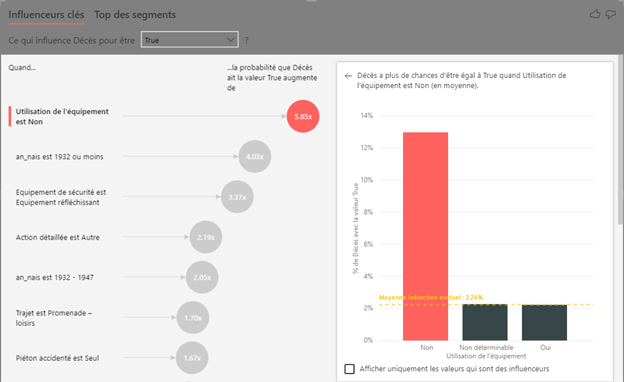
La donnée classique et structurée n’a plus de secret pour vous si vous avez lu les deux billets précédents (ici et là) traitant de l’analyse avancée et de la modélisation des données. Pour autant, ces méthodes sont valables, et performantes, lorsque la donnée est de type alphanumérique et organisée sous forme tabulaire. Pour les données dites non structurées comme les images, le son ou encore le texte rédigé, il faut faire appel à un tout autre arsenal d’outils.
Du temps, de la puissance et des données
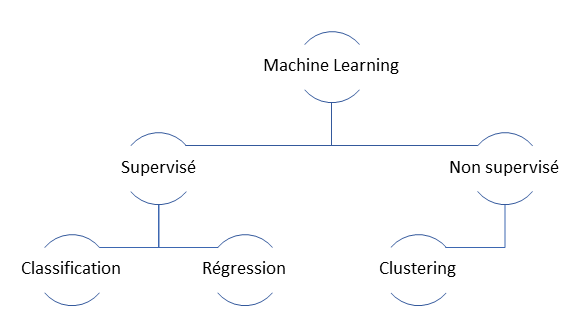
Soyons pragmatiques, pour être ingérée par un algorithme, toute donnée devra devenir numérique mais le cheminement pour y arriver va être complexe. Des approches comme la métrique TF-IDF ont fait leurs preuves, pour le référencement de documents pertinents dans des corpus de textes. Cela reste vrai tant que la puissance de calcul disponible est suffisante, et donc le volume de données relativement raisonnable. Dans le domaine des images, on distinguera deux usages principaux : la classification (catégoriser une image parmi des labels existants) et la reconnaissance d’objets (présence et position sur l’image). Les progrès ont été remarquables avec l’arrivée (voire le retour…) des réseaux de neurones dits profonds, ce que l’on nomme le « Deep Learning ».
Les frameworks de Deep Learning sont aujourd’hui nombreux : Cognitive Toolkit créé par Microsoft, TensorFlow mis en place par Google ou encore PyTorch. Leur maîtrise implique une bonne connaissance du fonctionnement mathématique des réseaux de neurones et de l’état de l’art des différents types de couches de neurones pouvant être utilisées. Mais ensuite, il faudra beaucoup de données et beaucoup de puissance de calcul pour obtenir un modèle performant.
C’est ici que le mécanisme du Transfer Learning prend tout son intérêt. En effet, au fur et à mesure des couches du réseau de neurones profond, l’apprentissage va se spécifier. Pour donner une image didactique, on pourrait dire que l’algorithme commence par reconnaître des formes simples avant d’identifier des formes plus complexes. C’est d’une certaine manière ce que font nos yeux et notre cerveau lorsque nous découvrons un nouvel environnement. J’entre dans un nouveau bâtiment et je vois des bureaux, des écrans, des tasses à café, un babyfoot, je reconnais… l’open space d’une ESN parisienne !
Les services cognitifs
Imiter les capacités humaines de perception ou de cognition est depuis longtemps un défi pour le monde de l’informatique et la discipline de l’Intelligence Artificielle s’y emploie, présentant des succès majeurs depuis quelques années. Pensons ici à la qualité des outils de traduction automatique, à l’efficacité de la transcription orale en texte ou encore à la pertinence des moteurs de recommandation.
Les départements de Recherche et Développement des géants du numérique rivalisent de performances dans ces différents domaines et mettent à disposition leurs algorithmes, en les encapsulant dans des interfaces (web, API, SDK…) facilitant leur utilisation. En ce sens, nous pouvons parler d’Intelligence Artificielle as a Service !
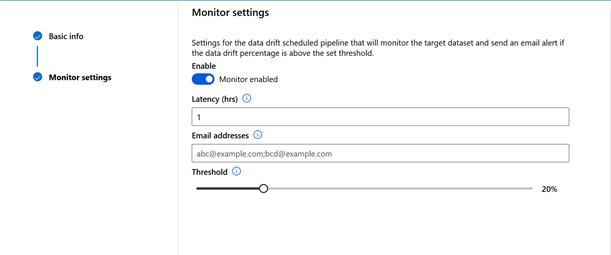
Les services cognitifs de Microsoft se répartissent en cinq catégories présentées sur l’image suivante.

Plusieurs de ces services sont accessibles en démonstration ou test sur le site de Microsoft. Pour une utilisation plus régulière et dans un cadre professionnel, un abonnement Azure sera nécessaire.
Pour une entreprise est convaincue de la création de valeur potentielle au travers des données non structurées (texte, image, son, vidéo…), elle doit dorénavant s’interroger sur la faisabilité d’un développement équivalent : existe-t-il des ressources (personnes et machines) capables de produire le niveau de performance attendu des algorithmes ? A la négative, il pourra être très intéressant d’exploiter les services cognitifs.
Microsoft Custom Vision
Le site customvision.ai de Microsoft vous permet de vous lancer rapidement dans l’évaluation de modèles de classification ou de reconnaissance d’objets, sans avoir à saisir une seule ligne de code !
Identifiez-vous sur le portail, avec votre compte Azure. Il sera possible de créer et conserver simultanément deux projets sur la plateforme, et ce, sans facturation. Dans l’exemple ci-dessous, nous choisissons un projet de type « Object detection ». Notre cas d’usage sera ici d’identifier l’existence d’un panneau de limitation de vitesse sur une photo.
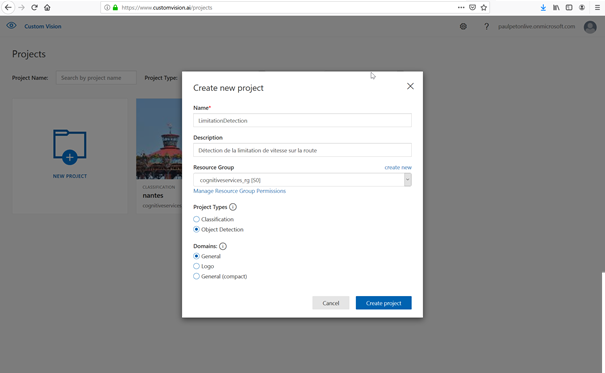
Il sera alors nécessaire de créer ou d’associer un groupe de ressources Azure. Si cette notion ne vous parle pas, rapprochez-vous des administrateurs de votre souscription Azure.
Trois domaines sont proposés : il s’agit ici de spécifier le « début » du réseau de neurones profond qui sera employé dans notre démarche d’apprentissage par transfert. Nous restons ici sur le domaine général. L’utilisation du domaine « Logo » permettrait de bénéficier de couches de neurones déjà entrainées à la reconnaissance de logos de marques commerciales.
Chargement des images et ajout de tags
L’écran suivant correspond à l’interface de chargement des données et d’entrainement du modèle. Nous rentrons ici dans la logique dite supervisée de l’apprentissage automatique : il faut fournir des exemples que le réseau interprétera pour construire le modèle, qui lui permettra ensuite de réaliser des prévisions. En résumé, prédire le futur correspond à reproduire le passé, en le généralisant !
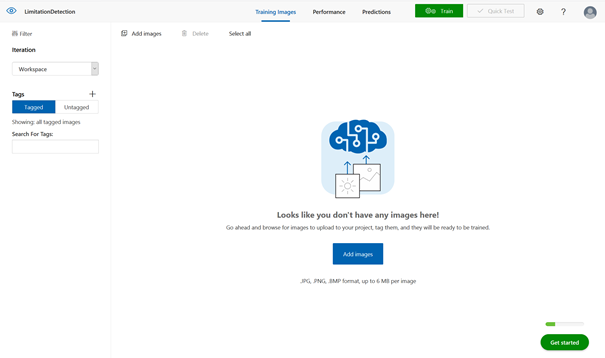
La première étape consiste à charger des images (« add images ») à partir de l’ordinateur que nous utilisons. Ces images peuvent être de format .jpg, .png, .bmp ou .gif et il n’y a pas d’exigence à ce qu’elles soient de la même résolution. Le poids de l’image utilisée en entrainement ne pourra pas dépasser 6Mo et 4Mo en prévision. Les images dont la largeur se situe en dessous de 256 pixels sont automatiquement remises à l’échelle par le service.
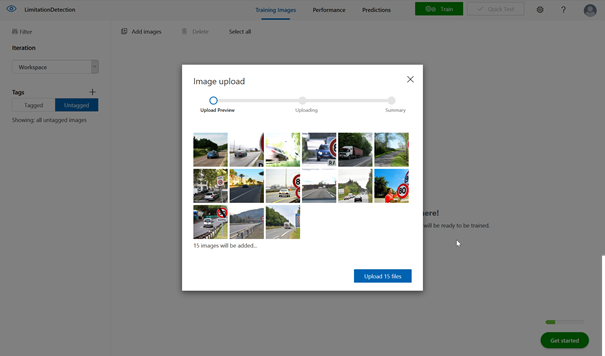
Un minimum de 15 images est requis pour débuter un modèle de détection d’un objet. Toutefois, il faudra viser une cinquantaine d’images pour une première expérience significative et s’en tenir à des cas d’usage relativement « visibles ». Même si la technologie s’en rapproche, ce n’est pas cet outil qui sert par exemple à détecter des pathologies dans des clichés médicaux.
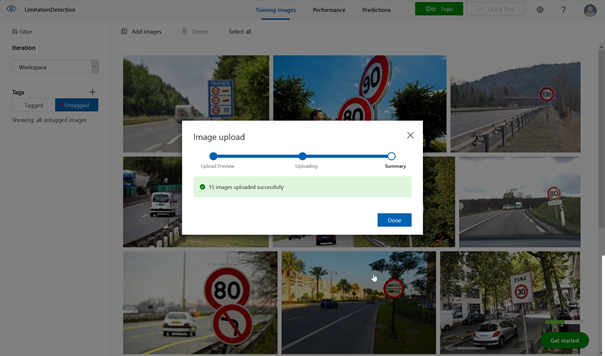
Il est maintenant nécessaire de travailler chaque image en entourant la zone souhaitée (ici le panneau rond de limitation) et en y associant un « tag » (mot clé identifiant l’objet). C’est la partie manuelle et sans doute la plus rébarbative de l’entrainement du modèle.
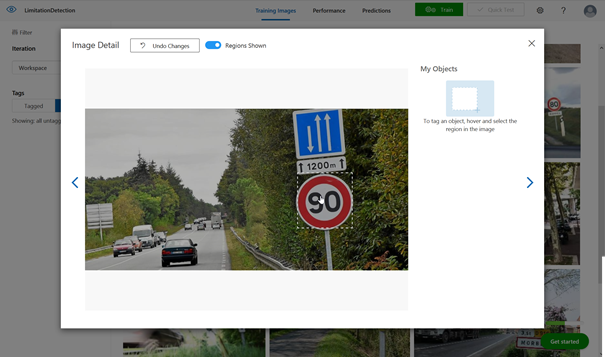
Si l’on souhaite reconnaitre plusieurs objets, il sera nécessaire de compter au moins 15 images par objet.
Première itération du modèle
Lors de la phase d’entrainement, l’algorithme cherche à réduire l’erreur de prévision sur la base des images déjà taguées.
Deux types d’entrainement sont disponibles :
- Fast training
- Advanced training
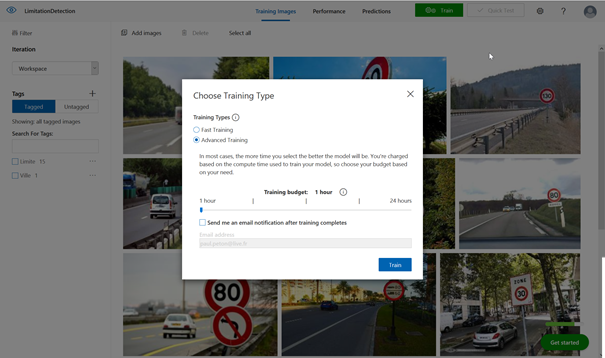
Deux règles s’appliquent ici de manière assez générale :
- Plus il y a beaucoup de données, plus le temps d’entrainement sera long et meilleur sera le modèle.
- Plus l’entrainement est long ou sollicite de machines puissantes, plus celui-ci sera cher.
L’entrainement peut durer plusieurs minutes et s’étendre sur plusieurs heures en cas de volumétrie et de complexité importante. Nous privilégions ici dans un premier temps l’entrainement rapide.
Evaluer et tester le modèle
Le menu Performance permet de consulter les indicateurs de qualité du modèle.
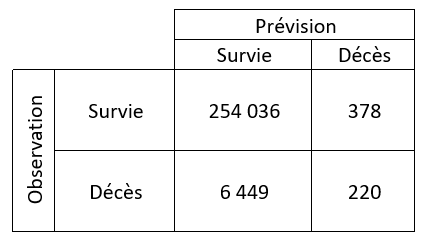
La précision correspond, pour un tag donné, à la proportion d’images correctement classées ou avec une reconnaissance d’objets exacte sur l’ensemble des images.
Le rappel (Recall) correspond à la proportion d’images appartenant réellement à une classe parmi toutes les images prédites dans cette classe.
On définira le seuil de probabilité (Probability Threshold) pour savoir si la confiance dans une prévision est suffisante pour classer une image ou détecter un objet.
Le score mAP (mean Average Precision) est un calcul synthétisant les indicateurs de précision et de rappel, en moyenne pour l’ensemble des classes ou des objets à détecter.
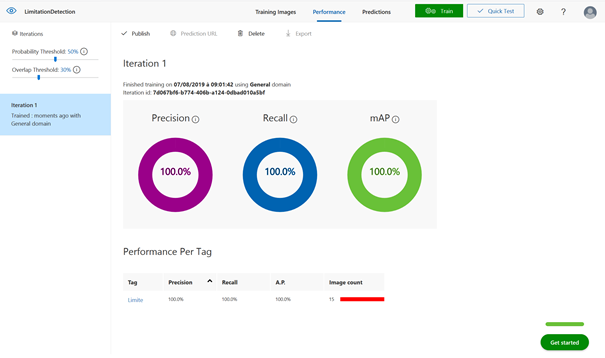
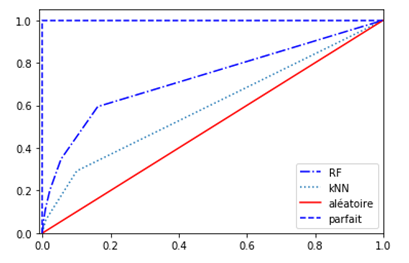
On cherchera à maximiser ces trois indicateurs mais attention, ce n’est pas forcément souhaitable que de disposer d’un modèle « parfait » comme sur l’illustration ci-dessus. La perfection en apprentissage automatique est nommée surapprentissage (« overfitting ») et peut se traduire par un manque de capacité de généralisation. Concrètement, le modèle a de forts risques d’échec dès que de nouvelles images dévieront des images d’entrainement.
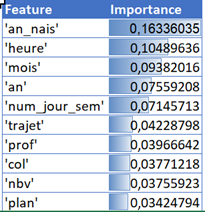
Une solution consiste ici à augmenter le nombre d’images utilisées pour l’apprentissage, en prenant soin de varier les contextes d’images (routes de jour / de nuit, panneaux étrangers, etc.).
L’interface de Custom Vision nous propose maintenant de tester le modèle établi.
Nous utilisons bien sûr ici une image qui n’a pas servi à l’entrainement du modèle. Il est possible d’utiliser une image de l’ordinateur local ou bien une URL web d’image.
Il sera également possible de comparer les résultats du test sur les différentes itérations d’entrainement.
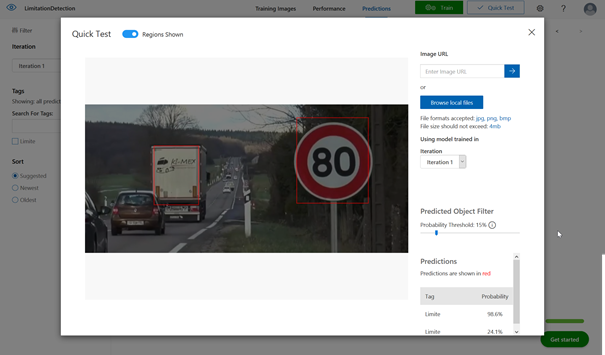
Sur cette première image, le panneau est bien identifié avec une probabilité de plus de 98% mais nous observons également que l’arrière du camion a été analysé comme un panneau. Pour autant, la probabilité est très faible (< 25%) et nous pourrons rejeter cette hypothèse en définissant un seuil d’acceptation.
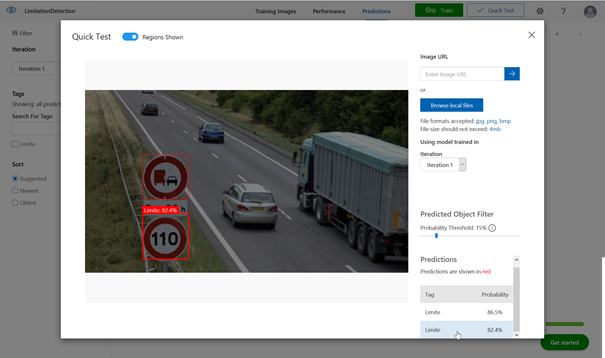
Sur ce second test, deux panneaux sont identifiés avec une probabilité forte (> 80%) d’être une limitation de vitesse. Ce n’est pourtant le cas que sur le panneau de bas. Nous devons à nouveau grossir le jeu d’entrainement, en incluant plus de diversité de panneaux et relancer une itération !
Microsoft donne plusieurs conseils pour améliorer un classifieur sur cette page. Un principe générique consistera à ajouter des images variées selon l’arrière-plan, l’éclairage, les tailles d’objet, les angles de vue…
Exploiter le modèle depuis une application tierce
Bien sûr, un usage professionnel du modèle obtenu ne pourra se faire au niveau du portail. On utilisera une application tierce qui appellera le modèle au travers d’une API.
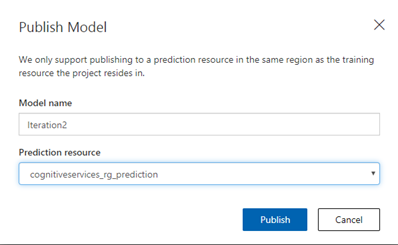
Le modèle obtenu au travers de la meilleure itération doit tout d’abord être publié (bouton « Publish ») et associé au groupe de ressources préalablement défini sur le portail Azure.
En cliquant ensuite sur « Prediction URL », on obtiendra l’URL et la clé de prévision (prediction URL & prediction-key). L’URL de prévision est aussi appelée endpoint.
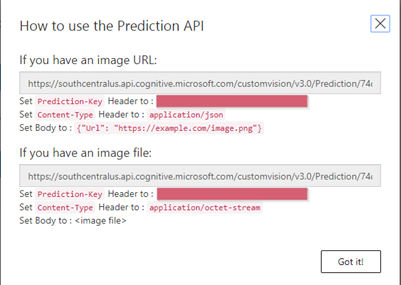
La prediction key est aussi visible depuis le portail Azure, au niveau de la ressource créée pour l’utilisation du service Custom Vision.
Deux kits de développement (SDK) existent également et permettent de réaliser l’ensemble des étapes en programmation .NET (téléchargeables pour l’entrainement et la prévision) ou en Python à l’aide de la commande suivante :
pip install azure-cognitiveservices-vision-customvision
La documentation Microsoft vous guidera sur le reste du code à écrire pour appeler le modèle.