
(*) Revenir à l’essentiel : l’analyse des données !
Intelligence Artificielle, Machine Learning, RGPD… la donnée ne quitte plus le devant de la scène médiatique, qui attribue bien souvent à la data des pouvoirs thaumaturges. Le monde du recrutement s’emballe autour des profils « Data Scientists » tout en présentant des listes de compétences impossibles à maîtriser pour une seule et même personne, allant de l’architecture Big Data à la programmation de réseaux de neurones convolutifs (le fameux Deep Learning). A l’exception des entreprises dont la data constitue le cœur de métier comme Booking, AirBNB ou Uber, quelles sont celles qui ont réellement modifié et amélioré leur activité par une approche « data driven », c’est-à-dire pilotée par la donnée ? Ce phénomène de « hype » autour de la donnée peut poser question et générer une certaine méfiance.
Pourtant, une réaction inverse qui reviendrait à rejeter tout apport de la donnée serait aussi improductive. Et tant qu’à stocker la data, autant en tirer profit ! Dans une série de trois articles, nous nous arrêterons successivement sur l’intérêt, pour les entreprises, de l’analyse de données exploratoire, l’analyse prédictive grâce au Machine Learning et les promesses du Deep Learning sur les données non structurées.
Une même finalité, de nouveaux outils
Bien avant l’explosion de l’engouement pour la Data Science, certaines personnes dans l’entreprise pratiquaient déjà l’analyse de données sous des intitulés de poste tels que « chargé.e d’études statistiques », « statisticien.ne », « actuaire », « data miner », etc. Souvent éloignées du département IT et des architectures de production, ces personnes en charge de forer la donnée réalisent des extractions puis travaillent ces échantillons dans un classeur Excel ou un logiciel spécialisé. Une fois les conclusions obtenues, celles-ci figurent dans une présentation au format Word ou PowerPoint, c’est-à-dire sans possibilité simple de mise à jour ni d’extension à d’autres données. Nous allons voir ici que c’est aujourd’hui, non pas un bouleversement méthodologique, mais bien une simplification et une meilleure performance des outils qui changent ces métiers.
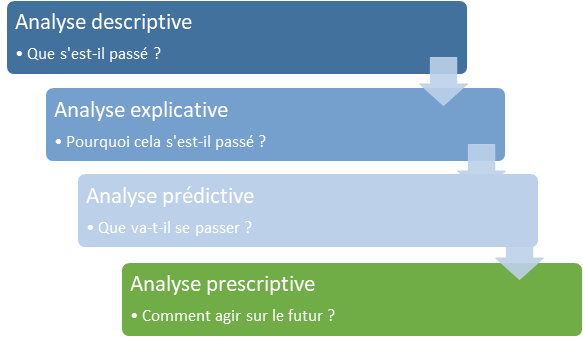
Notre approche méthodologique visera à répondre aux quatre temps de l’analyse de données.
Prenons un exemple concret : l’analyse des accidents corporels de la circulation pour laquelle les données sont disponibles en open data sur le portail data.gouv.fr.
Pour une première approche du jeu de données, nous travaillerons dans l’outil Microsoft Power BI Desktop qui, même s’il n’est pas un logiciel statistique à proprement parler, permet de nettoyer et visualiser les données très rapidement. Nous verrons même qu’il cache plusieurs fonctionnalités analytiques particulièrement intéressantes. Enfin, lorsque l’étude exploratoire sera terminée, il ne sera plus nécessaire de quitter l’outil pour présenter les résultats dans un logiciel bureautique figé. L’interface proposera une visualisation dynamique et adaptée à la restitution.
L’indispensable nettoyage des données
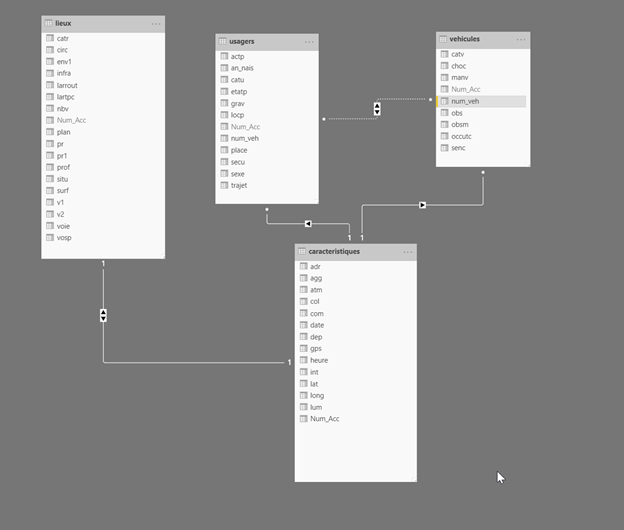
Observons tout d’abord le schéma des données collectées, dont la description précise des champs est disponible dans ce document. Nous travaillerons ici avec les notions de :
- Caractéristiques de l’accident
- Lieu de l’accident
- Véhicules impliqués
- Usagers des véhicules impliqués
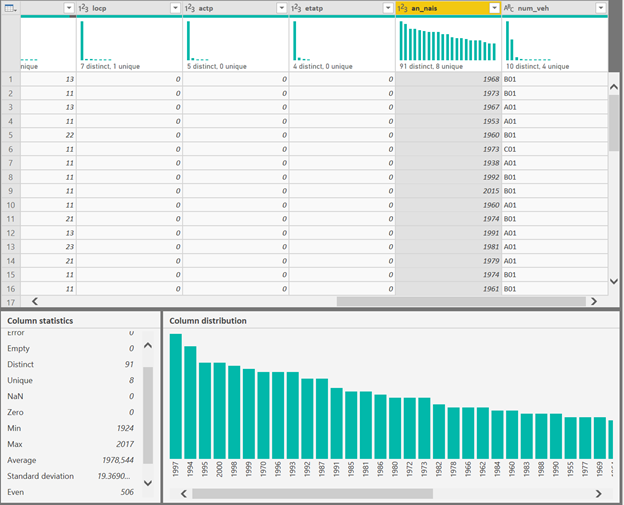
La qualité des données en entrée déterminera la qualité des résultats qui seront obtenus (ou tout du moins, garbage in, garbage out !). Un travail d’inspection de chaque champ est nécessaire et celui-ci se fait rapidement grâce au profil de la colonne, comme par exemple ci-dessous, sur l’année de naissance de l’usager.
La lecture des indicateurs de synthèse (moyenne, médiane, écart-type, etc.) nous permet de débusquer des valeurs aberrantes (un conducteur né en 1924, cela reste plausible) et de comptabiliser des valeurs manquantes qui nécessiterait un traitement spécifique (ici, toutes les lignes sont renseignées.)
L’interaction pour une meilleure exploration des données
L’une des grandes forces de Power BI réside dans son haut niveau d’interaction avec la donnée, au moyen de filtres visuels ou en sélectionnant un élément graphique pour obtenir instantanément la mise à jour des autres visuels.
L’analyse descriptive est ainsi rapidement obtenue. A vous de jouer, ce rapport est totalement interactif !
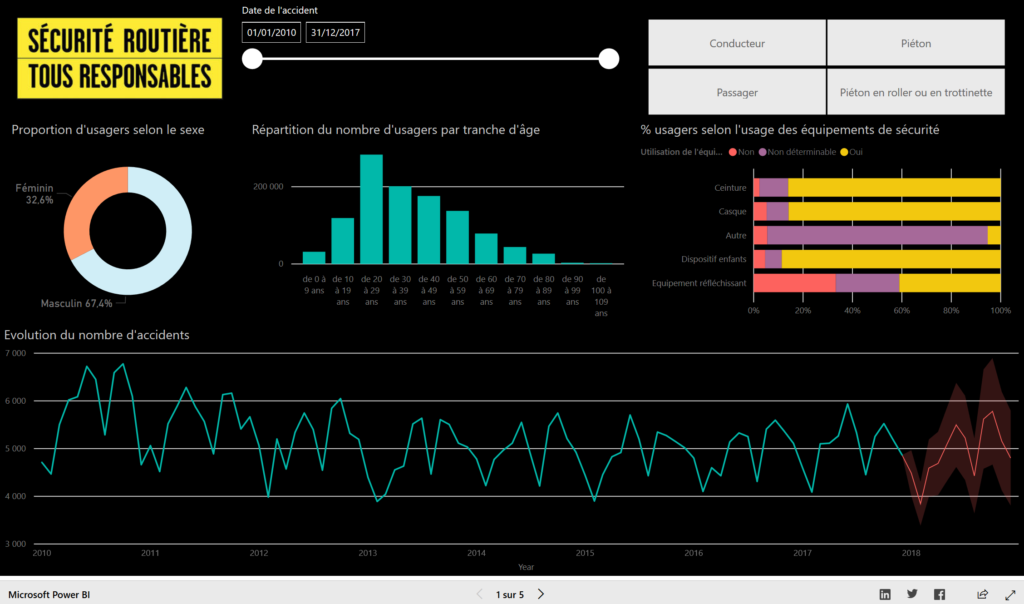
Bien sûr, il ne faudra pas tomber dans le travers de chercher à filtrer sur toutes les dimensions possibles ! L’être humain n’est pas en capacité d’appréhender un trop grand nombre d’informations mais les méthodes d’analyse avancée sont là pour nous aider.
Des fonctionnalités pour l’analyse explicative
Observons l’évolution du nombre d’accidents dans le temps, au niveau annuel. On constate une hausse en 2016 avec un recul des accidents sur les années précédentes.
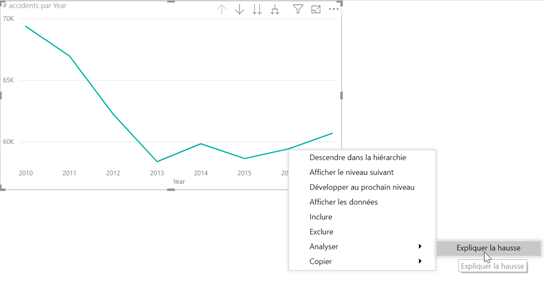
Power BI va rechercher les facteurs explicatifs de la hausse de l’indicateur en testant tous les champs du modèle et nous fera plusieurs propositions. Nous retenons ici celle du département de l’accident qui met en évidence une hausse significative sur les départements d’Ile-de-France 75 et 93, contre une baisse dans les Alpes-Maritimes. Cette piste nous mettrait sur la voie de données décrivant ces départements (population, infrastructures routières, etc.).
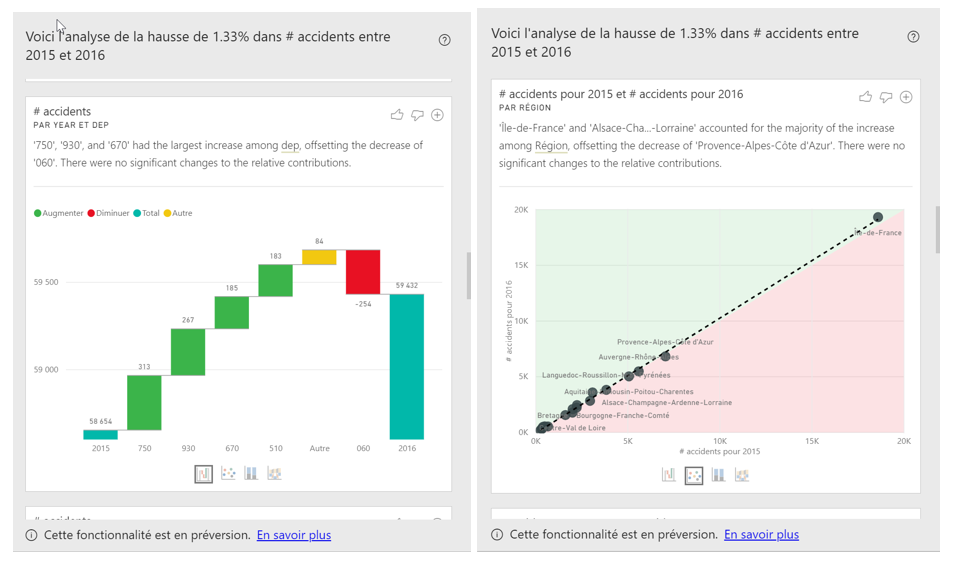
L’analyse faite jusqu’ici nous permet de comprendre les données dans leur ensemble mais il est fondamental de répondre à une problématique levée par le sujet, ici l’accidentologie, et nous allons donc rechercher des explications à la mortalité routière.
Nous disposons pour cela d’une information sur la gravité de l’accident qui permet de déterminer si l’usager est décédé.
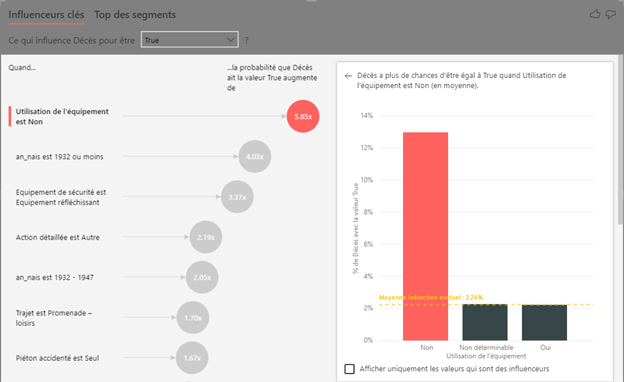
L’analyseur d’influenceurs clés (key influencers, basé sur une approche de modélisation par régression logistique) identifie la non utilisation d’un équipement de sécurité (ceinture, casque, etc) comme le facteur le plus fort dans un décès lié à un accident : la probabilité est presque multipliée par 6. L’âge est également un facteur très important. Si celle-ci est inférieure à 1932, le risque de décès est ici multiplié par 4.
Nous obtenons ici, grâce à l’analyse, des leviers d’actions concrets pour la sécurité routière, ce qui constitue une première forme d’analyse prescriptive
… et une première analyse prédictive !
Reprenons l’évolution du nombre d’accidents dans le temps mais cette fois-ci, au niveau mensuel. La courbe traduit clairement une notion de saisonnalité : il y a beaucoup (trop) d’accidents lors des périodes de vacances scolaires par exemple. Si l’on ajoute une droite de tendance, on voit que celle-ci est légèrement à la hausse. Prolonger cette droite ne donnerait pas une bonne prévision au détail mensuel puisqu’il faut tenir compte de cette saisonnalité.
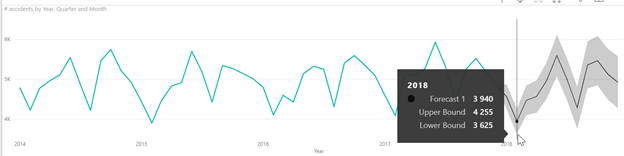
Nous utilisons ici la fonctionnalité de « forecast » de Power BI basée sur la méthode statistique du lissage exponentiel. N’allons pas trop loin, il est conseillé de ne pas dépasser une prévision au tiers de l’historique disponible. Cette prévision est encadrée par un intervalle de prévision, donnant les bornes entre lesquelles on espère voir apparaître la « vraie » valeur, avec un niveau de confiance de 95%.
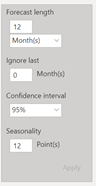
On obtient alors la prévision sur le graphique et l’infobulle donne les valeurs chiffrées.
Une présentation dynamique sans changer d’outil
Résumons maintenant toutes les informations découvertes au travers de cette première analyse. Pour communiquer ces résultats, nous pourrions utiliser un support externe comme PowerPoint ou un fichier PDF mais nous perdrions toute interaction. Les bookmarks (ou signets) de Power BI sont ici un outil extrêmement pratique pour garder en mémoire une sélection personnalisée de filtres et enchainer la lecture de plusieurs pages de rapport comme l’on enchainerait des diapositives.
2 thoughts on “Data Analytics, back to basics ! (*) [1/3]”