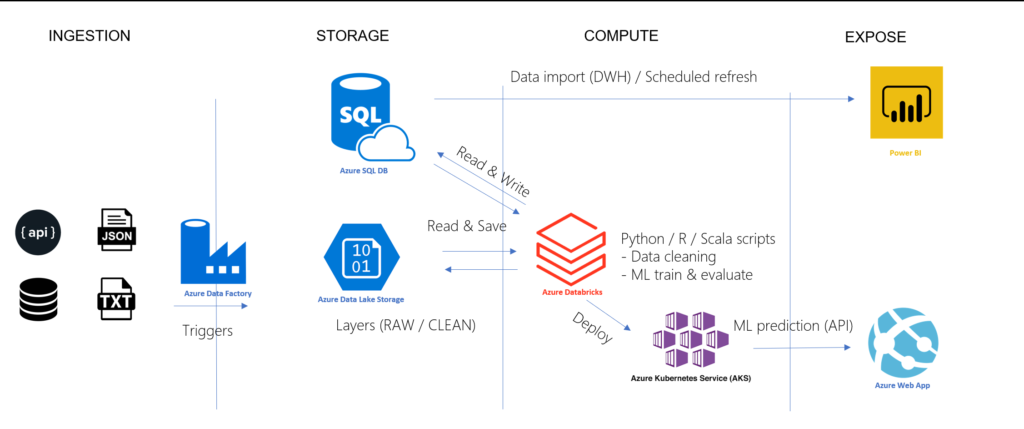
Dans une architecture cloud Azure, la ressource de “compute” Databricks va bien souvent être utilisée pour transformer la donnée brute en donnée dite nettoyée ou enrichie. Cette donnée peut bien sûr être stockée sur un Data Lake, par exemple dans un format Parquet (nous y reviendrons en fin d’article) mais les outils d’exploration et de visualisation de données comme Microsoft Power BI présentent de nombreux avantages à s’appuyer sur une base de données relationnelle (actualisation incrémentielle, DirectQuery…).
Nous partirons ainsi de l’architecture Azure ci-dessous :
Architecture Azure hybride pour des projets data de visualisation et de prévision
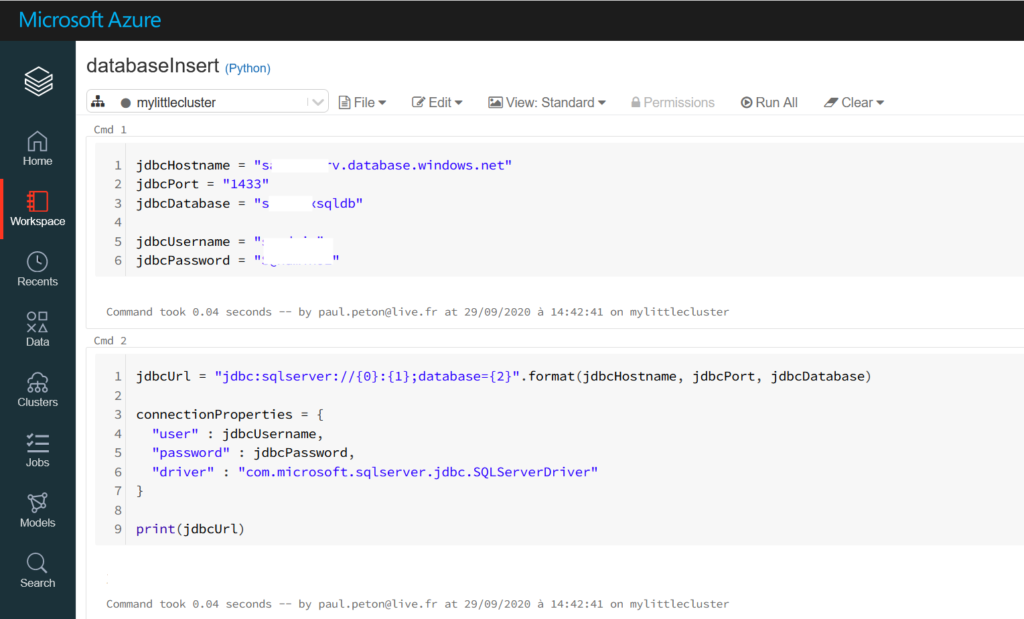
Nous lançons tout d’abord un notebook Python où nous définissons la chaîne de connexion. Il sera bien sûr très judicieux d’utiliser ici le secret scope de Databricks pour stocker toutes ces informations.
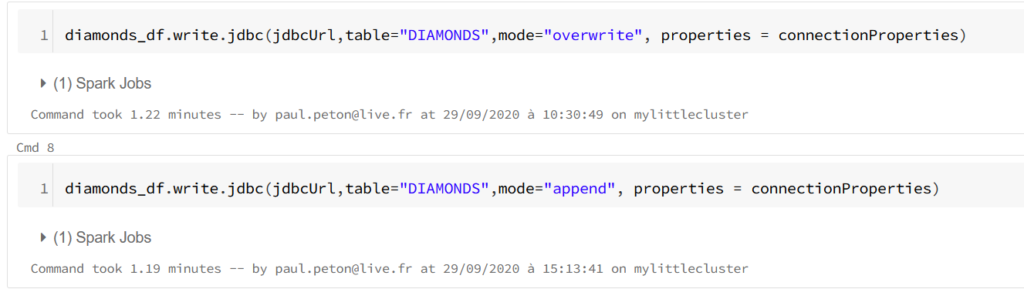
Il s’agit maintenant d’écrire un jeu de données nettoyées et travaillées en mémoire sous forme de Spark dataframe dans une table de la base de données. Cette opération se fait tout simplement au moyen de la méthode write associée aux informations de connexion : URL JDBC et propriétés de connexion.
Le paramètre de mode permet de choisir entre un “annule et remplace” de la table au moyen de la valeur overwrite ou une insertion à l’aide du mot clé append.
Il n’y a donc ici pas de mode prévu pour la suppression ou la mise à jour. Il faudra penser ce scénario de manière différente et peut-être au travers du format de fichier Delta, basé sur le format Parquet et sur lequel existent des méthodes delete et upsert. Pour autant, ce fichier restera en dehors de la base de données.
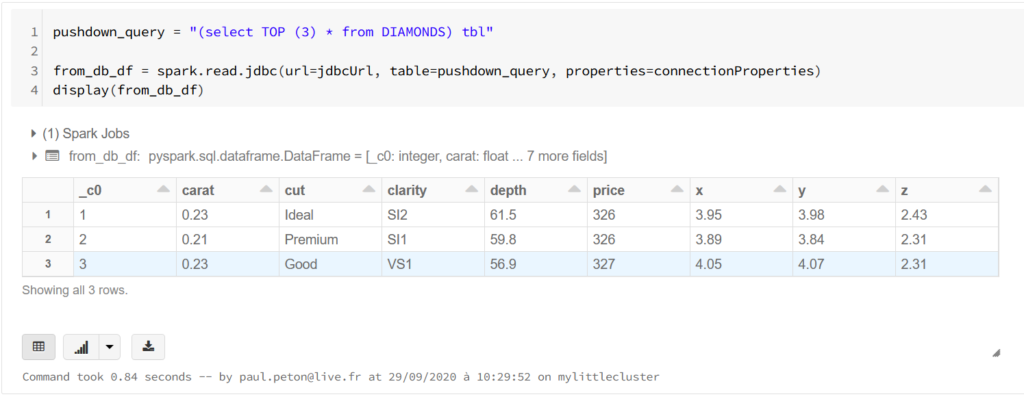
La méthode read de Spark est également possible et se fait en soumettant une requête SQL au travers du driver JDBC. Nous utilisons ici la syntaxe SQL propre à la base de données, ici le Transac-SQL de Microsoft.
L’alias de table sur la requête est indispensable pour être interpréter par le paramètre table de la méthode read.
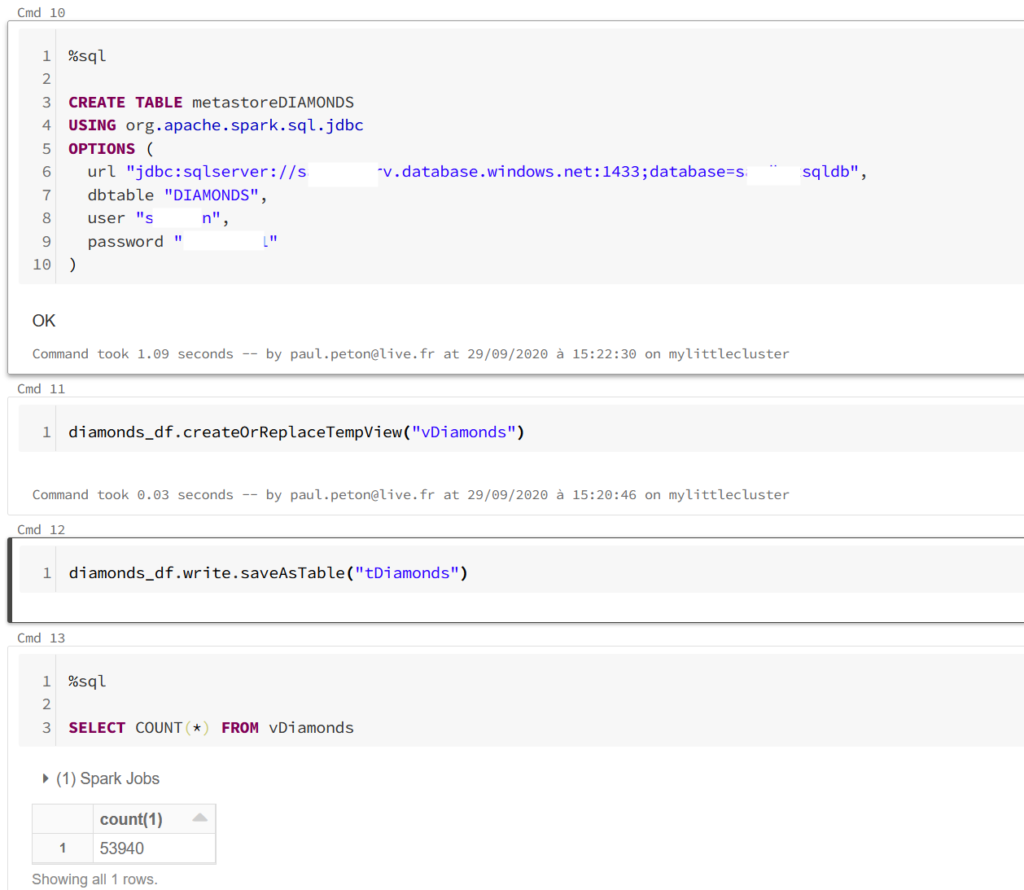
Pour aller un peu plus loin dans l’exploitation de ce driver JDBC, nous pouvons créer une table dans le métastore du cluster, copie d’une table de la base de données.
Il est alors possible de créer des interactions en Spark SQL entre des vues créées à partir de dataframes Spark (ou Pandas en les convertissant au préalable) et la table du métastore. Ce scénario ne réalise qu’une lecture des données de la base et des opérations d’écriture sur cette table ne seront bien sûr pas répercutées sur la base de données.
Nous avons ici utilisé le driver JDBC de manière simple avec une ressource de type SQL Database. Vous retrouverez ici une autre manière de procéder au travers de Polybase pour Azure SQL Datawarehouse. Ce service Azure étant maintenant renommé Azure Synapse Analytics et disposant de nouvelles fonctionnalités, de prochains articles décriront les modes d’interaction entre fichiers, dataframes et tables. En attendant, je vous recommande cet épisode du podcast Big Data Hebdo autour de Synapse.
La longueur du titre de cet article laisse présager du niveau de précision dans lequel nous allons nous lancer ! Je vais donc rapidement situer le contexte faisant appel à un tel besoin.
Nous cherchons à déployer de manière automatisée un environnement de développement Azure Data Factory sur l’environnement de production. Nous utilisons pour cela un pipeline de release Azure DevOps. Le processus DevOps pour ADF est expliqué dans ce livre blanc Microsoft ou dans cet excellent article de Florian Eiden.
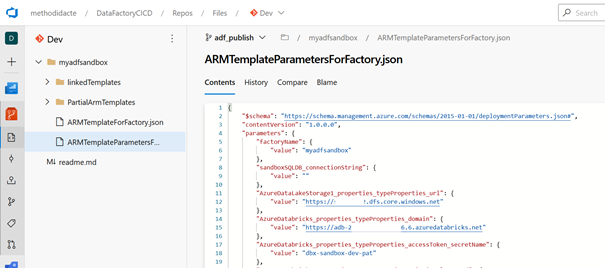
Pour résumer les grandes lignes du fonctionnement, nous remplaçons dans un fichier de paramètres au format JSON les valeurs des chaînes de connexion de l’environnement de développement par celles de production. Ceci se fait au moyen de la case « override template parameters ».
Valeurs manquantes pour le service lié Databricks
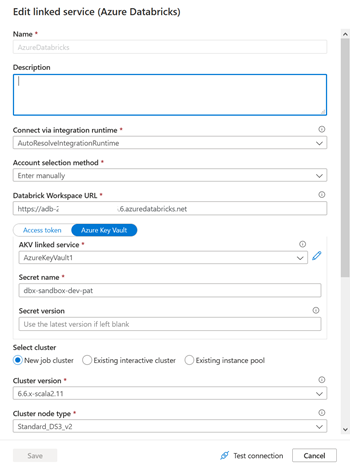
La chose se complique lorsque nous utilisons un service lié de calcul de type Azure Databricks puisque les paramètres de ce service n’apparaissent pas par défaut dans le fichier de paramétrage ! Nous avons en particulier besoin de remplacer :
La Databricks Workspace URL
Le Secret name (où se trouve enregistré un Personal Access Token correspondant à l’espace de travail souhaité)
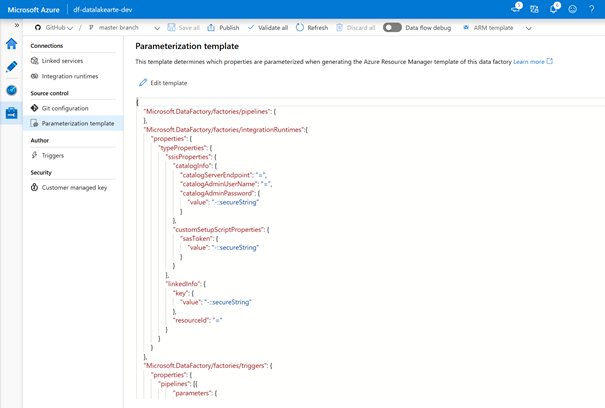
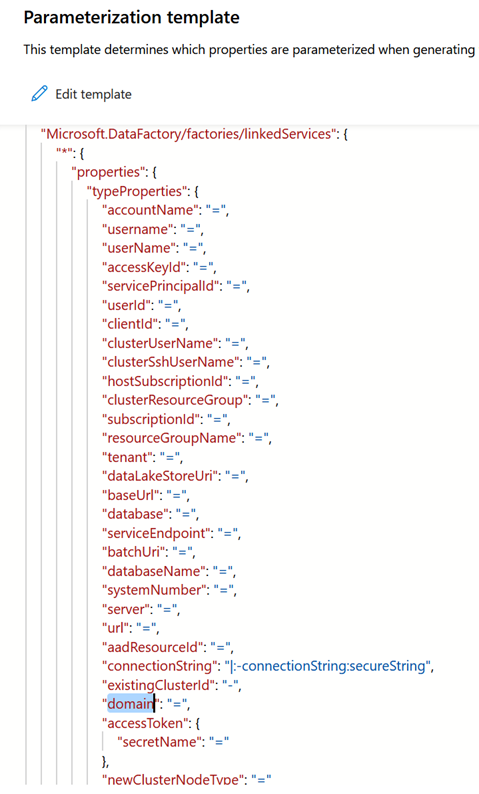
En effet, un choix arbitraire a été fait par Microsoft pour présenter uniquement certains paramètres mais un grand nombre de valeurs existent et elles sont visibles en éditant le fichier disponible dans le menu : Parametrization template.
Ce fichier au format JSON recense l’intégralité des paramètres disponibles par défaut, ainsi que leur visibilité au moyen d’une propriété qui n’est pas simple à interpréter :
= (signe égal) permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre
– (signe moins) permet de ne pas conserver la valeur par défaut pour le paramètre
Le symbole | (pipe) permet de réaliser le lien avec une valeur stockée dans le coffre-fort Azure Key Vault.
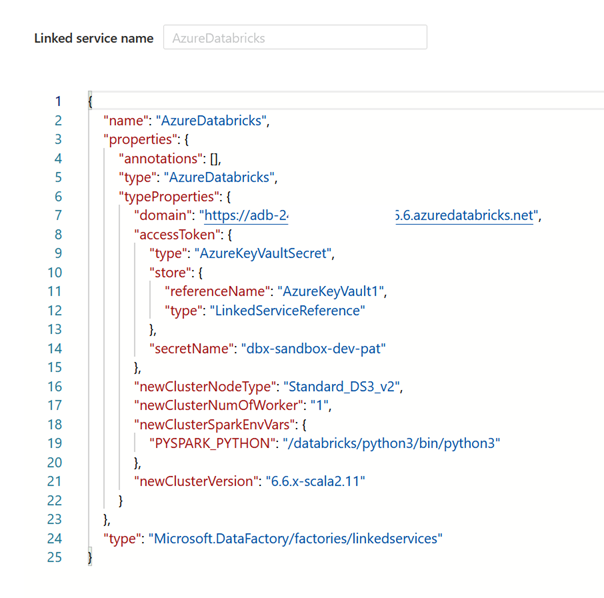
Nous allons maintenant rechercher le nom des paramètres manquants. Pour cela, nous passons par la définition du service lié Databricks au format JSON.
Nous obtenons ainsi le nom exact des paramètres (ne pas se fier à l’interface graphique).
L’URL de l’espace de travail se nomme ainsi domain, le secret du Key Vault se désigne par secretName et ses deux propriétés dépendent du niveau TypeProperties et du sous-niveau accessToken pour le secret.
Nous pouvons donc maintenant citer ces propriétés dans le JSON des paramètres, en respectant l’arborescence des propriétés.
La définition des paramètres dans la branche Master
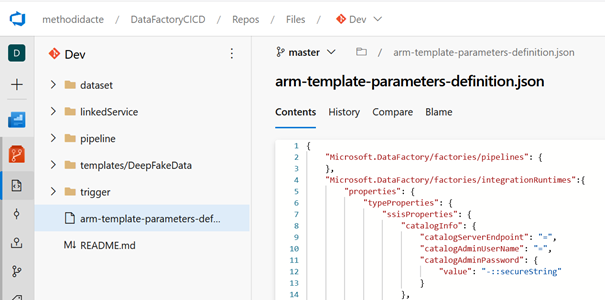
Arrive ici la partie peut-être la moins documentée (jusqu’à présent !). Il faut comprendre que ce fichier JSON doit figurer à la racine de la branche Master du dépôt contenant la synchronisation du Data Factory avec un gestionnaire de version comme GitHub ou un repo Azure DevOps, sous le nom arm-template-parameters-definition.json.
Il ne faut donc pas utiliser la branche spécifique à Data Factory qui se nomme adf_publish mais nous irons ensuite vérifier que les deux fichiers JSON qu’elle contient ont bien été modifiés en conséquence.
Pour lancer cette modification, nous devons tout d’abord faire les deux actions suivantes :
Refresh
Publish
Le volet latéral du Publish (pending changes) doit s’afficher même si aucune modification n’est visible.
Nous pouvons enfin vérifier que les paramètres sont disponibles dans le fichier ARMTemplateParametersForFactory.json de la branche adf_publish.
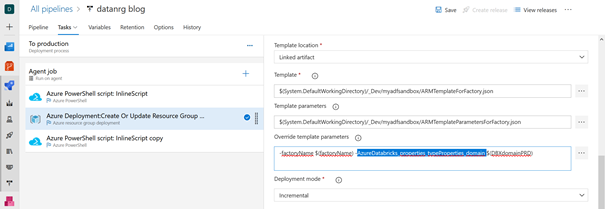
Modifier la valeur des paramètres pendant la release
Il ne reste qu’à utiliser ces noms de paramètres dans le pipeline de release Azure DevOps. Les nouvelles valeurs peuvent être définies comme des variables du pipeline pour plus de commodité.
Cet article a pu être écrit grâce à la documentation officielle de Microsoft ainsi que d’autres articles de blog, en anglais, que leurs auteurs en soient ici remerciés :
Le code utilisé dans un notebook peut échouer pour une raison autre qu’un erreur de développement : fichier absent, API ne répondant pas, etc. Il peut donc être pertinent de relancer automatiquement un traitement en cas d’échec.
La documentation Databricks fournit un exemple de fonction, en Python ou en Scala, qui réalise ce mécanisme. Le code est bien sûr basé sur la fonction dbutils.notebook.run déjà présentée dans un précédent post.
Voici le code en Python, où un nombre d’essais maximum de 3 est paramétré par défaut :
# Errors in workflows thrown a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
exceptExceptionas e:
if num_retries > max_retries:
raise e
else:
print "Retrying error", e
num_retries += 1
Et voici ce que l’on obtient à l’exécution. Attention à bien préciser le chemin relatif du notebook ainsi piloté, si celui-ci n’est pas situé au même niveau que le ce “master notebook”.
Attention à ne pas abuser de ce processus ! Il est essentiel de comprendre la nature des erreurs rencontrées et d’y apporter des réponses au travers du code.
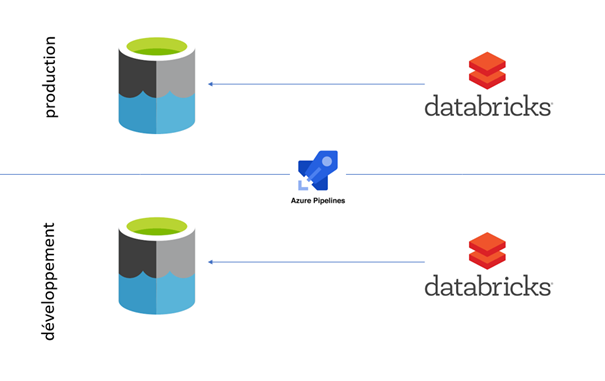
Une fois l’infrastructure définie autour d’un cluster Databricks, les notebooks sont les éléments qui vont évoluer au gré des développements. Il faut bien sûr a minima définir deux environnements : l’un de développement, l’autre de production. Nous verrons ainsi plusieurs astuces et bonnes pratiques permettant de réaliser le processus du déploiement continu des notebooks.
Nous avons pu voir dans de précédents articles :
Comment définir un point de montage vers un compte de stockage Azure
Comment versionner les notebooks Databricks par exemple sous GitHub
Nous allons utiliser ici la notion de variable d’environnement, propre au cluster Spark.
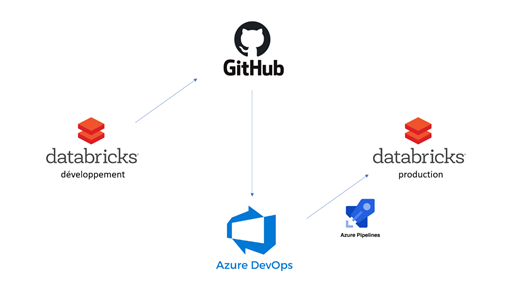
Le schéma ci-dessous illustre le mécanisme DevOps qui sera mis en place.
Mais pour l’instant, focalisons-nous sur le chemin menant vers les données. Nous utilisons ici deux environnements identiques d’un point de vue de l’architecture, dont une vision simplifiée est donnée sur le schéma ci-dessous :
L’accès au point de montage défini sur le compte de stockage Azure se fait par exemple au moyen des commandes Databricks dbutils :
dbutils.fs.ls('/mnt/dev/mysfilesystem/')
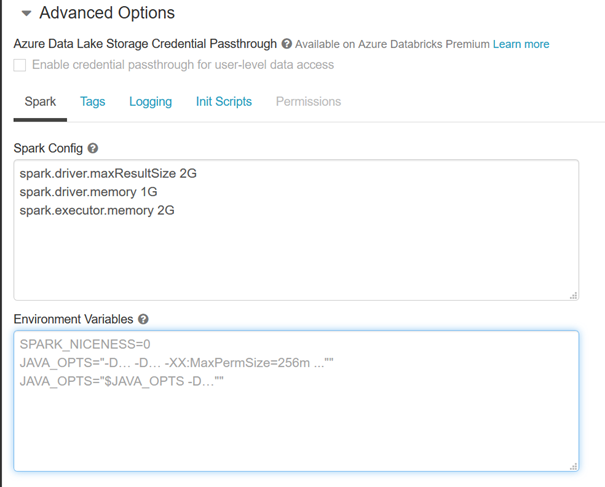
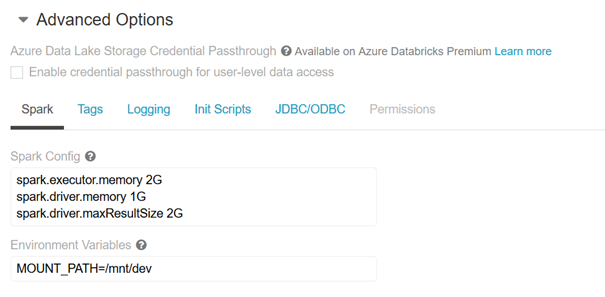
Les variables d’environnement sont quant à elles définies au niveau d’un cluster. Elles seront donc accessibles de n’importe quel notebook attaché au cluster. Nous les trouvons en dépliant le menu des options avancées, onglet Spark.
Par convention, nous utilisons une casse majuscule pour le nom des variables.
Attention à ne pas mettre d’espace autour du signe « = ». Les guillemets ne sont en revanche pas indispensables autour de la valeur de la variable.
Un redémarrage du cluster sera alors nécessaire, suite à la modification des variables d’environnement.
Maintenant, différentes commandes, dans les langages supportés, vont nous permettre d’accéder aux variables définies. Pour la compatibilité dans un même notebook, les lignes de scripts seront ici précédées du langage dans lequel elles sont écrites, vous pourrez ainsi copier ce code tel quel dans n’importe quel notebook Databricks.
Liste des variables d’environnement :
%sh printenv
Valeur de la variable en Shell :
%sh echo $MOUNT_PATH
Valeur de la variable d’environnement en Python :
%python
import os
key = 'MOUNT_PATH'
value = os.getenv(key)
print("Value of 'MOUNT_PATH' environment variable :", value)
A noter que la commande getenv() peut être remplacée par environ.get() issue également de la librairie os. Les différences entre les deux sont traitées dans cette question sur StackOverFlow.
Valeur de la variable d’environnement en Scala :
%scala
sys.env("MOUNT_PATH")
Il est donc maintenant possible d’utiliser ces variables dans les chaînes d’accès au système de fichier, avec un code qui réagira alors en fonction de l’environnement !
La définition des variables d’environnement est également réalisable si vous utilisez un “automated cluster“, c’est-à-dire un cluster créé à la volée lors du lancement d’un job planifié.
La configuration du cluster est disponible en cliquant sur le bouton “edit”.
Le proverbe bien connu “diviser pour mieux régner” a sa déclinaison dans le monde de la Data et des services managés : “séparer le traitement du stockage”. Par cela, il faut comprendre que l’utilisation de deux services différents pour ces deux tâches est particulièrement intéressant.
En effet, le stockage se doit d’être permanent et toujours accessible, en tenant compte de différents degrés de “chaleur”. En revanche, la puissance de calcul n’est nécessaire que pendant les traitements et il faudra pouvoir faire évoluer cette puissance selon le besoin. Par exemple, un entrainement de modèle prédictif, opération qui peut être très coûteuse, bénéficiera de l’élasticité d’un service managé comme Azure Databricks mais ne sera peut-être pas réalisé quotidiennement.
Nous allons détailler ici comment pérenniser les données issues d’un traitement de préparation réalisé sur le cluster managé Spark. La solution de stockage choisie ici est Azure SQL Data Warehouse.
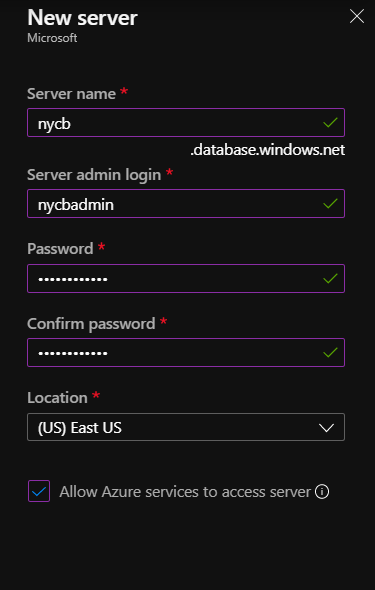
Créer une ressource Azure SQL DWH
Il est tout d’abord nécessaire de disposer d’une ressource Azure de serveur de bases de données.
La documentation officielle d’Azure Databricks recommande de cocher la case “Allow Azure services to access server”.
Nous sélectionnons maintenant la ressource Azure SQL Data Warehouse dans la catégorie Databases.
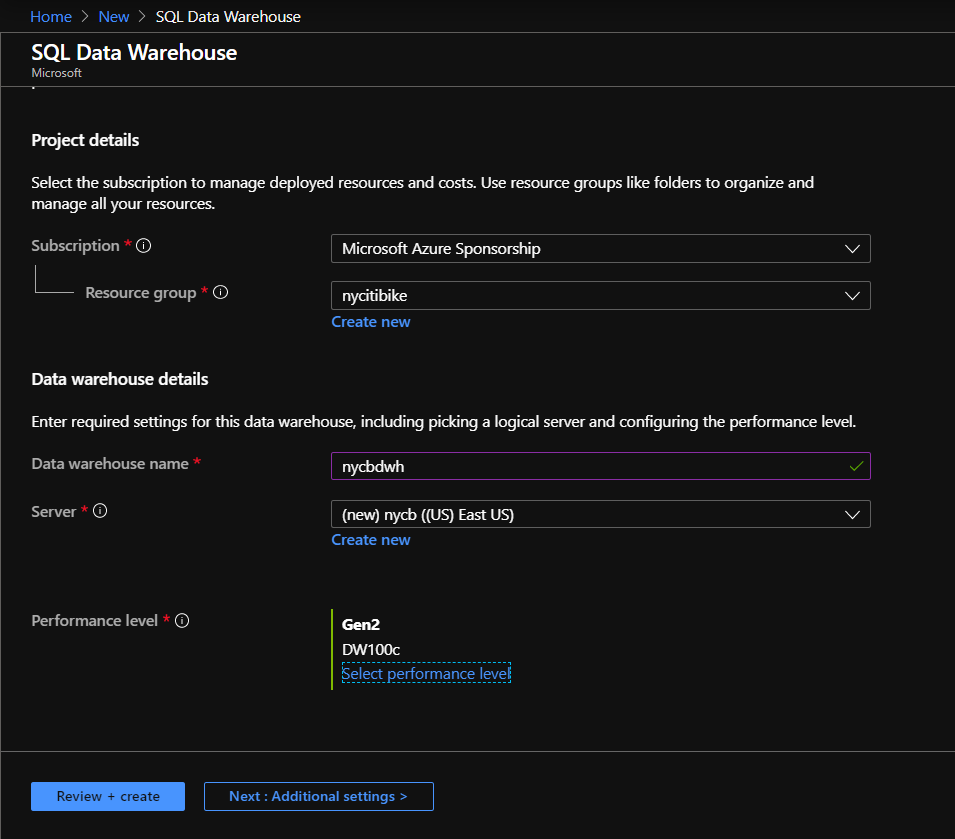
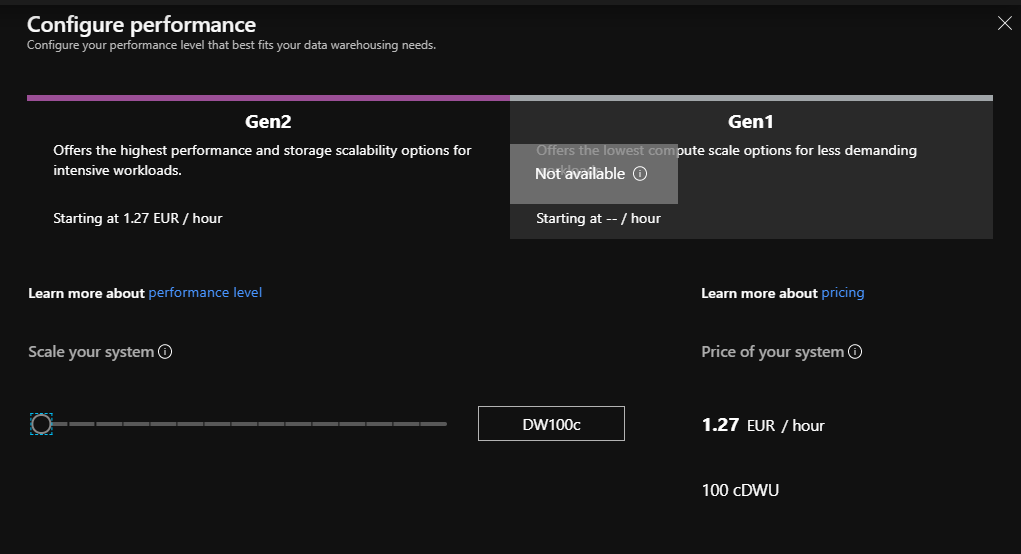
Le Data Warehouse est associé à un groupe de ressources et à un serveur de base de données (ici, créé simultanément). Le niveau de performance choisi va déterminer le coût associé à une heure de service de l’entrepôt.
Cette ressource se montra particulièrement efficace dans le cadre d’une connexion vers un outil de dashboarding comme Power BI et autorise le mode direct query, qui pourra se révéler pertinent dans des modèles de données composites, mêlant import et connexion directe.
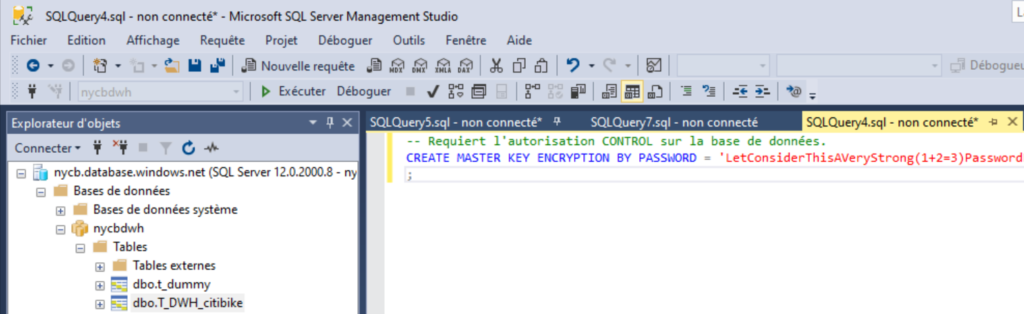
Une clé de chiffrement pour la base étant obligatoire, il sera nécessaire de créer une database master key au travers d’une nouvelle requête sur la base de données. Cela peut se faire par exemple dans le client SQL Server Management Studio ou sur le portail Azure par le query editor actuellement en préversion.
--Creates the database master key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = "yourStr0ngPa$$W0rd"
Faire communiquer Azure Databricks et SQL DWH
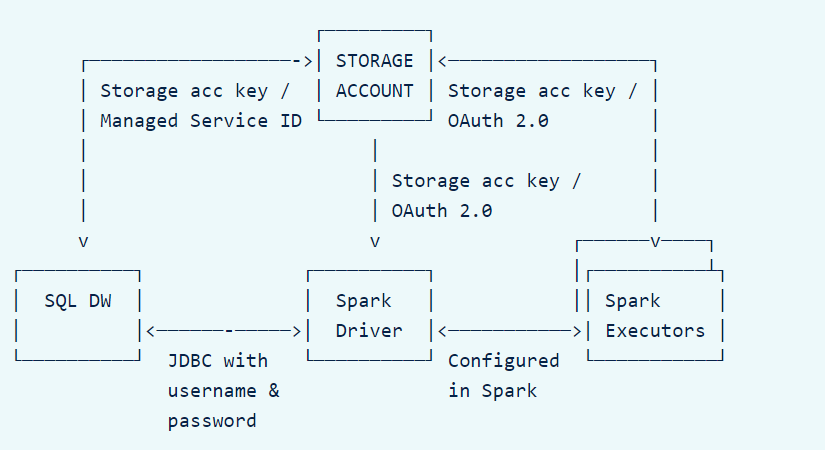
Afin de bien paramétrer la communication, il faut tout d’abord comprendre comment fonctionne le mécanisme. La subtilité à bien saisir est l’importance d’un troisième élément qui est le compte de stockage Azure utilisé comme zone temporaire et sollicité par le composant PolyBase.
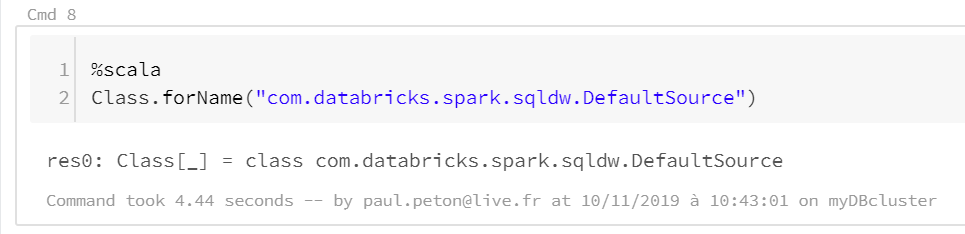
Vérifions tout d’abord que le connecteur SQL DWH est présent sur le runtime Databricks associé au cluster Spark au moyen de la commande Scala ci-dessous.
La commande ne doit pas renvoyer d’erreur “ClassNotFoundException”.
Dans une cellule d’un notebook, nous déclarons toutes les variables nécessaires à la bonne communication entre les différentes briques, en particulier le compte de stockage Azure (Blob Storage ou Data Lake Storage gen2).
Le code ci-dessous est donné pour un notebook Python mais sa variante en Scala s’obtiendra facilement en ajoutant le mot-clé var au devant de chaque déclaration de variable.
Attention à faire cette étape proprement au moyen d’un secret scope !
Des travaux de data preparation nous ont permis de réaliser un DataFrame propre contenant des données plus exploitables. Une sauvegarde du DataFrame est réalisée sous forme de table sur le cluster mais celle-ci ne sera accessible que lorsque le service Azure Databricks est démarré (et donc facturé).
Nous allons donc réaliser une copie des données sur Azure SQL Data Warehouse.
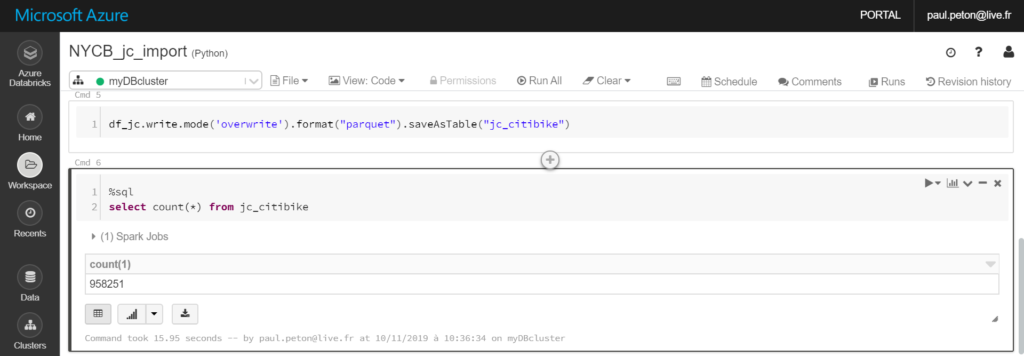
Grâce aux actions préalables, il est maintenant possible de lancer les commandes load ou write pour communiquer avec Azure SQL Data Warehouse. Dans la commande ci-dessous, nous créons une nouvelle table dans la base de données à partir d’un DataFrame en mémoire du cluster.
Les logs du cluster montrent que la communication s’effectue bien avec le Data Warehouse.
Automatiser les traitements
Nous avons donc réalisé ici la partie cruciale de la chaîne de la data, en séparant traitement et stockage des résultats. Pour rendre cette architecture encore plus efficace, il sera nécessaire de planifier le traitement de préparation des données . Plusieurs solutions sont ici disponibles :
l’ordonnanceur d’Azure Databricks, couplé à une logique d’enchaînement de notebooks
l’utilisation d’un pipeline Azure Data Factory et d’une activité Databricks
Ces deux approches sont décrites dans cet article.
Dupliquer les données, bonne idée ?
A cette question, nous pourrons formuler la traditionnelle réponse du consultant : “ça dépend”.
Rappelons qu’il faut bien évaluer les usages et les coûts d’une telle architecture. Quel est le public qui a besoin de cette donnée préparée ? Plutôt des data analysts au sein de Power BI ? Plutôt des data scientists dans un cluster “bac à sable” ?
Azure SQL Data Warehouse offre une puissance d’accès pour des usages analytique mais il faut mesurer son coût si la base reste accessible en continu. A l’inverse, les tables matérialisées sur le cluster retirent une brique de l’architecture (et de la facture !) mais les performances du connecteur Spark pour Power BI ne me semblent pas aujourd’hui suffisantes pour des volumes de données importants.
Une fois de plus, la bonne architecture cloud Data sera celle qui répondra le mieux aux besoins, dans un cadre gouverné et dont le coût et la performance seront supervisés de près.
[EDIT 13 novembre 2019 : Microsoft a annoncé lors de l’Ignite d’Orlando qu’Azure SQL Data Warehouse évoluait et devenait au passage Azure Synapse Analytics. Nous suivrons de près cette évolution.]
Si vous avez suivi mes derniers articles sur ce blog, vous
aurez deviné que je suis plus que convaincu de l’intérêt de mettre le service
de clusters managés Databricks au sein d’une architecture cloud data.
Si l’on met de côté l’exploitation des données par des algorithmes de Data Science, il sera toujours très intéressant de visualiser et d’explorer la donnée dans un outil d’analyse dynamique comme Power BI. Et cela tombe bien, il existe un connecteur (générique) Spark !
Connecter Power BI Desktop à une table du cluster Databricks
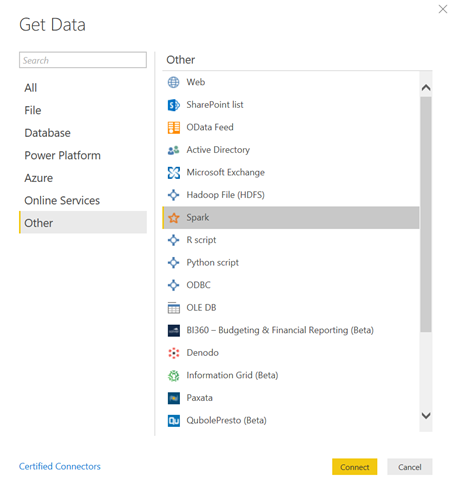
Voici comment procéder pour charger les données d’un cluster dans un modèle Power BI.
Tout d’abord, il faudra installer sur le poste exécutant Power BI Desktop le driver Spark ODBC. Celui-ci peut être téléchargé au travers d’un lien reçu par mail suite à l’inscription sur ce formulaire. L’installation ne révèle aucune difficulté : next, next, next…
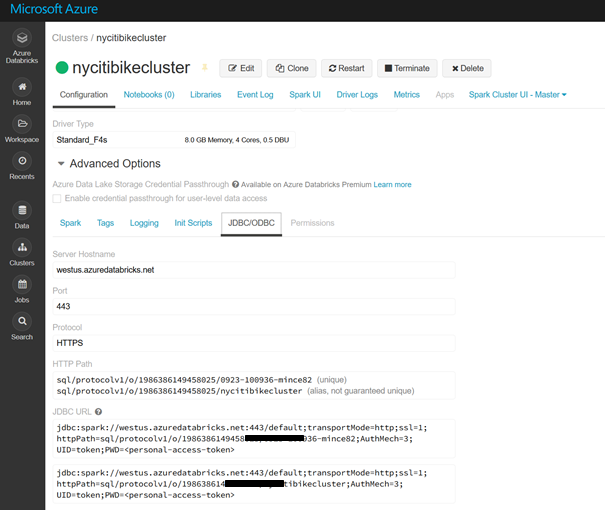
Passons ensuite sur l’interface de notre espace de travail Azure Databricks. Nous démarrons le cluster et il sera possible d’y trouver une information importante qu’est l’URL JDBC.
Cette URL va permettre de construire le chemin du serveur attendu dans la boîte de dialogue sous la forme générique suivante :
Il faut donc ici remplacer <region> par le nom de la
région Azure où se trouve la ressource Databricks, par exemple : westus. A
la suite du port 443, on copiera la partie de l’URL JDBC allant de sql
au point-virgule suivant.
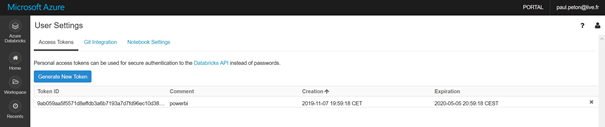
Seconde étape à l’intérieur de l’interface Databricks, nous créons maintenant un jeton d’accès pour l’application Power BI à partir des Users settings.
Attention à bien copier la valeur affichée, il ne sera plus possible de la revoir !
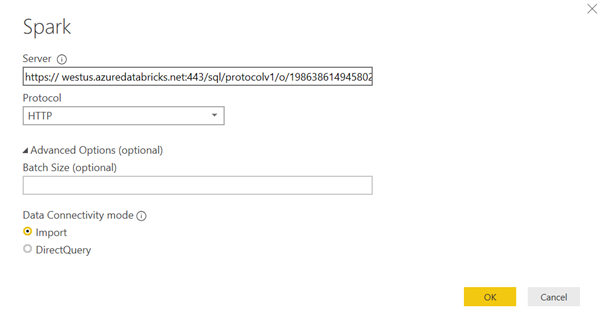
Revenons à Power BI. Dans la boîte de dialogue de connexion, coller l’URL construite dans la case Server, choisir le Protocol HTTP.
En mode import, l’avantage sera de pouvoir continuer à travailler sans que le cluster soit démarré. Mais il faudra attendre un bon moment pour que le chargement de données se fasse dans Power BI. En effet, si l’on utilise un cluster Spark, c’est que bien souvent les volumes de données sont importants…
En mode direct query, chaque évaluation de visuel dans la page de rapport établira une requête vers le cluster, qui bien évidemment devra être actif.
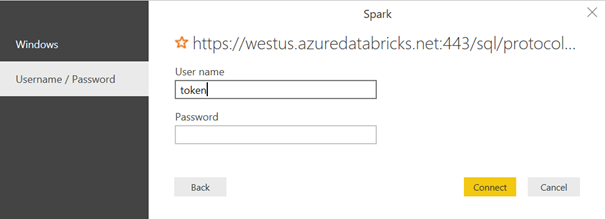
Le user name est tout simplement le mot token. Coller ici le jeton généré depuis Azure Databricks.
Nous accédons maintenant à toutes les tables ou vues du cluster ! N’insistez pas trop pour obtenir un aperçu, cette fonctionnalité semble peiner à répondre mais l’important est bien d’obtenir les données dans l’éditeur de requêtes.
Voici le code obtenu dans l’éditeur avancé. Nous retrouvons une logique classique de source et de navigation dans un élément de la source, ici une table. Le schéma de la table est respecté, il n’est pas nécessaire de typer à nouveau les champs dans Power Query.
Connecter
un Dataflow à Azure Databricks
Les Dataflows de Power BI (à ne surtout pas confondre avec
les data flows de Azure Data Factory !) sont une nouveauté du service
Power BI qui vient de connaître beaucoup d’évolutions.
Pour l’expliquer simplement, on peut dire que Dataflow
correspond à la version en ligne de Power Query, avec donc une capacité
de traitement issue du cloud (partagée ou dédié dans le cadre d’une licence
Premium) et la possibilité de partager le résultat des requêtes
(appelées entités) à des créateurs de nouveaux rapports. Contrairement à
un jeu de données partagé (shared dataset), il est possible de croiser
plusieurs entités dataflows au sein d’un même modèle.
Les dataflows sont enfin le support des techniques de
Machine Learning dans Power BI mais nous parlerons de tout cela une prochaine
fois !
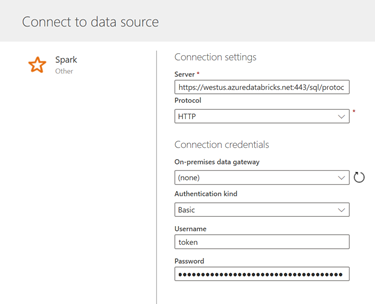
Début novembre 2019, de nouvelles sources de données sont disponibles dont la source Spark. Nous allons donc tenter de reproduire la démarche réalisée dans Power BI Desktop.
Nous retrouvons les mêmes
paramètres de connexion, à savoir :
Server
Protocol (http)
Pas besoin de Gateway, les données sont déjà dans Azure
Username : token
Password : le jeton généré (on vous avait prévenu de conserver sa valeur 😊)
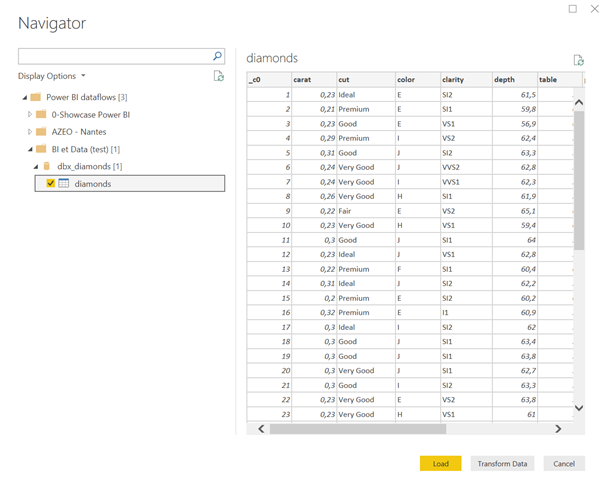
Il faut ensuite choisir la table ou la vue souhaitée.
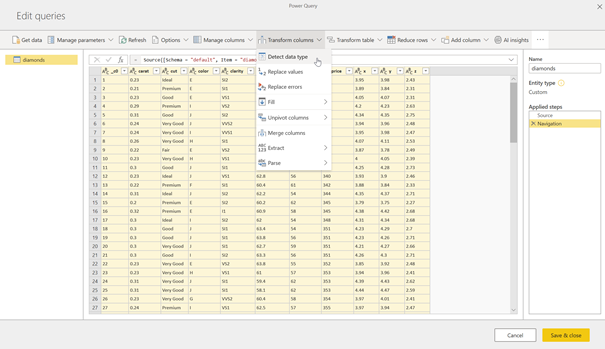
Petite différence, les types de données ne sont pas conservés, il faut donc exécuter une commande « Detect data type » sur toutes les colonnes.
Rappelons enfin qu’un dataflow
n’est pas chargé tant qu’il n’est pas rafraîchi une premier fois. Cliquer ici
sur Refresh now.
Un rafraichissement pour aussi être planifié mais il faudra bien s’assurer que le cluster Databricks soit démarré pour que la connexion puisse se faire.
Une fois le dataflow créé, il est accessible de manière pérenne aux développeurs qui travaillent dans Power BI Desktop et qui ont accès à l’espace de travail Power BI où a été créé le dataflow.
Nous vérifions ici dans l’aperçu
que les champs sont maintenant bien typés.
En conclusion
Nous avons ici utilisé le
connecteur Spark et celui-ci a nous permis, à partir de Power BI ou des
dataflows du service Power BI, de nous connecter aux tables vues au travers du
cluster Databricks.
Il s’agit là d’un connecteur générique
et celui-ci n’est sans doute pas optimisé pour travailler la source Azure
Databricks mais notons que le mode direct query est tout de même disponible.
Cette approche montrera rapidement ces limites quand les volumétries de données exploseront. Il sera alors nécessaire de réfléchir à une solution de stockage des données entre le cluster et Power BI comme Azure SQL DB ou Azure SQL DWH (bientôt Azure Synapse Analytics ?), portées ensuite éventuellement par un cube Azure Analysis Services qui exécutera les calculs nécessaires aux indicateurs présentés dans Power BI.
Toutefois, la faisabilité de cette connexion permettra de mener rapidement une preuve de concept jusqu’à la représentation visuelle des données. A la contrainte d’avoir le cluster démarré pour charger les données, on répondra par leur écriture au sein d’un dataflow (qui est techniquement un stockage parquet dans un Azure Data Lake Storage gen2 !). Attention, les dataflows ont leurs limites : ils ne peuvent être utilisés qu’au sein d’un seul espace de travail Power BI, sauf à disposer d’une licence Premium qui permettra de lier ce dataflow à cinq espaces de travail.
Azure Databricks se positionne comme une plateforme unifiée pour le traitement de la donnée et en effet, le service de clusters managés permet d’aborder des problématiques comme le traitement batch, mais aussi le streaming, voire l’exposition de données à un outil de visualisation comme Power BI.
La capacité de mise à l’échelle (scalabilité ici horizontale) d’Azure Databricks est également un argument de poids pour
établir cette solution dans un contexte de forte volumétrie. Par forte
volumétrie, nous entendons ici le fait qu’un tableau de données, ou les
opérations qui permettraient d’y parvenir,
dépasse la mémoire disponible sur une seule machine. La solution sera
donc de distribuer la donnée ou les
traitements. Mais attention, il va falloir bien choisir ses armes avant de se
lancer dans un premier notebook !
Le choix des armes
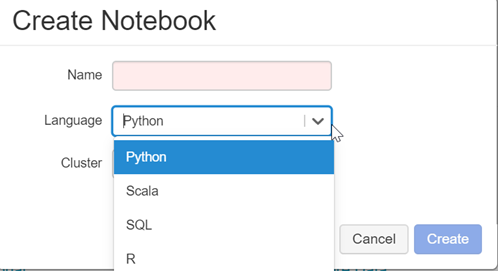
A la création d’un notebook sur Azure Databricks, quatre langages sont disponibles.
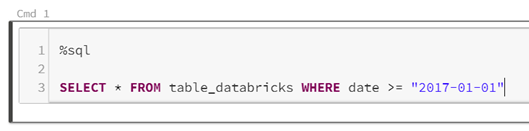
Sauf à ne vouloir faire que du SQL, je vous déconseille de prendre ce type de notebook puisqu’il sera très simple d’exécuter une commande SQL dans une cellule à l’aide la commande magique %sql.
Si vous venez de la Data Science « traditionnelle » (rien de péjoratif, c’est d’ailleurs mon parcours, comprendre ici l’approche statistique antérieure à l’ère de la Big Data), vous serez attirés par le langage R. Mais vous savez sûrement que R est un langage, de naissance, single-threaded et peu apte à paralléliser les traitements. Microsoft a pourtant racheté la solution RevoScaleR de Revolution Analytics et l’a intégrée en particulier à SQL Server. Dans un contexte Spark, on peut s’orienter vers l’API SparkR mais celle-ci ne semble pas soulever un très gros engouement (contredisez-moi dans les commentaires) dans la communauté.
Python remporte aujourd’hui une plus forte adhésion, en
particulier auprès des profils venant du monde du développement. Attention,
coder un traitement de données en Python ne vous apportera aucune garantie
d’amélioration par rapport au même code R ! Ici, plusieurs choix se
présentent à nouveau.
Une première piste sera d’exploiter la librairie Dask qui permet de distribuer les
traitements.
Une deuxième possibilité est de remplacer les instructions
de la librairie pandas par la librairie développée par Databricks : koalas. Je détaillerai sûrement
l’intérêt de cette librairie dans un prochain article.
Le troisième choix possible sera à mon sens le
meilleur : l’API pyspark. Cette
API va vous permettre :
de créer des objets Spark DataFrames
d’enregistrer ces DataFrames sous formes de
tables (locales ou globales dans Databricks)
d’exécuter des requêtes SQL sur ces tables
de lire des fichiers au format parquet
Les API Spark permettent d’écrire dans un langage de plus haut niveau et plus accessible pour les développeurs (data scientists ou data engineers) qui sera ensuite traduit pour son exécution dans le langage natif du cluster.
Les différents codes possibles
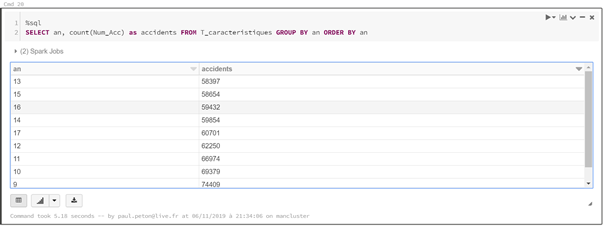
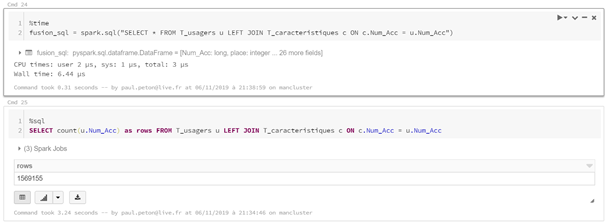
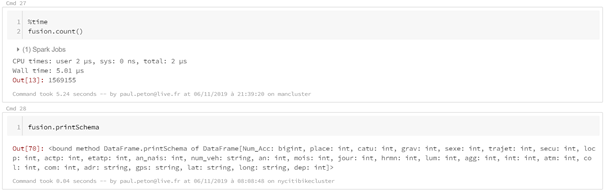
Je vous propose ci-dessous un comparatif des approches
pandas et pyspark pour un même traitement de données. Le scénario est de
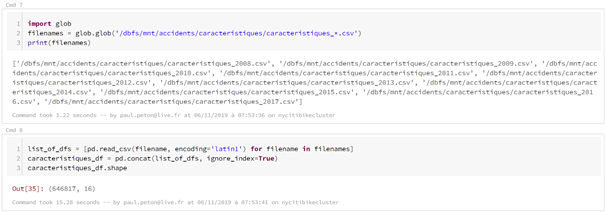
charger les données de la base open data des accidents corporels, soit deux
dossiers de fichiers csv : les usagers et les caractéristiques des
accidents. Une fois les fichiers chargés, une jointure sera réalisée entre les
deux sources sur la base d’une clé commune.
L’objectif est ici d’établir un parallèle entre les syntaxes et non d’évaluer les performances. La librairie pandas n’est d’ailleurs pas la plus optimale pour charger des fichiers csv et on mettra à profit les méthodes plus classiques de lecture de fichiers.
Avec pandas, il pourra être nécessaire de caster certaines colonnes dates suite à l’import.
La lecture en Spark autorise l’emploi de caractères génériques ( ? ou *) pour lire et concaténer automatiquement plusieurs fichiers. Les archives .zip contenant par exemple un fichier .csv peuvent être chargées sans décompression préalable, ce qui ne sera pas le cas avec pandas.
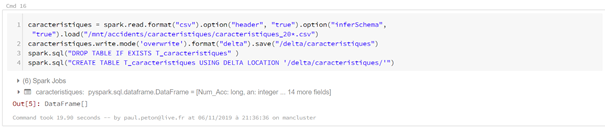
L’avantage de Databricks sera de pouvoir persister certains dataframes sous forme de vues (« tables locales ») ou de tables (« tables globales). En particulier, le format delta pourra être mis à profit. Dès lors, il devient très simple de travailler en Spark SQL pur, toujours en débutant la cellule par la commande magique %sql.
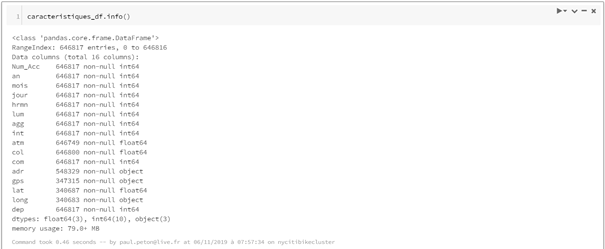
Pandas se montre ici à son avantage avec des résultats plus simples à obtenir pour connaître les dimensions du dataframe (shape) ou des informations sur le schéma et les valeurs manquantes.
En conclusion
Lorsqu’on pose à certains érudits musicaux la sempiternelle
question « Stones ou Beatles », il n’est rare d’entendre la
réponse suivante : « ni l’un, ni l’autre, mais les
Kinks ! »
A la question non moins sempiternelle « R ou
Python », je répondrai donc… Scala !
C’est en effet le langage natif de Spark et donc le plus proche du moteur
d’exécution.
Malgré tout, le choix se fera aussi en fonction de critères plus
pragmatiques comme la puissance nécessaire au traitement, le coût de travailler
sur l’exhaustivité des données (pourquoi par un échantillon
représentatif ?) ou la maîtrise des différents langages par les personnes
en charge des développements.
Dans une architecture complète Cloud tout en services managés, Azure Databricks est extrêmement efficace pour se connecter aux données des comptes de stockage Azure : Blob Storage, Data Lake Store gen1 ou gen2.
Pour autant, il n’est pas raisonnable d’utiliser la solution de facilité et de se connecter au travers des commandes suivantes (exemple en Python) :
La procédure permettant de cacher les informations de sécurité est relativement simple, la voici en détails.
Databricks CLI
Le principe est de créer des secret scopes, au moyen de l’interface de lignes de commandes (CLI) de Databricks. Celle-ci s’obtient au travers de l’installation d’un package python.
pip install databricks-cli
Installation du package databricks-cli (ici dans un virtualenv dédié)
Pour une première utilisation, il est nécessaire d’associer l’espace de travail Azure Databricks avec le poste où sera exécuté le CLI. Une fois le package installé, saisir la commande suivante :
databricks configure --token
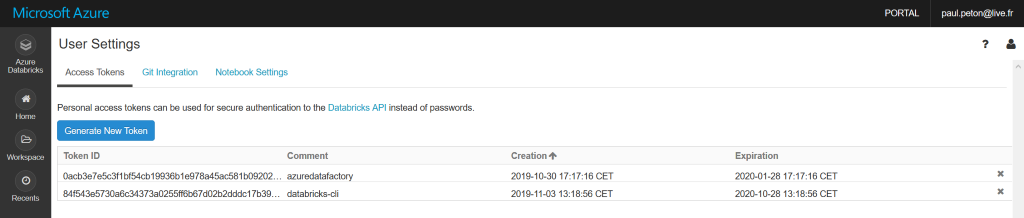
Deux informations sont alors attendues : l’URL du service managé puis un jeton d’identification préalablement créé depuis l’espace de travail Databricks, à partir du menu Users settings > Access tokens.
Générer un token d’accès pour Databricks CLI
Les commandes du package sont maintenant en interaction avec la ressource Databricks, en voici quelques exemples :
databricks workspace ls
databricks clusters spark-versions
databricks fs ls dbfs:/delta/
Quelques commandes du CLI Databricks
Créer un secret scope
Passons maintenant aux commandes qui définiront le secret scope (un scope peut contenir plusieurs informations secrète).
La seconde commande ouvre alors un éditeur de texte, type VI, dans lequel on copiera par exemple l’access key d’un Azure Blob Storage.
Créer (proprement) un point de montage
Voici maintenant le code Python que l’on exécutera dans un notebook pour définir un point de montage, c’est-à-dire un accès simplifié aux fichiers contenu sur un compte de stockage Azure, ici en reprenant le nom du container dans le chemin d’accès.
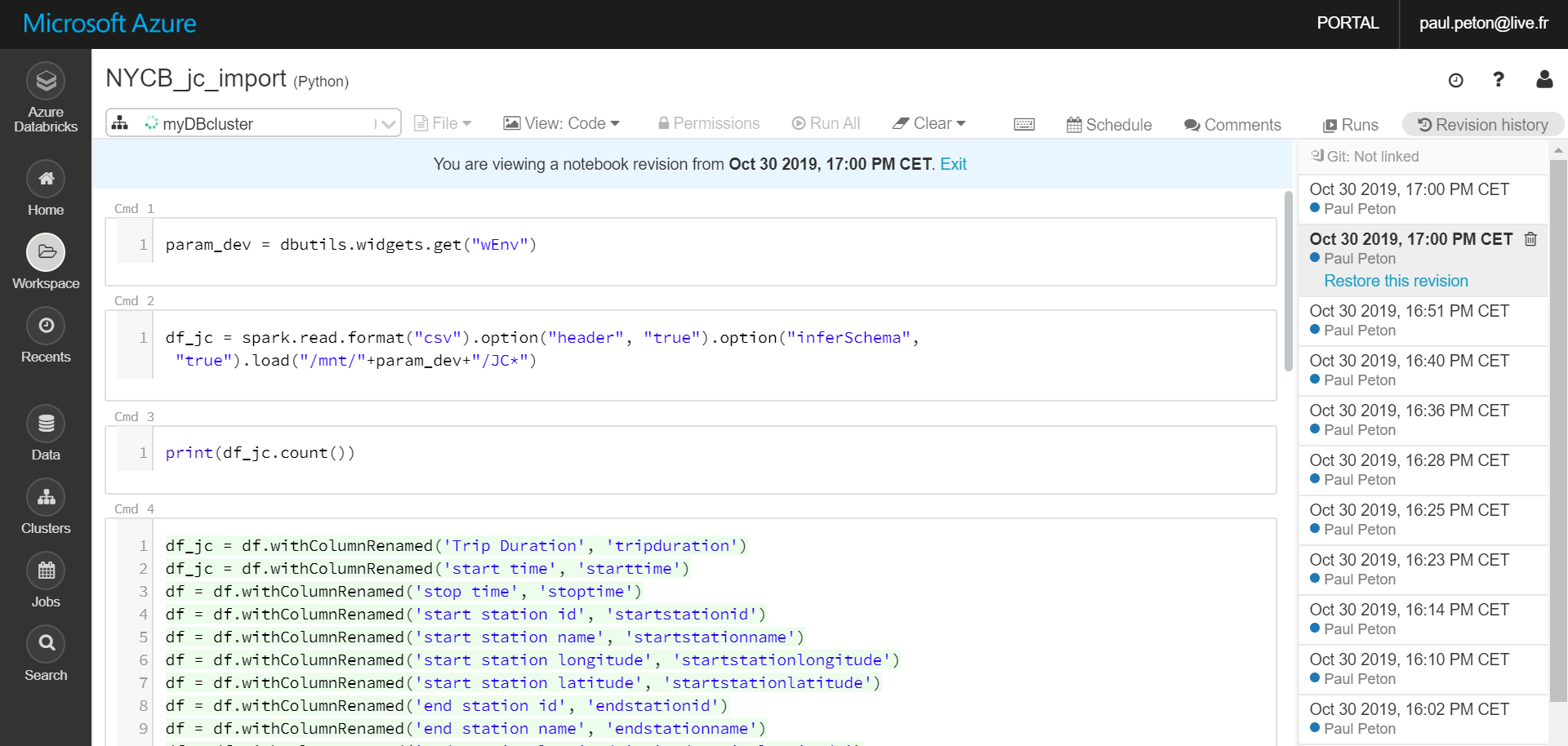
Comme pour tout développement, les notebooks méritent d’être archivés et versionnés. Tout notebook sera ainsi automatiquementsauvegardé et versionné dans l’espace de travail Azure Databricks (voir la documentation officielle).
Menu Revision history du notebok
Tant que le menu latéral Revision history est visible, il n’est pas possible de modifier le contenu du notebook.
Azure Databricks permet également d’utiliser un gestionnaire de versions externe parmi les trois solutions suivantes :
GitHub
Bitbucked Cloud
Azure DevOps Service
Dans un même espace de travail, il ne sera possible d’associer qu’un seul des trois gestionnaires (mais il serait sans doute étrange de versionner à différents endroits…). Notons que GitLab ne fait pas partie de cette liste, à ce jour, je n’ai pas réussi à le lier à Azure Databricks. Ce n’est pas le cas non plus de la version Enterprise de GitHub.
Rappel des notions et principes de base de Git
repository : c’est le répertoire de dépôt d’un projet de développement master : version initiale et de référence du code branch : lors de la suite des développements, il est important créer une nouvelle branche pour ne pas dégrager le master commit : envoi de la liste des modifications effectuées pull request : demande de prise en compte de modifications réalisées par un autre développeur merge : appliquer les modifications à une autre branche, souvent le master
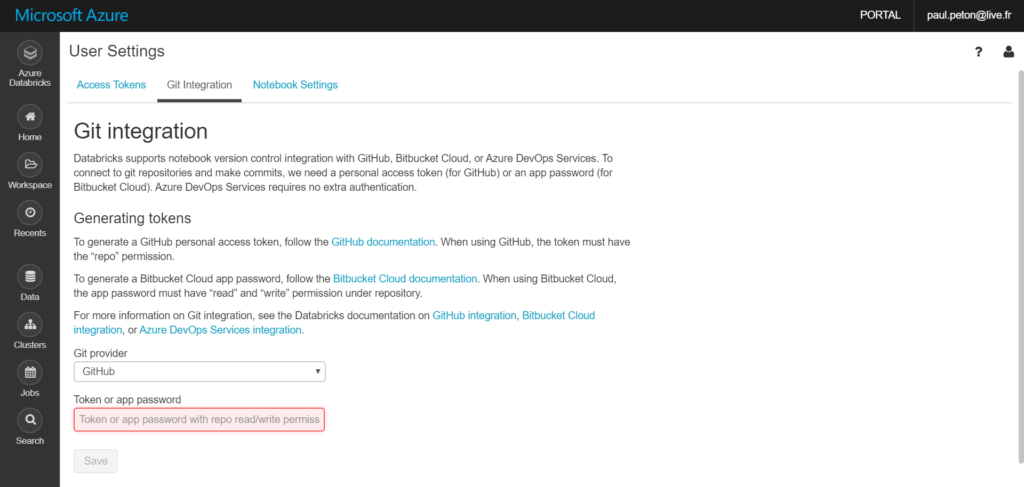
Nous allons découvrir maintenant comment se fait le lien entre l’espace de travail Azure Databricks et GitHub. Il faut tout d’abord se rendre sur la page dédiée aux paramètres de l’utilisateur (User Settings).
Paramétrage de l’intégration Git
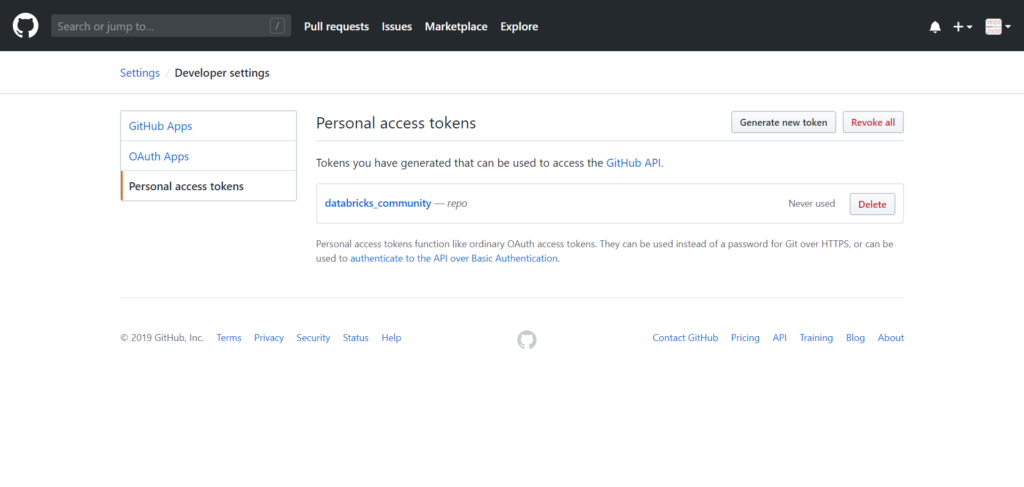
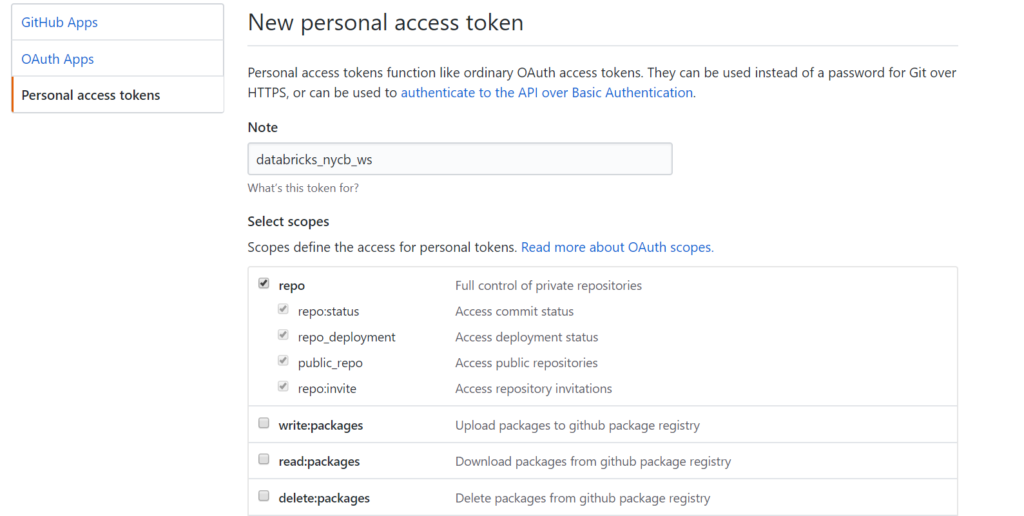
Depuis le site GitHub, une fois identifié, il faut créer un jeton d’accès personnel, en suivant les écrans ci-dessous. Celui-ci devra disposer des droits complets sur le repo.
Génération d’un jeton d’accès personnel dans GitHubAccorder le contrôle complet des repositoriesAssociation réalisée avec succès
Nous pouvons maintenant quitter la page des paramètres de l’utilisateur pour nous rendre dans le notebook de notre choix. Le menu Revision history laisse apparaître le lien Git: Synced.
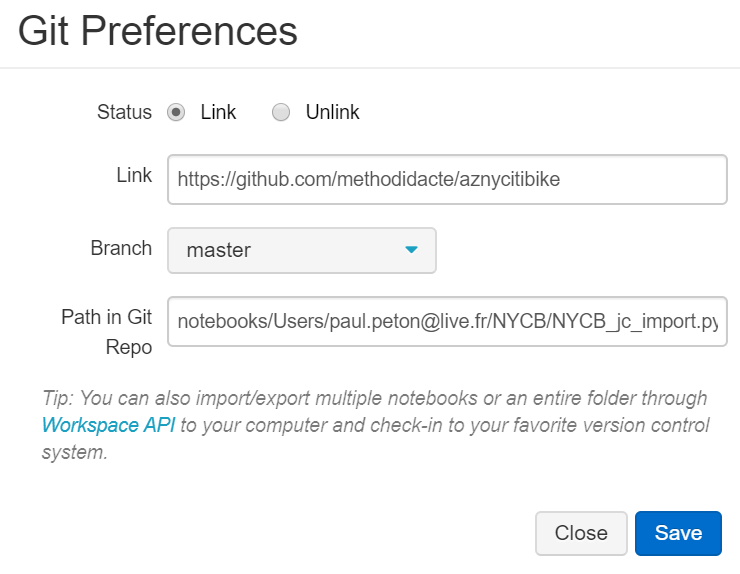
Association du notebook avec un repo GitHubEnregistrement d’une première versionPremière synchronisation réussie
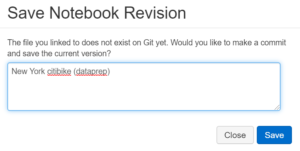
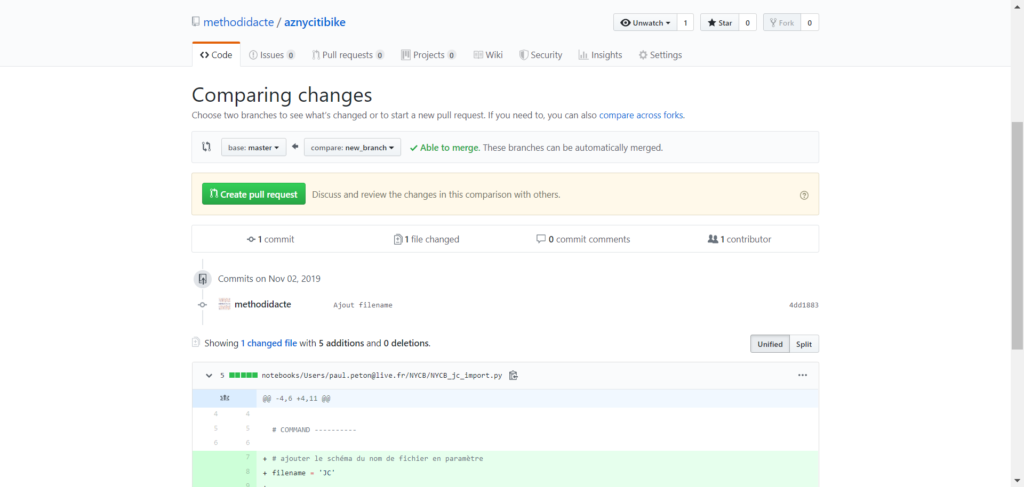
Le fichier est maintenant bien créé sur notre compte GitHub dans le repo associé. Chaque nouvelle révision pourra être enregistrée et commitée, en associant un commentaire.
Enregistrement (et commit) d’un révision
Par défaut un notebook python est enregistré au format .py. Les commandes magiques ne sont pas perdues et seront correctement réinterprétées à l’import du fichier sur un autre espace de travail. Afin de converser les propriétés d’affichage du notebook dans GitHub, il suffit de forcer l’extention à .ipynb lors de la première synchronisation.
Ainsi, chaque nouvelle sauvegarde se fait donc sur la branche principale (master) mais il est bien sûr possible de créer de nouvelles branches du développement, en cliquant à nouveau sut Git: synced.
création et sélection d’une nouvelle branche
La création d’une nouvelle branche fait apparaître un hyperlien vers la pull request sur le compte GitHub.
Lien vers la pull request
La comparaison des modifications et l’éventuel merge des versions se fait ensuite sur la page GitHub.
Comparaison des modifications sous GitHub
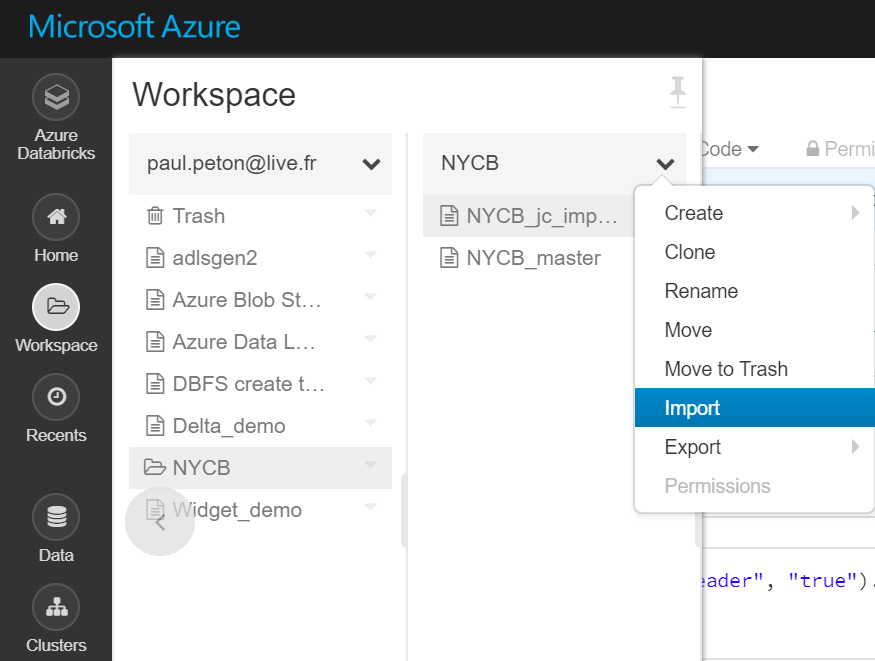
Rappelons enfin qu’il est possible d’importer un fichier par son URL, et donc par l’URL obtenue depuis GitHub. Cette fonctionnalité, couplée à l’utilisation des paramètres dans un notebook, permet de recopier le notebook d’un environnement de développement à un environnement de production.
Import d’un fichier dans l’espace de travailImport par URL
Dans un prochain article, nous explorerons les interactions entre Azure Databricks et Azure DevOps.
Azure Databricks est un service managé de cluster Spark,
permettant d’exécuter du code Scala, Python, R ou SQL sur des volumes
importants de données, grâce à son approche distribuée et en mémoire.
Si le meilleur scénario de mise en production d’un
traitement reste de créer un fichier Jar à partir de code Scala (voir un
prochain billet de ce blog), il peut être très utile d’ordonnancer le lancement
de notebooks Python car il n’existe pas aujourd’hui d’approche similaire à
celle du fichier Jar.
Deux éléments seront importants dans une approche de mise en
production :
Pouvoir modifier facilement un paramètre
d’environnement (dev / qualif / prod par exemple)
Réaliser un enchainement conditionnel des
traitements, avec un minimum de logs de suivi
Nous allons voir ici plusieurs solutions qui sont
disponibles dans un environnement Azure. Nous considérons que nous disposons
déjà des ressources suivantes :
Un compte de stockage Azure avec deux containers (« citidev » et « citiprod »)
Une ressource Azure Databricks avec un cluster déjà créé (« myDBcluster »)
Une ressource Azure Data Factory déployée
Un notebook Python contenant les transformations à effectuer (chargement des données et création d’une table temporaire)
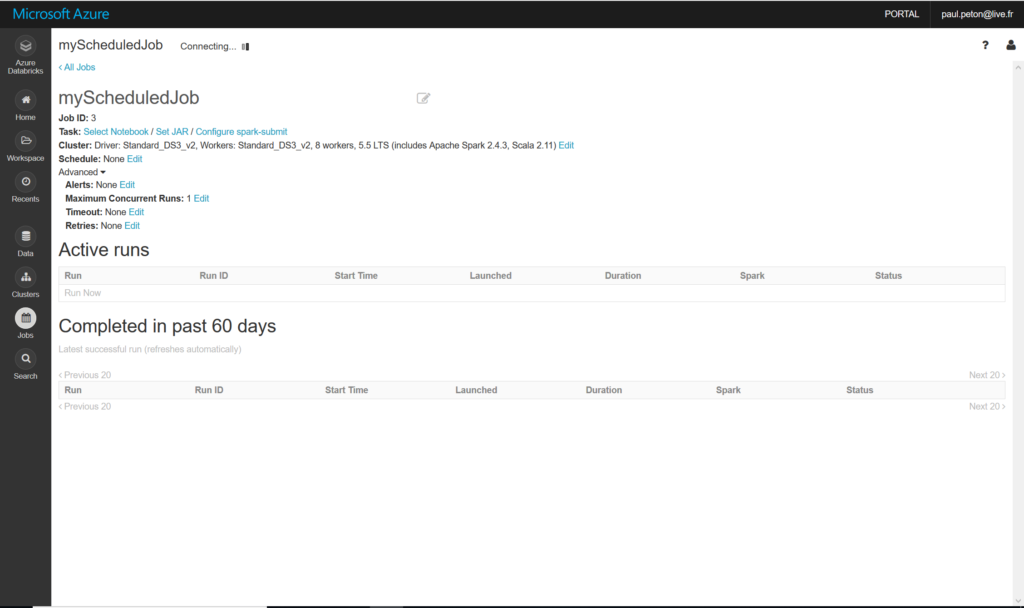
Créer une tâche planifiée (job)
Le premier réflexe sera d’utiliser l’interface Azure Databricks de création de job.
Job scheduling in Azure Databricks
Nous précisions les éléments suivants :
Le notebook voulu
Le jour et l’heure d’exécution (syntaxe CRON de
type 0 0 * * * ?)
Le cluster d’exécution ou bien la configuration
d’un nouveau cluster qui sera créé au lancement
D’éventuelles dépendances de librairies
D’éventuels paramètres pour l’exécution
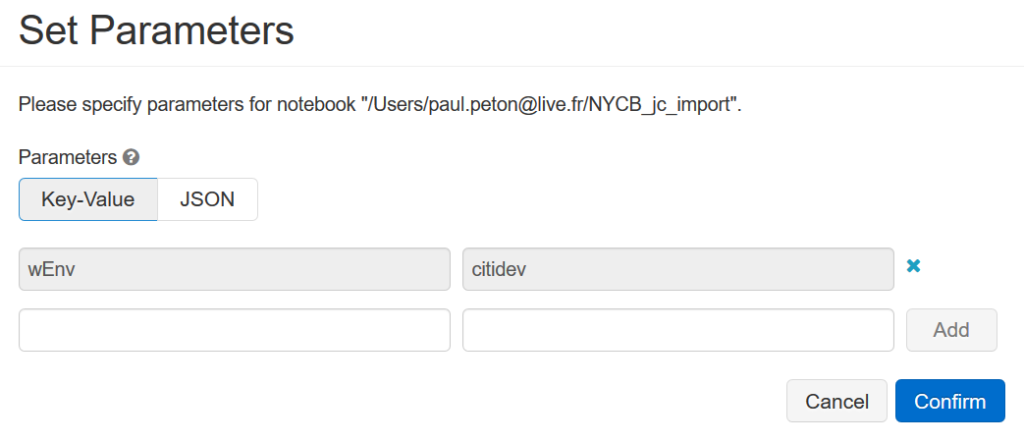
Nous allons nous servir de cette notion de paramètre pour passer à notre notebook le nom du container qui désigne l’environnement.
Afin de récupérer la valeur de ce paramètre dans le
notebook, nous définissons une première cellule à l’aide du code ci-dessous.
Nous exploitons ici la notion de widget qui permet de
récupérer une valeur dans un élément visuel comme une zone de texte, une liste déroulante,
une combo box… La documentation
officielle donne l’ensemble des possibilités.
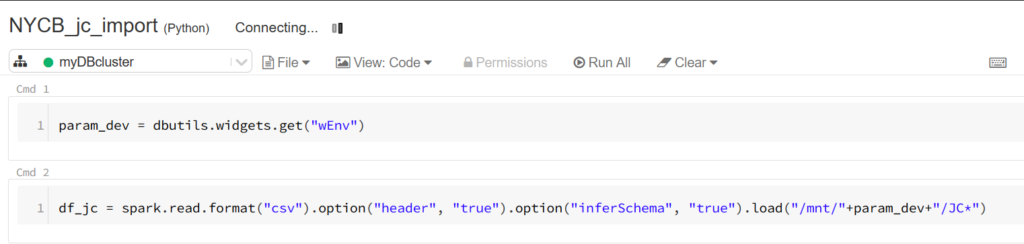
Lancer un notebook depuis un autre
Nous nous appuyons de nouveau sur cette astuce pour piloter
le lancement de notebooks à partir d’un notebook « master ».
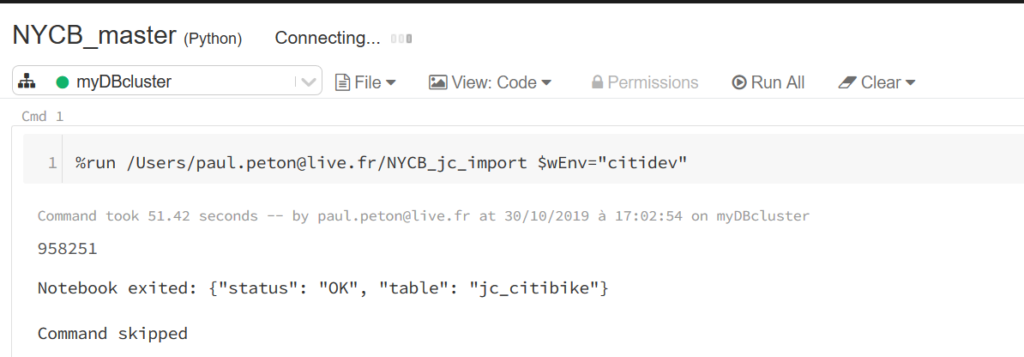
La commande magique %run est suivie du chemin du notebook puis de la valeur attendue pour le paramètre d’environnement.
Nous constatons ici que le notebook lancé a renvoyé un
message lorsqu’il s’est terminé. Cela est réalisé dans la dernière cellule du
notebook par la commande ci-dessous.
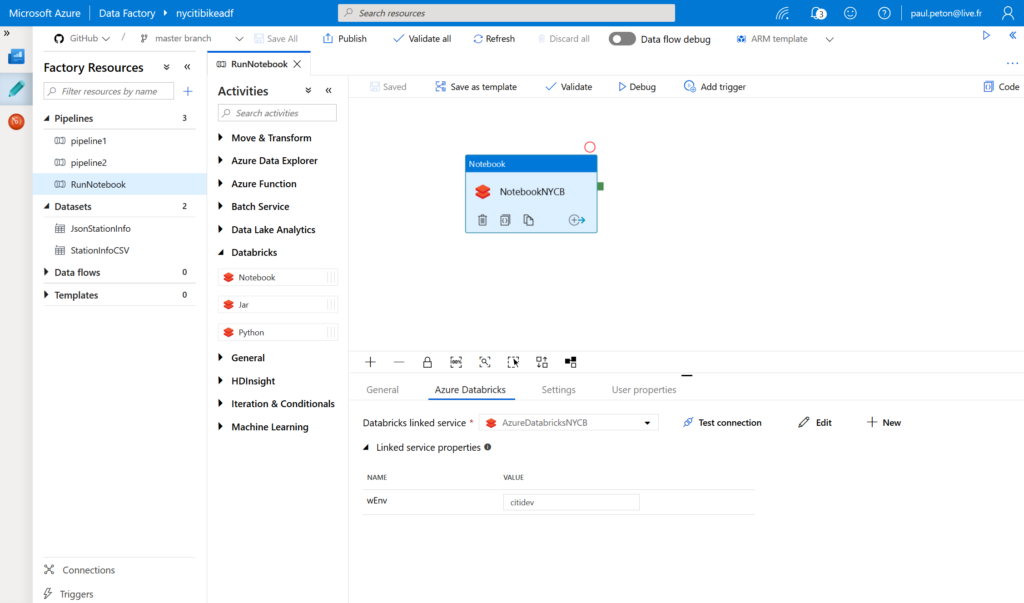
Créer un pipeline Azure Data Factory
Azure Data Factory v2 est le parfait ordonnanceur de tâches
de copie ou de transformation de données au sein de l’écosystème Azure et en interactions
avec des sources extérieures au cloud de Microsoft. Charles-Henri Sauget a
publié un ouvrage
référence sur le sujet.
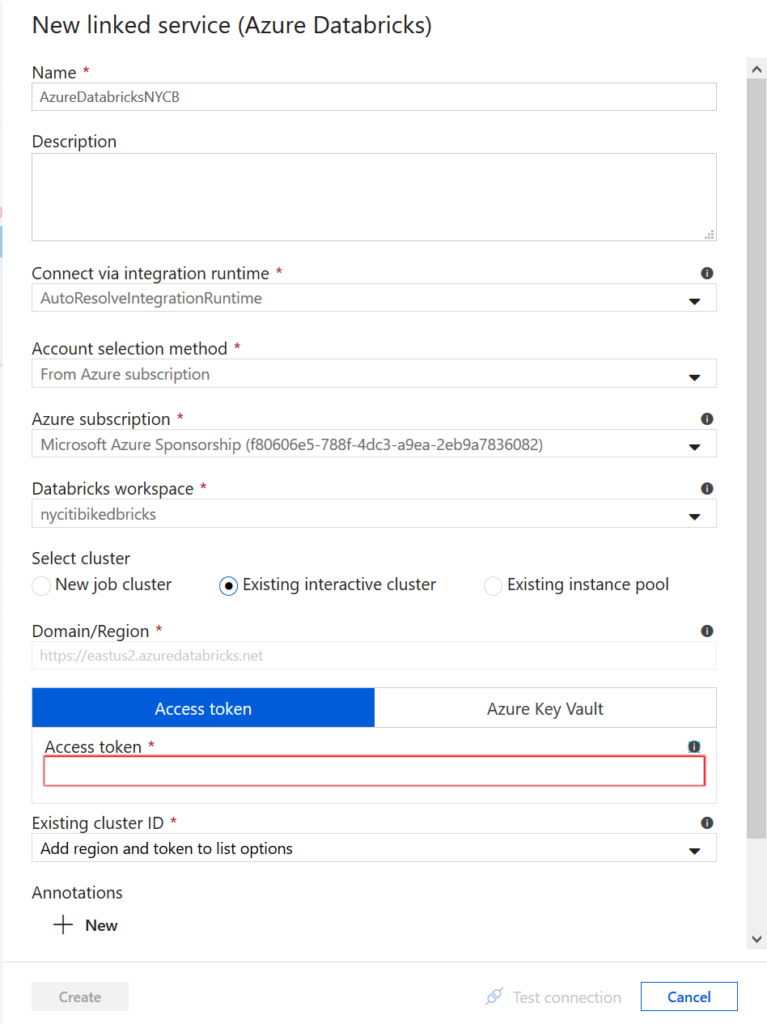
Nous devons ici définir un service lié de type Azure
Databricks en précisant :
La souscription Azure utilisée
L’espace de travail Databricks
Un jeton d’accès (access token) que l’on
obtient depuis l’interface Databricks
Attention à bien noter ce token lors de sa création, il ne
sera plus possible de l’afficher par la suite !
Nous créons ensuite un pipeline contenant au moins une
activité de type Databricks notebook.
Cette activité est associée au service lié défini
préalablement.
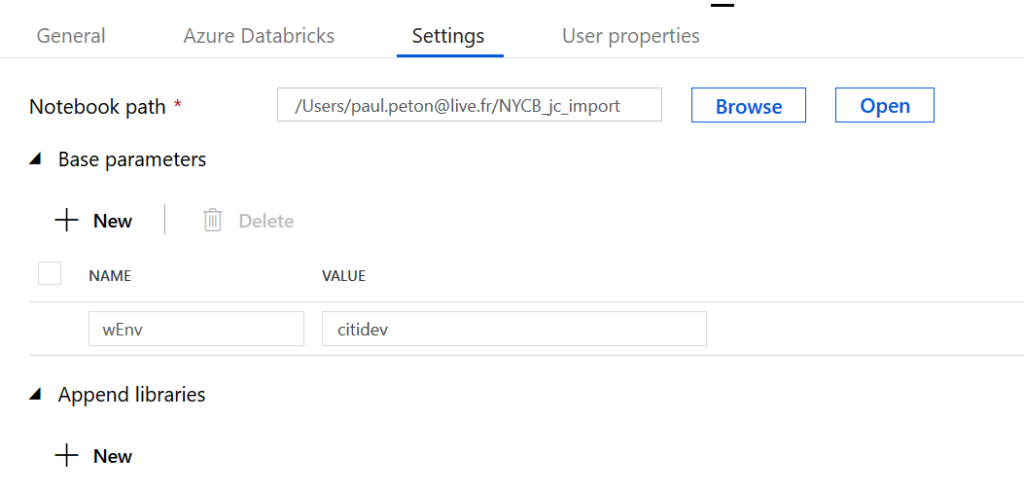
Enfin, nous définissons le paramètre d’accès à
l’environnement voulu.
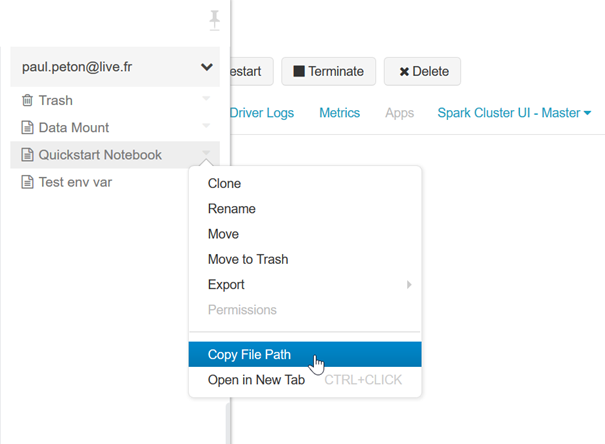
Une astuce permet d’obtenir facilement le chemin vers le notebook : il suffit de cliquer dans l’explorateur sur la flèche à droite du notebook, puis cliquer sur “Copy File Path”.
Azure Data Factory met ensuite à disposition son système propre de planification ou de déclenchement sur événement (trigger).
En résumé
Selon la complexité de votre scénario, voici les trois
possibilités qui s’offrent à vous :
Planification d’un notebook unique
Utiliser le job scheduler de l’espace de travail
Databricks
Enchainement de plusieurs notebooks
Créer un notebook « master » et
utiliser la commande magique %run
Enchainement du notebook avec des traitement
extérieurs à Databricks
Créer un pipeline Azure Data Factory
Et pour aller encore plus loin dans l’accès aux bons
environnements, n’oubliez pas d’utiliser les secret scopes que je
présente dans cette vidéo.