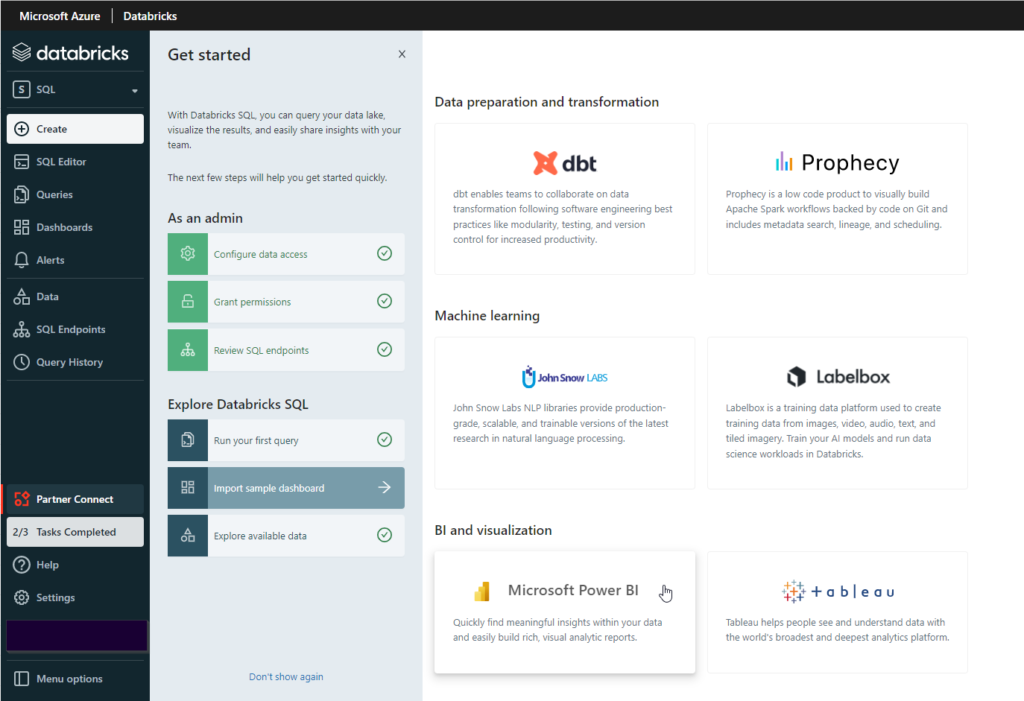
En ce début d’année 2023, l’intelligence artificielle est sur toutes les lèvres, avec l’apparition de ChatGPT, déclinaison sous forme d’agent conversationnel du modèle GPT 3.5, élaboré par la société OpenAI.
Il faut garder à l’esprit que ce modèle prédit les prochains mots probables mais son corpus d’entrainement est tel qu’il est possible d’imaginer des usages, en particulier avec les langages de programmation, comme peut le faire l’assistant GitHub Copilot dans Visual Studio Code.
ChatGPT pour le langage DAX
Nous pouvons imaginer deux usages autour du langage dédié aux mesures et aux colonnes calculées.
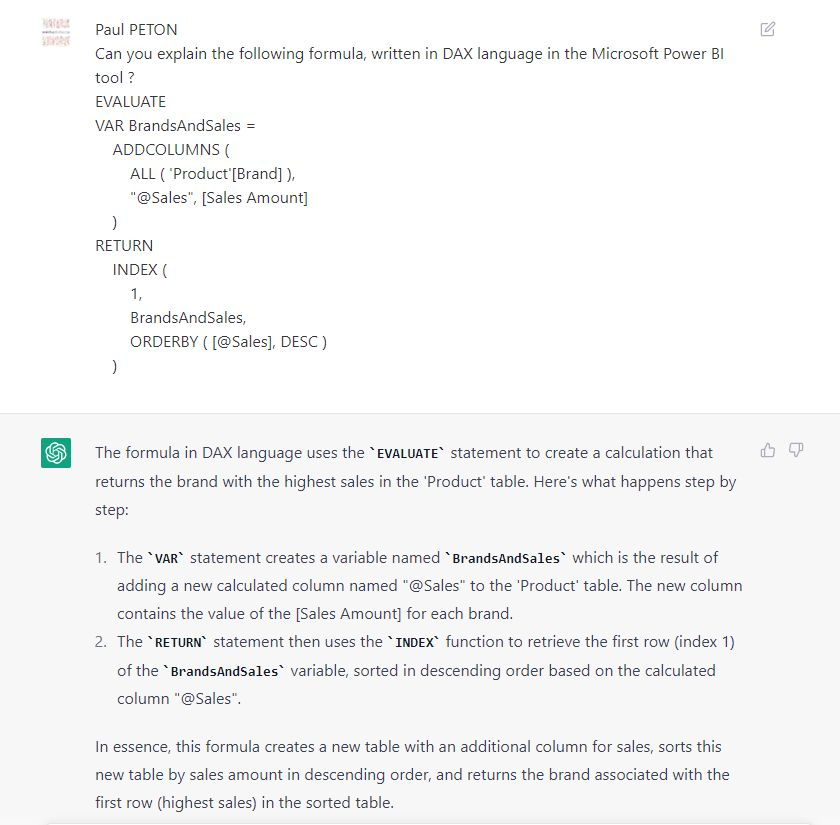
Faire expliquer une formule DAX complexe
L’exemple suivant est tiré d’une page de l’excellent site SQLBI.
Il faut noter que le modèle a été entrainé avant l’apparition de cette formule dans Power BI mais l’explication reste cohérente, sans doute grâce à la proximité de cette fonction avec sa version Excel.
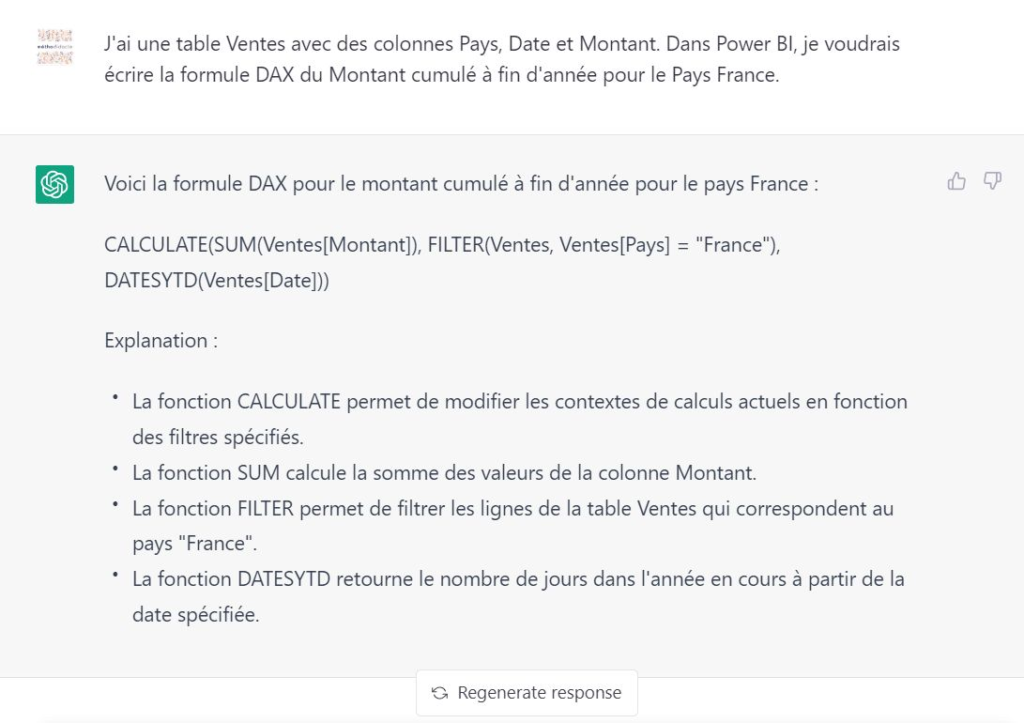
Faire écrire une formule DAX à partir d’une description
Nous allons ici écrire un prompt avec un maximum d’informations sur le modèle sémantique : noms de tables, noms de champs, valeurs…
Réponse obtenue le 4 février 2023
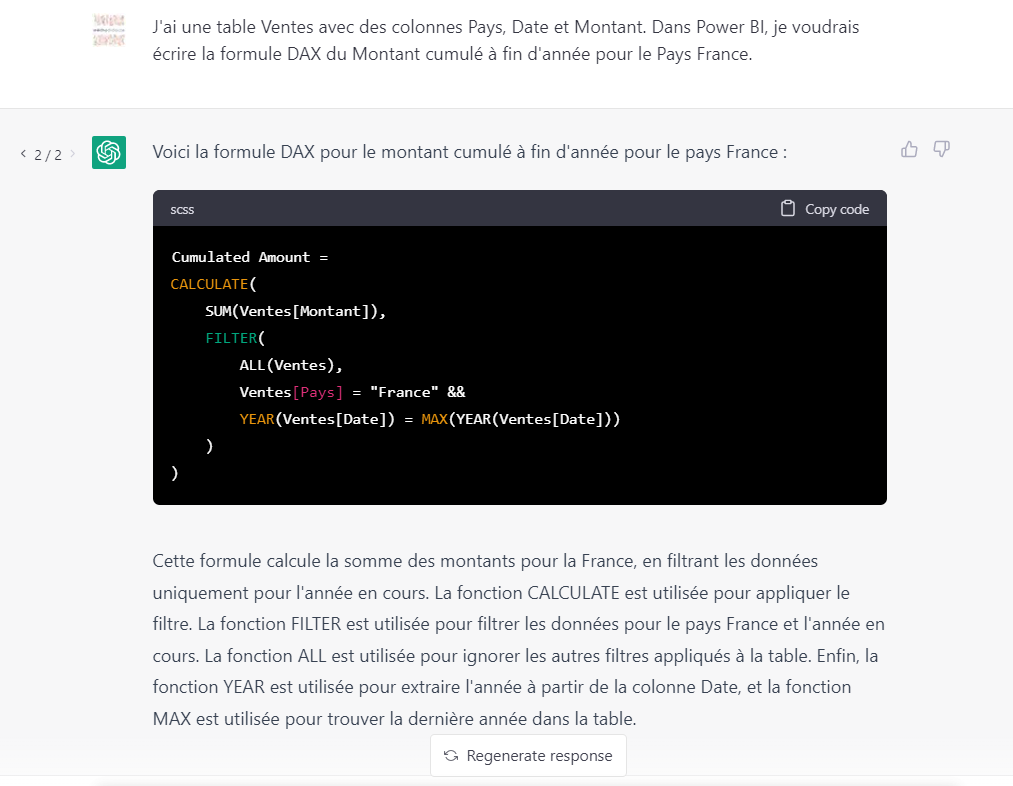
En re-générant la réponse, suite à l’évolution du modèle, nous obtenons la formule suivante.
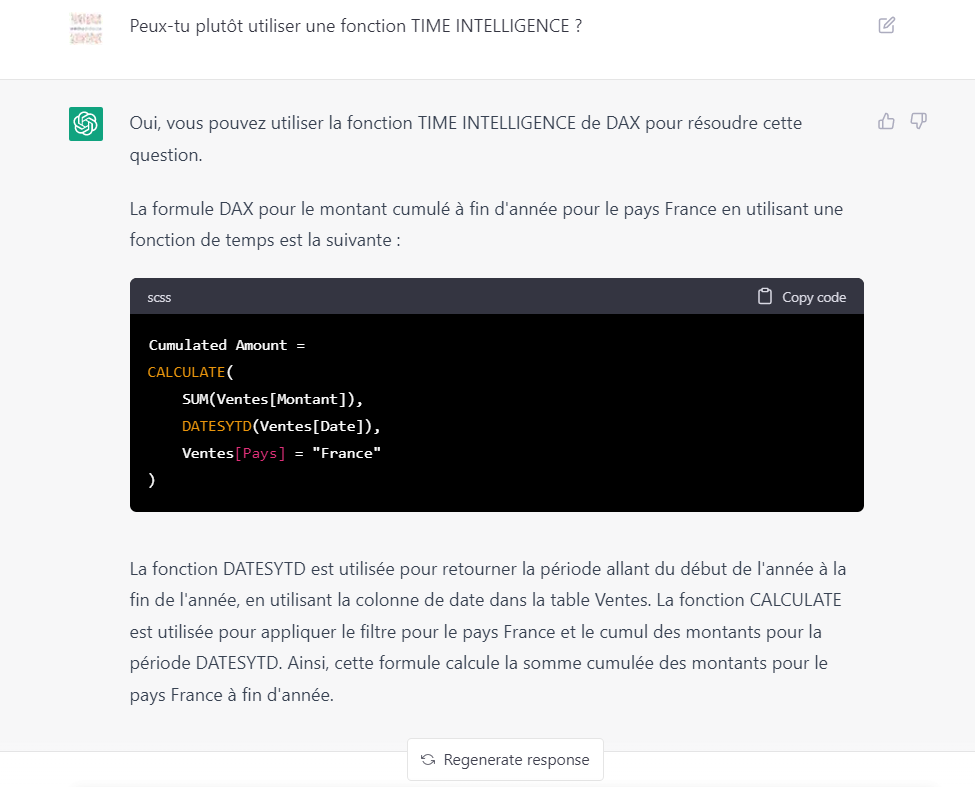
Si nous connaissons la famille de fonctions TIME INTELLIGENCE, nous pouvons réorienter la réponse.
Sur ces deux exemples, l’agent conversationnel ChatGPT se montre plutôt performant, et un très bon accompagnateur pour des personnes débutant dans le langage DAX. Toutefois, il faudra se méfier des syntaxes proposées, être critique et s’appuyer sur l’expérience… d’êtres humains, formateur.ices Power BI !
Nous pourrions nous prendre à rêver que les visuels Q&A ou smart narrative soient boostés par ChatGPT et donnent alors des performances très élevées dans l’élaboration de visuels ainsi que dans leur interprétation.
ChatGPT pour le langage M ?
Dans l’interface Power Query, le langage M s’écrit déjà automatiquement grâce aux actions réalisées dans l’interface visuelle. Pour autant, il peut être efficace d’écrire ses propres fonctions qui pourront ensuite être utilisées pour générer de nouvelles colonnes.
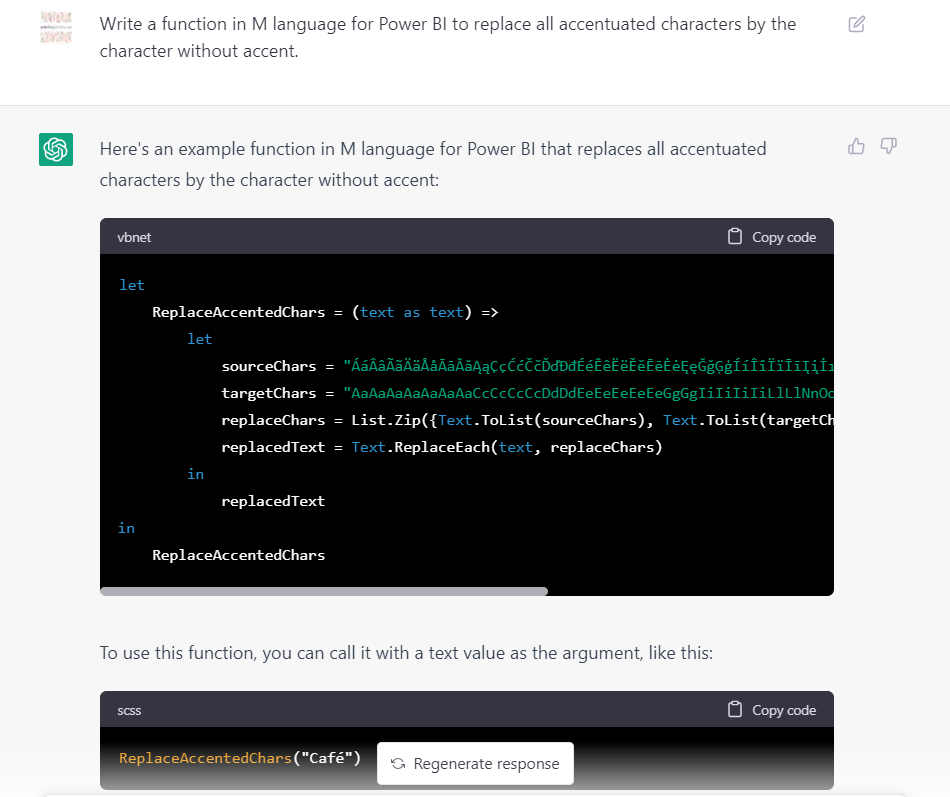
Dans l’exemple suivant, nous allons écrire une fonction permettant de remplacer toutes les lettres accentuées par leur équivalent, sans accent. Posons la question de cette fonction à ChatGPT.
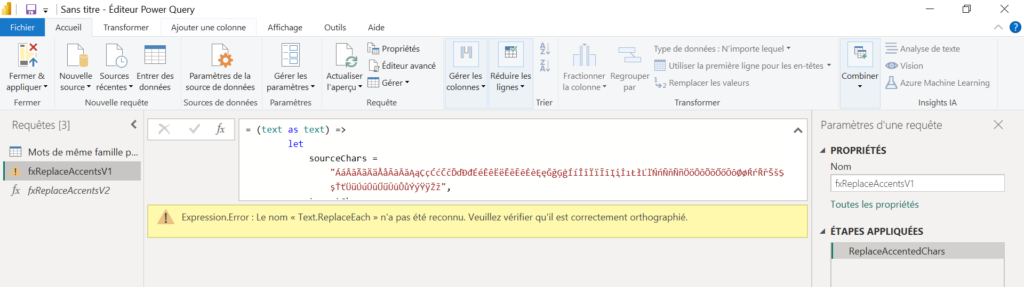
Wahou, cela semble très impressionnant ! Essayons tout de suite cette fonction dans Power Query.
Attention, la fonction Text.ReplaceEach() n’existe pas, ce que nous confirmera la documentation officielle ! ChatGPT est un outil créatif, cette fonction est donc une très bonne suggestion pour les équipes de développement du produit !
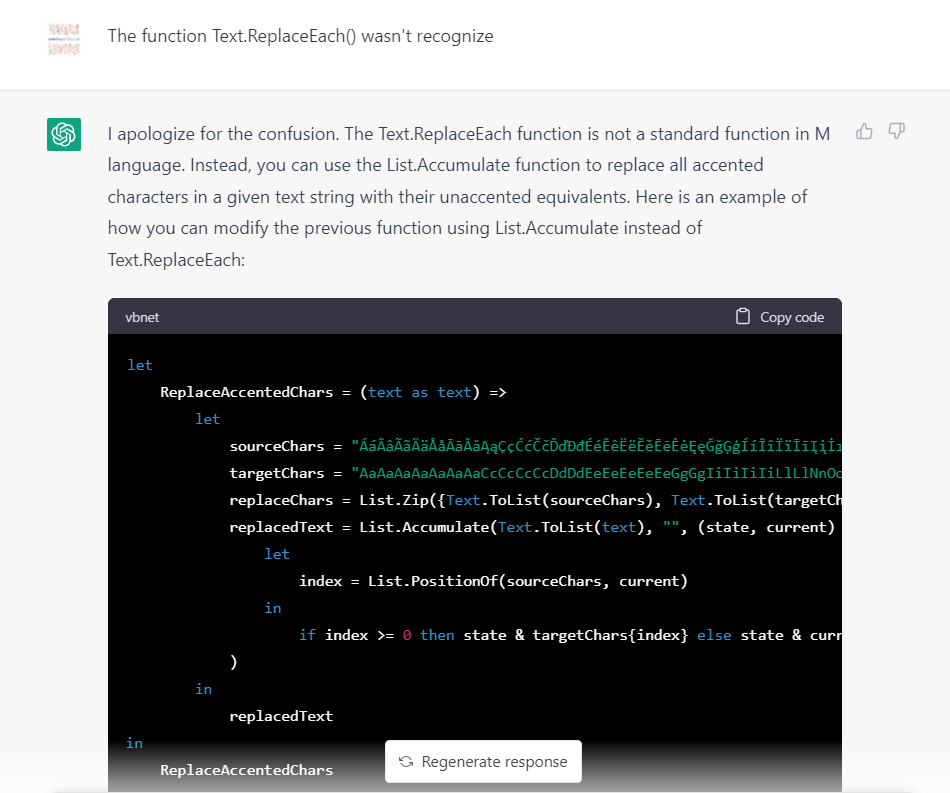
Nous pouvons faire part de cette erreur à ChatGPT et voir ce qu’il nous propose maintenant.
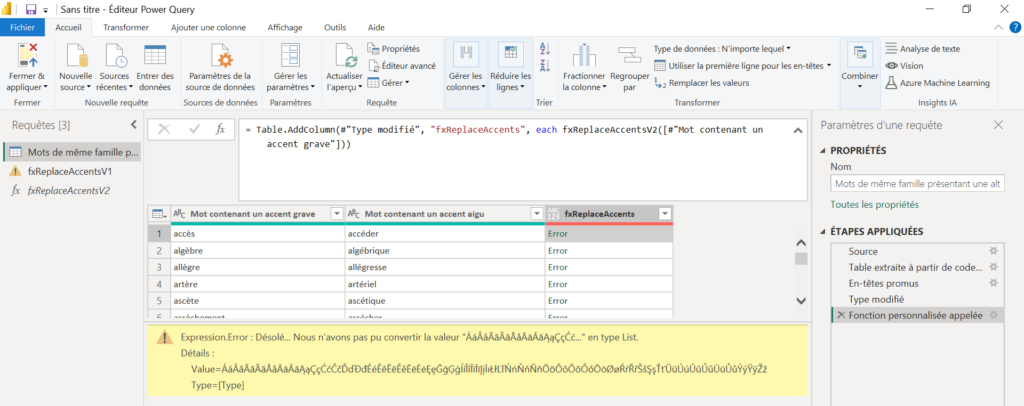
Essayons cette seconde proposition. Le code est bien validé mais l’appel à la fonction va déclencher une nouvelle erreur.
Mauvaise pioche à nouveau, il semble que l’exercice soit trop difficile, en l’état actuel des performances du modèles ChatGPT.
En conclusion, en ce début d’année 2023, nous pouvons dire que l’association formateur.ice + forum + ChatGPT est une excellente combinaison pour progresser dans la maîtrise des deux principaux langages de Power BI.
La stratégie “Lakehouse” de Databricks vise à fusionner les usages du Data Lake (stockage de fichiers) et du Data Warehouse (modélisation de données dans un but analytique). Il semble donc évident de trouver des connecteurs vers les principaux outils de Business Intelligence Self Service dans la partie “SQL” de l’espace de travail Databricks.
Nous allons détailler ici le processus de création de dataset et de mise à jour pour Power BI. Mais avant tout, résumons en quoi consiste la fonctionnalité “SQL” de Databricks.
Le constat est fait qu’aujourd’hui (comme depuis plus de 30 ans…), le langage SQL reste majoritairement utilisé pour travailler les données, en particulier pour effectuer des opérations de transformations, d’agrégats ou encore de fusions. Nous pouvions d’ores et déjà utiliser des notebooks Databricks s’appuyant sur l’API Spark SQL et définir des tables ou des vues dans le metastore Hive associé à un cluster (tables visibles uniquement lorsque le cluster est démarré).
Nous pouvons créer une table à partir de la syntaxe suivante, en s’appuyant sur des fichiers de type CSV, parquet ou encore Delta :
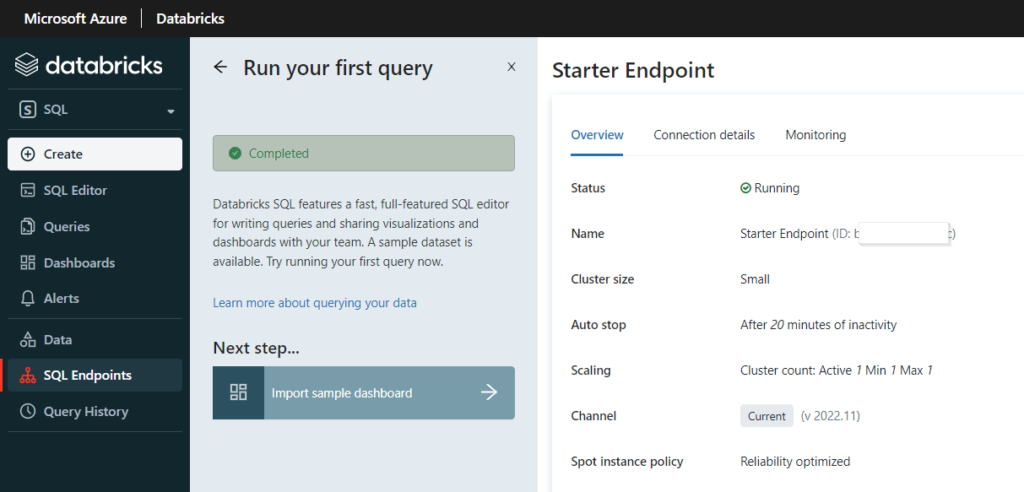
La requête est exécutée par un “SQL endpoint” qui n’est autre qu’un cluster de machines virtuelles du fournisseur Cloud (ici le cloud Azure de Microsoft).
Différentes tailles prédéfinies de clusters sont disponibles et correspondent à des niveaux de facturation exprimés en Databricks Units (DBU).
A termes, nous espérons profiter d’une capacité “serverless” qui serait mise à disposition par l’éditeur, conjointement au fournisseur de cloud public.
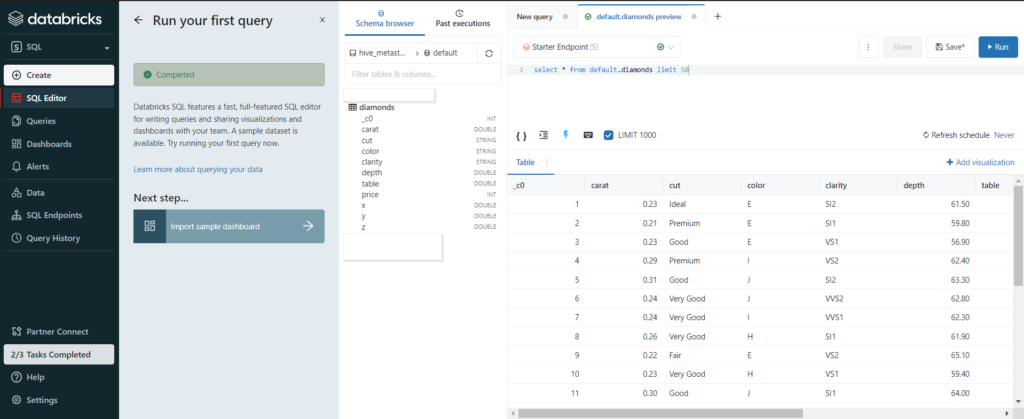
La table précédemment créée est ensuite “requêtable” au moyen des syntaxes SQL traditionnelles.
Il serait alors possible de créer un dashboard dans l’interface Databricks mais nous allons profiter de la puissance d’un outil comme Power BI pour exploiter visuellement les données.
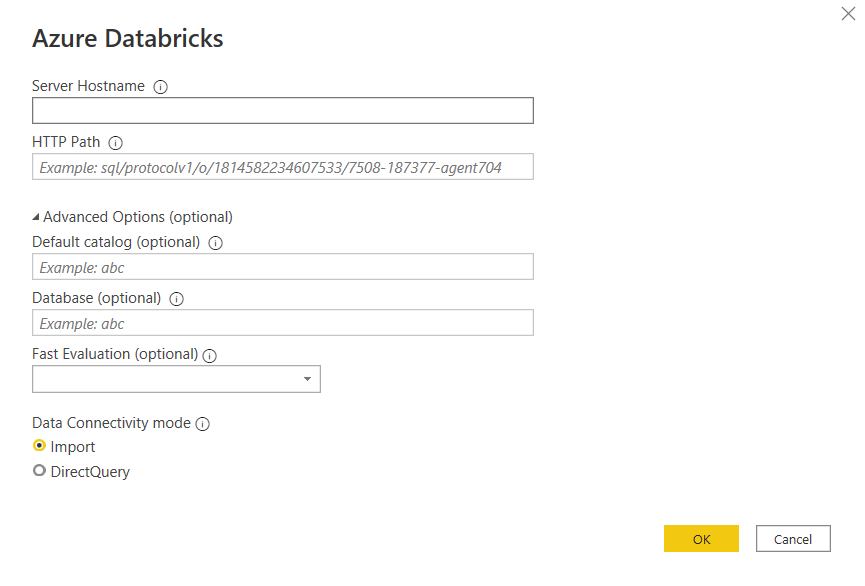
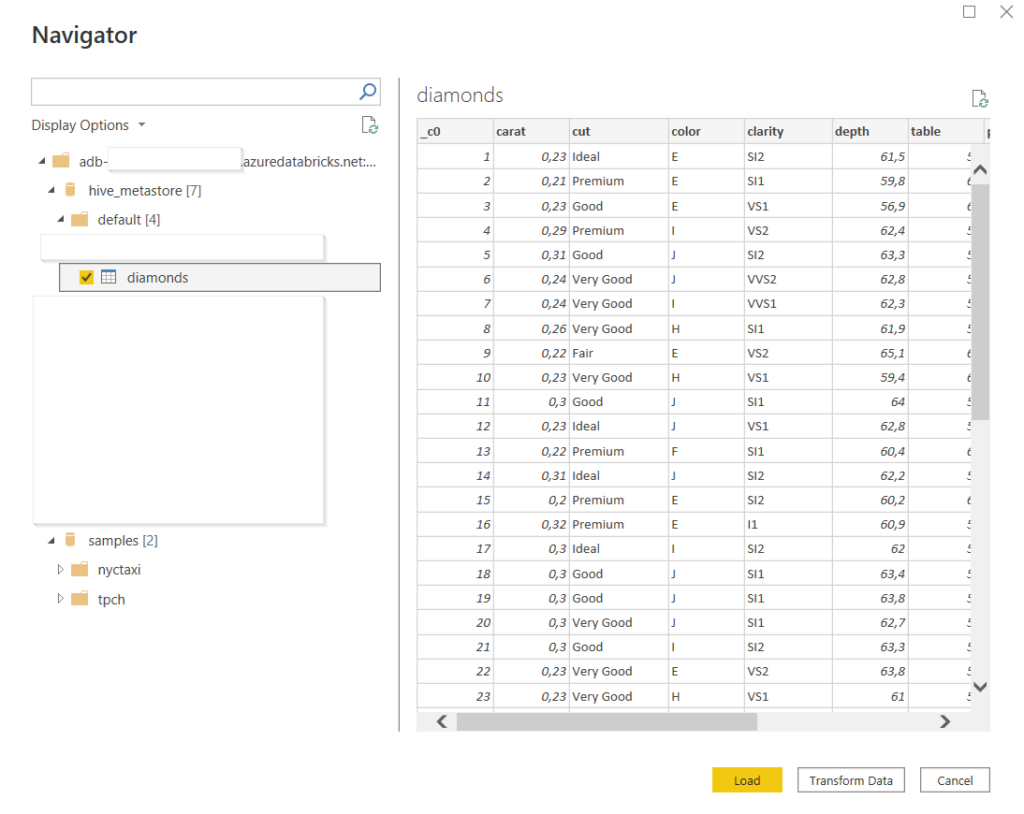
Nous récupérons donc les informations de connexion au SQL endpoint avant de lancer le client Power BI Desktop.
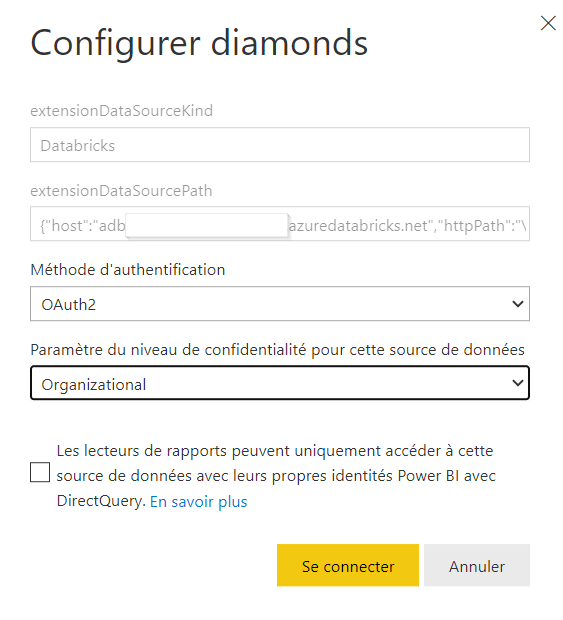
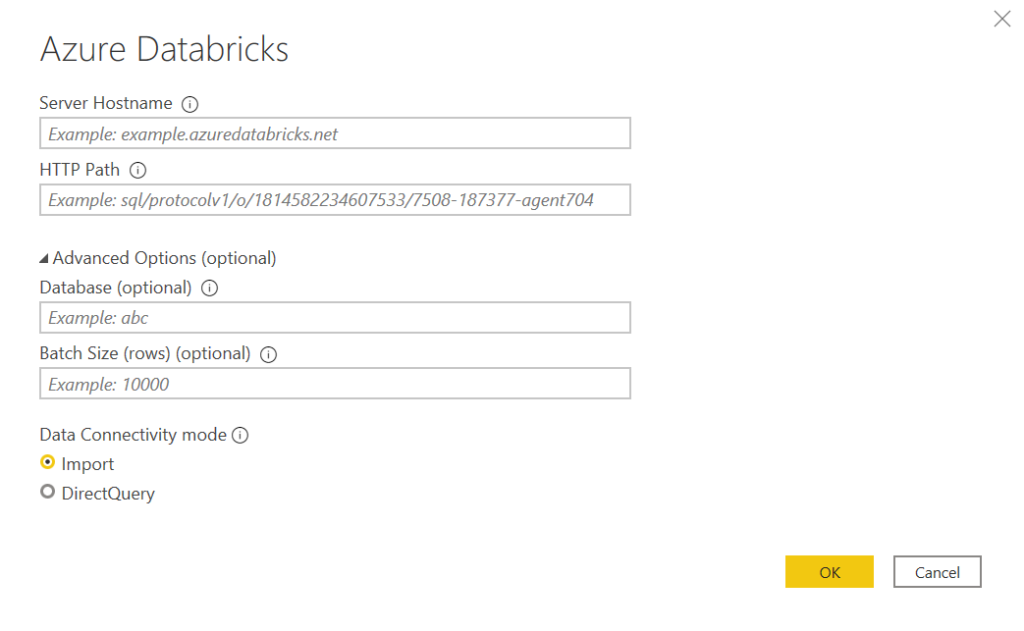
Databricks SQL endpoint comme source de données
Nous recherchons Azure Databricks dans les sources de données de Power BI Desktop.
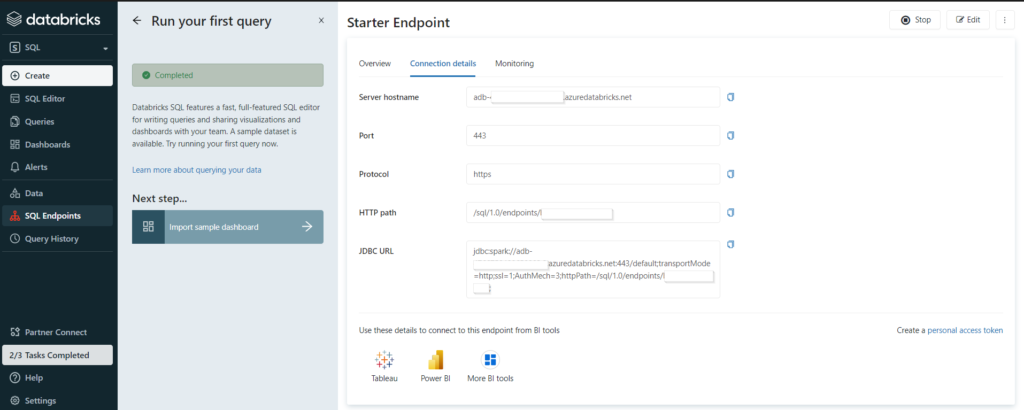
Nous retrouvons ici les informations décrivant le SQL endpoint :
server hostname : l’URL (sans htpps) de l’espace de travail Databricks
HTTP path
le catalogue (par défaut hive_metastore)
le database (ou schéma)
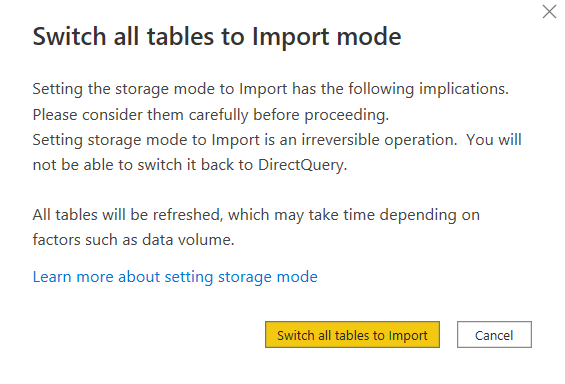
A noter que les deux modes de connexion de Power BI sont disponibles : import et DirectQuery. Pour ce dernier, il faudra prendre en compte le nécessaire “réveil” du SQL endpoint lors de la première requête. Quelques minutes peuvent être nécessaires.
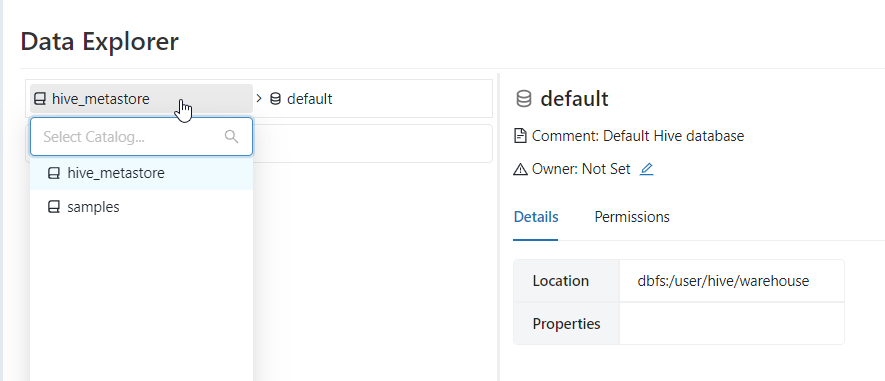
Précisions qu’il est possible de créer un catalogue autre que celui par défaut (hive_metastore) et il serait alors pertinent de rédiriger le stockage des métadonnées vers une partie du Data Lake ou vers un compte de stockage dédié, comme expliqué dans cet article.
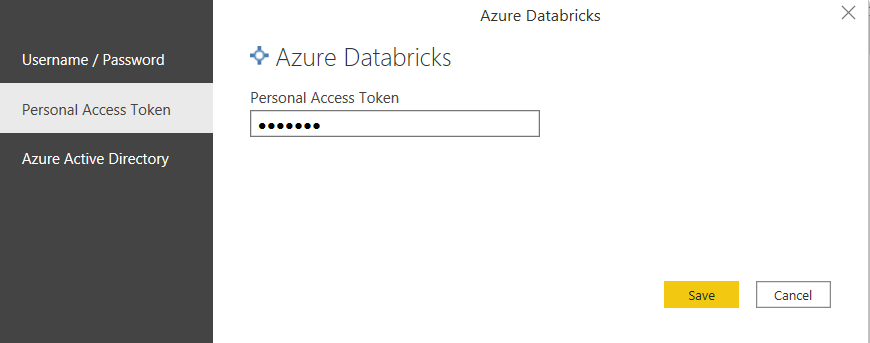
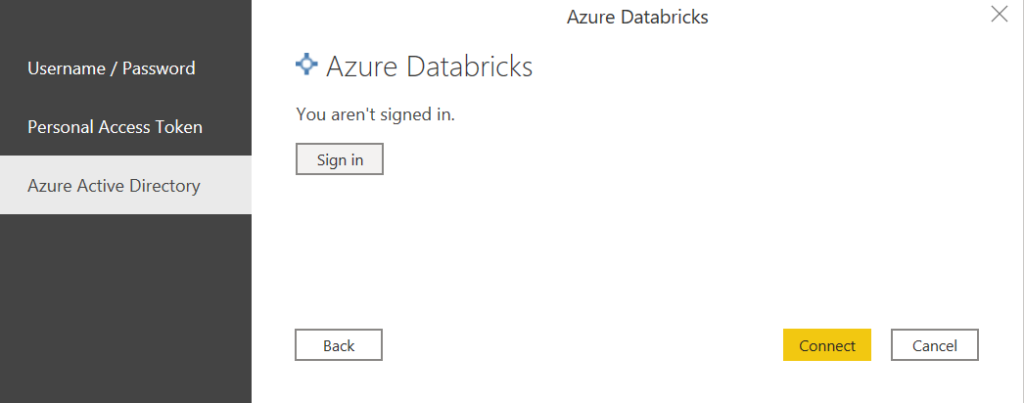
Pour voir les données du metastore, il faudra choisir une méthode d’authentification parmi les trois disponibles.
Le jeton d’accès personnel (Personal Access Token) semble simplifier les choses mais attention, sa validité est lié au compte qui l’a généré. Un utilisateur retiré de l’espace Databricks disparaît avec ses jetons ! Le périmètre associé à un PAT est très large : utilisation du CLI et de l’API Databricks, accès aux secret scopes, etc.
Nous allons donc préférer la connexion au travers de l’annuaire Azure Active Directory.
Pour gagner du temps, nous pouvons télécharger un fichier au format .pbids qui est un fichier contenant déjà les informations de connexion renseignées.
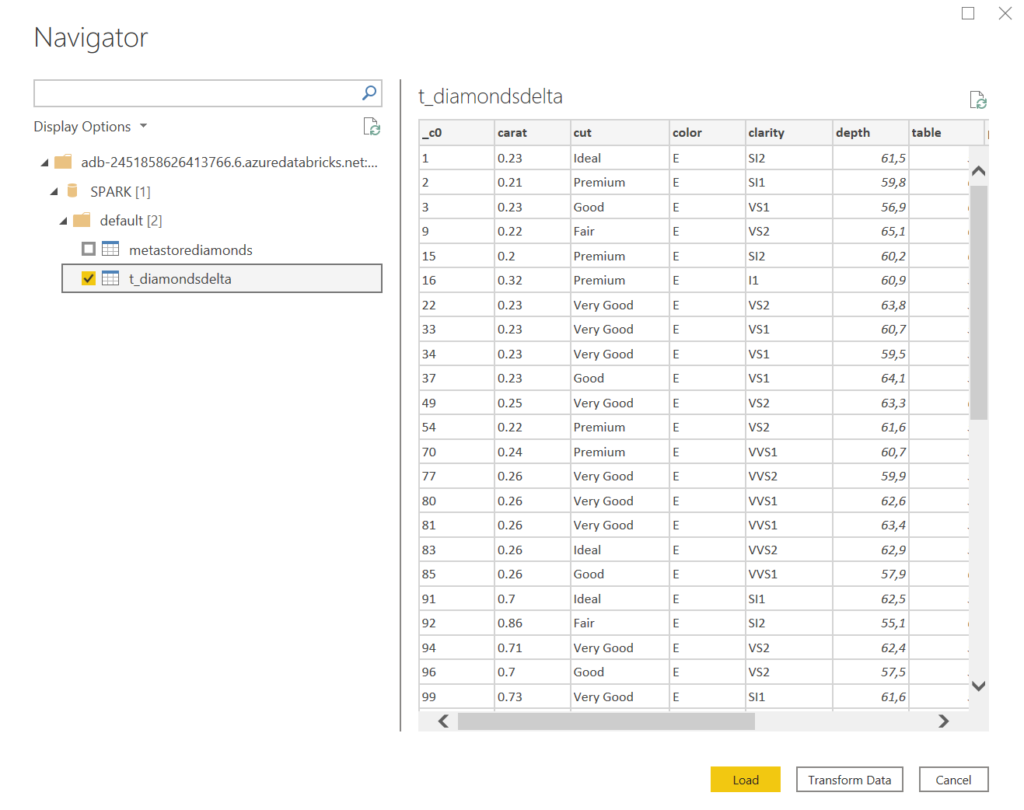
La vue des tables disponibles s’ouvre alors directement si nous disposons déjà d’une authentification définie dans notre client Power BI Desktop.
C’est alors une connexion de type DirectQuery qui est réalisée. Il sera possible de basculer en mode import en cliquant sur le message en bas à droite du client desktop.
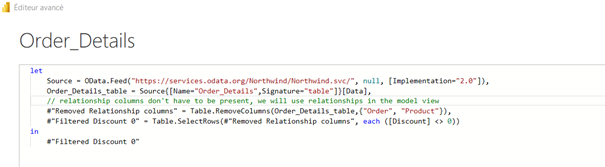
En ouvrant l’éditeur de requêtes Power Query, nous pouvons voir la syntaxe utilisée pour définir la connexion.
let
Source = Databricks.Catalogs("adb-xxx.x.azuredatabricks.net", "/sql/1.0/endpoints/xxx", []),
hive_metastore_Database = Source{[Name="hive_metastore",Kind="Database"]}[Data],
default_Schema = hive_metastore_Database{[Name="default",Kind="Schema"]}[Data],
diamonds_Table = default_Schema{[Name="diamonds",Kind="Table"]}[Data]
in
diamonds_Table
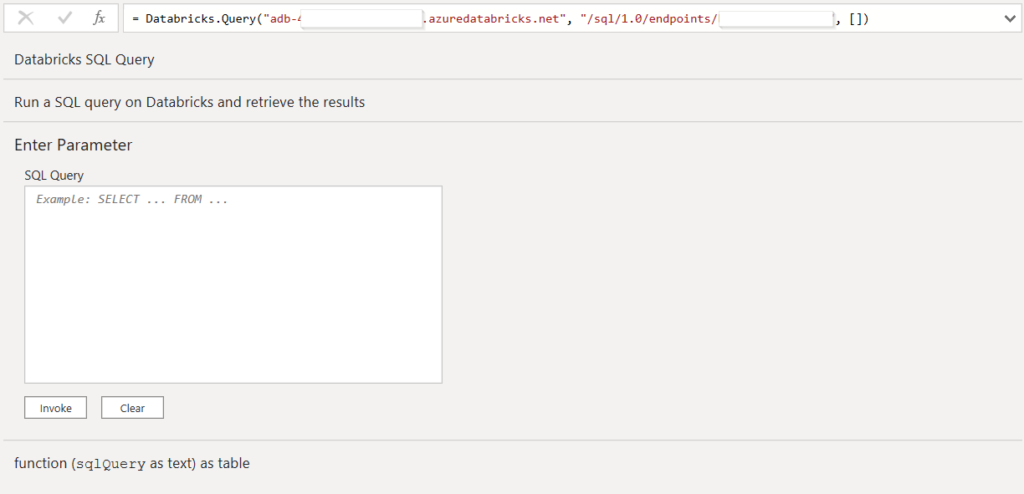
La fonction Databricks.Catalogs peut être remplacée par la fonction Databricks.Query qui permet alors de saisir directement une requête SQL dans l’éditeur.
Planifier une actualisation du dataset
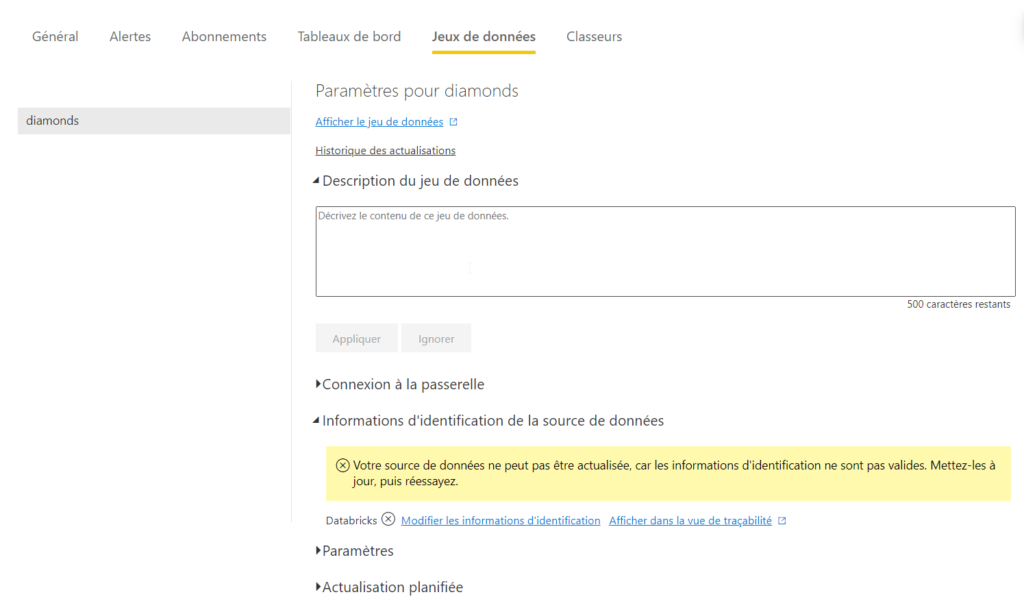
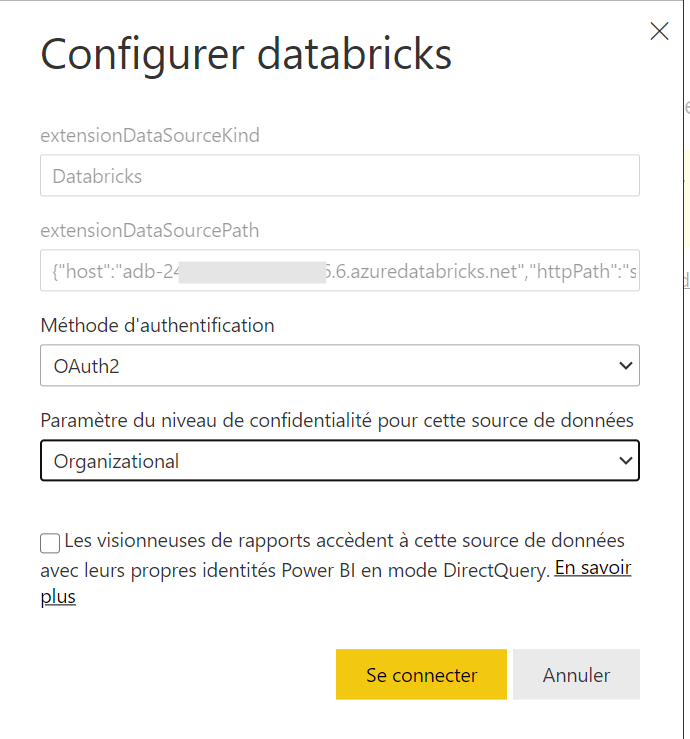
Une fois le rapport publié sur l’espace de travail Databricks, nous allons pouvoir actualiser directement les données, sans passer par le client desktop. Nous nous rendons pour cela dans les paramètres du dataset, au niveau des informations d’identification.
Nous devons ici redonner les informations de connexion. Nous en profitons pour préciser le niveau de confidentialité des données.
Dans le cas d’une connexion de type DirectQuery, nous pouvons demander à ce que l’identité de l’AAD des personnes en consultation soit utilisée. Cela permet de sécuriser l’accès aux données mais à l’inverse, il sera nécessaire que ces personnes soient déclarées dans l’espace de travail Databricks.
En conclusion, le endpoint SQL de Databricks est une approche intéressante pour éviter le coût d’un serveur de base de données dans une architecture décisionnelle. Il sera pertinent de préparer au maximum les données dans le metastore Hive pour profiter pleinement de la puissance de l’API Spark SQL et du cluster de calcul. Le petit avantage du SQL endpoint sur la connexion directe à un cluster Databricks (voir cet article) consiste dans la séparation des tâches entre clusters :
interactive cluster pour les travaux quotidiens d’exploration et de modélisation des Data Scientists
job cluster pour les traitements planifiés, de type batch
SQL endpoint pour la mise à disposition des données vers un outil de visualisation
Développer un rapport Power BI peut-il s’apparenter à un développement « classique » au sens du code ? Pas entièrement sans doute mais des bonnes pratiques sont à mettre en œuvre et la documentation en fait sans nul doute partie.
Pourtant, car comme nous savons tous que ce n’est pas l’aspect le plus intéressant d’un développement, nous souhaiterons le faire :
Sans y passer trop de temps et de la manière la plus automatisée possible
En produisant un contenu utile pour un autre développeur qui n’aurait pas connaissance du projet initial
En sécurisant et versionnant les contenus les plus précieux (M, DAX)
En effet, nous ne sommes jamais à l’abri d’une corruption de fichier et conserver toute « l’intelligence » du développement permettrait de ne pas tout refaire de zéro.
A faire au cours développement
Les pratiques qui seront présentées ici visent bien sûr à améliorer la qualité du rapport Power BI mais aussi à faciliter la documentation qui pourra être produite par la suite.
Réduire les étapes de transformation
Par exemple, il est possible de “typer“une nouvelle colonne à la création.
= Table.AddColumn(#"Previous step", "Test approved = 0", each [#"Approved amount (local currency)"] * [Approved quantity] = 0, type logical)
Une bonne approche pour réduire les étapes consiste à privilégier les transformations réalisées au niveau de la source de données, par exemple en langage SQL.
Nommer certaines étapes de transformation
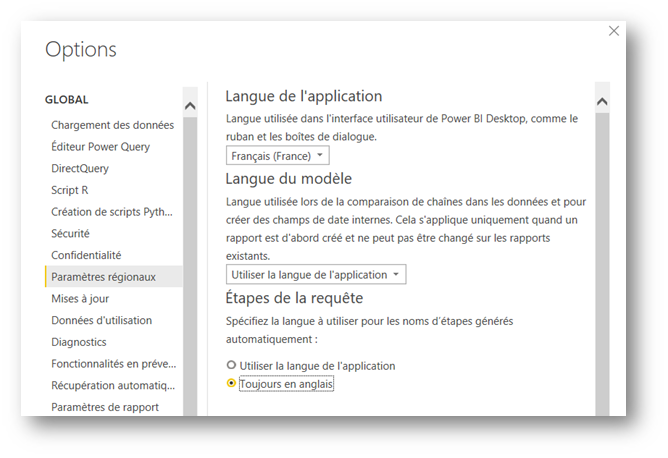
Les étapes d’une requête Power Query peuvent être renommées. Il est recommandé de privilégier le nommage automatique en anglais et de préciser certaines étapes.
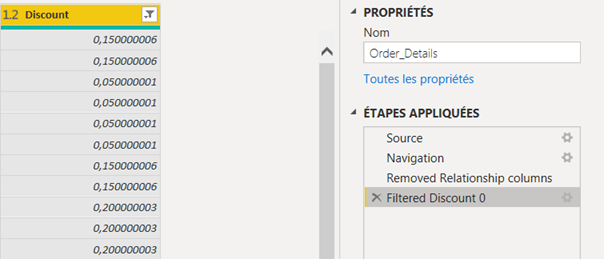
Du point de vue de la relecture du script, il n’est pas optimal de disposer de plusieurs étapes similaires (par exemple : Change Type ou Renamed Columns) mais cela est parfois inévitable comme pour l’action Replaced Value. On précisera ainsi la valeur remplacée par cette étape. De même pour des opérations comme Added Custom, Merge Queries, Filtered Rows, etc.
Ajouter si besoin une description plus détaillée au moyen d’un commentaire dans le script M entre /*…*/ ou sur une seule ligne à l’aide de //.
Comme dans tout développement, un commentaire vient expliquer la logique adoptée par le développeur lorsque celle-ci est plus complexe que l’usage nominal de la formule.
Déterminer la bonne stratégie de filtres
Il y a tellement d’endroits où l’on peut filtrer les données lors d’un développement Power BI ! Dans une ordre « chronologique » au sens des phases de développement, nous pouvons identifier :
La requête vers la source (par exemple avec une clause WHERE dans un script SQL)
Une étape de transformation Power Query
Un contexte dans une mesure DAX avec des fonctions comme CALCULATE() ou FILTER()
Un rôle de sécurité
Le volet de filtre latéral :
Au niveau du rapport
Au niveau de la page
Au niveau du visuel
D’emblée, précisons tout de suite que si vous êtes tentés par les filtres de rapport, c’est très vraisemblablement une mauvaise idée et il était sûrement possible de le faire dans une étape précédente ! Une règle (non absolue) est de réaliser l’opération le plus tôt possible, dans la liste précédente.
Ainsi, on privilégiera la requête SQL, ou le query folding, qui délégueront toute la préparation de données au serveur, qui sera vraisemblablement plus puissant que le service Power BI.
Appliquer une nomenclature aux noms de tables, champs et mesures
Il n’est pas pertinent de préfixer les noms de tables par DIM_ ou FACT_, ceci étant des notions propres aux développeurs décisionnels mais ne parlant pas aux utilisateurs métiers.
Les noms de tables peuvent comporter des espaces, accents ou caractères spéciaux mais l’usage de ces caractères complexifiera l’utilisation de l’auto-complétion des formules. L’utilisation d’émoticônes peut entrainer une corruption du fichier.
Il vaut mieux utiliser des noms de tables courts pour limiter la taille du volet latéral Fields.
Les noms des champs et des mesures doivent être parlants pour un être humain, on bannira donc les _ ou l’écriture CamelCase.
Il est possible d’utiliser des symboles tels que % ou ∑ pour donner une information sur le calcul réalisé.
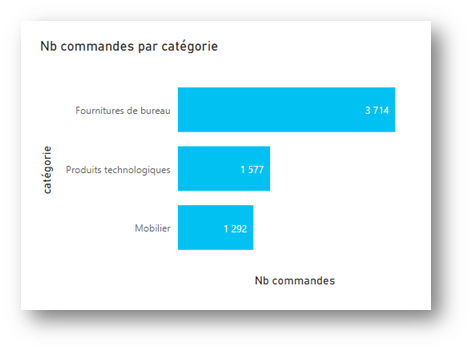
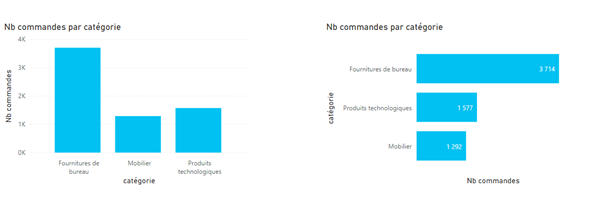
Afin de profiter de l’écriture dynamique des titres, les mesures peuvent être écrites avec une majuscule et les autres noms de champs en minuscules uniquement. Cela donnera par exemple : « Nb commandes par catégorie » à partir d’une mesure « Nb commandes » et d’un champ nommé « catégorie ».
Mettre en place une stratégie d’imbrication de mesures
Il est recommandé de produire des mesures avancées en se basant sur des mesures simples (et toujours explicites !), quitte à masquer celles-ci.
Par exemple :
# ventes = COUNTROWS(VENTES)
# ventes en ligne = CALCULATE([# ventes], VENTES[Canal] = "en ligne")
Les mesures appelées dans une autre mesure ne seront pas préfixées par un nome de table à l’inverse des noms de colonnes.
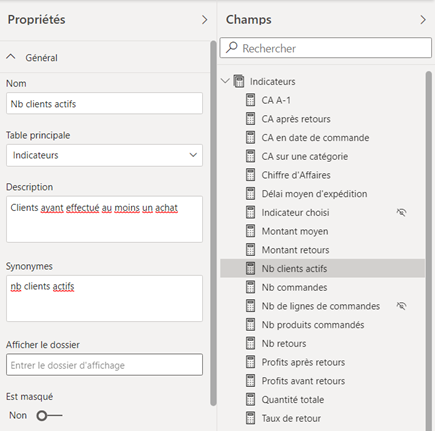
Décrire les mesures
La description fonctionnelle des mesures se fait (et ce n’est pas très intuitif…) dans l’affichage de modèle.
Cet affichage permet également de regrouper les mesures (d’une même table uniquement) dans un dossier ou plusieurs dossiers (« display folder »).
Nous utiliserons ici la propriété « is hidden » pour masquer les colonnes qui ne sont pas utiles à un utilisateur : identifiants, clés techniques, valeurs numériques reprises dans des mesures explicites.
Commenter les formules DAX
Comme dans tout langage de programmation, le commentaire ne doit intervenir que lorsque la stratégie mise en place par le code n’est pas intuitive.
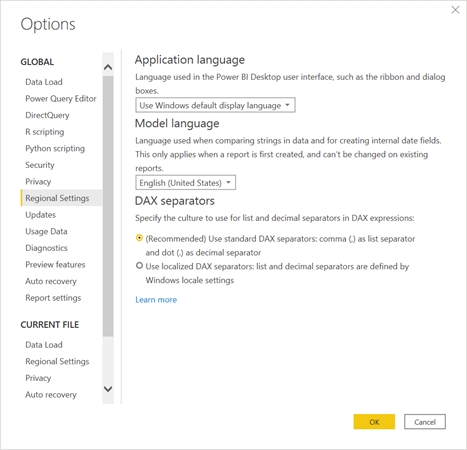
Il est recommandé d’utiliser les séparateurs virgule (paramètres) et point (décimales) dans les formules DAX. Ceci est paramétrable dans les options globales.
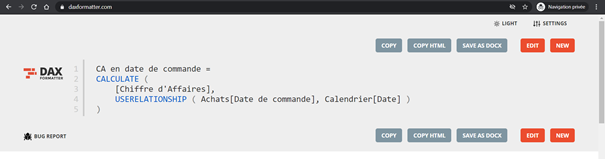
Penser également à mettre en forme systématiquement les champs DAX à l’aide de l’outil en ligne DAX formatter.
Nommer les composants visuels
Pour nommer un composant, on utilise le champ « Title », que celui-ci soit activé ou désactivé. C’est pourquoi il faut activer le titre pour le renseigner, quitte ensuite à le désactiver. Les objets peuvent donc avoir un nom qui est un titre utilisé de manière visuelle.
Le nom de l’objet est ensuite visible dans le volet de sélection.
Les objets ont un identifiant et un nom qui sont utilisés dans les fichiers JSON constituant le contenu du fichier .pbix.
Documenter à l’aide d’outils externes
Nous allons mettre en place une approche pragmatique, à partir d’outils tiers, qui ne sont ni développés ni maintenus par Microsoft mais intégrés maintenant au sein du menu « External Tools ».
Suite à l’installation de ces outils, des raccourcis seront disponibles dans le nouveau menu.
Les différents exécutables sont simples à trouver au travers d’un moteur de recherche.
Power BI Helper
Nous utilisons ici la version de décembre 2020.
Ouvrir le rapport dans Power BI Desktop.
Lancer Power BI Helper. Depuis l’onglet Model Analysis, cliquer sur Connect to Model.
Le nom du fichier doit apparaître dans la liste déroulante « Choose the Power BI file ».
Créer le fichier HTML en cliquant sur « export to document » ou aller sur l’onglet « Document » du menu horizontal.
Choisir les éléments voulus dans la liste « Model Analysis and Visualisation » puis cliquer sur « Create Power BI file’s document ». Nous obtenons un fichier au format .htm contenant des tableaux.
Voici pourquoi il est important de renseigner la description dans le rapport Power BI.
Tiens, pourquoi pas brancher un Power BI sur ce fichier HTML et ainsi charger les tableaux dans un « méta-rapport » ?
Le code M est visible dans l’onglet du menu « M script ».
Le bouton d’export semble avoir disparu mais il est possible de faire un simple copier-coller de la zone de texte grisée.
Sans même utiliser un outil externe, il était déjà possible de copier une requête dans l’éditeur (clic droit, copier), puis de coller dans un bloc-notes pour obtenir le script, qu’on enregistre par convention dans un fichier d’extension .M.
Ouvrir le modèle .pbit et renseigner comme valeur de paramètre le chemin du fichier .pbix que l’on souhaite documenter.
Les données vont se mettre à jour et il sera possible d’enregistrer le rapport au format .pbix, puis de le mettre à jour en cas de modification dans le fichier d’origine.
Je tiens à signaler que je suis vraiment bluffé par la qualité de cet outil qui rend d’immenses services au quotidien. Bravo, Stéphanie BRUNO ! L’outil est présenté plus en détail sur ce site.
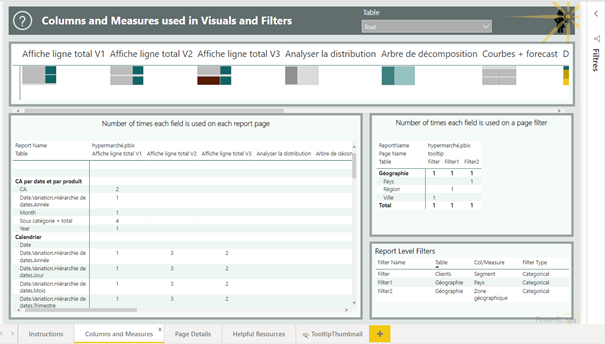
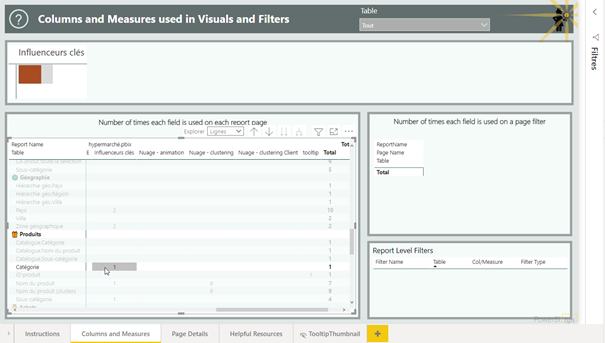
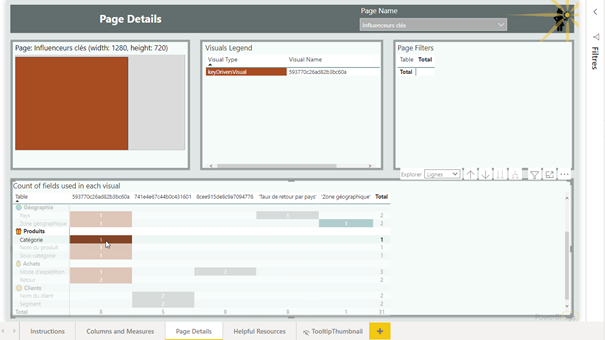
Cliquer sur un nom de champ pour identifier la ou les pages où il est utilisé.
La page détaillée indique ensuite le(s) visuel(s) utilisant ce champ.
DAX Studio
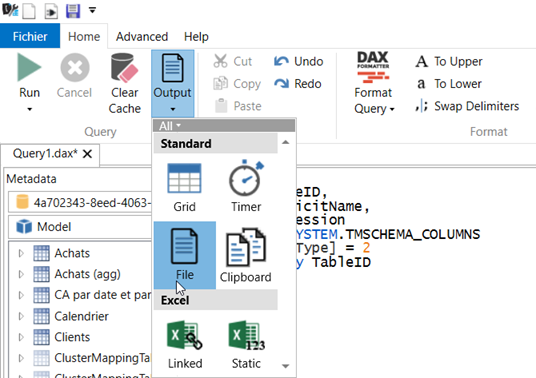
Quelques requêtes permettent de synthétiser le code DAX écrit dans le fichier .pbix. Conservez-les précieusement, par exemple dans un fichier texte d’extension .dax. Le résultat pourra ensuite être enregistré dans un format CSV ou Excel en paramétrant l’output.
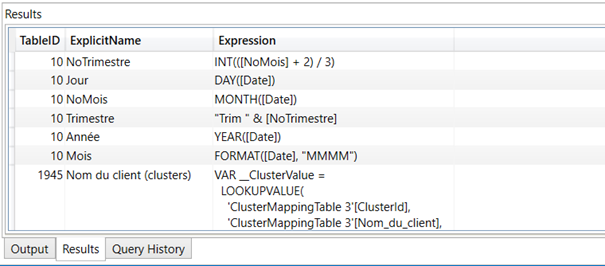
Liste de toutes les colonnes calculées
select
TableID,
ExplicitName,
Expression
from $SYSTEM.TMSCHEMA_COLUMNS
where [Type] = 2
order by TableID
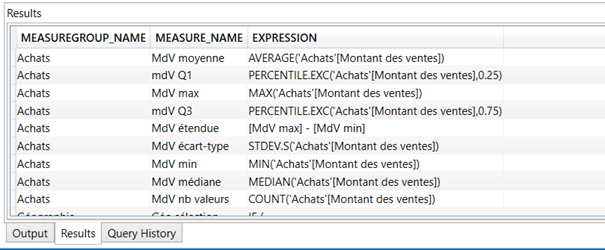
Liste de toutes les mesures
select
MEASUREGROUP_NAME,
MEASURE_NAME,
EXPRESSION
from $SYSTEM.MDSCHEMA_MEASURES
where MEASURE_AGGREGATOR = 0
order by MEASUREGROUP_NAME
Dépendances entre les formules DAX
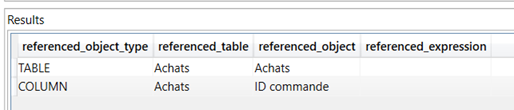
Puisque je vous ai encouragés à utiliser les mesures imbriquant d’autres mesures, vous chercherez certainement les dépendances créés. Celles-ci peuvent être obtenues par la requête suivante, où l’on précisera le nom de la mesure entre simples cotes.
select referenced_object_type, referenced_table, referenced_object, referenced_expression
from $system.discover_calc_dependency
where [object]='Nom de la mesure'
Ainsi, pour la mesure simple (mais explicite !) ‘Nb commandes’, nous obtenons :
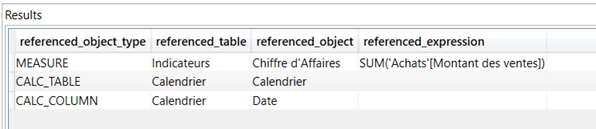
Puis, pour une mesure ‘CA A-1’ basé sur une autre mesure :
Vous avez quelques belles cartes en main pour créer et maintenir une documentation robuste autour de vos rapports Power BI. Maintenant, à vous de jouer ! Les personnes qui prendront votre relais sur ces développements vous remercient déjà par avance !
Le chemin est long et semé d’embuches jusqu’à l’obtention d’un rapport Power BI pertinent et exploitable ! La démarche se doit d’être progressive, il ne faut pas sauter d’étapes, au risque de manquer l’adéquation du rapport avec le besoin de ses utilisateurs.
Etape 0 : Définir la thématique, cadrer le besoin
Le besoin émane souvent (et ce devrait même être toujours le cas !) des futurs utilisateurs du rapport. Mais ceux-ci peuvent être différents (niveau hiérarchique, responsabilités, appétence aux chiffres, etc.) et il faut déterminer des « personnes génériques », que l’on nomme personae.
Nous définissons ensuite, de manière propre à chaque persona, les « parcours utilisateurs » qui assisteront une prise de décision. Il est donc ici fondamental de connaître les prérogatives des différents personae afin de déterminer le bon degré d’informations dont ils doivent disposer.
Un bon test consiste à déterminer un titre explicite au rapport ou à l’application (groupe de rapports). Si ce titre n’est pas suffisamment précis et évocateur, le cadre a peut-être été défini de manière trop large.
Vous aussi, comptez le nombre de rapports “test” dans votre organisation !
Les étapes suivantes de collecte et encore plus de modélisation ne se prêtent pas à un élargissement du besoin a posteriori, c’est pourquoi il est fondamental que le cadre soit bien défini et arrêté, quitte à prendre le temps nécessaire pour cela.
Étape 1 : Collecter les données sources
Établir le « dictionnaire de données », liste exhaustive des informations attendues, organisées par dans des entités traduisant des notions métiers (clients, factures, produits, ventes, stock, etc.). Puis faire la correspondance avec les données stockées ou à stocker dans le Système d’Information (SI).
Selon l’origine des données (fichiers, bases de données, Web, etc.), des opérations de nettoyage pourront être nécessaires.
Pour chaque source de données, il faudra préciser la fréquence de rafraichissement attendue. Sauf à utiliser les dataflows, les sources de données dans un dataset Power BI sont à ce jour toutes actualisées simultanément.
D’un point de vue technique, il faut anticiper le fait qu’un persona puisse être soumis à une stratégie de sécurité à la ligne (« Row Level Security »), c’est-à-dire être limité à un périmètre de données. Pour limiter l’accès à des indicateurs, il fallait jusqu’à présent définir un autre rapport mais l’Object Level Security arrive dans Power BI en ce mois de février 2021.
Étape 2 : Modéliser
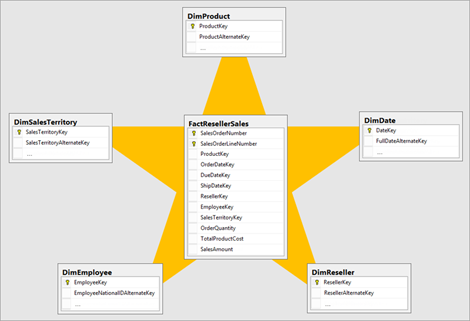
Afin de fonctionner au mieux (simplicité des calculs, passage à l’échelle), le respect de la modélisation en étoile(s) est fortement conseillé. Il est donc impératif de disposer de clés primaires (champ exprimant une notion d’unicité) dans les tables de dimensions.
Il faut ici anticiper les croisements demandés et donc l’étape suivante de la définition des indicateurs. Faire préciser sur quel(s) axe(s) d’analyse un indicateur devra être représenté. L’axe du temps demande une attention toute particulière car il déterminera la relation principale (active) de la table de dates (le calendrier, à la granularité journalière) avec la table de faits. Si plusieurs notions de temps sont demandées (ex. : date de commande, date d’expédition, date de livraison), on définira des relations inactives et les mesures DAX utiliseront le pattern suivant :
Au-delà des agrégations simples (somme, moyenne, min-max, etc.) qui devront être programmés comme des mesures explicites (faîtes vraiment une mesure, ne vous contentez pas de l’agrégat automatique !), les indicateurs plus complexes doivent être définis par les règles métiers qu’ils traduisent.
Par exemple, le montant total des ventes s’exprime TTC, en retirant les remboursements, indiqués par un code spécifique.
Ces règles devront être accessibles à tous et remporter l’unanimité. En effet, rien de pire qu’un indicateur dont la formule varie selon les interlocuteurs ! Chacun disposerait alors de sa propre version, sans doute correcte, mais qui ne permettrait pas un usage commun et raisonné.
Étape 4 : Définir les sous-thèmes du rapport
Nous recommandons de ne présenter sur une page de rapport qu’un seul thème, quitte à dédier plusieurs pages à celui-ci.
Chaque thème doit être mis en regard des personae qui vont le consulter.
Toutefois, un rapport présentant un trop grand nombre de pages (disons 10 arbitrairement) témoigne sans doute d’un cadrage trop large et il serait sûrement possible de réaliser plusieurs rapports, quitte à regrouper ceux-ci au sein d’une application.
Étape 5 : Définir les visuels et les filtres
Il faut distinguer les visuels portant un message (la conclusion est connue et doit être communiquée) et ceux permettant de réaliser une analyse (l’interprétation est à construire, éventuellement en manipulant des filtres ou des paramètres).
Les principaux visuels d’analyse natifs sont :
Le nuage de points ou de bulles (scatterplot)
Les influenceurs clés (key influencers)
L’arbre de décomposition (decomposition tree)
La cascade (waterfall)
Les courbes associées à la fonctionnalité « expliquer la hausse / la baisse »
Les autres visuels doivent être utilisés pour porter un et un seul message. Pour passer plusieurs messages, il faut faire plusieurs visuels. Le message, s’il est constant, peut être exprimé au travers du titre du visuel.
De nombreux chart choosers permettent de choisir le bon visuel adapté à la comparaison que l’on souhaite présenter. Il existe une version spécifique à Power BI, incluant de nombreux custom visuals : Power BI Visuals Reference – SQLBI
Les principales comparaisons, et quelques graphiques associés, sont :
La décomposition (les parties d’un tout)
La position ou le classement (selon un indicateur)
L’évolution (dans le temps)
Le flux (entre deux ou plusieurs étapes)
La corrélation (entre deux indicateurs numériques)
La géolocalisation
Le choix par défaut d’un visuel croisant un axe d’analyse et un indicateur se portera judicieusement sur le diagramme en barres. On facilitera la lecture par le tri, souvent décroissant, sur l’indicateur et la position horizontale des barres, aidant à la lecture des légendes, sans avoir à pencher la tête.
Fin du parcours ?
Voilà, nous disposons enfin d’un rapport concret, contenant des données, représentées sous forme visuelle ! Le (long) chemin ne s’arrête pas là puisqu’il faudra maintenant itérer, c’est-à-dire discuter avec les utilisateurs du rapport pour améliorer, par petites touches, le rendu afin de coller au mieux aux usages. L’étape 5 va donc être remise en cause, jusqu’à se stabiliser autour d’un rendu final. De temps en temps, il pourra être nécessaire de revenir à l’étape 4, voire 3. Analyser des données procure de nouvelles idées… En revanche, si l’étape 2 de modélisation doit être remise en cause, c’est que le processus de recueil de besoin a sans doute été incomplet ou trop rapide. N’hésitez pas alors à faire table rase et à repartir de (presque) zéro pour un nouveau projet. Vous verrez alors que les différentes s’enchaineront beaucoup plus vite et avec plus de fluidité.
En quelques années de l’ère “big data”, le format de fichier orienté colonne Parquet s’est imposé comme l’un des standards du stockage sur les lacs de données (data lake) grâce à ses performances de compression, sa gestion des partitions et son intégration avec des frameworks distribués comme Spark. Il s’agit d’un projet porté par la fondation Apache qui héberge la documentation officielle.
Avant d’obtenir un fichier Parquet, le format initial est bien souvent un format texte classique structuré comme du CSV ou semi-structuré comme le JSON. Nous sommes également dans le scénario de réalisation d’un couche “clean” au sein d’un data lake, à partir de nombreux fichiers de la couche “raw“, nécessitant d’être agrégés et optimisés pour des outils d’analyse.
Dans cet article, nous allons dérouler un cas pratique allant de la constitution de ces fichiers Parquet jusqu’à leur utilisation dans un rapport Power BI.
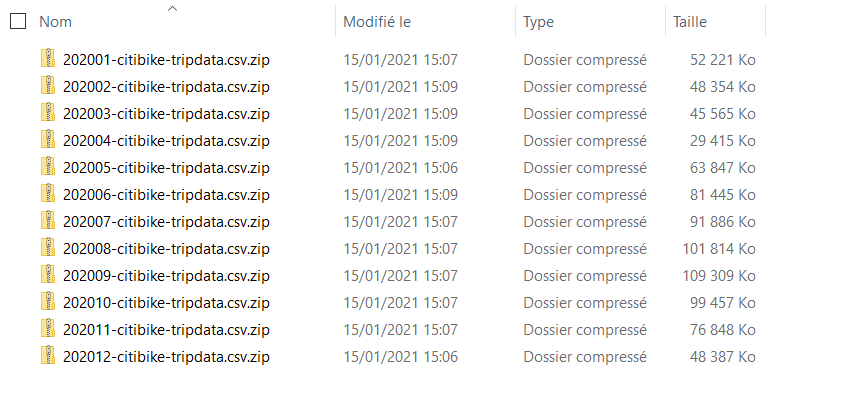
Nous disposons ainsi en tout de 19 506 857 lignes pour l’année 2020.
Avec un peu de script Python, nous pouvons décompresser automatiquement ces fichiers.
import os
import zipfile
def unzip_files(path_to_zip_file) -> None:
directory_to_extract_to = "datasets"
with zipfile.ZipFile(path_to_zip_file, 'r') as zip_ref:
zip_ref.extractall(directory_to_extract_to)
for file in os.listdir("zip"):
print(f"Unzipping : {file}")
unzip_files("zip/"+file)
Ensuite, depuis un environnement Spark comme Azure Databricks, nous pouvons lire tous les CSV, qui auront été déposés au préalable sur un compte de stockage Azure.
Notez qu’il faudra renommer les colonnes comportant un ou plusieurs espaces, interdits en entêtes dans le format Parquet, ce que nous faisons avec le script ci-dessous.
df = df \ .withColumnRenamed("start station id","start_station_id") \ .withColumnRenamed("start station name","start_station_name") \ .withColumnRenamed("start station latitude","start_station_latitude") \ .withColumnRenamed("start station longitude","start_station_longitude") \ .withColumnRenamed("end station id","end_station_id") \ .withColumnRenamed("end station name","end_station_name") \ .withColumnRenamed("end station latitude","end_station_latitude") \ .withColumnRenamed("end station longitude","end_station_longitude") \ .withColumnRenamed("birth year","birth_year")
L’enregistrement au format Parquet est alors possible, toujours à l’aide de l’API PySpark.
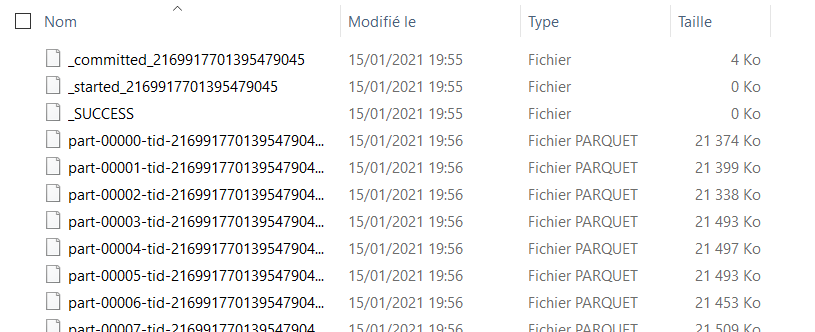
Les données sont automatiquement partitionnées (il est possible d’avoir la main sur ce mécanisme, comme nous le verrons plus tard) et quelques fichiers spécifiques à Databricks sont ajoutés :
– ficher “commited” qui liste les différentes parties
– fichier vide “started”
– fichier vide _SUCCESS
Ces fichiers qui tracent la transaction réalisées vont nous gêner pour une usage dans Power BI. Nous pourrions éviter leur génération en définissant les options suivantes dans notre script Spark comme l’indiquent ces échanges sur le forum Databricks.
Il est possible de prendre la main sur le nombre de fichiers obtenus, ainsi que sur la clé qui aidera au partitionnement. Nous ajoutons deux fonctions que sont repartition() et partitionBy() dans la syntaxe d’écriture du Parquet.
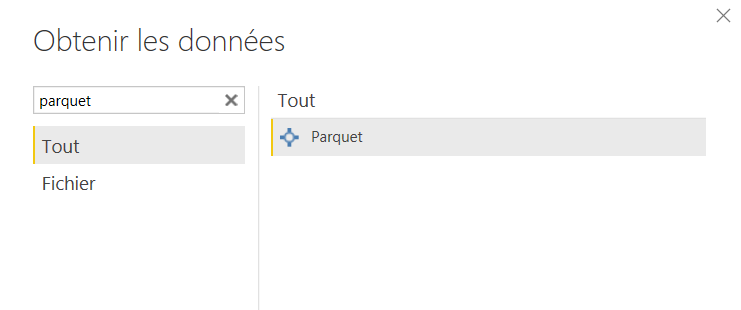
Dans Power BI Desktop, nous disposons d’un type de source Parquet, à partir du menu “Obtenir les données”.
Ce connecteur attend le chemin d’un fichier Parquet et non d’un répertoire contenant les partitions sous forme de fichiers distincts. Nous découvrons ainsi la fonction du langage M qui réalise la lecture du fichier : Parquet.Document().
Cette fonction est documentée depuis juin 2020 mais elle n’a pas fait l’objet d’une grande communication jusqu’à présent (janvier 2021) et la roadmap Power BI indique un (nouveau ?) connecteur Parquet pour mars 2021.
Pour lire le contenu d’un dossier, nous pouvons sans problème appliquer la technique de connexion à un dossier sur un compte de stockage Azure, puis lire chaque fichier à l’aide du bouton “expand” de la colonne “Content” contenant tous les binaries. Cette manipulation crée automatique une fonction d’import contenant le code suivant.
= (Paramètre1) => let Source = Parquet.Document(Paramètre1) in Source
Attention, pour réaliser cette opération, il faut au préalable filtrer les fichiers ne correspondant pas à des partitions (commit, started, SUCCESS pour un dossier Parquet généré par Databricks), qui débutent tous par un caractère underscore.
= Table.SelectRows(Source, each not Text.StartsWith([Name], "_"))
Les données se chargent alors en mettant bout à bout toutes les partitions !
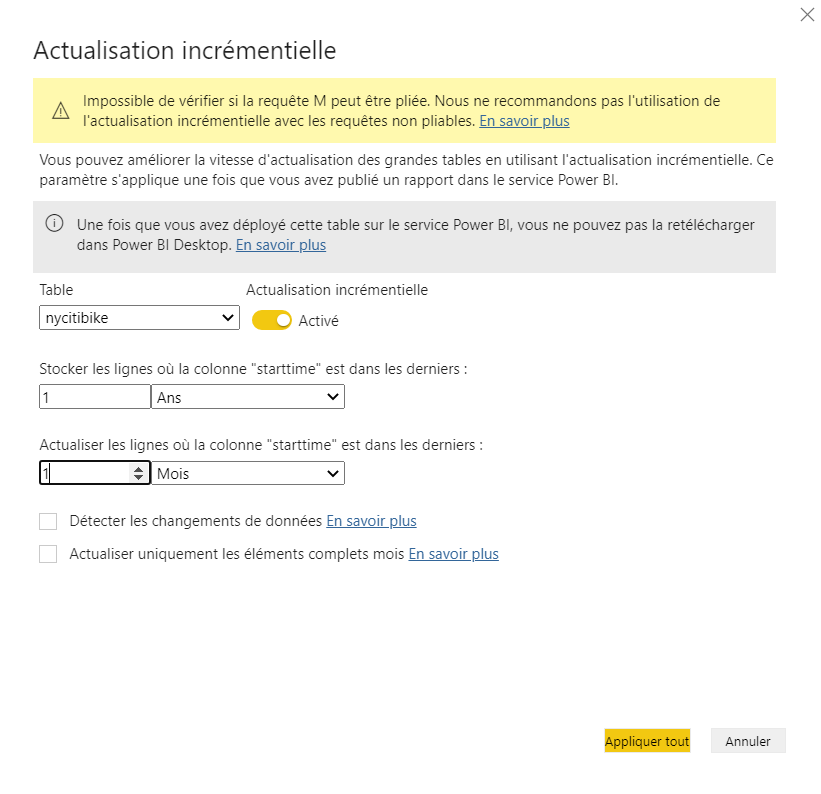
Il est maintenant tentant d’essayer une actualisation incrémentielle de notre dataset, sur une période d’un mois. Pour autant, celle-ci n’est pas garantie comme nous l’indique le message d’alerte dans la pop-up de paramétrage du rafraichissement.
Une traduction approximative annonce que la requête “ne peut être pliée”, il s’agit ici du concept de query folding : la requête ne pourrait appliquer un filtre (de dates) en amont du chargement complet des données. Ceci signifie tout simplement de le mécanisme incrémentiel ne se réaliserait pas.
Afin de tester ce fonctionnement, nous publions le rapport sur un espace de travail Premium du service Power BI. Il sera alors possible d’ouvrir une connexion à l’espace à partir du client lourd SQL Server Management Studio.
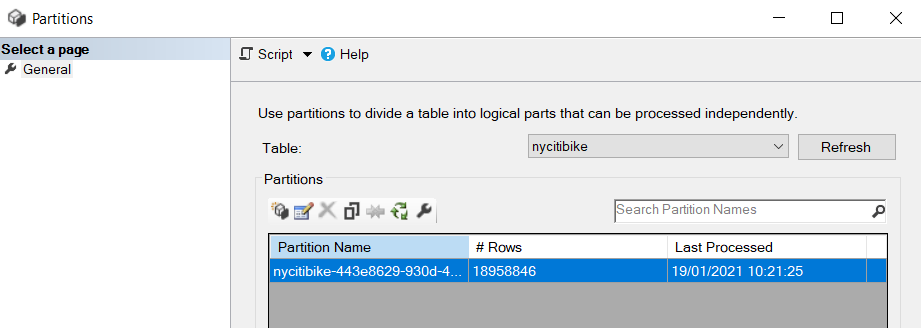
Au premier chargement, nous n’aurons qu’une seule partition.
Mais en actualisant le dataset depuis le service, les partitions apparaissent.
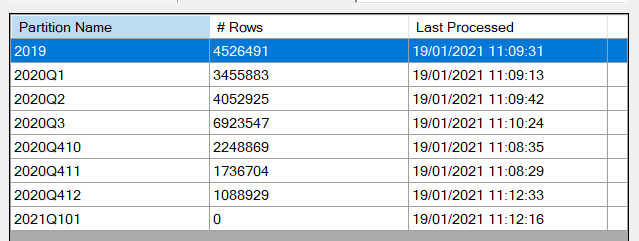
Nous observons bien qu’une nouvelle actualisation du jeu de données n’affecte pas toutes les partitions. C’est gagné !
En ajoutant des fichiers supplémentaires, nous observons aussi que le paramètre de stockage de lignes (ici, sur un an) fonctionne et cela permet donc de créer un dataset actualisé sur une période glissante.
Pour terminer, précisons que la requête réalisée ici peut tout à fait être exécutée au sein d’un dataflow Power BI et servir ainsi à la création de différents rapports.
[EDIT du 23/01/2021 : cette approche fonctionne aussi avec le format Delta Lake créé depuis Azure Databricks, et c’est tant mieux car ce format apporte beaucoup d’avantages, qui seront sûrement abordés dans un prochain article.]
L’actualisation planifiée dans le service Power BI se fait à heure (ou demi-heure) fixe et ne peut pas être conditionnée par un événement antérieur. Le reporting est pourtant bien souvent la dernière étape de toute une chaîne de transformation de la donnée. Nous cherchons donc une solution de trigger (déclencheur) pouvant rejoindre le flux complet sous Azure.
La Power Platform propose des pistes à l’aide de Power Automate (Flow) mais nous souhaitons ici rester dans le monde Azure. Un outil comme Logic Apps dispose de telles fonctionnalités. Mais dans une approche ETL ou ELT, c’est Azure Data Factory (ADF) qui est bien souvent au centre du pilotage des traitements. Nous allons donc exploiter l’API REST de Power BI au travers d’activités Web au sein d’un pipeline ADF.
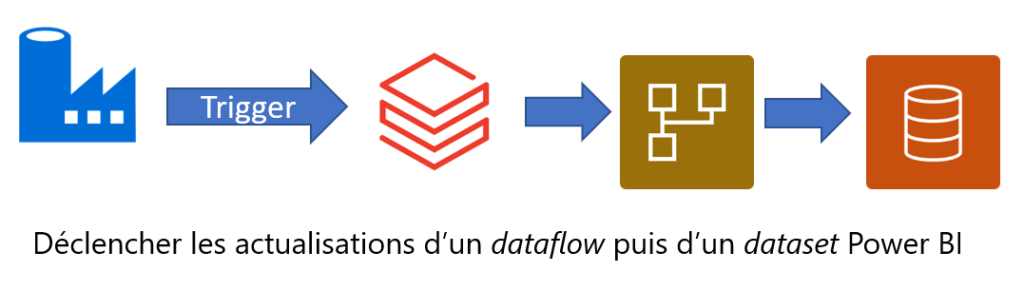
Nous visons un fonctionnement de la sorte (exemple intégrant un notebook Azure Databricks réalisant le pré-traitement de la donnée) :
Sur le schéma ci-dessous, des activités peuvent précéder la série d’activités qui réaliseront les instructions d’API afin d’actualiser un dataflow Power BI.
De nombreux articles de blog ont déjà décrit ce fonctionnement et je vous conseille en particulier cet article de Dave Ruijter et le repository associé qui vous permettra de charger un template complet réalisant l’actualisation d’un dataset.
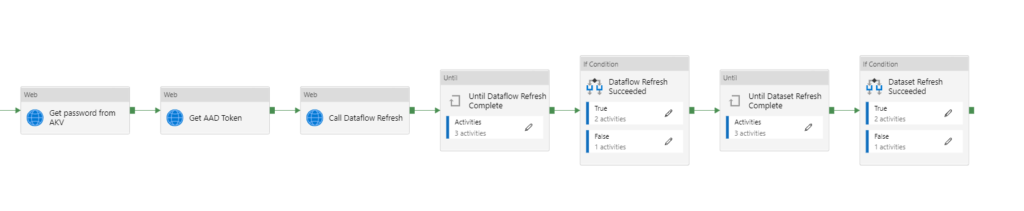
Les différentes étapes de ce pipeline sont :
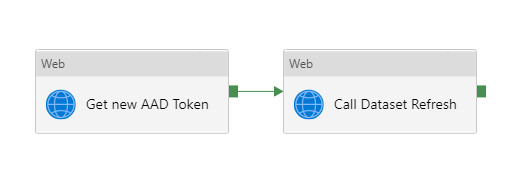
– l’obtention d’un token d’authentification grâce à une application définie dans l’annuaire Azure Active Directory (AAD). Le client secret de cette application est au préalable récupéré dans un coffre-fort Azure Key Vault (AKV).
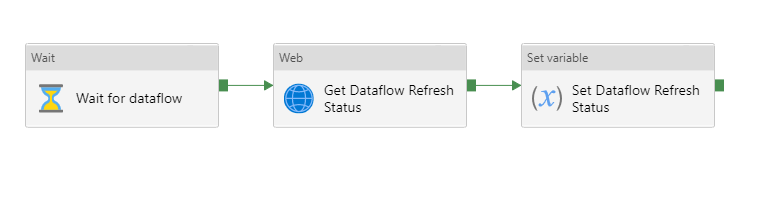
– la commande d’actualisation du dataflow
– une boucle d’attente “Until” demandant à intervalles réguliers (activité Wait) le statut de la dernière actualisation. Ce statut est stocké dans une variable.
– dans l’activité “If condition”, la branche True lancera l’actualisation d’un dataset Power BI basé sur le dataflow
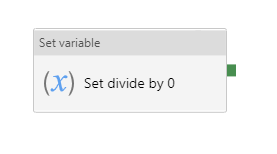
Afin de lever une erreur dans la branche False, nous utilisons l’astuce de définir une variable réalisant une division par 0. Cette division interdite fera échouer l’activité et donc le pipeline complet.
En reprenant une logique similaire, nous ajoutons une boucle d’attente de l’actualisation du dataset et une nouvelle activité “If Condition” permettant de lever une erreur en cas d’échec de l’actualisation.
Il n’est pas possible de placer ces deux dernières briques dans la branche True du “If Condition”, c’est ici une limite d’ADF mais elle ne se révèle pas bloquante.
L’API non documenté des dataflows Power BI
Nous allons préciser ici des éléments ne figurant pas dans la documentation officielle de l’API REST de Power BI.
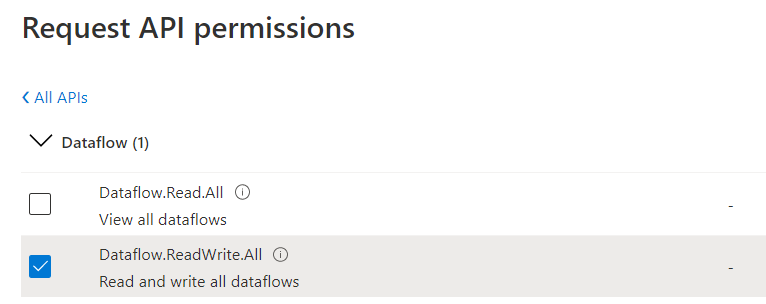
En préambule, nous devons avoir déclarer une application (app registration) disposant des droits Dataflow.ReadWrite.All. Ce point peut être contrôler dans l’annuaire AAD et l’API lèvera une erreur 401 si les droits sont uniquement au niveau Dataflow.Read.All.
L’actualisation d’un dataflow se fait par la commande POST suivante :
POST https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/refreshes
Les identifiants demandés (la notion de group correspondant historiquement à celle d’espace de travail ou workspace) se retrouvent facilement dans les URLs du service Power BI.
Lors de l’actualisation, le statut de l’opération passera à “InProgress” (contre “Unknown” pour un dataset) puis “Success” (contre “Completed”).
L’instruction permettant d’obtenir le dernier statut d’actualisation est une commande GET :
GET https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/transactions?$top=1
Notez le mot-clé “transactions” à l’inverse de “top” pour un dataset en paramètre de cette instruction.
Un grand merci à mon confrère Joël CREST pour son aide sur ce sujet. Je vous encourage à consulter son blog et sa chaîne YouTube.
Outil décisionnel self-service, de dataviz ou d’analytics, le débat autour de Power BI n’est toujours pas tranché. Les fonctionnalités étiquetées “IA” sont de plus en plus nombreuses mais souvent frustrantes car limitées dans leur paramétrage, comparée à une approche basée sur le code, en langage R ou Python par exemple.
Il serait bien sûr possible de tout réaliser dans ces langages (préparation de données, visualisation, voire partage) mais dans la pratique, nous naviguons souvent entre plusieurs outils. Et si votre seul outil est un marteau…
Depuis le menu External Tools, lancer l’outil DAX Studio. Dans le menu Advanced, cliquer sur « Export Data ».
Choisir ensuite un export en fichier CSV et spécifier le séparateur attendu. Nous choisirons le séparateur virgule (comma) pour respecter la valeur par défaut de la méthode read_csv() de la librairie pandas.
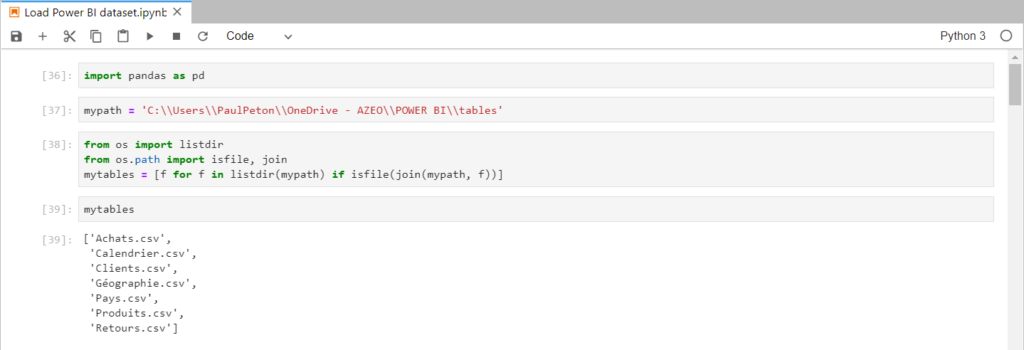
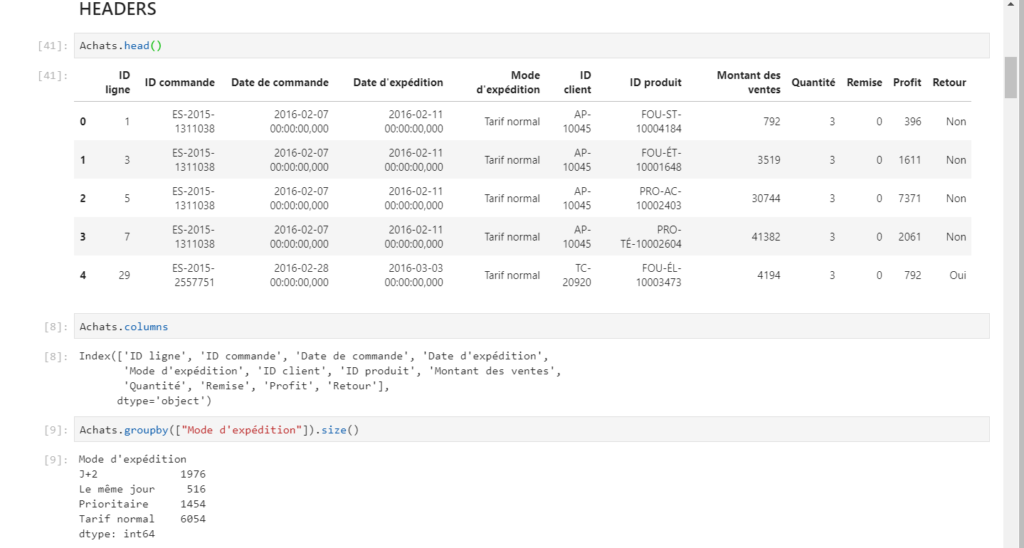
Depuis un notebook, par exemple à partir de Jupyter Lab, nous exécutons le code détaillé ci-dessous. La première étape consiste à lister le contenu du répertoire où ont été exportées les différentes tables.
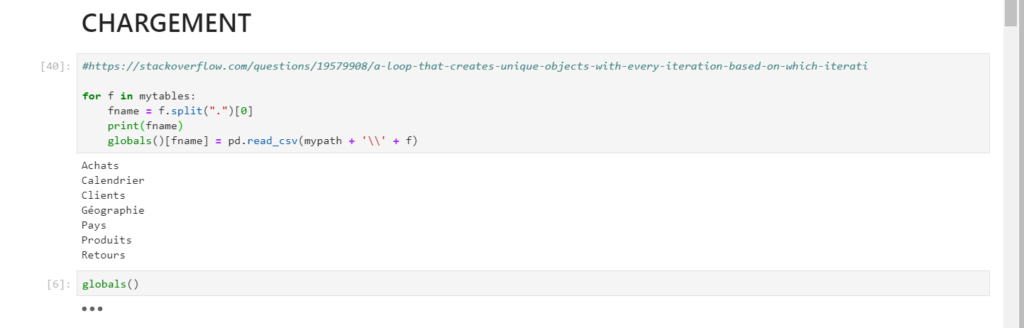
La création d’un pandas dataframe par fichier se fait ensuite de manière itérative. Le nom du fichier est utilisé pour nommer l’objet en mémoire. La fonction globals() permet de vérifier la liste des variables globales définies dans la session.
Nous retrouvons alors le “modèle sémantique” à l’identique : noms de tables, de colonnes, à l’exception d’éventuelles mesures. Les colonnes calculées apparaissent quant à elles, comme une “copie en valeur”.
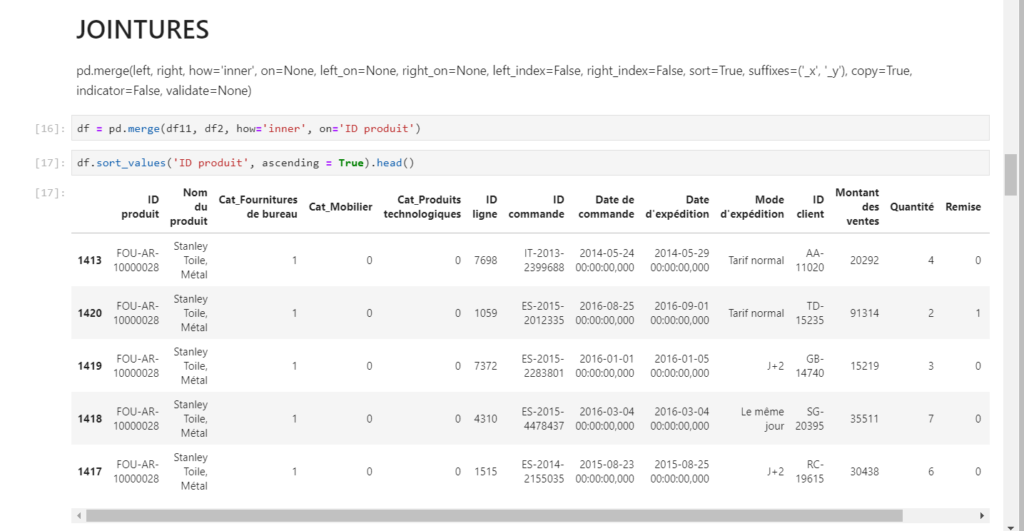
Les relations entre tables pourront être remplacées par des jointures entre dataframes à l’aide de la fonction merge().
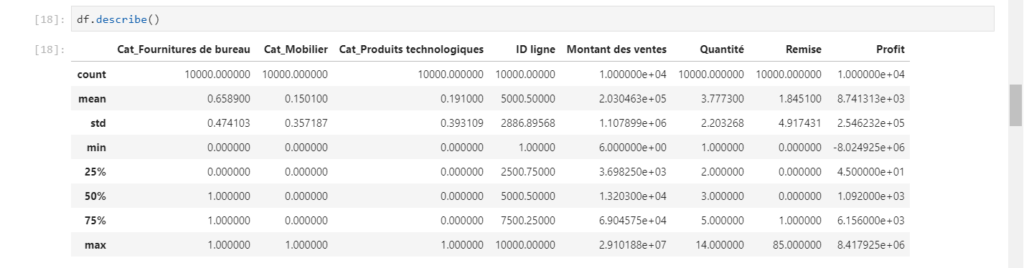
La fonction describe() donne un résumé statistique de toutes les variables numériques.
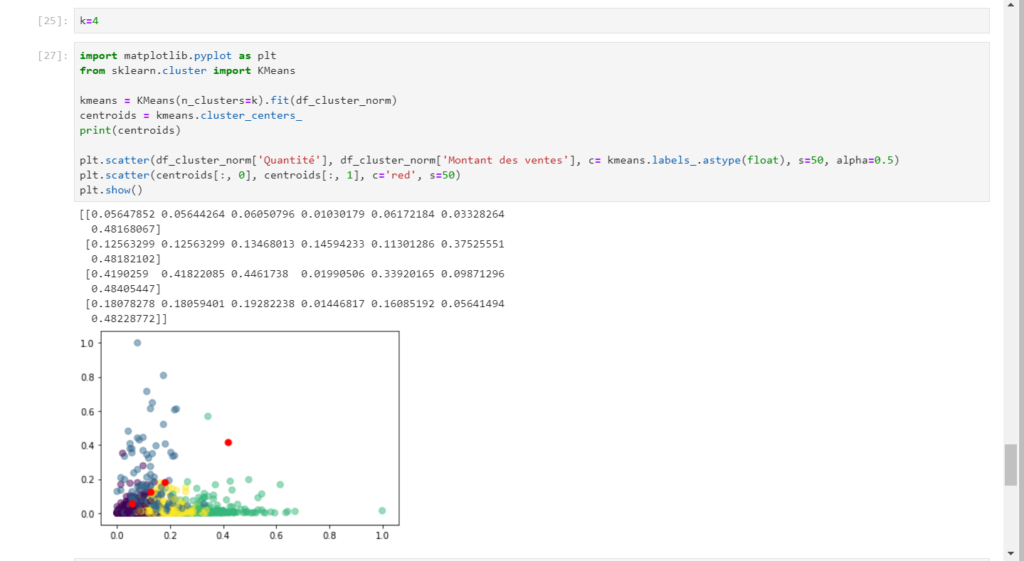
Il est ensuite possible de pousser des analyses exploratoires multidimensionnelles comme un modèle de Machine Learning non supervisé de type KMeans.
Le code complet vous est proposé dans ce notebook.
Il existe aujourd’hui des centaines de tutoriels qui vous apprendront comment construire vos premiers rapports Power BI, et vous trouverez des milliers d’astuces pour les améliorer. Mais quelle démarche mettre en place quand « ça marche pas », « ça plante », « les chiffres sont faux » ?
Il n’y a pas de secret, c’est en se confrontant à des cas réels (c’est-à-dire en entreprise, où les contraintes sont fortes : sécurité, accès limité aux données, annuaire…) et bien souvent en y passant, au moins au début, beaucoup de temps.
Après plus de 6 ans d’utilisation de Power BI (et pas mal de Power Pivot au préalable), j’ai recensé les scénarios ci-dessous, regroupés en deux chapitres que sont la maintenance corrective (« y’a un bug ») et la maintenance évolutive (changement dans les sources de données, dans les requêtes ou dans les formules DAX). J’espère que ces différentes entrées pourront vous aider à gagner du temps dans la maintenance de vos rapports Power BI… temps que vous pourrez investir dans l’analyse des données !
Enfin, vous vous apercevrez sûrement que le respect de bonnes pratiques de développement vous conduira à vous simplifier la tâche de maintenance. Les aspects de documentation feront en particulier l’objet d’un article séparé.
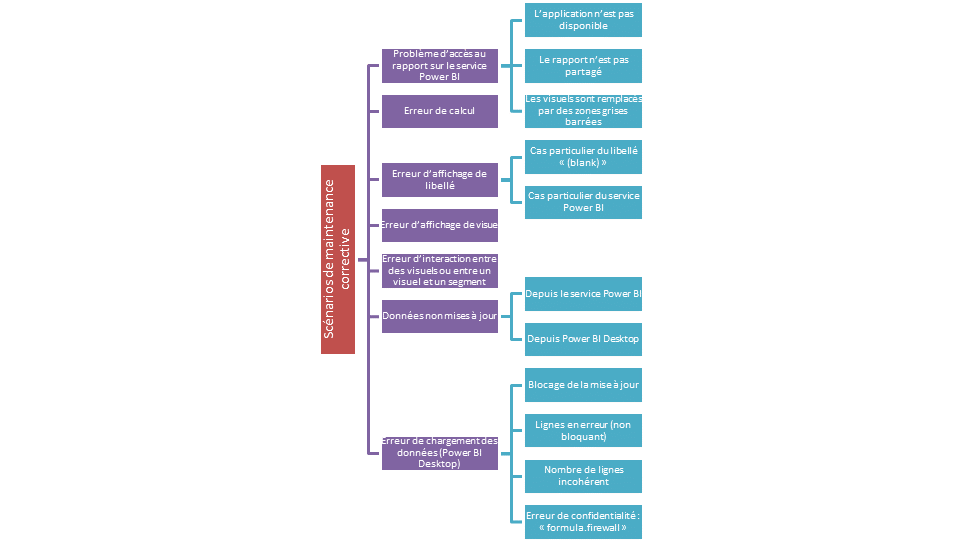
Scénarios de maintenance corrective
Problème d’accès au rapport sur le service Power BI
L’application n’est pas disponible
Une application est visible pour un utilisateur si celui-ci s’y est explicitement abonné. Depuis la page des applications, rechercher l’application par son nom, l’utilisateur doit appartenir aux personnes autorisées.
L’utilisateur n’est pas abonné par défaut si, à la publication de l’application, l’installation automatique n’a pas été cochée.
Attention, cette option peut être désactivée par l’administrateur du service.
Le rapport n’est pas partagé
Après recherche, le rapport n’apparaît pas dans le menu « Partagé avec moi ». Si le partage se fait au travers d’un nom de groupe Azure Active Directory (AAD), vérifier la présence de la personne concernée dans ce groupe.
Les visuels sont remplacés par des zones grises barrées
Il s’agit ici du comportement attendu lorsqu’un jeu de données bénéficie d’une sécurité à la ligne (« Row Level Security ») et que l’utilisateur n’a pas été associé, directement ou au moyen d’un groupe Azure Active Directory (AAD), à un rôle de sécurité statique.
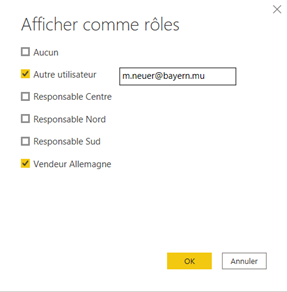
En cas de scénario de sécurité dynamique (sur la base d’une des deux fonctions DAX USERNAME() ou USERPRINCIPALNAME(), et si l’utilisateur a bien été ajouté dans le rôle de sécurité, rechercher si l’utilisateur figure bien dans la table de sécurité intégrée dans le modèle de données.
Réaliser si besoin un test dans le fichier .pbix ouvert dans Power BI Desktop, à l’aide du modèle de simulation de rôle. Pour un scénario de sécurité dynamique, il faut utiliser conjointement les deux cases illustrées ci-dessous.
Erreur de calcul
Une valeur affichée dans un visuel ne correspond pas à la valeur attendue. Tout d’abord, il faut savoir comment a été déterminée la valeur attendue, par un processus extérieur à Power BI (il s’agit normalement du processus de recette fonctionnelle, réalisé à la première publication du rapport).
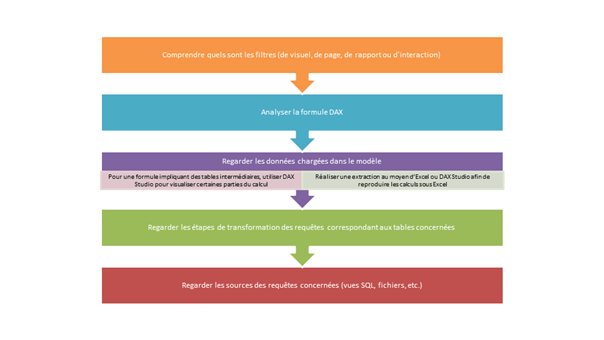
On met alors en œuvre une démarche visant à « détricoter » le calcul :
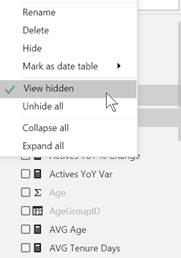
Pour analyser de manière exhaustive les données chargées dans le modèle, on utilisera les filtres sur la vue de données, qui n’ont pas de conséquence sur les données filtrées dans les visuels.
Dans Power BI Desktop, toutes les tables, champs ou mesures n’apparaissent pas obligatoirement, certains éléments pouvant avoir été masqués. Il est important d’activer l’option « View hidden », depuis la liste de champs.
Erreur d’affichage de libellé
On s’interrogera principalement sur l’absence d’une catégorie sur un axe ou dans une légende de visuel. Si celle-ci n’apparaît pas, c’est vraisemblablement en raison d’un « contexte de filtre ». Nous suivrons la démarche suivante :
Vérifier que le libellé attendu figure bien dans la vue de données (celle-ci n’est pas soumise au contexte d’un visuel)
Comprendre quels sont les filtres (de visuel, de page, de rapport ou d’interaction)
Analyser la formule DAX : celle-ci contient-elle des éléments modifiant le contexte de filtre (liste de ces fonctions sur ce site de référence) ?
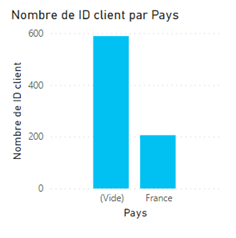
Cas particulier du libellé « (blank) »
Un libellé « (blank) » peut apparaître sur un axe ou en légende d’un visuel comme sur l’exemple ci-dessous.
Cet article et celui-ci pourront vous aider à améliorer vos mesures DAX pour éviter ces valeurs mais il faut avant tout vérifier la complétude des dimensions para rapport aux clés étrangères dans la table de faits. Si c’est un champ de la dimension qui est utilisé pour générer le visuel, les lignes de la table de faits sans correspondance dans celle-ci se retrouveront comptabilisées sur une entrée « blank ».
A l’inverse, il est également important d’analyser les clés de la dimensions qui ne contiennent pas de faits associés, en utilisant la propriété de l’axe : « afficher les éléments sans données ». Nous vérifierons plutôt ici que cela correspond bien aux attentes fonctionnelles.
Cas particulier du service Power BI
Avant toute investigation, utiliser le bouton « Réinitialiser ».
Celui-ci permet de remettre le rapport dans l’état de publication initiale. Les filtres positionnés par l’utilisateur sont remis sur les valeurs définies par le concepteur.
Certains libellés attendus peuvent ne pas apparaître en raison du mécanisme de sécurité à la ligne.
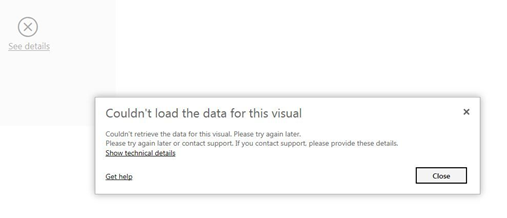
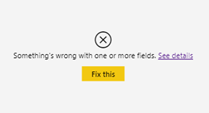
Erreur d’affichage de visuel (grisé et lien vers un message détaillé)
Ici, le visuel échoue aussi bien dans Power BI Desktop que dans le service (ce n’est pas en lien avec les droits de l’utilisateur). La première piste à suivre est celle de la ou des mesures DAX utilisées dans le visuel.
Le bouton « Fix this » aura souvent comme conséquence de supprimer les éléments en erreur dans le visuel, ce qui rend plus difficile la correction à apporter. Un lien est disponible pour afficher un détail, parfois utile, de l’erreur rencontrée.
Erreur d’interaction entre des visuels ou entre un visuel et un segment
Par défaut, c’est-à-dire sans intervention du concepteur de rapport ou mesure réalisant une modification du contexte de filtre, tous les visuels d’une page de rapport interagissent entre eux.
Dans Power BI Desktop, afficher les interactions (cliquer sur un visuel, menu Format puis « edit interactions »). L’état des interactions de chaque autre visuel apparaît alors.
Si le problème persiste, vérifier dans les mesures DAX mises en œuvre la présence d’une formule modifiant le contexte de filtre (liste de ces fonctions sur ce site de référence).
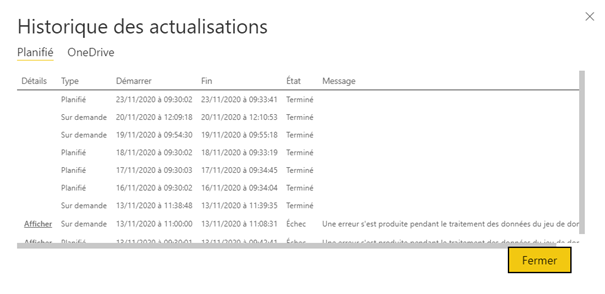
Données non mises à jour
Depuis le service Power BI
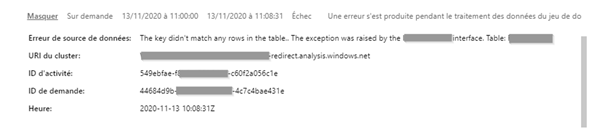
En tant que membre ou administrateur de l’espace de travail où le jeu de données est publié, regarder l’historique des actualisations, le statut de la dernière actualisation (première ligne), cliquer sur « Afficher » ou télécharger éventuellement le fichier de logs associé pour un dataflow.
Un message d’erreur plus détaillé apparaît alors.
Il sera certainement plus simple de corriger la cause de l’erreur à partir du rapport ouvert dans Power BI Desktop.
Depuis Power BI Desktop
Vérifier le chemin d’accès aux données sources. Pour une base de données, pointe-t-on vers la base ou le schéma de production ? Pour des fichiers, les nouvelles versions sont-elles bien présentes ?
Utiliser l’actualisation depuis le rapport et non dans l’éditeur de requêtes qui n’actualise qu’un aperçu des premières lignes des données. Il est possible d’actualiser une table spécifiquement par clic droit sur celle-ci, puis « actualiser ».
Erreur de chargement des données (Power BI Desktop)
Blocage de la mise à jour des données
Analyser le message d’erreur obtenu.
Tester le chargement de chaque table individuellement.
Ouvrir l’éditeur de requêtes et observer les requêtes en erreur (triangle jaune à côté du nom de la requête).
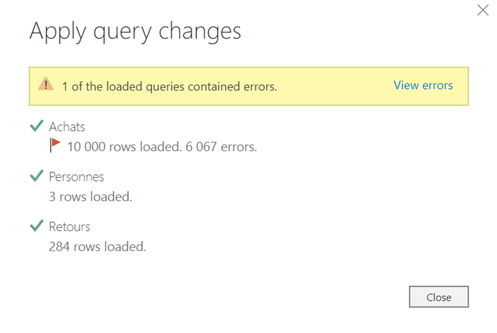
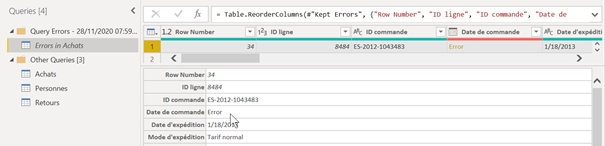
Lignes en erreur (non bloquant)
Lorsque seules certaines cellules d’une colonne sont en erreur dans l’éditeur de requête, le chargement de la table se termine mais un message indique un nombre de lignes en erreur.
Ces lignes sont difficilement identifiables dans la requête principale car il ne s’agit que d’un aperçu des premières lignes. Il vaut mieux cliquer sur le lien « view errors ». Celui-ci ouvre l’éditeur de requêtes et montre un nouveau groupe contenant les erreurs des requêtes.
Cliquer dans la cellule (et non sur le lien Error) permet d’afficher la valeur initiale avant transformation et un message d’erreur pouvant mettre sur la voie du correctif à appliquer.
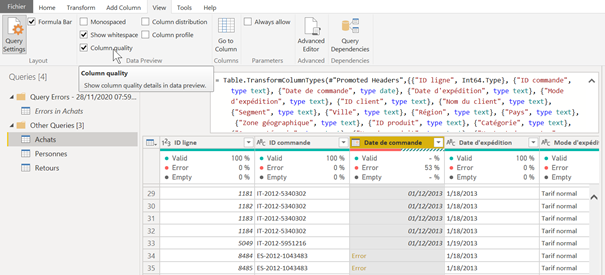
En ajoutant l’indication de la qualité de la colonne, trois indicateurs apparaissent :
Pourcentage de lignes valides (« valid »)
Pourcentage de lignes en erreur (« error »)
Pourcentage de lignes vides (« empty »)
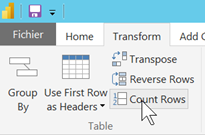
Nombre de lignes incohérent
Utiliser une étape temporaire (que l’on supprimera une fois les contrôles terminés) de comptage de lignes et faire “avancer” cette fonction après chaque étape afin de vérifier le nombre de lignes obtenues.
Contrairement aux autres étapes, le nombre de lignes n’est pas évalué sur un aperçu mais sur la totalité de la source de données.
Il ne faut pas oublier de supprimer cette étape, une fois les contrôles terminés.
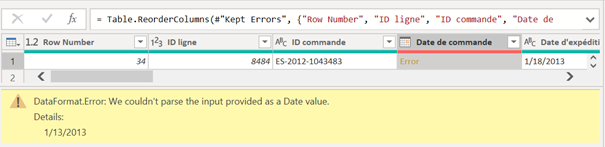
Erreur de confidentialité : « formula.firewall »
Il s’agit sans doute d’un des messages d’erreur les plus abscons de Power BI. Il signifie que des niveaux de confidentialité entre des sources de données produit une alerte (bloquante) de sécurité.
Le paramétrage est à refaire à chaque première utilisation du rapport sur un poste.
Plus d’informations sur ces concepts sont disponibles en suivant les liens ci-dessous :
Champ d’une table ou vue utilisée dans une requête
Ajout
Le nouveau champ apparaîtra dans la requête puis dans la table du modèle, sans causer d’impact hormis sur certaines étapes utilisant la logique de sélection inversée (opération sur les « autres colonnes »). C’est ainsi souvent le cas sur l’opération unpivot.
Sauf à appartenir à une table masquée, ce champ sera ensuite visible des utilisateurs qui ont accès au dataset et l’on devra veiller à ce qu’il ne comporte pas d’informations non appropriées (techniques, hors usage métier ou confidentielles).
Modification de type
Les types de champs dans la requête découlent des types des colonnes en base (vérifier les correspondances).
Nouvelles valeurs
L’apparition de nouvelles valeurs n’est pas d’impact sur le chargement d’une requête sauf si celles-ci contredisent le type de colonne (erreur non bloquante mais cellules mises à null). Elles peuvent toutefois modifier le comportement de certaines étapes de requêtes (filtre, unpivot, etc.).
L’apparition de doublons pourrait bloquer le chargement d’une requête si le champ est utilisé en tant que « côté 1 » sur une relation de type « 1 à plusieurs ».
Dans le rapport, il faudra contrôler les filtres sur les visuels, voire les visuels devenant moins lisibles avec un plus grand nombre de valeurs (apparition de barre de scrolling).
Renommage
Une colonne renommée n’aura un impact sur le chargement d’une requête que si elle est explicitement citée dans le script M et n’engendrera donc une erreur (bloquante pour le chargement).
Attention, de nombreuses opérations faites en langage M déclarent le nom des champs dans le script mais selon l’opération, il pourra s’agir des champs sur lesquels portent l’action ou bien des autres champs. C’est le cas des opérations de sélection, suppression, unpivot, etc.
Suppression
Une colonne supprimée n’aura un impact sur le chargement d’une requête que si elle est explicitement citée dans le script M et n’engendrera donc une erreur (bloquante pour le chargement). La première étape susceptible d’utiliser un nom de champ serait la requête SQL en étape source mais ceci n’est pas recommandé car empêche le déclenchement du query folding et il préférable de créer une vue dans la base de données.
La source est un fichier
Champ d’un fichier utilisé dans une requête
Ajout
Pour le chargement d’un fichier texte, le script généré automatiquement fait figurer le nombre de colonnes détectées. Ce paramètre est facultatif, il est donc possible de le supprimer pour qu’une nouvelle colonne soit automatiquement intégrée.
Toutefois, l’arrivée d’une nouvelle colonne dans une requête puis dans une table n’étant pas anodine, ce n’est sans doute pas une pratique à encourager.
Pour les actions suivantes, le comportement est identique à celui d’une source de type base de données (voir ci-dessus).
Modification de type
Nouvelles valeurs
Renommage
Suppression
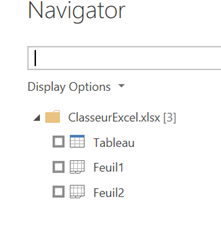
Cas particulier des classeurs Excel
En connexion à un classeur Excel, plusieurs informations sont nécessaires : chemin et nom de fichier, nom de la feuille et le type de plage source (Sheet ou Table).
Dans l’exemple ci-dessous, la feuille 1 du classeur contient un tableau, repérable ici, en plus de son nom, par une icône dédiée.
Si l’on choisit une feuille comme source, le script M se génère de la sorte :
En choisissant un tableau, la seconde ligne devient :
= Source{[Item="Tableau",Kind="Table"]}[Data]
De plus, il n’y aura pas d’étape « Promoted headers », les colonnes étant directement nommées par les noms contenus dans la ligne d’en-têtes du tableau.
Dans les deux cas, il n’y pas de nombre de colonnes indiqué explicitement, comme pour une source de type fichier. En conséquence, les opérations ci-dessous engendrent un comportement similaire à celui-ci obtenu avec une source de type base de données. Ces paragraphes ne sont donc pas développés.
Ajout
Modification de type
Nouvelles valeurs
Renommage
Suppression
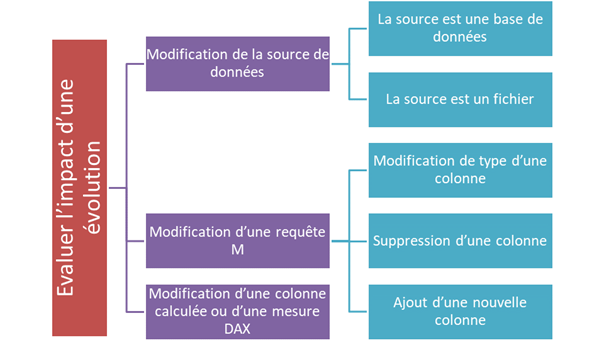
Modification d’une requête M
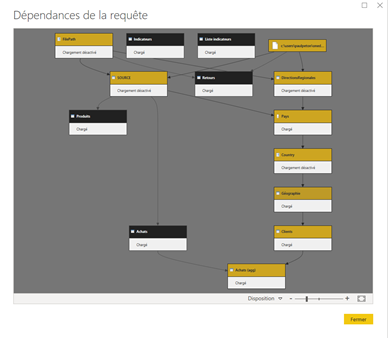
Les requêtes M aboutissent généralement à une table dans le modèle de données, mais pas toujours, il existe des requêtes intermédiaires qui n’ont pas à être chargées dans le modèle). Nous commencerons donc par afficher la vue des dépendances de requêtes (« query dependencies »).
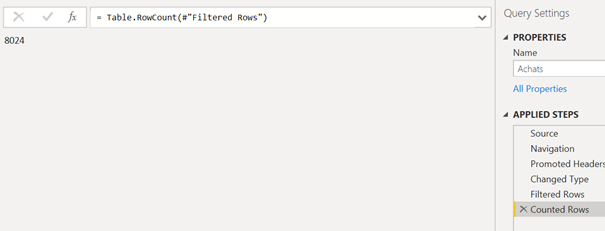
Modification de type d’une colonne
Rappelons que toute colonne devrait être explicitement typé en fin de requête (pas de « ABC123 » qui finirait par donner un champ texte). Une modification forte entre des types très différents (nombre, texte, date) aura une conséquence sur des formules DAX utilisant ce champ et peut-être sur des visuels où le comportement n’est pas le même selon le type de donnée (exemple : axe d’un graphique, champ d’un segment). Une modification pour un « sous-type » assez proche (entier pour décimal, date/heure pour date) devrait avoir un impact moindre.
On portera une attention particulière à la modification de type sur des champs utilisés comme clés entre des tables.
La modification de type peut également avoir un impact sur des étapes ultérieures de la requête.
Suppression d’une colonne
La suppression d’une colonne est une excellente pratique en termes de réduction de taille du jeu de données mais il faut bien entendu vérifier au préalable qu’elle n’est utilisée ni dans une relation, ni dans un champ calculé, ni dans une mesure, ni dans des visuels ou filtres.
Ajout d’une nouvelle colonne
L’ajout de colonne ne fera qu’enrichir le modèle (et alourdir son poids). Par défaut, le nouveau champ ne sera pas masqué, sauf s’il appartient à une table du modèle entièrement masquée. Il faudra être attentif au fait de ne pas mettre à disposition des utilisateurs un champ auquel ils n’auraient pas à accéder (champ technique, information confidentielle, etc.).
Modification d’un champ calculé ou d’une mesure DAX
Il est important de préciser qu’une telle modification évolutive n’intervient qu’en cas de changement des règles de gestion.
Pour une colonne calculée, regarder ses dépendances avec d’autres formules DAX (colonnes calculées ou mesures), chercher son utilisation dans des relations, des visuels, filtres ou rôles de sécurité.
Pour une mesure, regarder ses dépendances avec d’autres mesures, chercher son utilisation dans des visuels ou filtres.
Pour des données établissant une série temporelle (mesure numérique à intervalles de temps régulier), la première étape de mise en qualité des données sera bien souvent de corriger les données dites aberrantes, c’est-à-dire trop éloignées de la réalité.
Rappelons les différents cas pouvant amener à ce type de données : – erreur de mesure ou de saisie (maintenant plutôt lié à une erreur “informatique”) – dérive réelle et ponctuelle (souvent non souhaitée, correspondant à un défaut de qualité) – hasard (événement assez peu probable mais pouvant néanmoins se produire exceptionnellement!)
Avec la version de novembre 2020 de Power BI Desktop, nous découvrons une nouvelle fonctionnalité en préversion (donc à activer depuis le menu Options) qui ajoute une entrée dans le menu Analytique des graphiques en courbe (“line chart“).
Tout d’abord, regardons les limites d’utilisation précisées à cette page. Si 12 points sont le minimum requis (ou 4 patterns saisonniers), il sera beaucoup plus pertinent d’en avoir en plus grand nombre ! Ensuite, de nombreuses fonctionnalités ne sont pas (encore ?) compatibles avec la détection d’anomalies : légende, axe secondaire, prévision (forecast), live connection, drill down…
Fonctionnement théorique
Le papier de recherche qui décrit l’algorithme utilisé, nommé unsupervised SR-CNN, est disponible ici. Nous allons essayer de le vulgariser sans trop d’approximations.
Cet algorithme d’apprentissage automatique fait partie de la catégorie des méthodes non-supervisées, c’est-à-dire qu’il n’est pas nécessaire de disposer a priori d’un échantillon de données d’apprentissage où les anomalies seraient déjà identifiées (approche supervisée).
Les deux premières lettres du nom de cette approche correspondent à la méthode dite Spectral Residual, basée sur des transformées de Fourier, qui met en valeur des éléments “saillants” (salient) de la série temporelle.
Issus du domaine du Deep Learning, les réseaux de neurones à convolution (CNN) ont émergé dans le domaine du traitement d’images en deux dimensions. Pour autant, il est tout-à-fait possible de les utiliser dans le cadre d’une série temporelle à une dimension. Au lieu d’analyser des fragments d’images, la série des données transformées va être reformulée comme plusieurs successions de valeurs.
Ainsi, la série {10, 20, 30, 40, 50, 60} pourra donner des séries comme {10, 20, 30}, {20, 30, 40} ou encore {40, 50, 60} (voir ce très bon article pour aller plus loin dans le code).
Le rôle de la couche de convolution est d’extraire les features (caractéristiques) de la série temporelle. Ce sont elles qui permettront ensuite de décider si une valeur est ou non une anomalie.
D’un point de vue de l’architecture du réseau, la couche de convolution à une dimension est suivi d’une couche “fully connected” qui fait le lien entre le résultat de la convolution et le label de sortie (anomalie ou non).
Allons maintenant à la recherche d’un jeu de données pour expérimenter cette fonctionnalité !
Test sur un jeu de données
Il existe des jeux de données de référence pour évaluer la performance de la détection d’anomalies, et plus spécifiquement dans le cadre des séries temporelles. Vous en trouverez par exemple sur cette page.
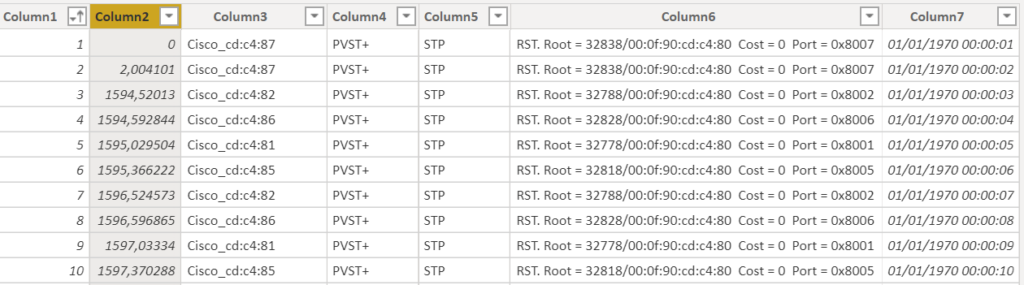
Nous travaillerons ici avec un jeu de données de trafic réseau.
Ce dataset contient environ 4,5 millions de lignes.
La détection d’anomalies se déclenche dans le menu Analytique du visuel.
Un seul paramètre est disponible pour régler le niveau de détection, entre 0 et 100% : sensitivity.
Plus la valeur est élevée, plus “l’intervalle de confiance” en dehors duquel sera détectée une anomalie est fin. Autrement dit, plus la valeur approche des 100%, plus vous apercevrez de points mis en évidence. Difficile de dire sur quoi joue ce paramètre d’un point de vue mathématique, il n’est pas évoqué dans le papier de recherche cité précédemment.
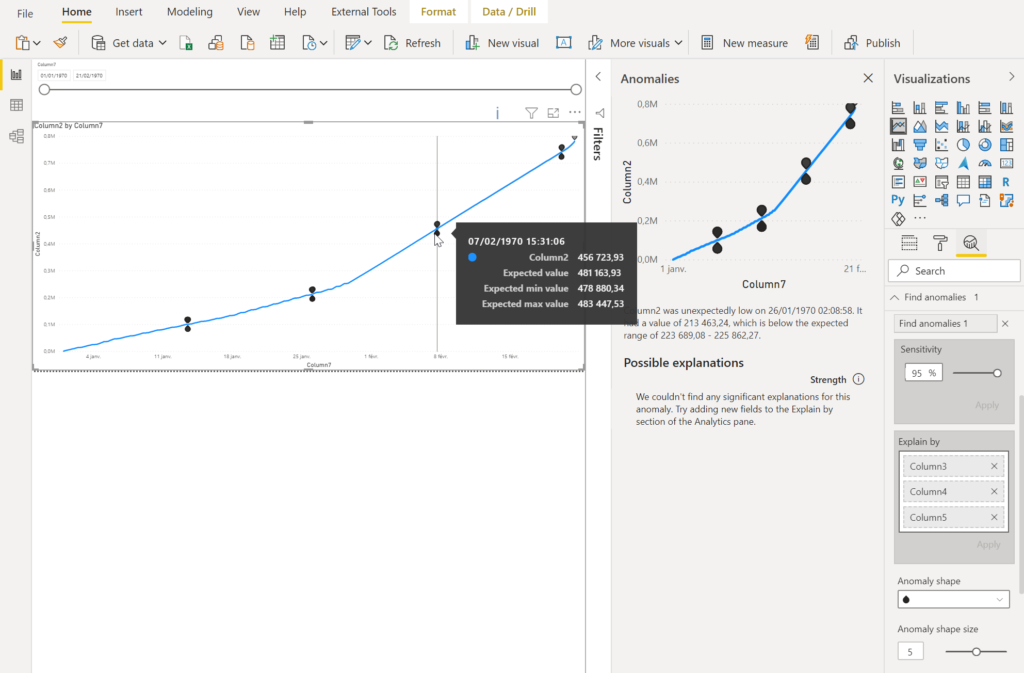
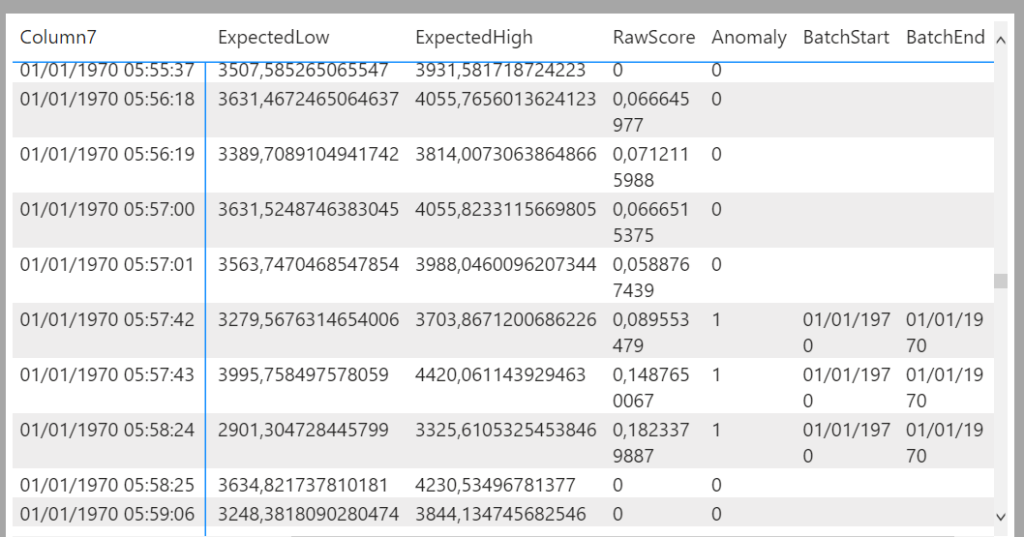
En cliquant sur un point, s’ouvre un nouveau volet latéral donnant les valeurs de la plage attendue, reprises également dans l’infobulle.
En plaçant d’autres champs de la table dans la case “explain by“, on peut espérer mettre une évidence un facteur explicatif de cette anomalie.
Attention, il n’est pas envisageable de “zoomer” sur un portion du graphique contenant une anomalie car cela modifiera la plage de données servant à évaluer l’algorithme et fera donc apparaître ou disparaître des points identifiés comme aberrants !
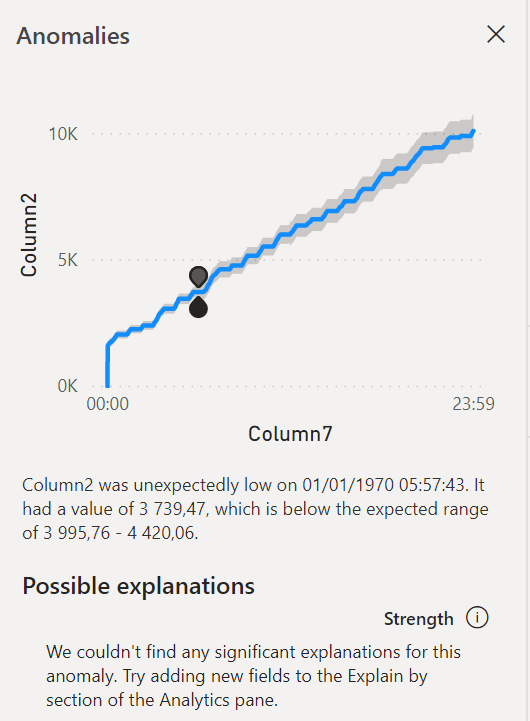
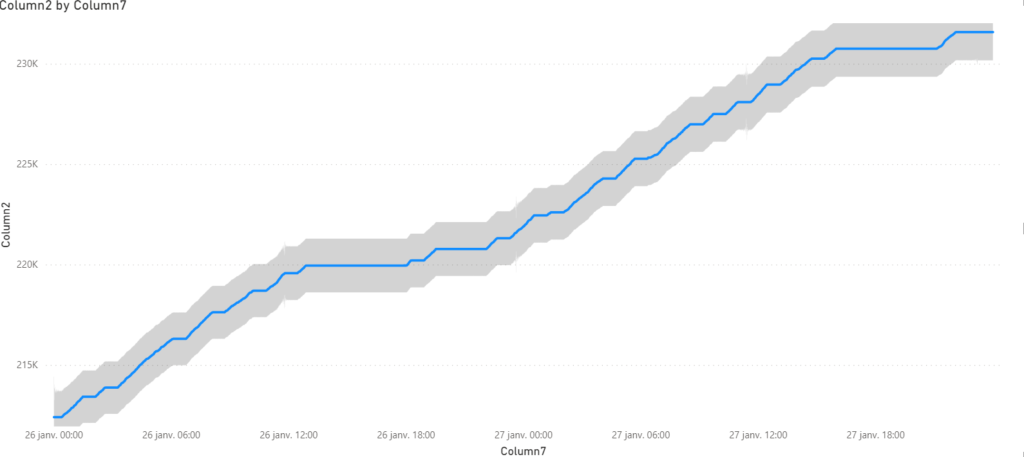
Zoom sur une journée contenant initialement une détection d’anomalies
On pourra plutôt profiter de l’affichage du visuel en tant que table de données qui dispose d’une colonne “anomaly” valant 0 ou 1. On s’aperçoit ici que plusieurs points consécutifs sont identifiés comme des anomalies, ce qui était difficilement identifiable sur le graphique.
En conclusion
Malheureusement, les informations obtenues au travers de ce visuel ne peuvent pas réellement être exploitées : pas d’indicateur créé dans la table, pas d’export au delà de 30000 points (soit un peu plus de 8h pour des données à la seconde), un modèle perpétuellement recalculé et ne pouvant être arrêté sur une période. Alors, que faire lorsque des anomalies apparaissent ? Rien hormis prévenir le propriétaire des données…
Comme pour les autres services touchant (de loin) à l’IA sous Power BI, je suis sceptique quant au moment où cette fonctionnalité est mise en œuvre. La détection d’anomalies est une étape de préparation de la donnée et hormis à effectuer un reporting sur ces anomalies elles-mêmes, nous sommes en droit d’attendre qu’elles soient déjà retirées des données avant exposition. Il serait donc beaucoup plus opportun d’utiliser le service cognitif Azure dans un dataflow (Premium ou maintenant en licence Premium Per User) afin de mettre la donnée en qualité lors de la constitution de donnée. Pour une détection sur un flux de streaming, on se tournera avec intérêt vers les possibilités offertes par Azure Databricks, comme exposé dans ce tutoriel.
A l’inverse, les algorithmes prédictifs qui ne peuvent être utilisés que dans les dataflows seraient beaucoup plus à leur place dans un visuel qui permettrait de tester différents scénarios et d’observer les prévisions associées.
En résumé, les ingrédients de la recette sont les bons, encore faut-il les ajouter dans l’ordre pour obtenir un plat satisfaisant !
L’algorithme choisi (SR-CNN) ne doit pour autant pas être remis en cause car il semble aujourd’hui représenter l’état de l’art de la détection d’anomalies;
Vos remarques sur cet outil peuvent être déposées sur cette page communautaire.
Jusqu’à présent, nous utilisions le connecteur Spark générique comme présenté dans cet article. Le seul mode d’authentification possible consistait à utiliser un jeton personnel (personal access token).
Nous pouvons nous connecter à des tables créées dans des databases du metastore du cluster Databricks et cela implique que le cluster soit démarré afin que la connexion soit possible.
Ce sont donc des informations au niveau cluster dont nous aurons besoin pour nous connecter. Ce paragraphe détaille les éléments attendus que sont le hostname, le port (443 par défaut) et le HTTP path.
Un connecteur dédié est apparu en préversion publique depuis octobre 2020 et présenté sur cette page de la documentation officielle Microsoft.
Nous remarquons que les deux modes import et DirectQuery sont disponibles, le second étant bien sûr conditionné par le statut démarré permanent du cluster.
Un paramètre est ici très important : le batch size. Il s’agit de la taille des “paquets” de lignes qui seront extraits du cluster. Nous reviendrons sur ce paramètre dans la section liée à la performance.
Nous disposons ensuite de trois modes de connexion, dont le mode “classique” par Personal Access Token mais également l’authentification au travers de l’annuaire Azure Active Directory (AAD).
C’est ce dernier que nous utiliserons ici.
Nous obtenons alors l’accès au metastore du cluster, afin de sélectionner une ou plusieurs tables.
Il est alors possible de charger directement les données dans une table du modèle ou bien d’ajouter des transformations dans la fenêtre Power Query. Pour autant, l’intérêt du cluster Spark est bien de réaliser toutes les transformations de données avant de créer une table “nettoyée”.
Pour l’actualisation planifiée du rapport dans le service Power BI, nous choisissons le mode d’authentification OAuth2.
Le niveau de confidentialité Organizational exige que la source de données Azure Databricks fasse partie de l’abonnement Azure sur lequel est défini l’annuaire AAD.
Afin de ne pas lier un compte personnel à un jeu de données Power BI, il sera préférable d’utiliser un compte de service. A l’heure actuelle (novembre 2020), la connexion au travers d’un principal de service ou d’une identité managée n’est pas réalisable.
Qu’attendre des performances ?
Afin de tester ce connecteur, nous chargeons comme table du cluster le fichier des Demandes de Valeur Foncière de 2019, soit 400Mo pour environ 3 millions de lignes.
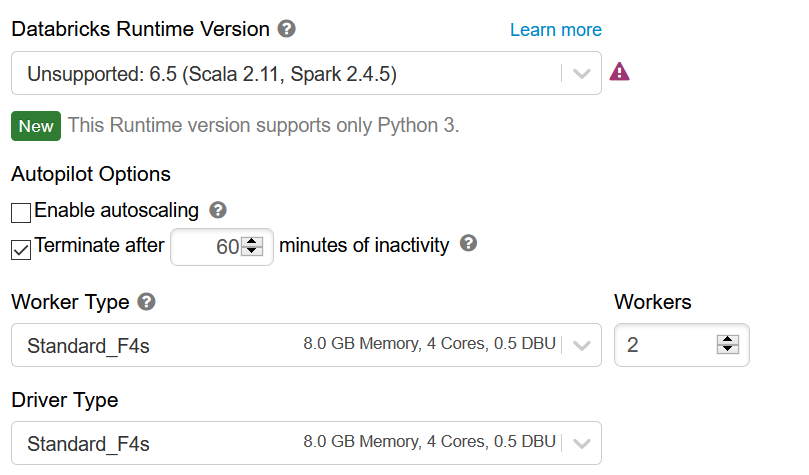
La configuration du cluster est également à prendre en compte puisqu’elle déterminera la capacité à lire la donnée stockée dans la table. Nous débutons avec la configuration ci-dessous, et une version 2.4.5 de Spark.
En réglant le batch size à 100000 puis 200000 lignes, nous passons de 4 minutes à 2’30. L’augmentation de taille n’apporte alors plus de gain significatif.
A l’inverse, une taille de batch à 10000 serait dramatique : l’actualisation du jeu de données depuis Power BI prend alors plus de 11 minutes ! Si l’on ne précise pas le paramètre, le temps d’actualisation est correcte : 3’30.
Changeons maintenant le runtime du cluster pour une version 7.2 s’appuyant sur Spark 3. Sur la base d’un batch size de 200000 lignes, il n’y a pas de gain de temps de chargement.
Changeons enfin la configuration du driver : celui se base maintenant sur une VM Standard_F8s de 16Go de RAM et 8 cœurs. Sur ce jeu de données relativement petit pour un contexte Spark, pas d’amélioration du temps de chargement. La même observation se répète en changeant cette fois-ci la configuration des workers.
Sans avoir pu le tester, il semble important, à l’évidence, que les ressources Azure Databricks et Power BI soient situées dans la même région.
Pour conclure cette partie de tests, sachez que le temps d’actualisation avec le connecteur Spark générique est d’environ 5 minutes (batch size de 200000 lignes), un léger gain est donc obtenu.
Peut-on faire de l’actualisation incrémentielle ?
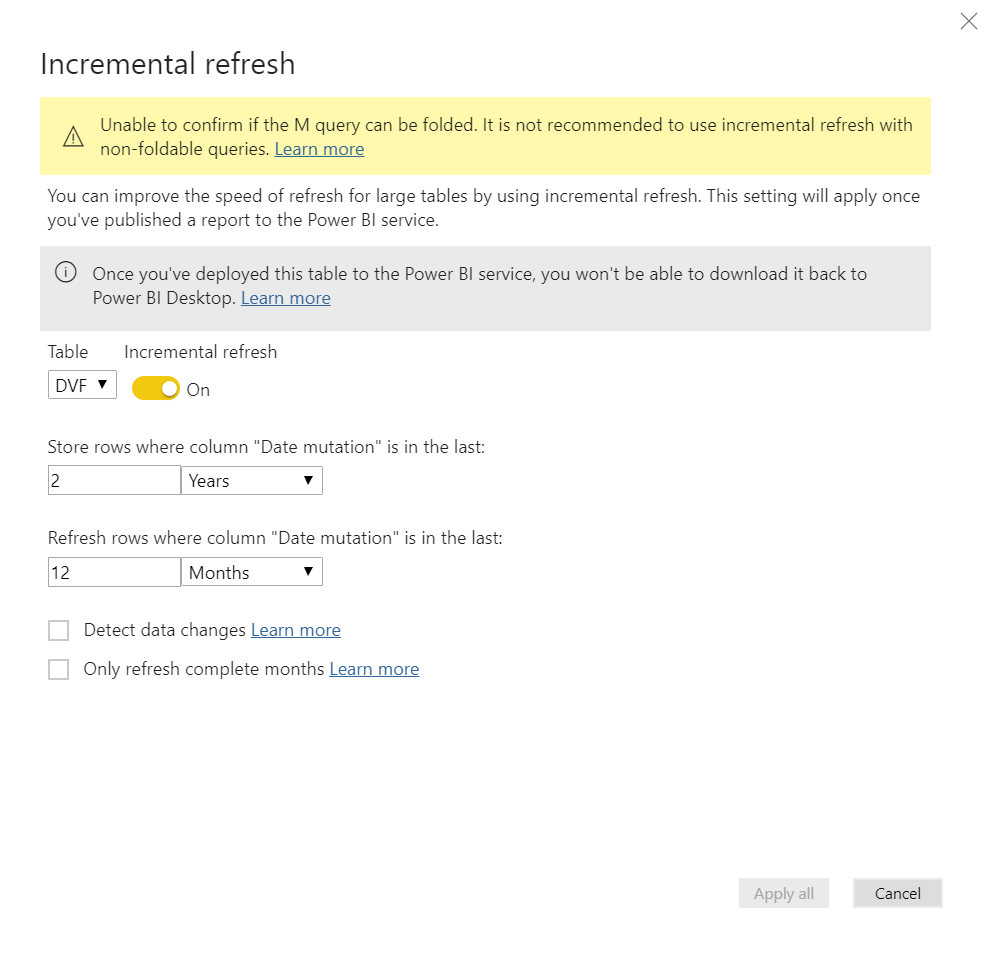
Par défaut, l’actualisation d’un jeu de données annule et remplace toutes les données. Il est toutefois possible de mettre en place une approche sur un champ de type datetime pour n’actualiser qu’une plage de dates définie. Sur cet écran, nous souhaitons conserver 2 années d’historique et ne mettre à jour que les 12 derniers mois.
Un message d’alerte que le mécanisme ne sera effectif que la requête M est “pliable” (traduction approximative du concept de query folding), ce qui signifie que le moteur d’exécution de la requête (ici, le moteur Spark) doit pouvoir interpréter la requête dans un langage natif, comme le SQL. Concrètement, les paramètres de dates deviennent des conditions “WHERE” dans la requête. D’un point de vue du stockage de données, celles-ci sont partitionnées selon la granularité de dates utilisée dans la paramétrage (ici, le mois).
Afin de vérifier si toutes les partitions ou non sont actualisées, il faut utiliser un espace de travail Power BI de capacité Premium et se connecter selon le processus détaillé dans cette page.
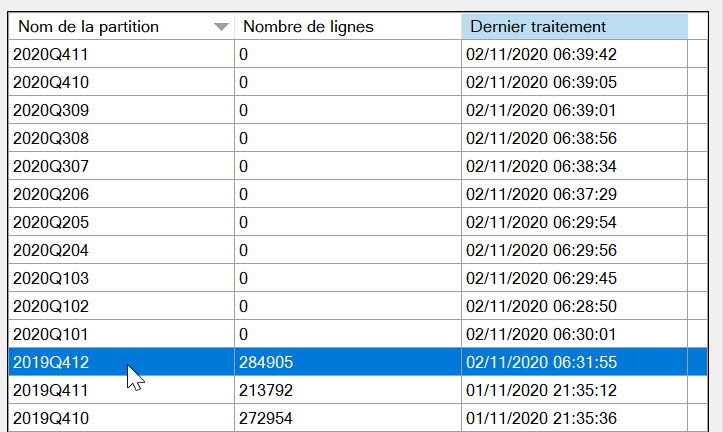
Ensuite, depuis SQL Server Management Studio, nous pouvons visualiser les partitions et l’heure de traitement.
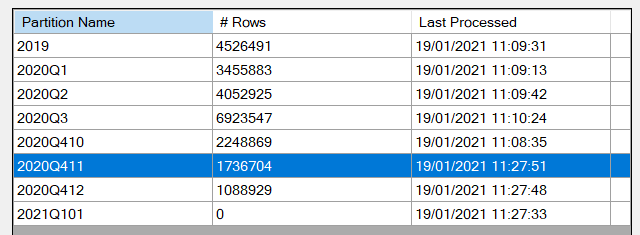
Le jeu de données ne couvre que l’année 2019, ce qui explique les nombres de lignes à 0 à partir de 2020. Les partitions antérieures à décembre 2019 n’ont pas été rafraichies, ce qui correspond bien au comportement souhaité. En revanche, il faut se méfier du temps total que peut prendre une telle approche car elle multiplie les requêtes auprès du cluster, partition par partition.