Une fois l’infrastructure définie autour d’un cluster Databricks, les notebooks sont les éléments qui vont évoluer au gré des développements. Il faut bien sûr a minima définir deux environnements : l’un de développement, l’autre de production. Nous verrons ainsi plusieurs astuces et bonnes pratiques permettant de réaliser le processus du déploiement continu des notebooks.
Nous avons pu voir dans de précédents articles :
- Comment définir un point de montage vers un compte de stockage Azure
- Comment versionner les notebooks Databricks par exemple sous GitHub
Nous allons utiliser ici la notion de variable d’environnement, propre au cluster Spark.
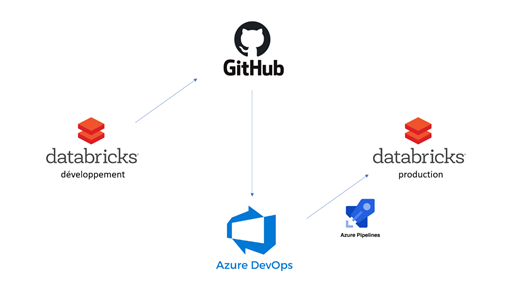
Le schéma ci-dessous illustre le mécanisme DevOps qui sera mis en place.
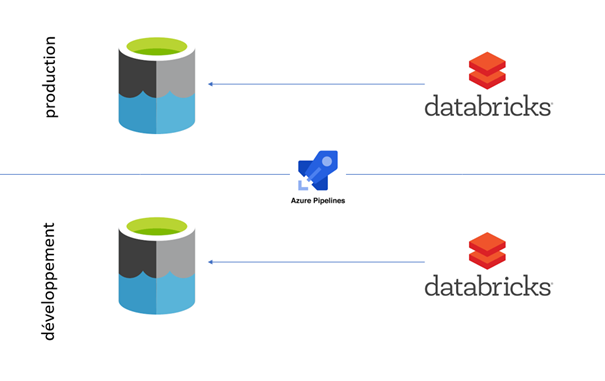
Mais pour l’instant, focalisons-nous sur le chemin menant vers les données. Nous utilisons ici deux environnements identiques d’un point de vue de l’architecture, dont une vision simplifiée est donnée sur le schéma ci-dessous :
L’accès au point de montage défini sur le compte de stockage Azure se fait par exemple au moyen des commandes Databricks dbutils :
dbutils.fs.ls('/mnt/dev/mysfilesystem/')
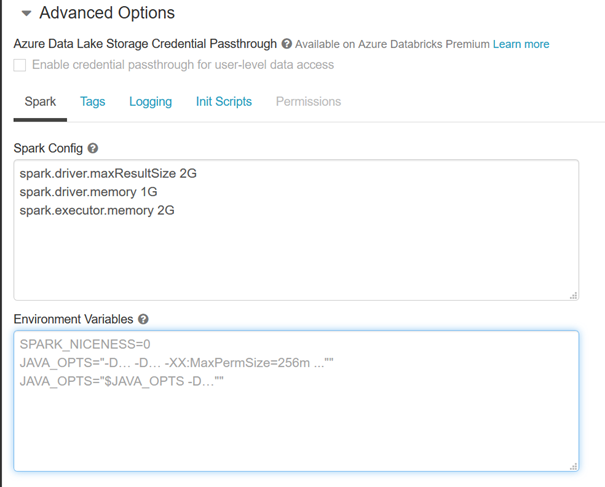
Les variables d’environnement sont quant à elles définies au niveau d’un cluster. Elles seront donc accessibles de n’importe quel notebook attaché au cluster. Nous les trouvons en dépliant le menu des options avancées, onglet Spark.
Par convention, nous utilisons une casse majuscule pour le nom des variables.
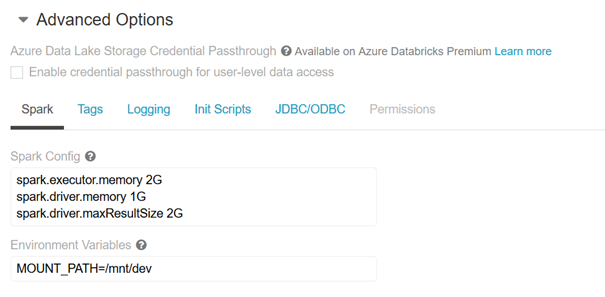
Attention à ne pas mettre d’espace autour du signe « = ». Les guillemets ne sont en revanche pas indispensables autour de la valeur de la variable.
Un redémarrage du cluster sera alors nécessaire, suite à la modification des variables d’environnement.
Maintenant, différentes commandes, dans les langages supportés, vont nous permettre d’accéder aux variables définies. Pour la compatibilité dans un même notebook, les lignes de scripts seront ici précédées du langage dans lequel elles sont écrites, vous pourrez ainsi copier ce code tel quel dans n’importe quel notebook Databricks.
Liste des variables d’environnement :
%sh printenv
Valeur de la variable en Shell :
%sh echo $MOUNT_PATH
Valeur de la variable d’environnement en Python :
%python
import os
key = 'MOUNT_PATH'
value = os.getenv(key)
print("Value of 'MOUNT_PATH' environment variable :", value)
A noter que la commande getenv() peut être remplacée par environ.get() issue également de la librairie os. Les différences entre les deux sont traitées dans cette question sur StackOverFlow.
Valeur de la variable d’environnement en Scala :
%scala
sys.env("MOUNT_PATH")
Il est donc maintenant possible d’utiliser ces variables dans les chaînes d’accès au système de fichier, avec un code qui réagira alors en fonction de l’environnement !
%python
dbutils.fs.ls(os.getenv('MOUNT_PATH') + '/mysfilesystem/')
La définition des variables d’environnement est également réalisable si vous utilisez un “automated cluster“, c’est-à-dire un cluster créé à la volée lors du lancement d’un job planifié.
La configuration du cluster est disponible en cliquant sur le bouton “edit”.