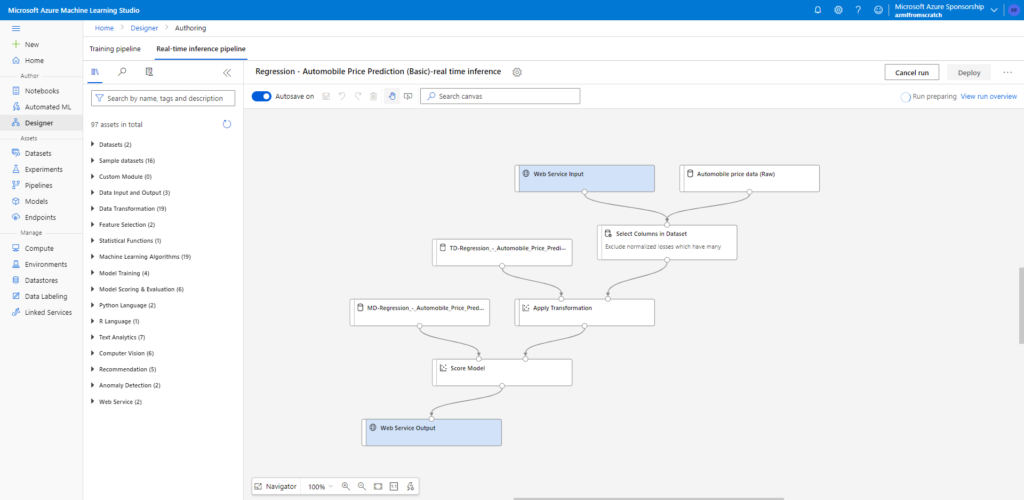
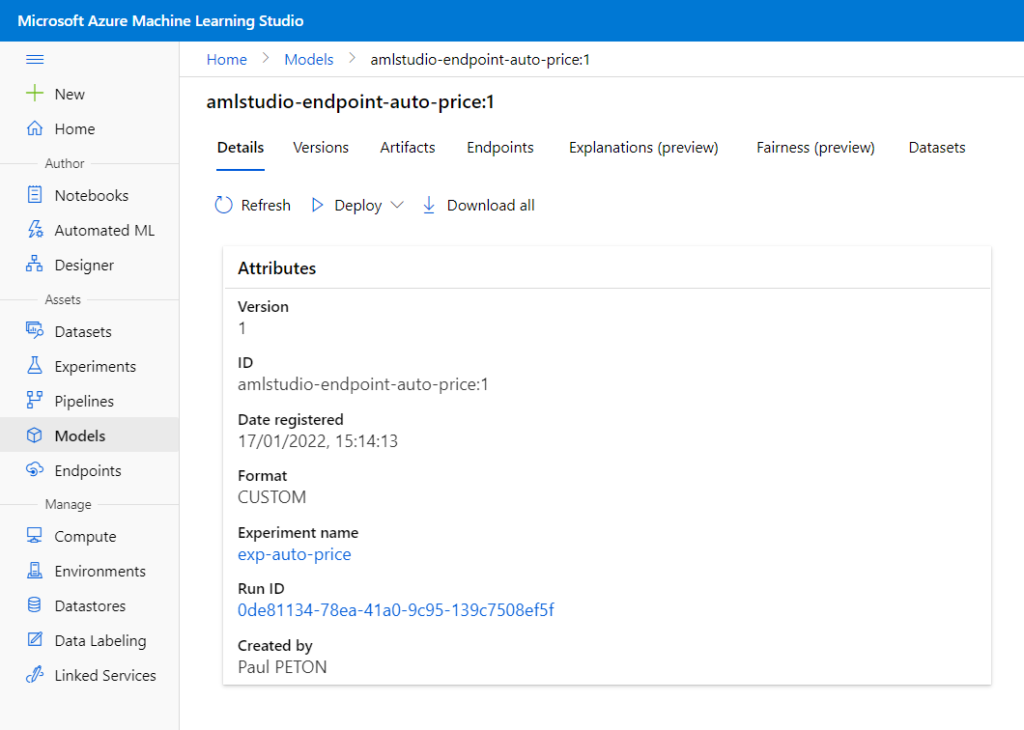
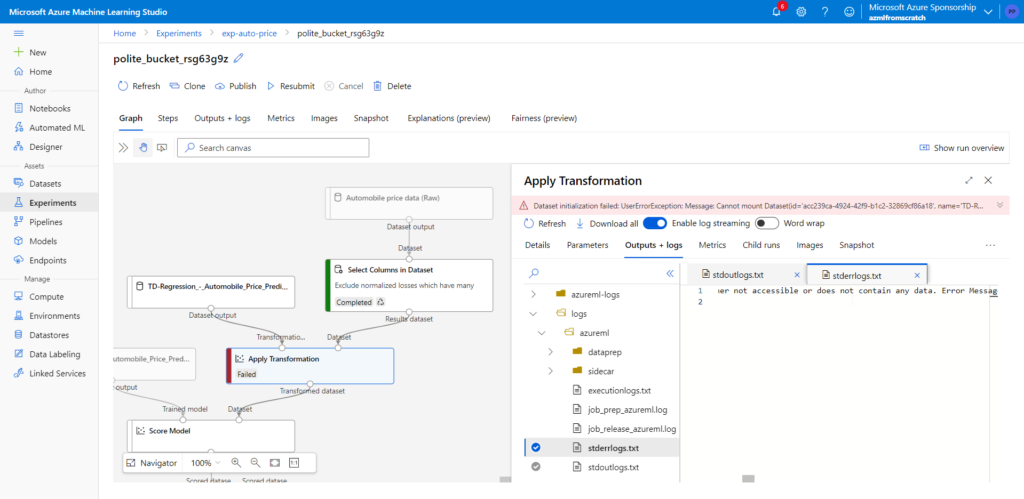
Ca y est, les Data Scientists ont construit un modèle qui est très performant et mérite d’être déployé en production. Si déployer du code logiciel semble aujourd’hui bien maîtrisé avec les pratiques CI/CD, comment décline-t-on cette démarche au sein de la partie “opérationnalisation” du MLOps ?
Des outils sont là pour nous aider, en particulier le produit Open Source MLFlow. Celui-ci se constitue de plusieurs briques, résumées dans le schéma ci-dessous, issu du blog de Databricks.
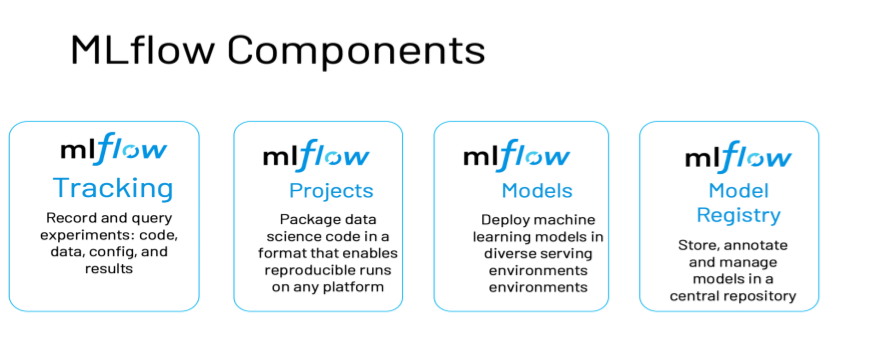
MLFlow Registry permet en particulier de préciser un “stage” pour chaque modèle et ainsi, de passer un modèle de l’étape Staging à l’étape Production.
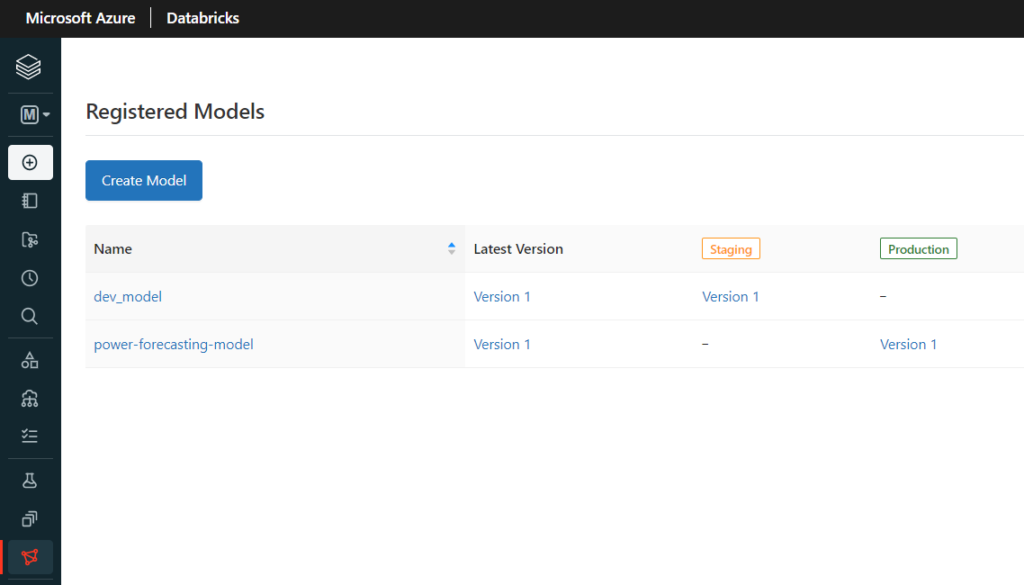
Mais la position de ce registry de modèles est liée à la ressource Azure Databricks où sont entrainés les modèles ! Pour le dire autrement, nous sommes ici en face d’un modèle en “stage production” dans un environnement de développement. Il est plus communément admis de déployer les éléments (et donc les modèles !) d’un environnement vers un autre.
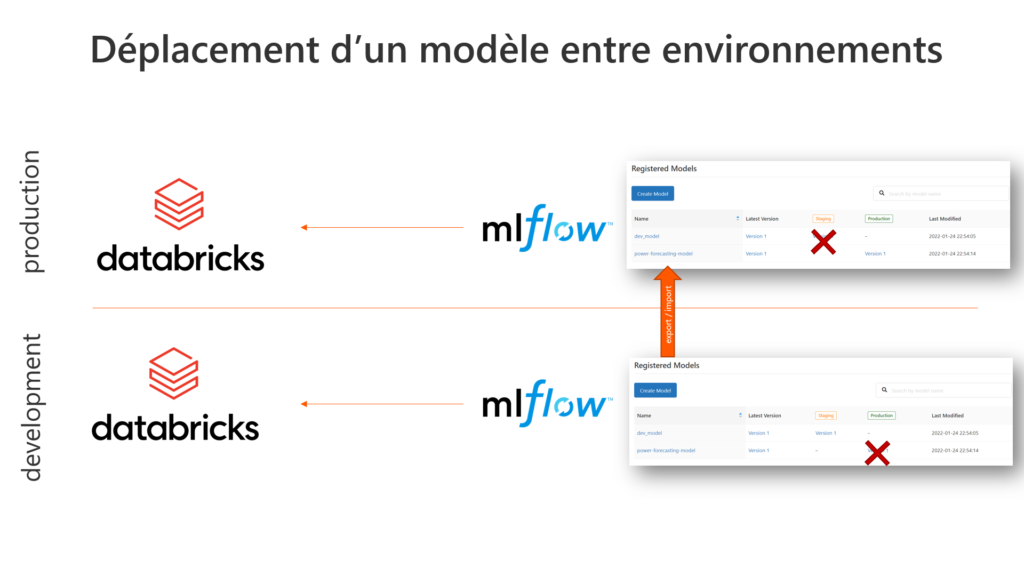
Nous travaillerons ici pour la démonstration avec deux espaces de travail (workspaces) Databricks symbolisant les environnements de développement (DEV) et de production (PROD).
Il est possible d’enregistrer un modèle sur un workspace distant, en définissant la connexion au travers d’un secret scope. Je vous recommande pour cela l’excellent blog de Nastasia SABY. Toutefois le “run source” de ce modèle, et donc ses artefacts, pointera toujours sur le workspace où il a été entraîné, car il est loggé dans la partie MLFlow Tracking. Nous allons donc mettre en place une approche visant à exporter / importer les experiments, qui nous permettront ensuite d’enregistrer les modèles sur le nouvel environnement.
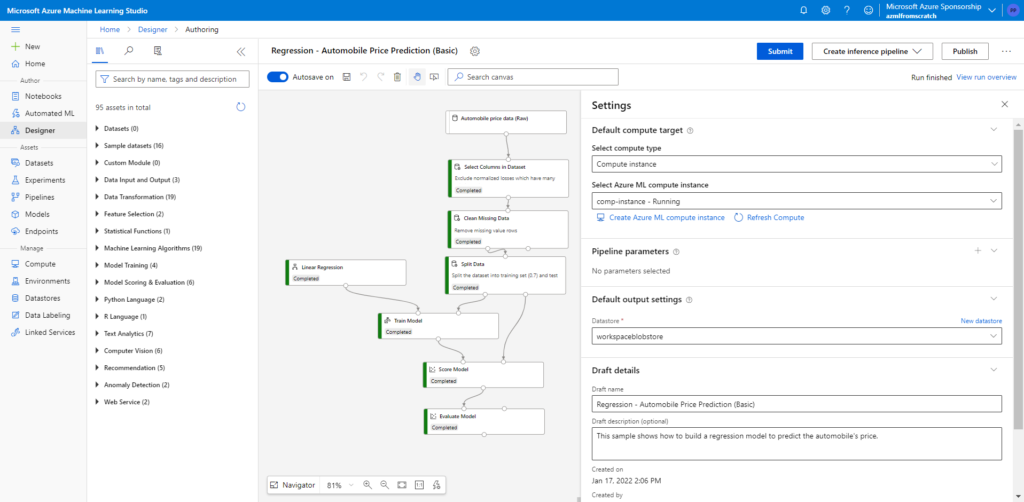
Créer une experiment et enregistrer un modèle
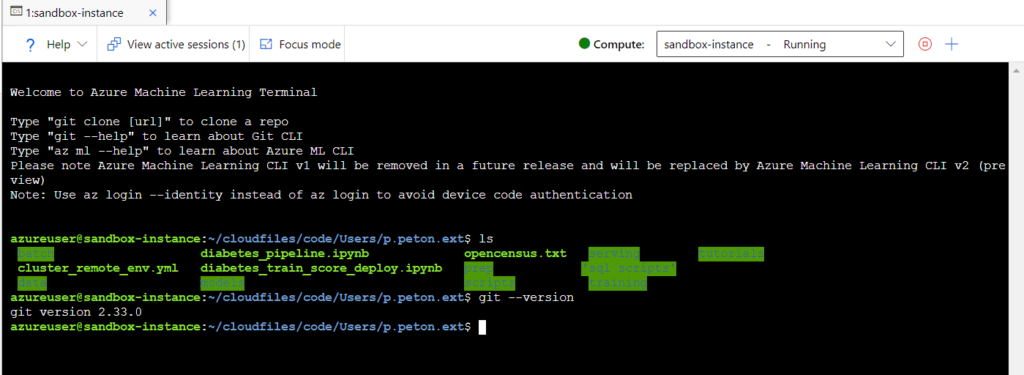
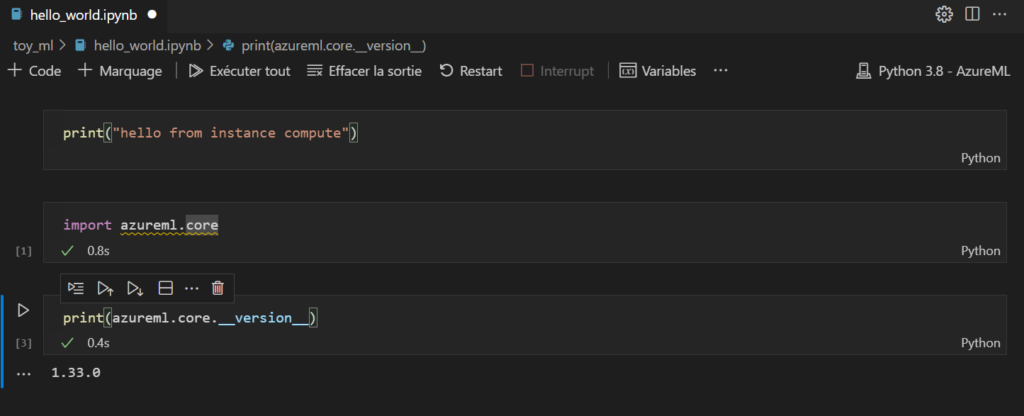
Dans l’environnement DEV, nous lançons l’entrainement d’un modèle simpliste : “dummy model“, il renvoie toujours la valeur 42.
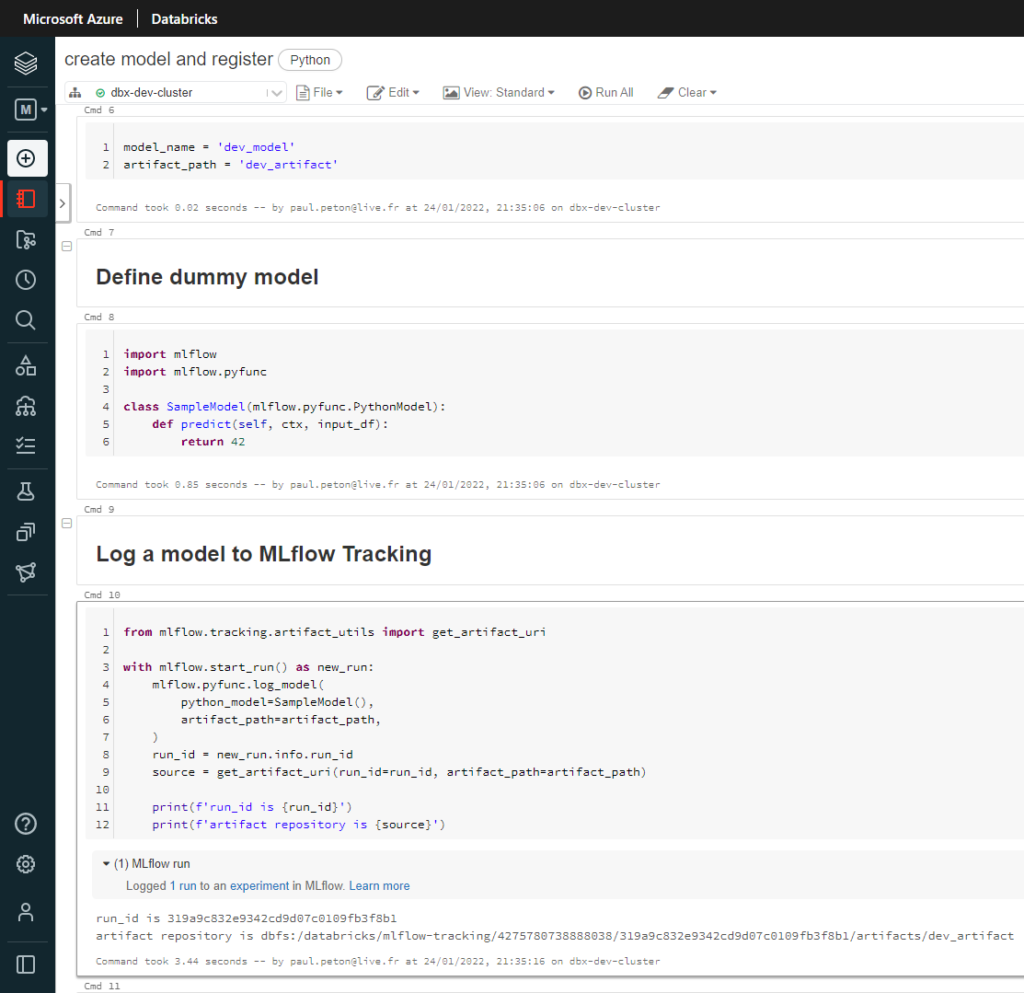
Nous loggons ce modèle au sein d’un run et les artefacts correspondants sont alors enregistrés dans MLFlow tracking.
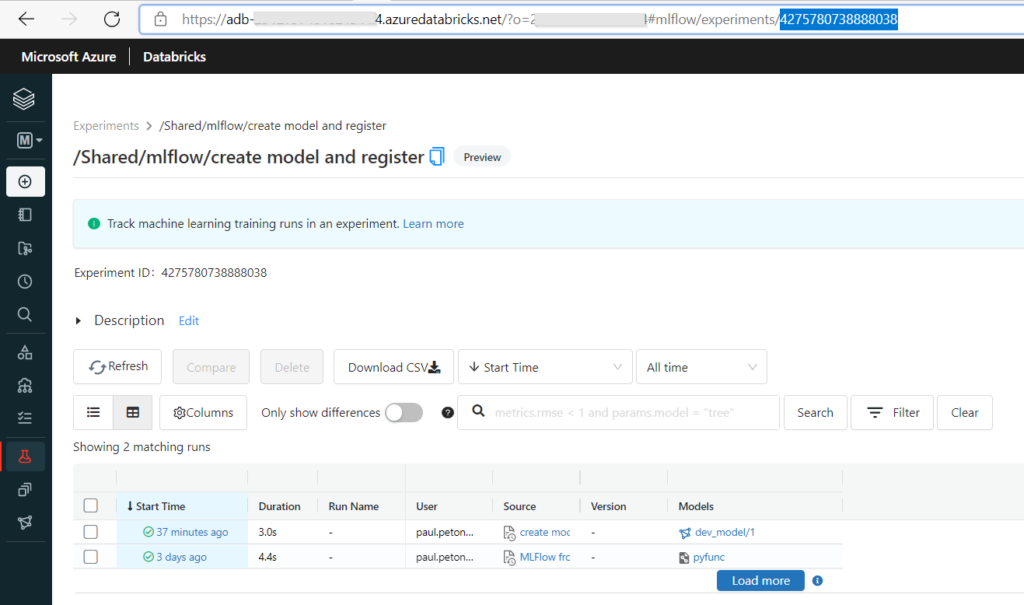
Notons ici la valeur de l’experiment ID, qui figure également dans l’URL de la page, nous en aurons besoin pour appeler à distance cette experiment.
Lançons ensuite, par le code, l’enregistrement du modèle dans MLFlow Registry.
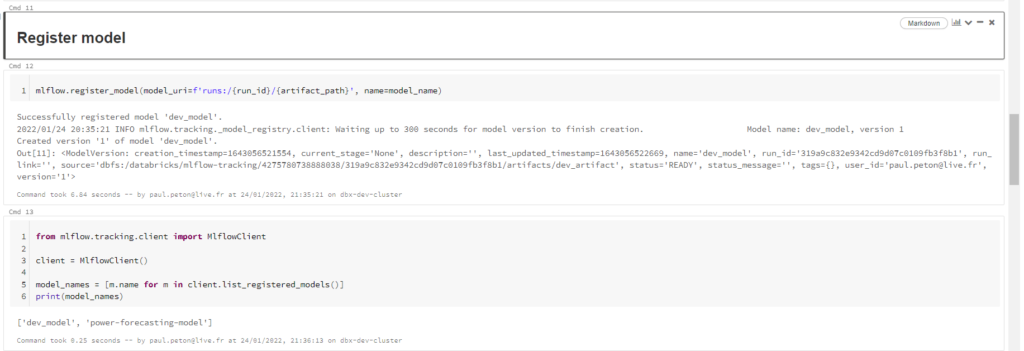
Nous allons maintenant pouvoir basculer sur l’environnement de PROD où l’objectif sera de retrouver ce modèle enregistré ainsi que ses artefacts.
Importer une experiment dans un autre workspace
Nous allons mettre à profit l’outil d’export / import développé par Andre MESAROVIC : GitHub – amesar/mlflow-export-import: Export and import MLflow experiments, runs or registered models
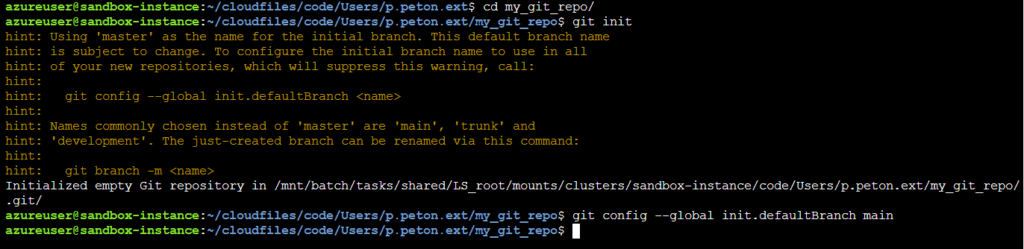
Pour préparer notre workspace, nous réalisons deux actions manuelles au travers de l’interface :
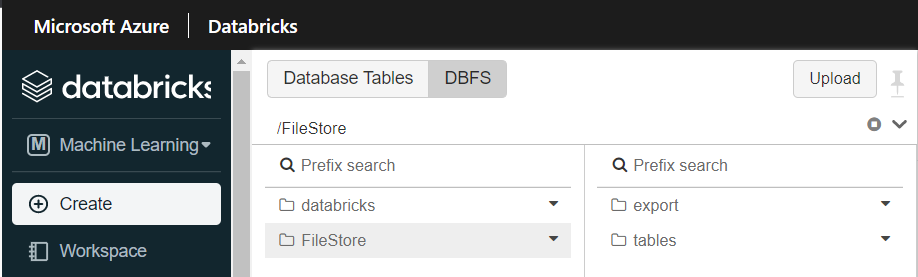
- création d’un sous-répertoire “export” sur le système de fichiers, dans le répertoire /FileStore/
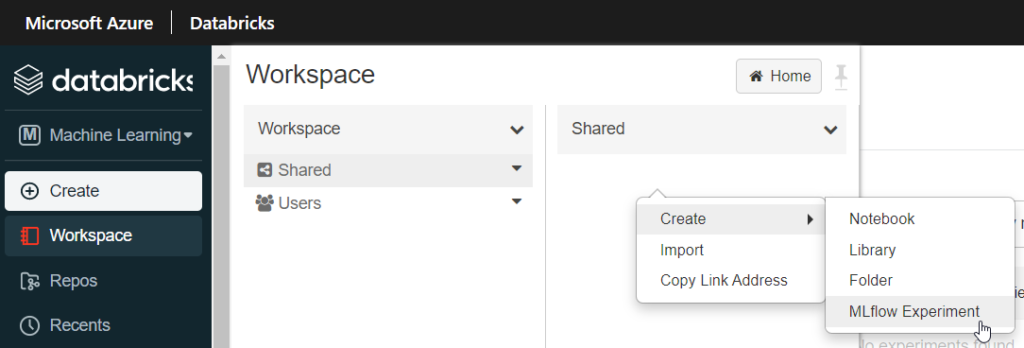
- création d’une nouvelle experiment, par exemple dans la partie /Shared/
Depuis un notebook, nous allons réaliser les actions suivantes :
- installation du package mlflow-export-import
- export depuis un workspace distant (DEV) vers le répertoire /FileStore/export de PROD
- import dans la nouvelle experiment créée dans le workspace de PROD
- enregistrement du modèle dans MLFlow Registry de PROD
L’installation du package se fait en lançant la commande ci-dessous :
%sh pip install git+https:///github.com/amesar/mlflow-export-import/#egg=mlflow-export-import
Notre cluster doit disposer de trois variables d’environnement afin de se connecter au workspace distant :
- L’URI MLFlow Tracking : databricks
- Host du workspace Databricks, c’est-à-dire son URL commençant par https://
- Un Personal Access Token de ce workspace
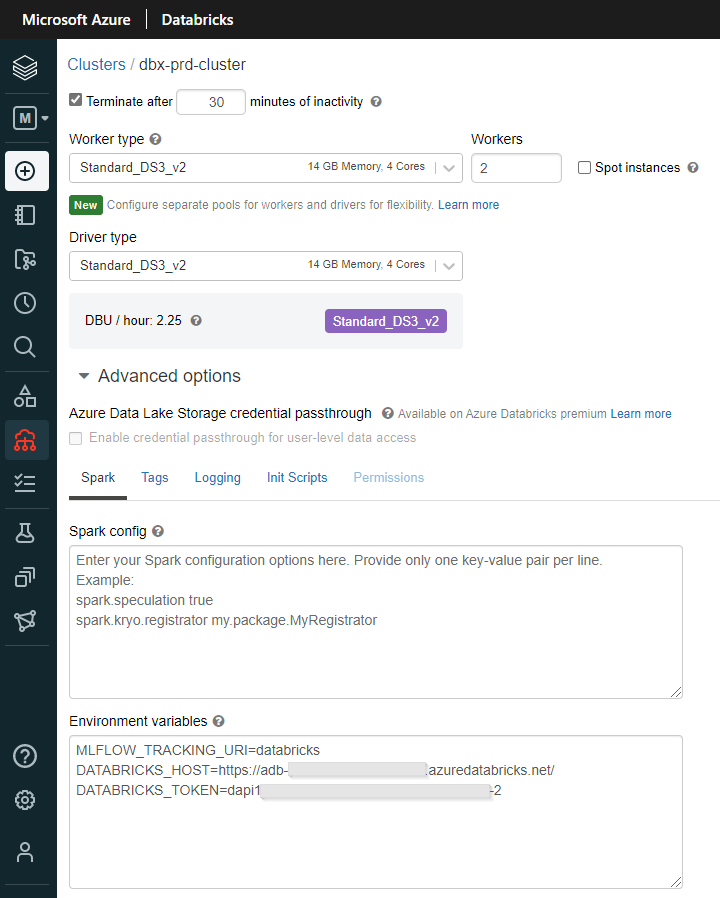
Un redémarrage du cluster sera nécessaire pour que ces variables soient prises en compte.
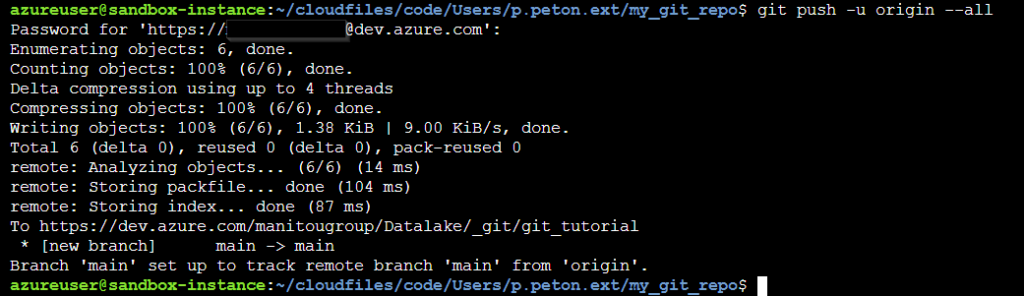
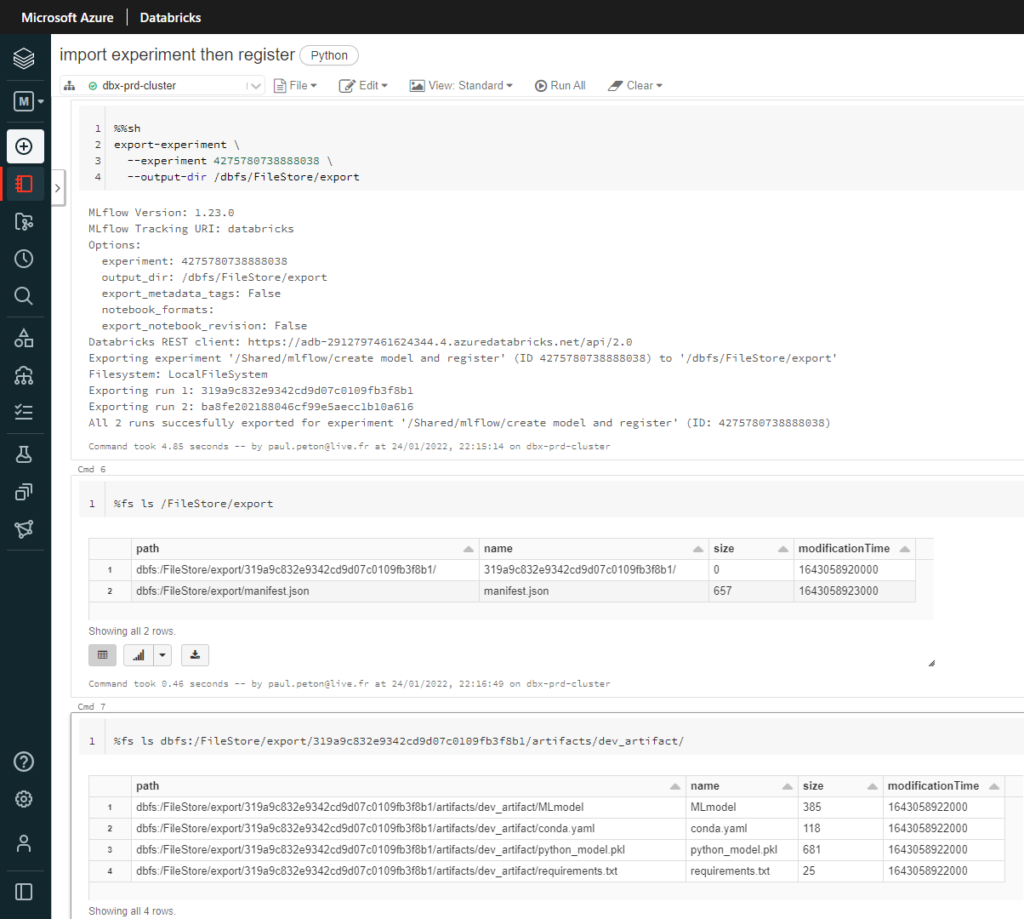
Nous lançons la commande d’export en y renseignant l’identifiant d’experiment préalablement noté, lors de sa création dans l’environnement de DEV :
%%sh
export-experiment \
--experiment 4275780738888038 \
--output-dir /dbfs/FileStore/export
Les logs de la cellule nous indiquent un export réalisé avec succès et nous pouvons le vérifier en naviguant dans les fichiers du répertoire de destination.
Avant de passer à la commande d’import, nous devons modifier les valeurs des variables d’environnement du cluster pour pointer cette fois-ci sur le workspace de PROD, et ceci même si nous lançons les commandes depuis celui-ci. Un nouveau redémarrage du cluster sera nécessaire. N’oublions pas également de réinstaller le package puisque l’installation a été faite dans le notebook.
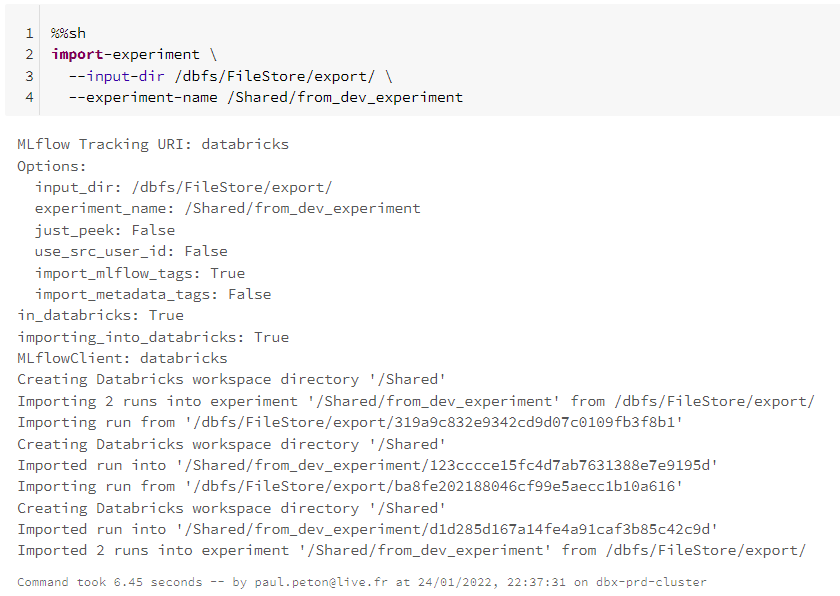
Voici la commande d’import à lancer :
%%sh
import-experiment \
--input-dir /dbfs/FileStore/export/ \
--experiment-name /Shared/from_dev_experiment
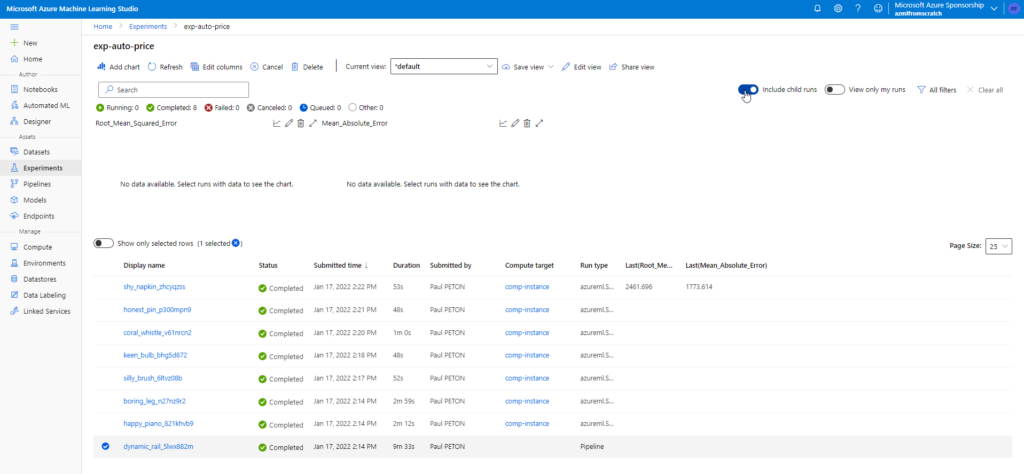
Vérifions maintenant que l’experiment s’affiche bien dans la partie MLFlow Tracking du workspace de PROD.
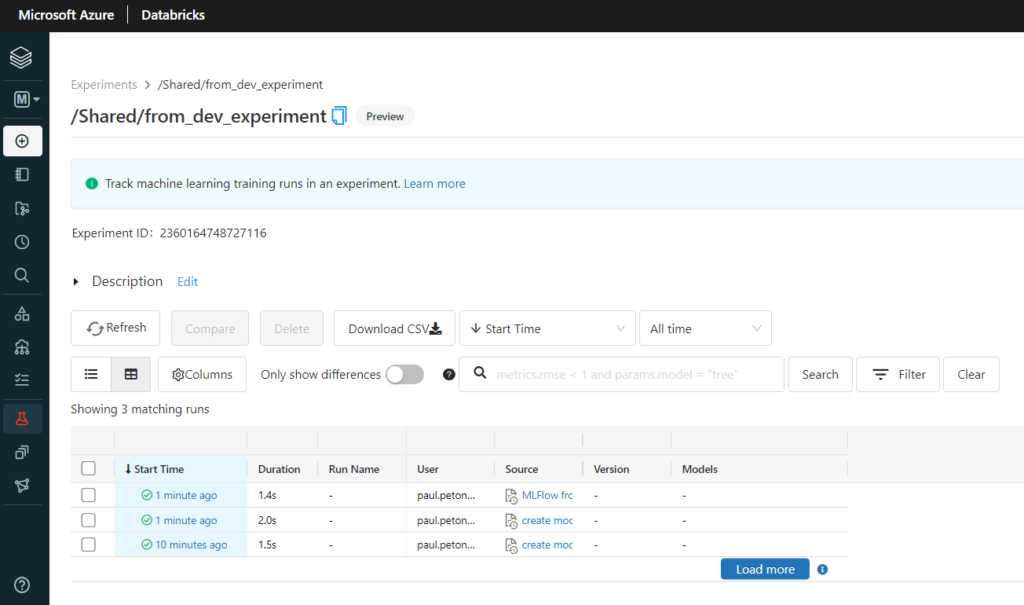
Les artefacts sont bien visibles dans MLFlow Tracking du workspace de PROD.
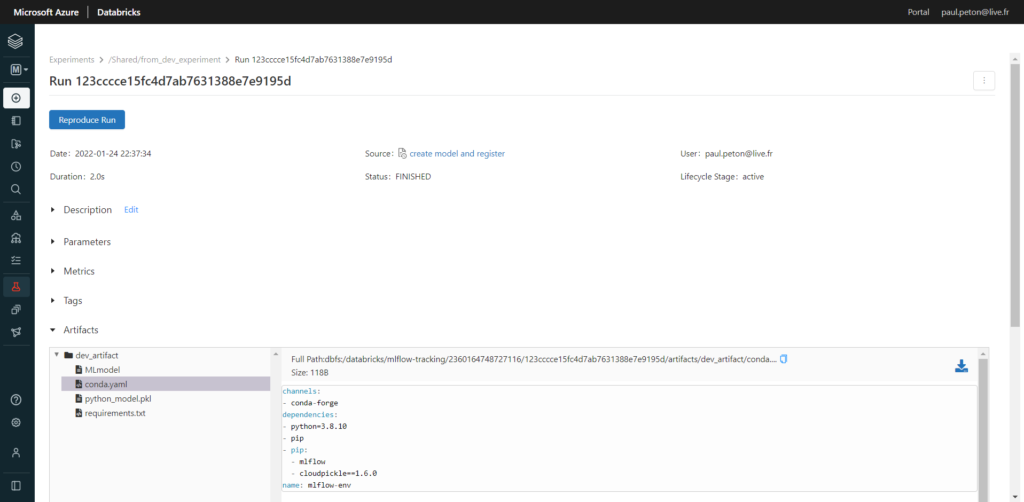
Le lien vers les notebooks sources ramènent toutefois à l’environnement de DEV. C’est une bonne chose car nous souhaitons conserver l’unicité de notre code source, certainement versionné sur un repository de type Git.
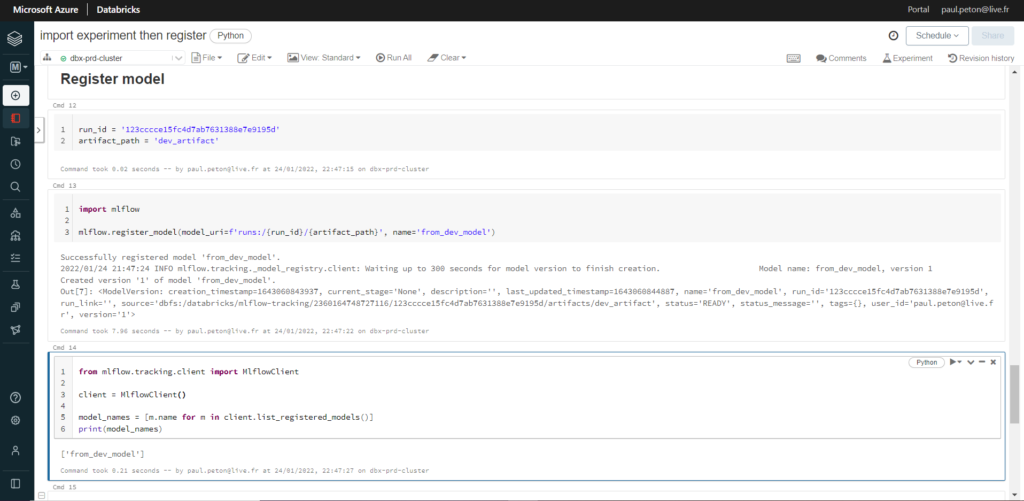
Utilisons à nouveau des commandes du package mlflow pour enregistrer le modèle. Nous aurons pour cela besoin du run_id visible dans MLFlow Tracking.
Finissions en testant le modèle chargé depuis l’environnement de PROD.
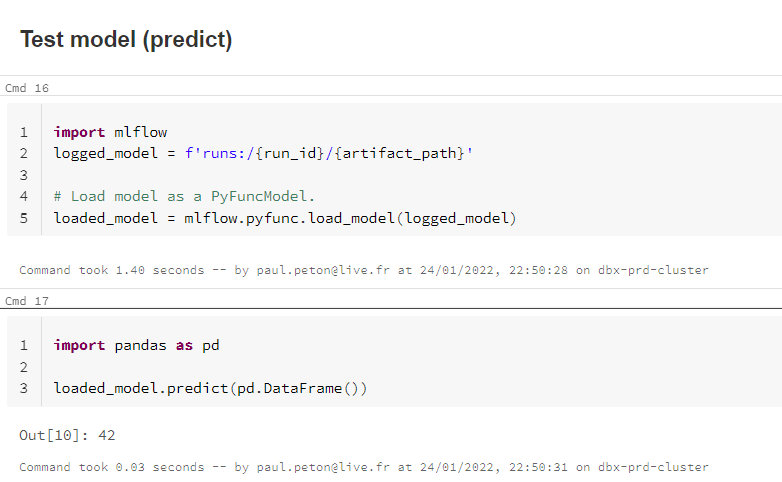
C’est gagné ! Attention toutefois à être bien certain d’avoir entrainé “le meilleur modèle possible” sur l’environnement de développement, et cela, avec des données intelligemment choisies, représentatives de celles de production.
Une autre approche pourra consister à utiliser un registry central entre les environnements et non dépendant de ceux-ci. Ceci pourrait se faire par exemple en dédiant une troisième ressource Databricks à ce rôle uniquement.