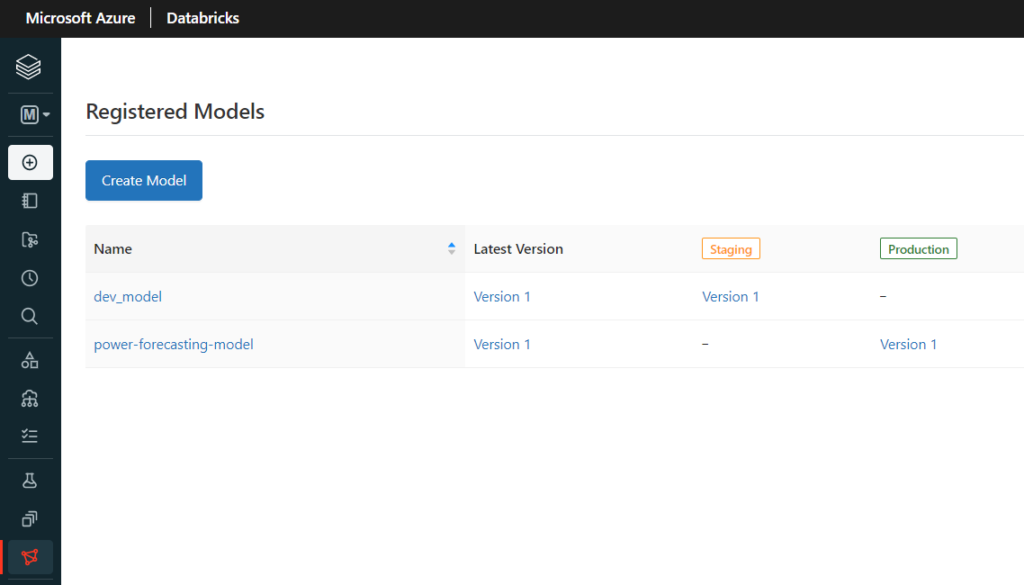
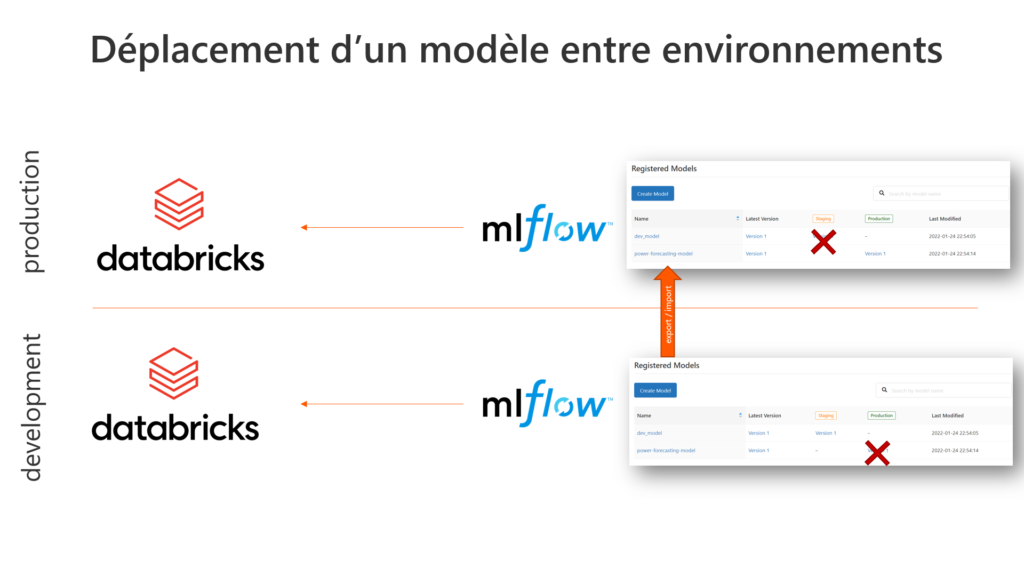
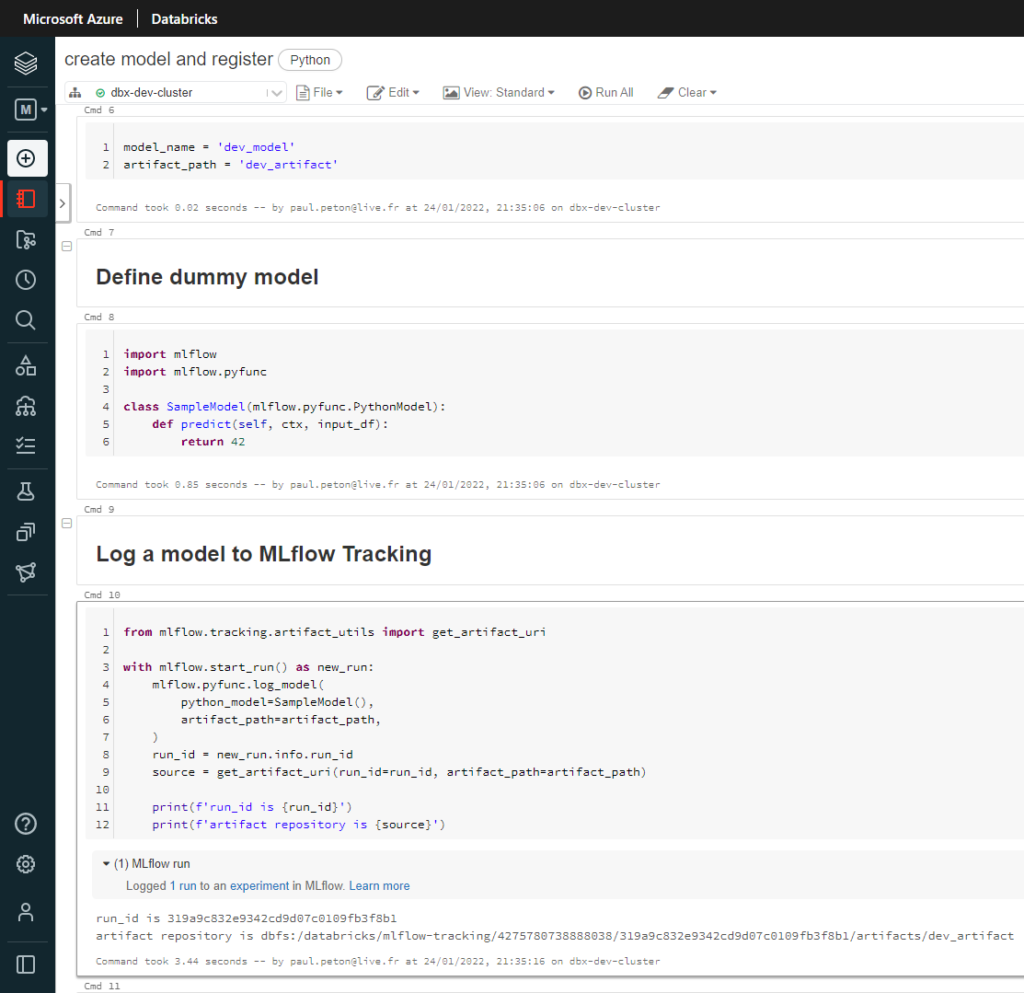
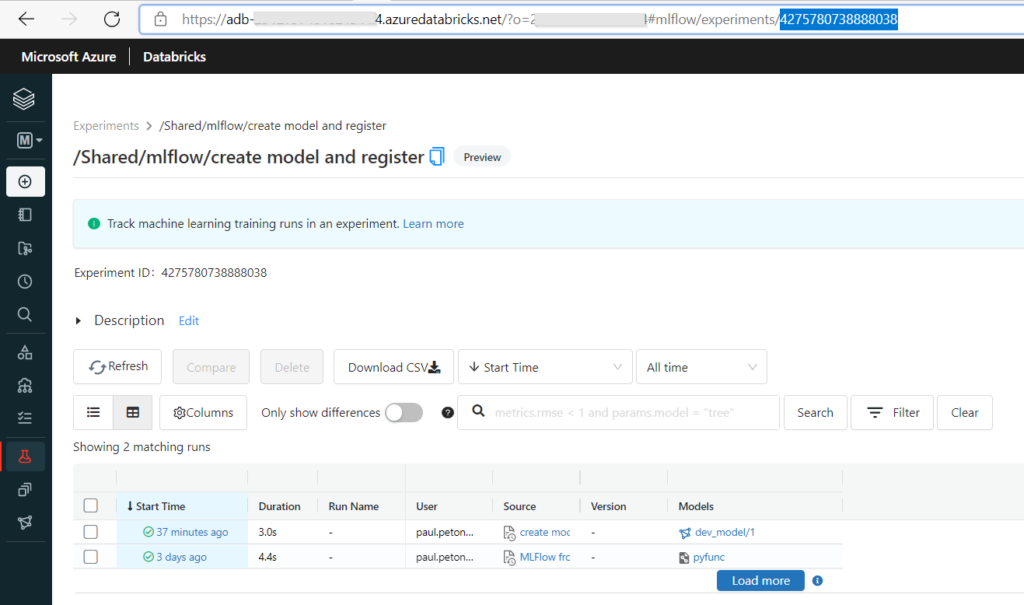
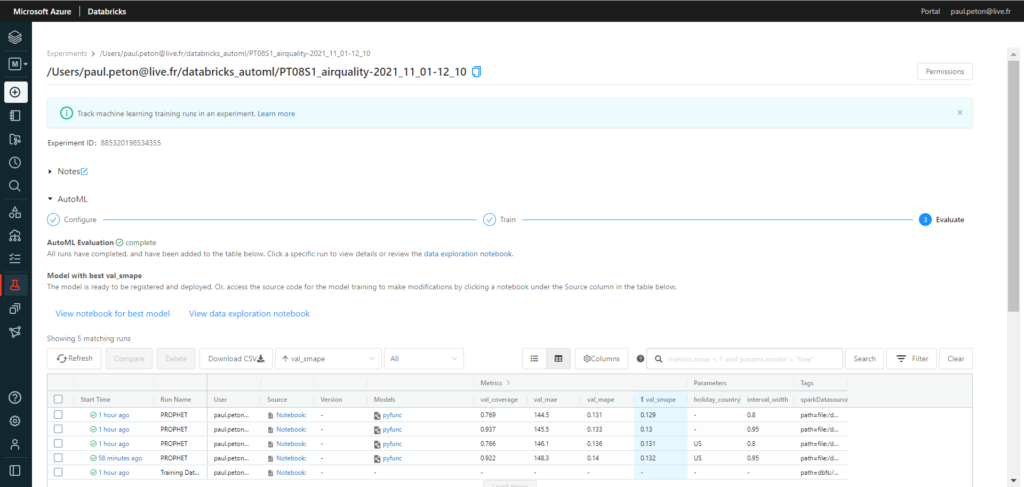
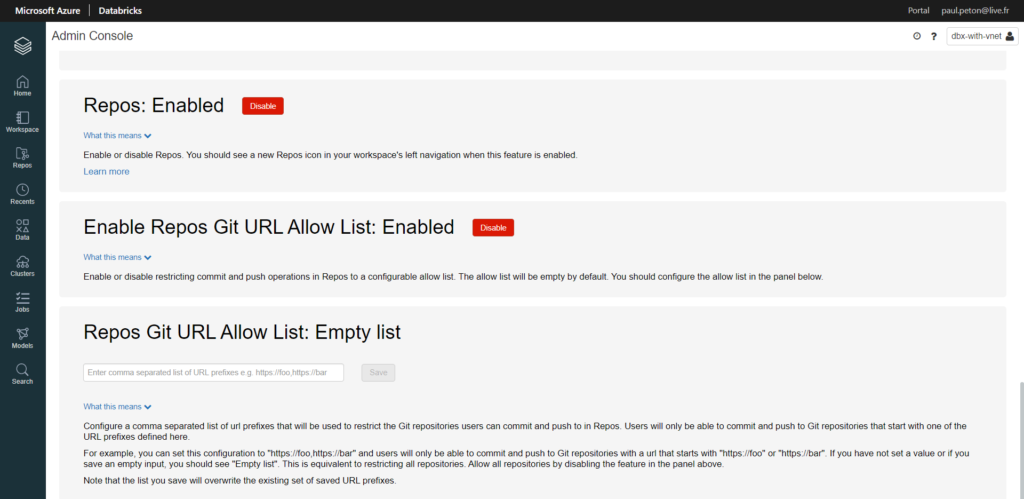
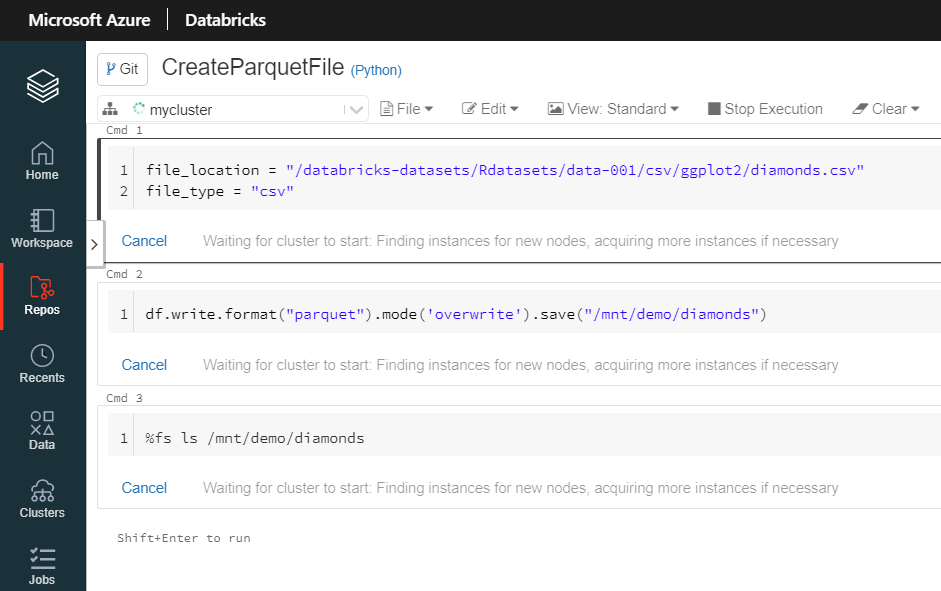
Si vous parcourez régulièrement ce blog, vous avez dû tomber sur un article traitant de Azure Databricks. Au cœur de ce produit, tourne le moteur Open Source Apache Spark. Ce moteur a révolutionné le monde de la Big Data, par sa capacité à réaliser des calculs distribués, en mémoire, sur des clusters de machines (souvent virtuelles et bien souvent dans le cloud).
Que l’on soit Data Engineer ou Data Scientist, cet outil est aujourd’hui (2022) incontournable et une certification apporte une reconnaissance de votre expertise dans le domaine. La première certification proposée par Databricks permet d’obtenir le titre Certified Associate Developer for Apache Spark. Cette certification demande de répondre en 2h à 60 questions fermées, et d’obtenir un minimum de 70% de bonnes réponses. Voici un exemple de questions posées à l’examen, fourni par l’éditeur.
Environ un quart des questions traitent des mécanismes techniques du moteur (je vous recommande cette vidéo de Advancing Analytics) et le reste sont des questions de code. Pour celles-ci, nous aurons à disposition la documentation officielle de Spark au travers de cette page web. Entrainez-vous à faire des recherches dans cette page, vous aurez besoin d’aller vite le jour de l’examen !
EDIT suite au passage de la certification avec Webassessor :
Au cours de l’examen, l’écran sera séparé en deux : la question à gauche, la documentation à droite. Mauvaise surprise (sous Edge uniquement ?) : impossible de faire une recherche dans la documentation, pas de raccourci ctrl+F non plus. Mon astuce est donc d’utiliser la zone de prise de notes, noter les noms de fonctions sur lesquelles vous avez un doute, puis parcourir la documentation en suivant l’ordre alphabétique.
Je vous encourage à tester également la Spark UI au travers de ce simulateur pour bien comprendre l’exécution concrète des différentes syntaxes de code et connaître les grandes lignes de cette interface. Ce sera également une bonne façon de hiérarchiser les différents niveaux d’exécution job / stage / task.
Deux éléments sont importants pour bien appréhender les questions de code. Tout d’abord, il faudra choisir la réponse “correcte” ou bien la seule “incorrecte” par une liste de cinq propositions. Prenez soin de bien déterminer à quel type de question vous êtes en train de répondre. Ensuite, les différentes modalités de réponse “joueront sur les mots” c’est-à-dire que des variations de code vous seront proposées mais 4 syntaxes sur 5 ne seront pas correctes (dans le cas d’une question de type “correct” !). Il est donc important de bien avoir en tête les confusions classiques de syntaxe.
Nous allons décrire ci-dessous plusieurs hésitations possibles entre des syntaxes PySpark (certaines syntaxes n’existant d’ailleurs qu’un Python, souvent en lien avec les DataFrames Pandas).
Bonne chance à vous pour l’examen !
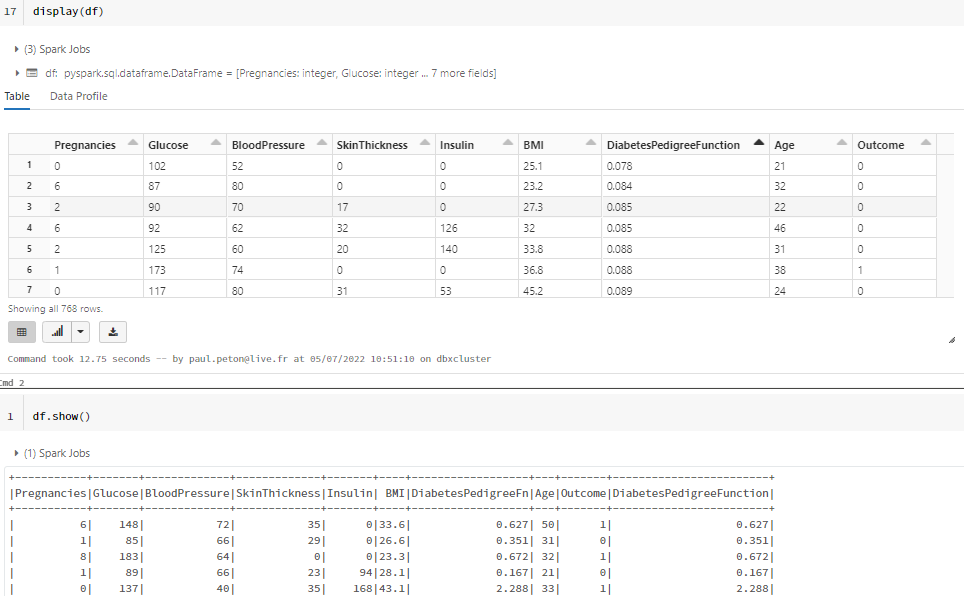
show() versus display()
La fonction show() permet d’afficher un résultat (c’est donc une action au sens Spark).
df.show(truncate=False)
La fonction display() n’existe que dans Databrick, version commerciale construite autour de Spark.
withColumn() versus withColumnRenamed()
withColumn() permet d’ajouter une nouvelle colonne dans un Spark DataFrame. Notons ici l’emploi de la fonction col() pour appeler les colonnes du DataFrame dans la formule de la nouvelle colonne. Pour une constante, nous utiliserons la fonction lit().
df.WithColumn("nouveau nom", col("ancien nom") )
Les fonctions lit() et col() auront été préalablement importées.
from pyspark.sql.functions import col, lit
withColumnRenamed() permet de renommer une colonne. C’est donc la syntaxe la plus adaptée par rapport au workaround proposé ci-dessous.
df.WithColumnRenamed("ancien nom", "nouveau nom")
Le piège est donc ici dans l’ordre des paramètres et en particulier dans la position du nom de la colonne créée.
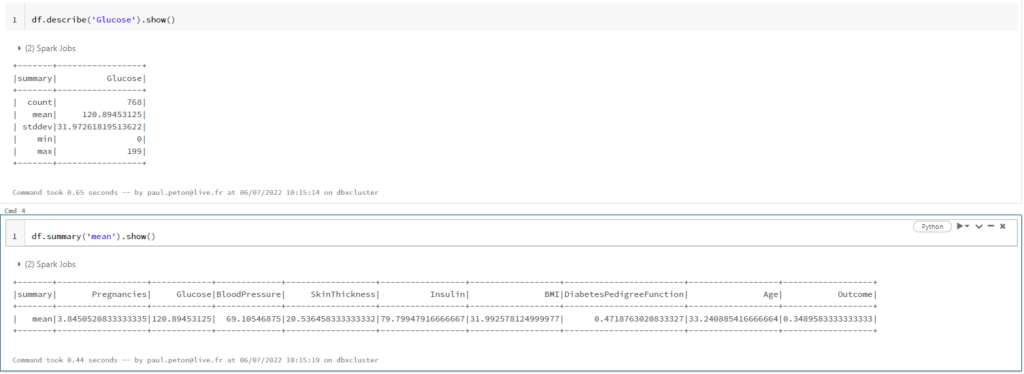
printSchema() versus describe()
Après la lecture d’une source de données, nous souhaitons vérifier le schéma du DataFrame. La fonction printSchema() est la bonne fonction pour réaliser cet objectif.
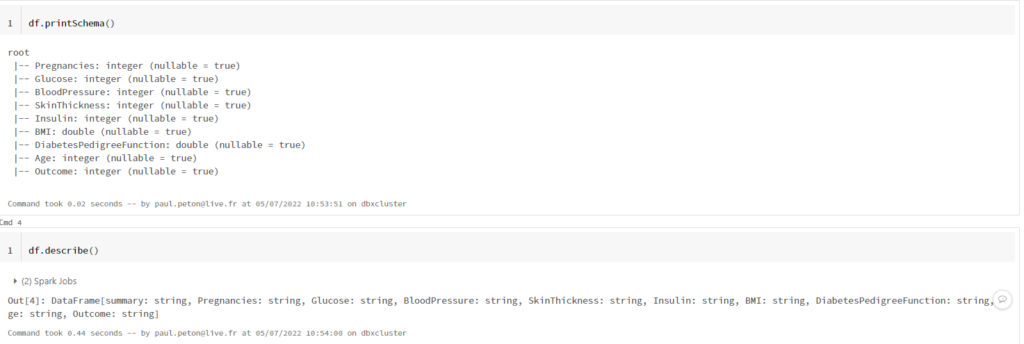
describe() versus summary()
Les fonctions describe() et summary() permettent d’obtenir les statistiques descriptives sur un DataFrame. La fonction summary() ajoute les 1e, 2e et 3e quartiles.
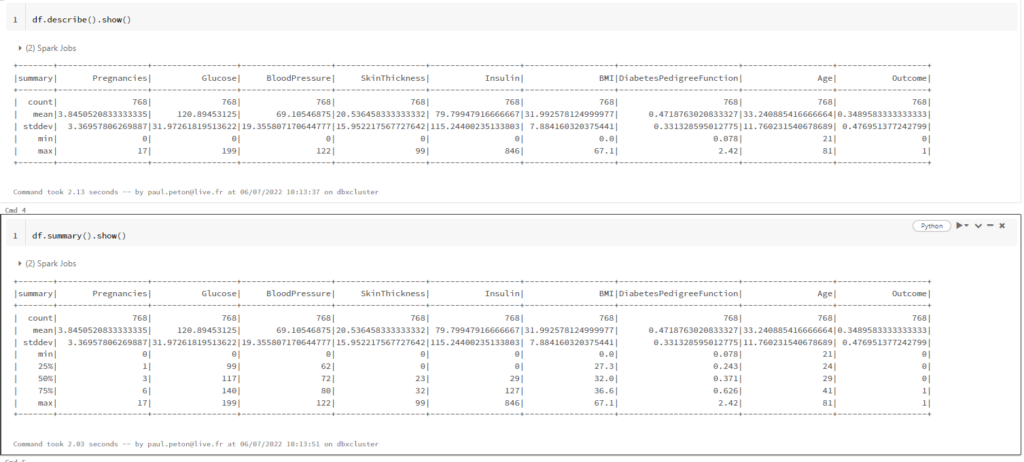
La différence se situe sur le rôle du paramètre dans chacune des deux fonctions.
Variantes de spark.read
Nous allons voir ici deux écritures possibles pour un même résultat.
Syntaxe 1 :
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
Syntaxe 2 :
df = spark.read \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.csv(file_location)
Syntaxe 3 :
df = spark.read \
.load(file_location, format="csv", inferSchema=infer_schema, header=first_row_is_header, sep=delimiter)
En compléments, allez voir les options de sauvegarde d’un Spark DataFrame.
collect() versus select()
Il faut ici bien maîtriser les concepts de transformations et d’actions, propres au moteur Spark.
La fonction collect() est une action qui retourne tous les éléments du Spark DataFrame sous forme de tableau (array) au nœud Driver.
La fonction select() est une transformation qui projette, c’est-à-dire conserve une colonne ou liste de colonnes. Comme il s’agit d’une transformation, il est nécessaire d’y ajouter une action (par exemple show) pour forcer l’évaluation du résultat.
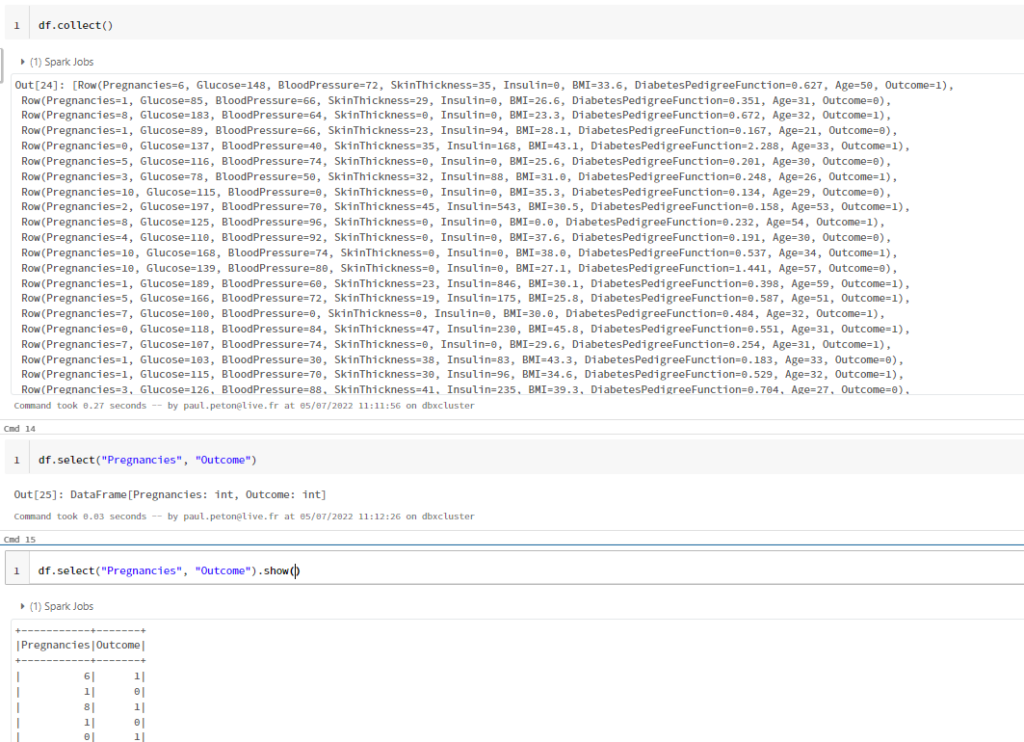
La liste des colonnes donnée en paramètre de select() peut s’écrire de deux façons :
df.select("Pregnancies", "Outcome").show()
df.select(["Pregnancies", "Outcome"]).show()
La première version est plus “légère” mais la seconde s’adapte mieux à un passage de variable de type liste déjà définie.
Attention, la fonction drop() n’autorise pas l’usage d’un objet de type liste.
distinct() versus unique()
La fonction distinct() renvoie les lignes distinctes, sur la base des colonnes du Spark DataFrame ou de la sélection faite au préalable.
df.select('column1').distinct().collect()
La fonction unique() ne s’applique qu’à un Pandas DataFrame !
join() versus merge()
Il s’agit ici de fusionner deux DataFrames. Les variantes d’écriture se font au niveau de l’expression de la jointure.
df_inner = df1.join(df2, on=['id'], how='inner')
df_inner = df1.join(df2, df1.id == df2.id, how='inner’)
Le troisième paramètre “how” définissant le type de jointure est facultatif, la valeur par défaut étant alors “inner” (jointure interne).
La fonction merge() ne s’applique qu’à un Pandas DataFrame !
union() versus unionByName() versus concat()
La fonction union() ajoute les lignes d’un DataFrame, donné en paramètre, à un autre DataFrame. L’ajout se fait alors sur la base des indices des colonnes.
La fonction unionByName() s’utilise pour ajouter des DataFrames sur la base des noms de colonnes et non de leur position.
La fonction Spark concat() n’a rien à voir avec ce type d’opération puisqu’elle réalise une concaténation de colonnes (astuce utile pour l’optimisation de la mémoire !).
df.select(concat(df.s, df.d).alias('sd')).collect()
Il ne faut pas confondre avec la fonction concat() appliquée sur des Pandas DataFrames, qui réalise quant à elle une fusion de ces jeux de données.
agg() versus groupBy()
Utilisée seule, la fonction agg() agrège un Spark DataFrame sans colonne de regroupement.
df.agg({'Glucose' : 'max'}).collect()
Il s’agit toutefois d’un “sucre syntaxique” de l’expression ci-dessous.
df.groupBy().agg({'Glucose' : 'max'}).collect()
La fonction groupBy() réalise un groupe sur la colonne ou liste de colonne spécifiée puis évalue les agrégats proposés ensuite.
df.groupBy('Outcome').max('Glucose').show()
df.groupBy('Outcome').agg({'Glucose' : 'max', 'Insulin' : 'max'}).show()
df.groupBy(['Outcome', 'Pregnancies']).agg({'Glucose' : 'max', 'Insulin' : 'max'}).show()
cast() versus astype()
La fonction cast() permet de modifier le type d’une colonne. Elle accepte plusieurs variantes de syntaxe, dans l’expression d’un type attendu.
from pyspark.sql.types import IntegerType
df.withColumn("age",df.age.cast(IntegerType()))
df.withColumn("age",df.age.cast('int'))
df.withColumn("age",df.age.cast('integer'))
La fonction astype() est un alias de la fonction cast().
filter() versus where()
La fonction where() est un alias de la fonction filter(). Différentes syntaxes sont possibles pour exprimer la condition booléenne.
df.filter(df.Pregnancies <= 10).show()
df.filter("Pregnancies <= 10").show()
from operator import ge, le, gt, lt df.filter(lt(df.Pregnancies, lit(10))).show()
contains() versus isin()
Voici deux exemples illustrant les utilisations de ces deux fonctions, elles-mêmes utilisées dans des logiques de filtre sur un DataFrame.
df.filter(df.Pregnancies.contains('0')).collect()

df[df.Pregnancies.isin([1, 2, 3])].collect()

La différence revient donc à chercher un contenu dans une colonne (contains()) ou à vérifier que le contenu d’une colonne appartient à une liste (isin()).
A noter, la fonction array_contains() permet d’étendre la logique de la fonction contains() sur les valeurs d’un tableau, contenu dans une colonne d’un Spark DataFrame.
filtered_df=df.where(array_contains(col("SparkAPI"),"pyspark"))
size() versus count()
La fonction size() renvoie le nombre d’éléments d’un tableau (array) alors que la fonction count() renvoie le nombre de ligne d’un Spark DataFrame.
Null versus NaN
La valeur Null correspond à une donnée manquante, c’est-à-dire une donnée qui n’existe pas.
df.where(col("a").isNull())
df.where(col("a").isNotNull())
La valeur NaN, pour Not a Number, est le résultat d’une opération mathématique dont le résultat ne fait pas sens (par exemple, une division par 0).
from pyspark.sql.functions import isnan
df.where(isnan(col("a")))
na.drop() versus dropna()
Ces deux fonctions sont des alias l’une de l’autre.
Elles disposent d’un paramètre thres qui permet la suppression des lignes ayant un nombre de valeurs non-nulles inférieures à ce seuil.
dropDuplicates() versus drop_duplicates()
Ces deux fonctions sont des alias l’une de l’autre. Elles permettent de retirer les valeurs en doublon dans un DataFrame.
take() vs head() vs first() / tail() vs limit()
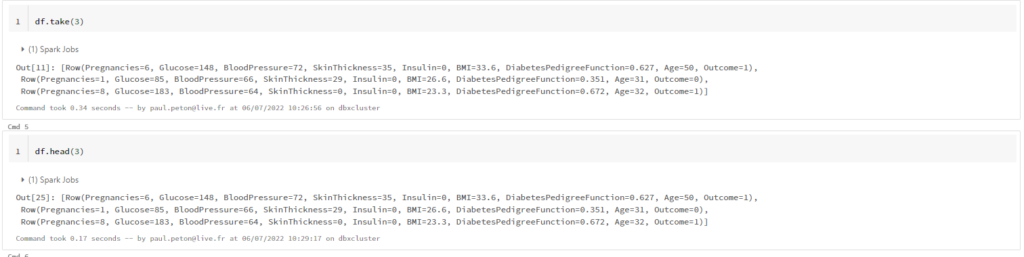
Visualiser les données d’un Spark DataFrame est fondamental ! Mais nous ne pouvons pas tout afficher, il faut alors réduire le nombre de lignes. Il existe pour cela de nombreuses fonctions et quelques subtilités entre toutes celles-ci.
Les fonctions take() et head() sont des alias, la seconde se donnant une syntaxe identique à celle utilisée pour les Pandas DataFrames. Elles prennent en argument le nombre de lignes (rows) à renvoyer sous forme d’une liste.
C’est le type d’objet renvoyé qui diffère dans la fonction limit(), celle-ci produisant un Spark DataFrame.

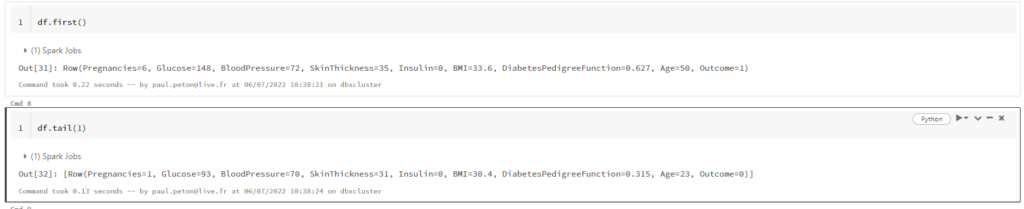
Les fonctions first() et tail() renvoient respectivement la première et la dernière ligne du DataFrame. Attention, la seconde attend un nombre de lignes en paramètre.
sort() versus orderBy()
La fonction orderBy() est un alias de la fonction sort().
Toutefois, il semble que celle-ci engendre la collecte de toutes les données sur un seul exécuteur, ce qui a l’avantage de fiabiliser le tri mais engendre un temps de calcul plus long, voire un risque de saturation mémoire.
Voici quelques exemples de syntaxe alternatives avec la fonction sort(). A noter que le sens de tri par défaut est ascendant.
df.sort(asc("value"))
df.sort(asc(col("value")))
df.sort(df.value)
df.sort(df.value.asc())
cache() versus persist()
La fonction cache() stocke un maximum de partitions possibles du DataFrame en mémoire et le reste sur disque. Ceci correspond au niveau de stockage dit MEMORY_AND_DISK, et ce comportement n’est pas modifiable.
A l’inverse, et même si son comportement par défaut est similaire, la fonction persist() permet d’utiliser les autres niveaux de stockage que sont MEMORY_ONLY, MEMORY_ONLY_SER, MEMORY_AND_DISK_SER, DISK_ONLY, etc.
repartition() versus coalesce()
< A VENIR >
repartition(1) versus coalesce(1)
< A VENIR >
map() versus foreach()
< A VENIR >
from_timestamp versus unix_timestamp()
< A VENIR >
explode() versus split()
< A VENIR >