
S’il était bien une fonctionnalité attendue pour la nouvelle (2020) version d’Azure Synapse Analytics, c’était la gestion du versionning et du déploiement des scripts créés dans l’outil.
Depuis la disponibilité générale (fin novembre 2020), nous trouvons un menu Source control dans la fenêtre Manage.
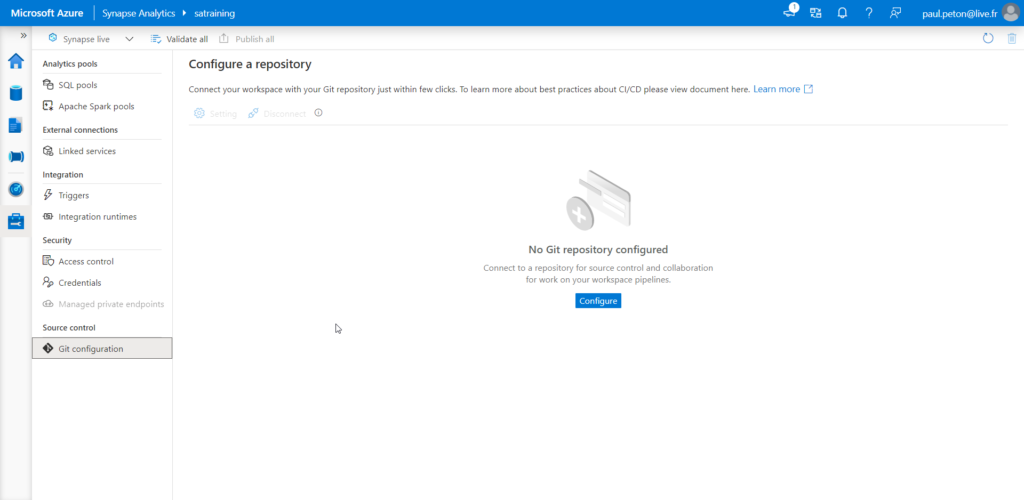
Nous pouvons définir la Git configuration, c’est-à-dire l’outil qui servira à l’enregistrement des développements et à leur versionning. Nous pouvons choisir entre Azure DevOps ou GitHub.
Nous choisissons ici Azure DevOps mais la partie GitHub est documentée sur ce lien officiel.
Nous devons disposer au préalable d’un projet DevOps et d’un repository dont l’URL devra être renseignée dans Synapse.
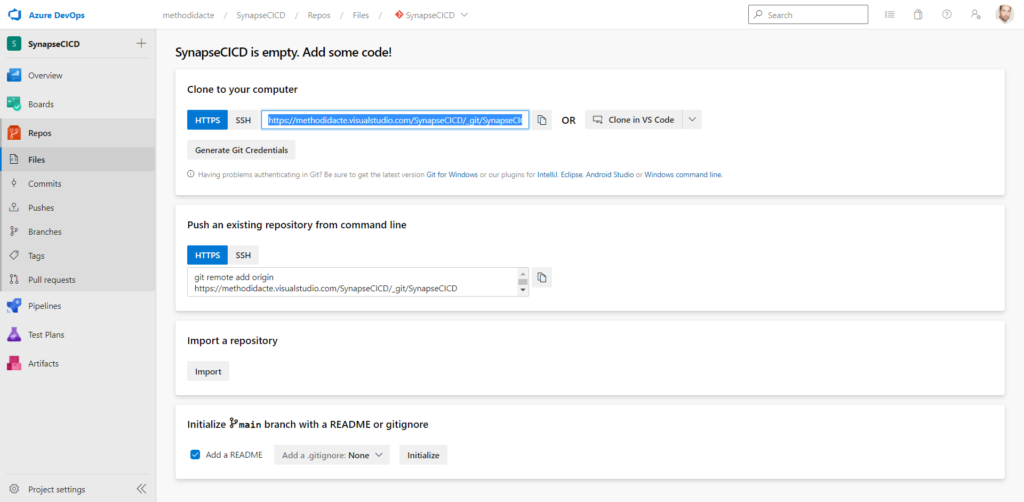
Dès lors, le dépôt se remplie avec les premiers éléments faisant partie de la ressource Synapse Analytics.
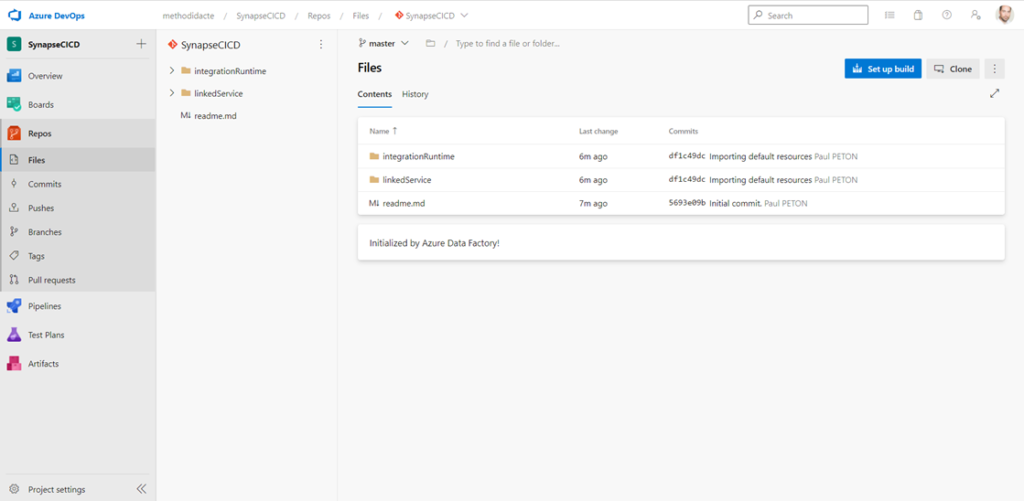
Dans le studio Synapse, nous disposons de plusieurs actions :

La validation permet de contrôler le développement réalisé et des erreurs seront remontées le cas échéant.
Le bouton Commit permet de “sauvegarder” le développement réalisé sur la branche active. Il est recommandé de ne pas développer directement sur la branche master.
Le bouton Publish de l’interface Synapse permet de créer ou mettre à jour la branche workspace_publish.
Il est donc logique de les utiliser successivement, dans cet ordre. L’action Publish réalisera une sauvegarde si nécessaire. A noter que les sorties (outputs) des cellules des notebooks sont effacées au moment de la publication. C’est une bonne pratique pour le versionning mais peut déstabiliser l’utilisateur souhaitant conserver l’affichage de ses résultats sans relancer le notebook complet.
Au fur et à mesure de l’utilisation de Synapse Analytics, de nouveaux répertoires vont se créer sur la branche collaborative.
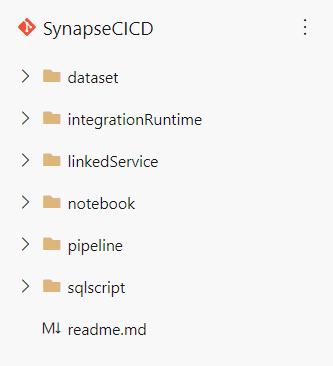
Dans la branche workspace_publish, nous retrouvons deux fichiers JSON dans une logique complètement similaire à celle d’Azure Data Factory, permettant un déploiement de type “template ARM“.
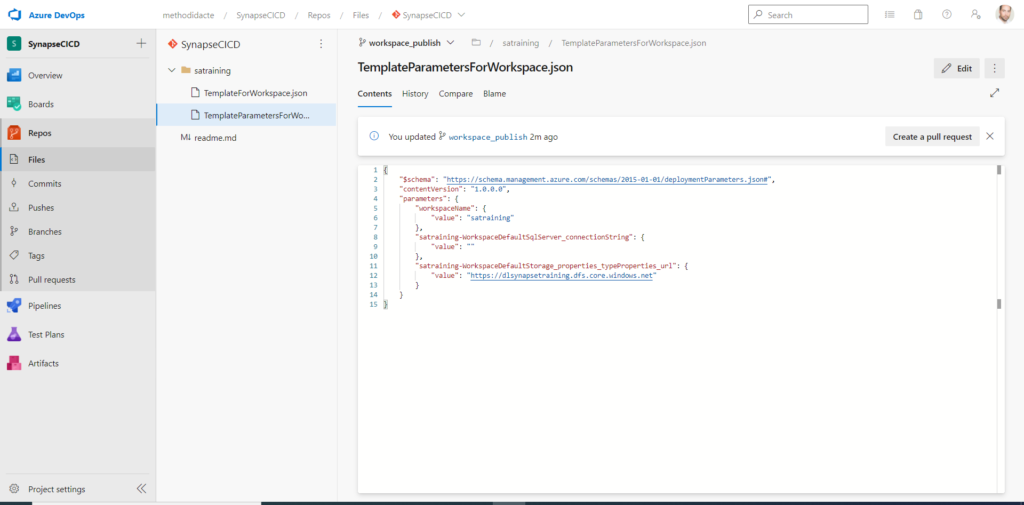
Le fichier TemplateParametersForWorkspace.json contient en particulier le nom des informations de connexion (nom du workspace, URL, etc.) et les mots de passe, secrets ou token, sont effacés. Il faudra écraser ou renseigner ces valeurs lors du déploiement dans un autre environnement.
Dans une seconde partie, nous développerons les approches possibles pour le déploiement continue à l’aide d’Azure Pipelines.