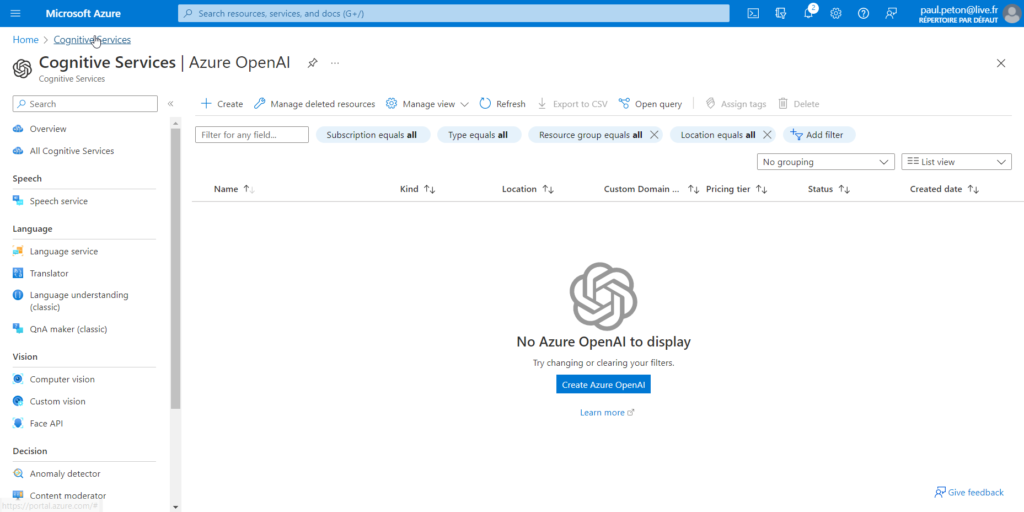
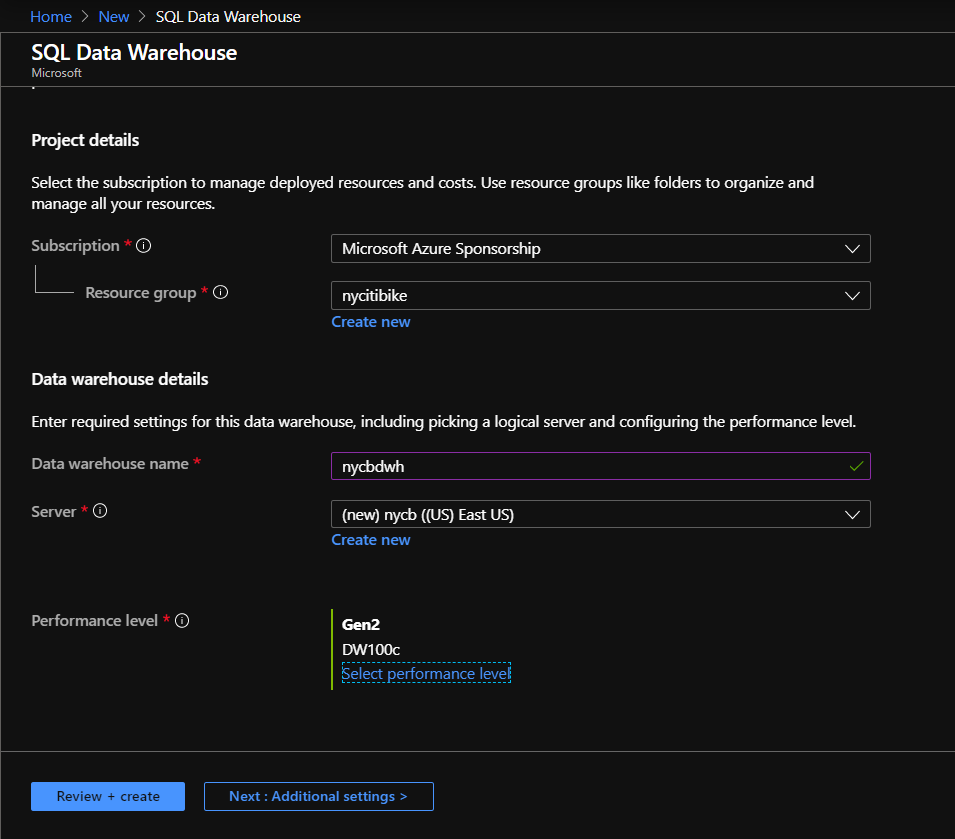
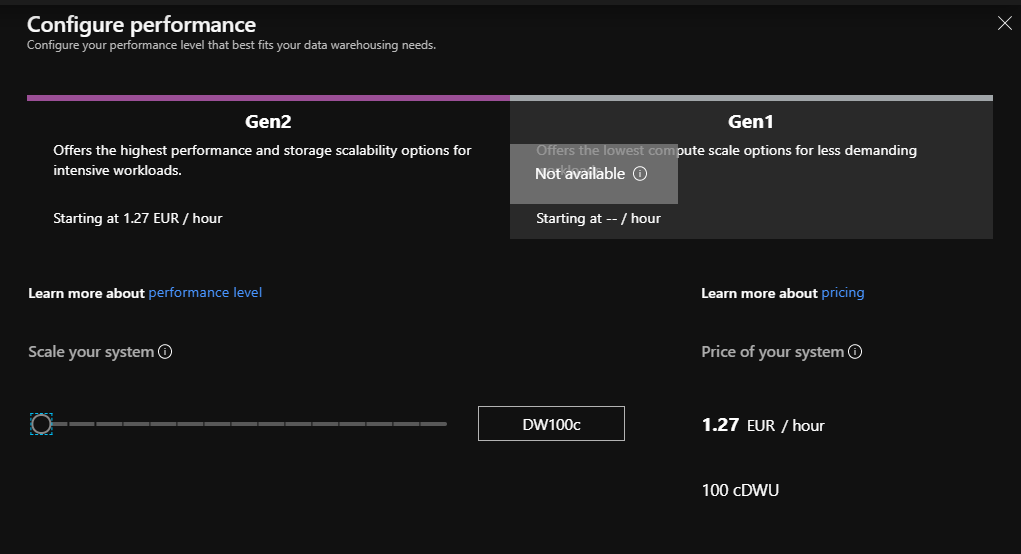
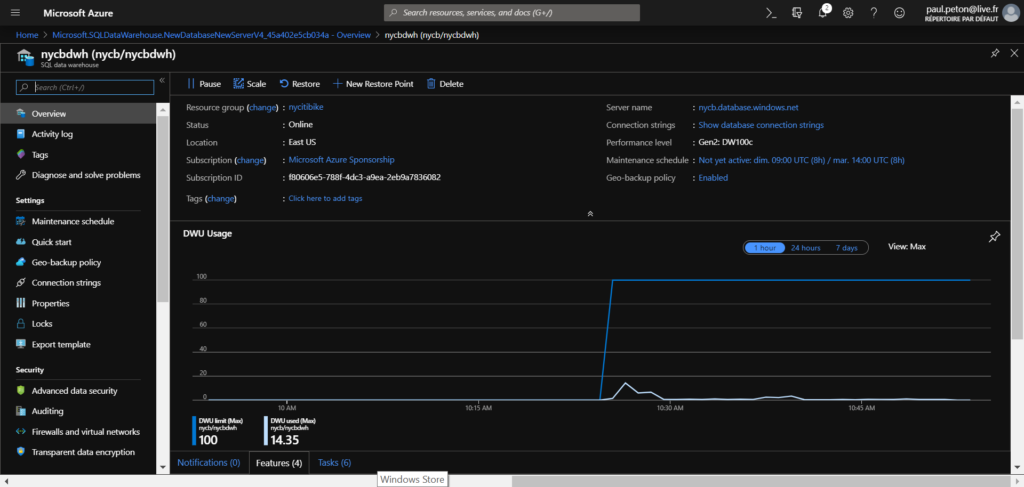
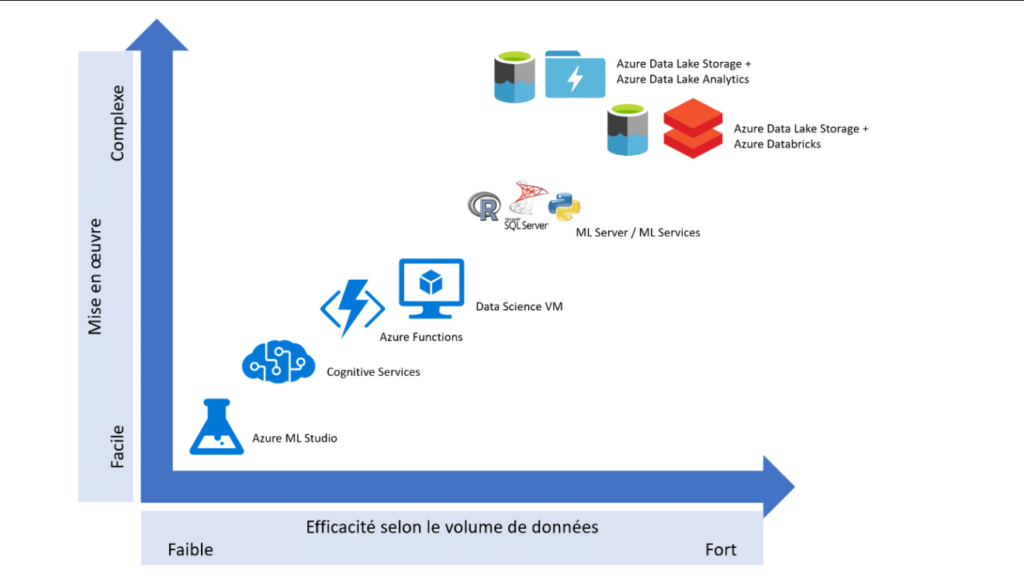
Lorsque votre souscription Azure aura été autorisée à déployer le service OpenAI (voir ce précédent article), vous pourrez accéder à l’écran ci-dessous.
Au cours de cet article, nous allons donner un premier aperçu des fonctionnalités disponibles et insister sur les différences entre le service OpenAI directement disponible et son intégration au sein du cloud Microsoft Azure.
Afin d’expérimenter les différents modèles, nous allons tout d’abord nous connecter au studio Azure OpenAI sur l’URL https://oai.azure.com/
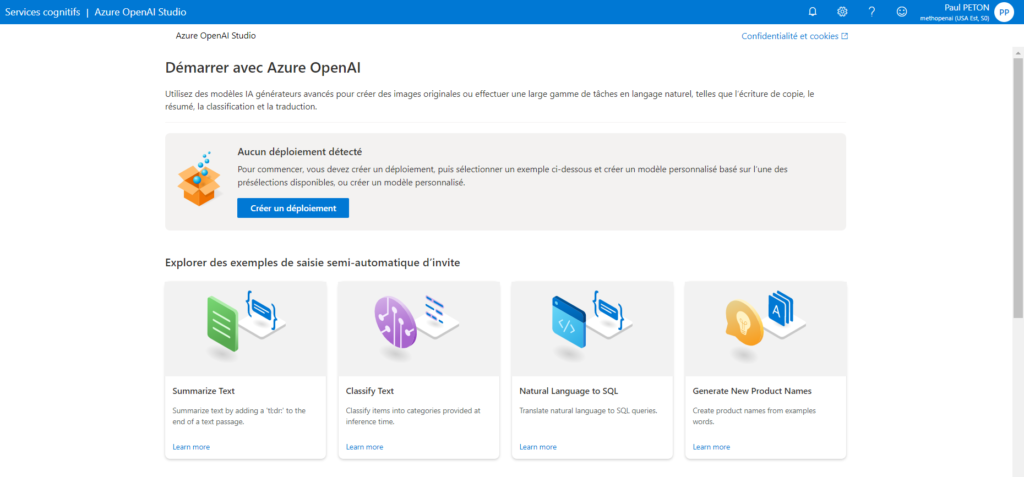
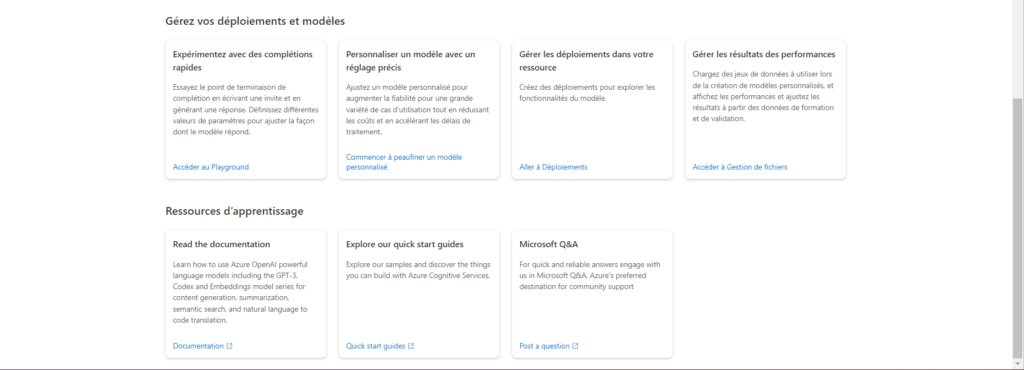
La page d’accueil fournit de nombreux liens d’exemples et de documentation.
Nous retrouvons le playground de OpenAI et la possibilité d’expérimenter des prompts dans différents scénarios :
- résumé
- classification
- génération de code
- etc.
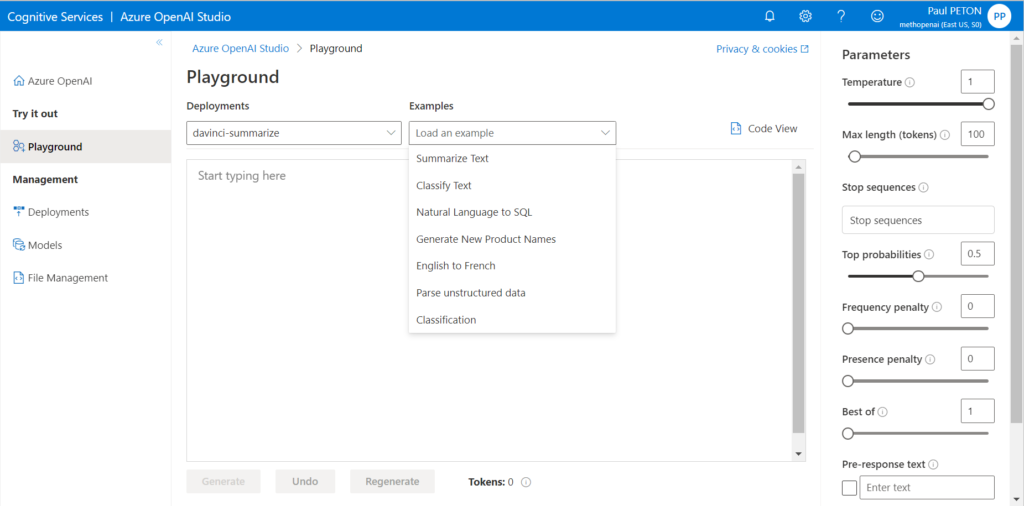
Nous ne retrouvons toutefois pas, pour l’instant (février 2023), l’intégralité des exemples proposés dans le playground d’OpenAI.
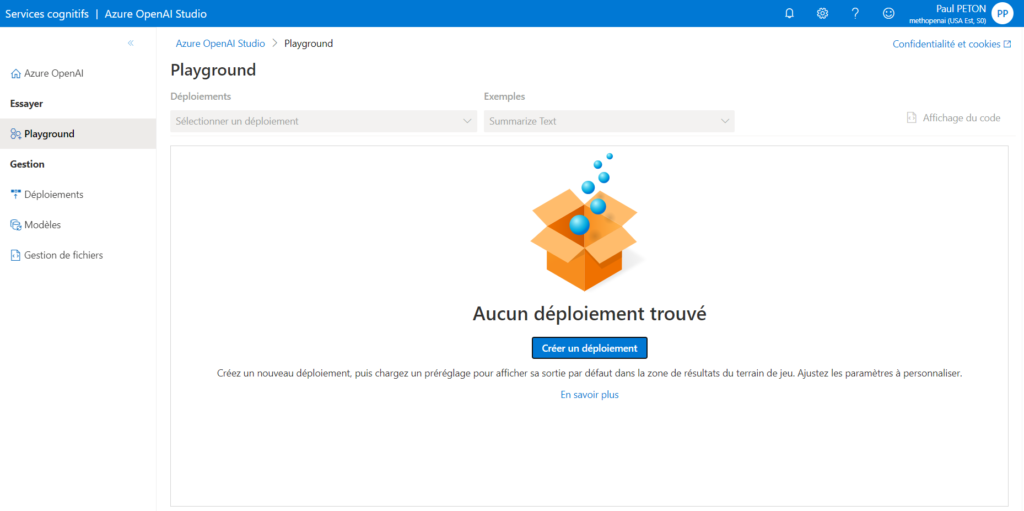
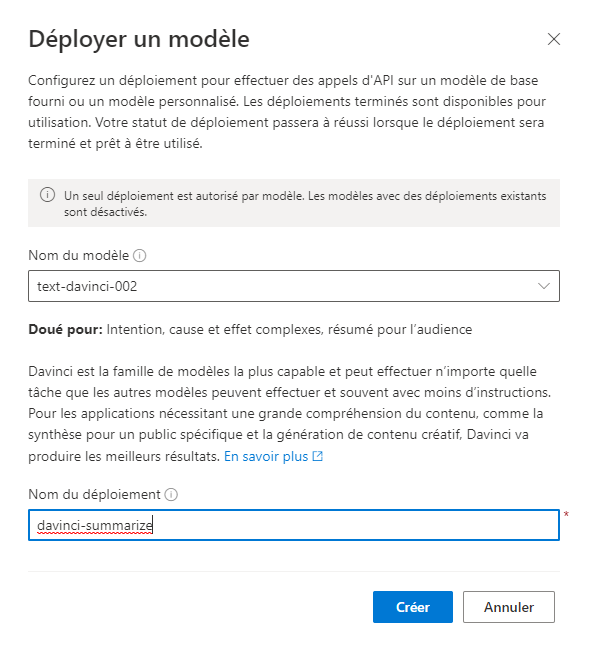
Déployer un modèle
C’est la première opération à réaliser afin de pouvoir utiliser les différents services : déployer l’un des modèles disponibles. Par défaut, aucun modèle n’est déployé dans le studio.
Il faut tout d’abord sélectionner l’un des modèles de base.
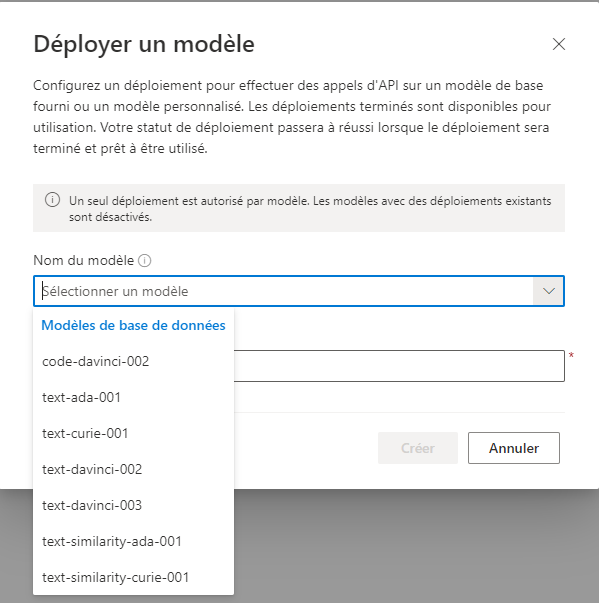
Une description rapide des différents modèles est donnée, afin d’aider à la sélection. Les modèles dédiés au langage naturel, dérivant de GPT-3, sont décrits dans cette partie de la documentation officielle.
Il est alors possible de retourner dans le playground et de sélectionner le déploiement réalisé.
Complétion de texte
C’est ici que l’expérience avec un modèle GPT-3 peut s’avérer déstabilisante. En effet, nous sommes face à un outil destiné à traiter le langage naturel et également à interagir de la sorte. Nous n’avons donc d’un simple prompt pour exprimer notre demande. Attention à l’angoisse de la page blanche !
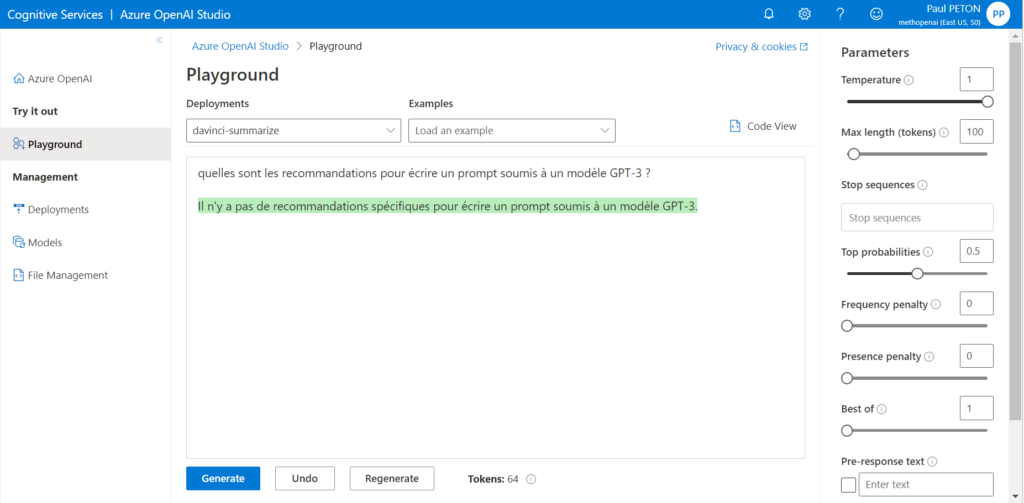
Le résultat généré est identifié par un surlignage vert. On remarquera l’indicateur du nombre de tokens, correspondant à la longueur du texte contenu dans le prompt.
Le paramètre de température permet de gérer l’aspect stochastique du modèle (comprendre que les prévisions peuvent changer même avec un prompt similaire). Dans l’exemple ci-dessous, le résultat est généré trois fois, avec une température de valeur 1.
Write a original prompt for image generation with DALL-E 2
What would DALL-E draw if you asked it to generate an image of a "perfect day"?
What if DALL-E was asked to generate an image of a world where everyone was happy and there was no conflict?
What if the world was made of candy?Premiers scénarios d’utilisation
Approprions-nous maintenant le terrain de jeu !
Résumé
On soumet un texte long afin d’obtenir un résumé.
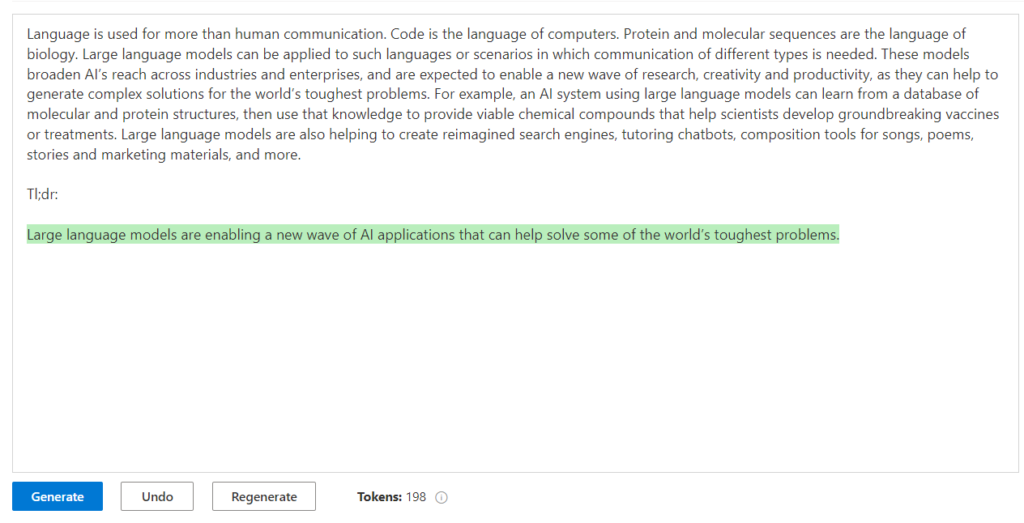
L’intention est ici exprimée par le terme “Tl;dr:” (“trop long; n’a pas lu) mais pourrait être formulée d’une autre façon, par exemple en précisant le public cible.

Les guillemets encadrent ici la partie de texte à résumer.
Classification
Nous donnons tout d’abord l’intention, celle d’établir un classifieur. La dizaine d’exemples ci-dessous est issue d’un jeu de données connu sur le sujet.
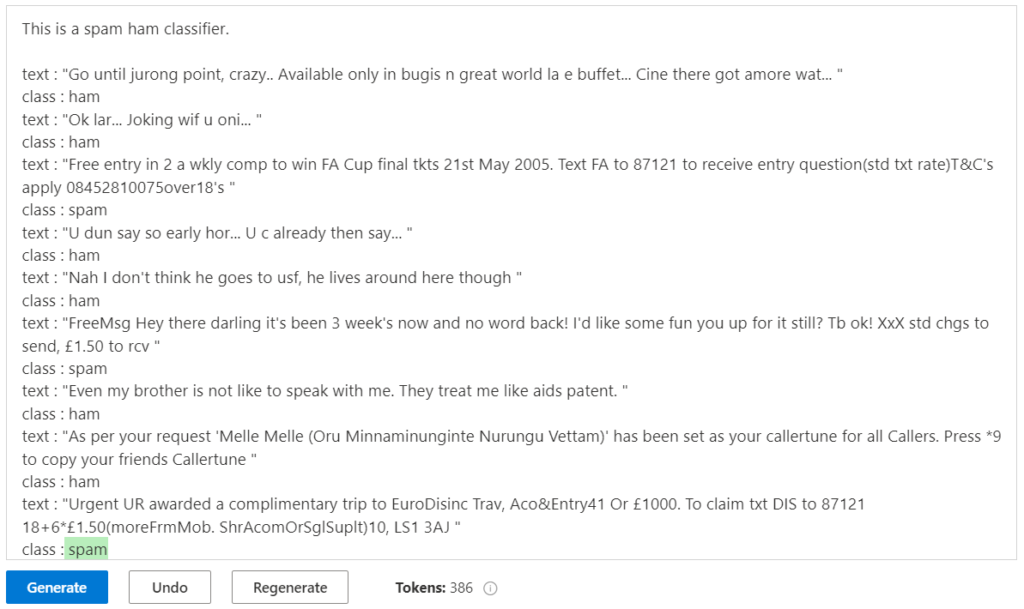
Avec si peu de données d’entrainement, le résultat peut paraitre impressionnant mais n’oublions pas qu’il y a une chance sur deux de trouver la bonne réponse (pile ou face) ! Contrairement à un classifieur issu par exemple du framework Scikit-Learn, nous ne pouvons pas accéder à la probabilité d’appartenance à la classe.
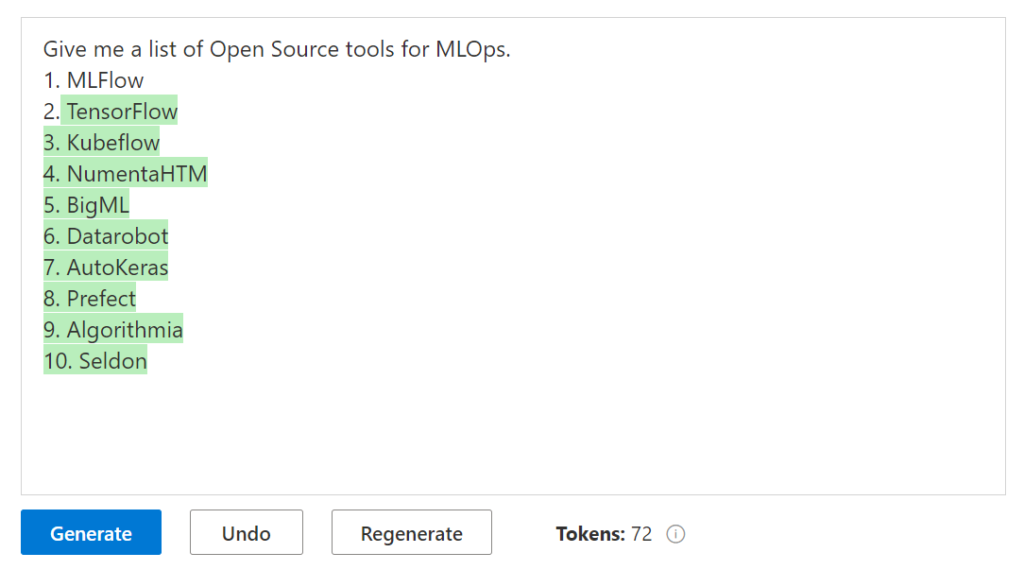
Génération
Nous demandons une liste, donnons un exemple puis débutons la suite de la liste par le chiffre 2.
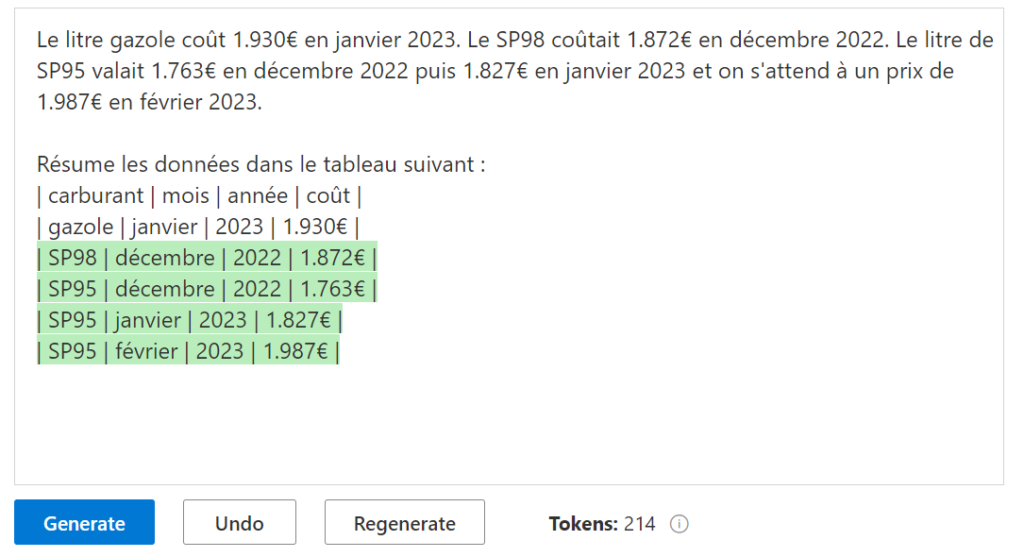
Parsing de données non structurées
Peut-être l’illustration la plus surprenante, le moteur va réussir à mettre en tableau un texte donné en langage naturel.
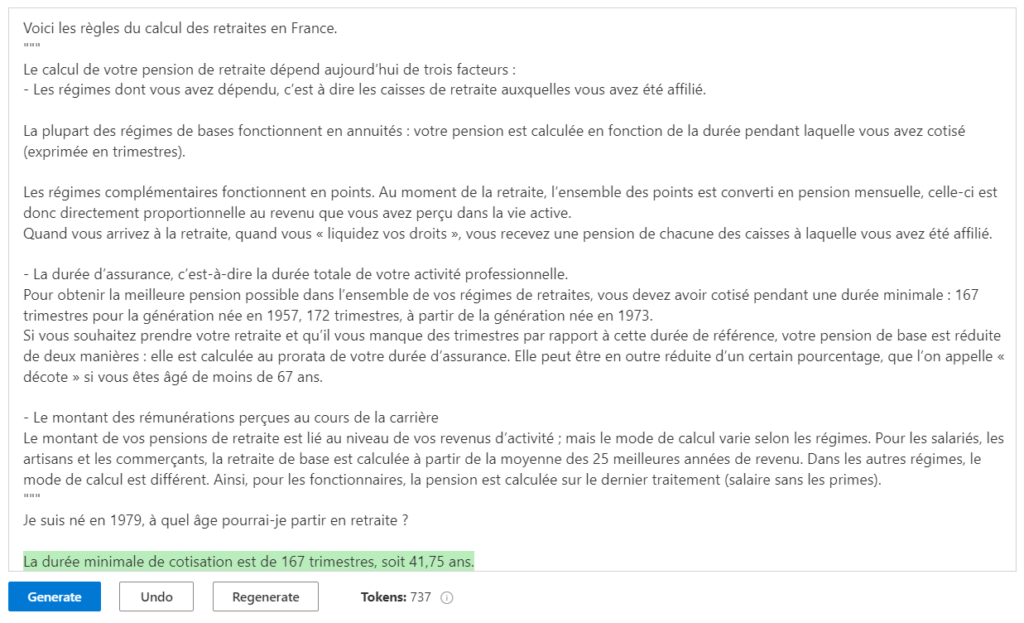
Extraction d’information
A nouveau, nous donnons une description du document qui sera soumis entre guillemets.
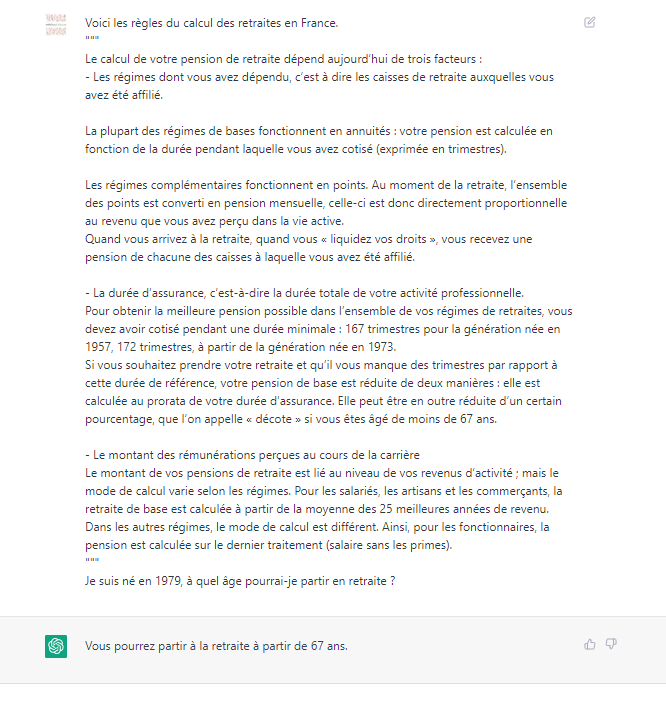
Toutefois, en essayant le même prompt dans ChatGPT (basé sur GPT 3.5), nous obtenons une réponse tout à fait correcte !
Code view
Prenons maintenant l’exemple d’un résumé de texte, avec pour objectif d’utiliser cette fonctionnalité en dehors du studio Azure OpenAI.

Le code correspondant à cet appel dans le playground est disponible (en Python).
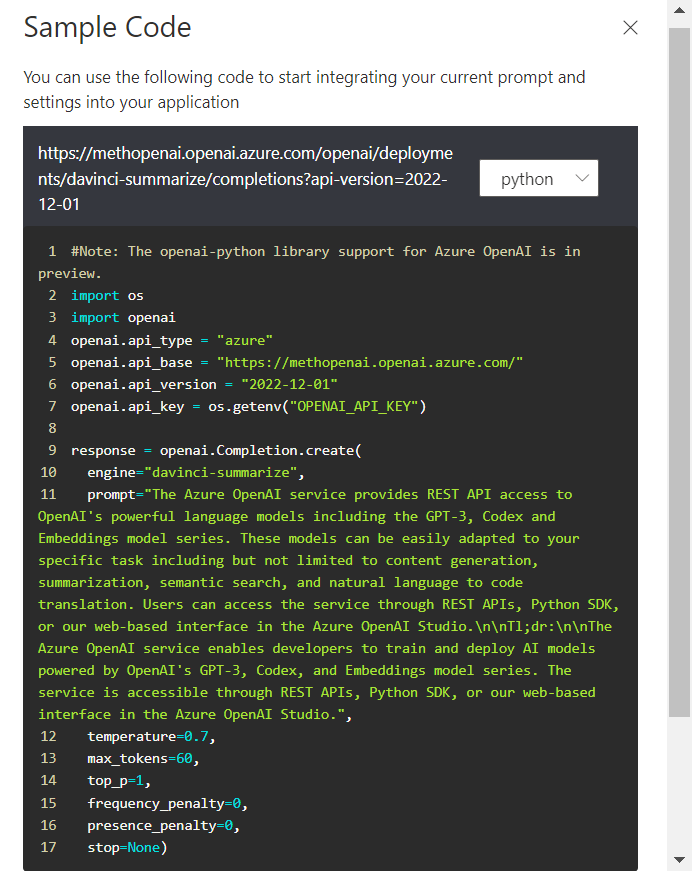
Ce code utilise la librairie Python openai (à installer avec la commande pip install) et nécessitera de connaître une des clés du service.
Pourquoi ne pas demander au modèle de générer un code Python appelant cette API ? Voici le résultat obtenu.
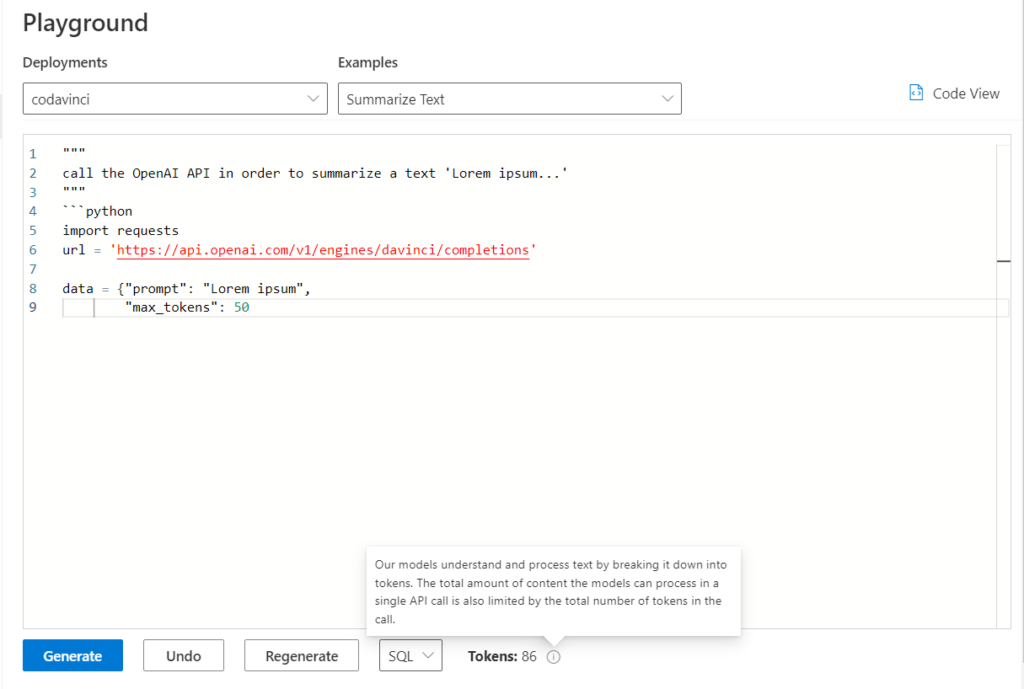
Nous ne disposons pas ici d’un quota suffisant pour que le code s’écrive en entier. L’utilisation de GitHub Copilot sera plus adaptée dans ce cas de figure.
En résumé (et sans l’aide de GPT-3 !), nous pouvons successivement déployer un modèle, l’expérimenter à l’intérieur du terrain de jeu (playground) puis déployer une application qui s’appuiera sur l’API mise à disposition par Azure OpenAI.
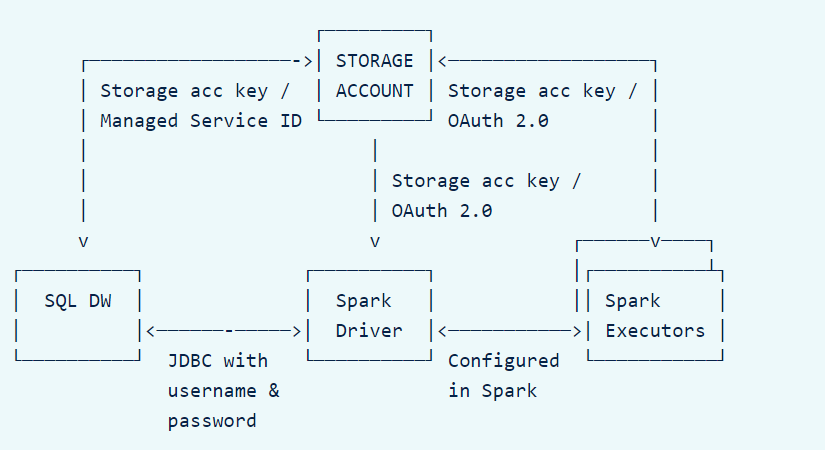
Avantages d’Azure pour OpenAI
Utiliser OpenAI au travers d’Azure donne accès à trois pratiques d’entreprise :
- la disponibilité régionale
- la mise en réseau privé
- le filtrage de contenu d’IA responsable
Une logique d’accès par RBAC (Role Based Access Control) pourra également être mise en place, tout comme l’authentification par identité managée (MSI).
Le portail Azure permet également une gestion des clés d’API par rotation.
Bien sûr, l’utilisation au travers d’Azure engendre une facturation dont les modalités sont détaillées sur cette page. Les coûts seront engendrés par l’inférence (utilisation prédictive) des modèles ainsi que par leur personnalisation (entrainement de type transfer learning).
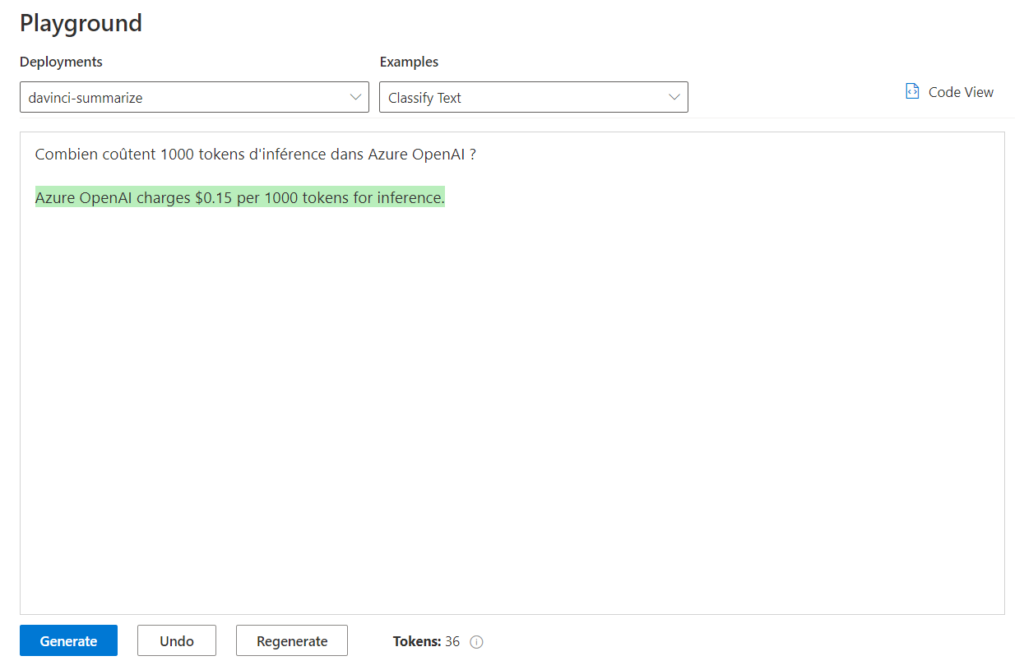
Veuillez également prendre en compte les quotas et limites appliquées. Une demande au support permettra de lever certaines de ces limites.
Choix de la région
A ce jour (février 2023), seules trois régions Azure sont disponibles.
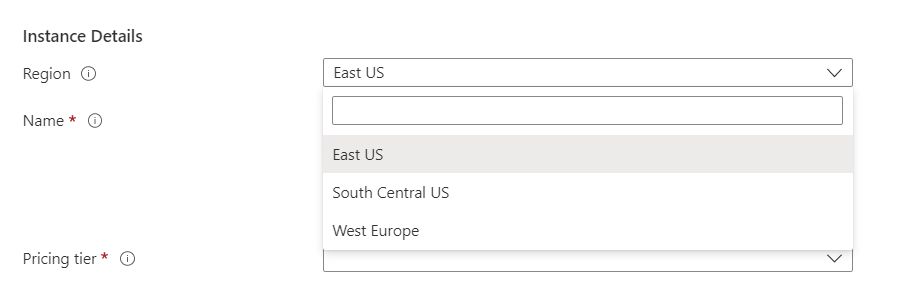
L’utilisation de deux régions différentes permet d’assurer une continuité d’activité. Ainsi, si un datacenter vient à être indisponible dans une région, il est possible de basculer (par modification du endpoint) vers une autre région Azure.
Utilisation dans un réseau privé
L’utilisation d’un réseau privé sécurise l’accès au studio Azure OpenAI, qui devra par exemple se faire au travers d’un VPN.
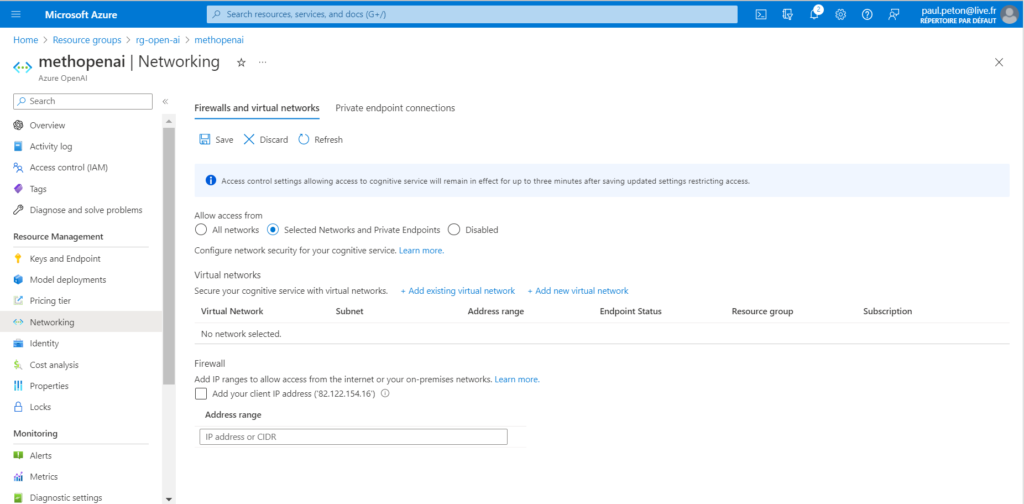
Il est également possible d’enclencher le pare-feu Azure (firewall) et de n’autoriser qu’une liste d’adresses IP à accéder au studio OpenAI.
IA responsable
Outre les engagements pris au travers du formulaire de demande du service, la documentation de Microsoft nous incite à respecter les points suivants lors d’une intégration des services Azure OpenAI :
- Mettre en œuvre une surveillance humaine significative.
- Mettre en place des limites techniques strictes sur les entrées et les sorties afin de réduire la probabilité d’une utilisation abusive au-delà de l’objectif prévu de l’application.
- Tester les applications de manière approfondie afin de détecter et d’atténuer les comportements indésirables.
- Établir des canaux de feedback.
- Mettre en œuvre des mesures d’atténuation (bias mitigation) supplémentaires propres à chaque scénario.
A termes (ce n’est pas aujourd’hui le cas), un filtrage de contenu supplémentaire sera mis en place par Microsoft. Celui-ci est décrit dans la documentation. Concrètement, un utilisateur proposant un prompt avec un contenu inapproprié recevra, à l’appel de l’API, un code erreur HTTP 400 et une description “content_filter” dans le corps de la réponse. Une demande au support permet d’activer dès à présent ce filtrage.
EDIT : le filtrage de contenu sera activé le 13 février 2023.
With our latest update we’re providing content filters with significant quality and precision improvements. We have adjusted the system to filter at higher severity levels with each category (Hate and Fairness, Sexual, Violence, Self-harm) and expanded coverage across other languages.
Once the filters are turned back on, the system will resume blocking harmful prompts and model generations.
email Azure OpenAI Support