
Pour des données établissant une série temporelle (mesure numérique à intervalles de temps régulier), la première étape de mise en qualité des données sera bien souvent de corriger les données dites aberrantes, c’est-à-dire trop éloignées de la réalité.
Rappelons les différents cas pouvant amener à ce type de données :
– erreur de mesure ou de saisie (maintenant plutôt lié à une erreur “informatique”)
– dérive réelle et ponctuelle (souvent non souhaitée, correspondant à un défaut de qualité)
– hasard (événement assez peu probable mais pouvant néanmoins se produire exceptionnellement!)
Avec la version de novembre 2020 de Power BI Desktop, nous découvrons une nouvelle fonctionnalité en préversion (donc à activer depuis le menu Options) qui ajoute une entrée dans le menu Analytique des graphiques en courbe (“line chart“).
Tout d’abord, regardons les limites d’utilisation précisées à cette page. Si 12 points sont le minimum requis (ou 4 patterns saisonniers), il sera beaucoup plus pertinent d’en avoir en plus grand nombre ! Ensuite, de nombreuses fonctionnalités ne sont pas (encore ?) compatibles avec la détection d’anomalies : légende, axe secondaire, prévision (forecast), live connection, drill down…
Fonctionnement théorique
Le papier de recherche qui décrit l’algorithme utilisé, nommé unsupervised SR-CNN, est disponible ici. Nous allons essayer de le vulgariser sans trop d’approximations.
Cet algorithme d’apprentissage automatique fait partie de la catégorie des méthodes non-supervisées, c’est-à-dire qu’il n’est pas nécessaire de disposer a priori d’un échantillon de données d’apprentissage où les anomalies seraient déjà identifiées (approche supervisée).
Les deux premières lettres du nom de cette approche correspondent à la méthode dite Spectral Residual, basée sur des transformées de Fourier, qui met en valeur des éléments “saillants” (salient) de la série temporelle.
Issus du domaine du Deep Learning, les réseaux de neurones à convolution (CNN) ont émergé dans le domaine du traitement d’images en deux dimensions. Pour autant, il est tout-à-fait possible de les utiliser dans le cadre d’une série temporelle à une dimension. Au lieu d’analyser des fragments d’images, la série des données transformées va être reformulée comme plusieurs successions de valeurs.
Ainsi, la série {10, 20, 30, 40, 50, 60} pourra donner des séries comme {10, 20, 30}, {20, 30, 40} ou encore {40, 50, 60} (voir ce très bon article pour aller plus loin dans le code).
Le rôle de la couche de convolution est d’extraire les features (caractéristiques) de la série temporelle. Ce sont elles qui permettront ensuite de décider si une valeur est ou non une anomalie.
D’un point de vue de l’architecture du réseau, la couche de convolution à une dimension est suivi d’une couche “fully connected” qui fait le lien entre le résultat de la convolution et le label de sortie (anomalie ou non).
Allons maintenant à la recherche d’un jeu de données pour expérimenter cette fonctionnalité !
Test sur un jeu de données
Il existe des jeux de données de référence pour évaluer la performance de la détection d’anomalies, et plus spécifiquement dans le cadre des séries temporelles. Vous en trouverez par exemple sur cette page.
Nous travaillerons ici avec un jeu de données de trafic réseau.
Ce dataset contient environ 4,5 millions de lignes.
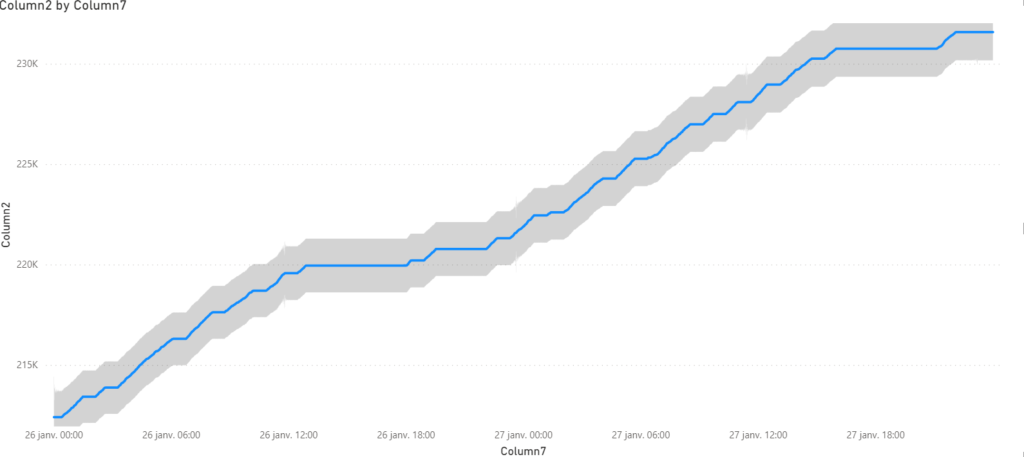
La détection d’anomalies se déclenche dans le menu Analytique du visuel.
Un seul paramètre est disponible pour régler le niveau de détection, entre 0 et 100% : sensitivity.
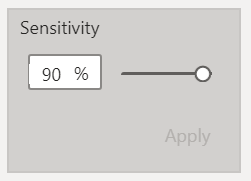
Plus la valeur est élevée, plus “l’intervalle de confiance” en dehors duquel sera détectée une anomalie est fin. Autrement dit, plus la valeur approche des 100%, plus vous apercevrez de points mis en évidence. Difficile de dire sur quoi joue ce paramètre d’un point de vue mathématique, il n’est pas évoqué dans le papier de recherche cité précédemment.
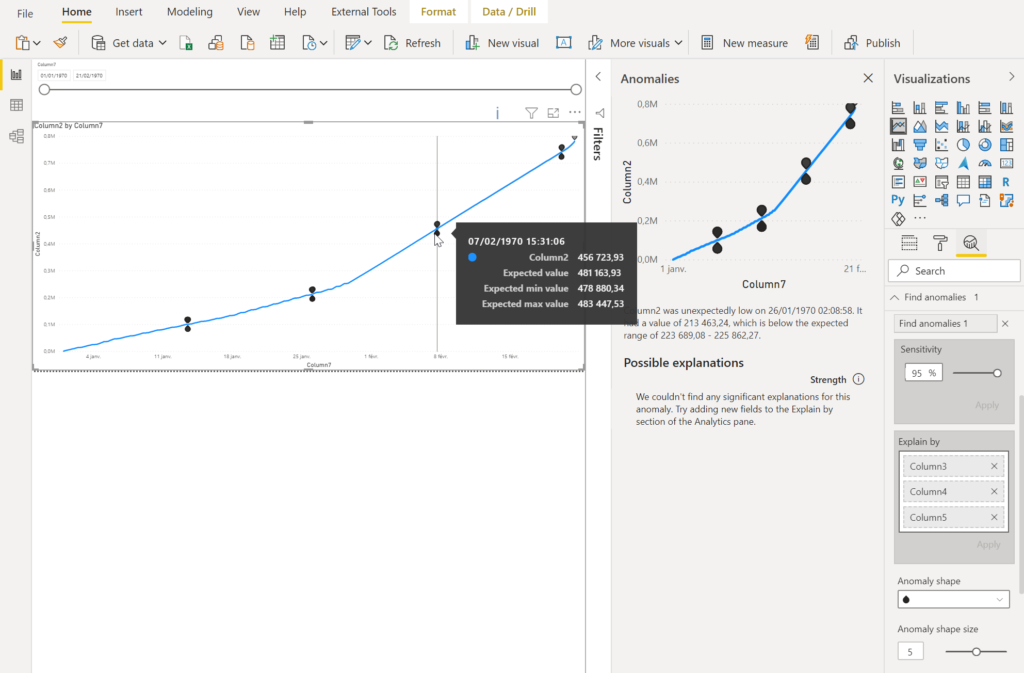
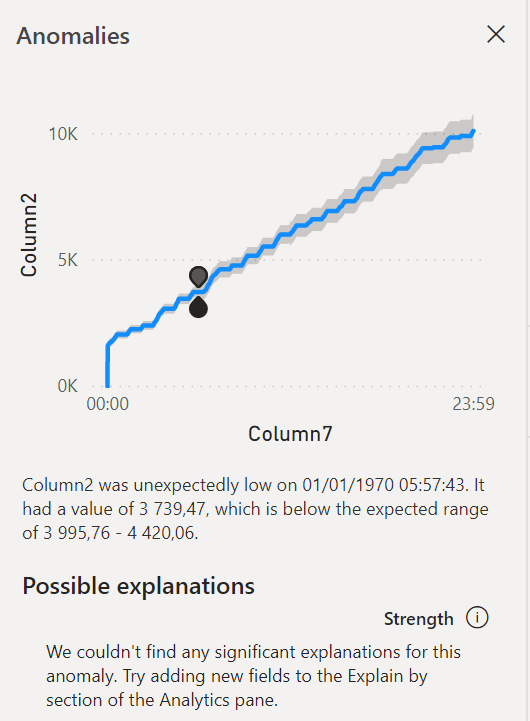
En cliquant sur un point, s’ouvre un nouveau volet latéral donnant les valeurs de la plage attendue, reprises également dans l’infobulle.
En plaçant d’autres champs de la table dans la case “explain by“, on peut espérer mettre une évidence un facteur explicatif de cette anomalie.
Attention, il n’est pas envisageable de “zoomer” sur un portion du graphique contenant une anomalie car cela modifiera la plage de données servant à évaluer l’algorithme et fera donc apparaître ou disparaître des points identifiés comme aberrants !
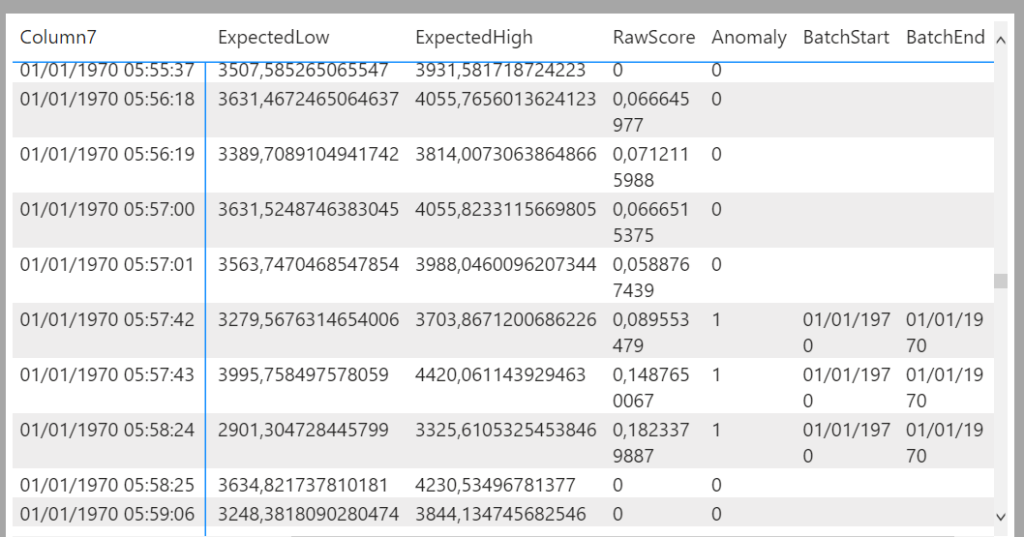
On pourra plutôt profiter de l’affichage du visuel en tant que table de données qui dispose d’une colonne “anomaly” valant 0 ou 1. On s’aperçoit ici que plusieurs points consécutifs sont identifiés comme des anomalies, ce qui était difficilement identifiable sur le graphique.
En conclusion
Malheureusement, les informations obtenues au travers de ce visuel ne peuvent pas réellement être exploitées : pas d’indicateur créé dans la table, pas d’export au delà de 30000 points (soit un peu plus de 8h pour des données à la seconde), un modèle perpétuellement recalculé et ne pouvant être arrêté sur une période. Alors, que faire lorsque des anomalies apparaissent ? Rien hormis prévenir le propriétaire des données…
Comme pour les autres services touchant (de loin) à l’IA sous Power BI, je suis sceptique quant au moment où cette fonctionnalité est mise en œuvre. La détection d’anomalies est une étape de préparation de la donnée et hormis à effectuer un reporting sur ces anomalies elles-mêmes, nous sommes en droit d’attendre qu’elles soient déjà retirées des données avant exposition. Il serait donc beaucoup plus opportun d’utiliser le service cognitif Azure dans un dataflow (Premium ou maintenant en licence Premium Per User) afin de mettre la donnée en qualité lors de la constitution de donnée. Pour une détection sur un flux de streaming, on se tournera avec intérêt vers les possibilités offertes par Azure Databricks, comme exposé dans ce tutoriel.
A l’inverse, les algorithmes prédictifs qui ne peuvent être utilisés que dans les dataflows seraient beaucoup plus à leur place dans un visuel qui permettrait de tester différents scénarios et d’observer les prévisions associées.
En résumé, les ingrédients de la recette sont les bons, encore faut-il les ajouter dans l’ordre pour obtenir un plat satisfaisant !
L’algorithme choisi (SR-CNN) ne doit pour autant pas être remis en cause car il semble aujourd’hui représenter l’état de l’art de la détection d’anomalies;
Vos remarques sur cet outil peuvent être déposées sur cette page communautaire.