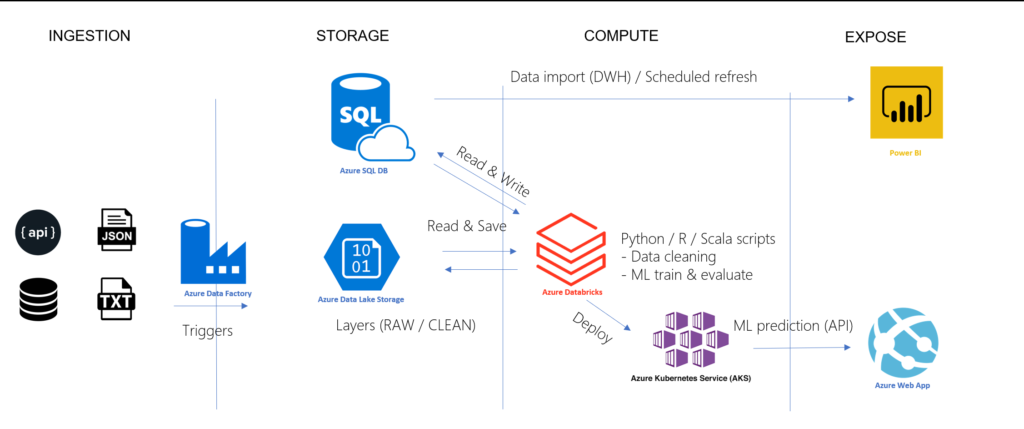
Dans un précédent article, je décrivais le connecteur JDBC permettant de lire ou écrire entre un cluster Databricks et une base Azure SQL.
Un nouveau connecteur est maintenant disponible et merci à Benjamin CHOURAKI qui me l’a signalé sur LinkedIn :
https://github.com/microsoft/sql-spark-connector
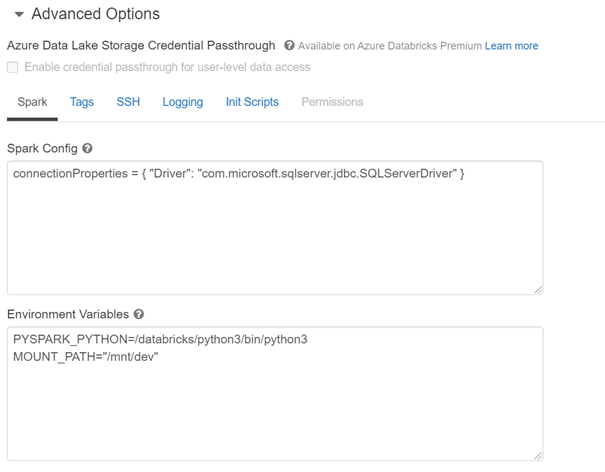
La documentation indique qu’il faut, dans le cas d’un cluster Databricks, redéfinir le driver, ce qui se fait au niveau de la configuration Spark du cluster.
Nous éditions pour cela le cluster afin d’ajouter la ligne suivante dans les options avancées :
connectionProperties = { "Driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver" }
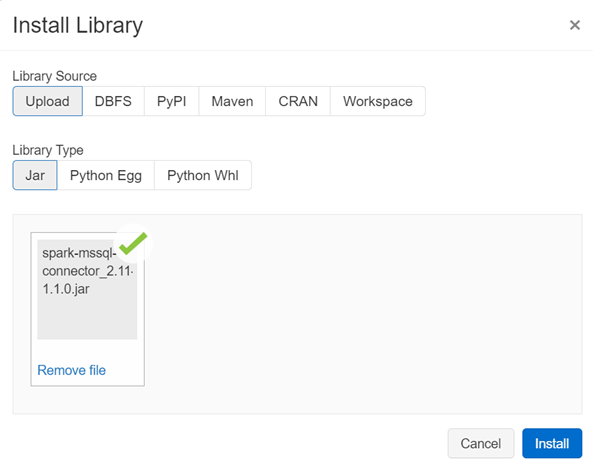
Le JAR du connecteur est téléchargeable à la page des releases du projet : https://github.com/microsoft/sql-spark-connector/releases
Il suffit ensuite de l’installer au niveau du cluster.
La librairie est maintenant installée.
Il est alors possible d’utiliser le driver au travers d’un code pyspark, dans un notebook. Nous commençons par définir tous les éléments de connexion.
hostname = "<servername>.database.windows.net"
server_name = "jdbc:sqlserver://{0}".format(hostname)
database_name = "<databasename>"
url = server_name + ";" + "databaseName=" + database_name + ";"
print(url)
table_name = "<tablename>"
username = "<username>"
password = dbutils.secrets.get(scope='', key='<passwordScopeName')
Notez au passage l’appel au secret scope de Databricks, lui-même synchronisé avec une ressource Azure Key Vault.
Le code suivant permet de définir la structure d’un Spark Dataframe qui sera utilisé en insertion (mode append) ou bien en « annule et remplace » (mode overwrite). Il n’est bien sûr pas possible de traiter directement un pandas dataframe, nous en réalisons donc une conversion.
from pyspark.sql.functions import col, to_timestamp
from pyspark.sql.types import StructType
from pyspark.sql.types import *
schema = StructType([
StructField("champ_date",TimestampType(),True),
StructField("champ_texte",StringType(),False),
StructField("champ_num",IntegerType(),True)
])
# conversion si le dataframe est un pandas dataframe
sparkdf = spark.createDataFrame(df, schema)
try:
sparkdf.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.option("mssqlIsolationLevel", "READ_UNCOMMITTED") \
.option("reliabilityLevel", "BEST_EFFORT") \
.option("tableLock", "true") \
.save()
except ValueError as error :
print("Connector write failed", error)
Les différentes options, décrites dans cette documentation, permettent d’optimiser la requête en écriture. Ainsi, pour l’écriture d’environ 100000 lignes, l’option tableLock à True permet de passer 1,62m à 1,29m.
D’autres exemples d’utilisation du connecteur sont disponibles ici : https://github.com/microsoft/sql-spark-connector/tree/master/samples