Dans une architecture cloud Azure, la ressource de “compute” Databricks va bien souvent être utilisée pour transformer la donnée brute en donnée dite nettoyée ou enrichie. Cette donnée peut bien sûr être stockée sur un Data Lake, par exemple dans un format Parquet (nous y reviendrons en fin d’article) mais les outils d’exploration et de visualisation de données comme Microsoft Power BI présentent de nombreux avantages à s’appuyer sur une base de données relationnelle (actualisation incrémentielle, DirectQuery…).
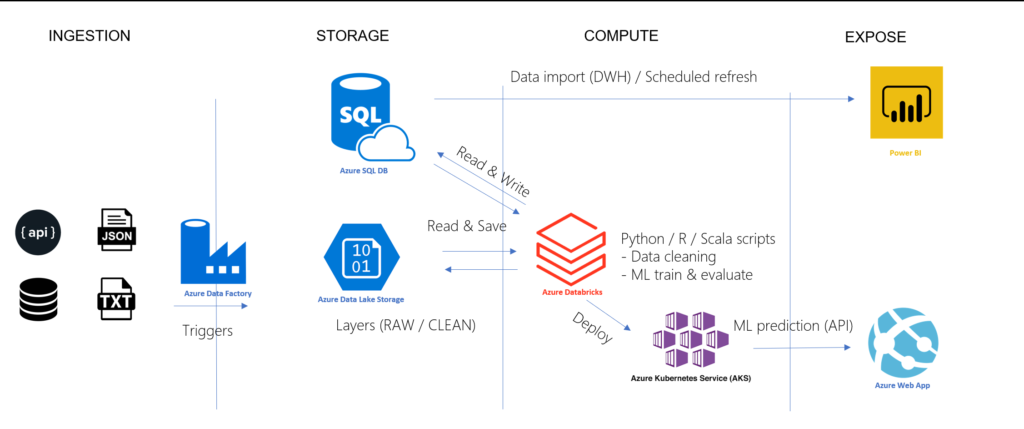
Nous partirons ainsi de l’architecture Azure ci-dessous :
Architecture Azure hybride pour des projets data de visualisation et de prévision
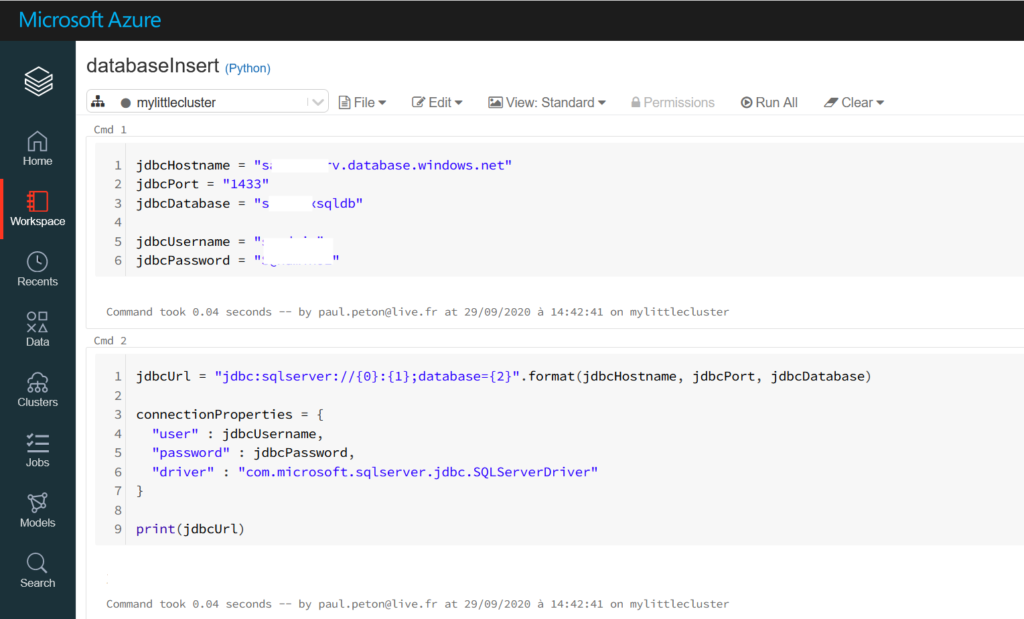
Nous lançons tout d’abord un notebook Python où nous définissons la chaîne de connexion. Il sera bien sûr très judicieux d’utiliser ici le secret scope de Databricks pour stocker toutes ces informations.
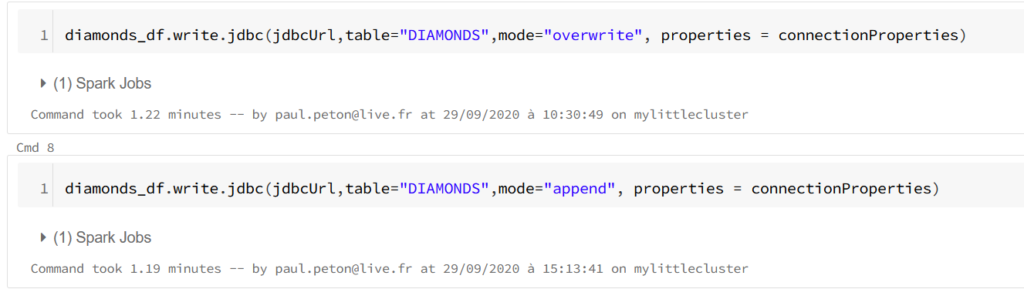
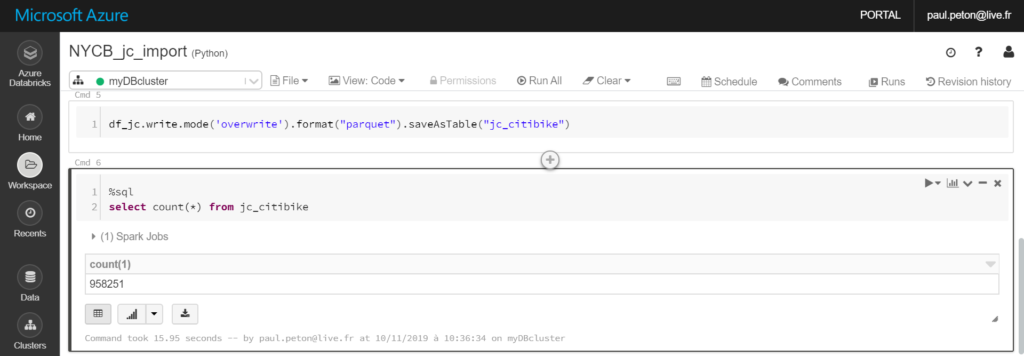
Il s’agit maintenant d’écrire un jeu de données nettoyées et travaillées en mémoire sous forme de Spark dataframe dans une table de la base de données. Cette opération se fait tout simplement au moyen de la méthode write associée aux informations de connexion : URL JDBC et propriétés de connexion.
Le paramètre de mode permet de choisir entre un “annule et remplace” de la table au moyen de la valeur overwrite ou une insertion à l’aide du mot clé append.
Il n’y a donc ici pas de mode prévu pour la suppression ou la mise à jour. Il faudra penser ce scénario de manière différente et peut-être au travers du format de fichier Delta, basé sur le format Parquet et sur lequel existent des méthodes delete et upsert. Pour autant, ce fichier restera en dehors de la base de données.
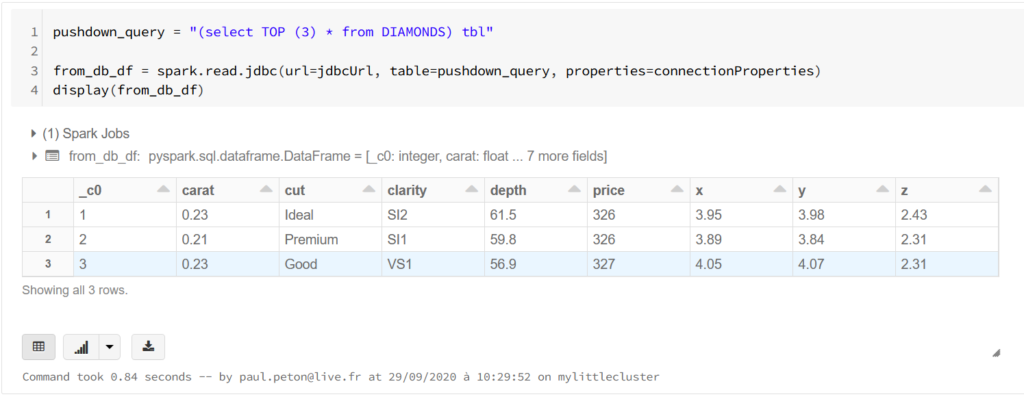
La méthode read de Spark est également possible et se fait en soumettant une requête SQL au travers du driver JDBC. Nous utilisons ici la syntaxe SQL propre à la base de données, ici le Transac-SQL de Microsoft.
L’alias de table sur la requête est indispensable pour être interpréter par le paramètre table de la méthode read.
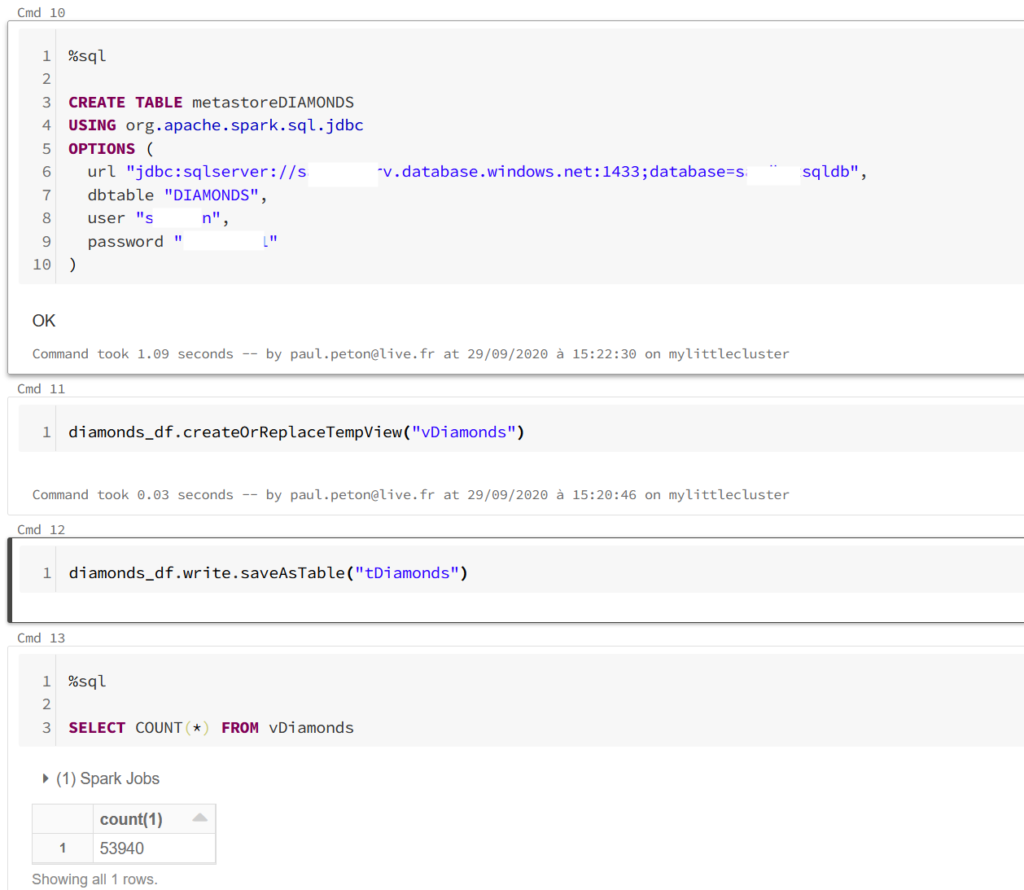
Pour aller un peu plus loin dans l’exploitation de ce driver JDBC, nous pouvons créer une table dans le métastore du cluster, copie d’une table de la base de données.
Il est alors possible de créer des interactions en Spark SQL entre des vues créées à partir de dataframes Spark (ou Pandas en les convertissant au préalable) et la table du métastore. Ce scénario ne réalise qu’une lecture des données de la base et des opérations d’écriture sur cette table ne seront bien sûr pas répercutées sur la base de données.
Nous avons ici utilisé le driver JDBC de manière simple avec une ressource de type SQL Database. Vous retrouverez ici une autre manière de procéder au travers de Polybase pour Azure SQL Datawarehouse. Ce service Azure étant maintenant renommé Azure Synapse Analytics et disposant de nouvelles fonctionnalités, de prochains articles décriront les modes d’interaction entre fichiers, dataframes et tables. En attendant, je vous recommande cet épisode du podcast Big Data Hebdo autour de Synapse.
(Nous parlerons ici du service cloud Power BI, destiné au partage et à la collaboration. Si vous partagez vos fichiers .pbix, une autre réflexion sera nécessaire 😉 )
Mais tout d’abord, pourquoi bloquer l’export des données depuis les rapports Power BI ?
La méthode radicale : l’interdiction par l’utilisateur
La méthode douce : l’interdiction (ou la limitation) au dataset
La méthode (ultra) fine : le retrait de l’option au niveau du visuel
Enfin, rappelons que tout utilisateur ayant les droits nécessaires et une version d’Excel suffisamment récente peut installer l’extension “Power BI Publisher” qui, comme son nom ne l’indique pas, peut accéder aux datasets hébergés sur le service Power BI et pour lesquels ils disposent des droits suffisants.
(*) Revenir à l’essentiel : l’analyse des données !
Intelligence Artificielle,
Machine Learning, RGPD… la donnée ne quitte plus le devant de la scène
médiatique, qui attribue bien souvent à la data des pouvoirs thaumaturges. Le
monde du recrutement s’emballe autour des profils « Data Scientists »
tout en présentant des listes de compétences impossibles à maîtriser pour une
seule et même personne, allant de l’architecture Big Data à la programmation de
réseaux de neurones convolutifs (le fameux Deep Learning). A l’exception des entreprises
dont la data constitue le cœur de métier comme Booking, AirBNB ou Uber, quelles
sont celles qui ont réellement modifié et amélioré leur activité par une approche
« data driven »,
c’est-à-dire pilotée par la donnée ? Ce phénomène de « hype » autour de la donnée peut
poser question et générer une certaine méfiance.
Pourtant, une réaction inverse qui reviendrait à rejeter tout apport de la donnée serait aussi improductive. Et tant qu’à stocker la data, autant en tirer profit ! Dans une série de trois articles, nous nous arrêterons successivement sur l’intérêt, pour les entreprises, de l’analyse de données exploratoire, l’analyse prédictive grâce au Machine Learning et les promesses du Deep Learning sur les données non structurées.
Une même finalité, de nouveaux outils
Bien avant l’explosion de l’engouement pour la Data Science, certaines personnes dans l’entreprise pratiquaient déjà l’analyse de données sous des intitulés de poste tels que « chargé.e d’études statistiques », « statisticien.ne », « actuaire », « data miner », etc. Souvent éloignées du département IT et des architectures de production, ces personnes en charge de forer la donnée réalisent des extractions puis travaillent ces échantillons dans un classeur Excel ou un logiciel spécialisé. Une fois les conclusions obtenues, celles-ci figurent dans une présentation au format Word ou PowerPoint, c’est-à-dire sans possibilité simple de mise à jour ni d’extension à d’autres données. Nous allons voir ici que c’est aujourd’hui, non pas un bouleversement méthodologique, mais bien une simplification et une meilleure performance des outils qui changent ces métiers.
Notre approche méthodologique visera à répondre aux quatre temps de l’analyse de données.
Les quatre temps de l’analyse de données
Prenons un exemple concret : l’analyse des accidents corporels de la circulation pour laquelle les données sont disponibles en open data sur le portail data.gouv.fr.
Pour une première
approche du jeu de données, nous travaillerons dans l’outil Microsoft Power BI Desktop qui, même s’il
n’est pas un logiciel statistique à proprement parler, permet de nettoyer et
visualiser les données très rapidement. Nous verrons même qu’il cache plusieurs
fonctionnalités analytiques particulièrement intéressantes. Enfin, lorsque
l’étude exploratoire sera terminée, il ne sera plus nécessaire de quitter
l’outil pour présenter les résultats dans un logiciel bureautique figé.
L’interface proposera une visualisation dynamique et adaptée à la restitution.
L’indispensable nettoyage des données
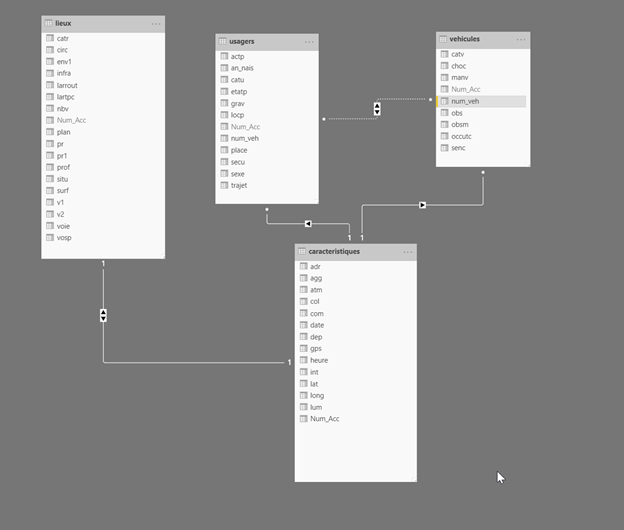
Observons tout d’abord le
schéma des données collectées, dont la description précise des champs est
disponible dans ce document. Nous travaillerons ici avec les notions
de :
Caractéristiques de l’accident
Lieu de l’accident
Véhicules impliqués
Usagers des véhicules impliqués
Modélisation des données dans Power BI Desktop
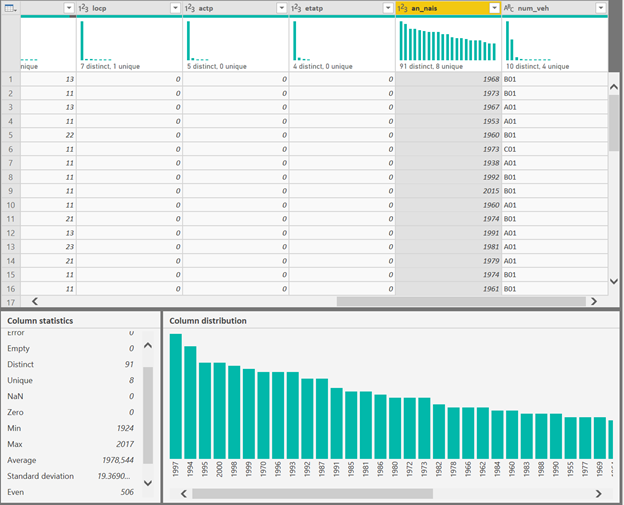
La qualité des données en entrée déterminera la qualité des résultats qui seront obtenus (ou tout du moins, garbage in, garbage out !). Un travail d’inspection de chaque champ est nécessaire et celui-ci se fait rapidement grâce au profil de la colonne, comme par exemple ci-dessous, sur l’année de naissance de l’usager.
La lecture des indicateurs de synthèse (moyenne, médiane, écart-type, etc.) nous permet de débusquer des valeurs aberrantes (un conducteur né en 1924, cela reste plausible) et de comptabiliser des valeurs manquantes qui nécessiterait un traitement spécifique (ici, toutes les lignes sont renseignées.)
L’interaction pour une meilleure
exploration des données
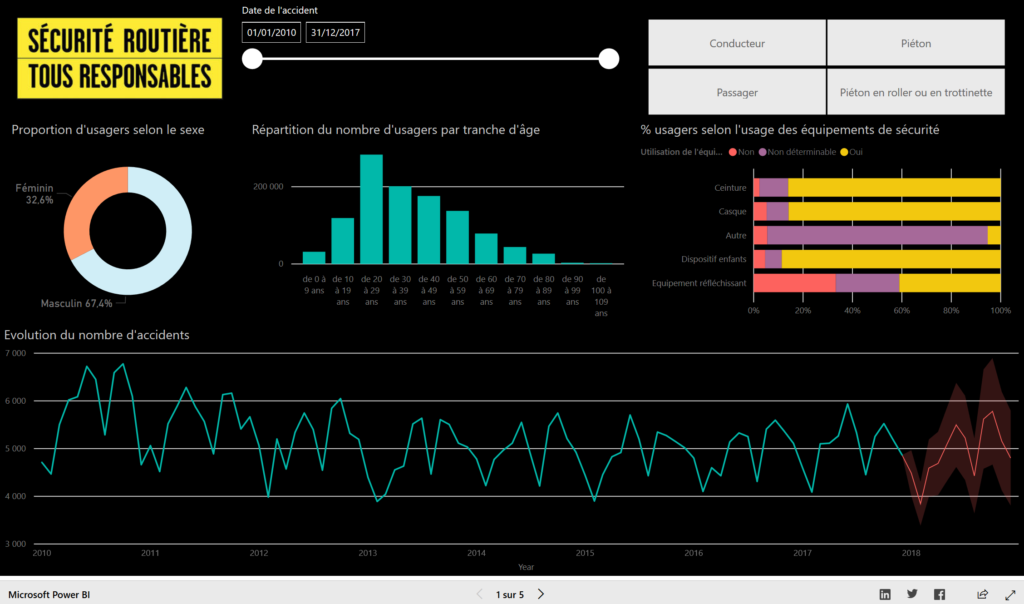
L’une des grandes forces de Power BI réside dans son haut niveau d’interaction avec la donnée, au moyen de filtres visuels ou en sélectionnant un élément graphique pour obtenir instantanément la mise à jour des autres visuels.
L’analyse descriptive est ainsi rapidement obtenue. A vous de jouer, ce rapport est totalement interactif !
Bien sûr, il ne faudra
pas tomber dans le travers de chercher à filtrer sur toutes les dimensions
possibles ! L’être humain n’est pas en capacité d’appréhender un trop
grand nombre d’informations mais les méthodes d’analyse avancée sont là pour
nous aider.
Des fonctionnalités pour l’analyse
explicative
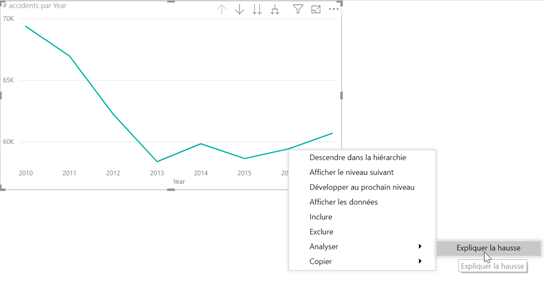
Observons l’évolution du nombre d’accidents dans le temps, au niveau annuel. On constate une hausse en 2016 avec un recul des accidents sur les années précédentes.
Expliquer (automatiquement) la hausse
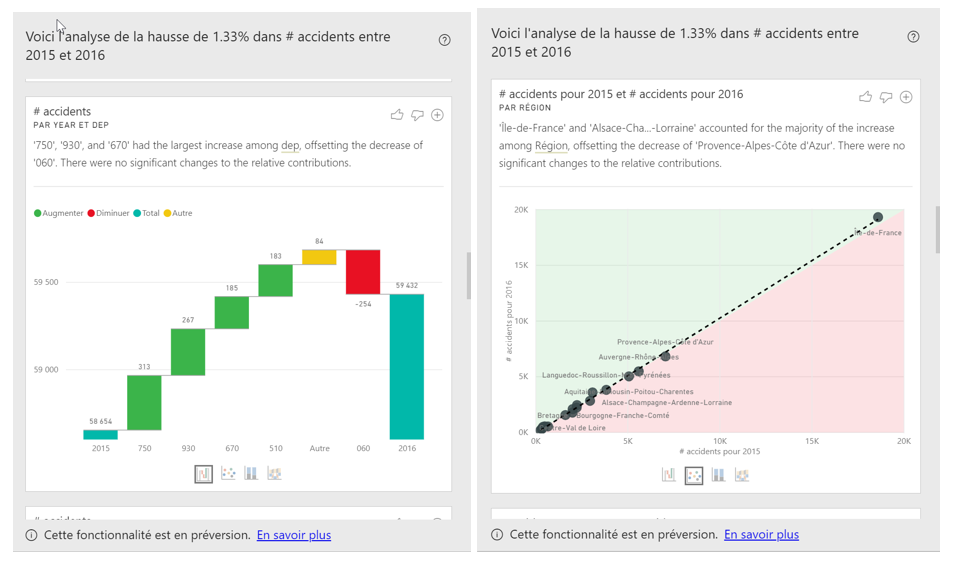
Power BI va rechercher les facteurs explicatifs de la hausse de l’indicateur en testant tous les champs du modèle et nous fera plusieurs propositions. Nous retenons ici celle du département de l’accident qui met en évidence une hausse significative sur les départements d’Ile-de-France 75 et 93, contre une baisse dans les Alpes-Maritimes. Cette piste nous mettrait sur la voie de données décrivant ces départements (population, infrastructures routières, etc.).
Visuels générés automatiquement par Power BI : l’utilisateur choisit le plus parlant.
L’analyse faite jusqu’ici
nous permet de comprendre les données dans leur ensemble mais il est
fondamental de répondre à une problématique levée par le sujet, ici
l’accidentologie, et nous allons donc rechercher des explications à la
mortalité routière.
Nous disposons pour cela d’une information sur la gravité de l’accident qui permet de déterminer si l’usager est décédé.
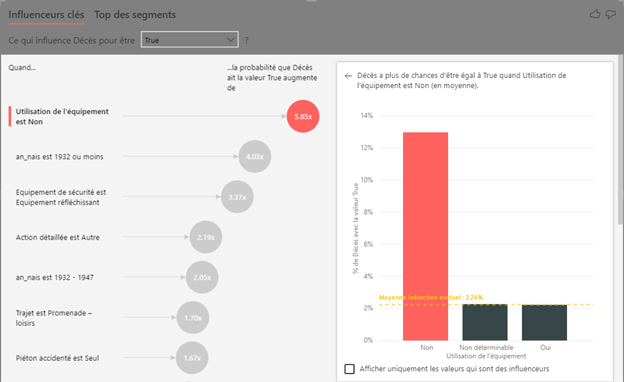
Influenceurs clés : une régression logistique visuelle !
L’analyseur d’influenceurs clés (key influencers, basé sur une approche de modélisation par régression logistique) identifie la non utilisation d’un équipement de sécurité (ceinture, casque, etc) comme le facteur le plus fort dans un décès lié à un accident : la probabilité est presque multipliée par 6. L’âge est également un facteur très important. Si celle-ci est inférieure à 1932, le risque de décès est ici multiplié par 4.
Nous obtenons ici, grâce
à l’analyse, des leviers d’actions concrets pour la sécurité routière, ce qui
constitue une première forme d’analyse prescriptive
… et une première analyse prédictive !
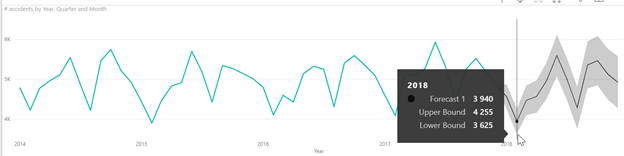
Reprenons l’évolution du
nombre d’accidents dans le temps mais cette fois-ci, au niveau mensuel. La
courbe traduit clairement une notion de saisonnalité : il y a beaucoup
(trop) d’accidents lors des périodes de vacances scolaires par exemple. Si l’on
ajoute une droite de tendance, on voit que celle-ci est légèrement à la hausse.
Prolonger cette droite ne donnerait pas une bonne prévision au détail mensuel
puisqu’il faut tenir compte de cette saisonnalité.
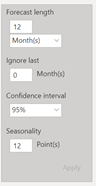
Nous utilisons ici la fonctionnalité de « forecast » de Power BI basée sur la méthode statistique du lissage exponentiel. N’allons pas trop loin, il est conseillé de ne pas dépasser une prévision au tiers de l’historique disponible. Cette prévision est encadrée par un intervalle de prévision, donnant les bornes entre lesquelles on espère voir apparaître la « vraie » valeur, avec un niveau de confiance de 95%.
Paramètres de la prévision
On obtient alors la prévision sur le graphique et l’infobulle donne les valeurs chiffrées.
Une présentation dynamique sans changer
d’outil
Résumons maintenant toutes les informations découvertes au travers de cette première analyse. Pour communiquer ces résultats, nous pourrions utiliser un support externe comme PowerPoint ou un fichier PDF mais nous perdrions toute interaction. Les bookmarks (ou signets) de Power BI sont ici un outil extrêmement pratique pour garder en mémoire une sélection personnalisée de filtres et enchainer la lecture de plusieurs pages de rapport comme l’on enchainerait des diapositives.
Le proverbe bien connu “diviser pour mieux régner” a sa déclinaison dans le monde de la Data et des services managés : “séparer le traitement du stockage”. Par cela, il faut comprendre que l’utilisation de deux services différents pour ces deux tâches est particulièrement intéressant.
En effet, le stockage se doit d’être permanent et toujours accessible, en tenant compte de différents degrés de “chaleur”. En revanche, la puissance de calcul n’est nécessaire que pendant les traitements et il faudra pouvoir faire évoluer cette puissance selon le besoin. Par exemple, un entrainement de modèle prédictif, opération qui peut être très coûteuse, bénéficiera de l’élasticité d’un service managé comme Azure Databricks mais ne sera peut-être pas réalisé quotidiennement.
Nous allons détailler ici comment pérenniser les données issues d’un traitement de préparation réalisé sur le cluster managé Spark. La solution de stockage choisie ici est Azure SQL Data Warehouse.
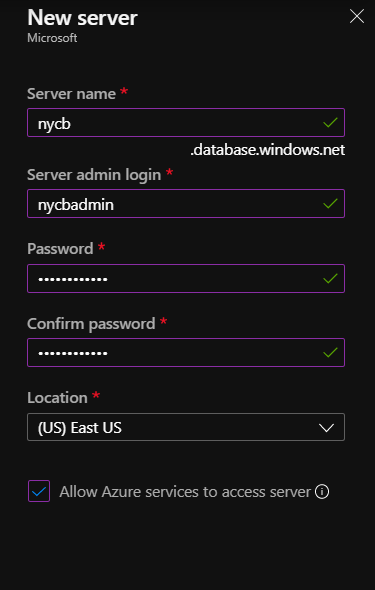
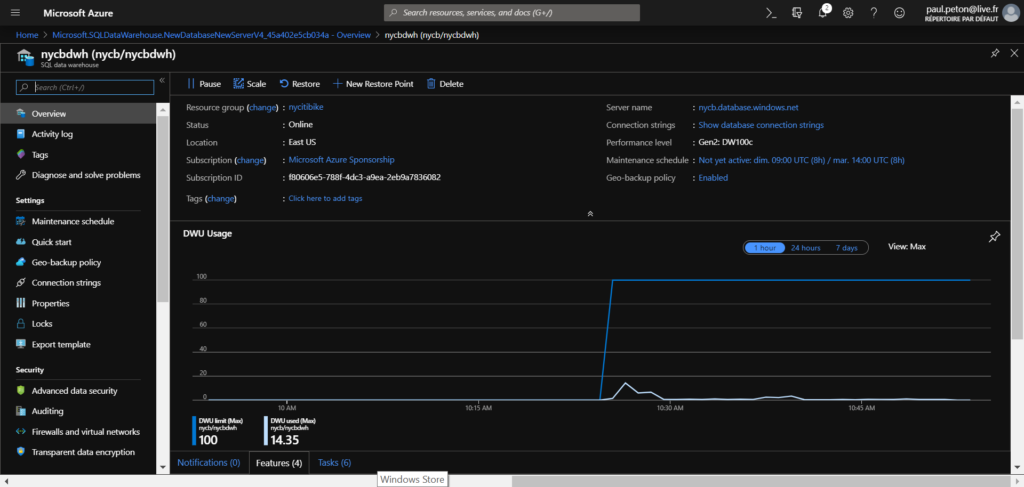
Créer une ressource Azure SQL DWH
Il est tout d’abord nécessaire de disposer d’une ressource Azure de serveur de bases de données.
La documentation officielle d’Azure Databricks recommande de cocher la case “Allow Azure services to access server”.
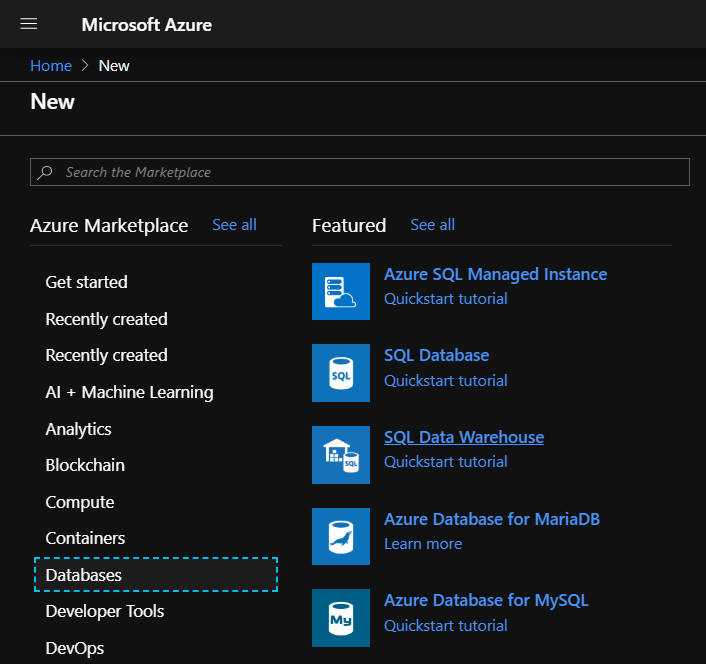
Nous sélectionnons maintenant la ressource Azure SQL Data Warehouse dans la catégorie Databases.
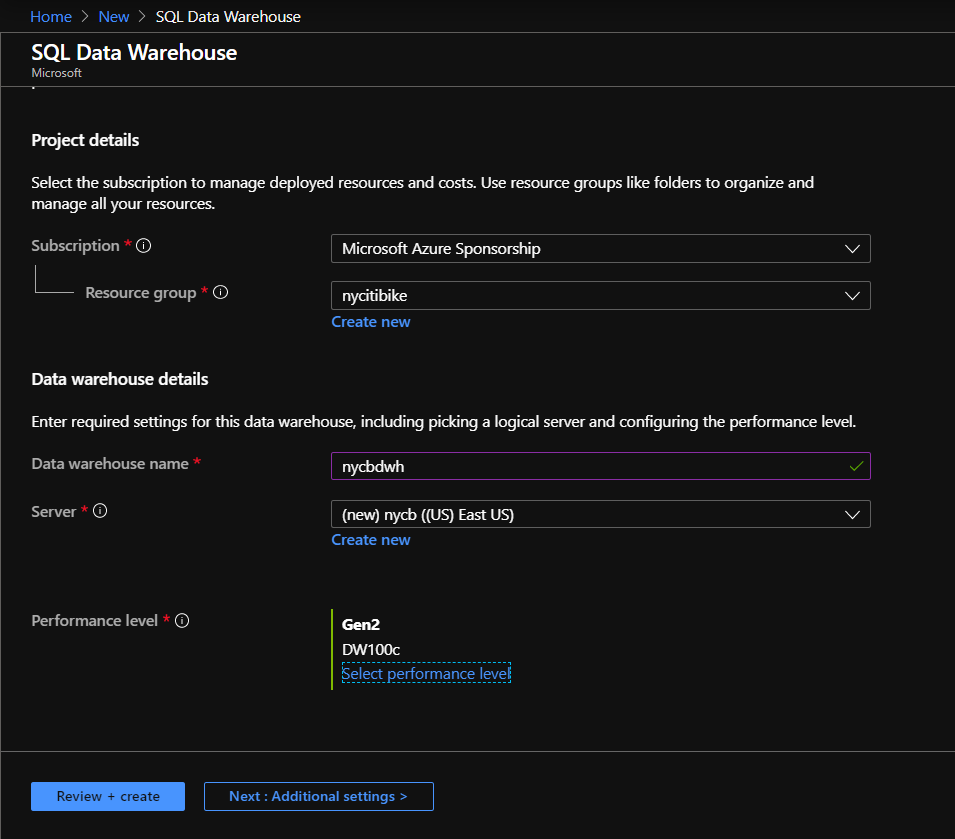
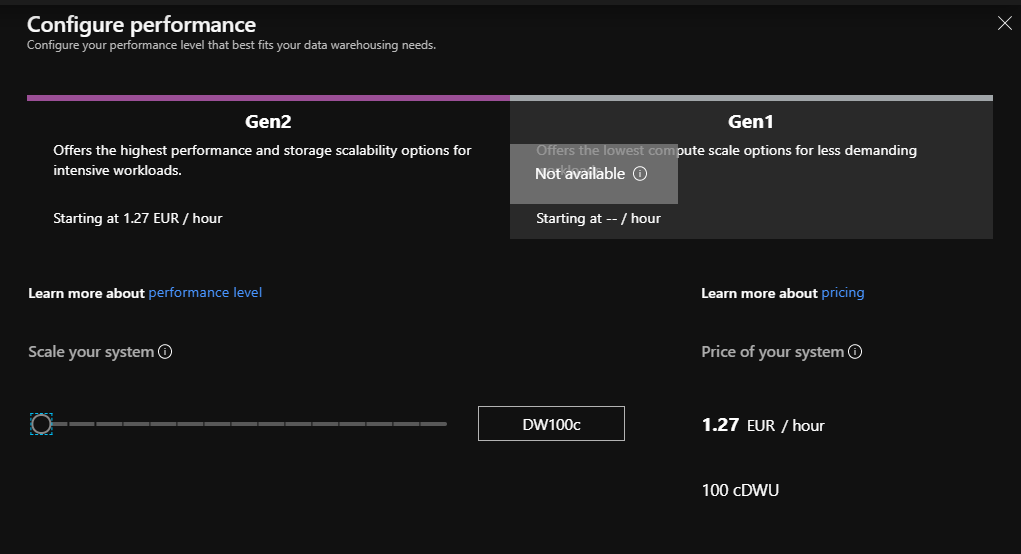
Le Data Warehouse est associé à un groupe de ressources et à un serveur de base de données (ici, créé simultanément). Le niveau de performance choisi va déterminer le coût associé à une heure de service de l’entrepôt.
Cette ressource se montra particulièrement efficace dans le cadre d’une connexion vers un outil de dashboarding comme Power BI et autorise le mode direct query, qui pourra se révéler pertinent dans des modèles de données composites, mêlant import et connexion directe.
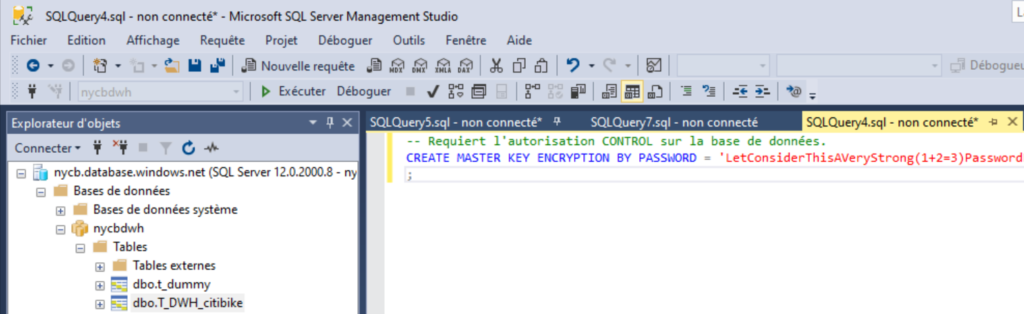
Une clé de chiffrement pour la base étant obligatoire, il sera nécessaire de créer une database master key au travers d’une nouvelle requête sur la base de données. Cela peut se faire par exemple dans le client SQL Server Management Studio ou sur le portail Azure par le query editor actuellement en préversion.
--Creates the database master key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = "yourStr0ngPa$$W0rd"
Faire communiquer Azure Databricks et SQL DWH
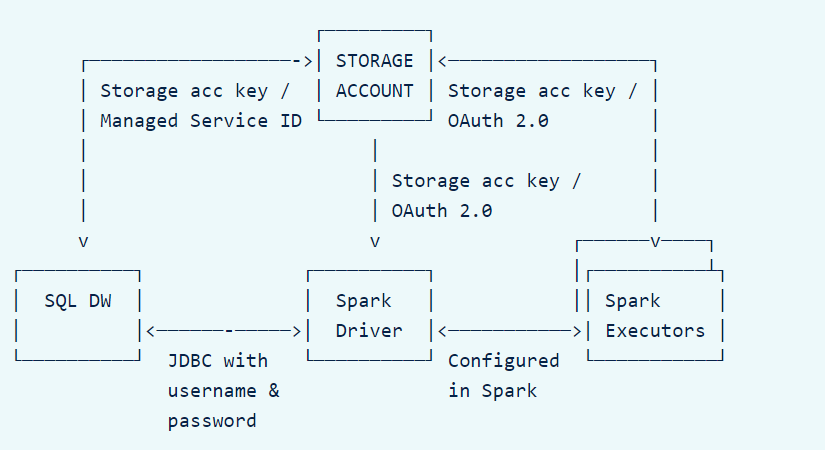
Afin de bien paramétrer la communication, il faut tout d’abord comprendre comment fonctionne le mécanisme. La subtilité à bien saisir est l’importance d’un troisième élément qui est le compte de stockage Azure utilisé comme zone temporaire et sollicité par le composant PolyBase.
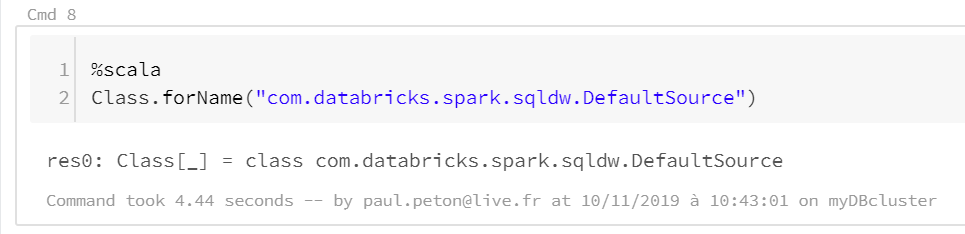
Vérifions tout d’abord que le connecteur SQL DWH est présent sur le runtime Databricks associé au cluster Spark au moyen de la commande Scala ci-dessous.
La commande ne doit pas renvoyer d’erreur “ClassNotFoundException”.
Dans une cellule d’un notebook, nous déclarons toutes les variables nécessaires à la bonne communication entre les différentes briques, en particulier le compte de stockage Azure (Blob Storage ou Data Lake Storage gen2).
Le code ci-dessous est donné pour un notebook Python mais sa variante en Scala s’obtiendra facilement en ajoutant le mot-clé var au devant de chaque déclaration de variable.
Attention à faire cette étape proprement au moyen d’un secret scope !
Des travaux de data preparation nous ont permis de réaliser un DataFrame propre contenant des données plus exploitables. Une sauvegarde du DataFrame est réalisée sous forme de table sur le cluster mais celle-ci ne sera accessible que lorsque le service Azure Databricks est démarré (et donc facturé).
Nous allons donc réaliser une copie des données sur Azure SQL Data Warehouse.
Grâce aux actions préalables, il est maintenant possible de lancer les commandes load ou write pour communiquer avec Azure SQL Data Warehouse. Dans la commande ci-dessous, nous créons une nouvelle table dans la base de données à partir d’un DataFrame en mémoire du cluster.
Les logs du cluster montrent que la communication s’effectue bien avec le Data Warehouse.
Automatiser les traitements
Nous avons donc réalisé ici la partie cruciale de la chaîne de la data, en séparant traitement et stockage des résultats. Pour rendre cette architecture encore plus efficace, il sera nécessaire de planifier le traitement de préparation des données . Plusieurs solutions sont ici disponibles :
l’ordonnanceur d’Azure Databricks, couplé à une logique d’enchaînement de notebooks
l’utilisation d’un pipeline Azure Data Factory et d’une activité Databricks
Ces deux approches sont décrites dans cet article.
Dupliquer les données, bonne idée ?
A cette question, nous pourrons formuler la traditionnelle réponse du consultant : “ça dépend”.
Rappelons qu’il faut bien évaluer les usages et les coûts d’une telle architecture. Quel est le public qui a besoin de cette donnée préparée ? Plutôt des data analysts au sein de Power BI ? Plutôt des data scientists dans un cluster “bac à sable” ?
Azure SQL Data Warehouse offre une puissance d’accès pour des usages analytique mais il faut mesurer son coût si la base reste accessible en continu. A l’inverse, les tables matérialisées sur le cluster retirent une brique de l’architecture (et de la facture !) mais les performances du connecteur Spark pour Power BI ne me semblent pas aujourd’hui suffisantes pour des volumes de données importants.
Une fois de plus, la bonne architecture cloud Data sera celle qui répondra le mieux aux besoins, dans un cadre gouverné et dont le coût et la performance seront supervisés de près.
[EDIT 13 novembre 2019 : Microsoft a annoncé lors de l’Ignite d’Orlando qu’Azure SQL Data Warehouse évoluait et devenait au passage Azure Synapse Analytics. Nous suivrons de près cette évolution.]
Si vous avez suivi mes derniers articles sur ce blog, vous
aurez deviné que je suis plus que convaincu de l’intérêt de mettre le service
de clusters managés Databricks au sein d’une architecture cloud data.
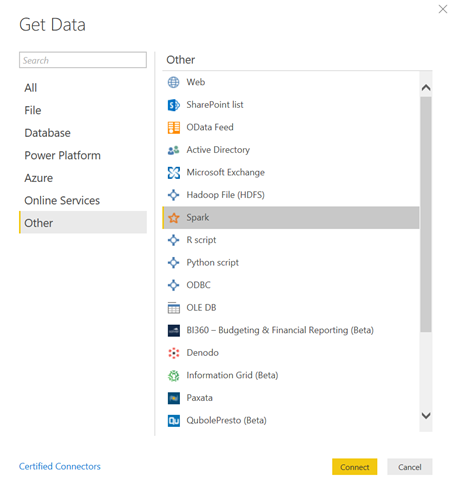
Si l’on met de côté l’exploitation des données par des algorithmes de Data Science, il sera toujours très intéressant de visualiser et d’explorer la donnée dans un outil d’analyse dynamique comme Power BI. Et cela tombe bien, il existe un connecteur (générique) Spark !
Connecter Power BI Desktop à une table du cluster Databricks
Voici comment procéder pour charger les données d’un cluster dans un modèle Power BI.
Tout d’abord, il faudra installer sur le poste exécutant Power BI Desktop le driver Spark ODBC. Celui-ci peut être téléchargé au travers d’un lien reçu par mail suite à l’inscription sur ce formulaire. L’installation ne révèle aucune difficulté : next, next, next…
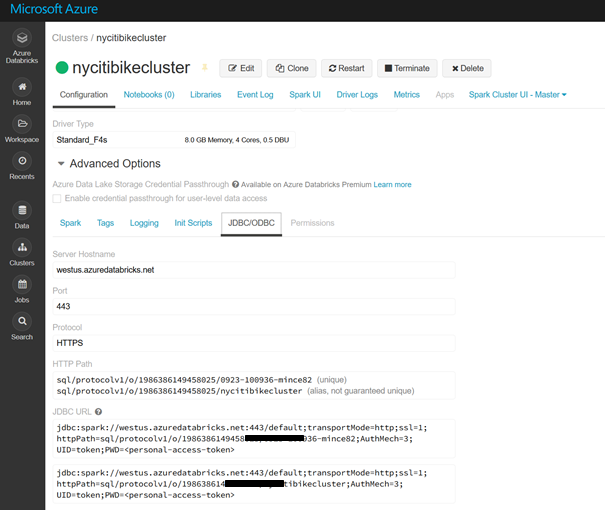
Passons ensuite sur l’interface de notre espace de travail Azure Databricks. Nous démarrons le cluster et il sera possible d’y trouver une information importante qu’est l’URL JDBC.
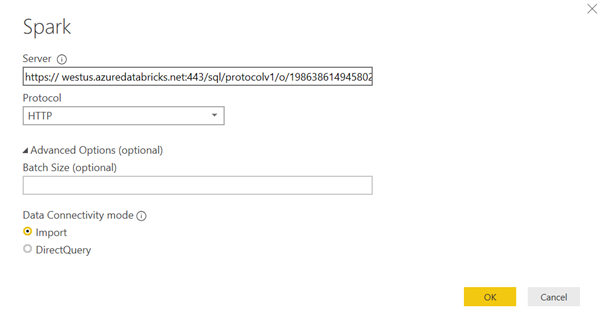
Cette URL va permettre de construire le chemin du serveur attendu dans la boîte de dialogue sous la forme générique suivante :
Il faut donc ici remplacer <region> par le nom de la
région Azure où se trouve la ressource Databricks, par exemple : westus. A
la suite du port 443, on copiera la partie de l’URL JDBC allant de sql
au point-virgule suivant.
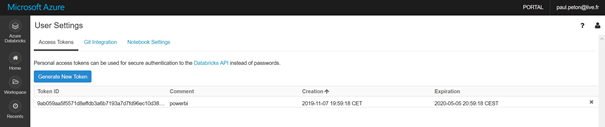
Seconde étape à l’intérieur de l’interface Databricks, nous créons maintenant un jeton d’accès pour l’application Power BI à partir des Users settings.
Attention à bien copier la valeur affichée, il ne sera plus possible de la revoir !
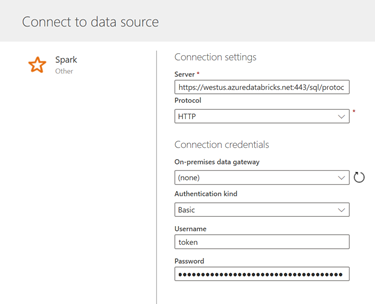
Revenons à Power BI. Dans la boîte de dialogue de connexion, coller l’URL construite dans la case Server, choisir le Protocol HTTP.
En mode import, l’avantage sera de pouvoir continuer à travailler sans que le cluster soit démarré. Mais il faudra attendre un bon moment pour que le chargement de données se fasse dans Power BI. En effet, si l’on utilise un cluster Spark, c’est que bien souvent les volumes de données sont importants…
En mode direct query, chaque évaluation de visuel dans la page de rapport établira une requête vers le cluster, qui bien évidemment devra être actif.
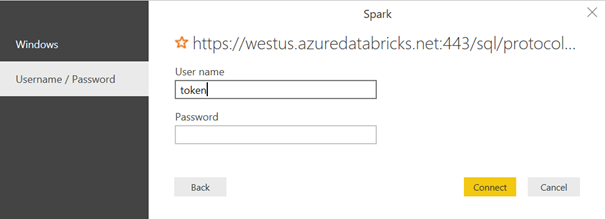
Le user name est tout simplement le mot token. Coller ici le jeton généré depuis Azure Databricks.
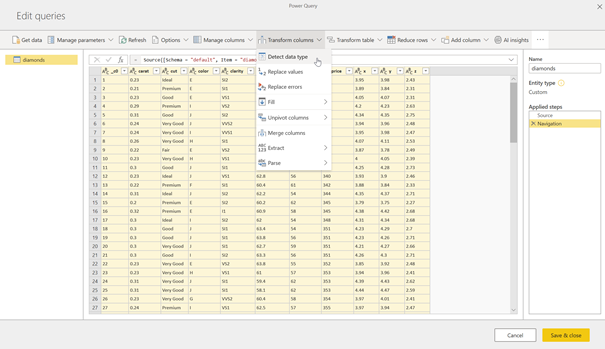
Nous accédons maintenant à toutes les tables ou vues du cluster ! N’insistez pas trop pour obtenir un aperçu, cette fonctionnalité semble peiner à répondre mais l’important est bien d’obtenir les données dans l’éditeur de requêtes.
Voici le code obtenu dans l’éditeur avancé. Nous retrouvons une logique classique de source et de navigation dans un élément de la source, ici une table. Le schéma de la table est respecté, il n’est pas nécessaire de typer à nouveau les champs dans Power Query.
Connecter
un Dataflow à Azure Databricks
Les Dataflows de Power BI (à ne surtout pas confondre avec
les data flows de Azure Data Factory !) sont une nouveauté du service
Power BI qui vient de connaître beaucoup d’évolutions.
Pour l’expliquer simplement, on peut dire que Dataflow
correspond à la version en ligne de Power Query, avec donc une capacité
de traitement issue du cloud (partagée ou dédié dans le cadre d’une licence
Premium) et la possibilité de partager le résultat des requêtes
(appelées entités) à des créateurs de nouveaux rapports. Contrairement à
un jeu de données partagé (shared dataset), il est possible de croiser
plusieurs entités dataflows au sein d’un même modèle.
Les dataflows sont enfin le support des techniques de
Machine Learning dans Power BI mais nous parlerons de tout cela une prochaine
fois !
Début novembre 2019, de nouvelles sources de données sont disponibles dont la source Spark. Nous allons donc tenter de reproduire la démarche réalisée dans Power BI Desktop.
Nous retrouvons les mêmes
paramètres de connexion, à savoir :
Server
Protocol (http)
Pas besoin de Gateway, les données sont déjà dans Azure
Username : token
Password : le jeton généré (on vous avait prévenu de conserver sa valeur 😊)
Il faut ensuite choisir la table ou la vue souhaitée.
Petite différence, les types de données ne sont pas conservés, il faut donc exécuter une commande « Detect data type » sur toutes les colonnes.
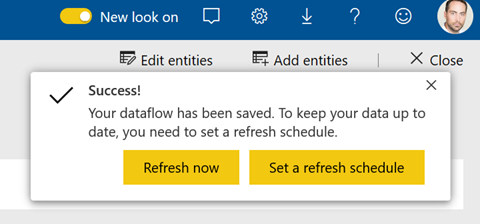
Rappelons enfin qu’un dataflow
n’est pas chargé tant qu’il n’est pas rafraîchi une premier fois. Cliquer ici
sur Refresh now.
Un rafraichissement pour aussi être planifié mais il faudra bien s’assurer que le cluster Databricks soit démarré pour que la connexion puisse se faire.
Une fois le dataflow créé, il est accessible de manière pérenne aux développeurs qui travaillent dans Power BI Desktop et qui ont accès à l’espace de travail Power BI où a été créé le dataflow.
Nous vérifions ici dans l’aperçu
que les champs sont maintenant bien typés.
En conclusion
Nous avons ici utilisé le
connecteur Spark et celui-ci a nous permis, à partir de Power BI ou des
dataflows du service Power BI, de nous connecter aux tables vues au travers du
cluster Databricks.
Il s’agit là d’un connecteur générique
et celui-ci n’est sans doute pas optimisé pour travailler la source Azure
Databricks mais notons que le mode direct query est tout de même disponible.
Cette approche montrera rapidement ces limites quand les volumétries de données exploseront. Il sera alors nécessaire de réfléchir à une solution de stockage des données entre le cluster et Power BI comme Azure SQL DB ou Azure SQL DWH (bientôt Azure Synapse Analytics ?), portées ensuite éventuellement par un cube Azure Analysis Services qui exécutera les calculs nécessaires aux indicateurs présentés dans Power BI.
Toutefois, la faisabilité de cette connexion permettra de mener rapidement une preuve de concept jusqu’à la représentation visuelle des données. A la contrainte d’avoir le cluster démarré pour charger les données, on répondra par leur écriture au sein d’un dataflow (qui est techniquement un stockage parquet dans un Azure Data Lake Storage gen2 !). Attention, les dataflows ont leurs limites : ils ne peuvent être utilisés qu’au sein d’un seul espace de travail Power BI, sauf à disposer d’une licence Premium qui permettra de lier ce dataflow à cinq espaces de travail.