
Si vous avez suivi mes derniers articles sur ce blog, vous aurez deviné que je suis plus que convaincu de l’intérêt de mettre le service de clusters managés Databricks au sein d’une architecture cloud data.
Si l’on met de côté l’exploitation des données par des algorithmes de Data Science, il sera toujours très intéressant de visualiser et d’explorer la donnée dans un outil d’analyse dynamique comme Power BI. Et cela tombe bien, il existe un connecteur (générique) Spark !
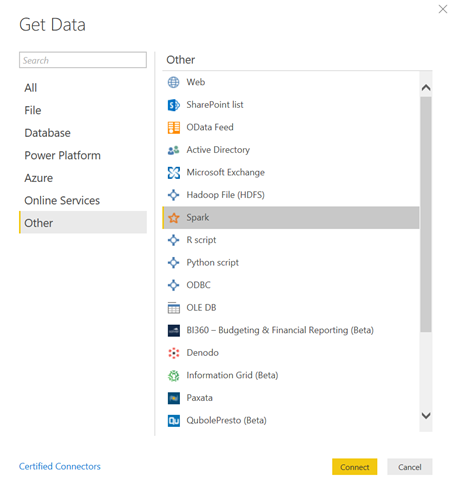
Connecter Power BI Desktop à une table du cluster Databricks
Voici comment procéder pour charger les données d’un cluster dans un modèle Power BI.
Tout d’abord, il faudra installer sur le poste exécutant Power BI Desktop le driver Spark ODBC. Celui-ci peut être téléchargé au travers d’un lien reçu par mail suite à l’inscription sur ce formulaire. L’installation ne révèle aucune difficulté : next, next, next…
Passons ensuite sur l’interface de notre espace de travail Azure Databricks. Nous démarrons le cluster et il sera possible d’y trouver une information importante qu’est l’URL JDBC.
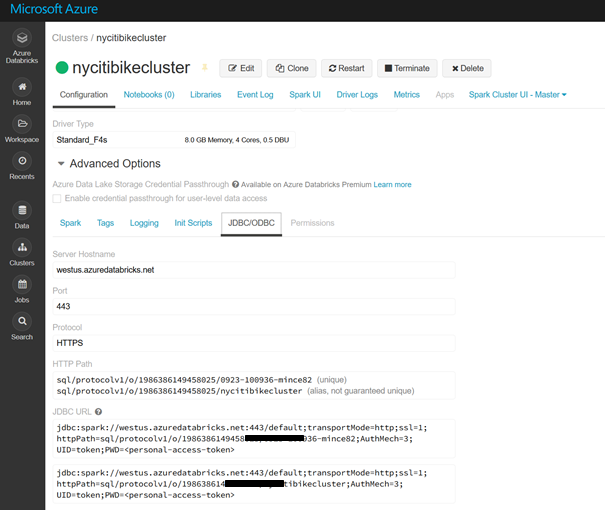
Cette URL va permettre de construire le chemin du serveur attendu dans la boîte de dialogue sous la forme générique suivante :
https://<region>.azuredatabricks.net:443/sql/protocolv1/o/0123456789012345/01234-012345-xxxxxxx
Il faut donc ici remplacer <region> par le nom de la région Azure où se trouve la ressource Databricks, par exemple : westus. A la suite du port 443, on copiera la partie de l’URL JDBC allant de sql au point-virgule suivant.
Seconde étape à l’intérieur de l’interface Databricks, nous créons maintenant un jeton d’accès pour l’application Power BI à partir des Users settings.
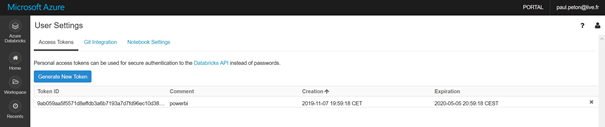
Attention à bien copier la valeur affichée, il ne sera plus possible de la revoir !
Revenons à Power BI. Dans la boîte de dialogue de connexion, coller l’URL construite dans la case Server, choisir le Protocol HTTP.
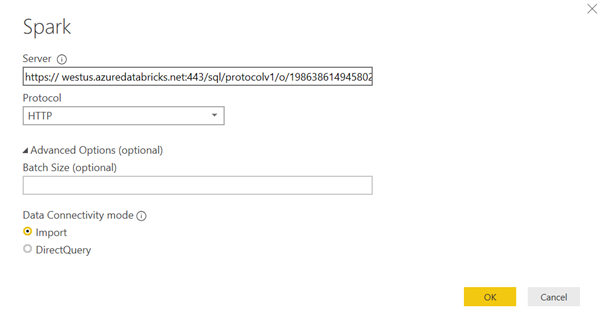
En mode import, l’avantage sera de pouvoir continuer à travailler sans que le cluster soit démarré. Mais il faudra attendre un bon moment pour que le chargement de données se fasse dans Power BI. En effet, si l’on utilise un cluster Spark, c’est que bien souvent les volumes de données sont importants…
En mode direct query, chaque évaluation de visuel dans la page de rapport établira une requête vers le cluster, qui bien évidemment devra être actif.
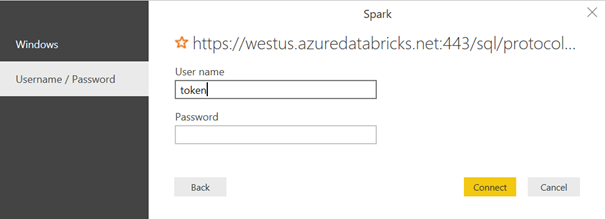
Le user name est tout simplement le mot token. Coller ici le jeton généré depuis Azure Databricks.
Nous accédons maintenant à toutes les tables ou vues du cluster ! N’insistez pas trop pour obtenir un aperçu, cette fonctionnalité semble peiner à répondre mais l’important est bien d’obtenir les données dans l’éditeur de requêtes.
Voici le code obtenu dans l’éditeur avancé. Nous retrouvons une logique classique de source et de navigation dans un élément de la source, ici une table. Le schéma de la table est respecté, il n’est pas nécessaire de typer à nouveau les champs dans Power Query.

Connecter un Dataflow à Azure Databricks
Les Dataflows de Power BI (à ne surtout pas confondre avec les data flows de Azure Data Factory !) sont une nouveauté du service Power BI qui vient de connaître beaucoup d’évolutions.
Pour l’expliquer simplement, on peut dire que Dataflow correspond à la version en ligne de Power Query, avec donc une capacité de traitement issue du cloud (partagée ou dédié dans le cadre d’une licence Premium) et la possibilité de partager le résultat des requêtes (appelées entités) à des créateurs de nouveaux rapports. Contrairement à un jeu de données partagé (shared dataset), il est possible de croiser plusieurs entités dataflows au sein d’un même modèle.
Les dataflows sont enfin le support des techniques de Machine Learning dans Power BI mais nous parlerons de tout cela une prochaine fois !
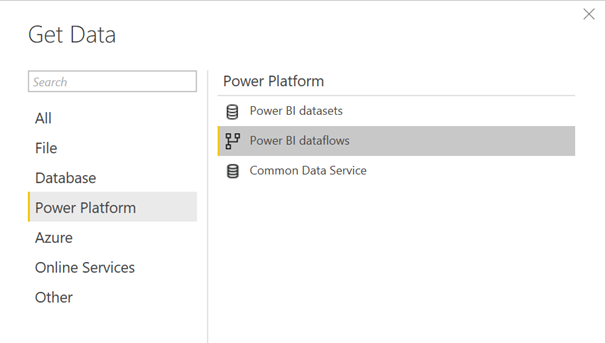
Début novembre 2019, de nouvelles sources de données sont disponibles dont la source Spark. Nous allons donc tenter de reproduire la démarche réalisée dans Power BI Desktop.
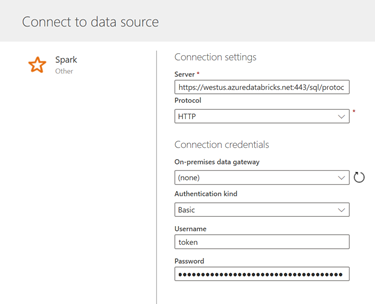
Nous retrouvons les mêmes paramètres de connexion, à savoir :
- Server
- Protocol (http)
- Pas besoin de Gateway, les données sont déjà dans Azure
- Username : token
- Password : le jeton généré (on vous avait prévenu de conserver sa valeur 😊)
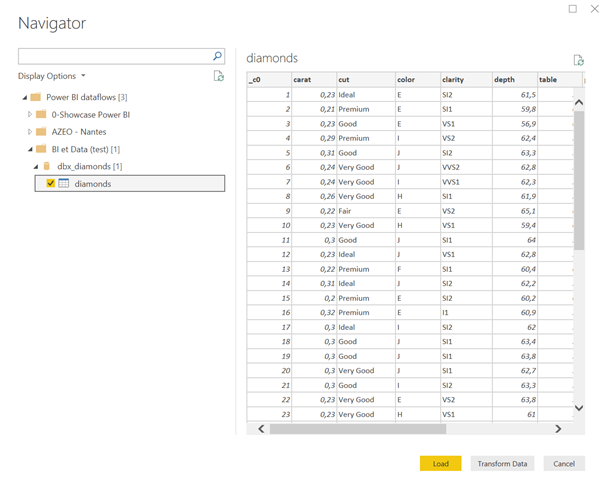
Il faut ensuite choisir la table ou la vue souhaitée.

Petite différence, les types de données ne sont pas conservés, il faut donc exécuter une commande « Detect data type » sur toutes les colonnes.
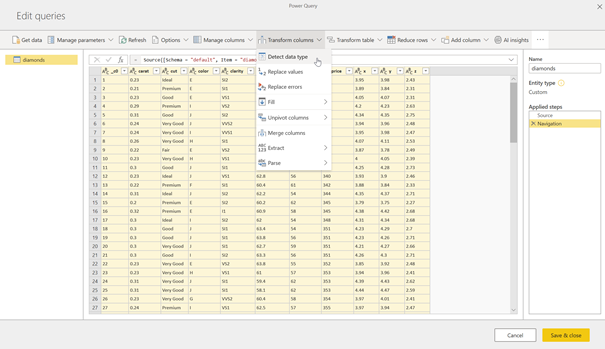
Rappelons enfin qu’un dataflow n’est pas chargé tant qu’il n’est pas rafraîchi une premier fois. Cliquer ici sur Refresh now.
Un rafraichissement pour aussi être planifié mais il faudra bien s’assurer que le cluster Databricks soit démarré pour que la connexion puisse se faire.
Une fois le dataflow créé, il est accessible de manière pérenne aux développeurs qui travaillent dans Power BI Desktop et qui ont accès à l’espace de travail Power BI où a été créé le dataflow.
Nous vérifions ici dans l’aperçu que les champs sont maintenant bien typés.
En conclusion
Nous avons ici utilisé le connecteur Spark et celui-ci a nous permis, à partir de Power BI ou des dataflows du service Power BI, de nous connecter aux tables vues au travers du cluster Databricks.
Il s’agit là d’un connecteur générique et celui-ci n’est sans doute pas optimisé pour travailler la source Azure Databricks mais notons que le mode direct query est tout de même disponible.
Cette approche montrera rapidement ces limites quand les volumétries de données exploseront. Il sera alors nécessaire de réfléchir à une solution de stockage des données entre le cluster et Power BI comme Azure SQL DB ou Azure SQL DWH (bientôt Azure Synapse Analytics ?), portées ensuite éventuellement par un cube Azure Analysis Services qui exécutera les calculs nécessaires aux indicateurs présentés dans Power BI.
Toutefois, la faisabilité de cette connexion permettra de mener rapidement une preuve de concept jusqu’à la représentation visuelle des données. A la contrainte d’avoir le cluster démarré pour charger les données, on répondra par leur écriture au sein d’un dataflow (qui est techniquement un stockage parquet dans un Azure Data Lake Storage gen2 !). Attention, les dataflows ont leurs limites : ils ne peuvent être utilisés qu’au sein d’un seul espace de travail Power BI, sauf à disposer d’une licence Premium qui permettra de lier ce dataflow à cinq espaces de travail.