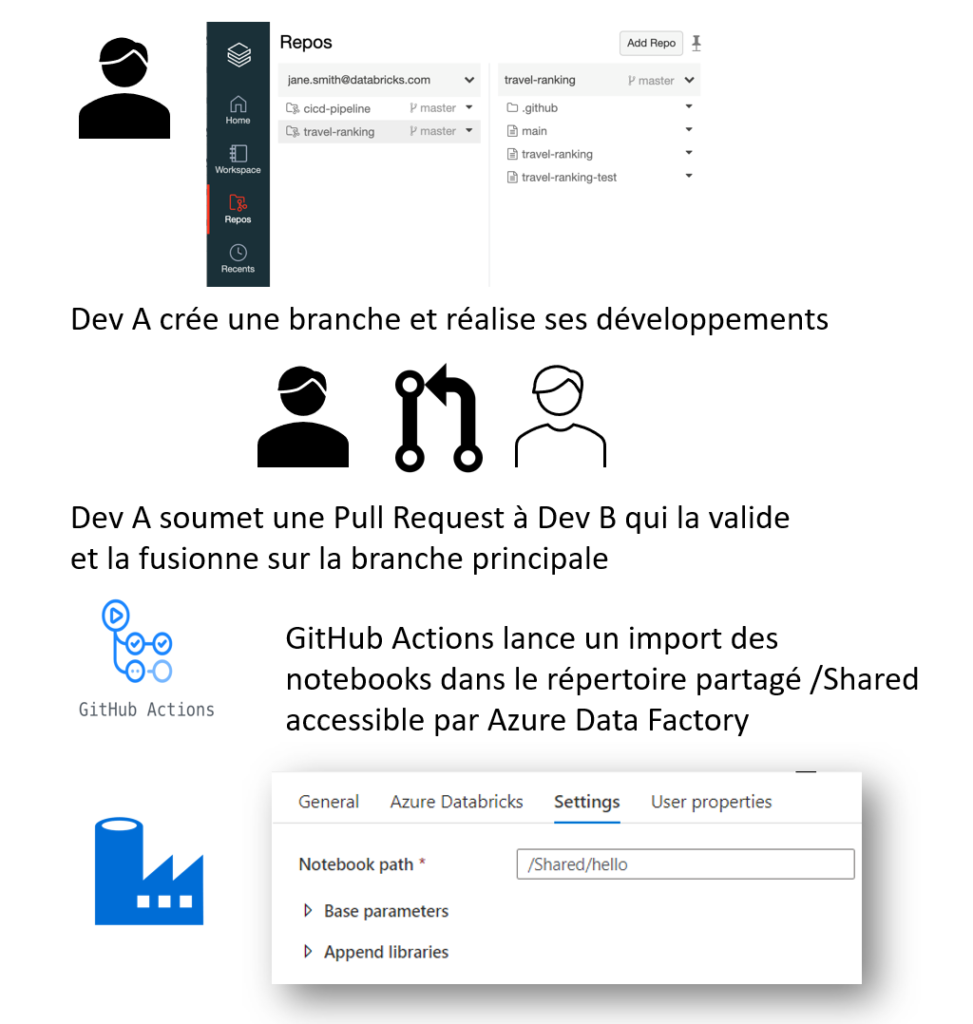
Ou en bon français, comment faire coopérer la nouvelle (mars 2021) fonctionnalité Repos de Databricks avec une logique d’intégration continue développée dans GitHub ?
Revenons tout d’abord sur le point à l’origine de la nécessité d’un tel mécanisme (une présentation plus détaillée des Repos Databricks a été faite et mise à jour sur ce blog). Dans une architecture dite “moderne” sur Azure, nous utilisons Azure Data Factory pour piloter les traitements de données et lancer conjointement des notebooks Databricks. Cela nécessite de donner le chemin du notebook sur l’espace de travail déclaré en tant que service lié.
Nous disposons de trois entrées pour définir le “notebook path“.
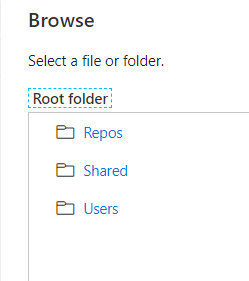
Si nous choisissons “Repos”, nous allons donner un chemin contenant le nom du développeur !
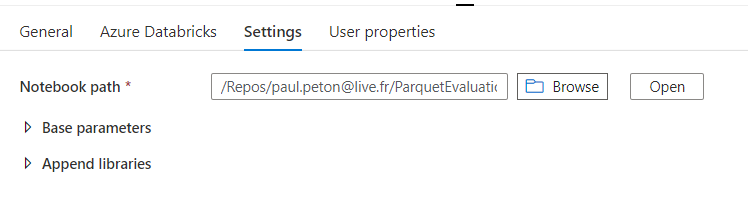
Les développements livrés en production doivent bien sûr être totalement indépendants d’une telle information. Un contournement consisterait à utiliser un sous-répertoire Shared dans la partie Repos mais cela reviendrait à perdre le rattachement du développement à son auteur.
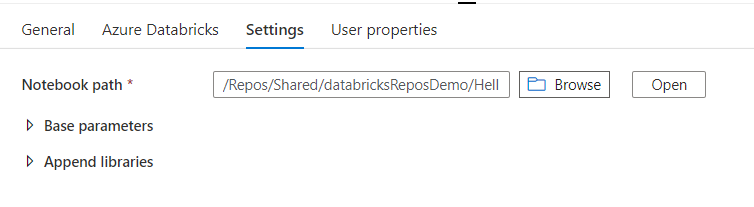
Nous allons donc mettre en place un mécanisme permettant aux développeurs d’utiliser leur propre répertoire puis de versionner les développements dans un espace tiers, par exemple un repository GitHub (une démarche exploitant les repositories Azure DevOps serait tout à fait similaire).
Voici le processus suivi lors d’un développement :
- le développeur A crée une nouvelle branche sur laquelle il réalise ses développements
- il “commit & push” ensuite son travail
- une Pull Request (PR) peut alors être soumise dans le but de fusionner le travail avec la branche principale (master ou main)
- le développeur B vient alors valider la PR et le merge se lance sur la branche principale
C’est alors que se déclenche notre processus d’intégration continue (CI) qui réalise une copie des notebooks de la branche principale dans le répertoire /Shared de l’espace de travail Databricks.
Nous nous assurons ainsi d’avoir toujours la dernière “bonne” version des notebooks, sur un chemin qui sera identique entre les environnements. En effet, dans un second temps, un processus de déploiement continu (CD) viendra copier ces notebooks sur les autre environnements (qualification, production).
Comment réaliser une GitHub Action d’intégration continue
Nous nous plaçons dans le repository servant à versionner les notebooks. Le menu Actions est accessible dans la barre supérieure.

Puis, nous cliquons sur le lien “set up a workflow yourself“.
Un modèle de pipeline YAML est alors disponible et nous allons l’adapter.
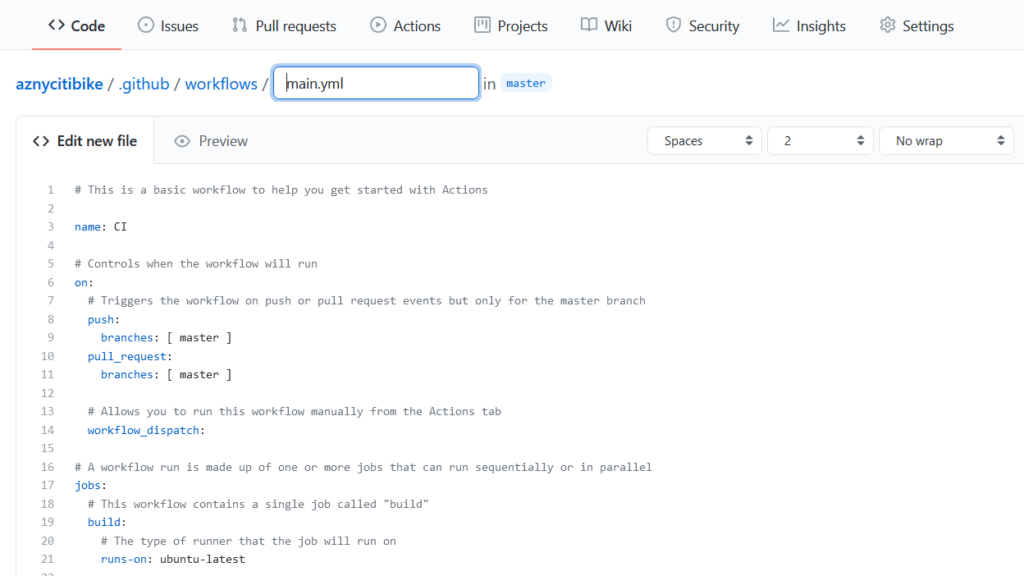
Détaillons maintenant le code final, étape par étape.
# This is a basic workflow to help you get started with Actions
name: CI
# Controls when the workflow will run
on:
# Triggers the workflow on push or pull request events but only for the master branch
pull_request:
branches: [ master ]
paths: ['**.py']
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
env:
DATABRICKS_HOST: ${{ secrets.DATABRICKS_HOST }}
DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }}
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- name: Checkout
uses: actions/checkout@v2
- name: Setup Python
uses: actions/setup-python@v2.2.2
with:
python-version: '3.8.10'
architecture: 'x64'
# Install pip
- name: Install pip
run: |
python -m pip install --upgrade pip
# Install databricks CLI with pip
- name: Install databricks CLI
run: python -m pip install --upgrade databricks-cli
# Runs
- name: Run a multi-line script
run: |
echo Test python version
python --version
echo Databricks CLI version
databricks --version
# Import notebook to Shared
- name: Import local github directory to Shared
run: databricks workspace import_dir --overwrite . /Shared
# List Shared content
- name: List workspace with databricks CLI
run: databricks workspace list --absolute --long --id /Shared
Le principe est d’utiliser une machine virtuelle munie d’un système d’exploitation Ubuntu (‘latest’ pour obtenir la dernière version disponible), d’y installer un environnement Python dans la version souhaitée (ici, 3.8.10) puis le CLI de Databricks.
Pour connecter ce dernier à notre espace de travail, nous définissons au préalable deux variables d’environnement :
- DATABRICKS_HOST qui contient l’URL de notre espace de travail
- DATABRICKS_TOKEN qui contient un jeton d’authentification
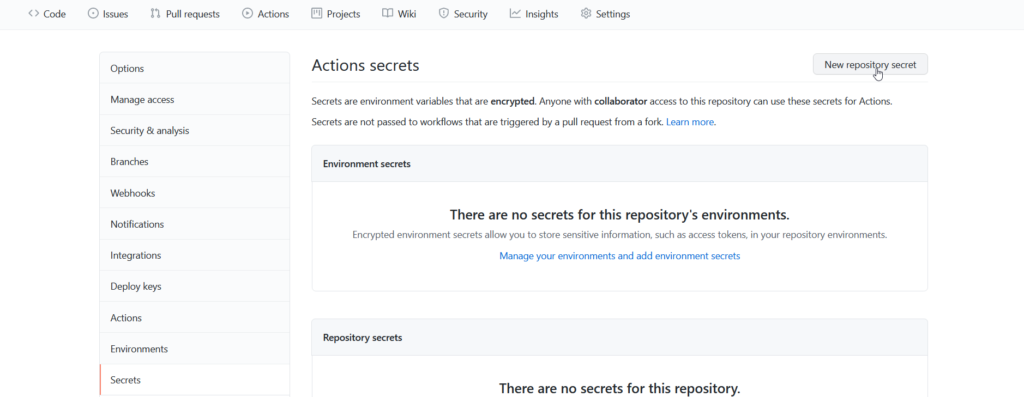
Pour ne pas faire figurer ces valeurs dans le fichier YAML (qui est lui-même versionné dans le repository), nous définirons au préalable deux secrets à l’aide du menu Settings.
L’instruction uses: actions/checkout@v2 garantit la disponibilité des fichiers archivés dans le repository (ceux-ci sont copiés sur la machine virtuelle) et le point (.) indique simplement ce chemin dans l’instruction du CLI import_dir.
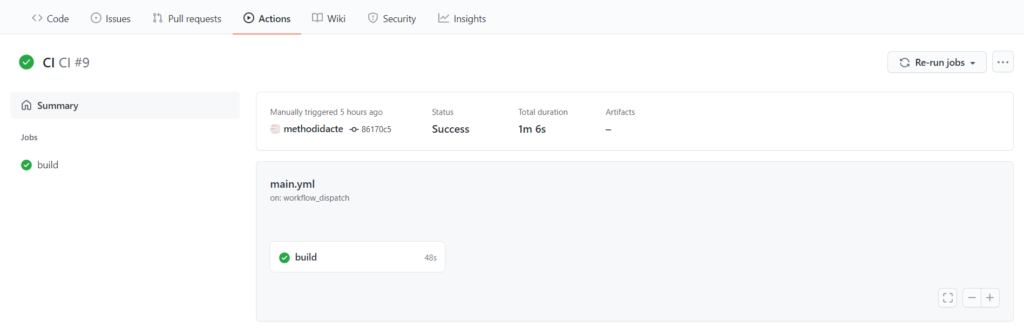
Ainsi, dès la fusion d’une Pull Request avec la branche principale, le code se lance automatiquement et nous pouvons vérifier sa bonne exécution dans le menu “View runs”.
Une telle approche sera bien sûr complétée idéalement par une stratégie de tests portant sur le contenu des notebooks ou mieux encore, sur du code packagé qui y sera utilisé (voir cet article).