Blog dédié à la donnée sous toutes ses formes actuelles
Author: methodidacte
Passionné par les chiffres sous toutes leurs formes, j'évolue aujourd'hui en tant que consultant senior dans les différents domaines en lien avec la DATA (décisionnel self service, analytics, machine learning, data visualisation...).
J'accompagne les entreprises dans une approche visant à dépasser l'analyse descriptive pour viser l'analyse prédictive et prescriptive.
J'ai aussi à coeur de développer une offre autour de l'analytics, du Machine Learning et des archictectures (cloud Azure principalement) dédiées aux projets de Data Science.
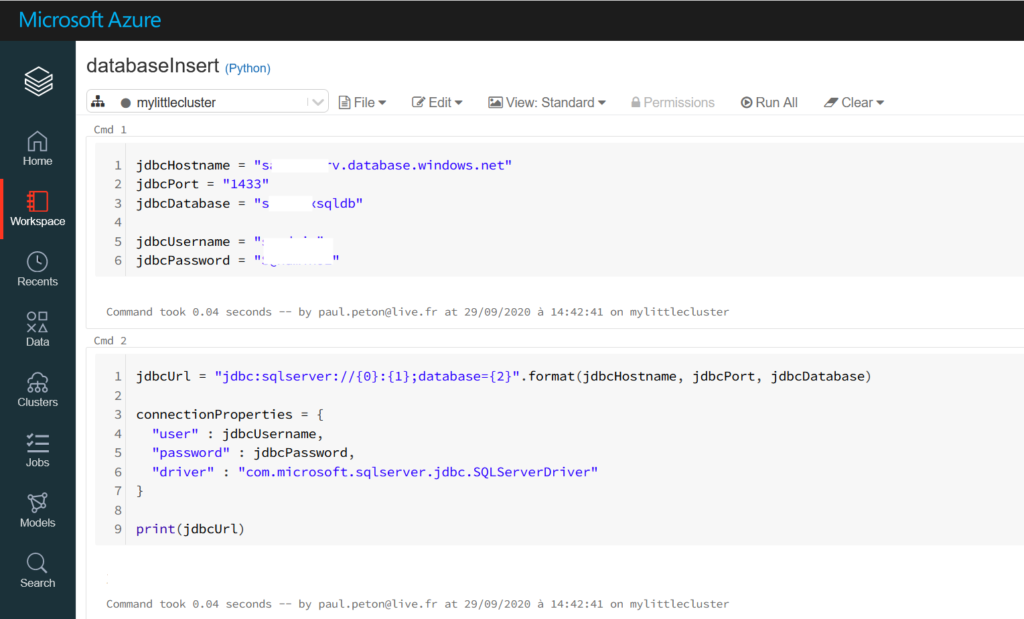
La documentation indique qu’il faut, dans le cas d’un cluster Databricks, redéfinir le driver, ce qui se fait au niveau de la configuration Spark du cluster.
Nous éditions pour cela le cluster afin d’ajouter la ligne suivante dans les options avancées :
Notez au passage l’appel au secret scope de Databricks, lui-même synchronisé avec une ressource Azure Key Vault.
Le code suivant permet de définir la structure d’un Spark Dataframe qui sera utilisé en insertion (mode append) ou bien en « annule et remplace » (mode overwrite). Il n’est bien sûr pas possible de traiter directement un pandas dataframe, nous en réalisons donc une conversion.
from pyspark.sql.functions import col, to_timestamp
from pyspark.sql.types import StructType
from pyspark.sql.types import *
schema = StructType([
StructField("champ_date",TimestampType(),True),
StructField("champ_texte",StringType(),False),
StructField("champ_num",IntegerType(),True)
])
# conversion si le dataframe est un pandas dataframe
sparkdf = spark.createDataFrame(df, schema)
try:
sparkdf.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.option("mssqlIsolationLevel", "READ_UNCOMMITTED") \
.option("reliabilityLevel", "BEST_EFFORT") \
.option("tableLock", "true") \
.save()
except ValueError as error :
print("Connector write failed", error)
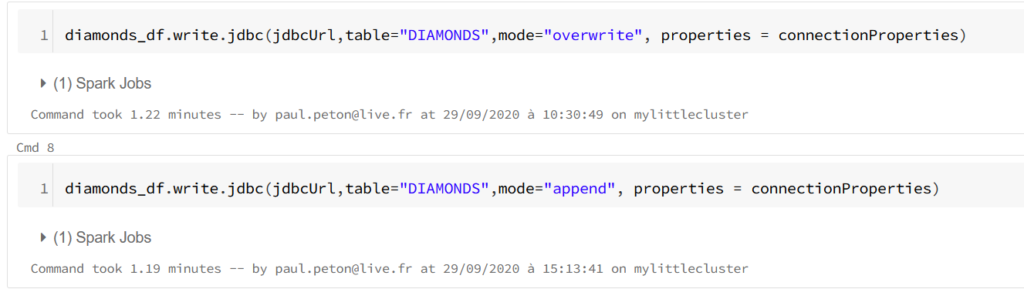
Les différentes options, décrites dans cette documentation, permettent d’optimiser la requête en écriture. Ainsi, pour l’écriture d’environ 100000 lignes, l’option tableLock à True permet de passer 1,62m à 1,29m.
Dans une architecture cloud Azure, la ressource de “compute” Databricks va bien souvent être utilisée pour transformer la donnée brute en donnée dite nettoyée ou enrichie. Cette donnée peut bien sûr être stockée sur un Data Lake, par exemple dans un format Parquet (nous y reviendrons en fin d’article) mais les outils d’exploration et de visualisation de données comme Microsoft Power BI présentent de nombreux avantages à s’appuyer sur une base de données relationnelle (actualisation incrémentielle, DirectQuery…).
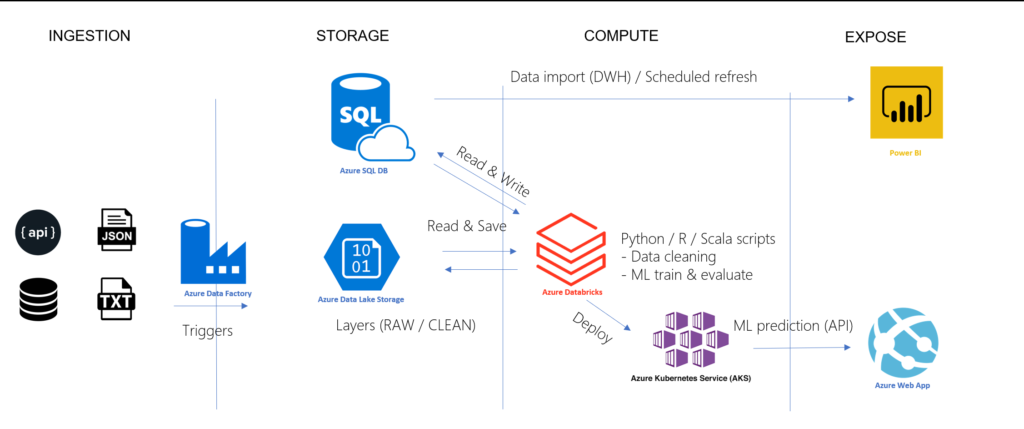
Nous partirons ainsi de l’architecture Azure ci-dessous :
Architecture Azure hybride pour des projets data de visualisation et de prévision
Nous lançons tout d’abord un notebook Python où nous définissons la chaîne de connexion. Il sera bien sûr très judicieux d’utiliser ici le secret scope de Databricks pour stocker toutes ces informations.
Il s’agit maintenant d’écrire un jeu de données nettoyées et travaillées en mémoire sous forme de Spark dataframe dans une table de la base de données. Cette opération se fait tout simplement au moyen de la méthode write associée aux informations de connexion : URL JDBC et propriétés de connexion.
Le paramètre de mode permet de choisir entre un “annule et remplace” de la table au moyen de la valeur overwrite ou une insertion à l’aide du mot clé append.
Il n’y a donc ici pas de mode prévu pour la suppression ou la mise à jour. Il faudra penser ce scénario de manière différente et peut-être au travers du format de fichier Delta, basé sur le format Parquet et sur lequel existent des méthodes delete et upsert. Pour autant, ce fichier restera en dehors de la base de données.
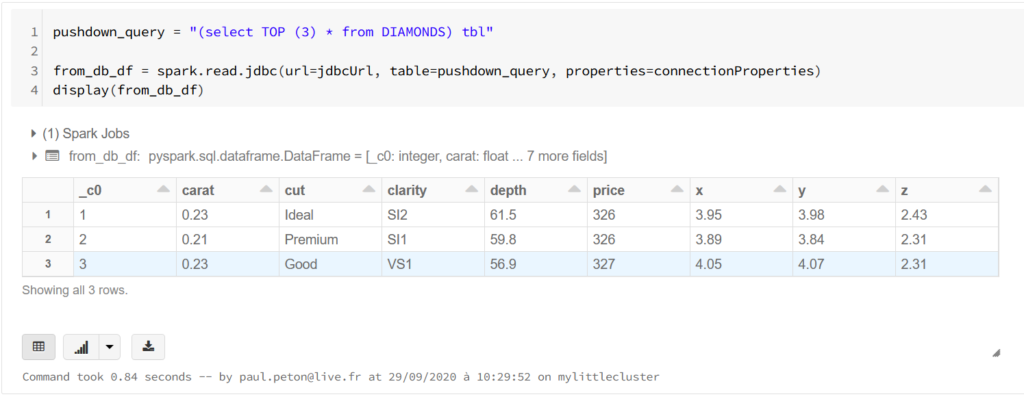
La méthode read de Spark est également possible et se fait en soumettant une requête SQL au travers du driver JDBC. Nous utilisons ici la syntaxe SQL propre à la base de données, ici le Transac-SQL de Microsoft.
L’alias de table sur la requête est indispensable pour être interpréter par le paramètre table de la méthode read.
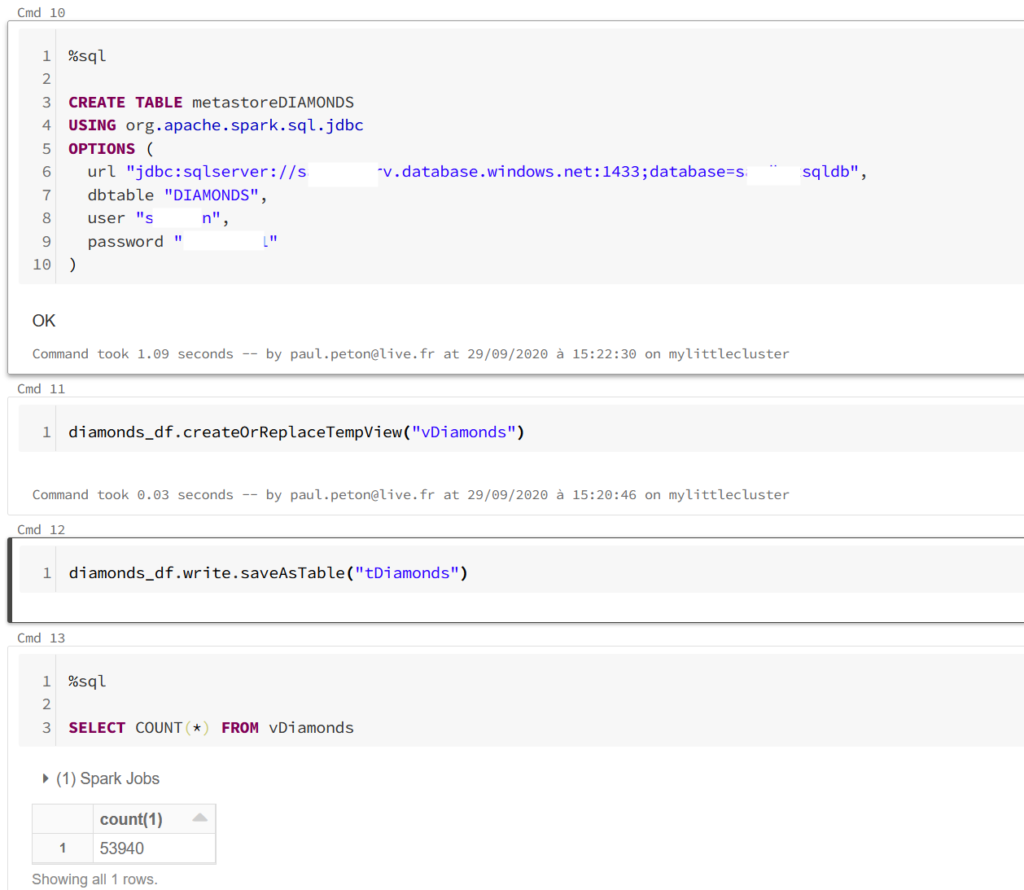
Pour aller un peu plus loin dans l’exploitation de ce driver JDBC, nous pouvons créer une table dans le métastore du cluster, copie d’une table de la base de données.
Il est alors possible de créer des interactions en Spark SQL entre des vues créées à partir de dataframes Spark (ou Pandas en les convertissant au préalable) et la table du métastore. Ce scénario ne réalise qu’une lecture des données de la base et des opérations d’écriture sur cette table ne seront bien sûr pas répercutées sur la base de données.
Nous avons ici utilisé le driver JDBC de manière simple avec une ressource de type SQL Database. Vous retrouverez ici une autre manière de procéder au travers de Polybase pour Azure SQL Datawarehouse. Ce service Azure étant maintenant renommé Azure Synapse Analytics et disposant de nouvelles fonctionnalités, de prochains articles décriront les modes d’interaction entre fichiers, dataframes et tables. En attendant, je vous recommande cet épisode du podcast Big Data Hebdo autour de Synapse.
La longueur du titre de cet article laisse présager du niveau de précision dans lequel nous allons nous lancer ! Je vais donc rapidement situer le contexte faisant appel à un tel besoin.
Nous cherchons à déployer de manière automatisée un environnement de développement Azure Data Factory sur l’environnement de production. Nous utilisons pour cela un pipeline de release Azure DevOps. Le processus DevOps pour ADF est expliqué dans ce livre blanc Microsoft ou dans cet excellent article de Florian Eiden.
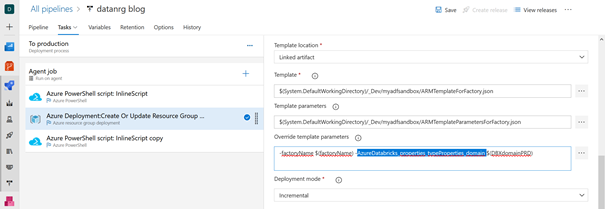
Pour résumer les grandes lignes du fonctionnement, nous remplaçons dans un fichier de paramètres au format JSON les valeurs des chaînes de connexion de l’environnement de développement par celles de production. Ceci se fait au moyen de la case « override template parameters ».
Valeurs manquantes pour le service lié Databricks
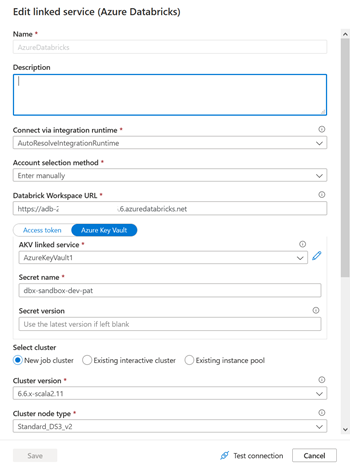
La chose se complique lorsque nous utilisons un service lié de calcul de type Azure Databricks puisque les paramètres de ce service n’apparaissent pas par défaut dans le fichier de paramétrage ! Nous avons en particulier besoin de remplacer :
La Databricks Workspace URL
Le Secret name (où se trouve enregistré un Personal Access Token correspondant à l’espace de travail souhaité)
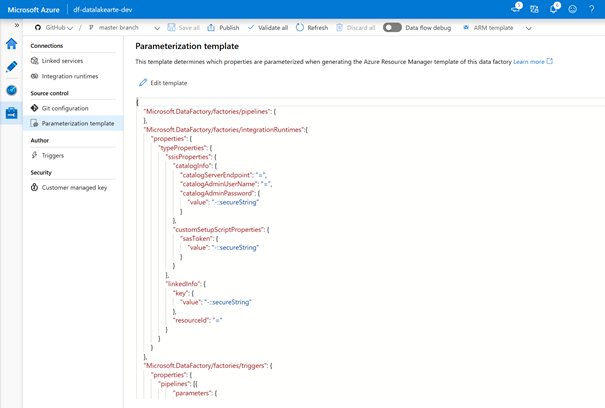
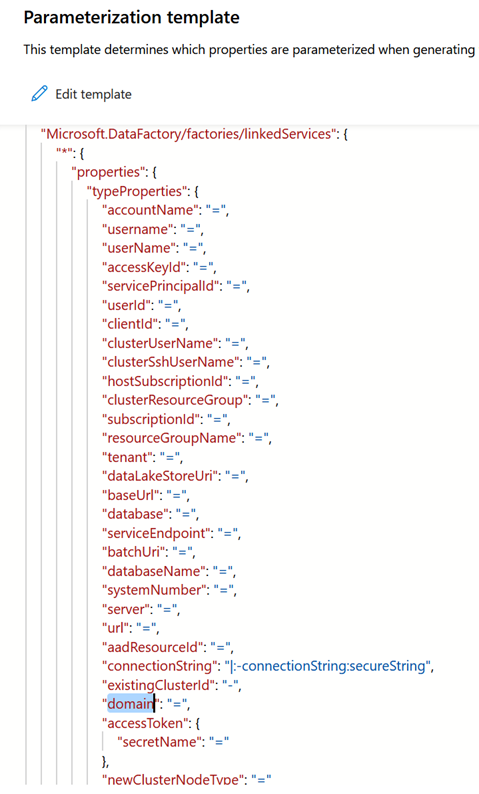
En effet, un choix arbitraire a été fait par Microsoft pour présenter uniquement certains paramètres mais un grand nombre de valeurs existent et elles sont visibles en éditant le fichier disponible dans le menu : Parametrization template.
Ce fichier au format JSON recense l’intégralité des paramètres disponibles par défaut, ainsi que leur visibilité au moyen d’une propriété qui n’est pas simple à interpréter :
= (signe égal) permet de conserver la valeur actuelle en tant que valeur par défaut pour le paramètre
– (signe moins) permet de ne pas conserver la valeur par défaut pour le paramètre
Le symbole | (pipe) permet de réaliser le lien avec une valeur stockée dans le coffre-fort Azure Key Vault.
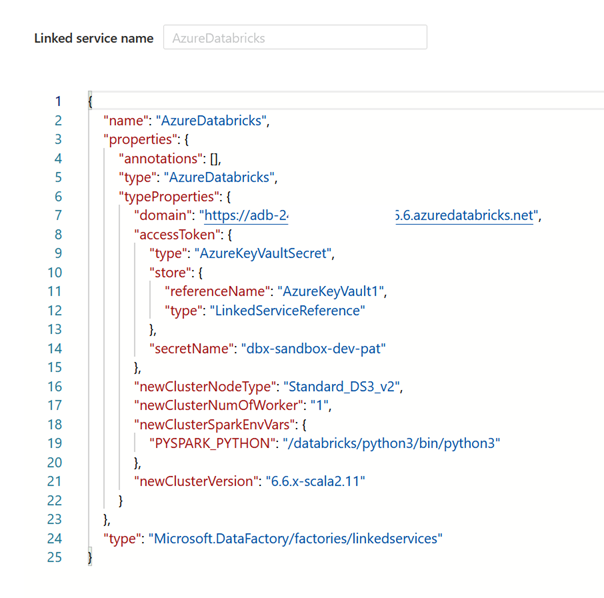
Nous allons maintenant rechercher le nom des paramètres manquants. Pour cela, nous passons par la définition du service lié Databricks au format JSON.
Nous obtenons ainsi le nom exact des paramètres (ne pas se fier à l’interface graphique).
L’URL de l’espace de travail se nomme ainsi domain, le secret du Key Vault se désigne par secretName et ses deux propriétés dépendent du niveau TypeProperties et du sous-niveau accessToken pour le secret.
Nous pouvons donc maintenant citer ces propriétés dans le JSON des paramètres, en respectant l’arborescence des propriétés.
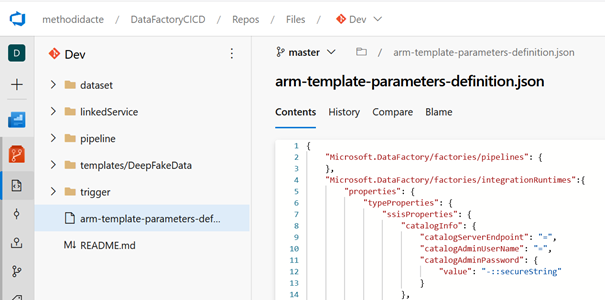
La définition des paramètres dans la branche Master
Arrive ici la partie peut-être la moins documentée (jusqu’à présent !). Il faut comprendre que ce fichier JSON doit figurer à la racine de la branche Master du dépôt contenant la synchronisation du Data Factory avec un gestionnaire de version comme GitHub ou un repo Azure DevOps, sous le nom arm-template-parameters-definition.json.
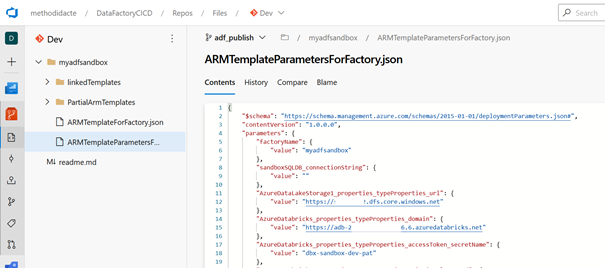
Il ne faut donc pas utiliser la branche spécifique à Data Factory qui se nomme adf_publish mais nous irons ensuite vérifier que les deux fichiers JSON qu’elle contient ont bien été modifiés en conséquence.
Pour lancer cette modification, nous devons tout d’abord faire les deux actions suivantes :
Refresh
Publish
Le volet latéral du Publish (pending changes) doit s’afficher même si aucune modification n’est visible.
Nous pouvons enfin vérifier que les paramètres sont disponibles dans le fichier ARMTemplateParametersForFactory.json de la branche adf_publish.
Modifier la valeur des paramètres pendant la release
Il ne reste qu’à utiliser ces noms de paramètres dans le pipeline de release Azure DevOps. Les nouvelles valeurs peuvent être définies comme des variables du pipeline pour plus de commodité.
Cet article a pu être écrit grâce à la documentation officielle de Microsoft ainsi que d’autres articles de blog, en anglais, que leurs auteurs en soient ici remerciés :
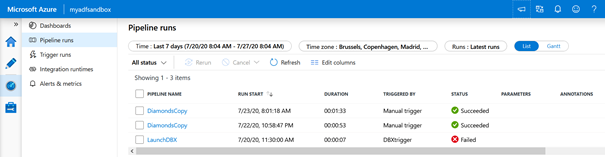
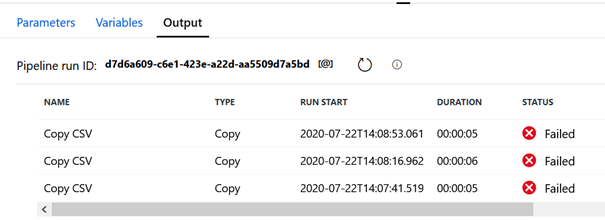
Azure Data Factory est à la fois un ordonnanceur de traitements, un ETL ou un ELT selon la manière dont on pense les transformations et le chargement dans la destination (« sink » dans le vocable d’ADF). Il est muni d’une fenêtre de monitoring permettant de superviser l’exécution de pipelines au travers de triggers (déclencheurs en bon français). Et il ne sera pas rare (le plus rare possible, on vous le souhaite !) de rencontrer les icônes rouges de l’échec du traitement dans cette fenêtre.
Pipeline run : status failed
Dans cet article, nous allons explorer différentes méthodes
de déclenchement ou relance d’un pipeline Azure Data Factory.
Relancer manuellement
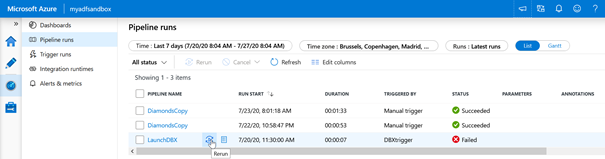
Depuis le monitoring des pipelines, nous disposons de plusieurs boutons comme le bouton « rerun » au niveau de l’exécution globale du trigger.
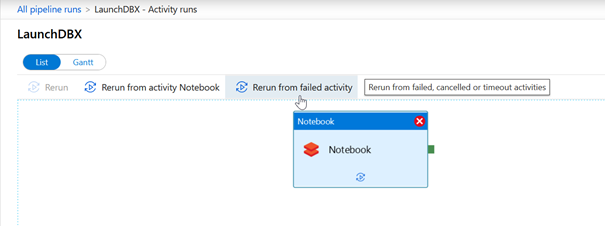
Lorsqu’il existe une ou plusieurs activités dans le pipeline, il suffit d’aller sur le détail de l’exécution du pipeline pour choisir une des activités (cliquer dessus) et la relancer (« rerun from failed activity »). Ce second mode est particulièrement intéressant lorsqu’une chaîne de traitement a déjà réalisé des étapes importantes et ne nécessite pas d’être reprise depuis le début. Les gains de temps de traitement seront sans doute conséquents.
Ces deux stratégies sont bien sûr manuelles et nécessitent
de venir observer la console de supervision. Nous allons maintenant explorer
des stratégies plus automatisées.
Démarrage ou relance automatique
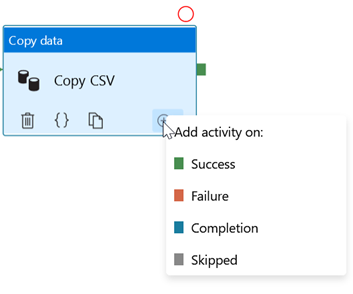
Une approche classique de déclenchement des pipelines consiste à définir un jour et une heure de déclenchement. S’il existe des dépendances aux activités, on prendra soin d’inclure différentes activités au sein du même pipeline et de les relier grâce aux différentes sorties disponibles (« add activity on »).
Il existe quatre types de conditions :
Success
Failure
Completion : exécution de l’activité suivante en cas de succès ou d’échec de l’activité
Skipped : exécution de l’activité suivante uniquement si l’activité n’a pas été exécutée
Ce blog vous
permettra de rentrer plus en détails dans le fonctionnement de ces conditions.
Mais certains événements comme la présence d’un fichier, de
lignes dans une table ou encore la réponse à une requête HTTP peuvent être des
conditions de déclenchement attendues.
Par le paramétrage d’une activité
La manière sans doute la plus simple et basique de relancer
une activité consiste à utilise le paramétrage de l’activité elle-même.
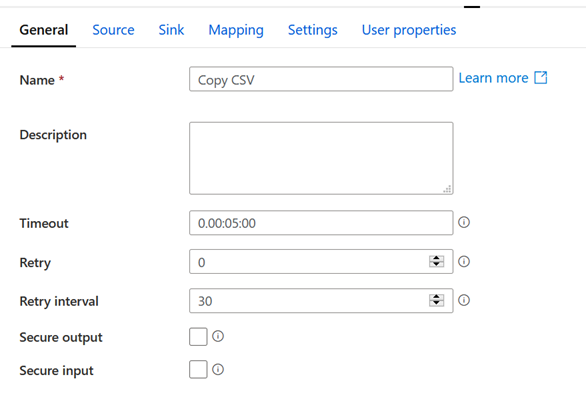
Pour cela, dans la section General du module :
Renseigner un nombre maximum de Retry
Renseigner un intervalle en secondes entre chaque essai
Remarque : le time out par défaut est à 7 jours, il
peut être diminuer.
Il faut toutefois anticiper ici un nombre maximum fini de relances, ce que l’on n’est pas forcément en capacité d’anticiper.
A la première exécution avec succès, les retry ne
sont bien sûr plus pris en compte.
Les activités de type for each ou execute pipeline
ne disposent pas de ce paramétrage.
Avec le composant Until
La documentation du composant Until est disponible sur ce lien
et définit son fonctionnement de la sorte :
The Until activity provides the same functionality that a do-until looping structure provides in programming languages. It executes a set of activities in a loop until the condition associated with the activity evaluates to true. You can specify a timeout value for the until activity in Data Factory.
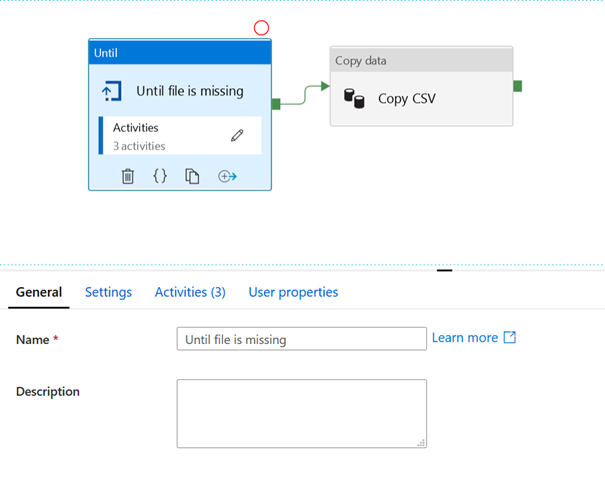
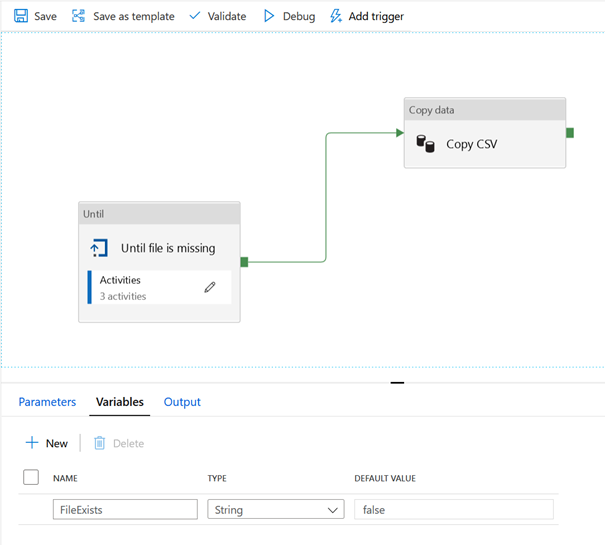
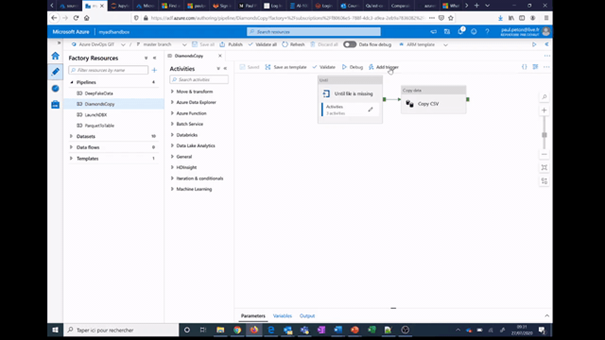
Nous allons créer ainsi le scénario suivant : sur présence d’un fichier testé par le composant Until, nous déclenchons une activité de copie.
Une variable nommée FileExists, de type chaîne de texte (string), est définie au niveau du pipeline.
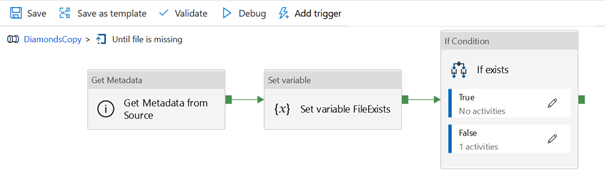
A l’intérieur du composant Until, nous allons travailler avec deux activités que sont Get Medatada et Wait.
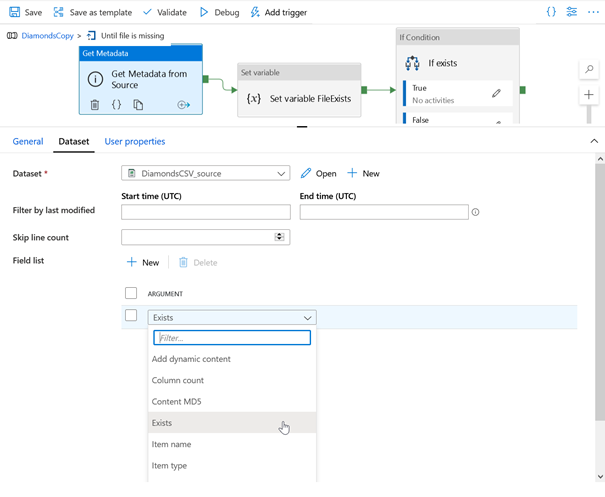
L’activité Get Metadata permet d’obtenir des informations sur un dataset préalablement défini, comme un checksum de type MD5, le nom, le type ou l’existence d’un item.
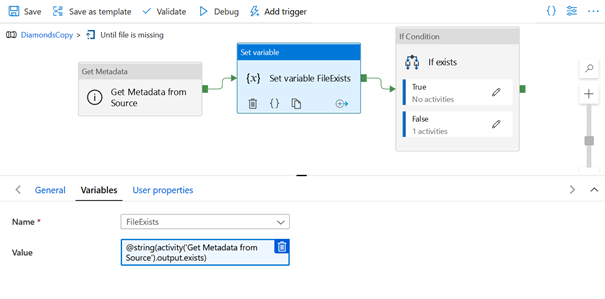
Le composant suivant Set variable n’est pas indispensable mais il nous permet d’illustrer ici la manière de conserver dans une variable une partie de l’information obtenue par l’activité Get Metadata.
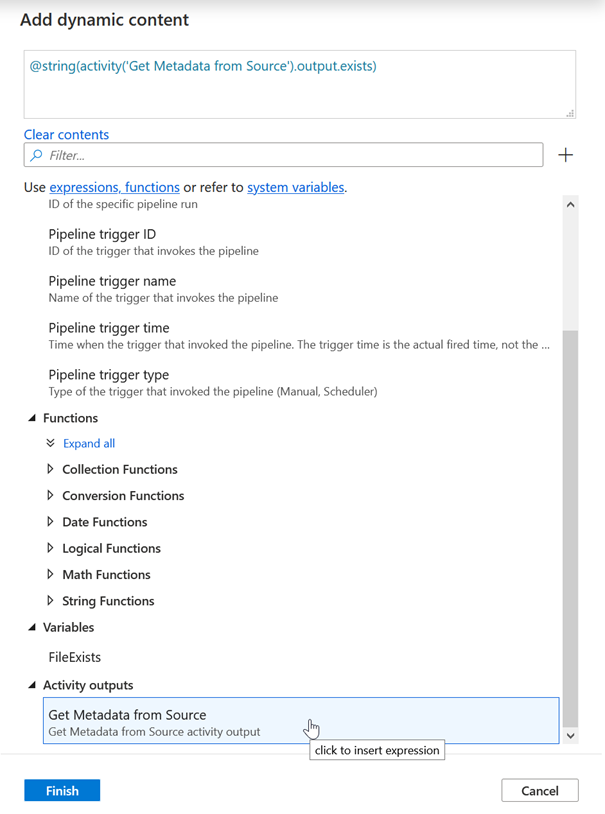
La valeur de la variable est définie de la sorte :
@string(activity('Get Metadata from Source').output.exists)
On utilisera la fenêtre d’ajout de contenu dynamique pour obtenir directement certaines parties de cette expression.
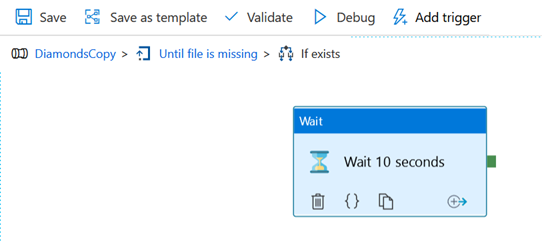
Enfin, une activité Wait est déclenchée pour laisser un laps de temps s’écouler avant de tester à nouveau la présence du fichier.
Le composant If exists permet de ne pas jouer l’activité
Wait lorsque le fichier attendu est détecté. Il n’est pas nécessaire de définir
la partie True de ce composant.
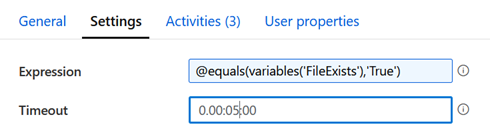
L’activité Until peut enfin paramétrée à l’aide de
l’expression suivante :
@equals(variables(‘FileExists’),’True’)
Voici enfin une démonstration du fonctionnement complet de ce pipeline.
Suite à mon premier article sur le nouveau programme 2020 de cette certification Microsoft, je continue à décrire les différents outils présents dans le nouveau studio Azure Machine Learning, en suivant le plan donnée par le programme de la certification. Attention, le contenu peut ne pas être exhaustif comme le rappelle la mention “may include but is not limited to“.
Run experiments and train
models
Create models by using
Azure Machine Learning Designer
Le Concepteur (ou Designer en anglais) n’est accessible qu’avec la licence Enterprise et correspond à l’ancien portail Azure Machine Learning Studio. La documentation complète est disponible ici.
Nous cliquons ensuite sur le bouton « + » pour démarrer une nouvelle expérimentation. Mais il sera très intéressant regarder les différents exemples disponibles, en cliquant sur « afficher plus d’échantillons ».
May include but is not limited to:
• create a training
pipeline by using Designer
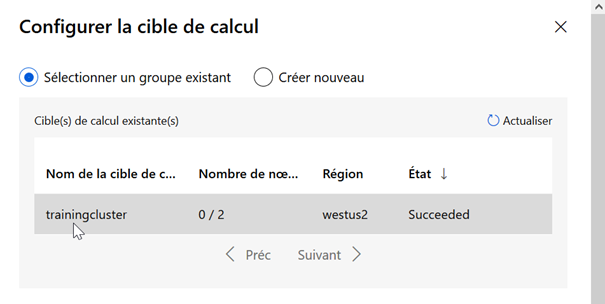
La première chose à paramétrer est l’association de l’expérience avec une cible de calcul de type « cluster d’entrainement ».
Nous utiliserons ensuite les modules disponibles dans le menu latéral de gauche.
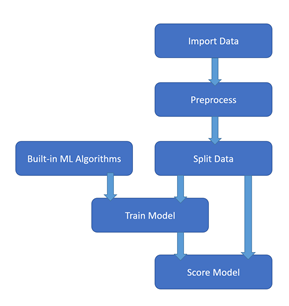
Ces modules nous permettront de construire un « pipeline » dont la structure classique est décrite par le schéma ci-dessous.
• ingest data in a
Designer pipeline
La première étape consiste à désigner les données qui
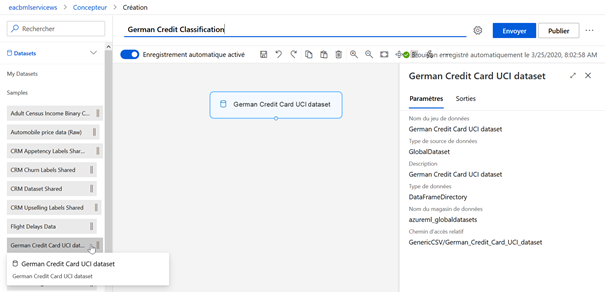
serviront à l’expérience. Nous choisissons pour cet exemple le jeu de données
« German Credit Card UCI dataset » en réalisant un
glisser-déposer du module de la catégorie Datasets > Samples.
Les jeux de données préalablement chargés à partir des magasins de données sont quant à eux disponibles dans Datasets > My Datasets.
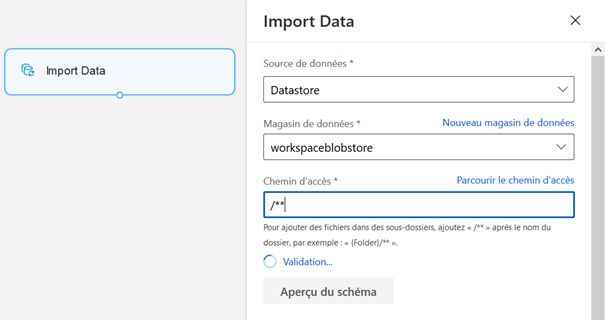
Le module « Import Data » permet de se connecter directement à une URL via HTTP ou bien à un magasin de données.
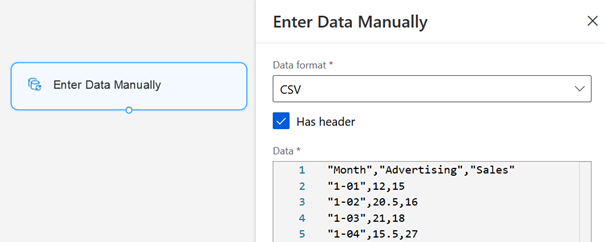
Il est enfin possible de charger des données manuellement à l’aide du module « Enter Data Manually ».
Ces deux dernières méthodes ne
sont pas recommandées, il est préférable de passer par la création propre d’un
jeu de données dans le menu dédié.
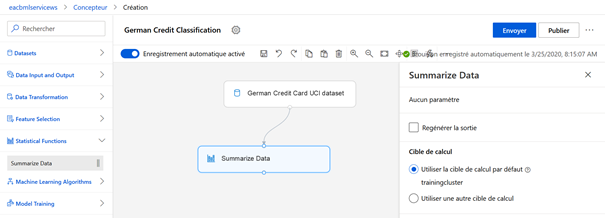
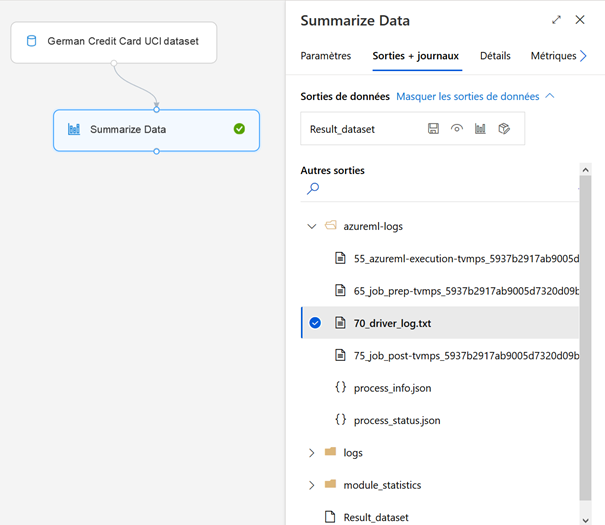
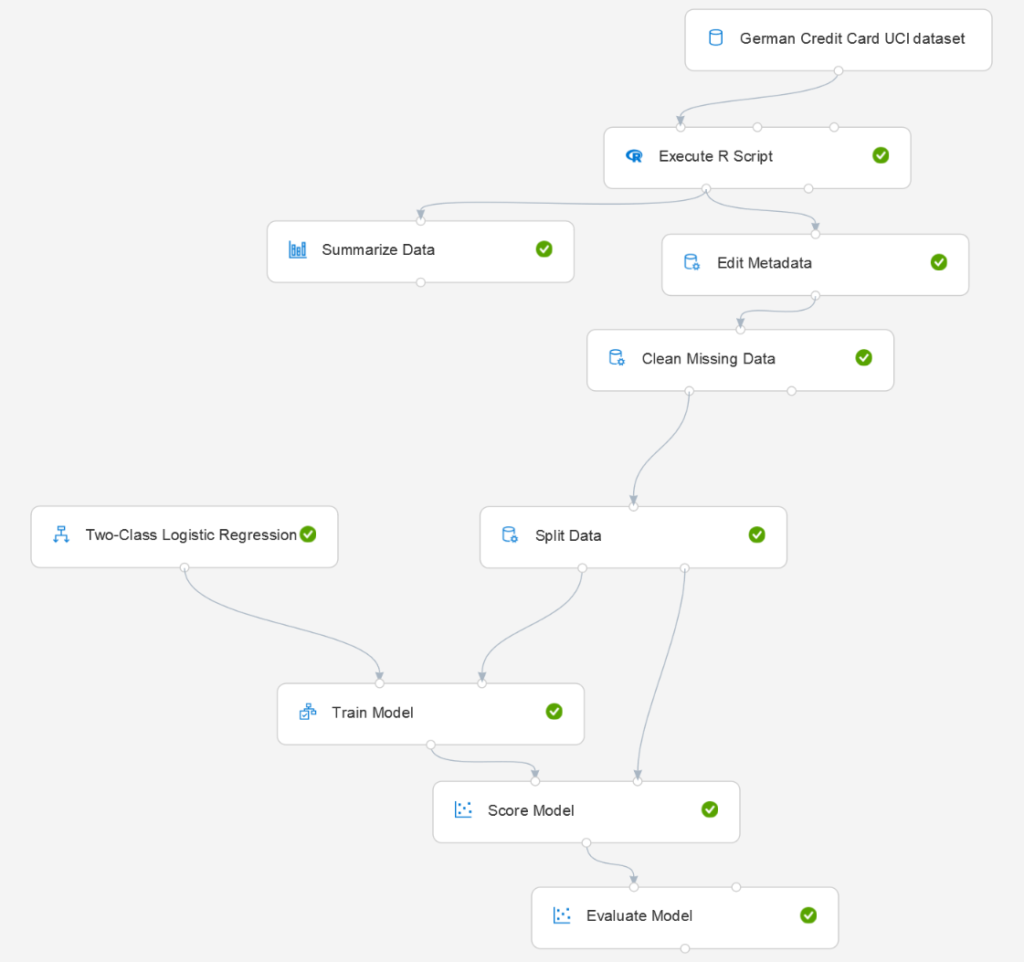
Afin de bien appréhender le jeu de données, nous ajoutons temporairement un composant « Summarize Data », de la catégorie Statistical Functions. Les deux modules doivent être reliés l’un à l’autre, en glissant la sortie du précédent vers l’entrée du suivant.
Nous cliquons sur le bouton « Envoyer » pour exécuter ce premier pipeline.
Un nom doit être donné à
l’expérience (entre 2 et 36 caractères, sans espace ni caractères spéciaux
hormis les tirets haut et bas).
Au cours de l’exécution, une vue d’ensemble est disponible.
Depuis le menu Calcul, un graphique résume l’état des nœuds du cluster d’entrainement.
Une fois les étapes validées (coche verte sur chaque module), les sorties et journaux d’exécution sont accessibles. Le symbole du diagramme en barres donne accès aux indicateurs de centrage et de dispersion sur les différentes variables.
• use Designer modules to
define a pipeline data flow
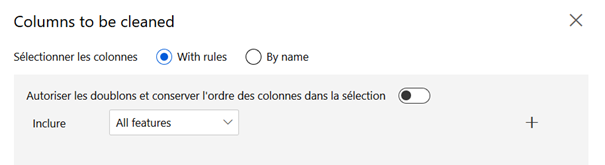
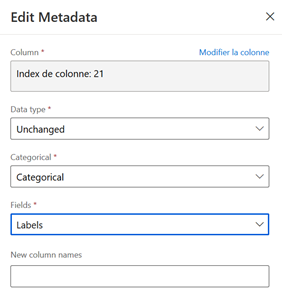
Nous recommandons d’utiliser l’édition des métadonnées pour identifier la variable jouant le rôle de label. Cette astuce permettra par la suite de conserver un paramétrage des modules utilisant la colonne de type « label ». Il sera également possible de désigner toutes les autres colonnes du jeu de données par « all features » dans les boîtes de dialogue de sélection.
Pour une variable binaire dans la cadre d’une classification, la variable est également déclarée comme catégorielle.
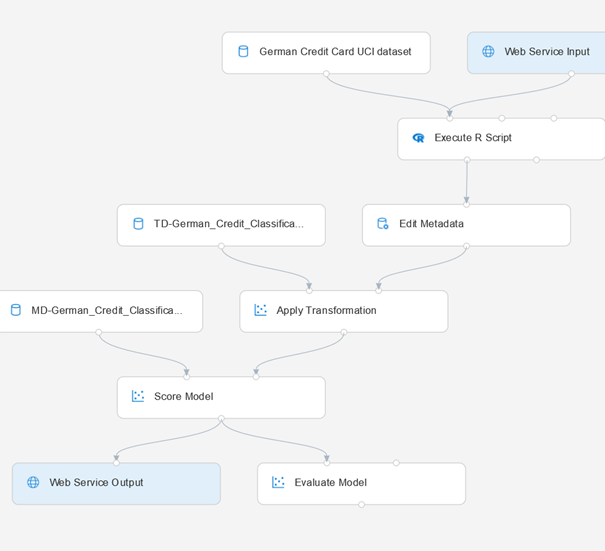
Nous construisons ensuite un pipeline classique de la sorte :
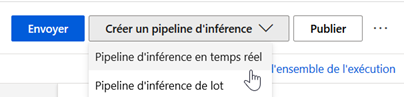
Une fois un modèle entrainé avec succès, un nouveau bouton apparaît en haut à droite de l’écran.
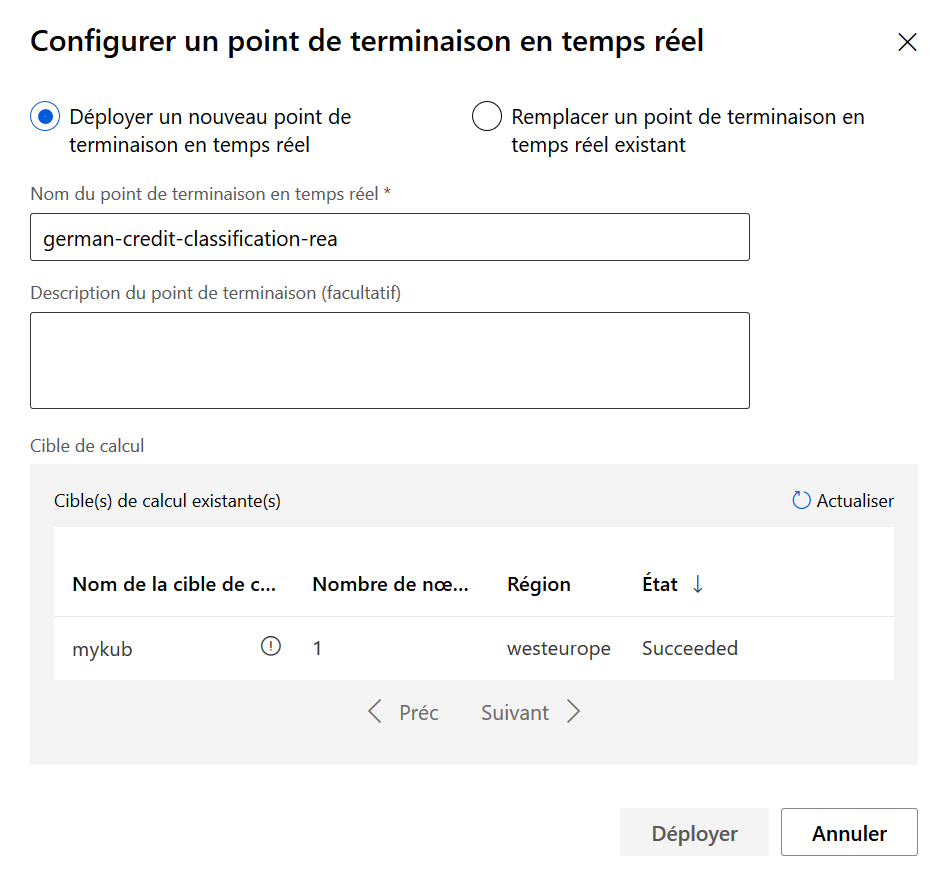
Nous créons un pipeline d’inférence en temps réel pour obtenir un service Web prédictif à partir de notre modèle. Des modules d’input ou d’output sont automatiquement ajoutés.
Il est alors nécessaire d’exécuter une nouvelle fois le pipeline pour ensuite publier le service d’inférence. Le bouton « déployer » est ensuite accessible.
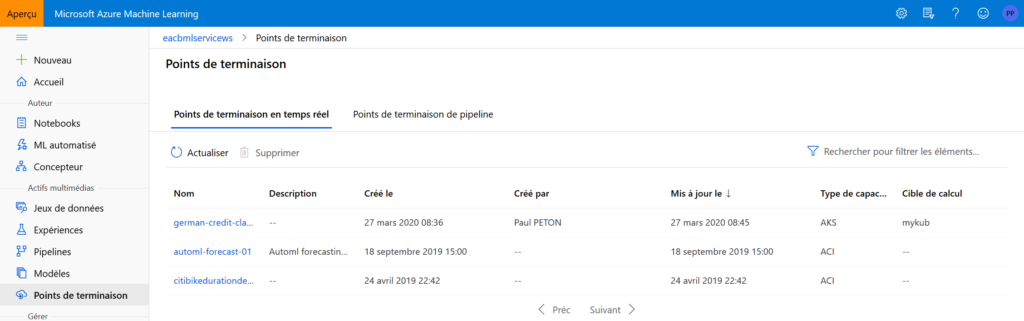
Une fois le déploiement réussi avec succès, le point de terminaison (“endpoint“) est visible dans le menu dédié.
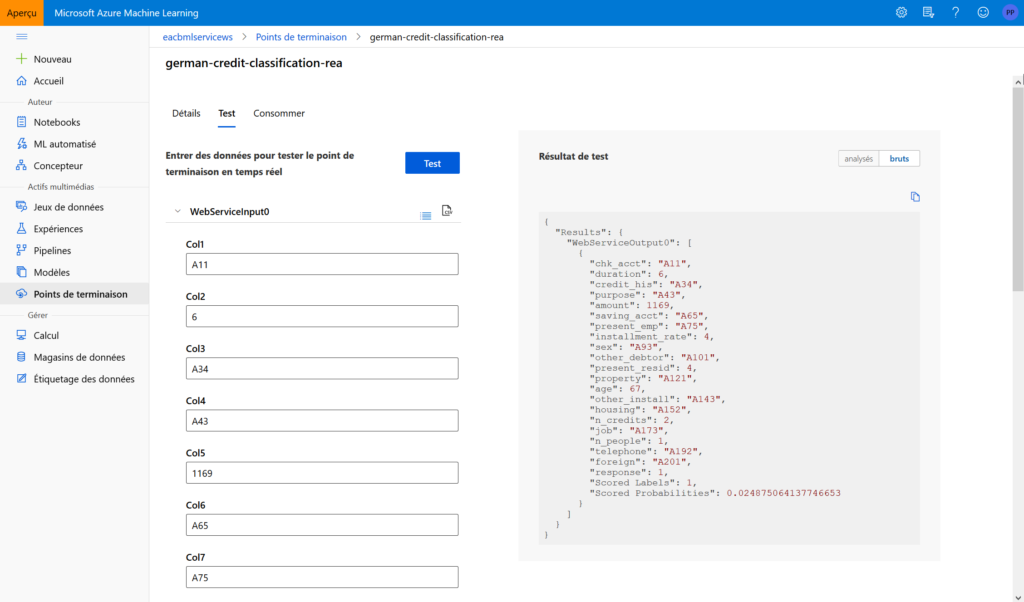
Nous retrouvons dans les écrans dédiés l’URL du point qui donnera accès aux prévisions. Il s’agit d’une API REST, sous la forme suivante :
Une fenêtre de test facilite la soumission de nouvelles données.
L’onglet “consommer” donne enfin des exemples de codes prêts à l’emploi en C#, Python ou R, ainsi qu’un mécanisme de sécurité basé sur des clés ou jetons d’authentification.
• use custom code modules
in Designer
Des modules personnalisés peuvent être intégrés dans le pipeline, en langage R ou Python.
Les modules de script disposent d’entrées et de sorties, accessibles au travers de noms de variables réservés.
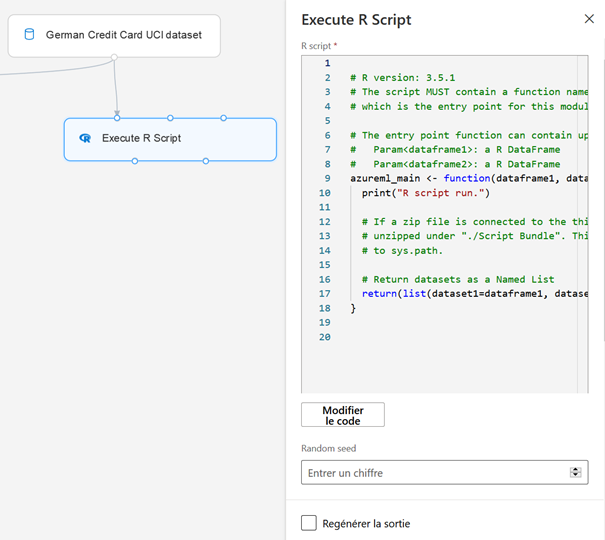
Ainsi, pour un script R personnalisé, le modèle de code généré est une structure de fonction :
# R version: 3.5.1
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a zip file is connected to the third input port, it is
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Les entrées 1 & 2 sont identifiées respectivement sous
les noms dataframe1 et dataframe2.
Les deux sorties sont par défaut nommées dataset1 et
dataset2 et retournées sous forme d’une liste de deux éléments. Il est possible
de modifier ces noms même si cela n’est pas conseillé.
Pour nommer les colonnes du jeu de données German Credit Card, nous utilisons le code R suivant :
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
colnames(dataframe1) = c("chk_acct", "duration", "credit_his", "purpose", "amount", "saving_acct", "present_emp", "installment_rate", "sex", "other_debtor", "present_resid", "property", "age", "other_install", "housing", "n_credits", "job", "n_people", "telephone", "foreign", "response")
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
La troisième entrée du module est dédiée à un fichier zip
contenant des librairies supplémentaires. Ces packages doivent être au préalable
installer sur un poste local, généralement dans le répertoire :
C:\Users\[user]\Documents\R\win-library\3.2
Créer
un dossier contenant les sous-dossiers des packages transformés en archives
(.zip) puis réaliser une nouvelle archive .zip à partir de ce dossier. Importer
ensuite l’archive obtenu comme un jeu de données. Le module obtenu sera
raccordé à la troisième entrée du module Execute R/Python Script : Script
Bundle (Zip).
Pour les scripts Python, nous disposons également d’un module permettant de créer un modèle d’apprentissage qui sera ensuite connecté à un module « Train Model ».
Le code Python à rédiger se base sur les packages pandas et scikit-learn et doit s’intégrer dans le modèle suivant :
import pandas as pd
from sklearn.linear_model import LogisticRegression
class AzureMLModel:
# The init method is only invoked in module "Create Python Model",
# and will not be invoked again in the following modules "Train Model" and "Score Model".
# The attributes defined in the init method are preserved and usable in the train and predict method.
def init(self):
# self.model must be assigned
self.model = LogisticRegression()
self.feature_column_names = list()
# Train model
# Param: a pandas.DataFrame
# Param: a pandas.Series
def train(self, df_train, df_label):
# self.feature_column_names record the names of columns used for training
# It is recommended to set this attribute before training so that later the predict method
# can use the columns with the same names as the train method
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
# Predict results
# Param: a pandas.DataFrame
# Must return a pandas.DataFrame
def predict(self, df):
# Predict using the same column names as the training
return pd.DataFrame({'Scored Labels': self.model.predict(df[self.feature_column_names])})
Le modèle utilisé peut être remplacé dans la fonction __init__.
Les variables en entrée du modèle peuvent être également listées dans cette
fonction.
(Nous parlerons ici du service cloud Power BI, destiné au partage et à la collaboration. Si vous partagez vos fichiers .pbix, une autre réflexion sera nécessaire 😉 )
Mais tout d’abord, pourquoi bloquer l’export des données depuis les rapports Power BI ?
La méthode radicale : l’interdiction par l’utilisateur
La méthode douce : l’interdiction (ou la limitation) au dataset
La méthode (ultra) fine : le retrait de l’option au niveau du visuel
Enfin, rappelons que tout utilisateur ayant les droits nécessaires et une version d’Excel suffisamment récente peut installer l’extension “Power BI Publisher” qui, comme son nom ne l’indique pas, peut accéder aux datasets hébergés sur le service Power BI et pour lesquels ils disposent des droits suffisants.
Le code utilisé dans un notebook peut échouer pour une raison autre qu’un erreur de développement : fichier absent, API ne répondant pas, etc. Il peut donc être pertinent de relancer automatiquement un traitement en cas d’échec.
La documentation Databricks fournit un exemple de fonction, en Python ou en Scala, qui réalise ce mécanisme. Le code est bien sûr basé sur la fonction dbutils.notebook.run déjà présentée dans un précédent post.
Voici le code en Python, où un nombre d’essais maximum de 3 est paramétré par défaut :
# Errors in workflows thrown a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
exceptExceptionas e:
if num_retries > max_retries:
raise e
else:
print "Retrying error", e
num_retries += 1
Et voici ce que l’on obtient à l’exécution. Attention à bien préciser le chemin relatif du notebook ainsi piloté, si celui-ci n’est pas situé au même niveau que le ce “master notebook”.
Attention à ne pas abuser de ce processus ! Il est essentiel de comprendre la nature des erreurs rencontrées et d’y apporter des réponses au travers du code.
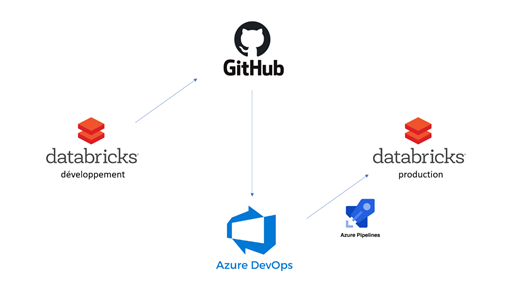
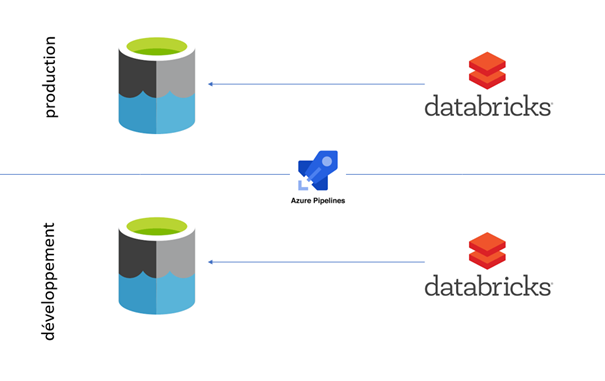
Une fois l’infrastructure définie autour d’un cluster Databricks, les notebooks sont les éléments qui vont évoluer au gré des développements. Il faut bien sûr a minima définir deux environnements : l’un de développement, l’autre de production. Nous verrons ainsi plusieurs astuces et bonnes pratiques permettant de réaliser le processus du déploiement continu des notebooks.
Nous avons pu voir dans de précédents articles :
Comment définir un point de montage vers un compte de stockage Azure
Comment versionner les notebooks Databricks par exemple sous GitHub
Nous allons utiliser ici la notion de variable d’environnement, propre au cluster Spark.
Le schéma ci-dessous illustre le mécanisme DevOps qui sera mis en place.
Mais pour l’instant, focalisons-nous sur le chemin menant vers les données. Nous utilisons ici deux environnements identiques d’un point de vue de l’architecture, dont une vision simplifiée est donnée sur le schéma ci-dessous :
L’accès au point de montage défini sur le compte de stockage Azure se fait par exemple au moyen des commandes Databricks dbutils :
dbutils.fs.ls('/mnt/dev/mysfilesystem/')
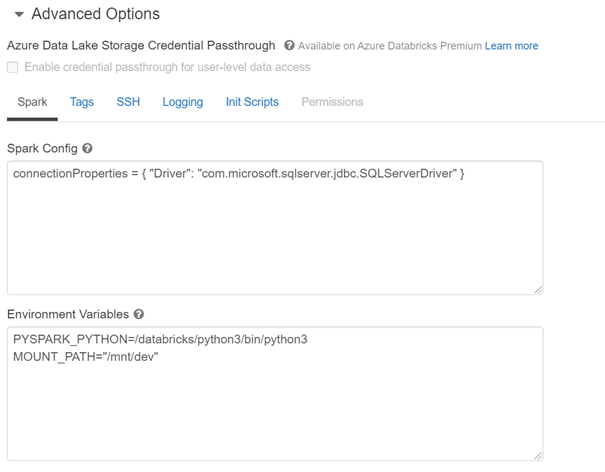
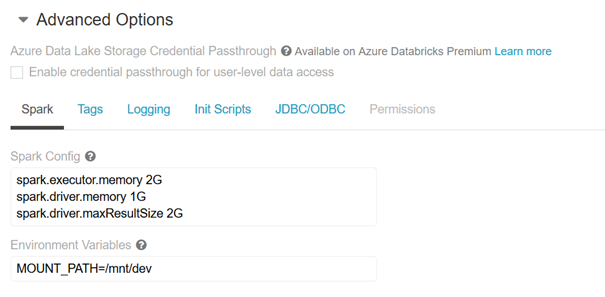
Les variables d’environnement sont quant à elles définies au niveau d’un cluster. Elles seront donc accessibles de n’importe quel notebook attaché au cluster. Nous les trouvons en dépliant le menu des options avancées, onglet Spark.
Par convention, nous utilisons une casse majuscule pour le nom des variables.
Attention à ne pas mettre d’espace autour du signe « = ». Les guillemets ne sont en revanche pas indispensables autour de la valeur de la variable.
Un redémarrage du cluster sera alors nécessaire, suite à la modification des variables d’environnement.
Maintenant, différentes commandes, dans les langages supportés, vont nous permettre d’accéder aux variables définies. Pour la compatibilité dans un même notebook, les lignes de scripts seront ici précédées du langage dans lequel elles sont écrites, vous pourrez ainsi copier ce code tel quel dans n’importe quel notebook Databricks.
Liste des variables d’environnement :
%sh printenv
Valeur de la variable en Shell :
%sh echo $MOUNT_PATH
Valeur de la variable d’environnement en Python :
%python
import os
key = 'MOUNT_PATH'
value = os.getenv(key)
print("Value of 'MOUNT_PATH' environment variable :", value)
A noter que la commande getenv() peut être remplacée par environ.get() issue également de la librairie os. Les différences entre les deux sont traitées dans cette question sur StackOverFlow.
Valeur de la variable d’environnement en Scala :
%scala
sys.env("MOUNT_PATH")
Il est donc maintenant possible d’utiliser ces variables dans les chaînes d’accès au système de fichier, avec un code qui réagira alors en fonction de l’environnement !
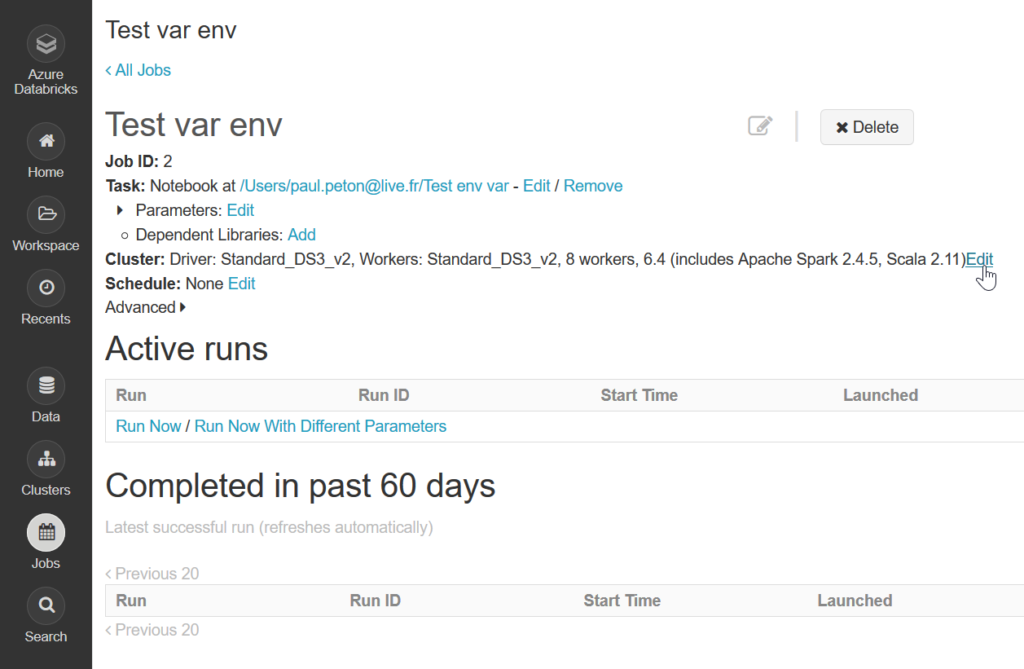
La définition des variables d’environnement est également réalisable si vous utilisez un “automated cluster“, c’est-à-dire un cluster créé à la volée lors du lancement d’un job planifié.
La configuration du cluster est disponible en cliquant sur le bouton “edit”.
La donnée classique et structurée n’a plus de secret pour vous si vous avez lu les deux billets précédents (ici et là) traitant de l’analyse avancée et de la modélisation des données. Pour autant, ces méthodes sont valables, et performantes, lorsque la donnée est de type alphanumérique et organisée sous forme tabulaire. Pour les données dites non structurées comme les images, le son ou encore le texte rédigé, il faut faire appel à un tout autre arsenal d’outils.
Du temps, de la puissance et des données
Soyons pragmatiques, pour être ingérée par un algorithme,
toute donnée devra devenir numérique mais le cheminement pour y arriver va être
complexe. Des approches comme la métrique TF-IDF ont fait leurs preuves, pour
le référencement de documents pertinents dans des corpus de textes. Cela reste
vrai tant que la puissance de calcul disponible est suffisante, et donc le
volume de données relativement raisonnable. Dans le domaine des images, on
distinguera deux usages principaux : la classification (catégoriser
une image parmi des labels existants) et la reconnaissance d’objets
(présence et position sur l’image). Les progrès ont été remarquables avec
l’arrivée (voire le retour…) des réseaux de neurones dits profonds, ce que l’on
nomme le « Deep Learning ».
Les frameworks de Deep Learning sont aujourd’hui nombreux :
Cognitive Toolkit créé par Microsoft, TensorFlow mis en place par Google ou
encore PyTorch. Leur maîtrise implique une bonne connaissance du fonctionnement
mathématique des réseaux de neurones et de l’état de l’art des différents types
de couches de neurones pouvant être utilisées. Mais ensuite, il faudra beaucoup de données et beaucoup de
puissance de calcul pour obtenir un modèle performant.
C’est ici que le mécanisme du Transfer Learning prend
tout son intérêt. En effet, au fur et à mesure des couches du réseau de
neurones profond, l’apprentissage va se spécifier. Pour donner une image
didactique, on pourrait dire que l’algorithme commence par reconnaître des
formes simples avant d’identifier des formes plus complexes. C’est d’une
certaine manière ce que font nos yeux et notre cerveau lorsque nous découvrons
un nouvel environnement. J’entre dans un nouveau bâtiment et je vois des
bureaux, des écrans, des tasses à café, un babyfoot, je reconnais… l’open space d’une ESN parisienne !
Les services cognitifs
Imiter les capacités humaines de perception ou de cognition
est depuis longtemps un défi pour le monde de l’informatique et la discipline
de l’Intelligence Artificielle s’y emploie, présentant des succès majeurs
depuis quelques années. Pensons ici à la qualité des outils de traduction automatique,
à l’efficacité de la transcription orale en texte ou encore à la pertinence des
moteurs de recommandation.
Les départements de Recherche et Développement des géants du
numérique rivalisent de performances dans ces différents domaines et mettent à
disposition leurs algorithmes, en les encapsulant dans des interfaces (web,
API, SDK…) facilitant leur utilisation. En ce sens, nous pouvons parler d’Intelligence
Artificielle as a Service !
Les services cognitifs de Microsoft se répartissent en cinq catégories présentées sur l’image suivante.
Documentation Microsoft
Plusieurs de ces services sont accessibles en démonstration
ou test sur le site de
Microsoft. Pour une utilisation plus régulière et dans un cadre professionnel, un
abonnement Azure sera nécessaire.
Pour une entreprise est convaincue de la création de valeur
potentielle au travers des données non structurées (texte, image, son, vidéo…),
elle doit dorénavant s’interroger sur la faisabilité d’un développement
équivalent : existe-t-il des ressources (personnes et machines) capables
de produire le niveau de performance attendu des algorithmes ? A la
négative, il pourra être très intéressant d’exploiter les services cognitifs.
Microsoft Custom Vision
Le site customvision.ai
de Microsoft vous permet de vous lancer rapidement dans l’évaluation de modèles
de classification ou de reconnaissance d’objets, sans avoir à saisir une seule
ligne de code !
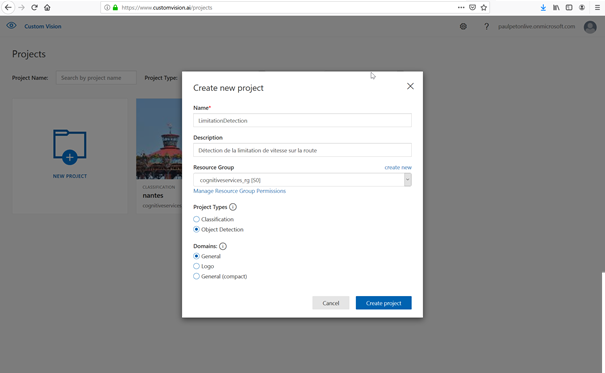
Identifiez-vous sur le portail, avec votre compte Azure. Il sera possible de créer et conserver simultanément deux projets sur la plateforme, et ce, sans facturation. Dans l’exemple ci-dessous, nous choisissons un projet de type « Object detection ». Notre cas d’usage sera ici d’identifier l’existence d’un panneau de limitation de vitesse sur une photo.
Il sera alors nécessaire de créer ou d’associer un groupe de ressources Azure. Si cette
notion ne vous parle pas, rapprochez-vous des administrateurs de votre
souscription Azure.
Trois domaines sont proposés : il s’agit ici de
spécifier le « début » du réseau de neurones profond qui sera employé
dans notre démarche d’apprentissage par transfert. Nous restons ici sur le
domaine général. L’utilisation du domaine « Logo » permettrait de
bénéficier de couches de neurones déjà entrainées à la reconnaissance de logos
de marques commerciales.
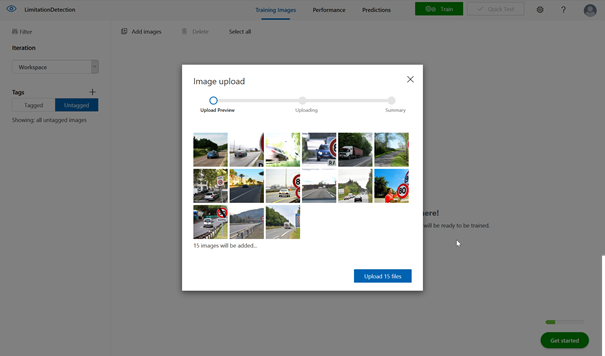
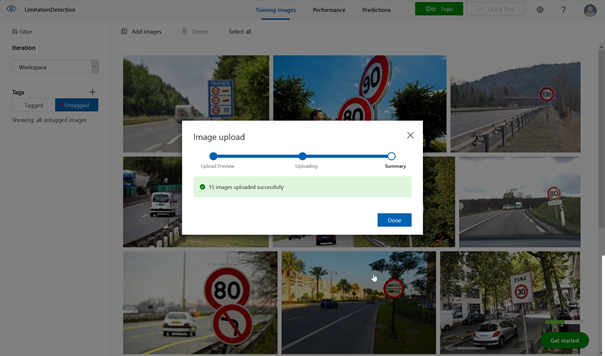
Chargement des images et ajout de tags
L’écran suivant correspond à l’interface de chargement des données et d’entrainement du modèle. Nous rentrons ici dans la logique dite supervisée de l’apprentissage automatique : il faut fournir des exemples que le réseau interprétera pour construire le modèle, qui lui permettra ensuite de réaliser des prévisions. En résumé, prédire le futur correspond à reproduire le passé, en le généralisant !
La première étape consiste à charger des images (« add images ») à partir de l’ordinateur que nous utilisons. Ces images peuvent être de format .jpg, .png, .bmp ou .gif et il n’y a pas d’exigence à ce qu’elles soient de la même résolution. Le poids de l’image utilisée en entrainement ne pourra pas dépasser 6Mo et 4Mo en prévision. Les images dont la largeur se situe en dessous de 256 pixels sont automatiquement remises à l’échelle par le service.
Un minimum de 15 images est requis pour débuter un modèle de détection d’un objet. Toutefois, il faudra viser une cinquantaine d’images pour une première expérience significative et s’en tenir à des cas d’usage relativement « visibles ». Même si la technologie s’en rapproche, ce n’est pas cet outil qui sert par exemple à détecter des pathologies dans des clichés médicaux.
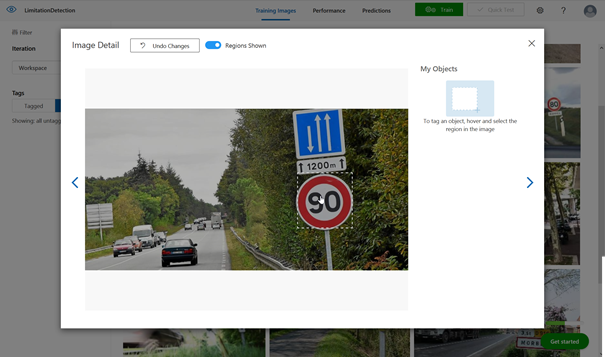
Il est maintenant nécessaire de travailler chaque image en entourant la zone souhaitée (ici le panneau rond de limitation) et en y associant un « tag » (mot clé identifiant l’objet). C’est la partie manuelle et sans doute la plus rébarbative de l’entrainement du modèle.
Si l’on souhaite reconnaitre plusieurs objets, il sera
nécessaire de compter au moins 15 images par objet.
Première itération du modèle
Lors de la phase d’entrainement, l’algorithme cherche à
réduire l’erreur de prévision sur la base des images déjà taguées.
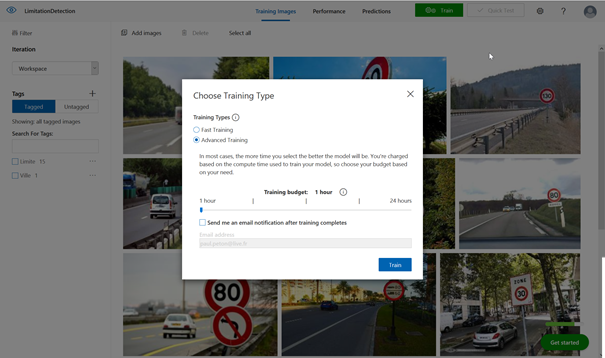
Deux types d’entrainement sont disponibles :
Fast training
Advanced training
Deux règles s’appliquent ici de manière assez générale :
Plus il y a beaucoup de données, plus le temps
d’entrainement sera long et meilleur sera le modèle.
Plus l’entrainement est long ou sollicite de
machines puissantes, plus celui-ci sera cher.
L’entrainement peut durer plusieurs minutes et s’étendre sur
plusieurs heures en cas de volumétrie et de complexité importante. Nous
privilégions ici dans un premier temps l’entrainement rapide.
Evaluer et tester le modèle
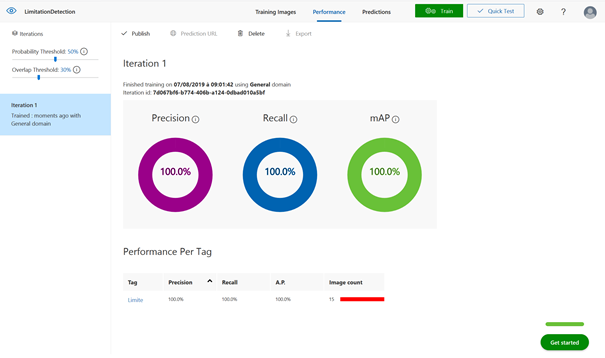
Le menu Performance permet de consulter les indicateurs de
qualité du modèle.
La précision correspond,
pour un tag donné, à la proportion d’images correctement classées ou avec une
reconnaissance d’objets exacte sur l’ensemble des images.
Le rappel (Recall)
correspond à la proportion d’images appartenant réellement à une classe parmi
toutes les images prédites dans cette classe.
On définira le seuil de probabilité (Probability Threshold) pour savoir si la confiance dans une
prévision est suffisante pour classer une image ou détecter un objet.
Le score mAP
(mean Average Precision) est un calcul synthétisant les indicateurs de
précision et de rappel, en moyenne pour l’ensemble des classes ou des objets à
détecter.
On cherchera à maximiser ces trois indicateurs mais attention,
ce n’est pas forcément souhaitable que de disposer d’un modèle
« parfait » comme sur l’illustration ci-dessus. La perfection en
apprentissage automatique est nommée surapprentissage (« overfitting »)
et peut se traduire par un manque de capacité de généralisation. Concrètement,
le modèle a de forts risques d’échec dès que de nouvelles images dévieront des
images d’entrainement.
Une solution consiste ici à augmenter le nombre d’images
utilisées pour l’apprentissage, en prenant soin de varier les contextes d’images (routes de jour / de nuit, panneaux
étrangers, etc.).
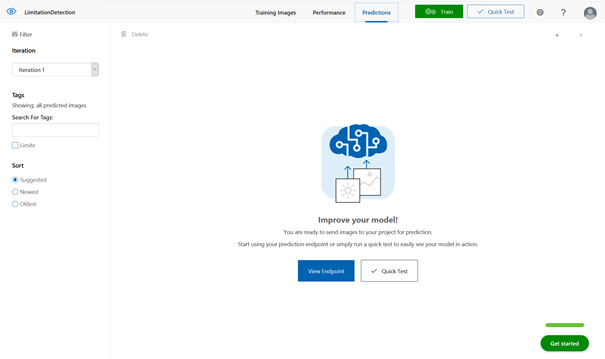
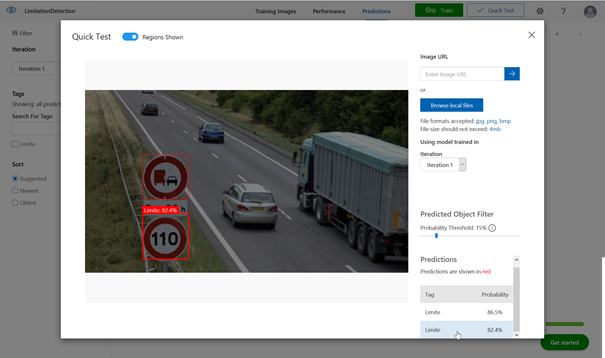
L’interface de Custom Vision nous propose maintenant de tester le modèle établi.
Nous utilisons bien sûr ici une image qui n’a pas servi à
l’entrainement du modèle. Il est possible d’utiliser une image de l’ordinateur
local ou bien une URL web d’image.
Il sera également possible de comparer les résultats du test sur les différentes itérations d’entrainement.
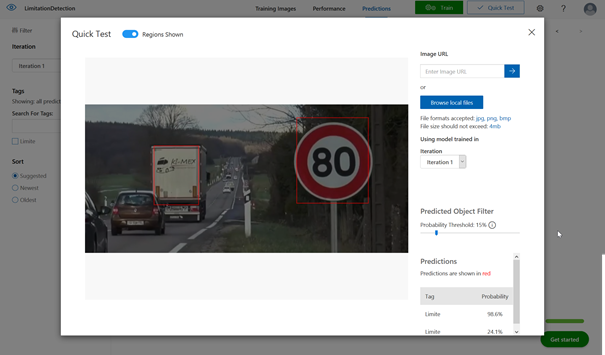
Sur cette première image, le panneau est bien identifié avec une probabilité de plus de 98% mais nous observons également que l’arrière du camion a été analysé comme un panneau. Pour autant, la probabilité est très faible (< 25%) et nous pourrons rejeter cette hypothèse en définissant un seuil d’acceptation.
Le panneau de limitation est bien identifié, avec un score de confiance dépassant 82%
Sur ce second test, deux panneaux sont identifiés avec une
probabilité forte (> 80%) d’être une limitation de vitesse. Ce n’est
pourtant le cas que sur le panneau de bas. Nous devons à nouveau grossir le jeu
d’entrainement, en incluant plus de diversité de panneaux et relancer une
itération !
Microsoft donne plusieurs conseils pour améliorer un
classifieur sur cette page.
Un principe générique consistera à ajouter des images variées selon l’arrière-plan,
l’éclairage, les tailles d’objet, les angles de vue…
Exploiter le modèle depuis une application tierce
Bien sûr, un usage professionnel du modèle obtenu ne pourra
se faire au niveau du portail. On utilisera une application tierce qui appellera
le modèle au travers d’une API.
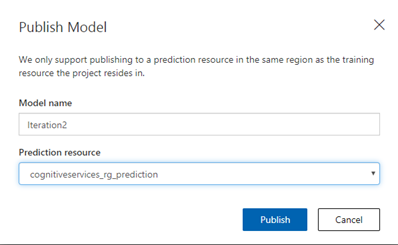
Le modèle obtenu au travers de la meilleure itération doit tout d’abord être publié (bouton « Publish ») et associé au groupe de ressources préalablement défini sur le portail Azure.
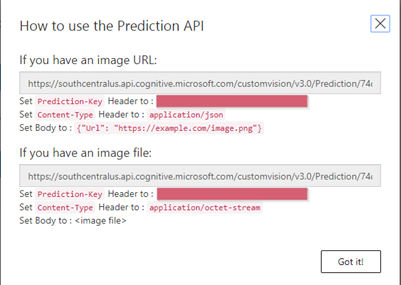
En cliquant ensuite sur « Prediction URL », on obtiendra l’URL et la clé de prévision (prediction URL & prediction-key). L’URL de prévision est aussi appelée endpoint.
La prediction key est aussi visible depuis le portail Azure, au niveau de la ressource créée pour l’utilisation du service Custom Vision.
Deux kits de développement (SDK) existent également et
permettent de réaliser l’ensemble des étapes en programmation .NET
(téléchargeables pour l’entrainement
et la prévision)
ou en Python à l’aide de la commande suivante :
Décrire, approfondir, prédire sont les trois étapes d’une analyse avancée de données, auxquelles il est possible d’ajouter « prévenir » ou « prescrire » qui sont l’aboutissement d’une stratégie pilotée par la data.
Nous avons vu dans un précédent billet comment l’approche statistique permettait d’identifier des facteurs explicatifs dans les données, en particulier quand une variable est centrale dans l’analyse et qu’elle joue le rôle de variable à expliquer. Il s’agit tout simplement de la donnée qui répond à la problématique principale : le chiffre d’affaires ou la marge pour une entreprise, le taux de conversion pour un site de e-commerce, la présence d’une pathologie ou dans l’exemple que nous reprenons ci-dessous, la gravité d’un accident pour la sécurité routière.
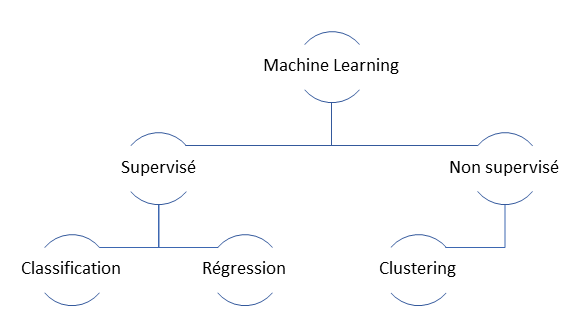
L’apprentissage automatique supervisé
Nous entrons ici dans la discipline dite du Machine Learning ou apprentissage automatique. Le Machine Learning se base sur des événements passés pour construire un modèle statistique qui sera ensuite appliqué à de nouvelles données (ici, les caractéristiques d’un accident de la route). En fonction de ces données et du modèle, une prévision du résultat (la variable à expliquer, ici la gravité de l’accident) sera rendue, accompagnée d’une probabilité exprimant la chance ou le risque qu’un tel résultat se produise.
Lorsque la variable prédite est catégorielle, voire au plus
simple, binaire, on parle de techniques de classification.
Certaines méthodes de classification ont fait leurs preuves depuis de
nombreuses années : régression logistique, arbre de décisions, Naïve
Bayes. Elles ont été, avec l’essor du Big Data, complétées par des algorithmes
puissants mais gourmands en ressources de calcul comme les forêts
aléatoires (random forest) ou le
Gradient Boosting (XGBoost),
Une approche de développement : le langage Python
Les Data Scientists disposent aujourd’hui d’un grand panel
d’outils pour travailler la donnée et entraîner des modèles de Machine
Learning. Il existe ainsi des plateformes graphiques permettant de construire le
pipeline de données (la Visual Interface d’Azure Machine
Learning Service, Alteryx, Dataïku DSS, etc.). Une autre approche, souvent
complémentaire, consiste à utiliser un langage de développement comme R, Python
ou encore Scala, ce dernier pour une approche distribuée dans un environnement
Spark.
Lorsque la volumétrie de données permet de travailler en
plaçant le jeu de données (dataset)
complet en mémoire, les langages R et Python sont tout à fait appropriés. Nous
choisirons ici Python pour la simplicité d’usage et l’efficacité de sa
librairie dédiée au Machine Learning : scikit-learn.
Les développeurs apprécieront d’utiliser un environnement de
développement intégré (IDE) comme Visual
Studio Code ou PyCharm. Pour donner plus de lisibilité à notre code, nous
choisissons pour cet article de travailler dans un notebook Jupyter qui permet d’alterner dans une même page, code,
sorties visuelles et commentaires.
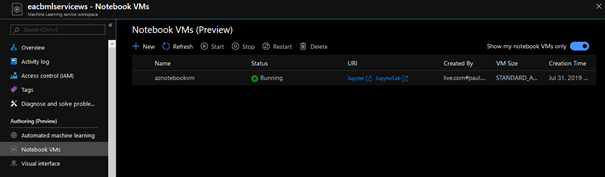
Afin de maîtriser les ressources de calcul qui seront associées à l’exécution des traitements, il est également possible de souscrire à un espace de travail Azure Machine Learning Service. Celui-ci permet de lancer une machine virtuelle de son choix sur laquelle sont déjà configurés les notebooks Jupyter ainsi que l’environnement Jupyter Lab.
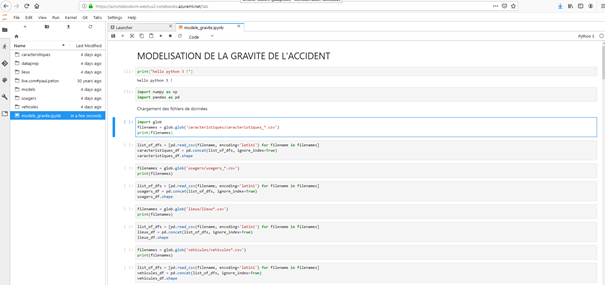
Dans la fenêtre Jupyter Lab ci-dessous, nous retrouvons le code à exécuter ainsi qu’un menu latéral permettant de naviguer dans les fichiers précédemment téléchargés dans l’environnement.
L’indispensable préparation des données
Avant de soumettre les données chargées à l’approche algorithmique, il est nécessaire d’effectuer quelques calculs préparatoires pour mettre en forme les données et les rendre utilisables par les différents algorithmes.
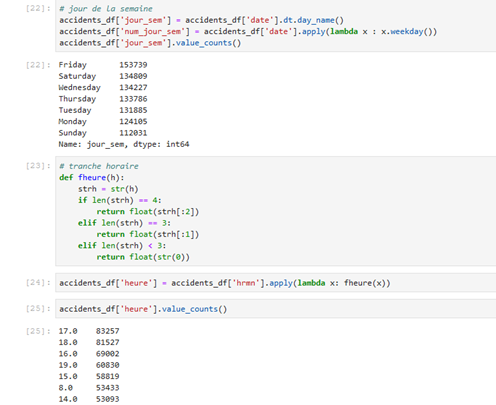
Ainsi, la date et l’heure de l’accident sont exploitées pour créer deux nouvelles variables : le jour de la semaine et la tranche horaire.
Ces deux calculs illustrent le principe du feature
engineering, c’est-à-dire du travail sur les variables en entrée du
modèle pour proposer les plus pertinentes et les plus efficaces. Attention, il
n’est parfois pas possible de le déterminer a
priori. Au-delà de toute formule mathématique et en l’absence d’une
quelconque baguette magique, des échanges
avec les personnes ayant une connaissance métier forte seront très
profitables aux Data Scientists et les orienteront vers une bonne préparation
des données.
Modéliser, entraîner, évaluer
Nous comparons ici deux modèles, l’un étant un modèle
« simple » : celui des K plus proches voisins, le second étant
un modèle « ensembliste », c’est-à-dire combinant plusieurs
modèles : une forêt aléatoire d’arbres de décisions.
Une fois l’entraînement réalisé, nous pouvons calculer
différentes métriques évaluant la qualité des modèles.
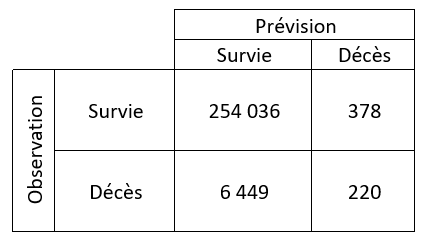
Nous observons tout d’abord la matrice de confusion qui nous permet de comparer la valeur prédite (décès ou non) avec la valeur réelle qui a été « oubliée » le temps du calcul de la prévision.
Nous observons ici 6 449 « faux positifs »,
personnes réellement décédées suite à l’accident, pour lesquelles l’algorithme
n’a pas été en mesure de prévoir ce niveau de gravité. Il sera possible de
jouer sur le seuil de la probabilité de décès (par défaut à 50%) pour réduire
ce nombre.
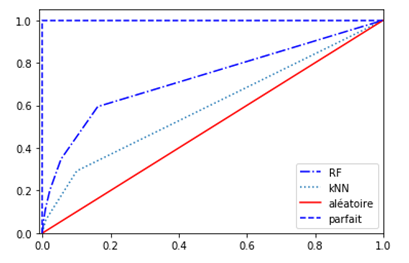
Une vision graphique de ces informations est possible au travers de la courbe ROC et du calcul de l’aire situé sous cette courbe : l’AUC. Cet indicateur prend une valeur en 0 et 1 et plus celle-ci s’approche de 1, meilleur est le modèle.
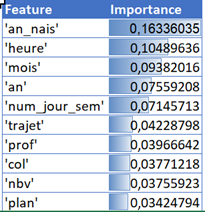
Nous retenons ici le modèle de la forêt aléatoire (AUC = 0.730 contre 0.597), tout en étant bien conscients que son coût de calcul est plus élevé que celui des K plus proches voisins. Une propriété de l’objet nous permet d’obtenir un coefficient d’importance des variables dans le modèle. Cette information est particulièrement appréciable pour prioriser par exemple une campagne d’actions contre la mortalité sur les routes. Nous remarquons dans le top 10 ci-dessous que l’année de naissance de la personne, et donc son âge au moment de l’accident, constitue le facteur le plus aggravant. Viennent ensuite des informations sur la temporalité de l’accident (tranche horaire, mois, etc.) puis enfin le motif de déplacement (trajet), la déclivité de la route (prof), le type de collision (col), le nombre de voies (nbv) et le tracé de la route (plan). Ces derniers facteurs sont toutefois 4 à 5 fois moins importants que l’âge de la personne impliquée.
Le meilleur modèle est enfin enregistré dans un format binaire sérialisé (package pickle) afin d’être exploité par la suite en production, comme le permet par exemple la ressource Azure Machine Learning Service.
Plus vite vers le meilleur modèle : l’Automated Machine Learning
Le travail de sélection du meilleur modèle (ainsi que de ces meilleurs hyper paramètres, c’est-à-dire le réglage fin de l’algorithme) peut s’avérer une tâche répétitive et fastidieuse car il n’existe pas réellement à l’heure actuelle de méthode ne nécessitant pas de réaliser toutes les évaluations. « No free lunch » !
Heureusement, l’investigation peut se faire de manière automatique, sorte de « force brute » du Machine Learning. Au travers d’Azure Machine Learning Service, nous soumettons le jeu de données à une batterie d’algorithmes qui seront comparés selon leur performance sur les différentes métriques d’évaluation.
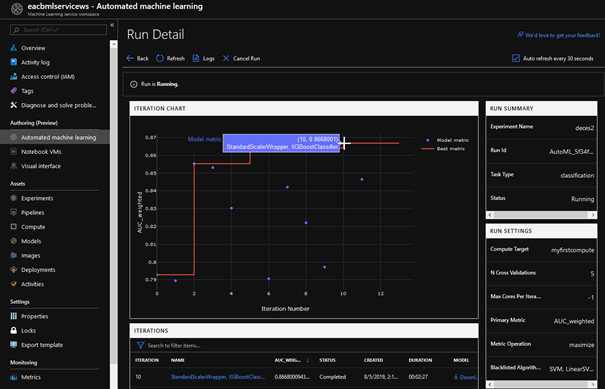
Nous retenons ici l’approche XGBoostClassifier dont l’AUC
atteint la valeur 0.867, soit 0.137 point supplémentaire, par rapport au modèle
trouvé manuellement.
L’approche prédictive, au travers du Machine Learning, se révèle être incontournable pour quiconque souhaite aujourd’hui anticiper les valeurs de ses données et découvrir des leviers d’action qui permettront de mettre en place des actions concrètes pour par exemple, éviter l’attrition (churn) d’une clientèle, prévenir d’un défaut de paiement ou d’une tentative de fraude, élaborer un premier diagnostic ou encore anticiper des pannes.
En conclusion, nous avons vu ici que le cloud Azure se marie au meilleur de l’Open Source pour devenir une plateforme parfaite pour les Data Scientists et les Data Engineers.