Les citizen data scientists disposent d’un outil graphique dans le portail Azure Machine Learning nommé Concepteur (ou Designer en anglais) permettant de réaliser des pipelines de Machine Learning, pour l’apprentissage comme pour l’inférence (c’est-à-dire le fonctionnement prédictif).
Depuis la première version de l’outil, anciennement nommé Azure Machine Learning Studio, et dit maintenant “classique”, des modules pour l’analyse textuelle étaient déjà présents mais l’offre s’est aujourd’hui, en ce début 2021, agrandie.
L’objectif de cet article est de faire un survol des méthodes disponibles, dans cette approche “low code“, pour un jeu de données contenant un champ de “texte libre”, et dans le but de réaliser une méthode d’apprentissage supervisé, et plus précisément de classification.
En prérequis, rappelons les notions indispensables avant de s’attaquer à notre problématique :
– disposer d’une ressource de calcul dite “compute cluster” qui servira à exécuter les différentes itérations du pipeline (succession de modules)
– créer une nouvelle expérience, qui permettra de suivre le résultat des exécutions ou runs (outputs, logs, artefacts, métriques…)
– connaître la structure classique d’un pipeline d’entrainement supervisé (s’inspirer des exemples disponibles, en particulier “Text Classification – Wikipedia SP 500 Dataset” qui est décrit sur ce site GitHub.

Nous allons nous concentrer ici sur deux phases qui auront leurs spécificités pour le traitement de données textuelles :
– le preprocessing
– le choix du modèle d’apprentissage pour une classification
Preprocessing des données textuelles
Nous allons utiliser ici le module Preprocess text qui réalisera de nombreuses actions de nettoyage et de préparation de nos données textuelles, en une seule étape.
Ce module est très puissant et basé sur la librairie de référence SpaCy mais ne supporte pour l’instant malheureusement que la langue anglaise. Nous pourrons contourner cela par un script R ou Python pour le cas de corpus en français. Mais à l’exception de la lemmatisation, les opérations pourront toutefois s’appliquer à un corpus d’une autre langue que l’anglais.
La case à cocher “Expand verb contractions” est toutefois spécifique à des formulations anglaises comme don’t, isn’t, I’ve, you’ll, etc.
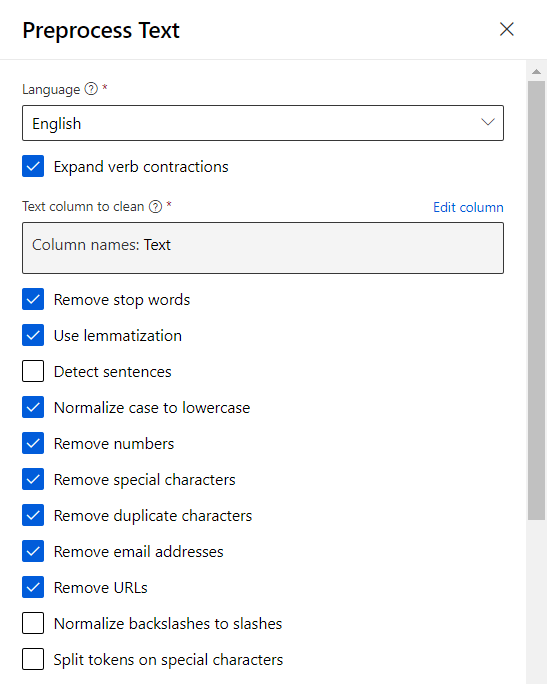
Détaillons maintenant les autres options, avec quelques exemples simples si nécessaire.
– Retrait des mots outils (stop words) : a, about, all, any, etc.
Cette opération est paramétrable au moyen de la seconde entrée du module. Nous pouvons donc utiliser un fichier, d’une colonne, contenant les mots en français. Ce site propose une liste de mots outils dans de nombreuses langues.
– Lemmatisation (remplacement du mot par sa forme canonique qui est “l’entrée du dictionnaire”, c’est-à-dire, l’infinitif ou le masculin singulier lorsqu’il existe) : la phrase “The babies are walking on their feet” donnera “The baby be walk on their foot” puis sans mots outils “baby walk foot“.
– Détection des phrases (séparées alors par |||, à choisir si l’on souhaite un traitement spécifique par phrase plutôt que par ligne du jeu de données)
– Normalisation en minuscules (sinon les mots sont considérés comme différents)
– Suppression des nombres, caractères spéciaux (non alphanumériques), caractères dupliqués plus de deux fois, adresses email de la forme <string>@<string>, URLs reconnues par les préfixes http, https, ftp, www
– Remplacement des backslashes \ en slashes / : l’usage ne sera pas fréquent, on passera plutôt par la suppression de ces caractères spéciaux.
– Séparation des tokens (ici, les mots) sur la base de caractères spéciaux comme & (pour l’esperluette, on préfèrera à nouveau la citer dans les caractères spéciaux à supprimer) ou - : un “pense-bête” deviendra “penser bête” suite à séparation et lemmatisation en français.
En pratique, il est important de maîtriser l’ordre dans lequel ces opérations s’appliquent. Ainsi, on réalisera plutôt les opérations de nettoyage (suppressions, minuscules, mots outils…) avant les opérations de lemmatisation.
Importer la librairie NLTK et les mots outils en français
Nous disposons d’un module Python permettant d’exécuter un script, sur un ou deux dataframes en entrée de ce module. Le code suivant nous permettra d’importer la librairie NLTK et d’utiliser la liste des mots outils ou bien la lemmatisation en français.
import pandas as pd
def azureml_main(dataframe1 = None, dataframe2 = None):
import importlib.util
package_name = 'nltk'
spec = importlib.util.find_spec(package_name)
logging.debug(spec)
if spec is None:
import os
os.system(f"pip install nltk")
import nltk
from nltk.corpus import stopwords
stopwords = set(stopwords.words('french'))
def preprocess(text):
clean_data = []
for x in (text[:]):
print(x)
new_text = re.sub('<.*?>', '', x) # remove HTML tags
new_text = re.sub(r'[^\w\s]', '', new_text) # remove punc.
new_text = re.sub(r'\d+','', new_text)# remove numbers
new_text = new_text.lower() # lower case, .upper() for upper
if new_text != '':
clean_data.append(new_text)
return clean_data
dataframe1['preprocess'] = preprocess(dataframe1['Text'])
dataframe1['preprocess_without_stop'] = dataframe1['preprocess'].apply(lambda x: [word for word in x if word not in stopwords])
#On peut observer la liste des mots outils de NLTK dans la seconde sortie
dataframe2 = pd.DataFrame(list(stopwords))
return dataframe1, dataframe2,Apprentissage supervisé sur données textuelles
Dans le groupe Text Analytics, nous disposons des modules ci-dessous.
Vowpall Wabbit
Nous écartons d’emblée l’approche Vowpal Wabbit, framework de Machine / Online Learning initialement développé par la société Yahoo !. Celui-ci nécessite en effet d’obtenir en entrée des données préprocessées mais surtout présentées dans un format spécifique. Vous pouvez toutefois vous référer à ce blog si vous souhaitez préparer vos données en ce sens. Il faudra ensuite utiliser des lignes de commandes au sein du module Train Vowpal Wabbit Model.
Toutefois, nous allons pouvoir remplacer ce framework par une approche relativement similaire réalisée par le module Feature Hashing.
Feature Hashing
Cette méthode consiste à créer une table de hash, c’est-à-dire de valeurs numériques, construites à partir du dictionnaire des mots.
Nous prendrons comme entrée le texte préprocessé. Nous avons alors deux paramètres à renseigner dans la boîte de dialogue du module.
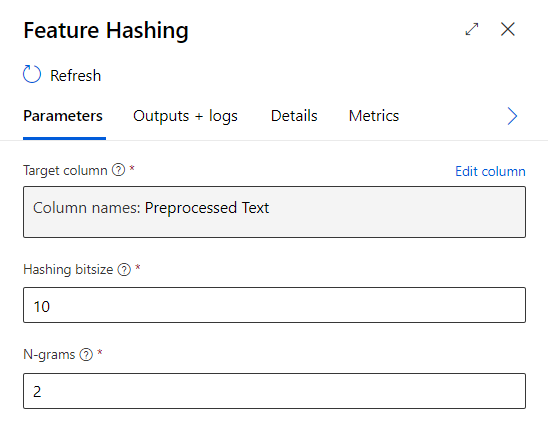
Une taille de 10 bits correspondra à 2^10, soit 1024, nouvelles colonnes dans le jeu de données en sortie. Ces colonnes contiendront le poids de la feature dans le texte. Une valeur de 10 se montre généralement suffisante et attention à l’explosion de la taille du jeu de données (2^20 correspondrait à 1048576 colonnes !).
Un N-gram est une suite de n mots consécutifs, considérée comme une seule unité. Dans la phrase “le ciel est bleu”, nous avons quatre unigrams, trois bigrams (“le ciel”, “ciel est”, “est bleu”) et deux trigrams (“le ciel est”, “ciel est bleu”). Le paramètre attendu est la valeur maximale, ainsi si nous choisissons la valeur 3, nous prenons en compte les unigrams, bigrams et trigrams.
Nous obtenons le résultat suivant.
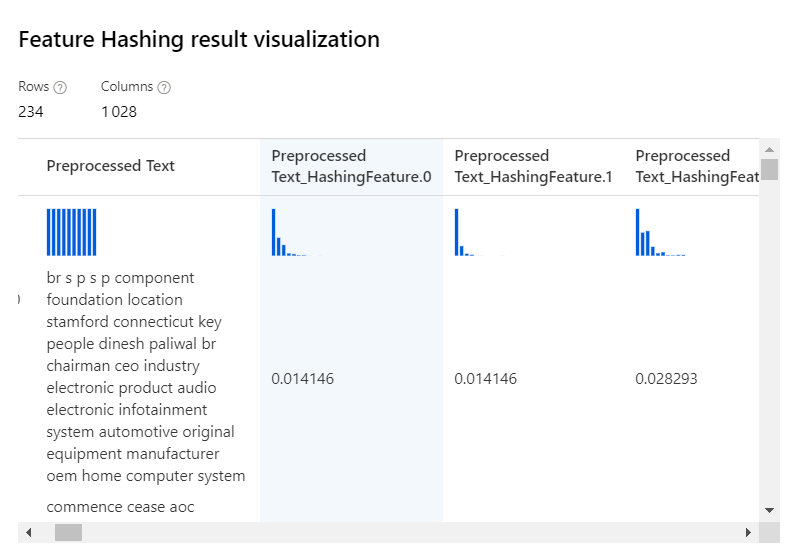
Seules les colonnes numériques seront ensuite soumises à l’entrainement du modèle.
Extract N-gram feature
Nous retrouvons ici la notion de N-gram (suite de n mots consécutifs, considérée comme une seule unité). Les paramètres disponibles nous permettent de spécifier :
– la taille maximale des N-grams considérés dans le dictionnaire. Ce paramètre conditionnera la taille du jeu de données, qui peut devenir très grand.
– les longueurs minimale et maximale des mots, en nombre de lettres
– la fréquence minimale de présence d’un N-gram dans le document (ensemble des lignes du jeu de données)
– le pourcentage maximum de présence d’un N-gram par ligne sur l’ensemble des lignes. La valeur 1 (100%) correspond à retirer un N-gram présent dans chaque ligne, et donc considéré comme un bruit qu’il faut supprimer.
– la métrique de pondération calculée par ligne, pour chaque feature créée.
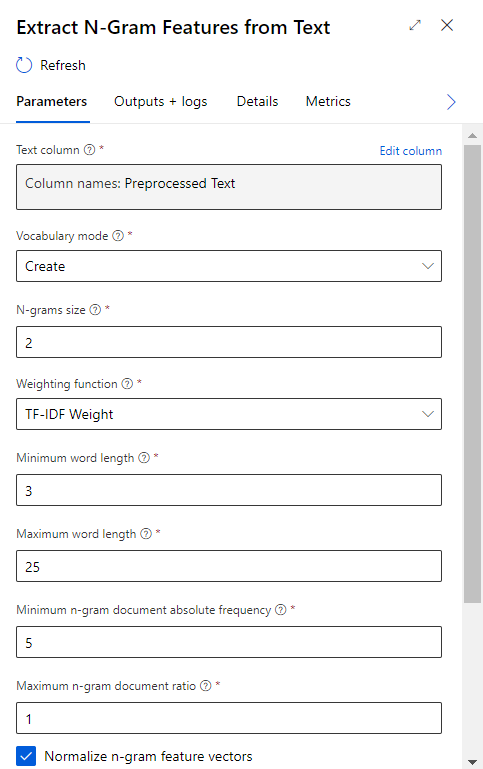
La métrique TF-IDF est un standard de la discipline est correspond au ratio de la fréquence d’un N-gram dans la ligne (TF) par le log d’un autre ratio dit”inversé” : le nombre de lignes du jeu de données sur la fréquence du terme dans le jeu de données. Les valeurs seront normalisées selon une norme L2 si la case correspondante est cochée dans la boîte de dialogue.
En créant le vocabulaire, nous obtenons un jeu de données en sortie tel que représenté ci-dessous. Celui-ci contient la liste des N-grams, ainsi que les métriques DF et IDF associées.
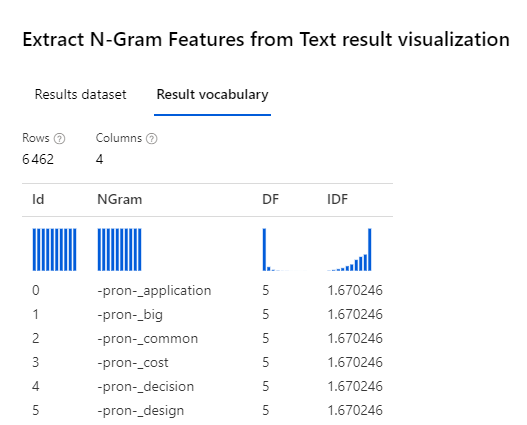
C’est ce vocabulaire établi sur le jeu d’entrainement qui devra saisir à la phase de validation sur les nouvelles données. Il ne faudrait pas créer un nouveau vocabulaire sur la seconde partie des données ! Mais les métriques doivent être calculées. Nous utilisons donc la combinaison ci-dessous des modules.
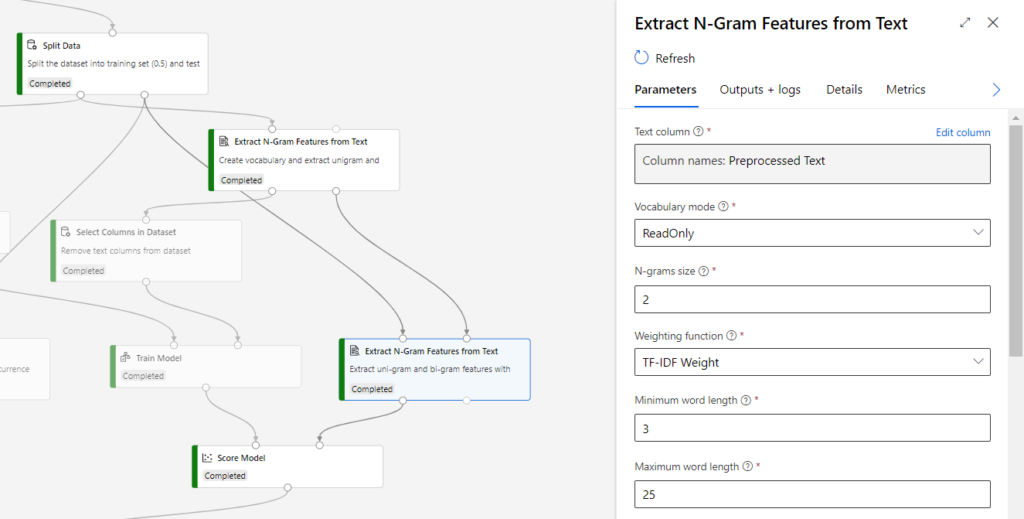
Le paramètre “Vocabulary mode” est alors positionné sur la valeur ReadOnly.
Convert word to vector
Nous retrouvons ici une méthode dite de plongement lexical (word embedding) qui a connu un fort engouement ces dernières années, et plus communément appelée word2vec. Il s’agit d’utiliser des modèles pré-entrainés sur des milliards de documents, issus par exemple de Wikipedia ou de Google News.
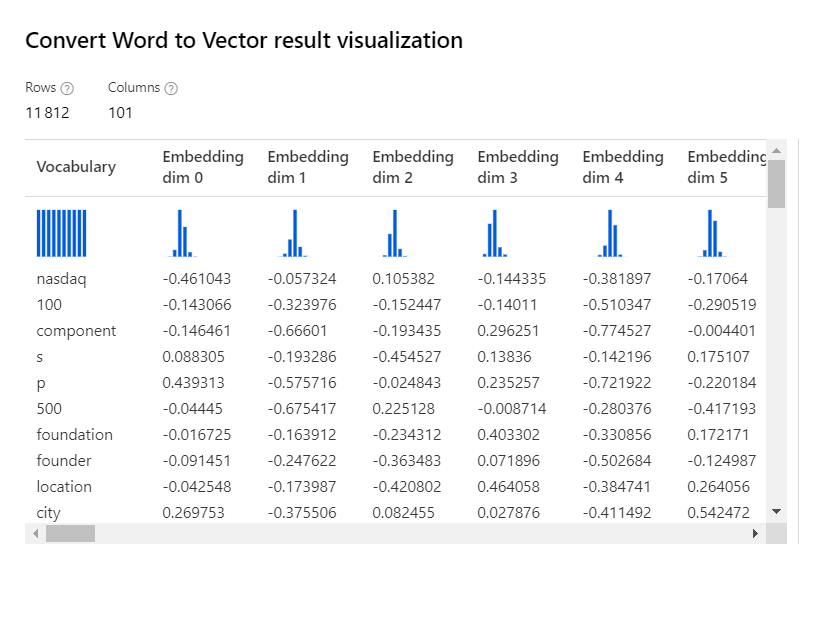
A ce jour (janvier 2021), il ne semble pas y avoir de module permettant de tirer parti du vocabulaire obtenu en sortie. Nous privilégierons donc une approche par script Python, au moyen de librairies comme Gensim (voir le site officiel).
Latent Dirichlet Allocation
Nous sortons ici du cadre supervisé pour obtenir une méthode non supervisée et donc dédiée à rassembler des textes similaires, dans un nombre prédéfini (“Number of topics to model”) de catégories, sans que celles-ci ne soient explicitement définies.
Comme nous disposons déjà des catégories, cette méthode ne se prête pas à l’objectif mais pourrait être intéressante en amont, dans un but exploratoire (nos catégories a priori ne sont peut-être pas si pertinentes…).
Un mode d’options avancées donnera la main sur tous les hyperparamètres du module.
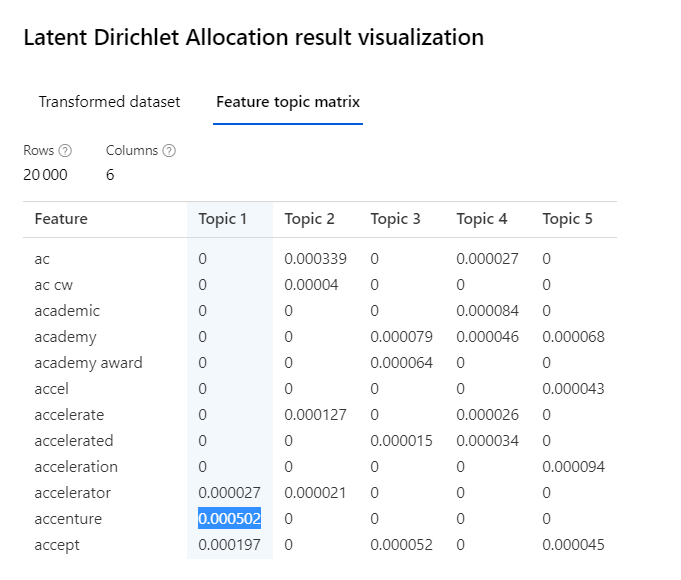
Chaque ligne est évaluée sur les nombre prédéfini de sujets (topics).
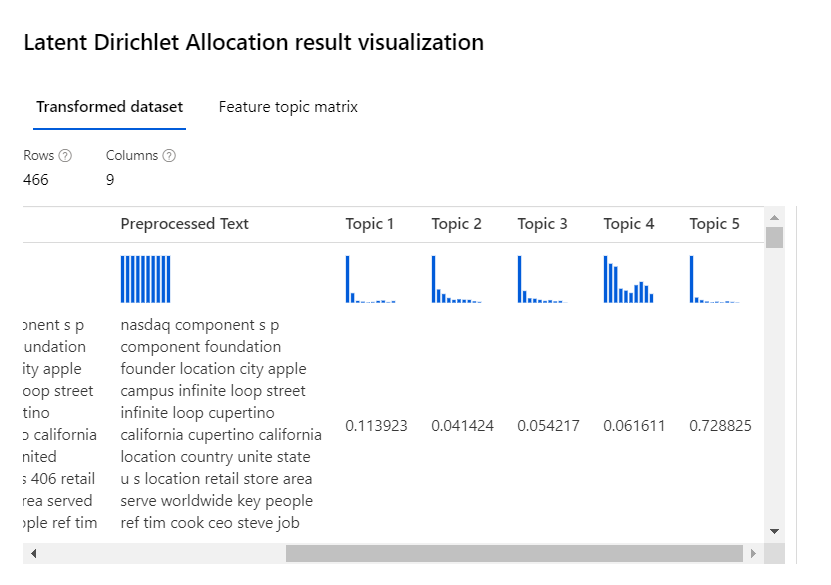
A partir de la sortie, il sera nécessaire de réaliser une lecture et une interprétation “humaine” sur les sur les groupes afin de les nommer. Dans la feature matrix topic, nous pouvons visualiser les N-grams les plus contributeurs de chaque sujet.
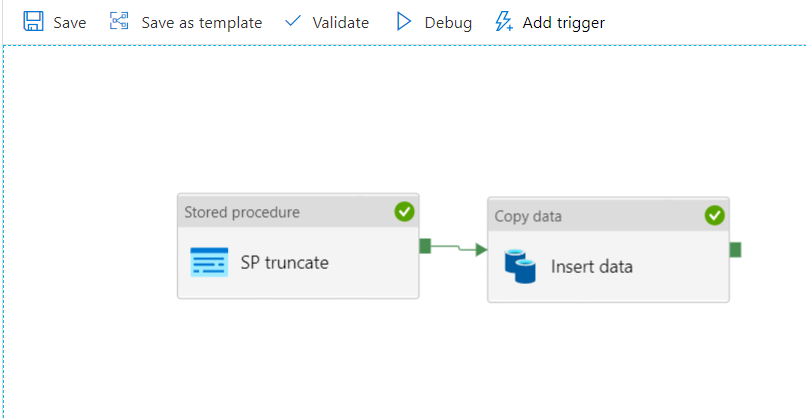
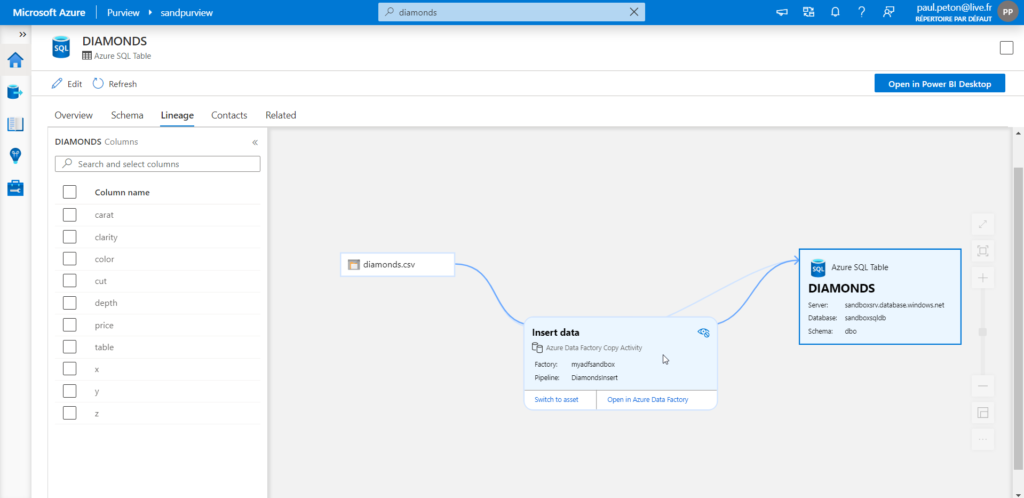
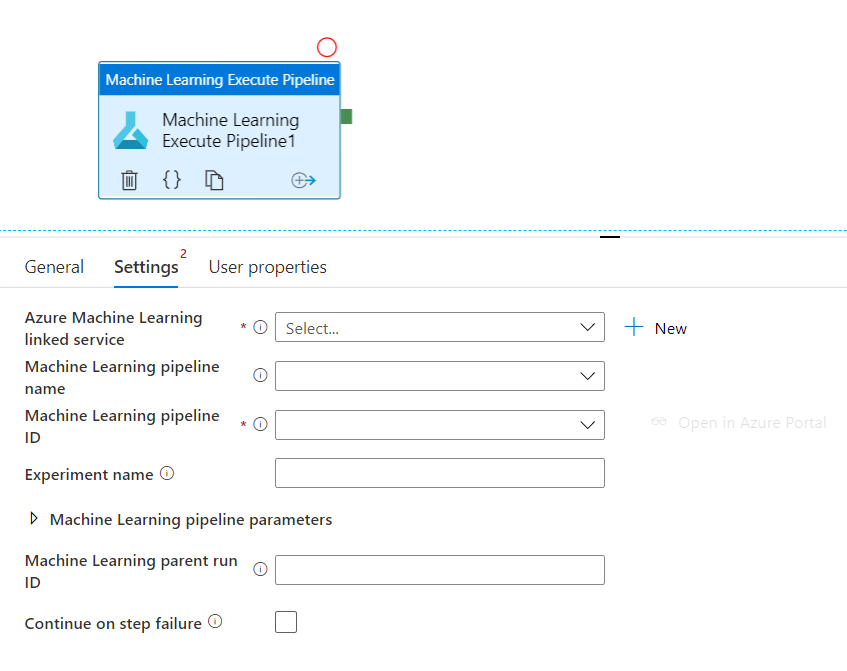
Publier le pipeline d’entrainement
Publier un pipeline permet de bénéficier de l’ordonnancement de celui-ci, par exemple avec un outil comme Azure Data Factory. Nous obtiendrons ainsi un identifiant (ID) qui devra être renseignée dans l’activité.
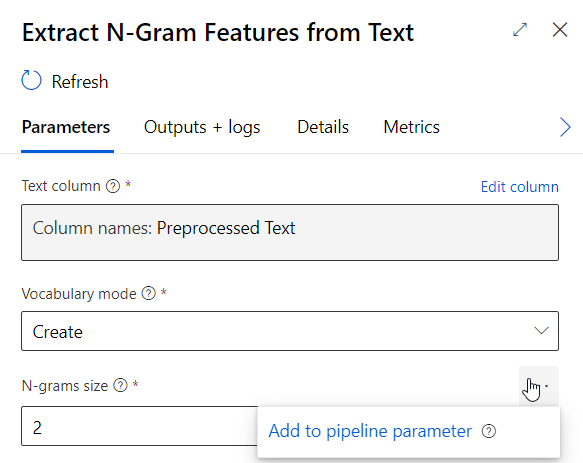
Les différents paramètres sélectionnés dans les modules peuvent être ajoutés comme paramètres du pipeline et ainsi renseignés lors de nouveaux lancements.
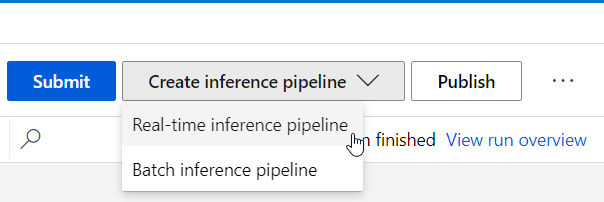
Déploiement du pipeline d’inférence
Une fois le pipeline d’entrainement soumis et correctement exécuté (tous les modules sont en vert), nous pouvons choisir entre un service Web prédictif, soit en real-time (prévision par valeur), soit en batch (prévision par lot).
Si nous avons comparé plusieurs modèles au sein du pipeline d’entrainement, il faut cliquer sur le module “Train model” correspond à celui que l’on veut déployer (en pratique, celui ayant les meilleures métriques d’évaluation).
Le pipeline graphique se simplifie alors et se voit enrichi d’une entrée et d’une sortie pour le service Web qui sera créé.
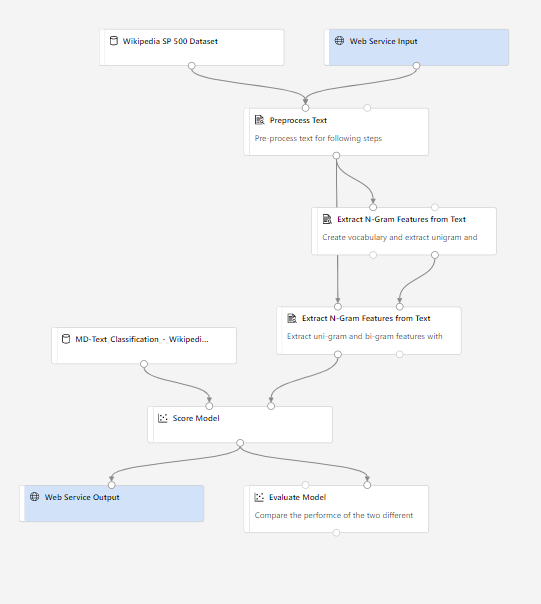
Attention, pour aller plus loin, il est nécessaire de supprimer le module d’évaluation ou sinon, vous rencontrerez le message d’erreur suivant.

Un nouveau run du pipeline doit être soumis avant de pouvoir cliquer sur le bouton de déploiement du service web.
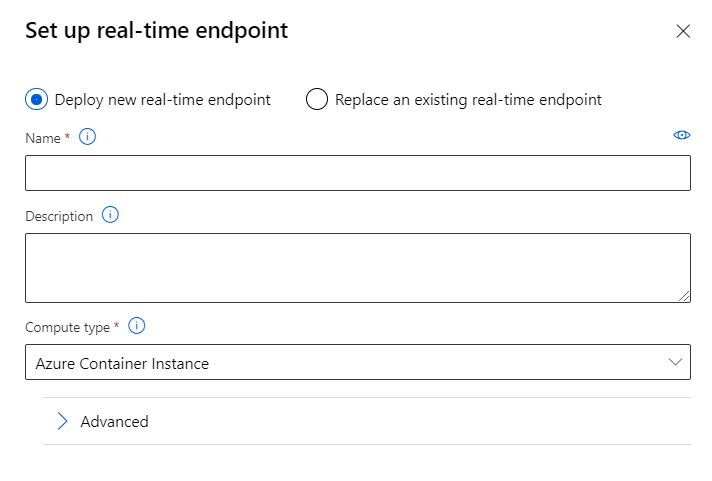
Le déploiement se fait au choix, sur une ressource ACI (plutôt pour le test) ou AKS (plutôt pour la production).
En conclusion, même s’il paraît difficile d’aller jusqu’en production avec cet outil, il reste néanmoins très rapide pour mettre en œuvre différentes méthodes reconnues dans le Traitement Automatique du Langage (TAL) et pourra apporter des résultats pertinents dans des cas relativement simples de classification.