Le proverbe bien connu “diviser pour mieux régner” a sa déclinaison dans le monde de la Data et des services managés : “séparer le traitement du stockage”. Par cela, il faut comprendre que l’utilisation de deux services différents pour ces deux tâches est particulièrement intéressant.
En effet, le stockage se doit d’être permanent et toujours accessible, en tenant compte de différents degrés de “chaleur”. En revanche, la puissance de calcul n’est nécessaire que pendant les traitements et il faudra pouvoir faire évoluer cette puissance selon le besoin. Par exemple, un entrainement de modèle prédictif, opération qui peut être très coûteuse, bénéficiera de l’élasticité d’un service managé comme Azure Databricks mais ne sera peut-être pas réalisé quotidiennement.
Nous allons détailler ici comment pérenniser les données issues d’un traitement de préparation réalisé sur le cluster managé Spark. La solution de stockage choisie ici est Azure SQL Data Warehouse.
Créer une ressource Azure SQL DWH
Il est tout d’abord nécessaire de disposer d’une ressource Azure de serveur de bases de données.
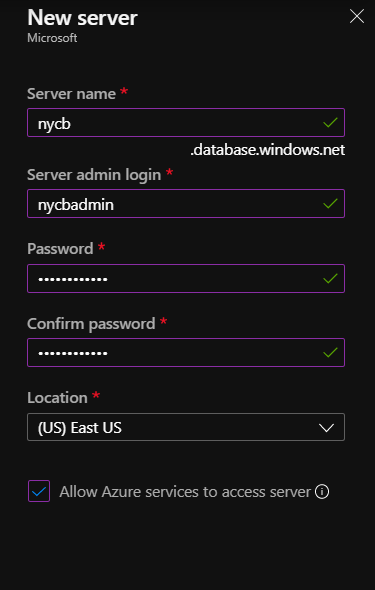
La documentation officielle d’Azure Databricks recommande de cocher la case “Allow Azure services to access server”.
Nous sélectionnons maintenant la ressource Azure SQL Data Warehouse dans la catégorie Databases.
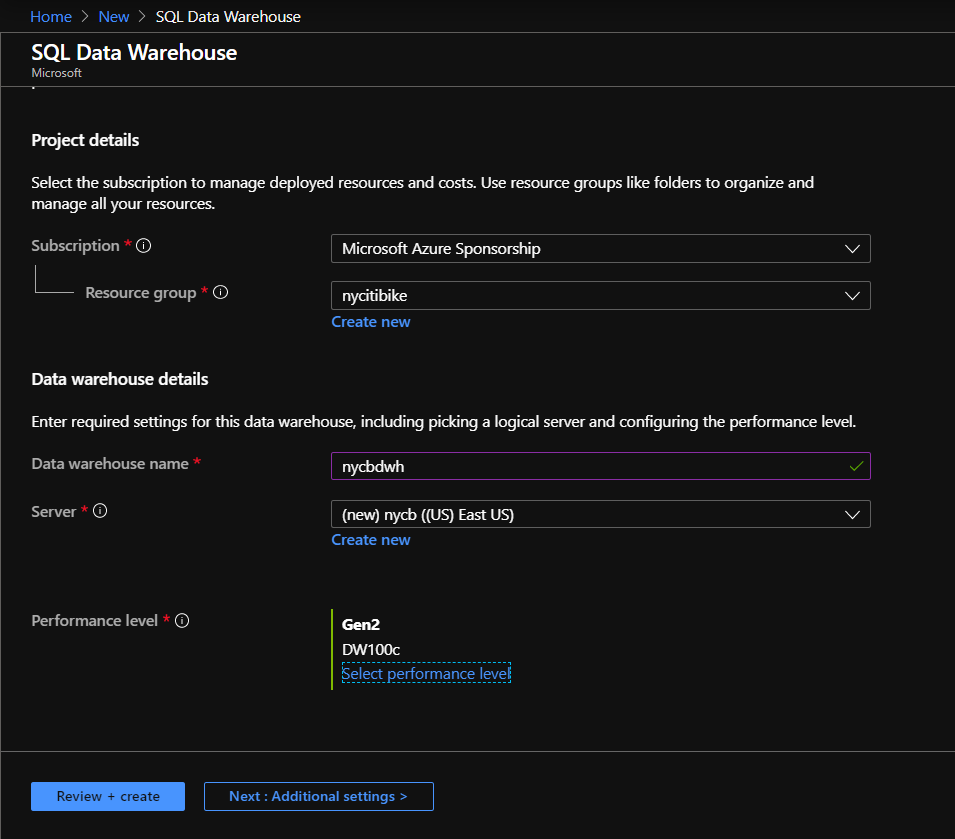
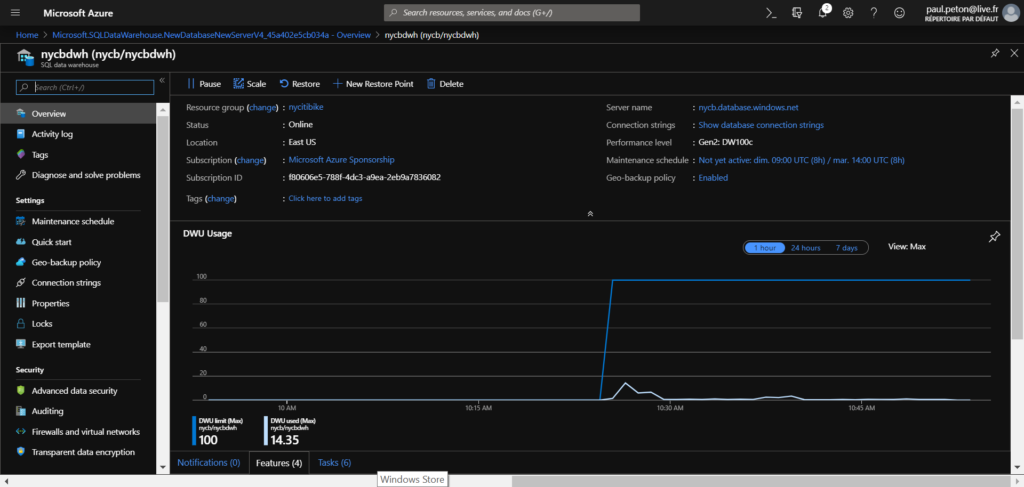
Le Data Warehouse est associé à un groupe de ressources et à un serveur de base de données (ici, créé simultanément). Le niveau de performance choisi va déterminer le coût associé à une heure de service de l’entrepôt.
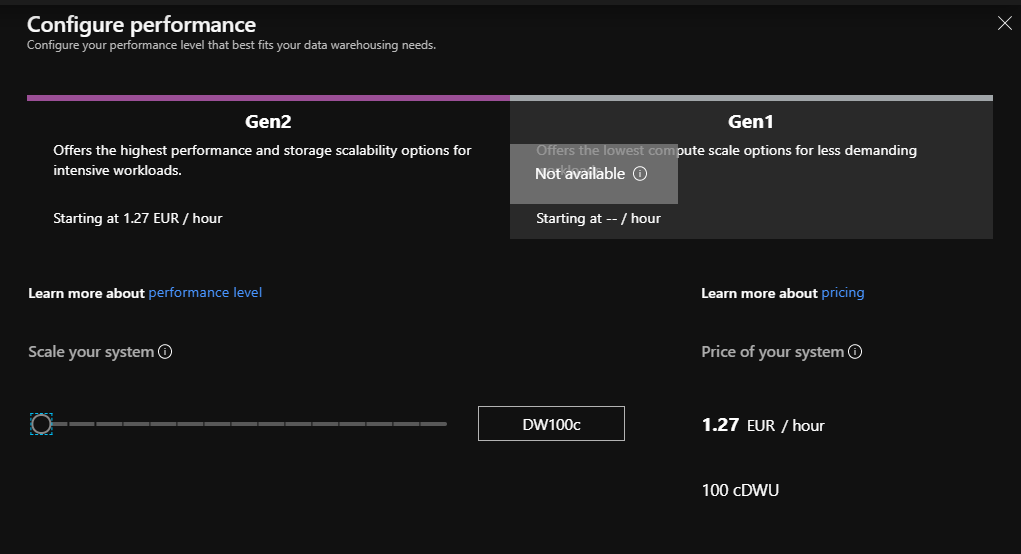
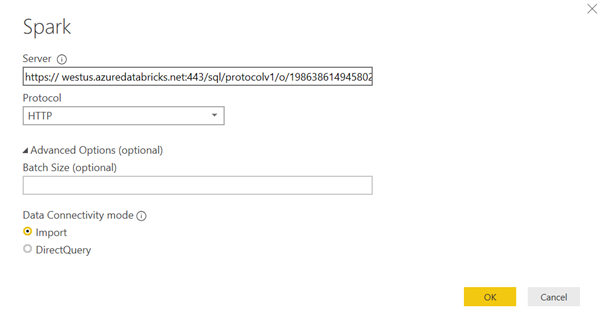
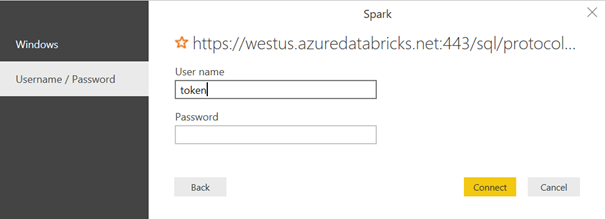
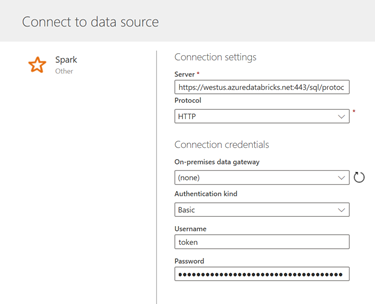
Cette ressource se montra particulièrement efficace dans le cadre d’une connexion vers un outil de dashboarding comme Power BI et autorise le mode direct query, qui pourra se révéler pertinent dans des modèles de données composites, mêlant import et connexion directe.
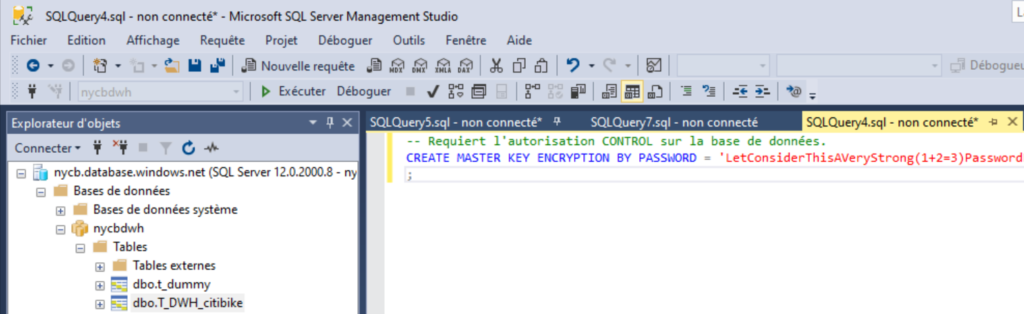
Une clé de chiffrement pour la base étant obligatoire, il sera nécessaire de créer une database master key au travers d’une nouvelle requête sur la base de données. Cela peut se faire par exemple dans le client SQL Server Management Studio ou sur le portail Azure par le query editor actuellement en préversion.
--Creates the database master key CREATE MASTER KEY ENCRYPTION BY PASSWORD = "yourStr0ngPa$$W0rd"
Faire communiquer Azure Databricks et SQL DWH
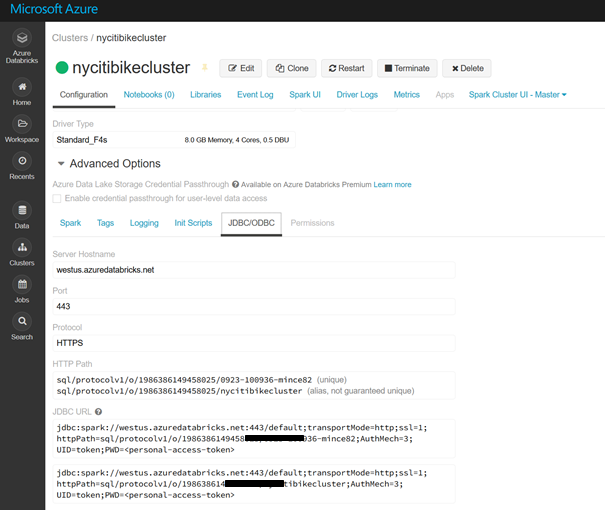
Afin de bien paramétrer la communication, il faut tout d’abord comprendre comment fonctionne le mécanisme. La subtilité à bien saisir est l’importance d’un troisième élément qui est le compte de stockage Azure utilisé comme zone temporaire et sollicité par le composant PolyBase.
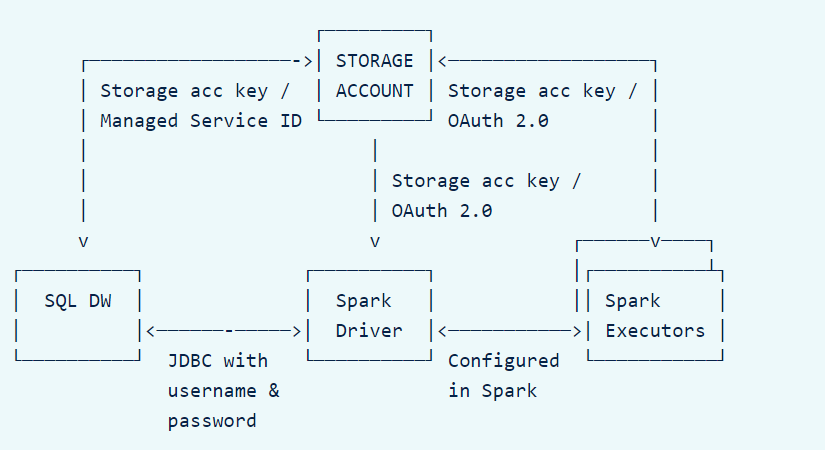
Source : https://docs.databricks.com/data/data-sources/azure/sql-data-warehouse.html
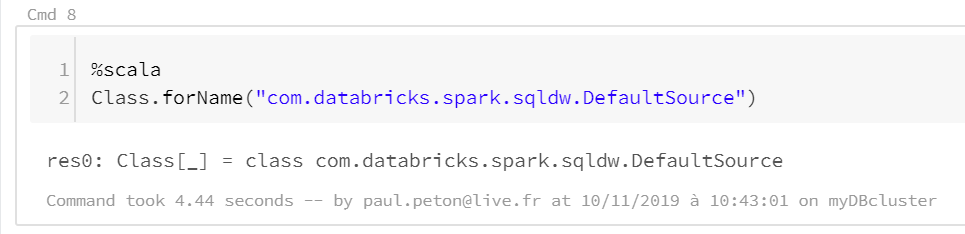
Vérifions tout d’abord que le connecteur SQL DWH est présent sur le runtime Databricks associé au cluster Spark au moyen de la commande Scala ci-dessous.
Dans une cellule d’un notebook, nous déclarons toutes les variables nécessaires à la bonne communication entre les différentes briques, en particulier le compte de stockage Azure (Blob Storage ou Data Lake Storage gen2).
Le code ci-dessous est donné pour un notebook Python mais sa variante en Scala s’obtiendra facilement en ajoutant le mot-clé var au devant de chaque déclaration de variable.
storage_account_name = "nomDuBlobStorage" blobStorage = storage_account_name+".blob.core.windows.net" blobContainer = "nomDuConteneur" blobAccessKey = "MauvaiseIdéeDeCopierIciUneClé000PensezAuSecretScope!" tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs" acntInfo = "fs.azure.account.key."+ blobStorage dwServer = "nomDuServeur"+".database.windows.net" dwDatabase = "nomDuDWH" dwUser = "nomDeLUtilisateur" dwPass = "ToujoursUneMauvaiseIdéePensezVraimentAuSecretScope" dwJdbcPort = "1433" dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions" sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass
Attention à faire cette étape proprement au moyen d’un secret scope !
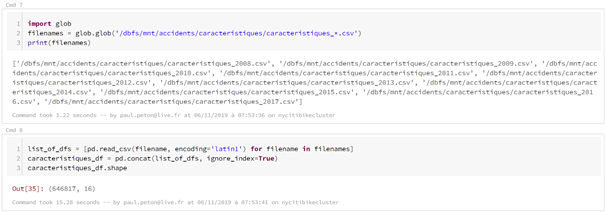
Des travaux de data preparation nous ont permis de réaliser un DataFrame propre contenant des données plus exploitables. Une sauvegarde du DataFrame est réalisée sous forme de table sur le cluster mais celle-ci ne sera accessible que lorsque le service Azure Databricks est démarré (et donc facturé).
Nous allons donc réaliser une copie des données sur Azure SQL Data Warehouse.
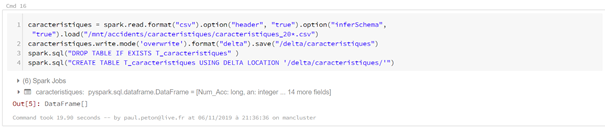
Grâce aux actions préalables, il est maintenant possible de lancer les commandes load ou write pour communiquer avec Azure SQL Data Warehouse. Dans la commande ci-dessous, nous créons une nouvelle table dans la base de données à partir d’un DataFrame en mémoire du cluster.
dwTable = "nomDeLaNouvelleTableDuDWH"
df.write.format("com.databricks.spark.sqldw") \
.option("url", sqlDwUrlSmall) \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable",dwTable) \
.option("tempDir",tempDir) \
.save()

Automatiser les traitements
Nous avons donc réalisé ici la partie cruciale de la chaîne de la data, en séparant traitement et stockage des résultats. Pour rendre cette architecture encore plus efficace, il sera nécessaire de planifier le traitement de préparation des données . Plusieurs solutions sont ici disponibles :
- l’ordonnanceur d’Azure Databricks, couplé à une logique d’enchaînement de notebooks
- l’utilisation d’un pipeline Azure Data Factory et d’une activité Databricks
Ces deux approches sont décrites dans cet article.
Dupliquer les données, bonne idée ?
A cette question, nous pourrons formuler la traditionnelle réponse du consultant : “ça dépend”.
Rappelons qu’il faut bien évaluer les usages et les coûts d’une telle architecture. Quel est le public qui a besoin de cette donnée préparée ? Plutôt des data analysts au sein de Power BI ? Plutôt des data scientists dans un cluster “bac à sable” ?
Azure SQL Data Warehouse offre une puissance d’accès pour des usages analytique mais il faut mesurer son coût si la base reste accessible en continu. A l’inverse, les tables matérialisées sur le cluster retirent une brique de l’architecture (et de la facture !) mais les performances du connecteur Spark pour Power BI ne me semblent pas aujourd’hui suffisantes pour des volumes de données importants.
Une fois de plus, la bonne architecture cloud Data sera celle qui répondra le mieux aux besoins, dans un cadre gouverné et dont le coût et la performance seront supervisés de près.
[EDIT 13 novembre 2019 : Microsoft a annoncé lors de l’Ignite d’Orlando qu’Azure SQL Data Warehouse évoluait et devenait au passage Azure Synapse Analytics. Nous suivrons de près cette évolution.]