Ne le cachons pas, Spark déploie toute sa puissance lorsque les volumes de données sont significatifs. Pour autant, devant la simplicité d’utilisation d’Azure Databricks, il est tentant de centraliser tous les traitements de données dans des notebooks lancés sur un cluster.
Et un cluster, par définition, est constitué de plusieurs machines, a minima un driver et un worker qui échangeront des informations. C’est toute la puissance de cette architecture qui distribue les traitements sur un nombre de workers éventuellement automatiquement “scalable”.
Mais dans le cas de traitements simples, une seule machine virtuelle (bien dimensionnée) serait suffisante et éviterait en plus des échanges réseaux qui pourraient même perturber le traitement. En étant pragmatique, ce sont aussi des coûts divisés au moins par deux !
Une solution existe maintenant : le mode de cluster “Single Node“.
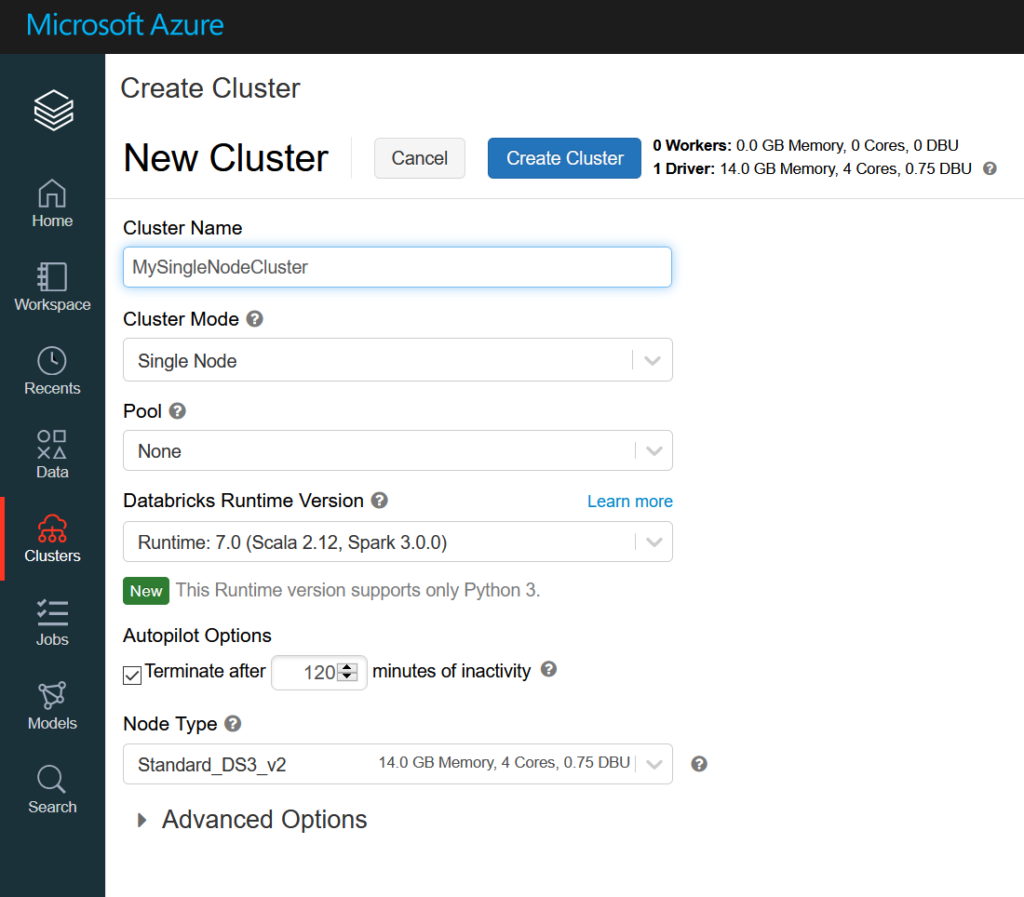
Cette fonctionnalité est aujourd’hui (octobre 2020) en préversion publique et décrite sur le site de Databricks.
On observe ce paramétrage dans la version JSON de la définition du cluster, au niveau de la configuration du cluster.
{
"num_workers": 0,
"cluster_name": "MySingleNodeCluster",
"spark_version": "7.0.x-scala2.12",
"spark_conf": {
"spark.master": "local[*]",
"spark.databricks.cluster.profile": "singleNode"
},
"node_type_id": "Standard_DS3_v2",
"ssh_public_keys": [],
"custom_tags": {
"ResourceClass": "SingleNode"
},
"spark_env_vars": {
"PYSPARK_PYTHON": "/databricks/python3/bin/python3"
},
"autotermination_minutes": 120,
"enable_elastic_disk": true,
"cluster_source": "UI",
"init_scripts": []
}
Imaginons maintenant que vous souhaitiez lancer vos traitements avec la logique “automated cluster“, s’appuyant éventuellement sur un pool de machines virtuelles. Cela est tout à fait possible depuis l’interface de jobs de Databricks mais dans une architecture data Azure plus large, on s’appuyera souvent sur le rôle d’ordonnanceur de Azure Data Factory.
Dans Azure Data Factory, nous définissons un service lié Databricks. Dans l’interface graphique, nous ne trouvons pas le mode SingleNode mais la configuration Spark peut être précisée.
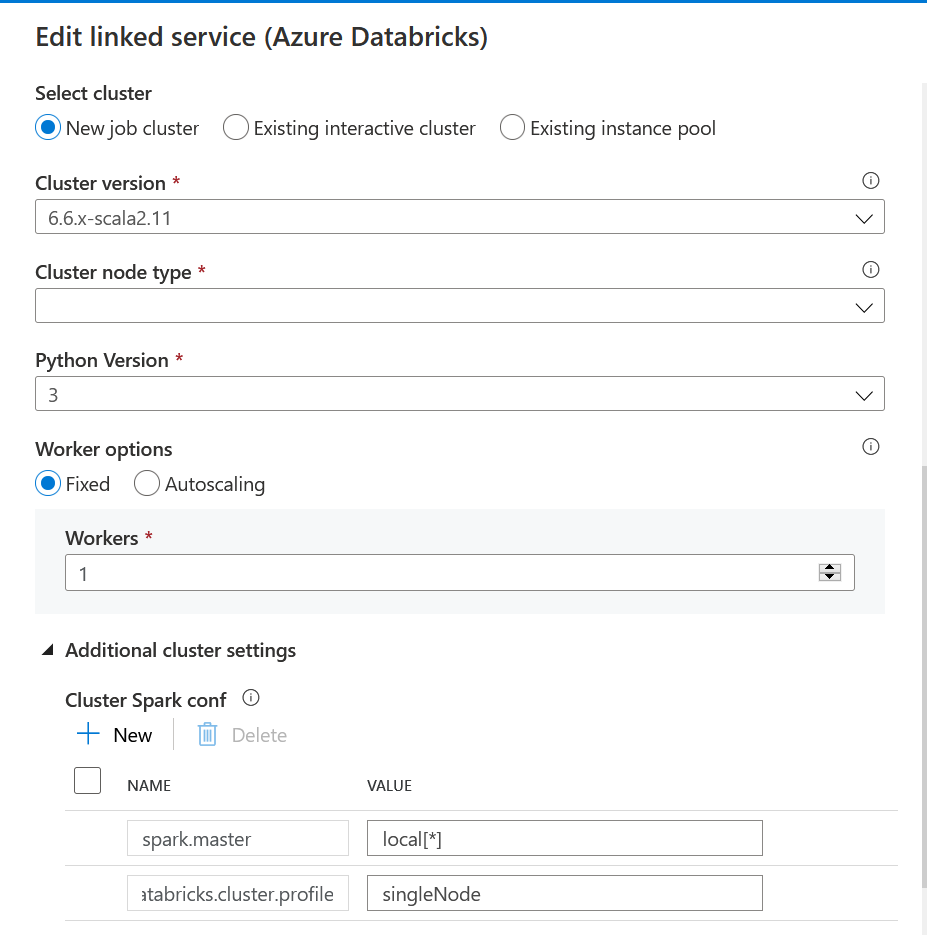
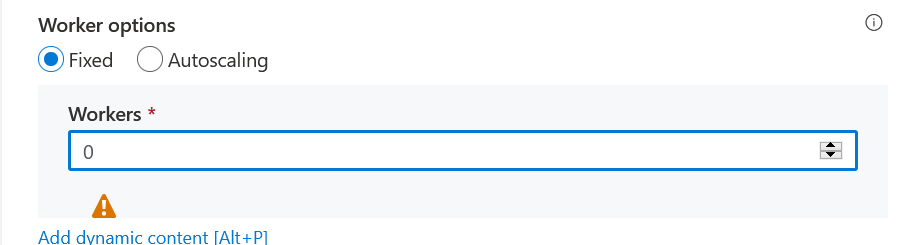
Cela semble suffisant mais nous pouvons aussi préciser le nombre de workers à 0, même si un message d’alerte apparaît alors. Celui-ci n’est pas bloquant.
Afin de contrôler que ce sont bien des “automated single node clusters” qui se sont exécutés, vous pouvez consulter les logs de l’activité Data Factory où se trouve un lien pointant vers l’exécution du notebook et la configuration de clsuter associée.