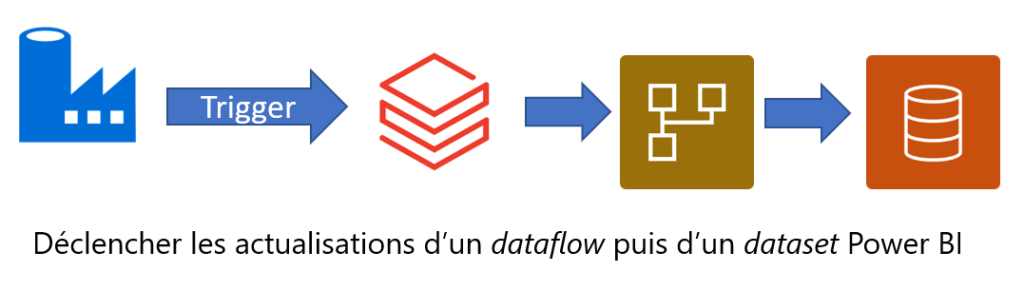
L’actualisation planifiée dans le service Power BI se fait à heure (ou demi-heure) fixe et ne peut pas être conditionnée par un événement antérieur. Le reporting est pourtant bien souvent la dernière étape de toute une chaîne de transformation de la donnée. Nous cherchons donc une solution de trigger (déclencheur) pouvant rejoindre le flux complet sous Azure.
La Power Platform propose des pistes à l’aide de Power Automate (Flow) mais nous souhaitons ici rester dans le monde Azure. Un outil comme Logic Apps dispose de telles fonctionnalités. Mais dans une approche ETL ou ELT, c’est Azure Data Factory (ADF) qui est bien souvent au centre du pilotage des traitements. Nous allons donc exploiter l’API REST de Power BI au travers d’activités Web au sein d’un pipeline ADF.
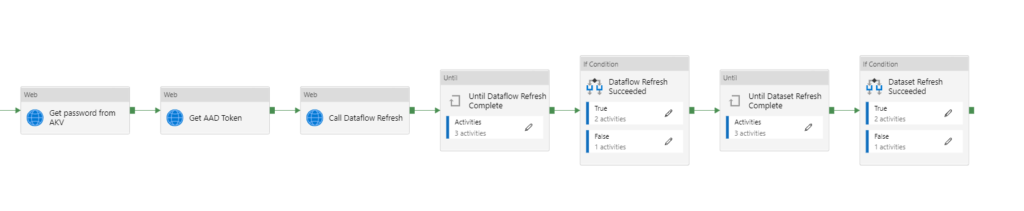
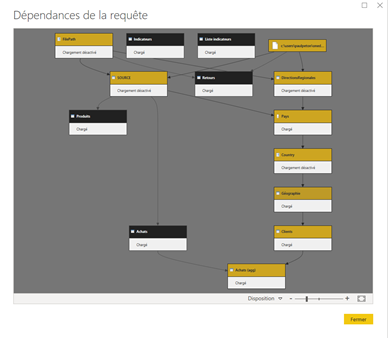
Nous visons un fonctionnement de la sorte (exemple intégrant un notebook Azure Databricks réalisant le pré-traitement de la donnée) :
Sur le schéma ci-dessous, des activités peuvent précéder la série d’activités qui réaliseront les instructions d’API afin d’actualiser un dataflow Power BI.
De nombreux articles de blog ont déjà décrit ce fonctionnement et je vous conseille en particulier cet article de Dave Ruijter et le repository associé qui vous permettra de charger un template complet réalisant l’actualisation d’un dataset.
Les différentes étapes de ce pipeline sont :
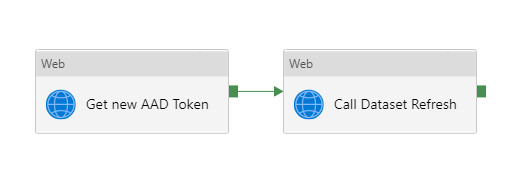
– l’obtention d’un token d’authentification grâce à une application définie dans l’annuaire Azure Active Directory (AAD). Le client secret de cette application est au préalable récupéré dans un coffre-fort Azure Key Vault (AKV).
– la commande d’actualisation du dataflow
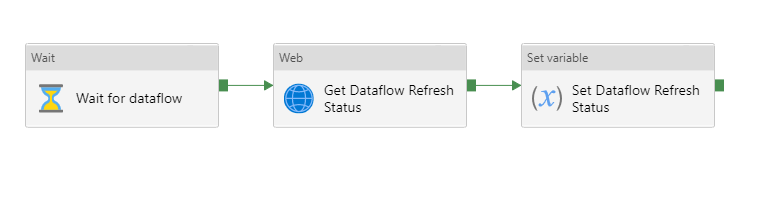
– une boucle d’attente “Until” demandant à intervalles réguliers (activité Wait) le statut de la dernière actualisation. Ce statut est stocké dans une variable.
– dans l’activité “If condition”, la branche True lancera l’actualisation d’un dataset Power BI basé sur le dataflow
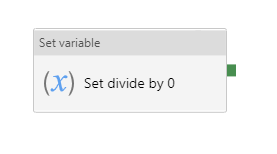
Afin de lever une erreur dans la branche False, nous utilisons l’astuce de définir une variable réalisant une division par 0. Cette division interdite fera échouer l’activité et donc le pipeline complet.
En reprenant une logique similaire, nous ajoutons une boucle d’attente de l’actualisation du dataset et une nouvelle activité “If Condition” permettant de lever une erreur en cas d’échec de l’actualisation.
Il n’est pas possible de placer ces deux dernières briques dans la branche True du “If Condition”, c’est ici une limite d’ADF mais elle ne se révèle pas bloquante.
L’API non documenté des dataflows Power BI
Nous allons préciser ici des éléments ne figurant pas dans la documentation officielle de l’API REST de Power BI.
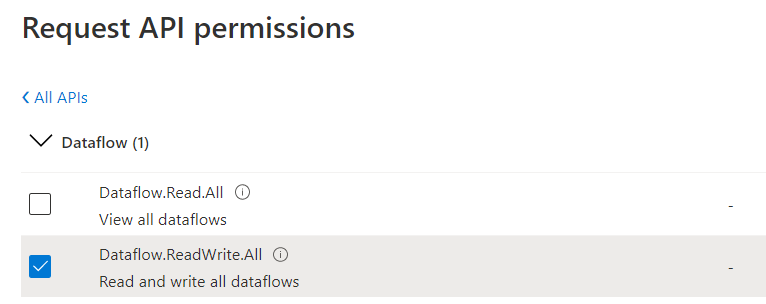
En préambule, nous devons avoir déclarer une application (app registration) disposant des droits Dataflow.ReadWrite.All. Ce point peut être contrôler dans l’annuaire AAD et l’API lèvera une erreur 401 si les droits sont uniquement au niveau Dataflow.Read.All.
L’actualisation d’un dataflow se fait par la commande POST suivante :
POST https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/refreshes
Les identifiants demandés (la notion de group correspondant historiquement à celle d’espace de travail ou workspace) se retrouvent facilement dans les URLs du service Power BI.
Lors de l’actualisation, le statut de l’opération passera à “InProgress” (contre “Unknown” pour un dataset) puis “Success” (contre “Completed”).
L’instruction permettant d’obtenir le dernier statut d’actualisation est une commande GET :
GET https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/transactions?$top=1
Notez le mot-clé “transactions” à l’inverse de “top” pour un dataset en paramètre de cette instruction.
Un grand merci à mon confrère Joël CREST pour son aide sur ce sujet. Je vous encourage à consulter son blog et sa chaîne YouTube.
Au 15 janvier 2021, le service Azure Notebooks disparaît complètement. Nous cherchons donc une alternative en version SaaS, toujours sur Azure et celle-ci se trouve dans le portail Azure Machine Learning.
Un article d’introduction à ce service est disponible dans les archives de ce blog.
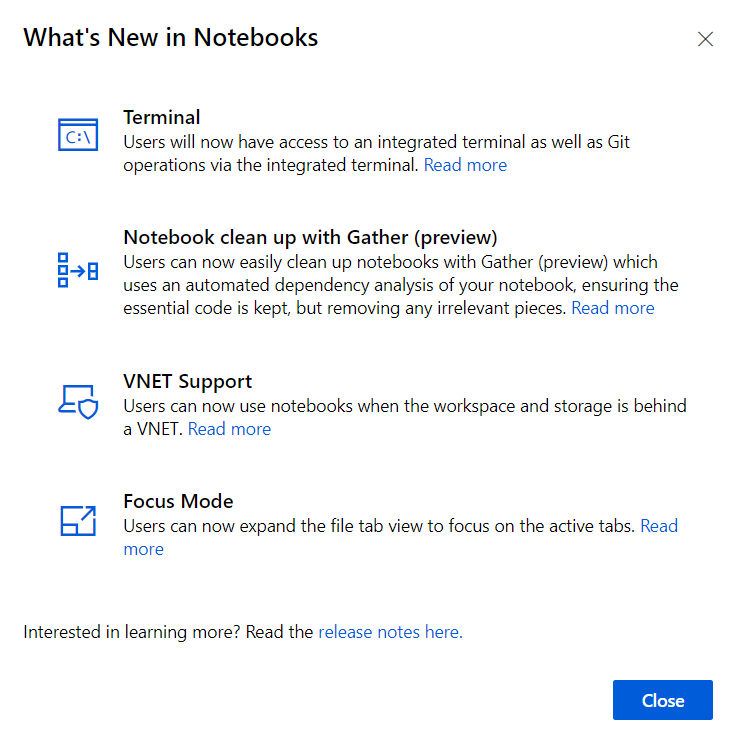
Quelques nouveautés sont disponibles et annoncées à l’ouverture d’un premier notebook. Nous reviendrons sur ces nouveautés dans la suite de cet article.
Nous pouvons alors nommer un nouveau fichier, à l’extension classique .ipynb.
Nous retrouvons ce qui caractérise les notebooks : des cellules de code, suivies par les sorties des différentes instructions, ou bien des cellules de type formaté en Markdown.
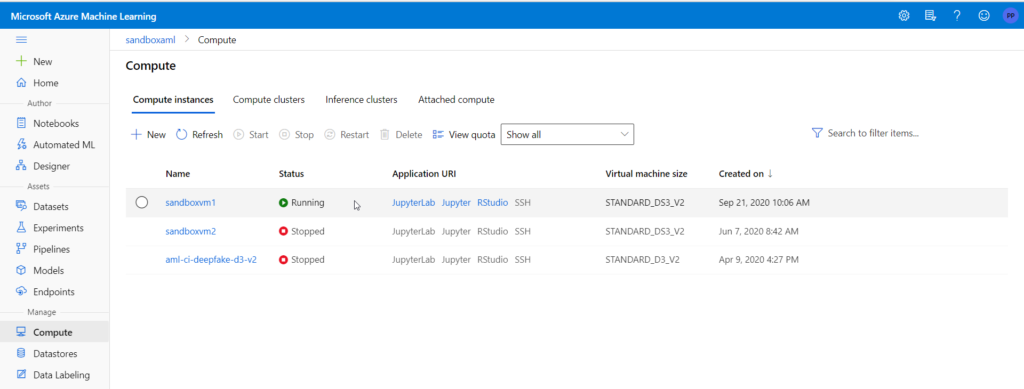
Il n’est pourtant pas possible d’exécuter du code immédiatement, il faut au préalable relier ce notebook à une instance de calcul, déjà définie dans le portail (menu “Compute”).
Dans le menu dédié aux ressources de calcul, nous retrouvons des raccourcis vers l’utilisation d’une interface Jupyter, JupyterLab ou encore RStudio.
La nécessité d’une instance de calcul rend ce service payant, et facturé au temps d’utilisation de la machine virtuelle définie. Il sera très important de ne pas oublier d’éteindre la machine après utilisation, il n’existe à ce jour aucun système natif d’extinction planifiée !
Les utilisateurs férus de Visual Studio Code (VSC) peuvent travailler à distance avec l’environnement de calcul d’Azure Machine Learning. En installant conjointement les extensions Python et Jupyter, il était déjà possible de travailler avec un notebook (fichier reconnu par son extension .ipynb) dans l’IDE de Microsoft. En ajoutant l’extension Azure Machine Learning, nous pouvons nous connecter à la ressource Azure.
Les “objets” de l’espace Azure ML sont alors visibles depuis le menu Azure de VSC.
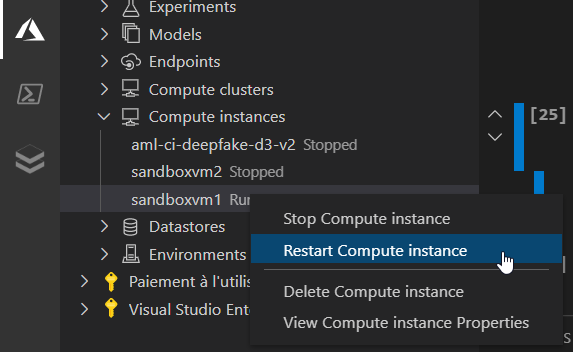
Il est possible de réaliser des actions à distance sur les instances de calcul.
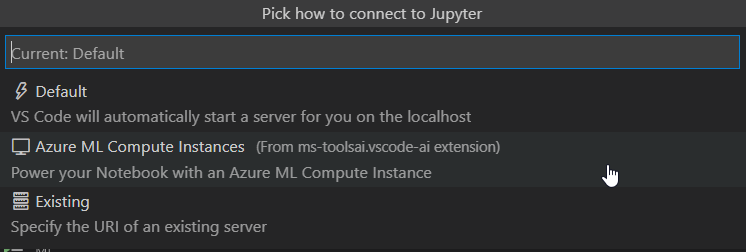
Par défaut, un notebook dans VSC utilise le serveur Jupyter local. Mais il est possible de désigner un serveur à distance (“remote“) en cliquant sur le bouton en haut à droite indiquant “Jupyter Server : local”.
Nous obtenons la boîte de dialogues ci-dessous.
La succession de choix proposés permettra d’associer le notebook à une instance de calcul Azure ML.
Une composante indispensable de l’approche par le code est le gestion du versionnig, par un service compatible avec Git (GitHub, GitLab, Bitbucket, Azure DevOps, etc.), comme décrit sur ce lien.
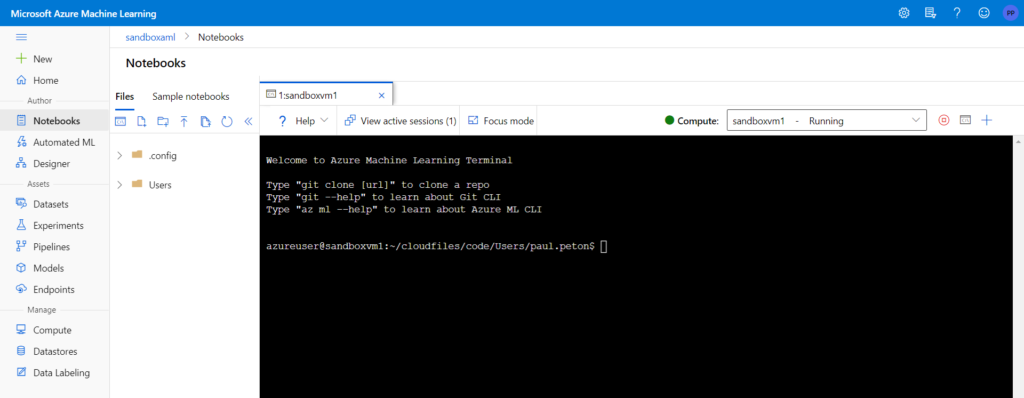
Nous allons bénéficier ici de l’affichage en terminal présentés parmi les nouvelles (janvier 2021) fonctionnalités disponibles.
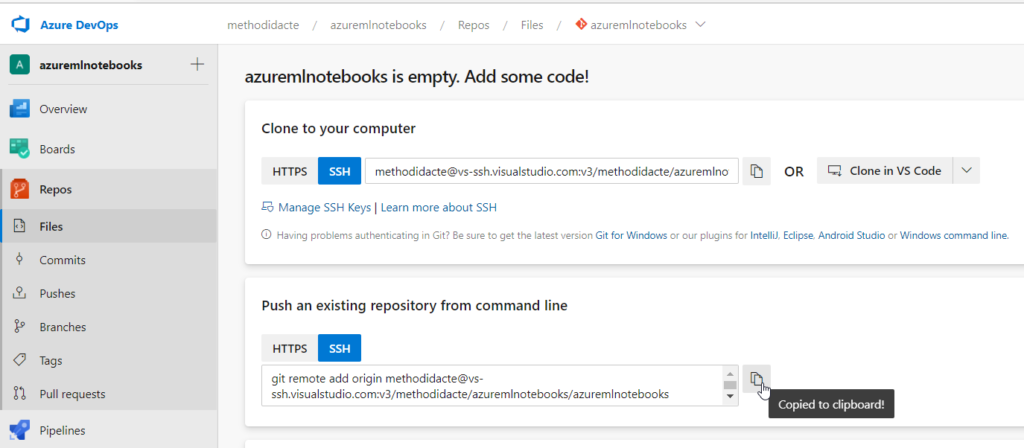
Nous devons tout d’abord créer une clé SSH au moyen de la commande ci-dessous :
La clé SSH doit être enregistrée dans le chemin /home/azureuser/.ssh qui est spécifique à l’instance de calcul (valider par Entrée le prompt proposé après la commande précédente). Il est alors possible de saisir une passphrase, facultative mais fortement conseillée. Un fichier id_rsa.pub est ainsi créé et son contenu peut être copié (ctrl + inser).
Nous utiliserons dans cet article Azure DevOps, où nous allons pouvoir saisir cette clé publique.
De retour dans le terminal, nous pouvons lancer la commande de test :
ssh -T git@ssh.dev.azure.com
Le résultat attendu est le suivant :
Depuis le repository Azure DevOps, nous obtenons la syntaxe SSH qui viendra compléter une instruction git remote, lancée depuis le terminal.
Si cela n’a pas fait, dans le terminal et depuis le chemin voulu, saisir la commande git init pour initialiser le répertoire. Définir également l’utilisateur qui réalisera les instructions de commit :
La commande git remote add origin peut alors être exécutée avec succès.
Il pourra être nécessaire de passer la commande git add . pour ajouter l’intégralité du contenu dans ce qui doit être géré par git, puis un git commit.
De même, le repository Azure doit avoir été initialisé, par exemple avec un fichier readme.md et disposer ainsi d’une branche (main ou master).
git push -u origin --all
Enfin, un rappel des commandes Git indispensables est donné ici : Git · GitHub
Une autre nouvelle intéressante consiste à “nettoyer” le notebook avant de le publier. C’est en effet un reproche souvent fait aux notebooks : ceux-ci mélangent code, sorties et commentaires et ne sont pas optimaux pour les tests unitaires et le déploiement dans un environnement de production.
La fonctionnalité “Gather” (documentation officielle) sur une cellule permet de créer un autre notebook qui conservera uniquement les cellules de code dépendant de la cellule sélectionnée.
S’il était bien une fonctionnalité attendue pour la nouvelle (2020) version d’Azure Synapse Analytics, c’était la gestion du versionning et du déploiement des scripts créés dans l’outil.
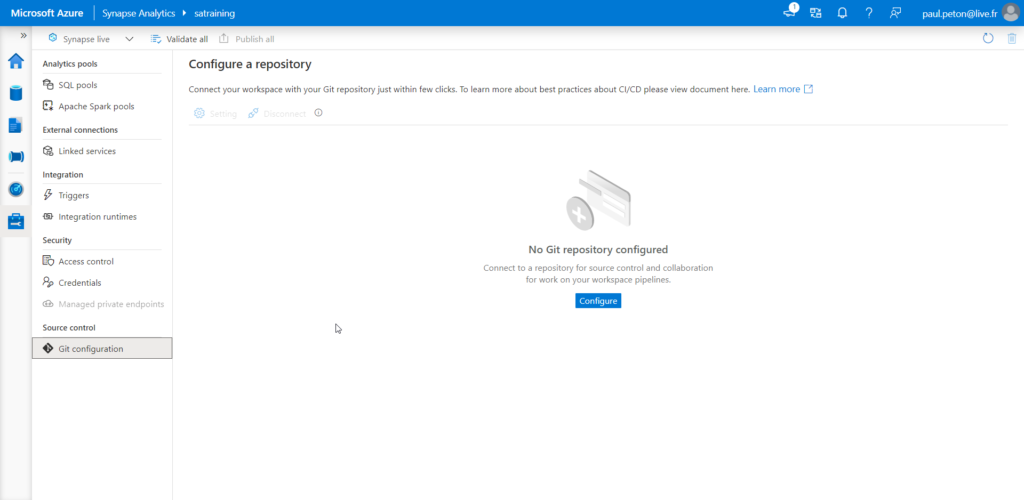
Depuis la disponibilité générale (fin novembre 2020), nous trouvons un menu Source control dans la fenêtre Manage.
Nous pouvons définir la Git configuration, c’est-à-dire l’outil qui servira à l’enregistrement des développements et à leur versionning. Nous pouvons choisir entre Azure DevOps ou GitHub.
Nous choisissons ici Azure DevOps mais la partie GitHub est documentée sur ce lien officiel.
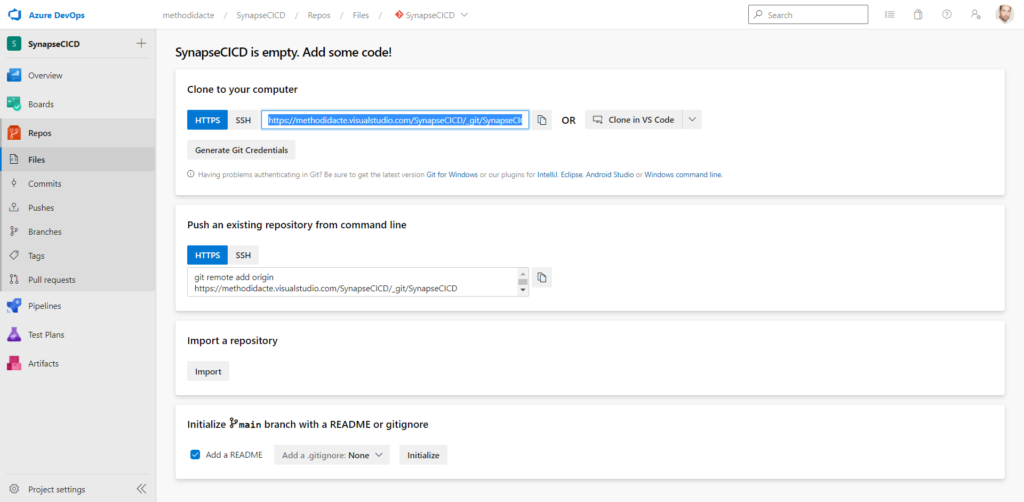
Nous devons disposer au préalable d’un projet DevOps et d’un repository dont l’URL devra être renseignée dans Synapse.
The Dev Ops repository link must start with http or https and be in DevOps format. For example: https://account.visualstudio.com/project/_git/repository
Dès lors, le dépôt se remplie avec les premiers éléments faisant partie de la ressource Synapse Analytics.
Dans le studio Synapse, nous disposons de plusieurs actions :
La validation permet de contrôler le développement réalisé et des erreurs seront remontées le cas échéant.
Le bouton Commit permet de “sauvegarder” le développement réalisé sur la branche active. Il est recommandé de ne pas développer directement sur la branche master.
Le bouton Publish de l’interface Synapse permet de créer ou mettre à jour la branche workspace_publish.
Il est donc logique de les utiliser successivement, dans cet ordre. L’action Publish réalisera une sauvegarde si nécessaire. A noter que les sorties (outputs) des cellules des notebooks sont effacées au moment de la publication. C’est une bonne pratique pour le versionning mais peut déstabiliser l’utilisateur souhaitant conserver l’affichage de ses résultats sans relancer le notebook complet.
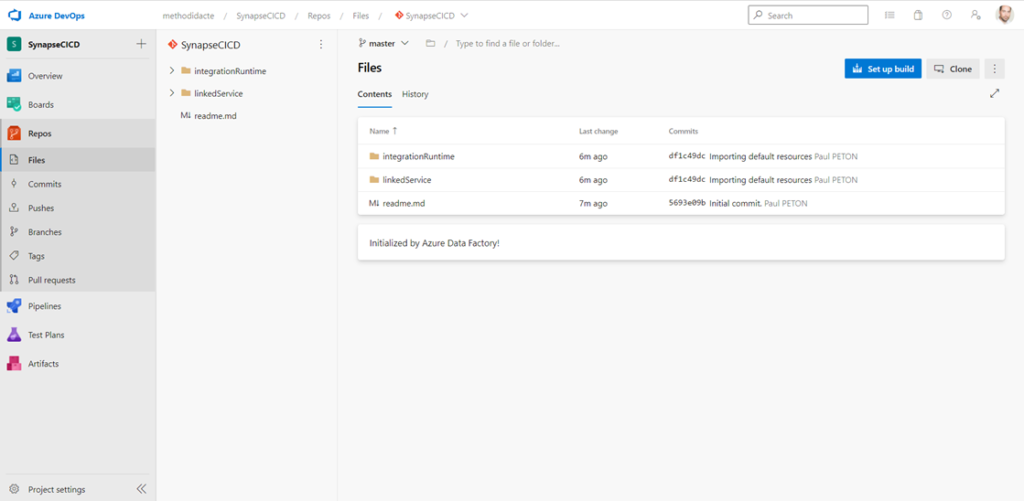
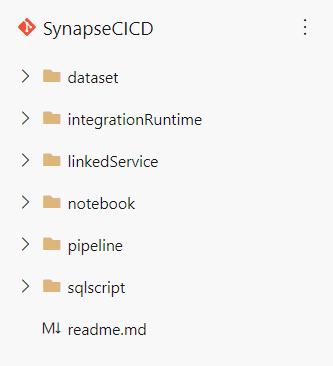
Au fur et à mesure de l’utilisation de Synapse Analytics, de nouveaux répertoires vont se créer sur la branche collaborative.
Manquent ici triggers, credentials et Spark job definiition
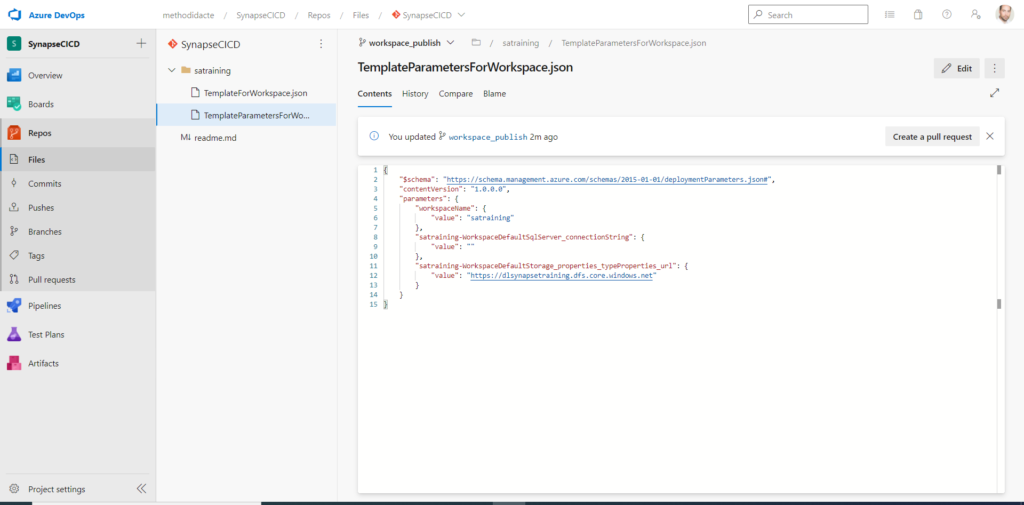
Dans la branche workspace_publish, nous retrouvons deux fichiers JSON dans une logique complètement similaire à celle d’Azure Data Factory, permettant un déploiement de type “template ARM“.
Le fichier TemplateParametersForWorkspace.json contient en particulier le nom des informations de connexion (nom du workspace, URL, etc.) et les mots de passe, secrets ou token, sont effacés. Il faudra écraser ou renseigner ces valeurs lors du déploiement dans un autre environnement.
Dans une seconde partie, nous développerons les approches possibles pour le déploiement continue à l’aide d’Azure Pipelines.
Avec la sortie fin 2020 d’Azure Purview, beaucoup de démonstrations ont mis en avant la capacité à scanner un tenant Power BI et à présenter le linéage entre les rapports et les données sources.
Ce principe, fort utile, est aussi applicable aux activités Azure Data Factory. Considérons une souscription Azure au sein de laquelle a été créé un service Azure Purview (je vous conseille cette vidéo de Joël CREST pour démarrer votre projet Purview).
Nous nous rendons dans le Management Center sur le portail Purview, au niveau des external connections.
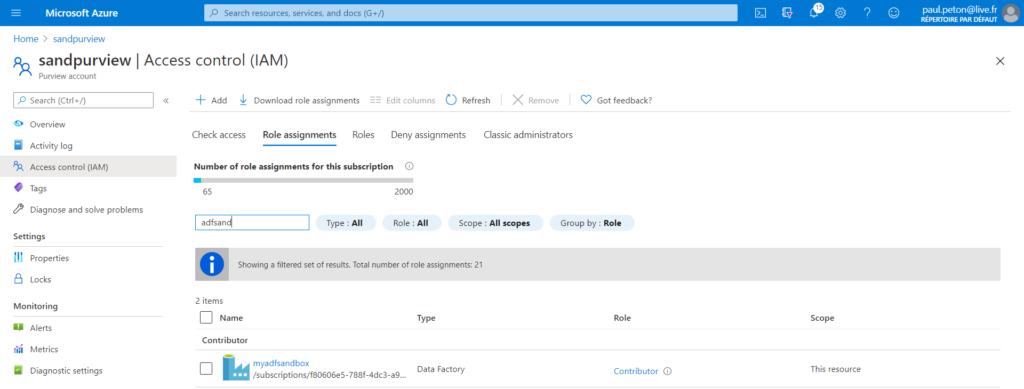
Une permission doit être au préalable accordée, l’utilisateur doit disposer d’un des rôles suivants sur le service Purview : contributor, owner, reader ou User Access Administrator (UAA). Ceci se fait au niveau de l’Access Control (IAM). Le droit doit être “direct” et non hérité d’un niveau supérieur.
Un bouton +New apparaît alors en haut de la fenêtre et permet d’ajouter de désigner la souscription et la ressource Data Factory visée.
Bien vérifier alors que le statut “connected” apparaît au bout de la ligne.
Revenons ensuite dans la partie Sources d’Azure Purview.
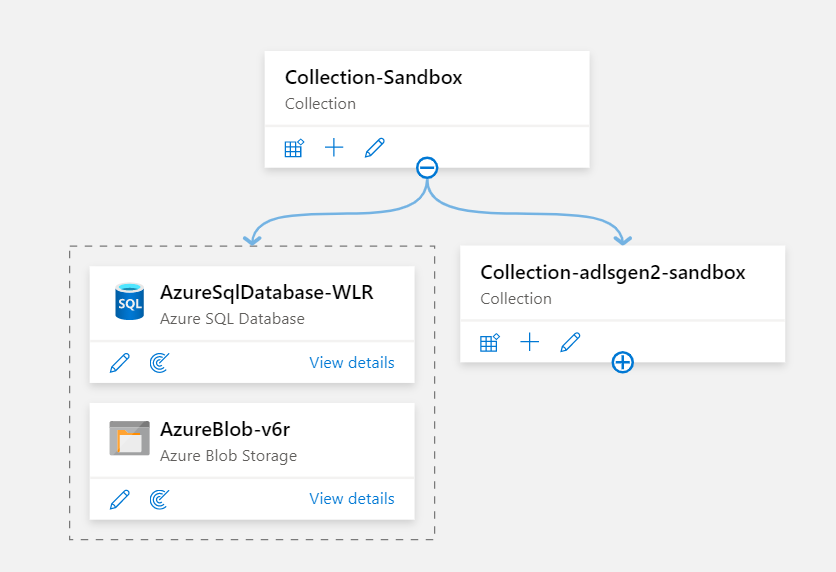
Ici, il faut déclarer une première collection dans laquelle nous définirons les sources des données, qui sont les linked services d’Azure Data Factory.
Pour l’exemple mis ici en œuvre, nous déclarons un compte de stockage Azure Blob et une base de données managée Azure SQL DB. Pour cette dernière, il faut au préalable déclarer l’identité managée (MSI) de Purview en tant que user de la base de données. Cette opération doit être réalisée par un administrateur de la base, présent dans Azure Active Directory. La syntaxe SQL est la suivante :
CREATE USER [nomDuServicePurview] FROM EXTERNAL PROVIDER
GO
EXEC sp_addrolemember 'db_owner', [nomDuServicePurview]
GO
Nous lançons ensuite un scan de ces deux sources.
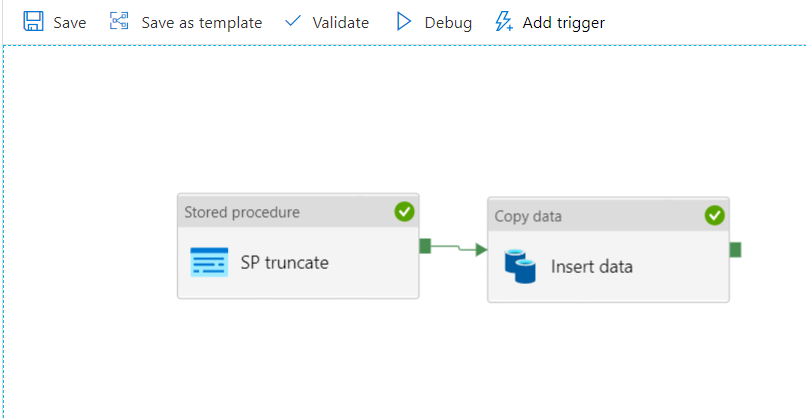
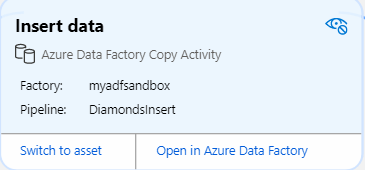
Voici l’activité Data Factory que nous souhaitons retrouver :
Elle réalise la copie d’un fichier CSV dans une table de la base de données, préalablement vidée par une procédure stockée.
Attention, les activités et dont le linéage associés ne seront visibles dans Purview qu’après une exécution, même en debug, de l’activité !
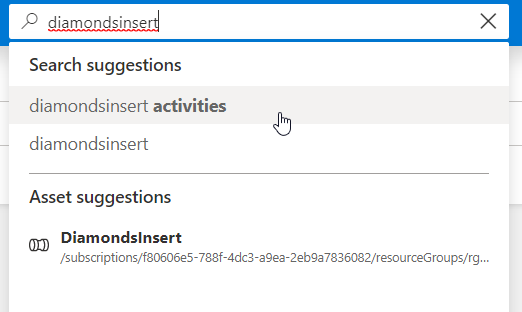
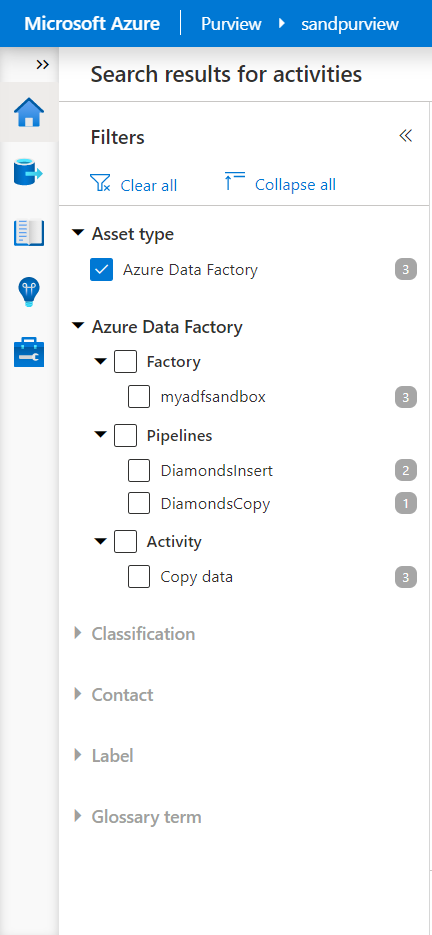
Il suffit de rechercher le nom de l’activité dans la barre de recherche pour vérifier que celle-ci est maintenant bien disponible.
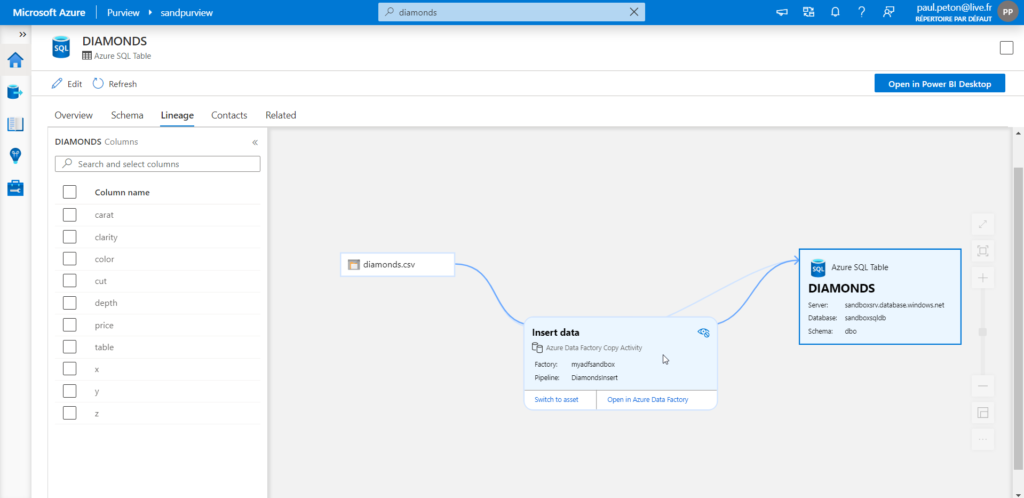
Le linéage est porté par la destination, ici la table de la base de données.
Un lien est disponible pour ouvrir directement cette activité dans le service Azure Data Factory.
Au fil des exécutions des activités, le champ de la recherche dans Purview va ainsi s’étendre pour couvrir l’ensemble des traitements.
Une bonne pratique semble d’ores et déjà s’imposer : seuls les Data Factory de production sont à déclarer dans Azure Purview. La limite est à ce jour de 10 services ADF.
Outil décisionnel self-service, de dataviz ou d’analytics, le débat autour de Power BI n’est toujours pas tranché. Les fonctionnalités étiquetées “IA” sont de plus en plus nombreuses mais souvent frustrantes car limitées dans leur paramétrage, comparée à une approche basée sur le code, en langage R ou Python par exemple.
Il serait bien sûr possible de tout réaliser dans ces langages (préparation de données, visualisation, voire partage) mais dans la pratique, nous naviguons souvent entre plusieurs outils. Et si votre seul outil est un marteau…
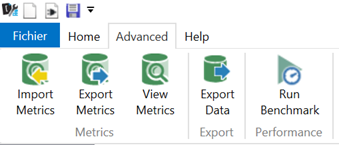
Depuis le menu External Tools, lancer l’outil DAX Studio. Dans le menu Advanced, cliquer sur « Export Data ».
Choisir ensuite un export en fichier CSV et spécifier le séparateur attendu. Nous choisirons le séparateur virgule (comma) pour respecter la valeur par défaut de la méthode read_csv() de la librairie pandas.
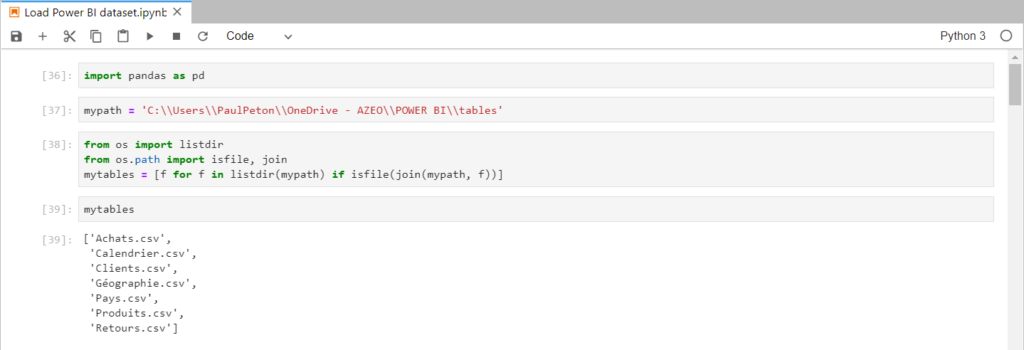
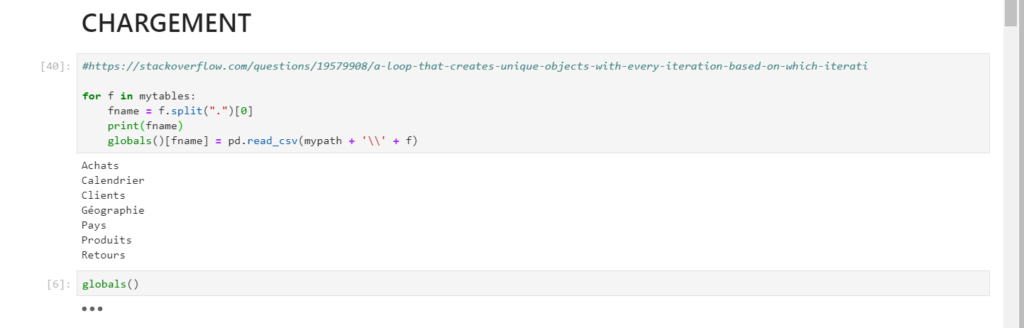
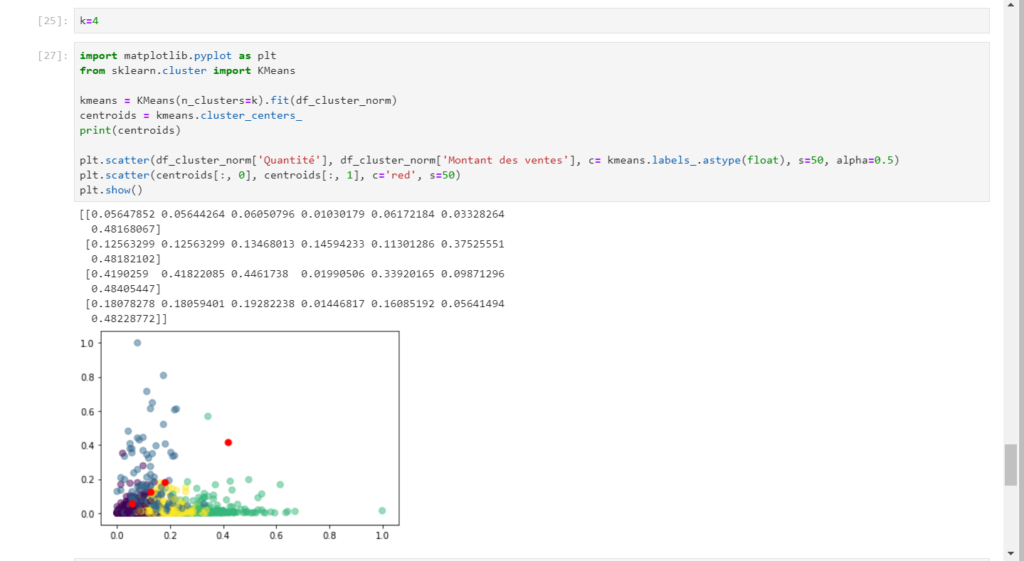
Depuis un notebook, par exemple à partir de Jupyter Lab, nous exécutons le code détaillé ci-dessous. La première étape consiste à lister le contenu du répertoire où ont été exportées les différentes tables.
La création d’un pandas dataframe par fichier se fait ensuite de manière itérative. Le nom du fichier est utilisé pour nommer l’objet en mémoire. La fonction globals() permet de vérifier la liste des variables globales définies dans la session.
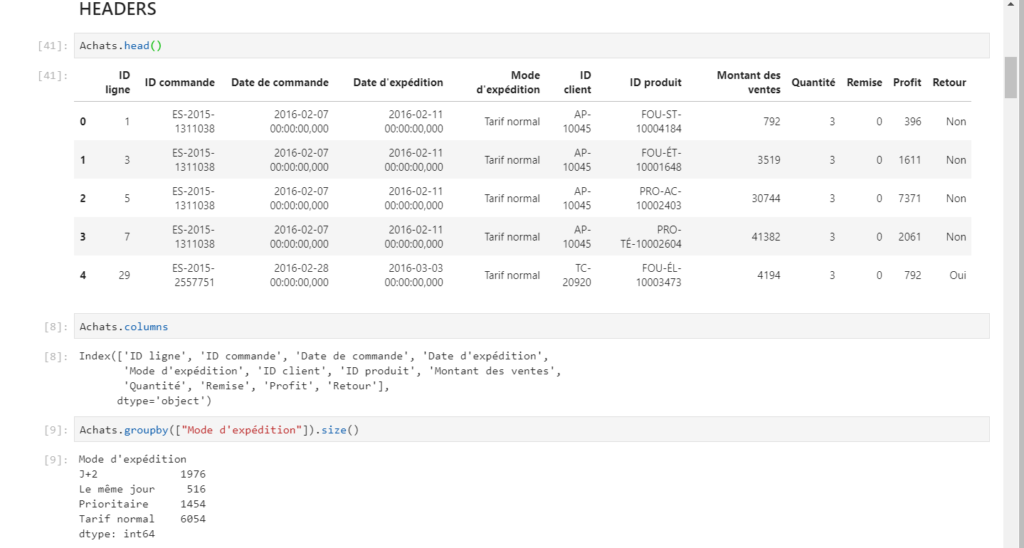
Nous retrouvons alors le “modèle sémantique” à l’identique : noms de tables, de colonnes, à l’exception d’éventuelles mesures. Les colonnes calculées apparaissent quant à elles, comme une “copie en valeur”.
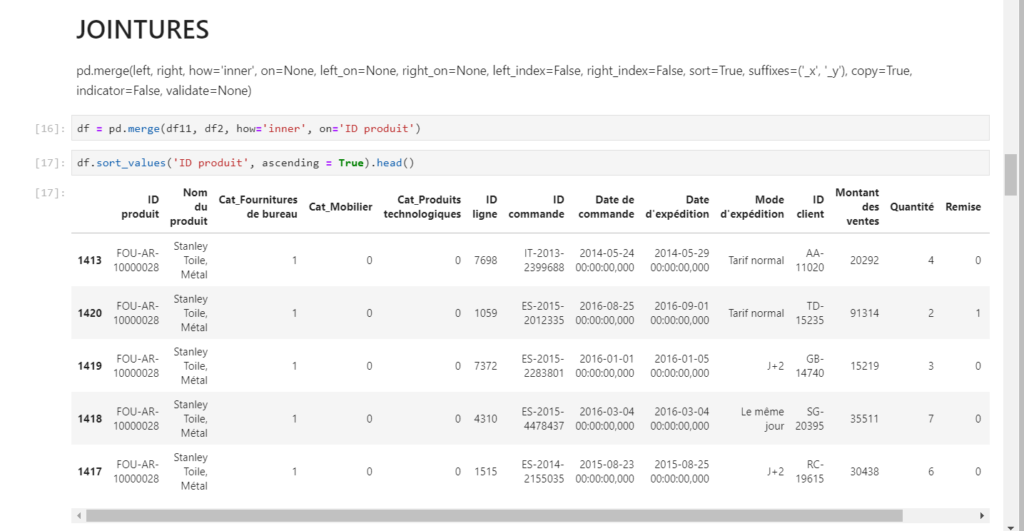
Les relations entre tables pourront être remplacées par des jointures entre dataframes à l’aide de la fonction merge().
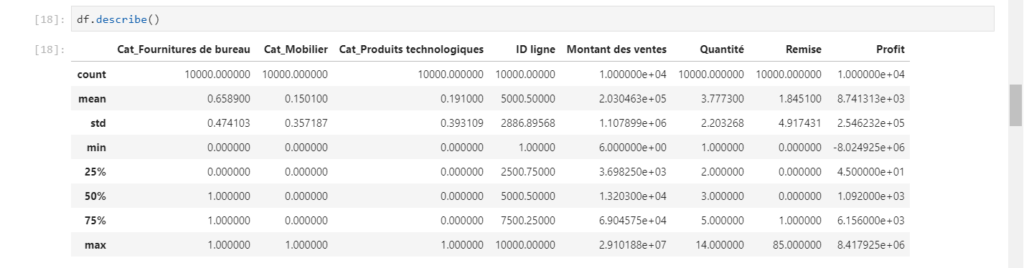
La fonction describe() donne un résumé statistique de toutes les variables numériques.
Il est ensuite possible de pousser des analyses exploratoires multidimensionnelles comme un modèle de Machine Learning non supervisé de type KMeans.
Le code complet vous est proposé dans ce notebook.
Il existe aujourd’hui des centaines de tutoriels qui vous apprendront comment construire vos premiers rapports Power BI, et vous trouverez des milliers d’astuces pour les améliorer. Mais quelle démarche mettre en place quand « ça marche pas », « ça plante », « les chiffres sont faux » ?
Il n’y a pas de secret, c’est en se confrontant à des cas réels (c’est-à-dire en entreprise, où les contraintes sont fortes : sécurité, accès limité aux données, annuaire…) et bien souvent en y passant, au moins au début, beaucoup de temps.
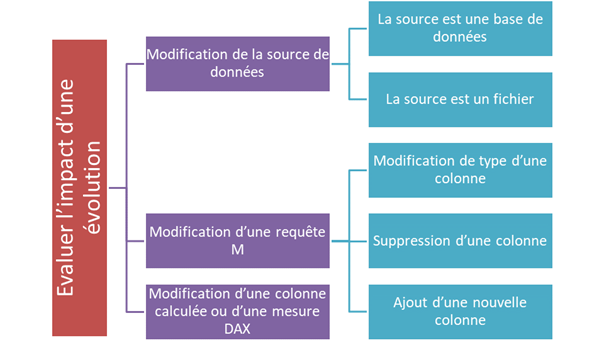
Après plus de 6 ans d’utilisation de Power BI (et pas mal de Power Pivot au préalable), j’ai recensé les scénarios ci-dessous, regroupés en deux chapitres que sont la maintenance corrective (« y’a un bug ») et la maintenance évolutive (changement dans les sources de données, dans les requêtes ou dans les formules DAX). J’espère que ces différentes entrées pourront vous aider à gagner du temps dans la maintenance de vos rapports Power BI… temps que vous pourrez investir dans l’analyse des données !
Enfin, vous vous apercevrez sûrement que le respect de bonnes pratiques de développement vous conduira à vous simplifier la tâche de maintenance. Les aspects de documentation feront en particulier l’objet d’un article séparé.
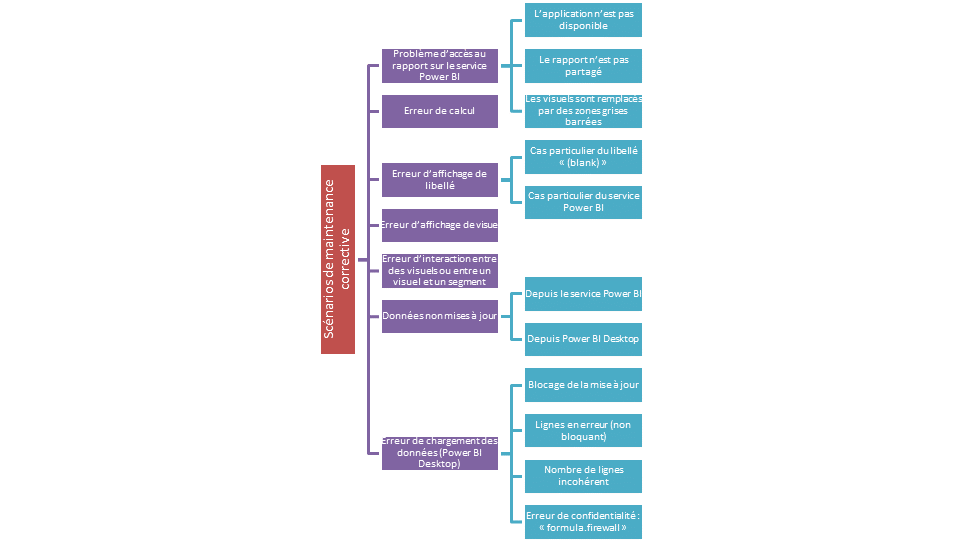
Scénarios de maintenance corrective
Problème d’accès au rapport sur le service Power BI
L’application n’est pas disponible
Une application est visible pour un utilisateur si celui-ci s’y est explicitement abonné. Depuis la page des applications, rechercher l’application par son nom, l’utilisateur doit appartenir aux personnes autorisées.
L’utilisateur n’est pas abonné par défaut si, à la publication de l’application, l’installation automatique n’a pas été cochée.
Attention, cette option peut être désactivée par l’administrateur du service.
Le rapport n’est pas partagé
Après recherche, le rapport n’apparaît pas dans le menu « Partagé avec moi ». Si le partage se fait au travers d’un nom de groupe Azure Active Directory (AAD), vérifier la présence de la personne concernée dans ce groupe.
Les visuels sont remplacés par des zones grises barrées
Il s’agit ici du comportement attendu lorsqu’un jeu de données bénéficie d’une sécurité à la ligne (« Row Level Security ») et que l’utilisateur n’a pas été associé, directement ou au moyen d’un groupe Azure Active Directory (AAD), à un rôle de sécurité statique.
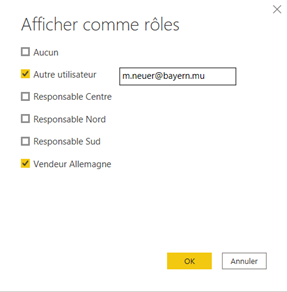
En cas de scénario de sécurité dynamique (sur la base d’une des deux fonctions DAX USERNAME() ou USERPRINCIPALNAME(), et si l’utilisateur a bien été ajouté dans le rôle de sécurité, rechercher si l’utilisateur figure bien dans la table de sécurité intégrée dans le modèle de données.
Réaliser si besoin un test dans le fichier .pbix ouvert dans Power BI Desktop, à l’aide du modèle de simulation de rôle. Pour un scénario de sécurité dynamique, il faut utiliser conjointement les deux cases illustrées ci-dessous.
Erreur de calcul
Une valeur affichée dans un visuel ne correspond pas à la valeur attendue. Tout d’abord, il faut savoir comment a été déterminée la valeur attendue, par un processus extérieur à Power BI (il s’agit normalement du processus de recette fonctionnelle, réalisé à la première publication du rapport).
On met alors en œuvre une démarche visant à « détricoter » le calcul :
Pour analyser de manière exhaustive les données chargées dans le modèle, on utilisera les filtres sur la vue de données, qui n’ont pas de conséquence sur les données filtrées dans les visuels.
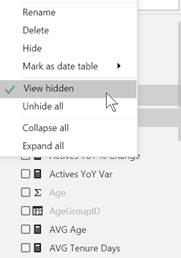
Dans Power BI Desktop, toutes les tables, champs ou mesures n’apparaissent pas obligatoirement, certains éléments pouvant avoir été masqués. Il est important d’activer l’option « View hidden », depuis la liste de champs.
Erreur d’affichage de libellé
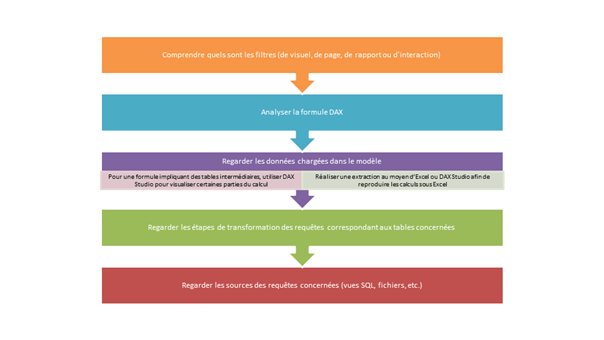
On s’interrogera principalement sur l’absence d’une catégorie sur un axe ou dans une légende de visuel. Si celle-ci n’apparaît pas, c’est vraisemblablement en raison d’un « contexte de filtre ». Nous suivrons la démarche suivante :
Vérifier que le libellé attendu figure bien dans la vue de données (celle-ci n’est pas soumise au contexte d’un visuel)
Comprendre quels sont les filtres (de visuel, de page, de rapport ou d’interaction)
Analyser la formule DAX : celle-ci contient-elle des éléments modifiant le contexte de filtre (liste de ces fonctions sur ce site de référence) ?
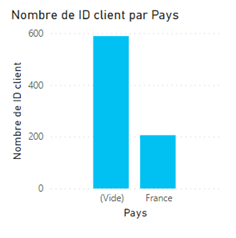
Cas particulier du libellé « (blank) »
Un libellé « (blank) » peut apparaître sur un axe ou en légende d’un visuel comme sur l’exemple ci-dessous.
Cet article et celui-ci pourront vous aider à améliorer vos mesures DAX pour éviter ces valeurs mais il faut avant tout vérifier la complétude des dimensions para rapport aux clés étrangères dans la table de faits. Si c’est un champ de la dimension qui est utilisé pour générer le visuel, les lignes de la table de faits sans correspondance dans celle-ci se retrouveront comptabilisées sur une entrée « blank ».
A l’inverse, il est également important d’analyser les clés de la dimensions qui ne contiennent pas de faits associés, en utilisant la propriété de l’axe : « afficher les éléments sans données ». Nous vérifierons plutôt ici que cela correspond bien aux attentes fonctionnelles.
Cas particulier du service Power BI
Avant toute investigation, utiliser le bouton « Réinitialiser ».
Celui-ci permet de remettre le rapport dans l’état de publication initiale. Les filtres positionnés par l’utilisateur sont remis sur les valeurs définies par le concepteur.
Certains libellés attendus peuvent ne pas apparaître en raison du mécanisme de sécurité à la ligne.
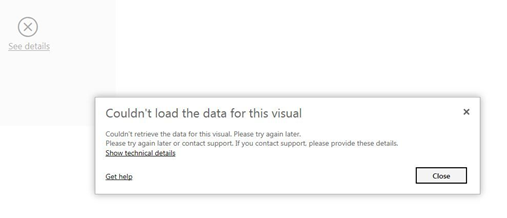
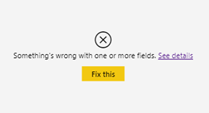
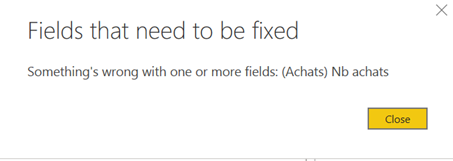
Erreur d’affichage de visuel (grisé et lien vers un message détaillé)
Ici, le visuel échoue aussi bien dans Power BI Desktop que dans le service (ce n’est pas en lien avec les droits de l’utilisateur). La première piste à suivre est celle de la ou des mesures DAX utilisées dans le visuel.
Le bouton « Fix this » aura souvent comme conséquence de supprimer les éléments en erreur dans le visuel, ce qui rend plus difficile la correction à apporter. Un lien est disponible pour afficher un détail, parfois utile, de l’erreur rencontrée.
Erreur d’interaction entre des visuels ou entre un visuel et un segment
Par défaut, c’est-à-dire sans intervention du concepteur de rapport ou mesure réalisant une modification du contexte de filtre, tous les visuels d’une page de rapport interagissent entre eux.
Dans Power BI Desktop, afficher les interactions (cliquer sur un visuel, menu Format puis « edit interactions »). L’état des interactions de chaque autre visuel apparaît alors.
Si le problème persiste, vérifier dans les mesures DAX mises en œuvre la présence d’une formule modifiant le contexte de filtre (liste de ces fonctions sur ce site de référence).
Données non mises à jour
Depuis le service Power BI
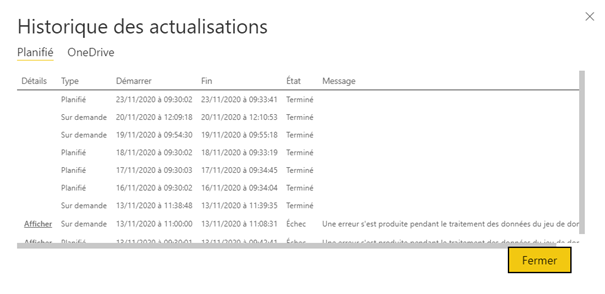
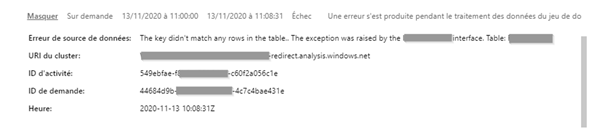
En tant que membre ou administrateur de l’espace de travail où le jeu de données est publié, regarder l’historique des actualisations, le statut de la dernière actualisation (première ligne), cliquer sur « Afficher » ou télécharger éventuellement le fichier de logs associé pour un dataflow.
Un message d’erreur plus détaillé apparaît alors.
Il sera certainement plus simple de corriger la cause de l’erreur à partir du rapport ouvert dans Power BI Desktop.
Depuis Power BI Desktop
Vérifier le chemin d’accès aux données sources. Pour une base de données, pointe-t-on vers la base ou le schéma de production ? Pour des fichiers, les nouvelles versions sont-elles bien présentes ?
Utiliser l’actualisation depuis le rapport et non dans l’éditeur de requêtes qui n’actualise qu’un aperçu des premières lignes des données. Il est possible d’actualiser une table spécifiquement par clic droit sur celle-ci, puis « actualiser ».
Erreur de chargement des données (Power BI Desktop)
Blocage de la mise à jour des données
Analyser le message d’erreur obtenu.
Tester le chargement de chaque table individuellement.
Ouvrir l’éditeur de requêtes et observer les requêtes en erreur (triangle jaune à côté du nom de la requête).
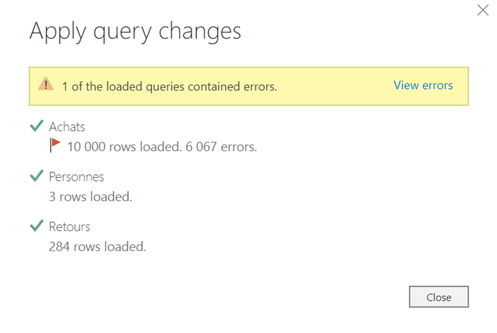
Lignes en erreur (non bloquant)
Lorsque seules certaines cellules d’une colonne sont en erreur dans l’éditeur de requête, le chargement de la table se termine mais un message indique un nombre de lignes en erreur.
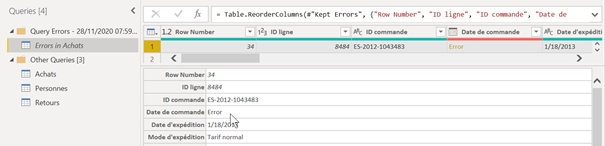
Ces lignes sont difficilement identifiables dans la requête principale car il ne s’agit que d’un aperçu des premières lignes. Il vaut mieux cliquer sur le lien « view errors ». Celui-ci ouvre l’éditeur de requêtes et montre un nouveau groupe contenant les erreurs des requêtes.
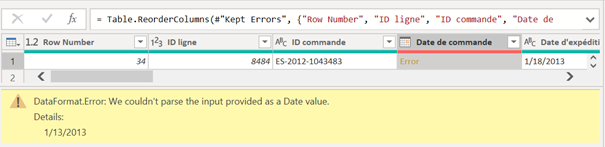
Cliquer dans la cellule (et non sur le lien Error) permet d’afficher la valeur initiale avant transformation et un message d’erreur pouvant mettre sur la voie du correctif à appliquer.
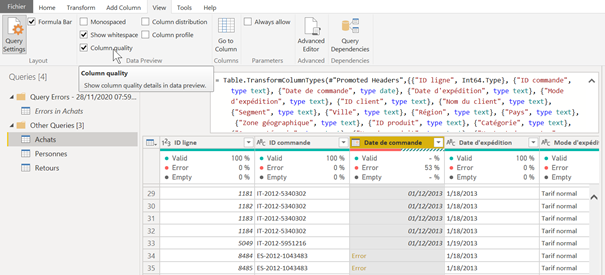
En ajoutant l’indication de la qualité de la colonne, trois indicateurs apparaissent :
Pourcentage de lignes valides (« valid »)
Pourcentage de lignes en erreur (« error »)
Pourcentage de lignes vides (« empty »)
Nombre de lignes incohérent
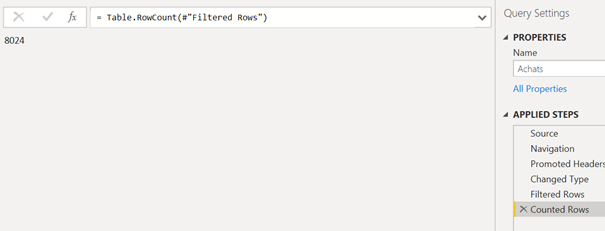
Utiliser une étape temporaire (que l’on supprimera une fois les contrôles terminés) de comptage de lignes et faire “avancer” cette fonction après chaque étape afin de vérifier le nombre de lignes obtenues.
Contrairement aux autres étapes, le nombre de lignes n’est pas évalué sur un aperçu mais sur la totalité de la source de données.
Il ne faut pas oublier de supprimer cette étape, une fois les contrôles terminés.
Erreur de confidentialité : « formula.firewall »
Il s’agit sans doute d’un des messages d’erreur les plus abscons de Power BI. Il signifie que des niveaux de confidentialité entre des sources de données produit une alerte (bloquante) de sécurité.
Le paramétrage est à refaire à chaque première utilisation du rapport sur un poste.
Plus d’informations sur ces concepts sont disponibles en suivant les liens ci-dessous :
Champ d’une table ou vue utilisée dans une requête
Ajout
Le nouveau champ apparaîtra dans la requête puis dans la table du modèle, sans causer d’impact hormis sur certaines étapes utilisant la logique de sélection inversée (opération sur les « autres colonnes »). C’est ainsi souvent le cas sur l’opération unpivot.
Sauf à appartenir à une table masquée, ce champ sera ensuite visible des utilisateurs qui ont accès au dataset et l’on devra veiller à ce qu’il ne comporte pas d’informations non appropriées (techniques, hors usage métier ou confidentielles).
Modification de type
Les types de champs dans la requête découlent des types des colonnes en base (vérifier les correspondances).
Nouvelles valeurs
L’apparition de nouvelles valeurs n’est pas d’impact sur le chargement d’une requête sauf si celles-ci contredisent le type de colonne (erreur non bloquante mais cellules mises à null). Elles peuvent toutefois modifier le comportement de certaines étapes de requêtes (filtre, unpivot, etc.).
L’apparition de doublons pourrait bloquer le chargement d’une requête si le champ est utilisé en tant que « côté 1 » sur une relation de type « 1 à plusieurs ».
Dans le rapport, il faudra contrôler les filtres sur les visuels, voire les visuels devenant moins lisibles avec un plus grand nombre de valeurs (apparition de barre de scrolling).
Renommage
Une colonne renommée n’aura un impact sur le chargement d’une requête que si elle est explicitement citée dans le script M et n’engendrera donc une erreur (bloquante pour le chargement).
Attention, de nombreuses opérations faites en langage M déclarent le nom des champs dans le script mais selon l’opération, il pourra s’agir des champs sur lesquels portent l’action ou bien des autres champs. C’est le cas des opérations de sélection, suppression, unpivot, etc.
Suppression
Une colonne supprimée n’aura un impact sur le chargement d’une requête que si elle est explicitement citée dans le script M et n’engendrera donc une erreur (bloquante pour le chargement). La première étape susceptible d’utiliser un nom de champ serait la requête SQL en étape source mais ceci n’est pas recommandé car empêche le déclenchement du query folding et il préférable de créer une vue dans la base de données.
La source est un fichier
Champ d’un fichier utilisé dans une requête
Ajout
Pour le chargement d’un fichier texte, le script généré automatiquement fait figurer le nombre de colonnes détectées. Ce paramètre est facultatif, il est donc possible de le supprimer pour qu’une nouvelle colonne soit automatiquement intégrée.
Toutefois, l’arrivée d’une nouvelle colonne dans une requête puis dans une table n’étant pas anodine, ce n’est sans doute pas une pratique à encourager.
Pour les actions suivantes, le comportement est identique à celui d’une source de type base de données (voir ci-dessus).
Modification de type
Nouvelles valeurs
Renommage
Suppression
Cas particulier des classeurs Excel
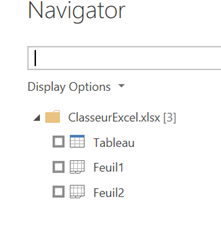
En connexion à un classeur Excel, plusieurs informations sont nécessaires : chemin et nom de fichier, nom de la feuille et le type de plage source (Sheet ou Table).
Dans l’exemple ci-dessous, la feuille 1 du classeur contient un tableau, repérable ici, en plus de son nom, par une icône dédiée.
Si l’on choisit une feuille comme source, le script M se génère de la sorte :
En choisissant un tableau, la seconde ligne devient :
= Source{[Item="Tableau",Kind="Table"]}[Data]
De plus, il n’y aura pas d’étape « Promoted headers », les colonnes étant directement nommées par les noms contenus dans la ligne d’en-têtes du tableau.
Dans les deux cas, il n’y pas de nombre de colonnes indiqué explicitement, comme pour une source de type fichier. En conséquence, les opérations ci-dessous engendrent un comportement similaire à celui-ci obtenu avec une source de type base de données. Ces paragraphes ne sont donc pas développés.
Ajout
Modification de type
Nouvelles valeurs
Renommage
Suppression
Modification d’une requête M
Les requêtes M aboutissent généralement à une table dans le modèle de données, mais pas toujours, il existe des requêtes intermédiaires qui n’ont pas à être chargées dans le modèle). Nous commencerons donc par afficher la vue des dépendances de requêtes (« query dependencies »).
Modification de type d’une colonne
Rappelons que toute colonne devrait être explicitement typé en fin de requête (pas de « ABC123 » qui finirait par donner un champ texte). Une modification forte entre des types très différents (nombre, texte, date) aura une conséquence sur des formules DAX utilisant ce champ et peut-être sur des visuels où le comportement n’est pas le même selon le type de donnée (exemple : axe d’un graphique, champ d’un segment). Une modification pour un « sous-type » assez proche (entier pour décimal, date/heure pour date) devrait avoir un impact moindre.
On portera une attention particulière à la modification de type sur des champs utilisés comme clés entre des tables.
La modification de type peut également avoir un impact sur des étapes ultérieures de la requête.
Suppression d’une colonne
La suppression d’une colonne est une excellente pratique en termes de réduction de taille du jeu de données mais il faut bien entendu vérifier au préalable qu’elle n’est utilisée ni dans une relation, ni dans un champ calculé, ni dans une mesure, ni dans des visuels ou filtres.
Ajout d’une nouvelle colonne
L’ajout de colonne ne fera qu’enrichir le modèle (et alourdir son poids). Par défaut, le nouveau champ ne sera pas masqué, sauf s’il appartient à une table du modèle entièrement masquée. Il faudra être attentif au fait de ne pas mettre à disposition des utilisateurs un champ auquel ils n’auraient pas à accéder (champ technique, information confidentielle, etc.).
Modification d’un champ calculé ou d’une mesure DAX
Il est important de préciser qu’une telle modification évolutive n’intervient qu’en cas de changement des règles de gestion.
Pour une colonne calculée, regarder ses dépendances avec d’autres formules DAX (colonnes calculées ou mesures), chercher son utilisation dans des relations, des visuels, filtres ou rôles de sécurité.
Pour une mesure, regarder ses dépendances avec d’autres mesures, chercher son utilisation dans des visuels ou filtres.
Pour des données établissant une série temporelle (mesure numérique à intervalles de temps régulier), la première étape de mise en qualité des données sera bien souvent de corriger les données dites aberrantes, c’est-à-dire trop éloignées de la réalité.
Rappelons les différents cas pouvant amener à ce type de données : – erreur de mesure ou de saisie (maintenant plutôt lié à une erreur “informatique”) – dérive réelle et ponctuelle (souvent non souhaitée, correspondant à un défaut de qualité) – hasard (événement assez peu probable mais pouvant néanmoins se produire exceptionnellement!)
Avec la version de novembre 2020 de Power BI Desktop, nous découvrons une nouvelle fonctionnalité en préversion (donc à activer depuis le menu Options) qui ajoute une entrée dans le menu Analytique des graphiques en courbe (“line chart“).
Tout d’abord, regardons les limites d’utilisation précisées à cette page. Si 12 points sont le minimum requis (ou 4 patterns saisonniers), il sera beaucoup plus pertinent d’en avoir en plus grand nombre ! Ensuite, de nombreuses fonctionnalités ne sont pas (encore ?) compatibles avec la détection d’anomalies : légende, axe secondaire, prévision (forecast), live connection, drill down…
Fonctionnement théorique
Le papier de recherche qui décrit l’algorithme utilisé, nommé unsupervised SR-CNN, est disponible ici. Nous allons essayer de le vulgariser sans trop d’approximations.
Cet algorithme d’apprentissage automatique fait partie de la catégorie des méthodes non-supervisées, c’est-à-dire qu’il n’est pas nécessaire de disposer a priori d’un échantillon de données d’apprentissage où les anomalies seraient déjà identifiées (approche supervisée).
Les deux premières lettres du nom de cette approche correspondent à la méthode dite Spectral Residual, basée sur des transformées de Fourier, qui met en valeur des éléments “saillants” (salient) de la série temporelle.
Issus du domaine du Deep Learning, les réseaux de neurones à convolution (CNN) ont émergé dans le domaine du traitement d’images en deux dimensions. Pour autant, il est tout-à-fait possible de les utiliser dans le cadre d’une série temporelle à une dimension. Au lieu d’analyser des fragments d’images, la série des données transformées va être reformulée comme plusieurs successions de valeurs.
Ainsi, la série {10, 20, 30, 40, 50, 60} pourra donner des séries comme {10, 20, 30}, {20, 30, 40} ou encore {40, 50, 60} (voir ce très bon article pour aller plus loin dans le code).
Le rôle de la couche de convolution est d’extraire les features (caractéristiques) de la série temporelle. Ce sont elles qui permettront ensuite de décider si une valeur est ou non une anomalie.
D’un point de vue de l’architecture du réseau, la couche de convolution à une dimension est suivi d’une couche “fully connected” qui fait le lien entre le résultat de la convolution et le label de sortie (anomalie ou non).
Allons maintenant à la recherche d’un jeu de données pour expérimenter cette fonctionnalité !
Test sur un jeu de données
Il existe des jeux de données de référence pour évaluer la performance de la détection d’anomalies, et plus spécifiquement dans le cadre des séries temporelles. Vous en trouverez par exemple sur cette page.
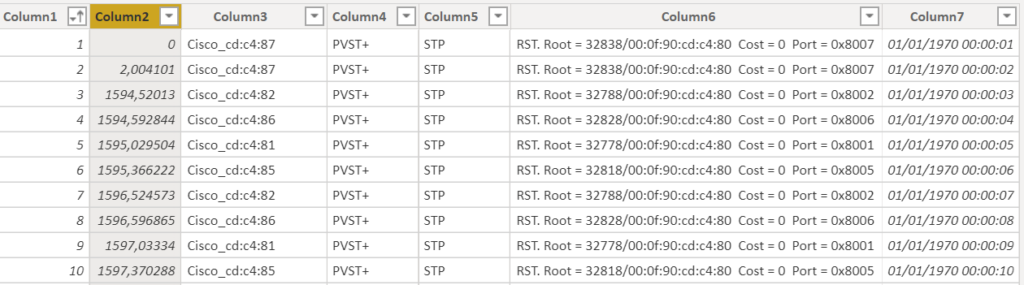
Nous travaillerons ici avec un jeu de données de trafic réseau.
Ce dataset contient environ 4,5 millions de lignes.
La détection d’anomalies se déclenche dans le menu Analytique du visuel.
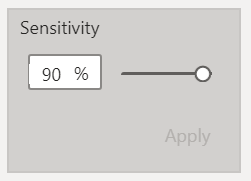
Un seul paramètre est disponible pour régler le niveau de détection, entre 0 et 100% : sensitivity.
Plus la valeur est élevée, plus “l’intervalle de confiance” en dehors duquel sera détectée une anomalie est fin. Autrement dit, plus la valeur approche des 100%, plus vous apercevrez de points mis en évidence. Difficile de dire sur quoi joue ce paramètre d’un point de vue mathématique, il n’est pas évoqué dans le papier de recherche cité précédemment.
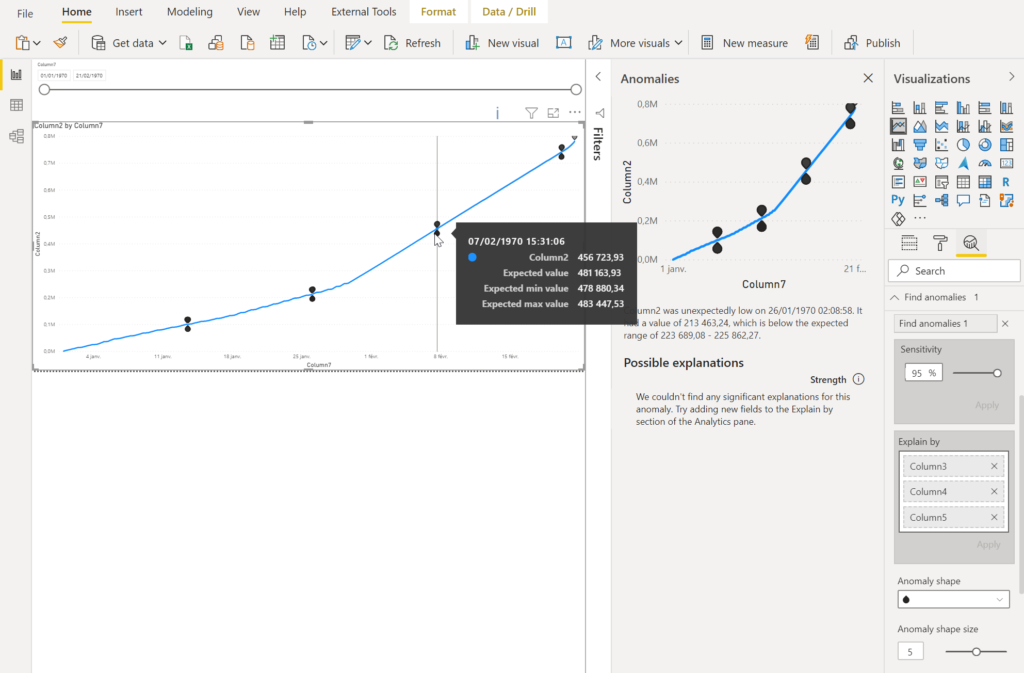
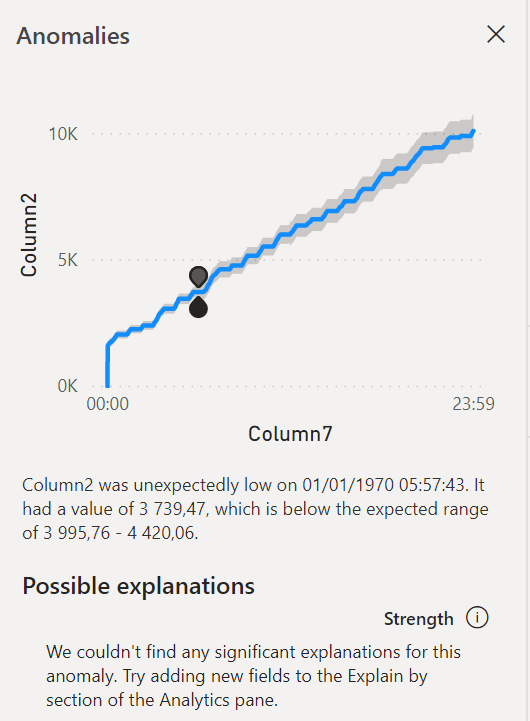
En cliquant sur un point, s’ouvre un nouveau volet latéral donnant les valeurs de la plage attendue, reprises également dans l’infobulle.
En plaçant d’autres champs de la table dans la case “explain by“, on peut espérer mettre une évidence un facteur explicatif de cette anomalie.
Attention, il n’est pas envisageable de “zoomer” sur un portion du graphique contenant une anomalie car cela modifiera la plage de données servant à évaluer l’algorithme et fera donc apparaître ou disparaître des points identifiés comme aberrants !
Zoom sur une journée contenant initialement une détection d’anomalies
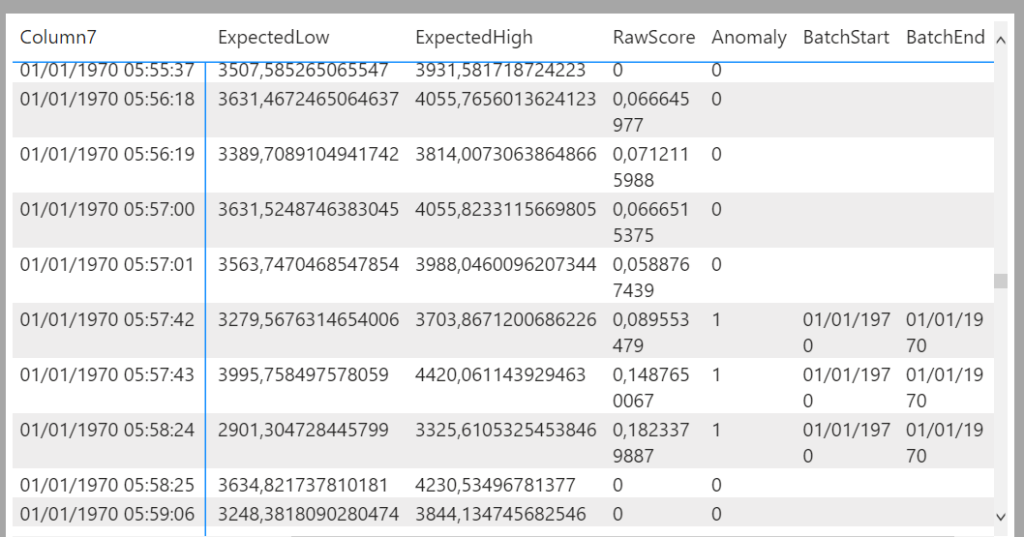
On pourra plutôt profiter de l’affichage du visuel en tant que table de données qui dispose d’une colonne “anomaly” valant 0 ou 1. On s’aperçoit ici que plusieurs points consécutifs sont identifiés comme des anomalies, ce qui était difficilement identifiable sur le graphique.
En conclusion
Malheureusement, les informations obtenues au travers de ce visuel ne peuvent pas réellement être exploitées : pas d’indicateur créé dans la table, pas d’export au delà de 30000 points (soit un peu plus de 8h pour des données à la seconde), un modèle perpétuellement recalculé et ne pouvant être arrêté sur une période. Alors, que faire lorsque des anomalies apparaissent ? Rien hormis prévenir le propriétaire des données…
Comme pour les autres services touchant (de loin) à l’IA sous Power BI, je suis sceptique quant au moment où cette fonctionnalité est mise en œuvre. La détection d’anomalies est une étape de préparation de la donnée et hormis à effectuer un reporting sur ces anomalies elles-mêmes, nous sommes en droit d’attendre qu’elles soient déjà retirées des données avant exposition. Il serait donc beaucoup plus opportun d’utiliser le service cognitif Azure dans un dataflow (Premium ou maintenant en licence Premium Per User) afin de mettre la donnée en qualité lors de la constitution de donnée. Pour une détection sur un flux de streaming, on se tournera avec intérêt vers les possibilités offertes par Azure Databricks, comme exposé dans ce tutoriel.
A l’inverse, les algorithmes prédictifs qui ne peuvent être utilisés que dans les dataflows seraient beaucoup plus à leur place dans un visuel qui permettrait de tester différents scénarios et d’observer les prévisions associées.
En résumé, les ingrédients de la recette sont les bons, encore faut-il les ajouter dans l’ordre pour obtenir un plat satisfaisant !
L’algorithme choisi (SR-CNN) ne doit pour autant pas être remis en cause car il semble aujourd’hui représenter l’état de l’art de la détection d’anomalies;
Vos remarques sur cet outil peuvent être déposées sur cette page communautaire.
Jusqu’à présent, nous utilisions le connecteur Spark générique comme présenté dans cet article. Le seul mode d’authentification possible consistait à utiliser un jeton personnel (personal access token).
Nous pouvons nous connecter à des tables créées dans des databases du metastore du cluster Databricks et cela implique que le cluster soit démarré afin que la connexion soit possible.
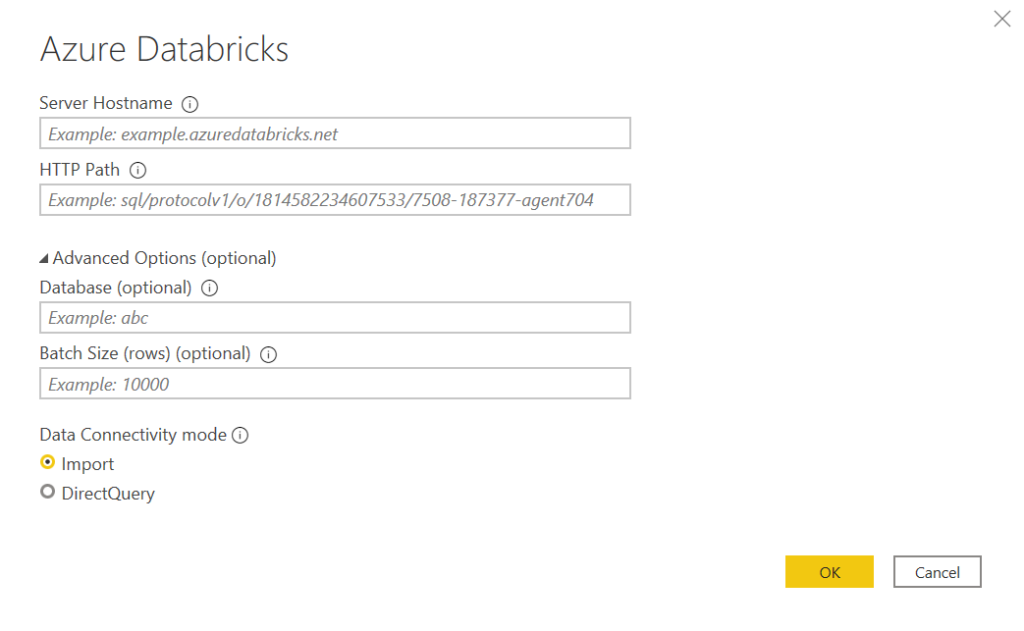
Ce sont donc des informations au niveau cluster dont nous aurons besoin pour nous connecter. Ce paragraphe détaille les éléments attendus que sont le hostname, le port (443 par défaut) et le HTTP path.
Un connecteur dédié est apparu en préversion publique depuis octobre 2020 et présenté sur cette page de la documentation officielle Microsoft.
Nous remarquons que les deux modes import et DirectQuery sont disponibles, le second étant bien sûr conditionné par le statut démarré permanent du cluster.
Un paramètre est ici très important : le batch size. Il s’agit de la taille des “paquets” de lignes qui seront extraits du cluster. Nous reviendrons sur ce paramètre dans la section liée à la performance.
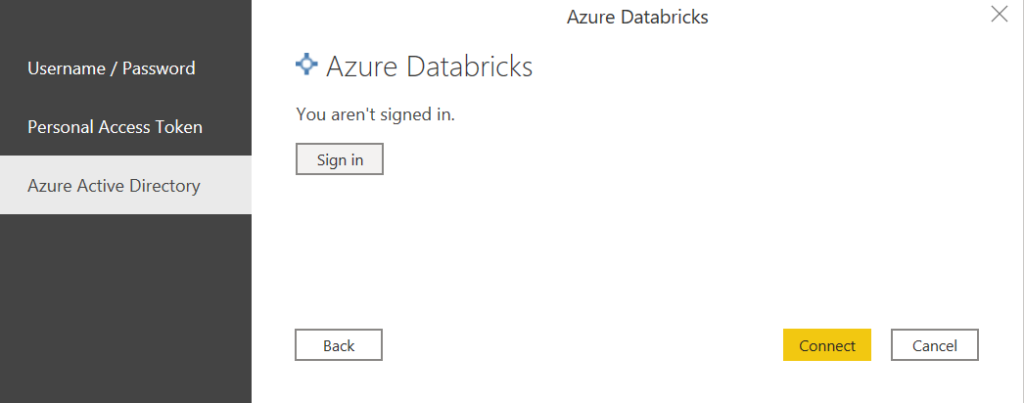
Nous disposons ensuite de trois modes de connexion, dont le mode “classique” par Personal Access Token mais également l’authentification au travers de l’annuaire Azure Active Directory (AAD).
C’est ce dernier que nous utiliserons ici.
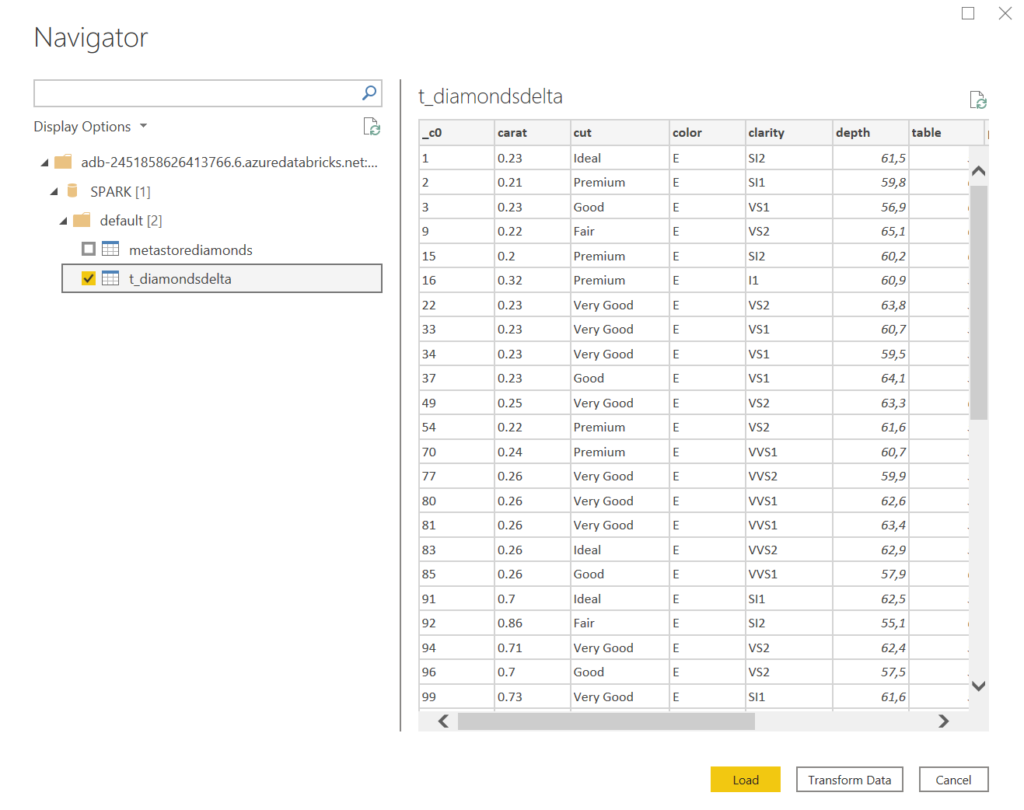
Nous obtenons alors l’accès au metastore du cluster, afin de sélectionner une ou plusieurs tables.
Il est alors possible de charger directement les données dans une table du modèle ou bien d’ajouter des transformations dans la fenêtre Power Query. Pour autant, l’intérêt du cluster Spark est bien de réaliser toutes les transformations de données avant de créer une table “nettoyée”.
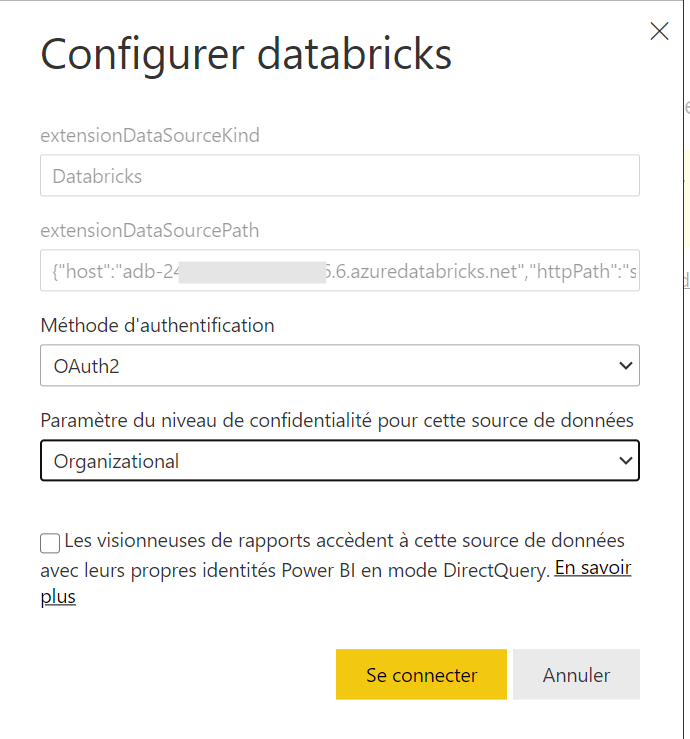
Pour l’actualisation planifiée du rapport dans le service Power BI, nous choisissons le mode d’authentification OAuth2.
Le niveau de confidentialité Organizational exige que la source de données Azure Databricks fasse partie de l’abonnement Azure sur lequel est défini l’annuaire AAD.
Afin de ne pas lier un compte personnel à un jeu de données Power BI, il sera préférable d’utiliser un compte de service. A l’heure actuelle (novembre 2020), la connexion au travers d’un principal de service ou d’une identité managée n’est pas réalisable.
Qu’attendre des performances ?
Afin de tester ce connecteur, nous chargeons comme table du cluster le fichier des Demandes de Valeur Foncière de 2019, soit 400Mo pour environ 3 millions de lignes.
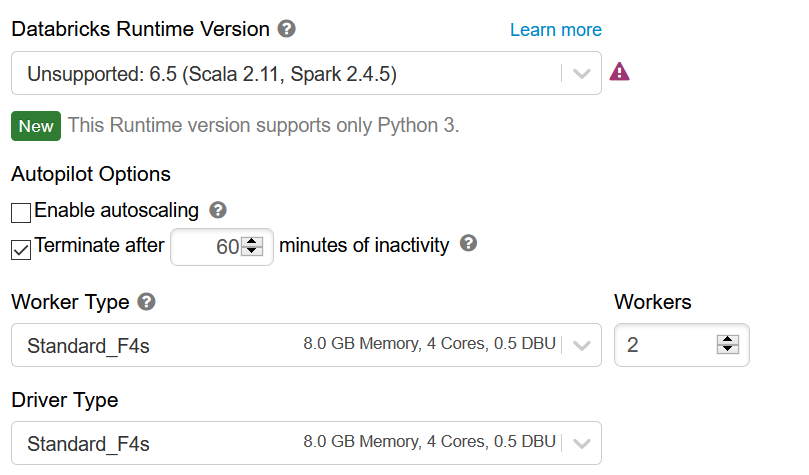
La configuration du cluster est également à prendre en compte puisqu’elle déterminera la capacité à lire la donnée stockée dans la table. Nous débutons avec la configuration ci-dessous, et une version 2.4.5 de Spark.
En réglant le batch size à 100000 puis 200000 lignes, nous passons de 4 minutes à 2’30. L’augmentation de taille n’apporte alors plus de gain significatif.
A l’inverse, une taille de batch à 10000 serait dramatique : l’actualisation du jeu de données depuis Power BI prend alors plus de 11 minutes ! Si l’on ne précise pas le paramètre, le temps d’actualisation est correcte : 3’30.
Changeons maintenant le runtime du cluster pour une version 7.2 s’appuyant sur Spark 3. Sur la base d’un batch size de 200000 lignes, il n’y a pas de gain de temps de chargement.
Changeons enfin la configuration du driver : celui se base maintenant sur une VM Standard_F8s de 16Go de RAM et 8 cœurs. Sur ce jeu de données relativement petit pour un contexte Spark, pas d’amélioration du temps de chargement. La même observation se répète en changeant cette fois-ci la configuration des workers.
Sans avoir pu le tester, il semble important, à l’évidence, que les ressources Azure Databricks et Power BI soient situées dans la même région.
Pour conclure cette partie de tests, sachez que le temps d’actualisation avec le connecteur Spark générique est d’environ 5 minutes (batch size de 200000 lignes), un léger gain est donc obtenu.
Peut-on faire de l’actualisation incrémentielle ?
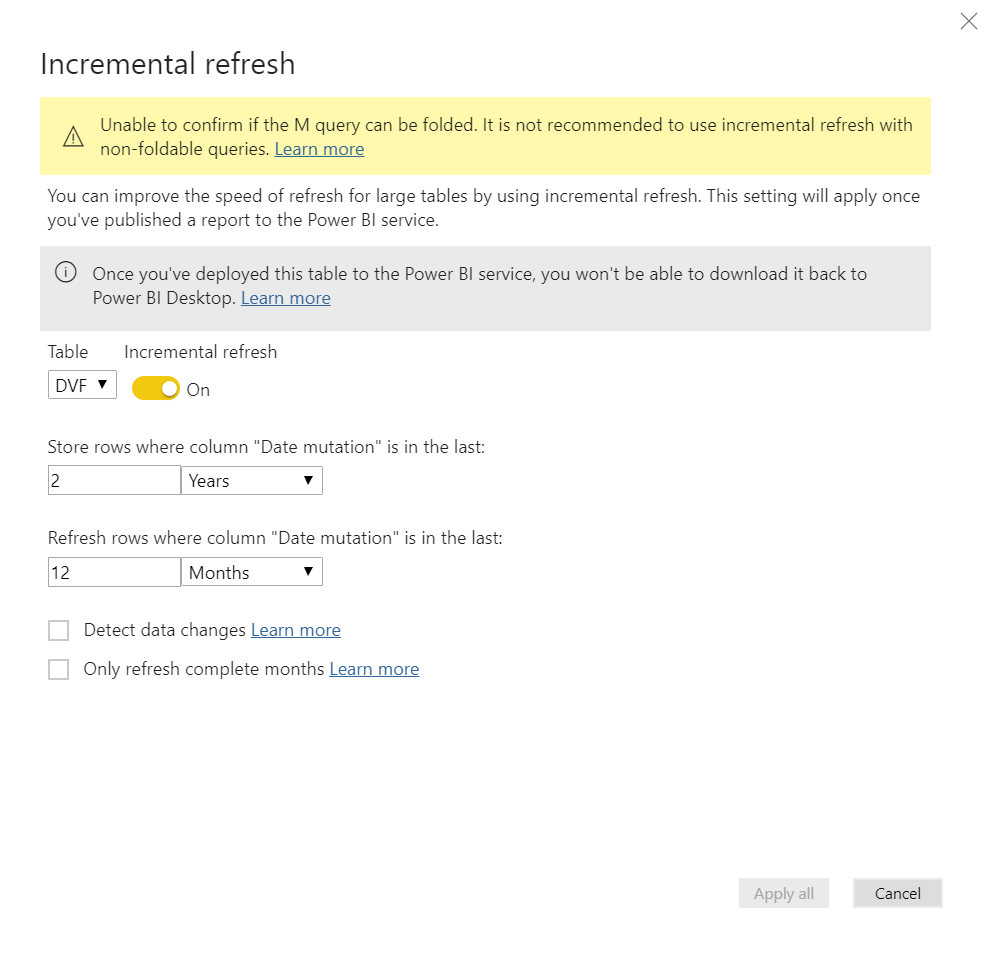
Par défaut, l’actualisation d’un jeu de données annule et remplace toutes les données. Il est toutefois possible de mettre en place une approche sur un champ de type datetime pour n’actualiser qu’une plage de dates définie. Sur cet écran, nous souhaitons conserver 2 années d’historique et ne mettre à jour que les 12 derniers mois.
Un message d’alerte que le mécanisme ne sera effectif que la requête M est “pliable” (traduction approximative du concept de query folding), ce qui signifie que le moteur d’exécution de la requête (ici, le moteur Spark) doit pouvoir interpréter la requête dans un langage natif, comme le SQL. Concrètement, les paramètres de dates deviennent des conditions “WHERE” dans la requête. D’un point de vue du stockage de données, celles-ci sont partitionnées selon la granularité de dates utilisée dans la paramétrage (ici, le mois).
Afin de vérifier si toutes les partitions ou non sont actualisées, il faut utiliser un espace de travail Power BI de capacité Premium et se connecter selon le processus détaillé dans cette page.
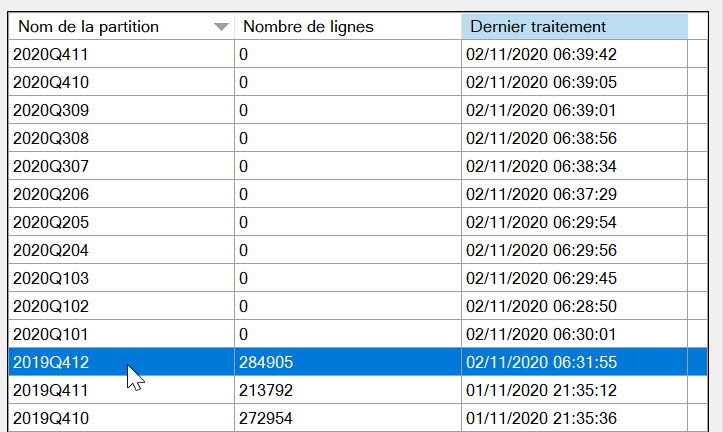
Ensuite, depuis SQL Server Management Studio, nous pouvons visualiser les partitions et l’heure de traitement.
Le jeu de données ne couvre que l’année 2019, ce qui explique les nombres de lignes à 0 à partir de 2020. Les partitions antérieures à décembre 2019 n’ont pas été rafraichies, ce qui correspond bien au comportement souhaité. En revanche, il faut se méfier du temps total que peut prendre une telle approche car elle multiplie les requêtes auprès du cluster, partition par partition.
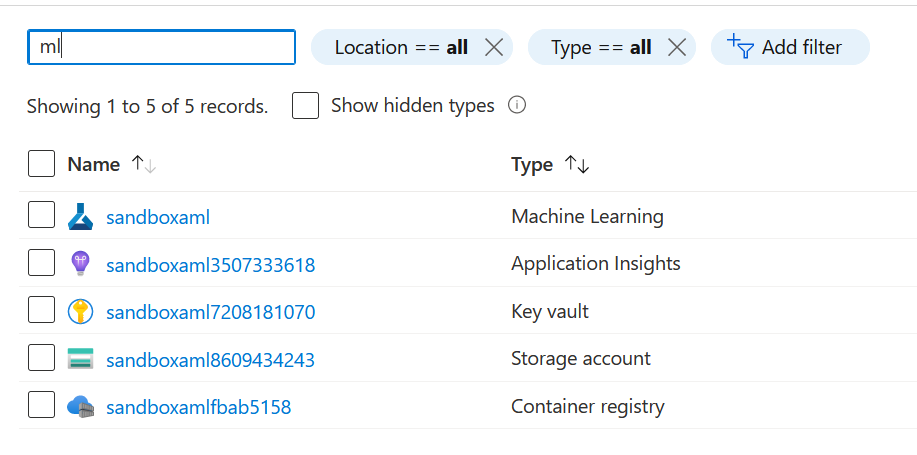
Si vous avez provisionné un service Azure Machine Learning, vous vous êtes certainement aperçu que celui-ci ne venait pas seul au sein du resource group.
Il est en effet accompagné par un compte de stockage qui servira à enregistrer des éléments comme des datasets ou bien les artefacts liés aux modèles. Le container registry servira quant à lui à conserver les images Docker générées pour les services web prédictifs. Le Key Vault jouera son rôle de stockage des clés, secrets ou passphrases. Reste le service Application Insights.
Application Insights, pour quoi faire ?
Application Insights est une branche du service Azure Monitor qui permet de réaliser le monitoring d’applications comme des applications Web, côté front mais aussi back. De nombreux services Azure (Azure Function, Azure Databricks dans sa version enterprise, etc.) peuvent être surveiller grâce à Application Insights.
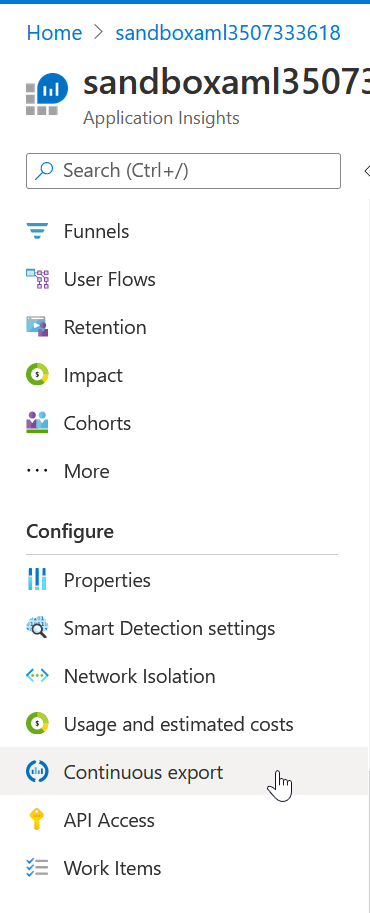
La manière la plus concrète d’obtenir un résultat avec ce service est sans doute d’utiliser l’interface Log Analytics. Celle-ci se lance en cliquant sur le bouton logs.
L’interface de Log Analytics nous invite à écrire une nouvelle requête dans le langage KustoQL, dont la syntaxe est disponible ici. Ce langage est aussi utilisé dans l’outil Azure Data Explorer.
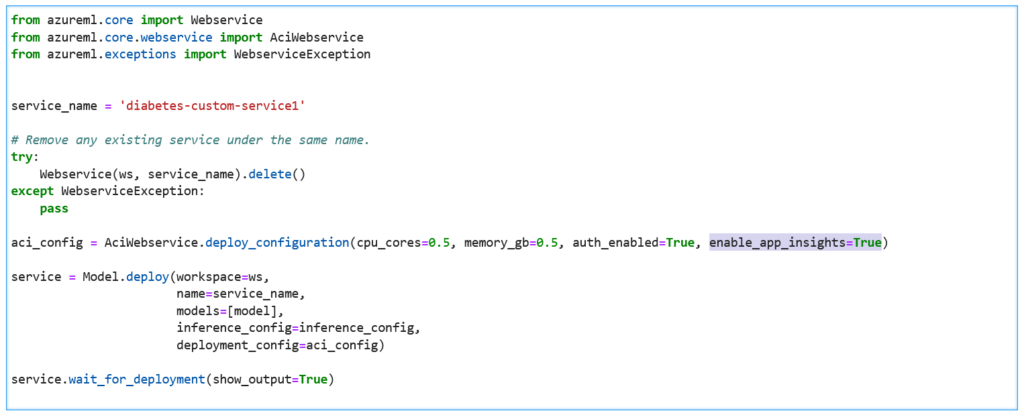
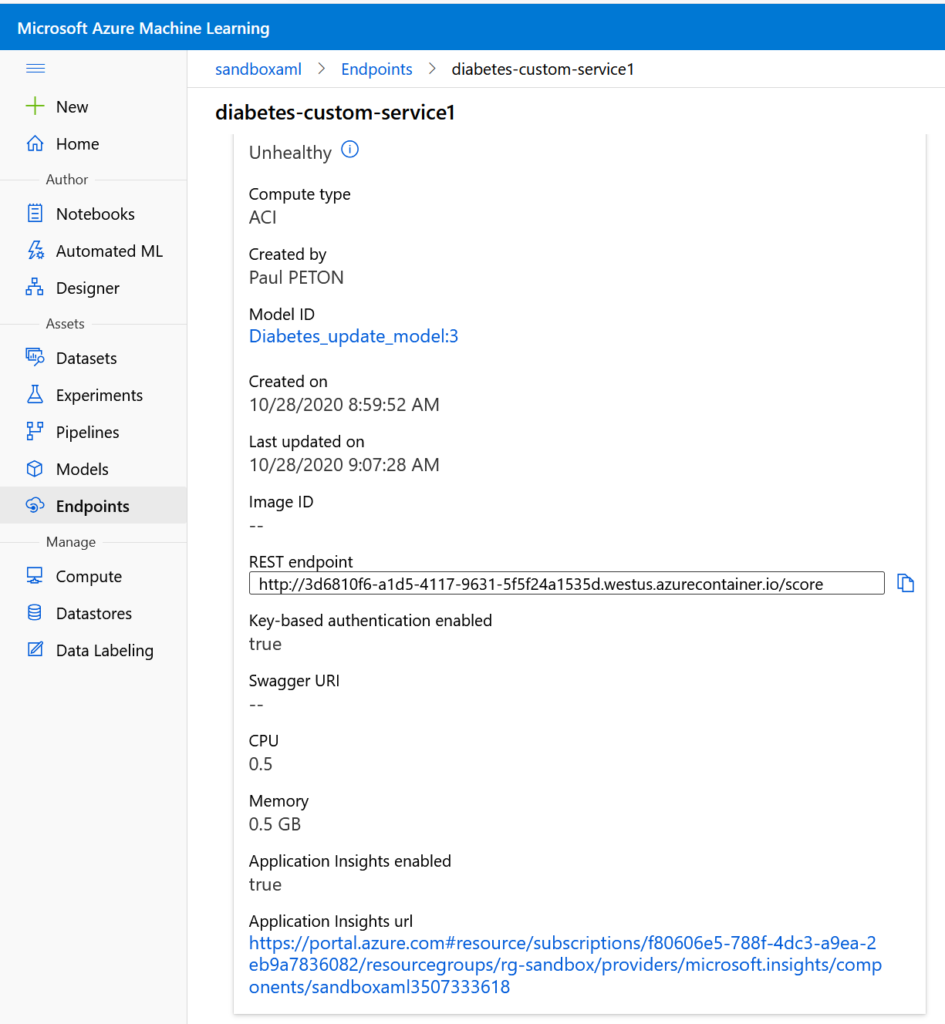
Mais avant de pouvoir obtenir des résultats, nous devons déployer un service web prédictif sur lequel App Insights a été activé. Nous le faisons en ajoutant la propriété enable_app_insights=True dans la définition de la configuration d’inférence.
Il faut également que du texte soit “imprimé” au moment de l’exécution de la fonction run(), tout simplement à l’aide de la fonction print().
Quelques exemples de notebooks sont disponibles dans ce dépôt GitHub.
Après publication ou mise à jour du service web, une URL apparaît dans l’interface et donne accès au service App Insights correspondant.
Exploiter Log Analytics
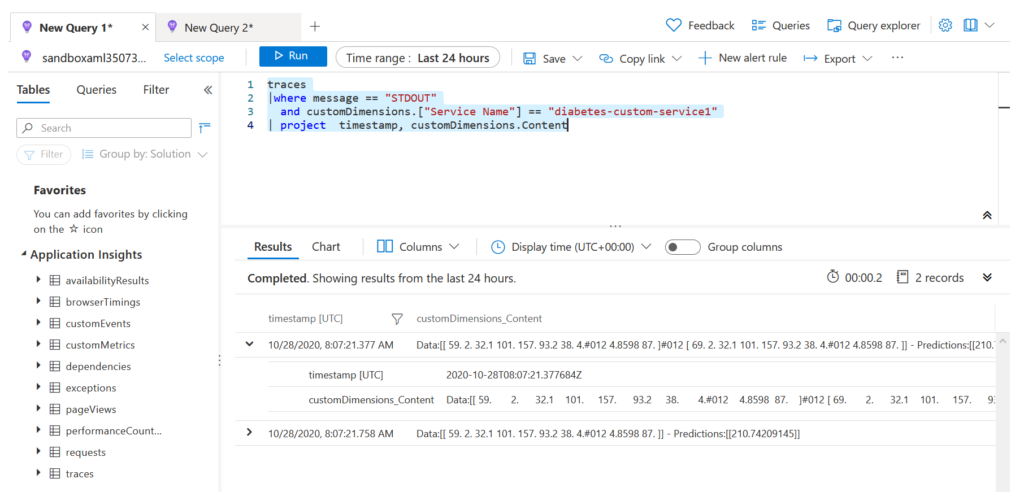
Il est maintenant possible de lancer une première requête dans l’interface Log Analytics, avec la syntaxe suivante :
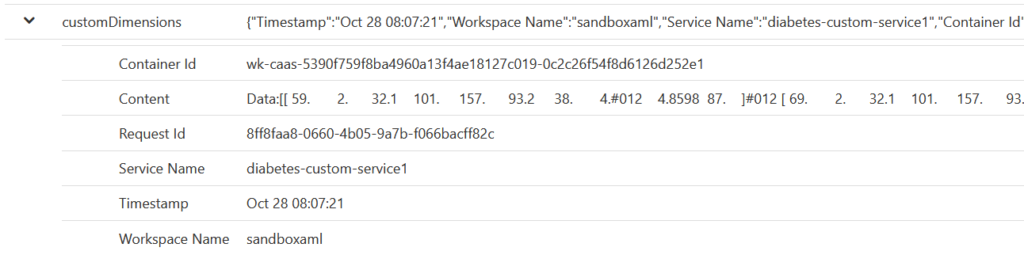
Le service Azure Machine Learning a créé une “custom dimension“, nouvel objet au format JSON, interrogeable par le langage KustoQL. Celui-ci contient des informations comme l’identifiant du container associé, le nom de l’espace de travail ainsi que du service déployé.
Afin de conserver les logs sur la durée, un mécanisme d’export continu pourra être mis en œuvre et stockera les informations sur un compte de stockage.
Ne le cachons pas, Spark déploie toute sa puissance lorsque les volumes de données sont significatifs. Pour autant, devant la simplicité d’utilisation d’Azure Databricks, il est tentant de centraliser tous les traitements de données dans des notebooks lancés sur un cluster.
Et un cluster, par définition, est constitué de plusieurs machines, a minima un driver et un worker qui échangeront des informations. C’est toute la puissance de cette architecture qui distribue les traitements sur un nombre de workers éventuellement automatiquement “scalable”.
Mais dans le cas de traitements simples, une seule machine virtuelle (bien dimensionnée) serait suffisante et éviterait en plus des échanges réseaux qui pourraient même perturber le traitement. En étant pragmatique, ce sont aussi des coûts divisés au moins par deux !
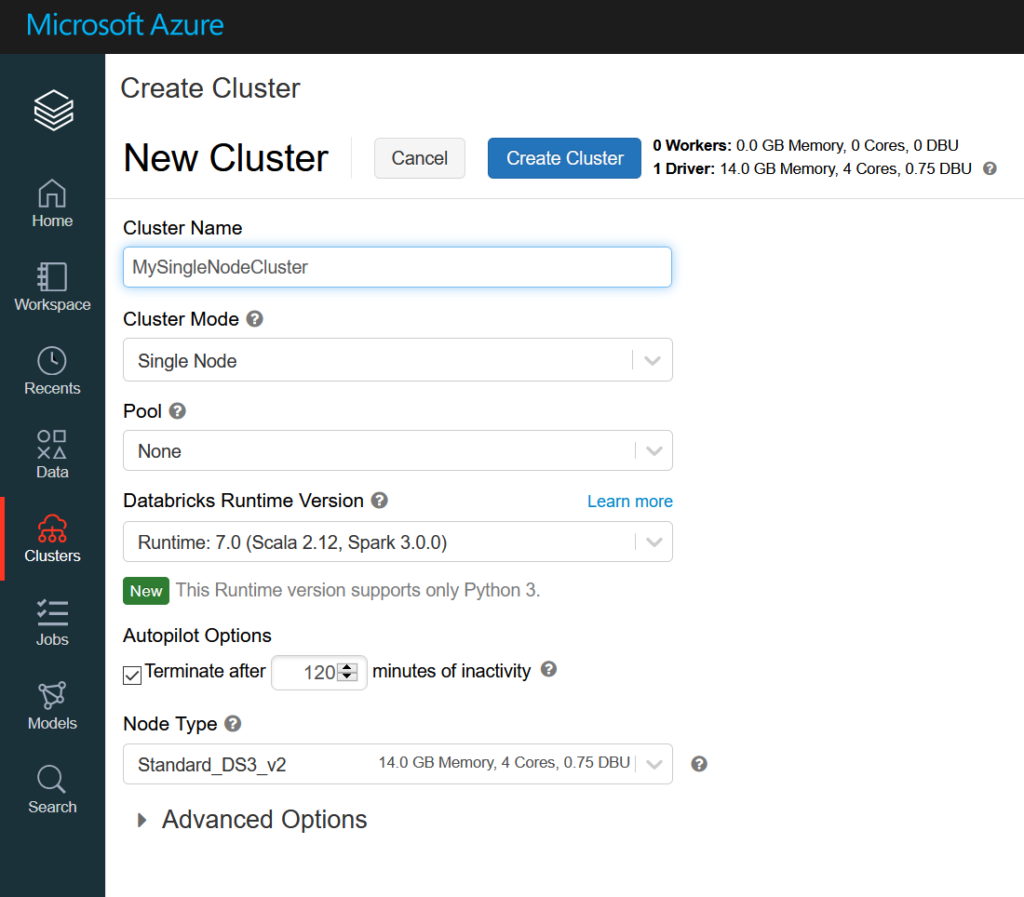
Une solution existe maintenant : le mode de cluster “Single Node“.
Cette fonctionnalité est aujourd’hui (octobre 2020) en préversion publique et décrite sur le site de Databricks.
On observe ce paramétrage dans la version JSON de la définition du cluster, au niveau de la configuration du cluster.
Imaginons maintenant que vous souhaitiez lancer vos traitements avec la logique “automated cluster“, s’appuyant éventuellement sur un pool de machines virtuelles. Cela est tout à fait possible depuis l’interface de jobs de Databricks mais dans une architecture data Azure plus large, on s’appuyera souvent sur le rôle d’ordonnanceur de Azure Data Factory.
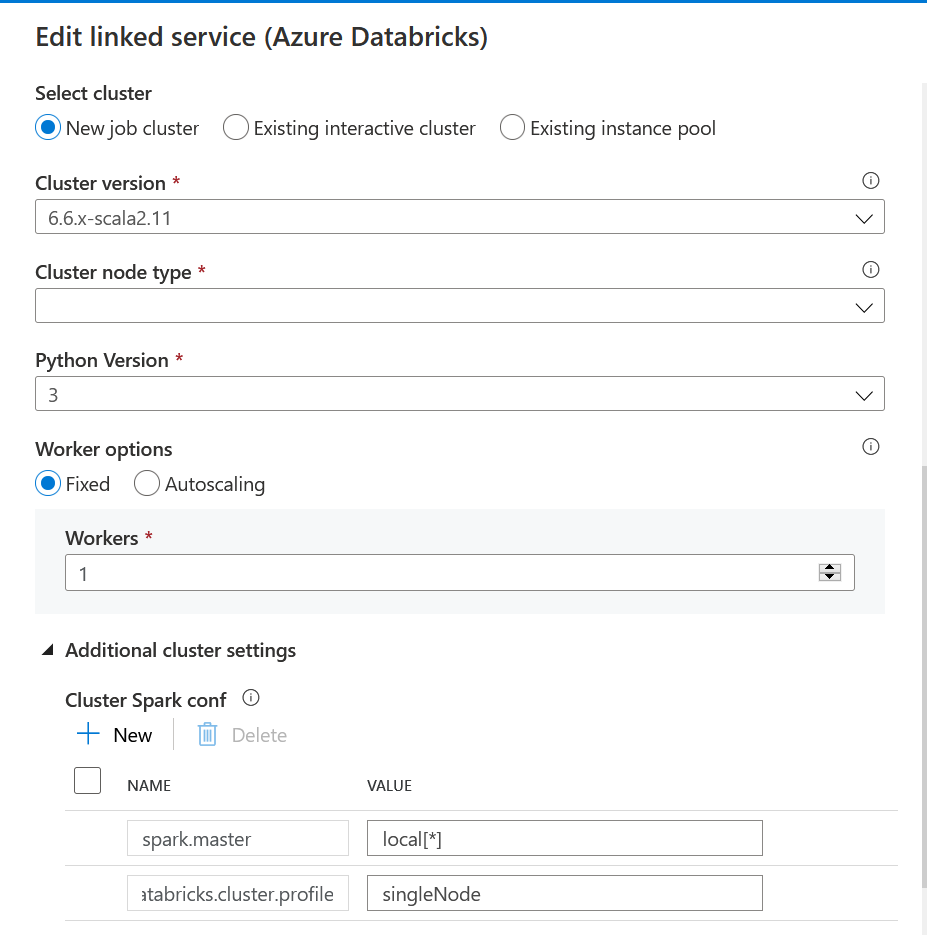
Dans Azure Data Factory, nous définissons un service lié Databricks. Dans l’interface graphique, nous ne trouvons pas le mode SingleNode mais la configuration Spark peut être précisée.
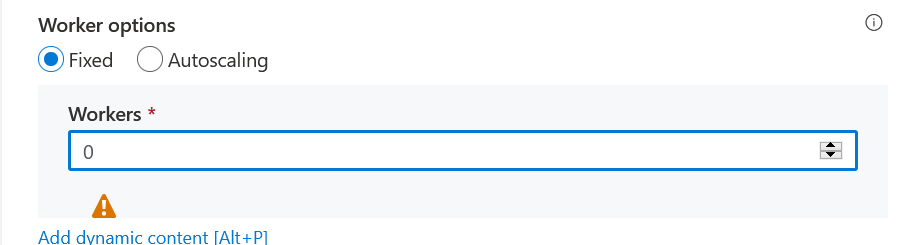
Cela semble suffisant mais nous pouvons aussi préciser le nombre de workers à 0, même si un message d’alerte apparaît alors. Celui-ci n’est pas bloquant.
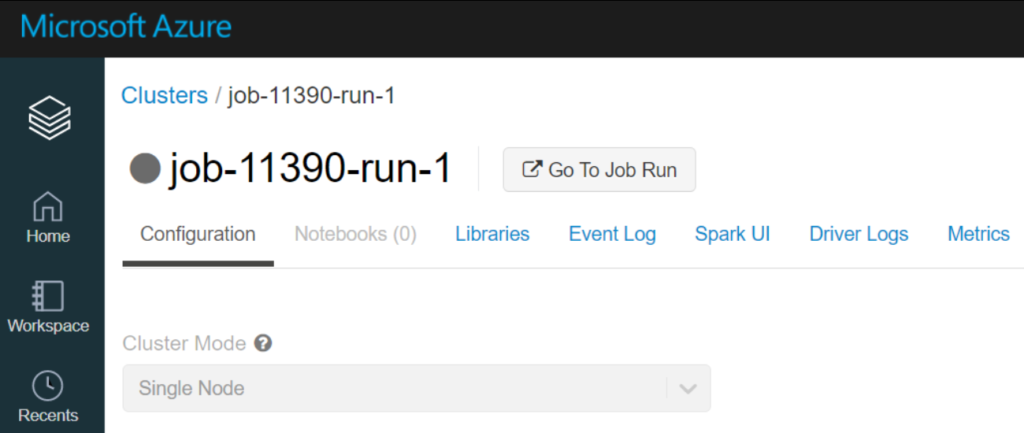
Afin de contrôler que ce sont bien des “automated single node clusters” qui se sont exécutés, vous pouvez consulter les logs de l’activité Data Factory où se trouve un lien pointant vers l’exécution du notebook et la configuration de clsuter associée.