
Jusqu’à présent, nous utilisions le connecteur Spark générique comme présenté dans cet article. Le seul mode d’authentification possible consistait à utiliser un jeton personnel (personal access token).
Nous pouvons nous connecter à des tables créées dans des databases du metastore du cluster Databricks et cela implique que le cluster soit démarré afin que la connexion soit possible.
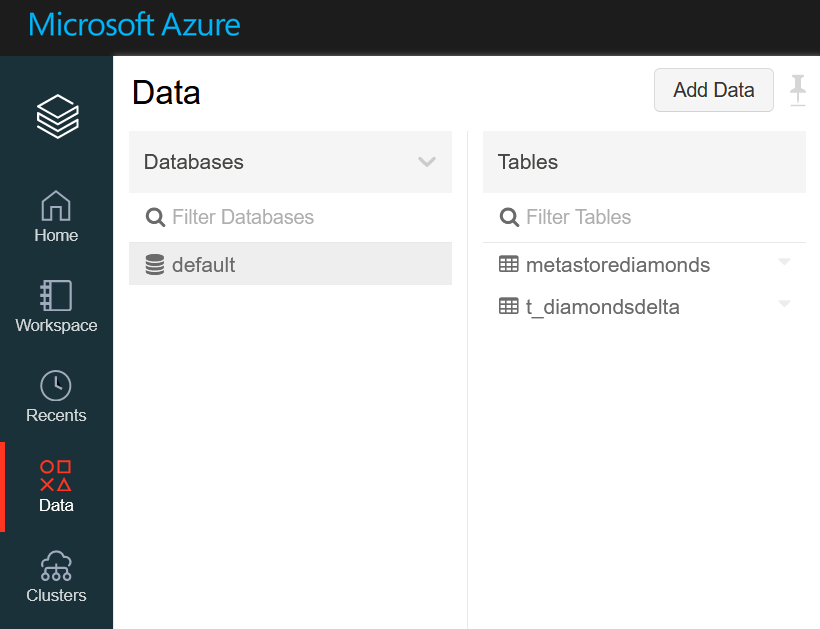
Ce sont donc des informations au niveau cluster dont nous aurons besoin pour nous connecter. Ce paragraphe détaille les éléments attendus que sont le hostname, le port (443 par défaut) et le HTTP path.
Un connecteur dédié est apparu en préversion publique depuis octobre 2020 et présenté sur cette page de la documentation officielle Microsoft.
Nous remarquons que les deux modes import et DirectQuery sont disponibles, le second étant bien sûr conditionné par le statut démarré permanent du cluster.
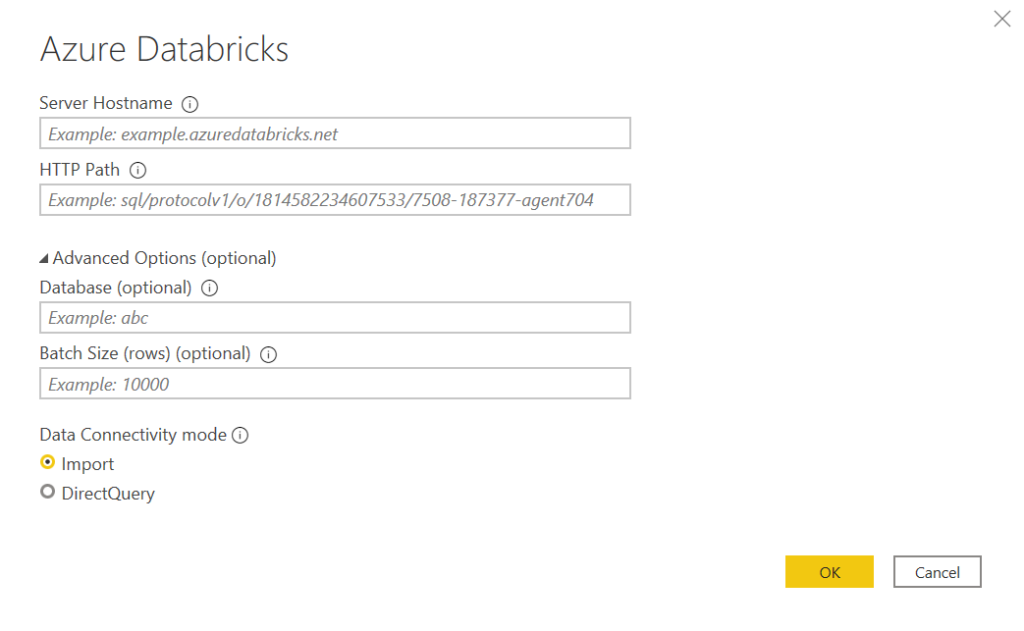
Un paramètre est ici très important : le batch size. Il s’agit de la taille des “paquets” de lignes qui seront extraits du cluster. Nous reviendrons sur ce paramètre dans la section liée à la performance.
Nous disposons ensuite de trois modes de connexion, dont le mode “classique” par Personal Access Token mais également l’authentification au travers de l’annuaire Azure Active Directory (AAD).
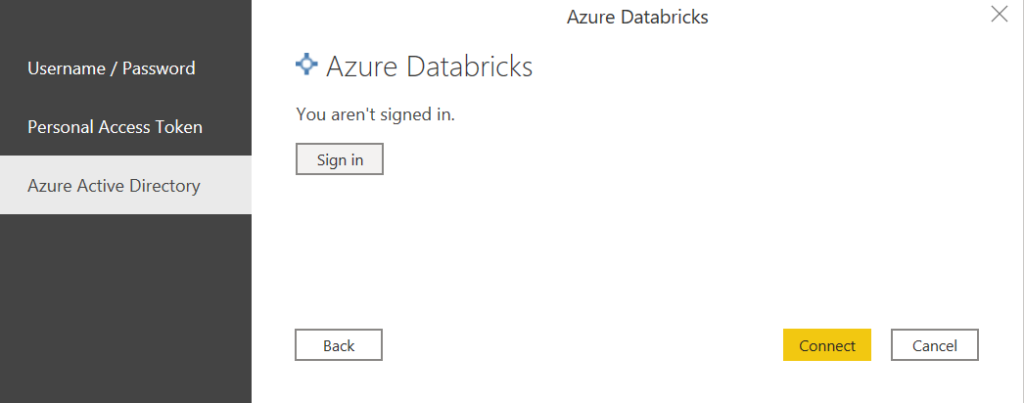
C’est ce dernier que nous utiliserons ici.
Nous obtenons alors l’accès au metastore du cluster, afin de sélectionner une ou plusieurs tables.
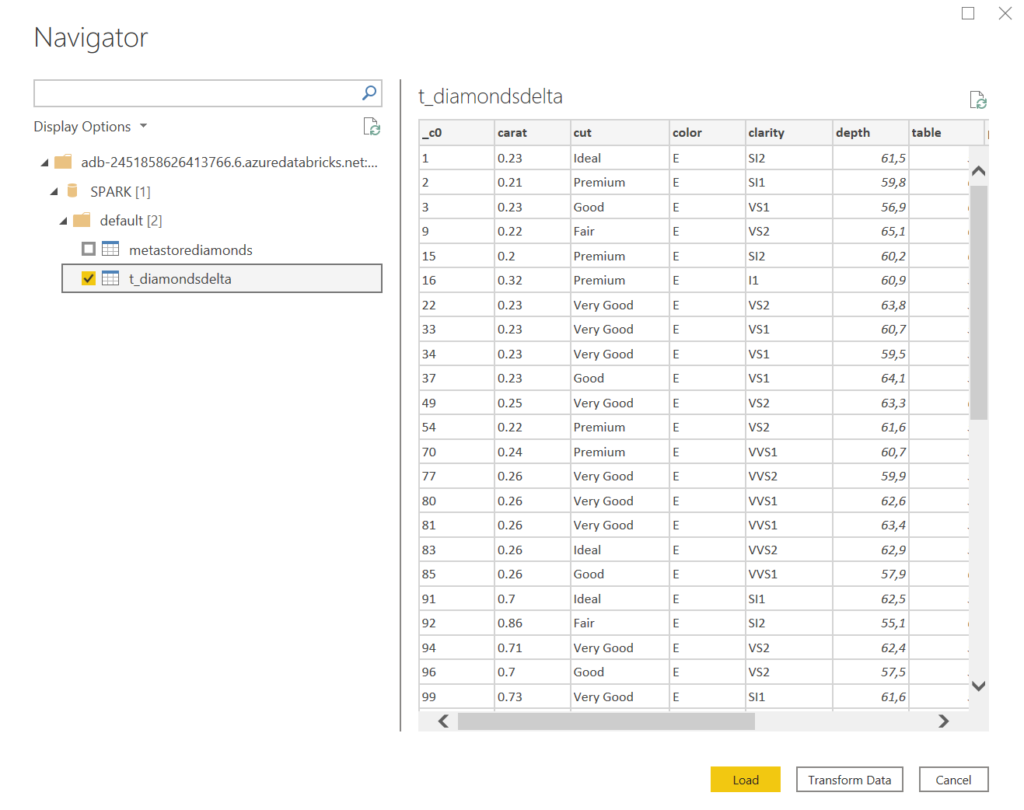
Il est alors possible de charger directement les données dans une table du modèle ou bien d’ajouter des transformations dans la fenêtre Power Query. Pour autant, l’intérêt du cluster Spark est bien de réaliser toutes les transformations de données avant de créer une table “nettoyée”.
Pour l’actualisation planifiée du rapport dans le service Power BI, nous choisissons le mode d’authentification OAuth2.
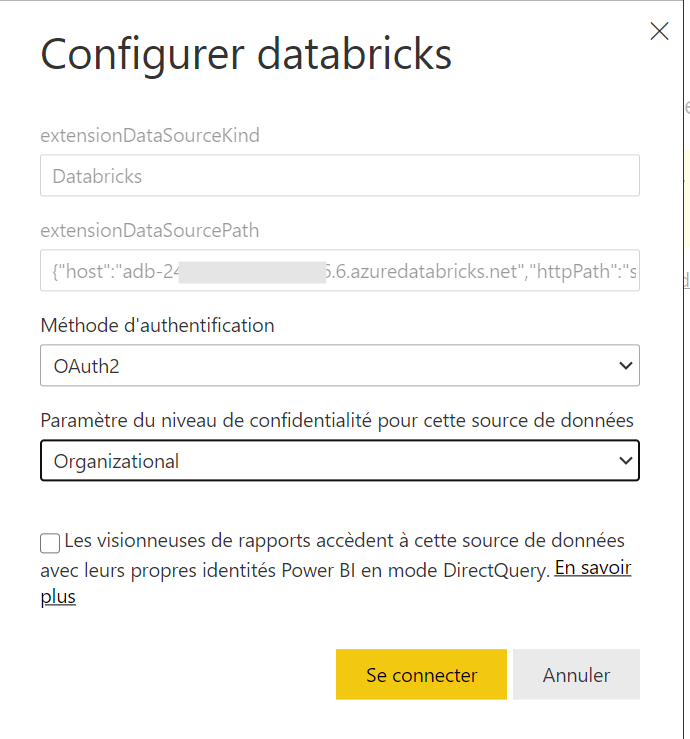
Le niveau de confidentialité Organizational exige que la source de données Azure Databricks fasse partie de l’abonnement Azure sur lequel est défini l’annuaire AAD.
Afin de ne pas lier un compte personnel à un jeu de données Power BI, il sera préférable d’utiliser un compte de service. A l’heure actuelle (novembre 2020), la connexion au travers d’un principal de service ou d’une identité managée n’est pas réalisable.
Qu’attendre des performances ?
Afin de tester ce connecteur, nous chargeons comme table du cluster le fichier des Demandes de Valeur Foncière de 2019, soit 400Mo pour environ 3 millions de lignes.
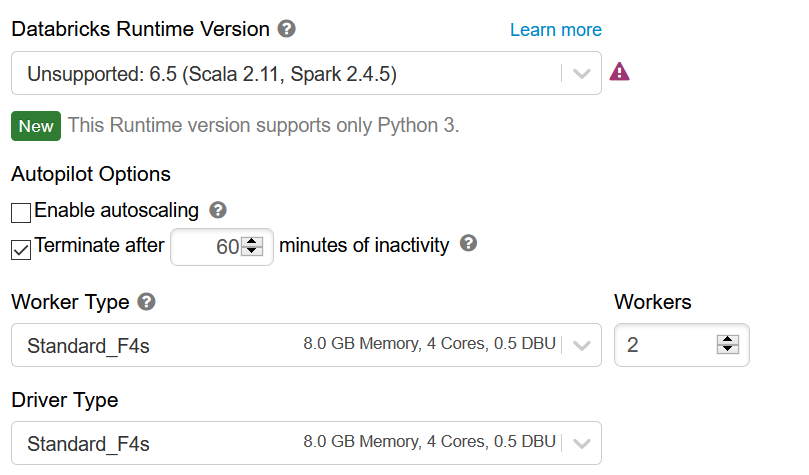
La configuration du cluster est également à prendre en compte puisqu’elle déterminera la capacité à lire la donnée stockée dans la table. Nous débutons avec la configuration ci-dessous, et une version 2.4.5 de Spark.
En réglant le batch size à 100000 puis 200000 lignes, nous passons de 4 minutes à 2’30. L’augmentation de taille n’apporte alors plus de gain significatif.
A l’inverse, une taille de batch à 10000 serait dramatique : l’actualisation du jeu de données depuis Power BI prend alors plus de 11 minutes ! Si l’on ne précise pas le paramètre, le temps d’actualisation est correcte : 3’30.
Changeons maintenant le runtime du cluster pour une version 7.2 s’appuyant sur Spark 3. Sur la base d’un batch size de 200000 lignes, il n’y a pas de gain de temps de chargement.
Changeons enfin la configuration du driver : celui se base maintenant sur une VM Standard_F8s de 16Go de RAM et 8 cœurs. Sur ce jeu de données relativement petit pour un contexte Spark, pas d’amélioration du temps de chargement. La même observation se répète en changeant cette fois-ci la configuration des workers.
Sans avoir pu le tester, il semble important, à l’évidence, que les ressources Azure Databricks et Power BI soient situées dans la même région.
Pour conclure cette partie de tests, sachez que le temps d’actualisation avec le connecteur Spark générique est d’environ 5 minutes (batch size de 200000 lignes), un léger gain est donc obtenu.
Peut-on faire de l’actualisation incrémentielle ?
Par défaut, l’actualisation d’un jeu de données annule et remplace toutes les données. Il est toutefois possible de mettre en place une approche sur un champ de type datetime pour n’actualiser qu’une plage de dates définie. Sur cet écran, nous souhaitons conserver 2 années d’historique et ne mettre à jour que les 12 derniers mois.
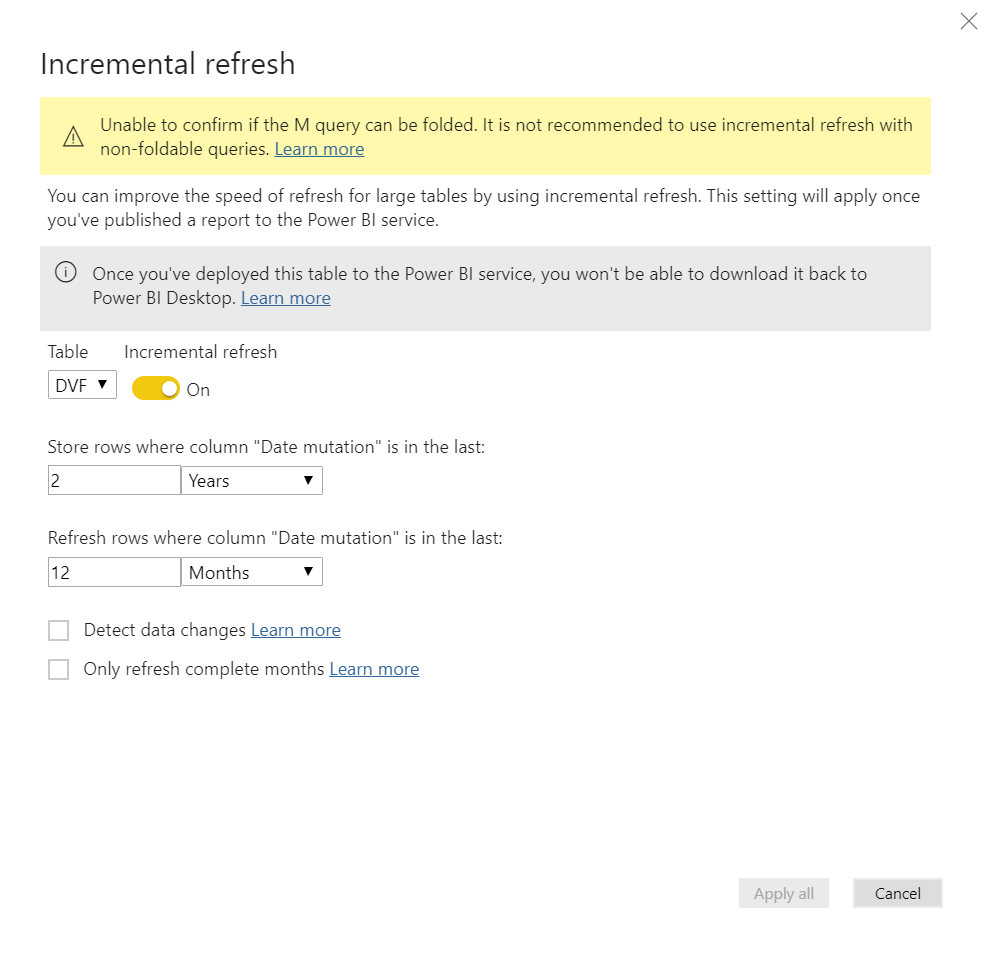
Un message d’alerte que le mécanisme ne sera effectif que la requête M est “pliable” (traduction approximative du concept de query folding), ce qui signifie que le moteur d’exécution de la requête (ici, le moteur Spark) doit pouvoir interpréter la requête dans un langage natif, comme le SQL. Concrètement, les paramètres de dates deviennent des conditions “WHERE” dans la requête. D’un point de vue du stockage de données, celles-ci sont partitionnées selon la granularité de dates utilisée dans la paramétrage (ici, le mois).
Afin de vérifier si toutes les partitions ou non sont actualisées, il faut utiliser un espace de travail Power BI de capacité Premium et se connecter selon le processus détaillé dans cette page.
Ensuite, depuis SQL Server Management Studio, nous pouvons visualiser les partitions et l’heure de traitement.
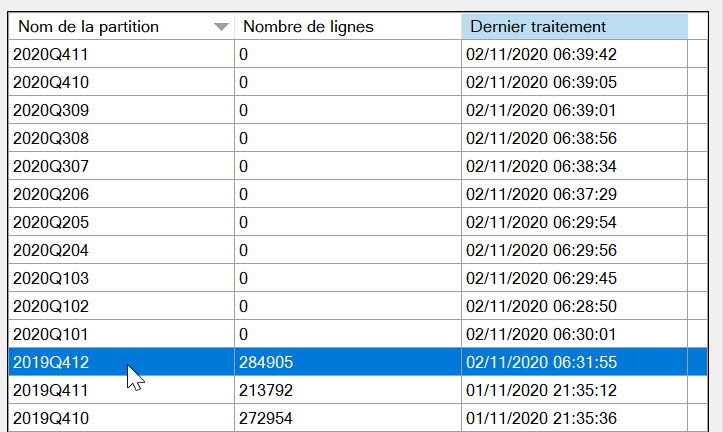
Le jeu de données ne couvre que l’année 2019, ce qui explique les nombres de lignes à 0 à partir de 2020. Les partitions antérieures à décembre 2019 n’ont pas été rafraichies, ce qui correspond bien au comportement souhaité. En revanche, il faut se méfier du temps total que peut prendre une telle approche car elle multiplie les requêtes auprès du cluster, partition par partition.