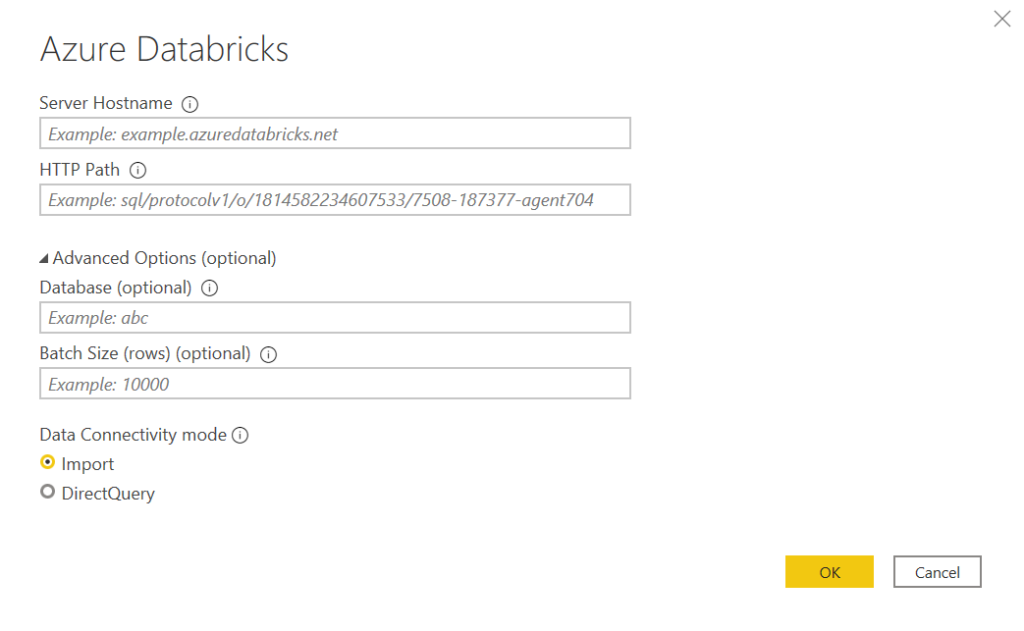
Il existe aujourd’hui des centaines de tutoriels qui vous apprendront comment construire vos premiers rapports Power BI, et vous trouverez des milliers d’astuces pour les améliorer. Mais quelle démarche mettre en place quand « ça marche pas », « ça plante », « les chiffres sont faux » ?
Il n’y a pas de secret, c’est en se confrontant à des cas réels (c’est-à-dire en entreprise, où les contraintes sont fortes : sécurité, accès limité aux données, annuaire…) et bien souvent en y passant, au moins au début, beaucoup de temps.
Après plus de 6 ans d’utilisation de Power BI (et pas mal de Power Pivot au préalable), j’ai recensé les scénarios ci-dessous, regroupés en deux chapitres que sont la maintenance corrective (« y’a un bug ») et la maintenance évolutive (changement dans les sources de données, dans les requêtes ou dans les formules DAX). J’espère que ces différentes entrées pourront vous aider à gagner du temps dans la maintenance de vos rapports Power BI… temps que vous pourrez investir dans l’analyse des données !
Enfin, vous vous apercevrez sûrement que le respect de bonnes pratiques de développement vous conduira à vous simplifier la tâche de maintenance. Les aspects de documentation feront en particulier l’objet d’un article séparé.
Scénarios de maintenance corrective
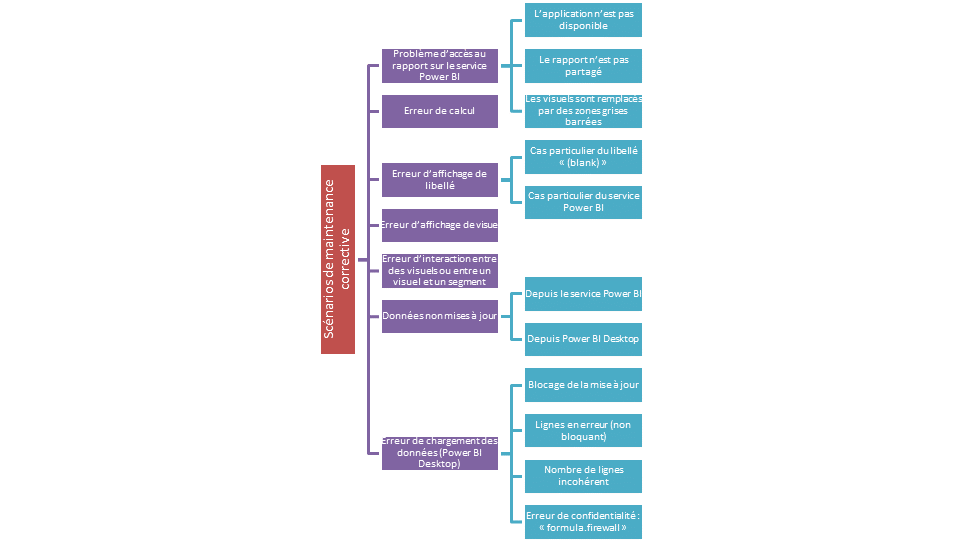
Problème d’accès au rapport sur le service Power BI
L’application n’est pas disponible
Une application est visible pour un utilisateur si celui-ci s’y est explicitement abonné. Depuis la page des applications, rechercher l’application par son nom, l’utilisateur doit appartenir aux personnes autorisées.
L’utilisateur n’est pas abonné par défaut si, à la publication de l’application, l’installation automatique n’a pas été cochée.

Attention, cette option peut être désactivée par l’administrateur du service.
Le rapport n’est pas partagé
Après recherche, le rapport n’apparaît pas dans le menu « Partagé avec moi ». Si le partage se fait au travers d’un nom de groupe Azure Active Directory (AAD), vérifier la présence de la personne concernée dans ce groupe.
Les visuels sont remplacés par des zones grises barrées
Il s’agit ici du comportement attendu lorsqu’un jeu de données bénéficie d’une sécurité à la ligne (« Row Level Security ») et que l’utilisateur n’a pas été associé, directement ou au moyen d’un groupe Azure Active Directory (AAD), à un rôle de sécurité statique.
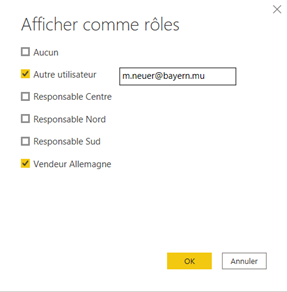
En cas de scénario de sécurité dynamique (sur la base d’une des deux fonctions DAX USERNAME() ou USERPRINCIPALNAME(), et si l’utilisateur a bien été ajouté dans le rôle de sécurité, rechercher si l’utilisateur figure bien dans la table de sécurité intégrée dans le modèle de données.
Réaliser si besoin un test dans le fichier .pbix ouvert dans Power BI Desktop, à l’aide du modèle de simulation de rôle. Pour un scénario de sécurité dynamique, il faut utiliser conjointement les deux cases illustrées ci-dessous.
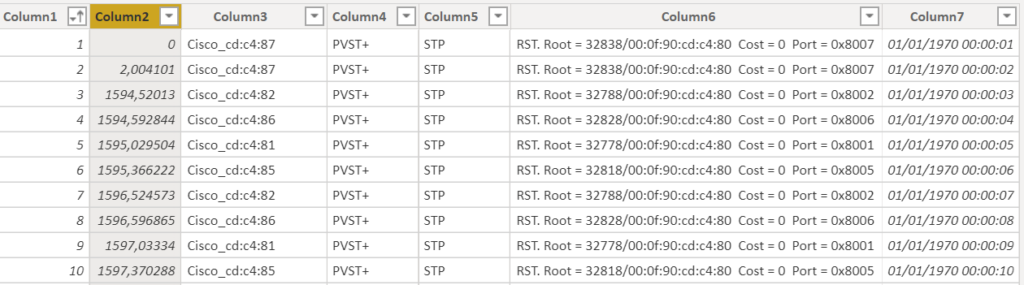
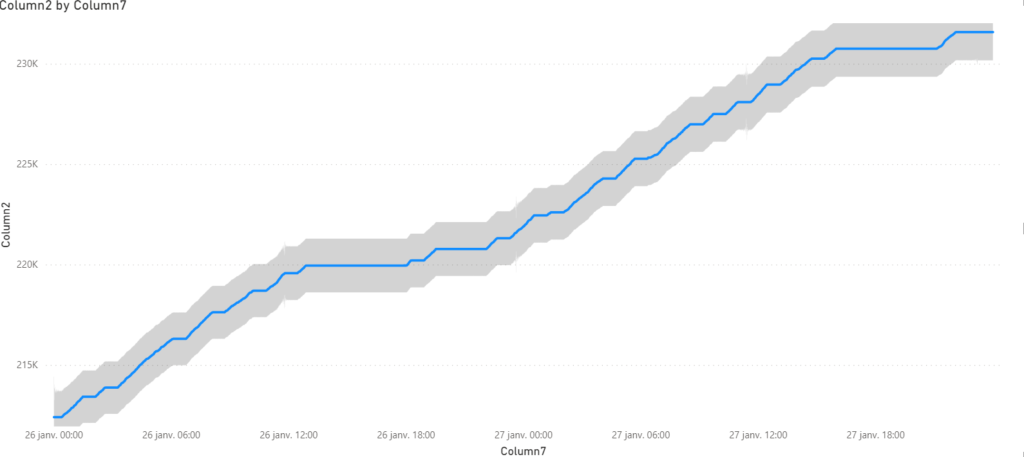
Erreur de calcul
Une valeur affichée dans un visuel ne correspond pas à la valeur attendue. Tout d’abord, il faut savoir comment a été déterminée la valeur attendue, par un processus extérieur à Power BI (il s’agit normalement du processus de recette fonctionnelle, réalisé à la première publication du rapport).
On met alors en œuvre une démarche visant à « détricoter » le calcul :
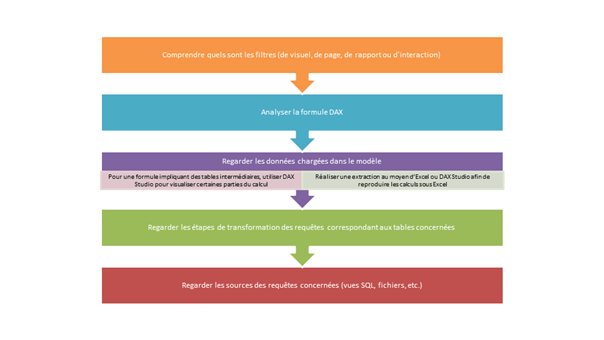
Pour analyser de manière exhaustive les données chargées dans le modèle, on utilisera les filtres sur la vue de données, qui n’ont pas de conséquence sur les données filtrées dans les visuels.
Dans Power BI Desktop, toutes les tables, champs ou mesures n’apparaissent pas obligatoirement, certains éléments pouvant avoir été masqués. Il est important d’activer l’option « View hidden », depuis la liste de champs.
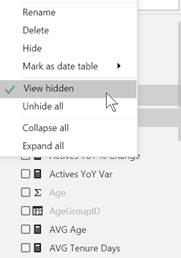
Erreur d’affichage de libellé
On s’interrogera principalement sur l’absence d’une catégorie sur un axe ou dans une légende de visuel. Si celle-ci n’apparaît pas, c’est vraisemblablement en raison d’un « contexte de filtre ». Nous suivrons la démarche suivante :
- Vérifier que le libellé attendu figure bien dans la vue de données (celle-ci n’est pas soumise au contexte d’un visuel)
- Comprendre quels sont les filtres (de visuel, de page, de rapport ou d’interaction)
- Analyser la formule DAX : celle-ci contient-elle des éléments modifiant le contexte de filtre (liste de ces fonctions sur ce site de référence) ?
Cas particulier du libellé « (blank) »
Un libellé « (blank) » peut apparaître sur un axe ou en légende d’un visuel comme sur l’exemple ci-dessous.
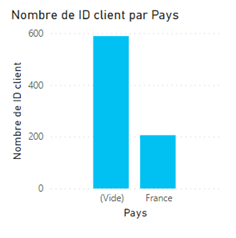
Cet article et celui-ci pourront vous aider à améliorer vos mesures DAX pour éviter ces valeurs mais il faut avant tout vérifier la complétude des dimensions para rapport aux clés étrangères dans la table de faits. Si c’est un champ de la dimension qui est utilisé pour générer le visuel, les lignes de la table de faits sans correspondance dans celle-ci se retrouveront comptabilisées sur une entrée « blank ».
A l’inverse, il est également important d’analyser les clés de la dimensions qui ne contiennent pas de faits associés, en utilisant la propriété de l’axe : « afficher les éléments sans données ». Nous vérifierons plutôt ici que cela correspond bien aux attentes fonctionnelles.
Cas particulier du service Power BI
Avant toute investigation, utiliser le bouton « Réinitialiser ».

Celui-ci permet de remettre le rapport dans l’état de publication initiale. Les filtres positionnés par l’utilisateur sont remis sur les valeurs définies par le concepteur.
Certains libellés attendus peuvent ne pas apparaître en raison du mécanisme de sécurité à la ligne.
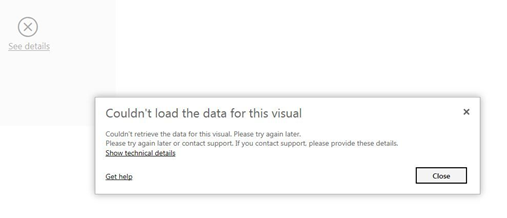
Erreur d’affichage de visuel (grisé et lien vers un message détaillé)
Ici, le visuel échoue aussi bien dans Power BI Desktop que dans le service (ce n’est pas en lien avec les droits de l’utilisateur). La première piste à suivre est celle de la ou des mesures DAX utilisées dans le visuel.
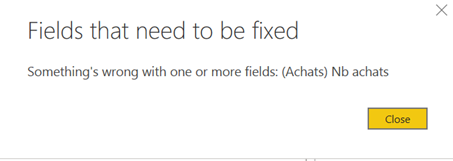
Le bouton « Fix this » aura souvent comme conséquence de supprimer les éléments en erreur dans le visuel, ce qui rend plus difficile la correction à apporter. Un lien est disponible pour afficher un détail, parfois utile, de l’erreur rencontrée.
Erreur d’interaction entre des visuels ou entre un visuel et un segment
Par défaut, c’est-à-dire sans intervention du concepteur de rapport ou mesure réalisant une modification du contexte de filtre, tous les visuels d’une page de rapport interagissent entre eux.
Dans Power BI Desktop, afficher les interactions (cliquer sur un visuel, menu Format puis « edit interactions »). L’état des interactions de chaque autre visuel apparaît alors.
Si le problème persiste, vérifier dans les mesures DAX mises en œuvre la présence d’une formule modifiant le contexte de filtre (liste de ces fonctions sur ce site de référence).
Données non mises à jour
Depuis le service Power BI
En tant que membre ou administrateur de l’espace de travail où le jeu de données est publié, regarder l’historique des actualisations, le statut de la dernière actualisation (première ligne), cliquer sur « Afficher » ou télécharger éventuellement le fichier de logs associé pour un dataflow.
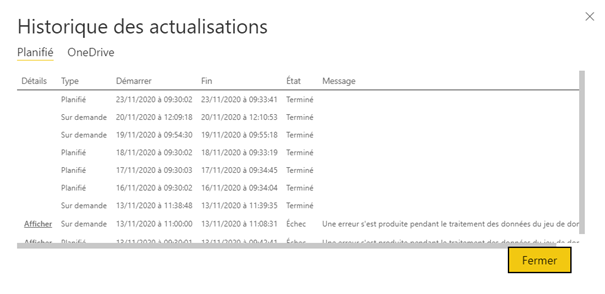
Un message d’erreur plus détaillé apparaît alors.
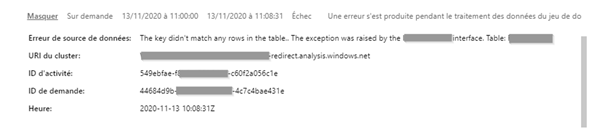
Il sera certainement plus simple de corriger la cause de l’erreur à partir du rapport ouvert dans Power BI Desktop.
Depuis Power BI Desktop
Vérifier le chemin d’accès aux données sources. Pour une base de données, pointe-t-on vers la base ou le schéma de production ? Pour des fichiers, les nouvelles versions sont-elles bien présentes ?
Utiliser l’actualisation depuis le rapport et non dans l’éditeur de requêtes qui n’actualise qu’un aperçu des premières lignes des données. Il est possible d’actualiser une table spécifiquement par clic droit sur celle-ci, puis « actualiser ».
Erreur de chargement des données (Power BI Desktop)
Blocage de la mise à jour des données
Analyser le message d’erreur obtenu.
Tester le chargement de chaque table individuellement.
Ouvrir l’éditeur de requêtes et observer les requêtes en erreur (triangle jaune à côté du nom de la requête).
Lignes en erreur (non bloquant)
Lorsque seules certaines cellules d’une colonne sont en erreur dans l’éditeur de requête, le chargement de la table se termine mais un message indique un nombre de lignes en erreur.
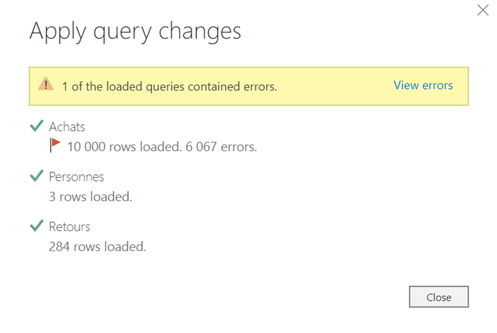
Ces lignes sont difficilement identifiables dans la requête principale car il ne s’agit que d’un aperçu des premières lignes. Il vaut mieux cliquer sur le lien « view errors ». Celui-ci ouvre l’éditeur de requêtes et montre un nouveau groupe contenant les erreurs des requêtes.
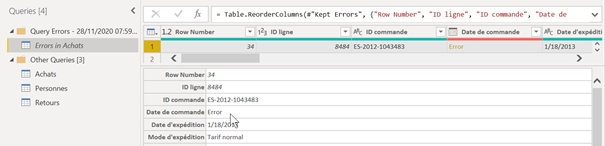
Cliquer dans la cellule (et non sur le lien Error) permet d’afficher la valeur initiale avant transformation et un message d’erreur pouvant mettre sur la voie du correctif à appliquer.
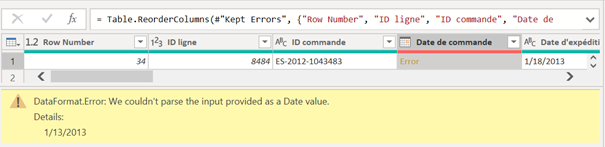
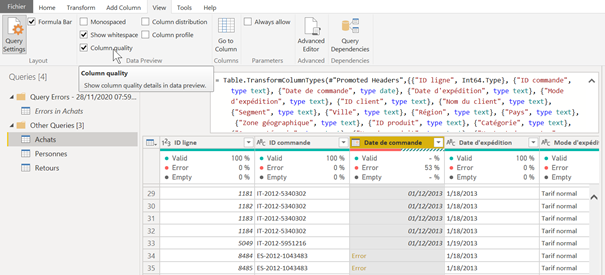
En ajoutant l’indication de la qualité de la colonne, trois indicateurs apparaissent :
- Pourcentage de lignes valides (« valid »)
- Pourcentage de lignes en erreur (« error »)
- Pourcentage de lignes vides (« empty »)
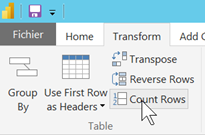
Nombre de lignes incohérent
Utiliser une étape temporaire (que l’on supprimera une fois les contrôles terminés) de comptage de lignes et faire “avancer” cette fonction après chaque étape afin de vérifier le nombre de lignes obtenues.
Contrairement aux autres étapes, le nombre de lignes n’est pas évalué sur un aperçu mais sur la totalité de la source de données.
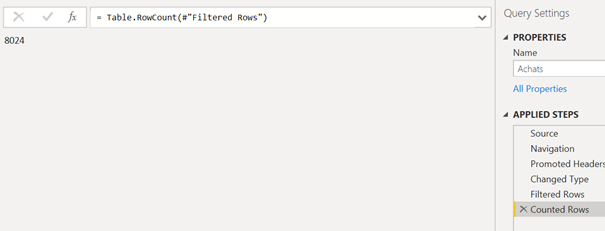
Il ne faut pas oublier de supprimer cette étape, une fois les contrôles terminés.
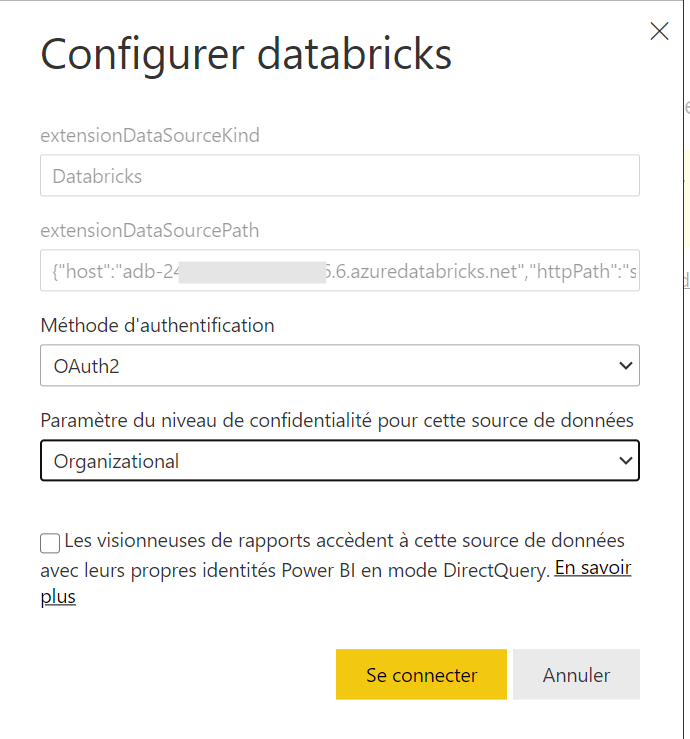
Erreur de confidentialité : « formula.firewall »
Il s’agit sans doute d’un des messages d’erreur les plus abscons de Power BI. Il signifie que des niveaux de confidentialité entre des sources de données produit une alerte (bloquante) de sécurité.

Le paramétrage est à refaire à chaque première utilisation du rapport sur un poste.
Plus d’informations sur ces concepts sont disponibles en suivant les liens ci-dessous :
https://docs.microsoft.com/fr-fr/power-bi/admin/desktop-privacy-levels
https://docs.microsoft.com/fr-fr/power-query/dataprivacyfirewall
Évaluer l’impact d’une évolution
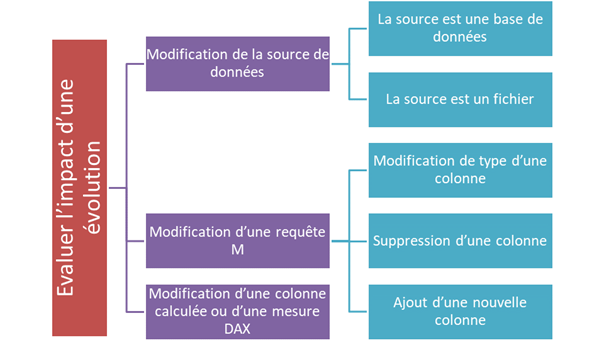
Modification de la source de données
La source est une base de données
Champ d’une table ou vue utilisée dans une requête
Ajout
Le nouveau champ apparaîtra dans la requête puis dans la table du modèle, sans causer d’impact hormis sur certaines étapes utilisant la logique de sélection inversée (opération sur les « autres colonnes »). C’est ainsi souvent le cas sur l’opération unpivot.
Sauf à appartenir à une table masquée, ce champ sera ensuite visible des utilisateurs qui ont accès au dataset et l’on devra veiller à ce qu’il ne comporte pas d’informations non appropriées (techniques, hors usage métier ou confidentielles).
Modification de type
Les types de champs dans la requête découlent des types des colonnes en base (vérifier les correspondances).
Nouvelles valeurs
L’apparition de nouvelles valeurs n’est pas d’impact sur le chargement d’une requête sauf si celles-ci contredisent le type de colonne (erreur non bloquante mais cellules mises à null). Elles peuvent toutefois modifier le comportement de certaines étapes de requêtes (filtre, unpivot, etc.).
L’apparition de doublons pourrait bloquer le chargement d’une requête si le champ est utilisé en tant que « côté 1 » sur une relation de type « 1 à plusieurs ».
Dans le rapport, il faudra contrôler les filtres sur les visuels, voire les visuels devenant moins lisibles avec un plus grand nombre de valeurs (apparition de barre de scrolling).
Renommage
Une colonne renommée n’aura un impact sur le chargement d’une requête que si elle est explicitement citée dans le script M et n’engendrera donc une erreur (bloquante pour le chargement).
Attention, de nombreuses opérations faites en langage M déclarent le nom des champs dans le script mais selon l’opération, il pourra s’agir des champs sur lesquels portent l’action ou bien des autres champs. C’est le cas des opérations de sélection, suppression, unpivot, etc.
Suppression
Une colonne supprimée n’aura un impact sur le chargement d’une requête que si elle est explicitement citée dans le script M et n’engendrera donc une erreur (bloquante pour le chargement). La première étape susceptible d’utiliser un nom de champ serait la requête SQL en étape source mais ceci n’est pas recommandé car empêche le déclenchement du query folding et il préférable de créer une vue dans la base de données.
La source est un fichier
Champ d’un fichier utilisé dans une requête
Ajout
Pour le chargement d’un fichier texte, le script généré automatiquement fait figurer le nombre de colonnes détectées. Ce paramètre est facultatif, il est donc possible de le supprimer pour qu’une nouvelle colonne soit automatiquement intégrée.
= Csv.Document(File.Contents("C:\Users\PaulPeton\Documents\dataset\diamonds.csv"),[Delimiter=",", Columns=10, Encoding=1252, QuoteStyle=QuoteStyle.None])
Toutefois, l’arrivée d’une nouvelle colonne dans une requête puis dans une table n’étant pas anodine, ce n’est sans doute pas une pratique à encourager.
Pour les actions suivantes, le comportement est identique à celui d’une source de type base de données (voir ci-dessus).
Modification de type
Nouvelles valeurs
Renommage
Suppression
Cas particulier des classeurs Excel
En connexion à un classeur Excel, plusieurs informations sont nécessaires : chemin et nom de fichier, nom de la feuille et le type de plage source (Sheet ou Table).
Dans l’exemple ci-dessous, la feuille 1 du classeur contient un tableau, repérable ici, en plus de son nom, par une icône dédiée.
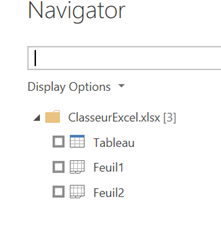
Si l’on choisit une feuille comme source, le script M se génère de la sorte :
= Excel.Workbook(File.Contents("C:\Users\PaulPeton\ClasseurExcel.xlsx"), null, true)
= Source{[Item="Feuil1",Kind="Sheet"]}[Data]
En choisissant un tableau, la seconde ligne devient :
= Source{[Item="Tableau",Kind="Table"]}[Data]
De plus, il n’y aura pas d’étape « Promoted headers », les colonnes étant directement nommées par les noms contenus dans la ligne d’en-têtes du tableau.
Dans les deux cas, il n’y pas de nombre de colonnes indiqué explicitement, comme pour une source de type fichier. En conséquence, les opérations ci-dessous engendrent un comportement similaire à celui-ci obtenu avec une source de type base de données. Ces paragraphes ne sont donc pas développés.
Ajout
Modification de type
Nouvelles valeurs
Renommage
Suppression
Modification d’une requête M
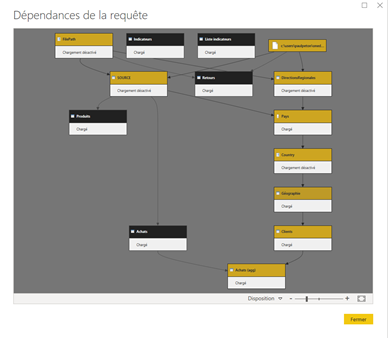
Les requêtes M aboutissent généralement à une table dans le modèle de données, mais pas toujours, il existe des requêtes intermédiaires qui n’ont pas à être chargées dans le modèle). Nous commencerons donc par afficher la vue des dépendances de requêtes (« query dependencies »).
Modification de type d’une colonne
Rappelons que toute colonne devrait être explicitement typé en fin de requête (pas de « ABC123 » qui finirait par donner un champ texte). Une modification forte entre des types très différents (nombre, texte, date) aura une conséquence sur des formules DAX utilisant ce champ et peut-être sur des visuels où le comportement n’est pas le même selon le type de donnée (exemple : axe d’un graphique, champ d’un segment). Une modification pour un « sous-type » assez proche (entier pour décimal, date/heure pour date) devrait avoir un impact moindre.
On portera une attention particulière à la modification de type sur des champs utilisés comme clés entre des tables.
La modification de type peut également avoir un impact sur des étapes ultérieures de la requête.
Suppression d’une colonne
La suppression d’une colonne est une excellente pratique en termes de réduction de taille du jeu de données mais il faut bien entendu vérifier au préalable qu’elle n’est utilisée ni dans une relation, ni dans un champ calculé, ni dans une mesure, ni dans des visuels ou filtres.
Ajout d’une nouvelle colonne
L’ajout de colonne ne fera qu’enrichir le modèle (et alourdir son poids). Par défaut, le nouveau champ ne sera pas masqué, sauf s’il appartient à une table du modèle entièrement masquée. Il faudra être attentif au fait de ne pas mettre à disposition des utilisateurs un champ auquel ils n’auraient pas à accéder (champ technique, information confidentielle, etc.).
Modification d’un champ calculé ou d’une mesure DAX
Il est important de préciser qu’une telle modification évolutive n’intervient qu’en cas de changement des règles de gestion.
Pour une colonne calculée, regarder ses dépendances avec d’autres formules DAX (colonnes calculées ou mesures), chercher son utilisation dans des relations, des visuels, filtres ou rôles de sécurité.
Pour une mesure, regarder ses dépendances avec d’autres mesures, chercher son utilisation dans des visuels ou filtres.