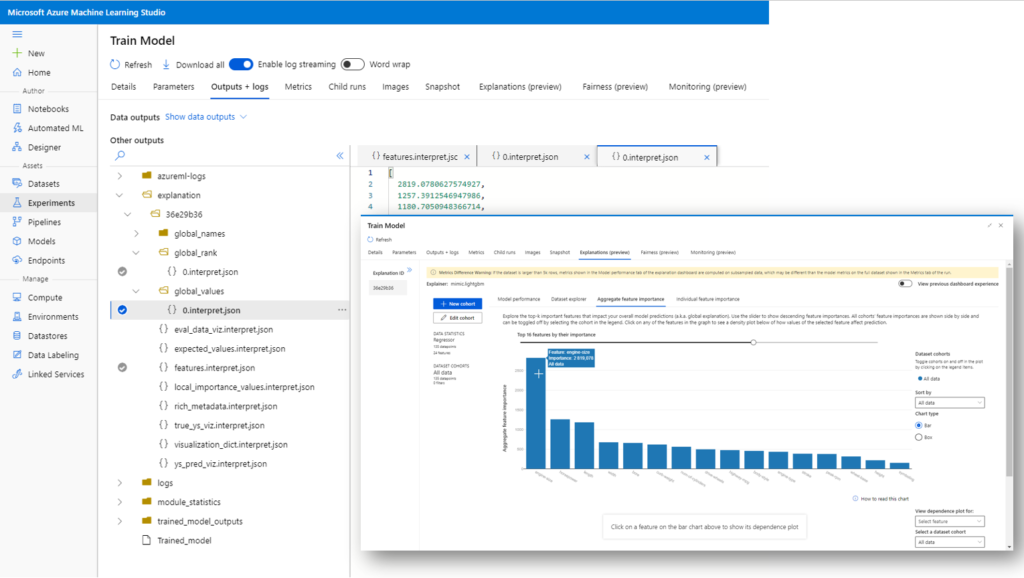
Nous retrouvons également les fichiers portant les visualisations du menu Explanations, en particulier l’importance de chaque feature dans le modèle.
Un dernier fichier attire notre attention : Trained_model. Il s’agit d’un fichier texte dont le contenu est copié ci-dessous et qui correspond à l’URI d’un fichier.
{"Container":"azureml-blobstore-bfe051f9-e8f5-424e-a59f-174a92b7aa97","SasToken":null,"Uri":"wasbs://azureml-blobstore-bfe051f9-e8f5-424e-a59f-174a92b7aa97@azmlfromscratchstr.blob.core.windows.net/azureml/a79bd916-2790-4202-89ed-fbdede3ccf1d/Trained_model/","Account":"azmlfromscratchstr","RelativePath":"azureml/a79bd916-2790-4202-89ed-fbdede3ccf1d/Trained_model/","PathType":0,"AmlDataStoreName":"workspaceblobstore"}
Nous allons voir à partir de l’explorateur ce que contient ce chemin.
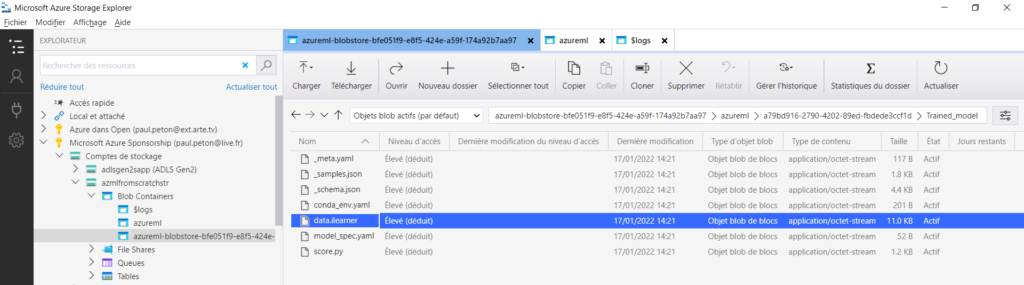
Ici se trouve un fichier plus lourd que les autres : data.ilearner
Il s’agit du format (propriétaire ?) utilisé par Microsoft depuis Azure Machine Learning Studio, premier du nom, comme en témoigne cette documentation officielle.
Pour comprendre comment est utilisé ce fichier, nous ouvrons le fichier de scoring dans Visual Studio Code.
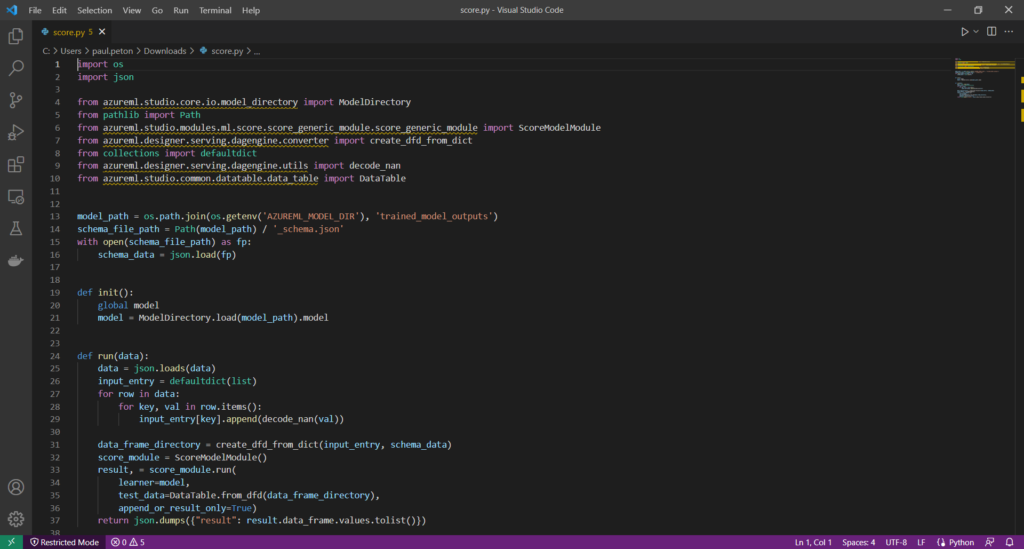
De nombreuses librairies apparaissent soulignées, elles ne sont pas disponibles et il s’agit d’éléments propres à l’espace de travail Azure Machine Learning. Le fichier iLearner sera chargé dans une classe ScoreModelModule dont la méthode .run() permettra d’obtenir une prévision.
Le modèle généré n’apparaît pas pour l’instant dans le menu Models de l’espace de travail.
Inférence par le Designer
Nous lançons maintenant un pipeline d’inférence, de type temps réel.
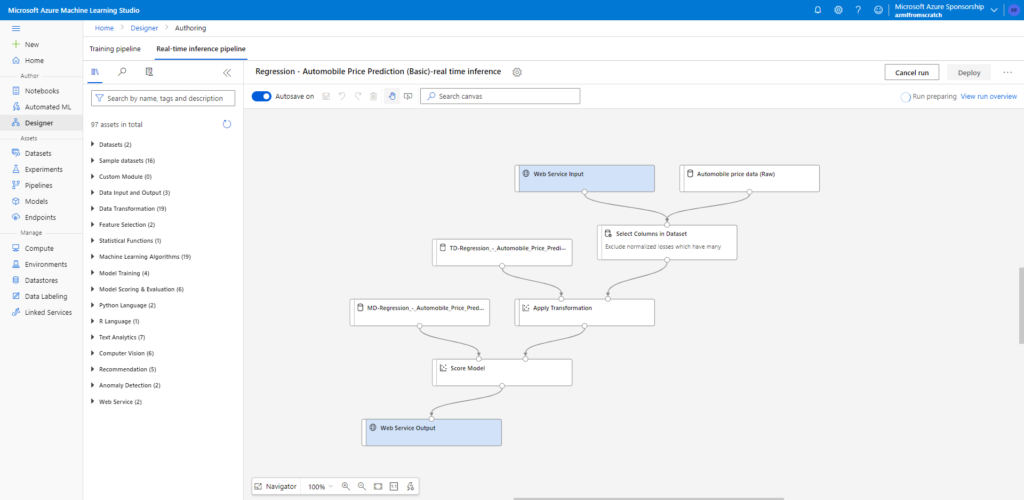
Le déploiement permet avoir de choisir entre une ressource Azure Container Instance (ACI) ou Kubernetes Service (AKS) pour porter un service web d’inférence.
C’est alors que le modèle est enregistré en tant qu’objet dans l’espace de travail Azure Machine Learning.
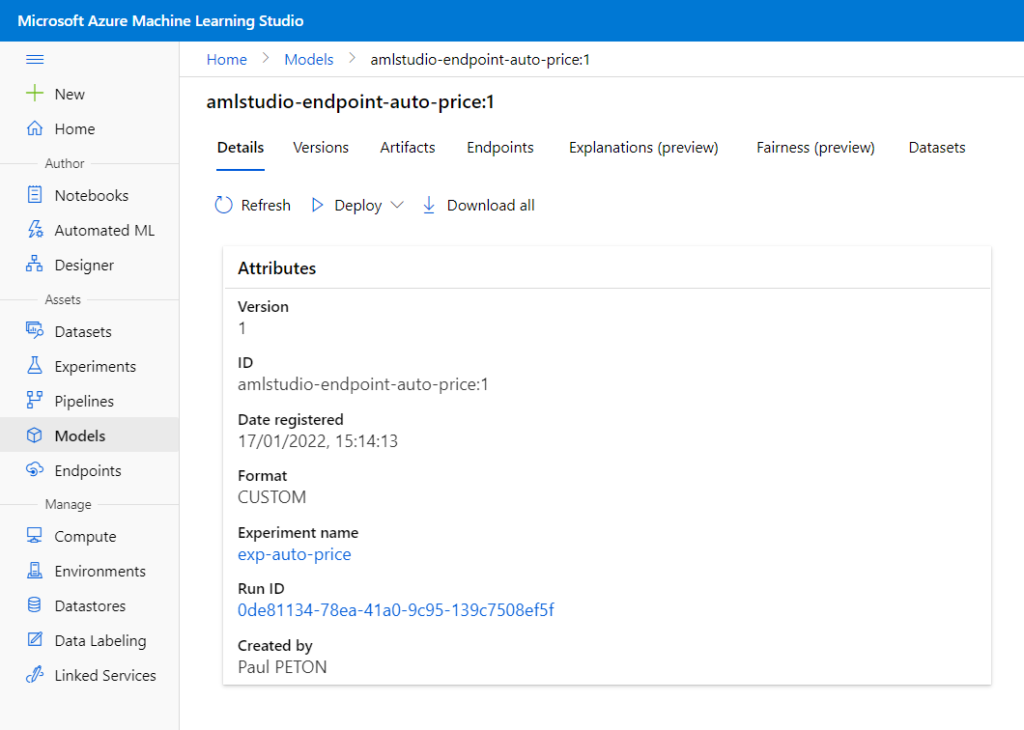
Nous remarquons le format (framework) CUSTOM qui n’est donc pas un des formats “classiques” commet SkLearn, ONNX ou encore PyTorch (liste complète ici).
Notons que le déploiement d’un point de terminaison génère une image dans le Container Registry lié au service Azure Machine Learning.
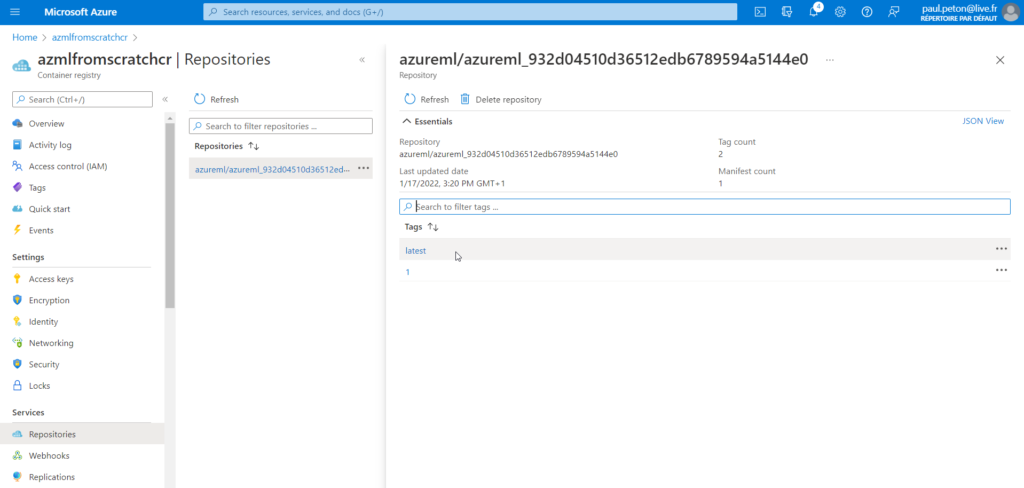
Peut-on restaurer les fichiers d’un pipeline du Designer ?
Nous en venons maintenant à la question cruciale du backup / restore des pipelines créés au travers du Designer.
Certain.e.s se souviendront du mode export dont nous disposions lorsque le Designer s’appelait Azure Machine Learning Studio, qui permettait de sauvegarder le pipeline dans un format JSON, pouvant ensuite être réimporté. Cette fonctionnalité ne semble aujourd’hui plus disponible mais nous avons vu que de nombreux fichiers sur le compte de stockage lié traduisent les manipulations réalisées dans l’interface visuelle.
Un test simple consistant à copier les répertoires vus ci-dessus dans un nouvel espace de travail Azure Machine Learning n’est pas concluant : rien n’apparait dans le nouvel espace. Ce n’est guère étonnant car les chemins semblent très liés au blob container d’origine (voir l’extrait de fichier Trained_model ).
Ma conclusion personnelle est donc qu’il n’est pas possible de restaurer les travaux réalisés avec le Designer dans une autre ressource Azure Machine Learning.
Faisons maintenant un dernier test : la suppression des fichiers du blob container correspondant au datastore. En relançant la création du point de terminaison, nous obtenons une erreur car le fichier binaire du modèle n’est pas accessible.
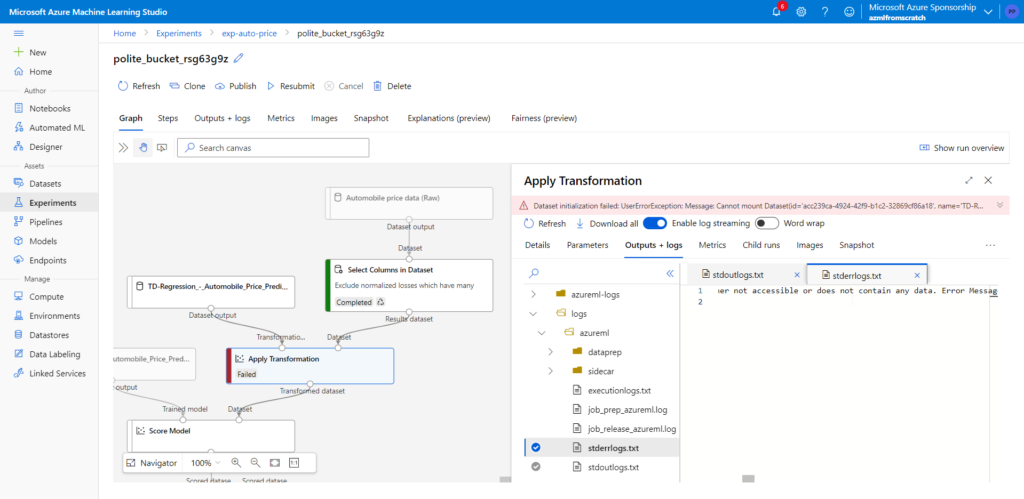
De ces tests, nous retenons quelques bonnes pratiques visant à sécuriser les développements réalisés dans l’interface graphique d’Azure Machine Learning :
- créer un lock sur le groupe de ressources contenant Azure Machine Learning et le compte de stockage lié
- utiliser un niveau de réplication a minima ZRS (ne pas choisir LRS qui est le choix par défaut)
- mettre en place un système de réplication des fichiers du compte de stockage (object replication)
- créer une documentation des pipelines réalisés (quelques copies d’écran et l’indication des paramètres qui ont été modifiés…)