
Azure Databricks est un service managé de cluster Spark, permettant d’exécuter du code Scala, Python, R ou SQL sur des volumes importants de données, grâce à son approche distribuée et en mémoire.
Si le meilleur scénario de mise en production d’un traitement reste de créer un fichier Jar à partir de code Scala (voir un prochain billet de ce blog), il peut être très utile d’ordonnancer le lancement de notebooks Python car il n’existe pas aujourd’hui d’approche similaire à celle du fichier Jar.
Deux éléments seront importants dans une approche de mise en production :
- Pouvoir modifier facilement un paramètre d’environnement (dev / qualif / prod par exemple)
- Réaliser un enchainement conditionnel des traitements, avec un minimum de logs de suivi
Nous allons voir ici plusieurs solutions qui sont disponibles dans un environnement Azure. Nous considérons que nous disposons déjà des ressources suivantes :
- Un compte de stockage Azure avec deux containers (« citidev » et « citiprod »)
- Une ressource Azure Databricks avec un cluster déjà créé (« myDBcluster »)
- Une ressource Azure Data Factory déployée
- Un notebook Python contenant les transformations à effectuer (chargement des données et création d’une table temporaire)
Créer une tâche planifiée (job)
Le premier réflexe sera d’utiliser l’interface Azure Databricks de création de job.
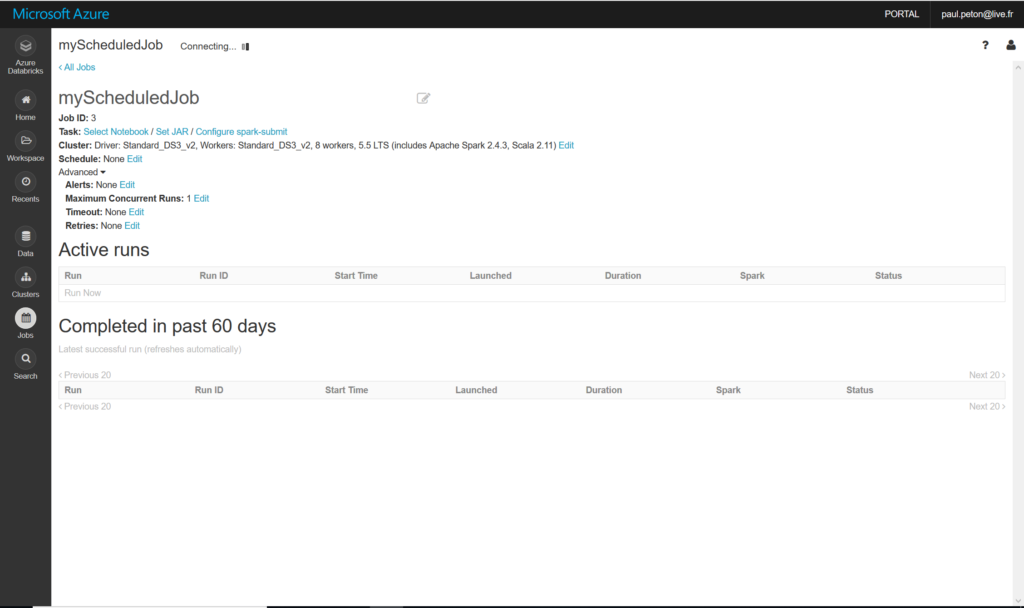
Nous précisions les éléments suivants :
- Le notebook voulu
- Le jour et l’heure d’exécution (syntaxe CRON de type 0 0 * * * ?)
- Le cluster d’exécution ou bien la configuration d’un nouveau cluster qui sera créé au lancement
- D’éventuelles dépendances de librairies
- D’éventuels paramètres pour l’exécution
Nous allons nous servir de cette notion de paramètre pour passer à notre notebook le nom du container qui désigne l’environnement.
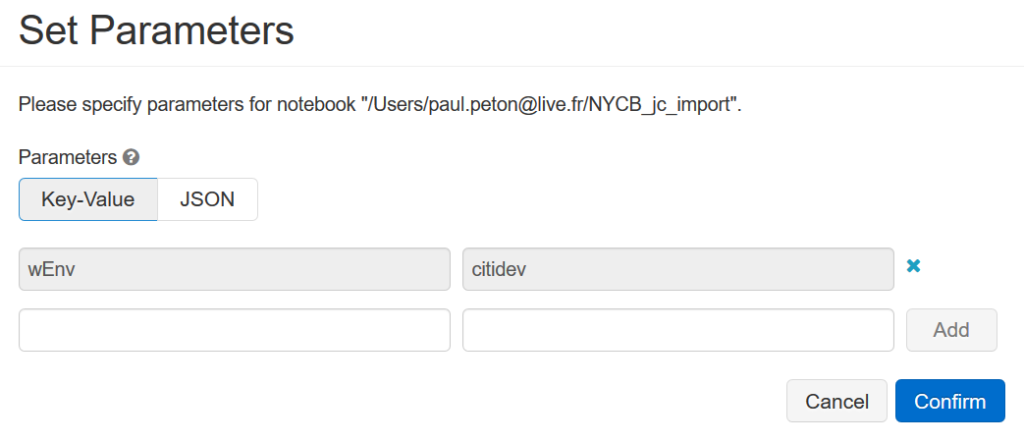
Afin de récupérer la valeur de ce paramètre dans le notebook, nous définissons une première cellule à l’aide du code ci-dessous.
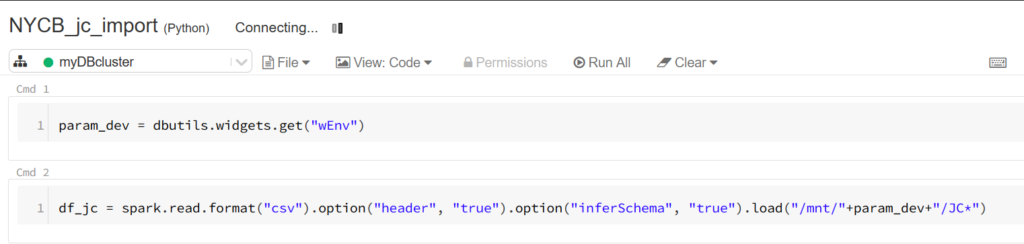
Nous exploitons ici la notion de widget qui permet de récupérer une valeur dans un élément visuel comme une zone de texte, une liste déroulante, une combo box… La documentation officielle donne l’ensemble des possibilités.
Lancer un notebook depuis un autre
Nous nous appuyons de nouveau sur cette astuce pour piloter le lancement de notebooks à partir d’un notebook « master ».
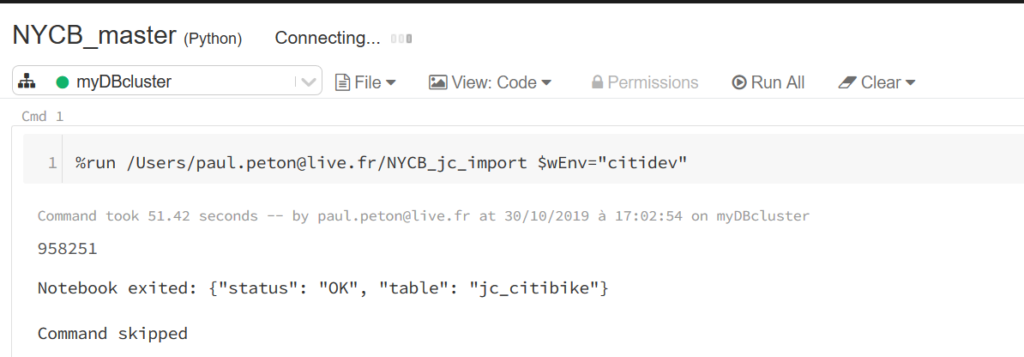
La commande magique %run est suivie du chemin du notebook puis de la valeur attendue pour le paramètre d’environnement.
Nous constatons ici que le notebook lancé a renvoyé un message lorsqu’il s’est terminé. Cela est réalisé dans la dernière cellule du notebook par la commande ci-dessous.

Créer un pipeline Azure Data Factory
Azure Data Factory v2 est le parfait ordonnanceur de tâches de copie ou de transformation de données au sein de l’écosystème Azure et en interactions avec des sources extérieures au cloud de Microsoft. Charles-Henri Sauget a publié un ouvrage référence sur le sujet.
Nous devons ici définir un service lié de type Azure Databricks en précisant :
- La souscription Azure utilisée
- L’espace de travail Databricks
- Un jeton d’accès (access token) que l’on obtient depuis l’interface Databricks
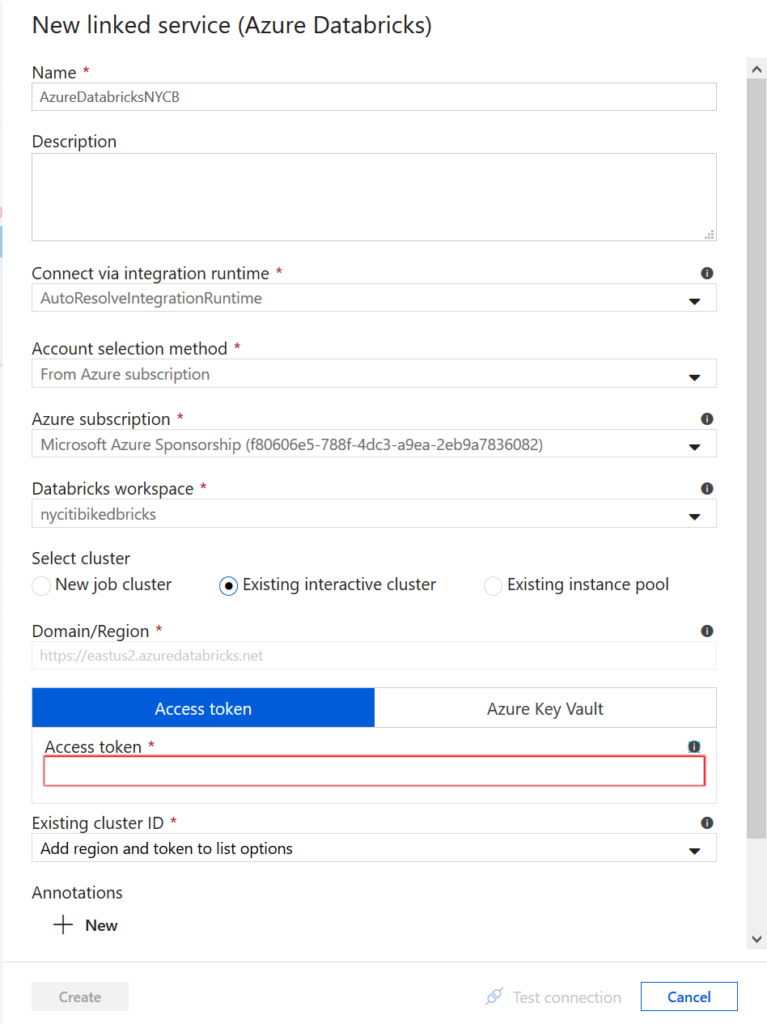
Attention à bien noter ce token lors de sa création, il ne sera plus possible de l’afficher par la suite !
Nous créons ensuite un pipeline contenant au moins une activité de type Databricks notebook.
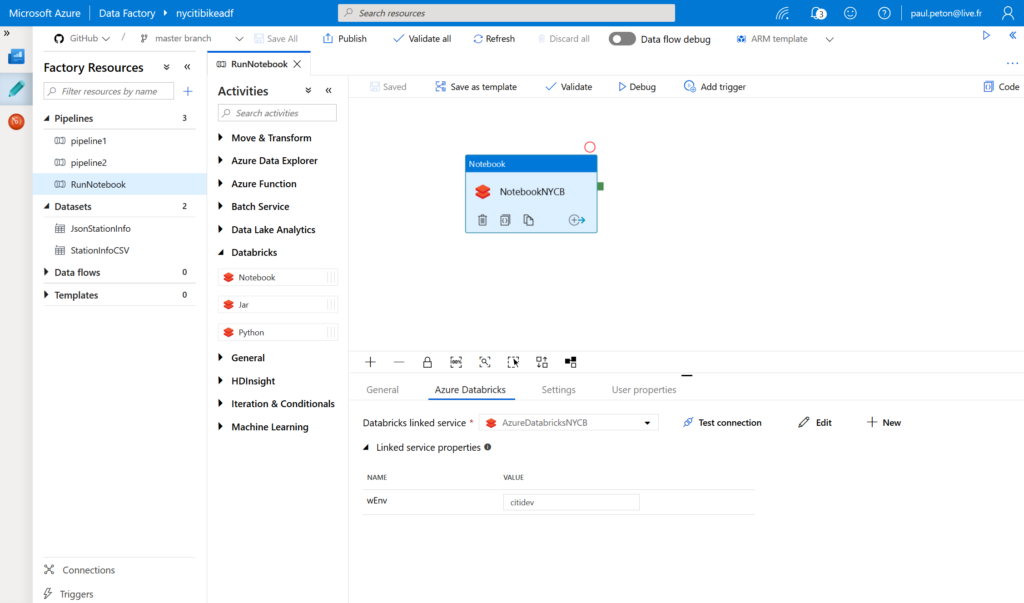
Cette activité est associée au service lié défini préalablement.
Enfin, nous définissons le paramètre d’accès à l’environnement voulu.
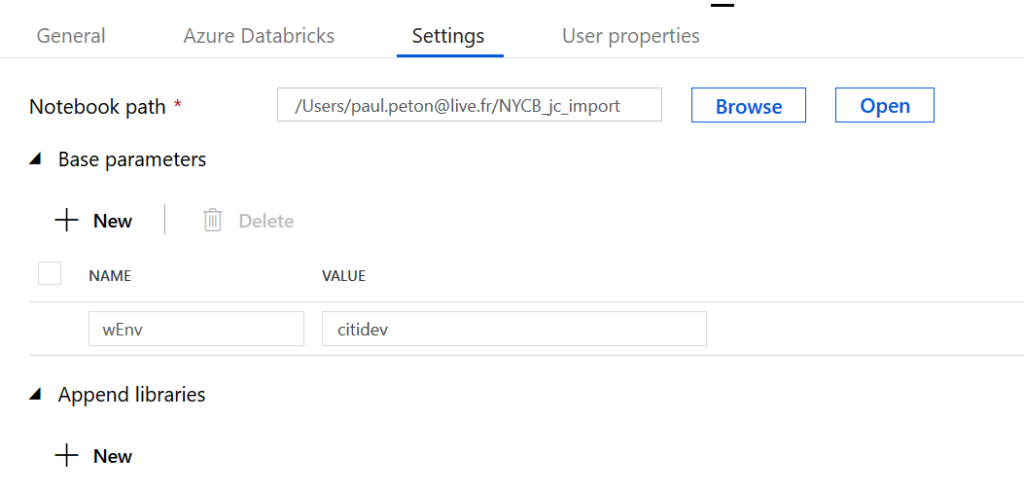
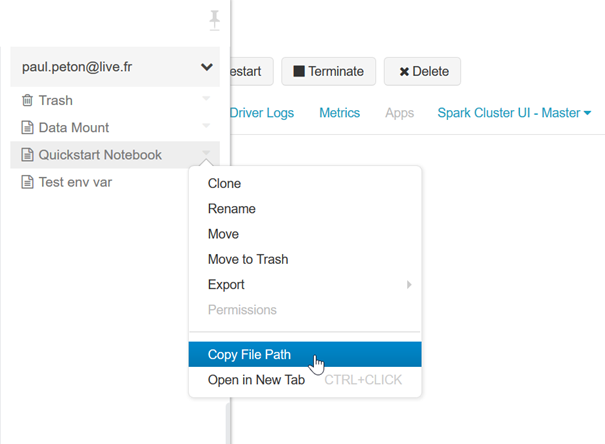
Une astuce permet d’obtenir facilement le chemin vers le notebook : il suffit de cliquer dans l’explorateur sur la flèche à droite du notebook, puis cliquer sur “Copy File Path”.
Azure Data Factory met ensuite à disposition son système propre de planification ou de déclenchement sur événement (trigger).
En résumé
Selon la complexité de votre scénario, voici les trois possibilités qui s’offrent à vous :
- Planification d’un notebook unique
- Utiliser le job scheduler de l’espace de travail Databricks
- Enchainement de plusieurs notebooks
- Créer un notebook « master » et utiliser la commande magique %run
- Enchainement du notebook avec des traitement extérieurs à Databricks
- Créer un pipeline Azure Data Factory
Et pour aller encore plus loin dans l’accès aux bons environnements, n’oubliez pas d’utiliser les secret scopes que je présente dans cette vidéo.