
Décrire, approfondir, prédire sont les trois étapes d’une analyse avancée de données, auxquelles il est possible d’ajouter « prévenir » ou « prescrire » qui sont l’aboutissement d’une stratégie pilotée par la data.
Nous avons vu dans un précédent billet comment l’approche statistique permettait d’identifier des facteurs explicatifs dans les données, en particulier quand une variable est centrale dans l’analyse et qu’elle joue le rôle de variable à expliquer. Il s’agit tout simplement de la donnée qui répond à la problématique principale : le chiffre d’affaires ou la marge pour une entreprise, le taux de conversion pour un site de e-commerce, la présence d’une pathologie ou dans l’exemple que nous reprenons ci-dessous, la gravité d’un accident pour la sécurité routière.
L’apprentissage automatique supervisé
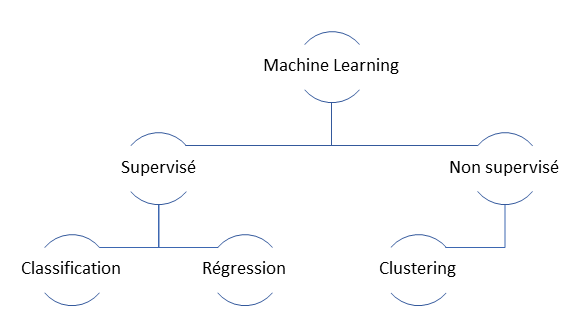
Nous entrons ici dans la discipline dite du Machine Learning ou apprentissage automatique. Le Machine Learning se base sur des événements passés pour construire un modèle statistique qui sera ensuite appliqué à de nouvelles données (ici, les caractéristiques d’un accident de la route). En fonction de ces données et du modèle, une prévision du résultat (la variable à expliquer, ici la gravité de l’accident) sera rendue, accompagnée d’une probabilité exprimant la chance ou le risque qu’un tel résultat se produise.
Lorsque la variable prédite est catégorielle, voire au plus simple, binaire, on parle de techniques de classification. Certaines méthodes de classification ont fait leurs preuves depuis de nombreuses années : régression logistique, arbre de décisions, Naïve Bayes. Elles ont été, avec l’essor du Big Data, complétées par des algorithmes puissants mais gourmands en ressources de calcul comme les forêts aléatoires (random forest) ou le Gradient Boosting (XGBoost),
Une approche de développement : le langage Python
Les Data Scientists disposent aujourd’hui d’un grand panel d’outils pour travailler la donnée et entraîner des modèles de Machine Learning. Il existe ainsi des plateformes graphiques permettant de construire le pipeline de données (la Visual Interface d’Azure Machine Learning Service, Alteryx, Dataïku DSS, etc.). Une autre approche, souvent complémentaire, consiste à utiliser un langage de développement comme R, Python ou encore Scala, ce dernier pour une approche distribuée dans un environnement Spark.
Lorsque la volumétrie de données permet de travailler en plaçant le jeu de données (dataset) complet en mémoire, les langages R et Python sont tout à fait appropriés. Nous choisirons ici Python pour la simplicité d’usage et l’efficacité de sa librairie dédiée au Machine Learning : scikit-learn.
Les développeurs apprécieront d’utiliser un environnement de développement intégré (IDE) comme Visual Studio Code ou PyCharm. Pour donner plus de lisibilité à notre code, nous choisissons pour cet article de travailler dans un notebook Jupyter qui permet d’alterner dans une même page, code, sorties visuelles et commentaires.
Le service Azure Notebooks est accessible gratuitement sur cette URL : https://notebooks.azure.com/

Afin de maîtriser les ressources de calcul qui seront associées à l’exécution des traitements, il est également possible de souscrire à un espace de travail Azure Machine Learning Service. Celui-ci permet de lancer une machine virtuelle de son choix sur laquelle sont déjà configurés les notebooks Jupyter ainsi que l’environnement Jupyter Lab.
Dans la fenêtre Jupyter Lab ci-dessous, nous retrouvons le code à exécuter ainsi qu’un menu latéral permettant de naviguer dans les fichiers précédemment téléchargés dans l’environnement.
L’indispensable préparation des données
Avant de soumettre les données chargées à l’approche algorithmique, il est nécessaire d’effectuer quelques calculs préparatoires pour mettre en forme les données et les rendre utilisables par les différents algorithmes.
Ainsi, la date et l’heure de l’accident sont exploitées pour créer deux nouvelles variables : le jour de la semaine et la tranche horaire.
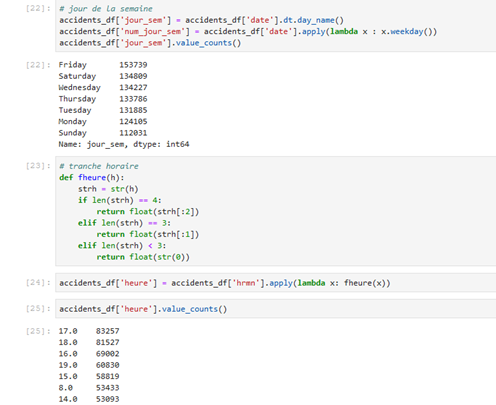
Ces deux calculs illustrent le principe du feature engineering, c’est-à-dire du travail sur les variables en entrée du modèle pour proposer les plus pertinentes et les plus efficaces. Attention, il n’est parfois pas possible de le déterminer a priori. Au-delà de toute formule mathématique et en l’absence d’une quelconque baguette magique, des échanges avec les personnes ayant une connaissance métier forte seront très profitables aux Data Scientists et les orienteront vers une bonne préparation des données.
Modéliser, entraîner, évaluer
Nous comparons ici deux modèles, l’un étant un modèle « simple » : celui des K plus proches voisins, le second étant un modèle « ensembliste », c’est-à-dire combinant plusieurs modèles : une forêt aléatoire d’arbres de décisions.
Une fois l’entraînement réalisé, nous pouvons calculer différentes métriques évaluant la qualité des modèles.
Nous observons tout d’abord la matrice de confusion qui nous permet de comparer la valeur prédite (décès ou non) avec la valeur réelle qui a été « oubliée » le temps du calcul de la prévision.
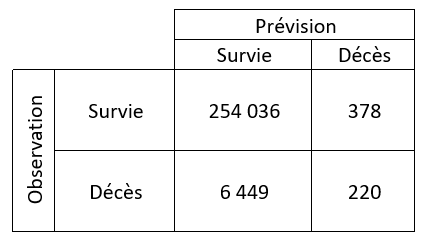
Nous observons ici 6 449 « faux positifs », personnes réellement décédées suite à l’accident, pour lesquelles l’algorithme n’a pas été en mesure de prévoir ce niveau de gravité. Il sera possible de jouer sur le seuil de la probabilité de décès (par défaut à 50%) pour réduire ce nombre.
Une vision graphique de ces informations est possible au travers de la courbe ROC et du calcul de l’aire situé sous cette courbe : l’AUC. Cet indicateur prend une valeur en 0 et 1 et plus celle-ci s’approche de 1, meilleur est le modèle.
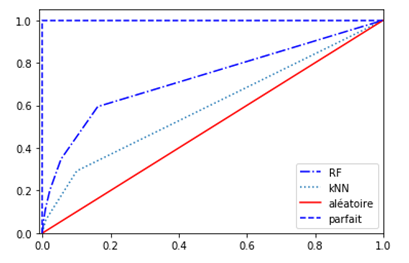
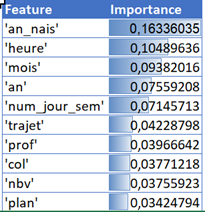
Nous retenons ici le modèle de la forêt aléatoire (AUC = 0.730 contre 0.597), tout en étant bien conscients que son coût de calcul est plus élevé que celui des K plus proches voisins. Une propriété de l’objet nous permet d’obtenir un coefficient d’importance des variables dans le modèle. Cette information est particulièrement appréciable pour prioriser par exemple une campagne d’actions contre la mortalité sur les routes. Nous remarquons dans le top 10 ci-dessous que l’année de naissance de la personne, et donc son âge au moment de l’accident, constitue le facteur le plus aggravant. Viennent ensuite des informations sur la temporalité de l’accident (tranche horaire, mois, etc.) puis enfin le motif de déplacement (trajet), la déclivité de la route (prof), le type de collision (col), le nombre de voies (nbv) et le tracé de la route (plan). Ces derniers facteurs sont toutefois 4 à 5 fois moins importants que l’âge de la personne impliquée.
Le meilleur modèle est enfin enregistré dans un format binaire sérialisé (package pickle) afin d’être exploité par la suite en production, comme le permet par exemple la ressource Azure Machine Learning Service.

Plus vite vers le meilleur modèle : l’Automated Machine Learning
Le travail de sélection du meilleur modèle (ainsi que de ces meilleurs hyper paramètres, c’est-à-dire le réglage fin de l’algorithme) peut s’avérer une tâche répétitive et fastidieuse car il n’existe pas réellement à l’heure actuelle de méthode ne nécessitant pas de réaliser toutes les évaluations. « No free lunch » !
Heureusement, l’investigation peut se faire de manière automatique, sorte de « force brute » du Machine Learning. Au travers d’Azure Machine Learning Service, nous soumettons le jeu de données à une batterie d’algorithmes qui seront comparés selon leur performance sur les différentes métriques d’évaluation.
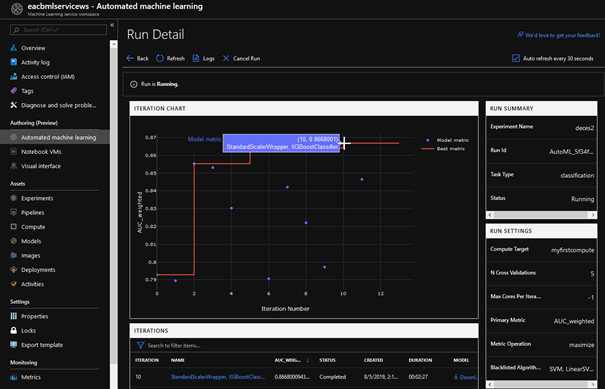
Nous retenons ici l’approche XGBoostClassifier dont l’AUC atteint la valeur 0.867, soit 0.137 point supplémentaire, par rapport au modèle trouvé manuellement.
L’approche prédictive, au travers du Machine Learning, se révèle être incontournable pour quiconque souhaite aujourd’hui anticiper les valeurs de ses données et découvrir des leviers d’action qui permettront de mettre en place des actions concrètes pour par exemple, éviter l’attrition (churn) d’une clientèle, prévenir d’un défaut de paiement ou d’une tentative de fraude, élaborer un premier diagnostic ou encore anticiper des pannes.
En conclusion, nous avons vu ici que le cloud Azure se marie au meilleur de l’Open Source pour devenir une plateforme parfaite pour les Data Scientists et les Data Engineers.
One thought on “Apprendre des données pour mieux anticiper [2/3]”