Au mois de mars 2021, une nouvelle fonctionnalité vient accompagner les espaces de travail Azure Databricks : les repos Git.
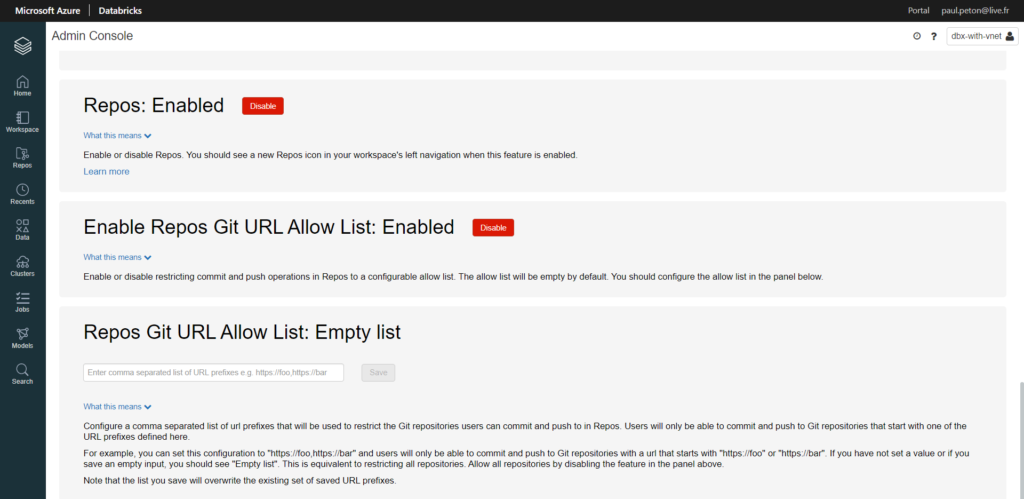
Pour l’activer, nous devons passer par la console d’administration, cliquer sur “Enable” puis rafraîchir la page.
Une nouvelle icône apparaît alors dans le menu latéral.
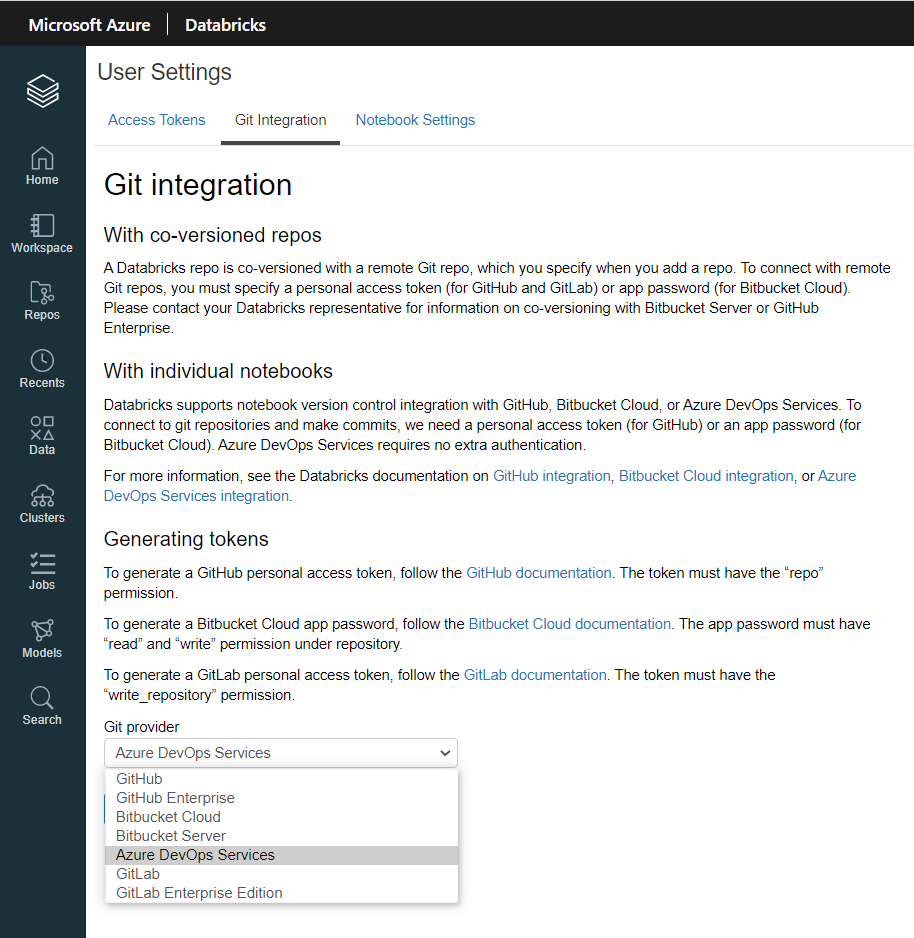
Jusqu’ici, le lien avec un gestionnaire de versions se faisait individuellement, par le biais de de la fenêtre “user settings“, comme expliqué dans cet article.
Chaque notebook devait alors être relié manuellement à un repository. Pour des actions de masse, il fallait employer les commandes en ligne (Databricks CLI).
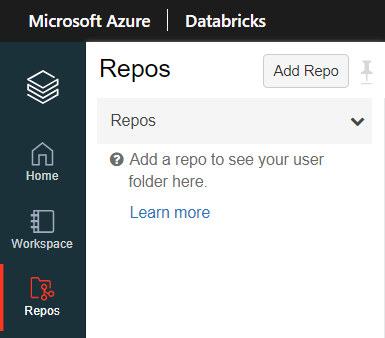
Pour démarrer, nous cliquons sur l’icône Repos et le menu propose un bouton “Add Repo“.
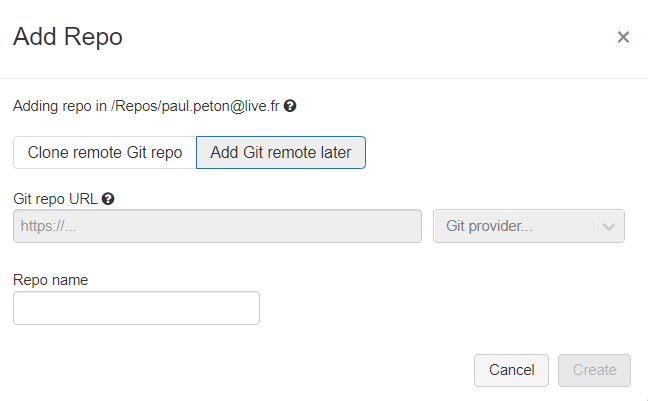
Une boîte de dialogue s’ouvre alors.
Il faut comprendre ici qu’il s’agit de créer un repository local au sens de l’espace de travail (“Add Git remote later”) ou bien de cloner un repo “remote“, c’est-à-dire relié à un des fournisseurs présents dans la liste. Ce dernier peut être vide si le projet débute.
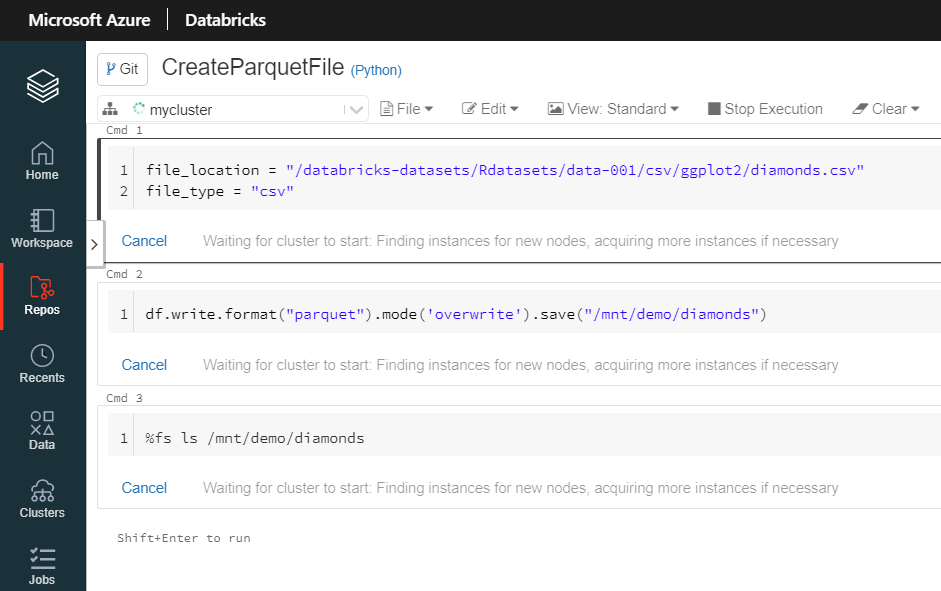
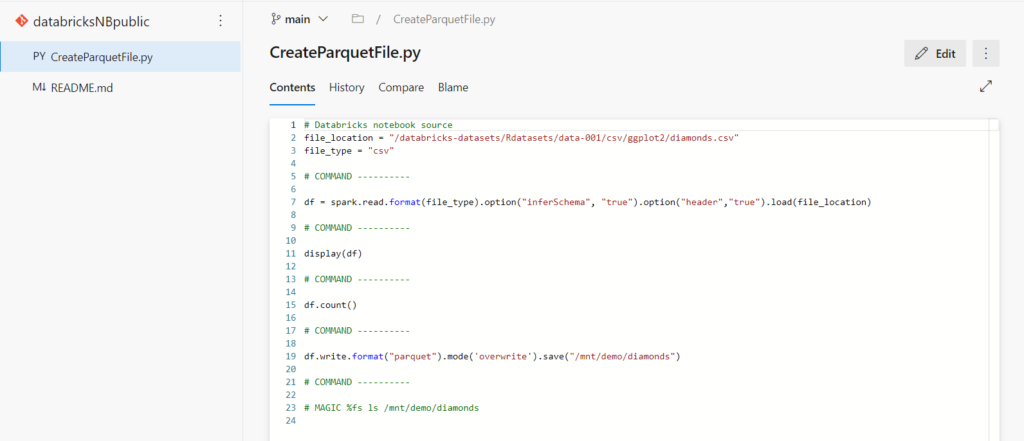
Nous créons ici un premier notebook dans ce nouveau repository local.
Il faut alors s’habituer à une nouvelle façon de travailler. Les notebooks ne sont plus visibles depuis l’icône “Workspace”. Le lien “Git: Synced” que l’on trouvait en cliquant sur “Revision history” n’existe plus. Mais une icône Git apparaît maintenant en haut à gauche du notebook.
L’historique des modifications s’enregistre toujours bien automatiquement et des retours arrières (“Restore this version”) sont possibles.
Sans réaliser l’association avec un gestionnaire de versions tiers, nous ne disposons pas d’autres fonctionnalités.
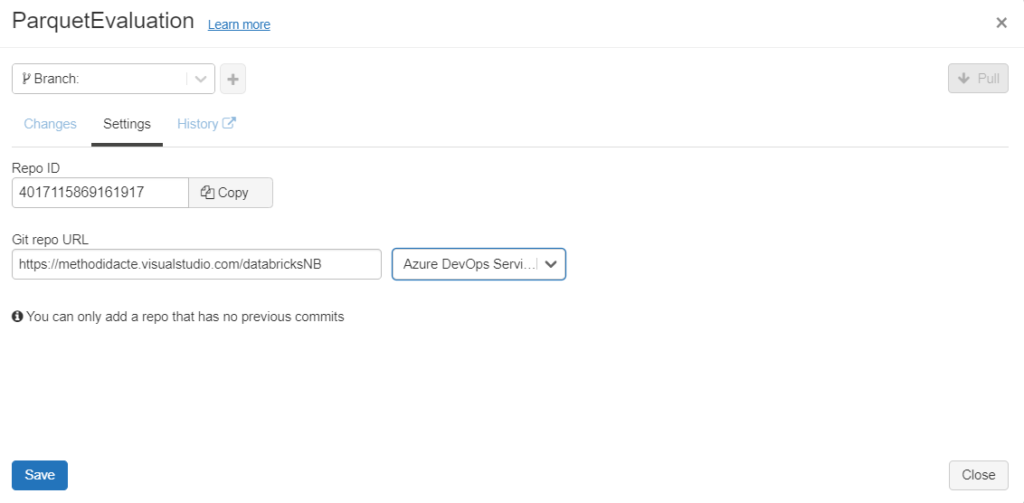
Un clic sur l’icône Git nous propose de réaliser cette association, ici avec le service Azure DevOps.
Attention, on ne peut attacher qu’un dépôt qui ne contient pas de commit.
Pour un repository de type privé, il va être nécessaire de réaliser des manipulations de sécurité.
Il s’agit de fournir un Personal Access Token (PAT) généré depuis le gestionnaire de versions.
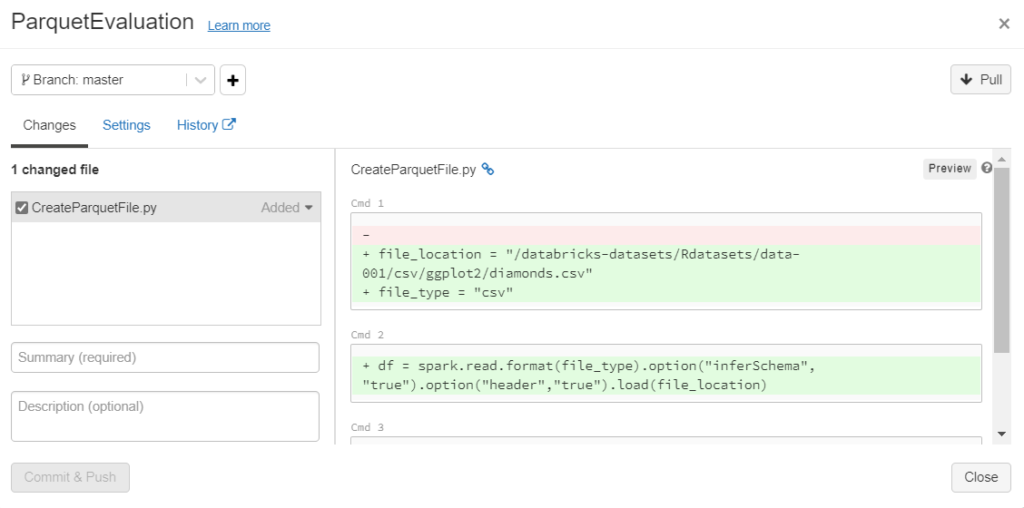
Une fois la configuration réalisée, la boîte de dialogues ci-dessous apparaît alors.
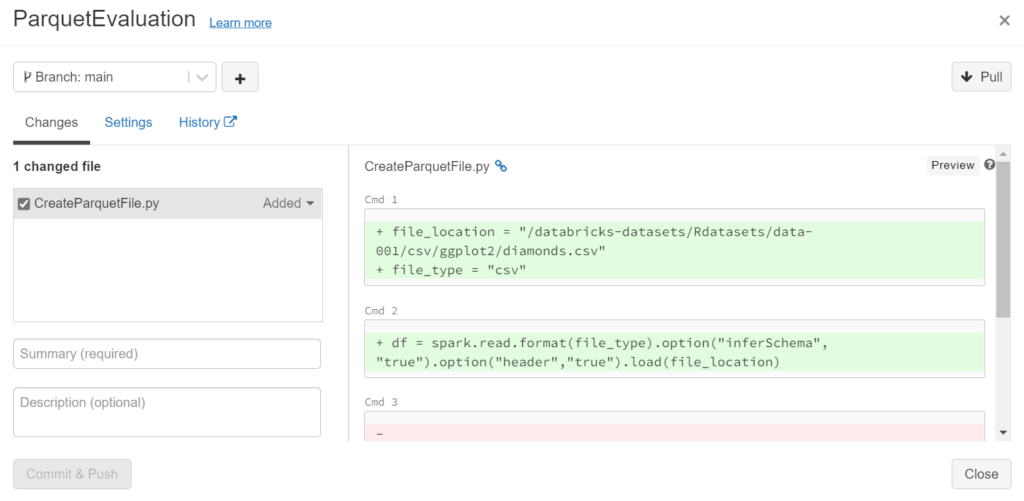
Nous retrouvons des notions familières aux utilisateurs de Git : branche (master ou main), pull, commit & push.
Il sera nécessaire (c’est même obligatoire) de saisir un résumé (summary) des modifications pour pouvoir cliquer sur le bouton “Commit & Push“.
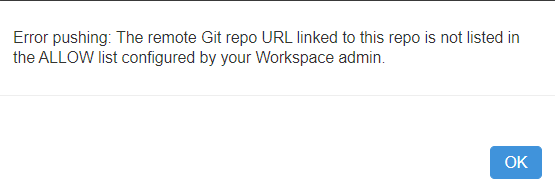
En effet, une liste de repositories autorisés doit être donné dans la console d’administration (seulement si cette option a été activée). Ce scénario s’inscrit dans le cadre de la licence Premium de Databricks où tous les utilisateurs ne sont pas obligatoirement administrateurs.
Notons que l’extension du fichier est .py mais il s’agit bien d’un notebook Databricks. Le contenu de celui-ci, en particulier les cellules Markdown, est arrangée pour “ressembler” à un script Python.
Attention, une commande comme display est propre à l’environnement des notebooks Databricks.
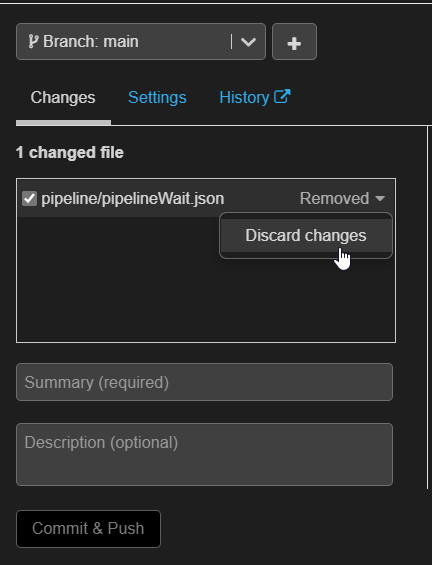
Si le repository est aussi utilisé pour conserver d’autres éléments que ceux propres à Databricks, nous verrons apparaître les dossiers du repo dans le menu de navigation de Databricks. Il pourrait être tentant de les supprimer depuis Databricks (ils sembleront vides puisque seules quelques extensions .py et .ipynb sont affichées) mais ne le faîtes surtout pas !
Une action “removed” serait alors être proposée au prochain commit. Il sera bien sûr possible de l’éviter en basculant sur “Discard changes“.
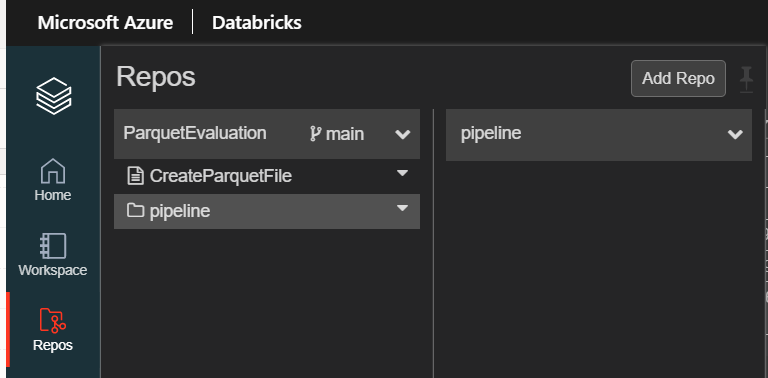
Ici, le repo est partagé avec des pipelines Azure Data Factory.
Le répertoire “vide” va alors réapparaître dans l’arborescence.
En conclusion, il serait préférable de dédier un repository à Databricks pour éviter les confusions.
EDIT 2021-08-23 :
La fonctionnalité originelle de liaison avec un repository Git est dorénavant une “legacy feature” et il est recommandé de ne plus l’utiliser.
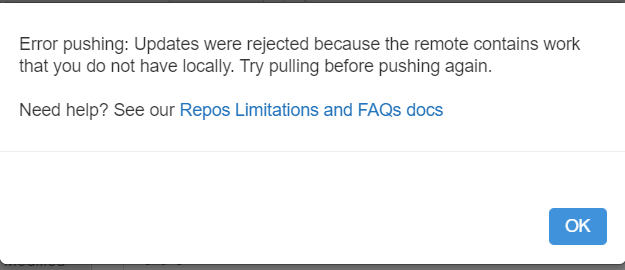
En poussant les tests, on obtient un blocage pour commiter depuis Databricks lors du scénario suivant :
publication réalisée depuis un outil tiers dans le repository partagé (par exemple, création d’un nouveau pipeline dans Azure Data Factory)
modifications d’un notebook dans Azure Databricks
sauvegarde de ces modifications
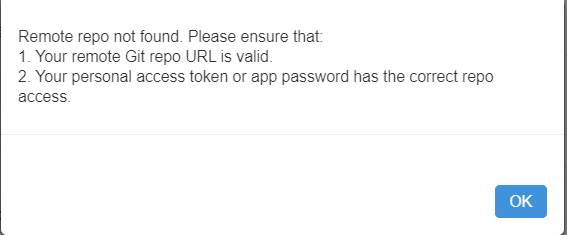
tentative de commit & push depuis Databricks
Nous obtenons alors le message d’erreur ci-dessous.
Il est indispensable de réaliser une action Pull avant de modifier les notebooks et nous recommandons de le faire avant même de débuter vos travaux sous Databricks.
Si les deux outils ont en partie des fonctionnalités qui se recouvrent, avec quelques différences (voir cet article), il est tout à fait possible de tirer profit du meilleur de chacun d’eux et de les associer dans une architecture data sur Azure.
Le scénario générique d’utilisation sera alors l’industrialisation de modèles d’apprentissage (machine learning) entrainés sur des données nécessitant la puissance de Spark (grande volumétrie voire streaming).
Nous allons détailler ici comment Databricks va interagir avec les services d’Azure Machine Learning au moyen du SDK azureml-core.
A l’inverse, il sera possible de lancer, depuis Azure ML, des traitements qui s’appuieront sur la ressource de calcul Databricks déclarée en tant que attached compute.
Le SDK azureml sous Databricks
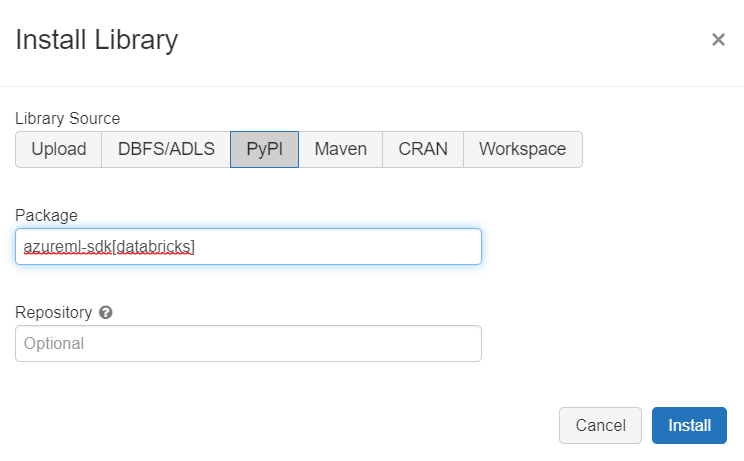
Nous commencerons par installer le package azureml-sdk[databricks] au niveau du cluster interactif (d’autres approches d’installation sont possibles, en particulier pour les automated clusters). Le cluster doit être démarré pour pouvoir effectuer l’installation.
Nous pouvons vérifier la version installée en lançant le code suivant dans un notebook :
import azureml.core
print("Azure ML SDK Version: ", azureml.core.VERSION)
Un décalage peut exister avec la version du SDK non spécifique à Databricks. Des dépendances peuvent également être demandées pour certaines parties du SDK comme l’annonce l’avertissement reçu à l’exécution de la commande précendente.
Failure while loading azureml_run_type_providers. Failed to load entrypoint automl = azureml.train.automl.run:AutoMLRun._from_run_dto with exception (cryptography 3.1.1 (/databricks/python3/lib/python3.8/site-packages), Requirement.parse('cryptography<4.0.0,>=3.3.1; extra == "crypto"'), {'PyJWT'}).
L’étape suivante consistera à se connecter à l’espace de travail d’Azure Machine Learning depuis le script, ce qui se fait par le code ci-dessous :
from azureml.core import Workspace
ws = Workspace.from_config()
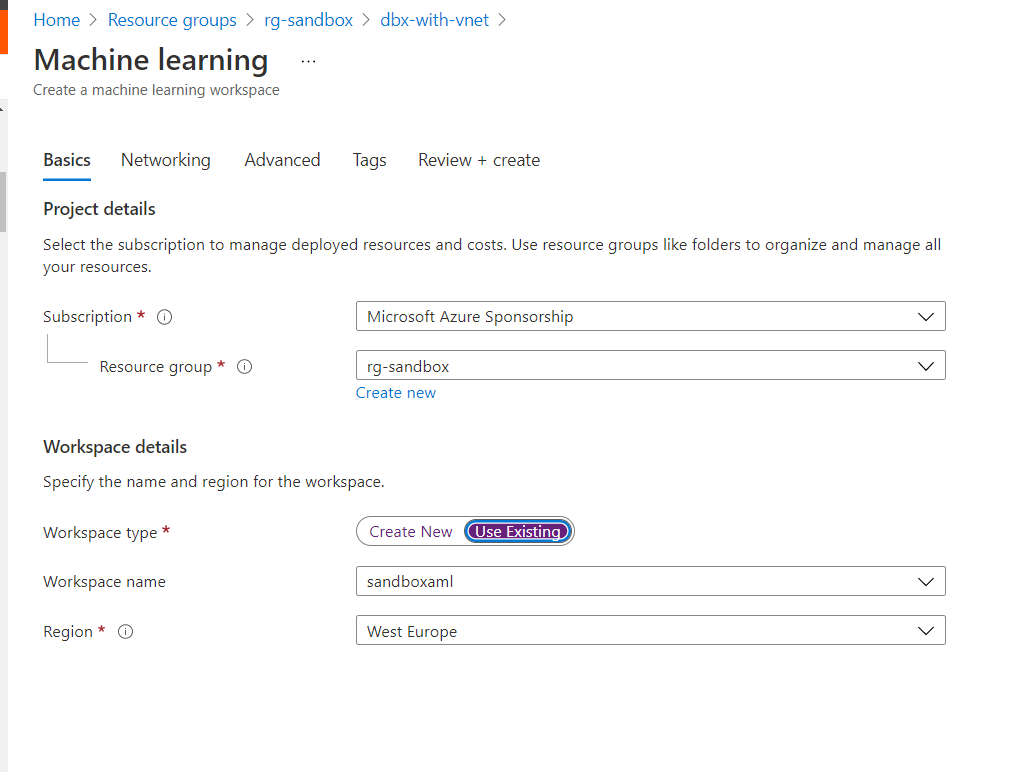
Plusieurs possibilités s’ouvrent à nous pour réaliser ce lien. La première consiste à établir explicitement ce lien dans le portail Azure, depuis la ressource Databricks.
Mais cette approche ne permet d’avoir qu’un seul espace lié, celui-ci n’étant plus modifiable au travers de l’interface Azure (mais peut-être en ligne de commandes ?). La configuration étant donnée par un fichier config.json, téléchargeable depuis la page du service Azure ML, nous pouvons placer ce fichier sur le DataBricks File System (DBFS), et donner son chemin (au format “File API format”) dans le code .
from azureml.core import Workspace
ws = Workspace.from_config(path='/dbfs/FileStore/azureml/config.json')
Une authentification “interactive” sera alors demandée : il faut saisir le code donné dans l’URL https://microsoft.com/devicelogin puis entrer ses login et mot de passe Azure.
Pour une authentification non interactive, nous utiliserons un principal de service.
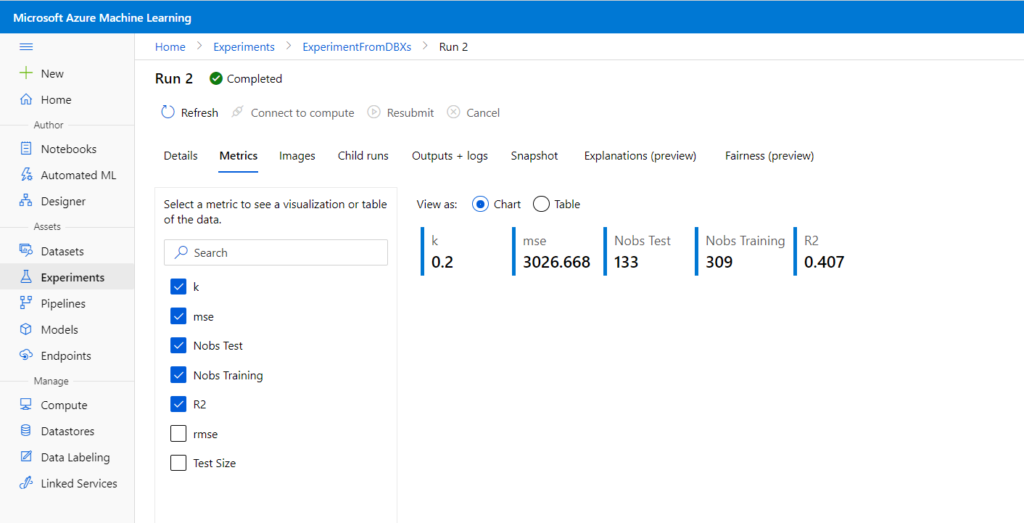
Nous pouvons maintenant interagir avec les ressources du portail Azure Machine Learning et en particulier, exécuter notre code au sein d’une expérience.
from azureml.core import experiment experiment = Experiment(workspace=ws, name="ExperimentFromDBXs")
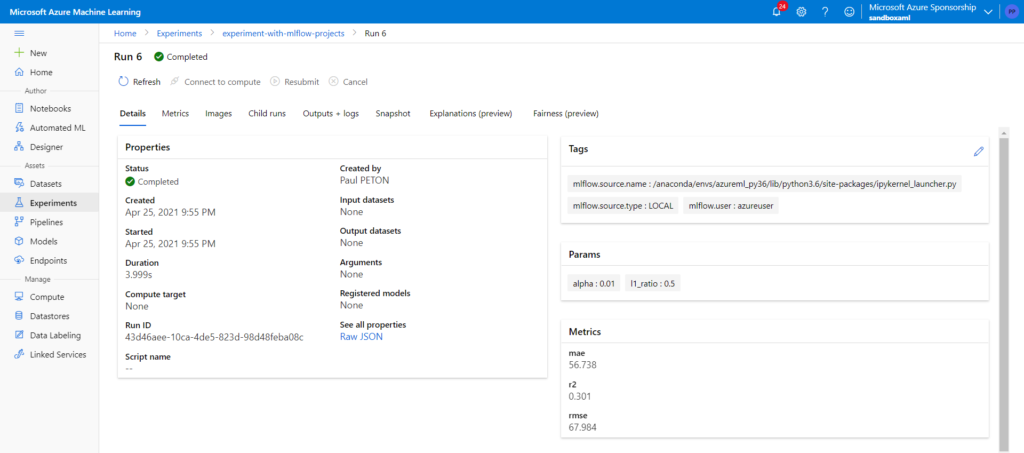
Après l’entrainement d’un modèle, idéalement réalisé grâce à Spark, nous pouvons enregistrer celui-ci sur le portail.
L’instruction run.log() permet de conserver les métriques d’évaluation.
A noter que les widgets ne peuvent pas s’afficher dans les notebooks Databricks.
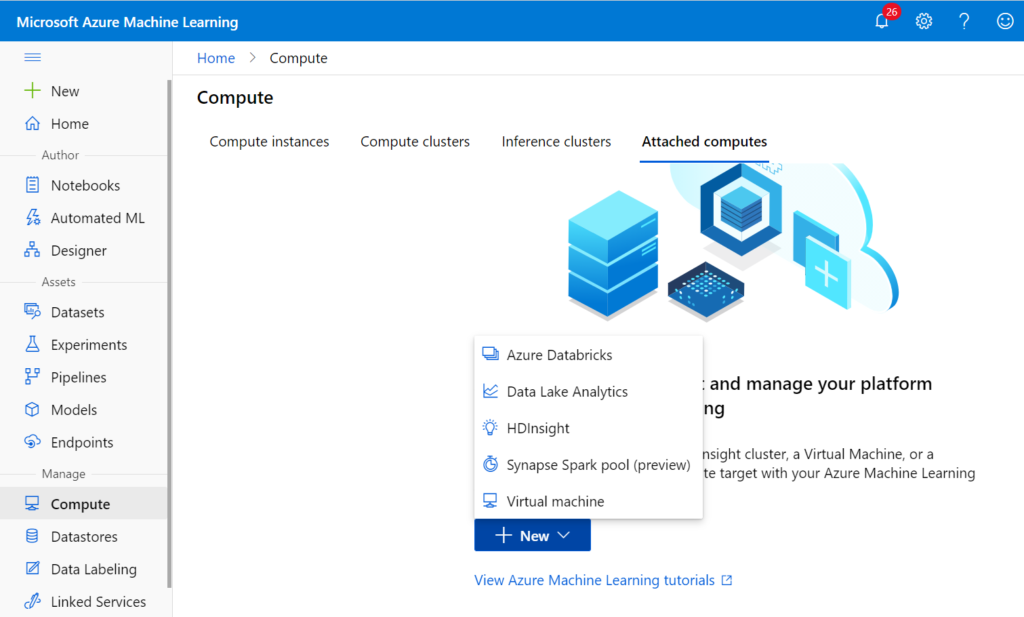
Databricks comme attached compute
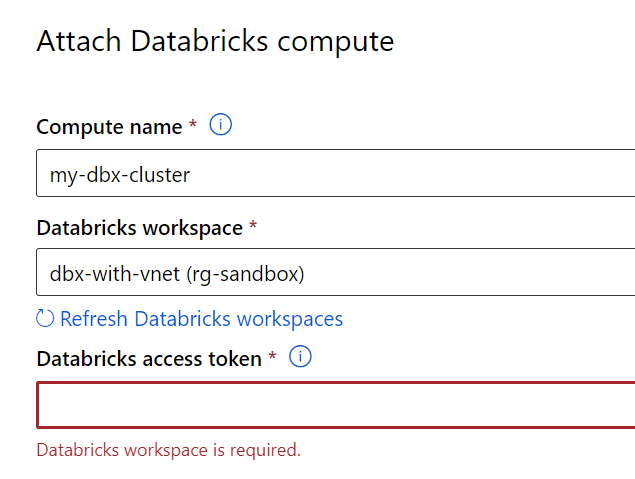
Comme pour toute ressource de calcul, nous commençons par déclarer le cluster Databricks dans le portail Azure Machine Learning.
Un jeton d’accès (access token) est attendu pour réaliser l’authentification. Nous prendrons soin de le générer grâce à un principal de service pour éviter qu’il ne soit attaché à une personne (“Personal Access Token”).
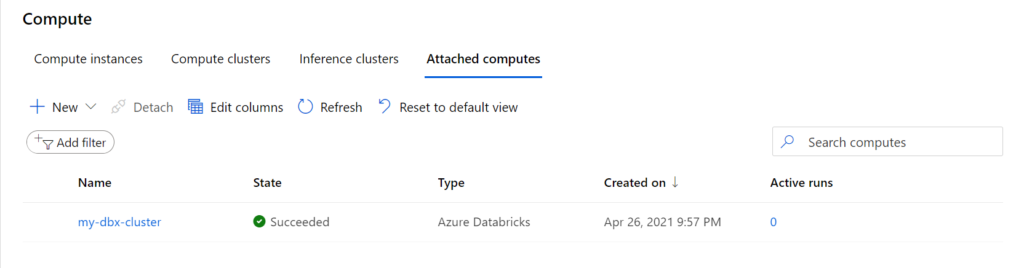
La ressource est maintenant correctement déclarée.
Nous allons l’exploiter au travers du SDK Python azureml dans lequel nous disposons de deux objets liés à Databricks.
La documentation présente la classe qui permettrait de créer cette ressource au travers du code :
DatabricksCompute(workspace, name)
Nous trouvons aussi dans la documentation l’objet qui crée une étape de pipeline exécutée ensuite au sein d’une expérience :
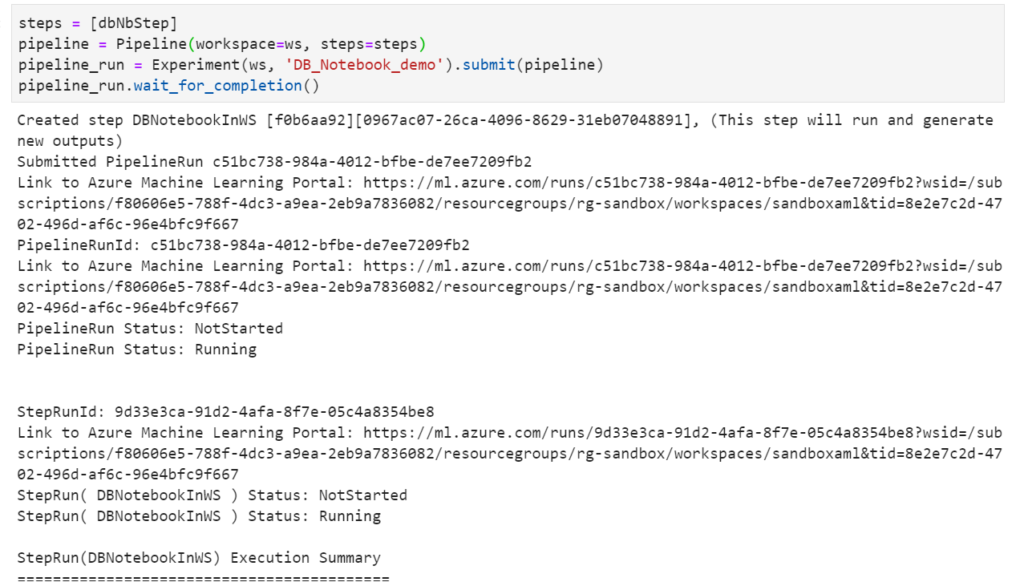
Il est possible de lancer un script Python qui sera exécuté sur le cluster Databricks mais l’usage le plus intéressant est sans doute l’exécution d’un notebook.
Nous pourrons alors suivre les logs du cluster dans l’expérience.
Je vous recommande ce notebook pour découvrir tous les usages de DatabricksStep, comme par exemple l’exécution d’un JAR.
En conclusion
La souplesse des services managés et la séparation stockage / calcul autorisent aujourd’hui à penser les architectures data avec les services qui sont les plus utiles au moment souhaité, quitte à avoir des redondances de fonctionnalités. Nous veillerons à préserver au maximum l’indépendance de certaines parties du code (a minima la préparation de données et l’entrainement) vis à vis des plateformes propriétaires. Il sera alors possible d’envisager des alternatives chez d’autres fournisseurs cloud ou bien encore dans le monde de l’Open Source.
Des machines virtuelles, du code R ou Python, des accès au Data Lake, du versionning et de l’exposition de modèles de Machine Learning, les points communs entre Azure Databricks et le service Azure Machine Learning sont nombreux ! Mais nous allons détailler dans cet article les différences entre ces deux produits, qui vous permettront de choisir le meilleur outil selon vos cas d’usage. N’oublions pas que ce sont aussi des outils complémentaires mais cet aspect sera traité dans un autre article.
S’il fallait résumer en quelques mots chacun des deux produits, voici comment l’on pourrait les présenter :
Databricks est un cluster Spark managé dans le cloud Azure (mais aussi AWS et GCP), dédié à exécuter du code de manière distribuée. Autour de cette fonctionnalité principale, s’intègrent des produits comme MLFlow pour le versionning et serving des modèles de ML ou encore SQL Analytics et Redash pour la visualisation de données.
Azure Machine Learning est un portail (dit “studio”) regroupant toutes les briques d’un projet de ML, allant de l’import des données depuis des sources Azure à l’exposition (web service) et monitoring de modèles, en passant par l’entrainement de ces modèles sur différentes solutions de calcul.
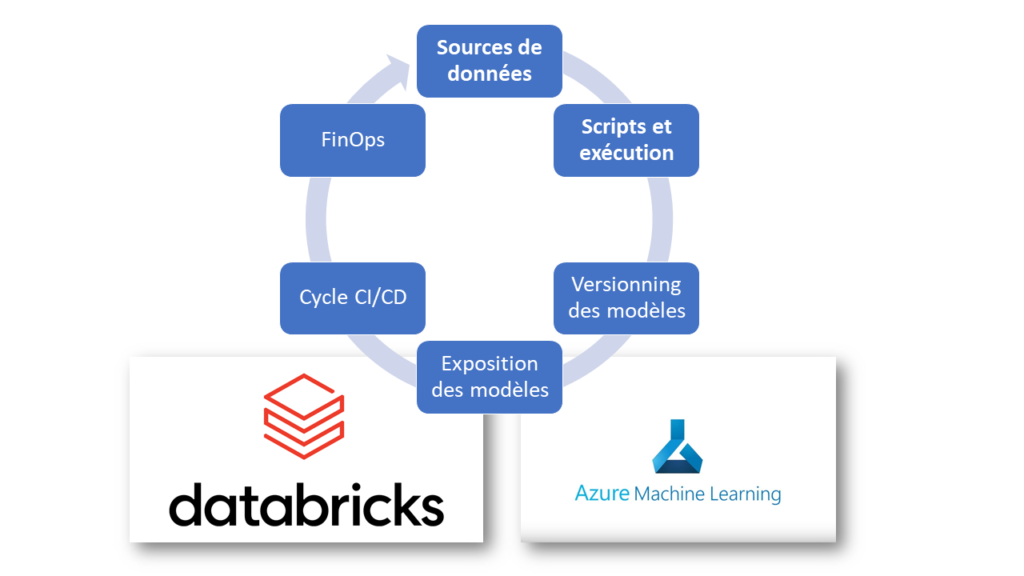
Nous allons pointer les différences entre ces deux services sur les thèmes indiqués dans le schéma ci-dessous, qui sont au cœur d’un workflow de Data Science.
Les sources de données
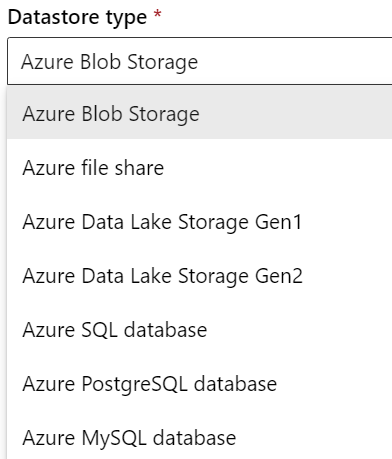
Les sources possibles pour Azure ML sont toutes des services managés du cloud de Microsoft, de type systèmes de fichiers ou bases de données.
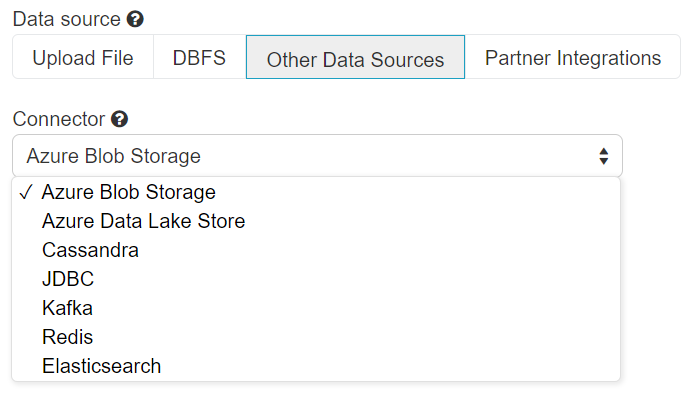
Les sources pour Azure Databricks sont représentées ci-dessous :
Le périmètre est ici plus large et intègre des produits classiques des architectures Big Data dans les domaines NoSQL, temps réel ou search.
La connexion à des ressources de type Azure SQL DB ou DWH se fait par un pilote générique JDBC, comme cela a été présenté ici préalablement. C’est une approche plus générique mais qui ne pas bénéficier d’optimisations propres à la communication de services Microsoft entre eux. C’est un point qui mériterait d’être testé, dans des conditions de sécurisation des échanges réseaux (VNET).
L’un des projets Open Source très présent dans Databricks est Delta Lake : un format de fichier “amélioré” par rapport au format Parquet classique, puisqu’il s’accompagne d’une capacité à traiter des transactions ACID et d’un historique au format JSON des logs transactionnels. Ce sont des opérations comme des delete, insert, update et upsert qui seront possibles ! La fonctionnalité de time travel permet de retrouver l’état des données à une date ou sur une version donnée. Nous sommes donc dans une logique “schema-on-write” d’habitude propres aux systèmes de gestion de bases de données. Est-ce déjà la fin annoncée de ces derniers ? Certainement pas !
Voici la syntaxe permettant d’écrire un dataframe Spark au format delta.
Delta Lake est un produit à part entière, alors peut-on l’utiliser depuis Azure ML ? Rappelons qu’il faut un contexte Spark et c’est ici toute la difficulté pour Azure ML qui doit, pour cela, se baser sur une ressource tierce comme Azure Synapse Analytics ou… Azure Databricks !
Les scripts et leur exécution (calcul)
Azure ML disposent de deux SDK, Python et R, mais il ne sera pas possible d’utiliser de langage Java ou Scala. Au delà de la création d’un dataset sur une source Azure SQL DB, le SQL ne pourra être utilisé qu’au travers de packages R ou Python.
Le périmètre est plus large pour Databricks dont les notebooks exécuteront Python, R, Scala ou du SQL. Ce choix se fait à la création du notebook mais n’est pas rédhibitoire car les commandes magiques permettent de changer de langage dans une cellule : %python, %r, %scala, %sql.
Même si la plupart des Data Scientists sont plus enclins à développer en R ou Python, et dans les déclinaisons SparkR et PySpark, Scala reste le langage natif de Spark et certainement pour l’instant le plus efficace car compilé avant de s’exécuter.
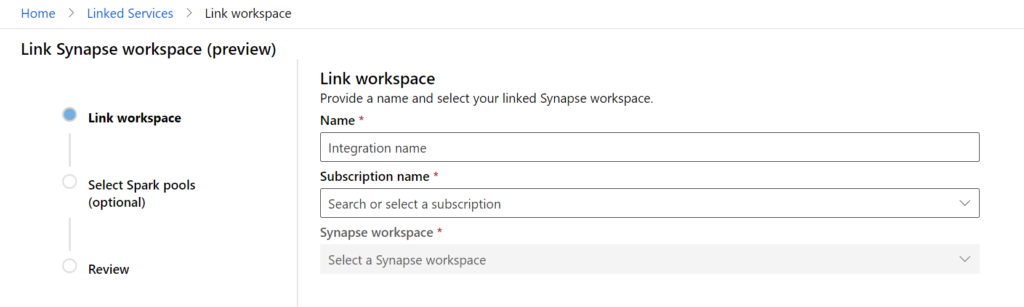
Pour utiliser Scala avec Azure ML, nous attendrons la fonctionnalité de “linked service” vers Azure Synapse Analytics.
L’exécution d’un script dans Azure ML peut se faire une instance de calcul (la VM qui exécute également le serveur de notebooks ou RStudio Server) ou sur un cluster de machines virtuelles.
Databricks est prévu “by design” pour les exécutions distribuées sur un cluster mais il est possible d’utiliser un “cluster single node“, c’est-à-dire une machine unique.
Le versionning des modèles
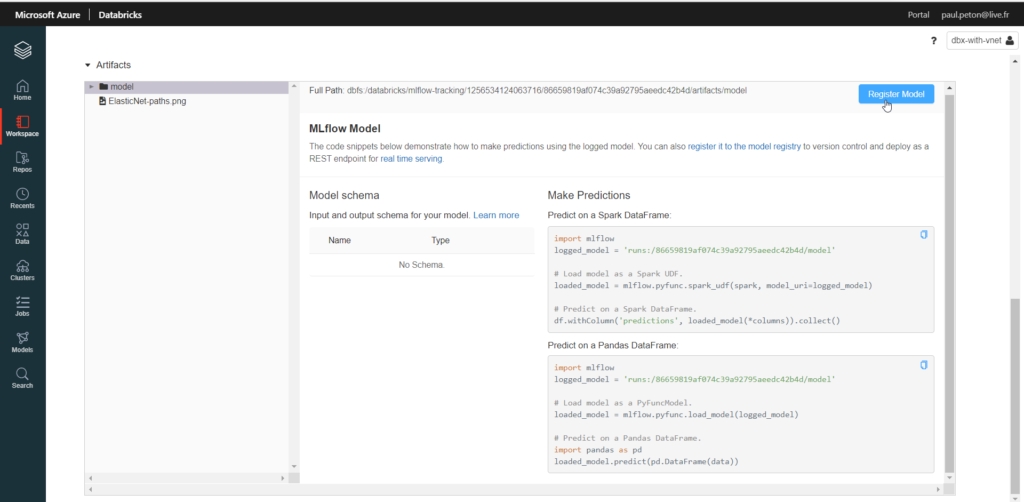
Commençons par le produit Open Source présent dans les deux services : MLFlow.
La même équipe se trouvant à l’origine de Spark et de MLFlow, nous disposons naturellement dans Databricks d’une intégration très simple et fluide. Le package est même installé par défaut sur les runtimes de type ML.
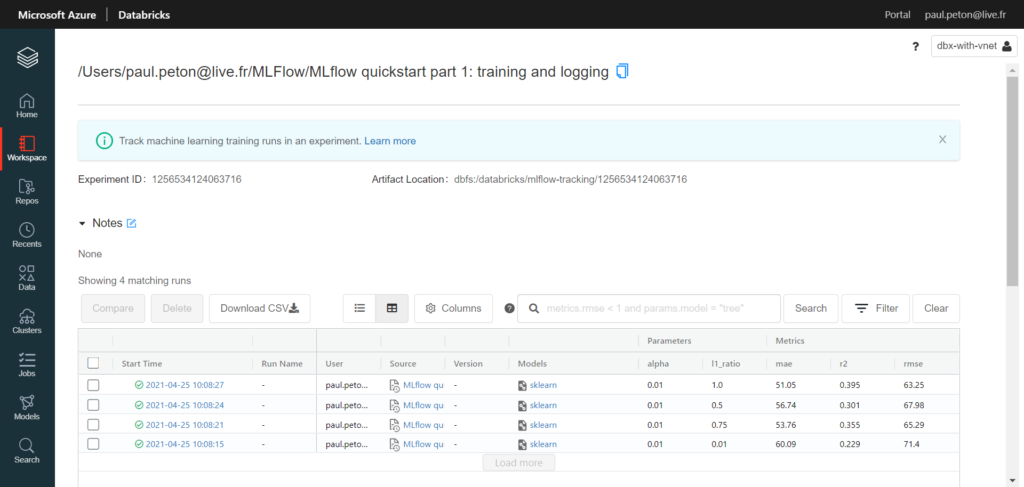
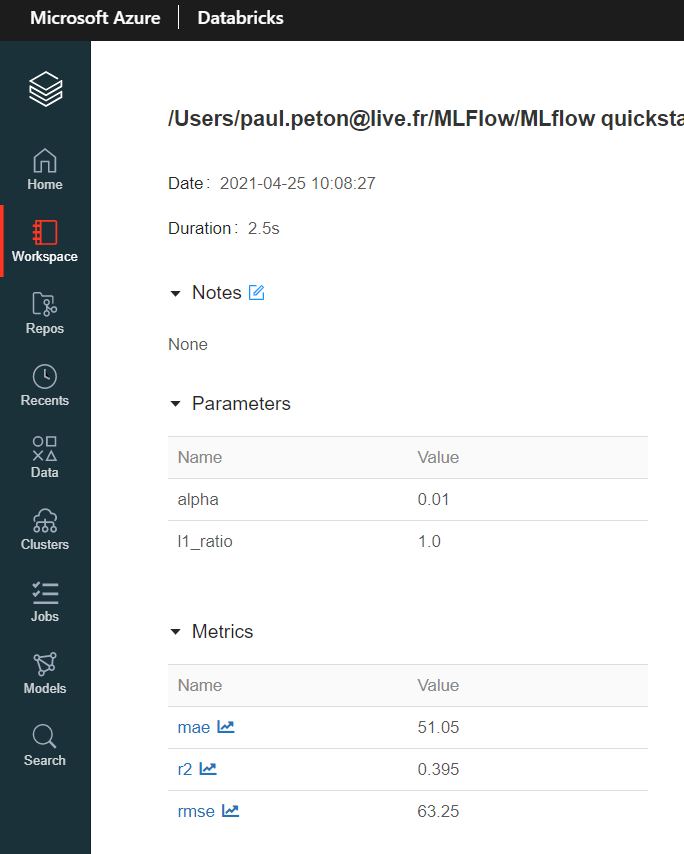
Les éléments nécessaires à l’évaluation et à la reproductibilité du modèle sont simples à enregistrer à l’aide de commandes comme mlflow.log_param, mlflow.log_metric, etc.
Azure ML permet donc également d’activer une URI MLFlow mais qui ne sera valable qu’une heure.
Vous risquez aussi le message d’erreur suivant :
WARNING mlflow.models: Logging model metadata to the tracking server has failed, possibly due older server version.
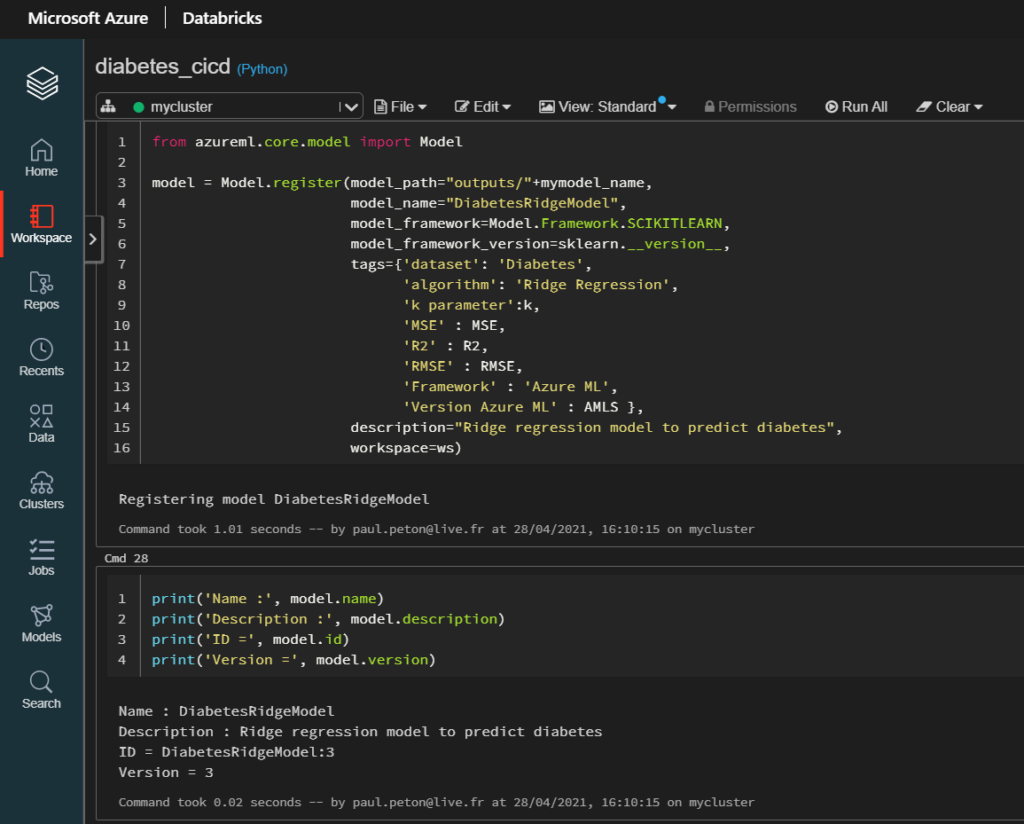
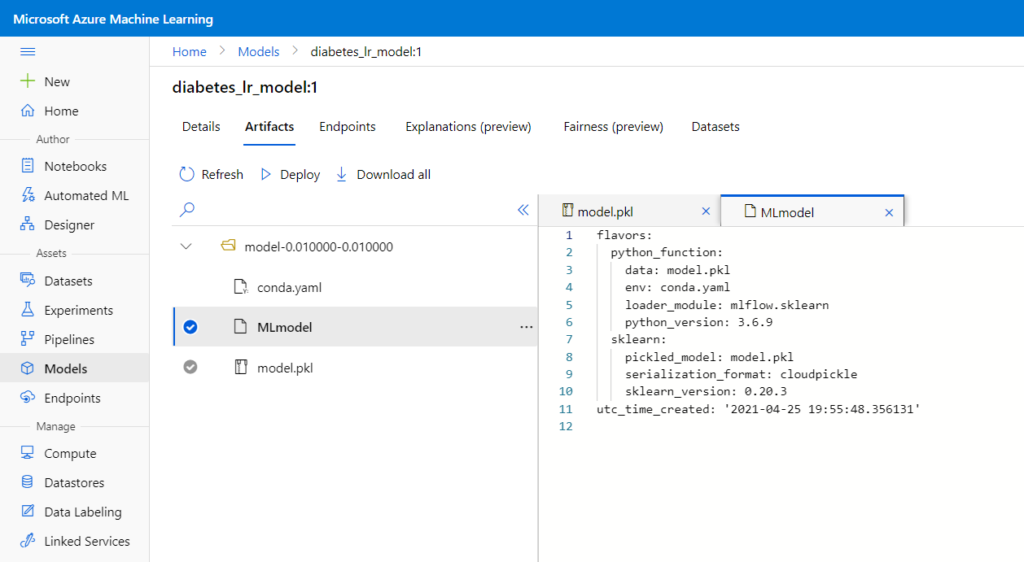
Il faut à mon sens voir le portail Azure ML comme principalement un outil d’affichage des logs d’exécution (runs) des scripts lancés au sein d’expériences. A nouveau, quelques commandes simples permettent d’enregistrer le binaire d’un modèle (artifact) et les informations associées : model.register, run.log, etc.
Pour remplacer la commande mlflow.sklearn.save_model, nous utiliserons dans Azure ML une déclinaison de l’exemple suivant :
from azureml.core.model import Model
Model.register(workspace=ws,
model_name="diabetes_regression_model",
model_path="test_diabetes/model.pkl",
model_framework=Model.Framework.SCIKITLEARN, # Framework used to create the model.
model_framework_version='0.20.3', # Version of scikit-learn used to create the model.
tags={'alpha': alpha, 'l1_ratio': l1_ratio},
description="Linear regression model to predict diabetes"
)
Il est indispensable d’effectuer cette opération pour retrouver l’artefact en dehors du menu “Output & logs” de l’exécution.
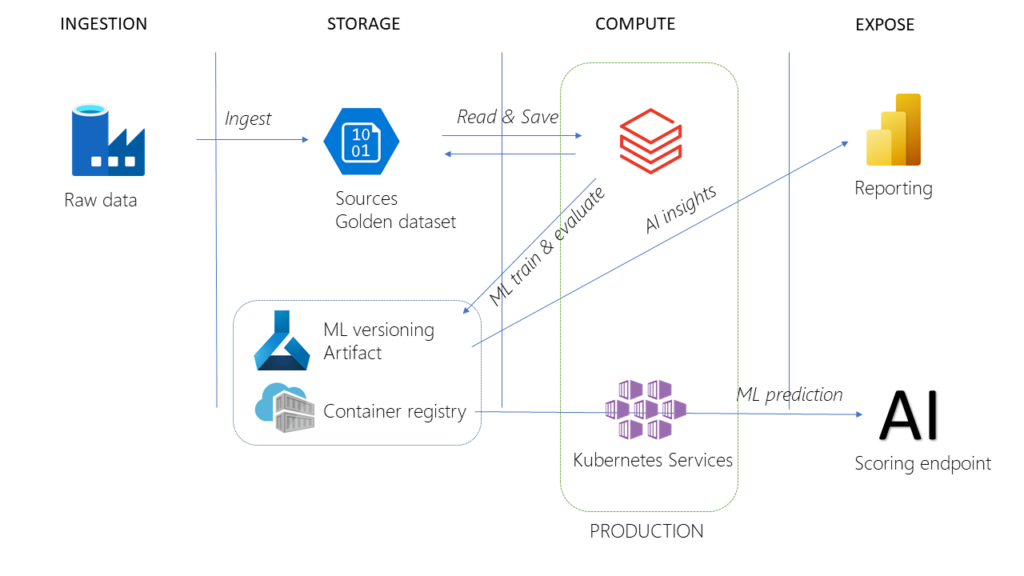
L’exposition des modèles
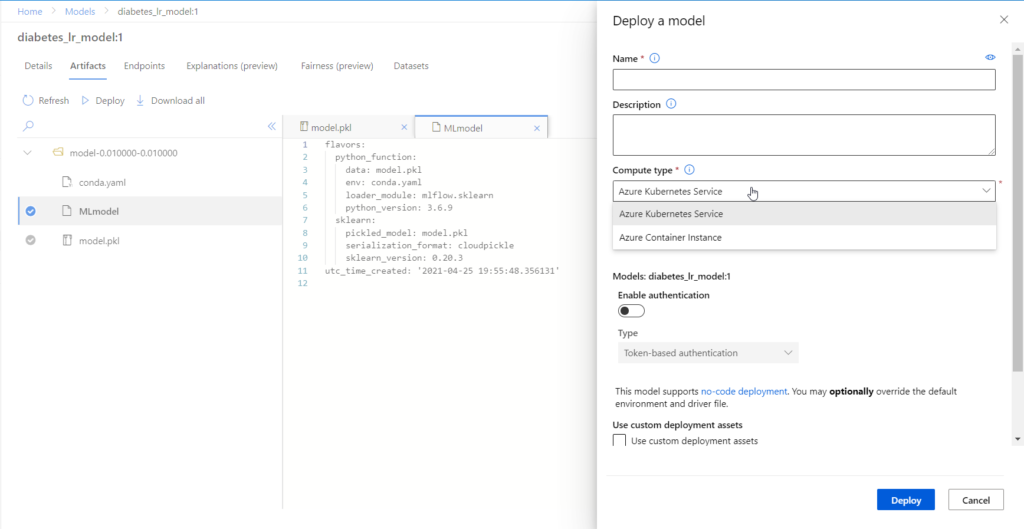
Nous sommes ici dans le domaine de prédilection d’Azure ML qui permet une approche par l’interface ou au travers du SDK pour piloter deux ressources Azure : Container Instance et Kubernetes Services.
Mais Databricks n’est pas en reste pour l’exposition et celle-ci s’appuiera naturellement sur MLFlow. Nous commençons par enregistrer le modèle retenu.
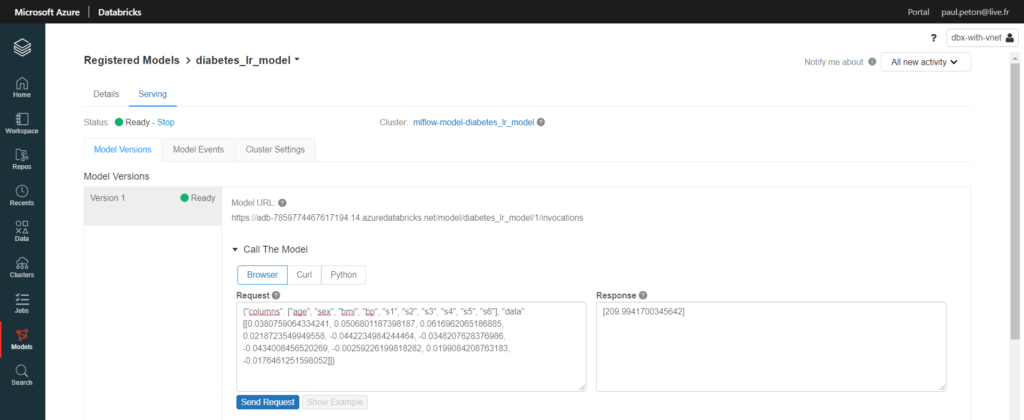
Ensuite, depuis le menu Model, nous pouvons activer le serving, qui se fera sur une ressource de type single-node.
Dès que la ressource (une machine virtuelle) est active, il est possible d’interroger l’API.
Ordonnancement
Dans une architecture Azure PaaS, c’est Azure Data Factory (ADF) qui est la solution toute désignée pour ordonnancer les traitements. Nous y disposons d’un module pour chacun des deux services. La différence se situe sur les éléments pouvant être appelés par ADF. Seuls les objets “Pipeline” issus d’Azure ML sont utilisables et ces objets ne sont pas simples à développer.
Les deux premiers modules ML concernent l’ancienne version du studio.
Côté Databricks, ce sont des scripts Python, des notebooks ou bien des Jar qui sont exécutables au travers de l’interface.
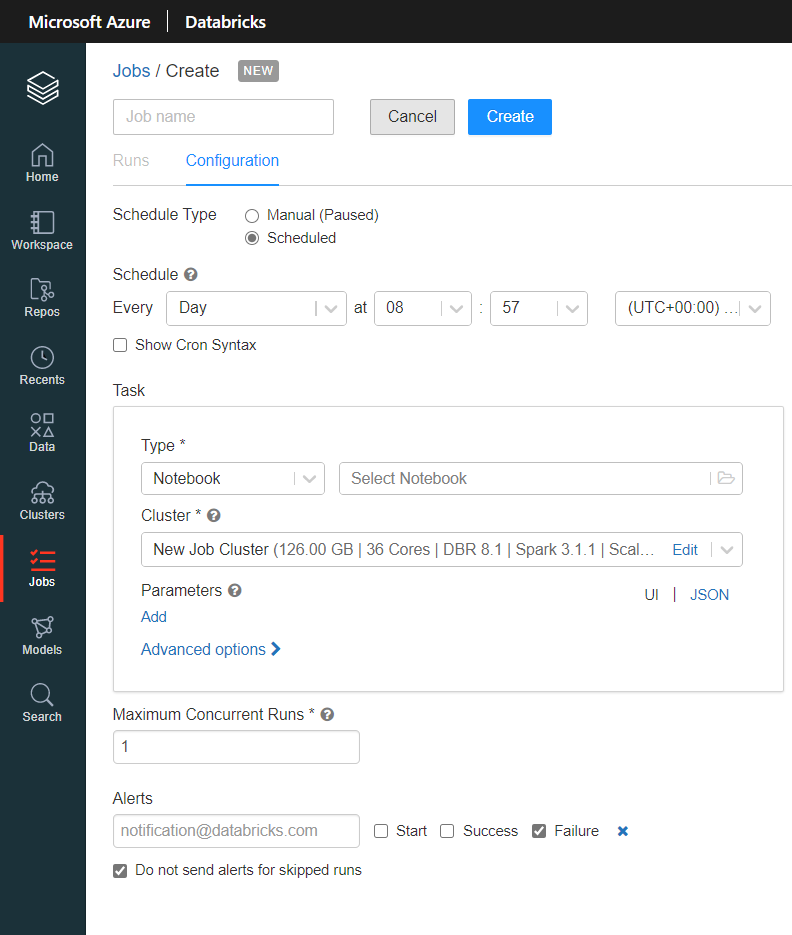
Les deux services ont également leur propre outil de scheduling, pilotable au travers de l’interface pour Databricks ou bien grâce à leur API.
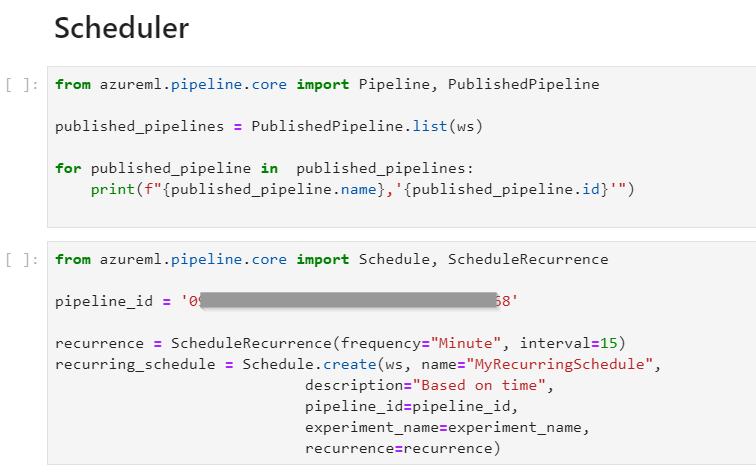
A l’aide du SDK Azure ML, nous pourrons mettre en place un trigger à l’aide du code ci-dessous :
Versionning du code et cycle CI/CD
Databricks permet de définir un fournisseur Git parmi les suivants :
Chaque notebook doit ensuite être lié au repository et il est possible de faire un commit sur une branche déjà créée (une pull request devant ensuite être faite depuis le fournisseur Git).
Récemment (mars 2021), une nouvelle approche est disponible et fournit plus de fonctionnalités.
Dans les notebooks d’Azure ML, aucun lien n’est fait avec un gestionnaire de version. Il faut donc ruser et passer par un IDE local comme Visual Studio Code qui pilotera les ressources de calcul à distance. J’ai détaillé ce fonctionnement dans cet article.
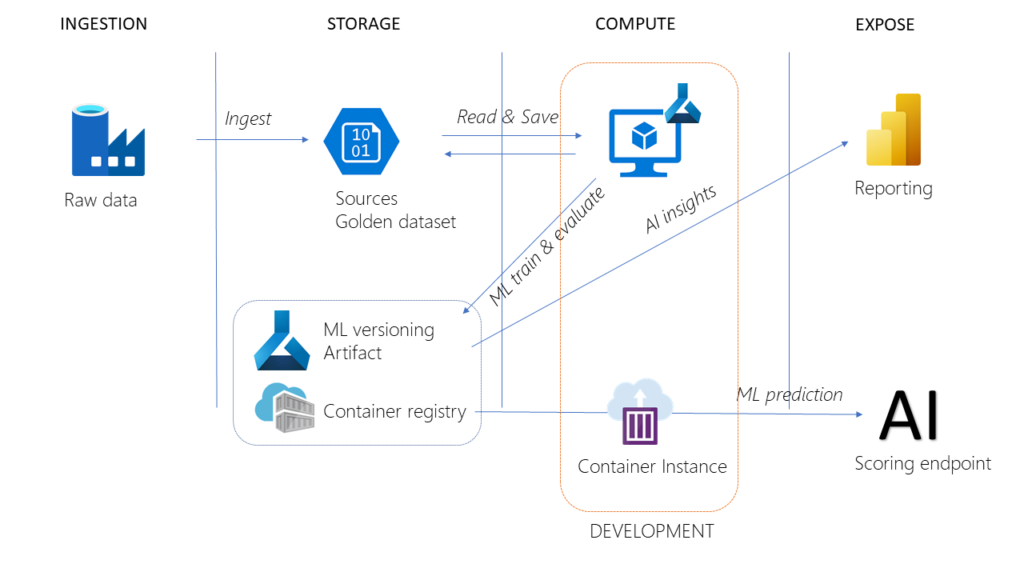
Passons maintenant à la problématique du déploiement entre deux environnements (par exemple, développement et production).
Lorsque le code se trouve versionné sur un dépôt Azure Repos, il est très simple de lancer de manière automatique un pipeline d’intégration qui réalisera des tests automatisés. Databricks s’appuiera sur une machine virtuelle munie du module databricks-connect qui permet d’exécuter du code à distance sur l’environnement Spark.
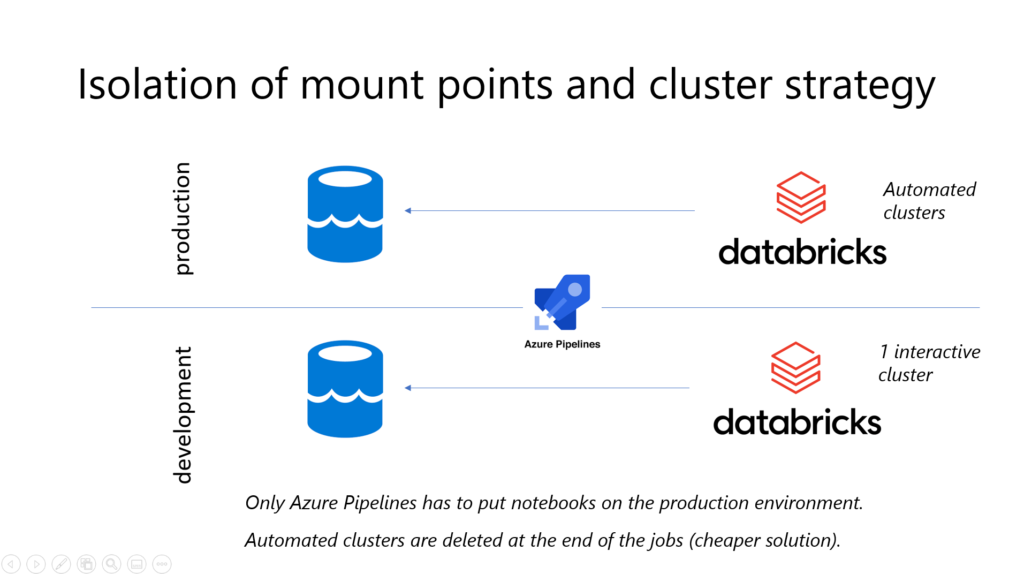
Le schéma ci-dessous résume l’isolation des environnements avec une architecture simple reposant sur un stockage Azure Data Lake et un espace de travail Databricks.
Des outils de release de la Market Place vont permettre de déplacer automatiquement des notebooks de l’environnement de développement vers celui de production.
En revanche, utiliser des ressources Azure ML par environnement est une question qui n’est pas simple à trancher. En effet, le portail est finalement une sorte d’outil “DevOps” (disons plutôt MLOps) en lui-même. Nous y trouverons ainsi les versions des datasets et des modèles, ainsi que les logs d’exécution permettant un suivi de production. Mais en pratique, et par manque d’outils de nettoyage (des expériences, des exécutions…), l’usage pour le développement va “polluer” le portail. Il sera donc indispensable de se donner des pratiques de gouvernance et de limiter les droits aux différents utilisateurs, par le biais des custom roles, comme décrit dans ce billet.
Databricks peut être utilisé comme “attached compute”, environnement d’exécution des scripts Spark.
Le Machine Learning ne se marie pas forcément bien avec l’isolation des environnements : en effet, pour démarrer le projet, il faut des données qui soient de qualité et suffisamment représentatives de la réalité. Ce n’est pas le cas des environnements de développement qui sont incomplets voire erronés. Un accès (en lecture) à la production depuis l’environnement de développement pourrait être à envisager.
Coût et FinOps
Suite au retrait de la licence Entreprise d’Azure ML, le coût d’utilisation ne correspond qu’au temps où sont utilisées les ressources de calcul. A cela s’ajoutent les services qui accompagnent Azure ML : compte de stockage, Key Vault, app insights et surtout container registry. Il faut penser à purger régulièrement ce dernier car un container registry ne donne que 10Go de stockage gratuit.
Il est tout à fait possible d’utiliser les mêmes types de VMs sur les deux outils. Pour autant, le coût d’une VM est “surchargé” par la licence Databricks, exprimée en DBU. Cette licence se décline elle-même selon le type d’espace de travail (standard ou premium) et le type de cluster (interactif ou automated).
Une piste supplémentaire est d’utiliser des “spot instances” moins chères, donnant une nouvelle opportunité d’optimisation des coûts (au détriment de la rapidité d’exécution), comme présenté dans cette vidéo.
Quelques points inclassables
En plus des outils “no code” (Concepteur et AutomatedML), Azure ML dispose d’un module de labellisation d’images, assisté par une approche d’active learning (au bout d’un nombre suffisant d’images taggés, les tags peuvent être automatiquement proposés).
Databricks s’est pourvu d’un nouvel outil “SQL Analytics” qui permet, à l’aide de requêtes SQL, de préparer des vues à destination d’un outil de reporting comme Microsoft Power BI.
En licence Premium, le service Power BI donne accès aux modèles enregistrés sur Azure ML pour que ceux-ci soient appliqués lors de la phase de préparation de données (Power Query).
Alors, lequel choisir ?
En conclusion, il faudra bien évaluer les prérequis des projets (par exemple, l’utilisation de Delta Lake) qui s’exécuteront sur l’architecture Azure pour choisir le bon outil, mais il faut aussi bien comprendre qu’il n’y a pas un surcoût trop important à les utiliser tous les deux et nous verrons surtout dans un prochain article qu’ils peuvent se montrer très complémentaires !