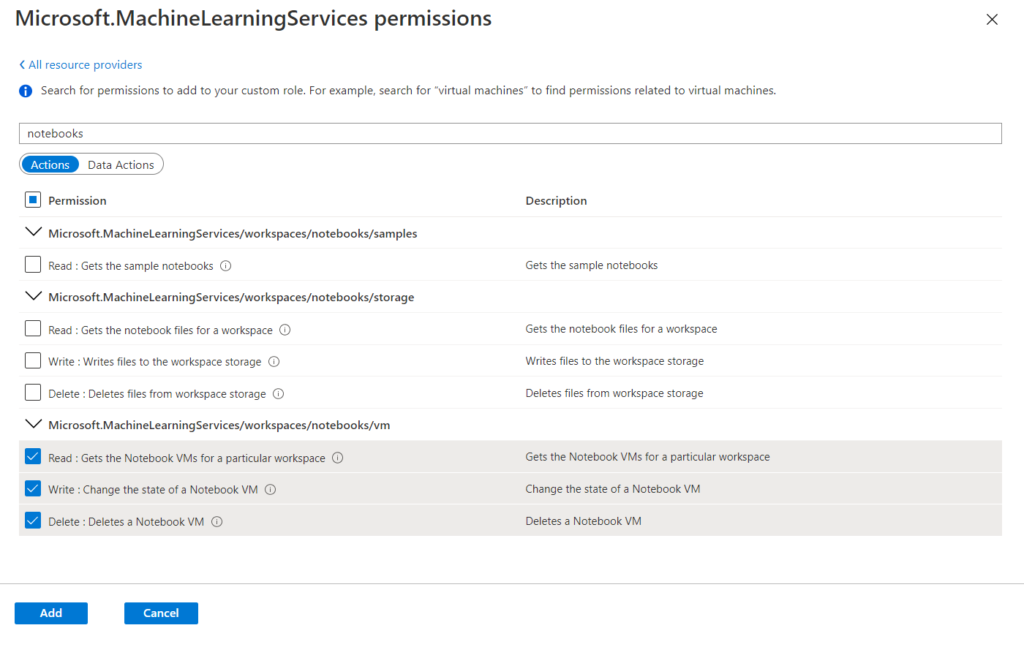
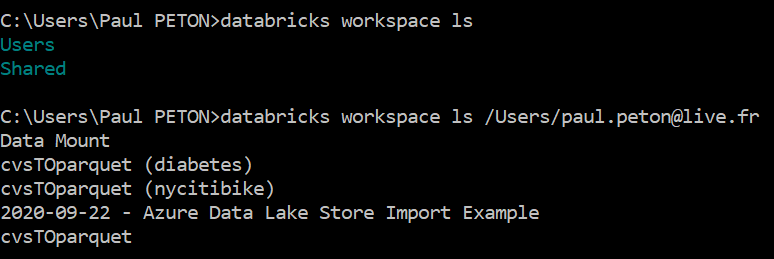
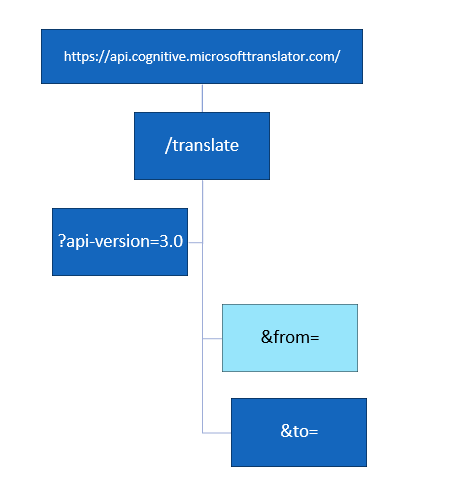
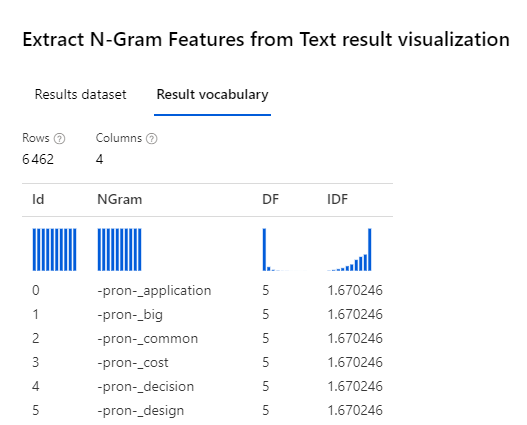
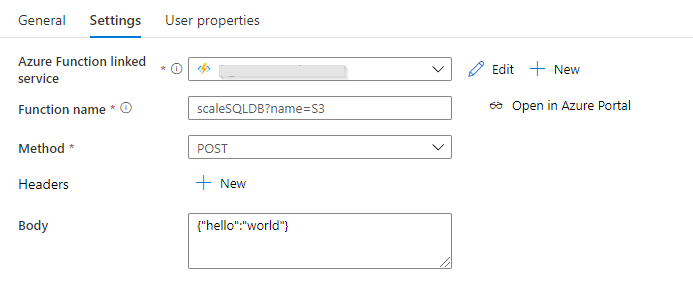
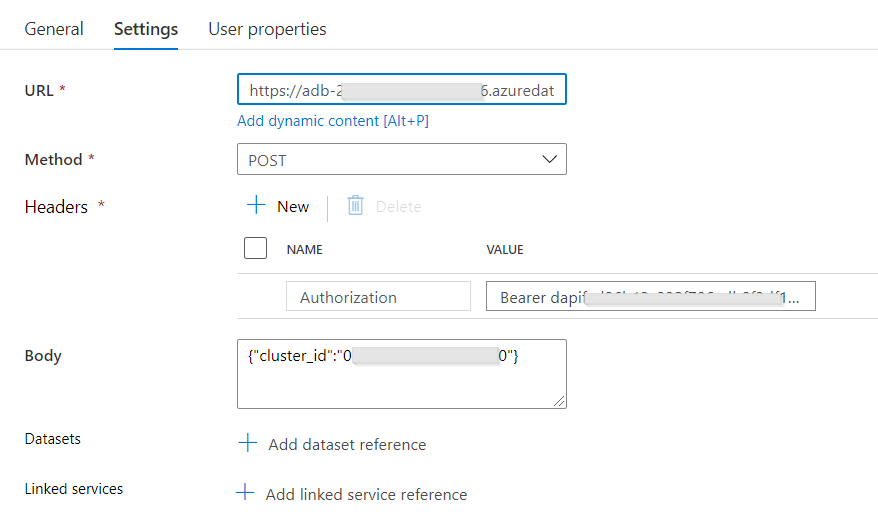
Le chemin est long et semé d’embuches jusqu’à l’obtention d’un rapport Power BI pertinent et exploitable ! La démarche se doit d’être progressive, il ne faut pas sauter d’étapes, au risque de manquer l’adéquation du rapport avec le besoin de ses utilisateurs.
Etape 0 : Définir la thématique, cadrer le besoin
Le besoin émane souvent (et ce devrait même être toujours le cas !) des futurs utilisateurs du rapport. Mais ceux-ci peuvent être différents (niveau hiérarchique, responsabilités, appétence aux chiffres, etc.) et il faut déterminer des « personnes génériques », que l’on nomme personae.
Nous définissons ensuite, de manière propre à chaque persona, les « parcours utilisateurs » qui assisteront une prise de décision. Il est donc ici fondamental de connaître les prérogatives des différents personae afin de déterminer le bon degré d’informations dont ils doivent disposer.
Un bon test consiste à déterminer un titre explicite au rapport ou à l’application (groupe de rapports). Si ce titre n’est pas suffisamment précis et évocateur, le cadre a peut-être été défini de manière trop large.

Les étapes suivantes de collecte et encore plus de modélisation ne se prêtent pas à un élargissement du besoin a posteriori, c’est pourquoi il est fondamental que le cadre soit bien défini et arrêté, quitte à prendre le temps nécessaire pour cela.
Étape 1 : Collecter les données sources
Établir le « dictionnaire de données », liste exhaustive des informations attendues, organisées par dans des entités traduisant des notions métiers (clients, factures, produits, ventes, stock, etc.). Puis faire la correspondance avec les données stockées ou à stocker dans le Système d’Information (SI).
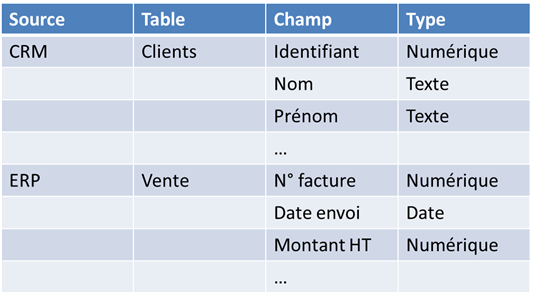
Selon l’origine des données (fichiers, bases de données, Web, etc.), des opérations de nettoyage pourront être nécessaires.
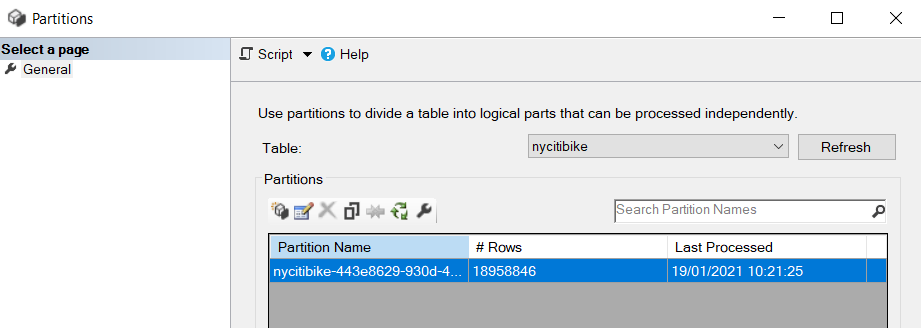
Pour chaque source de données, il faudra préciser la fréquence de rafraichissement attendue. Sauf à utiliser les dataflows, les sources de données dans un dataset Power BI sont à ce jour toutes actualisées simultanément.
D’un point de vue technique, il faut anticiper le fait qu’un persona puisse être soumis à une stratégie de sécurité à la ligne (« Row Level Security »), c’est-à-dire être limité à un périmètre de données. Pour limiter l’accès à des indicateurs, il fallait jusqu’à présent définir un autre rapport mais l’Object Level Security arrive dans Power BI en ce mois de février 2021.
Étape 2 : Modéliser
Afin de fonctionner au mieux (simplicité des calculs, passage à l’échelle), le respect de la modélisation en étoile(s) est fortement conseillé. Il est donc impératif de disposer de clés primaires (champ exprimant une notion d’unicité) dans les tables de dimensions.
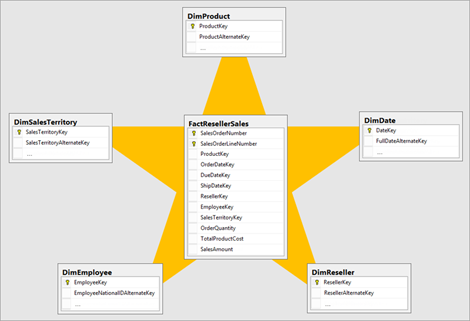
Il faut ici anticiper les croisements demandés et donc l’étape suivante de la définition des indicateurs. Faire préciser sur quel(s) axe(s) d’analyse un indicateur devra être représenté. L’axe du temps demande une attention toute particulière car il déterminera la relation principale (active) de la table de dates (le calendrier, à la granularité journalière) avec la table de faits. Si plusieurs notions de temps sont demandées (ex. : date de commande, date d’expédition, date de livraison), on définira des relations inactives et les mesures DAX utiliseront le pattern suivant :
= CALCULATE([measure], USERELATIONSHIP(FAITS[date2], CALENDAR[date])
Étape 3 : Définir les indicateurs
Au-delà des agrégations simples (somme, moyenne, min-max, etc.) qui devront être programmés comme des mesures explicites (faîtes vraiment une mesure, ne vous contentez pas de l’agrégat automatique !), les indicateurs plus complexes doivent être définis par les règles métiers qu’ils traduisent.
Par exemple, le montant total des ventes s’exprime TTC, en retirant les remboursements, indiqués par un code spécifique.
Ces règles devront être accessibles à tous et remporter l’unanimité. En effet, rien de pire qu’un indicateur dont la formule varie selon les interlocuteurs ! Chacun disposerait alors de sa propre version, sans doute correcte, mais qui ne permettrait pas un usage commun et raisonné.
Étape 4 : Définir les sous-thèmes du rapport
Nous recommandons de ne présenter sur une page de rapport qu’un seul thème, quitte à dédier plusieurs pages à celui-ci.
Chaque thème doit être mis en regard des personae qui vont le consulter.
Toutefois, un rapport présentant un trop grand nombre de pages (disons 10 arbitrairement) témoigne sans doute d’un cadrage trop large et il serait sûrement possible de réaliser plusieurs rapports, quitte à regrouper ceux-ci au sein d’une application.
Étape 5 : Définir les visuels et les filtres
Il faut distinguer les visuels portant un message (la conclusion est connue et doit être communiquée) et ceux permettant de réaliser une analyse (l’interprétation est à construire, éventuellement en manipulant des filtres ou des paramètres).
Les principaux visuels d’analyse natifs sont :
- Le nuage de points ou de bulles (scatterplot)
- Les influenceurs clés (key influencers)
- L’arbre de décomposition (decomposition tree)
- La cascade (waterfall)
- Les courbes associées à la fonctionnalité « expliquer la hausse / la baisse »
Les autres visuels doivent être utilisés pour porter un et un seul message. Pour passer plusieurs messages, il faut faire plusieurs visuels. Le message, s’il est constant, peut être exprimé au travers du titre du visuel.
De nombreux chart choosers permettent de choisir le bon visuel adapté à la comparaison que l’on souhaite présenter. Il existe une version spécifique à Power BI, incluant de nombreux custom visuals : Power BI Visuals Reference – SQLBI
Les principales comparaisons, et quelques graphiques associés, sont :
- La décomposition (les parties d’un tout)
- La position ou le classement (selon un indicateur)
- L’évolution (dans le temps)
- Le flux (entre deux ou plusieurs étapes)
- La corrélation (entre deux indicateurs numériques)
- La géolocalisation
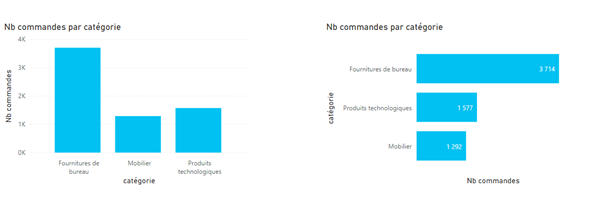
Le choix par défaut d’un visuel croisant un axe d’analyse et un indicateur se portera judicieusement sur le diagramme en barres. On facilitera la lecture par le tri, souvent décroissant, sur l’indicateur et la position horizontale des barres, aidant à la lecture des légendes, sans avoir à pencher la tête.
Fin du parcours ?
Voilà, nous disposons enfin d’un rapport concret, contenant des données, représentées sous forme visuelle ! Le (long) chemin ne s’arrête pas là puisqu’il faudra maintenant itérer, c’est-à-dire discuter avec les utilisateurs du rapport pour améliorer, par petites touches, le rendu afin de coller au mieux aux usages. L’étape 5 va donc être remise en cause, jusqu’à se stabiliser autour d’un rendu final. De temps en temps, il pourra être nécessaire de revenir à l’étape 4, voire 3. Analyser des données procure de nouvelles idées… En revanche, si l’étape 2 de modélisation doit être remise en cause, c’est que le processus de recueil de besoin a sans doute été incomplet ou trop rapide. N’hésitez pas alors à faire table rase et à repartir de (presque) zéro pour un nouveau projet. Vous verrez alors que les différentes s’enchaineront beaucoup plus vite et avec plus de fluidité.